将棋プログラムにおける
プランニングと評価
平成
16 年度 卒業論文
山形大学工学部情報科学科
グリムベルゲン研究室
学生番号 01515094
氏名 森 健太郎
概要
コンピューターゲームには探索が必要不可欠である.しかし,その探索には 水平線問題が付きまとう.そこで,水平線の向こう側を見越した探索をすべく, 人間の考え方に近いプランニングを探索に適用した.その結果,将棋のプログ ラムにおいて序盤の守りである囲いを組むことができた.これにより,水平線 の向こうを見越した探索が可能となった.目次
1 序論 ... - 1 - 1.1 人工知能の歴史 ... -1- 1.2 ゲームの歴史 ... -3- 1.3 ゲームプログラミング ... -5- 1.4 本研究の目的 ... -6- 2 研究の背景 ... - 8 - 2.1 探索... -8- 2.1.1 ゲーム木 ... - 8 - 2.1.2 局面の評価 ... - 9 - 2.1.3 Minimax 探索 ... - 10 - 2.2 探索の問題点 ... -16- 2.3 将棋とプランニング ... -17- 2.3.1 プランニング ... - 17 - 2.3.2 水平線問題解決へのアプローチ ... - 17 - 3 研究内容 ... - 19 - 3.1 探索とプランニング ... -19- 3.2 定跡とプラン ... -21- 3.2.1 矢倉囲い ... - 21 - 3.2.2 矢倉囲いのプラン... - 22 - 3.3 プランのボーナス値 ... -23- 3.4 前提条件 ... -25- 4 実験結果と考察 ... - 26 - 4.1 ボーナス値の偏り ... -26- 4.2 実際に指した手 ... -28- 4.2.1 矢倉囲いのプランと指し手 ... - 28 - 4.2.2 船囲いのプランと指し手 ... - 30 - 4.2.3 居飛車穴熊のプランと実際の指し手 ... - 31 - 4.2.4 左美濃のプランと実際の指し手 ... - 32 - 4.3 プラン全体の考察 ... -33- 5 まとめと今後の課題 ... - 34 - 参考文献 ... 35-1 序論
本研究は人工知能の一分野であるゲームプログラミングについての研究であ る.では,そもそも人工知能とは一体何なのか.人工知能の定義は,広い意味 では“コンピュータシステム等に知的な活動をさせることを総称して人工知能” であり,もう少し狭い意味で取ると“知識や推論等を用いて行う処理”となる. 本研究の説明の前に,人工知能の歴史を振り返って人工知能とはどういうも のなのかを説明したいと思う.1.1 人工知能の歴史
AI の研究はコンピュータの出現とほぼ同時期に開始された.1950 年代初頭の 研究者が注目したのはゲームプログラミング,具体的には西洋での主要なゲー ムであるチェスプログラムの開発であった. 1956 年夏,アメリカニューハンプシャー州ダートマス大学で後にダートマス 会議と呼ばれる会議があった.この会議で初めてAI という言葉が世に現れた. AI 研究の初期,すなわち 1970 年代までの主要なテーマは,ゲーム・パズル のプログラミング,プランニング,定理証明が挙げられる.この頃は「人間は ある一般的な能力を持っており,これにより人間の知的な行動が引き起こされ る」と考えられていた.そして「コンピュータを知的にするには,状況に応じ て動作する判断能力を与える必要がある」とし,「この能力は問題に依らない一 般的なものである」という意識があった.したがってこの一般的能力こそが知 能とされていた.しかし,この時代に対象としたのは比較的単純化された世界 における問題であり,現実の諸問題に適用できるかどうかの見通しは立っていなかった. 1969 年,J.McCarthy と P.J.Hayes が人工知能にとって最大の問題である「フ レーム問題」を指摘した.これは今からしようとしていることに関係のあるこ とがらだけを選び出すことが,実は非常に難しいという問題である.例えばロ ボットに輪投げをさせようとする.そうすると投げる輪の初速度や投擲角度, 輪の回転数などを考えなければならないが,さらに輪投げをする場所が屋外な ら,風の影響や気温,湿度までも考慮しなければならないかもしれない.人工 知能は輪投げをする以前に,様々な条件の内どれが関係のある条件なのかを調 べるために無限の計算が必要になって止まってしまうのである.しかもこの問 題は,人間は普通遭遇しない(人間は考えなくてよいことは考えない為)のだ が,解決できない問題でもある. 1977 年,E.A.Feigenbaum は講演を行い,「知識工学」なる新しい研究分野 を生み出した.注目すべき点は,知識工学が問題個別の知識の重要性を示した ことである.1970 年頃までの AI 研究では,問題に依存しない一般的能力(知能) を追求していたが,結果的には現実問題に対応できる成果は得られなかった. そこで問題の固有の知識を集め,それを基にした有用なシステム作りを知識工 学は強調したのである.E.A.Feigenbaum の提言を機に,エキスパートシステ ムに代表される知識ベースシステムがAI 研究の大きな柱となってくる. 70 年代後半から知識表現への積極的な取り組みが始められ,知識の表現,利 用,獲得など,いわゆる知識情報処理が注目されてきた.さらにこれらの研究 成果と相まって,画像認識,自然言語処理,音声認識,エキスパートシステム などの応用分野でも大きな前進が記された. 80 年代に入ると全世界的に AI 研究が活発化した.この傾向は大学などの研 究機関のみならず産業界にも広がり,社会をも巻き込むブームとなった.
しかし90 年代半ばに入るとそれまでの AI ブームが下火を迎えた.期待され たエキスパートシステムは部分的には成功を収めたものの,やはり様々な状況 に対する適応性は低く,結局,知的システムと言っても,頭の硬い,融通の利 かない「知的さ」でしかなかった. いま,AI 研究は転換期を迎えている.現実世界の動的環境に存在するエージ ェントを想定して,知能そのものを問い直そうという動きがそれである. このように,様々な分野で新しい概念やアイデアを取り入れながらAI 研究は 今もその活躍の場を広げている[1].
1.2 ゲームの歴史
本研究に関連するゲームプログラミングの歴史について同様に見ていく.ゲ ームプログラミングの歴史はチェスプログラムの歴史と言っても過言ではない. なぜなら,西洋ではチェスは人類の英知の象徴とされ,強いチェスプログラム を開発することは,すなわち知的な振る舞いをするコンピュータの開発と考え られたからである. 機械によるゲームプレイングはプログラム可能なコンピュータが開発される よりずっと古くから研究されていた.1769 年には W.von Kempelen が Turk と いうチェスプレイング自動機械を展示した[2].これは実際には機械によるもの ではなく,中に小柄な人間のチェスプレイヤーが隠れてプレイしていたもので, この頃から人々は機械にチェスをさせることを望んでいたことがわかる. 1846 年に C.Babbage が機械によるゲームプレイング実現の可能性について のまじめな議論を初めて行った.最初の動くゲームプレイング機械は1890 年頃 スペインの技術者 L.T.Quevedo によって作られた.“KRK”というチェスの終械で,機械がキングとルークの側,人間がキングだけの側として戦う.この機 械のプレイは正確で,いかなる局面からスタートしても(機械が先手を持てば) 人間のキングを詰むことができた.しかしこのチェスの終盤の適切な戦略は十 分に単純で,人間にも記憶してアルゴリズム的に実行できるものだった. 1946 年に最初のプログラム可能なコンピュータが開発されて以来,コンピュ ータチェスの様々なアイデアが考えられ,研究された.C.E.Shannon が 1950 年に,現代のゲームプレイングプログラムの基本となる原理を示した論文を発 表し,翌年の 1951 年,A.Turing がチェスの一局を完全にプレイする始めての プログラムを書いた.しかしこのプログラムはコンピュータ上では一度も動か されずに終わった.一局を通してはプレイできなかったものの,D.G.Prinz は詰 めチェスを解くプログラムを書いて実際にコンピュータ上で走らせた.初めて 一局を通してプレイできるチェスプログラムが書かれたのは,1958 年, A.Bernstein によってだった. H.Simon は 1958 年に「10 年以内にコンピュータのプログラムが世界チャン ピオンに勝つ」と予測したが,1967 年の MacHack6 は人間とまともにプレイで きる程度の実力だった.結局,チェスプログラムが世界チャンピオンに勝った のは,1997 年,IBM 社の Deep Blue だった[3].こうして C.E.Shannon がゲー ムプログラミングの基本原理を発表してから約半世紀後,人間よりも強いコン ピュータチェスプログラム開発は区切りがついたと言えよう.今後はさらにチ ェスよりも選択肢が多く,複雑とされる将棋や囲碁といった新たなゲームに研 究の場を移している. また,チェス以外のゲームでは,バックギャモンにおいて G.Tesauro によっ て作られたTD-GAMMON が 1998 年に当時の世界チャンピオン M.Davis と対 戦し,僅差で敗れはしたが,世界でもトップクラスの実力を認められている.
この TD-GAMMON は新たな機械学習法を備えており,ゲームプログラミング においてのみならず機械学習の分野においても成功例として挙げられる. このように,人工知能のゲームプログラミング以外の分野の技術を用いて結 果として成功を収めるといった例がある.
1.3 ゲームプログラミング
強いゲームプログラムの実現は,上記の様に人工知能の誕生以前から盛んに 研究され続けている.それは,ゲームプログラミングの特徴として,ルールが 明確である(フレーム問題が起きない),勝ち負けがはっきりつくなど,研究の 題材として扱いやすい点が挙げられる.これらは他の人工知能の研究分野には 見られない特徴である.よって,TD-GAMMON における機械学習のように, 他分野で研究された技術を試験的に実装するのに適している. ここで将棋というゲームについて説明したいと思う.将棋は二人零和有限確 定完全情報ゲームと呼ばれるゲームである.「零和」とは二人の得点の合計が 0 になる,つまり相手にとっての損がそのまま自分にとっての得になるという特 徴を示す.「有限」とは,いつかは必ず終わることを示し,「確定」とは偶然の 要素に左右されないことを示す[4].「完全情報」は相手に自分の手を隠さないこ とを示す. これに分類されるゲームの特徴は,理論上は完全な先読みが可能であり,双 方のプレーヤーが最善手を打てば,必ず先手必勝か後手必勝か引き分けかが決 まるという点である.実際には完全な先読みを人間が行う事は困難であるため, ゲームとして成立する. そこでゲームプログラミングではこの種類のゲームを解く手段として探索とを用いることのできない,あるいは用いないときに, 実際に試行錯誤すること によって解を得ようとする行動のことである.具体的にはある局面から可能な 全ての手を考え,その手を指した局面からまた一手というように,全ての可能 な手と局面を考えることを言う. この手法では,将棋と同じ種類のゲームである三目並べならまだしも,チェ スや将棋などの終局までの手数が多いゲームでは,先読みする手数が増えれば 予想される局面の数が指数関数的に増えていくため,初期局面から終局まで読 みきることは事実上不可能である. そこで探索は深さ,または時間によって打ち切られる.前者は何手先まで読 んだら(終局まで読みきっていなくても)そこで終了し,後者は決められた時 間を経過したらそこで終了する方法である.しかしこれは終局まで読みきって いないため,あいまいさが生じる.このあいまいさの為に,勝利という目標に とって合理的でない手を打つことになる. では人間のプロの棋士はどうであろうか.探索の深さで言えばコンピュータ の方が短い時間で深く読むことができる.実際に,終局まで読む詰め将棋では プロ棋士でも読みきれないような問題も解くことができる.しかしプロ棋士は 順を追って先読みするのではなく,数手もしくは数十手先の局面を想定し,そ の局面に近づくように手を指していく.これは人工知能におけるプランニング という手法に良く似ている.
1.4 本研究の目的
プランニングとは与えた目標を達成するために必要な行動の系列を生成する ものであり,上記のように将棋のプロ棋士の考え方に近い手法であると考えら れる.本研究の目的は,これを用いて探索によって生じるあいまいさを抑える2 研究の背景
1 章ではゲームプログラミングの抱える問題点と本研究の目的を述べたが,2 章では問題となる探索や評価の方法,そしてその解決策として考えられ,本研 究の目的でもあるプランニングについて説明する.2.1 探索
探索とは,何か問題を解くにあたって,有効な解析的な解法を用いることが できない場合,試行を繰り返すことで解を得る行動のことを言う.まず解くべ き問題を状態と状態変化に分ける.将棋ならば,盤面の駒の配置と指し手の持 ち駒が状態であり,交互に駒を動かすことが状態変化に当たる.最初に与えら れる状態を初期状態といい,目的とする状態は最終状態と呼ばれる.初期状態 から最終状態に至る,状態及び状態変化の並びが解となる. 2.1.1 ゲーム木 一般的に,探索を行う場合,局面や駒の動きを表現する為にゲーム木を用い る.ゲーム木とは,現在の局面から派生する局面の展開を木の形で表したもの である.ゲーム木において,一つ一つの展開される局面をノード(節点)と呼び, そこから派生する駒の動きを枝と呼ぶ.ゲーム木の頂点のノードを根と呼ぶ. あるノードから派生したノードを子と呼び,元のノードを親と呼ぶ.それ以上 派生していないノード,つまり子を持たないノードを葉と呼ぶ.終局となるノ ードでは,【図2.1】の様に勝ち,負け,引き分けを決めることができる.図2.1:ゲーム木の例 このゲーム木を用いて探索を行う場合,木構造を全て表すことができれば全 ての局面を展開できたことになり,ゲームの勝ち負けがはっきりとわかる.し かし実際にはごく単純なゲームを除いてはノードの数や,探索にかかる時間も 膨大になる為,不可能である.その為,実際のゲームでは探索に制限時間を設 け,制限時間内で探索できる最大の深さまで探索した後,局面の形勢を判断す る評価関数を用いて最大の深さのノードを評価する方法が用いられる. 2.1.2 局面の評価 ここで,ゲームプログラミングにおいて探索と並び重要とされる評価関数に ついて説明する.評価関数とは,ある局面の有利さを数値として表すものであ る.なぜこの評価関数が必要不可欠かと言えば,【図 2.1】のように終局までゲ 葉 葉 葉 葉 葉 葉 葉 葉 葉 根 終局 勝ち 引分け 勝ち 引分け 勝ち 負け 負け 勝ち 引分け
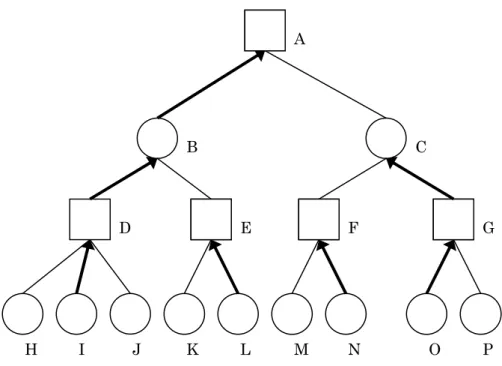
ーム木が展開でき,勝敗が明確になる場合は探索によって解が得られる.しか し実際には,与えられた時間内に初期局面から終局まで読みきることは(三目 並べのような簡単なゲームを除いて)不可能であるため,途中で打ち切る必要 がある.ここで,その局面が自分にとってどのくらい有利か,どれだけ勝利に 近いかを判断する為に評価関数が必要になるのである. 例えば将棋では,駒それぞれの価値や,駒の位置,王将の危険度などを判断 し,それを数値化することでコンピュータはその局面が自分側にとって有利か どうかを判断する. 2.1.3 Minimax 探索 Minimax 法というのは,自分側は自分の利益が最大になるように行動し,相 手側は自分側の利益が最小になるように行動する,という仮定の下で探索を行 う手法である. この場合,相手は完璧なプレイヤーであると仮定している.このような仮定 の下で自分の手を選択すれば,もし相手がこちらの利益を最小にするような手 を打ってこなかった場合,つまりこちらの読みが外れた場合,予想よりも得を することになる. Minimax 法の 3 手探索の例を【図 2.2】に示す.
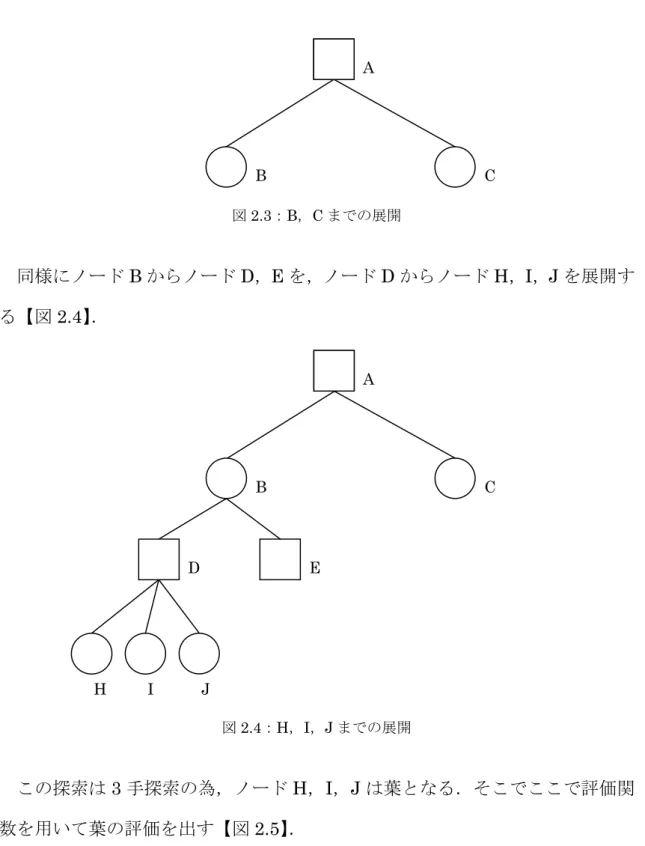
図2.2:Minimax 法の 3 手探索の例 Minimax 法の手順を書くと次のようになる. ①葉(一番下のノード)の評価値を評価関数によって求める. ②子の評価値が全て定まっているようなノードにおいて ・ 自分の番であれば子の中から最大のものを選び,ノードの評価値とする. ・ 相手の番であれば子の中から最小のものを選び,ノードの評価値とする. ③根のスコアが求まるまで②のステップを繰り返す. 【図2.2】で探索する順を説明する.まず,初期局面であるノード A からノー ドB,C を展開する【図 2.3】. 0 2 6 4 9 8 5 7 3 7 2 7 9 6 2 7 A B C D E F G H I J K L M N O P
図2.3:B,C までの展開 同様にノードB からノード D,E を,ノード D からノード H,I,J を展開す る【図2.4】. 図2.4:H,I,J までの展開 この探索は3 手探索の為,ノード H,I,J は葉となる.そこでここで評価関 数を用いて葉の評価を出す【図2.5】. A B C A B C D E H I J
ノードD は自分の手番なのでノード H,I,J の内,最も高い評価値を選ぶの で,ノードD の評価値は 7 となる【図 2.6】. 5 7 3 A B C D E H I J 図2.5:葉の評価 5 7 3 7 A B C D E H I J 図2.6: ノード D の評価値の決定
ノードE でも同様にすると【図 2.7】のようになる. 図2.7:ノード E の評価値の決定 ノードB は相手番なので評価値は最小のものを選ぶ.ここではノード D の 7 を選ぶ【図2.8】. 9 8 5 7 3 7 9 A B C D E H I J K L 9 8 5 7 3 7 7 9 A B C D E H I J K L 図2.8:ノード B の評価値の決定
ノードC から展開されるノードでも同様にすると【図 2.9】の様になる. 図2.9: ノード C の評価値の決定 最後にノード A に高い方(このときはノード B)の評価値を選び,3 手探索 終了となる【図2.10】. 図2.10: 3 手探索終了 0 2 6 4 9 8 5 7 3 7 2 7 9 6 2 A B C D E F G H I J K L M N O P 0 2 6 4 9 8 5 7 3 7 2 自分の番 相手の番 自分の番 7 9 6 2 7 A B C D E F G H I J K L M N O P
2.2 探索の問題点
様々な探索法や探索の効率を上げる方法は存在するが,そのどれもがやはり 開始から終局まで読みきることはできない.そこで探索を途中で打ち切る必要 があり,以下の問題が生じる. 例えばn 手先まで探索したとする.するとコンピュータには n 手先までの展 開が全てわかっていることになる.しかしこれは逆に言えば n+1 手より先は全 くわかっていないということになる【図2.11】. これは重大な問題である.n 手先では有利に見えても,実はその先に落し穴が 待ちうけていた,などということにもなりうる.逆に,不利なようで実は有利 な手を見落としてしまうということも起こりうる. 図2.11:探索の問題 例えば将棋では,自分の歩で相手の銀を取れる局面で探索を打ち切った場合, 駒の価値を重要視してその手を選ぶかもしれない.しかしその先を探索すれば, 逆に自分の飛車を相手の歩で取られる局面があるかもしれないのだ.探索を打 ち切った時点では有利と思われた手が,その少し先で不利に転じる可能性があ 7 2 自分の番 相手の番 7 9 6 2 7 A B C D E F G ? ? ?る.これをゲーム木の末端を水平線に例えて水平線問題と言う. この問題に対し,対応策として静止探索がある.これは駒の取り合いや強制 手筋(相手がそれに対応せざるを得ない手)が存在する局面では探索を続け, 駒の取り合いや強制手筋が存在しない静かな局面,つまり駒の損得による評価 があまり変化しない局面になるまで深く探索を行うものである. しかしこの方法では水平線問題を根本的に解決したとは言えない.確かに探 索を行いn 手先まで読み,さらに n+1 手先の相手の反撃の一手まで読めるだろ う.だがさらにそこから数手先の反撃に対する守りや,終局までの様子は依然 わからないままなのである. そこで,水平線の向こう側を見越した道標が必要と考えられる.
2.3 将棋とプランニング
将棋のプロ棋士は頭の中で一手一手順を追って手を進めるよりも,おおよそ の駒の配置を思い浮かべ,そこまでの手順を辿って考える.これはプランニン グの手続きによく似ている. 2.3.1 プランニング プランニングは探索とは異なり,初期状態,ゴール状態,可能な行為を与え ることで,ゴール状態までの行為の列(プラン)を生成する.探索は闇雲に試 行錯誤型であるのに対し,プランニングは目標を持って手を進めるのである. 2.3.2 水平線問題解決へのアプローチ 探索には必ず水平線問題が発生する.これに対し,水平線の向こうに存在すたせる. 将棋に例えれば,将棋には王将の周りの囲い方,さらにそれらを有効に崩す 戦法など,様々な定跡が存在する.定跡は先人の経験と研究による,現時点で 最善と思われる手順の指し手である.ここで矢倉囲いという囲いを組みたいと する【図2.12】.矢倉囲いは先手後手合わせて最短でも 25 手必要になる.将棋 は1 局面に対し可能な着手は平均 80 手あるとされる[5].ということは,25 手 探索では3.7×1047ノード調べる必要がある.仮にチェスのDeepBlue の様に秒 間2 億ノード探索できる将棋マシンがあったとして,25 手探索をさせた場合, 5.9×1020日かかる.これではゲームとして成り立たない. そこでプランニングにより矢倉囲いを与え,そこまでの指し手を生成させる. この指し手を探索に組み合わせることで,探索としては矢倉囲いが完成した局 面まで深く探索はできないが,探索と指し手には矢倉囲いへの方向性を持たす ことができる.次章で実際の方法について説明する. 図2.12:矢倉囲い
3 研究内容
2 章では探索の問題点とその解決策を提案したが,3 章では解決案としてのプ ランニングを探索にどのように関係させるか,また具体的にどのようなプラン を実行させるか例を挙げて説明する.3.1 探索とプランニング
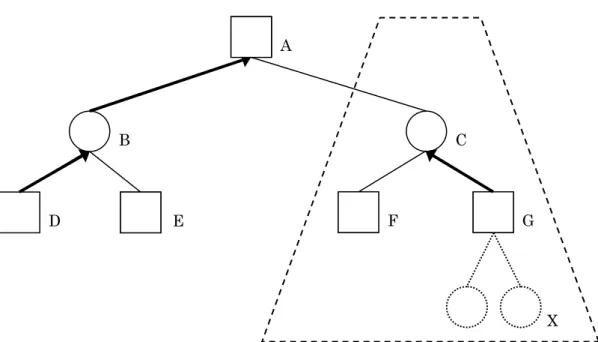
2 章でも説明した通り,【図 3.1】の探索ではコンピュータはノード B への手 を指す. 図3.1:水平線問題 しかし,ノードB より低い評価値のノード C が,未探索だが評価値が高いノ ードX に到達するとわかっていれば,ノード C への手を指す方が将来的に有利 になる.この探索にプランニングを用いた様子が【図3.2】である. 7 2 7 9 8 2 7 A B C D E F G 9 X 水平線図3.2:プランニングによる評価値へのボーナス ノードX を目標状態とすると,自分側はノード C への手を指さなければなら ない.【図3.2】ではαの値が 6 以上ならノード C への手を指す【図 3.3】.この 様に,プランニングでノードC への手をプランとして生成し,ノード C 以下の ノード全ての評価値にボーナス値6 を与える. 7 2 7 9 8 2 7 A B C D E F G 9 X
+α
7 8 7 9 14 8 8 A B C D E F G 15 図3.3:ボーナスによる評価値の変更 X+6
以上の様に,生成されたプランにある手が探索の中に存在する時,そのノー ド以下の評価値をボーナス値によって底上げしてやることで,探索の限界であ る水平線の向こうを見越した着手が可能となる.
3.2 定跡とプラン
将棋には定跡がある.それは現時点で最善手と考えられるものであると 2 章 で述べた.そこで,その定跡からある囲いまでの手順をリスト化して,プラン ニングによって生成されるプランとして使用することが望ましいと考える. しかし,定跡は相手も定跡通り指す上では役に立つが,自分か相手どちらか が定跡から外れれば,そこからは探索による読み合いの勝負になる為,あくま で目的は定跡通りに手を進めることではなく,囲いが完成する局面に到達する ことと考える.以下に例として矢倉囲いを説明する. 3.2.1 矢倉囲い 矢倉囲い自体について説明する【図3.4】. 図3.4:矢倉囲い 相手の状況によって,一番端の歩が上がっていたり,角が移動していたりするが,【図 3.4】のような駒組が矢倉囲いである.この囲いは 7 八の金を守って いる駒が王だけなので,横からの攻撃にはそれほど強くないが,上部からの攻 撃には強いという特徴がある. 3.2.2 矢倉囲いのプラン 矢倉囲いのプランは具体的には以下のようになる. 7 六歩→6 六歩→6 八銀→7 八金→5 八金→7 七銀→6 七金右→6 九王→5 六歩 →7 九角→6 八角→7 九王→8 八王 状況によって順序は変わるが,どういった動きになるか,局面と並べて考える. 【図3.5】初期局面 図では囲いに関係しない駒は省く. 【図3.6】5 八金まで ①7 六歩 ②6 六歩 ③6 八銀 ④7 八金 ⑤5 八金 図3.5:初期局面 図3.6:5 八金まで
【図3.7】7 九角まで ① 7 七銀 ② 6 九玉 ③ 5 六歩 ④ 7 九角 【図3.8】6 八角まで ① 6 七金 ② 6 八角 【図3.9】8 八玉まで ① 7 九玉 ② 8 八玉
3.3 プランのボーナス値
上で説明したそれぞれの手について,ボーナス値を定める.このボーナス値 は, ① 囲いを組む ② 手数を損しない 図3.7:7 九角まで 図3.8:6 八角まで 図3.9:8 八角まで④ 飛車などの大駒を取られてしまう場合はプランを後回しにする の4 つの条件を満たす値が望ましいと考えられる. ①は最低条件であるが,例外もある. 相手が急戦をしかけたときや,相手の 攻め方と設定した囲いとの相性によっ ては無理に囲わない方がよい場合もあ る. ②について,【図 3.10】では 7 九角 の前に7 九玉を指した為に 2 手損にな る. ③について,同じく矢倉囲いを目指 した場合だが,【図3.11】のように囲い の途中で玉の守りが薄くなる場面が出 ても芳しくない. ④について,【図 3.12】ではあと 3 手で矢倉囲いが完成するが,その前に 飛車が取られてしまう.こういった局 面では,プランよりも先に相手の駒を 取る必要がある. つまり,囲いに行ける状況ならプランニングによって囲いを目指し,駒の取 り合いのような急な展開が予想されるときはプランよりそちらを優先するボー ナス値を設定する. 図3.10:手損の例 図3.11:手順の失敗例 図3.12:駒損の例
3.4 前提条件
前節でプランのボーナス値の条件を挙げたが,【図3.10】や【図 3.11】のよう な状態で,ボーナス値のみで手順を細かく指定することは難しい.そこで,プ ラン中のある手を指す前に必ず指していなければならない手を指定し,その手 を指して初めて指せる,という条件を設ける.これを前提条件と呼ぶことにす る. 4 章でプランのボーナス値と実際にプログラムが指した手を検証する.4 実験結果と考察
3 章で説明したように,定跡を参考にしながら囲いまでのプラン作成を目的と して研究を進めてきたが,3 章で述べた矢倉囲いだけではなく,他にも船囲い, 左美濃,居飛車穴熊の 4 つの居飛車の囲いを作成した.ここで居飛車の囲いに 限定した理由として,相居飛車戦の定跡は多く,相振り飛車戦の定跡は比較的 少ないことから,参考とする定跡が多い方が研究を進める上で都合がいいと考 えたことを挙げる.4.1 ボーナス値の偏り
プラン中の手それぞれにボーナス値を与えるわけだが,そのボーナス値には 偏りがある.主に手順が先の手は値が高く,手順が後になるほど値が低くなる. これは値に偏りを与えたプランと,値を全く均等に与えたプランを比較した時, 偏りを与えたプランはその値が大きい手から順に指したためである【表4.1】. 値に偏りのあるプラン 値が均等のプラン プランの手順 指した手 ボーナス値 指した手 ボーナス値 1 7 六歩 7 六歩 350 9 六歩 200 2 5 八金 5 八金 200 5 八金 200 3 6 八玉 6 八玉 190 5 六歩 200 4 7 八玉 7 八玉 175 6 八玉 200 5 5 六歩 5 六歩 160 7 八玉 200 6 9 六歩 9 六歩 125 7 六歩 200 表4.1:ボーナス値の偏りによる手順の違い(※プランは船囲い) 表のプランは船囲いのプランである.ボーナスの総和はどちらも同じである.船囲いは手数が少なく,初手での探索で読みきることが可能である.値に偏り があるプランと均等のプランどちらもプランの最後まで探索することが可能で, 比較対象として適しているためここで例として挙げる.なお,このプランには どちらも「6 八玉の前に 5 八金を指す」という前提条件を用いている.表を見る と,値が均等であるプランの指し手はプラン通りの順では指していないが,偏 りのあるプランの指し手は実際のプラン通り指している.これから,ボーナス 値の大きい手から優先的に指していくことがわかった. 以上のことから, ・ プランの手順は手のボーナス値の大きい順 ・ 囲い到達の失敗,または手損が発生する場合,前提条件を用いる としてプランを作成した.
4.2 実際に指した手
プランのボーナス値,および前提条件について述べたが,以下に4つの囲い とそのボーナス値,前提条件を結果として記載する. さらに実際に指した手について①~④の条件を満たすことを検証する. ① 囲いを組む ② 手数を損しない ③ 王を危険にさらさない ④ 飛車などの大駒を取られてしまう場合はプランを後回しにする 4.2.1 矢倉囲いのプランと指し手 矢倉囲いの特徴は,3 章でも述べたが 7 八の金を守っている駒が王だけなので, 横からの攻撃にはそれほど強くないが,上部からの攻撃には強いという特徴が ある.【表4.2】にプランの手とボーナス値,そして実際の指した手を示す. 図4.1:矢倉囲いプランの手順 前提条件 ボーナス値 実際の手順 1 ① 7 六歩 300 7 六歩 ① 2 ② 5 六歩 200 7 八金 ④ 3 ③ 6 八銀 190 6 八銀 ③ 4 ④ 7 八金 170 7 七銀 ⑥ 5 ⑤ 5 八金 160 5 六歩 ② 6 ⑥ 7 七銀 150 6 六歩 ⑧ 7 ⑦ 6 九玉 140 5 八金 ⑤ 8 ⑧ 6 六歩 130 6 九玉 ⑦ 9 ⑨ 6 七金右 6 九玉 120 6 七金 ⑨ 10 ⑩ 7 九角 5 六歩 90 4 八銀 11 ⑪ 6 八角 7 九角 80 7 九角 ⑩ 12 ⑫ 7 九玉 6 八角 70 6 八角 ⑪ 13 ⑬ 8 八玉 7 九玉 70 7 九玉 ⑫ 14 8 八玉 ⑬ 表4.2:矢倉囲いのプランと実際に指した手 プランの手順と実際に指した手順の誤差は1~3 手であった.これは,プラン によるボーナス値は指した局面以下に与えられ,手順が変わってもボーナス値 の総和は変わらないためと考えられる. プランのボーナス値を設定する上での条件①は囲いを組んだことからクリア している.②については前提条件によってクリアしている.③の条件について も,6 七金を指す前に 6 九玉を指すという前提条件でクリアしている.④につい ては,実験で使用したプログラムの駒の価値がそれぞれ歩は 100 点,香車と桂 馬が300 点で,それ以外の駒は 450 点以上と設定されているため,プランのボ ーナス値と比べても駒損以上のボーナスは与えないと考えられる.
4.2.2 船囲いのプランと指し手 船囲いの特徴は,玉の上部からは弱いが,手数がかからず,横からは強いこ とが挙げられる.さらにこの船囲いから矢倉囲い,左美濃,穴熊に発展するこ ともできる.以下にプランの手とボーナス値,そして実際の指した手を示す 【表4.3】. プランの手順 前提条件 ボーナス値 実際の手順 1 ① 7 六歩 350 7 六歩 ① 2 ② 5 八金右 200 5 八金 ② 3 ③ 6 八玉 5 八金右 190 6 八玉 ③ 4 ④ 7 八玉 175 7 八玉 ④ 5 ⑤ 5 六歩 160 5 六歩 ⑤ 6 ⑥ 9 六歩 125 9 六歩 ⑥ 表4.3:船囲いのプランと実際に指した手 表を見ると,プランと実際の指した手順は一致している.よって条件①~④ も満たしている. 図4.2:船囲い
4.2.3 居飛車穴熊のプランと実際の指し手 居飛車穴熊の特徴は,必要な手数が多くなるが,玉が自陣の端に閉じこもり 相手の攻め駒から遠くなることで,守りが堅くなることである.以下にプラン の手とボーナス値,そして実際の指した手を示す【表4.4】. プランの手順 前提条件 ボーナス値 実際の手順 1 ① 7 六歩 350 7 六歩 ① 2 ② 6 六歩 200 5 八金 ③ 3 ③ 5 八金右 180 6 八玉 ④ 4 ④ 6 八玉 180 7 八玉 ⑤ 5 ⑤ 7 八玉 150 7 七角 ⑥ 6 ⑥ 7 七角 6 八玉 180 6 六歩 ② 7 ⑦ 8 八玉 140 8 八玉 ⑦ 8 ⑧ 9 八香 8 八玉 160 9 八香 ⑧ 9 ⑨ 9 九玉 150 9 九玉 ⑨ 10 ⑩ 8 八銀 9 九玉 190 8 八銀 ⑩ 11 ⑪ 7 九金 150 6 八金 ⑫ 12 ⑫ 6 八金 9 九玉 120 7 八金 ⑬ 13 ⑬ 7 八金 120 7 九金 ⑪ 表4.4:居飛車穴熊のプランと実際に指した手 表を見ると,6 六歩が遅れた点と最後の金の順序が入れ替わった点を除けばほ 図4.3:居飛車穴熊
直前の手より高いが,前提条件により探索に渡さないようにしている.これに より①~④の条件を満たした. 4.2.4 左美濃のプランと実際の指し手 左美濃の特徴は玉の上部が船囲いより相手陣に近く薄いが,反面横や下部か らの攻めには船囲い以上に強い点が挙げられる.以下にプランの手とボーナス 値,そして実際の指した手を示す【表4.5】. プランの手順 前提条件 ボーナス値 実際の手順 1 ① 5 八金 270 6 八玉 ② 2 ② 6 八玉 190 7 六歩 ⑧ 3 ③ 7 八玉 180 7 八玉 ③ 4 ④ 8 六歩 160 5 八金 ① 5 ⑤ 8 七玉 160 8 六歩 ④ 6 ⑥ 7 八銀 8 七玉 160 8 七玉 ⑤ 7 ⑦ 9 六歩 8 七玉 130 9 六歩 ⑦ 8 ⑧ 7 六歩 120 7 八銀 ⑥ 表4.5:左美濃のプランと実際に指した手(※対振り飛車) 左美濃は居飛車の囲いだが,相居飛車戦になると全く囲わなかった.表の手 順は相手が振り飛車の時の手順である. 図4.4:左美濃囲い
4.3 プラン全体の考察
プラン実行中に指した手は全てプランの中の手だったが,手順はプラン通り であったのは船囲いだけであった.これはプランによるボーナス値は指した局 面以下に与えられ,手順が変わってもボーナス値の総和は変わらない為と考え られる. また,穴熊のような比較的手数のかかるプランは手順通りに着手させること が困難である.これはプランの手数が多いほどボーナス値の偏りが相対的に小 さくなるためだと考えられる.手数の多いプランは前半部,後半部のように段 階的に探索に影響させることができればより容易に囲いまでの着手を方向づけ ることが可能だと考えられる.5 まとめと今後の課題
今回の実験はプランニングによって囲いを組むことを目標とした.また,こ の時次の①~④を満たしていることを条件とした. ① 囲いを組む ② 手数を損しない ③ 王を危険にさらさない ④ 飛車などの大駒を取られてしまう場合はプランを後回しにする 結果として条件を満たし,囲いを組むことは成功した. 囲いを組むことには成功したが,プランと実際の指し手の手順には誤差があ った.今回は囲いのプランであるため,手順については相手側を考える必要性 が薄かったが,今後必要と思われる攻めのプランでは相手の応手によって成否 が大きく異なると考えられる.そのため,ボーナス値の差以外で明確に手順を 定める方法が必要と考えられる. また,今の段階では一つのプランを実行し始めると,そのプランが終了する までずっとボーナス値を与え続けてしまうので,失敗が確定した場合の強制終 了と,その状態からの再プランニングが課題として考えられる.参考文献
[1] 馬場口登, 山田誠二: 人工知能の基礎, 昭晃堂, (1999). [2] 人工知能学会, http://www.ai-gakkai.or.jp/jsai/
[3] J. Schaeffer: A Gamut of Games, AI Magazine, vol.22, no.3, pp.29-45, (2001).
[4] WikiPedia,http://ja.wikipedia.org/