住宅ローンにおける生存時間解析
辻谷将明
g、外山信夫
ggSurvival analysis for housing loan data
Masaaki TSUJITANI and Nobuo TOYAMA † ††あらまし 従来、生存時間解析では打切り例を取扱う方法として、Cox の比例ハザードモデルが 広範に用いられてきた。しかし、住宅ローンの融資データのように、共変量の値が時間と共に変化 する時間依存型データが含まれている場合、Cox の比例ハザードモデルには、多くの問題点が存在 する。本稿では、二項分布に基づく部分ロジスティック回帰モデルを拡張し、階層型ニューラルネ ットによる生存時間解析を試みる。データ解析の目的が予測にあるなら、母集団構造の非線形性を 摘出するだけでは不十分で、適切な非線形モデルで記述しなければならない。ニューラルネットワ ークモデルを想定し、ブートストラップ法による隠れユニット数の決定やモデル妥当性の検証、お よび生存関数の予測や残差プロットなどについても考察する。 キーワード 比例ハザードモデル、時間依存型データ、部分ロジスティックモデル、ブートスト ラップ法、逸脱度、残差プロット 1.はじめに 人間の脳・神経系の情報処理を模倣したニューロ・コンピューテイングが新しい展開をみせている。 1985 年以降、階層型ニューラルネットは、バックプロパゲーション・アルゴリズムの開発を契機と し、分類問題の視座から脚光を浴びている[1]。更に近年、ニューラルネットによる生存時間解析が、 Cox の比例ハザードモデルに対抗して注目されつつある[2],[3]。しかし、住宅ローンの融資データの ように、共変量の値が時間と共に変化する時間依存型データが含まれている場合、Cox の比例ハザ ードモデルには、多くの問題点が存在する。 本稿では、二項分布に基づく部分ロジスティック回帰モデル[4],[5]を援用し、階層型ニューラルネ ットワークによる生存時間解析を試みる。ニューラルネットワークモデルを想定し、ブートストラ ップ法[1]によるモデル妥当性の検証、および隠れユニット数の決定を行う[6]。更に、共変量の有 意性検定に基づく生存関数の予測や残差プロットについても考察する。本方式は、生存時間そのも のを共変量として取込み、部分ロジスティックモデルを援用することによって、1) 時間依存型デー タの取扱いが容易、2) 観測期間全体を考慮に入れて解析、3) 比例ハザード性の制約が不要、4) 共 変量の非線形性を考慮、5)死亡例が少ない場合も適用可、などの利点をもつ。 g 大阪電気通信大学 総合情報学部,寝屋川市
Faculty of Information Science & Arts, Osaka Electro-Communication University, 18-8 Hatsu-cho, Neyagawa-shi, 572-0833 Japan
gg
住宅金融公庫 住宅総合調査室,東京都
2. 階層型ニューラルネット 時間依存型の生存データの実際例として、住宅ローンの融資データを取上げる。例えば、図 1 の ような住宅ローンの返済パターンを考える。観測期間が 1984 年から 2001 年までのとき、A 氏は、6 年目に返済不能(死亡)、B 氏は 5 年目でも返済中(打切り)である。通常の比例ハザードモデルによ る解析では、A 氏は生存時間が 6 で死亡、B 氏は 5 年目に打切りとなる。 ’85 ’86 ’87 ’88 ’89 ’90 返済不能 A 氏 (死亡) ’97 ’98 ’99 ’00 ’01 返済中 B 氏 (打切り) 1 2 3 4 5 6 年数 図 1 住宅ローンの返済パターン
Fig.1 Repayment pattern of housing loan
エンドポイントに影響を与える共変量(因子)として、ボーナス返済率、手持ち金、失業率および 地価増減率を取上げる。この中で失業率と地価増減率は、時間依存型データになる。すなわち、図 2,3 のように時系列データになるため、返済時期によって、共変量の値が変動する。このように時 間とともに変化する時間依存型データが含まれる場合、従来の Cox の比例ハザードモデルでは、比 例ハザード性が成立たない[7]。 5 -0.1000 0.0000 0.1000 0.2000 1981 1986 1991 1996 地価増減率 西暦 資料:(財)日本不動産研究所 図2. 地価増減率の時系列変動 Fig.2 Time series change in land price
一般に、d 番目の被験者(それを#d で示す)による入力データをXl< >d =
(
al< >d ,xl< >1d ,xl< >2d ,...,xlI< >d)
と書く。A 氏(#d)のデータは、表 1 のようになる。表 1 は、1 人の被験者が 6 個の観測値を生成して いる。 6 失業率 西暦 2.00 3.00 4.00 5.00 1980 1985 1990 1995 2000 図3. 失業率の時系列変動Fig.3 Time series change in unemployment rate
表 1 A 氏(#d)の入力データ Table 1 Input data for #d 時間区間 l 生存時間 d l a< > ボーナス返 済率 1d l x< > 手持金 2 d l x< > 失業率 3 d l x< > 地価増減 率 4d l x< > 1 0.5 0.00 720 万 2.64 -0.015 2 1.5 0.00 720 万 2.93 -0.020 3 2.5 0.00 720 万 3.23 -0.013 4 3.5 0.00 720 万 3.36 -0.016 5 4.5 0.00 720 万 3.48 -0.034 6 5.5 0.00 720 万 4.33 -0.038 2.1 部分ロジスティックモデル グループ化された生存データについて考案された、二項分布に基づく部分ロジスティック回帰モ デル[5]をベルヌーイ試行に援用する。時間依存型共変量をもつグループ化されていないデータにつ いて、(離散)ハザード関数に対する部分ロジスティックモデル
(
)
0 0 1 , , 1; 1, 2, , ; 1, 2, , 1 exp -d d d d l l l I l d d d l i li i h t x l l d a x β β < > < > < > < > < > < > = = ≡ = ⎡ ⎧ ⎫⎤ + ⎢ ⎨ + ⎬⎥ ⎩ ⎭ ⎣∑
⎦ x = n)
(1) を提案する。ここに、n は総被験者数で、 は d 番目の被験者に対する時間区間の個数である。表 1 の場合、共変量は d l(
5 =I 個で、その個体は、6(=ld)個の区間をもつ。 のすべての個体に 対する表 1 のような共変量を入力データとする。生存時間値そのものを共変量として取込むことに よって、観測期間全体を考慮した時間依存型データの取扱いが容易になる。この部分ロジスティッ クモデルをニューラルネット表示すると 図 4 のようになる。 887 n=t
x
1
x
2
x
3
x
4
1
i
α
β
1
入力層⎯⎯
恒等変換⎯⎯
→
隠れ層⎯⎯⎯⎯⎯
ロジット変換→
出力層 図 4 部分ロジスティック回帰モデルのニューラルネット表現 Fig. 4 Representation of partial logistic regression model by neural networkJ さて、入力 d が与えられたとき、隠れ層の第 l < > X j( 1, 2,..., )= ユニットの活性値 0 0 1 , 1; 1,..., ; 1,..., ; 1,..., I n d d d lj l ij li j d d i d u< > αa< > α x< > α d l l l j J = = = +
∑
≡ =∑
= = に、恒等変換 d d lj ij y< > =u< > を施すと、隠れ層の第 j ユニットの出力値y が決まる。これが、出力層への活性値 lj 0 1 d d l j lj j v< > β y< > β = =∑
, 0 ≡1 となる。 d にロジット変換を施すと、最終出力(離散ハザード関数) l v< > 0 0 1 1 exp -1 (2) 1 <d> <d> l l 1 I d d j l ij li j=0 i I <d > d l i li i h x a x β α α γ γ < > < > = < > = ⎡ ⎛ ⎞⎤ + ⎢ ⎜ ⎟⎥ ⎝ ⎠ ⎣ ⎦ = ⎡ ⎤ +⎢ + ⎥ ⎣ ⎦∑
∑
∑
( )= + x が得られる。これは、グループ化されていないデータに対する部分ロジスティック回帰モデル(1)と等価 である。これを図 5 のような階層型ニューラルネットワークに拡張する。t
x
1x
2x
3x
4 jβ
ij
α
入力層⎯
ロジット変換⎯⎯⎯⎯
→
隠れ層⎯⎯⎯⎯⎯
ロジット変換→
出力層 図 5 階層型ニューラルネットFig.5 Feedforward neural netwok
(
1, 2,..., d = n)
番目の入力Xl< >d が与えられたとき、隠れ層の第j( 1, 2,..., )= J ユニットの活性値 (3) 0 , 1; 1,..., ; 1,..., ; 1,..., I d d d lj l ij li 0 j d i u< > αa< > α x< > x l l d n j = = +∑
≡ = = = Jが定まる。(3)式の活性値 d にロジット(シグモイド)変換 lj u< >
(
)
1 1 exp d lj d lj y u < > < > = + − (4) を施すと、隠れ層の第 j ユニットの出力値y が決まる。これが、出力層への活性値 lj (5) 0 , J d d d l j lj l 0 j v< > β y< > y< > = =∑
≡0 となる。v
l< >d にロジット変換を施すと、最終出力(離散ハザード関数)(
)
(
)
0 0 1 1 1 exp 1 exp 1 exp d d l l d l J j I j d d l ij li i h v a x β α α < > < > < > = < > < > = = = ⎡ ⎤ + − ⎧ ⎫ ⎢ ⎪ ⎪⎥ ⎪ ⎪ ⎢ ⎥ + ⎢− ⎨ ⎬⎥ ⎛ ⎛ ⎞⎞ ⎪ ⎪ ⎢ ⎪ + ⎜−⎜ + ⎟⎟⎪⎥ ⎢ ⎩ ⎝ ⎝ ⎠⎠⎭⎥ ⎣ ⎦∑
∑
X (6) が得られる。(6)式から分るように、最終出力は入力Xl< >d =(
tl< >d ,xl< >1d ,xl< >2d ,...,xlI< >d)
の非線形関数 であり、比例ハザード性を仮定していない。また、ロジット変換を用いているため、死亡例の少な いデータにも適用できる。 次いで、リンク荷重θ =(
α β α,)
, =(
α α,{ }
ij)
,β =( )
{ }
βj′
を推定するため、 1 1: ( , ] 0 : l l l d l A t t d o.w. δ< > = ⎨⎧ = − ⎩ 時間区間 で個体 が死亡v
l< >d=
(
δ
1<d>,
δ
1′
< >d,
δ
2< >d,
δ
2′
< >d,
,
δ
l< >−d1,
δ
l−< >1d)
1 1: ( , ] 0 : l l l d l A t t d o.w. δ′< > = ⎨⎧ = − ⎩ 時間区間 で個体 が打切り(
,)
d <d> d l l δl < > < > ′ = v v と定義する。ただし、 d は#d の最初の l-1 個の時間区間に対する履歴、 l < > v vl′< >d はδl< >d を含むまでvl< >d を拡張した履歴である。二項分布(グループ化されたデータ)に対する部分ロジスティック回帰モデ ル[5]を援用し、ベルヌーイ試行(グループ化されていないデータ)のもとでのリンク荷重θ を推定す る。 d l < > v が与えられたとき、δld < >はベルヌーイ試行(
)
, , d e l B 1 h< >θ に従う。ここに、 , d l h< >θ は離散ハザー ド関数である。そして、 d が与えられたとき、 l < > ′ v δl′< >d は局外パラメータς に依存するが,θ には依 存しない分布に従うと仮定する。全対数尤度は ( )(
)
(
) (
)
(
)
(
) (
)
(
)
, 1 1 2 2 1 1 1, 1 1, 1 1 , , , 1 , ln , ln , , , , , , ln 1 ln 1 ln ln 1 ln 1 ln ln 1 d d d d d d d d n d d d d d d l l d n d d d d d d d d d d d d l l l l l l d d d l l L f h h f h h f h ς δ δ δ δ δ δ δ δ δ δ δ δ δ δ < > < > < > < > < > < > = < > < > < > < > < > < > < > < > < > < > < > < > = < > < > ′ ′ ′ = ⎡ ′ ′ ′ ′ ⎤ = ⎣ + − − + + + + − − + ⎦ = + −∏
∑
v v θ ς θ θ ς θ θ θ θ θ ς(
) (
)
{
,}
(
)
1 1 1 1 ln 1 ln . (7) d d l l n n d d d d l l l l d l d l h f δ < > < > < > < > = = = = ⎡ ⎤ ⎡ ′ ′ ⎤ − + ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ ⎣ ⎦∑ ∑
θ∑ ∑
ς v となる。すなわちlnL
(
θ ς,)
=lnL( )
θ + Lln( )
ς}
, hθ (8) と書ける。(8)式の第 1 項 (9)( )
{
,(
) (
)
1 1 ln ln 1 ln 1 , d l n d d d d l l l l d l L δ< > h< > δ< > < > = = ⎡ ⎤ = ⎢ + − − ⎥ ⎣ ⎦∑ ∑
θ θ を部分対数尤度と呼ぶ(本例の場合、 である)。第 2 項 1 887, 1945 n d d n l = =∑
= ln L( )
ς は、θ に依存し ない。(9)式は、通常の意味での対数尤度ではないが、かなり広い条件のもとで、最尤推定量(MLE) の漸近的性質をもつことが証明されている[8]。(9)式を最大にするhˆl< d >( l d (すなわち、 < > x ) θˆ) が最尤推定量となる。 2.2 隠れユニット数の決定 ニューラルネットは、母集団モデルの近似であるため、真のモデルと想定したそれとは分離して いる(model misspecified)と考えるべきである[9]。この点から、母集団に真のモデルが含まれているこ とを前提にした AIC によるモデル選択は妥当ではない。本稿では、ブートストラップ法を活用し、 隠れユニット数を決定する。 競合するモデルが複数個あるとき、対数尤度の比較によってモデルを選択すると、自由なパラメ ータ数の大きいモデルほど選ばれやすい。EIC[10],[11]は、対数尤度のバイアスをブートストラップ 法を用いて直接推定している。ブートストラップ法に基づくバイアス推定は次の通りである[1],[12]: Step 1 初期標本X = X{
< >1 ,X< >2 ,...,X< >n}
から、リサンプリングによりブートストラップ標本{
<1>* 2 * *}
,
< >,
,
< >n=
*X
X
X
X
を生成する。ただし、Xの成分X< >d をX< >d =(
Xl< >d ,δ
l< >d)
、 とする。(
, 1 , 2 ,...,)
d d d d d l al xl xl xlI < > = < > < > < > < > X Step 2 b(=1, ,B)番目のブートストラップ標本 *( )
b X について( )
(
)
( )
(
)
(
)
( )
(
( )
)
(
)
ˆ ln ; : ˆ ln : ˆ ln ; : L L ; b L b b 初期標本の対数尤度 ブートストラップ標本の推定値に基づく初期標本の対数尤度 ブートストラップ標本の対数尤度 θ θ θ * * * X X X X X X を計算する。 Step 3 Step 1,2 をB(=400)回繰り返す。 Step 4 バイアスのブートストラップ推定は( )
(
( )
)
(
)
(
(
( )
)
)
* * * * 1 1 ˆ ˆ ln ; ln ; B b C L b b L B = ⎡ ⎤ ≅∑
⎣ X θ X − X θ X b ⎦ (10) となる。 このとき、ブートストラップ法に基づく情報量規準( )
(
ˆ)
* =-2lnL ; 2 EIC Xθ
X + C (11) が得られ、EIC が最小のモデルを最適として選択することができる。隠れユニット h=1∼4 に対する EIC 値を図 6 に与えておく。同図から、h=3 で EIC 値が最小になる。なお参考までに、クロス・バ リデーション法による隠れユニット数の決定を付録に与えておく。図 6 EIC 値 隠れユ 1350 1370 1390 1410 1430 1450 1470 1 2 3 4 ニット数
Fig. 6 Values of EIC 2.3 適合度検定 モデル適合度は、逸脱度(deviance) Dev=2 ln⎡ L
(
max)
−lnL( )
; ˆ ⎤= -2lnL( )
; ⎣ X θ ⎦ X θˆ (12) を用いて検証できる。ここに、(
)
(
) {
}
1 1 ln max ln 1 ln 1 0 d l n d d d d l l l l d l L δ< > δ< > δ< > δ< > = = ⎡ ⎤ =∑∑
⎣ + − − ⎦= となる。しかし、本稿で取上げているベルヌーイ試行に従う二値データの場合、(12)式の漸近カイ 二乗性は成立たない[13],[14]。そこで、初期標本 に基づいて、ブートストラップ法による逸脱度 の棄却点を算出する。 X Step 1 B (=400)個のブートストラップ標本 * X を生成する。 Step 2 b(=1, ,B)番目のブートストラップ標本 *( )
b X について、逸脱度( )
(
)
(
{
( )
ˆ(
*( )
)
}
)
2 ln max ln ; Dev b = ⎡⎢ L − L b b ⎤⎥ ⎣ X*θ
X ⎦ (13) を計算する。 Step 3 *なら、有意水準 Dev Dev≥ αでモデルは妥当でないとみなす。ここに、Devは初期標本に対 する(12)式の逸脱度で、( )
* Dev =Dev b を小さい順に並べたときの第 番目の値j 、α = 1 - j(
B + 1)
とする。 住宅ローンの融資データについて、隠れユニット 3 個の最適なニューラルネットワークモデルを 当てはめた際、ブートストラップ標本に基づく逸脱度のヒストグラムは図7のようになる。(12)式 の逸脱度は となり、5%棄却点 1489.46 より小さいので、モデルの妥当性が示唆され る。ブートストラップ標本に基づく逸脱度の QQ プロットを描くと図 8 のようになり、かなり正規 分布に近いことも分る。 1325.30 Dev=1100 1200 1300 1400 1500 1600 0 50 100 150 図 7 ブートストラップ法による逸脱度のヒストグラム Fig. 7 Histogram of the bootstrapped deviances
-3 -2 -1 0 1 2 3 Normal Distribution 1100 1200 1300 1400 1500 ( ) Dev b 標準正規分位点 図 8 ブートストラップ法による逸脱度の QQ プロット Fig. 8 Q-Q plot of the bootstrapped deviances
ちなみに、部分ロジスティックモデル(1)を住宅ローンの融資データに当てはめたとき、 を得る。提案法で隠れユニットを 3 にすると 1549.24 EIC= EIC=1358.66となり、モデルはかな り改善される。 3.生存関数の予測と残差プロット 3.1 生存関数の予測 共変量の有意性を検定するには、尤度比検定統計量
(
[ ] ˆ)
( )
2 lnλ 2 ln⎡ L i ; ′ lnL ; ˆ ⎤, − = − ⎣ X θ − X θ ⎦ (14) を計算すればよい。ここに、lnL( )
X;θˆ は初期標本{
1 2}
, , , n < > < > < > = X X X X に対する部分対数尤)
度であり、ln(
[ ]; ˆ i L X θ′ は共変量X< >i を除去したときのそれである。帰無仮説が真なら、(14)式の 2 lnλ − は漸近的に自由度 d.f.=3 のカイ二分布に従う。参考までに、時間依存型比例ハザードモデル [15],[16]に基づく Wald 検定のカイ二乗値も表 2 に載せておく。同表から、有意水準α=0.05で、す べての共変量が有意である。 表 2 共変量の有意性検定 Table 2 Significant test for covariates共変量 Wald カイ二乗値 ボーナス返済率 323.76 手持金 65.82 失業率 37.40 地価増減率 8.06 次に、共変量の群間比較を行うため、推定生存関数をグラフ表現する。離散ハザード関数の推定 値hˆl< >d (xl< >d )が求まると、離散時点 での生存関数は
)
i l t( )
(
1 1 d l i l S t h< > ≤ ≤ =∏
− (15) と推定される。例えば、表1の個体に対する生存関数は、図 9 のように推定される。 生存率0
1
2
3
4
5
0.5
0.6
0.7
0.8
0.9
1.0
生存年数 図 9 表1の個体に対する生存関数の推定 Fig.9 Estimation of survival function for the individual in Table 1これらの推定生存関数を用い、生存曲線の群比較のため、直接平均法[17],[18]
( )
[ ]( )
1 1 ˆ g ˆ n g g i i g S t S t n = =∑
を採用する。ここに、ˆ[ ]g( )
は、時点 t における群 g の推定生存関数とし、 i S t n は群 g の個体数であg る。図 10∼12 に、手持ち金、ボーナス返済率、およびボーナス返済の有無による比較を与えておく。 例えば、手持ち金の 3 つの群(二千万円以上、一千万円以上二千万円未満、一千万円未満)ごとに、 各離散時点 におけるすべての個体について、生存関数の平均を求め、 を横軸にすると図 10 が 得られる。表 2 で手持ち金の有意性は立証されたが、図 10 から、手持ち金が一千万円以下の場合、 l a al生存関数は他に比べて低くなることが分かる。また図 11,12 からボーナス返済率やボーナス返済の 有無によっても、生存関数はかなり異なることが明らかである。
0.0
2.0
4.0
6.0
8.0
10.0 12.0
14.0
0.80
0.85
0.90
0.95
1.00
一千万円以下
一千万円以上
二千万円未満
二千万円以上
生存 率 生存時間 図 10 手持ち金による生存関数の比較Fig.10 Comparison of survival function by initial endowment
0.5 3.0 5.5 8.0 10.5 13.0 15.5 18.0 0.87 0.92 0.97 ボーナス返済率 30%以上 ボーナス返済率 30%未満 生存 率 生存時間 図 11 ボーナス返済率による生存時間の比較
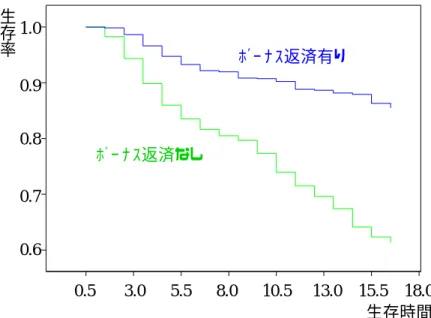
ボーナス返済有り ボーナス返済なし 0.5 3.0 5.5 8.0 10.5 13.0 15.5 18.0 生存時間 0.6 0.7 0.8 0.9 1.0 生存 率 図 12 ボーナス返済の有無による生存関数の比較
Fig. 12 Comparison of survival function by choice of seasonal repayments
参考までに、図 12 のボーナス返済の有無による生存関数の比較に(1)式の部分ロジスティックモデル (1)の結果(点線)を加えると図 13 のようになる。 0.5 3.0 5.5 8.0 10.5 13.0 15.5 18.0 0.5 0.6 0.7 0.8 0.9 1.0 生存関 数 ボーナス返済あり ボーナス返済なし 生存時間 図 13 ボーナス返済の有無による生存関数の比較(点線:部分ロジスティック回帰モデル) Fig. 13 Comparison of survival function by choice of seasonal repayments: Dotted lines indicate partial
logistic regression model 3.2 残差プロット 生存時間解析には、打切りデータが伴うため通常の線形回帰モデルの残差を適用することはでき ない。本稿では、被験者ごとの逸脱度残差[13]
(
)
(
)
{
}
< 1 ˆ ˆ sgn( ) 2 ln 1 ln 1 d l d d d d d d l l l l l l l Dev > δ< > h< > δ< > h< > δ< > h< = =∑
− − + − − ˆ d> (16) を採用する。隠れユニット数が 3 のニューラルネットに対する逸脱度残差のインデックス・プロッ トを図 14(a)に示す。同図から明らかなように、すべての残差はほぼ直線上にあり、外れ値の存在は認められず、モデルの妥当性が示唆される。ちなみに、部分ロジスティックモデルに対する逸脱度残 差のインデックス・プロットを図 14(b)に示す。ニューラルネットに対する逸脱度残差のほうがやや 小さくなっており、モデル適合度の良さが示唆される。 -7 -5 -3 -1 1 3 5 0 200 400 600 800 -7 -5 -3 -1 1 3 5 0 200 400 600 800 (a) ニューラルネット (b) 部分ロジスティックモデル 図 14 逸脱度残差のインデックス・プロット
Fig.14 Index plot of Cox-Snell residuals 4. 性能比較 生存時間解析には、Cox の比例ハザードモデルが広範に活用されてきた[7]。Cox の比例ハザードモ デルは、生存時間(観測時点)t のハザード関数を (17)
( )
0( )
1 , exp I i i i h t λ t x = ⎡ = ⎢⎣ ⎦∑
x β ⎤⎥ と表す。ここで、ベースラインハザード関数λ0( )
t は観測時点 の関数であって、共変量 t(
x1, ,xI)
= x を含んでいない。共変量の値が時間とともに変化する時間依存型データが含まれる 場合、従来の Cox の比例ハザードモデルは、比例ハザード性が成立たない[7]。すなわち、時間依存 型の場合、共変量x( )
t =(
x t1( )
, ,x tI( )
)
をもつ患者とz( )
t =(
z1( )
t , ,zI( )
t)
である患者とのハザ ード関数の比が観測時点 t に依存する。 ハザード関数h(
x( )
t t,)
は、(17)式より ⎞ ⎟ ) j < i(
( )
)
0( )
( )
(18) 1 , exp I i i i h t t λ t β x t = ⎛ = ⎜ ⎝∑
⎠ x となる。ここに、観測時点 t における i 番目の共変量の値である。 次に、時間依存型生存データの解析でよく用いられる区分指数モデルを取上げる。各時間区間ではハ ザードを一定とする。J 個の区間があるとき、区間 j を[aj−1,aj で表す。被験者 i に対するハザードを( )
exp(
)
, 1 i j i j h t =λ βx a− ≤t a すなわち lnh ti( )
=αj +βx とする。 比例ハザードモデル、区分指数モデル、および部分ロジスティックモデル(1)のもとでの有意性の Wald 検定結果を表 3 に与えておく。同表から明らかなように、ニューラルネット(h=3)では、すべての共変 量が有意になったが、これらの 3 つのモデルでは、地価増減率の有意性を検出できない。表 3 有意性の Wald 検定の結果 Table 3 Results of Wald test of significance
共変量 比例ハザードモデル 区分指数モデル 部分ロジスティックモデル ボーナス返済率 83.45 84.08 90.42 手持金 52.76 52.01 74.04 失業率 30.91 30.00 30.46 地価増減率 0.061 0.006 1.80 参考までに、時間依存型比例ハザードモデルで、共変量の初期値のみを用いた場合[13]の共変量 の有意性に対する Wald 検定の結果を表4 に示す。2
(
)
1 0.05 3.84 χ = より、比例ハザードモデルでは、 地価増減率が有意にならず、表 3 に比べて検定統計量の値もかなり小さくなる。 表 4 共変量の初期値のみを用いた場合の結果 Table 4 Results for models without time-dependent covariates共変量 Wald カイ二乗値 ボーナス返済率 89.84 手持金 50.53 失業率 8.46 地価増減率 2.82 5. 結び 共変量の値が時間とともに変化する時間依存型データが含まれる場合、従来の Cox の比例ハザー ドモデルには、比例ハザード性が成立たないなどの多くの問題点が存在する。この点を踏まえ本稿 では、二項分布に基づく部分ロジスティック回帰モデルを援用し、階層型ニューラルネットワーク による生存時間解析を試みた。ニューラルネットワークモデルを想定し、住宅ローンの融資データ の解析を通じ、ブートストラップ法によるモデル妥当性の検証、および隠れユニット数の決定を行 った。更に、共変量の有意性検定に基づく生存関数の予測や群間比較、および残差プロットについ ても考察した。 今後の課題としては、i) 時間依存型共変量を伴う比例ハザードモデルの比例ハザード性の検証、
ii) 共変量の選択,iii) 任意の観測時点における短期生存率の予測、iv) 影響分析などが挙げられる。
付録: クロス・バリデーション法 初 期 標 本
{
1 2}
, < >,..., < >n < > X = X X X か ら i 番 目 のX
< >i を 除 去 し た 訓 練 標 本 を X[ ]i ={
1 2 1 1}
, < >,... < − >i , < + >i ,…, < >n < > X X X X X 、訓練標本X に基づく[ ]i θ の推定量をθˆ(
X[ ]i)
とする。このと き、クロス・バリデーション規準 ( )(
)
(
( ))
{
,ˆ [ ] , [ ]}
1 1 2 ln 1 ln 1 i i i l n i i l l l l i l CV δ< > h δ< > h = = ⎡ ⎤ = − ⎢ + − − ⎥ ⎣ ⎦∑ ∑
規準 θ θ X ˆ X (A.1) が最小になる隠れユニット数を最適とする。ここに、 は除去した i 番目の個体における l 番 目の観測値に対する(6)式の予測値である。 ( )[ ] ˆ , i l hθ X ( )(
)
(
( ))
{
,ˆ [ ] ,ˆ [ ]}
1 1 1 ln 1 ln 1 i i i l n i i l l l l i l h h n δ δ < > < > = = ⎡ ⎤ + − − ⎢ ⎥ ⎣ ⎦∑ ∑
θ X θ X は、予 測対数尤度の平均値で、便宜上これを-2n 倍した量が(A.1)式である。住宅ローンの融資データに対して、隠れユニット数が 1∼4 個のニューラルネットワークモデルを 当てはめ、最適な隠れユニットの決定を行う。CV 値をプロットすると、図 A.1 のようになり、隠 れユニット 3 個が最適である(参考までに、AIC 値も載せておく)。
1350
1370
1390
1410
1430
1450
1470
1490
1 2 3 4 AIC CV 隠れユニット数 図 A.1 CV および AIC 値 Fig.A.1 Values of CV and AIC参考文献
[1] M.Tsujitani, and T.Koshimizu, “Neural Discriminant Analysis,” IEEE Trans. Neural Networks, vol.11, pp.1394-1401, 2002.
[2] E.Biganzoli, P.Boracchi, and E.Marubini, “A general framework for neural network models on censored survival data,” IEEE Trans. Neural Networks , vol.15, pp.209-218, 2002.
[3] E.Biganzoli, P.Boracchi, L.Marriani, and E.Marubini, “Feed forward neural networks for the analysis of censored survival data: a partial logistic approach,” Statist., Med., vol.17, pp.1169-1186,1988.
[4] D.R.Cox, “Partial likelihood,” Biometrika, vol. 62, pp.269-276,1975.
[5] B.Efron, “Logistic regression, survival analysis, and Kaplan-Meier curve,” J. Amer. Statist. Assoc., vol.83, pp.414-425, 1988.
[6] 辻谷将明、外山信夫 “ニューラルネットと生存解析,” 平成 14 年度科学研究費シンポジウム「計算機志向
の統計手法の理論と応用」,2002.
[7] D.G.Altman, and B.L.De Stavola, “Practical problems in fitting a proportional hazards model to data with updated measurements of the covariates,” Statist. Med., vol.13, pp.301-341,1994.
[8] P.K.Andersen, and R.D.Gill, “Cox’s regression model for counting process: A large sample study,” Ann. Statist., vol.10, pp.1100-1120,1982.
[9] V.Anders, and O.Korn, “Model selection in neural networks,” Neural Networks, vol.12, pp.309-323, 1999. [10] M.Ishiguro, Y.Sakamoto, and G.Kitagawa, “Bootstrapping log likelihood and EIC, an extension of AIC,”
Ann. Inst. Statist. Math., vol.49, pp.411-434, 1977.
[11] S.Konishi, and G.Kitagawa, “Generalized information criteria in model selection,” Biometrika, vol.83, pp.875-890, 1996.
[12] 辻谷将明 “ニューラルネット、生存時間解析、そしてリサンプリング法,” 平成 14 年度科学研究費シン
ポジウム「バイオスタティスティックスの数理的基礎」,2002.
[13] D.Collett, “Modelling Survival Data in Medical Research,”Chapman and Hall, London, 1994.
[14] J.M.Landwehr, D.Pregibon, and A.C.Shoemaker, “Graphical methods for assessing logistic regression models,” J. Amer. Statist. Assoc., vol79, pp.61-71, 1984.
[15] J.D.Kalbfleisch, and R.L.Prentics, “The Statistical Analysis of Failure Time Data,” 2nd ed., John Wiley, New York, 2002.
[16] J.F.Lawless, “Statistical Models and Methods for Lifetime Data,” 2nd ed., John Wiley, New York, 2003. [17] B.H.Markus, E. R.Dickson, P.M.Grambsch, T.R.Fleming, V.Mazzaferro, G.B.G.Klintmalm, R.H.Wiener,
D.H. Van Thiel, and T.E.S.Starzl, “Efficacy of liver transplantation in patient with primary biliary cirrhosis, New Enbl. J. Med., 320, 1709-1713, 1989.
[18] B.L. Thomsen, N.Keiding, and D.G.Altman, “A note on the c alculation of expected survival,” Statist. Med., 10, 733-738.
Survival analysis for housing loan data
Masaaki Tsujitani1 and Nobuo Toyama2
1) Faculty of Information Science & Arts, Osaka Electro-Communication University 2) Research & Survey Department, The Government Housing Loan Corporation of Japan
In the present paper, we discuss the role of survival analysis by using feed-forward neural network model to estimate hazard rates and survival curves. Proposed herein is a simple, more precise technique that incorporates follow-up data in the development of the model when the data consist of ungrouped binary responses and a set of time-dependent covariates. Statistical techniques are formulated based on the bootstrapping and cross-validation computed from the likelihood when selecting the optimum number of hidden units. There are no standard procedures to assess the overall goodness-of-fit of a time-dependent model. By introducing the bootstrapping into the neural network model, the deviance allows us to test the goodness-of-fit of the model. We additionally propose the residual plots in order to identify in neural network model fitting. These methods are illustrated through the analyses of housing loan data.
[英文アブストラクト]
Suggested here is a survival analysis by incorporating follow-up data in the development of the model and to estimate survival function when the data consist of ungrouped binary responses and a set of time-dependent covariates. From an information-theoretic point of view, we illustrate that the criterion based on the bootstrapping and cross-validation can be an alternative to AIC computed from the likelihood when selecting the optimum number of hidden units for neural network model. We additionally propose the residual plots in order to identify in neural network model fitting. These methods are illustrated through the study of housing loan data.
[キーワード]
Proportional hazards regression model, Time-dependent covariates, Partial logistic regression models, Bootstrapping, Cross-validation, Deviance, Residual plot
*
Corresponding author.