「音声アシスト」の音声認識と自然言語処理の開発
磯 健一
1,a)颯々野 学
1 概要:「音声アシスト」は音声対話によってモバイル端末から多様な情報へのアクセスを提供するアプリ ケーションである.ヤフーが提供する各種情報サービス(経路探索,天気情報,ニュース,ウェブ検索,地 図,店舗情報,Q&A,知恵袋)を自然な音声対話によって一元的に利用することができるほか,モバイル 端末の操作(アラーム設定,アプリ起動,電話発信,カレンダー・連絡先検索,ウェブ読み上げ)もサポー トしている. ユーザの発話は超大語彙の音声認識によってテキストに変換され,意味理解サーバに送られて発話意図や 固有名,数値表現などが抽出されて,発話意図に応じて用意した応答テンプレートにもとづいて応答文が 作成され,モバイル端末上で音声合成により応答される仕組みである. 本稿では「音声アシスト」を構成する音声認識プラットフォームYJVOICEと音声対話を支える自然言語 処理技術について紹介する.Development of speech recognition and natural language processing for
ONSEI Assist service
Abstract: “ONSEI Assist” is a voice dialog application for mobile devices that enables various kinds of in-formation retrieval including train route, weather, news, web, map, shops and Q&A. It also supports mobile device operations such as alarm setting, application launch, dialing, calendar and address book search. The user input utterance is recognized by a very large vocabulary speech recognition system and sent to a server for semantic analysis which extracts the user’s intention including named entities and prepares a response sentence.
This article describes the speech recognition platform “YJVOICE” and the natural language processing technologies for “ONSEI Assist”.
1.
はじめに
スマートフォンの普及に伴い,音声入出力による情報ア クセスへの期待が高まっている.Googleの音声検索(日本 語版2009年12月,[1])をはじめとして,AppleのSiri(2012 年3月,[2])やNTTドコモのしゃべってコンシェル(2012 年3月,[3]),など本格的な音声認識を搭載したアプリケー ションの認知が広まり,実用的な利用も増えてきている. ヤフーでもモバイルデバイスからの情報アクセスの主要 コンポーネントの一つとして音声対話への取り組みを進め ている.2011年3月から日本語音声検索サービスを開始 して,iOS向け「音声検索」アプリケーション[4]を皮切 りに,多くのスマートフォン向けアプリケーションに音声 1 ヤフー株式会社Yahoo! JAPAN研究所Yahoo! JAPAN Research, Yahoo Japan Corporation, 9-7-1 Akasaka, Minato-ku, Tokyo 107–6211, Japan
a) [email protected] 検索機能を提供している.さらに2012年3月からは音声 対話サービス「音声アシスト」[5]をリリースして,音声認 識,自然言語理解,音声合成を組み合わせた音声対話によ る情報アクセスサービスの提供を開始した. 本稿では「音声アシスト」サービスを構成している音声 認識プラットフォームYJVOICEと,自然言語理解技術に ついてその概略を紹介する.
2.
音声認識プラットフォーム YJVOICE
2.1 構成 音声認識プラットフォームYJVOICEでは,分散音声認識(DSR, Distributed Speech Recognition)の構成を採用
している.スマートフォンなどのクライアントデバイス上 でマイクロホンから音声を取得しながら逐次サーバに送信 して,サーバ上では受信した音声情報を順次デコーダに入 力して音声認識を行う構成である.
クライアントでは音声をブロック単位に圧縮(speex, flac 形式など)してサーバへ送信している.サーバにはapache HTTPサーバのモジュールとして音声認識デコーダを実装 した.通信プロトコルにはhttpsを使用している.apache を利用することによりセキュリティの担保と,クライアン ト数増加に伴うスケーラビリティの確保,そして音声認識 デコーダ(モジュール)の死活管理,などが容易にできると いう利点がある. 以下で音声認識デコーダを構成する音響モデル,言語モ デル,WFSTデコーダについて説明する. 2.2 音響モデル 音響モデル学習用の音声データには,サービス開始後に サーバに蓄積された音声ログ(男女比やSNRのバランスに 配慮して発話を選んで書き起こしを作成)を使用している. HMMのMLおよびMPE学習の統計量計算には並列分 散処理システムHadoop[6]を利用している.複数台のサー バを利用して並列高速化するためには,事前に学習データ を複数サーバに適切に分配しておき,各サーバでローカル な学習データから統計量を算出することが望ましい.しか し増加を続ける大量の学習データを適切に(100∼1000台 規模の)サーバに分配することは容易ではない.サーバダ ウンも考慮するとさらに管理が難しくなる. Hadoopでは構成する各サーバのローカルハードディス クを仮想的に単一ファイルシステム(HDFS, Hadoop Dis-tributed File System)と見なすことができ,学習データを
HDFSにコピーすると自動的に各サーバへ配信管理が行わ れる.さらにreplication機能により,データブロックのコ ピーが異なるサーバに保持されるように自動管理されるた め,サーバダウンにも頑健である. 作成したHMMは3状態32混合ガウス分布のトライフォ ンHMMで,決定木を用いておよそ3000状態にクラスタ リングしている.特徴ベクトルは38次元(MFCC 12,パ ワー1次元およびMFCCの1・2次微分)を使用している. 2.3 言語モデル 音声検索用言語モデルの学習には,ウェブ検索クエリロ グ(検索頻度情報付き),および各種バーティカル検索クエ リログ(辞書,地図,乗換,きっず,ファイナンス,など各 サービス内の検索クエリログ),SNSログ,音声検索ログの 書き起こしテキスト,などを用いている.これらのコーパ スを形態素分割して検索頻度を利用してNグラム頻度カウ ントを算出している(各サービスのクエリログはHadoop 上で管理されており,それらを利用して集計している). 語彙数は頻度上位の約100万語として,エントロピー基 準によるpruningを行い,バイグラム約30M個,トライグ ラム約25M個のトライグラム言語モデルを作成している. 2.4 WFSTデコーダ デコードにはWFST方式のデコーダを開発した[7].デ コーダの基本機能に加えて,実用上の必要性から以下の諸 機能を実装した. • WFSTコンパクト化による省メモリ • 単語境界位置の検出 • 動的文法のサポート • 複数発音を有する単語の発音検出 • 認識結果候補と信頼度出力 以下,これらの追加機能を説明する. 2.4.1 WFSTコンパクト化による省メモリ デコード用WFSTは次式の手順で構築している[8].
π(eps(min(det(C◦ det(L ◦ min(det(G ◦ T ))))))) (1)
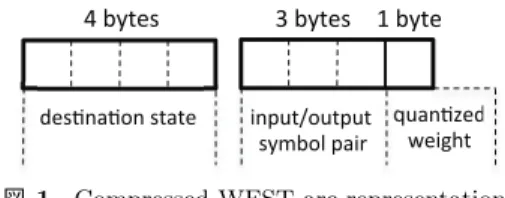
ここでCは文脈依存音素(トライフォン),Lは単語発音辞 書,Gはトライグラム言語モデル,T は単語間無音を表す WFST,πは補助記号除去,epsはϵ正規化を表す. WFSTは状態と状態間遷移(以下,アーク)の集合で定 義され,各アークは「遷移先状態番号」,「入力記号」,「出力 記号」,「重み係数」の4個の情報で定義される(各4バイ トなら計16バイト).各状態はその状態を起点とするアー ク数と,それらアーク情報へのポインタで構成される(各 4バイトなら計8バイト). 語彙数100万語のWFSTでは状態数,アーク数ともに 108個ほどになり,デコーダ使用メモリの大半を占める. そこでアークのメモリ使用量を削減するために,入力記号 (日本語トライフォンなら105種類ほど)と出力記号(語彙 数,106語)のペア化と,重み係数の量子化[9]を行った. 前者により入力記号・出力記号あわせて8バイトを3バイ トに削減できた(大半のトライフォン入力記号に対する出 力記号はϵであることが主因).後者では256点に量子化 することにより1バイトに削減した(認識精度劣化なし). あわせて1アークを8バイト(64bit CPUでの処理に都合 がよい)で保持することができ(図1),顕著な処理負荷増 やプログラム複雑化なしで50%の圧縮率を得た.なお文 献[10]ではアークのアドレスをページ化したり,アークの 要素値を隣接アークとの差分で表すなどして,より高い圧 縮率(約35%)を達成している. !"#$%&'( )&*+,-
.(/0-&1 2(/0-&1 3(/0-&
'&1$#"$4#(1-"-& *#5!-64!-5!-( 107/48(5"*9
図1 Compressed WFST arc representation.
上述の圧縮WFSTに対応したデコーダを開発して評価
実験を行った.比較のためにオープンソースのWFSTデ
コーダ(Juicer ver1.0.0, decoderLite, [11])と非WFSTデ コーダ(Julius ver.4.2.1, [12])も使用した.Julius用言語
50 55 60 65 70 75 80 0.1 1.0 S.Acc (%)
RTF(Real Time Factor)
Real Time Factor and Memory Usage vs Sentence accuracy
0.5 2.0 3.0 4.0 5.0 1.8GB 1.8GB 2.0GB 2.3GB 2.6GB 2.9GB 3.8GB 8.9GB (memory usage) 9.4GB 9.8GB 9.9GB 10.0GB 1.5GB 1.5GB 1.6GB 1.6GB1.7GB 1.7GB 1.7GB 1.8GB 1.5GB 1.6GB 1.6GB proposed juicer ver.1.0.0 julius ver.4.2.1 (larger 2grams) julius ver.4.2.1 図2 文正解率vs RTF モデルには学習用コーパスから前向きバイグラムと後ろ向 きトライグラムを作成して使用した.評価データは音声検 索ログから,パラメータ調整用(以下dev, 2011年9月から 1万発話)とオープン評価用(以下eval, 2012年1月から1 万発話)を選んだ.認識結果の正誤判定はあらかじめ用意 した正解文との比較で行った.文誤り率(SER)の算出で は,正解文と認識結果文の表記(漢字仮名混じり)または読 みが完全一致した場合に正解と数えている.
実験はCPU Intel⃝ XeonR ⃝ X5675(3.07GHz, 6R コア, 12MBキャッシュ),メモリ128GB,CentOS 5.4.3 64bit,
GCC ver.4.1.2のサーバ上で行った.図2に評価データ
evalに対する文誤り率(SER)と実時間比(RTF, Real Time Factor,音声長とデコード所要時間の比)を示した.図中 の数字(単位GB)はデコード中の最大使用メモリ量であ る.各デコーダのパラメータ(ビーム幅,仮説数,言語モ デル重み係数,挿入ペナルティなど)はdevを用いて調整 した.Juliusではデコード第1パスでパラメータ削減なし のバイグラムを使用した場合(図中の青線)と,WFSTと 同様のエントロピー閾値を用いてパラメータ削減したバイ グラムを使用した場合(同ピンク線)を示した. 前述の圧縮WFSTを用いた内製デコーダはRT F = 1.0 の動作点で約2.3GBのメモリを使用するが,Juicerでは 約4.3倍の9.9GBを要している.一方,非WFSTデコー ダ(デコード時に言語モデルと木構造単語辞書を統合す る)Juliusでは,WFSTデコーダに比べてメモリ使用量が 少ない(1.6GB,0.7倍)ことがわかる. 2.4.2 単語境界位置の検出 音声認識アプリケーションでは音声認識結果の確認や修 正のときに,ユーザが指定した単語位置から音声を再生し たい場合がある.しかし式(1)のWFSTでは決定化(det) や最小化(min)によって,出力記号(単語)の位置が動い てしまうため,デコード中に単語境界を検出するのは難し い(1パス処理後に再アライメントするなどの必要がある). そこでデコード用WFSTを構成する単語発音辞書Lの 各単語発音記号列の次に単語終端を表すアーク(入力記号 は単語IDを含む特殊発音記号,出力記号は空記号)を挿入 して式(1)の処理を行った[13].処理後に特殊発音記号を 空記号に,対応する出力記号を単語IDに置換した.これ により1パスデコードにおいて出力記号(単語ID)から単 語境界位置を検出することが可能になった. 2.4.3 動的文法のサポート 音声認識アプリケーションではアプリケーションごと, あるいはエンドユーザごとに用意した語彙や言い回しを 音声認識可能にしたい場合が生じる.たとえばアプリケー ションに依存した音声コマンドや,エンドユーザのアドレ ス帳に登録されている人名などを認識させたい場合である. そこで事前に用意した共通WFSTと,上述のように実 行時に個別に用意された追加のWFST(以下,動的文法 WFST)を組み合わせてデコードする必要性が生じる.動 的文法WFSTを組み合わせたデコード方法としてはsplice 接合する方法[14]や,式(1)のWFST合成の一部を実行 時に行うOn-the-Fly合成による方法[15]などが知られて いる.後者ではGとC,Lの合成が事前には行われないた
め,WFST保持メモリ量が低減できるメリットがあるが, 式(1)の全体最適化が行えないデメリットがある. 我々は前者に近い方式でデコーダを実装した.事前に用 意する共通WFST中には動的に呼び出したい文法を特殊 な単語X(その発音記号も特殊音素記号x)として組み込 んで,通常の式(1)の合成と最小化を行う.デコード時に 特殊音素記号xを含むトライフォンへ仮説を展開すると きに,動的文法WFSTへの接合をオンデマンドに行って いる.[14]では事前に両方のWFSTの接合部分をすべて の可能なトライフォンを想定して展開しておく必要がある が,我々の実装では仮説伝搬時にオンデマンドで展開して いる点などが異なっている. 2.4.4 複数発音を有する単語への対応 人名や地名などでは,同じ単語表記に対して複数の異な る発音が定義されている場合がある.たとえば人名「高田」 に対して「タカダ」,「タカタ」,「コーダ」,地名「日本橋」 に対して「ニホンバシ(東京)」,「ニッポンバシ(大阪)」の ような場合である.音声対話システムで認識結果に応じて 読み上げを行う場合や乗換案内検索を行う場合は,音声認 識結果からこれらの発音の区別を検出したい場合がある. そこで言語モデルGでは発音による違いを考慮せずに 「高田:{タカダ/タカタ/コーダ}」を出力記号として扱い, 単語発音辞書Lでは各発音に対する単語表現の末尾にどの 発音が選択されたかを識別する特殊発音記号を挿入してお く(前述の単語終端アークと共用可能).これにより式(1) の処理はそのままに,最終的に構築されたWFSTの出力 記号には発音の区別を埋め込むことができる. 2.4.5 認識結果候補と信頼度出力 デコーダは認識結果として音素ラティスを出力する.多 様な認識結果出力形式をサポートするために,音素ラティ スから単語ラティス,単語コンフュージョンネットワーク などを生成する後処理を追加した. 音素ラティス上で音素遷移ごとに事後確率を算出して, 事後確率による音素遷移のpruningを行いながら単語ラ ティスを生成する.Nベスト候補文出力は単語ラティスか ら生成している.さらに単語ラティスから単語コンフュー ジョンネット(WCN, Word Confusion Networks)を生成 している.WCN生成アルゴリズムは[16], [17]などが知ら れているが,ここでは後者のpivotに基づく方法(1位仮説 の単語列をpivotとして,単語ラティス中の単語遷移をま とめる方法)を実装した.pivot法で生成されるWCNでは 一般に1位仮説の単語数よりもスロット数が増えてしまう ので,アルゴリズム終了後に1位仮説のセグメンテーショ ンに応じてスロットをマージする処理を追加している. 2.5 アプリケーション ヤフーでは2011年3月に音声認識サービスを開始して, 最初のアプリケーションとしてiOS向けの「音声検索」(図 3, [4])をリリースした.ヤフーが提供する各種の検索サー ビス(ウェブ,画像,Twitter,地図,路線,知恵袋,オー クション,ショッピング,人物,レシピ)を横断的に音声 で検索できるアプリケーションである.これまでに累計で 百数十万回以上ダウンロードされている. 図3 アプリケーション「音声検索」(iOS向け) その後,社内向けにクライアント開発用のSDKを用意 して,多数のiOS向け,Android向けアプリケーションに 音声検索機能が搭載されている.
3.
音声アシスト
3.1 音声アシストとは 「音声アシスト」は前述の音声認識プラットフォーム YJVOICEと自然言語処理を組み合わせた音声対話機能を 有するアプリケーション(Android向け,図4,[5])である. 2012年4月にAndroid向けにリリースされて,スマート フォンへのプレインストールやGoogle Playからのダウン ロード(約50万回以上)で提供され,年間で約2000万発 話ほど利用されている. 図4 音声アシスト(Android向け)「音声アシスト」は音声対話によって以下のようなサー ビスの一元的な利用をサポートしている(図5). • 経路探索(「品川から六本木まで」,「到着は何時?」) • 天気情報(「今日の天気は?」,「雨は降るかな?」) • ニュース(「総選挙のニュースを教えて」) • ウェブ・画像検索(「スカイツリーを検索」) • 地図(「ここはどこ?」) • 店舗情報(「近くのコンビニ」) • アラーム(「明日7時15分に起こして」) • 時刻・日付・祝日問い合わせ(「正月まであと何日?」) • アプリ起動・端末操作(「カメラを起動」,「音を大きく」) • 連絡先(「佐藤さんのメールアドレスは?」) • 電話発信(「佐藤さんに電話をかけて」) • カレンダー(「来週の月曜の予定は?」) • Q&A(「インドネシアの通貨は?」) • 知恵袋(「ホットケーキとパンケーキの違いを知恵袋で 検索」) • 読み上げ(ブラウザ・メール連携) 3.2 構成 クライアント・サーバ構成であるが,サーバ側は前述の 音声認識プラットフォームYJVOICEに加えて,自然言 語処理による意味理解サーバ,応答生成サーバ,音声合成 サーバ,などから構成されている. クライアントではマイクロホンからの音声を音声認識 サーバへ送信して認識結果テキストを受信して,そのテキ ストを意味理解サーバへ送信する.意味理解サーバでは音 声認識結果テキストから発話意図の判別と変数情報(固有 名や数値表現など)の抽出,変数情報の変換,などを行い, 応答パターンを生成して応答生成サーバへ渡す.応答生成 サーバでは各種サービスAPIを利用して応答に必要な情 報を取得して応答文を完成し,さらに音声合成サーバを利 用して応答文の読み上げ用韻律情報を付与して,クライア ントへ返信する.クライアントでは応答結果を表示すると ともに,音声合成で応答文を読み上げる. 3.3 音声認識結果テキストからの意味理解処理 発話意図ごとにあらかじめ用意した句パターンと大規模 な固有名辞書などを組み合わせて,音声認識結果テキスト とパターンマッチすることによって,発話意図の判別と変 数情報の抽出を同時に行っている.機械学習による意図判 別などと比べると,パターンの追加・削除がインクリメン タルに可能であり,例外的な発話や雑談表現への対応もや りやすいというメリットがある. 3.4 複数発話にわたる文脈情報の扱い 上述のような発話単位の処理において,複数の連続発話 にわたる文脈情報を意味理解に利用するために,クライア ントは過去数文の意味理解の結果をキャッシュしておき, それらを現発話の音声認識結果に添付して意味理解サーバ へ送信している.これにより「品川から六本木まで」とい う発話の次に「到着は何時?」と発話した場合に,直前発話 の発話意図分類(路線探索)や変数情報(出発・到着駅)な どを文脈として参照しながら意味理解処理を行っている. 3.5 雑談 上述のような目的志向型の対話に加えて,ユーザを楽し ませる簡単な雑談に対する応答にも力を入れている.雑談 には挨拶,ボットの属性をたずねる会話(誕生日,性別,年 齢,好きなもの,...),ボットにお願いする会話(つきあっ て,友達になって,励まして,面白いこと言って),相づ ち,体調や心情を吐露する会話(眠い,疲れた,お腹すい た),ボットの能力や反応を試す会話(足し算をさせる,好 き・嫌いと言ってみる)など,さまざまな対話が含まれる. あらかじめ想定した雑談パターンを限定的に用いて,そ れら以外の発話に対しては「分かりません」と答える,一 律にランダムな回答をする,ウェブ検索に誘導する,など を多用してしまうと対話の楽しさを大きく削いでしまう. そのため多少の誤りは許容しても,さまざまな回答ができ るよう工夫している.
4.
おわりに
本稿ではモバイル音声対話アプリケーション「音声アシ スト」と,その音声認識プラットフォームYJVOICE,自 然言語対話処理技術について紹介した. 今後は普及が加速するスマートフォンに加えて,より多 様なモバイルデバイスの出現が予想される.さまざまなモ バイルシーンでユーザに情報サービスを提供するために は,音声認識ではとくにハンズフリーにおける性能改善が 重要な技術課題と考えている.また自然言語意味理解では さまざまな応用場面に適用するためのドメイン適応や知識 管理技術の開発が望まれている. ユーザの課題解決を支援する最も自然なインターフェー スとして「音声アシスト」を今後さらに発展させていきた いと考えている. 参考文献[1] M.Schuster, K.Nakajima, “Japanese and Korean Voice Search,” in ICASSP 2012.
[2] J.R.Bellegarda, “Large-Scale Personal Assistant Tech-nology Deployment: The Siri Experience,” in
Inter-Speech 2013. [3] 吉村健, “しゃべってコンシェルと言語処理,”情報処理学 会研究報告, vol.2012-SLP-93, No.4. [4] 音 声 検 索 (iOS 用), 入 手 先 ⟨http://visseeker2.yahoo-labs.jp/voicesearch/⟩ [5] 音声アシストfor Android, 入手先⟨http://v-assist.yahoo.co.jp⟩
図5 音声アシストの利用例
[6] Hadoop,入手先⟨http://hadoop.apache.org⟩
[7] K.Iso, E.Whittaker, T.Emori, J.Miyake, “Improvements in Japanese Voice Search,” in InterSpeech 2012. [8] C.Allauzen et al.,“A generalized construction of
inte-grated speech recognition transducers,” in ICASSP, 2004.
[9] P.A.Chou et al., “Entropy-Constrained Vector Quanti-zation,” IEEE Trans. ASSP, vol.37, pp. 31-42, 1989. [10] D.Caseiro, “WFST Compression for Automatic Speech
Recognition,” in InterSpeech, 2010.
[11] D.Moore et al., “Juicer: A Weighted Finite-State Trans-ducer speech decoder,” in MLMI, 2006.
[12] A.Lee et al., “Recent Development of Open-Source Speech Recognition Engine Julius,” in APSIPA, 2009. [13] A.Serralheiro et al., “Towards a Repository of Digital
Talking Books,” in EuroSpeech, 2003.
[14] J.Schalkwyk et al., “Speech Recognition with Dynamic Grammars Using Finite-State Transducers,” in
Eu-roSpeech, 2003.
[15] C.Allauzen et al, “A Generalized Composition Algo-rithm for Weighted Finite-State Transducers,” in
Inter-Speech, 2009.
[16] L.Mangu et al., “Finding Consensus in Speech Recog-nition : Word Error Minimization and Other Applica-tions of Confusion Networks,” Computer Speech and Language, vol.14, no.4, pp.373-400, 2000.
[17] D.Hakkani-Tur et al., “Beyond ASR 1-best: Using word confusion networks in spoken language understanding,” Computer Speech and Language, vol.20, no.4, pp.495-514, 2006.