共変量の調整について
第9回
Armitage
勉強会
土居正明
1
はじめに
1.1
本稿の内容
本稿では「共変量の調整」のごく一部を扱います。交絡している共変量、交絡はしていないけれど影響のある共変量、の 2つに対して、モデルを用いた調整(共分散分析)をする場合としない場合(t検定)にどのような違いがあるのかを、具体 例を通して見ていきます。なお、共変量としては、応答変数と直線関係があるもののみを扱います。最後に「背景因子の各 項目に関して群間比較の検定を行って、有意差のついたもの(の中のめぼしいもの)を共変量として調整する」という、た まに行われている方法の是非についての個人的見解を述べます。1.2
注意点
本稿のデータは全て架空データです。「実際のデータはこんな関係にはならない」ということをご存知の方は教えてくだ さい。また、本文中では図表を作成するSASプログラムは省略して、補足でProc GLMのオプションをいつくかご紹介し ます。 また、検定は基本的に両側検定です。2
交絡
2.1
例
1:調整すると影響がなくなる例(交絡その
1)
2.1.1 性別ごとの収縮期血圧プロット まず、具体例をみていきましょう。以下は、男女50人ずつの収縮期血圧を性別ごとにプロットしたものです。 図1 性別ごとの収縮期血圧のプロットこのプロットから「性別によって収縮期血圧が異なる」と言えるでしょうか? 参考のために、このデータに対してt検定 で性別の差を検討した結果も載せておきます。 統計量 平均の 平均の 変数 sex N 信頼限界の 平均 信頼限界の 標準偏差 標準誤差 最小値 最大値 下限 上限 y 女性 50 116.45 119.6 122.75 11.071 1.5657 93.906 154.32 y 男性 50 127.27 130.7 134.13 12.072 1.7073 102.68 163.37 y Diff (1-2) -15.7 -11.1 -6.504 11.582 2.3165 t検定 変数 手法 分散 自由度 t値 Pr>|t| y Pooled Equal 98 -4.79 <.0001 標本平均は男性130.7に対して女性119.6であり、11.1違います。また、t検定のp値は0.0001より小さく、有意水準 0.05で十分に有意差があります。これより、男性の方が血圧が高いのではないか? という気がしてきましたでしょうか。 2.1.2 体重のプロット さて、ここでふと「血圧は体重に影響を受けるはずだ」と思ったとします。そして、さらに「男性の方が体重が重いので は?」と思ったとしましょう。そこで、次に 性別ごとに体重のデータをプロット してみることにします。 図2 性別ごとの体重のプロット 男女でだいぶ違いがあるようですね。ついでにt検定もしてみましょう。
統計量 平均の 平均の 変数 sex N 信頼限界の 平均 信頼限界の 標準偏差 標準誤差 最小値 最大値 下限 上限 x 女性 50 48.883 50.214 51.546 4.6862 0.6627 41.734 66.356 x 男性 50 53.785 55.262 56.74 5.1979 0.7351 44.028 65.512 x Diff (1-2) -7.012 -5.048 -3.084 4.9486 0.9897 t検定 変数 手法 分散 自由度 t値 Pr>|t| x Pooled Equal 98 -5.10 <.0001 標本平均は男性の方が5kgくらい重く、p値は0.0001より小さいですので、有意水準0.05で考えても有意です。このよ うに、男女の間で体重の分布が異なっているようです*1。そして、この結果から「男性の方が収縮期血圧が高いのは、単に 男性の体重が重いことの影響で、性別はそれほど重要ではないのでは?」という疑問が出てきたとしましょう。 2.1.3 体重で調整したプロット 上の疑問を受けて、縦軸は収縮期血圧のままで、横軸に体重をとってプロット してみることにします。 図3 体重で調整した収縮期血圧のプロット この図から、性別に関わらず収縮期血圧と体重の関係は同じ直線で表されるように見えます。つまり、「収縮期血圧に とって重要なのは体重であり、性別は本質的要因ではなさそう」という気がしてきます。 では続いて、体重を共変量として調整した共分散分析 を行ってみましょう。結果は以下のようになります*2。 *1男女の間での体重の分布が異なるかどうかについて今回は検定をしていますが、有意差があることと男女間で体重の分布が(医学的に意味があるく らい)異なることは必ずしも一致しません。有意差がある場合は「同じではない」とは言えますが、「どのくらい違うか」については推定の結果を 見てみないと分かりませんし、また検定の一般論から、有意差がないからといって「同じ」とも言えません。ですが、有意差は「重要な情報の1つ」 にはなりますので、推定の結果などから総合的な判断をするための道具としていただくのがよいかと思います。 *2ここで重要な注意点ですが、共変量が両群で「ずれすぎている」ときに共分散分析は妥当ではないといわれています。この点は、補足でさらにくわ しく述べます。
変動因 自由度 平方和 平均平方 F値 Pr>F Model 2 12613.94771 6306.97385 169.29 <.0001 Error 97 3613.73757 37.25503 Corrected Total 99 16227.68528 変動因 自由度 Type III平方和 平均平方 F値 Pr>F sex 1 21.372367 21.372367 0.57 0.4506 x 1 9533.205941 9533.205941 255.89 <.0001 性別「sex」のp値は0.4506となり、体重で調整した結果、有意差がなくなってしまいました。一方、体重「x」の方には 有意差があります。性別に「有意差がない」ことで「性別の影響がない」という言い方をするのは言いすぎですが、それで も図3と一緒に見てみますと、「性別よりも体重の方が重要な因子である」ということは明らかでしょう。
さらに、推定の結果も見てみましょう。model分に”/ solution clparm”を加えると、以下の出力が得られます*3。
パラメータ 推定値 標準誤差 t値 Pr>|t| 95%信頼限界 Intercept 20.55955993 B 6.93919926 2.96 0.0038 6.78717027 34.33194959 sex女性 -1.04010430 B 1.37322916 -0.76 0.4506 -3.76558405 1.68537544 sex男性 0.00000000 B . . . . . x 1.99305978 0.12459289 16.00 <.0001 1.74577737 2.24034219 Note:X’Xは特異行列です。正規方程式には、一般化逆行列が使用されています。 文字’B’が付けれられた推定値は、一意的な推定値ではありません*4。 このとき、性別のところの値は「体重xで調整した性別の影響」です。つまり、今の場合 体重が同じ場合の性別の影響 と いうことになります。いま、この「体重で調整したあとの性別の影響」は男女間で1.04しか異なりません。血圧で1.04の違 いというのは誤差だと考えるのが妥当だと思われます。したがって、推定の結果まで考慮しても「体重を考慮するなら、性別 は重要な因子ではなさそう」という風に考えられるでしょう*5。なお、今回のデータは架空データですので、医学的結論を 100%は信頼しないでください。 *3”solution”がパラメータ推定値などを、”clparm”がそれに加えて 95 %信頼区間を出力します。共分散分析のプログラムの全文は補足に示しました。 *4この Note を大まかにご説明します。今回はたとえば男女の影響を推定する際「男性=0」という制約条件を入れて考えています。ですが、別の制 約条件、たとえば「男性+女性= 0」を入れて推定することもでき、その場合は推定値が別の値になります。このように’B’ がついている推定値は、 制約条件の入れ方によって値が変わるのです。 *5少し回りくどい言い方をしていますが、性別と体重の間には常にそこそこ強い相関があると思われますので、このデータをもとに「男性に高血圧対 策が必要」という観点での医療政策を考えるのは「間違い」とは言えないと思います。男性を選んだ結果、重要な要因である「体重」の重い人が結 果的にそこそこ多く選ばれることになるからです。ですが、そうすると大雑把に考えて「体重の軽い男性」には無駄ですし、「体重の重い女性」は 恩恵にあずかることができません。ですので、「性別ではなく体重が重い人に高血圧対策が必要」という政策の方が「より正しい」政策だと思われ ます。個人的見解としては、このように「正解は何か(○か×か)」ではなくて、「より妥当なのは何か (better なのはどちらか)」を探るのが統計学 の基本的な姿勢だと思います。「どのモデルを用いるべきか」などの問題についても同様で、「正しいモデル」と「間違ったモデル」があるのではな く、「より妥当なモデル」と「他と比較して妥当でないモデル」がある、という風に考えるのがよいのではないかと思います。つまり、「あるモデル を用いるのが本当はよいけれど、当てはめが難しいなどの理由で仕方なく別のモデルを用いる」などの状況で「仕方なく」別のモデルを用いた場 合、その結果を「間違い」と判断するのではなくて、「結果に十全の信頼は置かないけれど、それなりに意味のある解析」と考えるのがよいのではな いか、ということです。ある意味で大変当たり前のことですが、このようなことを統計を担当されない方に対して明確に言語化して説明できるよう になっておくことが、統計家にとって大変重要だと考えていますので、念のため書いておきます。具体例を挙げますと、たとえば薬物動態の解析 で、「主要な解析ではモデルによらない解析が普通なのに、PPK(母集団薬物動態解析)ではモデルを使うのが普通ですけど、そんなことしていい んですか?」という質問をされたときに、きちんとお返事ができるようになっておきましょう、ということです。
2.1.4 t検定と共分散分析の比較 上で見ましたt検定と共分散分析の結果を表にしてまとめておきましょう。 手法 男女の差(絶対値) 標本標準偏差 有意差 t検定 11.1 11.6 あり 共分散分析 1.0 6.1 なし このように、男女の差がt検定の場合では11.1もあったのですが、実はこのうちの多くは体重の影響でした。体重を調整 してやった結果、男女差は1.0程度の違いになってしまい、男女間の有意差が消えてしまったのでした。なお、ここで共分 散分析のところの標本標準偏差*6は、共分散分析の分散分析表の”Error”の”平均平方”のところの値のルートをとってやった ものになります。つまり、√37.3 = 6.1となります*7。 2.1.5 まとめ 例1をまとめます。今回は、「収縮期血圧を性別ごとにプロット」してみると、性別によって収縮期血圧の値が異なってい るようでした。ですが、「体重が収縮期血圧と関係あるのでは?」という疑問が浮かびました。さらにこのとき、体重の性 別による分布が異なっているようでした。そこで「収縮期血圧に影響があるのは性別よりもむしろ体重では?」と思い、体 重を横軸にとって男女別にプロットしてみると、男女ともにほぼ同じ直線上にありました。そこで、「体重の影響を調整し た、収縮期血圧の性別間の差」を共分散分析で見ていきますと、性別間の有意差はなくなってしまいました。このように、 性別の差だと思われていたものの、大部分は体重の影響だと解釈できました。 雑な言い方をしますと、このように収縮期血圧と性別の関係を考えているときに、両群でアンバランスな「体重」という因 子が結果をゆがめてしまっているような場合、「収縮期血圧と性別の関係に体重が交絡している可能性がある」と言います。
2.2
例
2:調整すると影響がでてくる例(交絡
2)
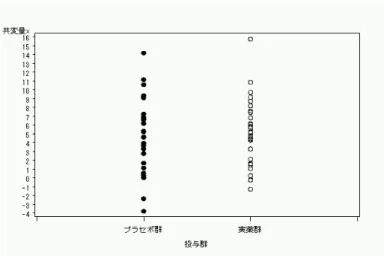
では次の例です。今度は薬剤の効果を見る比較試験の場合を考えます。応答変数yの値は小さい方がよい としましょう。 例1と同じく各群50例ずつです。 2.2.1 応答変数の群ごとのプロットとt検定 群ごとのプロットは以下の通りです。 図4 投与群ごとの応答変数yのプロット *6「標本」という言葉は、データから得られた推定値であることを強調するためにつけています。 *7別の言い方では、”Error”の”平均平方”の部分の値が分散の推定値となる、ということです。どちらでもほぼ同じに見えますね。t検定で群間を比較してみますと、 統計量 平均の 平均の 変数 dose N 信頼限界の 平均 信頼限界の 標準偏差 標準誤差 最小値 最大値 下限 上限 y プラセボ群 50 22.957 25.474 27.991 8.8567 1.2525 8.7731 48.316 y 実薬群 50 23.48 26.181 28.881 9.5022 1.3438 0.147 47.26 y Diff (1-2) -4.352 -0.706 2.9391 9.1851 1.837 t検定 変数 手法 分散 自由度 t値 Pr>|t| y Pooled Equal 98 -0.38 0.7014 このように、群間の標本平均の差は0.7くらいで標準誤差は1.8くらいですので、両群には誤差程度の違いしかなさそう です*8。t検定のp値は0.7014ですので、有意水準0.05で有意差とは程遠い結果となっています。ここまでの情報だけで は、両群に違いはなさそうに思えます。 2.2.2 共変量の分布 さて、ここで例1と同様に「ある共変量xが応答変数yに影響を与えているかも」と思ったとします。そして、「共変量 xが両群で偏っていないか」が気になったとします。この共変量xを群ごとにプロットしてみましょう。 図5 投与群ごとの共変量xのプロット だいぶ偏りがあります。先ほどとは逆に、「この共変量の偏りが、実際には存在する実薬の効果を覆い隠している」可能 性が出てきます。先ほどと同様に、念のためxの群間差をみるt検定の結果も載せておきましょう。 *8標準偏差は「データのばらつき」で、標準誤差は「標本平均のばらつき(標本平均の標準偏差)」です。今興味があるのは「標本平均の値にどの程度 信頼がおけるか」ですので、標準偏差でなく標準誤差で「0.7 という値の信頼性」を考えます。また、有意差だけでなく推定値の値自身を考えるこ とも重要です。
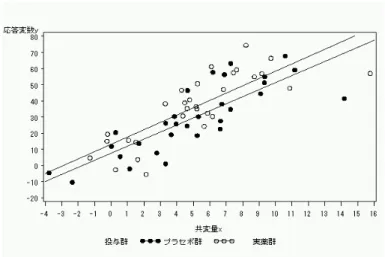
統計量 平均の 平均の 変数 dose N 信頼限界の 平均 信頼限界の 標準偏差 標準誤差 最小値 最大値 下限 上限 x プラセボ群 50 4.4943 5.3135 6.1328 2.8828 0.4077 -0.383 11.332 x 実薬群 50 6.8843 7.7772 8.6702 3.1419 0.4443 -1.424 14.269 x Diff (1-2) -3.66 -2.464 -1.267 3.0151 0.603 t検定 変数 手法 分散 自由度 t値 Pr>|t| x Pooled Equal 98 -4.09 <.0001 となり、やはり共変量xは有意水準0.05で有意差がつくほど両群に偏りがあります。 2.2.3 共変量で調整した解析 では、この共変量で調整してみましょう。縦軸に応答変数y、横軸に共変量xを持ってきてプロットします。 図6 共変量xで調整した応答変数yのプロット 明らかに、実薬群の方が下にあります。今、応答変数は「小さい方がよい」ですので、図4から共変量xの分布が両群で 偏っていたために実際の薬効が過小評価されて、群間差がないように見えた、のではないかと思えてきます。 実薬群の方が下にあることは大体分かりましたが、この差が「(誤差的なばらつきを考慮しても)十分な差」なのかどうか は図だけでは分かりません。共変量で調整した共分散分析も行っておきましょう。 変動因 自由度 平方和 平均平方 F値 Pr>F Model 2 7533.384392 3766.692196 489.13 <.0001 Error 97 746.977786 7.700802 Corrected Total 99 8280.362178
変動因 自由度 Type III平方和 平均平方 F値 Pr>F
dose 1 889.212565 889.212565 115.47 <.0001
x 1 7520.909275 7520.909275 976.64 <.0001
となります。薬剤群doseにも共変量xにも有意差がついています。これで「薬剤の影響」が「ある」ことは分かりまし
た。次に、その影響が「医学的に意味があるか」を判断するには推定値が必要になりますので、推定値を出力してみましょ う。例1と同様にmodel文に”/solution clparm”を付け加えると、以下の出力が得られます。
パラメータ 推定値 標準誤差 t値 Pr>|t| 95%信頼限界 Intercept 3.584008459 B 0.82270482 4.36 <.0001 1.951167133 5.216849786 doseプラセボ群 6.451886876 B 0.60041554 10.75 <.0001 5.260228231 7.643545521 dose実薬群 0.000000000 B . . . . . x 2.905497330 0.09297224 31.25 <.0001 2.720973175 3.090021485 Note:X’Xは特異行列です。正規方程式には、一般化逆行列が使用されています。 文字’B’が付けれられた推定値は、一意的な推定値ではありません。 これより、各群の応答変数yを共変量xで表した関係式は プラセボ群:y = 3.58 + 6.45 + 2.91x (= 10.03 + 2.91x) 実薬群 :y = 3.58 + 2.91x (= 3.58 + 2.91x) となります*9。この式は「共変量xが同じ人を考えた場合、実薬群はプラセボ群より6.45小さくなります」「共変量xが1 増加すると、応答変数yは2.91増加します」ということを示しています。 さて、この式は共変量xの入った式であまり見易くはありません。そこで、「xに全体の平均値x¯を代入してやって、両 群を1つずつの数値で代表させよう*10」と考えます。これが、最小2乗平均です。いま、xの全体での平均をProc MEANS で求めると 分析変数: x共変量x N 平均 標準偏差 最小値 最大値 100 6.5453926 3.2452716 -1.4236279 14.2692448 となりx = 6.55¯ ですので、各群の最小2乗平均 は プラセボ群:y = 3.58 + 6.45 + 2.91ˆ · ¯x = 3.58 + 6.45 + 2.91 · 6.55≒29.1 実薬群 :y = 3.58ˆ + 2.91· ¯x = 3.58 + 2.91· 6.55≒22.6
となります。Proc GLMでは、modelステートメントの下にlsmeansステートメント”lsmeans dose;”を付け加えることで、
以下の出力が得られます*11。 最小2乗平均 dose yの最小2乗平均 プラセボ群 29.0535160 実薬群 22.6016291 *9各群別々の回帰直線でなく、平行な直線を当てはめて「2 群同時の回帰直線」です。 *10群ごとの平均ではないところに注意してください。 *11正確なプログラムは、補足を参照してください。
有効数字の影響で、手計算は少し大雑把に表示していますが、大体一致しています。 2.2.4 t検定と共分散分析の比較 t検定と共分散分析の結果を表にしてまとめます。 手法 群間差(絶対値) 標本標準偏差 有意差 t検定 2.5 3.0 なし 共分散分析 6.5 2.8 あり 今度は例1とは逆で、t検定では群間差が2.5しかなかったですが、実はそれは共変量xが両群で偏っていたことが原因で、 xで調整してやると群間差が6.5まで大きくなり、有意差がつきました。また、共分散分析の標本標準偏差は、例1と同じ く分散分析表の”Error”の”平均平方”のところのルートをとって、√7.7 = 2.8です。 2.2.5 まとめ 例2をまとめます。今回は最初の例とは逆で「投与群ごとのyプロットでは両群に差はなさそう」だったのが、「共変量 xの群間の分布に差があり」結果として、「共変量xの影響を調整すると、投与群間の差が出てきた」ことになります。 このような場合も、「応答変数yに対する投与群の影響に対して、共変量xが交絡していた可能性がある」と言います。
2.3
交絡とは
では、上の2つの例をもとに「交絡とは何か?」を考えていきましょう。ただ、厳密な定義は大変ですので、19BioSの資 料「カテゴリカルデータ解析(2)」(寒水先生)から、交絡の 必要条件 を引用させていただくことにします*12。 (1)応答変数に因果的に影響する:リスク要因 (2)比較する集団間で分布が異なる:不均衡 (曝露要因と交絡要因に関連がある) (3)因果連鎖の中間にない です。(1), (2)については、例1・例2ともに明らかでしょう。(3)は少し意味が分かりづらいと思いますので、ご説明し ます。 たとえば、そこそこ血圧の高い人たちを集めて、「食事療法を行う群」と「無処置群」に分けて「脳卒中の発生割合」を比 較することを考えたとします。このとき、食事療法の影響としては、「まず血圧が下がって、その結果として脳卒中のリス クが減少する」という関係が考えられます。つまり、 「食事療法」→「血圧低下」→「脳卒中リスク減少」 という因果関係です。このとき「血圧低下」は「食事療法の結果」ですので、これは「治療効果の一部」です。交絡要因は「説 明変数」つまり「原因」の側ですので、このような「結果の一部」を持ってくるのは妥当ではない と判断されて、「交絡要 因ではない」とみなされるのです*13。 くり返しになりますが、ここで挙げたのは交絡の「定義」ではありません。ですが、直感的に理解していただくには、(1) ∼(3)の方がよいと思い、ここではそれに留めることにします。 *12原著をチェックしていないので孫引きで申し訳ないのですが、寒水先生のテキストにはこの条件の引用元はGreenland, S. and Robins, J. M. Identifiability, exchangeability, and epidemiological confounding. International Journal of Epidemiology 1986;15:413-419.
Rothman, K. J., Greenland, S. Modern Epidemiology, 2nd ed. Philadelphia: Lippincott and Raven, 1998.
と書いてあります。
3
例
3
:交絡していないが影響のある共変量
さて、ランダム化比較試験 ではランダム化を行いますので、理想的には両群の背景情報などはバランスがとれるはずで す*14。そう考えると、上のように「背景の分布が異なっているとき」というのは、ランダム化比較試験ではそれほど多くな いと思われます*15。 では次に、先ほどの 交絡の条件(2)を除いた場合、つまり、共変量xが、リスク要因ではあるものの両群でバランスがと れている場合を考えてみましょう。 まずは、応答変数yをプラセボ・実薬両群60例ずつプロットしてみます。今回はyは大きい方がよいとします。 図7 応答変数yの群ごとのプロット では、前と同じように応答変数yに対して群間比較のt検定を行います。 統計量 平均の 平均の 変数 dose N 信頼限界の 平均 信頼限界の 標準偏差 標準誤差 最小値 最大値 下限 上限 y プラセボ群 60 23.937 29.459 34.98 21.374 2.7594 -10.42 67.793 y 実薬群 60 30.817 36.236 41.654 20.975 2.7078 -5.529 74.552 y Diff (1-2) -14.43 -6.777 0.8789 21.176 3.8661 t検定 変数 手法 分散 自由度 t値 Pr>|t| y Pooled Equal 118 -1.75 0.0822 標本平均は両群で6.8くらい違います。実薬群のほうが大きいように見えるものの、p値は0.0822と、有意水準0.05で は有意差はありません。では次に、この 応答変数yに影響を与えることが分かっている共変量xを考えます。投与群ごと にプロットしてみると、 *14現実的には、必ずしもきちんとバランスがとれているとは限りません。 *15逆に、疫学ではランダム化が難しい場合も多いですので、交絡をどう調整するかが死活的に重要になってきます。図8 共変量xの群ごとのプロット となり、1∼2点気になる点があるものの、大体両群でバランスがとれています。t検定してみると、 統計量 平均の 平均の 変数 dose N 信頼限界の 平均 信頼限界の 標準偏差 標準誤差 最小値 最大値 下限 上限 x プラセボ群 60 3.962 4.994 6.026 3.9949 0.5157 -3.765 14.197 x 実薬群 60 4.2014 5.1546 6.1078 3.6898 0.4763 -1.273 15.766 x Diff (1-2) -1.551 -0.161 1.2297 3.8454 0.7021 t検定 変数 手法 分散 自由度 t値 Pr>|t| x Pooled Equal 118 -0.23 0.8194 であり、標本平均の差は0.16しか違いませんし、検定の結果からみても差があるようには見えません。では、今度は縦軸 をy、横軸に共変量xをとってプロットしてみます。すると、
図9 共変量xで調整した応答変数yのプロット となります。かなり重なっていて分かりづらいですので、群ごとに別々に回帰直線を引きました。すると、「大体平行」 「実薬群の方が上にあるっぽい」ことが分かります*16。ですが、この2本の直線の間に(データのばらつきを考慮したうえ で)十分な差があるかどうかは、やはり直感的には分かりにくいですので、共分散分析で比較してみます*17。 変動因 自由度 平方和 平均平方 F値 Pr>F Model 2 35916.53973 17958.26986 114.36 <.0001 Error 117 18373.02321 157.03439 Corrected Total 119 54289.56294 変動因 自由度 Type III平方和 平均平方 F値 Pr>F dose 1 1102.09815 1102.09815 7.02 0.0092 x 1 34538.70408 34538.70408 219.94 <.0001 となり、投与群の影響「dose」の部分のp値は0.0092となり、有意水準0.05で有意差がつきました。推定値は パラメータ 推定値 標準誤差 t値 Pr>|t| Intercept 13.30234710 B 2.23796616 5.94 <.0001 doseプラセボ群 -6.06241693 B 2.28840583 -2.65 0.0092 dose実薬群 0.00000000 B . . . x 4.44910146 0.29999683 14.83 <.0001 Note:X’Xは特異行列です。正規方程式には、一般化逆行列が使用されています。 文字’B’が付けれられた推定値は、一意的な推定値ではありません。 *16今回は y は「大きい方がよい」ですので、これは「実薬群が効いている」ことを示しています。 *17共分散分析では両群に「傾きの同じ直線」を当てはめて、その差を検討します。今回は、別々に回帰直線を当てはめても、「大体平行」ですので、大 体上の図の 2 本の直線の差に一致します。
となり、両群に平行線を当てはめると プラセボ群:y = 13.30− 6.06 + 4.45x (= 7.24 + 4.45x) 実薬群 :y = 13.30 + 4.45x (= 13.30 + 4.45x) となります。共変量xが共通なときの群間差は6.06となります。共変量xの両群合わせた平均をProc MEANSで出力し ますと 分析変数: x共変量x N 平均 標準偏差 最小値 最大値 120 5.0743056 3.8300419 -3.7646217 15.7657095 より、x = 5.07¯ となります*18。これより最小2乗平均は プラセボ群:y = 13.30ˆ − 6.06 + 4.45¯x = 13.30 − 6.06 + 4.45 · 5.07≒29.80 実薬群 :y = 13.30ˆ + 4.45¯x = 13.30 + 4.45· 5.07≒35.86 となります。SASでは、model文の下に”lsmeans dose; ”を付け加えることで、
最小2乗平均 dose yの最小2乗平均 プラセボ群 29.8160306 実薬群 35.8784476 と出力されます。
3.1
t
検定と共分散分析の比較
t検定と共分散分析の結果をまとめます。 手法 群間差(絶対値) 標本標準偏差 有意差 t検定 6.8 21.2 なし 共分散分析 6.1 12.5 あり 今回は、t検定を共分散分析に変更した場合、群間差は逆に少し小さくなりました。ですが、標本標準偏差の減少が大きい ため、共分散分析では有意差がついたわけです。また、先と同様標本標準偏差は分散分析表の”Error”の”平均平方”のルート で√157.0 = 12.5です。3.2
まとめ
まとめます。今回は、共変量を考える前に応答変数yには有意差はありませんでした。そこでyに影響を与える共変量x を考え、その群間での分布を考えてみたところ、共変量の分布はほとんど同じでした。それでも、共変量xで調整した共分 散分析を考えると、投与群間で差があるという結果になりました。3.3
バイアスと精度の意味
上の例の結果を解釈するために、バイアスと精度という言葉を大雑把にご説明します。 *18くり返しになりますが、「両群合わせた平均」です。「バイアスがない(=不偏である)」とは、要は「たくさん試験をくり返して毎回ある推定値を計算して、その『推定値の 標本平均』を考えると、ほぼ真の値に一致する」ということです。逆に「バイアスがある」というのは、「たくさん試験をく り返して毎回推定値を計算して、その推定値の標本平均を考えても、真の値との間にずれがある」ということです*19。 例1・例2では、体重で調整しない場合、男女差(群間差)にバイアスが入っていたのです。 一方、「精度」とはバラツキの大きさのことで、表現を変えると「結果の再現性」のことです。「精度がよい」つまり、バ ラツキが小さいということは、「次に同じ試験を繰り返しても大体同じような値が出やすい」ということです。したがって、 再現性が高く、その値自身が信頼のおけるものとなります。 例3では、群間差にバイアスはほとんどないようですが、図7のような単純な群ごとのプロットでは「バラツキ」と思わ れていたものの一部が、実は「共変量xの影響」と考えられ、「本来のバラツキはもっと小さかった」ということになったの です。それにより群間差の推定値はほぼ同じでも、バラツキの小ささからこの値の信頼性が高くなり、結果として有意差が 得られたわけです*20。つまり「共変量xで調整したことで精度が上がって有意差が得られた」ということです。
4
全体のまとめ:背景因子の検定について
では全体のまとめとして、「背景因子の各項目について群間比較の検定をして、有意差がついたものを共変量として扱う」 というやり方の是非について検討しましょう。 まず、結論から述べます。今までの内容を理解されている方には容易に同意していただける方が多いと思うのですが、 このような調整方法は妥当ではない というのが私の意見です。というのは、今まで見てきました通り、「両群に不均衡があ ろうが無かろうが、応答変数に影響を与える因子は調整して解析する方がよい」からです。 つまり、応答変数に影響のある共変量を用いないで解析した場合、 ・両群に不均衡がある場合(交絡している場合) → 群間差にバイアスが入る ・両群に不均衡がない場合 → 精度が低下する(バラツキが不当に大きくなる) となります。つまり、与える影響は異なりますが、どちらも最善とは言えない解析を行っていることになります。 逆に言いますと 共変量を用いて解析した場合 ・交絡している場合 → 群間差のバイアスの減少 ・交絡していない場合 → 精度向上(バラツキの減少) が見込めるわけです。 以上より、「ある共変量で調整を行うかどうか」の判断で重要なのは、「その共変量が応答変数に影響を与えているかどう か」であって、「両群に偏りがあるか(交絡であるか)」は本質ではない、ということになります*21。 最後に注意点をあげておきます。本稿では共変量に対して応答変数が直線的に変化する場合のみを扱いました。しかし共 変量と応答変数の関係は必ずしもこのようになるとは限りません。このようにはならない場合は、「調整して解析する」と いっても別の方法が必要になります。 *19つまり、体重が交絡している例 1 では、何回試験を繰り返しても男性の方が体重が重くなる場合がほとんどですので、t 検定では「男性の方が血圧 が高い」という偏った結論が何度も得られます。つまり、男女差にバイアスが入っていることになります。 *20つまり t 検定のときは「群間差(の推定値)は 6.8 ですけど、6.8 という値にはあまり自信がありません」という状況だったのが、x で調整してやっ た結果、「群間差(の推定値)は 6.1 ですけど、この値はそこそこ自信ありますよ」という状況に変わったのです。帰無仮説は「(群間差)=0」です ので、今回は群間差の推定値が小さくなったことよりもバラツキが小さくなったことの影響の方が大きく、共分散分析で有意差がついたのです。 *21もちろん、「交絡要因かどうか」について検討を加えることには価値がありますので、「交絡かどうかがどうでもよい」わけではありません。が、そ れは「その因子を共変量として解析に入れるか入れないか」を判断する際の本質ではない、ということです。補足
1
:
SAS
プログラミング
本稿で使用した解析を行うSASプログラムを書いておきます。データはyが応答変数、xが共変量、doseが投与群です。
共分散分析は
proc glm data=d1; class dose;
model y= dose x / solution clparm ; lsmeans dose;
run; quit;
で行います。model文中の”solution”でパラメータ推定値を算出し、パラメータの信頼区間を”clparm”で算出します。そし
て、それらを用いて投与群doseの最小2乗平均値を出すのが”lsmeans”ステートメントです。