2020(
平成31)
年度 修士論文居住空間におけるユーザコンテキストを用いた 行動推薦に関する研究
Study on Context-aware Action Recommendation in Living Space
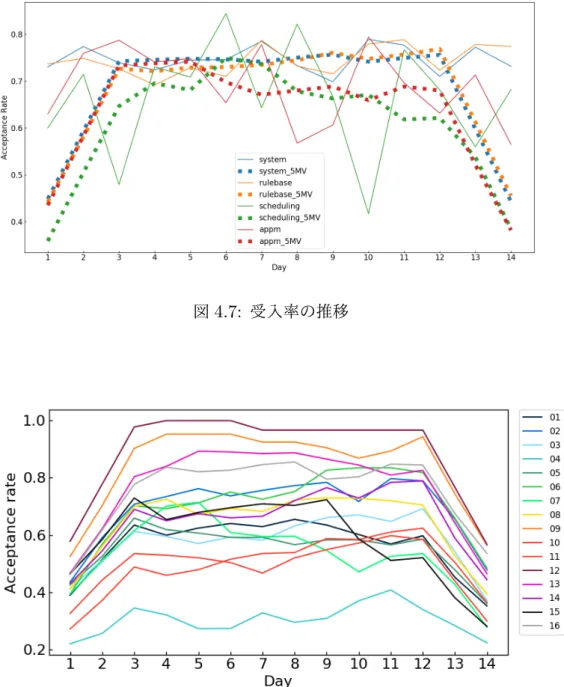
2020(
令和2)
年2
月21
日 提出首都大学東京大学院
システムデザイン研究科 システムデザイン専攻 情報科学域 高間研究室
学習番号
18860609
白井 佑要旨
本論文では,
wellbeing
向上を目的とした,居住空間におけるユーザコンテキストを用 いた行動推薦システムを提案する.近年,高齢化などの影響を受け,起床在宅率が増加し ており,自宅での過ごし方に注目が集まっている.また,健康の定義が見直され,単に病 気・病弱でない状態とするのではなく,身体的,精神的,社会的状態などといった要素か らなる多面的な概念であるwellbeing
の向上に注目が集まっている.このような背景か ら,居住空間のwellbeing
を向上させることが重要であると考える.居住空間における
wellbeing
を向上させるために,その定義を行い,wellbeing
を向上 させる要因を考える必要がある.多くの研究者によって様々なwellbeing
が定義されて いるが,その中でもより代表的かつ多面的なDiener
らの定義において扱われている,身 体的,精神的,環境的状態を本研究で扱うwellbeing
の要因とする.これら3
つの要因と 日常生活行動が相互に作用するの考えに基づき,日常生活行動を推薦するシステムを提 案する.推薦する行動の決定には,上述の3
状態を考慮する他,ある行為(生活行動)を 行う時間帯には個人に依存しない共通性があるとの想定から国民生活時間調査に基づく 行為者率を考慮する.本論文では,これら3
要因と行為者率をユーザコンテキストと定 義する.生活行動を推薦する場合, 行動ごとに特徴が異なるため,単一のアルゴリズムでは効 果的な推薦が難しいと考える.よって,提案システムでは推薦戦略をコンテキストの観 点から介入型と行動型に大別する.介入型は上述の
3
要因に基づくものであり,その行 動を推薦する根拠を,心拍数や脳波といった内的要因,室温や騒音といった外的要因,時 刻や曜日といった時間的要因に分類する.行動型は行動間の関連性に基づくものであり,過去の行動パターンに基づくパターン予測,直前の行動を用いて次の行動を決定論的に選 択する順展開計画,次の行動を予測しそれに必要な行動を決定論的に選択する逆展開計画 に分類する.推薦モジュールとして,介入型はルールベース,パターン予測型は
APPM (App for Prediction by Partial Matching)
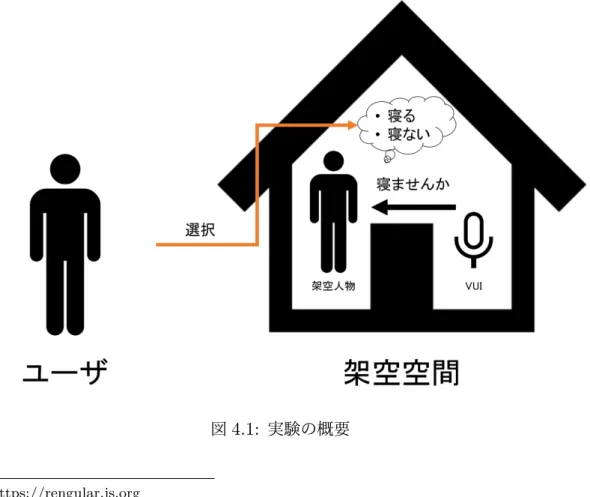
,展開計画型はスケジューリングアルゴリズ ムを採用する.各推薦モジュールから同時に推薦が行われた場合,推薦された行動を全 て提示してしまうのは心理学における決断疲れの観点から不適であることから,睡眠型 バンディットを採用し,推薦する行動を選択する.バンディットの学習は,推薦行動に対 するユーザの受理もしくは拒否といった2
値のフィードバックに基づき行い,行動選択 にはロジスティック回帰モデル上の睡眠型トンプソン抽出を用いる.シミュレータを用 いた評価実験やVUI (Voice User Interface)
を用いた実地実験により,提案システムの 有効性を検証する.本論文は
5
章から構成される.1
章では,本論文における研究背景および研究目的について記述する.
2
章では,QOL (Quality Of Life)
やwellbeing
などの幸福に関する概念 や,生活行動推薦システムといった関連研究について記す.3
章では,wellbeing
向上を 目的とした,居住空間におけるユーザコンテキストを用いた行動推薦システムを提案す る.4
章では,提案システムの評価実験結果を示す.シミュレーション実験では,シミュ レータ内で2
週間,指定したペルソナに従って仮想的な生活を送ってもらった結果に基 づき,推薦した行動がどの程度受け入れられたかを示す受入率や,wellbeing
向上したか を評価する累積wellbeing
によって提案システムの有用性を評価する.実地実験では,著 者の居住環境にGoogle Home
を設置し,実際に利用した場合の問題点や改善点などにつ いて考察する.5
章では,本論文で提案したシステムの概要についてまとめるとともに,今後の展望について述べる.
Abstract
This thesis proposes a user context-aware action recommendation system in living space to improve wellbeing. Recently the time spent at home increases by various fac- tors such as aging and in-house wellbeing has gained attention. Health is not defined as the absence of disease, but as the concept related with wellbeing, which relates with physical, mental, and social state. Therefore, to improve in-house wellbeing, people should take appropriate actions considering those states.
When recommending daily actions that will contribute to the improvement of in- house wellbeing, it is difficult that a single algorithm provides various kinds of actions on the basis of different factors and knowledge. Furthermore, when multiple actions can be recommended, letting users select appropriated one from those candidates would put a burden on them. Considering these problems, this thesis proposes a hybrid recommendation system, which consists of 3 recommendation modules and a contextual multi-armed bandit.
The effectiveness of the proposed system is evaluated in terms of acceptance rate
of recommended actions and cumulative wellbeing.
目次
1
はじめに6
2
関連研究9
2.1
健康・幸福. . . . 9
2.1.1 Wellbeing . . . . 9
2.1.2 QOL (Quality Of Life) . . . . 10
2.1.3 Wellness . . . . 11
2.2
日常生活行動. . . . 11
2.2.1
行動の分析に関する研究. . . . 11
2.3
推薦手法. . . . 12
2.3.1
一般的な推薦手法. . . . 13
2.3.2
バンディット. . . . 13
2.3.3
行動推薦. . . . 14
3
提案手法16 3.1
推薦戦略の分類. . . . 16
3.1.1
介入型. . . . 16
3.1.2
行動型. . . . 17
3.2
提案システム. . . . 17
3.3
行為者率の更新. . . . 20
3.3.1
初期化. . . . 20
3.3.2 MAP (Maximum A Posteriori)
推定. . . . 20
3.3.3
多項分布. . . . 20
3.3.4
ディリクレ分布. . . . 21
3.3.5 MAP
推定値の導出. . . . 21
3.4
推薦モジュールによる行動抽出. . . . 22
3.4.1
行動パターン. . . . 22
3.4.2
ルールベース. . . . 24
3.4.3
スケジューリング. . . . 24
3.5
バンディットによる行動選択. . . . 26
3.5.1
事前分布の設定. . . . 27
3.5.4
行動の選択・報酬の観測. . . . 28
3.6
推薦説明文の生成. . . . 30
3.6.1
テンプレートベース. . . . 30
3.6.2
ルールベース. . . . 30
4
評価実験32 4.1
シミュレータによる評価実験. . . . 32
4.2
実験内容. . . . 32
4.3
実験結果. . . . 39
4.4
実地による評価実験. . . . 58
4.5
実験内容. . . . 58
4.6
実験結果. . . . 58
5
おわりに63
1
はじめに本論文では,
wellbeing
向上を目的とした,居住空間におけるユーザコンテキストを用 いた行動推薦システムを提案する.近年,高齢化などの影響を受け,図1.1
のように起床 中の在宅率が年々増加[1]
しており,自宅での過ごし方に注目が集まっている.特に居住 空間の健康に関連した概念であるQOL (Quality Of Life)
の向上に対する関心も高まっ てきている.関連する製品・サービスとして,コニカミノルタではQOL
を支えるサービ スブランドHitomeQ (
ひとめく) [2]
が展開され,富士ソフトでは日常会話の話相手や健 康体操のインストラクタの役割を勤めることが可能なロボットPALRO [3]
が開発されて いる.また,近年健康の定義が見直され,単に病気・病弱でない状態とするのではなく,身体的,精神的,社会的状態などといった要素からなる多面的な概念である
wellbeing
の 向上に注目が集まっている.このような背景から,居住空間のwellbeing
を向上させるこ とが重要であると考える.居住空間における
wellbeing
を向上させるために,その定義を行い,wellbeing
を向上 させる要因を考える必要がある.多くの研究者によって様々なwellbeing
が定義されている.
Adams
らはwellness
を身体的,精神的,感情的,知的,心理的,社会的側面からなる概念として
[4]
,Rath
らはwellbeing
を職業的,社会的,財的,身体的,地域的側面 からなる概念として定義している[5]
.数ある定義の中でもより代表的かつ多面的な尺度 はDiener
らが提案したものであり[6]
,既存の尺度を元に形成されており,wellbeing
の構成要素を網羅していると主張されている.しかし,各要素に関する具体的な定義は示 されていない.包括的視点から
wellbeing
の構成要素を明確にすることを目的とした文 献[7]
では,文献[6]
を含む複数の尺度を構成要素の観点から分類しており,これらの構 成要素についての定義も記している.そのため,本論文では文献[7]
の定義を採用する.その中で,多くの尺度で共通して扱われている身体的状態と精神的状態に加え,居住空間 との密接な関係がある環境的状態の
3
状態を本研究で扱うwellbeing
の要因とする.文 献[7]
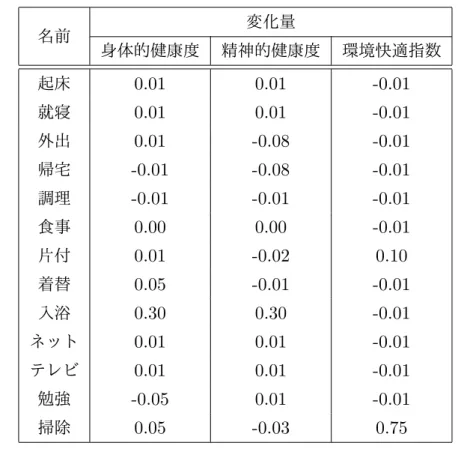
では,身体的状態は,筋肉の緊張,コレステロール値,血圧などの物理的指標や,食習慣,運動レベルなどの行動に関連し,精神的状態は感情やストレスの対処に関連する ものとして定義している.環境的状態は居住環境や職場環境,コミュニティ,そして自然 環境に関連するものとして定義している.この定義を参考に本論文では,身体的状態を 身体運動に影響されるとする乳酸の蓄積度,精神的状態をストレスに影響されるとする 認知能力の程度,環境的状態を居住環境の快適度として定義する.
本論文では,身体的,精神的,環境的状態と日常生活行動が相互に作用するとの考えに 基づき,日常生活行動を推薦するシステムを提案する.推薦する行動の決定には,上述の
3
状態を要因として考慮する他,ある行為(生活行動)を行う時間帯には個人に依存しな い共通性があるとの想定から,国民生活時間調査に基づく行為者率[1]
を考慮する.行為 者率とはある時間帯に当該行動を行った人の全体に占める割合であり,時間帯ごとの行 動の生起確率として利用できると考える.本論文では,これら3
要因と行為者率をユー ザコンテキストと定義する.また,日常生活行動の定義を,日々の生活で行われている万 人に共通する動作とする.具体的な行動としては睡眠や,朝食,入浴,掃除などが挙げら れる[1]
.日常生活行動を推薦する場合, 行動ごとに特徴が異なるため,単一のアルゴリズムで は効果的な推薦が難しいと考える.例えば,ある時刻を過ぎたら就寝を推薦する場合で あればルールベースが適するが,過去の行動パターンから行動を推薦する場合には適さ ない.よって,本論文では推薦対象となる行動の特徴に基づき複数の推薦アルゴリズム を採用する.具体的には,推薦戦略をコンテキストの観点から介入型と行動型に大別す る.介入型は上述の
3
要因に基づき,現在の行動が完了しているかどうかといった状態 に関わらず,条件を満たしている行動を推薦する.その行動を推薦する根拠を,心拍数や 脳波といった内的要因,室温や騒音といった外的要因,時刻や曜日といった時間的要因に 分類する.行動型は行動間の関連性に基づくものであり,過去の行動パターンに基づくパターン 予測,直前の行動を用いて次の行動を決定論的に選択する順展開計画,次の行動を予測 しそれに必要な行動を決定論的に選択する逆展開計画に分類する.推薦モジュールとし て,介入型はルールベース,パターン予測型は
APPM (App for Prediction by Partial
Matching) [8]
,展開計画型はスケジューリングアルゴリズムを採用する.ルールベースでは,身体的に疲れている状態を検知した場合に入浴や就寝を推薦する.スケジューリ ングでは,食事後に食器の片付け,
APPM
では行動パターンからテレビ視聴といった行 動を推薦する.各推薦モジュールから同時に抽出が行われた場合,推薦された行動を全て提示してし まうのは心理学における決断疲れ
[9]
の観点から好ましくないため,多腕バンディット 手法によって推薦する行動を選択する.具体的には,各日常生活行動をアームとみなし,各推薦モジュールに推薦された行動以外を選択不能とする睡眠型バンディット
[10]
を採 用する.バンディットの学習は,推薦行動に対するユーザの受理もしくは拒否といった2
値のフィードバックに基づき行い,行動選択にはロジスティック回帰モデル上の睡眠型 トンプソン抽出を用いる.シミュレーション実験や
VUI (Voice User Interface)
を用いた実地実験により,提案 システムの有効性を検証する.シミュレーション実験では,工学系大学生・大学院生16
名に提案システムを組み込んだライフシミュレータを用いてあるペルソナになりきり,仮 想的な生活を送って貰い,その中で生活行動の推薦を受け容れるかどうかを選択してもら う.この実験では,提案システムを推薦の受入率やwellbeing
の観点から評価する.VUI
を用いた実地実験では,Google Home
を介して居住者に生活行動を推薦した場合の主観 的な評価を定性的に行う.2
関連研究2.1
健康・幸福一般に知られている健康の定義は心身ともに健やかな状態であることである
[11]
が,近年,「身体的,精神的,社会的に良好な状態であること
[12]
」,「心身の健康,人間関 係,仕事に対するやりがい,居住環境,余暇活動などの状態[13]
」としてより広義に再 定義されている.前者はwellbeing,
後者はQOL (Quality Of Life)
の定義の1
つであ る.本論文では,健常者を対象にしている点,構成要素の定義をする文献が多く存在する 点からwellbeing
の概念を採用する.本節では,wellbeing, QOL
に関する研究に加え,wellbeing
に関連した概念であるwellness
に関する研究を取り上げる.2.1.1 Wellbeing
Wellbeing
とはwell (
良い) being (
であること)
の造語であり,良い状態であること を意味する.研究によってwellbeing, well being, well-being
のように表記が統一され ていないが,本論文ではwellbeing
を用いる.この単語は世界保健機関(WHO: World
Health Organization)
憲章において,健康を定義する文章の中で以下のように使われている
[12]
.Health is a state of complete physical, mental and social well-being and not merely the absence of disease or infirmity.
この「良い」の定義については多く議論されているが,主に以下の
3
つが挙げられる[14]
.医学的アプローチ 機能障害がない状態 快楽的アプローチ 気分が良い状態
持続的幸福的アプローチ 人生に意義を見出し,自分の潜在能力を最大限に発揮してい る状態
医学的アプローチでは,病気ではない状態を良い状態であるとしている.一般的な健 康の定義に似た定義であり,医学的アプローチにおける
wellbeing
は予防や治療による改 善が行われる.快楽的アプローチでは,多くの快楽を感じ,気分が良い状態を「良い」状 態としている.この快楽は,目標の達成や人生における様々な結果に対する快,不快を意 味する.持続的幸福的アプローチでは,wellbeing
を構成する要素(
人間関係など)
にお いて,良い結果を出している状態を「良い」状態としている.医学的アプローチでは疾患に対して予防や治療が施されるのに対して,快楽的,持続的 幸福的アプローチでは疾患の有無に関わらず,現状をより良くするような促進に関する方 策がとられる.本論文においては疾患の予防や治療ではなく,万人を対象した
wellbeing
の向上(
促進)
を目的としているため,後者の2
つの定義が対象となる.wellbeing
の構成要素の定義や,その尺度を提案している研究は数多く存在する.Timothy
らはwellbeing
の構成要素を有能感,情緒不安定,没頭,意義,楽観性,ポジティブ感情,良好な人間関係,心理的回復力,自尊心,回復力の
10
要素と定義し ている[15]
.また,Seligman
はポジティブ感情(Positive emotion)
,物事への積極性(Engagement)
,他人との良好な関係(Relationship)
,人生に対する意義(Meaning)
,達成感
(Accomplishment)
の5
要素からなると考え,これをPERMA
モデルと呼んでいる[16]
.いずれの定義も,特定の状況や状態に対する心理状態にフォーカスしている特徴が ある.
2.1.2 QOL (Quality Of Life)
QOL
の定義は様々であり,国内においては以下のような障害者のQOL (
生活の質)
が 定義されている[17]
.障害者によっての生活の質とは、日常生活や社会生活のあり方を自らの意思で決 定し、生活の目標や生活様式を選択できることであり、本人が身体的、社会的、文 化的に満足できる豊かな生活を営めることを意味します。
一般的な定義としては,
Spilker
はQOL
を身体的状態(physical status and functional abilities)
,精神的状態(psychological status and well-being
),社会的交流(social inter- action)
,経済的・職業的状態(economic and / or vocational status)
,宗教的・霊的状 態(religious and / or spiritual status)
の5
領域からなるとしている[18]
.QOL
の尺度は主に特定の病気に特化しない汎用評価法と特定の疾患や部位に注 目した疾患特異的評価法に分けられる.汎用評価法としては,SIP (Sickness Impact Profile)[19]
やNHP (Nottingham Health Profile)[20]
などが挙げられる.SIP
は動作や 行動からHRQOL (Health Related Quality Of LIfe)
と呼ばれる健康に関連したQOL
を捉える評価法であり,栄養摂取や睡眠,家事,感情などの14
カテゴリの項目からなる.NHP
は主観的健康を測定するための患者報告アウトカムであり,主に健康と生活に関す る項目から構成される.前者は痛みや情動反応,後者は家事や趣味に関する項目から構 成される.アに対する満足度などの
19
要素からなる肝臓病に特化した尺度,GOHAI
は機能面,心 理社会面,不快感の3
要素からなる口腔に特化した尺度である.これらの
QOL
の尺度は,疾患に関連した尺度が多く,主に医学,看護学分野で用いら れる.また,健常者向けの尺度の確立は不十分と言われている[21]
.2.1.3 Wellness
Dunn
はHigh level wellness
をa condition of change in which the individual moves forward, climbing toward a higher potential of functioning[22]
と定義している.Well-
ness
はwellbeing
と同様に状態を表しているが,定義がより具体的である点においてwellbeing
と異なる.Dunn
はwellness
の構成要素として,個人のウエルネス(Individual Wellness)
,家 族のウエルネス(Family Wellness)
,地域のウエルネス(Community Wellness)
,環境 のウエルネス(Environmental Wellness)
,社会のウエルネス(Social Wellness)
の5
要 素を挙げている[22]
.National Wellness Institute
*1 はwellness
の構成要素として,感 情的(emotional)
,職業的(occupational)
,身体的(physical)
,社会的(social)
,知的(intellectual)
,魂的(spiritiual) wellness
の6
つを挙げている[23]
.しかし,これらに関する評価尺度については調べた限りでは存在しない.
2.2
日常生活行動日常生活行動は人が日常生活において繰り返す基本的かつ具体的な活動と定義されて いる
[24]
.例えば,食事,更衣,入浴などが挙げられる.また,NHK
は日常生活行動を 上述の様な必需行動の他,拘束行動,自由行動の3
つに分類している文献[1]
.拘束行動 は買い物や仕事などの家庭や社会生活の維持向上のために行う義務性の高い行動,自由 行動はテレビの視聴や友人との付き合いといった人間性を維持向上させるために行う自 由裁量性の高い行動として定義されている.以降,日常生活行動を行動と呼ぶ.2.2.1
行動の分析に関する研究行動の分析に関する研究は,対象ユーザの情報をアンケートやデバイスなどを用いて 直接取得する方法をとる侵襲的
(intrusive)
アプローチと,すでに生活環境に組み込まれ ているデバイスなどを用いて間接的に情報を取得する非侵襲的(non-intrusive)
アプロー チに大別される.前者はユーザの行動および行動に関する情報を直接取得するため,分 析をしやすい利点があり,既存研究の多くが該当する.しかし,情報を直接取得するため にデバイスを設置,装着する必要があり,プライバシーやユーザの負担などが懸念され*1https://www.nationalwellness.org
る.後者は間接的に情報を取得するため,分析結果で知見が得られにくい問題点が挙げ られ,既存研究は数少ない.しかし,プライバシーは保護され,金銭的コストが抑えられ る利点がある.本論文はコンテキストをデバイスを用いて直接的に取得するため,侵襲 的アプローチに位置づけられる.
前ら
[25]
,野間らは[26]
アンケートを用いた行動に関する分析を行なっている.前ら は居住空間におけるエネルギー消費構造の解明を目的とした生活行動の分析をしている[25]
.アンケートでは起床,外出,帰宅,就寝,自宅での朝昼晩の食事と入浴の時刻に関 する設問を設定している.外出,起床在宅,就寝在宅をそれぞれ0, 1, 2
に割り当て15
分ごとの状態を表し,1
日を表現した96
次元ベクトルを用いて男性勤め人,女性勤め人,専業主婦別にクラスタ分析をしている.その結果,勤め人におけるクラスタごとの外出 時刻に大きな差異はないが,帰宅時刻に差異が見られること,専業主婦におけるクラスタ ごとの就寝時刻に差異が見られることなどの知見が得られたとしている.
野間らは省エネを目的としたライフスタイルの分析を行なっている
[26]
.アンケート では家族構成や部屋の間取り,夏冬別の家電の使用状況や起床就寝,外出帰宅時刻などに 関する設問を設定している.夏に関するアンケート回答結果を元に各家庭の3
時間ごと のエアコン,照明,テレビの使用の有無を1
と0
に対応づけ,24
次元のベクトルに表現 する.800
世帯分の24
次元ベクトルをデータ点として主成分分析をし,第一主成分,第 二主成分をそれぞれ1
日の家電機器使用量,家電機器使用ピーク時期を表すものとして 可視化している.エアコン,テレビ,照明のそれぞれの消費電力と使用時間の積の和を節 約志向指数として,この値を用いてヒートマップとして可視化した結果に基づき,時間帯 別のエアコン,照明,テレビの利用率についてそれぞれ異なる特徴を持つ10
個のクラス タがあることを示した.Shirai
らは電力データからユーザの行動に関する分析を行なっている[27, 28]
.QOL
向上のための行動推薦への活用を想定した,ライフパターンの理解を目的として分析を 行っている.独居高齢者
13
世帯の1
年分の電力データから各日の起床,朝食,昼食,夕 食,就寝時刻を推定し,これらの推定時刻を特徴量としてk-means
を用いてクラスタリ ングした結果,全国平均に近い時刻に起床した日は3
食を自宅で摂る傾向があるなどの 知見が得られている.2.3
推薦手法日常生活において我々は気づかないところで,推薦システムを利用している.
Web
広 告や動画サイトで表示されるおすすめの動画,Amazon
*2や価格.com
*3でのオススメの商品など.これらは全て推薦システムにより推薦されている.以降では,一般的な推薦手 法を取り上げたあとに,バンディットアルゴリズムについて説明する.
2.3.1
一般的な推薦手法協調フィルタリングは評価値を元に類似するユーザ・アイテムを推薦する手法である
[29]
.類似度の計算にはcos
類似度やJaccard
係数,相関係数などが使われる.シンプル な方法だが,データセットの評価値がスパースな場合や新規ユーザ・アイテムに対して推 薦できなかったり,精度低下することが知られている.協調フィルタリングではユーザ・アイテムに関する特徴が考慮されていなかったが,
コンテンツベースフィルタリングではアイテムの内容
(
コンテンツ)
に関する特徴を考 慮する[30]
.例えば,アイテムを記事とすると内容は文章になる.単語の重要度を測るTF-IDF
を用いて記事ごとのベクトルを求め,記事間の類似度を算出する.特徴を適切に設定しないと,十分な推薦精度が得られない可能性がある.
知識ベース型推薦ではユーザが明示的に指定する要求を元に推薦を行う.この手法に は制約ベース型
[31]
と事例ベース型[32]
の2
種類があり,前者では推薦ルールを充足す るアイテムの集合を抽出し,後者ではユーザの要求に類似したアイテムの集合を抽出し,ユーザにより評価された結果を元にアイテムの集合を更新していく.事前に記述された 知識を活用するため,新規ユーザに対しても精度の高い推薦が行える利点がある.
2.3.2
バンディットバンディット問題は腕と呼ばれる選択肢の集合から
1
つの腕を選び,この選択に対す る報酬を獲得するという手続きを繰り返す中で報酬の最大化を目指す問題である.この 目的を達成するには腕の集合の中から高い報酬が得られる腕を探す必要がある.この手 続きを探索と呼び,探索結果を元に腕を選択する手続きを活用と呼ぶ.探索や活用をど う行うかといった戦略は方策と呼ばれる.本節では代表的な3
つの方策を紹介する.ϵ
貪欲法は,全試行回数,腕の数をT, K,
ハイパパラメータϵ ( ∈ [0, 1])
とすると,T ϵ/K
回ずつすべての腕を選択し,得られた報酬が最大となる腕を残りの回数T − T ϵ
回選択す る戦略をとる[33]
.アルゴリズムがシンプルで実装コストが低く解釈がしやすい利点が あるが,ϵ
が大きいと,最適な腕を見つけるための探索回数が多くなることで,十分な活 用ができなくなり,ϵ
が小さいと探索が不十分になり,活用の段階で不適切な腕を選び続 けてしまう恐れがある.このように,ϵ
により,結果が大きく変化するため,この値の調 整が重要になる.腕ごとに報酬の分布がある場合,選択回数が少ない腕の標本平均は母平均に収束して いない可能性が高く,
ϵ
貪欲法ではこの問題に対応できない.この問題に対し,UCB
(Upper Confidence Bound)
方策[34]
では各腕k (k = 1, 2, ..., K )
を1
回ずつ選択した後に腕ごとの期待値を元に腕を選択する.時刻
t (t = 1, 2, ..., T )
における腕k
の期待値µ
k(t)
を式(1)
のように表す.µ ˆ
k(t), N
k(t)
はそれぞれ時刻t
における行動k
に関する報 酬の標本平均,t
までのk
の選択回数を示す.µ
k(t) = ˆ µ
k(t) +
√ log t
2N
k(t) (2.1)
UCB
方策では,選択回数が少ないほど第2
項の値が大きくなるため,選択回数が少な い腕も選ばれる可能性がある.この補正項によりϵ
貪欲法に比べ探索と活用のバランス をとりながら腕の選択ができる.Thompson Sampling
はベイズ推定した期待値を用いる確率一致法である[35]
.確率一致法とは腕の期待値の分布に従って確率的に行動を選択する手法であり,上述した
ϵ
貪 欲法とUCB
方策のように得られた期待値をもとに決定論的に腕を選択する手法とは異 なる.期待値の分布は任意の事前分布と尤度関数の積によって表現できる.この期待値 の分布に従い腕を選択し,観測された報酬をもとに事後分布を更新する.この手法にお ける利点は,問題設定に応じて事前分布を自由に設定できる点,腕の期待値に従い行動を 選択できるため,ϵ
貪欲法のように不適な腕を選択し続ける問題に対応している点などが 挙げられる.2.3.3
行動推薦行動を推薦する研究は対象としている行動が単一か複数かで分類できる.前者の研究 では,起床
[36]
や薬の服用[37]
などの行動を対象としており,詳細な推薦を行っている 研究が多い.沖らは起きたい時刻と,起きたい度合いを設定することで,ユーザの好みや状況を考慮 した,起床支援インタフェースを提案している
[36]
.例えば,起きたい度を低く設定する 場合,光だけを用いるが,高く設定すると,光に加え音楽やLee
らは高齢者を対象とした服用推薦システムを提案している[37]
.薬ケースにスイッ チセンサを付与した自作デバイスと専用のディスプレイを用いて,薬の服用状況をユー ザに通知する.服用すべき薬が入っていない蓋を開けた場合や,未服用の場合は,その旨 をユーザに知らせる.直感的でわかりやすいシステムであり,ユーザ実験により定量的 に有効性が示されたが,システムの利用後に規則正しい薬の服用が習慣化されなかった 課題がある.複数の行動を対象としている研究
[38, 39]
では,食事や,掃除,運動などを対象として活の質は,電力コスト,健康,快適度,家族団らんの
5
要素からなるものとして,これら の値が最大となるような一日の行動スケジュールを作成している.この研究では,睡眠,食事,入浴,調理,身支度などの
20
種類の行動を推薦対象としている.Gao
らは,身体 的,認知的,感情的,社会的側面からなるウェルネスの向上を目的とした日常生活行動プ ランの推薦手法を提案している[39]
.ユーザプロファイル,過去の行動パターン,ウェル ネスを定量的に表現するウェルネススコアを元に,より健康的な日常生活行動のパター ンを作成している.この研究では,起床や昼寝,テレビの視聴,読書などの30
種類の行 動を推薦対象としている.複数の行動を対象とした研究は少ない.
3
提案手法3.1
推薦戦略の分類本章では,
wellbeing
と日常生活行動の間に相互作用があるとの考えに基づき,日常生活 行動推薦システムを提案する.現在,複数の日常生活行動を対象とする推薦システムの研 究は少ないが,単一の日常生活行動を対象としている研究は多い[36, 40, 41, 42, 43, 44]
. しかし,複数の日常生活行動を対象とする場合,単一の推薦アルゴリズムでは効果的な推 薦が難しいと考える.例えば,ある時刻を過ぎたら就寝を推薦する場合であればルール ベースが適するが,過去の行動パターンから行動を推薦する場合には適さない.よって,本論文では推薦対象となる行動の特徴に基づき複数の推薦アルゴリズムを採用する.具 体的には,推薦戦略をコンテキストの観点から介入型と行動型に大別し,それらを複数の アルゴリズムを用いてカバーする.それぞれの戦略についての説明を以下に示す.
3.1.1
介入型介入型は現在の行動が完了しているかどうかによらず,条件を満たす行動を推薦する.
行動を推薦する根拠を,内的要因,外的要因,時間的要因に分類する.図
3.1
は介入型推 薦戦略の概要を示したものである.図3.1
において橙色の実線は,考慮する要因の変化を 示す.閾値を表す黒色破線を超えた場合に特定の行動を推薦する.各要因の概要は以下 のとおりである.図
3.1:
介入型推薦戦略の概要(a)
行動パターン(b)
順展開計画(c)
逆展開計画 図3.2:
行動型推薦戦略の概要内的要因 脳波や心拍数,歩数といった生理学的・解剖学的情報を示す生体情報 外的要因 室温や湿度,騒音といった部屋の状況に関する情報
時間的要因 日時や曜日といった時間に関する情報
3.1.2
行動型行動型は行動間の関連性に基づき推薦を行うものであり,現在の行動が完了したタイ ミングで推薦を行う.順展開計画,逆展開計画,行動パターンの
3
種類に分類する.以下 の説明において図中の橙色,水色,太線は,それぞれ推薦において考慮する行動,推薦さ れる行動,現在の行動を示す.・ 行動パターン
(
図3.2(a))
過去の行動パターンから次の行動を予測し,起こりそうな行動を推薦する.例えば,行 動パターンが勉強,ゲーム,勉強の場合に,次の行動としてゲームを推薦する.
・ 順展開計画
(
図3.2(b))
現在の行動と紐付く行動を推薦する.行動パターンに似た戦略だが,現在の行動以外 は考慮せずに,決定論的に次の行動を推薦する点に違いがある.例えば,現在の行動が食 事の場合,次の行動として食器の片付けを推薦する.
・ 逆展開計画 図
3.2(c))
将来実行すべき行動
(
ゴール)
を設定し,その達成に必要な行動を逆算して推薦する.例えば,ゴールが食事の場合,次の行動として食事を行うための準備である調理を推薦 する.
3.2
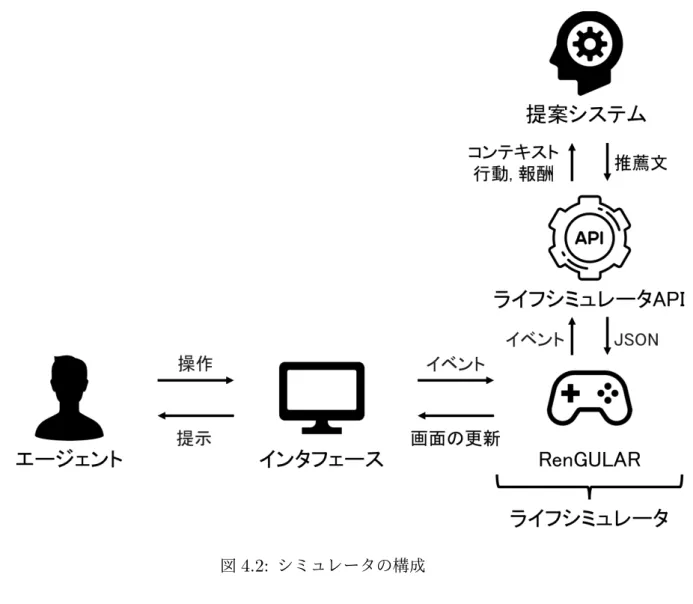
提案システム提案システムは図
3.3
に示すように,行為者率の更新,
推薦モジュールによる行動の推 薦,
睡眠型バンディットによる行動の選択・推薦,
フィードバックによる学習の4
つの要素技術で構成される.提案システムは複数のアルゴリズムを組み合わせたハイブリッド 型推薦システムとして位置づけられる.特に,状況に応じて推薦手法を切り替える特徴 から,切り替え型ハイブリッド推薦システム
[14]
に分類される.本システム構成の利点 は拡張性・網羅性・逐次性の3
点である.拡張性は推薦モジュール間の相互関係を考慮せ ずに推薦モジュールの追加・変更が可能であることを意味する.網羅性は異なる推薦モ ジュールを組み合わせることで,多様な日常生活行動を網羅できることを意味する.逐 次性はユーザのフィードバックを元に逐次的に学習を行うことを意味する.これにより,短期的,長期的問わずユーザのライフスタイルの変化に対応が可能である.提案システ ムにおける処理の流れは,以下のようになる.
1.
現在の行動を観測,行為者率分布を更新2.
現在の行動,コンテキストを元に,各推薦モジュールが行動を推薦3. 2
で推薦された行動の中から,コンテキストを元にユーザに推薦する行動を睡眠型 バンデットを用いて1
つ選択4. 3
で選択した行動,コンテキストを元に推薦説明を生成してユーザに提示5.
ユーザのフィードバックに基づき学習図
3.3:
提案システムの構成以降で扱う記号は以下の通りとする.
表
3.1:
記号の一覧記号 定義
t
start∈ R
+ 実験開始時刻t
end∈ R
+ 実験終了時刻ω ∈ R
+ 影響度K
行動の数D
実験日数L
時間間隔数S = { s
l| l = 1, 2, ..., L }
時間間隔の集合A = { a
k| k = 1, 2, ..., K }
行動の集合A
PAT⊆ A
行動パターンにより生成された行動の集 合A
RB⊆ A
ルールベースにより生成された行動の集 合A
SCH⊆ A
スケジューリングにより生成された行動 の集合c
p(t) ∈ [0, 1]
時刻t
における身体的状態c
m(t) ∈ [0, 1]
時刻t
における精神的状態c
e(t) ∈ [0, 1]
時刻t
における環境的状態c
d(t)
時刻t
における0:00
からの経過時間C(t) = { c
p(t), c
m(t), c
e(t), c
d(t) }
時刻t
におけるコンテキストの集合µ
s= (µ
as∈ [0, 1] |∀ a ∈ A, ∑
a∈A
µ
as= 1), s ∈ S
時間間隔
s ∈ S
の行動a ∈ A
を選択する 多次元確率分布β
as∈ R , ∀ s ∈ S, ∑
a∈A
β
as= 1
文献[1]
に基づく時間間隔s ∈ S
におけ る行動a ∈ A
の行為者率α
s= (α
as∈ R
+| a ∈ A), s ∈ S
時間間隔s ∈ S
における行動a ∈ A
の疑 似観測回数を表す多変量γ
s(t) = (γ
as(t) ∈ N
0| a ∈ A), s ∈ S t
startからt
の間のスロット∀ s ∈ S
にお ける総実観測回数以下にそれぞれの手続きについて詳細に説明する.
3.3
行為者率の更新NHK
国民生活調査の行為者率にバイアスDω
を乗じた値を超パラメータとしたディ リクレ分布を事前分布として扱う.この事前分布に基づき,ある時刻t
の該当する時間間 隔s
における各行動の対応する生起確率µ
sを点推定するまでの導出過程を説明する.3.3.1
初期化実験開始時刻を
t
startとし,α
as, γ
as(t
start) ( ∀ s ∈ S, a ∈ A)
をそれぞれ式(3.1), (3.2)
と定める.ここで,時間間隔s ( ∈ S)
を1
日を一定間隔(4
章の実験では15
分)
で分割し た時間帯として定義する.影響度ω
は超パラメータであり、実観測回数に対する擬似観 測回数の比重の大きさを意味する.文献[1]
に基づく時間間隔s ∈ S
における行動a ∈ A
の行為者率をβ
asとする.α
as= Dωβ
as, s ∈ S, a ∈ A (3.1)
γ
as(t
start) = 0, s ∈ S, a ∈ A (3.2)
3.3.2 MAP (Maximum A Posteriori)
推定本章では,各行動の観測回数
(γ
s(t))
に基づいて,時間間隔s ( ∈ S)
におけるa ( ∈ A)
の生起確率µ
as を推定したい.最尤推定によってµ
sを推定した場合,t
の値が小さい時 は観測が十分ではないため,推定値は信用ならない.前述のとおり,NHK
国民生活調査 の行為者率に基づく事前分布を採用することで,γ
s(t)
の観測が十分で無い場合の推定値 の信頼問題は解消される.事前分布が与えられた場合の点推定はMAP
推定により行う.3.3.3
多項分布時間間隔
s
において,時刻t
までに,∑
a∈A
γ
as(t)
回の独立した試行を行った結果,行 動a
をγ
as(t)
回観測したものとする.さらに,s
におけるa
の生起確率µ
asより,γ
sの 分布は以下のように表現できる.p(γ
s= γ
s(t) | µ
s) = Γ( ∑
a∈A
γ
as(t) + 1)
Π
a∈AΓ(γ
as(t) + 1) Π
a∈Aµ
γasas(t), s ∈ S (3.3)
3.3.4
ディリクレ分布次に,
µ
sの分布について考える.擬似観測回数α
sが与えられた時のµ
sの分布はディ リクレ分布に従うものとする.p(µ
s| α
s) = Γ( ∑
a∈A
α
as)
Π
a∈AΓ(α
as) Π
a∈Aµ
αasas−1, s ∈ S (3.4)
3.3.5 MAP
推定値の導出式
(3.3, 3.4)
を用いて,γ
s(t)
が得られた後のµ
s の事後分布を最大化するµ
s(t)
は下 式のように表される.µ
s(t) = arg max
µs
p(µ
s| γ
s= γ
s(t), α
s)
= arg max
µs
{ p(γ
s= γ
s(t) | µ
s)p(µ
s| α
s) } , s ∈ S (3.5)
時刻t
における式(3.3), (3.4)
の対数尤度をそれぞれL
Multi, L
Dir とする.L
Multi(t) = ln p(γ
s= γ
s(t) | µ
s)
= ln Γ( ∑
a∈A
γ
as(t) + 1)
Π
a∈AΓ(γ
as(t) + 1) + ∑
a∈A
γ
as(t) ln µ
as, s ∈ S (3.6)
L
Dir(t) = ln p(µ
s| α
s)
= ln Γ( ∑
a∈A
α
as)
Π
a∈AΓ(α
as) + ∑
a∈A
(α
as− 1) ln µ
as, s ∈ S (3.7)
式(3.5)
の最大値を求めるために,式(3.6,3.7)
のµ
as(t)
についての偏微分から,極値 を求めることを考える.ただし,µ
as(t)
には行動に関して総和が1
となる制約があり,こ れを同時に満たす解を求める必要があるため,ラグランジュの未定乗数法を用いて,式(3.8)
を最大化する問題とする.L(t) = ln { p(γ
s= γ
s(t) | µ
s)p(µ
s| α
s) } + λ ( ∑
a∈A
µ
as− 1 )
, s ∈ S (3.8)
∂L(t)
∂µ
as= ∂L
Multi(t)
∂µ
as+ ∂L
Dir(t)
∂µ
as+ λ
= γ
as(t) µ
as+ α
as− 1 µ
as+ λ, s ∈ S (3.9)
∂L(t)
∂µas
= 0
となるµ
as(t)
は式(10)
となる.µ
as(t) = − γ
as(t) + α
as− 1
λ , s ∈ S (3.10)
∑
a∈A
µ
as(t) = 1, ∀ s ∈ S
,式(3.10)
より,λ
は式(11)
となる.λ = − { ∑
a∈A
γ
as(t) + ∑
a∈A
(α
as− 1) }
, s ∈ S (3.11)
式
(3.10)
,(3.11)
より,推定値は式(12)
となる.µ
as(t) = γ
as(t) + α
as− 1
∑
a′∈A
γ
a′s(t) + ∑
a′∈A
(α
a′s− 1) , a ∈ A, s ∈ S (3.12)
3.4
推薦モジュールによる行動抽出本 節 で は ,
3.1
節 で 述 べ た6
種 類 の 戦 略 に 対 し て ,行 動 パ タ ー ン ,ル ー ル ベ ー ス,スケジューリングのアルゴリズムを適用し,それぞれから得られた行動の集合A
PAT, A
RM, A
SCHを生成するまでの過程を説明する.3.4.1
行動パターン行 動 パ タ ー ン に 基 づ く 推 薦 に は ,
Application Prediction by Partial Matching
(APPM) [8]
採用する.APPM
はアプリ起動ログを元に次に起動するアプリを予測するために提案された手法であり,短期的・長期的パターンの両方を考慮したマッチングを 行う点が特徴である.本論文では,
APPM
におけるアプリを行動と置き換えることで,行動パターンの予測に適用する.これにより,短期的,長期的行動パターンを考慮した 予測が可能となる.
APPM
はパターンの更新と予測処理から構成される.それぞれの説 明を以下に記す.・パターンの更新
図
3.4:
パターン更新の例ンをゲーム,勉強,ゲーム,勉強とすると,文字列は,
abab
と表現できる.ここで,現 在の行動としてゲームを観測した場合,文字列はababa
と更新される.・予測
予測の流れは以下の通りである.生成された予測行動
a
とすると,行動パターンによ り生成される行動の集合はA
PAT= { a }
と記述できる.1.
文字列strings
の末尾からn ( ≤ len(strings))
字の文字列を部分文字列prefix
と して定める.例としてstrings = abcababcababbbab
,n = 2
とすると,prefix
はab
となる.2. strings
の先頭から順に,prefix
と一致する箇所を探し,その直後の文字を取り出す.表
3.2
に示す例では,正解欄に取り出された文字を示している.この例では6
回マッチしている.次に,prefix
直後の文字の予測を行う.それまでに取り出され た直後の文字の,出現回数上位2
文字を予測結果とする.表3.2
の3
回目につい て予測を行う場合,それ以前にa, c
が1
回ずつ直後の文字として抽出されている ため,予測結果は{ a, c }
となる.出現回数上位2
文字が3
文字以上存在する場合,最後に出現したのが直近のものを優先して採用する.正解が予測結果のどちらか と一致していれば◯,そうでなければ×を判定結果として格納する.ただし,最初 に一致した箇所については判定を行わない.



![表 4.2: 推薦行動の実行時間 行動 実行時間 [ 分 ] 起床 15 就寝 240 外出 15 帰宅 15 調理 15 食事 30 片付 15 着替 15 入浴 30 ネット 30 テレビ 30 勉強 60 掃除 30 4.3 実験結果 図 4.7 は受入率の推移を示す.横軸は経過日数,縦軸は受入率の平均を示している. 青,橙,緑,赤線はそれぞれ全ての協力者の日ごとのシステム全体,ルールベース,スケ ジューリング,行動パターンの受入率の平均値を示しており,破線は 5 点移動平均を示 している. 5 点移](https://thumb-ap.123doks.com/thumbv2/123deta/10131555.1965443/40.892.348.539.121.523/ネットそれぞれシステムルールベーススケジューリングパターン.webp)