JAIST Repository
https://dspace.jaist.ac.jp/
Title
隠れマルコフモデルを用いた手話単語認識システムAuthor(s)
伊藤, 徳広Citation
Issue Date
2000‑03Type
Thesis or DissertationText version
authorURL
http://hdl.handle.net/10119/1346Rights
Description
Supervisor:堀口 進, 情報科学研究科, 修士修 士 論 文
隠れマルコフモデルを用いた 手話単語認識システム
指導教官
堀口 進 教授
北陸先端科学技術大学院大学 情報科学研究科 情報システム学専攻
マルチメデ ィア統合システム講座
810012
伊藤 徳広
2000年2月15日
Copyright c
2000byNorihitoITO
目 次
1 序論 1
1.1 研究の背景と目的 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 本論文の構成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 隠れマルコフモデルでの手話単語認識手法 3 2.1 初めに . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.2 従来の手話単語認識手法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.2.1 DPマッチング法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2.2 FFTによる認識手法 . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2.3 HMMによる認識手法 . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.3 認識モデル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3.1 手話単語の構造 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.3.2 手話単語の基本動作認識 . . . . . . . . . . . . . . . . . . . . . . . . 9
2.4 隠れマルコフモデル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.4.1 隠れマルコフモデルの特徴 . . . . . . . . . . . . . . . . . . . . . . . 11
2.4.2 マルコフモデルの学習法 . . . . . . . . . . . . . . . . . . . . . . . . 12
2.4.3 基本動作を用いた隠れマルコフモデルでの手話単語認識 . . . . . . 13
2.5 ベイズ法による手形認識 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.6 手話単語認識法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.7 まとめ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3 手話単語認識システム構成 17
3.1 はじめに . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.2 システム構成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.3 入力装置 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.4 手話単語の切り出し法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.4.1 速度による切り出し . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.4.2 角度変移による切り出し . . . . . . . . . . . . . . . . . . . . . . . . 23
3.5 切り出し性能の評価 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.6 基本動作の認識過程 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.6.1 KL法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.6.2 基本動作の選定 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.6.3 学習性能評価 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.7 ベイズ法を用いた手形認識 . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.8 手話単語辞書の構成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.9 単語認識アルゴリズム . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.9.1 構築辞書データの内訳 . . . . . . . . . . . . . . . . . . . . . . . . . 39
4 手話単語の認識実験と評価 41 4.1 はじめに . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.2 認識対象単語 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.3 手話単語認識実験 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.3.1 特定話者 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.3.2 不特定話者 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.3.3 従来法との比較 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
4.4 まとめ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5 結論 52
5.1 今後の課題 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
謝辞 54
研究業績 55
6 付録 57
6.1 特定話者学習収束実験結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
6.2 複数話者学習収束実験結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
6.3 形状別平均認識率 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
図 目 次
2.1 DPマッチング . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2 隠れマルコフモデル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3 指形状一覧図 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.4 辞書データ構成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
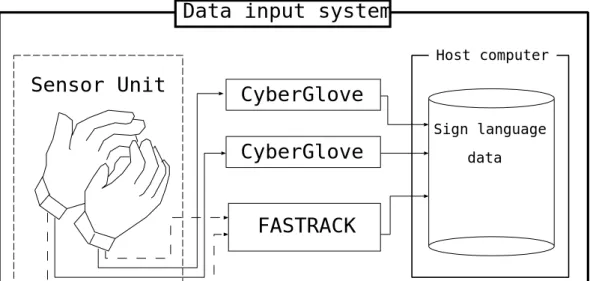
3.1 手話単語データ入力システム . . . . . . . . . . . . . . . . . . . . . . . . . 18
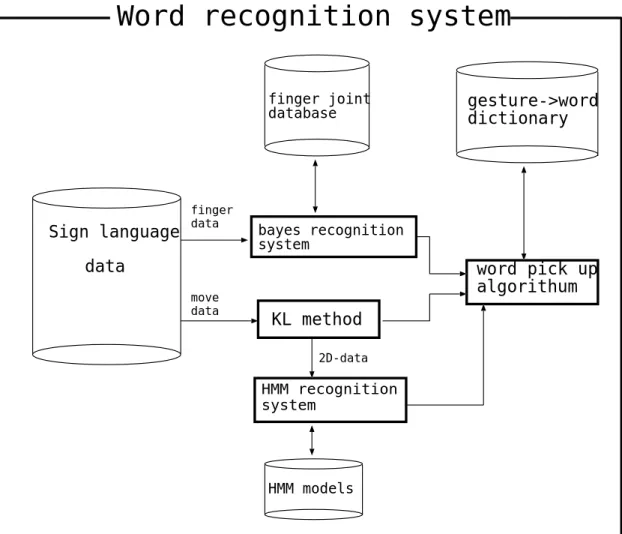
3.2 認識システムモデル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.3 Cyberglorve . . . 20
3.4 FASTRACK . . . 20
3.5 手形状入力装置の関節角測定点 . . . . . . . . . . . . . . . . . . . . . . . . 21
3.6 医者1(速度変位) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.7 医者1(角度×速度変位). . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.8 医者2(速度変位) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.9 医者2(角度×速度変位) . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.10 北1(速度変位) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.11 北1(角度×速度変位) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.12 北2(速度変位) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.13 北2(角度×速度変位) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.14 部屋1(速度変位) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.15 部屋1(角度×速度変位) . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.16 部屋2(速度変位) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.17 部屋2(角度×速度変位) . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.18 自動切断例 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
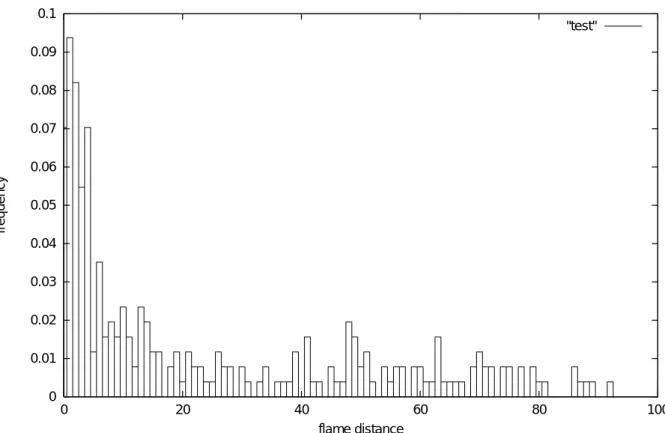
3.19 自動切り出し精度 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.20 平面への運動軌跡の投影 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
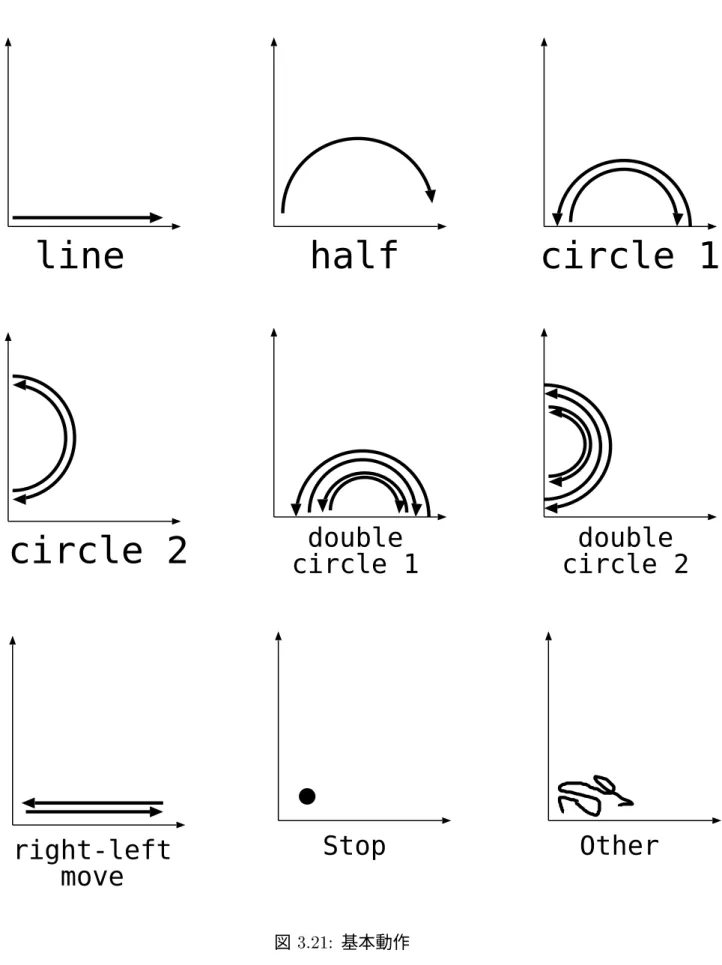
3.21 基本動作 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.22 ベイキス型HMMの例 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.23 学習話者一名での収束例(収束終了) . . . . . . . . . . . . . . . . . . . . 33
3.24 学習話者一名での収束例(未収束). . . . . . . . . . . . . . . . . . . . . . 34
3.25 学習話者四名での収束例(収束終了) . . . . . . . . . . . . . . . . . . . . 35
3.26 学習話者四名での収束例(未収束). . . . . . . . . . . . . . . . . . . . . . 36
3.27 手形識別処理 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.28 辞書構成詳細 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.1 要素別認識結果(辞書使用済み) . . . . . . . . . . . . . . . . . . . . . . . 44
4.2 要素別認識結果(辞書未使用) . . . . . . . . . . . . . . . . . . . . . . . . 44
4.3 要素別認識結果(辞書1:学習・登録同一人物) . . . . . . . . . . . . . . 47
4.4 要素別認識結果(辞書2:学習複数・登録一人) . . . . . . . . . . . . . . 48
4.5 要素別認識結果(辞書3:学習・登録複数人). . . . . . . . . . . . . . . . 49
6.1 直線動作の学習サンプル数と認識率の関係 . . . . . . . . . . . . . . . . . . 57
6.2 半円動作の学習サンプル数と認識率の関係 . . . . . . . . . . . . . . . . . . 58
6.3 円(1)の学習サンプル数と認識率の関係 . . . . . . . . . . . . . . . . . . 58
6.4 円(2)の学習サンプル数と認識率の関係 . . . . . . . . . . . . . . . . . . 59
6.5 2重円(1)の学習サンプル数と認識率の関係. . . . . . . . . . . . . . . . 59
6.6 2重円(2)の学習サンプル数と認識率の関係 . . . . . . . . . . . . . . . . 60
6.7 往復の学習サンプル数と認識率の関係 . . . . . . . . . . . . . . . . . . . . 60
6.8 停止の学習サンプル数と認識率の関係 . . . . . . . . . . . . . . . . . . . . 61
6.9 その他の学習サンプル数と認識率の関係 . . . . . . . . . . . . . . . . . . . 61
6.10 直線動作の学習サンプル数と認識率の関係 . . . . . . . . . . . . . . . . . . 62
6.11 半円動作の学習サンプル数と認識率の関係 . . . . . . . . . . . . . . . . . . 63
6.12 円(1)の学習サンプル数と認識率の関係 . . . . . . . . . . . . . . . . . . 63
6.13 円(2)の学習サンプル数と認識率の関係 . . . . . . . . . . . . . . . . . . 64
6.14 2重円(1)の学習サンプル数と認識率の関係. . . . . . . . . . . . . . . . 64
6.15 2重円(2)の学習サンプル数と認識率の関係 . . . . . . . . . . . . . . . . 65
6.16 往復の学習サンプル数と認識率の関係 . . . . . . . . . . . . . . . . . . . . 65
6.17 停止の学習サンプル数と認識率の関係 . . . . . . . . . . . . . . . . . . . . 66
6.18 その他の学習サンプル数と認識率の関係 . . . . . . . . . . . . . . . . . . . 66
6.19 円・2重円の学習収束結果(話者一名) . . . . . . . . . . . . . . . . . . . 67
6.20 円・2重円の学習収束結果(話者四名) . . . . . . . . . . . . . . . . . . . 68
表 目 次
2.1 日本手話の音韻表記方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2 本システムでの認識分類 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.1 自動切り出し対象単語 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.2 分割数一致率(%):話者A . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.3 学習サンプルデータ内訳 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
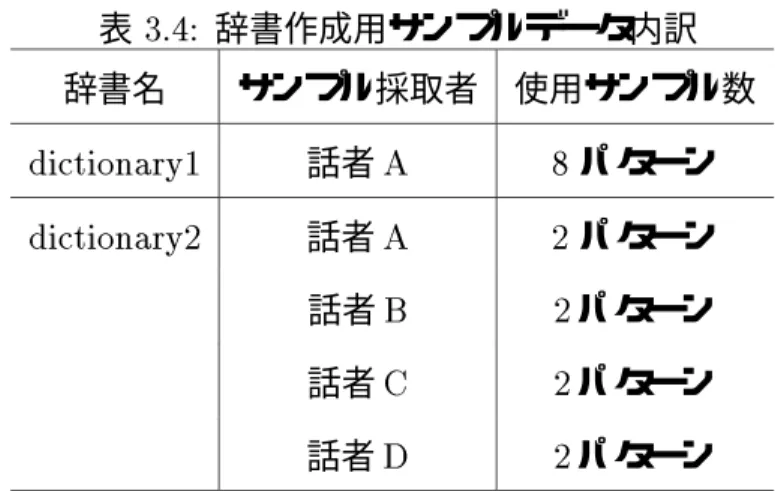
3.4 辞書作成用サンプルデータ内訳 . . . . . . . . . . . . . . . . . . . . . . . . 40
4.1 対象単語 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.2 特定話者実験条件 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.3 特定話者認識実験 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.4 特定話者認識実験(辞書作成未使用) . . . . . . . . . . . . . . . . . . . . . . 46
4.5 ベクトル重みによる認識率の変化 . . . . . . . . . . . . . . . . . . . . . . . 46
4.6 不特定話者認識用辞書一覧 . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.7 辞書1(学習・登録、同一話者)を用いた場合の認識率. . . . . . . . . . . 48
4.8 辞書2(学習複数・登録同一話者)を用いた場合の認識率 . . . . . . . . . . 49
4.9 辞書1(学習・登録、複数話者)を用いた場合の認識率. . . . . . . . . . . 50
第
1章 序論
1.1
研究の背景と目的
近年、聴覚障害者の社会進出にともなって、聴覚障害者と健聴者がコミュニケーション をとる機会も増えている。聴覚障害者と健聴者がコミュニケーションをとる手段として、
主に手話や筆談、および手話通訳士による手話の通訳などが考えられる。しかし、筆談は 聴覚障害者、健聴者双方に負担がかかる上、コミュニケーション速度も遅いという難点が ある。一方、手話通訳士を介する場合、双方のコミュニケーションは最も容易な域になる が、手話通訳サービスは予約が必要であり、手話通訳士の数も限られていることから、利 便性に問題がある。そのため、聴覚障害者の大きなにコミュニケーション手段である手話 を自動認識するシステムへの要求が高まっており、さまざまな手法での手話認識が試みら れている。
手話認識システムでは、入力データとして画像を使う場合と、3次元空間中での手指の 位置座標を使う場合がある。後者は近年のデバイス技術の発達により、位置及び手形状を 数値化する手形状入力装置を用いて細かな手形状やその向きを読みとる事が可能なので、
認識可能な単語数の増加が容易となってきている。この手形状入力装置を用いた手話認識 システムとして佐川ら[1]が行なったDPマッチング法を用いたものが挙げられる。この システムでは620語もの単語を98.7%という高い認識率で認識可能であった。しかしな
がら、この認識結果を出すためには個人データで構成されている辞書が必要であるという 問題がある。DPマッチング法はその認識率を上げる為に拘束条件を厳しくすると、個人 の癖などの影響を受けやすくなる傾向があるため、使用者を限定する事になってしまう。
より多くの話者が使用できる手話認識システムを構築するためには、個人の癖を取り除く ような認識手法を検討する必要がある。
近年、音声分野で使われていた隠れマルコフモデル(HMM)を手話認識手法に使用す る試みが行なわれている。HMMは学習という過程を通して統計的にパターンを処理出来 るので、データの揺らぎに強いという特徴を持っており、不特定話者の単語認識に適して いる。そこで本論文では、入力デバイスとしては装着型の手形状入力装置を、認識モデル としてはHMMを用い、より多くの話者に対応した手話認識システムの構築を試み、その 結果について検証した。
1.2
本論文の構成
本論文の構成は以下の通りである。第二章で過去の研究における問題点をまとめ、本論 文で使用するHMMの概要を述べる。第三章では本研究で提案する手話単語認識システム の構成を示す。さらに、手話単語認識で必要となる手話単語切り出し手法、およびHMM の学習収束判定に関して検討する。第四章では手話単語認識システムの性能評価を行な い、認識率や未知話者での認識結果に関して議論する。第五章において本研究で得られた 結果をまとめ、結論とする。さらに今後の課題を示す。
第
2章
隠れマルコフモデルでの手話単語認識手法
2.1
初めに
本章では、従来の手話単語認識システムについて述べ、その特徴や問題点を提示する。
次に本論文で使用する隠れマルコフモデルの概要を述べ、このモデルを使用した手話単語 システムの認識過程を示す。
2.2
従来の手話単語認識手法
聴覚障害者は他者とコミュニケーションを取る手段として、主に手話や筆談などを用て いる。特に手話はコミュニケーション速度という点において筆談より優れているため、聾 唖者の日常的なコミュニケーション手段としてよく用いられている。しかし現状では手話 を理解出来る人間の数は少なく、聴覚障害者が社会生活の上で他者との意志疎通にストレ スを感じるケースも多い。また、他者との意志疎通の方法として手話通訳士を挟んで行な う場合もあるが、この場合でも手話通訳士の利用制限やプライバシー問題などの数多くの 課題がある。この様な状況から、コンピュータによる手話認識システムの要望が発生して おり、現在までにさまざまな研究がなされている。
2.2.1 DPマッチング法
手話動作の認識において最も有名な手法の一つとして佐川ら[1]のDPマッチングによ る認識方法が上げられる。この手法は識別対象を特定の個人に限定した場合、90%以上 という非常に高い認識率を得る事が出来る。
DPマッチング法では、まず動的計画法(Dynamicprograming)に基づいて各パターン 間の距離を定義し、辞書中のパターンと入力パターン間の距離を計算して、最も距離の小 さいパターンを認識結果として採用する手法である。
x x x
x x x
0 i I
0 j J
(l) (l) (l)
’
x x (l)
F
c c
c c
c
c
1 2
3 4
5
k
=(0,0)
i j
=(I,J)
図 2.1: DPマッチング
例えば長さがI、J0の時系列パターンX、X(l)があるとする。この時、図2.1に示した 様にX ;X(l)を対応づける関数F を考えると、関数X;X(l);F は次の様に定義する事が出 来る。
X =x
0
;x
1
;x
2 111;x
i
;111;x
I
(2.1)
X (l)
=X (l )
0
;x (l )
1
;x (l )
2
111;x 0(l)
i
;111;x 0(l )
I
(2.2)
F =c(1);c(2);c(3)111;c(k) (2.3)
ここで、F はパターンx;x(l)で構成されるi;j平面上の点を結んだ関数である。これに重 みwkを定義すると、時系列パターンx;x(l)の距離dは、
d(x;x (l)
)=min
F 8
<
: P
K
k =1 w
k d
k (x
i 0
;x (l)
i )
P
K
k =1 w
k
9
=
;
(2.4)
と表せる。なお、重みwkとは関数Fに関連した正の係数である。ここでwk =(ik0ik 01)+
(j
k 0j
k 01 );(i
0
=j
0
=0)とするとPkk =1 w
k
=I+Jとなる。
これにより式(2.4)の分母はF の内容に依存せず、つねに一定値I+I0となる。よって 時系列パターンx;x(l)の距離d(x;x(l ))は次のようになる。
d (l)
(x)= 1
I+I 0
min
F 8
<
: J
X
j=1 w
j d
j (x
0
i
;x (l )
i 9
=
;
(2.5)
この様に各パターンとの距離を算出し、最も距離が近いものを選択パターンとして決定す る手法がDPマッチングである。しかし、この重みづけと整合窓の大きさのパラメータを 一般化するのが困難である、という問題点が上げられる。特に、複数話者を対象とした場 合、パラメータ設定が個人差により大きな影響を受ける為、より一層設定が困難になって しまう傾向がある。
2.2.2 FFTによる認識手法
DPマッチングではその性質上、同一カテゴリに属するデータの分散はある程度少なく なければならないが、不特定話者を対象とした場合、どうしてもデータに大きな分散が生 じるので認識が困難となる。そこで、時系列データである手話をフーリエ変換して、周波 数成分で識別する手法を鈴木[2]が提案している。
入力されるデータをN個の離散データxnとした場合、有限区間の離散的フーリエ変換 法であるDFTを用いると、離散データxnとそのフーリエ係数Xkは式2.6,2.7で表せる。
X(k)= 8
>
>
<
>
>
: P
N01
n=0
x(n)W k n
n
; 0k N 01
0; other
(2.6)
x(n)= 8
>
>
<
>
>
: 1
N P
N01
k=0
X(k)W 0k n
N
;0k N 01
0; other
(2.7)
時系列データを変換し、周波数成分で比較するには通常、時間領域で同じ長さの区間を 区切りFFTを行なうが、手話単語データは時間方向に非線形な伸縮を伴う。そこで、線 形補間を用いて固定の長さに時間軸を正規化した後、FFTを行なう事により時間軸上の 伸縮問題を解決している。
これにより、特徴ベクトルの要素数がN、時系列データを長さMに正規化したデータ をFFTで処理すると、周波数領域では複素数値をとるためN ×2M の行列データとな る。これを改めてN×Mの行列にし、このデータでそれぞれの要素の平均値と分散を求 める事でパターンマッチングが可能となる。
この手法での認識結果3名の複数話者を対象とした場合は83.4%と高い認識率を示し た。しかし、人数が増えていくにしたがって認識率の低下が著しくなるために、不特定話 者の認識には十分ではない。
2.2.3 HMMによる認識手法
音声分野で使われていた隠れマルコフモデル(HMM)をジェスチャー認識に使用する という試みが近年行なわれており、その一環としてHMMによる手話認識の研究がなされ ている。HMMの理論的なモデル説明については、2.4章で詳しく述べることとし、本章 では過去の研究成果などついて概要を簡単に述べる。
HMMとは図2.2の様に幾つかの遷移状態Si(i =1;2;3;111)をもつオートマトンの事 である。このモデルは各状態に移る遷移確率(aij)と、その遷移時に、入力事象が発生 する出力確率(bij)をもっている。このモデルに、ある入力事象X(x1;x2;x3;111;xI)が 入力されると、入力事象xiごとに状態Siがさまざまに変化する。その中で、最終の事象
x
Iの時に最終状態(図2.2ではS4)となる遷移過程で得られる確率の合計を受理確率と 呼ぶ。例えば、図2.2に入力事象X(x1;x2;x3;x4)が入力されると状態S1から4へ変化す
S S S S
output probability
output probability
output probability
1 2 3 4
a
a
a
a a
a a
11
12
22
23
33
34
44
12 b 23 b 34
b
x x x
出力確率 は各 にそれぞれ存在する なお b ij a ij
図 2.2: 隠れマルコフモデル
る経路は4つとなるので、この時のHMMの受理確率P(X jM)は次の様になる。
S
1
!S
1
!S
2
!S
3
!S
4
: P
1
=a
11 b
11 (x
1 )1a
12 b
12 (x
2 )1a
23 b
23 (x
3 )1a
34 b
34 (x
4 )
S
1
!S
2
!S
2
!S
3
!S
4
: P
2
=a
12 b
12 (x
1 )1a
22 b
22 (x
2 )1a
23 b
23 (x
3 )1a
34 b
34 (x
4 )
S
1
!S
2
!S
3
!S
3
!S
4
: P
1
=a
12 b
12 (x
1 )1a
23 b
23 (x
2 )1a
33 b
33 (x
3 )1a
34 b
34 (x
4 )
S
1
!S
1
!S
2
!S
3
!S
4
: P
1
=a
12 b
12 (x
1 )1a
23 b
23 (x
2 )1a
34 b
34 (x
3 )1a
44 b
44 (x
4 )
P(X jM)=P
1 +P
2 +P
3 +P
4
(2.8)
HMMとは、こうしてある入力事象Xが、あるマルコフモデルMで起きうる確率を受 理確率P(X jM)として表現できるモデルの事である。
これを手話などの動作認識に応用するには、認識動作ごとにマルコフモデルを作成し、
各マルコフモデルの遷移確率と出力確率を認識すべき事象が入力された時に、最も受理確 率が高くなる様に設定する。これにより、ある入力事象が与えられた時、各モデルの受理 確率の違いから、入力事象の識別が可能となる。HMMを使用した手話認識方法[3]では、
画像から得られた手の位置と方向を用い40種類のアメリカ手話を95パーセント以上の認 識率で認識する事に成功している。
HMMは学習によって得られたデータを統計的に処理できるモデルなので、入力データ の揺らぎに強いという特徴を持つ。その為、不特定話者での認識などに向いていると考え られる。しかし、マルコフモデルは使用前に予め遷移確率や出力確率を「学習」という形 で決定する必要があり、その為に多量のサンプルデータが必要となる。その結果、手話単 語の増加に伴って用意するべきサンプルデータ量も膨大となるために、現在約3000語と いわれる手話の全てを認識するのは困難であることが問題である。
2.3
認識モデル
DPマッチング法などと違って、HMMでは学習したデータでパラメータを設定してい るのでデータの揺らぎに強く、不特定話者による手話の認識の手法として期待出来る。し かし、従来のHMMを用いた研究では認識率こそ良いものの、各手話単語ごとに一つの
HMMを使用していた為、単語数増加に伴って必要となるHMMの数が大幅に増加し、そ
れに比例して学習サンプルも必要になってくる。そこで、本研究では手話単語一つを幾つ かの部分単語に分割し、部分単語ごとに認識する方法をとる。これによって、複数の部分 単語から構成されている手話単語は、この組合せで表現が可能となる。これによって従来 法で問題となる単語学習サンプル増加の問題を解決する。本節では単語の分割に際し、分 割の参考となった手話の音韻表現と、それを元に分類した基本動作の概念、両者を統合し た単語認識方法について述べる。
2.3.1 手話単語の構造
本研究での認識対象である日本手話は、現在でもその動作を記号などにより表記する完 全な方法は確立されてはいない。しかしながら、比較的よく使われる表現方法というもの は存在する。そこで、本研究ではこの中で神田ら[4]が考案した手話表記法を元に動作な どの認識分類を考えることにした。これによると、手話は大まかには「手の形」「動き」
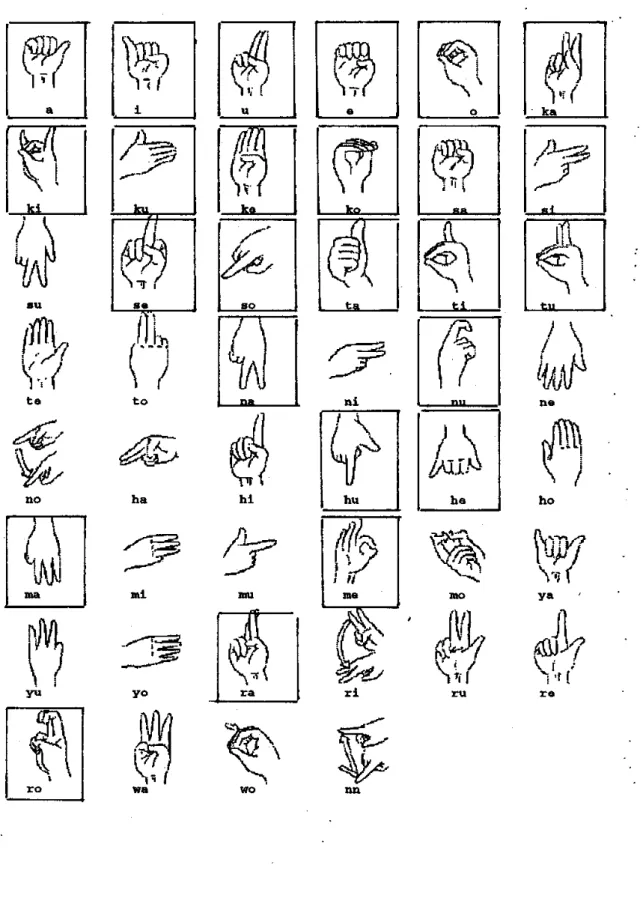
「位置」の3要素で構成されており、「手の形」は幾つかを基本的な手形とその変形過程 などを、「動き」は空間に描く軌跡やその大きさなどを、「位置」はその描かれた軌跡が どの位置か(例:頭・顔・肩など)などを表現している。表2.1に神田らの手話表記法の 概要を示す。
手話の音韻表現とは、これら手形や動きなどに記号を割り当て、記号の並びによって動 的な情報である手話を、記号という静的なもので表現する事である。
2.3.2 手話単語の基本動作認識
手話使用者の腕の動きに注目すると、その動きは一つ、または複数からなる数種類の線 形状から構成されているケースが多い。事実、手話の音韻表現においても直線や曲線・四 角などでその動作を表現している。この様な種類の動きは、手話を構成している基本的な 動きの要素であると考えられる。以後、この様に手話の動作を構成している基本的な運動 を基本動作と呼ぶ。
表 2.1: 日本手話の音韻表記方法 分野 表記方法
手の形 基本的な指の形として46種類のパターンを採用
(図2.3参照)
これに指の変化で6パターン
動き 方向・軌跡・様態・位置などで構成
ここでの軌跡とは線形状で、直線と曲線の2種類 様態は動作の大きさや繰り返しなど
位置 位置は手話が行なわれている場所 例えば顔・頭・肩など
2.4
隠れマルコフモデル
本研究で用いる隠れマルコフモデルとはオートマトンの一種で、元々は音声分野におい て音声認識モデルとして使われていたモデルである。しかし、認識などで一番困難である パラメータの設定が、学習という作業で決定できるために、近年さまざまな認識に使われ る様になった。オートマトンは初期状態から最終状態までの道筋が、入力によって一意に 決まる決定性オートマトンと、どの様な道筋を通るかは不明な、非決定性オートマトンの
2種類がある。HMMはこのうち非決定性オートマトンに分類される。
HMMは先に図2.2に示した様に、幾つかの状態Siとそれを結ぶ遷移確率aij、各遷移確率 に付随する出力確率bij(k)から構成されている。HMMにあるパターン系列y=y1;y2;:::yr を入力すると初期状態から最終状態へと状態が変化し、そのパターンがHMMで生起す る確率P(y j M)(M はHMMによって表現されモデル )を知る事が出来る。この確率
P(y jM)はq=qi0;qi1;:::;qiT を状態遷移系列とすれば式(2.9)のように書ける。
P(yjM)=
i
0
;i
1
;:::;i
r
P(y jq;M)1P(qjM) (2.9)
一般に、P(y j M)の値は次の様に求められる。まず、入力としてN 個の観測データ
Y =(y
1
;y
2
;:::;y
N
)が得られたとする。この時、時刻tに観測データy1;y2;:::;ytを生成 して状態siに滞在する前向き確率(フォワード 変数)を式(2.10)の様に定義する。
(i;t)= X
j
(j;t01)a
ji b
ji (y
t
) (2.10)
なお、ajiは状態sjから状態siへの遷移確率を、bji(yt) は状態sjから状態siへの遷移 の際にシンボルytを生成する確率である。今、初期状態から最終状態への遷移可能な全 ての状態間遷移ではなく、最大確率を与えるパスのみを求めるとすると、
(i;t)=max
j
f(j;t01)a
ji b
ji (y
t
)g (2.11)
式(2.11)を対数変換すると、
log(i;t)=max
j
flog(j;t01)+loga
ji
+logb
ji (y
t
)g (2.12)
となり、対数尤度の和により確率を求める事が出来る。この手法をビタビ・アルゴリズ ム(Viterbi alogrithm)と呼んでいる。
2.4.1 隠れマルコフモデルの特徴
第2.4節で述べた様にHMMはあるパターン系列が入力された時、そのパターンが初期 状態から最終状態まで遷移しうる確率を求められる。つまり、識別したい時系列パターン を入力した時に、高い確率で最終状態まで行き着けるように遷移状態確率と出現確率を設 定しておけば、それに近いパターンでは高い確率で、遠いパターンは低い確率で最終状態 に到達する様にする事が出来る。HMMではこのパラメータ設定過程を学習と呼び、多く
の学習サンプルを使ってパラメータの推定を行なう。学習過程において、各パラメータに は学習したパターンの統計的な情報が保存されることとなるので、データの揺らぎに対し て強くなるという特性がある。
2.4.2 マルコフモデルの学習法
HMMのパラメータは、入力されたデータに対して起きる状態遷移が観測できないた め、直接最尤推定する事ができない。そこで、バウム-ウェルチのパラメータ推定法によ り、観測シンボル系列Y が与えられた時P(Y jM)(M は初期確率:i,遷移確率:aij,出現 確率: bij(k)で構成されているHMM)が最大となるパラメータを推定することにする。
まず、2.4節で述べた前向き確率に加えて、時刻tに状態siに滞在し、観測データY =
y
t
;y
t+1
;:::;y
T を生成する後向き確率(backward porbability)を2.14、2.14に定義する。
p(y
t
;y
t+1
;:::;y
T )=
X
i
(i;t) (2.13)
(i;t) = X
j a
ij bij(y
t
)(j;t+1) (2.14)
さらにモデルM がY を出力する場合において、時刻tに状態siからsjへ移行し、シン ボルytを出力する確率としてを2.15で定義する。
(i;j ;t)=
(i;t01)a
ij b
ij (y
t
)(j;t)
P(Y jM)
(2.15)
すると式(2.10)(2.14)(2.15)を用いて、HMMの各パラメータは次の再推定の繰 り返しによって求める事が出来る。
^
i
= P
j
(i;j;1)
P
i P
j
(i;j;1)
(2.16)
^ a
ij
= P
T
t=1
(i;t01)1a
ij 1b
ij (y
t
)1(i;j)
P
t
(i;t)1(i;t)
= P
t
(i;j;t)
P
t P
j
(i;j;t)
(2.17)
^
b
ij (k)=
t;yt=k
(i;j;t)
P
t
(i;j;t)
(2.18)
複数の学習サンプルがある場合は、全ての学習用サンプルに関してこの計算を行なって からパラメータを一回更新し、その値が収束するまで繰り返す。
2.4.3 基本動作を用いた隠れマルコフモデルでの手話単語認識
本研究ではこのHMMを使って手話の基本動作を認識し、手形の情報と併せて最終的に 手話単語認識システムを構築する。基本動作の区分は手話の音韻表現を参考にする。しか し、音韻表現においての記述区分では、表記の汎用性を持たせるために動作区分を細かく 分けているうえ、その定義も曖昧である。その為、この区分をそのまま認識区分として使 用するには問題がある。そこで、本研究ではある程度まとまった動作を一つの動作として 扱う事により、音韻表記の場合に起こる定義の曖昧性を抑える。
2.5
ベイズ法による手形認識
手話の音韻表現では指の動きが無いかぎりは、一つの記号で手形を表現している。しか し、実際の手話動作では手話の最中に手形は微妙に変化してしまう。特に手首を動かす運 動では、手首の動きにつられて手形も変化しやすい。しかし、通常の会話で使われる手話 は、腕の動きが停止している事は殆んど無いと言ってよい。停止した場合でも、すぐに他 の手話へ移行する事が多いため、運動停止時のみの手形認識は誤認識しやすいと予想され る。その為、手話動作の手形認識は、運動中・停止中どちらとも一つの手形として特定す るのは困難である。
そこで本研究では得られたデータの各フレームごとに手形を特定し、一つの手話動作中 に含まれる各手形の分布割合を手形認識の方法として用いる事とした。これにより、一つ の手形にする場合に問題になる指の曲げ伸し運動にも対応する事ができるうえ、手首など の運動による手形の変化もある程度反映させる事が可能となる。