経時データのモデリング
(2)
第
11回BioS継続勉強会
土居 正明
本日の内容
• 前回と同じ本、G.Verbeke, and G.Molenberghs.著 “Linear Mixed Models for Longitudinal
Data”(Springer, 以下「テキスト」と呼びます) の10 章をまとめます。
• 誤差が独立でない場合を扱います。
• 参考文献は、今回と次回の内容を合わせたもので す。
本日の内容
はじめに(データの紹介・モデリングの基礎)
10.1 Introduction
10.2 An Informal Check for Serial Correlation
10.3 Flexible Models for Serial Correlation
10.4 The Semi-Variogram
10.5 Some Remarks
4
注意
• テキストは、記号の使い方等が結構いい加減です (確率変数とその実現値の使い分け、など)。 • 数理的な部分で、たまに間違い(誤植と呼ぶには大 きいもの)もあります。 • 本資料ではテキストより記号等を変更しています。 大抵は意図的に「修正」していますので、大体はこっ ちの方が正しいです(が、誤植は結構あるはずで す)。• LMMは線形混合効果モデル(Linear Mixed Model) の略です。
• 分散成分の推定には、特に断りがなければREML
はじめに
6
はじめに
症例 の 個の時点 のデータが 1症例の経時変化 である。10章のテーマは 1. 時点ごとのデータの相関(系列相関)の有無の判断 2. 系列相関がある場合はそのモデリング である。本書を通して大事なこと
• 目的は
探索解析
– 本当のモデルは分からないので、探索しましょう。
– 「使える」モデルをみつけるための「試行錯誤」の方 法論を考えましょう。
Essentially, all models are wrong,
本質的問題
と
暫定的解決
• 時点ごとの相関が存在するとして、「どういう関数で 表されるか」を正確に知るのは一般に不可能。 • 複雑な関数になることも想定されるが、通常、指数 関数を用いたモデリングで十分なことが多い。 • 指数関数は「本質的に時点ごとの相関関係を表現 している」訳ではなく、 – ある種の微分方程式の解として自然に現れる – 現実的に、いくつかのデータに対するFittingが悪くない ことなどから、便宜的に使用される。統計で最も重要なこと(私見)
• 全てのtoolは不完全である。 – プロットして目視・尤度比検定・情報量規準など、どれも 「決定的」な知識はくれない。 – 「これさえしておけば絶対大丈夫」という人は信用しては いけません。 • しかし、「不完全だからいい加減でよい」わけではな い。むしろ「不完全なので、一層注意深く観察・検討 しよう」という態度が重要。 – 最終モデルに対しても、「もしかしたら不完全かも」と思う こと。ただし、「現在の知識・情報・技術ではここが限界」と いうまで検討することが大事。10
モデリングとは(私見)
• 「全く分からない」から入って、 「少しは分かったかも
」で終わるもの。 • 「完全に分かる」=「真のモデルが分かる」は(人間の 力では)あり得ない。 • 情報がさらに蓄積すれば、構築されるモデルは変わ りうる。 • あまり自信のない判断をせざるを得なくなるときもあ るが、その時は「ここで微妙な判断をした」ということ を忘れないことが重要。 → 自分のモデルを冷静に評価すること経時データのモデリング
• 決めなければいけないものがたくさんある
( ・ は9章までのテーマ) 平均構造 変量効果の 分散構造 誤差の相関構造 10章のテーマ どの要因を選ぶか? (3.8)今回のモデルの
固定効果、変量効果、誤差
固定効果: → に依存しない。 → 全症例・投与群など、複数の個人に 共通の部分。 変量効果: → に依存する。 → 被験者特有の部分。被験者内変動。 誤差 : → 固定効果・変量効果で説明できない データのばらつき。被験者間変動。症例は固定効果か変量効果か?
• どちらでも解析することは可能
– 症例内のデータの相関を考慮した解析を行うた め、変量効果を用いることが多い。
モデリングで決めなければいけないこと
• どの変数が入るか?
– 時間、性別、・・・etc• どういう風に入るか?
– 時間の1次関数?2次関数? – 変数はそのままでOK? 変換してから入れる? – 誤差は独立?相関あり? – 変量効果同士の相関は?本章であつかう実データの紹介
(
Prostate Data:前立腺癌のデータ)
• 詳しくは2.3.1節参照 • 前立腺癌は、アメリカでは男性の癌による死亡の2番 目の原因。治療にお金もかかる。 – 早期発見が重要。• PSA (prostate-specific antigen) がマーカーになる。 • PSAは正常細胞にも癌性前立腺細胞にも含まれる
本章であつかう実データの紹介
(
Prostate Data:前立腺癌のデータ)
• BPH(benign prostatic hyperplasia, 良性前立腺過形成) でもPSAが大きくなる。
• Pearson et al. (1991)によると、 PSAの値だけで判断し た場合、最大60%のBPH患者が前立腺癌と誤診される。
→ 現状では、PSAは前立腺癌のマーカーとして不十分。
前立腺癌だけを 検出する判断基準を導けるような モデルを作りたい(目的)。
Prostate Data 個人ごとのデータの推移(図2.3)
(横軸は診断前の時間:
右が過去
)
これを 区別する モデリングを したい テキスト13P より引用本章であつかう実データの紹介
(
Prostate Data:前立腺癌のデータ)
【仮説】
PSAの変化率 を見れば、前立腺癌の早期発見ができる のではないか? → PSAの数値だけではなくて経時変化の仕方まで よく見れば、よりよい前立腺癌のマーカーに なるのでは? → 時間に依存した部分に注目 単位時間あたりの変化:正しい意味での「率」本章であつかう実データの紹介
(
Prostate Data:前立腺癌のデータ)
BLSA (Baltimore Longitudinal Study of Aging)のデータ → Pearson et al. (1994)参照。 • デザイン – 後ろ向きCase-Control研究。 – 凍結させた血清サンプルを使用 • 被験者の内訳は – 前立腺癌:18例 • 局所浸潤性癌(L/R Cancer):14例 • 転移性癌(Metastaic Cancer):4例 – 良性前立腺過形成(BPH):20例
本章であつかう実データの紹介
(
Prostate Data:前立腺癌のデータ)
【選択基準】 1. 泌尿器科医によって、前立腺癌、BPHによる単純前立 腺摘出術、前立腺の病気はない、と診断されるまでに7 年以上の追跡調査のデータがある。 2. 病理学的診断により確認されている 3. 診断の前に前立腺の手術がないデザインの詳細
• 診断時の年齢、追跡期間は対照群、BPH群、前立 腺癌群でマッチングした。 • 50歳以上ではBPHの罹患率が高すぎるため、対照 群を見つけるのが難しかった。 – 対照群は、BPH群に比べて、初回来院や診断時の年齢 がだいぶ若い。 • 局所浸潤性癌と転移性癌を分けて考えた。 • PSAは指数関数的に増加するので、対数を考え、0 に近い値であることも考慮して、 をプロットした。Prostate Data
人口統計学的データなど(表
2.3)
テキスト12P
国立がんセンターの
Webページ
(http://ganjoho.jp/public/cancer/data/prostate.html)よりタンデムR法の「グレーゾーン」の の値は
Prostate Data 個人ごとのデータの推移(図2.3)
(横軸は診断前の時間:
右が過去
)(再掲)
これを 区別する モデリングを したい テキスト13P より引用誤差とは?
• 誤差
というからには、
独立同分布
が基本で
は? 少なくとも独立性は欲しい。
– 「誤差が相関する」というのは不思議な表現。 – 「モデリングが不十分」と解釈するべきでは? • 誤差が相関がある場合、その要因を取り出して、 「変量効果によるモデリング」+「(独立同分布の)誤差」 となるまでモデリングを続けたい(理想)探索:モデルを段々複雑にしていく
(1)固定効果のみのモデル(固定効果以外は全て誤差) (2)変量効果をいくつか入れたモデル 相関構造が複雑 → 別の要因の影響では? を分解 この相関構造は? → 複雑なら、別の要因を考える系列相関
(Serial Correlation)
• いくつかの変量効果を入れた後
– 個人のデータの経時推移による相関が に 残っているか? – 残っているなら、その部分を「時間依存する要因」 として取り出したい。 – 逆に、とりあえず取り出して見て、「相関が無視で きるか」を考えてみては? 誤差 時間に依存する部分(変量効果) この部分の相関が 十分大きいかどうかをみる本章で扱うモデル(一般形)
誤差:独立同分布 時点ごとの相関 → ここが本題 (10.1) 独立 誤差 系列相関10.2 An Informal Checks for
Serial Correlation
モチベーション
• 系列相関があるかどうかを検討したい。
→ 誤差が独立同分布かどうかが気になる
• (注意)前節と少し記号使いが異なり
ます。
32
本章で何度か出てくる重要なこと
(誤差と残差の関係)
y -1 0 1 2 3 4 5 6 7 8 9 x -2 -1 0 1 2 3 4 5 6 y -1 0 1 2 3 4 5 6 7 8 9 x -2 -1 0 1 2 3 4 5 6 真のモデル 推定したモデル 誤差は未知 残差は既知 誤差 残差 データは同じ本章で何度か出てくる重要なこと
(誤差と残差の関係)
• 「誤差」と「残差」は違います。
– 誤差:真のモデルに入っているもの。未知。 – 残差:モデルを当てはめた後、データと推定値 (や予測値)とのズレ。既知。• 「残差は誤差の予測値」
と考えることができます。
– 誤差 の性質を検討して、「誤差は未知だから、代わ りに残差 でその性質を満たすかどうか検討する。 大体性質同じでしょ?」という論法が、本章でよく用い34
系列相関
が必要かどうかの検討
ここが邪魔 → ここがなければ、「時点ごとで独立等分散なら はいらない」 と判断できそう 誤差 時点ごとの相関 (3.11)を「穏便に」(他の要素に影響のないように)消したい
固定効果を除いた部分 →
36
直交補空間
の における直交補空間 を含む の基底を1つとり、 Schmidt の直交化法で正規直交基底 を作る。 をとる。 は の正規直交基底 ( の構成方法) とおく。 1次独立と仮定 次元ベクトル空間 は から 具体的に構成できる行列
の性質
とおくと、正規直交基底の性質より、
また、直交補空間の性質から
となる。従って、
を、 に射影する 作用素は
だが、簡単のため、最初の を除いて の
となる。これより、
が独立同分布に従うかどうかを調べれば、 が 0 かどうか(系列相関があるかどうか)分かる。 しかし、誤差 は未知。そこで、 から、残差 を の代わりにする。 → が独立同分布か よって、 残差は誤差の 予測値 最小2乗推定量は 平均構造が正しく 特定されていれば 不偏推定量 予測
系列相関が必要かどうかの
手順のまとめ
1. から を求める。 2. 外れの少なそうな平均モデルを仮定して、 を求める。 3. が独立同分布か 調べる。 独立同分布っぽい : 系列相関なさそう 独立同分布っぽくない : 系列相関ありそう【テキストの修正
1】
(10.4.4 も同じ)
p136 の1行目で とし、同ページ 10.2 の 8 行目で 残差 として、この分散を としているが、これは間違い。残差の部分を ではなく を考える10.3 Flexible Models for
Serial Correlation
モチベーション
• 系列相関がある場合、パラメトリックなモデリ
ングを行い、
LMMの枠組みで推定を行いた
い。
46
系列相関をモデル化したい
たとえば、 時間が離れるほど、(通常は) 時点間の相関は減少する 「相関の減少の仕方」をモデル化したい → いくつか関数を作ってみる。 → 多項式よりは柔軟な関数にしたい。 時点1 時点2 時点3 時点4 時点1 時点2 時点3 時点4仮定と関数の導入
何か仮定をおかないと漠然としすぎるので、以下の仮定 をおく。 【仮定】 2時点間の相関の強さは「どれだけ離れているか」 のみに依存する 時点 と時点 の間の相関が、関数 を用いて 自身には 依存しないたとえば、
のとき、
の関数形 を決めたい
Royston and Altman(1994)の関数
(fractional polynomial)
とおく。ただし、 とする。 0 も 負の数 も 無理数 もOK → 多項式より 柔軟 に対して、 (10.2)50
Lesaffre, Asefan, and Verbeke (1999)
の関数
Royston and Altmanの関数は のとき困る。 → 以下のように変更する
そして、 を
とモデル化する(なお、 )
初回観察日
【テキストの修正
2】
は の誤植。
SASの現状(ver 6.2)など
• 系列相関に式(10.3)を用いて、ML、REML推定を行う ことは、SAS ver 6.2 では無理。 – 他の数値計算ソフトなら可能らしい(確認してません) • 最尤法の数値計算は収束しないことがある。 – SASで扱えるモデルに対しては、 PARM オプションで初期 値を変更してみる。 – 著者らの経験では、一般に が大きくなると収束しない場 合が増える → を小さく固定して、 を変化させる のがよいのでは?具体例:
Prostate Data
【固定効果(平均構造)】 ・ 切片、時点、時点の2乗、年齢 【変量効果】 ・切片、時点、時点の2乗 これらは 3章と同じ系列相関の構造
に対して、 や を変更した色々なモデルを当てはめる。 → モデルによっては、計算が収束しないこともある
(いくつか試した中で)
尤度関数が最大なモデル
指数関数 Gaussian 含まれる 表10.1 (10.4) 大 ⇒ 系列相関の推定は 正しくできていなさそう テキスト139P より引用56
【重要なポイント】
「尤度関数が最大のモデル」=「最もよいモデル」 と条件反射するのは「思考停止」。 ⇒ 尤度関数の値はあくまで「目安」 ここから先で「モデル構築」の腕前が試される ・変数の数が多い場合、fittingはよくて当たり前。 ・もっと変数が少なくて、「fittingがほとんど変わらない」 かつ「系列相関の推定がもっと妥当」なモデル はないか? ⇒ 他のモデルも検討してみる。 指数関数、Gaussian例:
Prostate Data(図10.1)
モデルによる推定曲線の違い
実線:尤度最大のモデル 点線(短い方):Gaussian モデルによって結構違う ように見える 3つとも大体近いのでは? (指数関数の方が、少し 尤度最大のモデルに近い) テキスト140PSASでは は出ない。
表
10.2 SAS の出力:系列相関は指数関数
テキスト141P より引用 少しは改善モチベーション
• 前節では、系列相関の関数
に対してパ
ラメトリックなモデリングを行った。しかし、
– パラメトリックモデルでは扱いきれない – パラメトリックモデルの妥当性を保障したい場合なども考慮して、ノンパラメトリックな推定
方法を考えたい。
Semi-Variogramとは
・10.3 節のアプローチ → 線形混合モデルでパラメトリックに考えた ・Semi-Variogramはノンパラメトリックな方法。 (論文) Diggle (1988) : random-intercept の場合のみ Verbeke, Lesaffre and Brand (1998)変量効果を切片項にのみ含むモデルを考える。
変量切片
とおくと、
(10.5)
続き(ただし
4時点に限らない一般論)
分散は時点によらず
時点 と の相関は、
対角成分
固定効果
とおく。
を、Semi-Variogram と呼ぶ。 から、右辺の を とした、 以上をまとめると、 なお、 を仮定 遠く離れた2時点間の相関はほぼ0 同一症例の時点間差
図
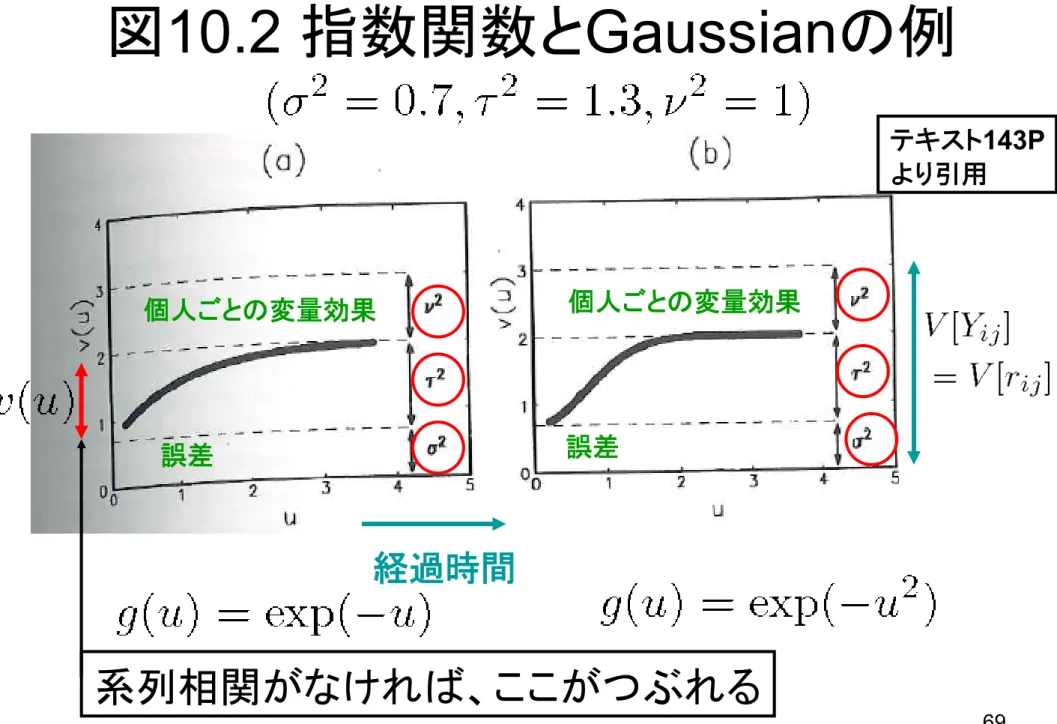
10.2 指数関数とGaussianの例
経過時間 誤差 個人ごとの変量効果 誤差 個人ごとの変量効果 系列相関がなければ、ここがつぶれる テキスト143P より引用70
Semi-Variogram
の推定方法
から、 を全 に対してプロットして、Smoothingする。 ノンパラメトリック に、前ページのように にモデルを当てはめない。 縦軸: 横軸:の推定方法
異なる個人間の場合、全て独立となるので、
は で足されたものの数 これより、
変量切片 とおくと、 となる。 (10.5)
忘れた頃だと思うので、復習。
変量効果 誤差 系列相関 → 相対的に小さいと74 縦方向のつぶれ具合で、 系列相関の有無のInformal Check ができる。 と比べて が 大きい → 系列相関 必要では? テキスト143P より引用
図
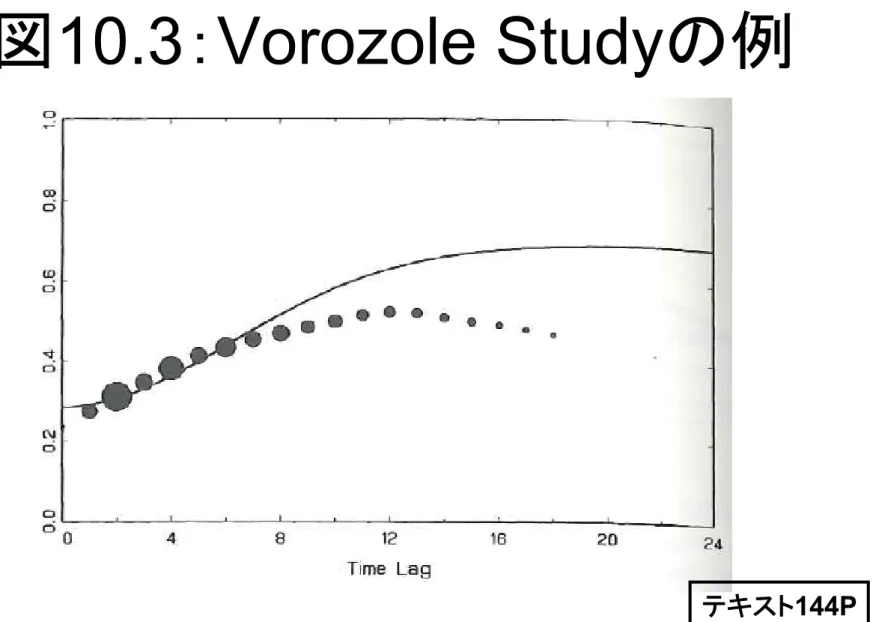
10.3:Vorozole Studyの例
テキスト144P
図
10.3 Vorozole Study
• 固定効果は以下のものを考えた
– 時間 – 時間×ベースライン – 時間の2乗 – 時間の2乗×ベースライン• 変量効果は切片のみ
• 系列相関はGaussian
+ 独立同分布(正規分布)に従う誤差
補足
• より詳しい話は
Diggle, Liang, and Zager (1994)
“ Analysis of Longitudinal Data” のChapter
5
10.4.4 変量効果を追加したモデル
•
前節では変量効果が切片項だけに含まれ
るモデルを考えた。
– 本節では、他の変量効果も追加したモデルを考 えたい。
79
一般のモデルの場合
の部分を消したい。 1. を考える (10.2節参照) 2. を考える 考えられる 方法どっちがよいか?
(2. の欠点)
・ は の正規性に強く依存する(7.8.2節参照)。 ・ 分散共分散構造 の特定に大きく依存する。
成分を とおく。このとき ここで、以下のようにおく。
84 いま、 から、 ・・・ (i) ・・・ (ii) より、 (i) =
(ii)の計算
対角成分
まとめ
(10.6) { (i) + (ii) } より、 未知パラメータ 既知定数 期待値が、未知パラメータの線形結合 → (データの数) > (未知パラメータ数) なら線形回帰できる これの数は データ依存87
パラメータ推定(理想)
◎ の数が少ない場合 (規定来院日からのズレがほとんどない場合) → のうち、値の異なるものを小さい順に並べて とおく。 → とし、 を応答変数、パラメータを•
を「曲線として推定」するのではなくて、
離散的な点
を推定する。
• (10.6)より、
を
1パラ
メータにする方が便利。
パラメータ推定(現実:方法)
実際は、 のバリエーションが多すぎる。 → 全体からいくつか取り出して、小さい順に並べ とする。 → 離散的な点しか推定されない。 → 残りの に対応する部分は、線形補間する。 → 要は、折れ線で回帰分析を行っている。 の最大値パラメータ推定(現実:論点
1)
・ をどうやって決めるか? → 増やすと補間の精度が上がるが、 パラメータが増えて、パラメータ推定の 精度は下がる。 (著者らの推薦する方法) を全て計算し、その %点をとる。 ・ を決めた後、どの点を とするか。パラメータ推定(現実:論点
2)
• Verbeke (1995) によると、シミュレーションの結果、 データごとに相関が高すぎて、多重共線性が起きる。 → Ridge回帰で回避できる。 • の選び方は一意的ではない。 → 系列相関がない場合、式(10.6)は に依存 しない。 → (対偶) を変更したとき、推定された様子が 変わるようなら、系列相関がある。• Verbeke et al(1995) によると、経験的に の変 更にあまり影響を受けない の推定方法がある。
– ただし、系列相関の存在の有無・タイプについての結論 は上の方法と変わらないことが多い。
例:
Prostate Data (図10.4)
実線:Semi-Variogram(ノンパラ) 点線:Gaussianを用いたパラメトリックな推定 → Gaussian で十分よさそう ほぼ一致 テキスト148P より引用• Prostate Dataの解析結果のまとめ – パラメトリックな検討結果 → 指数関数がよさそう – ノンパラメトリックな検討結果 → Gaussian がよさそう ⇒ 変量効果がある場合、系列相関のモデルを1つに特定する のは難しい (True Model の特定はやっぱり難しい)。 • 著者らの経験によると、重要なことは – 系列相関をモデルに入れること(最重要) – 正しく系列相関をモデル化すること(あくまでその次) • とにかく、「系列相関の有無」が最重点の検討課題。 → これが正しくできれば、そこそこ Useful Model で は?
本日のまとめ
1. 系列相関が必要かどうかの informal check の方法を みた。 • 変量効果のデザイン行列 の列ベクトルから生成されるベ クトル空間への射影(みたいなもの)を考えた。 2. 系列相関のパラメトリックなモデル化を考えた• 指数関数、Gaussian、多項式より柔軟な Lesaffre, Asefan, and Verbeke の関数を用いたモデル化。
3. 系列相関のノンパラメトリックな推定方法を考えた
• パラメトリックモデルよりも柔軟なモデリング
テキストの参考文献
(1)
Altham,P.M.E. (1984) Improving the precision of estimation by
fitting a model. Journal of the Royal Statistical Society, Series
B, 46, 118-119.
Diggle,P.J. (1988) An approach to the analysis of repeated measures. Biometrics, 44, 959-971.
Diggle,P.J., Liang,K.-Y., and Zeger,S.L. (1994) Analysis of
Longitudinal Data. Cxford Science Publications. Oxford:
Clarendon Press.
Lesaffre,E., Asefa,M., and Verbeke,G. (1999) Assessing the
goodness-of-fit of the Laird and Ware model: an example: the Jimma Infant Survival Differential Longitudinal Study. Statistics
in Medicine, 18, 835-854.
Morrell, C.H., Pearson,J.D., and Brant,L.J. (1997) Linear
transformations of linear mixed-effects models. The American
テキストの参考文献
(2)
Pearson,J.D., Kaminski,P., Metter, E.J., Fozard, J.L., Brant,L.J.,
Morrell,C.H., and Carter,H.B. (1999) Modeling longitudinal rates of change in prostate specific antigen during aging. Proceedings
of the Social Statistics Section of the American Statistical Association, Washington, DC, pp.580-585.
Pearson,J.D., Morrell, C.H., Landis,P.K., Carter,H.B., and Brant,L.J. (1994) Mixed-effects regression models for studying the natural history of prostate disease. Statistics in Medicine, 13, 587-601 Royston,P. and Altman,D.G. (1994) Regression using fractional
polynomials of continuous covariates: parsimonious parametric modelling. Applied Statistics, 43, 429-468.
Self,S.G. and Liang,K.Y.(1987) Asymptotic properties of maximum likelihood estimatiors and likelihood ratio tests under
テキストの参考文献
(3)
Stram,D.O and Lee,J.W. (1994) Variance components testing in the longitudinal mixed effects model. Biometrics, 50, 1171-1177.
Stram,D.O and Lee,J.W. (1995) Correction to: Variance components testing in the longitudinal mixed effects model. Biometrics, 51, 1196.
Verbeke,G., Lesaffre,E, and Brant,L.J. (1998) The detection of residual serial correlation in linear mixed models. Statistics in
追加の参考文献
Box,G.E.P (1976). Science and Statistics. Journal of American
Statistical Association, 71, 791-799.
Box,G.E.P (1979). Robustness in the Strategy of Scientific Model
Building. Robustness in Statistics:Proceedings of a Workshop(1979)
edited by R.L.Launer and G.N.Wilkinson. 201-236.
Box,G.E.P. and Draper,N.R.(1987). Empirical Model-Building and
Response Surfaces. Wiley.
土居正明, 横道洋司, 青山淑子, 五百路徹也, 中村竜児, 吉田和生, 白岩健, 松下勲, 西山毅, 井上永介, 上原秀昭, 山口亨, 酒井美良 訳(2011). 線形モデルとその拡張-一般化線形モデル、混合効果モ デル、経時データのためのモデル-, 株式会社シーエーシー.
(McCulloch,C.E., Searle,S.R, and Neuhaus, J.M. (2008)
Generalized, Linear, and Mixed Models 2nd edition. Wiley.)
松山裕, 山口拓洋編訳(2001). 医学統計のための線形混合モデル-SAS によるアプローチ, サイエンティスト社. (Verbeke,G. and
Molenbergh,G.M.ed. (1997). Mixed models in Practice – A