を使って統合する
多様なフォーマットのデータを組み合わせ、無料のツールを使って RDF
に自動変換し、1 つのレポートとして作成する
Bob DuCharme Solutions Architect TopQuadrant 2010年 9月 28日 多様な RDF データ・セットを組み合わせる方が、他の一般的なフォーマットの多様なデータ・ セットを組み合わせるよりも簡単です。互いに大きく異なる RDF 以外のデータ・セットの場 合も、RDF に変換してから組み合わせて新しいコンテンツを作成するのは簡単です。この記 事では、スプレッドシートのデータ、Web サービスから取得した CSV データ、Web サイトの フィールドのデータを統合し、1 つのレポートにする方法について学びます。 セマンティック Web 技術の中核は RDF です。RDF は W3C の標準であり、すべてのデータを、ト リプルと呼ばれる 3 つの部分で構成される文に分解します。データがトリプル・データ・モデル に適合し、トリプルストアという特殊なデータベースに保存されている場合には、セマンティッ ク Web 技術を使用するメリットは明らかです。しかしそれは、データがリレーショナル・データ ベースやスプレッドシートなど、従来のフォーマットで保存されている場合には RDF 技術に何も メリットがないという意味ではありません。オープンソースや商用のツールを利用することで、 それらのフォーマットのデータをトリプルに変換することができ、多様なソースから得られる多 様なフォーマットのデータを容易に組み合わせることができます。大きく異なるソース間で相互 参照を行いたい場合や、あるソースのデータを別のソースのデータで強化したい場合には、一時 的にトリプルに変換することで、非常に手軽にデータを統合できるようになります。よく使われる頭文字語
• CSV: Comma-Separated Value • HTML: HyperText Markup Language • RDF: Resource Description Framework• SPARQL: SPARQL Protocol and RDF Query Language • URI: Uniform Resource Identifier
• URL: Uniform Resource Locator • W3C: World Wide Web Consortium • XML: Extensible Markup Language
• XSLT: Extensible Stylesheet Language Transformations
Linked Data (「参考文献」) として誰もが利用できるデータが増えているため、ローカルに保存さ れたデータをそれらのデータによって強化し、よりリッチで興味深いデータにすることができま す。その一例として、この記事では Excel® スプレッドシートで表現された、架空のアナリストに よる「BUY (買い)」、「SELL (売り)」、「HOLD (中立)」の推奨情報に、上場企業の公開データを 追加することで、魅力的で有益なレポートを作成します。このアプリケーションの入力、出力、 スクリプト (どれも無料のソフトウェアを使用しています) は、「ダウンロード」セクションから 入手することができます。
トリプルを扱う
トリプルの各部分は正式には、主語、述語、目的語と呼ばれます。従来のデータベースを扱って きた人であれば、これらの各部分をそれぞれ、リソース識別子、属性名、属性値と考えることが できます。例えば、リレーショナル・データベースまたはスプレッドシートの中にある、94321 という番号を持つ従業員のデータに、採用日として 2007-10-14 という値が含まれている場合、こ のデータをトリプルで容易に表現することができます。 トリプルの主語と述語は、曖昧さを完全に排除するために URI として表現する必要があります。 トリプルがよく使用される分野では、URI として表現するための標準的なスキーマとベスト・プ ラクティスが成熟しつつあります。一意の識別子によってコンテキストが追加されるということ は、トリプルの集合の中でデータ構造を指定するためのスキーマは、推論や制約チェックのため のメタデータを追加するには便利ではあっても、(必須ではなく) オプションであるということで す。リレーショナル・データや XML データから成る多種多様なデータ・セットを組み合わせる場 合、最も困難な作業はデータ・セットのスキーマ間で対応する部分を突き合わせる作業であるこ とを考えると、RDF スキーマが不要ならば、複数の RDF データ・セットを組み合わせるのは遥か に簡単になることは理解できると思います (多くの場合は単純にファイルを連結するだけです)。 データのサブセットを抽出し、そのデータをソート、再配列してアプリケーション・ロジックを 実装するために、リレーショナル・データベースには SQL があり、XML には XSLT と XQuery があ ります。RDF には、RDF と対になる W3C 標準として、トリプルに対してクエリーを実行するため の SPARQL があります。いくつかトリプルを組み合わせた後に処理を行う場合、SPARQL は特に便 利です。それについては、この記事で説明します。単純なスプレッドシートを入力し、有用なレポートを出力する
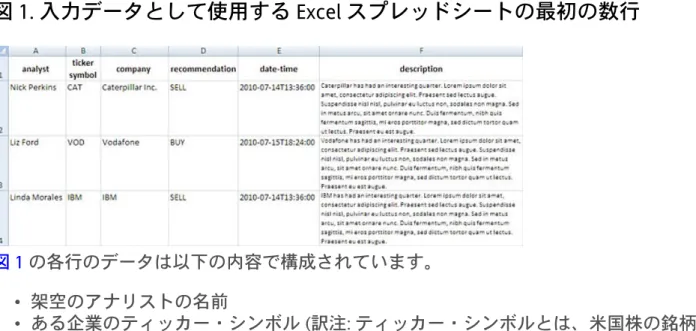
図 1 は、analystRecs.xls という Excel ファイルの最初の数行を示しています (「ダウンロード」を参 照)。図 1. 入力データとして使用する Excel スプレッドシートの最初の数行
図 1 の各行のデータは以下の内容で構成されています。 • 架空のアナリストの名前 • ある企業のティッカー・シンボル (訳注: ティッカー・シンボルとは、米国株の銘柄識別コー ドのこと) • その企業の名前 • その企業の株式に関する、(ランダムな) BUY/SELL/HOLD の推奨 • その推奨の日付と時刻 • その企業に関する分析。この分析の大部分は、レイアウトの外観をテストするために従来か ら出版社で使用されている「ロレム・イプサム」のテキストで構成されています (訳注: ロレ ム・イプサムとは、典型的なダミー・テキストのこと)。 図 2 は、スプレッドシートで 3 番目に記載されている企業 (IBM) の情報を強化し、最終的なレ ポートとして表示したものです。図 2. IBM に関するデータを強化して最終的なレポートとして表示したもの
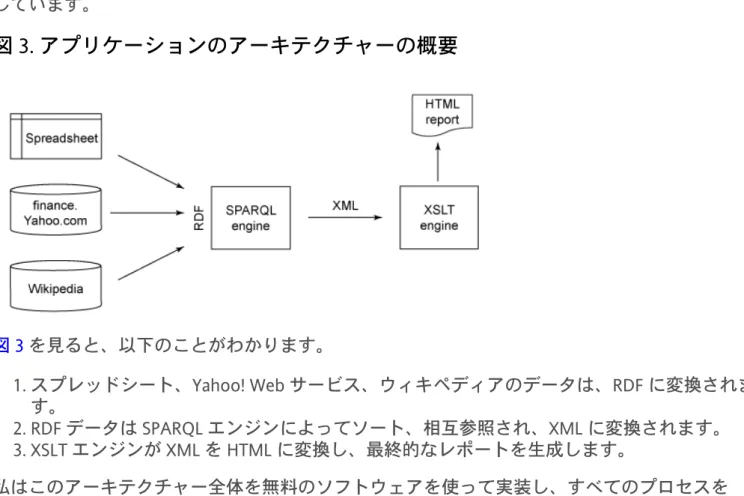
図 2 には、Excel ファイルから抽出した推奨情報、アナリスト名、企業分析、推奨日の他に、この レポートを生成したスクリプトの実行時点での最新株価、昨年の財務データ、そしてその企業の 説明が含まれています。株価データは finance.yahoo.com という無料の Web サービスから取得し ており、この Web サービスではデータを CSV で返します。また、2009年の数字と企業の説明は ウィキペディアから取得しています。図 3 は、これらの入力からレポートを作成したアプリケーションのアーキテクチャーの概要を示 しています。
図 3. アプリケーションのアーキテクチャーの概要
図 3 を見ると、以下のことがわかります。 1. スプレッドシート、Yahoo! Web サービス、ウィキペディアのデータは、RDF に変換されま す。 2. RDF データは SPARQL エンジンによってソート、相互参照され、XML に変換されます。 3. XSLT エンジンが XML を HTML に変換し、最終的なレポートを生成します。 私はこのアーキテクチャー全体を無料のソフトウェアを使って実装し、すべてのプロセスを build.bat という 10 行 (空白とコメントを含めず) のバッチ・ファイルで処理しました。同じアー キテクチャーを商用ツール (TopQuadrant の TopBraid Composer など) を使用して実装することも できます。TopBraid Composer によっていくつかの開発ステップの自動化や、コーディング量の 削減が可能になります。しかし具体的な実装よりも重要な点は、ツールの選択肢が増え、さまざ まなアーキテクチャーを実装できるようになっており、セマンティック Web データの標準を使用 して柔軟かつ手軽にデータを統合することができる、という点です。データを変換する
Excel から RDF への変換における苦労
多くの無料ユーティリティーや商用製品の機能により、スプレッドシートを RDF に変換する ことができます。ただし既存の無料ユーティリティーは、スプレッドシートの多様なレイア ウトを扱おうとしているため複雑であり、また学術的なプロジェクトの場合が多いため、ド キュメントが十分ではなく、使いやすくはありません。また、こうした無料ツールの場合、 「スプレッドシートを読み取る」と言っても通常はスプレッドシート・プログラムによって エクスポートされた CSV を読み取ることを意味し、実際にスプレッドシートのバイナリー・ ファイルを読み取るわけではありません。私は Python を使って Excel データを RDF に変換することにしました。バイナリーの Excel ファイ ルを読み取るための面倒な部分は Lingfo という無料の Python ライブラリーが処理してくれるた め、ほとんど手間をかけずに、読み込んだ各セルに対して RDF トリプルを生成する簡単な Python スクリプトを作成することができます。
finance.yahoo.com という Web サイトは、適切な URL を指定すると最新の株価データをカ ンマ区切りリストで返す Web サービスを提供しています。例えば以下の URL を指定する と、IBM、Nokia、Honda のデータを取得することができます。 http://download.finance.yahoo.com/d/quotes.csv?f=sl1d1t1ohgv&e=.csv&s=IBM,NOK,HMC 返されるデータには要求された各企業の行が含まれ、データ・フィールドの指定はデータを要求 するための URL の中で f= パラメーターによって行います。 この Web サービスにより、株価データが取得され、単純なデータ構造の中に保存されるため、 あとはそのデータを RDF に変換するだけです。Perl に組み込みの split() 関数を使うと、何 かで区切られたテキストを容易に分割することができます。そこで私は、それを行うための yahooCSV2RDF.pl という簡単な Perl スクリプトを作成しました (CSV から RDF への変換を Python を使って行うこともできたのですが、私はこれまで同じようなスクリプトを Perl で非常に数多く 作成してきたので、この Perl スクリプトを短時間で作成できることがわかっていたのです)。この スクリプトのロジックの大部分は、単純に日付フィールドと時刻フィールド (7/22/2010 と 4:00pm など) とを組み合わせ、より ISO 8601 に準拠した、ソートが容易で他のシステムで再利用しやす いフォーマット (2010-07-22T16:00:00 など) にしているにすぎません。 ウィキペディアのデータの変換に関しては、私が追加で行う必要がある作業はありませんでし た。DBpedia プロジェクトによって、ウィキペディアのページの右側にしばしば表示される灰色 の四角いボックス「infobox」のフィールドのデータから、十億を超えるトリプルが作成され、保 存されています。例えば、ウィキペディアで Nokia のページ (http://en.wikipedia.org/wiki/Nokia) を表示すると、infobox が表示されます。DBpedia で Nokia のページ (http://dbpedia.org/page/ Nokia) を表示すると、Nokia の infobox 情報と、さらにその他の情報が表示されます。これらの情 報を、SPARQL 問い合わせ言語を使って容易に照会することができます。
DBpedia の Web サイトには、データに関する SPARQL クエリーを入力できるページが含まれてい ます (http://dbpedia.org/snorql/)。そのページに以下のクエリーを入力すると、Vodafone に関し て DBpedia に保存されているすべてのトリプルを要求することができます。 CONSTRUCT { <http://dbpedia.org/resource/Vodafone> ?p ?o } WHERE { <http://dbpedia.org/resource/Vodafone> ?p ?o } このクエリーを URI に保存すると (適切な文字エスケープを行ってから保存する必要がありま すが、ほとんどのプログラミング言語では 1 つの関数呼び出しで文字エスケープを行うことが できます)、その URI と、URI の送信および結果の取得ができる任意のプログラムを使うこと で、Vodafone のトリプルを取得することができます。そうしたプログラムの 1 つがオープン ソースの cURL ユーティリティーです。例えば、Windows® または Linux® のコマンドラインで 以下の内容を入力すると、cURL によって Google のホーム・ページのコピーがダウンロードさ れ、googleHomepage.html ファイルの中に保存されます。
curl http://www.google.com > googleHomepage.html
バッチ・ファイルまたはシェル・スクリプトを使うことで、アプリケーションから cURL を 呼び出すことができます。DBpedia から企業データを取得するためには、build.bat によって
getDbpediaData.bat という別のバッチ・ファイルを呼び出します。getDbpediaData.bat の各行で cURL を呼び出し、特定の企業のデータを取得します。これらの呼び出しの引数として提供される URL の中に、上記のように SPARQL の CONSTRUCT クエリーをエスケープしたバージョンが含まれ
ています。
組み合わせたデータにクエリーを実行する
すべてのデータの RDF バージョンを収集した後、私は別の SPARQL クエリー (リスト 1) を使用し て、最終的なレポートのためのデータを抽出しました。
リスト 1. 最終的なレポートのためのデータを抽出する SPARQL クエリー
# PickDataForReport.spq: select data from the combination of RDF sources # used to create the fake analyst report. Bob DuCharme 2010 no warrantee # expressed or implied.
PREFIX fn: <http://www.w3.org/2005/xpath-functions#> PREFIX xs: <http://www.w3.org/2001/XMLSchema#> PREFIX ar: <http://www.snee.com/ns/analystRatings#> PREFIX sq: <http://www.rdfdata.org/2009/12/stockquotes#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?tickerSymbol ?coName ?analyst ?description ?recommendation ?recDateTime ?lastPrice ?quoteDateTime ?dayHigh ?dayLow ?openingPrice ?volume ?revenue ?netIncome ?abstract
WHERE {
?analystData ar:analyst ?analyst ; ar:company ?coName;
ar:description ?description ; ar:tickersymbol ?tickerSymbol ; ar:recommendation ?recommendation ; ar:date-time ?recDateTime .
?quoteData sq:tickerSymbol ?tickerSymbol ; sq:lastPrice ?lastPrice ; sq:dateTime ?quoteDateTime ; sq:dayHigh ?dayHigh ; sq:dayLow ?dayLow ; sq:lastPrice ?lastPrice ; sq:openingPrice ?openingPrice ; sq:volume ?volume .
# Next line is why we added language tags to coName: so we # could compare it to ?dbURI rdfs:label properly.
?dbpURI rdfs:label ?coName .
?dbpURI <http://dbpedia.org/ontology/revenue> ?revenue . OPTIONAL {
?dbpURI <http://dbpedia.org/ontology/netIncome> ?netIncome . } .
OPTIONAL {
?dbpURI <http://dbpedia.org/ontology/abstract> ?abstract . FILTER (lang(?abstract) = "en") .
} . } この SPARQL クエリーには、さまざまなファイルから取得したデータのどれを組み合わせるのか に関するロジックが少し含まれていますが、このロジックは非常に単純です。このクエリーは少 し長いと思えるかもしれませんが、それはデータから抽出すべきフィールドの数が多いためにす ぎません。
このローカルの SPARQL クエリーを実行するために、ここでは arq コマンドライン・ユーティリ
ティーを使います。arq はオープンソースで Java™ ベースの Jena フレームワークの一部です (「参 考文献」を参照)。build.bat の行のうち、arq を呼び出す行の中で、以下の 3 種類の情報を指定し
ます。
• 入力データ・ソース (この場合には複数のソース) • 実行する SPARQL クエリーのファイル名
• 結果を SPARQL Query Results XML Format で取得する必要があることを示す結果のフォーマッ ト
クエリーの結果は reportData.xml というファイルに保存されます。
このコマンドは、どのデータを入力として使うのかを、--data スイッチを使って arq に指示し
ます。図 3 のアーキテクチャーの図では 3 つのソースのデータを組み合わせることになってい ますが、これらのデータを組み合わせるための特別なユーティリティーは必要ありませんでし た。build.bat バッチ・ファイルによって、これらの --data パラメーターを 4 つ、arq を呼び出す
コマンドラインに単純に追加しています (4 番目のパラメーターは企業名で構成されるファイル用 です。このファイルは相互参照を容易にするためにアプリケーションによって作成されます)。リ スト 2 は build.bat バッチ・ファイルの行のうち、その処理を行うための行を示しています (ここ ではスペースの関係で分割しています)。この行で、さまざまな引数を使って Java プログラムを呼 び出し、その結果を reportData.xml ファイルにリダイレクトします。
リスト 2. arq コマンドによって、データ・ソース、SPARQL クエリーを実行する場
所、結果のフォーマットを指定する
java -cp %CP% arq.arq --results=XML --query=PickDataForReport.spq
--data=analystRecs.rdf --data=coNamesWithLangTags.n3 --data=quoteData.rdf --data=dbpedia.n3 > reportData.xml
SPARQL Query Results XML Format とはどんなものなのでしょう。SPARQL に関する議論のほとん どは問い合わせ言語 (Query language) とプロトコル (Protocol) に焦点を絞っており、SPARQL と いう名前の Q と P はそれに由来しています。SPARQL Query Results XML Format は SPARQL クエ リー・プロセッサーによって返されるデータの XML 構造を定義するための、独立した仕様です (「参考文献」を参照)。このフォーマットは非常に単純であり、比較的単純な XSLT スタイルシー トによって十分処理することができます。そこで今度は build.bat バッチ・ファイルの最終ステッ プとして、最終的な HTML レポートを作成する方法を説明します。
レポートを生成する
多用途の XML
最近の電子出版システムで中心的に使われている媒体は XML であり、この記事のプロ ジェクトの XML によって、単なる HTML への変換以上のさまざまなことが可能です。例え ば、W3C の XSL-FO 標準を使用することで XSLT スタイルシートを作成して PDF バージョン を作成したり、SONY の e-Book リーダーや iPhone、iPad などで読むのに適した epub 電子 書籍作成したり、あるいは XML ベースのデータベースに XML を保存し、あとで XQuery を 使ってクエリーを実行したりすることもできます。このプロジェクトの最も困難な部分、つまり 3 つのソースからデータを抽出し、それらを 組み合わせて典型的なツールで使用できるフォーマットにするという部分は既に終了して
おり、その部分はそれほど難しくはありませんでした。残っているのは、最後のステップで 生成された XML を HTML に変換することですが、build.bat バッチ・ファイルでは、それを SPARQLXML2HTML.xsl という XSLT スタイルシートを使って行います。クエリー・エンジンによっ て返される XML は通常のテーブル形式の構造を持っているため、スタイルシートに必要なもの を見つけ、analystReport.html レポートを作成するのは非常に容易です。(私はオープンソースの C ライブラリー libxslt に含まれている xsltproc という XSLT プロセッサーを使用してスタイル
シートを適用しました。xsltproc の代わりに Xalan または Saxon を使用するためには、コマンド
ラインでパラメーターの順序を変更するだけでよいのです。)
クエリーの結果が SPARQL Query Results XML Format 仕様に準拠する場合、その結果は 1 つの大き な sparql 要素であり、ヘッダー情報は head 要素の中に、実際の結果は results 要素の中にあり
ます。results 要素には結果の各行を表す result 要素があり、各 result 要素にはその行の各値
を表す binding 要素があります。 リスト 3 は result 要素を処理するための、SPARQLXML2HTML.xsl の XSLT スタイルシートのテン プレートを示しています。
リスト 3. result 要素を処理するための XSLT スタイルシートのテンプレート
<xsl:template match="s:result"> <tr><td colspan="3"><hr/></td></tr> <tr> <td><xsl:apply-templates select="s:binding[@name='coName']"/></td> <td colspan="3"><xsl:apply-templates select="s:binding[@name='tickerSymbol']"/> $<xsl:apply-templates select="s:binding[@name='lastPrice']"/> at <xsl:apply-templates select="s:binding[@name='quoteDateTime']"/> </td> </tr> <tr> <td><b>2009 figures:</b></td> <td> <b>Revenue </b> <xsl:apply-templates select="s:binding[@name='revenue']"/> </td> <td> <b>Net Income </b> <xsl:apply-templates select="s:binding[@name='netIncome']"/> </td> </tr> <tr> <td colspan="3"> <xsl:apply-templates select="s:binding[@name='abstract']"/> </td> </tr> <tr class="rec"> <td> <b>Analyst </b> <xsl:apply-templates select="s:binding[@name='analyst']"/> </td> <td> <b>Recommendation </b> <xsl:apply-templates select="s:binding[@name='recommendation']"/> </td> <td><b>Date </b> <xsl:apply-templates select="s:binding[@name='recDateTime']"/> </td> </tr> <tr> <td colspan="3"> <xsl:apply-templates select="s:binding[@name='description']"/> </td> </tr> </xsl:template> リスト 3 のテンプレートによって HTML の表の 1 つの行が作成され、その行の各セルは、返され た情報、またはその情報のラベルを保持します。
ドライバー・バッチ・ファイル
build.bat バッチ・ファイルは以上のすべてを以下の 10 ステップで結合します。1.arq ユーティリティーが含まれるように Java のクラスパスを設定します。この行は、ARQROOT
環境変数が arq ユーティリティーのホーム・ディレクトリーに設定されていることを前提と
しています (arq のドキュメントに関しては「参考文献」を参照してください)。
2. Python スクリプト xls2rdf.py を使用してスプレッドシート analystRecs.xls からデータを読み取 り、RDF として analystRecs.rdf ファイルに保存します。
3.arq と、augmentAnalystRecs.spq ファイルに保存された SPARQL クエリーによって
analystRecs.rdf から企業名を読み取り、coNamesWithLangTags.n3 というファイルを作成しま す。coNamesWithLangTags.n3 には、各企業名に en という言語タグが含まれています。その
ため、企業名と DBpedia データとを容易に相互参照することができます。
4. XSLT スタイルシート MakeGetTickerInfo.xsl を analystRecs.rdf に適用し、getTickerInfo.bat というバッチ・ファイルを出力します。この getTickerInfo.bat バッチ・ファイルによって Yahoo! のサービスから株価データを取得します。
5. getTickerInfo.bat を実行すると、このバッチ・ファイルが Yahoo! のデータを quoteData.csv と いう CSV ファイルとして取得します。
6. Perl スクリプト yahooCSV2RDF.pl を実行し、quoteData.csv ファイルを quoteData.rdf という RDF ファイルに変換します。
7. XSLT スタイルシート MakeGetDbpediaData.xsl を analystRecs.rdf に適用し、DBpedia から企業 データを取得するバッチ・ファイル、getDbpediaData.bat を作成します。このバッチ・ファ イルの各行で cURL を呼び出し、引数として URI を渡します (この URI には、1 つの企業の データを取得するための SPARQL クエリーが埋め込まれています)。 8. バッチ・ファイル getDbpediaData.bat を実行し、その出力を dbpedia.n3 ファイルに配置しま す。 9. 先ほど作成された 4 つのデータ・ファイル (analystRecs.rdf、quoteData.rdf、coNamesWithLangTags.n3、dbpedia.n3) に対して PickDataForReport.spq の SPARQL クエリーを実行し、その結果の XML バージョンを reportData.xml に含めるようにします。 10. XSLT スタイルシート SPARQLXML2HTML.xsl を reportData.xml ファイルに適用し、最終的なレ ポート・ファイル analystReport.html を作成します。
他のツールでも、これらのステップの一部を統合したり自動化したりすることで、もっと単純に 同じアーキテクチャーを実装できるかもしれません。しかし基本として必要な作業は同じです。
アプリケーションを拡張する
3 つのソースのデータを組み合わせ、9 つの企業に関する 1 つのレポートを作成するという例 は、ここで説明した手法の使い方としては非常に規模の小さなものです。オープンソースの D2RQ インターフェースを使用するとリレーショナル・データをトリプルの集合として扱え るため、ここで使用したデータを前述のアプリケーションに取り込むことができます。例え ば、顧客の株式ポートフォリオに関するデータをリレーショナル・データベース・システム (MySQL、DB2、Oracle など) に保管する金融機関を考えてみてください。この記事で説明したア プリケーションに少し追加するだけで、その金融機関は analystReport.html と同じようなカスタマ イズしたレポートを顧客ごとに生成することができます (例えば、その顧客の保有している株式 と、(Yahoo! から取得した株価を持ち株数と掛け算して得られる) 最新時価だけが含まれたレポー トなど)。 このアプリケーション自体には、RDF Schema も OWL オントロジー言語も必要ありません。ただ し、そうしたスキーマのメタデータも同じくトリプルに保存されるため、スキーマのメタデータ を取り入れる必要がある場合には、それをもう 1 つの入力として、上記で組み合わせたデータを 強化し、レポートを作成することができます。ルールや、何と何が等価であるか、あるいはその 他の関係についてのメタデータを、コンパイル対象のコードに含めるのではなく、スキーマ標準 を使って保存すると、ビジネス・ロジックの保守が容易になり、移植性も高まるというメリット があります。 Linked Data ソースの世界が拡大するにつれ、より多くのデータをアプリケーションに組み込むこ とができるようになります。またセマンティック Web 標準によって新たな柔軟性が生まれ、そ うしたデータと他のデータ・ソースとをうまく組み合わせられるようになります。また多くの企 業では、これらの標準に準拠するツールとして、企業の各組織にばらばらに存在するデータを組 み合わせた上で公開するのに役立つツールを探しています。そうした作業を容易に行えるツール はありますが、この記事で説明したように、おなじみで信頼性の高い使い古したツールや手法で あっても、そうしたデータを有用な新しい方法で組み合わせる上では重要な役割を果たすことが できます。ダウンロード
内容 ファイル名 サイズ
著者について
Bob DuCharmeBob DuCharme は、セマンティック Web アプリケーションのモデリング、開発、デ プロイのためのソフトウェアを提供する TopQuadrant のソリューション・アーキテ クトです。彼は 4 冊の本を執筆しており、また情報技術に関するオンライン記事や印 刷記事を 100 本近く執筆していますが、そのどこにも「functionality」という単語を 使っていません。彼のブログ、http://www.snee.com/bobdc.blog を見てください。 © Copyright IBM Corporation 2010 (www.ibm.com/legal/copytrade.shtml) 商標 (www.ibm.com/developerworks/jp/ibm/trademarks/)