井上 克己
電気通信大学大学院 情報理工学研究科
情報・ネットワーク工学専攻 博士(工学)学位申請論文
2020 年 3 月
博士論文審査委員会
主査 範 公可 教授
副主査 石橋 孝一郎 教授
委員 崎山 一男 教授
委員 三輪 忍 准教授
委員 内山 邦男 招聘研究員
著作権所有者
井上 克己
2020 年 3 月
Katsumi Inoue
Currently, the computers we use every day are Neumann computers. This computer has high versatility and is used in various fields. A full-scale big data society and a highly intelligent infor- mation processing society have begun,however,semiconductor miniaturization technology known as Moore’s Law will soon reach its limits. In view of the above background, it is necessary to solve the biggest problem of the Neumann computer. Neumann-type computing is based on sequen- tial processing computing using two devices:a computing device and a storage device or memory.
Therefore,the biggest problem is the bus bottleneck the Neumann bus bottleneck between the computing device and the storage or memory device. Against this background, research has been accelerated to improve information processing The addition of computing function in the memory has been studied as in-memory computing technology. And also, the addition of a computing function near of the memory has been studied as a near-memory computing technology. Many of the goals of these studies are to solve the Neumann bass bottleneck. In addition, it is nec- essary to know that it is not reasonable to make arithmetic units such as arithmetic logic units
(ALUs)and floating-point units(FPUs), which are Central Processing Unit(CPU)or Graph- ics Processing Unit(GPU)arithmetic units, repeatedly execute processing such as information detection . This study Memory Computing Processor belongs to in-memory computing and aims to fundamentally solve the problem of information detection . The Memory Computing Processors are devices in which an arithmetic device and a storage or memory device are mounted on the same semiconductor chip in order to solve the adverse effects caused by the separation of the arithmetic device and the storage or memory device. The Memory Computing Processors specializes only in information detection processing, which is difficult for CPU and GPU, In the Memory Computing Processors,Group Array Processors(GAPs)are used in large quantities to reduce the operating cost of computing devices to low-cost, space-saving computing units, and to execute massively parallel computing in chips enables high-speed, power-saving processing. In addition, memory computing processors eliminate the need for information discovery indexes and metadata, simplifying information processing and reducing expertise. Detection of infor- mation by the memory computing processor is quick, and has the effect of saving power and simplifying information processing. In the future, information processing will be mainly divided between CPU and GPU, which are conventional processors, and in-memory computing processors such as the memory computing processor in this study.
井上 克己
現在,私たちが日常使用しているコンピュータはノイマン型コンピュータである.このコンピュー タは汎用性が高く様々な分野で利用されている.本格的なビッグデータ社会と高度な知的情報処理 社会が始まっているが,ムーアの法則で知られる半導体微細化技術が間もなく限界を迎える.以 上の様な背景を考慮すると,ノイマン型コンピュータ最大の課題を解決する必要がある.ノイマ ン型コンピューティングは,コンピューティングデバイス(CPU:Central Processing Unit並びに
GPU:Graphics Processing Unit)と,ストレージデバイスやメモリの2つのデバイスを使用した
逐次処理コンピューティングが基本である.従って,コンピューティングデバイスと,ストレージ デバイスやメモリの2つのデバイス間のバスボトルネック(ノイマンバスボトルネック)が最大 の問題である.以上の様な背景から,メモリを静的デバイスから動的デバイスに変更する事によ り,情報処理効率を改善するための研究が加速されている.メモリの中にコンピューティング機 能を追加したものは,インメモリコンピューティングテクノロジーとして研究されている.また,
メモリの近くにコンピューティング機能を追加したものは,ニアメモリコンピューティング技術 として研究されている.これらの研究の目的の多くは,ノイマンバスボトルネックを解決するた めの研究である.更にCPUまたはGPU演算ユニットである算術論理ユニット(ALU:Arithmetic Logic Unit)や,浮動小数点ユニット(FPU:Floating Point Unit)などの演算ユニットに「情報 検出」などの処理を繰り返し実行させる事は合理的ではない事を理解する必要がある.この研究 の「メモリ一体型プロセッサ」はインメモリコンピューティングに属し,「情報検出」の問題を根 本的に解決する事を目的としている.メモリ一体型プロセッサは,演算デバイスとメモリの分離 による課題を解決するために,演算デバイスとメモリが同じ半導体チップに搭載されているデバ イスである.メモリ一体型プロセッサは,中央処理装置(CPU)およびグラフィックス処理装置
(GPU)にとって困難な「情報検出」処理のみに特化している.メモリ一体型プロセッサにおいて は,コンピューティングデバイスの運用コストを低コストで省スペースのコンピューティングユ ニットに削減するために,Group Array Processor(GAP)が大量に使用され,チップ内で超並列 計算を実行し,高速で省電力な処理を可能にする.さらに,メモリ一体型プロセッサを使用する と「情報検出」のためのインデックスとメタデータが不要になり,情報処理が簡素化され,専門 知識を削減する事が可能になる.メモリ一体型プロセッサによる「情報の検出」は,速くて省電 力,かつ情報処置を平易化する効果がある.今後は従来型プロセッサであるCPUやGPUと,本 研究のメモリ一体型プロセッサなどのインメモリコンピューティングプロセッサの分業処理が情 報処理の主流になるものと考える.
目次
第1章 序論 1
1.1 現在のコンピュータの問題 . . . . 2
1.2 本研究の目的 . . . . 2
1.3 最新のインメモリコンピューティングの研究事例(ハードウェア技術) . . . . 2
1.3.1 バスボトルネックの解消を目指した研究事例 . . . . 2
1.4 コンピュータの利用技術(ソフトウェア技術). . . . 4
1.4.1 データベースの検索の一般例 . . . . 4
1.4.2 データのクラス分けの一般例 . . . . 4
1.4.3 画像認識の一般例 . . . . 4
1.5 メモリ一体型プロセッサ . . . . 5
1.6 本論文の構成 . . . . 5
第2章 データベースプロセッサ 7 2.1 前書き . . . . 7
2.2 データベースプロセッサのハードウェア . . . . 8
2.2.1 一般的なメモリの構成 . . . . 8
2.2.2 データベースプロセッサの基本構成 . . . . 9
2.2.3 データベースプロセッサの演算回路 . . . . 10
2.3 データベースプロセッサの使用方法 . . . . 12
2.3.1 1ビット演算器によるバイナリデータの比較演算 . . . . 12
2.3.2 データ一致比較演算 . . . . 14
2.3.3 データ大小比較(範囲比較)演算 . . . . 15
2.3.4 カウント演算 . . . . 16
2.3.5 ビットマップインデックス検索 . . . . 18
2.4 データベースプロセッサの直並列接続演算 . . . . 20
2.5 FPGAによるデータベースプロセッサ . . . . 22
2.6 データベースプロセッサの応用システム事例 . . . . 22
第3章 データクラス分け演算プロセッサ 27 3.1 データの検索や探索の概念 . . . . 27
3.2 データクラス分けの例 . . . . 29
3.3 データクラス分け演算プロセッサの構成 . . . . 30
3.3.1 データクラス分け演算プロセッサの全体構成 . . . . 30
3.3.2 データクラス分け演算プロセッサの動作原理 . . . . 31
3.3.3 データクラス分け演算プロセッサの詳細 . . . . 32
3.3.4 データクラス分け演算プロセッサの演算器 . . . . 34
3.4 データクラス分け演算プロセッサの応用例:ヒストグラムカウンタ . . . . 35
3.4.1 アイテムの頻出カウンティング . . . . 35
3.4.2 ヒストグラムカウンタ回路構成 . . . . 35
3.4.3 関連研究との比較 . . . . 38
第4章 集合演算プロセッサ 41 4.1 ハードウェアパターンマッチングの研究事例 . . . . 41
4.1.1 画像データの物体認識 . . . . 41
4.1.2 ピクセル並列演算について . . . . 43
4.1.3 画像認識の歴史と現状 . . . . 44
4.2 集合演算の概要 . . . . 44
4.2.1 これまでの集合演算 . . . . 44
4.2.2 データの位置を含んだ集合演算 . . . . 46
4.2.3 集合演算エレメントの記述例 . . . . 47
4.2.4 新しい集合演算に関わるデータの値 . . . . 48
4.2.5 新しい集合演算に関わるデータの位置 . . . . 49
4.3 データの位置を含んだ集合演算式の実施例 . . . . 50
4.3.1 集合演算によるパターンマッチング . . . . 51
4.3.2 集合演算による領域内マッチング . . . . 51
4.3.3 集合演算による物体形状検出 . . . . 54
4.3.4 括弧付き集合演算 . . . . 58
4.3.5 集合演算式の付帯事項 . . . . 58
4.4 画像集合演算エミュレータ . . . . 60
4.4.1 画像集合演算エミュレータの構成 . . . . 60
4.4.2 画像集合演算エミュレータによる集合演算例 . . . . 60
4.4.3 集合演算エミュレータによる演算時間 . . . . 68
4.5 集合演算プロセッサ . . . . 70
4.5.1 集合演算プロセッサの構成概要 . . . . 70
4.5.2 FPGAによる画像集合演算の実装例. . . . 72
4.5.3 ASICによる集合演算プロセッサの実装 . . . . 74
4.5.4 主なスペック . . . . 74
4.5.5 回路構成 . . . . 75
4.6 ハードウェアパターンマッチングの性能評価 . . . . 78
4.6.1 CPUによる従来技術と集合演算の時間の比較 . . . . 78
4.6.2 他の画像マッチング技術との比較 . . . . 80
4.7 AIとしての活用. . . . 81
4.7.1 ルールベースのテンプレートパターンマッチング . . . . 81
4.7.2 網羅的テンプレートパターンマッチング . . . . 82
4.8 2次元以外の集合演算. . . . 84
4.8.1 1次元情報の集合演算. . . . 84
4.8.2 3次元情報の集合演算. . . . 84
第5章 結論 85
5.1 メモリ一体型プロセッサの総括 . . . . 85
5.2 新たな情報処理の実現に向けて(ハードウェア) . . . . 88
5.2.1 自己完結型情報処理 . . . . 89
5.2.2 情報処理効率(電力性能) . . . . 89
5.2.3 汎用性 . . . . 89
5.3 新たな情報処理の実現に向けて(ソフトウェア) . . . . 89
5.3.1 情報探し処理の前処理が不要な情報処理 . . . . 89
5.3.2 プロセッサ間対話型情報処理 . . . . 90
5.3.3 IoT情報処理分野への応用 . . . . 90
5.3.4 人工知能(AI)の進化 . . . . 90
5.4 メモリ一体型プロセッサの克服すべき課題 . . . . 91
5.4.1 メモリ一体型プロセッサ共通の課題 . . . . 91
5.4.2 データベースプロセッサ . . . . 91
5.4.3 データクラス分け演算プロセッサ . . . . 91
5.4.4 集合演算プロセッサ . . . . 91
5.5 最後に . . . . 92
参考文献 92
研究業績 102
謝辞 105
著者略歴 106
図 目 次
2.1 一般的なメモリの構成. . . . . 8
2.2 データベースプロセッサの構成. . . . . 9
2.3 データベースプロセッサの1ビット論理演算器の回路構成. . . . . 11
2.4 1ビット演算器によるデータ一致比較演算. . . . . 14
2.5 1ビット演算器によるデータ大小比較演算. . . . . 15
2.6 1ビット演算器によるデータの加算演算. . . . . 17
2.7 1ビット演算器によるビットマップインデックスの検索. . . . . 19
2.8 データベースプロセッサの直並列接続構成. . . . . 21
2.9 ビットマップインデックスクリエータ(BIC)の構成例. . . . . 23
2.10 クエリロジックアレー(QLA)の構成例. . . . . 24
3.1 データの検索や探索の概念. . . . . 27
3.2 データクラス分け演算プロセッサの構成. . . . . 30
3.3 データの比較の概念. . . . . 31
3.4 データクラス分け演算プロセッサ. . . . . 33
3.5 データクラス分け演算プロセッサの比較演算器. . . . . 34
3.6 FPGAによるヒストグラムカウンタシステムの構成. . . . . 35
3.7 FIC回路の詳細. . . . . 36
3.8 クラス分類マトリックスの例. . . . . 37
3.9 ヒストグラム加算器の構成. . . . . 38
4.1 画像データの物体認識の例. . . . . 42
4.2 ピクセル並列演算の例. . . . . 43
4.3 集合演算の例. . . . . 45
4.4 集合演算に関わるデータの値の例. . . . . 48
4.5 集合演算に関わるデータの位置の例. . . . . 50
4.6 集合演算式の例−パターンマッチングの例. . . . . 52
4.7 集合演算式の例−領域内マッチング1の例. . . . . 53
4.8 集合演算式の例−領域内マッチング2の例. . . . . 55
4.9 集合演算式の例−物体の形状検出1の例. . . . . 56
4.10 集合演算式の例−物体の形状検出2の例. . . . . 57
4.11 集合演算式の例−括弧付き集合演算の例. . . . . 59
4.12 集合演算エミュレータ. . . . . 61
4.13 集合演算エミュレータによる集合演算結果. . . . . 62
4.14 集合演算エミュレータの演算式(サンプル1〜3). . . . . 64
4.15 集合演算エミュレータの演算式(サンプル4〜6). . . . . 65
4.16 集合演算エミュレータの演算式(サンプル7〜10). . . . . 66
4.17 集合演算エミュレータの演算式(サンプル11,12). . . . . 67
4.18 集合演算プロセッサの構成例. . . . . 71
4.19 2次元パターンマッチングアルゴリズム. . . . . 72
4.20 パターンマッチングのクエリ. . . . . 73
4.21 人物顔のパターンマッチングの例. . . . . 73
4.22 SOPの回路ブロック図. . . . . 75
4.23 ピクセル回路図. . . . . 76
4.24 ピクセル回路レイアウト. . . . . 77
4.25 SOPの回路レイアウト. . . . . 78
4.26 演算速度検証用パターン. . . . . 79
4.27 網羅的色彩パターン. . . . . 82
4.28 網羅的領域パターン. . . . . 83
4.29 網羅的形状パターン. . . . . 83
表 目 次
2.1 1ビット演算器によるバイナリデータの比較演算. . . . . 13
2.2 BIC32K16システムのFPGA実装結果. . . . . 24
2.3 BIC32K16システムと他のプラットフォームとの比較. . . . . 25
3.1 FICハードウェアとの性能評価. . . . . 39
4.1 CPUによるパターンマッチング処理時間.. . . . 69
4.2 FPGA実装による画像パターンマッチング演算性能評価. . . . . 74
4.3 集合演算に必要なクロック数. . . . . 79
4.4 演算時間比較結果. . . . . 80
4.5 ASIC実装による画像パターンマッチング演算性能評価. . . . . 81
5.1 プロセッサの相違点. . . . . 86
5.2 メモリ一体型プロセッサのまとめ. . . . . 87
第 1 章 序論
ノイマン型コンピュータは,CPUとメモリ及びハードディスクなどのストレージとバスを通じ て,命令やデータを授受する構成である.CPUとメモリやストレージ間のデータ転送速度とCPU の速度には大きな差があるため,CPU処理能力がデータ転送能力によって制約を受ける事になり,
この現象は「フォン・ノイマン・ボトルネック」と呼ばれ現在のコンピュータの最大の問題点と なっている.ノイマン型コンピュータを高速に動作させるためには,CPUの動作を高速にしたり,
CPUを増やしたり,CPUとメモリ間にキャッシュメモリなどを配置する必要がある.しかし近年 CPUの動作速度や処理性能の向上があまり期待出来なくなってきた.
ポストムーア社会や高度知的情報処理社会を迎えるにあたり,CPUやGPUとメモリによる従 来型のコンピューティングから,メモリを静的なデバイスから動的なデバイスに変革し情報処理 の効率化を図るメモリ主導型研究が加速している.主に4種類のメモリ主導型コンピューティン グ技術がある[1],[2].
1. ニアメモリコンピューティング(Near Memory Computing):データ移動に起因する消費電 力の削減とメモリ帯域の活用を目的に,メインメモリの近くで演算を行うアーキテクチャで ある.
2. インメモリコンピューティング(In Memory Computing):目的はニアメモリコンピューン ティングと同様であるが,主にスピントルクトランスファーRAM(STT RAM),相変化メ モリー(PCM),抵抗RAM(RRAM)などの新しい不揮発性メモリテクノロジー(NVM)
を利用してメモリの内部で演算を行うアーキテクチャである.
3. コンピューティングインメモリ(Computing In Memory):インメモリコンピューティング の一種であり,CiMでのデータ転送を最小限に抑えるために,デジタル積和演算(Digital multiply-and-accumulate: MAC)アレイがメモリアレイ自体に組み込まれてる.CiMでは,
ベクトル行列の乗算がアナログ計算で並列に実行され,入力ベクトルが複数の行をアクティ ブにし,内積は入力電圧とセルコンダクタンスの乗算として得られ,部分和(partial sum)は 列電流によって加算される.アレイのエッジにあるアナログ-デジタルコンバーター(ADC) は部分和をバイナリビットに変換する.
4. インメモリデータベースシステム(In Memory Database System):ハードディスクを使わ ず,全てのデータをメモリ上に持つ事により処理を高速化する技術の総称で,従来のハード ディスクを基本としたシステムと比較して1,000倍,1万倍,10万倍といった桁違いの処理 時間の短縮を記録した例が報告されている.本方式は既存のメモリ(DRAM)を大量に利用 する事で実現するものである.
このようなメモリ主導型コンピューティングの研究の背景は,CPUやGPUとメモリ間のバスボ トルネックの問題を解消する事による情報処理の効率化や,電力消費の抑制が主な目的である.メ モリ主導型コンピューティングが近年盛んに研究される背景には,シリコン貫通ビア(TSV)に
よるウエファの3Dスタック技術などの製造技術の進化がある[2].従って多くの研究は,新しい 半導体プロセス技術を利用したメモリとCPUやGPUの組み合わせによるコンピューティングの 研究であるが,アクセラレータとメモリなどを組み合わせした半導体アルゴリズム技術の研究も 含まれている.
1.1 現在のコンピュータの問題
現在のコンピュータは算術演算の機械化が誕生のきっかけである.現在のコンピュータの基本は CPUとメモリによる逐次処理であるので汎用性が高く,算術演算のみならず様々な情報処理に幅 広く利用されている.CPUが処理する情報処理は極めて広範囲であり,OS処理,算術演算処理,
制御処理,通信処理,検索,照合,認識や認証など多岐に渡っている.しかしながら,プロセッ サとメモリが物理的に分離している事に起因するバスボトルネックという宿命があるので,苦手 な(効率の悪い)処理をCPUにさせている事が少なくない.
CPUとメモリ間のバスボトルネックによる問題が顕在化しているもの,まだ顕在化していない もの,情報処理全体の中で影響の大きなものからあまり影響されないものまで様々である. しか しながらメモリやストレージの中から特定の情報を探し出す処理を伴う検索,照合,認識,クラ ス分けなどの処理は繰り返し実行されるので,CPUとメモリによるステップバイステップの処理 の場合著しく効率の悪い処理となる.
メモリやストレージの中から特定の情報を探し出す処理を伴う検索,照合,認識,クラス分け などの処理は,メモリやストレージ上のデータから情報検出を高速に実現するために構造化デー タであるメタデータを作成し,このメタデータを利用して検索,照合,認識,クラス分けする以 外高速化は図れない.しかしながらこのメタデータは更新処理の負担が常に存在し,システムと して捉えれば情報処理全体のパフォーマンスに影響を及ぼしている.
1.2 本研究の目的
このような観点から,同一ウエファ上にメモリ並びにコンピューティング用の演算器を実装した インメモリコンピューティングをメモリ一体型プロセッサとして定義するとともに,CPUやGPU が苦手な処理を,複雑なソフトウェアアルゴリズムを使用する必要がある情報処理と定義して,特 にCPUとメモリ間で頻繁に行われる「情報の検出」処理が抱える問題を解決するハードウェアア ルゴリズムが本研究の目的である.
1.3 最新のインメモリコンピューティングの研究事例(ハードウェ ア技術)
1.3.1 バスボトルネックの解消を目指した研究事例
先に示したように近年CPUとメモリ(ストレージ)間のバスボトルネックの本質的な解決を目 的とした研究が活発化している.以下に2つの研究事例を示す.
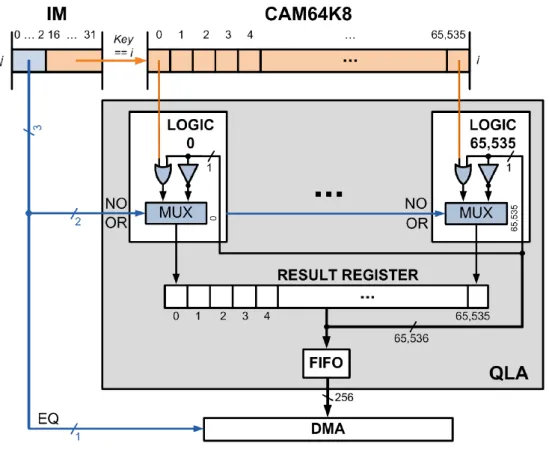
• X-SRAM:Enabling In-Memory Boolean Computations in CMOS Static Random Access Memories [3]
本文献は,フォン・ノイマン型コンピュータのボトルネックに関連するオーバーヘッドを軽減する ために提案されたものであり,メモリ内でブール演算を可能にするための研究について述べられ ている.CPUがメモリ上に記憶された情報の中から必要なデータを受け取り,受け取ったデータ を基にCPUが何らかの処理を行い,CPUがその処理した結果をまたメモリに戻す事を繰り返す これまでの情報処理の場合,演算時間のロスはもとより演算における消費電力も問題である事か ら,この提案ではSRAM(Static Random Access Memory)のメモリ内に128ビットや256ビッ
トのNAND,NORやXORその他の論理演算素子を埋め込み,メモリ内でこれらのブール演算を
する取り組みが示されている.本文献では,X-SRAMインメモリ命令を使用する事により,128 ビットおよび256ビットキーのそれぞれについて,ECBモード(Electronic CodeBook mode)の 情報処理で最大74.7%および74.6%までメモリアクセスを削減出来たと報告されている.
• Neural Cache:Bit-Serial In-Cache Acceleration of Deep Neural Networks [4]
本文献は,SRAM構成メモリに記憶されたビットシリアルデータを1ビット演算器で加減算演算 を実現するもので,CPUのキャッシュメモリのニューラルネットワークとして利用されている.
Neural Cacheアーキテクチャは,キャッシュ内で畳み込み型,完全接続型,およびプール中のレ
イヤーを完全に実行し,提案されたアーキテクチャは,キャッシュ内の量子化および正規化をサ ポートする.実験結果として,Inception v3モデルのための最先端のマルチコアCPU (Xeon E5) の7.7倍,サーバークラスGPU(Titan Xp)の18.3倍の推論遅れ時間を改善した.また,Neural Cacheは推論スループットをCPUより12.4倍(GPUより2.2倍)向上させ,消費電力をCPUよ り59%(GPUより61%)削減出来たと報告されている.
以上2つの研究事例に示されている演算器の構成は,本論文に提案されているデータベースプ ロセッサの1ビット演算器の構成と同様のものであり,データベースプロセッサ,メモリ一体型プ ロセッサの必要性や有効性を裏付けするものである.また,これらの研究事例において,演算速 度や電力性能の2つが主体となっているものの,インデックスの問題解決などの情報の検出に係 る共通の問題については言及されていない.
本論文の研究ではさらに一歩踏み込んでインデックスの問題解決並びに,CPUやGPUが苦手 な処理を広範囲にカバーする事を考慮した3種類のメモリ一体型プロセッサを提案するとともに,
従来型CPUやGPUの得意なところと,メモリ型一体型プロセッサの得意なところを分業させる 事により,コンピュータ全体の性能を向上させる分業コンピューティングソリューションを提案 するものである.
本論文で取り上げる3つのメモリ一体型プロセッサのデータベースプロセッサは,研究業績・国 際学会発表(7)で示すようにFPGAで実装済みである.データクラス分け演算プロセッサは,研 究業績・国際学会発表(2)(4)(5)で示すようにFPGAで実装済みである.集合演算プロセッサは,
研究業績・国際学会発表(8)-(14)で示すようにFPGAで実装済みであり,いずれも実用化可能で ある.応用例については3つのメモリ一体型プロセッサの各章に示す.
1.4 コンピュータの利用技術(ソフトウェア技術)
1.4.1 データベースの検索の一般例
SQLは最も一般的なデータベース言語である.データベースの中から特定のデータを探し出す
SELECT処理などは,適切に作成されたインデックスがない場合大幅に検索が遅くなる.データ
ベースの代表的なインデックスは,B-TREE,HASHやバイナリーサーチなどである.しかしな がら,これらのインデックスを作成するための時間が掛かるのみならず,データの変化に合わせ インデックスのメンテナンス処理(更新処理)をする必要がある.従って,CPUの負荷を削減さ せるための対策が必要になるので,専門性が高くなり汎用化が困難である.近年メインメモリで
あるDRAM(Dynamic Random Access Memory)の容量が大きくなるとともに価格が安くなり,
大量のデータをメインメモリDRAMに搭載し高速な処理を行うインメモリデータベースシステム が普及してきた.しかしながらこの場合でも,CPUとDRAMメモリのデータ転送バンド幅(バ スボトルネック)でデータの検索速度は制限されるので,大量のデータを処理する場合にはイン デックス作成が必要である.
インデックスなどのメタデータにより検索性能は大幅に向上するものの,リアルタイム性が要 求されるシステムにおいては,インデックス作成の前処理時間やインデックスのメンテナンス処 理(更新処理)が課題となる.
本研究のデータベースプロセッサは,以上のような課題を解決する事を目的としたメモリ一体 型プロセッサである.
1.4.2 データのクラス分けの一般例
データのクラス分けとは,与えられたデータの中から同一のデータや類似するデータを比較検 索し,その結果に基づき分類するものである.例えば個人データベースの場合,身長・体重・年 齢や同姓同名など同一のデータや類似するデータを比較検索し,クラス分けする処理を前処理な しで行う場合,データの数をN とするとN×(N −1)/2≃N2/2の比較検索演算が必要となる.
クラス分けはデータ解析やデータマイニングのみならずAI(人工知能)に欠かせない情報処理 であり,本研究のデータクラス分け演算プロセッサは同一のデータや類似するデータの比較検索 に関わる情報処理を効率化して,以上のような課題を解決する事を目的としたメモリ一体型プロ セッサである.
1.4.3 画像認識の一般例
画像認識処理は,フーリエ変換,HaaRアルゴリズム,HOGアルゴリズムやSIFTアルゴリズム などが代表的なアルゴリズムである.しかしながら,これらのアルゴリズムを実現するための前 処理に大きな時間が必要となるのでリアルタイム処理が困難になっている.画像認識処理はデー タベース以上に専門性が高く汎用化が困難である.画像認識の最も基本的処理であるパターン認 識並びにその手段であるパターンマッチング処理は,CPUやGPUが苦手な処理(効率の悪い処 理)の一つであり膨大な演算時間を必要とする.従って多くの場合パターン認識は機械学習で実現 する事が一般的になっていた. しかしながら機械学習によるパターン認識は専門性が高く,精度を 上げるために多くの時間がかかる,汎用化が困難などの課題を抱えていた.このような背景から
画像パターン認識は機械学習の一種であるニューラルネットワークを用いた深層学習(DL:Deep Learning)が主流になってきた.しかしながら深層学習技術は
1. 学習のために大量のデータが必要である.
2. 学習のために大量の時間が必要である.
3. 学習のために計算パワーの高い演算器(大電力消費)が必要である.
4. 標準化・汎用化がしにくい.
5. 「入力」に対する「結果」が検証出来ない.
6. 専門性が高く,開発・運用コストが高くなる.
などの課題があり問題解決の研究が進められている.特にバッテリー駆動やエッジ処理など省電 力が求められる分野では新しいAI技術が求められている.
本研究の画像認識用集合演算プロセッサは,これまで困難であったハードウェアパターンマッ チングによる高速なパターン認識を実現する事を目的としたメモリ一体型プロセッサである.
1.5 メモリ一体型プロセッサ
メモリ一体型プロセッサは,CPUやGPUが苦手な処理である情報の検出を含む検索,照合,認 識,クラス分けなどの処理に特化したプロセッサで,現在のコンピュータの宿命であるバスボト ルネックの問題を解決する事を目的としてデータ(メモリ)と演算器とを同一ウエファ上に一体
(1チップ)化した半導体デバイスである.CPUやGPUの苦手な処理を補完するこれらのデバイ スは,演算効率を高めるために検索,照合,認識,クラス分けなどの処理をする機能以外含まな い構成にすると共に,演算器はデータ(メモリ)に融合し易い小規模な構成である.このような 構成にする事により
1. 自己完結型処理が可能となる(CPUの手間を掛けずにデバイス内部で所定の処理を完結する)
2. 情報処理効率が向上する(並列性が高く高速化が図れ,インデックス作成などの前処理が不 要になる)
3. 電力性能が向上する(データの移動を最小限にしてシステム全体の電力を削減する)
以上のような効果を目指すものである.
メモリ一体型プロセッサは様々なタイプのものが考えられるが,本論文ではこれまで開発実績 のあるデータベースプロセッサ,データクラス分け演算プロセッサ並びに集合演算プロセッサの3 種類のメモリ一体型プロセッサに焦点をあてて説明する.
1.6 本論文の構成
本論文では,筆者により日本国内並びに海外での特許を取得済みの内容[5]-[18]及び国内外に発 表した学会論文や学術論文の内容 [19]-[41]に基づいて,3種類のメモリ一体型プロセッサを取り 上げる.
1. 第2章でデータベースの検索や照合に特化したデータベースプロセッサを紹介する.
2. 第3章でデータのクラス分けに特化したデータクラス分け演算プロセッサを紹介する.
3. 第4章で画像認識に特化した画像用集合演算プロセッサを紹介する.
最後に結論及び今後の課題について述べる.
第 2 章 データベースプロセッサ
2.1 前書き
コンピュータの誕生直後から,様々なデータ処理方法(コンピュータの利用方法)が研究されて きた.SQLは最も一般的なデータベース言語であり標準化されたシステムである.データベース の中から特定のデータを探し出す処理などは,適切に作成されたインデックスがない場合大幅に 検索が遅くなる.データ検索のために利用されるB-TREE,HASH-TABLEはその代表例である.
インデックスを利用する事により検索や照合の時間は大幅に削減されるものの,インデックスを 作成するための最適アルゴリズムの用意,インデックス作成のための前処理時間,インデックス 更新のための更新時間,そのためのCPUの負担,電力が必要である事に留意する必要がある.
近年,取り扱いするデータの量が巨大化する事から,汎用化や標準化する事に重点を置くより,
データの構成や利用目的に合わせたNoSQLタイプのデータベースが一般的になってきた.また メインメモリであるDRAMの容量が大きくなるとともに価格が安くなり,大量のデータをメイン メモリ(DRAM)に搭載し高速な処理を行うインメモリデータベースシステムも急速に普及し始
めている [42], [43].これらのシステムは1985年に発表された研究 [44] など古くから研究されて
きたコンピュータの利用アルゴリズムの研究が源流となっている.また,高速なデータ処理を目 指してビット配列,ビットシリアルやビットマップなどデータの行列変換を行ったインデックス の研究が進められてきた[45]-[49].さらに,ソーティング,ランキング,スヌーピング,結合など データ処理に係る個別の処理を効率化する取り組みも盛んに行われている[50]-[53].以上の研究 は,ソフトウェアアルゴリズムによるデータ処理の効率化,高速化の事例である.
間もなくムーアの法則によるコンピュータ(CPU)の性能向上が期待出来なくなる事から,近 年FPGAやASICなどのハードウェアを用いてデータ処理を高速化する取り組みが紹介されてい る.FPGAを用いたデータ処理の高速化の事例は[50]-[53]に紹介されている.ASICなどのハード ウェアを用いてデータ処理を高速化する事例は[54]-[60]に紹介されている.このように,データ 処理における高速化,効率化,低電力化の研究は,コンピュータのハードウェアの歴史とともに 様々な利用技術(アルゴリズム)が研究されてきた.
データベースプロセッサは様々なデータ処理の中で,データの検索・照合などデータ(情報)を 探し出す必要がある処理の高速化・効率化を目的としたメモリ一体型プロセッサである.このプ ロセッサは,データを検索・照合する際のインデックスの必要がない事,インデックスがなくても 高速である事,データを探しまわるCPUの負担が大幅に軽減出来る事が最大の特徴である.また このプロセッサは直並列に配列して利用する事が出来,それぞれのプロセッサが独立してSIMD 型データ処理を行うので,データが大きくなっても常に一定の処理時間で済む.一般のメモリ同 様に低電力でも高効率の検索・照合などのデータ処理を行う事が出来るなど,従来の情報処理方 法には見られない様々な特徴を持つ.
2.2 データベースプロセッサのハードウェア
2.2.1 一般的なメモリの構成
図2.1は一般的なメモリの構成を示す.
図 2.1: 一般的なメモリの構成.
図に示すメモリは,アドレスデコーダやデータバスなどの機能回路は省略されている.このメ モリは自由に情報データが書き込み読み出し可能な構成で,1ワードがnビットのデータ幅で,N のアドレスを持ち,メモリ全体がN ×nビットセルからなる記憶セルから成り立っており,アド レスデコーダなどの手段で外部から1からNまでのアドレスが選択可能になっている.
現在のCPUによる情報処理は,メモリのデータ幅が8ビット,16ビットや64ビットなど一定 のデータ幅(ワード幅)で,情報データの検索の場合アドレス数が1Mアドレスや1Gアドレスな ど,いわば縦長構成のメモリのアドレス空間をCPUが順次アドレスをアクセスし,データを読み 込む必要がある.CPUの性能がいくら速くなっても,メモリやストレージからデータを読み出す
時間はメモリやストレージの仕様で規定されるバンド幅で決まり,これがボトルネックになり情 報処理全体のパフォーマンスに影響を与える結果となっている.
2.2.2 データベースプロセッサの基本構成
図2.2はデータベースプロセッサの構成を示す.
図 2.2: データベースプロセッサの構成.
図2.1同様図2.2においてもアドレスデコーダやデータバスなどの機能回路は省略されている.
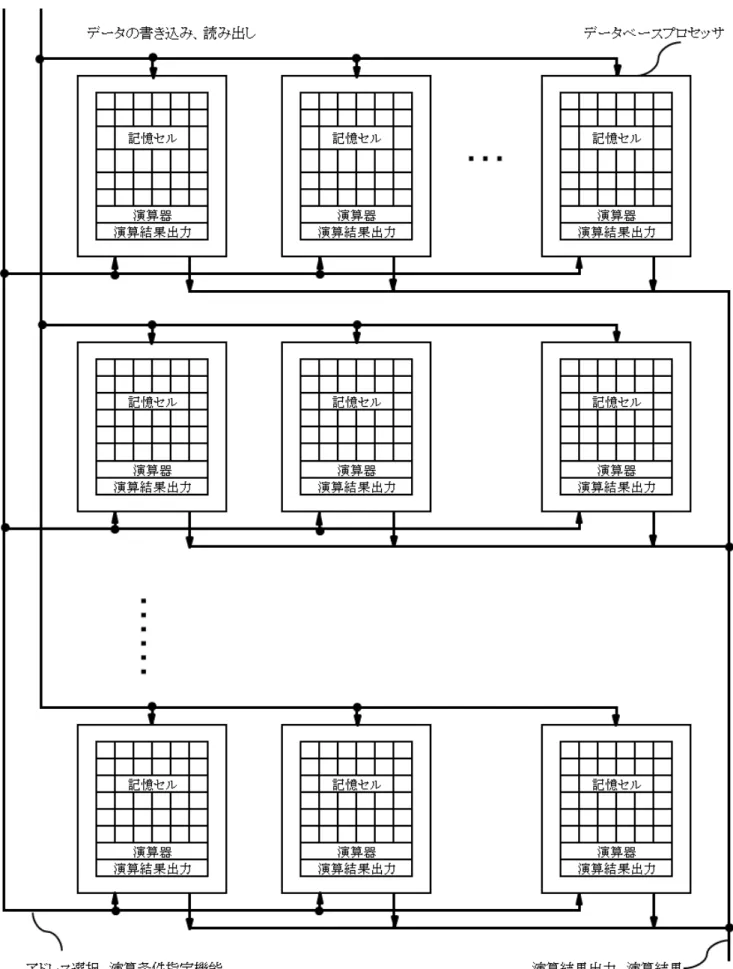
データベースプロセッサは,以上説明の一般のメモリのデータの幅とアドレスの概念を逆転させ る考えで成り立っており,並列度を上げて演算効率を高めるためにデータの幅(n)を数万から数 百万などに拡大して利用する事が最大の特徴である.また,情報処理方法は1ビット単位のビッ トシリアルSIMD(Single Instruction Multiple Data)演算が基本となっている.
以上説明の通り,データベースプロセッサはデータベーステーブル構造の行列構成を逆転した 構成であるので,外部メモリからデータを転送する場合にはこのプロセッサ内部もしくは外部で 64×64ビット,128×128ビットなど適切なサイズのデータブロックの行列変換を行い,このデー タベースプロセッサの記憶セルに行列変換したデータを書き込み読み出し可能な構成にする.通 常のメモリの1ワードnビットの幅は,本データベースプロセッサの場合データベースのレコード 数(n)に相当し,1レコードのデータが縦列に配列され,アドレスのNは1レコードのフィール ドデータ長に相当する.つまり,このデータベースプロセッサのメモリ部(データベース部)は,
1レコードがNビットのフィールドデータ長でnレコードのデータテーブルとなっている.デー タテーブルの下段に設けられた演算器は後述する1ビット演算器であり,1ビット演算器は選択指 定されたアドレスの記憶セルのビットセルのデータ毎に対し,論理記憶,論理積,論理和,論理 否定(NOT),排他論理和,全加算,その他のオプション機能,並びにその組み合わせの演算器 が指定した演算条件で全レコード並列に1ビット毎にSIMD演算が実行出来る構成となっている.
また,この1ビット演算器の演算結果を外部に出力するため,優先順出力回路(プライオリティ アドレスエンコーダ出力回路)などの演算結果出力機能が備えられている.後述するが,このメ モリの大半はメモリセルそのものであり,そのごく一部のみが1ビット演算器並びに演算結果出 力機能であるので,一般メモリに省スペースでこれらの機能を組み込み,データベースの検索や 照合に最適なメモリ一体型プロセッサを実現する事が出来る.
2.2.3 データベースプロセッサの演算回路
通常の演算器,例えばCPUの心臓部に相当するALUの場合32ビットや64ビットなど多数ビッ トであるのに対し,データベースプロセッサの演算器は先に示した通り,超並列SIMD型1ビッ ト演算器で構成される事が特徴である.
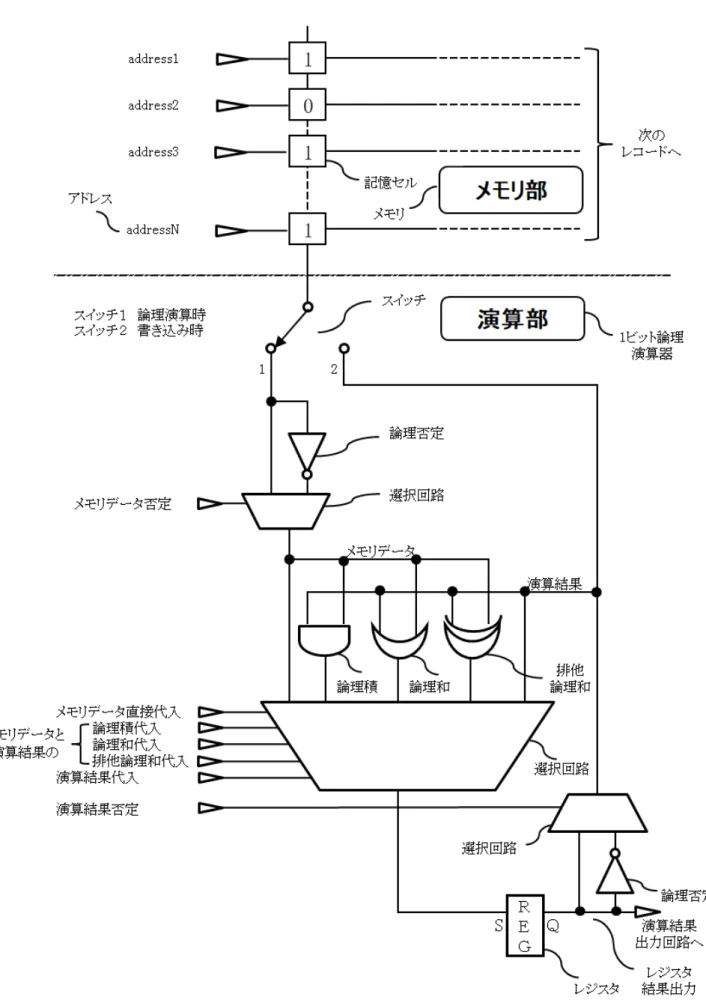
図2.3はデータベースプロセッサの1ビット演算器の回路構成を示す.データベースプロセッサ のアドレスによって選択された1ビットのメモリ記憶セルのデータを演算する1ビット論理演算 器の回路とSIMD演算の内容を説明する.データベースプロセッサの1ビット演算器の回路構成 のスイッチを1の位置に切り替えると,1ビットの論理演算が実現出来る構成となっている.図に 示す通り,回路構成は論理積,論理和,排他論理和,論理否定,レジスタ(REG),選択回路で 構成される極めて単純な構成である.排他論理和は,論理積,論理和,論理否定の組み合わせで 演算出来るので必ずしも必要ではないが,後述する加算演算などの利用頻度が高い場合には組み 込んでおくとよい.アドレスにより選択されたメモリ記憶セルからの1ビットのデータは,選択 回路で正論理,または負論理(論理否定)が選択可能になっている.同様にレジスタの結果出力 も正論理,または負論理(論理否定)が選択可能な構成となっている.以下にSIMD演算の内容 を説明する.
1. メモリから読み出された正論理もしくは負論理のデータをメモリデータとして,レジスタ
(REG)へ直接代入する.
図 2.3: データベースプロセッサの1ビット論理演算器の回路構成.
2. 演算結果であるレジスタの正論理もしくは負論理の結果出力を,再度レジスタへ直接代入 する.
3. 正論理もしくは負論理のメモリデータと演算結果であるレジスタの正論理もしくは負論理の 結果出力を,論理積,論理和,排他論理和のいずれかの演算を実行し,その結果をレジスタ へ代入する.
以上の演算を全レコード並列にSIMD演算指定出来る構成になっている.また,この1ビット 論理演算結果はスイッチを2の位置にする事によって,アドレスにより選択された記憶セルにレ ジスタ演算結果を記憶する事が出来る構成である.この機能により過去の演算結果を活用する事 が可能になるので,多彩な演算が可能になる.1ビット演算結果は通常勝ち残りレコードとなりレ コード数が大幅に絞り込まれるので,プライオリティアドレスエンコーダ出力回路などの演算結 果出力機能から勝ち残りレコードの番地を外部に出力する.
CPUの心臓部であるALUは,例えば64ビットデータ2組みを一括して演算する必要があるの で1ユニットの回路の規模が大規模にならざるを得ないが,この構成の1ビット演算器はデータ の検索や照合に特化(限定)した構成であるので,1ユニットの回路規模が百トランジスタ程度,
演算結果出力を含めても数百トランジスタ程度で実現出来,省スペース回路でしかもビットシリ アルの1ビット演算の組み合わせで多様な演算が実現出来るので,超並列処理の演算ユニットと して最適である.
2.3 データベースプロセッサの使用方法
データベースプロセッサはインデックスなどの情報探しのためのメタデータが不要である.し かも後述するように,データの大きさに関わらず常に一定の時間で必要とする情報を探し出す事 が可能になる.一例を挙げれば,SQLデータベースのSELECT処理をインデックスなしで高速に 実現する事や,AI認証に必要とされるデータ照合や全文検索のビットマップインデックスなどの 検索に好都合である.以下にデータベースプロセッサの代表的な使い方について述べる.
2.3.1 1 ビット演算器によるバイナリデータの比較演算
表2.1はデータベースプロセッサの1ビット演算器によるデータ比較演算の演算式を示す.ここ では4ビット2進数の場合のデータの比較演算つまり,一致,大小,範囲演算を1ビット毎にビッ トシリアルで行う場合の演算式を示したものである.表示するように,10進数は2進数に変換さ れ,何れの場合もMSB(Most Significant Bit)である「8」からLSB(Least Significant Bit)で ある「1」まで割り付けされた「8」,「4」,「2」,「1」の各ビットのアドレスを比較する演算条件に適 合するように選択し,ビットシリアルに論理否定,論理積,論理和する事で,「一致」,「以上」,「未 満」のデータを検出する事が可能である事を示している.表2.1を参考に演算条件を「以下」や
「範囲」にする事も,任意の多数ビットデータの比較の演算条件式も容易に設定する事が出来る.
これらの演算を実施する上で,中間の演算結果を一時退避して記憶する必要がある場合は,例え ばアドレスNを一時演算バッファーとして利用するとよい.更に,次に説明する何れの演算にも 応用する事が出来る.
表 2.1: 1ビット演算器によるバイナリデータの比較演算.
10進数 2進数
比較条件 演算式
「8」 「4」 「2」 「1」 0
一致 「/8」∗「/4」∗「/2」∗「/1」
0 0 0 0 以上 N/A
未満 N/A
1
一致 「/8」∗「/4」∗「/2」∗「1」
0 0 0 1 以上 「8」+「4」+「2」+「1」
未満 /(「8」+「4」+「2」+「1」) 2
一致 「/8」∗「/4」∗「2」∗「/1」
0 0 1 1 以上 「8」+「4」+「2」
未満 /(「8」+「4」+「2」) 3
一致 「/8」∗「/4」∗「2」∗「1」
0 0 1 1 以上 「8」+「4」+(「2」∗「1」)
未満 /(「8」+「4」+(「2」*「1」)) 4
一致 「/8」∗「4」∗「/2」∗「/1」
0 1 0 0 以上 「8」+「4」
未満 /(「8」+「4」) 5
一致 「/8」∗「4」∗「/2」∗「1」
0 1 0 1 以上 「8」+「4」∗(「2」∗「1」)+「4」∗(「2」+「1」) 未満 /(「8」+「4」∗(「2」+「1」)+「4」∗(「2」+「1」)) 6
一致 「/8」∗「4」∗「2」∗「/1」
0 1 1 0 以上 「8」+(「4」∗「2」∗「1」)+(「4」∗「2」) 未満 /(「8」+(「4」∗「2」∗「1」)+(「4」∗「2」)) 7
一致 「/8」∗「4」∗「2」∗「1」
0 1 1 1 以上 「8」+(「4」∗「2」∗「1」)
未満 /(「8」+「4」∗「2」∗「1」) 8
一致 「8」∗「/4」∗「/2」∗「/1」
1 0 0 0 以上 「8」
未満 /(「8」) 9
一致 「8」∗「/4」∗「/2」∗「1」
1 0 0 1 以上 (「8」∗「4」)+(「8」∗「2」)+(「8」∗「1」) 未満 /((「8」∗「4」)+(「8」∗「2」)+(「8」∗「1」)) 10
一致 「8」∗「/4」∗「2」∗「/1」
1 0 1 0 以上 (「8」∗「4」)+(「8」∗「2」)
未満 /((「8」∗「4」)+(「8」∗「2」)) 11
一致 「8」∗「/4」∗「2」∗「1」 1 0 1 1 以上 (「8」∗「4」)+(「8」∗「2」∗「1」)
未満 /((「8」∗「4」)+(「8」∗「2」∗「1」)) 12
一致 「8」∗「4」∗「/2」∗「/1」
1 1 0 0 以上 「8」∗「4」
未満 /(「8」∗「4」) 13
一致 「8」∗「4」∗「/2」∗「1」
1 1 0 1 以上 「8」∗「4」*(「2」+「1」)
未満 /(「8」∗「4」*(「2」+「1」)) 14
一致 「8」∗「4」∗「2」∗「/1」
1 1 1 0 以上 「8」∗「4」∗「2」
未満 /(「8」∗「4」∗「2」) 15
一致 「8」∗「4」∗「2」∗「1」
1 1 1 1 以上 N/A
未満 N/A
( / : 論理否定; ∗ : 論理積; + : 論理和)
2.3.2 データ一致比較演算
図2.4はデータベースプロセッサの1ビット演算器によるデータ一致比較演算方法を示す.ここ では2進数8ビットのデータの一致演算の例である.
図 2.4: 1ビット演算器によるデータ一致比較演算.
例えば,アドレス10を最上位ビット(MSB)「128」としてアドレス17を最下位ビット(LSB)
「1」とする8ビットのデータをフィールドに割りつけした場合を考える.8ビットのデータである ので256通りのデータを記憶する事が可能であり,アドレス10からアドレス17の8つのアドレス を適切に選択し演算する事により,256通りのデータの中から完全一致のデータを検出してそのレ コードの番地を出力する事が可能になる.例えば,10進データ値「10」=2進数「00001010」を 完全一致で探す場合,アドレス10を最上位ビット(MSB)「128」としてアドレス17を最下位ビッ ト(LSB)「1」まで8回演算し「00001010」であるデータを検出すればよい.
図の下方に示す通り,本例ではMSBのアドレス10から「128」,「64」,「32」,「16」,「8」,「4」,
「2」,「1」の順に演算を行っている.この際,2進数「00001010」の「0」の桁の場合は論理否定,
「1」の桁の場合は正論理で,8回の論理積演算(勝ち抜き演算)を繰り返し,勝ち残った13およ び25の2つのレコードが10進データ値「10」として検出される.本例の場合,最後まで勝ち残っ たレコード13,25が10進データ値「10」,2進数データ値「00001010」である.以上のような1 ビット演算を繰り返す事により任意の値のデータ値を検出する事が出来る.
2.3.3 データ大小比較(範囲比較)演算
図2.5はデータベースプロセッサ1ビット演算器によるデータ大小比較演算方法を示す.
図 2.5: 1ビット演算器によるデータ大小比較演算.
これまでの説明は,10進データ値「10」の完全一致を求めるものであったが,10進データ値
「10」以上を探す場合,図に示す通りMSBのアドレス10からアドレス13まで4回アドレスの論 理和を取る事により,10進データ値が「16」以上のレコードをまとめて検出する事が出来る.更 に下位4ビットのアドレスの15と16の論理和と,アドレス14を論理積演算する事により,10進 データ値「10」以上「16」未満を求め,先ほどの10進データ値が「16」以上のレコードと論理和 をとる事により,10進データ値「10」以上のデータ値のレコードを検出する事が出来る.
ここではレコード2,3,· · ·,nが10進データ値「10」以上である.更に図に示す通り,10進 データ値「10」以上のデータ値のレコードを否定すれば「10」未満つまり「9」以下のレコードが 検出される.本例の場合,レコード1,8,14が10進データ値「10」未満である.その他のデータ 値や範囲検索も以上と同様な1ビット演算を繰り返し行えばよい.またデータの長さ(通常のメ モリの場合はデータの幅に相当)は2のべき乗数以外の9ビットや10ビット,17ビットや33ビッ トにする場合でも極めて単純であり,必ずしもアドレスが連続されている必要もない.つまりこ のデータベースプロセッサは,ある/なしの1ビットデータから256ビットなど,任意のデータ の長さのデータをレコード内のフィールドデータとして割り付けする事が出来る.
例えば,個人情報などの場合「氏名」,「住所」,「勤務先」,「生年月日」,「身長」,「体重」,「性別」
などデータの長さは様々であり,必要最低限のデータの長さを割り付けし,必要なデータが格納 されているアドレスだけ演算させ,必要のないアドレスは演算させないように出来る(無駄なメ モリアクセスを避ける事が出来る)事が大きな特徴である.
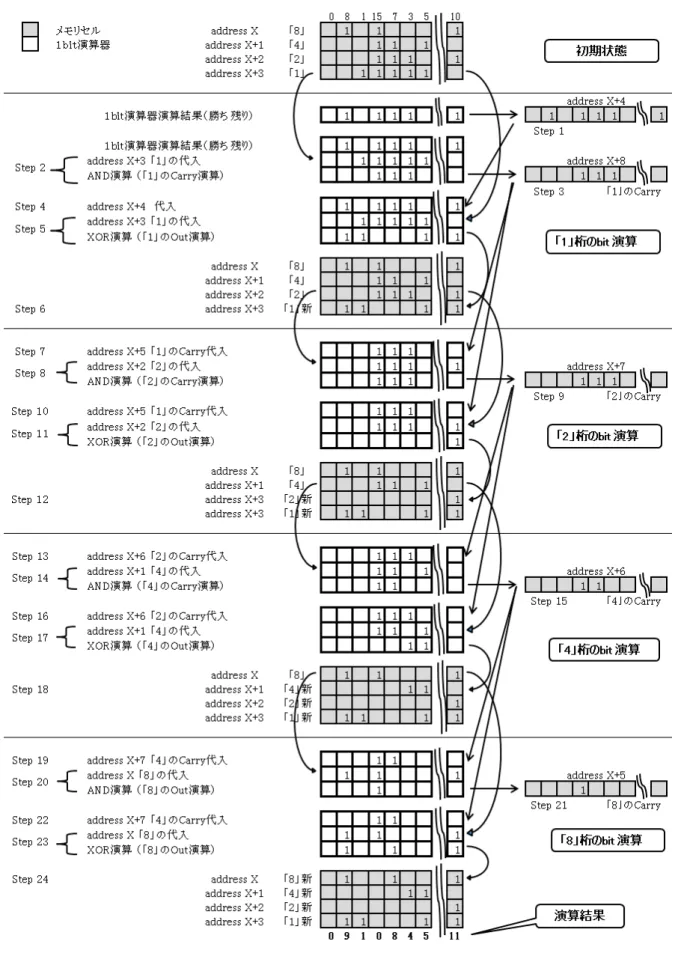
2.3.4 カウント演算
図2.6はデータベースプロセッサの1ビット演算器による加算カウント演算方法を示す.ここで は,レコードデータの加算カウントの例を示すものであり,2進数,4ビットデータの加算カウン トを実行するためのアドレス,レコードの割り付けの例を示している.図の上段の初期状態に示 す通り,「8」,「4」,「2」,「1」の4ビットデータはアドレスXからアドレスX+3番地までカウン トデータが割り付けられ,左側のレコードより初期値として,「0,8,1,15,7,3,5,〜10」の 10進数によるカウントデータが書き込まれている.1ビット演算器の演算結果(勝ち残り)が左 側のレコードより「0,1,0,1,1,1,0〜1」である場合,現在のカウントデータに以上の1ビッ ト演算器(REG)の演算結果(勝ち残り)を加算し,加算演算結果として「0,9,1,0,8,4,5,
〜11」を求める場合の考え方を示す.1ビット演算を繰り返し加算処理を行う場合,加算結果の桁
上げ(Carry)アドレスと1ビット演算器結果を一時記憶するバッファーアドレスをワークエリア
として利用する事により,カウンタ機能を実現する事が出来る.
ここでは,アドレスX+4を1ビット演算器バッファー,アドレスX+5〜アドレスX+8を 各ビットのキャリーデータとしている.初期状態ではこれらのアドレスはクリアし,オール「0」 状態としておく.以下に,以上割り付けされたカウントデータ並びにワークアドレスを利用して 加算カウントを行う場合の例を示す.
図の上から順番に,初期状態,「1」の桁のビット演算,「2」の桁のビット演算,「4」の桁のビット 演算,「8」の桁のビット演算,演算結果が示されている.
• ステップ1: 1ビット論理演算器の内容を1ビット演算器バッファー,アドレスX+4に退 避させておく.1ビット演算器(REG)の内容は変化しない.
• ステップ2: カウントデータの「1」の桁のビット,アドレスX+3の内容を代入し,1ビッ ト演算器(REG)の演算結果と論理積演算させる.演算結果データは「1」の桁のビットの キャリーデータである.
• ステップ3: このキャリーデータをアドレスX+8に代入する.
• ステップ4: 1ビット演算器バッファーであるアドレスX+4から,初期状態(加算値)の 1ビット演算器のデータを代入する.
図 2.6: 1ビット演算器によるデータの加算演算.