パーソナル・テキストマイニング技術の可能性
大野邦夫
, 石沢朋, 横田久弥
株式会社ジャストシステム
1 はじめに
先の報告[1]で、オントロジ構築の方法として、図1に 示す「情報メディア階層とデータ型」の関係に基づき、 論理(Boolean)、数理(Int, Float)、自然言語の語彙 (Char, String)、クラス階層を取り上げ、さらにその 考え方について日本規格協会のAIODS委員会で執筆し た書籍で解説した[2]。 他方、今後のユビキタスネットワーク社会において、 いつでもどこでも個人を支援する情報系のオントロジ的 な枠組みとしてPIMオントロジを提案しその検討経緯を 紹介した[3]。これまで、PIMオントロジに関しては、 OWL言語(OWL−DL)に基づく論理・クラス階層オン トロジ、ベイズモデルに基づく数理オントロジを対象に 検討してきた。語彙に基づくオントロジに関しては、 アッパー・オントロジに属する自然言語理解の技術が進 展しないと到底無理であろうと考えていたところである が、最近パーソナルユースを前提にしたテキスト・マイ ニング・ツールが商品化されたので、その適用について 検討を試みることにした。本報告では、そのツールの紹 介を行い、PIM分野への適用可能性について検討する。HUMAN
COMPUTER
Type/Class
Shouts, Gestures
Videos, Sounds
Cave paintings
Figures, Pictures
Hieroglypics
GUI
Ideographs
Kanji
Phonograms
Alphabets
Algebra
Numbers
Modern logic
Binary theory
Object Types
(Class)
Char, String
Int, Float
Boolean
図1 情報メディア階層とデータ型の関係2 TRUSTIA
2.1 テキスト・マイニング技術の進展
テキスト・マイニングとは、形式化されていないテキ ストデータ(通常の自然文)をデータマイニング手法を 使って解析することを通じて一定の知見や発想を得るテ キストデータ分析手法の総称である。従来のデータマイ ニングは、データベースを活用して、大量データから仮 説構築に役立つ、新たな知見の発見が狙いであった。す なわち仮説の検証を目的とするデータ分析ではなく、大 量のデータに潜んでいる思いもしなかったデータの関係 性や意味を発掘(発見)するために、さまざまな角度か らデータを検討することであった。 テキスト・マイニングは、データマイニングにおける データベースの代わりに形態素解析や係り受けを抽出す る程度の構文解析されたテキストデータを用いる。言い 方を変えると、形態素解析されたテキストデータの要素 を用語辞書を通じて品詞などの属性を抽出し、データ ベース管理するのである。その要素は、単語、品詞、出 現頻度などであるが、これらのデータをマイニングする ことにより大量の文章や文字・句に埋もれている関係性 を 発 掘 す る 。 こ こ で 紹 介 す る ジ ャ ス ト シ ス テ ム の TRUSTIAでは、その関係性を文章や句の意味レベルに 拡張し、否定表現、複合語句、係り受けなどの関係を解 析することを可能にしている。2.2 TRUSTIAの概要
TRUSTIAは企業で実績のあるサーバ・サイド・ソ リューションの本格的なテキストマイニングシステム [4]をPC環境で実現し、家庭用・個人用ソフトウエアと したものである。マイニングの専門家ではない一般ユー ザの使用を考慮し、ユーザインタフェースに表やグラフトなどとの有機的な連携を考慮し、テキストファイルを CSV形式で管理している。 TRUSTIAは、テキストマイニング技術を提供するソ フトウエアであるが、抽象的なテキストマイニング技術 だけでは一般利用者には分かりにくいので具体的な使用 法の一例として授業支援を対象としている。授業支援の 応用パラダイムは、種々の用途に拡張可能であり、将来 的には、ブログやSNSなどに適用することを通じて、 PIMオントロジ構築の一環として適用可能ではないかと 考えている。 MiningAssistant TeachingAssistant メール CSV CSV CSV グラフ グラフ 受講者 教師 図2 TRUSTIAのシステム構成 TRUSTIAは、図2に示すようにMiningAssistant(テ キスト分析)とTeachingAssistant(授業支援)と呼ば れる2種類のシステムから構成されている。MiningAs-sistantでは、下記のような基本的なテキストマイニング 機能を提供している。 SCSVファイルとして保存されたテキスト情報を読 み込んで分析する S 分析結果をCSVファイルとして出力する S グラフを画像ファイルとして保存可能 S メールアンケートの作成・収集を支援する簡易ア ンケート機能の提供 TeachingAssistantはテキストマイニング(Minin-gAssistant)を学校教育や企業内教育、各種学校、塾な どの授業支援に適用するためのアプリケーション環境で 下記の機能を提供している。 S メールを介した授業支援(出欠管理、提出物管 理) S 履修管理・授業管理 S 課題提出管理 S 成績管理(授業毎・学生毎) S 変更・履歴管理 TRUSTIAを使用するには、図3に示すように、データ 収集 → データ加工 → 辞書登録 → 統計解析 → 主題分析 → 傾向把握 → 表現抽出 → 属性把握 → 語彙分析といっ たテキストマイニング・プロセスを経る。以下、具体的 に上記プロセスと機能について紹介する。 表現抽出 属性把握 語彙分析 データ収集 データ加工 形態素解析 構文解析 用語辞書 辞書登録 統計解析 主題分析 傾向把握 応用環境(TeachingAssistant) 図3 MiningAssistantの構成
2.3 データ収集
データ収集は携帯電話やパソコンのメールを使って簡 単に行うことができる。メールで収集したデータは、自 動的にCSVファイルとして保存され、そのまま分析を行 うことが可能である。またWeb上での掲示版やアンケー トフォームで収集した意見も同様にCSVファイルとして 保存可能である。図4にアンケートによる収集画面の例 を示す。図4 アンケート収集画面例
2.4 データ加工
CSVファイルとして自動的に保存されたデータを分析 の目的に合わせて加工するフェーズである。図5は画面 例である。データの抽出(形態素・構文解析)、置換 図5 データ加工画面例 (内容を揃える)、集約(グループ化)などが可能であ る。関数やマクロを使わずに整理できるので、簡単に データベースの作成を行うことができる。2.5 辞書登録
データの内容や分析の目的に合わせた語句の辞書登録 を行うことで、分析の精度を向上させることが可能であ る(図6)。「同義語の登録」では同じ意味を持つ語句の 登録を行う。 「アフェクト度の登録」では語句に対して好評・不 評、肯定的・否定的といった言葉の重み付けを行う。例 えば、「大きい」という形容詞は、建物や公園に対して であれば好評であるが、ノートPCや携帯電話に対して は不評であろう。このように、特定の言葉が持つ意味が 状況(コンテキスト)に応じて変わり得る場合に、その 言葉の肯定的か否定的かの特性を事前に与えておくと データ集計上有効である。 このデータは、主に「傾向把握」の評価分布図を作成 する際の指標となる。調査の対象によって意味合いが変 わる語句に対して好評・不評を設定することで、評価の 精度を向上させることができる。用語の登録は、分析前 でも分析の途中でも簡単に行うことができる。2.6 統計解析
読み込んだデータを解析して、データ全体の大まかな 傾向をつかむ。データ総数、語句数、品詞ごとの出現比 率などの基本情報から、名詞句、形容詞句、動詞句それ ぞれのトップ10、係り受け関係などの統計的データを一 覧表示する。 (図7)2.7 主題分析
主題分析では、類似内容の文章を抽出し、分類・関係 付けを行う。主題となる語句は、各グループの中から もっとも特徴的な言葉を自動的に拾い出す。主題の関係 性は樹形図で表示され、枝分かれした節目を手がかり に、重要と思われる主題や、それぞれの主題がどのよう な関係でグループ化されているかを把握することができ る。各主題は近くに並んでいるほど内容の関連性が高 く、遠く離れているほど低くなる。(図8)2.8 傾向把握
事象や回答者ごとの印象・評価・要望などを把握す る。 (1)「評価分析」: 文章から好評・不評の表現を見つけ出し、グラフとし て表示する。 対象語句の好評・不評の度合いをマッピングする。 縦軸はアフェクト度を表し、上にゆくほど好評で、下 にゆくほど不評であることを示す。横軸は出現頻度を表 し、右にゆくほど出現頻度が高いことを示す(図9)。 (2)「感性分析」: 個別の属性特有の感性を把握する。 形容詞句と名詞との係り受けの関係に注目して分析を 行う。 感性を示す形容詞句と属性をグラフ上にマッピング し、関連の強さを相互の距離で把握する(図10)。図6 辞書登録画面例 図7 統計解析画面例 (3)「行動分析」: 動詞句と属性を同時にマッピングすることで、動詞句 と属性との関連性の強さ(距離)を把握することでき る。どのような属性が「∼した」「∼したい」と思って いるかを知ることができる。 (4)「現象分析」: 名詞句と属性をマッピング表示することで、名詞句と 属性との関連性の強さ(距離)を把握することできる。 あるテーマについて「どうしたいか」を知ることができ る。
2.9 表現抽出
本文に対して名詞句、形容詞句、動詞句を選択し、内 容を絞り込んで分析を行う。文章表現の偏りから、その 属性の特徴を把握することができる。(図11)2.10 属性比較
分析結果を年代や性別、出身地といった属性によって 比較し、属性ごとの傾向や分布などを把握する(図12 )。語句の表現や主題と、属性のクロス集計や経時的推 移を示す事もできる(図13)。2.11 語彙分布
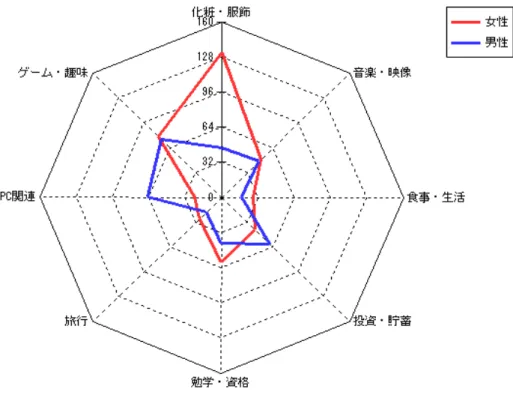
分析軸を決めて、その軸に適した言葉を登録すると、 分析対象から言葉をカウントし、レーダーチャートに表 示できる。それを属性ごとに重ねて表示すると、その差 異を簡単に発見することが可能である。(図14)3 テキストマイニングの適用分野
3.1 データマイニングとの関係
テキストマイニングは、データマイニングが用い等れ ていた分野の延長上で用いられる例と、データマイニン グとは異なる分野で新規に用いられる例がある。前者の 例としては、流通分野におけるCRMが挙げられる。例 えば、顧客へのアンケートの自由回答、コールセンター やWebサイトなどに寄せられるユーザーからの定性情報 や掲示板への書き込みなどを解析することによって、顧図8 主題分析画面例 図9 評価分析画面例 客や市場のニーズを抽出したり、自社製品への不満点を 分析するといった使い方が可能である。またEメールに よる顧客からの問い合わせに対して、これを自動的に解 釈して返答したり、関係担当者へ転送するといったソ リューションにも応用されている。 冒頭で紹介したPIMオントロジ応用分野は、PIMオン トロジ自体がスケジュール・データ、アドレス帳デー 図10 感性分析例 タ、位置情報などの「データ」を扱うので、これらの分 野のデータマイニングの延長上にテキストマイニングも 存在すると考えられる。この領域については、後に改め て考察する。
図12 属性比較の例 図13 経時的推移の例 図11 表現抽出画面例 他方、後者の新規に用いられる例としては、従来デー タベースとは無縁であった、業務分野が挙げられる。オ フィス文書がWebやEメールの導入で、紙からテキスト ファイルに移行したような分野である。言い方を変える と、従来データベース管理を行う企業情報システムなど の恩恵に浴さないで、オフィス・スーツやEメール文書 をテキストファイルで管理しているような小規模の組織 が対象となる。そのような組織は、学校や塾のような教 育機関、町医者や老人ホームのような医療福祉分野、小 規模自治体や公益組織のような公共機関などが対象にな る。これまでに具体的に適用された事例を以下に紹介す る。
3.2 TRUSTIAによる事例
最も簡単かつ汎用的な活用法は、アンケート調査の分 析である。以下のような事例がTRUSTIAの解説書に紹 介されている[5]。 3.2.1 学校・教育機関 少子化、定員割れなど、大学をはじめとする最近の教 育機関の経営環境は厳しい状況に置かれている。特色あ る大学作りを目指した大学改革の一環として教育評価の 実施が義務付けられようとしている。しかし、現状の形 式的な評価ではその効果は不十分であり、より事実に立 脚した具体的な評価が求められている。そのような背景 の下で、教師が行う授業改善や研究室で行ったフィール ド調査の事例が紹介されている。 3.2.2 企業・公益法人 企業が扱う情報の大半は、非定形のテキスト情報であ る。これらは、企業にとって貴重な財産であるが、雑多 に積み上げられて放置されている場合も少なくない。特 に、顧客からのテキスト情報は、新たな市場ニーズを発 掘するために有効である。そのような事例として、営業図14 語彙分布の例 部門が行う顧客ニーズ調査とマーケッティング部門が行 う商品動向調査の例が紹介されている。 3.2.3 自治体 政策に関する公聴会での意見収集やWeb上のパブリッ クコメントの収集など、住民の声を行政に反映させる取 り組みが多くの自治体で行われている。これらの情報の 分析には、多くの時間を要することから、単純な集計の みによる定量的な情報分析に留まる例も多く見受けられ る。そのような状況でも、テキストマイニングを適用す ると、住民の意見を容易に分析することができる。
4 PIM分野への適用
4.1 PIMオントロジ
PIM情報は、スケジュール管理をコアに、アドレス帳 (関係者としての個人データベース)、時刻データ、場 所(位置)情報、組織情報などを関係付けた情報ネット ワークとして管理される。スケジュールの履歴をデータ ベースとして管理し、人、場所、組織などを系統的に管 理分析すると、その関係が構造を持ち、オントロジ的な 関係を形成する。その概要を図15に示す。 PIMオントロジは、異なる個々人のPIM情報環境をさ らに相互に関係付ける枠組みである。異なる個々人の PIM情報環境は同一ではないであろう。現にWindows環 境でOutlookでPIM管理している人もいれば、携帯電話 上のPIMを用いている人もいる。これらのデータの相互 運用を可能とし、連携する情報から推論される関係を通 アドレス帳 組織情報 位置情報 スケジュール 購買履歴 電話履歴 生活履歴情報 訪問履歴 TV視聴履歴 図15 PIM情報の構成 じて新たな情報を構築し、ビジネスやサービスに資する ことがPIMオントロジの目的である。4.2 PIMオントロジの実装
PIMオントロジの基本データは、iCalendarで代表さ れるスケジュールデータである。個々人のスケジュール は、連続するイベントで記述される。そのイベントは、 名称、開始時刻、終了時刻、関係者、場所、コメントな どの項目で定義される。OWLのクラス階層で記述してProtegeを用いて表示し た例を図16に示す。この図の詳細は文献[1]を参照して 欲しい。 図16 Protegeによるスケジュール項目階層 なお、PIMオントロジは必ずしもOWLで実装される わけではない。データマイニングやテキストマイニング の活用を考えると、OWLで実装するよりは、RDBか XML−DBで実装する方が実用的であろう。
4.3 データマイニングの適用
PIMオントロジの応用手法として、生活履歴データを データマイニングするア プローチが存在する。ス ケ ジュール帳、アドレス帳、ToDoリスト、購買履歴、 TV番組予約リスト、TV番組視聴履歴、などなど、電子 的に記録され得る生活履歴は幅広く考えられる。 最近、携帯電話(FOMA903iシリーズ)にGPSが実装 され、観測された位置データをメールで送付したりiア プリで処理することが可能になった。その結果、PIM領 域で可能性のあったサービスの具体性が一挙に高まった と考えられる。スケジュール帳の場所欄に記された企業 名の番地から現在地との関係が定まり、その間の交通手 段の候補を乗り換え案内ソフトから入手するといったこ とが可能である。 購買履歴データは、従来は販売企業がポイントカード で管理していたが、それをPIMで行うとPIM−CRMと言 うべきデータベースになる。このデータベースを、家族 単位で管理すると家計簿に近い概念になり、家計簿は節 約のための古典的なデータマイニングツールのようなも のである。 このようなアプローチにより、生活履歴情報をデータ マイニングし、生活にフィードバックしたり、公的な サービスに結びつけたり、CRMの拡張としてビジネス に生かしたりすることが可能であろう。しかしその実現 のためには、技術的な課題だけでなく、法的、制度的な 課題も存在する。4.4 テキストマイニングの適用
PIMオントロジにテキストマイニングを導入するの は、前項のデータマイニングと連携したアプローチが必 要になるであろう。 先ず、有望な領域は、Eメールである。Eメールを発 信者、タイトル、キーワードなどのカテゴリ毎に分類す ることは現在のツールでも可能であるが、テキストマイ ニングを用いると、より具体的意味内容で分類すること が可能になると思われる。最近のEメールのスパムフィ ルターはかなり改善されたとは言っても、それをすり抜 けるメールも多い。テキストマイニングは、そのような スパムメールの除去にも有効であろう。 次に、適用が有望なのは、SNSやブログである。日記 に書かれた内容をテキストマイニングすることにより、 より具体的な意味内容の索引の作成が可能となるであろ う。さらにコメントやトラックバックにもマイニングの 対象を広げることにより、議論されるテーマの展開や推 移についての把握が可能になる。SNSのコミュニティの 掲示板などもテキストマイニングの対象になり得る。掲 示板の内容とそれへのコメントの関係、関連する主題の 分類やキーワードの統計などを通じて、コミュニティ全 体の意見の集約などが可能になる。コミュニティにおけ るアンケート機能が提供されているSNSもあるので、こ の領域にTRUSTIAのアンケート分析機能をそのまま適 用することも可能である。5 考察
以上のようにテキストマイニング機能をEメールや SNS、ブログなどに適用すると、それらの内容把握に有 益そうであることが分かる。だがそれらの機能とPIMと の関連は必ずしも明白ではない。この議論はデータマイ ニングの場合にも存在するのであるが、データマイニン グ結果やテキストマイニング結果が、グラフで表示され て、それとPIMとがどう関係するかが問題である。 データマイニングの世界では、マイニングの結果から ルールを抽出し、それを推論に役立てるというアプロー チが存在する。このアプローチは、確信度付きの知識 ベースに対する推論に近い概念であるが、このような知 識ベースに相当する情報をOWLかRDFで構築すること は可能であろう。他方、テキストマイニングを通じてこのようなアプ ローチは可能か否かは興味ある課題である。データマイ ニングの対象が、状態(属性)と値という関係の対で膨 大なデータが蓄積され、クロス集計したりして、確信度 付きの傾向、ルールが抽出され得るのに対し、テキスト マイニングの場合はそれほど明確な普遍性のある傾向は 得にくいのではないかと思われる。 データマイニングによる確信度付きの傾向・ルールに よる関係の管理は数理オントロジの領域である。それに 対し、テキストマイニングの領域は、統計データを用い ることに関しては数理オントロジの領域だが、それに基 づいて、同義語、類義語を定義したり、アフェクト度を 適用したりするアプローチは自然言語の語彙オントロジ と言えるのかもしれない。その可能性を見極めるために は、さらにTRUSTIAを活用する具体的な検討が必要で あろう。 データマイニング、テキストマイニングの概念を加え た、PIMの情報環境を示すと図17のようになるであろ う。 アドレス帳 組織情報 位置情報 スケジュール ブログ 購買履歴 電話履歴 生活履歴情報 訪問履歴 TV視聴履歴 SNS Eメール Text Mining Data Mining 図17 データマイニング、テキストマイニングを加えたPIM情報の構成