日本地理言語学会第2回大会予稿集
Proceedings of the Second Annual Meeting of
the Geolinguistic Society of Japan
2020 年 9 月 27 日
27th September, 2020
オンライン
Online
日本地理言語学会第二回大会プログラム
日時:2020年9月27日(日) オンラインによる一日開催 参加費:無料 〇本会は会員制度をとっておりませんので、どなたでも参加できます。 〇Zoomを利用して開催します。発表者・司会者と聴講を希望される方は以下のURLで、参加申し込みを お願いします。折り返し、ZoomのURLをお知らせします。 https://forms.gle/AA5uopHegL5Jeptr8 〇研究発表スケジュール: 9月27日(日) 以下、日本時間 900-1030 司会: 福嶋秩子(新潟県立大学) 1.語境界線(isogloss)から観察するアラビア語諸方言の様相 長渡陽一(東京外国語大学特別研究員) 2. 東南アジア大陸部諸語における発声類型の地理分布 倉部慶太(東京外国語大学アジア・アフリカ言語文化研究所) 3. 横浜ドイツ人学校におけるドイツ語の方言接触-綴り<s>におけるスピーチ・アコモデーション- 金田懐子(東京大学)・松本和子(東京大学) 1045-1145 司会: 岸江信介(奈良大学) 4. サハリンの朝鮮語話者コミュニティーにおける方言・言語接触 ‐ 音節核のヴァリエーションに関 する事例研究 ‐ 吉田さち (跡見学園女子大学)・松本和子 (東京大学) 5. 計量的分析における統語関係を反映させた変数及び行列設定の試み –ロマンシュ語の否定を例に– 清宮貴雅(東京外国語大学博士後期課程) 1145-1300 昼休憩1300-1430 Chair: Ray Iwata (Komatsu University)
6. Disappearing overcounting numeral systems in the Luzon–Taiwan area Izumi Ochiai (Hokkaido University)
7. Mapping the Case Systems among Kuki-Chin-Naga Languages in Northeast India MURAKAMI Takenori (Kyoto University)
8. Geolinguistic significance of the Phongpa dialect in the history of Yunnan Tibetan Hiroyuki SUZUKI (Fudan University)
1445-1545 Chair: Mitsuaki Endo (Aoyama Gakuin University)
9. A Geolinguistic Survey of Jianyin and Tuanyin in Rizhao dialect of Chinese Qi Haifeng (Shanghai International Studies University)
10. 最近隣法による文字変異の地図化と語彙拡散の計量化 古スペイン語重子音文字 ss の歴史・地理的解釈 上田博人(東京大学)・Leyre Martín Aizpuru (Universidad de Sevilla)
語境界線(isogloss)から観察するアラビア語諸方言の様相 長渡陽一(東京外国語大学特別研究員) 本発表の目的は、アラビア語の主な方言の基礎語彙の語境界線(isogloss)を地図化し、使 用語彙の異同の様相を考察することである。方言間の語境界線は、Swadesh(1955)の基礎語 彙 100 語のうち、同一語彙について隣接している方言が同源語でないものを使うときに境界線 を引く。アラビア語の主要な方言である、モロッコ方言、エジプト方言、シリア方言、イラク方言 と、周縁方言とされるマルタ語とチャド方言の 6 つを扱う。マルタ語は、モロッコ方言とともに西 方言をなす。チャド方言は東方言がスーダンからアフリカ中央部へ移動したものである。 アラビア語諸方言の地理的研究は、語彙などの地図の集大成(Behnstedt & Woidich 2011) や、語彙や文法項目によって周圏的分布などを確認した研究(Ratcliffe forthcoming)な どがある。基礎語彙による統計法では通常、方言(言語)間の同源語の共有数に注目するが、 その地理的分布はあまり可視化されない。また方言語彙地図では、通常は複数の語彙の分布 を 1 枚に示すことには限界がある。しかし、地図上に複数の語彙の分布境界線(語境界線)を 引くことにより、方言域全体の複数の語彙の異同がある程度可視化することができる。 各語彙の境界線を引いた結果、西方言(モロッコ方言、マルタ語)と東方言の境界となるとこ ろでは 20 前後の語境界があって、東方言どうしの語境界より多いが、東西を分ける境界のうち 6 方言中マルタ語のみの 8 語などを除くと、東西の境界をなす語境界線は 5 語(茶色)であるこ と、また西方言どうしのマルタ語とモロッコ方言との境界も 22 語あって、マルタ語と東方言との 境界をなす語境界と同数であることが明らかとなった。さらに、東方言内の境界をなす境界線 は、全域でさまざまに異なる語彙(赤色)であることも分かった。なぜこれらの語彙(赤色)が多 くの方言で異なっているかについて今後の考察が必要である。 複数の語彙の語境界線を 1 枚の地図に可視化することで、方言全域の以上のような分布様 相が見えた。
東南アジア大陸部諸語における発声類型の地理分布
倉部慶太(東京外国語大学アジア・アフリカ言語文化研究所)
発声類型(phonation type)は母音の喉頭特徴であり、通常の modal voice に加えて、
creaky voice や breathy voice などが知られる(Ladefoged 1971)。発声類型は東南アジア 大陸部の様々な言語に報告されている。これらには、ピッチや分節音と相関するものと 独立したもの、音声的なものと音韻的対立をなすものなど様々なタイプがある。その重 要性にもかかわらず、東南アジア大陸部における発声類型の地理的分布はいまだ充分に
知られていない。たとえば、WALS では発声類型は扱われていない。また、UPSID、
PHOIBLE 2.0、The database of Eurasian phonological inventories などの音韻論の大規模デ ータベースでも東南アジア大陸部諸語の発声類型については、数地点に限られている。 本発表では、同地域の発声類型の地理言語学的研究の第一歩として、この地域で各発 声類型がどのような地理的分布を示すかを、主に二次資料に基づきながら報告する。ま た、これらの分布についてどのような解釈が与えられるか考察を行う。以下の地図は東
南アジア大陸部を中心に、音声的であれ音韻的であれ、各言語をcreaky (creaky voice が
顕著)、breathy (breathy voice が顕著)、mixed (creaky と breathy がともに顕著) 、no(発声 類型が顕著でない)に分類して示したものである。
参考文献
横浜ドイツ人学校におけるドイツ語の方言接触 -綴り<s>におけるスピーチ・アコモデーション- 金田懐子(東京大学)・松本和子(東京大学) 1. はじめに 本発表は日本におけるドイツ語の方言接触とスピーチ・アコモデーションに関する予備調査 の結果を報告するものである.2018 年現在,約 15,000 人のドイツ語話者が日本に滞在してお り(法務省, 2018),ドイツ語話者を配偶者に持つ家庭と共に在日ドイツ語話者人口を構成して いると考えられる.横浜ドイツ人学校には 2019 年現在小学生から高校生まで約 500 人の児 童・生徒が在籍し,ドイツ語話者コミュニティを形成している.当該コミュニティに関する先行研 究は乏しく,生徒2 名の日独コードスイッチングに関する研究(今村, 2013)はあるものの,ドイツ 語の方言には言及していない.ドイツ語圏は独・墺・スイス各国の標準ドイツ語および多種多 様な地域方言が存在することで知られているため,ドイツ語圏各地からもたらされた様々な変 種が日本で接触した結果どのようなドイツ語が日本のドイツ人学校で使用されているか,という 観点からの言語学的調査を行うことは方言接触の分野に新たな事例を提供するものと考える. 本発表では,まずドイツ語の諸方言およびドイツ語圏各国における標準語について概説し, コミュニティの方言背景を整理する.次にドイツ語圏の方言地図を参照しながら,日本のドイツ 人学校で観察された発音の変異とアコモデーションの諸要因を考察していく. 2. 分析の枠組み 以下を分析の理論的枠組みとして採用する.まずGiles et al. (1987) の提唱する「スピーチ・
アコモデーション理論 (speech accommodation theory)」である.これは話者が相手によって話 し方を無意識的に,あるいは意識的に調整する習性を類型化したものであり,相手に受け入 れられるために相手の話し方へ近づけようと適応する行為を「収斂 (convergence)」,逆に相手 との距離を示すために相手の話し方との違いを大きくする行為を「拡散(divergence)」と呼ぶ. こうしたアコモデーション行為が継続する期間によって異なる結果をもたらすことが指摘されて い る . 相 手 の 話 し 方 に 近 づ け よ う と す る 「 短 期 間 の ア コ モ デ ー シ ョ ン 行 為(short-term accommodation) 」 は 一 時 的 な 適 応 ・ 調 整 で あ る が , そ れ が 長 期 間 に 渡 る と (long-term accommodation)話者自身の話し方が永続的に変化・定着する可能性がある(Britain, 2018). 一方 Chambers (1992)は,英国に移住したカナダ人児童が長期間のアコモデーション行為 を行った結果として児童の話し方にもたらされた変化の特徴を 8 つの法則で説明し,第二方 言習得の過程を解いた.そのひとつが,綴りと矛盾したイギリス英語の「R-lessness の習得(car のr を発音しないこと)」と比べ,綴り字に則った「T-Voicing の減少(better の t の有声化を無声 化にすること)」が早い,つまり「第二方言習得において綴り字に則した発音の変異形ほど習得 されやすい」という法則である. また,第二方言習得には話者の社会的ネットワークの特性が関係していることが明らかにな っている.Kerswill & Williams (2000)は,英国のニュータウンでみられた子どもの言語使用の 研究から,年齢が上がるほど,また社交的で友達どうしのグループによく溶け込んでいる子ど もほど親と異なる言語使用を身につける,つまり子どもの話し方は成長とともに友達からの影
響を強く受けるようになるということを示している. 3. ドイツ語の諸方言・各国の標準語
ドイツ語圏の諸方言は国境を超えて連続しており,図 1 の よ う に ド イ ツ 北 部 の「 低 地 ド イ ツ語 諸 方 言 (Low German dialects)」,ドイツ中部の「中部ドイツ語諸方言 (Middle German dialects)」とドイツ南部・墺・スイスの「上 部ドイツ語諸方言(Upper German dialects)」に細分化さ れる(Knöbl, 2011).一方,独・墺・スイス各国において 各々の「標準語」とされるドイツ語変種が確立しているこ とが指摘されている(高橋, 2009; Ehrlich, 2009, Soukop & Moosmüller, 2011; Scherrer & Rambow, 2010). 4. 予備調査の概要 予備調査ではドイツ人学校において10~17 歳の生徒 20 名(男性 12 名,女性 8 名)より① 出身地や家族・交友関係などの話者情報,②単語の読み上げ(50 語),③ピクチャータスク (17 語),④談話データを収集した.調査は校内で標準ドイツ語を用いて生徒と一対一でのイ ンタビュー形式で実施した.本発表では話者情報と母音に先行する綴り<s>を含む 20 個の単 語(表 4,5 を参照)の読み上げ結果(計 396 トークン)を定量的・定性的に分析していく. 5. 分析 5.1. 在日ドイツ人コミュニティの方言背景 まず,どのようなドイツ語の方言が日本のドイツ 人学校へもたらされたかを探る.図2 は調査対象 の生徒およびその両親の出身地を3 節で示した 方言区分(図 1)に基づいて整理したものである. ここから,①日本生まれの生徒(8 名)と日本人を 母親として持つ生徒(11 名)が半数前後を占める こと,②ドイツ南部・墺・スイスなどの上部ドイツ語 諸方言地域出身者である生徒(8 名)と父親(12 名)がおおよそ半数を占めることが示された. 図3, 4 は上記 3 国を含むドイツ語圏全域における母音に先行する綴り<s>の発音の変異形 の地理分布を語頭・語中別に示している.現代ドイツ語の標準発音を定めた辞典 Duden Aussprachwörterbuch (2000)によれば,母音に先行する綴り<s>はほぼ常に有声音[z]で発音さ れるが,Kleiner & Knöbl (2011ff.) による研究では低地ドイツ語諸方言地域では[z],中部・上 部ドイツ語方言地域では[s]で発音され,また語頭の方がより[s]で発音されやすいという傾向が あることがわかる1.先ほどの生徒およびその両親の主な出身地(赤丸で囲んだ地域)では 3 つ の変異形が使用されているため,ドイツ人学校でこうした変異形が接触していると考えられる. 本予備調査の一環として行った語末の<ig>に関する考察では,短期間のスピーチ・アコモ デーションが日々営まれた結果,出身者の比率の高い上部ドイツ語諸方言に生徒の発音が 近づいていっている可能性が示されたが(金田・松本, 2019),インタビューではほとんどの生徒 1 今回の分析では,図中の無声軟音[z̥]は無声歯茎摩擦音[s]の項目にまとめて取り扱う.
が「学校では標準ドイツ 語を使用している」と回 答した.日本のドイツ人 学校へ通う生徒は,ドイ ツ語学習者である母親 が話すと推測される標 準形[z]の影響が見られ るのか,それとも上部ド イツ語方言地域の出身 者である生徒や父親の 方言形[s]が好まれるの か,それともそもそも校 内という公の場で調査を 行ったことから標準形[z] 以外が使用される余地はないの か,ここから考察していく. 5.2. 言語環境の比較 表1 は単語の読み上げ結果を示している. 標準形[z]の発音が大多数を占めていることか ら(86.9%),[s]使用地域出身の生徒や[s]使用 地域出身の父親をもつ生徒であっても標準形 [z]を採用していることがわかる. 言語環境に着目し,語頭と語中のデータを 分けて示したのが表2, 3 である.語頭と語中 での比率を比べると,中部・上部ドイツ語方言 の変異形[s]の使用率が語中(9.6%)に比べ語 頭で高く(18.5%),先行研究の傾向と一致して いることがわかる. 5.3. 単語間のゆれ 表4, 5 は単語ごとの各変異形の使用率を示 したものである.方言形の使用率が比較的高 い「満腹の」「息子」「だから」「お菓子」といった 語彙は家庭で使用される生活語彙であること から方言形が出やすい可能性が考えられる. 一方,「効果的な」の方言形使用率の高さに ついては前の子音の影響など今後より詳細な 分析が必要である. また,英語と綴りが一致する単語(表 4, 5 中で黄色い背景で表示)のうち「信号」「すごい」で 方言形[s]の使用率が高いことについては,英語の発音規則に沿う変異形が選択されているこ
とが考えられる.単語リストを渡した際に,リスト中の単語を英語だと勘違いして英語風に発音 した生徒もおり,また両親が会話に英語を使用/友人と英語で話す機会がある/英語圏に在住 した経験があるといった生徒が半数を占めていたことから,英語が堪能な生徒は英語の発音 規則がドイツ語の発音に影響するのではないかと推察される.これが,Chambers (1992)の提 唱した法則のように綴りが発音に与えた影響なのか,それとも自然発話においても英語と綴り・ 意味が共通する単語は発音が英語に寄っていくのかは,今回の分析からは定かでない. 5.4. 話者間・話者内・兄妹間のゆれ 表 6 は話者一人一人の実現形を示している2.話者間で発音にゆれがみられることがわかる. 表6 中で水色の背景で示した話者 O と話者 H はそれぞれ方言形[s]で発音する比率が 90%, 65%と他の話者と比べて突出して高い.二人はスイス出身であり,インタビューでも特に顕著な スイス方言が見られたため,出身地の方言が影響していると考えられる.他のスイス出身話者 にはそのような傾向はみられなかった. また,全ての単語を標準形で発音したのは話者C, D, E, L, N, Q, S, T の 8 名 (表 6 中の*) のみであり,半数以上の生徒は少なくとも一単語以上を方言形で発音している,つまり話者内 で発音にゆれがみられることがわかる.兄妹間では,話者 F と T の兄妹(表 6 中の黄色の背 景)では話者 T は全ての単語を標準形[z],話者 F は二つの単語を方言形[s]で発音した一方, 話者I と G の双子(表 6 中のピンク色の背景)は五つの単語の語頭,二つの単語の語中で発 音が異なり,傾向はバラバラであった.これらの結果は親の影響よりも身近な友人の影響によ って生徒の発音が変容し得ることを示唆しており,子どもの話し方は成長とともに友達からの影 響を強く受けるようになるというKerswill & Williams (2000)の指摘を裏付けると考えられる.
2 紙幅の制限のため,ここでは生徒と両親の国籍や出生地,生徒の性別等の情報は含めなかったが,そうした生
6. 結論 本発表では,日本在住のドイツ語話者がもたらしたドイツ語諸方言がドイツ人学校で接触し 方言混交が生じる中で,生徒のあいだで身近な友人たちの話し方に近づけるアコモデーショ ン行為が生じている事例を提示した.生徒の母音に先行する綴り<s>の発音は標準形が多数 派であり,先行研究と同様に方言形[s]は語中よりも語頭で生じやすい傾向がみられた.同一 話者内や兄妹間での発音のゆれは,生徒の話し方が友人の影響によって変容していることを 示唆すると考えられる.一方,英語の綴りの影響については更なる精査が必要とされる.今後 は談話データと読み上げデータのスタイル差の比較を行うとともに,在校生全体の出身地別 人口内訳や教師に関する追加調査,matched-guise test を用いた話者の意識(perception)に関 する実験などを行い,より詳細に分析していきたい.また,同一話者から再度データを収集し, 実時間(real-time)における変化が観察されるかどうか継続して調査考察していきたい. 参考文献 (Selected references):
Britain, David (2018). Dialect contact and new dialect formation. In C. Boberg et al. (Eds.), Handbook of dialectology, 143-158. Oxford: Blackwell.
Chambers, J. K. (1992). Dialect Acquisition. Language, 68(4), 673-705.
Ehrlich, Mag. Karoline (2009). Die Aussprache des österreichischen Standarddeutsch– umfassende Sprech- und Sprachstandserhebung der österreichischen Orthoepie. MA thesis, Universität Wien.
Giles, Howard, Mulac, Anthony, Bradac, James J., Johnson, Patricia (1987). Speech accommodation theory: The first decade and beyond. Communication Yearbook, 10, 13–48. Kerswill, Paul, & Ann Williams (2000). Creating a new town koine: Children and language
change in Milton Keynes. Language in Society, 29(1), 65-115.
Kleiner, Stefan & Knöbl, Ralf (2011ff.). Atlas zur Aussprache des deutschen Gebrauchsstandards. URL: http://prowiki.ids-mannheim.de/bin/view/AADG/ (2019 年 12 月 27 日閲覧)
Knöbl, Ralf (2011). Aspects of pluricentric German. In Soares da Silva, Augusto, Torres, Amadeu, Gonçalves, Miguel (Eds.), Línguas Pluricêntricas: Variação Linguística e Dimensões Sociocognitivas / Pluricentric Languages: Linguistic Variation and Sociognitive Dimensions, 427-441. Braga: Aletheia,
Scherrer, Yves & Rambow, Owen (2010). Word-based dialect identification with georeferenced rules. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, 1151-1161. MIT: Massachusetts.
Soukop, Barbara, & Moosmüller, Sylvia (2011). Standard language in Austria. In Kristiansen, Tore & Coupland, Nikolas (Eds.), Standard languages and language standards in a changing Europe, 39-46. Oslo: Novus Press.
金田懐子・松本和子 (2019). 「横浜ドイツ人学校におけるドイツ語の方言接触-スピーチ・ア コモデーション理論の検証-」 『日本地理言語学会第 1 回大会予稿集』,45-49. 河崎靖 (2008). 『ドイツ方言学 ことばの日常に迫る』 現代書館
高橋秀彰 (2009). 「標準ドイツ語の収束と分散―標準変種の確立と脱標準化に関する考察 ―」 『関西大学外国語教育研究』17, 83-98.
サハリンの朝鮮語話者コミュニティーにおける方言・言語接触 ‐音節核のヴァリエーションに関する事例研究‐ 吉田さち (跡見学園女子大学)・松本和子 (東京大学) 1. はじめに 本発表はロシア連邦サハリン州(旧樺太)の朝鮮語1話者コミュニティーにおける方言・ 言語接触とコイネー形成に関する研究の途中経過を報告するものである.本研究では20 世紀初頭から現在までサハリンの朝鮮語変種がどのように変容しているのか,その変化 の過程と結果および諸要因を解明することを目指している. 戦後,大部分の日本人が樺太から引き揚げたが,日本時代に主に朝鮮半島南部から渡 ってきた朝鮮民族は残留を余儀なくされた.戦前は日本人と同じ学校で教育を受け,戦 後は民族学校等で北朝鮮出身者より教育を受けた(Fajst & Matsumoto 2020).60 年代半ば に民族学校が閉鎖されソ連への同化とロシア語への言語シフトが進み(李月順 2016), 90 年の韓ソの国交樹立後は現代韓国語との接触が増えている (金美貞 2008).本発表で はこうした多言語・多方言が交差するサハリンの朝鮮語変種の変異と変化を考察する. 2. 分析の枠組み
分析の枠組みとして「コイネー化のプロセス(koineisation processes)」(Trudgill 1986, Britain 2018)と「フィーチャープール(feature pool)」(Mufwene 2001, 2008)を採用し,「傍 層ストランド(adstrate strand)」(Schneider 2007)の概念も加える.まず方言接触によって 新たなコイネーが形成される際にたどる言語的プロセスの中で最も一般的なプロセス として「平準化(leveling)」が挙げられる.これは方言混合において多数派の変異形が生 き残り,有標な変異形が消失する現象を指す.本研究では移住当初の多数派の方言形(慶 尚道など南部方言)が生き残るかどうかを検証する.また複数の方言形が接触した結果, どのインプット方言にも存在しない「中間的な方言形(interdialect form)」が生まれるこ ともあるため,こうした現象へも注視していく.一方「フィーチャープール」とは方言 接触・言語接触の状況下で,様々な方言・言語要素が話者の頭の中に蓄積されている状 況を抽象的に表わす概念であり,話者はフィーチャープールから既存の要素を選択した り,複数の要素を組み合わせ新たな構造を作り出したりする.ここで重要なのは,言語 接触の環境下では「外来言語要素(xenolectal feature)」も加えられる点である(松本・奥村 2019: 252-3).つまり樺太時代の日本語や戦後のロシア語からの言語要素も彼らの朝鮮 語のフィーチャープールに含まれると予測される.さらに「傍層ストランド」(Schneider 2007)とは初期の移住者よりも遅れて入植する集団からの言語的影響を表すために用い られる概念で,樺太時代に入植した朝鮮半島南部出身の話者において,戦後のサハリン の歴性的変遷の中で接触を持つに至った北朝鮮の変種や現代韓国語の要素が含まれる 場合2は「傍層言語要素(adstrate feature)」として扱う. 1 本発表では朝鮮民族の言語の名称として「朝鮮語」を用い,専ら韓国で話されている変種を指す際には 「韓国語」と呼ぶこととする. 2 戦後,民族学校へ通った話者に北朝鮮の言語要素が含まれる場合やドラマ鑑賞や訪問,学習を通して現
3. 調査の概要 2019 年 9 月,ユジノサハリンスク市内で朝 鮮語話者9 名(30 代~90 代の男女,慶尚道出身 5 名, 江原道出身 2 名, 慶尚道出身の夫を持つ 日本人女性 1 名, 韓国内の出身地域不明 1 名) を対象に面接式で①話者の言語生活に関する 調査,②語彙調査(翻訳式・なぞなぞ式)3(計 134 語)を行った.基礎資料として日本統治時代の 1910 年代から 1930 年代にかけて小倉(1944ab) が朝鮮半島全土で行った方言調査を用いた4. 本発表では音節核の変異を分析する.日本統 治下に作られた朝鮮語の標準語5では半母音(/j/ と/w/)を含む多重母音で発音されていた音節核 が,慶尚道方言等では半母音のない単独母音や その他の方言形で発音される傾向にあった.調 査語彙のうち音節核に変異が見られる単語延 べ35 語(/j/を含みうる単語 23 語,計 170 トー クン,/w/を含みうる単語 12 語,計 78 トークン) を対象として,合計248 トークンを分析する6. 4. 分析 4-1. 単語間のゆれ 図1 は 1910 年代から 1930 年代当時の「비녀(かんざし)」[pi-njɔ]の変異形の地理的分 布を示した方言地図である(福井 2018: 32 改編).在樺コリアンの出身地で最も多い慶尚 道を赤枠で示している.ここから移住当初は標準形[pi-njɔ]は中央部で僅かに確認される 少数派で,ソウル周辺では[pi-na],慶尚道では[pi-nɛ]等,朝鮮半島全域で半母音のない 単独母音が優勢であったことが分かる.以下,サハリンでの調査結果を考察する. 表1・2 は,半母音/j/を含みうる語における半母音/j/を含む多重母音と半母音/j/無しの 単独母音のトークン数と割合を語頭・語中別に示している.標準形である/j/を含む多重 である南部地域の方言が家庭では優勢であったのに対し,民族学校での教授言語は教員が北朝鮮出身であ っため北部地域の方言が用いられていたという. 3 調査語彙は,小倉(1944ab)の調査結果を元にした 2 つの方言地図(中井・亀山 2007; 福井 2017, 2018)を 活用し,①慶尚道の方言の音韻的特徴がみられること,②平壌の音韻的特徴がみられること,③日常生活 でよく使われる語彙,④在日コリアンコミュニティーで使われてきた語彙,という基準で選ばれた. 4 移住当初の方言調査を基礎資料としたのは,移住者の方言接触と変容を分析するためには移住当初の方 言との比較を行うことが重要だからである(松本 2016). 5 朝鮮語における標準語の制定は, 日本統治下である 1912 年の「普通学校用諺文綴字法」まで遡る(李翊 燮・李相億・蔡琬, 2004).当初はソウル方言を標準語とし韓国ではそれを継承したが,北朝鮮では後に平 壌方言を標準語として定めるとともに「文化語」と命名した (李翊燮・李相億・蔡琬 2004).しかし当時 作成された方言地図が以下で示すように,当時の標準語とされる変異形が必ずしもソウルで観察されるわ けではない点に留意されたい. 6 本発表では暫定的に,語彙を覚えていない場合はカウントせず,方言形と標準形の両者を発話した際は それぞれカウントした.また,半母音を含み得ない語形を回答したものは暫定的に「その他」としてカウ ントした.今後方針を固めていきたい. 図 1.「かんざし」の分布(福井 2018)
母音は語頭では90%以上,語中では約 5 割現れた.一方,/j/無しの単独母音は語中での み32.2%現れた.語頭では半母音を伴う多重母音が多く,語中では半母音無しの単独母 音も用いるという結果は,「慶尚道方言の半母音/j/は語頭でよく現れるが,子音・母音間 では現れにくい」という出現の制約(趙義成 2007)に合致するものである. 表1. 語頭に半母音/j/を含む多重母音と半母音/j/無しの単独母音のトークン数と割合 調査語彙 /j/を含む多重母音 /j/無し単独母音 その他 計 양념장 (ヤンニョムジャン) [jaŋ-njɔm-dʒaŋ] 10 (100.0%) 0 (0.0%) 0(0.0%) 10 (100%) 육교 (陸橋)[juk-ʔkjo] 1 (50.0%) 0 (0.0%) 1 (50.0%) 2 (100%) 여우 (狐) [jɔ-u] 8 (100.0%) 0 (0.0%) 0 (0.0%) 8 (100%) 여자친구 (彼女) [jɔ-dʒa-tʃhin-gu] 6 (85.7%) 0 (0.0%) 1 (14.3%) 7 (100%) 여학생 (女学生) [jɔ-hak-ʔsɛŋ] 6 (85.7%) 0 (0.0%) 1 (14.3%) 7 (100%) 예절 (礼節) [je-dʒɔl] 2 (100.0%) 0 (0.0%) 0 (0.0%) 2 (100%) 여름 (夏) [jɔ-rɯm] 7 (100.0%) 0 (0.0%) 0 (0.0%) 7 (100%) 양쪽 (両方) [jaŋ-ʔtʃok] 5 (83.3%) 0 (0.0%) 1 (16.7%) 6 (100%) 연애 (恋愛) [jɔ:-nɛ] 5 (83.3%) 0 (0.0%) 1 (16.7%) 6 (100%) 計 50 (90.9%) 0 (0.0%) 5 (9.1%) 55 (100%) 表2. 語中に半母音/j/を含む多重母音と半母音/j/無しの単独母音のトークン数と割合 調査語彙 /j/を含む多重母音 /j/無し単独母音 その他 計 양념장 (ヤンニョムジャン) [jaŋ-njɔm-dʒaŋ] 1 (10.0%) 9 (90.0%) 0 (0.0%) 10 (100%) 새벽 (朝焼け) [sɛ-bjɔk] 5 (71.4%) 2 (28.6%) 0 (0.0%) 7 (100%) 별 (星) [pjɔ:l] 5 (83.3%) 1 (16.7%) 0 (0.0%) 6 (100%) 혀 (舌) [hjɔ] 3 (42.9%) 1 (14.3%) 3 (42.9%) 7 (100%) 뼈 (骨) [ʔpjɔ] 1 (12.5%) 7 (87.5) 0 (0.0%) 8 (100%) 무명 (木綿) [mu-mjɔŋ] 0 (0.0%) 0 (0.0%) 5 (100.0%) 5 (100%) 비녀 (かんざし) [pi-njɔ] 1 (20.0%) 3 (60.0%) 1 (20.0%) 5 (100%) 병아리 (ひよこ) [pjɔŋ-a-ri] 5 (83.3%) 1 (16.7%) 0 (0.0%) 6 (100%) 벼 (稲) [pjɔ] 0 (0.0%) 1 (33.3%) 2 (66.7%) 3 (100%) 형 (兄) [hjɔŋ] 11 (91.7%) 0 (0.0%) 1 (8.3%) 12 (100%) 며느리 (嫁) [mjɔ-nɯ-ri] 4 (44.4%) 5 (55.6%) 0 (0.0%) 9 (100%) 변소 (便所) [pjɔn-so] 3 (20.0%) 5 (33.3%) 7 (46.7%) 15 (100%) 저녁 (夕) [tʃɔ-njɔk] 7 (87.5%) 1 (12.5%) 0 (0.0%) 8 (100%) 겨울 (冬) [kjɔ-ul] 5 (71.4%) 0 (0.0%) 2 (28.6%) 7 (100%) 병 (病気) [pjɔ:ŋ] 6 (85.7%) 1 (14.3%) 0 (0.0%) 7 (100%) 計 57 (49.6%) 37 (32.2%) 21 (18.3%) 115 (100%) 「かんざし」に関しては,移住当時の朝鮮半島全域・慶尚道で優勢であった[pi-nɛ]が 過半数(60%)を占める等,平準化・創始者効果を支持する結果となった.標準形[pi-njɔ] は20%のみで,仕事や親族訪問等で韓国を訪問する慶尚道出身の二世の話者によるもの であった.「傍層言語要素」として現代韓国語の標準形が話者のフィーチャープールに 加わっていることが伺える. 次に「便所」[pjɔn-so]に関しては,5 名の話者が昔は「변소」[pjɔn-so]または「벤소」 [pen-so]を使っていたが,今は「화장실(化粧室)」[hwa-dʒaŋ-ʃil]を用いると回答した.近 年,韓国との往来が盛んになり「傍層言語要素」として現代韓国語の標準形が在樺コリ アンに組み込まれている様子が伺える.さらに,昔は日本語で「便所」と呼んでいたと
答えた話者も 2 名おり,かつては日本語も 「外来言語要素」としてフィーチャープー ルに加わっていたことが判明した.「육교 (陸橋)」[juk-ʔkjo]に対する回答では「륙교」 [rjuk-ʔkjo]が 1 トークン存在した.語頭に/r/ が立つのは北朝鮮の標準語の発音である. この話者の祖父は江原道出身の一世で父は サハリンから中央アジアに移住し,極東経 由でサハリンに戻っている.話者は自らを ソ連系朝鮮人だと認識していた.これが「傍 層言語要素」として今後こうしたルーツを 持たない在樺コリアンへも広がるかどうか 注視したい. 一方,図2 は当時の「가위 (はさみ) 」[ka-wi] の変異形の地理的分布を示した方言地 図である(中井・亀山 2007 改編).ここから ソウル周辺で標準形[ka-wi]が散在するが, [ka-sɛ]が南北に広く分布し,慶尚道では[ka-ʃi -ge]が優勢であることが分かる. 表3. 語頭に半母音/w/を含む多重母音と半母音/w/無しの単独母音のトークン数と割合 調査語彙 /w/を含む多重母音 /w/無しの単独母音 その他 計 외할아버지 (外祖父) [we:-ha-ra-bɔ-dʒi] 5 (71.4%) 0 (0.0%) 2 (28.6%) 7 (100%) 외할머니 (外祖母) [we:-hal-mɔ-ni] 5 (71.4%) 0 (0.0%) 2(28.6%) 7 (100%) 외삼촌 (母方のおじ) [we:-sam-tʃhon] 6 (85.7%) 0 (0.0%) 1 (14.3%) 7 (100%) 왜놈 (倭奴) [wɛ-nom] 2 (50.0%) 1 (25.0%) 1 (25.0%) 4 (100%) 計 18 (72.0%) 1 (4.0%) 6 (24.0%) 25 (100%) 表4. 語中に半母音/w/を含む多重母音と半母音/w/無しの単独母音のトークン数と割合 調査語彙 /w/を含む多重母音 /w/無し単独母音 その他 計 바위 (岩) [pa-wi] 2 (25.0%) 1 (12.5%) 5 (62.5%) 8 (100%) 가위 (はさみ) [ka-wi] 2 (22.2%) 0 (0.0%) 7 (77.8%) 9 (100%) 화로 (火鉢) [hwa:-ro] 2 (100.0%) 0 (0.0%) 0 (0.0%) 2 (100%) 까마귀 (からす) [ʔka-ma-gwi] 6 (75.0%) 2 (25.0%) 0 (0.0%) 8 (100%) 잎사귀 (葉) [ip-ʔsa-gwi] 0 (0.0%) 1 (10.0%) 9 (90.0%) 10 (100%) 종업원 (従業員) [tʃo-ŋɔ-bwɔn] 1 (33.3%) 0 (0.0%) 2 (66.7%) 3 (100%) 귀 (耳) [kwi] 5 (62.5%) 3 (37.5%) 0 (0.0%) 8 (100%) 사마귀 (あざ・いぼ) [sa-ma-gwi] 2 (40.0%) 2 (40.0%) 1 (20.0%) 5 (100%) 計 20 (37.7%) 9 (17.0%) 24 (45.3%) 53 (100%) 表 3・4 は半母音/w/を含みうる語における半母音/w/を含む多重母音と半母音/w/無し の単独母音のトークン数と割合を語頭・語中別に示したものである.標準形の/w/を含む 多重母音は語頭で72%,語中では 37.7%と低い.一方,/w/無しの単独母音は語中でのみ 17%現れ,その他の語形が 45%も占めた./j/と同様に語頭では半母音/w/を含む多重母音 として現れ,語中では単独母音で現れる割合が高まる傾向が観察された. 図2「はさみ」の分布(中井・亀山 2007)
「はさみ」に関しては標準形[ka-wi]は少数派で,移住当時南北に広がっていた[ka- sɛ] や慶尚道の[ka-ʃi-ge]等の方言形(その他に分類)が優勢であった.また当時の方言地図に は存在しない[ka-ʃwe] [ka-ʃi-ri]という発音も見られた.慶尚道の[ka-ʃi-ge]と標準形[ka-wi], 両変異形から一部を取り込んだ「中間方言形」の可能性も考えられる.今後より詳しく 探っていきたい. 4.2. 話者間のゆれ 図3 は半母音の/j, w/を含 み得る単語の全トークンの 発音を話者毎に示したもの である.トークン数に違い はあるが,ほぼ全話者にお いて/j, w/を含む多重母音の 占める割合が高いという共 通性が見られた.ただし慶 尚道の方言においても語頭 では/j, w/を含む多重母音を用 いることから,単純に標準形へ収斂していると結論付けるのは尚早かもしれない.特に 90~60 代では多重母音の割合が半分以下であり,単独母音や「その他」は方言形で埋め 尽くされていた.このことから高齢層ほど方言形を保ち,世代が進むにつれて現代の韓 国語の影響が強まる傾向が示唆されたと言えるであろう. 5. 結論 本稿は20 世紀前半に朝鮮半島各地からもたらされた朝鮮語の諸方言が日本統治下の 樺太の地で接触した結果,方言混合によって「中間方言形」が誘発され,また在樺コリ アンの出身地として多数派を占める慶尚道方言をはじめ当時の朝鮮半島で優勢形であ った方言形が生き残るという「平準化」が高齢層の間で起きていた事例を提供した.一 方,韓ソ国交樹立によって往来が盛んになり,中年層は現代韓国語の標準語を取り入れ 「傍層言語要素」が拡大している状況を捉えることができた.日本語の影響は語彙レベ ルで観察されたが,高齢層に限られているため今後は消滅していくと思われる.戦後加 わった北朝鮮の変種や,サハリンの主要言語であるロシア語からの影響は今回の変異項 に限ってはあまり見られなかった.しかし調査中の雑談で北朝鮮の文化語の語彙 「동무(友人)」やロシア語の影響も散見されたため,今後も注視していきたい. 参考文献 (Selected References) 趙義成 (2007)「慶尚道方言とソウル方言」野間秀樹 (編著)『韓国語教育論講座』第 1 巻,くろしお出版 Fajst, V. & Matsumoto, K. (2020) Japanese and Korean loanwords in a Far East Russian variety: Human mobility and language contact in Sakhalin.. Asian and
African Languages and Linguistics 14: 155–195.
福井玲 編 (2017) (2018)「小倉進平『朝鮮語方言の研 究』所載資料による言語地図とその解釈―第1・2 集」, 東京大学人文社会系研究科 韓国朝鮮文化 研究室. 李翊燮 共編 (2004)『朝鮮語概説』,大修館書店. 松本和子 (2016)「社会言語学の研究動向と方言研究 との接点―接触日本語変種の研究を中心に―」『方 言の研究』2: 131-150. 松本和子・奥村晶子 (2019) 在日ブラジル人移民の コイネー形成―方言接触,創始者効果,フィーチ ャープールの検証―『社会言語科学』22(1):249–262. 中井精一・亀山大輔 編 (2007)『朝鮮半島言語地図』, 富山大学. 小倉進平(1944ab)『朝鮮語方言の研究』上下巻,岩 波書店. 図3. 多重母音と単独母音の話者別トークン数と割合
計量的分析における統語関係を反映させた変数及び行列設定の試み – ロマンシュ語の否定を例に –
清宮貴雅(東京外国語大学博士後期課程) 0. 序論
地図形態の語彙形態や音声の類似性に基づいた数値化を使用している計量方言学的 研究は,Goebl (1992),Yarimizu et al. (2004),Kawaguchi (2007, 2020),Nerbonne et al. (1999), Heeringa & Nerbonne (2001)など数多く存在する。これらの研究では,標 準語化のプロセスや 1 つの特定の参照地点からの言語差を分析していることが多く,数 値の和,即ち言語的距離の和の値をクラスタリング分析に使用する行列に使用している。 しかし,統語関係を考慮に入れた地図データの数値化はあまり行われていない。また, ある特定の参照地点を設けずに言語的距離の近い方言同士の分類を行う場合にも,数値 の和を使用する行列を使用することが妥当なのかに関しては疑念を抱く。 1. ロマンシュ語と否定文 ロマンシュ語はスイスのグラウビュンデン州で話されるロマンス語の 1 つである。ロ マンシュ語は同州の西から,スルシルヴァン,ストシルヴァン,スルミラン,ピュテー ル,ヴァラーデルの大きく 5 つの地域語に分かれている。東部のピュテールとヴァラー デルを合わせてラディン語(もしくはエンガディン方言),地理的な観点からストシル ヴァンとスルミランを合わせて中央ロマンシュ語と呼ぶ。さらに中央ロマンシュ語と最 西部のスルシルヴァンを合わせてレナン語と呼ぶこともある。 各地域語の文法書によれば,平叙文においては,西部のスルシルヴァンとストシルヴ
ァンでは*BICC-から派生した否定辞 buca/betg が定動詞に後続する形で,東部のヴァ
ラーデルとピュテールではラテン語nōnから派生した否定辞nuが定動詞に先行する形 で否定文を構成する。中部のスルミランでは両者の中間的とも言える,二つの異なる否 定辞na及びbetgで定動詞を挟み否定文を作成する。 2. 研究目的 本研究では,「地図形態の語源・音声・統語関係を反映させた数値化を用いる場合, 階層的クラスタリング分析においては,どのような変数及び行列を使用するべきか」を ロマンシュ語の否定文を例に考察する。具体的には,3 つの異なる変数及び行列パター ンから作成した 3 つのデンドログラムを分析する。なおロマンシュ語の否定に関する計 量方言学的な研究は行われておらず,この点においても本研究は新規性が高いといえる。 3. 研究対象 本研究では,ロマンシュ語圏が調査対象地域として扱われている言語地図 Sprach-
und Sachatlas Italiens und der Südschweiz(『イタリア・南スイス言語民族地図』,以下 AIS)を使用する。本研究の調査対象とするロマンシュ語圏の地点数は 19 地点である。 AIS の地図の中から,以下の 15 の否定文の地図を分析の対象とした1:52, 69, 355, 653, 1144, 1278, 1615CP, 1621a, 1621b, 1630, 1641, 1647, 1651, 1658, 1678。これらの 地図における第一形態のみを分析の対象としたため,最終的に全 285(19 地点×15 表 現)形態を分析の対象としている。 4. 数値化及び行列の作成手順
Yarimizu et al. (2004) ,Kawaguchi (2007, 2020),清宮 (投稿中) を基に,表 1 の様 な点数化の判断基準を設けた。数値は 0 から 10 であり,数値が大きければ大きいほど, 形態統語的な差が大きいことを示している。 表 1. 点数化の判断基準 値 判断基準 例 語源 音声 統語位置 地点 A 地点 B 0 ○ ○ ○ V + [buk] V + [buk] 1 ○ × ○ V + [buk] V + [bec] 2 ○ ○ × V + [buk] [buk] + V 3 ○ × × V + [buk] [bec] + V 4 △ △ × V + [bec] [n] + V + [bec] 5 △ × × V + [buk] [n] + V + [bec] 7 × × ○ [buk] + V [nu] + V 8 × × × V + [buk] [nu] + V
10 × × × che S + V + [buk] da + INF + [buk]
次に本研究で使用する 3 つの変数・行列のパターン(以下パターン 1,パターン 2, パターン 3)について説明する。 パターン 1 は,従来広く使用されてきた数値の和を変数とした行列である。従って値 が 0 に近ければ近いほど,2 地点間の言語的距離が近くなり,値が大きければ大きいほ ど,2 地点間の言語的距離は遠くなる。行列数は地点数×地点数で求めることができ, 今回は 19 地点を対象としているため,19×19 の行列となる。 図 2 は,クラスタリング分析時に使用するパターン 2 の変数・行列を簡略化した図で ある。パターン 2 では,数値化した値を編集することなく,そのままの形で使用する。 このパターンの行列数は,地点数×地点数×地図数で求めることができる。本研究では 1 地図 1621 のように,1 枚の地図に複数の異なる否定文が記載されている場合は,便宜的 に 1621a, 1621b として表記した。CP は地図の余白に補足として書かれている表現である。
15 の否定表現における 19 地点の形態を分析の対象としているため,19×285 の行列と なる。 図 1. パターン 2 の行列例 パターン 3 は,数値化の値(cf.表 1)をカテゴリーと考え,そのカテゴリーに分類さ れる形態の数を基に変数を算出,使用した行列である。このパターンの行列数は,地点 数×地点数×値の種類で求めることができる。本研究では,19 地点,9 種類の値を使用 するため,19×171 の行列となる。 図 2. パターン 3 の行列例 なお本研究では,距離測定方法としてウォード法を,距離は平方ユークリッド距離を 使用した。また素データではなく,行列内の数値を標準化した標準化データを用いてデ ンドログラムを作成した。 5. 分析 図 3 は,対象とした 15 の否 定文で見られた各地点の否定 辞の傾向をまとめたものであ る。西部~中部では*BICC-派 生の否定辞(▲▼△▽◇)が, 東部ではnōn から派生した否 定辞(□)が,中部では形態的 にその中間的な否定辞(○)が 使用されていた。この分布は, 各地域語の文法書の記述とあ る程度一致する。 図 3. 否定辞の分布
作成された 3 つのデンドログラムを A と B の 2 つに分けた場合,全てのデンドログ ラムで大クラスターA と B の構成要素(= 地点)は同じであった(cf.図 4)。大クラス ターA はラディン語の 6 地点と地点 27(否定辞としてnu(n)を使用)で,大クラスター B はそれ以外の地点(否定辞として*BICC-系及び複合否定を使用)で構成されている。 大クラスター単位では,3 つのデンドログラムを比較することができないため,各デン ドログラムを 3 つの中クラスター■,▲,●に分けて分析を行った。3 つのデンドログ ラムで,結合の順番こそ異なるものの,中クラスター■の構成要素は同じである。本研 究では以下の 2 つの観点からデンドログラムの分析を進める:①クラスター●と▲の構 成要素,②クラスター■の結合の順番。 図 4. 各パターンの行列で作成したデンドログラム クラスター▲は,3 つのデンドログラムでその構成要素が異なっている。パターン 1 ではクラスター▲は地点 25, 15, 17 で構成されている。一方で,パターン 2 と 3 では, クラスター▲は地点 25 だけである。地点 15 及び 17 は,他の 17 地点の形態に対して 値 10 となる形態が 1 つずつ含まれる。地点 25 では他の 18 地点に対して 5 となる形態 (na + V + betg)が 4 つ含まれている。パターン 1 は言語的差の和を変数としており, 最終的に得られた数値の大きさがこれら 3 地点で類似していたため,同じクラスターに 分類されたと考えられる。ただし,これら 3 地点は統語・形態・音声的に類似している わけではない。このことから,パターン 1 のデンドログラムは言語的特徴を反映しきれ ていない可能性があるということができる。 クラスター■は,3 つのデンドログラムで構成要素の結合の過程が異なっている。パ ターン 1 と 3 では,地点 7 と 28 が結合した後,地点 9,19,27 の順で(7 28)に 1 つず つ結合していく。一方パターン 2 では,地点 7 と 28 が結合しその後地点 9 が(7 28)に 結合する過程は同じだが,地点 19 と 27 が一度結合したあとに小クラスター(7 9 28)に 結合する。これら 5 地点の語形態を観察すると,地点 27 では基本的に否定辞nu(n)の 母音が円唇後舌狭母音[u]で実現されているのに対して,他の 4 地点では円唇後舌め広 めの狭母音[ʊ]で実現されている。すなわち地点 27 の語形態は,他の地点の語形態とは 多少ではあるが音声的に異なっていることがわかる。このことから,パターン 2 のデン ドログラムも言語的特徴を反映しきれていない可能性があるということができる。
6. 結論 3 つのデンドログラムの分析から,パターン 1 とパターン 2 の行列では,言語的事実 に合った分類ができていない可能性を指摘した。従って,パターン 3 の「数値化の値を カテゴリーと考え,そのカテゴリーに分類される形態の数を基に変数を算出,使用した 行列」が,言語的事実を総合的に反映したデンドログラムを作成していると結論付ける ことができる。しかし,地点数や変数の増減によってクラスタリング結果が左右される 可能性も大いに考えられる。そのため,AISの他の単語・表現の地図や,『フランス語言 語地図』における否定文の地図を用いて同様の分析を行い,本結論及び本研究で使用し た行列の妥当性についても検証していきたい。 主要参考文献
Goebl, H. (1992), “Problèmes et méthodes de la dialectométrie actuelle (avec application à l’AIS) ”. Euskaltzaindia/Académie de la langue basque (ed.): Nazioarteko dialektologia biltzarra. Agiriak/ Actes du Congrès international de dialectologie (Bilbo/Bilbao 1991). Bilbo/Bilbao: Euskaltzaindia, pp. 429-475.
Heeringa, W. & Nerbonne, J. (2001), “Dialect areas and dialect continua”. Language Variation and Change, 13(3), pp. 375-400.
Jaberg, K. & Jud, J. (1928). Der Sprachatlas als Forschungsinstrument : Kritische Grundlegung und Einführung in den Sprach- und sachatlas italiens und der Südschweiz. Halle.
—— (1960). Index zum sprach- und sachatlas italiens und der Südschweiz : Ein propädeutisches etymologisches Wörterbuch der italienischen mundarten. Bern: Stämpfli.
Jaberg, K., Jud, J. et al. (1928-1940). Sprach- und sachatlas italiens und der Südschweiz, Zofingen (Schweiz: Ringier & Co.). (http://www3.pd.istc.cnr.it/navigais-web/).
Kawaguchi, Y. (2007), “Is it possible to measure the distance between near languages ? A case study of French dialects”, in Langues proches – Langues collatérales, L’Harmattan, pp. 81-88. —— (2020). “Standardization and distance: A case study of the linguistic atlas of Champagne and Brie (ALCB)”, Bamberger Beiträge zur Englischen Sprachwissenschaft Bd.59, Peter Lang, pp. 269-276.
Nerbonne, J., Heeringa, W. & Kleiweg, P. (1999), “Edit distance and dialect proximity”. Time Warps, String Edits and Macromolecules: The Theory and Practice of Sequence Comparison, 15 pp. V-XVI.
Planta, R. et. al. (1939 -). Dicziunari rumantsch grischun, Cuera: Bischofberger.
Yarimizu, K. et al. (2004). “Multi Analysis in Dialectology – A Case study of the Standardization in the Environs of Paris”, Linguistic Informatics 3, Tokyo University of Foreign Studies, pp. 99-119.
清宮貴雅 (投稿中).「ロマンシュ語とフランコプロヴァンス語の類似性の計量方言学的分析」,『ロ マンス語研究』, 53 号.
Disappearing overcounting numeral systems in the Luzon-Taiwan area*
Izumi Ochiai (Hokkaido University)
According to Menninger (1969: 76), “overcounting” numeral systems count numbers usually starting from 11 using a numeral that indicates the next upper level of the multiples of tens (referred to as an overcounter in this paper), i.e., 20, in the case of a decimal system. Overcounting is contrasted with “undercounting,” which he refers to as the common counting method. For example, to count 16, the digit 6 is placed on the next lower level of the multiples of tens (referred to as undercounter in this paper), which is 10 (e.g., “6 and 10” or “6 and 1 10”). In overcounting numeral systems, 16 is expressed in a manner such as “6 going to the 2nd 10.”
Overcounting numeral systems are found throughout the world, seen in Germanic languages as well as the languages of their Uralic neighbors, in Mayan languages, and in Ainu (Menninger 1969: 69–70, 76–80). They are also seen in Old Turkish (Izui 1939), Tibeto-Burman languages (Mazaudon 2010), and Austronesian languages (Ochiai 2014).
In Austronesian-speaking areas, overcounting numeral systems have been observed in North-Central Vanuatu in languages such as Tutuba, Tamambo, Tangoa, Akei, and Big Nambas according to Ochiai (2014). For example, in Tutuba (Naito 2011: 152), 26 is expressed bas “20 30th 6” as seen in the example (1) below.1 This
expression specifies both levels of the multiples of tens to which the unit 6 is placed, that is, both the undercounter “20” and the overcounter “30” are expressed. In addition, the overcounter is expressed by the ordinal numeral, “30th.” As for word order, the undercounter comes first followed by the overcounter in the ordinal form (shown in bold face) and the digit. Naito (2011: 153) also says that the undercounter, 20, can be omitted, i.e., 30th 6, as seen in (2), because the numeral can be identified simply by specifying the overcounter. The structure of overcounting as seen in (1) is referred to as “the long form,” and that of (2) is referred to as “the short form.”
Tutuba (Vanuatu, Malayo-Polynesian, Oceanic)
(1) ngavul-erua ngavul-etol-na eono (2) ngavul-etol-na eono
ten-two ten-three-ORD six ten-three-ORD six
“20” “30th” “6” “30th” “6”
* The author delivered a talk titled ‘Overcounting in Austronesian’ at National Taitung University on June 11, 2019.
The audience included Amis, Puyuma, Paiwan and Yami people. They were surprised that their ancestors used overcounting numeral systems, which indicates that these systems have been forgotten.
1 Keys to the abbreviation are: CM (case marker); LNK (linker); ORD (ordinal).
Among the overcounting languages in North-Central Vanuatu, only Tutuba is reported to have the short form; in addition, only Tamambo is reported to have overcounting for numerals from 11 to 19, whereas other overcounting languages in this area use undercounting for 11 to 19 and start overcounting from 21 (Ochiai 2014: 274).2
This paper proposes that, in the Austronesian-speaking area, overcounting numeral systems are observed not only in North-Central Vanuatu, but also in areas stretching from the Northern Luzon to Southern Taiwan (Map 1). By investigating previous studies, the following languages in this area were found to have had, or to still have, overcounting numeral systems: Amis, Puyuma, Paiwan, Yami, Itbayat, Ivatan, Ilokano, Ibanag, Ibaloi, Pangasinan, Kapampangan, and Tagalog (Map 2). These languages belong to the Malayo-Polynesian subgroup of the Austronesian language family excepting Amis, Puyuma and Paiwan, which are collectively called Formosan languages.
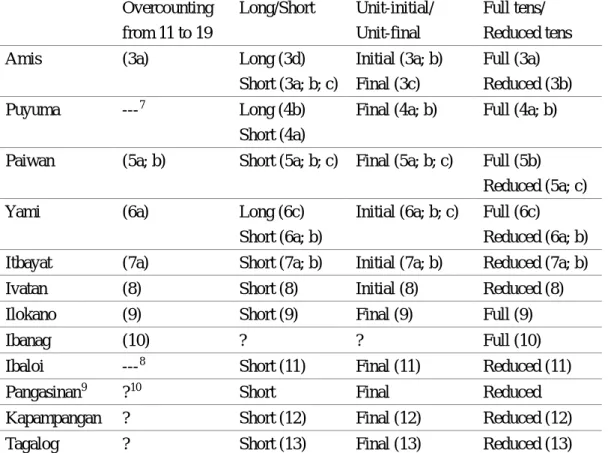
The data on the overcounting numeral system for each language are shown in examples from (3) to (13).3 In all cases, the overcounter appears in the ordinal form, similar to the Tutuba examples. However, there are structural variations among overcounting numeral systems in this area. First, the overcounting begins from 11 in some languages and from 21 in other languages. The structure can be long as in (1) or short as in (2). The unit included in the interval of tens (or the unit of tens in the interval of hundreds) either follows the overcounter as in the Tutuba examples (unit-final), or precedes the overcounter (unit-initial). The overcounter in ordinal from either appear in its full form, such as 20th and 30th, similar to the Tutuba examples, or in its reduced form such as 2nd and 3rd, which omit the expression for tens (or hundreds). These patterns are summarized in Table 1, which includes example numbers for corresponding cells.
(3) Amis (Taiwan, Formosan)
a. 11 cacay ko saka tosa a poloq (1 LNK ORD 2 LNK 10) “1 going to the 20th” b. 11 cacay ko saka tosa (1 LNK ORD 2) “1 going to the 2nd”
2 Ochiai (2014) uses the term “additive counting,” which is interpreted to mean “an undercounting numeral system”
in this paper. Also, it is possible that the other overcounting languages of North-Central Vanuatu may have had the short form alongside the long form but only the long form was recorded.
3 The sources for the overcounting numeral system in each example are as follows: (3a; c; d), (4a), (5a; c), and (6a;
b;c) are from Abe (1930); (3b) and (5b) are from Ogawa (1932); (4b) is from Ino (1907); (7a; b) is from Yamada (2002), (8) is from Reid (1966); (9), (10), (12) and (13) are from Ogawa (1944); and (11) is from Scheerer (1905). The source data cited from the previous studies has been orthographically modified by the author. In addition, the interlinear glosses have been added in parentheses by the author, followed by the literal translation of the numerical expressions. Map 2: Overcounting languages in the Luzon-Taiwan
c. 21 saka tolo to cacay (ORD 3 LNK 1) “1 going to the 3rd” d. 191 soqot siwa a poloq saka tosa safaw to cacay4
(100 9 LNK 10 ORD two add LIN one) “100, 90 going to the 2nd, add one” (4) Puyuma (Taiwan, Formosan) 5
a. 21 mika maka-telru-n ra sasaya (ORD 30 LNK 1) “1 going to the 30th”
b. 21 makaputa’an mika maka-tatelru-n ra sasaya (20 ORD 30 LNK 1) “20, 1 going to the 30th”
(5) Paiwan (Taiwan, Formosan)
a. 11 pus’ia dusa no ita (ORD 2 LIN 1) “1 going to the 2nd”
b. 11 pus’ia dusa puruq no ita (ORD 2 ten LIN 1) “1 going to the 20th” c. 21 pus’ia curu no ita (ORD 3 LIN 1) “1 going to the 3rd”
(6) Yami (Taiwan, Malayo-Polynesian)
a. 11 asa ika duwa (1 ORD 2) “1 going to the 2nd”
b. 21 asa ika tilu (1 ORD 3) “1 going to the 3rd”
c. 58 lima ngalanan yakano wau ya sika anem ngalanan (5 10 LIN 8 LIN ORD 6 10) “50, 8 going to the 60th”
(7) Itbayat (Batan, Malayo-Polynesian)
a. 11 a’sas cha rwa (1 ORD 2) “1 going to the 2nd” b. 21 a’sas cha tlo (1 ORD 3) “1 going to the 3rd” (8) Ivatan (Batan, Malayo-Polynesian)
11 qo qasas cha roa (CM 1 ORD 2) “1 going to the 2nd”
(9) Ilokano (Batan, Malayo-Polynesian)
11 kan ika dua pollot maisa (? ORD 2 10 one) “1 going to the 20th” (10) Ibanag (Luzon, Malayo-Polynesian)
Overcounter from 11 to 19: min ica rua fulu (? ORD 2 10) “(a unit from) the 20th” (11) Ibaloi (Luzon, Malayo-Polynesian)6
31 ka-appat ne saxei (ORD-4 LNK one) “1 going to the 4th” (12) Kapampangan (Luzon, Malayo-Polynesian)
21 meka tolo ng metung (ORD 3 LNK 1) “1 going to the 3rd”
(13) Tagalog (Luzon, Malayo-Polynesian)
21 maika tlo ng isa (ord 3 lnk 1) “1 going to the 3rd”
This overcounting numeral system shows no special pattern depending on the subgrouping. The numerals 11 to 19 do not rely on overcounting in either Formosan (Puyuma) or Polynesian (Ibaloi). The long form is seen in Formosan (Amis, and Puyuma) and
Malayo-4 In this expression, the overcounter 2nd refers to 200, which is a multiple of hundreds. The unit 1 is not expressed by
overcounting but by undercounting, i.e., it is additive.
5 In Puyuma, tens are derived by the circumfixation of maka-…-n to the unit (in this case telru “three”), according to
Zeitoun, Teng and Ferrell (2010: 868).
6 For Ibanag, Ogawa (1944: 465) gave only the expression for the overcounter. He did not mention whether a unit
Polynesian (Yami), and vice versa for the short form. The unit-initial is seen in both Formosan (Amis) and Malayo-Polynesian (Yami, Itbayat, and Ivatan), and vice versa for the unit-final. For the overcounter, the ordinal form of tens in its non-reduced form (e.g., 20th, 30th), are seen in Formosan (Amis, Paiwan, and Puyuma) and Malayo-Polynesian (Yami, Ilokano, and Ibanag), and vice versa for the reduced tens.
Table 1: Austronesian languages with overcounting numeral systems in the Luzon-Taiwan area Overcounting from 11 to 19 Long/Short Unit-initial/ Unit-final Full tens/ Reduced tens
Amis (3a) Long (3d)
Short (3a; b; c) Initial (3a; b) Final (3c) Full (3a) Reduced (3b) Puyuma ---7 Long (4b) Short (4a)
Final (4a; b) Full (4a; b)
Paiwan (5a; b) Short (5a; b; c) Final (5a; b; c) Full (5b) Reduced (5a; c)
Yami (6a) Long (6c)
Short (6a; b)
Initial (6a; b; c) Full (6c) Reduced (6a; b) Itbayat (7a) Short (7a; b) Initial (7a; b) Reduced (7a; b)
Ivatan (8) Short (8) Initial (8) Reduced (8)
Ilokano (9) Short (9) Final (9) Full (9)
Ibanag (10) ? ? Full (10)
Ibaloi ---8 Short (11) Final (11) Reduced (11)
Pangasinan9 ?10 Short Final Reduced
Kapampangan ? Short (12) Final (12) Reduced (12)
Tagalog ? Short (13) Final (13) Reduced (13)
A feature common to these languages with overcounting numeral systems is that they have the full set of numerals from 1 to 10, i.e., perfect decimals, and that this set in most cases reflects the Proto-Austronesian numerals from 1 to 10: *əsa,*duSa, *təlu, *Səpat, *lima, *ənəm, *pitu, *walu, *Siwa, and *(sa-)puluq (Blust 2013: 278). Ochiai (2020) modified this Proto-Austronesian numeral set saying that it had numerals up to *Səpat “4” and that the others are later innovations. Time of the innovated numeral set from 1 to 10 described above can be referred to as post-Proto-Austronesian. Intriguingly, among more than twenty Formosan languages, only Amis, Puyuma and Paiwan have a “10” that reflects the post-Proto-Austronesian *puluq (Amis poloq; Puyuma
7 In Puyuma, numerals from 11 to 19 are expressed by undercounting numeral system, e.g., moktop misama-ra rua
(Ino 1907: 367), which is glossed by Ino as “10 surplus 2.”
8 In Ibaloi, numerals from 11 to 19 seem to be expressed by an undercounting numeral system, i.e., sawal ne saxei “11”
(Scheerer 1905: 155), which is likely analyzed as “10 plus 1.”
9 For Pangasinan, Ogawa (1944: 465) gave no examples of overcounting, but he simply mentioned that Pangasinan
also has an overcounting numeral system and that its structure is almost the same as that of Kapampangan. Therefore, the analysis of Kamampangan in Table 1 adopted that of Pangasinan.
10 Ogawa (1944: 465) gave no examples for the numeral system from 11 to 19 in Pangasinan, Kapampangan or Tagalog.
However, according to other sources, it seems to be not overcounting but undercounting. Blake (1925: 22) has labi-ng
isa (more-LNK 1) “11” for Tagalog. Similar expressions are seen in labi-n sakey “11” (Benton 1971: 221) in Pangasinan, and labi-ng metung “11” (Hiroaki Kitano, p.c.) in Kapampangan.
pulru; Paiwan puruq).11 These three languages are spoken in southern Taiwan, mostly in the coastal areas rather than in the high mountains, which could have facilitated these people’s sea-faring traffic to and from the Bashi Channel. Overcounting numeral systems and the innovation of *puluq common to southern Taiwan and northern Luzon may suggest a new way of subgrouping these languages, although the possibility of the overcounting numeral systems having been borrowed cannot be ruled out.12
Overcounting numeral systems in the Luzon-Taiwan area have been disappearing, as they have been replaced by undercounting numeral systems or loanword numerals. For instance, Ogawa (1944) notes that overcounting numeral system that had existed in Tagalog has been lost. Paiwan also seems to have lost the overcounting since Ogawa (1932), because “11” is expressed by undercounting, ta-puluq saka ita (1-10 plus 1), in Ferrell (1980: 41) as opposed to (5a; b).13 For Ivatan, Reid (1966: 106) comments that “Younger Ivatan speakers rarely use this [overcounting] construction. Instead they use Spanish numerals.”
References
Abe, Akiyoshi (1930) Bango Kenkyu. Taihoku: Bango Kenkyu Kai.
Benton, Richard K. (1971) Pangasinan Dictionary. Honolulu, University of Hawaii Press.
Blake, Frank R. (1925) A grammar of the Tagalog language, the chief native idiom of the Philippine islands. New Haven: American Oriental Society.
Blust, Robert. 2013. The Austronesian languages. Canberra: Australian National University, Research School of Pacific and Asian Studies.
Constantino, Ernesto (1971) Ilokano dictionary. Honolulu, University of Hawaii Press.
Dita, Shirley (2010) A reference grammar of Ibanag: phonology, morphology and syntax. Saarbrücken: Lambert Academic.
Ferrell, Raleigh (1982) Paiwan Dictionary. Canberra: Department of Linguistics, Research School of Pacific Studies, The Australian National University.
Ino, Kanori (1907) Taiwan doban no kazu no kannen no.5, puyumazoku. The Journal of the Anthropological Society
of Tokyo 255: 374–378.
Izui, Hisanosuke (1939) Tokketsugo niokeru susi no sosiki nitsuite, Journal of the Linguistic Society of Japan 1: 54– 59.
Mazaudon, Martine (2010) Number-Building in Tibeto-Burman Languages. In Stephen Morey and Mark Post (eds.)
North East Indian Linguistics, Vol. 2, 117–148. New Delhi: Cambridge University Press India.
Ochiai, Izumi (2014) Overcounting in North-Central Vanuatu languages and its distribution, Kyoto University
Linguistic Research 33: 229–252.
Ochiai, Izumi (2020) Proto-Austronesian *lima revisited: From archaic “hand” in Atayalic languages. Language and Linguistics in Oceania 12: 1–18.
Ogawa, Naoyoshi (1932) Taiwan bango no susiyoho no nirei, In: Kanazawa hakase kanreki shukugakai (eds.)
Tokyogogaku no kenkyu: Kanazawa hakase kanreki kinen, 573–579. Tokyo: Sanseido.
Ogawa, Naoyoshi (1944) Indoneshiago ni okeru taiwan takasagogo no ichi. In: Hirano Yoshitaro ed. Taiheiyô Vol.1, 451–502. Tokyo: Kawade Shobo.
Reid, Lawrence A. (1966) An Ivatan syntax. University of Hawaii: Pacific and Asian Linguistics Institute. Scheerer, Otto (1905) The Nabaloi Dialect. Manila: Bureau of Public Printing.
Menninger, Karl (1969) Number words and number symbols: a cultural history of numbers [translated by Paul Broneer from the revised German edition] Cambridge, Mass.: MIT Press.
Naito, Maho (2011) The Tutuba Language: A Descriptive Study. Kyoto: Kyoto University Press. [In Japanese] Yamada, Yukihiro (2002) Itbayat-English dictionary. Osaka: Faculty of Informatics, Osaka Gakuin University. Zeitoun, Elizabeth, Stacy, Fang-ching Teng, Raleigh Ferrell (2010) Reconstruction of ‘2’ in PAN and related issues.
Language and Linguistics 11(4): 853–884.
11 These forms are from (Ogawa 1944). Rukai has the similar form polroko; however, Zeitoun et al. (2010: 864 –865)
say that this could be a loan from because it does not reflect the proto-form *puluq.
12 Amis, Puyuma, and Paiwan peoples could be Malayo-Polynesian outliers who travelled to Taiwan.
13 Similarly, 11 in Ilokano, sanga pulo ket maysa (1 10 LNK? 1), in Constantino (1971: 332) is no longer overcounting
as opposed to (9), and 11 in Ibanag, kara tadday (LNK? one), seem in Dita (2010: 239) is no longer overcounting as opposed to (10).
Mapping the Case Systems among Kuki-Chin-Naga Languages in Northeast India
MURAKAMI Takenori (Kyoto University)
Kuki-Chin-Naga is a possible suggested-branch within Tibeto-Burman languages and it is considered as a combination of Central and Southern Naga clusters plus Kuki-Chin languages together with the disputed affiliation of Manipuri (Meiteilon), all of which are spoken in Northeast India and its bordering regions in Myanmar. Naga languages are conventionally divided along the geographical scheme into Northern, Central, Southern but Northern Naga languages are thought to belong to Brahmaputran or Sal branch with Bodo-Garo and Jingpho-Luish and distant from Kuki-Chin-Naga. Central is actually a conglomerate of Aoic with Angami-Pochury, Southern being Tangkhulic with ‘Zemeic’ or more precisely, better to be called Zeliangrongic or Zeliangrong-Maram-Thangal. Kuki-Chin-Naga languages share a lot of vocabulary with a few easily-recognizable sound correspondences and grammatical features but has clear and distinct geographical distribution of different case marking patterns within.
Central and Southern Naga languages and Manipuri generally have composite of 2 other case markers for ablative, one of which being mostly instrumental, and non-obligatory agent marking by instrumental case marker, which closely resembles to ergative constructions employing instrumental form in other Tibeto-Burman languages but hardly triggered by any specific grammatical or syntactical condition and even behave like just topic marker. In contrast, Kuki-Chin languages tend to have separate ablative marker derived from verb unrelated to other case markers and obligatory ergative marking with instrumental in transitive sentences, with the exception of supposed ‘Northwestern’ or ‘Old Kuki’ group, some of which being located in Naga contact zone (shown as mixed area in [Fig. 1]) and some tribes call themselves Naga in the category of ethnic nomenclature, and show similar behavior with Central and Southern Naga clusters in case marking systems although the vocabulary and other grammatical features are obviously close to Kuki-Chin. Another important device for sorting these languages is overt and frequent genitive marking in the languages of Northern Manipur and Southern Nagaland which might well be considered as areal feature and separate themselves from Aoic of Central Naga and Kuki-Chin, which basically prefer zero for genitive.
[Fig. 1]vertical line : composite ablative and non-obligatory agent marking with instrumental, horizontal line : ablative derived from verb and obligatory agent marking with instrumental in transitive sentences
(https://www.researchgate.net/profile/Surendra_Prajapati/publication/23658415, taken and modified by the presenter)
This presentation explores into the geolinguistic arrangement of Kuki-Chin-Naga languages in the viewpoint of case marking systems and discuss the viable subgrouping proposals within this branch.