卒業論文
「
Tweet
で降雨情報をジオコーディング」学籍番号 12D8104007G 荒井 晶弘
中央大学理工学部情報工学科 田口研究室
2016
年3
月i
■目次
第1章 序論
1.1 背景
1.2 目的
1.3 本論文の構成
第2章
2.1 概要 2.2 用語
2.2.1 アカウント 2.2.2 ツイート 2.2.3 タイムライン
2.2.4 リツイート 2.2.5 お気に入り
2.2.6 フォロー&フォロワー 2.2.7 公開/非公開設定 2.2.8 リプライ 2.2.9 ハッシュタグ 2.3 Twitter API 2.3.1 概要
2.3.2 Twitter REST API 2.3.3 Twitter Streaming API 2.3.4 OAuth認証
2.3.5 API Rate Limit 2.3.6 Twitter4J
第3章 形態素解析ツール
MeCab
3.1 形態素解析 3.2 MeCab 3.2.1 IPA辞書
3.2.3 形態素解析システム
第4章
Geocoding
第5章 提案システムii
第6章 実行結果&考察6.1 実験 6.2 考察1 6.3 データ収集
6.3.1 日本の地域別ツイート量 6.3.2 日本の地域別ユーザー数 6.3.3 天気図
6.4 考察2
第7章 結論&課題 参考文献
実装環境 付録A 図表
B
1
第1章 序論
1.1 背景
2006
年7
月にサービスを開始し、日は浅いが今では広く普及している。スマートフォンなどの携帯情報端末からの利用も盛んで、今ではどこでも使える一番 身近なコミュニケーションツール、もしくは情報収集ツールとなった。利用のしやす さからリアルタイムで身近に起こった些細なことなども「ツイート」(Twitterの用語 等は第2章で説明する)という情報として得られるようになった。そして
しかし、既存の研究は「リツイート」の拡散モデルや「ツイート」の投稿時間や使 用されるワードの変化などの研究が多いように見える。この他に「ツイート」から得 られる情報は無いか考えてみることにした。
1.2 目的
本論文では「ツイート」の情報を解析することで位置情報を取得してみたいと考え た。そして位置情報を取得することで身の回りで起こった事象に対して人が「ツイー ト」する行為が地域によって違うということが示せるのではないだろうか。
そこで、どこでも起こりうる事象を例にして解析を試みることにした。本研究では
「雨」を検索対象とすることにした。理由としては雨という事象が頻繁に起こるので 十分なツイートを取得できると考えた。また、雨がいつどこで起こったのか正確なデ ータが気象庁から簡単に手に入る。これにより雨という事象に反応し投稿した「ツイ ート」から得られた位置情報とその時刻にその場所で雨が降っていたかを参照するこ とができる。これにより「雨」が降っているにもかかわらず全く気にしない地域や、
逆に過剰に反応している地域が見えてくると考える。
また、
PHP
やRuby
でプログラムを書いているが 今回はJava
を使って取得していこうと考えている。理由の一つは使用言語が多様な方が
由は卒論は大学4年間の集大成であり、自分が学んできたことを活かす場であると考 えているので、中央大学情報工学科で学んできた
Java
の知識を活かしたいと思った2
からである。1.3 本論文の構成
第1章では序論として研究の背景と目的を述べる。第2章では本論文の研究対象で
ある
析について述べる。第4章では位置情報の取得に関するシステムについて述べる。第 5章では本研究の提案システムについて述べる。第6章では実行結果と考察について 述べる。第7章は結論と課題について述べる。
3
第2章
2.1 概要
140
字以内のテキストと写真や動画等が付属された「ツイート」を不特定多数にリアルタイムで発信し、自分が選んだ人の「ツイ ート」を受信できるサービスのことである。匿名が基本であり、オープンであるが故 に他人との繋がりを作りやすく、また気軽に「ツイート」ことができるので個々の発 信する情報は多種多様であり
2014
年10
月の2
億8400
万人であり日本国内だけで1980
万人ものユーザーがいる(http://gaiax-socialmedialab.jp/socialmedia/368)。またモバ イルユーザー全体の約80%が Twitter
を利用していることからスマホなどの常に携帯 しているものから簡単に情報を得ることが可能で、私たちにとって一番身近な情報収 集ツールと言える。2.2 用語
2.2.1 アカウント
アカウントとは
2.2.2 ツイート
2.2.3 タイムライン
系列順に並べられたログ全体を指す。
2.2.4 リツイート
他人のツイートを自分が再びツイートする行為。自分のフォロワーのタイムライン にそのフォロワーがフォローしていない人のツイートを載せることができる。タイム
4
ラインには元のツイートの投稿時間ではなくリツイートした時の時間が参照される。
2.2.5 お気に入り
自分の気に入ったツイートに目印をつける行為。お気に入りに登録することで後で 容易に見返すことができる。本来は以上のような役割であったが、ツイートした本人 に対しそのツイートを読んだことを知らせる行為として使われることもある。
2.2.6 フォロー&フォロワー
他のユーザーのツイートを自分のタイムラインに載るようにする行為をフォロー いう。また、自分をフォローしている状態にあるユーザーのことをフォロワーという。
2.2.7 公開/非公開設定
他のユーザーが自分のツイートやプロフィールを公開または非公開にすることがで きる設定のことを指す。誰でも見ることができるアカウントのことを公開アカウント といい、相互にフォローした相手でないと見ることができないアカウントを非公開ア カウントという。
2.2. 8 リプライ
特定のユーザーに対してツイートする行為である。「@+ユーザー名」をツイートに 記すことでリプライすることができる。またリプライをしたユーザーとリプライされ たユーザーを両方フォローしている場合に自分のタイムラインにも載るようになる
(例外もあり)。
2.2.9 ハッシュタグ
「#+単語」とツイートに記す行為である。ハッシュタグを付けることで同じハッ シュタグの検索が可能になったり、自分がなんの話をしているのか明確にするために 付けたりする。
2.3 Twitter API 2.3.1 概要
Web
サイトやアプリケーションから5
トの変更や参照・検索など)を利用できるようサービスである。APIとは
Application
Programing Interface(アプリケーション
プログラミング インターフェース)の省略語である。これによりアプリケーションを使って
Twitter API
は大きく分けてREST API,Streaming API
の2
種類がある。2.3.2 Twitter REST API
Twitter REST API
はAPI
である。REST
とは「パラメータを指定して特定のURL
にHTTP
で アクセスすると、XML で記述されたメッセージが送られてくるようなシステムおよ び 呼 び 出 し イ ン タ ー フ ェ ー ス (「RESTful API
」 と 呼 ば れ る ) の こ と 」(http://e-words.jp/w/REST.html)であり REST API
とはREST
の原則に沿った形で設 計されたAPI
を指す。本研究で使用する
API Version1.1
における仕様は以下の通りである.全てのREST API
の呼び出しにはOAuth
認証が必要である(2.3.4 で説明)。取得できるデータはJSON(JavaScript Object Notation)のみである。一定時間あたりに使用できる回数に
制限がある(API Rate Limit)(2.3.5で説明)。2.3.3 Twitter Streaming API
Streaming API
はREST API
と違いREST API
よりこちらを使用した方が良い。2.3.4 OAuth
認証Twitter API
を利用するにはOAuth
認証が必要である。OAuthとは、あるサービス上のユーザーが利用する情報を他のサービスに受け渡すための仕様である。これは 個人情報を与えることを意味しており,受け渡す際には必ず認証を行う必要がある。
そしてこの認証を
OAuth
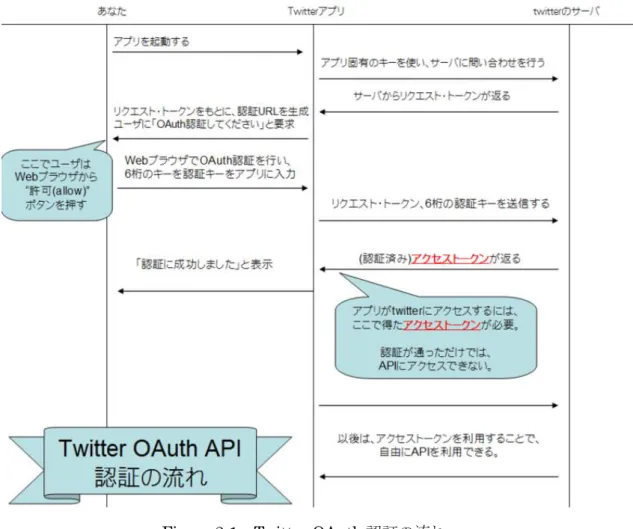
認証という。6
Figure 2-1 Twitter OAuth
認証の流れ(引用:aruto「「OAuth認証が通ると、アプリ作者からはDMも何もかも見放題」という書き
方は誤解を招く」, http://blog.aruto.info/entry/20100803/twitter_oauth)
上の図は
OAuth
認証の流れを図にしたものである。アクセス・トークンとはを暗号化してまとめた文字列である。リクエスト・トークンとは
Web
アプリが2.3.5 API Rate Limit
Twitter API
の使用する際の回数制限のことを指す。この回数制限は使用するAPI
毎(機能毎)に課せられている。この制限を超えてしまうとタイムラインの取得や検索 などが行えなくなる。
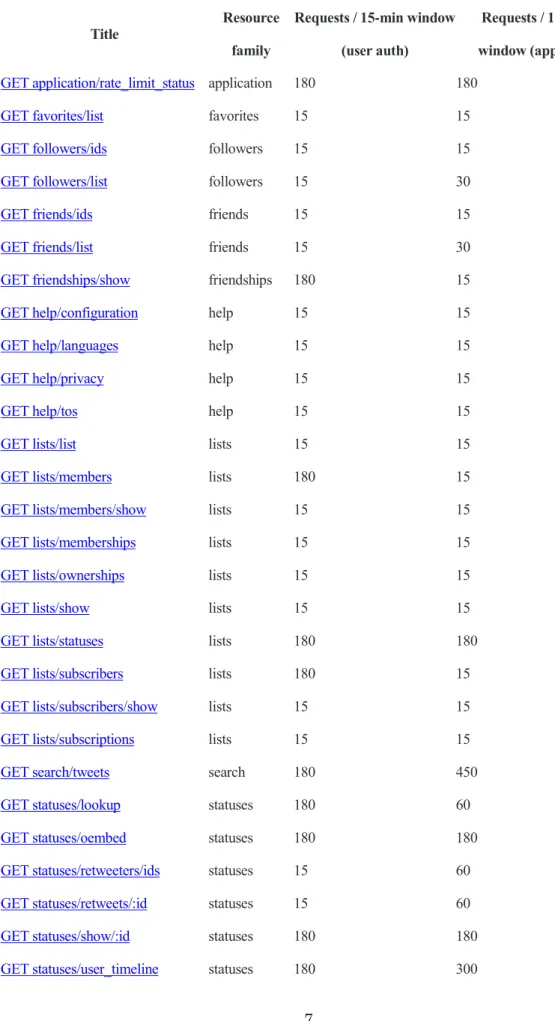
7
Table 2-1 Rate Limits: Chart
Title Resource
family
Requests / 15-min window (user auth)
Requests / 15-min window (app auth) GET application/rate_limit_status application 180 180
GET favorites/list favorites 15 15
GET followers/ids followers 15 15
GET followers/list followers 15 30
GET friends/ids friends 15 15
GET friends/list friends 15 30
GET friendships/show friendships 180 15
GET help/configuration help 15 15
GET help/languages help 15 15
GET help/privacy help 15 15
GET help/tos help 15 15
GET lists/list lists 15 15
GET lists/members lists 180 15
GET lists/members/show lists 15 15
GET lists/memberships lists 15 15
GET lists/ownerships lists 15 15
GET lists/show lists 15 15
GET lists/statuses lists 180 180
GET lists/subscribers lists 180 15
GET lists/subscribers/show lists 15 15
GET lists/subscriptions lists 15 15
GET search/tweets search 180 450
GET statuses/lookup statuses 180 60
GET statuses/oembed statuses 180 180
GET statuses/retweeters/ids statuses 15 60
GET statuses/retweets/:id statuses 15 60
GET statuses/show/:id statuses 180 180
GET statuses/user_timeline statuses 180 300
8
Title Resource
family
Requests / 15-min window (user auth)
Requests / 15-min window (app auth)
GET trends/available trends 15 15
GET trends/closest trends 15 15
GET trends/place trends 15 15
GET users/lookup users 180 60
GET users/show users 180 180
GET users/suggestions users 15 15
GET users/suggestions/:slug users 15 15
GET
users/suggestions/:slug/members users 15 15 (引用:Twitter Developers「API Rate Limits:Chart」,
https://dev.twitter.com/rest/public/rate-limits)
2.3.6 Twitter4j
Twitter4J
はTwitter API
のJava
ラッパ(元のクラスでは利用できない別の環境で も利用できるようにその間に入れるものを指す)である。本研究ではjava
を使いたい のでTwitter4J
を使用します。9
第3章 形態素解析ツール
MeCab
3.1
形態素解析自然言語で書かれた文を、文法のルール等を元に形態素(言語として意味を持つ最小 単位の単語)に分割する技術である。この際、辞書(品詞等の情報付きの単語リスト)を 参照することで「品詞」、「活用形」,「基本形」,「読み」等の情報を得ることができ る。
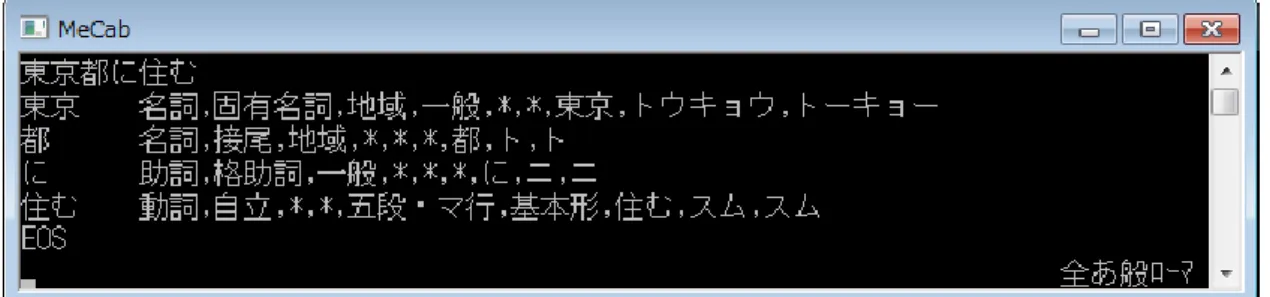
単語<tab> 品詞1,品詞2,品詞3,品詞4,活用型,活用系,基本形,読み,発音 EOS: End of sentence
Figure 3-1 形態素解析の例
(引用:工藤 拓「日本語解析ツール MeCab,CaboChaの紹介」)
また、明示的な単語境界が無い言語(日本語など)では、分かち書き(文章において語 の区切りに空白を挟んで記述すること)することが難しくその解析に膨大なデータを 必要とするため言語ごとに適した形態素解析をする必要がある。
3.2 MeCab
京都大学情報学研究科−日本電信電話株式会社コミュニケーション科学基礎研究所 共同研究ユニットプロジェクトを通じて開発されたオープンソースの汎用日本語形態 素解析エンジンのことである。他の日本語形態素解析エンジン(ChaSen,JUMAN)と比 べ解析精度が高く処理も早い。またさまざまな言語(perl/ruby/python/java/C#)から呼 び出すことができる。
10 3.2.2 IPA
辞書MeCab
が形態素解析をする際に参照する辞書である。単語の品詞解析や、解析対象文を分かち書きしたもののコスト計算をする際に用いられる。
Figure 3-2 IPA
品詞体系 (引用:形態素解析ツールの品詞体系)3.2.3 形態素解析システム
形態素解析の流れは以下の通りである。
1.文字列を入力 2.辞書引き
3.いくつかのパターンの分かち書きを構成する 4.得られた単語列のパターンのコストを計算する 5.計算結果からコストが最小となるものを出力する
11
となる。今回は例として「東京都に住む」を入力したとする。
【1. 文字列を入力】
Figure 3-3 MeCab
入力画面【2. 辞書引き】
現時時点では単語の区切りが成されていないので、入力された文字列の先頭から
IPA
辞書に検索をかける。辞書検索のためのデータ構造は以下の図の通りである。Figure 3-4 辞書検索の仕組み
(引用:工藤 拓「MeCab 汎用日本語形態素解析エンジン」)
このデータ構造(トライ木)を用いることで入力文字列の長さ
n
に対し時間O(n)で探
索できる。【3. いくつかのパターンの分かち書きを構成する】
12
辞書検索によって文字列をいくつかの分かち書きのパターンを得ることができる。
例では以下のようになる。
Figure 3-5 分かち書きのパターン
(引用:工藤 拓「MeCab 汎用日本語形態素解析エンジン」)
上図のように、
6
パターンの分かち書きが得られる。「に」の品詞は動詞と助動詞の 2つである点に注意する。【4. 得られた単語列のパターンのコストを計算する】
IPA
辞書には一つの単語の出現しやすさである生起コストと二つの単語の繋がりや すさである連接コストが記されている。それぞれのコストを参照し全ての分かち書き のパターンの合計コストを計算する。Figure 3-6 コスト計算
(引用:形態素解析ツールの品詞体系)【5.計算結果からコストが最小となるものを出力する】
4での計算結果で最小のものを出力する。例の結果は以下の通りである。
13
Figure 3-7 MeCab
解析結果上記の結果を見ての通り,地名を表す「東京」の品詞解析は「名詞,固有名詞,地域,
一般」に分類される。これを利用しツイート本文とユーザープロフィールの住所に記 載されている文字列から地名を表すワードを取得する。
14
第4章
Geocoding
4.1 概要
ジオコーディングとは地名や住所といった情報が指し示す場所の地理座標(緯度経 度)を付加することである。
4.2 方法
国土交通省が行っている位置参照情報ダウンロードサービスに「大字・町丁目レベ ル位置参照情報」がある。これは「日本における住所体系のうち、市、町、村、区、
特別区の直下に属す行政区である「大字」、「町丁目」、 自治体によっては「町字」を 示す住所代表点と、その住所代表点が示す位置座標を対応づけた情報」
(
「国土交通省 ホ ー ム ペ ー ジ 」 の 「 位 置 参 照 ダ ウ ン ロ ー ド サ ー ビ ス 」 の 項http://nlftp.mlit.go.jp/isj/index.html)のことである。以下の図はその情報の一部であ
る。Figure 4-1 位置情報参照データ
(引用:国土交通省「位置参照情報ダウンロードサービス」)
ジオコーディングしたい地名をこのデータと参照することで地理座標を得ることが できる。逆に地理座標から地名を得たい場合も同様。
15
第5章 提案システム
5.1 概要
ツイートから位置情報を取得し、それを可視化する。そのための提案システムは以 下の通りである。
1. ツイートの検索&取得。
2. ツイートから必要な情報を取得しデータベースに収納する。
3. 形態素解析により位置情報を示すワードを取得する 4. 得られたワードを位置参照情報と参照し地理座標を得る。
5. 得られた地理座標を地図上にプロットする。
5.2 検索(search/tweets)
本研究では
Twitter Rest API
のGET search/tweets
とTwitter Streaming API
のGET statuses/sample
を使ってツイートを検索し取得する。5.2.1 GET search/tweets
Twitter Rest API
のエンドポイント(リソースに対して固有の一意なURI)である
search/tweets
を使ってツイート本文に出現する単語、もしくは投稿したユーザーを検索してツイートを取得できる。setQuery()の中にワードもしくは@を含めたユーザ ー名を入れることで検索対象を選択できる。また
stLang()に ja
を指定することで日本 語のツイートだけを検索できる。// 検索ワードをセット(""を含む日本語Tweet)
query.setQuery("雨");
//検索tweetの言語を指定 query.setLang("ja");
(参照:付録A, A.1(rainmongo.java))
5.2.2 GET statuses/sample
全ユーザーが公開しているツイートの中から
1%のツイートを無作為に取得できる
Twitter Streaming API
のエンドポイントである。また、Twitter Streaming APIは16
日本語によるフィルタリングが未対応なので取得したツイートが日本語かどうか判別 するコードを書く必要がある。
5.3 必要なデータの抽出
取得したツイートから「ツイート本文」「GPS」「投稿日時」「投稿ユーザーのプロ フィール:場所」を抽出しデータベースに収納する。
例:"text" : "えー兵庫で雨降ってきたぞぉ 勘弁してくれ~" ,
"date" : "2016/01/13 15:41:08" , "address" : "神奈川 川崎♂"
(text:ツイート本文,date:ツイート投稿日時,address:ユーザープロフィールに記載されている住所)
5.4 位置情報の抽出
ツイートから位置情報を得るためにまず「GPS」のデータを参照する。データがあ った場合このデータを位置情報としてデータベースに収納する。
もし、データが入ってなかった場合は「ツイート本文」を
MeCab
を使い形態素解 析を行う。出力された結果から固有名詞,地域,一般に分類された単語を抽出し位置情 報含むワードとしてデータベースに収納する。上記2つの方法から位置情報が得られなかった場合はユーザープロフィールの 住所の項目に書かれている文字列を
MeCab
を使いワードを抽出しデータベースに収 納する。例:"text" : "えー兵庫で雨降ってきたぞぉ 勘弁してくれ~" ,
"date" : "2016/01/13 15:41:08" , "address" : "神奈川 川崎♂" , "ward" : "兵庫"
(ward:text または address から得られた地名ワード)
5.5 ジオコーディング
5.4
で得られたワードを位置参照情報と参照して得られた地理座標をデータベース に収納する。例:"text" : "えー兵庫で雨降ってきたぞぉ 勘弁してくれ~" ,
"date" : "2016/01/13 15:41:08" , "address" : "神奈川 川崎♂" , "ward" : "兵庫" ,
17
"geocodinglat" : 33.270948 , "geocodinglng" : 130.314291
(geocodinglat& geocodinglng:ward の地名をジオコーディングして得られた座標の緯度と経度)
5.6 プロット
地図上に地理座標をプロットするために
Tree-maps(http://www.tree-maps.com/prot/#)を使用する。Tree-maps
は地図に関する
WEB TOOL
のサイトである。緯度経度の値を入力するとそれらを地図上にプロットしてくれる。
18
第6章 実行結果と考察
6.1 実験 1
Twitter REST API
を使い「雨」のワードが含まれるツイートを2016
年1
月13
日15
時37
分から2016
年1
月14
日15
時39
分を対象に34070
個取得してみた。取得 したツイートを第5章で説明した通りに解析した結果の例を以下に示す。Figure 6-1 Tweet
データ及び解析結果34070
個のツイートにGPS
情報が付加されていたのが16
個、ユーザープロフィールに場所が記載されていたものが
19651
個、ツイート本文及びプロフィールの場所に 地名を指すワードが検出できたものが8399
個、ツイートの解析結果から地理座標を 取得できたものが7718
個という結果になった。得られたデータを1時間毎に分けて地図上にプロットした結果の一部を以下に示す。
19
Figure 6-2 ツイートの位置情報の可視化 (参照:図表 B.1)
Figure6-2
に記されているマークに書かれている数字はツイート数を表しており何も書かれていないものはツイート数が1個という意味である。また青色のマーカーは ツイート数が
1
桁、黄色のマーカーは2
桁、赤色のマーカーは3
桁であることを表し ている。6.2 考察1
実験
1
の結果を見ると大阪付近のツイート量が多いことが明白である。これは単に大阪に
多いのか、データを収集した日時に大阪では大雨が降っていたのかという考えが生ま れてくる。そこで以上のデータを収集し比較してみる。
20 6.3 データ収集
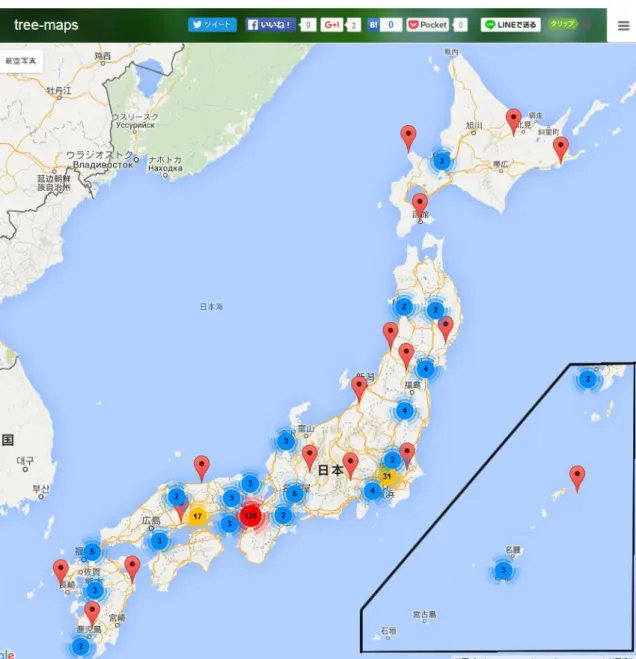
6.3.1 日本の地域別ツイート量
Twitter Streaming API
を使って「雨」などの特定のワードで検索をかけるのではなく日本ユーザーの純粋なツイートから位置情報を取得することで日本の地域毎のツ イート量を調べた。約1時間分のツイート
10114
個の結果を以下に示す。Figure 6-3 日本のツイートの可視化
21 6.3.2 日本の地域別ユーザー数
Figure 6-4 都道府県毎の Twitter
ユーザー数(引用:Twitter
ユーザー数【総数順】 [ 2013年第一位 東京都 ],http://todo-ran.com/t/kijis/13528)
22 6.3.3 天気図
Figure 6-5 天気図(降雨)
(引用:tenki.jp,アメダス実況, http://www.tenki.jp/amedas/) (参照:図表 B.2)
6.4 考察 2
6.3.1と6.3.2のデータを比較してみるとユーザー数とツイート数は比例しており、東京,
愛知,大阪付近のツイート数が多いのがよくわかる。またこれらのデータと6.1の結果とを 比較してみると東京、大阪付近の「雨」ツイート数が多いことが納得できる。逆に、愛知 付近の「雨」ツイート数が少ないように見える。以上より気になった地域と6.3.3の天気 図を元にいくつか地域をピックアップして表を作った。それを以下に示す。
Table 6.4-1 データ比較表
都道府県 ユーザー数 平均ツイート数 「雨」ツイート数 降雨の有無
東京都 488020 338 65 無
大阪府 179332 127 203 有
神奈川県 177072 114 11 無
愛知県 103673 76 5 無
23
埼玉県 96943 62 4 無
愛媛県 10190 18 10 有
青森県 9917 17 2 無
福井県 7317 6 9 有
先ほどユーザー数に比べて「雨」ツイート数が少ないと思われた愛知県だったが、Table
6.4-1 を見ると特に問題が無いことがわかった。また、平均ツイート数がほぼ同じである
大阪府と神奈川県を比較すると雨によるツイート数の増加の多さが見て取れる。東京都の
「雨」ツイート数が多いのはユーザー数が多いからだと考えていたが、他の雨が降ってい なかった県のユーザー数と「雨」ツイート数の比率を見るとやはり東京都だけ「雨」ツイ ート数が多いことがわかった。さらに雨が降った県ではどれも「雨」ツイート数が平均ツ イート数を大幅に上回る結果となったが、愛媛県の「雨」ツイート数は平均ツイート数の 約半分という結果になった。
以上のことから普段から雨のことを気にしている地域や、雨に対して反応する地域、そ して逆に雨に対して反応しない地域などがあることがわかった。
24
第7章 結論と課題
7.1 結論
本研究では取得したツイートの約
1/5
から地理座標を取得することに成功した。ま た「雨」というワードに絞ることで天気図等を参照することで雨に対するツイートの 変化及び地域別のツイートの違いがわかった。7.2 今後の課題
今回は
MeCab
を使って地名を抽出し国土交通省のデータを元に地理座標を取得し た。しかし位置情報を有する単語は地名だけではない。観光スポットや建物といった ものも位置情報を有している。そのためにMecab
が使用する辞書の強化や地名以外 も地理座標に変換できる策を考えていきたい。25
謝辞
本研究を進めるにあたり、丁寧に指導して下さった田口東先生に感謝します。研究 テーマがなかなか決まらず悩んでいた私を温かく助言、御力添えしてくださったこと 感謝しています。またゼミを通して多くの発見や知識、そして卒論を進める刺激を与 えてくれた田口研究室の皆様に感謝します。
26
参考文献
[1]ツイナビ,ツイッター用語, http://twinavi.jp/
[2]工藤
拓(2009), MeCab汎用日本語形態素解析エンジンhttp://www.jtpa.org/wp-content/uploads/2014/06/MeCab.pdf
[3]
工藤 拓(2009), 日本語解析ツールMeCab,CaboCha
の紹介http://chasen.naist.jp/chaki/t/2009-09-30/doc/mecab-cabocha-nlp-seminar-2009.pdf
[4]形態素解析ツールの品詞体系,
http://www.unixuser.org/~euske/doc/postag/index.html
[5]Java
でMongo
を使ってみる, BIZREACH -Lab-,http://lab.bizreach.co.jp/978/[6]「Java」文字列の中に日本語が含まれてるかどうかの判断,
韓国人の東京生活,http://ameblo.jp/kongbab04/entry-11087732125.html
[7]Java Tips:文字列の部分一致検索を行うには ,ITmedia
エンタープライズ,http://www.itmedia.co.jp/enterprise/articles/0407/12/news003.html
[8] Twitter4J, http://twitter4j.org/ja/index.html
[9]各種ジオコーディング api
の罠と対処法,文系プログラマによるTIPS
ブログ,http://www.bunkei-programmer.net/
[9]大倉一馬(2013), Twitter
における時系列変化解析に関する研究,http://www.qos.tu.chiba-u.jp/thesis/2012_b4_okula.pdf
[10]山本保子(2014),
受動的なhttp://sp.cei.uec.ac.jp/thesis/yamamoto_sotsuron2013.pdf
27
[11]【決定版】Twitter API
にも使われるOAuth
認証のしくみ,https://colo-ri.jp/develop/2010/09/twitter_api_oauth.html
[12]
「OAuth認証が通ると、アプリ作者からはDM
も何もかも見放題」という書き方 は誤解を招く, http://blog.aruto.info/entry/20100803/twitter_oauth[13]API
とは?API Rate Limitってなに?,http://service.sakuraweb.com/fuyutiger/blog/2010/07/apiapi-rate-limit.html
[14]Twitter API
を使ってみる,http://www.antun.net/tips/api/twitter.html[15]パク・スミン,韓国人の東京生活「
「Java」文字列の中に日本語が含まれてるかどうかの判断」, http://ameblo.jp/kongbab04/entry-11087732125.html
[16]tree-maps, http://www.tree-maps.com/prot/
[17] Twitter4J
で Twitter の Stream API を使う,http://dotnsf.blog.jp/archives/1011811296.html
[18]TwitterDevelopers,https://dev.twitter.com/
28
実装環境
【PCスペック】
オペレーティングシステム:Windows 7 Home Premium 64 bit プロセッサ:Intel® Core™ i7-2670QM CPU @ 2.20GHz(8 CPUs) メモリ:8192MB RAM
【統合開発環境】
Eclipse(eclipse4.5)
【形態素解析システム】
MeCab(mecab-0.996) IPA
辞書【TwitterAPI】
Twtter API ver.1.1
【Twitter4j】
Twitter4j-4.0.4
【データベース】
mongodb-win64-3.2.0
29
付録A プログラム
A.1. Twitter
から「雨」を含むTweet
を取得し必要なデータをデータベース(MongoDB) に収納するプログラム(rainmongo.java)import java.util.Calendar;
import java.util.TimeZone;
import com.mongodb.BasicDBObject;
import com.mongodb.DB;
import com.mongodb.DBCollection;
import com.mongodb.Mongo;
import twitter4j.GeoLocation;
import twitter4j.Query;
import twitter4j.QueryResult;
import twitter4j.Status;
import twitter4j.Twitter;
import twitter4j.TwitterException;
import twitter4j.TwitterFactory;
public class rainmongo {
public static void main(String[] args) throws TwitterException { try {
// 接続とDB取得
Mongo mongo = new Mongo("localhost", 27017);
DB db = mongo.getDB("thesis");
// コレクションの取得
DBCollection collection = db.getCollection("rain");
// 初期化
Twitter twitter = new TwitterFactory().getInstance();
Query query = new Query();
//JSTの時刻を取得する。
Calendar cal = Calendar.getInstance(TimeZone.getTimeZone("JST"));
//一度で取得するtweetの数を指定 query.setCount(100);
// 検索ワードをセット(""を含む日本語Tweet)
query.setQuery("雨");
for(int k=1;k<=1000;k++){
// 検索して結果を表示
QueryResult result = twitter.search(query);
for (Status status : result.getTweets()) {
//取得した日時をJST(日本標準時)に変換
cal.setTime(status.getCreatedAt());
//ツイートから改行記号を除去(半角スペースに変換)
String strText = status.getText();
strText = strText.replaceAll("¥r¥n"," ");
strText = strText.replaceAll("¥r"," ");
strText = strText.replaceAll("¥n"," ");
//ツイートからタブ記号を除去(半角スペースに変換)
strText = strText.replaceAll("¥t"," ");
if(strText.matches(".*@.*") | strText.matches(".*@.*") | strText.matches(".*#.*") | strText.matches(".*#.*") | status.isRetweet() | strText.startsWith("QT"))
{
}else {
30
Double lat = null;
Double lng = null;
//tweetからGPSの情報を取得
GeoLocation location = status.getGeoLocation();
if( location != null ){
double dlat = location.getLatitude();
double dlng = location.getLongitude();
lat = dlat;
lng = dlng;
}
//ユーザーのプロフィールの住所設定から取得
String state = status.getUser().getLocation();
// ドキュメントの挿入
BasicDBObject doc = new BasicDBObject();
doc.put("text", strText);
if(lat != null)
{
//doc.put("GPS", Arrays.asList(lat, lng));
doc.put("GPSlat", lat);
doc.put("GPSlng", lng);
}
//Calendarオブジェクトを整形する
doc.put("date",
String.format("%1$tY/%1$tm/%1$td %1$TH:%1$TM:%1$TS",cal));
if("".equals(state)){
}else{
doc.put("address", state);
}
//insert
collection.insert(doc);
}
try{
Thread.sleep(110); //""ミリ秒Sleepする //api制限対策 }catch(InterruptedException e){}
}
if (result.hasNext()) {
query = result.nextQuery();
System.out.println(k);
} else {
System.out.println(0);
break;
} }
} catch (Exception e) { e.printStackTrace();
} } }
A.2.
データベースに収納したtweet
のデータをMeCab
で形態素解析し、地名を指すワードを抜き取りデータベースに収納するプログラム(getward.java)
import com.mongodb.DB;
import com.mongodb.DBCollection;
import com.mongodb.DBObject;
import com.mongodb.Mongo;
import net.moraleboost.mecab.Lattice;
import net.moraleboost.mecab.Node;
import net.moraleboost.mecab.Tagger;
import net.moraleboost.mecab.impl.StandardTagger;
public class getward {
public static void main(String[] args) { try {
31
int i=0;
// 接続とDB取得
Mongo mongo = new Mongo("localhost", 27017);
DB db = mongo.getDB("thesis");
// コレクションの取得
DBCollection collection = db.getCollection("rain");
for (DBObject obj :collection.find()) { System.out.println(i++);
//mecab解析文字数制限回避
if(i>=0 && i<1500){
System.out.println(i);
if((obj.get("GPSlat")) == null){
//object型をstring型に変換
String strtext = obj.get("text").toString();
// Taggerを構築。
// 引数には、MeCabのcreateTagger()関数に与える引数を与える。
Tagger tagger = new StandardTagger("");
// Lattice(形態素解析に必要な実行時情報が格納されるオブジェクト)を構築
Lattice lattice = tagger.createLattice();
// 解析対象文字列をセット
lattice.setSentence(strtext);
// tagger.parse()を呼び出して、文字列を形態素解析する。
tagger.parse(lattice);
// 一つずつ形態素をたどりながら、表層形と素性を出力
Node node = lattice.bosNode();
String ward = "";
while (node != null) {
String surface = node.surface();
String feature = node.feature();
if(feature.matches(".*固有名詞,地域,一般.*")){
ward = surface;
}
node = node.next();
}
if("".equals(ward) && obj.get("address") != null){
// 解析対象文字列をセット
lattice.setSentence(obj.get("address").toString());
// tagger.parse()を呼び出して、文字列を形態素解析する。
tagger.parse(lattice);
// 一つずつ形態素をたどりながら、表層形と素性を出力
node = lattice.bosNode();
while (node != null) {
String surface = node.surface();
String feature = node.feature();
//地名を示すワードを取得
if(feature.matches(".*固有名詞,地域,一般.*")){
ward = surface;
}
node = node.next();
}
}
if("".equals(ward)){
}else{
obj.put("ward", ward);
collection.save(obj);
}
// lattice, taggerを破壊
lattice.destroy();
32
tagger.destroy();
} }
}
} catch (Exception e) { e.printStackTrace();
} } }
A.3.
位置参照情報をmongodb
に収納するプログラム(addressdata.java)import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.text.DecimalFormat;
import java.text.Format;
import java.util.StringTokenizer;
import com.mongodb.BasicDBObject;
import com.mongodb.DB;
import com.mongodb.DBCollection;
import com.mongodb.Mongo;
public class addressdata {
public static void main(String[] args) { for(int k=1;k<48;k++){
System.out.println(k);
//変数を2桁に整える
Format f = new DecimalFormat("00");
//参照ファイルにパスを通す
String filePath = "C:/Users/gullen/Downloads/位置参照情報 /"+f.format(k)+"000-08.0b/"+f.format(k)+"_2014.csv";
try {
// 接続とDB取得
Mongo mongo = new Mongo("localhost", 27017);
DB db = mongo.getDB("thesis");
// コレクションの取得
DBCollection collection = db.getCollection("address2");
File csv = new File(filePath);
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(csv),"SJIS"));
// 最終行まで読み込む
String line = "";
while ((line = br.readLine()) != null) {
// ドキュメントの挿入
BasicDBObject doc = new BasicDBObject();
// 1行をデータの要素に分割
StringTokenizer st = new StringTokenizer(line,",");
int i = 0;
String text = null;
while (st.hasMoreTokens()) {
text = st.nextToken();
if(i==1)doc.put("prefecture", text);
if(i==3)doc.put("district", text);
if(i==5)doc.put("town", text);
if(i==6)doc.put("lat", text);
33
if(i==7)doc.put("lng", text);
i++;
}
//insert
collection.insert(doc);
} br.close();
} catch (FileNotFoundException e) {
// Fileオブジェクト生成時の例外捕捉
e.printStackTrace();
} catch (IOException e) {
// BufferedReaderオブジェクトのクローズ時の例外捕捉
e.printStackTrace();
} } }
}
A.4. Tweet
に含まれていた地名を位置参照情報から探し出しその地名の緯度経度を抜き出し
mongodb
に収納するプログラム(findaddress.java)import java.util.Arrays;
import java.util.regex.Pattern;
import com.mongodb.BasicDBObject;
import com.mongodb.DB;
import com.mongodb.DBCollection;
import com.mongodb.DBObject;
import com.mongodb.Mongo;
public class findaddress {
public static void main(String[] args) { try {
// 接続とDB取得
Mongo mongo = new Mongo("localhost", 27017);
DB db = mongo.getDB("thesis");
// コレクションの取得
DBCollection rain = db.getCollection("rain");
DBCollection address2 = db.getCollection("address2");
//条件検索指定
BasicDBObject ward = new BasicDBObject("ward",(new BasicDBObject("$ne",null)));
BasicDBObject GPS = new BasicDBObject("GPSlat",(new BasicDBObject("$ne",null)));
BasicDBObject query1 = new BasicDBObject("$or",Arrays.asList(ward,GPS));
for (DBObject obj :rain.find(query1)) { if(obj.get("GPSlat") == null){
int k = 0;
int length = 25;
//tweetから取得した地名ワード
String ward1 = obj.get("ward").toString();
//like検索
Pattern p = Pattern.compile(ward1);
BasicDBObject perfecture = new BasicDBObject("prefecture",p);
BasicDBObject district = new BasicDBObject("district",p);
BasicDBObject town = new BasicDBObject("town",p);
for (DBObject obj2 :address2.find(perfecture)) { if(k == 0){
Double lat = Double.parseDouble(obj2.get("lat").toString());
Double lng = Double.parseDouble(obj2.get("lng").toString());
obj.put("geocodinglat",lat);
obj.put("geocodinglng",lng);
34
rain.save(obj);
k=1;
}
}
if(k==0){
for (DBObject obj2 :address2.find(district)) { if(obj2.get("district").toString().length() < length){
length = obj2.get("district").toString().length();
Double lat = Double.parseDouble(obj2.get("lat").toString());
Double lng = Double.parseDouble(obj2.get("lng").toString());
obj.put("geocodinglat",lat);
obj.put("geocodinglng",lng);
rain.save(obj);
k=1;
}
}
}
if(k==0){
for (DBObject obj2 :address2.find(town)) { if(obj2.get("town").toString().length() < length){
length = obj2.get("town").toString().length();
Double lat = Double.parseDouble(obj2.get("lat").toString());
Double lng = Double.parseDouble(obj2.get("lng").toString());
obj.put("geocodinglat",lat);
obj.put("geocodinglng",lng);
rain.save(obj);
k=1;
}
}
}
}else{
obj.put("geocodinglat",obj.get("GPSlat"));
obj.put("geocodinglng",obj.get("GPSlng"));
rain.save(obj);
} }
} catch (Exception e) { e.printStackTrace();
} } }
A.5. Streaming API
を使った日本語のみを取得するプログラム(japansample.java)import java.util.Calendar;
import java.util.TimeZone;
import com.mongodb.BasicDBObject;
import com.mongodb.DB;
import com.mongodb.DBCollection;
import com.mongodb.Mongo;
import twitter4j.GeoLocation;
import twitter4j.StallWarning;
import twitter4j.Status;
import twitter4j.StatusDeletionNotice;
import twitter4j.StatusListener;
import twitter4j.TwitterStream;
import twitter4j.TwitterStreamFactory;
import twitter4j.conf.Configuration;
import twitter4j.conf.ConfigurationBuilder;
35
public class steamtwitter4j {
//OAuth認証
private static final String CONSUMER_KEY = "******************";
private static final String CONSUMER_SECRET = "******************";
private static final String ACCESS_TOKEN = "***********************";
private static final String ACCESS_TOKEN_SECRET = "*********************";
// 接続とDB取得
static Mongo mongo = new Mongo("localhost", 27017);
static DB db = mongo.getDB("thesis");
// コレクションの取得
static DBCollection collection = db.getCollection("japansample");
public static boolean containsNihongo(String str) { for(int i = 0 ; i < str.length() ; i++) {
char ch = str.charAt(i);
Character.UnicodeBlock unicodeBlock = Character.UnicodeBlock.of(ch);
if (Character.UnicodeBlock.HIRAGANA.equals(unicodeBlock))
return true;
if (Character.UnicodeBlock.KATAKANA.equals(unicodeBlock))
return true;
if (Character.UnicodeBlock.HALFWIDTH_AND_FULLWIDTH_FORMS.equals(unicodeBlock))
return true;
if (Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS.equals(unicodeBlock))
return true;
if (Character.UnicodeBlock.CJK_SYMBOLS_AND_PUNCTUATION.equals(unicodeBlock))
return true;
}
return false;
}
public static class MyStatusListener implements StatusListener {
// コレクションの取得
//DBCollection collection = db.getCollection("japansample");
public void onStatus(Status status) {
//文字列の中に日本語が含まれている場合のみ取得する
if (containsNihongo(status.getText()) == true){
Double lat = null;
Double lng = null;
String state = "";
// ドキュメントの挿入
BasicDBObject doc = new BasicDBObject();
//ツイート本文取得
String strText = status.getText();
doc.put("text", strText);
//位置情報が含まれていれば取得する
GeoLocation location = status.getGeoLocation();
if( location != null ){
double dlat = location.getLatitude();
double dlng = location.getLongitude();
lat = dlat;
lng = dlng;
doc.put("GPSlat", lat);
doc.put("GPSlng", lng);
}
//ユーザーのプロフィールの住所設定から取得 state = status.getUser().getLocation();
if("".equals(state)){
}else{
doc.put("address", state);
}