The Use of Air-Pressure Sensor in Electrolaryngeal Speech Enhancement Based on Statistical Voice Conversion
4
0
0
全文
(2) The main differenc巴 of these systems is the sound sources 3.1. Speaking-aid system for EL speech 13). (2) Recording. This system conv巴rting EL speech into normal speech is the most basic system among our proposed systems. The four com ponents of this system are the same as Fig. 2.. This system. is supposed to be used in situations in which only converted speech is mainly presented to listeners, such as t巴lecommunica. (1) Electrolarynx. tion or lectures. To present normal speech, this syst巴m estlmates target spec. Airflow. tral,Fo, and aperiodic compon巴nts of th巴 巴xcitation signaJ from. 総 (4) Conver!ed normal speech. o凶y source spectral information, since the numb巴r of vibra tions of the EL is tìxed, and therefore, the produced EL sp巴ech does not have effectiveFo information. In the VC part, sp巴c tral segmental f,巴ature vectors of the source EL speech are used. Figure 2: 0νerview 01 proposed speaking-aid s\古fem fhaf en. to compensate for lost information in the user's articulation. hances EL speech lIsing air-presslll官sensor. Th巴se feature vectors are constructed by following procedur巴S. First, static feature vectors at frames t土L are concatenated as ,__T __T . __T ' . Then, a low dimensional. training data of the source speech at frame t, a feature vector For the training data of the target sp巴巴ch, a joint featur巴 vector. lx, ー L, ・ ,x,' , . . , Xt"+LJl T feature vector X, is extract吋from c,. aG恥仏iI is trained to describe th巴joint probability density of the. 3.2. Speaking-aid system for EL speech using extremely. capturing dynamic movement is used, which is denoted as. Y, = [y;r,ムyi]T is used.. X ,.. c, -. After p即aring these traini月data,. ー riaE EL EE 一一. source and th巴 target feature vectors as follows:. smaU sound source signals 18). A!. P(X"y,1入). =. 乞 ωrnN ( [X;r,y;r]T;μfhf) ) ,. μ μ. はm仰い m. Y ばm μ. m.=l. _. The four components of lhis system are also the sam巴 as Fig. 2 This syst巴m employs another sound source unit generating ex. :E I I :E�;�: 2 1) 2����:: 12 23) |. 2はY) m -. lremely small signals [9] to address not only unnaturally sound ing EL speech but also the noisy sound sources generaled from lhe EL. EL spe巴ch using the small signal is captur巴d using a. where N(-;μ,:E) denotes the Gaussian distribution wilh a. mean vectorμand a covariance matrix. :E.. Non-Audible Murmur (NAM) microphone [10], which is at. m denotes the mix. tached on the muscle at the back of the user's neck.. ture component index, and 1\1 d巴not巴s the total number of the mixture components. A param巴ter sel of the GMM is d巴noted full c∞O肝V刊川川ar叩nar 悶 ma剖tn町ce白s. J日r:fC ). soft tissues of the head.. f. :E�ぽ:ffリ引,l"川'). IS conve口巴d to normal speech. This system is supposed to be. vecω町rs of t山h巴. used in users' daily conv巴rsations as well as tel巴commurucatlOn,. 1 h mη I出. since the sound sources and the pr吋uced EL(small) spe巴ch is. mixt凶ur,陀巴 compon巴叩nt for t出h巴 source and the target features, respectively.. :E;;; X). (XY ). ces and :E i;;'. , J. _ _.J. :E;,;:n � (Y X ) :Ei,; .. and. and. " }. __. assumed not to b巴 heard by listeners. The VC method of this. r巴pres巴nt the covarianc巴 ma肝. syslem is the same as the system described in Section 3.1.. repr巴sent lhe cross-covariance ma-. trices of the mth mixture component for the source and the tar get featur巴s, respectively. X. =. [X;r, .. ,X:J]T. 4.. Proposed speaking-aid system with the alr-pressure sensor. 2.2. Conversion part Let. The captured body-conductα1 EL. spe巴ch using the small sound source s】gnals (EL(small) speech). for刊川1汀In耐I. J江r )hr巴p陀m鉛悶悶巴釘nt t山h巴 mean. and μ. NAM. microphone captures the small-power巴d EL spe巴ch through the. byλ, which consists of weightsωm山,m巴an ve伐cω町r尽sμJr 'jy川\'川,η) and n巴印nt岱s μ. by PCA proc巴dure. and. Y. =. [Y;r,・・・,Y:J]T. In order to estimate more naturalFo contours, this paper intro. be a. duces the use of the air-pressure sensor [1] described in Sec. tIme sequ巴nce of th巴 source and the targ巴t feature vectors, re. tion 1 to obtain intentionaJly controll巴dFo contours of the EL. spectively, wh巴re T denotes th巴 number of frames. The con verted static feature sequ巴nce. Ý. -. [ý;r,... , ý:J]T. speech us巴d in our aid system. This paper proposes th巴 other. is d巴teト. sp巴aking-aid syst巴m as shown in Fig. 2, which conve口s EL. mined to m以imize the likelihood of the conditional probability. sp巴巴ch produced using this air-pressure sensor (EL(air) speech). Y given X as follows: U=argITZxP(Y|XJ)st卯. density of. to normal sp巴巴ch. This system is supposed to be used in the same situations as the system described in Section 3.1. AlthoughFo contours of EL speech are intentionalJy con. where W is a matrix to extend the slatic fealUre sequenc巴 to. trolled by lhe speaker, these contours do not vary smoothJy as. dynamic features [7]. as voiced phonemes in EL sp巴ech because the EL always gen. th巴 parameter vector sequence consisting of the static and th巴. shown in Fig. 4. Moreover, aU phon巴mes are basically produc巴d. Th巴 converted speech quality can be more enhanced by con. erates the sound source signals during speaking. Cons巴quently, it is essentiaJly diffìcull for laryng巴ctomees to produce a natural. sid巴ring the global variance (GV) param巴ters [4]. 3.. Fo contour with the EL even if they use the air-pressure sen. sor. Therefore, we use bo出spectral andFo information of th巴. Conventional speaking-aid systems using. EL(air) sp巴ech for estimating more naturaJFo contours. In the. GMMゐased VC. VC part, the source data for th巴Fo estimation are prepar,巴d as. We have so far proposed two types of speaking-aid systems con. follows. Segmental fealUre vectors of the spectrum and theFo. verting differ巴nt typ巴s of EL sp巴町h signals to normal speech. an巴 independently constructed in the same manner as described. ウt ρhu. 1629.
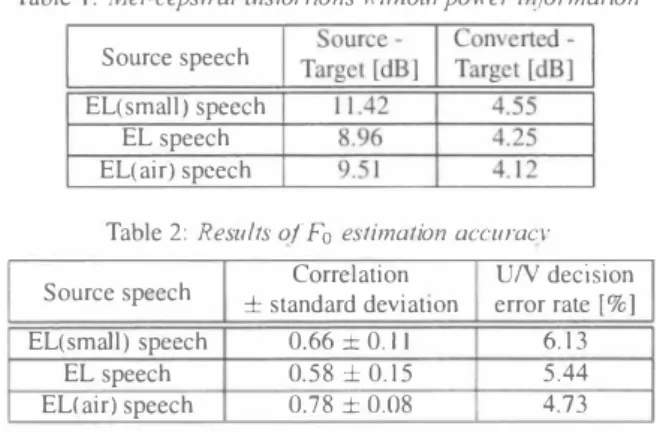
(3) Static leature vectors olspectrum. Static leature vectors 。IF.. Table 1: Mel-cepstral disforfions l1'irh o uf po wer in[ormafion Source speech. Segmental leature vectors 01 F.れ. EL(small) sp民ch EL speech EL(air) speech Table 2: Results ol"Fo estimation acc uraCl・. Figur巴 3: Flow charf of constructing segmentalfeaf ure vecfors using spectral and Fo_(eafure vecfors. in Section 3.1, and the source data ar巴 obtain巴d by concalenal ing these vectors as Fig. 3 shows Tt is 巴ss巴ntial in VC 10 use source and target features that are correlating with each other. To obtain出ese data, a laryn gectome巴 has trained how to controlFo using the air-pr巴ssu陀 sensor for one month. Th巴 laryng巴ctomee has further trained to control Fo for more three weeks so that the pitch of the EL(剖r) speech sounds similar to that of the target normal speech. After this training, EL(air) speech was record巴d. However, we have noUc巴d that it is too difficult to !lÙ!lÙC the target pitch pattem by controlling Fo with breathing air. Moreover, Fo patt巴ms of the recorded EL(air) sp巴巴ch are significantly di仔巴rent from those of the target normal sp巴巴ch. Th巴refor巴, we have addi tionally recorded target normal sp巴ech for the r巴corded EL(air) speech. In this r巴cording, a target speaker has b巴巴n asked to utter normal speech while mi!lÙcking the pitch pattems of the recorded EL(air) speech as naturally as possible. Note that the Fo contours of th巴 r巴corded EL(air) speech are still different from thos巴 of the re-recorded target normal spe巴ch as shown in Fig. 4. For example, anFo contour of the recorded EL(air) spe巴ch varies discontinuously; on the other hand, that of th巴 target normal speech varies smoothly and naturally. These dif ferences are r巴mov巴d by the VC in our proposed system. 5.. Source speech. Correlatio日 士standard deviatJOn. UN d巴ctSlon error rat巴[%]. EL(small) spωch EL speech EL(air) speech. 0.66土0.1 1 0.58土0.15 0.78土0.08. 5.44 4.73. 6.13. accuracy. The Fo accuracies wer巴 evaluated by unvoiced or voiced (UN) decision error rates and the correlation coefficient betw巴en target and conv巴目巴d Fo contours Six non-Iaryngectome巴s su剛氏Uv巴Iy evaluat巴d 1) intelligト bility, 2) naturalness, and 3) pr巴f巴renc巴, which were all rated uSlßg a 白ve-point-scaled opinion sco陀 ( 1 : Bad - 5: Excell巴nt) Sev巴n kinds of stirnuli w巴r巴 巴valuat巴d: analysis-synthesized tar get normal speech, three kinds of record巴d source speech sig nals (EL speech, EL(small) speech, and EL(air) spe巴ch), and three kinds of the convened speech signals from each so町ce sp巴ech. \\弓1en synth巴sizing the speech waveforms, the GV pa rameters of only th巴 conven巴d spec汀a were taken into account 5.2. Experimental resuIts 5.2.1. Objectil'e results. Table 1 shows the results of mel-c巴pstral distonion. As the la ble shows, VC pow巴rfully enhances spectral performance of lhe source sp巴巴ch. Th巴 r巴sults of EL and EL(air) spe巴ch conv巴rSJOn are much better than the results of the EL(small) speech conver sion. This is becauseEL and EL(air) speech contain much more information than EL(small) speech. As Table 2 shows, EL(air) s戸ech conversion achieves higher correlation and less UN d巴cision errors than other re sults. Th巴E巴 r巴sults d巴monstrat巴 that the use of the air-pr巴ssure S巴nsor e仔ecUv巴Iy improves theFo巴stlmatlOn accuracy. Fig. 4 shows an example of Fo of the EL(air) speech, the conv巴目巴d sp巴巴ch, and the target spe巴ch, resp巴ctively. As this 白gure shows, VC powerfully works to make th巴Fo contours of th巴 EL(air) speech smoothJy and continuously varying while suitably switching voic巴d or unvoiced decisions. Experimental evaluations. 5.1. Experimental conditions. The source speaker was on巴 laryngectomee (Japanes巴 male), who was pro自cient in speaking with an EL. The target speaker was one non-Iaryng巴ctomω (also a Japan巴se mal巴) Both speakers recorded 50 phoneme-balanced sentences which S巴円ed as our回ining data and 30 utterances of newspaper ani c1es which served as our t巴st data. The sourc巴 speak巴r record巴d three kinds of alaryngeal speech, which w巴re EL sp巴ech, EL(small) speech using pulse train with 100 Hz, and EL(air) speech. EL(air) sp巴巴ch and normal speech were recorded using the me出od described in Section 4.. 5.22 Su勾Eι'flve re四Ifs. Fig. 5 shows the mean opinion score (MOS) for each t巴st A Tnt巴lIigibility. The number of mixture components of the GMMs to esti mate spectrum, aperiodic components, and Fo was set to 32, 32, and 64, resp巴ctively. The o th through 24th mel-c巴pSlral co-. The intelligibility of source EL spe巴ch is higher scored than that of oth巴r conve口ed speech signals. This is b巴cause the source speaker well knows how to produce intelligibl巴 EL sp巴巴ch. The degradation of the int巴lligibility by VC is future work. On the other hand, the scores of EL and EL(air) speech conversion stay at almost 3.5, and therefore, w巴 believe that these results are acceptabl巴. efficients, which were extracted by mel-cepstral analysis [ 11], th were used as the source spectral parameters in which the 0'" co巴f白cient captured power information. The concatenating frame length for the source segmental feature v巴ctors was set 10 8 After the concatenation of frames. 50- and 2-dimensional com ponents were extracted fram巴 by frame to construCl spectral and Fosegmental f,巴ature vectors, respectively. Acoustic features of th巴 target speech were extracted by STRAIGHT analysis [ 12]. B Naturaln巴ss The naturalness of巳ach conv巴れ巴d speech is scor巴d higher than each source speech. Moreover, the rating for conv巴rted. M巴I-c巴pstral distonion measur巴d the spectral conversion. 1630. 168-.
(4) i �f ! ��� [l rrlb r--l. -U ω O E. sit 川川山 内 1111 向、 州 J I- - 一 W 4UIE m rli. EE'B -f aE --・4E'E -小 6 11UZ1 lil-5 J1 1E15 九 児 ~ 叩 m 一 4 」 | | 封「 4 1 S ,M 'a a E e B I l l 1 e ト ・m ω 3 hけU 3 ・m a l l i T T 1 開 m hー州 MM \ 町 、Il|L | | 〆 2 2 Jm 1 E 町 U a m E i hUN onu c --il o l-L nU PD nu rD nu nu nu ζd 門t nu nu Ed 門4 A斗 司4 41 AQ 司〆』41 【N Z 】 £ー 【N Z 】 。h h [[1. 23ly:\mninlJ| 23fTIl-J両百J昨日:1 �ここノ 但� �ここJ 足立 VC from VC from VC from EL(small) speech. EL speech. 5timuli. EL(air) speech. Figure 5: S u勿'ective result by six n on-lar)'ngect omees.. speech from EL(air) speech has a higher sco陀than that from EL sp巴巴ch. Therefore, the use of the air-pressure sensor is e仔巴ctlve for improving the naturalness.. ' o rg'. and 'cv' denote 0げ'ginal and converted speech, respecti vel\', [3J K. Nakamura,. T. T,ωa, H, Saruwatari胡 唱 d K. Shikano,“Electrola. ryngeal Speech Enhancement Based on Statistical Yoice Conver. C Pref(巴r巴nce. sion",Proc. Interspeech 2∞9 - Eurospeech:1431-1434, Brighton, U.K., Sep. 2009. The converted speech from the EL(air) speech is scored higher than that from the EL speech. This is because the im prov巴m巴nt of the naturalness of the converted speech has af fect巴d the subjects much more than the degradation of intelli 印刷l】ty. From this result, we conclude that出e use of the air pr巴ssure sensor effectively improves the voice quality of the converted speech signals. 6.. [4J T. Toda, A. W. Black, and K. Tokuda, “Yoice Conversion Based on Maximum Likelihood Estimation of Spectral Parame ter Trajectory",æEE Trans. Audio, Speech and Language Proc 15(8):2222-2235, Nov. 2007 [5J Y. Stylianou, O. Cappe, and E. Moulines,“Continuous probabil.is tic transform for voice conversion", IEEE Tr出lsaction on Speech 叩d Aud旧 Proc. (SAP), 6(2): 131ー142, 1998 [6J A. Kain皿d M. W. Macon,“ Spectral voice conversion for text-to speech synthesis", Proc. ICASSP 1998:285-288, Seattle, U.S.A.,. C onclusion. May 1998. This paper introduced an air-pressure sensor and propos巴d a speaking-aid system to enhanc巴 EL(air) speech using a GMM bas巴d VC method. It was shown that the results of this EL(air) sp巴ech conversion were better than thos巴 of EL speech conver sion. Experim巴ntal results demonstrated the e仔'ectiveness of the use of山e aH-pressure sensor.. [7J K. Tokuda, T. Yoshimura, T. Masuko, T. Kobayashi, 出d T Kitam町a,“Speech parameter generation algorithms for H品仏小 based speech synthesis", Proc.ICASSP 2000:1315-1318, Istan bul, Turkey, June 2000. [ 8J K. Nakam町a,T. Toda, H. Saruwatari, and K.Shikano,“'A Speech Communication Aid System for Total Laryngectomees Using Yoice Conversion of Body Transmitted Arti自cial Speech", æ. 7.. ICE Trans. Information and Systems, J90-0(3):780-787, 2007 (in. Acknowledgements. Japanese) [9] Y. Hosoi回d T. Sakaguchi, "Silent voice input system without. The authors are grat巴ful 10 Prof. Hid巴ki Kawahara of Wakayama Un iversi ty, Japan, for permission to use the STRAIGHT analysis-synth巴sis method. This research was sup po口ed in pa口 by MIC SCOPE. This res巴arch was also supported in part by Grant-in-Aid for JSPS FeUows. 8.. exhalation -theory叩d applicat旧nsーへTechnical Report of æICE, SP2003-105: 13-16,2003 [IOJ. Nakajima, H. K出hioka, K. Shikano,叩d N. Campbell, “Re. of Interspeech 2005:293-296, Lisbon, Portugal, Sepl. 2005 い1J T. Fukada, K. Tokuda, T. Kobayashi,四d S. lmai,“伯adaptive algorithm for mel-cepstral analysis of speech," Proceedi.ngs of In. References. [1] N.Uemi, T. !fukube, M. Takahashi,副d. Y.. modeling of the Sensor for Non-Audible Murrnur (NAM)ぺProc. J.. ternational Conference on Acoustics, Speech and Signal Pr田ess. Matsushima, “Oesign. ing (ICASSP), Yol. 1, pp. 137-140, San Francisco, USA, March 1992.. of a New Electrolarynx Having a Pitch Control FunctionヘPro ceedings of 3rd æEE lntemational Workshop of Robot and Hu. [12J H. Kawahara, 1. Masuda-Katsuse,胡d A. de Cheveigné, “Re structuring speech r巴presentat旧出using a pitch-adaptive time. man Comrnunication: 198-203, Nagoya, Japan, July 1994 [2) K. Murak国ni, K. Araki, M. Hiroshige, 加d K. Tochina】, “A. frequency smoothing胡d 叩instantaneous-frequency-based. Method for Speech Transform from Electrolaryngeal Speech to. fD. extraction: Possible role of a repetitive structure in sounds",. Normal Speech (in Japanese)ぺæICE Trans. J87-0-1(11): 1030-. Speech Comrnunication, 27(3-4):187-207, Apr. 1999. 1040,Nov. 2004. 163 1. -169-.
(5)
図



関連したドキュメント
To solve this drawback, we developed a new system capable of detecting the accident in the washing place together with the pulse and respiration rate using a bath mat type
Tendeloo(19)ノ淋巴循環遽度ノ門門又ハ墾1血が結核誘護ノ因ヲナスト言フニ想到スレバ呼吸
淋巴腺 殆ド無鐘化ノモノアリ叉賢二大型淋巴球及ビ網状織内殺細胞楠粗二充チ鑓索チ翻メス皮質縞
In order to estimate the noise spectrum quickly and accurately, a detection method for a speech-absent frame and a speech-present frame by using a voice activity detector (VAD)
朱開溝遺跡のほか、新疆維吾爾自治区巴里坤哈薩 克自治県の巴里坤湖附近では、新疆博物館の研究員に
There is a stable limit cycle between the borders of the stability domain but the fix points are stable only along the continuous line between the bifurcation points indicated
In analogy with Aubin’s theorem for manifolds with quasi-positive Ricci curvature one can use the Ricci flow to show that any manifold with quasi-positive scalar curvature or
We obtain a ‘stability estimate’ for strong solutions of the Navier–Stokes system, which is an L α -version, 1 < α < ∞ , of the estimate that Serrin [Se] used in
