Extreme Big Data 時代に向けた
TSUBAME スーパーコンピュータでの取り組み
佐藤 仁, 松岡 聡 東京工業大学 学術国際情報センター [email protected] 概要:2010 年 11 月より、東京工業大学学術国際情報センターでは、スーパーコンピュータ 「TSUBAME2」の運用を行ってきた。近年、様々な分野で、大規模なデータ処理の需要が高まって きており、TSUBAME2 上でも、例外ではなく、実験器や観測器、あるいは、スーパーコンピュータ 上のシミュレーションから生成された大量のデータに対する分析処理への対応の要求が非常に大き くなってきている。本稿では、TSUBAME2 上での大規模データ処理に関する活動の一部を紹介し、 将来のスーパーコンピュータ上での大規模データ処理にむけた活動について述べる。1 はじめに
近年、情報技術の発達により、人類の取り扱う データ量が爆発的に増加している。例えば、Google 社では1 日に 20 PB 以上のデータに対してクラ スタ計算機を用いた並列分散処理を行っていると 報告されている。科学技術計算の分野においても この傾向は当てはまり、高エネルギー物理学、生 物学、天文学などの分野においても大規模なデー タに対して並列分散処理を行う試みが広く行われ ている。東京工業大学(東工大) 学術国際情報セン ター(GSIC)では、2010 年 11 月よりスーパーコン ピュータ「TSUBAME2」の運用を行ってきた。 このTSUBAME2 も、例外ではなく、実験器や観 測器、あるいは、スーパーコンピュータ上のシミ ュレーションから生成された大量のデータに対す る分析処理への対応の要求が非常に大きい。 本稿では、TSUBAME2 上での大規模データ処 理に関する活動の一部を紹介する。まず、 TSUBAME2 の大規模データ処理を支えるアーキ テクチャの構成の現状を示し、ひとつの事例とし て、どのようにストレージ構成が変遷してきたか を示めす。また、TSUBAME2 上で動作する大規 模データ処理関連のソフトウェアについて紹介し、 最後に、将来のスーパーコンピュータ上での大規 模データ処理にむけた活動について述べる。2 TSUBAME2 の構成
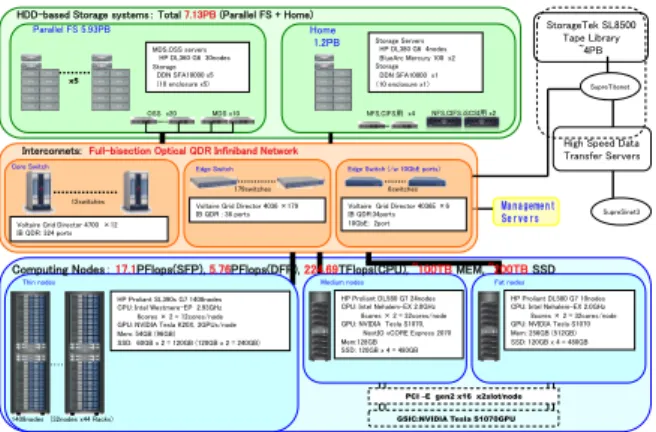
2010 年 11 月、東工大 GSIC では、スーパーコ ンピュータ「TSUBAME2.0」[1]の運用を開始し た。さらに、2013 年 9 月、これまで TSUBAME2.0 に搭載されていたNVIDIA M2050 GPU アクセラ レータをNVIDIA Tesla K20X へと置き換え、既 存のTSUBAME2.0 をアップグレードし、理論ピ ーク性能 5.76PFlops(倍精度)、17.1PFlops(単精 度)の TSUBAME2.5 の運用を開始した。図 1に、 現在の TSUBAME2 の全体の構成について示す。 2013 年 9 月現在、TSUBAME2 は、1422 台の計 算ノードからなり、総メインメモリ容量は 80TB を超える。また、各計算ノードにはSSD が搭載さ れ、総容量は190TB 以上となっている。これらの 計算ノードは、フルバイセクション構成の QDR Infiniband ネットワークにより相互に接続され、 さらに、7PB 超の HDD によるストレージ領域や 4PB のテープライブラリ領域とも接続されており、 大規模データ処理にも適した構成となっている。 この章では、まず、2013 年 9 月現在の TSUBAME2 (version 2.5)の構成に触れ、その後、TSUBAME2 上での大規模データ処理を支えるストレージの構 成 の 詳 細 に つ い て 述 べ る 。x5
GSIC:NVIDIA Tesla S1070GPU PCI –E gen2 x16 x2slot/node
図 1 TSUBAME2 の全体構成 2.1 計算ノード TSUBAME2 の計算ノードは、1408 台の Thin ノード、24 台の Medium ノード、10 台の Fat ノ ードと呼ばれる計算ノード群からなる。これらの 計算ノードの違いは主には搭載されるメモリ容量 の違いからなる。これらの全ての計算ノード上で、 OS として、標準的な Linux である、64bit 対応の x86 ベースの SuSE Linux Enterprise Server 11 が動作している。従って、標準的なデスクトップ PC やサーバで動作する多くのオープンソースソ フトウェアは特別な改変をすることなく動作させ ることが可能である。
Thin ノードは HP ProLiant SL390s G7 からな り、CPU として Intel Xeon X5670 2.93GHz (6 core)を 2 socket、GPU アクセラレータとして NVIDIA Tesla K20X を 3 つ搭載する。メインメ モリとして計54GB (一部 96GB)の DDR3 メモリ を搭載し、また、60GB (一部 120GB)の SSD 2 台 をRAID0 によりローカルストレージを構成する。 また、40Gbps の QDR Inifniband の HCA (Host Channel Adaptor)を 2 つ持ち、各計算ノードやス トレージへ接続されている。
一方、Medium ノードと Fat ノードはともに HP ProLiant DL580 DL からなり、CPU として Intel Xeon X7550 2.0GHz (8 core)を 4 socket、 GPU ア ク セ ラ レ ー タ と し て NVIDIA Tesla S1070 (Medium ノードでは一部 NextIO vCORE Express 2070 を搭載) を備える。Medium ノード では計128GB、Fat ノードでは DDR3 メモリを計 512GB(一部 256GB)搭載するが、ローカルストレ ージは Medium ノード、Fat ノードとも 128GB のSSD4 台を RAID0 として構成する。この他に、 40 Gbps の QDR Infiniband の HCA を 1 つ持ち、 他の計算ノードやストレージへ接続されている。 2.2 ネットワーク 各 計 算 ノ ー ド と ス ト レ ー ジ と の 間 は 、QDR Infiniband のインターコネクトにより接続される。 このインターコネクトは、2 段のスイッチからな るファットツリー・フルバイセクション構成で Dual rail により各 rail がファットツリーを構成 する。エッジスイッチとして36 ポートの Voltaire GridDirector 4036 を 185 台(うち、6 台は Voltaire GridDirector 4036e)を持ち、各エッジスイッチの ポートのうち、18 ポートは上流のコアスイッチに 接続され、残りの18 ポートは下流のノードに接続 さ れ る 。 コ ア ス イ ッ チ は 324 ポ ー ト の GridDirector 4700 で、各 rail につき 6 台、計 12 台存在する。各ノードは 2 本の 40Gbps QDR InfiniBand によりエッジスイッチに接続され、2 本は Dual rail のそれぞれに接続される。各スト レージは、5 台の Voltaire GridDirector 4036 か らなるエッジスイッチに接続され、これらのエッ ジスイッチは Dual rail の片方の各コアスイッチ と 2 本の QDR InfiniBand によりファットツリ ーで接続される。 2.2 ストレージ TSUBAME2.5 のストレージは、1.2 PB のホ ーム領域と 6PB の並列ファイルシステム領域 から構成される。 ホーム領域は、1 台の DDN SFA 10000 スト レージシステムを、FC8 ネットワークを介して、 4 台の HP ProLiant DL 380 G6 サーバと 2 台の BlueArc Mercury 100 サーバに接続した構成と なっている。ホーム領域は、QDR Infiniband
や10Gbps Ethernet 経由で NFS, CIFS, iSCSI
などでアクセスされ、TSUBAME2.5 上の/home 領域の提供や、教育、事務などの学内向けの様々 なストレージサービスの用途に使用している。 並列ファイルシステム領域は、TSUBAME1.0 の運用経験を基にI/O のスケーラビリティと信 頼 性 を 実 現 す る た め に 分 割 さ れ た 複 数 の Lustre[2]、及び、GPFS[3]からなる並列ファイ ルシステムで構成される。総計で 30 台の HP ProLiant DL 360 G6 サーバに、DDN SFA 10000 をバックエンドのストレージシステムと
して、それぞれをQDR Infiniband を介してネ ットワークに接続した構成となっている。並列 ファイルシステム領域の構成は、TSUBAME2 の運用が進むにつれ、利用状況に応じて再構成 を行い変遷しているため、この点の詳細につい ては、次章で詳しく述べる。 これらのホーム領域、及び、並列ファイルシ ステム領域のストレージは、計 4 PB の Sun SL8500 のテープライブラリに接続され、適時 バックアップされる。また、テープライブラリ は、階層型ファイルシステムの基盤レイヤとし ての利用もされている。 こ れ ら の ス ト レ ー ジ 構 成 に 加 え て 、 TSUBAME2.5 で は 、 各 計 算 ノ ー ド が 120-240GB の SSD をローカルストレージとし て持ち、アプリケーションの一時ファイル生成 やチェックポイントなどのような細粒度な I/O のために使用される。 また、東工大GSIC では、2012 年 9 月末より、 TSUBAME2 の「革新的ハイパフォーマンス・ コンピューティング・インフラ(HPCI)」の共用 運用を開始した。HPCI では、現在、広域での データ共有環境の整備が進められており、理化 学研究所計算科学研究機構、及び、東京大学情 報基盤センターに設置されたストレージシステ ムを広域分散ファイルシステム「Gfarm」[4]で 連携し、「HPCI 共用ストレージ」を構築してい る。東工大GSIC においても、この HPCI 共用 ストレージの資源の一部として利用するために 600TB のストレージ(DDN SFA 12000)の導入 を進めており、 広域分散環境での大規模データ の高度な利用の推進や、次世代のスーパーコン ピュータのための大規模データ共有手法の検討 を進めている。
3 TSUABME2 のストレージ構成の変遷
前節でも述べたとおり、TSUBAME2 のストレ ージの構成は、これまで利用状況により変遷して きた。この章では、TSUBAME2 のストレージの 構成が、どのような理由によりどのように変更し てきたか、について具体的に述べる。 3.1 TSUBAME2 稼働直後のストレージ構成 2010 年 11 月、TSUBAME2 の稼働直後の並列 ファイルシステム領域のストレージ構成(2010 年 11 月 〜 2011 年 3 月 ) を 図 2 に 示 す 。 MDS$x10 OSS$x20 Thin$Nodes Medium/Fat$Nodes Infiniband$QDR$Network$for$MPI“Global$Work$Space”$#1 “Global$Work$Space”$#2 “Global$Work$Space”$#3 “Scratch”$$ “cNFS/Clusterd$Samba$w/$GPFS”$$ “NFS/CIFS/iSCSI$by$BlueARC”$$ Infiniband$QDR$Network$for$LNET$and$Other$Services
図 2 TSUBAME2 のストレージ構成 (2010 年 11 月-2011 年 3 月)
この地点では、全ての並列ファイルシステム領 域は、/work0, /work1, /work9, /gscr の 4 つの Lustre ファイルシステムとして構成されていた。 これは、TSUBAME1 の運用経験から、分割して 複数のファイルシステムを構成したほうが、I/O のスケーラビリティと信頼性を実現しやすいと判 断 し た た め で あ る 。 こ の う ち 、/wor0 は 、 TSUBAME2 のユーザへの MPI-IO などの並列 I/O を伴うアプリケーション用のデータ領域、 /gscr は、Gaussian など、大量の中間ファイルの 生成やスクラッチ I/O を伴うアプリケーション用 の領域としての使用を意図した。また、/work1 は TSUBAME1 からの移行用のデータの保存領域と して利用し、/work9 は未使用とした。図 3に、各 /work0、/work1, /gscr と同一の Lustre ファイル システムの構成とその上での I/O スループット性 能の結果について示す。Lustre ファイルシステム は、プロセスからの並列 I/O に高い性能を示すこ と が 伺 え る 。 Client'#1 Client'#2 Client'#3 Client'#4 Client'#5 Client'#6 Client'#7 Client'#8 IB'QDR'Network SFA 10k 600 Slots Data 560x 2TB SATA 7200 rpm 図 3 Lustre の構成と I/O スループット性能 3.2 階層型ファイルシステムの導入 TSUBAME1 の運用において、運用の末期であ る2009 年、2010 年は、ストレージの利用率が常
に80%〜90%となり、容量不足に陥り、運用に深 刻な支障をきたしていた。このような背景により、 2010 年 3 月、Sun SL8500 のテープドライブを導 入し、この慢性的なストレージ容量不足状態を劇 的に改善して、効率的なストレージ利用の促進を 図った。 一方、このテープライブラリの導入は、主に、 バックアップ用途を意図しており、TSUBAME2 のユーザからは利用しづらいものであった。しか し、数十〜数百テラバイト、ないし、ペタバイト 規模の大容量のストレージを必要とするアプリケ ーションユーザの要求が年々増加しており、ユー ザ自身によるストレージ領域の不要データのテー プライブラリ領域へバックアップや、必要データ のテープライブラリからストレージ領域へリスト ア、などの要望が高まり、既存のインフラでは対 応できないことが問題となった。 そこで、上記のような問題を解消するために、 テープライブラリと連携して階層的なデータ管理 機能を持つストレージシステムの導入を進め、 HSM(Hierarchical Storage Management)機能を 持つGPFS 並列ファイルシステムの配備を行った。 図 4がその構成図である。4 台の HP ProLiant DL 380 G6 と 4 台の HP ProLiant DL 360 G6 が NSD サーバとして動作し、2 台の DDN SFA 10000 ス トレージシステムとQDR Infiniband を介して接 続され、ストレージ機能を提供する。DDN SFA 10000 内は、System Pool と TSM (Tivoli Storage Manager) Pool と2つのパーティッションに分割 して構成される。System Pool は GPFS による実 際のファイルの格納のための領域として機能し、 GPFS の機能である ILM(Information Lifecycle Management)機能により定期的にアクセス頻度 の少ないファイルをTSM Pool へファイルを転送 する。TSM Pool は、TSM によりテープライブラ リへファイルをバックアップ、ないし、リストア するためのバッファ領域として機能する。これら の機能が協調動作することにより、ユーザからは 透過的に利用できる階層的なファイルシステムを 構 成 す る 。 GPFS%#0% 785.05TB% Inode 1%Bil. GPFS%#1% 785.05TB% Inode 1%Bil. System%Pool TSM%Pool GPFS%HSM%Client%
TSM%Client GPFS%HSM%Client%TSM%Client
TSM%Server TSM%Server 図 4 階層型ファイルシステムの構成 図 5 に GPFS ファイルシステムの構成とその上 でのI/O スループット性能を示す。Lustre と比較 して、若干性能が低いものの、複数プロセスから の大量の逐次アクセス性能では Lustre よりも良 好 な 結 果 を 得 て い る こ と が 伺 え る 。 図 5 GPFS の構成と I/O スループット性能 図 6にGPFS 直後の TSUBAME2 のストレージ の全体構成を示す。Lustre 領域はこれまでと同様、 /work0、/work1, /gscr との 3 つの Lustre ファイ ル シ ス テ ム と し て 構 成 さ れ た 。Lustre 領域と GPFS 領域の使い分けは、Lustre が従来の並列 I/O を伴うもの、GPFS はテープライブラリと連動し て動作するため、大量のデータを伴うビッグデー タ向けのアプリケーションのものを意図した。 MDS$x10 OSS$x20
“Global$Work$Space”$#1 “Global$Work$Space”$#2 “Global$Work$Space”$#3 “Scratch”$$ “cNFS/Clusterd$Samba$w/$GPFS”$$ “NFS/CIFS/iSCSI$by$BlueARC”$$ Infiniband$QDR$Network$for$LNET$and$Other$Services 図 6 TSUBAME2 のストレージ構成 (2011 年 4 月〜2012 年 3 月) 3.1 大規模ストレージの耐故障性 2011 年度末から、TSUBAME2 の利用が進み、 ストレージへのアクセス集中による I/O スループ
ットの低下や、ストレージの故障などが頻発する ようになった。 ハードウェアの故障としては、HDD 故障やスト レージコントローラの故障が圧倒的に多かった。 しかし、これらの故障は、大抵の場合、コンポー ネントの交換により対応可能であり、交換も運用 中に可能であるため、ユーザへの影響はほとんど 見られなかった。 一方、ソフトウェアの故障に関しては、Lustre やGPFS など、フェイルオーバなど耐故障機能を サポートしているものの、ユーザへ多大な影響を 与えた。例えば、Lustre においては、ソフトウェ アのバグによるOSS や MDS のハングアップ、 対象としているストレージ領域がinvisible になる などの事象が発生し、ストレージサーバが過負荷 状態になり、I/O スループットが著しく低下した。 GPFS では、ネットワーク故障の影響により、 GPFS のメタデータに不整合が発生した。前者の 事象は、ストレージアクセスに対して、サーバ数 が少なすぎることが問題であり、後者に関しては、 ストレージのネットワークを共用しているがため に問題が発生したため、サーバ増加と分離された ストレージネットワークの構築を行った。図 7 が 全体構成である。TSUBAME1 の経験よりこれま で少数のファイルシステムを複数構築し運用を行 ってきたが、近年、Lustre のソフトウェアの性能、 や安定性の向上により大規模環境での運用でも問 題ないと判断したため、このような構成変更を行 った。これらの改良以降、TSUBAME2 のストレ ー ジ は 安 定 的 に 稼 働 し て い る 。 GPFS with HSM
Infiniband QDR Network for LNET and Other Services
10GbE × 2 QDR IB (4x) × 16 GPFS#1GPFS#2 GPFS#3GPFS#4 FC SFA10k #6 HOME System application HOME iSCSI “cNFS/Clusterd Samba w/ GPFS” “NFS/CIFS/ iSCSI by BlueARC” Lustre /work0 /work1 /gscr0 Lustre 3.6 PB SFA10k #5 SFA10k #4 SFA10k #3 /data0 /data1 SFA10k #1 SFA10k #2 /hpci0 2.4 PB HDD + 4PB Tape SFA12k #1
Gfarm for HPCI
600TB QDR IB (4x) × 16 QDR IB (4x) × 20 QDR IB (4x) × 20 QDR IB (4x) × 4 図 7 TSUBAME2 のストレージ構成 (2013 年 9 月現在)
3 データインテンシブミドルウェアの
整備状況
TSUBAME2 では、大規模データ処理向けのソ フトウェアに関しても整備を進めている。ここで は、それらのいくつかの事例について紹介する。 3.1 並列ワークフロー 一般的なスーパーコンピュータでは、他のジョ ブの影響を受けることなく計算資源を効率良く利 用するために、バッチジョブスケジューラを介し てジョブ実行を行っている。TSUBAME2 でも、 PBS Pro を用いている。一方、科学技術計算では、 同種のジョブを、パラメータを変えて大量に実行 するパラメータサーベイ型のアレイジョブや、依 存関係のあるジョブを多数実行するようなワーク フロー型のジョブなど、複雑なジョブの実行を要 求するものが非常に多い。このようなジョブに対 応するために、TSUBAME2 では GXP make など ワークフローツールの整備を進めている。 GXP make[5]は、東京大学を中心に開発が進め られている並列ワークフローシステムである。 make は、プログラムのコンパイル、リンクの際 にソースファイル間の依存関係を自動的に解決し、 目的のファイルを生成することを支援するユーテ ィリティである。make と並列分散シェルである GXP[6]の組み合わせにより、依存関係のあるジョ ブのワークフローとしての実行を可能にしている。 もともと、GXP はグリッド環境のような広域並列 環境での利用を指向していたが、バッチジョブス ケジューラでの利用にも対応し、TSUBAME 上の PBS Pro への利用も可能になっている。また、 TSUBAME では、一部、PBS Pro をカスタマイズ したコマンドを使用しているが、これらへの対応 も行っている。 また、TSUBAME2 では、GXP をワークフロー 型のジョブだけでなく、パラメータサーベイ型の ジョブへも対応を進めている。元来、バッチジョ ブスケジューラであるPBS Pro でもパラメータサ ーベイ型のアレイジョブの実行が可能であるが、 TSUBAME2 では、大量のアレイジョブを大規模 に実行した場合、スケジュールのための時間、オ ーバーヘッドが著しく増大するという問題が発生 した。GXP make ではこのようなオーバーヘッド が少ないため、これらの事象に対応するためにGXP make を基盤に PBS Pro のアレイジョブ実 行の際のコマンド群と類似したコマンドを提供し ている。 3.2 MapReduce MapReduce は、近年注目されている、大規模デ ータに対する並列分散処理を行うためのプログラ ミングモデルであり、分散したkey-value のペア データに対して統一的な操作を並列で適用し,デ ータへのアクセスの局所性を考慮したスケーラブ ルなデータ処理を実現する。データ処理のプロセ スをMap,Shuffle,Reduce の 3 つのフェーズに 分 解 し 、Map フ ェ ー ズ で 入 力 デ ー タ と な る key-value ペアから中間データとなる key-value ペアを生成し、Suffle フェーズで同じ key に対し てvalue のリストを生成し、Reduce で中間データ をShuffle することにより得られた key と value のリストから最終出力となるkey-value のペアデ ータを生成するというものである。典型的な例で は、ウェブのデータ解析などの処理に適用され、 数千台規模の大規模なクラスタ計算機において、 ノード数に応じたスケーラビリティを得ている。 また、様々な機械学習アルゴリズムへMapReduce を適用して有効を示した事例をはじめ、機械学習 ライブラリであるAache Mahout やグラフマイニ ングシステムのPEGASUS などの MapReduce ア プリケーションのエコシステムも構築されつつあ る。 TSUBAME2 においても、ユーザからの大規模 データ処理への要望は高く、MapReduce 処理の代 表的なオープンソース実装である Hadoop[7]を実 行したいというものも挙がっている。そこで、我々 は、Hadoop を TSUBAME2 での実行に適するよ うに改良した Tsudoop[8]と呼ばれるツールを開 発している。TSUBAME2 は、バッチジョブスケ ジューラである PBS Pro が動作しているため Hadoop との連携動作が必要であったり、ストレ ージもLustre, GPFS、計算ノードのローカルスト レージのSSD など、典型的な Hadoop の実行環境 とは若干異なる部分があったりし、また、GPU ア クセラレータのHadoop からの活用法も明らかで ない。 Tsudoop は、TSUBAME2.0 上のジョブスケジ ューラであるPBS Pro や、Lustre などの並列フ ァイルシステム、ノード上の複数のSSD からなる ローカルストレージなどの既存のシステムと協調 動 作 し て 、 オ ン デ マ ン ド で TSUBAME2.0 に Hadoop 環境を構築し、ユーザの MapReduce ア プリケーションを実行する。実行の終了後は、自 動 的 に Hadoop 環境の破棄を行う。図 8 は 、 Tsudoop の概要図である。また、GPU アクセラレ ータの活用に関しても、GPU アクセラレータ上で Map タスクを動作させ、自動的に CPU と GPU アクセラレータ間で Map タスクのハイブリッド スケジューリングを行う手法の開発などを進めて
い る 。
File%Systems%(HDFS,%Lustre,%etc.)
file
node node node node
Task+ Tracker
node Job+ Tracker
Job Job Job Job
PBS%Pro%
Task+
Tracker TrackerTask+ TrackerTask+
①+run+tsudoop4sub+by+user+ ②+acquire+compu:ng+nodes++ +++++++by+using+PBS+Pro+ ③+invoke+JobTracker+and+TaskTrackers+ +++++++(op:onally++NameNode+and+DataNode)+ client+ ④+submit++a+MapReduce+job+to+the+JobTracker++ ⑤+run+Map Reduce+tasks+on+the+TaskTracker+nodes+++ ⑥ I/O+to+FSs+(HDFS,+Lustre,+etc.)+++ ⑦ kill+JobTracker+and+TaskTrackers,++ +++++++++(op:onally+NameNode+and+DataNode).+
file file file file file
図 8 TSUDOOP の構成
4 おわりに〜将来に向けて
現状の「ビッグデータ」は、データ量が高々 数百ギガバイト~ペタバイト級であり、その用 途は「顧客の全体的な購買動向を調査、その為 時系列的に伝票のデータマイニングを行う」等 で、数台~数百台の安価なクラスタやクラウド 上の HDD にファイルとして分散し、処理はリ ニアスキャンや、RDB からのインデクシング アルゴリズムの拡張で済む場合が多い。その理 由は(1)データが企業内に閉じている「サイロ 化」のため、データ量・種別とも少ない、(2)ビ ッグデータの黎明期で、そのようなデータの「制限」によりアプリのバラエティが少なく機 能要求が低い、(3) ビッグデータに供されるハ ードウェアやシステムソフトウェアの性能が低 く、(1)-(2)の自己抑制が働く、という悪循環が 考えられる。 実際、Google は 2008 年に「ペタバイトソー ト(実際は高々10 テラ要素)」をサーバ 4800 台・ HDD4 万 8 千器で 6 時間にて達成し、2011 年 にはサーバ8000 台で 33 分に短縮した。その資 源量は世界のトップ 10 スパコンに匹敵するが、 ソート速度は高々55 億要素/秒であり、ペタバ イト級のメモリを持つトップスパコンなら 100 倍~500 倍の速度が得られることを予測できる。 非定型ビッグデータ処理の下地のグラフ処理も、 処 理 速 度 の 世 界 ラ ン キ ン グ の Graph500 (http://www.graph500.org) は全てスパコンが 占め、IDC・クラウドの影はない。この理由は 本質的で、「真の」ビッグデータ処理は、本質 的にハード的にメモリ・ネットワーク・I/O バ ンド幅を要求し、かつそれらを生かすシステム ソフトウェアを要求するが、Google, Amazon, MS Azure 等の現状のビッグデータに供される ハードウェアやシステムソフトウェアはIDC・ クラウドのweb やビジネスホスティングからの 転用であり、超高性能 I/O 性能を達成するのが 困難だからである。 例えば、IDC の典型的なネットワークは各ノ ードの 1GbE がラック単位(20-40 ノード)で縮 退した 10GbE に集約され、上位層はさらに縮 退される。それ故、(近年は多少改善されつつ も)IDC の 10 万ノード級ネットワークのバイセ ク シ ョ ン バ ン ド 幅 は 高 々 数 テ ラ ビ ッ ト/秒・ end-to-end のレーテンシはサブミリセカンドが 典 型 で あ る 。 一 方 ス パ コ ン 東 工 大 TSUBAME2.0 は 1400 ノードにもかかわらず 220 テラビット/秒のバイセクションバンド幅を 持ち、レーテンシは僅か2 マイクロ秒で、高性 能システムソフトウェアでその性能が維持され ている。I/O も、IDC・クラウドでは仮想化等 の多大なオーバーヘッドで低性能化しており、 GFS(Google File System)等のクラウドのファ イルシステムでは、容量は数十万台で数百ペタ バイト級だが、I/O 性能は低い。 このようなIDC・クラウドの処理環境でも、 現状の小規模レベルの「ビッグデータ」ならば 当面問題ない。しかし、ビッグデータは先の量 的・質的進化とともに急速に変容する事が予測 され、Intel 等も同様の指摘をしている。特に オープンアクセスの一般化によるデータの公共 化と、同時に、センサ及びユビキタスネットワ ークの進化でIoT(Internet of Things)が本格化 により、ビッグデータは「一見相関がない、エ クサ~ゼータ~ヨッタバイト/年にも及ぶ、一 見無関係な様々な超大量の継続的な多次元・マ ルチ解像度のデータストリームから意味のある 情報を抽出し、単なる解析だけでなくシミュレ ーションとリアルタイムでマッチングする」処 理 に 変 貌 す る 。 ま た 、 処 理 形 態 も 、 MapReduce などを用いたリニアなスキャンや インデキシングでの高速化では不十分で、莫大
なデータのO(n log n), O(m×n), …の、計算や
データ転送コストが高い複雑なアルゴリズムで の処理が必須となる。このような変貌は、オー プンデータが主流になってきた科学研究の世界 では先駆けて起こっており、総称的に「データ
科学」あるいは「Data Intensive Computing」
等と呼ばれるが、それを実現するための現状の ビッグデータインフラの不備が多く指摘されて いる。 我 々 は 、 こ の よ う な 状 態 を Extreme Big Data(EBD)と呼び、上述のような問題を解決す るような研究活動、例えば、フラッシュなどを はじめとする不揮発性メモリの活用手法、大規 模データ処理へのアクセラレータの活用、など を現在積極的に進めている。成果の一部は、次 世代のスーパーコンピュータの設計、構築に活 用されることを目指している。
参 考 文 献
[1] Satoshi Matsuoka, Takayuki Aoki, Toshio Endo, Hitoshi Sato, Shin’ichiro Takizawa, Akihiko Nomura, and Kento Sato, “TSUBAME2.0: The First Petascale Supercomputer in Japan and the Greatest Production in the World”, Comtemporary High Performance Computing From Petascale toward Exascale Chapter 20, pp. 525-556, 2013.
[2] Lustre , “http://www.lustre.org”
[3] Frank Schmuck and Roger Haskin, “GPFS: A Shared-Disck File System for Large Computing Cluster”, Proceedings of the FAST ’02 Conference on File and Storage Technologies.
[4] Gfarm, “http://datafarm.apgrid.org/”
[5] Kenjiro Taura, Takuya Matsuzaki, Makoto Miwa, Yoshikazu Kamoshida, Daisaku Yokoyama, Nun Dun, Takeshi Shibata, Choi Sung Jun, Jun’Ichi Tsuji, “Design and implementation of GXP make – A workflow system based on make”, Future Generation Computer Systems, Volume 29 Issue 2, 2013. [6] GXP, “http://www.logos.ic.i.u-tokyo.ac.jp/gxp/” [7] Hadoop,”http://hadoop.apache.org/" [8] 佐 藤 仁 , 松 岡 聡 , “TSUBAME2.0 上 で の Hadoop の性能評価”, 情報処理学会研究報告 2011-HPC-129(16), pp. 1-8, 2011.