JAIST Repository: クラスタ型データパスによるスーパースカラプロセッサの低消費電力化
12
0
0
全文
(2) vo. l48 No.SI G 13( ACS19). Aug・2 0 07. 情報処理学会論文誌 :コンピューテ ィングシステム. クラス タ型 デ ータバ スによる スーパ ース カラプ ロセ ッサの低 消費電 力化 佐. 藤. 幸. 紀 十, ☆. 鈴. 木. 健. 一 十. 中. 村. 椎. 男 十. スーパースカラ方式プロセ ッサの広域的なデータバスを複数の局所性 を持つ処理要素 ( PE) に分 割 してクラスタ化することにより,低消費電力で高並列な処理が可能である. しか しなが ら,データ バスを分割する度合いを増すにつれて,局所化 された処理要素間の通信や負荷不均衡により高並列な pE が効果的に活用できないため,結果的にクラスタ化を行わない場合 と比べで性能が低下する恐れ がある.本論文では,クラスタ型スーパースカラプロセ ッサの利点である低消費電力性 をさらに引 き 出すために,クラスタ化 を進めた場合の I PC の低下を抑える手法を提案する.局所化された処理要素 を効率良 く利用するために,プログラムに内在する命令の逐次性 に着日する.プログラムの逐次性の 指標 としてプログラム実行時のオペラン ドの状態 とレジスタファンアウ トを利用 してプログラムの逐 次性 をクラスタ型プロセッサの局所的処理に対応させる. さらに,局所化 された高並列な処理要素を 有効利用するために隣接する PE において協調処理 を行 うことを提案する.実行駆動 シミュレーショ ンを実施 した結果,隣接 PE の協調 を行 うことにより,高並列な処理業素を効率良 く利用 しつつ, レ ジスタファイルの消費電力をクラスタ化を行わない場合 と比べて 12分の 1程度に削減可能であるこ とが分かった.. Des i gnn igaI 」 o wpowe rSuper s c aa lrPr oc es s or e apat h Bas donIsC t l use tr edDat Y UKI NORISATO, *,rK ENI CHISUzUKI landTADAO N AKAM URAI use tr i ngt heco. mpl e xandcenr tal i zeddaa tpat s s or , hsofs upe r s caa lrpr oc e sno it 1 0 Rece nt l y,Cl cal i zedPEs( cu lse tr s )be co. mes. apopua lrappr oac ht orli ea zel owpowe randhh i gl ypar al l e l l Zd e cr eas hepe pr oces s or l owe ve r,cu lse t ,r i ngt , endst ode et r f or manceofapr s orbec eof oces aus s,t lnceamongPEs. h t it ner PE cmI l unc iat i onand wor kl oad i mbaa hi spape r ,wef oc t l SOn o l i onsi yi tt otel h oca. l i ze. dpr oce s s igo n ncl use tr ed s eque nt , il ai yofi nsr tuc t npr ogr amsandappl t pr oce s s or om tea lsi sofs eqt l Ct n il a i t ,. yus i n. gOPer ands tt ,, ausandris eg t e rf anout,We h nay s.Fr sanef f ec t i veappr g bor pr e s entt oope r at , i onofnei h i ngPEsi ht ope ml li dpr oac r f or oca ze oI , hatc h es ul t ce s s lgl n naC l use tr e dpr oces s or .Fr om ter sofe xecut i ondi rve r. ]. s. i mult ai ons,acl use tr e d pr oces 5 01 ・Wi t ht hecooper at i onofneih g bor i ngPEac hi e vesbe t t e rI PC wl hf t ase trs ,mal l erand l owerene r gyl ・ e gl St eri fl est hanote , h rs ce h mess of al '. c ons. i de r ed.. Thi smeanst , hat , t hecu lse tr l ng r at onorneih t h dvana wi t ht hecoope oc s s or i g bor i ngPEsboos stea tgesorcu dpr lse tr e e s .. 列処 理 を活 用 で きる よ うにす るだ けで な く,消費 電力. 1. は じ め に. の増 大 を招 くよ うな複雑 なハ ー ドウェア構造 とな らな. 近年 主流 であ る スーパ ー スカ ラプ ロセ ッサ にお いて. い こ とが 求 め られ て い る. この よ うな背 景 にお い て,. は,利用 可 能 な並 列度 を増加 させ る につ れ て, レジス. ス ーパ ー ス カ ラの デ ー タバ ス に対 して ク ラス タイヒを. タファイルや フ ォワーデ ィング機構 な どの デー タバ ス. 行 った クラス タ型 ス ーパ ース カ ラプ ロセ ッサ が注 目を. を構 成す る要素 は複雑 化 し,その 回路規模 や消費電 力. 集 め て い る. 従 来 の スーパ ー スカ ラ方式 の 問題 とされ ていた広域. は急激 に増 大 す る こ とが 知 られ てい る. したが って ,. 的かつ複雑 なデ ー タバス は, ク ラス タ化 を行 うこ とに. マ イ クロプロセ ッサ の設計 にお いて,命令 レベ ルの並. よ り複数 の局所 化 され たノ 」 、 規模 なデ ー タバ ス に分割 さ れ る.一般 的 にデ ー タバ ス を構 成す る重 要 な要素 で あ. 十東北大学大学院情報科学研究科. Gl adua t cSco h olofI no fl ・ mat i onScl e ne CST , oo hkuUnl ve l S t y i. る レジス タフ ァイルや命令 発行 キ ューは,マ ルチ ポー ト化 され た レジス タセ ル に よ り構成 され るため,エ ン. ☆ 現在,北陸先端科学技術大学院大学情報科学センター. トリ数 や ポ ー ト数 に比例 して遅 延 時 間, 回路 面積 ,潤. l PlS ee r. l t. ywi t , hCcnc tro frhf ol ma t , i onSc i enc e,. J AI ST 84.
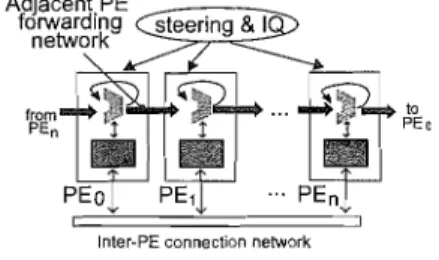
(3) Vo l .48 No・SI G1 3( ACS1 9 ). クラスタ型データバスによるスーパースカラプロセッサの低消費電力化. 賛電力が増大す ることが知 られている. したが って, クラスタ型 プロセ ッサにおいて クラスタ化 を行 う度合 いを増す につれて,それ らの遅延時軋. 回路面積,潤. 費電力 を削減することが可能である.また,クラスタ 化によ りフォワーディング機構 を同一の PE に限定す ることも,フォワーデ ィング機構 の遅延 を支配する と いわれる配線遅延 を減少す る点で有効 である1). クラス タ型 プロセッサ において クラスタ化 を行 う度 合いを増す につれて,低消費電力化 に代表 されるクラ スタ化の利点の恩恵が期待 される反面 ,PE 間の通信 や負荷の不均衡が発生す るため,クラスタ化 を行 わな か った場合 と比べて I PCが低下すると予想 される.そ こで,本論文では,データバ スをクラスタ化する度合. 8 5. l ne tトPEc onnc el 1 0nnto ew. 図 1 X* Y 柿成のクラスタ型ス-パース カラプロセ r k Fi g.I. ッサ A clustered stlperSCalar pI ・ OCeSSOI ・W i th X *Y conf iguratO ln. いを増す ことによ り低消費電力化 を図 りつつ,プログ ラムに内在する命令の逐次性 をふまえつつ命令列 を構 築する.さらに,命令列の処理 をクラスタ化 により生. r Jlr sdl hSPp ()Tep a h I Pl e, l ne s t l Cueue nLl a. じた局所的な構造 における処理- と対応 させて処理 を 行い,クラス タ化 された高並列 な処理要素 を効率良 く 利用す る方式の確立 を目指す. 3) は,スーパー スカ ラ方式 の よう 命令 の逐次性 2),. な命令 レベル並列性 を利用する方式 においては利用 さ れなかったが, クラスタ型 プロセ ッサのようなハー ド. pEw.. -. ■s s UE. REG う erEX. 仲)PL Pl 加hgofn a ie ehet tトPErsr euLo cmr mn l 喝I n. l -. パイプラインの l m Tl l e ti mi ng ofthe構造 pl pel i ne. 図2 Fl g 2. ウェア構造 における局所性 を利用する方式 においては ソフ トウェアの局所性 を見出す重要 な概念 となる.こ. 帽) と表す.また, クラス タ化 を行 うデー.タバス. のような命令の逐次性 の概念 をクラス タ型スーパース. 素 は レジスタファイル とフォワーデ ィング回路 と の要. カラ方式の命令 ステアリング方式 とデータバスの構造. それ以外のデー タバスの構成はスーパースカラ方 し,. に応用することで, クラス タ化 による I PC の低下 を. 同 じである とした. クラスタ化 によ り, レジス タ式 と. 抑 えつつ,データバスの分割で得 られた低消費電力化. イルは各 pE に 1つずつ配置 され,演算結果 の ファ. の利点 を最大 限に活用する手法 を提案する.. ワーデ ィングも同一 PE内のみに限定 される.クフォ. 本論文 の構成 を以下 に示す.2章では,本論文 にお. タ化 によ り局所化 された各 PE における レジスタラス. いて想定するクラス タ型スーパースカラプロセ ッサの. イルの構成方式 として,各 レジス タファイルに個 ファ. 構成 と実験環境 を述べ る.3章では,プログラムに内. レジスタインスタンスが保持 される非重複分散 レ別の. 在する命令の逐次性 の傾 向について解析 を行い,解析. タファイル構成 を採用 した4),. の結果得 られた知見 をクラスタ化 されたデー タバス上. 図 2() a に lp A ha16 224のパイプラインの構成を 5) ス とした本論文 で想 定す るパ イプライ ン構成 を示 ベー. で利用する手法 を論 じる.4章では, 逐次性 をさらに. ジス. 効率良 く利用するために,隣接 PE間の協調動作 を提. クラス タ化 に対応するために,MAP ステー ジに す.. 案 し,評価す る,5章では,提案す る手法 の I PC と. て命令 ステア リング機構がそれぞれの命令 に対 しおい. レジス タファイルの消費エネルギーの比較か ら,隣接. 行する PEの割付 けを行 うと同時に, 演算結果のて実. pEの協調 による低消費電力化の効果 を見積 もる.6章. 先の レジスタを割 り付 ける と変更 した.命令 は M出力. では関連研究 について論 じる,7章 は結論である.. ステージにおいてステア リングされた後,命令キ AP. 2. ク ラ ス タ型 ス ー パ ー ス カ ラ プ ロセ ッサ 2. 1 マイクロアーキテ クチ ャの概要. ( I Q)に格納 され,I SSUEステージにてオペ ランュー 利用可能であれば命令 は wa ke upされる,wa ke uドが れた命令は対応する PEの演算資源が利用可能で pさ. 図 1 に本論文で想定するクラスタ型スーパースカラ. e l e c tされ,REG ステージにおいて レジス タあれ ばs. プロセ ッサ を示す.本論文では, クラス タ型 プロセ ッ. み込 まれた後 ,EX ステージにおいて実行 され が読. サの構成 を Ⅹ* Y( Ⅹ:PE致 ,Y:pE 内の命令発行. 演算結果のフォワーディング回路の クラスタ化 る..
(4) 情報処理学会論文誌 :コンピューティングシステム. 86. 0. 図 3 他 PE からの レジスタの ead Fi g・3 Thep I. Pel P Er e g is t err 読み込み l n. et i miga n ti ne tr. s L r l J C l. l DLd ne v. l n. 表 1 主要 なアーキテ クチ. 07. Dt aadpn ee P e r a " e d T r s m. Tabl nantar c hi t e ャパ ラ メタ e1 Domi cu tr alpar amet er s, Toura l lmet i nsr nt u c t l O nSr br a n c hp e dl Ct Ol ・. Ft ec hand Br anc d e c oo dr e hpr e d it c. t Q,FQ,LQ,SQ s i ze l s R s OB s i ze Lu II ewi dt h LI D. c c a a ce. ce h h. 8. .ア. Åug.2 e n c e9 「 a P h. eZ l ll a pr ope ry t ll e ands Fi g. 4 Par al ける並列性 と逐次性のT 対係 l nani S e que ns t Z . uc t l On. 6 4. 2 5 6. 1 2 i s 8 s u KB】 ei. nt oa tl 8. り,オペ ラ. t l r u c t O nSe q u e n c e 図 4 命令列 にお. ne C・ ムは 1G 命令 フォワー ドした後の 100M. 128KB.2way. 用する PE ン ドを生成す る PE とそのオペ ラン ドを利. を行 3. った. 命令 の逐 次性 とクラ. 命令 の実行. が利用可能が同一が否かによって,未解決 となった際の挙動が異なる.同一 オペ ラン PE 内ド. クラスタ型スーパースカラス タ型 ス ーパ ー ス カラ. 演算器 によ り人力オペ ラン ドを生成する場合,オペの. 化の恩恵 によ りそのデータバ プロセ ッサは,クラスタ. ン ドは フォワーディング回路 によ り転送 されるため ラ. により得 られる IPC が 香 ,PE 間の通信や負荷不均衡スを低消費電力化する反. 連続 して処理 を進行することがで きる. しか し,人 ,. 低下す ることが知 られている5).そ こで,本質的に. オペ ラン ドが異なる PE の演算器か ら転送 されて く力. 必要な PE 間の通信や負荷不均衡 を回避 しつつ処理不. 場合 は,図 2() b に示す ようにオペラン ドの転送 る. 行 うことによ り IPC の低下 を抑 えることが必要で を る.IPC の低下 を抑 えるため には, プログラム. サ非重複分 イクル余分 にかかると想定 した.. に2. あ. 局所性 を見出 し,クラスタ型 プロセ ッサの局所化か ら. 力オペラン散 ドは利用可能な状態であ レジス タファイル方式の場合,すでに人. たハー ドウェア構造 に対応付 けて命令 を局所的に処理 され. れた pE 内の レジスタファイルに. することが有用であると考 えられる.本論文では,プ. るが,割 り付 けら. こる.この場合,他 PE の レジスタファイルより 存在 しないことがお. ログラムの局所性 を抽出する 性 2)・ 3) に着 日する.. 延 を行 う必要がある.本論文では,この転送 にかかる遅 転送 スを 3 は他 pE か らの レジ 1サ イクルと想定 PE した.図 間通信のタイ ミングを示す. タ読み込みのための. 尺度 として,命令の逐次. プログラムにおける逐次性 を定量的に評価するため に, レジスタを媒介 としたデータ依存関係 のある 2つ の命令が実行 される時間差 を距雅 ととらえ,この距離. 22 . 実験条件 プログラムの性質や クラス タ ロセ ッサ を評価する実 セ ッ トの si m- al. 型スーパー スカラプ 験 は, Si mpl eScla a rV4 ツール. れてい くと仮定 し 1命令ずつ逐次的に実行 さ に着 目する.プログラムが 令間の距離 をそのて,データ依存関係 のある 2つの命 た とえば,図. ha6) をベ ース とす るサ レー イクル精度 の実行駆動型 シp ミュレータを用いて行 った.本 シ ミュ. 示す.残 タの主要なアーキテ りの構成や,キャ クチ ャパ ラメー タを表 1 に. 間に実行 された命令数 と定義する2).. てお り,距 4 において,命令 i 2 は命令 i Oに依存 し スーパ ースカラプロセ ッサにおいて 離 は 2である. 離が短い依存関係 はフォワーデ ィング機 は,命令 間の距. M al pha2126. 4 と同様 とした. 延は ッシュ,機能ユニ ッ トの遅 udi,r o りa4 auのベ o),S 00C ,rwd wc di PEC2 c j g ed aa na ch よ つ ンチ マ ー0ク ( dj peg, pe iBe. よ り 7 つ のベ ンチ マ ー ク (gzi p, vpr, perl bmk, bli p,t wol f. PUit n. c, m c f , gc. )mp のベ ンチマー クは, Co を選び実験 を行った.すべて i aq C comp l erv65 . に. イルした. t-d Me i Be s. hn ac. r h ed の各 オプ プションを用 ログラムは終了するま いて コンパ よ f as. no n a_ り-04 -. で命令の実行 を行 った.SPEC2000it n の各 プロ グラ. J n s.
(5) ACSL Vol ・48 No SC I 1 3( 9). クラスタ型データバスによるスーパースカラプロセッサの低消費電力化. ワーデ ィングに必要 となるサイクル数が増加 した場合, すなわち演算結果が次のサ イクルで利用で きな くなっ た場 合,性 能が大 き く低 下す るこ とが報告 されてい る9) . 10 ) .これより,命令 間の距離が短いデータ依存 に よ り構成 される命令列 は,データフローグラフ上の ク リテ ィカルパ ス となる傾 向が強い と推定 される. スーパースカラ方式 において並列度 を増加 させ るに つれて,命令 間の距離が短い依存関係 を実行するうえ で鍵 となるフォワーディング機構 の遅延 は著 しく増加 し,プロセ ッサの動作周波数 を低下 させ る原因 となる. クラスタ型スーパースカラプロセッサは,フォワーディ. 87. オペランドの状態ごとの依存のある命令間距離の分布 ( spEC20 c i n t平均) 00 Ta bl e2 Tl l edi s t r i bt u i o. nofdi sa tnc ebe t we e nde pe ne dnt i ns t r uc t i ons ba s e d on t hi er ope r and s tt aus c s ( SPEC20 00 c i nta vg・ ) , di sa tnc e ∫ 3 2 r e ay d 0. 0% 01 .% 4 5 0, 0 % unr e a dy 1 5. 2% ll 01 .% 0. 2% . 6% di 7. 9 % 61 .% 3. 6% 8 r sa ed t an y c e 6 9 1 0 7 0. 3% 0 ul ー r 3 2% 01 .% 05 .% 2 e a dy 0 3. 2% 2. 31 1 3 di sa tnc ll e . 2% 1 . 7% 1 2 0. 5 r e ay d 05 .% 1 4 1 5 + 0. 3 % 1 . 1 % 1 % 0. . 5% unr e a dy 1 2% 27. 9% 表2. ン グ機構 についてクラス タ化 を行 うことによ り,この 遅延の増加 の問題 を解決 している1).一方で,クラス. る命令 間の距離は. タ化 した場合,命令ステアリングによっては命令間の. があることが推測オペ ラン ドとの状態 と強い相関関係. . 2%. 0. 9 %. 7. 2%. 距離が厘 い依存関係 の間にも pE 間通信や リソース競 合が発生する可能性がある.た とえば,図 4のデータ. 令間の距離 クラス タ型スーパースカラプロセ される, ッサにおいて,令. フロ・ 7 -グラフにおいて灰色で示 される処理 の クリティ. 処理する方式 が短いデー として, タ依存 のある命令列 を効率良 く ! r eady1 ( n o tr e ad dy y) リ ング方式が提案 されている 命令 ステア 1 ) .! 方式 r e a. PC は低下する. カルパ ス上に遅延が挿入された場合 ,I. 以上 をまとめる と,クラスタ型 プロセ ッサにおいて. に示 したように命令間の距離が短いデー タ依 は,表 2. 命令 間の距離が短い依存関係 をどの ように実行するか. ある命令 はオペラン ドの状態が未解決である存 関係の. により,得 られる I PC は大 きく影響 を受ける.そこで,. 高いことを利用する.命令間の距離 を直接 カ可能性が. クラスタ型 プロセ ッサにおいて命令 ステアリングを行. る代わ りにオペ ラン ドの状態 を尺度 とするのウン トす は,依存. う際の依存のある命令間の距離の傾 向を調べ るために,. のある命令 間の距離 をつねに観測することは距離 を保. 依存のある命令間の距離 とオペ ラン ドの状態の関係 に. 持する巨大なテーブルを必要 とし現実的でないためで. ついて調査 を行 った.オペ ラン ドの状態 は,アウ トオ ブオーダ実行のためにつねに監視 されいる状態であ り,. ある. ! r eady 方式 は未解決 オペ ラン ドを持つ命. オペ ラン ドをフェツナする際 においてオペ ラン ドが利. テ ィカルパ ス上に存在する命令 として優先的令 をクリ. r eady)か利用可能でない ( unr eady)かのい 用可能 (. 通信や リソース競合 を起 こさない ようにステに PE 間. ずれかである.命令が I Q にデ ィスパ ッチ された際に 依存のあるオペ ラン ドがすでに利用可能である場合は. す る.具体的には,未解決なオペ ラン ドを少 ア リング. 即座 に実行可能 として waket l p され る.図 4 のデー. り付 け,非 クリテ ィカルな命令 である解決済みオ PE に割. 1つ持つ命令 をそのオペ ラン ドが生成 されるな くとも. タ依存 グラフにおいて,命令 i 3 まで実行が完了 して. ン ドか らなる命令 は負荷最小 の PE に割 り付 ける.負 ペラ. 4,1 5の入力オペ ラン ドは r eady いるとすると,命令 i. 2 荷最小の PE を推定するために DCOUNT 指標 1. 6の人力 オペラン ドは unr 状態であ り,命令 1 eady状 態である.. 用いた.DCOUNT は 命令の個数 をカ. )を. ,各 pE にデ ィスパ ッチ された. 表 2 に依存 のある命令間の距離 の分布 を調べ た結 果 を示す.デー タ依存関係 は, レジスタを介 した命令. を推測す 比 較 対るための指標 象 とす ウンタを用いて監視 る命 であ 令 スる. テ し,各 PE の負荷. 間に真依存 ( RedAf a t e rWr i t edepe ndence is ) があ る場合のみ を計測 し,メモ リを介 した依存 は検 出が困. ア リ ン グ方 式 と して RMBS ( Reis gt e rMappn i vanced_ gり上 Bas edるS t e e r i ng ),Ad RMBS の 2つ を取 3 ) げ 1 .R MBS は-. 難なため除外 した.表中の値 は,デー タ依存 関係があ. paa lc hara l らが提案 したデー タ依存 に基. る命令 に対 して命令 間の距離 と先行 す るオペ ラン ド. と同様 の方式 であ り,あ る命 令 の オペ ラン づ く方式 1 ). の状態 を調査 し,命令間距維 ごとに集計 した値 を全体 の依存 関係 の数 で正規化 した ものである.結果 よ り,. があ れ る場合 ,必ず依存 のあ る先行命令が割 り ドに依存 付けら. unr eadyのオペ ラン ドは依存がある命令 との距離が短. てい る van PE のいずれか に命令 を を追加 割 りした依存 付 ける.関 Adced_ RMBS1) 2 は,負荷分散. eadyのオペ ラン ドは依存のある命令 との距離が く,r. 長い傾向があることが分かる. したが って,依存のあ.
(6) 情報処理学会論文誌 :コンピューティングシステム. 88. Aug.2007. 表 3 オペ ラン ドの状態 に韮づ く命令 ステアリング方式 と正規化. I PC. Tabl e4 Thedi s t l i but i onoropel C2000it cn 平均) ( SPEC200. Tabl e3 I nsr tuc t i o. ns t eer i ngbas e donopea lnds tt aus e s i 2 1 edI PC, andten h o. l mal RMB Advanc ed_. RMB. ands t at us e s. Medi aBenc ha Vg. SPEC2000avg 10 .0 . 1. 0 1 . 00. ! r eady. 1. 式 に各 pEの DCOUNT11 .3. 1 . 02. 1 . 08. ・ ) I cn i tavg( 表 5 レジスタファンアウ0 S PE ト の分布 C2 00 0n cn it平均) Tabl e5 Thedi a st r i but i onofr egse i trf o ( SPEC2 000ci nta 」. 負荷の集中が起 こった と見指標が間借 を超 えた場合 に 命令 を割 り付 けるとい う動な して負荷が最小 の PEに. R P e e r a 」 nout gse itlf. ut s. vg・ ) I. 表 3 は 8*1構成 におけ 作 を追加 した方式である.. PC を RMBSの I PC との I る命令 ステア リング方式 ご. ce na t」 ge[ %]とえば,図 4 におい 推測 される.た. ここで,各 p Eは 40本の で正規化 した結果である.. が未解決である場合 , ! 1 ・ ea. RMBS方式 よ り 上 PCが 1. ready 方式 は RMB レジスタを持つ とした.実 験結果 よ り, !. S方式や advanced. PEに割 り付 け られる. しdy 方式では i 4と 1 5は同一 よりpE内で同時実行可能 か しなが ら, クラスタ化 に. これ より,データ依存関係 割 ほ ど高 い ことが分かる.. リソース競合 のため i 5. て命令 i 3の結果. な命令数は制限 されるため,. みで命令 をステアリングすや負荷分散 といった項 目の 理時間を決定するクリティることは,プログラムの処. ある. そこで,命. る可能性が高い といえる.カルパスの遅延 を増大 させ. ファンアウ ト令間の依存関係の広が に着 目す る14).ここで,レジスタ りを表す レジスタ. してオペ ラン ドの状態 を指また,命令の逐次性 を考慮. アウ トを 「 あるレジスタに値が書 き込 まれてか ファン. の実行が遅れて しまう場合が. PC を得 られるといえる.以上 標 とす ることで高 い I. の レジスタに次の書 き込みがあるまでの読み出 ら,そ. スタ型スーパースカラプロか ら,命令の逐次性 はクラ. 数」 と定義す る.図 4 のデー タ依存 グラフにおい しの回. の度合 いを増 した場合 に もセ ッサ において クラスタ化. は,命令 i 2は命令 i Oに依存 してお り,命令 i 3の. PC の低下 を防 ぐための 重要な概念であ り,オペ ラ I ン ドの状態は命令 の逐次性 を定量的に測 る 1つ の指標であるといえる.. ス表 タファンアウ トは 2である. 5 にレジスタフ. て レジ. 示す.レジス タファン ァンアウ トの分布 を調べた結果 を く,平均 6% 5 とな. 4 クラスタ型スーパースカ . 隣接 PE の協調. アウ トが 1である命令は黄 も多. ある命令は平均 1った.レジス タファンアウ トが 2で. 費電力化 と高並列 な処理 をラプロセッサ において低消. ウ トが 0となる命令 5%を占め,また,レジスタファンア. 逐次性 は重要な概念である両立 させ るためには命令の. が 2以下の命令 は. 測 る 1つの指標 と してオ .命令の逐次性 を定量的に. を含めるとレジスタファンアウ ■ ト. クラス タ化 を行全体の うこ 9割 を占めることが分かった.. が,オペ ラン ドの状態が命ペ ラン ドの状態 に着 目 した. トが 1を超 える場合の とにより, レジスタファンアウ. に表 しているか を詳細 に調令の逐次性 をどの程度的確. E間通信や リソース競合が発生 し後続命令 において P. Q にディスパ ッチ べ る必要があ る.そ こで, 命令が I ペラン ドの状態の分布 を調 される際の命令 に対するオ. ッサの場合 ,PE内での同時実 行可能な命令数は ロセ 1であるため,レジ. 示す.1つの命令 は人力 と査 した.その結果 を表 4 に. 成の クラスタ型 プ. やす くなる.た とえば,8*1構. トが 2の後続命令 を同一 P Eに割. ス タプア@ /アウ. とりうるため,オペ ラン ドして 2つ までオペ ラン ドを. 競合が発生する.表 5の ようにレり付 けるとリソース. 場合 に分類 される.表 中のの状態 nul lは入力 とあわせて オペ ラン 9通 りの ドが. が 2以上の ものは全体の 30% を ジスタファンアウ ト タファンアウ トが 2以上の場合 占めるため, レジス. な くとも 不要である場合 表 4 よ り,少を示す. 持つ命令 は 7% 5 を占め, 1つの未解決 オペ ラン ドを. ることが望 そ こで, まれる.. も並列実行 を可能にす. 利用可能 にある命令 は 25% 逆 にすべ てのオペ ラ ン ドが オペ ラ ン ドの状態 の分布. を占めることが分かった.. の 7% 5 を占める未解決 オにお いて,依然 と して残 り. E内において リソースペ ラン ドを持つ命令 どう L がP 競合 を起 こ していることが. 表 4 命令 に対するオペ ラン ドの状態 (P S E.
(7) Vo l ・4 8 No・SI G1 3( ACS1) 9. 8 9. クラスタ型データバスによるスーパースカラプロセッサの低消戟 電 力 化. e. ce hm r FO st eeT es. 3 2 1 a a d pc meP 馴 dl 1 E L o P E E 1 s J l l n b a d e dP. T F O a t e m e E r ) el do 1 . 3 s 5 2+ .4 ap m d lc e np tE P E Dy n aml Cl ns t r u c. t 1 0. nSe qu en c e. ( b ) F O 4 s c h e m e. t l o ec l neトPEc onn t. Fi. 図 5 AdJaCCntPE Forn wa ne l t ・ w do ig r n k ( AF) 鰍 炎 図7. レジスタ77ンアウ. ° e dPE nba. Fl g7 工 nst-. 1 1 に 弘 命令ステアリン グ ucti o. ISteern ig b a se dづく ol lt l l er egse it lr a nOut.. tPE Forwa g・ 5 Adjacen l SS di AF)conf p E 州 , H U r E ng ( i gulati on. G磯 鰍 R E. ( a ). CJ o. I V e n t i o. l・. か ら予測す るのではな く, レジス タに値が書 き込 まれ てか らその レジス タを読 んだ回数 をカ ウ ン トす る こ とによ り得 られる レジスタ使 用回数 ( 動 的な レジスタ. d l n ae lx e c u t l O nO F d e p e ne AJ d da n t n i n s hc r wa r b C eH q ( n g n E j h y Q r k b)E ) : e c u t l 0 n. D f. d e p e ne dn t ) n s l r u c t l 0S nu S l n gAFn e 【 w o r k. 図6. 依存のある命令の実行の梯子. ファンア ウ ト) を指標 とす る.提案す るレ ンアウ トの数 に基づ く命令 ステア リング手 ジスタファ ように実現す る.未解決 オペ ラン ドを持つ法 は以下の レジス タファンアウ トの備 によ り,未解決命令 は動 的. Fl g 6 Executi on ofde. る ラン ド を生成す る PEあるいはその右側 に隣接す オペ よ. pendenti nsr t ucti ol l S. PE に命 令 を割 り付 ける.未解決オペ ラ ン ドをまった く. の隣接 p をステア リングす ることか らなる.1方向 うに命令 的なコスE間の通信経路 とした理 由は,ハー ドウェア. い命令 図 は負荷黄小 の PE に割 り付 ける.. 傾向 をふ トの面 とプログラムにおける命令列の特性の. ア リ 7にレジスタファンアウ トの数 に基づ く命令 ステ. 所的な通信経路 PE間に 1方向の局 まえたことによる.隣接 を. トの閥値 ング手法の詳細 によ り様 々な構成が可 を示す.動 的 レジス タファンアウ. 持 たな. 理的な距離が配線追加す るコス トは,隣接 PE 間の物. ス タファンアウ トが 2である命 能 となるが,特 に レジ. 雑度 も低 いこ とか遅延が問題 ら,1分 にノ にな 」 、さ らない程度 に短 く複. 方式 と,PE 間通信の ロス を 令のみ に着 目 した FO2. た, レジス タファンア ウ トが 2以い と考 え られ る. ま. を同 レジスタファンアウ トが 4までの命令 最小限 とす るため に動的. 占め ることか ら, レジスタファン 下の命令 が 90% を. いは隣接 pE. 令の転送 を想定 した 1方向の通. アウ トが 2である命. 一 PEある. 1 9 7では,命令 に割 り付 ける FO4 の 2つi を取 げる.[ i,i,i,i l 2 3方式 4は命令 O り上. を利用 し,命令 i Oは実行 されてい ないため結果 の結果 は れる. 図 5 は隣接 pE 間の 協. a dj. ac e n. tPE 演. 信経路 で十分 と考 え ら. AF: 調 を行 うため の構成 ( Fo r war di l l g) を示 す.各 pE にお ける. すべ ての隣接 pE間 PE に直接バ イパ スす る通信経路が 算 の結果 を隣接 形成 す る.図 6 は,に追加 され,全体 と してルー プを の PE で実行 され る様 依存 のあ る命令が 隣接 す る 2つ 成 においては依存 の による遅延が発生 においては依存. a )の従来 の構 子 を示 す.図 6( あ る命令の実行 の間に PE 間通信. b の AF構成 して しまうが,図 6(). 未 l, 解決であ る場合 を想定 してい る. この とき,倉令 i. i 2,i,1 3 4の動 的 レジスタファンアウ ト はそれぞれ 1, 2,3 図 ,4 7( aであ る. であ る命令 を隣 )7 02方式 は動 的 レジスタファンアウ トが 2 i 2は隣接 す る P接 E PE にステア リングす るため,命令 3や i 4は負荷最 小 の PE に割 り に割 り付 け,命令 i レジス タファンア 7( b4 )F 付け ウられる.図 トが 2または でO4方式 は動的 令,その命令 を隣接 pE にステア リングす ある る命令 た の場. 2 4は隣接す る PE に,命令 i 3は命 令 i,i で実行 隣接 で きる.のあ る 2つの命令が連続す るサ イクル PE 間の フォワーデ ィング経路 るため に, レジス タファンア ウ トの. を有効 に活用す. テア リング手法 を提案す る.この命令 数 に基づ く命令 ス ステア リン 続命令 法 は レジス を並列 タファンアウ に実行 す ることを目的 トが 1 よ り大 と きい場 合 の後 グ手 ファンアウ トは But す る. レジスタ t sら15) の ように過去 の履歴 など. ( a ) F O 2. め,令.
(8) 情報処理学会論文誌 :コンピューティングシステム. 90. □C o nr vr ( ) ad y EA コ F FO2. ヰ∩ 壷. 8AF FO 4 □AF Abea l l. 3 5. 2. 35. v e d y r a 肝l F O 2. 02. Åug. AF A・ F A . b F e O " 4 a. 9 =15. 1. 00. 05. 10. 20. 30. 1 n s t r u c l 1 0 nS Sta l l ep d. 0. t. -. ~. ∴. 8 隣接 PE問の協 調 の効. ee f F et csoc fo o prt eal C ) nO f果. Fg8 i. Th 図. jc1) n t , p也 s . a dae 散 を行 う命令 ステアリングを提案 している 6 . し l l aらはデータ依存関係がある場合 PE に ,演算 結果 なが をつねに隣接する ら,Abe かし. なわち,オペ ラン ドの状態や書 レジスタファンアウ き込むとしている.す よらずつね. トに. る命令 リングである. ステアリ したがって,負荷分散が我々の提案す PE に割 り付けるとい う命令 ステア に隣接 想 される.. 07 ∩ 竺 壷空_ R = s o u r 声o ∩ .20. ング手法 と比べてうま くいかないと予. 価実験 PE の協調の効果 を確かめるために評 提案する隣接 を行 った.図 8は,8*1構成 において隣接 pE 間の協調 を評価 した結果である.各 PE の レジスタ数 を 32 とし,隣接 PE 間の協調の効果 を的確 に把握す るためにバ ン ド幅が 1の PE 間通信共有バスをモデル onvは隣接 pE のフォワーデ ィング 化 した.図中の c. 機構 を持 たない構成 を示 し,AF は隣接 PE 間にフォ ワーディング機構 を追加 した構成 を示す.また,各構 成の後 ろに利用 した命令 ステアリング方式が示 されて リング手法は PE の協調 を行 う構成 について命令ステア いる.隣接 FO2 ,FO4 ,Ab e l l a の 3種 隣接 pEの協調を行 うために通信経路を追 類 を用いた. あるいは FO4命令 ステアリングを行. 加 し,FO2. pC を うことにより,従 来の構成 と比べ て 1割 ほど 【 O させ ることが 可能である.FO2ステアリングと F 向上. を比べた場合 ,FO2ステアリング 4ステアリング 達成で きることが分か の方が高い I PC を くの命令が割 り付 けらる.これは,隣接する PE に多 本来の処理のために必れると,隣接する PE における I PC が低下 して しま 要な リソースを奪 って しまい, うためン と思われる. Abea l l らの命令ステアリ , c onv構成 と比べて もI グは PCが低いことがある.Ab e l l a らの行った実験. NT ベ ンチマークを 8 いても sp甘C2000I PC は c onv構成 おいて実行 した I SPEC2000FP プログラ on 成 とした場合は c. にお. *1 AF棒成 に. よりも l PC が低 く,. ムを実行 した場合や 8*2AF構. 報告 している16). したがって を達成すると v構成 より,Ab 高い I P C l l は依 e aらの手法. C o n. 亘. 40. 50.
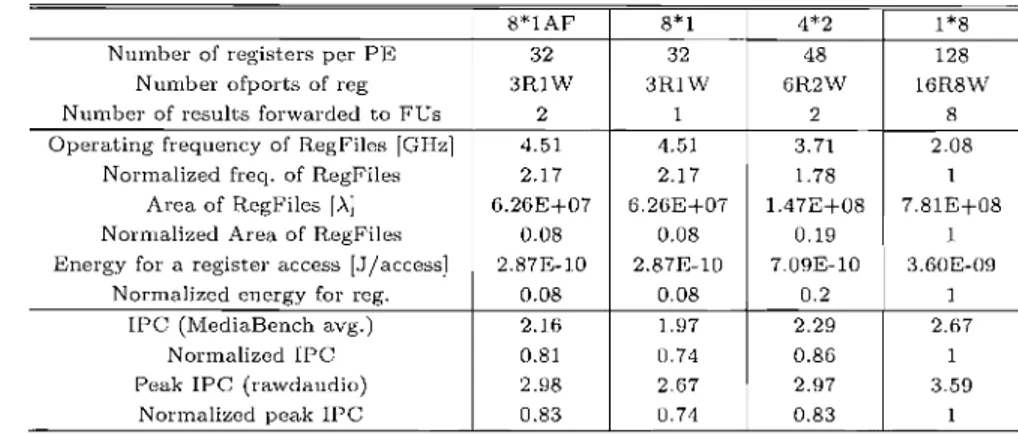
(9) Vol ・48 No・SI C 13( ACS 19). クラスタ型データバスによるスーパースカラプロセッサの低消費電力化 表 6 クラスタ化の効果 と t pc. Tabl c6 Thee f f ec t sofcl us t c l lngandt heI PC obt al nCd 8*lAF Nl l mbe rof t el Spe rPl ∃ Numb Nu e 70 l l l b f e ro l e S r ut l l e sf g pi o s o r r t wa so l ・ r d一 eg e dt oF. Ar eaofRe q gFofRegFi l e s i l e s Enel No r ma l l Ze dAr e ao f Re r A g ] F l e s gyr o上ar e gi s t e l ・ a c c e s s[ Ji / Nor mal i Z ・ ede a c c es s ] ne r gyf o上r e 岩 . I PC ( Medi aBenc havg・ ). 32 3RIW 1. 4. 51. UG Ope r at i ngf r eque ncyOfRe gFl l Nor mal i zcdf r c csr GHz I. 4* 2 48 6R 2 2W. 4. 6. 2 1 77 2 6. E +0 0. 08 2. 87E1 0 C I 21 . 06 8 0. 81. . 57 1 6 21 . 20 6. E+0 08 7 1D 2. 87E0. 08 07 1. 94 7. 08 2. 29. 08 2. 93 8. 2. 07 64 7. 2 08 . 93 7 6. PeNor mal i zedl PC No a l kI ma P l C( l aWdaudi o). サ における PE 間の フォ. 8*1. 32 3RIW 2. i zedpeakI PC. ロセ ッサの動作 周波数 を決定す ワーデ るう ィング経路 の遅延 はプ. ス タファイルの動 作周波数 と消費エ ネルギーは CACT1. パ ス とな らない と考 える.Abe. 用 いて見積 もった.半導体の. えで クリテ ィカル. l l aら16)は,隣接. 間の フォワーデ ィング経. PE. 2. 0モデル1 7)を. 07/ 皿 を 設計 ルールは 0.. 想定 した.また, レジス. かない とい うことを裏付路 の遅延が性能低下 に結 び付. レジス タファイルに必要 なポー ト数 タフ ァイルの面積 は各 pE の. ルで実際 に レイアウ トをけるため,機能ユニ ッ トレベ. eの手法 18)・ 力 と して Le. デ ィング経路 に必要 な レ行い,隣接 pE 間の フォワー. 2人 - 0. 07I L. 内での フォワーデ ィング イア ウ ト上 の距離 は同一 pE と見積 もった. フォワーに必要 な距経 と同程度 である. とレジスタ数 を入. 1 9)に よ り算 出 した. ここで, クラス タ型 と等 しい ッサとして計算 した. mプロセ. 動作 速度,消費エ ネルギー,お の構成 , レジス タファイルの. 結果 を転送す るバスの配線 デ ィング機構 における遅延 は. に示す.各構成 の命令 ステア リング手法 よび面積は の関係 を表 6. れてい ることをふ まえる と遅延が支配的 となるといわ. 造 は FO2,そのほかは! ra ed. の遅延 はフォワーデ ィン. 1), フォワーデ ィング機構. の各 PE の レジス タファ. ,8*1AF 構. y手法 とした.X* Y 構成. に比例 す るとい える. しグ径路 の レイアウ ト上の距離. 数は pE 内の FU のた. の フォ. と pE 間通信 の共有バめの 2Y リー ドY ライ トポー ト. たが って,隣接 PE 間の結果. 性能低 下 ワーデ ィング経路 は十分 に局所 的であ るため, 間のフォワーデ 隣接 PE に結 び付 か ない といえる.. イルにおいて,必要 なポー ト. した.各構成の レジスタフ スのための Y リー ドポー トと ては, クラス タ化 を行 わなァイルの レジスタ数 につい. サの動作速度低下 を引 き起ィング経路の遅延が プロセッ. クラス タ化 を行 った構成 にい構成 の 128 を基準 とし,. pE 間の協調 による IPC. 数分 に分割 し, PE ごと. こさないのであれば,隣接. ついては 128 を pE の個. 理能力 を向上 させ るとい の向上 はプロセ ッサ全体 の処. 均衡 を是正す るため に分割 の利用可能 さh な レジスタ数の不. フォワーデ ィング回路 をえる.一 方で,隣接 PE 間に. 16個 を加 えるとした. 8*1AF. タ化の度合い を低下 してい 追加す ることによ り,クラス. ルの構成 は 8*1構成 と同一 とな 構成の レジス タファイ. *1構成 にお なる.た とえば 8 る場合 と非常 に近い構成 と. 成は 4*2. うと, 4*2構成 に近 い構成. あ るが,構成 とフォワーデ ィング経路 の個数は同一で. いて隣接 PE の協調 を行. る要素 は レジス タフ ァイルとなる.両者 の構成 を分 け つの PE が独立 して 1つ. の構成であ る. これは,I. た レジスタファイルに る. また, 8*1AF 構. 型 プロ 表 6にクラ レジス スタ タフ ァイルが異 なる. フ ァイル と IPC の評価 セ ッサの構成 ごとに レジス タ. いる と想定 してい るための レジスタファイルを備 えて. タファイルの動作周波数を行 は,高 った結 果 を示 す. レジス. ど, レジスタファイル も分散 であ され,小 る. クラスタ化 面積で低 を行 うほ. ほ ど高速化が可能 とい うことが度 にクラス タ化 を行 う. 力かつ高速な動作が期待 され る半面,通信 に 消費電. パ ースカラプロセ ッサ を. 分か る.8-way のス-. 場合 に レジス タファイルの動作周 8個の PE にクラス タ化 した 低下が予想 クラス タ型 され プロセ る. ッサ. よる性 能. 2 は,クラス タ化 を行 わない構成 (1*8) と比べ て 波数. を調 を分散す ることによる影響 において, レジス タファイル. にクラス タ化 した場合 には 1. ファイルの動作 速度,消費エ わべ レギー,な るため に, らびに必要 レジス タ. となる面積 の見積 りを行 った. レジ. . 17倍 , 4 個 の PE 91.
(10) 9 2. 情報処理学会論文誌 コンピューティングシステム. ジス タアクセスのために必要なエ れ レギーは,高度 に. Aug.2 0 0 7. りレジス タファイルの動作周波数の向上や面積の削減. クラス タ化 を行 うほ ど大幅 に減少す ることが分か る.. といった効果 を期待で きる点 もクラス タ化の有効性 を. 面積 と消費エネルギーはほぼ同等の傾 向を示 し,8個. いっそ う引 き立 たせ る方式であるといえる.. の PE にクラスタ化 した場合はクラス タ化 を行 わない 場合 と比べ て 1 2分 の 1程度 に,4個の PE にクラス タ化 した場合 は 5分の 1程度 となる.. 6. 関 連 研 究 本研 究 においてベ ース と した未解決 オペ ラ ン ドを. 同時発行可能な命令数が増加するにつれて, レジス. 持 つ命 令 をデ ー タ依存 に基 づ きス テ ア リ ング を行. タファイルの消費電力の増大がプロセ ッサ を実装する. う!1 ・ e ady方式 をさらに拡張 した命令 ステア リング方. tb r lらは20),8命令 うえでの大 きな制約 となる.Zyla 同時発行可能なスーパースカラプロセ ッサ において レ. 式 として,依存のある命令間の発行時間差 に基づ き命. ジス タファイルの消費電力 はキャッシュを除 くコア全. 式 は,命令 キューにおける発行時間差 を算出す るため. 1i ds t )がある21).l di s t方 令ステアリングを行 う方式 (. 体で約 4割 を占めることを示 している. レジス タファ. に,ステア リングされた命令 に対 して PE ごとに通 し. イルの クラス タ化 を行 うことによりデータバスにおけ. cl itne( 1i ds) t 番号 を付 ける.この番号の差 を Loadsac. る消費電力の 4割分 を 1 2分の 1に削減で きるとする. と呼ぶ.未解決のオペ ラン ドとその依存する先行命令. と,データバスの消費電力は元の 6割程度 となる. し. di s tが閥個 を超 えない場合 ,RMBS方式 と同 の間の l. たがって,クラス タ化 によ りレジス タファイルのアク. 様 のステアリングを行 う.開催 を超 えた場合 は,その. セスごとの消費エネルギーを大幅 に削減す ることは,. 命令 は PE 同通信 を挿入 して も I PC には影響がない. プロセッサの低消費電力化 に大 きく貢献するといえる.. と判断 され,負荷が最小の PE に割 り付け られる.負. クラスタ化 によりレジスタファイルを分割す ること. され 荷 の状況 は PE 内の末発行命令数 を用 いて監視 ′. によりI PC は低下する.I PC について,Me di aBe nc h. る.! r e ady方式 は,1 di s t方式の距離 の開催 を無限大. の平均 を比較 した ところ,8*1構成 は 1 *8構成 か ら. として未解決 オペ ラン ドの場合 はつねに同一 PE に割. 26%ほど I PC が低下 したが,8*1 AF構造 においては 1 *8構成 よ り 1 9%ほどの低下 に抑 えられることが分か. り付 ける とした場合 と同等である. また ,1 di s t方式 は,! 1 ・ ed ay方式 と比べて番号の生成や記1 嵐 距離の算. *8構成か ら 1 4%ほど I PC が る.一 一方 ,4*2構成 は 1. 也,比較 にハー ドウェアを追加す る必要がある.. 低下 している,. 本論文で提案 しているレジス タファンアウ トに基づ. クラス タ化 された構成において,どの程度の I PCが. く命令ステアリングと服部 らの l di s t方式 21) はある動. 期待で きるかを調べるために,ベ ンチマークを通 して. 的な指標 に対 して特定の開催 を与 え命令 をステアリン. のI PC の最大値であるピー ク I PC を比較 した ( 表 6. di s t グする点 においては共通である. しか しなが ら,1. 下段).クラスタ化 を行 っていない 8 wa y構成の スー. *8構成の ピーク I PC は 3. 59であ. パースカラである 1. 方式 は隣接する PE に命令 をステアリングする基準 を 設定するのが困難であるのに対 し,我々の提案手法は. り,8*1 AF構成 は 1*8構成 と比べ て 1 7%だけ ピーク. 命令の逐次性 を意識 しつつ隣接 PE に命令 をステア リ. I PC が低下 している.8*1 AF構成 は 4* 2 ] 構成の ピー PC をわずかだが凌駕 している.この結果は,クラ クI. アの違いとしては,動 的 レジス タファンアウ トを観測. スタ化の度合いを増加 させて も,隣接 間 PE の協調 に. するためには レジス タごとに使用 された回数 をカウン. ングを行 うことが可能である.必要 となるハー ドウェ. より効率良 く処理 を行 えば性能低下 を回避可能である. ds it トす るカウンタを必要 とす る-方で,服部 らの I. ことを示唆 している.本実験 においては,コンパイラ. 方式 は発行時間差 を算出するために命令キューデ の中の. の出力するバ イナ リコー ドをその まま人力 としたが,. エ ン トリ間の距離 を測 るハー ドウェアを必要 とす る.. アセンブ リレベルの最適化 を行 うことにより,隣接す. 服部 らはクリテ ィカルパス情報 を過去の履歴か ら推. る PE の協調 を支援す ることによ りさらに高い I PC. 測 し,クラス タ型スーパースカラプロセ ッサの命令ス. を達成で きると考 え られる.. テアリングに応用するという報告 も行っている22). し. 以上 よ り,8*1 AF構成 は 4*2構成 と比べ て レジス. か しなが ら,クリティカルパス情報だけでは不十分で. タファイルの消費電力 を 2分の 1以上削減 しつつ,同. あ り負荷情報 を組み合わせ ることが重要 と述べている. 等 レベルの I PC を達成するといえる. したがって,隣. ので,適 切な命令のステ7 リングの基準が重要である. 接 間PEの協調は,クラス タ化 による低消費電力化 と. と考 え られる.本論文 においては隣接 PE 間の協調動. いう利点 を最大限 に活用す る と同時 に,高 い I PC を. 作 を行 うためにオペ ラン ドの状態 とレジス タファンア. 達成する方式であるといえる.また,クラスタ化 によ. di s tの ような指標 や ク ウ トとい う指標 を用 いたが ,1.
(11) vo l4 . 8 No.SI G1 3(. ACS1 9. ). クラスタ型データバスによるスーパースカラプロセッサの倣 桐 J t I . = l d力化. リテイカルパス情報か ら適 切な指標 を見つけ出 し隣接. pE 間の協調動作 を行 うことも考 え られる.命令 ステ アリングのための指標 を得 るためのハー ドウェアコス トを含めて適切 な命令 ステアリング手法 を確立するこ. 9 3. l owe re ne r gy. ,Pr o c. ・35. t h armualACM/E I EE o a r c hJ i t e c i ur e7 mt e r na t i onals y mpo s Z , um o nMwr p. p. 1 7. 1. -1. 2( 8. 2. 002. ) . P. 9. )Hr s hi ,D・ ,Jouppi ,N. i ke s h,M. S. ge r , ,Bur c. kl e r Ke ,SW . " Far k a s,K. I .and Shi vau km P: .Theopt i. mallicd og e pt hpe rpI Ph enes t age i s6t o8FO4i nve re trdl ea ys,Pr o c . 29 t hamu r al it ne r nat i o nals u m, pos i um o n Compue tra r c, h乞 t e cu tr 1. 4. 1. 2. 4(. 2. c,pp・ 002. ) . le, :I nc r eas i ngpr ang E.andCar mcan,D・ o1. 0)Spr e by i mpl e me nt i ng de e pe r c e s s orpe r f or manc pp le l i ne s ,Pr o c .29t har mualit ne r nat i o nas ly me r c, ht t ur C ,p p.. 25. -3. 4. pos i um o. n CompIL t ra C C t ( 2002. ) , ao. ,Sur ,K・and Nakamur ll)St ,Y・ Jk ui a,T・ : Anoper al l ds tt ausbas e. di nsr tuc t i onse te r l ng o l use tr e. s cc h nl Cfrc dar c hi t ecu tr e s ,Pr o c .2005. ne fr e nc trDe s i g n It ne r na如 nalCo eo nCompue ) ( CDES' 05. ,. pp.. 16. 8. 11. 7. 4( 2. 005. ) 1. 2. )Par ce r i s a,J,. -. M.andGonr Jl ac z,A・ :Re duc i ng wi r ede l aype na lt yt hr oug h Va luepr e di c t i on, Pr o c .33r da nnual7t , ne r nat i o nals y mpos mm on 31. 7. -3. 2. 2. ra Or C h ,. 加c t ur e,pp,. 6(. 000) . MIC , 1. 3. )Cana. l ,R. ,Par c er i s a,J. l M・and Gonzae ly J A∴ A CostE庁e c t i veCl use tr e d Ar c hi t e cu tr e , 9It Pr o c .. 19. 9. ne r na. t wnalCo ne fr e nc eo nPa r al l e lAr c hi t e c t ur e sa ndCompi l at i o n Te c hmq. ue s, 8(. 1. 9. 9. 9. ) . pp.. 1 6. 0 -1. 6. aj an,R・ ,He )Sana kr a li nga. m7K・ ,Nagar c kl e r , 1. 4. Scaa lbl S.andBur ge r 7D∴A Te eAr cn l lOl ogyLP,5t C hi t e c t o as urefrF tCl oc ksandHi h , g I h Worso kh ,ponte h ,I nt r ac t nBe e nCompi e i o t we l ) . e r. sa n. dCo m, puc trAr c, hi t e c t ur e s( 2001. e r i zn igand 1. 5. )Bu. t t s ,.. ∫A,andSohi ,G. S: .Cl l ar aCt pr e di c t i ngva luede gr e eofus eっPr ・3. 5. l h ,ano c nualACM/I E. EE i. ne tr nat i o nals y mpo s mm L,OT I e,pp.. 15. 1. 2. 6(. 2. 002. ) . t ur M甘 CO ra r C h , i t e C n Gonzle a z, A・ )Abe la7 ∫. ad :Ⅰ nher e nt l y 1. 6. Wor kl oa. dBaa lnc e d Cl use tr e d Mi c r oal ・ C l li t c c ( l r,. とは今後 の課題である.. 7. 結. 論. 本論文では,クラスタ型スーパースカラプロセ ッサ の利点である低消費電力性 をさらに引 き出すため に, プログラムに内在する逐次性 に着 E lL,クラスタ化 さ れたデータバス上 において効率的に実行す ることを試 みた.: プ ログラム中の逐次性の指標 として命令実行時 にオペ ラン ドの状態 とレジスタファンアウ トを観測 し, 隣接する PE において協調 を行 うことを提案 した.秤 価実験 の結果,隣接 PE 間の協調 を行 うことによ り, 従来手法 よ り I PC の低下 を抑 えつつ, レジス タファ イルV) 消費電力 を大幅 に削減で きることが分か った.. 参. 考. 文. 献. )Paa l , S, , NP. ad n Smi t h, 1. li har a. . Jouppi J.. E: . Co. mpl e x. i t yee f c. t i v. es upe r s ca larpr oc es I s or s,Pr o c .2 4. t ha r mualmt e r nat wnals y mp o206. 1 2. 1. 8. s i um o n Co m, pue tr ar c, hi t e c t ur e,pp. ( 1. 9. 9. 7. ) ・ 2)佐藤幸紀,鈴木健一,中村維男 :プログラムにお ける命令の並列性 と逐次性 について,情報処理学会 3 2004. 研究会報告 2004. 1. ,pp. 112(. 5. 7. ・ 1. 2. ARC) ・ 3)佐藤寿倫 :命令 レベル逐次 プロセッサ,情報処理. 006. ) . 学会研究報告 2. 1. 6. 9. ,pp.. 49. -5. 4(. 2. 006. ARC.Non4)Ll os a,J. ,Va le r o. ,M.andAyguade,E: Cons i se tntDualRe gse itrFi l e st oRe dt l C eRe gi se tr Pr e s s ur e,Pr o c .ltI s EEE Smp y o s mm onmp. hPe r f o r manc eCo mpue trAr c hi t e c t ur e, p. p.. 22. -3. 1(. 1. 9. 9. 5. ) i a,T∴Po 5)Sao Y・ 】Sur z uki K・andNakamur t , , we l ' mat i ono fPar Es t i t i t. i one. d Re gse itrFi l e si na Cl ure. wi hPe manc dAr c hi t ec. t t. r f or eEvaL use tr e. EI CE 升ans.I T l ・ f or mat i o na nd Sy s uat i on,I t e ms,Vol Ego. D,No., 3 pp.. 62. 7. 1. 6. 3. 6(. 2. 007. ) . .. 6)De s i kan,R . , B ur ge r,D・and Ke c kl I. : cr ,SW Meas ur i ngExpe r i me na tlEr r ori nMi c r opr oce s s orSi mult ai on,Pr o c . 28t h J a r mualit ne r nat i o nal s ympo su Tm,OnCompue trar c hi t e cu tr e,pp・ 2. 6. 6. 2. 7. 7(. 2. 00号 S・ gse itrt ,GI 7)Fhnkl ( l f f i c n,M.andSohi i :Re r a1 1 a s i r eaml ii nngi o t ly sfrs ne tr opca lt .i onc om-. munc iat i on i nf ine gr ai n par al l e lpr oce s s or s, Pr o c .25t hamu r alit ne r nat wnals y m′ po s i um o n 23. 6. -2. 4. 5( 1. 9. 9. 2. ) . Mi c r o ar c hi t e c t ur e,pp.. j a ykumar,TA : 8. k,I , D・andVi ・P , owe )Pa r l lM・ N. olhih ge pe ・ t duc i ngl ・ e gse itl ,pOl Re Sf・ rse d and. A. l. t u. e. r 】Pr o c. .lot hI EEE I ne tr nat i o nalPar al e l l a n dDi s t r i bt ue dPr o c e s s mgSm y po s i um,p・ 2. 0a ( 2005 ) ・ , NI P・ : CACTI )Re i nman, G・ and Jouppi 1. 7. 20 ,:AnI ne tgr ae td Cac heTi migad n n Po we r e Modl e,Tc c hnc ia lr e por t s e ar 7WRL Re c h R′ 000) I por t2000/. 7(. 2. i z e r l l e ・Or gse itl )Le e,C∴CodeOpt mi sadR ga 1. 8. co trAr c hi nz ia. t i onso. frVe t e cu tr e s ,Ph. D.Thev.ofCal 9. 9. 2. ) , i f or naa i tBc rc kl c. y( 1. s i s,Uni ,Vae lr z,. D, os a . o,礼 / 1. ・andAygl ld ae, 1. 9. )Lope ,Ll ostC o. l l S. C. i ou. sSt r ae tge ist oI ncr eas ePe r E∴C. f or. man. c cofNume r i calPr ogr amson Aggr e s s i veVLI c hi. t e cu tr e s ,. I EEE 7 7 ans ・Com・ W Ar. 1(. ,Vol . 50,pp. 1 03. 3. -1. 05. 2. 001. ) . put . , I.
(12) 9 4. 情報処理学会論文誌 :コンピューティングシステム. 2. 0)Zyuban. ,VV・a . l l d Kogge,PM∴ . Ih ne r e nt l y Lo we r Powe I I Hi ghmaI Pe r f o r I Ce S upe r s c aa lr Ar c hi t e cu tr e s .I EEE 升a ns .Co mpui . ,Vol , 50, No1. 3,pp・ 2. 6. 8. -2. 8. 5(. 2. 001. ) . 2. 1. )服部直也,高田正法,岡部 淳,入江英嗣,坂井 修一,田中英彦 :発行時間差 に基づいた命令 ステ ア リング方式,情報処理学会論文誌 :コンピュー テ ィングシステム,Vo. l45,No. SI Gllp , p. 8093. ( 2. 004. ) i )服部直也 高田正法,岡部 淳,入江英嗣,坂井 2. 2. 修一,田中英彦 :クリテ ィカルパス情報 を用いた 分散命令発行型マイクロプロセ ッサ向けステア リ ング方式,情報処理学会論文誌 :コンピューティン グシステム,VoI A57NoI SI G6,pp・ 1. 2. -2. 2( 2. 004. ) ・. 平成 4年東北大学工学部 正会員) 科卒業.平成 6年東北大学機械工学 大学院情 報科学研 究科 博士前期 2年 博士課程 ( 9年 同 ( 機械工学専攻)修了.平成 の課程 同年,宮城工業高等専門学校情報 情報基礎科学専攻)修了. デザ イン学科助手 に 採用.平成 11年同講師に昇任.平成 1 5年か ら東. ( 平成 1 9年 1月 22日受付) ( 平成 1 9年 4月 27日採録). 平成 佐藤 1 幸紀 ( 正会員) 3 年東北大学工学部機. 5年東北大学 大学院情報科 能工学科卒業.平成 1 械知 程修了.平成学研究科前期 1 8年東北大学大 2年の課 博士 ( 情 入社後. 情報科学研究科後期 3年の課程修了, 学院. 報科学).同年 ファインアーク株式会社入社.. 民間等共同研究員研究 として組み込みプロセ も東北大学大学院情報科学研究科大学院研究生, テムの低電. ッサ シス. 4月 より北 力化 に関す る研究開発 に従事.平成 1 9年. セ ンター). 陸先端科学技術大学院大学助数 ( 情報科学 テムやその応用に関する研 計算機 アーキテクチ ャ,高性能計算 シス 究 に従事.. 鈴木 健一 (. 0 0 7 Åug.2.
(13)
図
関連したドキュメント
および皮膚性状の変化がみられる患者においては,コ.. 動性クリーゼ補助診断に利用できると述べている。本 症 例 に お け る ChE/Alb 比 は 入 院 時 に 2.4 と 低 値
平均的な消費者像の概念について、 欧州裁判所 ( EuGH ) は、 「平均的に情報を得た、 注意力と理解力を有する平均的な消費者 ( durchschnittlich informierter,
エネルギー大消費地である東京の責務として、世界をリードする低炭素都市を実 現するため、都内のエネルギー消費量を 2030 年までに 2000 年比 38%削減、温室 効果ガス排出量を
・カメラには、日付 / 時刻などの設定を保持するためのリチ ウム充電池が内蔵されています。カメラにバッテリーを入
・電源投入直後の MPIO は出力状態に設定されているため全ての S/PDIF 信号を入力する前に MPSEL レジスタで MPIO を入力状態に設定する必要がある。MPSEL
①正式の執行権限を消費者に付与することの適切性
消費電力の大きい家電製品は、冬は平日午後 5~6 時前後での同時使用は控える
なお,今回の申請対象は D/G に接続する電気盤に対する HEAF 対策であるが,本資料では前回 の HEAF 対策(外部電源の給電時における非常用所内電源系統の電気盤に対する
