Title
論説 : 東京方言におけるdephrasingの生起要因 : 統語
機能、モーラ数及び発話速度による影響
Author(s)
全, 美炷
Citation
言語社会, 9: 417-403
Issue Date
2015-03-31
Type
Departmental Bulletin Paper
Text Version publisher
URL
http://doi.org/10.15057/27238
Right
1.導入
本稿は、発話の韻律構造において、隣接する二つ以上のアクセント句が一つのアクセン ト句(以下、句と略す)にまとまる dephrasing 事象がどのような環境で生じるかを検討す るものである。関連要因として統語機能、モーラ数、発話速度を取り上げ、『日本語話し言 葉コーパス』(Corpus of Spontaneous Japanese、以下 CSJ)を対象に定量的に検討する。
1.1 Dephrasing とは 東京方言において一つの語を単独で発音する場合、例えば「メジʼルシ」を単独で発音す る場合は、第 1 モーラから第 2 モーラにかけてピッチ(声の高さ)が上昇した後、第 2 モー ラの後ろで下降してからは、再び上昇せず最後のモーラまでほぼ平らに続く。しかし、ほ かの語に後続して発音する場合、アクセント核(ピッチの下降)は保持されるが、第 1 モー ラから第 2 モーラにかけての上昇は、次の(ア)と(イ)ように、生じることもあれば生じな いこともある。 (ア) アカイ メジルシ (イ) アカイメジルシ 一般に、ピッチの上昇を基準としたひとまとまりを「句」と呼び、このときのピッチの上 昇を「句頭の上昇」と呼ぶ。そして(イ)のように、単独発話では二つ以上の句であったも 論説
東京方言における dephrasing の生起要因
統語機能、モーラ数及び発話速度による影響全美炷
のが一つの句に融合することを dephrasing と呼んでいる。研究者によっては“minor phrase boundary deletion rules”(McCawley 1968)、“minor phonological phrase incor-poration”(Kohno 1980)、“compression of minimal minor phrases”(Poser 1984)、“minor phrase formation”(Kubozono 1993)と表現されることもあるが、本稿では dephrasing に 統一する。 Dephrasing は様々なレベルの韻律単位で生じるが、本稿では文節単位で生じる dephras-ing を対象とし、検討する文節数を 2 文節に限定する。すなわち、トーキョー ニワ(東 京には)のように(助詞ニワの冒頭にピッチの上昇が生じている場合)、1 文節が 2 句を形 成する場合は対象とせず、文節を句の最小単位とする(橋本 1934)。 1.2 先行研究 モーラ数が多い場合は一つの句を形成し難い傾向があることが指摘されている (Poser 1984)。その関係を定量的に検討した全(2013、2014)によれば、2 文節の合計モー ラ数が増加するに従い、dephrasing 率は単調に減少する。全(2014)は、CSJ を対象に 6~13 モーラで構成された 2 文節の dephrasing 率を調査した結果、6 モーラから順に 0.81、0.68、0.55、0.48、0.34、0.32、0.27、0.17 であったと報告している。
Pierrehumbert and Beckman (1988)及び Sugahara (2002)には、2 文節の前部にフォ ーカスがあるとき dephrasing が生じることが示唆されている。 アクセント型の組み合わせと dephrasing 生起に関する研究も行われているが、どのよ うなアクセント型の組み合わせにおいて dephrasing が生じるかについては研究者の間 で見解が分かれている。例を挙げると、前部・後部のいずれかが無核語である場合に dephrasing が生じるという指摘(McCawley 1968)、後部が無核語である場合に生じると いう指摘(Kohno 1980)、前部が無核語である場合に生じるという指摘(Poser 1984)があ る。 Dephrasing が生じる修飾関係としては、連用修飾と連体修飾(Kohno 1980)、「形容詞 +名詞」と「動詞+名詞」(Poser 1984; 全 2013、2014)が報告されている。
Kohno (1980)は ko tori ni tu metai mi zu o yat -ta の四つの句をより速いスピー ドで発話すると、ko tori ni tu metai mizu o yat-ta のように、二つの句になる傾向があ るとし、発話速度が dephrasing 生起に影響する可能性を示唆している。
ったのは、Sugahara (2002)と全(2013、2014)のみである。また、従来複数の要因が指摘さ れているものの、要因間の交互作用を検討した研究はほとんどなく、dephrasing の生起 環境については、まだ十分な検討がなされていないのが現状である。 1.3 研究方法 本稿で取り上げる要因は、統語機能、モーラ数及び発話速度である。まず、どのような 観点から統語機能を要因として捉えるかを述べる。 先行研究では、例えば「赤い目印が」「赤い目印で」については、2 文節の前部と後部の関 係に注目してこれらすべてを連体修飾として扱っており、それぞれが持つ統語機能の違 いは問題にしていない。しかし、日常の会話においては「赤い目印」のように名詞の形で 発話が終了する場合よりは、「赤い目印が」「赤い目印で」のように格助詞が後続し、述語を 修飾する形で用いられるのが一般的である。この場合、前者は必須補語、後者は副次補語 として機能することになる。 そこで本稿では、2 文節の統語機能に注目し、統語機能の違いが dephrasing 生起にど のように関わるかを検討する。具体的には、使用頻度の高いニ・デ・ガ・ヲ格を対象に dephrasing の生起率を比較分析し、結果を考察する。ニ・デ格は、対象や主体を表す場合 と場所、手段、頻度、時間などを表す場合があるが、前者はガ・ヲ格と機能的に重複するの で、後者に限定する。分析の際にはニ・デ・ガ・ヲ格における dephrasing 率を個別に算出 し、4 節の議論では統語機能の観点から分析結果を解釈する。格助詞に先行する連体修 飾は「形容詞+名詞(以下 AN)」「動詞+名詞(以下 VN)」「名詞ノ+名詞(以下 NN)」をす べて対象とする。 モーラ数については 2 文節の合計モーラ数を対象とする。CSJ-Core(2 節参照)から連 体修飾に格助詞が後続する 2 文節を抽出したところ、2 文節の合計モーラ数が 6~9 モー ラより大きいか小さい場合は、連体修飾の種類及び格助詞の種類によって dephrasing の 生起度数が 0 であることが多かった。例えば、合計モーラ数が 10 モーラである場合、 「VN ヲ格」は dephrasing の生起度数が 49 であるのに対し、「AN ヲ格」は 0(ゼロ)であっ たが、このような場合は連体修飾(VN vs. AN)による影響を評価できないため除外した。 従って、最終的に対象とした 2 文節の合計モーラ数はこの 6~9 モーラである。各文節の 最小モーラ数は 2 モーラ、最大モーラ数は 6 モーラである。発話速度は、2 文節における 1 秒間の平均モーラ数を基準とした。本稿で検討する要因及び水準をまとめると表 1 の
ようになる。 表 1 要因及び水準 要因 水準 例 ① 統語機能 ニ格 デ格 ガ格 ヲ格 (新しい車) に・で・が・を (借りた本) に・で・が・を (隣の家) に・で・が・を ② 2 文節の合計モーラ数 6∼9 モーラ ③ 発話速度 (連続変数)
2.データ
CSJ には、約 752 万語に及ぶ大規模の音声データが格納されている。本研究ではこの うち、約 50 万語に対して韻律研究用アノテーションが施された CSJ-Core(前川 2004、 2006)を対象とした。 CSJ-Core は、学会講演、模擬講演、対話、再朗読の 4 種類の音声タイプに分類されてい る(表 2)。学会講演は、理工学、人文、社会の 3 領域に及ぶ種々の学会における研究発表 を実況録音したもので、模擬講演は、「人生で一番嬉しかったこと」「私の住んでいる街」な どの日常的話題についてスピーチを行ったものである。対話は、学会講演ないし模擬講 演に関してインタビュアーが様々な質問を発し、話者がこれに答える形式の対話である。 再朗読は、同一話者による同一の言語音が自然発話と再朗読とでどのように異なるかを 見るため設計されたものである。ただし、再朗読は、自発性という面で他の音声タイプと 性質が異なると判断し除外した。従って、今回分析対象としたのは、学会講演、模擬講演、 対話の 3 種類である。 CSJ-Core における話者別の出生年度は、1930~1954 年度が 27 名、1955~1964 年度が 35 名、1965~1979 年度が 77 名で収録当時(1999~2003 年度)若い世代が多数含まれている(1)。 CSJ-Core の音声は、東京ないし首都圏(千葉、埼玉、神奈川の 3 県)で出生した話者のもの に限定されているが、これは、韻律情報付与方式が東京方言のアクセント体系に依存して いるからである。表 2 CSJ-Core の内訳(前川 2010 を参考に作成) 音声タイプ 女性話者 男性話者 時間数* 学会講演 23 45 14.2 模擬講演 38 37 15.0 対話 3 3 3.0 再朗読 3 3 1.4 計 67 88 33.6 *発話間のポーズを除去した実質発話時間 2.1 CSJ-Core からのデータ抽出 データ検索に用いたアノテーションの種類は、韻律情報、係り受け構造情報、文節情報 及び形態論情報である。データ検索には CSJ-Core の RDB(小磯・伝・前川 2012)を利用 した。必要な情報を筆者が手作業で抽出し分析に用いた場合はそれを明記する。 まず、連体修飾 AN・VN・NN は、品詞情報(形態論情報内)を利用して抽出した上で、係 り受け構造情報を利用して 2 文節の前部と後部とが係り受け関係にあるものに限定した。 さらに、2 文節が連続するものを対象とするため、前部の終了時刻と後部の開始時刻が一 致するものに限定した。AN・VN の前部には、連体形のみが含まれるようにし(例:楽し い旅行、分析した時)、連体形以外の非自立語が含まれるもの(例:検討すべき問題点)は 事例を見ながら手作業で除外した。 格助詞の抽出は、名詞(後部)に後続する非自立語の品詞を格助詞に限定し、さらにニ・ デ・ガ・ヲ格に絞った。ニ・デ格は、「やはり人が一つの場所に集まるというのはですね」 「軽いジョギングで行くと二十分ぐらい」のように 2 文節全体が副詞として機能するもの だけを採用し、「メーカーの人に組んでもらって」「全国の警察で受理した 110 番の件数 は」のように対象や主体を表す場合は、事例を見ながら手作業で除外した(1.3 節参照)。 2 文節の合計モーラ数は韻律情報から各文節のモーラ数を抽出して計算した。語中の ポーズ、言い直しや言い間違い、フィラー、笑いながらの発話など、非流暢性要素を含む発 話(小磯・西川・間淵 2006)は対象外とした。
東京方言における句(accentual phrase、あるいは minor phrase)は、最大 1 個までのア クセント核を持ちうる韻律単位と定義されており(McCawley 1968、Poser 1984、Pierre-humbert and Beckman 1988)、CSJ-Core でも一つの句に含まれるアクセント核数は 1 個 までに制限されている(五十嵐・菊池・前川 2006)。「有核語+有核語」で構成された 2 文
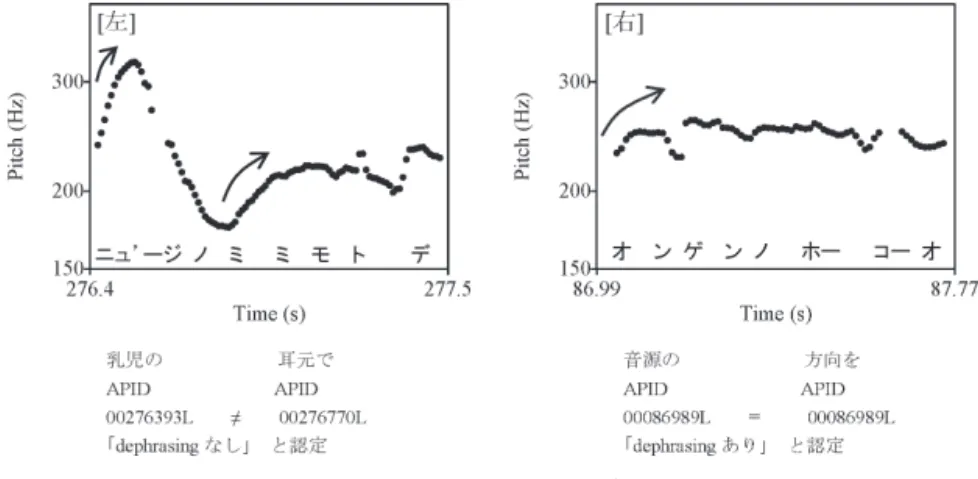
図 1 CSJ-Core から抽出した F0 曲線及び APID 節は dephrasing の有無を比較できないため対象から外した。各文節のアクセント核の 有無に関する情報は手作業で検索した情報を利用した。 なお、本稿で使用するデータは、全(2013、2014)で用いられたデータの中から、連体修飾 (AN、VN、NN)に格助詞ニ・デ・ガ・ヲ格が後続する 2 文節を抽出したものである。デー タ数は全(2013、2014)の約 1/3 に相当する。 2.2 Dephrasing の認定方法 CSJ-Core には dephrasing の有無に関するアノテーションが提供されておらず、手作 業で dephrasing の有無を認定する必要がある。以下では、本研究における dephrasing の認定方法について述べる。すべての過程は CSJ-Core のアノテーションを利用して行 った。 図 1[左]と[右]は、CSJ-Core から話者 1 名が発話した「ニュʼージノミミモトデ」と「オ ンゲンノホーコーオ」の F0(音声の基本周波数)曲線及び APID(句の固有 ID)を示した ものである。横軸は発話時刻[秒]、縦軸は F0[Hz(logarithmic)]、そして図中の矢印(筆 者による)は句頭の上昇を示している。句頭の上昇は通常、文節の第 1 モーラから第 2 モ ーラにかけて生じるが、第 1 モーラにアクセント核がある場合は第 1 モーラ内で生じる ことが多く([左]「ニュʼージノ」)、第 2 モーラが特殊モーラである場合は第 1 モーラから 第 3 モーラにかけて生じることが多い([右]「オンゲンノ」)。CSJ-Core ではこのような 句頭の上昇を基準として[左]は二つの句、[右]は一つの句と認定されており、[左]には
00276393L、00276770L、[右]には 00086989L という句の開始時刻を基準とした APID が 付されている。[右]のように 2 文節が一つの句にまとまるときは、前部と後部とに同じ APID が付与されているので、2 文節を抽出した後、前部・後部の APID が同一である 2 文節を dephrasing が生じたと認定した。
3.結果
本節では、要因別 dephrasing 率を分析し全体的な傾向を把握した後、ロジスティック 回帰分析により各要因の有効性を検討する。Dephrasing の有無を認定した結果は、 「dephrasing あり」を 1、「dephrasing なし」を 0 とした 2 値データに変換して用いた。ま ず、統語機能を要因とした分析結果を述べる。 3.1 統語機能(ニ・デ・ガ・ヲ格) CSJ-Core から 2 文節を抽出した結果、計 2059 サンプルが得られた(延べ数)。表 3 は 左列から順に、格助詞の種類、サンプル数(N)、dephrasing の生起度数そして dephrasing 率を示している。Dephrasing 率は、ニ格が 0.71、デ格が 0.66、ガ格が 0.58、ヲ格が 0.45 で、 ニ・デ格がガ・ヲ格より高くなっていることがわかる。 表 3 ニ・デ・ガ・ヲ格における dephrasing 率 格助詞 N dephrasing あり dephrasing 率 ニ 549 390 0.71 デ 280 184 0.66 ガ 742 428 0.58 ヲ 488 218 0.45 全体 2059 1220 0.59 3.2 2 文節の合計モーラ数(6~9 モーラ) 図 2 は、2 文節の合計モーラ数と dephrasing 生起との関係を示している。6 モーラか ら順に 0.82、0.68、0.53、0.46 となっており、モーラ数の増加に伴い dephrasing 率が減少し ていることがわかる。さらに、このような傾向は、ニ・デ・ガ・ヲ格のいずれにおいても認 められる(図 3)。特に、ニ・デ格がガ・ヲ格より高値を示し、3.1 節で検討した格助詞と dephrasing との関係が一定に保たれていることが読み取れる。図 4 発話速度による dephrasing 率 図 5 格助詞別発話速度による dephrasing 率 図 2 2 文節の合計モーラ数による dephrasing 率 図 3 格助詞別 2 文節の合計モーラ数によるdephrasing 率 3.3 発話速度 発話速度は 1 秒間の平均モーラ数を基準とし、1 秒間の平均モーラ数は 2 文節の合計 モーラ数を 2 文節の持続時間[秒]で除して求めた。結果を図 4 に示す(2)。同図より、発 話速度が増加するにつれ、dephrasing 率も増加していることがわかる。さらに、ニ・デ・ ガ・ヲ格のいずれにおいても同様の傾向が見られる(図 5)(3)。図 5 に示されている dephrasing 率は、全体的にニ格が最も高く、その次にデ格、ガ格、ヲ格の順に高くなって おり、3.1 節の結果と整合する。
図 6 Dephrasing の有無別 2 文節の合計モーラ数による発話速度
図 6 は、dephrasing が 生 じ た 2 文 節「dephrasing あ り」と 生 じ て い な い 2 文 節 「dephrasing なし」の発話速度を比較したものである。「dephrasing あり」が「dephrasing なし」より高く、またこのような傾向は 6~9 モーラのいずれにおいても認められる。図 6 は 1 秒間の平均モーラ数を基準としたものであるが、これを 10 秒に換算すると、例えば 2 文 節 の 合 計 モ ー ラ 数 が 6 モ ー ラ で あ る 場 合、「dephrasing あ り」は 91.6 モ ー ラ、 「dephrasing なし」は 85.0 モーラとなるので、「dephrasing あり」が 10 秒間に 6.6 モーラ 速く発音されたことになる。 3.4 AIC 最小モデル 要因間の交互作用を含む複数の変数の中からどのような変数を採用したモデルが統計 的に良いモデルであるかを検討する。モデル選択を行う基準はいくつかあるが、本稿で は一般によく使われている AIC (Akaikeʼs Information Criterion)によりモデル選択を 行う。
AIC は次のように、モデルの当てはまりの悪さ(deviance)を基準としている。よって、 複数のモデルの中では AIC が最も小さいのが最良のモデルとなる。
AIC = -2{(最大対数尤度)-(パラメータ数)} = Deviance + 2(パラメータ数)
各モデルの AIC を検討するために、R(Ver.3.0.2)言語の glm 関数を用いて、dephrasing の有無(1、0)を目的変数とし、切片、統語機能、2 文節の合計モーラ数、発話速度、統語機能 と 2 文節の合計モーラ数の交互作用、統語機能と発話速度の交互作用、そして 2 文節の合 計モーラ数と発話速度の交互作用を説明変数としたロジスティック回帰分析を実施した (変数増減法)。分析の結果、切片、統語機能、2 文節の合計モーラ数、発話速度を同時に組 み込んだモデルが AIC 最小モデルとして選択され(表 4 の s+k+m+h)、統語機能、2 文 節の合計モーラ数、発話速度は dephrasing 生起に関する予測変数であるが、要因間の交 互作用は予測変数ではないことが示された。各モデルの AIC は表 4 の通りである。 表 4 各モデルの AIC モデル AIC s # 切片 2785.4 s+k #k=統語機能 2710.8 s+m #m=2 文節の合計モーラ数 2641.5 s+h #h=発話速度 2744.8 s+k+m 2590.6 s+k+h 2657.1 s+m+h 2574.1 s+k+m+k : m 2591.0 s+k+h+k : h 2660.8 s+m+h+m : h 2576.1 s+k+m+h 2511.4 s+k+m+h+k : m 2512.6 s+k+m+h+k : h 2515.7 s+k+m+h+m : h 2513.4 (表中の+は説明変数の追加、:は交互作用項を表す) 表 5 の Estimate 列は AIC 最小モデル(s+k+m+h)に含まれた説明変数の係数であ る。2 文節の合計モーラ数の係数が負の値をとっているのは、2 文節の合計モーラ数の増 加は dephrasing 率を低下させる効果を持つことを示し、発話速度の係数が正の値をとっ ているのは、発話速度の増加は dephrasing 率を上昇させる効果を持つことを示している。 また、ニ・デ格の係数がガ・ヲ格の係数より大きいのは、前者が後者より dephrasing 率を 上昇させる効果が大きいことを示している。表 5 における格助詞の係数は、デ格の係数 を 0 に設定した上で、ニ・ガ・ヲ格に変わった場合に、0 と設定しておいた係数がそれぞれ どのように変化するかを示したものである。他の格助詞を基準値とした分析においても 同様の結果が得られており、dephrasing 率を高める効果はニ・デ格〉ガ・ヲ格の順に大き
いとまとめることができる。 なお、AIC 最小モデルを用いて個々の発話の dephrasing の有無を予測した結果と、実 際に観測された dephrasing の有無との一致率(正答率%)を調査したところ、正答率は 66.68% であった。切片のみを含むモデル(表 4 中の s)の正答率が 59.25% であったので (表 3 の 0.59 を%に換算した値)、AIC 最小モデルを用いることで 7.43% 向上したことに なる。 表 5 Dephrasing の有無を目的変数とし、統語機能、2 文節の合計モーラ数、発話速度を説 明変数としたロジスティック回帰分析結果
説明変数 Estimate Std. Error z-value Pr (>|z|)
切片 2.99 0.42 7.11 p<.001 2 文節の合計モーラ数 -0.56 0.05 -11.66 p<.001 発話速度 0.23 0.03 8.64 p<.001 デ格 0.00 ガ格 -0.50 0.15 -3.21 p<.01 ニ格 0.11 0.16 0.67 p=.51 ヲ格 -0.93 0.16 -5.64 p<.001
4.議論
格助詞ニ・デ・ガ・ヲにおける dephrasing 率を分析した結果(3.1 節参照)、ニ・デ格の方 がガ・ヲ格より dephrasing 率が高いことがわかった。以下では、統語構造とフォーカス との相関を論じた安井(1983)及び田窪(1987)、そしてフォーカスとイントネーションと の関係を記述した郡(1989)に基づいて 3.1 節の分析結果を考察する。先行研究によって は「焦点」という語を用いることもあるが、その場合は原文のまま表記する。安井(1983)は、「They wanted to buy a new car (彼らは新しい車を買いたいと思っ た)」において、名詞を修飾する形容詞は、統語的にみれば存在しなくてもよい随意的要素 に過ぎないが、赤い4 4車、大きい4 4 4車などを除外して新しい4 4 4車に範囲を狭めるという点で限定 を行うと述べている。 田窪(1987)は、焦点位置は、潜在的焦点位置と実際の焦点位置とがあるが、このうち統 語的に決定できるのは潜在的焦点位置のみであり、実際の焦点は潜在的焦点位置の中か ら文脈によって決まるとしている。田窪(1987)は、英語において無標の場合に潜在的焦 点位置にくるのは補語と制限的修飾語句であるという Greenbaum(1969)の理論が日本
語の場合にもある程度認められることを統語構造と情報構造の相関を利用して説明して いる。 安井(1983)及び田窪(1987)の理論によれば、統語構造だけを基準とした場合にフォー カスが置かれるのは、義務的要素(以下、必須補語)ではなく随意的要素(以下、副次補語) である。本稿で扱ったニ・デ・ガ・ヲ格の中では、ニ・デ格の方にフォーカスが置かれると いうことになる。 郡(1989)は、フォーカスは、フォーカス語の後に続く語群のイントネーションに影響を 及ぼすと記述している。具体的には、フォーカスのある部分は F0 ピークが増大し、フォ ーカス以後の語群はフォーカスのある部分の F0 ピークを引き継ぐ形で文末に向かって 緩やかに下降していくとしている(4)。本稿では、ニ・デ格が含まれた 2 文節全体にフォー カスがあると解釈しているが、この場合も郡(1989)と同様に考えることができる。すな わち、フォーカスにより 2 文節の前部で増大した F0 ピークがそのまま後部に引き継が れ、その結果 2 文節全体が一つの句にまとまると考えることができる。 次に、3.2 節では、2 文節の合計モーラ数 6~9 モーラを対象に、モーラ数と dephrasing 生起との関係を検討した。Dephrasing 率は 2 文節の合計モーラ数が増加するにつれ減 少したが、これは、Poser(1984)及び全(2014)で言及されているように、発話の際にモー ラ数の長大な句の形成を避ける傾向があるためと考えられる(5)。 さらに、発話速度による dephrasing 率を検討した結果(3.3 節参照)、発話速度が増加す るにつれ、dephrasing 率が上昇することが示された。また合計モーラ数 6~9 モーラのい ずれにおいても「dephrasing あり」の方が「dephrasing なし」より発話速度が一貫して高 かった。Dephrasing は句頭の上昇の消失により認定されるので、発話速度が速い方が dephrasing 率が高いということは、発話速度の速い方が句頭の上昇が消失しやすい環境 であることを意味する。従って、句頭の上昇は発話速度によってダイナミックに変動す る性質を持つといえる。 最後に、AIC 最小モデルとして三つの要因を同時に組み込んだモデル(切片を含む)が 選択されたが、この 3 要因のうち AIC 最小値を示したのは 2 文節の合計モーラ数である (表 4 中の s+m、AIC=2641.5)。このことは、3 要因の中では、2 文節の合計モーラ数を 説明変数としたモデルの予測精度が最も良いことを示している。
5.まとめと今後の課題
本稿では、統語機能(ニ・デ・ガ・ヲ格)、2 文節の合計モーラ数(6~9 モーラ)及び発話速 度が dephrasing 生起に及ぼす影響を定量的に検討した。結果をまとめると以下のよう になる。 第一に、統語機能によって dephrasing 率が異なることがわかった。Dephrasing 率は 必須補語(ガ・ヲ格)より副次補語(ニ・デ格)の方が高かった。 第二に、2 文節の合計モーラ数が増加するにつれ dephrasing 率は低下した。 第三に、発話速度が増加するに従い、dephrasing 率は上昇した。また、6~9 モーラのい ずれにおいても dephrasing の生じた 2 文節が dephrasing の生じていない 2 文節より発 話速度が高かった。 第四に、統語機能、2 文節の合計モーラ数、発話速度を同時に組み込んだモデルが AIC 最小モデルとして選択され、3 要因とも dephrasing 生起に関する予測変数であることが 統計的に立証された。 第五に、三つの要因の中では、2 文節の合計モーラ数による予測精度が最も良いことが 示された(AIC 最小)。 第六に、統語機能と 2 文節の合計モーラ数の交互作用、統語機能と発話速度の交互作用、 及び 2 文節の合計モーラ数と発話速度の交互作用は、dephrasing 生起に関する予測変数 ではなかった。 このうち、第二は Poser (1984)の主張及び全(2013、2014)の分析結果とよく整合し、第 三は Kohno (1980)の主張と整合している。ただし、Poser (1984)、Kohno (1980)では定 量分析を行っていないのに対し、本稿では定量的に検討した点が異なる。そして、第一、 第四、第五、第六は本研究で得られた新たな知見である。 本稿では、統語機能、モーラ数、発話速度の 3 要因について検討したが、アクセント型の 組み合わせ、話者属性(男女・年齢)、音声タイプなどを要因に加えることにより、より良い AIC モデルを見出せる可能性があると思われる。また、本稿では統語構造的な観点から 副次補語(ニ・デ各)にはフォーカスがあると解釈したが、倒置により強調される要素にも フォーカスが置かれることが予想されるので検討する必要があると思われる。今後は、 アクセント型の組み合わせ、話者属性、音声タイプ及び倒置構造を中心に dephrasing の 生起環境を検討する予定である。註 ( 1 ) 表 2 の話者数(計 155 名)と一致しないのは、表 2 では音声タイプによって話者が重複してい る場合があるためである。 ( 2 ) 図 5 の横軸の範囲に合わせて作成した。 ( 3 ) サンプル数が 5 以下のものは図に示していない。 ( 4 ) F0 曲線はアクセント型の組み合わせとも関連するが、本稿では触れない。 ( 5 ) 2 文節を構成する前部・後部の各モーラ数と dephrasing の関係については全(2014)を参照さ れたい。 参考文献 五十嵐陽介・菊池英明・前川喜久雄(2006)「韻律情報」『日本語話し言葉コーパスの構築法』(国立国語 研 究 所 報 告 124)347︲453, http://www.ninjal.ac.jp/corpus_center/csj/k-report-f/07.pdf(2014 年 8 月 1 日アクセス). 小磯花絵・西川賢哉・間淵洋子(2006)「転記テキスト」『日本語話し言葉コーパスの構築法』(国立国語 研究所報告 124)23︲132, http://www.ninjal.ac.jp/corpus_center/csj/k-report-f/02.pdf(2014 年 8 月 1 日アクセス). 小磯花絵・伝康晴・前川喜久雄(2012)「『日本語話し言葉コーパス』RDB の構築」『第 1 回コーパス日 本語学ワークショップ予稿集』393︲400. 郡史郎(1989)「強調とイントネーション」杉藤美代子(編)『講座日本語と日本語教育 2 ― 日本語の 音声・音韻(上)』明治書院,316︲342. 全美炷(2013)「2 文節の修飾関係及びモーラ数による dephrasing 生起の予測」『第 27 回日本音声学 会全国大会予稿集』203︲208. 全美炷(2014)「『日本語話し言葉コーパス』を用いた dephrasing 生起要因の分析 ― 修飾関係及び モーラ数の効果 ― 」『音声研究』1︲₁₃. 田窪行則(1987)「統語構造と文脈情報」『日本語学』6(5),明治書院,37︲48. 橋本進吉(1934)『国語科学講座Ⅵ 国語法要説』明治書院. 前川喜久雄(2004)「『日本語話し言葉コーパス』の概要」『日本語科学』15,111︲133. 前川喜久雄(2006)「概説」『日本語話し言葉コーパスの構築法』(国立国語研究所報告 124)1︲21, http://www.ninjal.ac.jp/corpus_center/csj/k-report-f/01.pdf(2014 年 8 月 1 日アクセス).
前川喜久雄(2010)「日本語有声破裂音における閉鎖音調の弱化」『音声研究』14(2),1︲15. 安井稔(1983)「修飾ということ」『日本語学』2(10),10︲17.
Greenbaum, Sidney (1969) Studies in English Adverbial Usage. Florida: University of Miami Press.
Kohno, Takeshi (1980) “On Japanese Phonological Phrases.” Descriptive and Applied Linguistics 13, Tokyo: ICU, 55︲69.
Kubozono, Haruo (1993) The Organization of Japanese Prosody. Tokyo: Kurosio Publishers. McCawley, James D. (1968) The Phonological Component of a Grammar of Japanese. The
Hague: Mouton.
Pierrehumbert, Janet B. and Mary E. Beckman (1988) Japanese Tone Structure. Cambridge, Mass.: MIT Press.
Poser, William J. (1984) “The Phonetics and Phonology of Tone and Intonation in Japanese.” Ph.D. thesis, MIT.
Sugahara, Mariko (2002) “Conditions on post-focus dephrasing in Tokyo Japanese.” In Bernard Bel and Isabelle Marlien (eds.) Proceedings of the 1st International Conference on Speech Prosody, Aix-en-Provence, 655︲658.