-1-
拡張現実感における
直感的操作環境の実現に関する研究
山梨大学大学院
医学工学総合教育部
博士課程学位論文
2015年3月
杉浦 篤志
-3- 論文内容の要旨 論文題目:拡張現実感における直感的操作環境の実現に関する研究 氏 名:杉浦 篤志 拡張現実感は,現実環境に情報機器を用いて仮想環境を重畳して提示する技術であ る.現実環境の物体に関する文字などの視覚的情報をはじめ様々な情報の付加・強調 を行い,ユーザに提供することが可能となる.拡張現実感に関するソフトウェア開発 や周辺機器の技術革新により,広く一般にも利用されるようになってきた.拡張現実 感を実現するための多くのシステムでは,視覚情報提示に HMD(Head-Mounted Display) が利用される.また,現実環境における操作や作業を支援するという観点から,携帯 電話等の情報端末の画面を使用した提示方法も多く利用されている. 拡張現実感を実現するための基盤技術として,①仮想物体とのインタラクション技 術,②現実環境と仮想環境の位置統合技術の 2 つが挙げられる.本論文では,より直 感的な操作が可能な拡張現実環境を簡単に実現するための新たなインタラクション手 法と位置情報統合手法の実応用システムを提案する. 既存の仮想物体とのインタラクション技術として,キーボードなどのキー入力,タ ッチパネルへのタッチ入力,そして,音声入力がある.また,実物体とのインタラク ションと同様に,仮想物体を手で直接操作する方法に関する研究も多くなされている. しかし,従来の手法では簡単なジェスチャで仮想物体を操作するために特殊なデバイ スを必要としたり,簡単なデバイスであるが特殊なジェスチャ操作を必要としたりす るなどの問題がある. 仮想物体とのインタラクション技術を向上させるため,仮想物体を手で直感的に操 作することを可能にするインタフェースの構築を目標とする.ボタンを指で押す動作 に類似したジェスチャと仮想物体を指でポインティングするジェスチャの 2 つを合わ せたジェスチャをクリック動作と呼び,クリック動作で仮想ボタンを直感的に操作す ることを提案する.クリックは GUI(Graphic User Interface)において最も基本的で重 要な操作である.アイコンに様々な機能を割り当てクリック操作することで様々な操 作や指示ができる.GUI におけるクリックと同様にアイコンに見立てた仮想ボタンに 様々な機能を割り当て,クリック動作で入力する.それによりクリック動作だけで様々 な操作や指示を行うことができる.よって,拡張現実感においてクリック動作が有効 な入力操作になると考えられる. 拡張現実感実現のためには 1 台のカメラが搭載された HMD や携帯端末が用いられ ることが多いが,1 台のカメラのみでは指と仮想物体の正確な奥行き関係を計算でき ないために,奥行き方向に指が移動するジェスチャであるクリック動作の認識が困難 であった.そこで,本研究では 1 台のカメラでクリック動作が認識できる手法を提案 する. 予備実験において,利用者が仮想ボタンに対してどのようにクリック動作を行うか を観測する.その実験結果より,仮想ボタンを指先でポインティングする動作と指先 で押すときの速度および急減速を調べることでクリック動作の検出が可能であること を見出した.この事実に基づいて,1 台のカメラから指先の速度および急減速を算出
-4- する手法と指先のポインティングを視覚的なフィードバックにより提示する仮想ボタ ンを設計した.また,クリック動作の認識アルゴリズムを 2 種類設計した.1 つめは 指先の速度および加速度から指先の状態を停止,通常動作,速い動作,急減速の 4 つ の状態に分類し,指先の状態遷移によりクリック動作を認識する手法を開発した.2 つめはクリック動作に特徴的な動作である急減速を検出することでクリック動作を認 識する手法を開発した.提案手法の有効性は,画面上に十字型に仮想ボタンを配置し た文字入力型インタフェースおよび仮想ボタンの間隔を文字入力型より狭く配置した 電卓型インタフェースにより入力を行わせる被験者実験によって検証した.被験者の インタビュー結果から一般的な携帯端末操作に不慣れな被験者に対しても直感的な仮 想ボタンへのクリック動作が実現できていることを確認した.また,指先の急減速の 検出によるクリック動作認識の結果が,文字入力タスクでは F 値が 0.961,電卓入力タ スクでは F 値が 0.972 となり高い検出率となった. 2 つめの基盤技術である現実環境と仮想環境の位置情報の統合技術では大きく 2 つ の方法があり,GPS(Global Positioning System)と様々なセンサを利用した方法とカメ ラを用いて画像処理を利用した方法がある.GPS とセンサを利用する方法では GPS に より情報端末の位置を取得し,情報端末に内蔵されている加速度センサなどから情報 端末の姿勢を推定して,現実空間と仮想空間の位置情報を統合する.カメラを用いた 画像処理を利用した方法ではマーカを用いた手法があり,比較的簡単に導入でき精度 が高い.カメラでマーカを撮影し,撮影された画像内にあるマーカ形状を取得する. それと事前に取得してあるマーカ情報を比較し,マーカの位置や姿勢を推定し,現実 空間と仮想空間の位置合わせを行う.マーカを用いた手法での問題点は,マーカの隠 蔽によりマーカ情報が取得できず,仮想物体の表示が途切れてしまう場合があること である. マーカの隠蔽問題を解決するために,マルチマーカとマルチカメラを用いてマーカ 情報の補完をする方法がある.この方法はある特定のカメラでは隠蔽されたマーカの 情報を別のカメラから取得した同じマーカの情報を利用することにより隠蔽されたマ ーカの情報を補完し,隠蔽されたマーカ上でも仮想物体を表示させることができる. 本研究では,この方法を利用した実応用システムとして警察,検察による現場検証用 映像のインハウス制作支援システムを提案する. 裁判員制度により,裁判官と国民から選ばれた裁判員がそれぞれの知識と経験を活 かしつつ一緒に裁判内容を判断するようになった.裁判員は一般市民で構成されるた め,一般市民でも理解しやすい裁判資料が求められている.テレビ番組などでは事件 等の再現映像に 3 次元 CG 映像が広く利用されているが,現状の裁判資料では 3 次元 CG 映像の利用が少ない.これは秘密情報保持により外部委託が難しく,CG 映像制作 は専門知識が必要であり警察,検察によるインハウス制作は困難であった. そこで,現場に多数のカメラを設置し,被害者用マーカや凶器用マーカを配置する. それにより犯罪現場環境は現実環境で被害者や凶器は仮想物体で表示し,犯人役を演 技者が演技することで拡張現実感を利用した現場検証用の環境を実現する.このよう に,犯罪状況を演技者が演じるだけで現実環境と人物動作を反映した CG 合成映像を 生成する手法を構築する.マルチカメラを用いて人物や物体によって隠蔽されたマー カの情報を補完し,マーカの隠蔽問題の解決を図る.また,演技の素人である演技者 が仮想物体との位置関係を把握できるように,演技者(一人称)及び視聴者(三人称) 視点映像を取得し演技者へ提供する.評価実験によりマルチカメラとマルチマーカに
-5- より隠蔽されたマーカの情報が補完可能であることを確認した.仮想オブジェクトに 対して仮想凶器を指す動作中の 1000 フレームに対して補完処理がない場合はマーカ の隠蔽により 235 フレームのみ仮想凶器を表示したが,補完処理を追加することによ り 1000 フレーム全てで仮想凶器を表示することが可能となった.また,演技者へ三人 称視点映像の提示の有無により仮想物体の位置関係の把握しやすさの確認も行った. 三人称視点映像をサムネイルで利用者に提示することで正確性が向上し,操作時間を 短縮することができた. 拡張現実感を実現するための基盤技術である仮想物体とのインタラクション技術に おいて 1 つのカメラで直感的な仮想ボタン操作のインタフェースを構築し,仮想物体 とのインタラクション技術を向上させた.もう 1 つの基盤技術である現実環境と仮想 環境の位置情報の統合技術ではマルチカメラとマルチマーカによるマーカ情報補完の 手法を利用し,実応用システムとして犯罪現場検証用の映像生成システムを構築し, 拡張現実感環境の利用範囲を広げた.これらの技術向上により拡張現実感における直 感的操作環境の実現を行った. キーワード 拡張現実感,インタフェース,ウェアラブルシステム,ジェスチャ認識,マルチカメ ラ,マルチマーカ,情報補完.
-6-
SUMMARY OF DISSERTATION
TITLE : Realization of Natural Operating Environments for Augmented Reality NAME : Atsushi Sugiura
Augmented Reality (AR) technology supports displaying virtual objects in video captured real world. Supplementary information can be added in the video. AR technology has becoming more and more popular thanks to the innovation of peripheral devices and software technologies. HMD (Head-Mounted Display) is used for presenting information in most AR systems. Recently, affordable mobile phone based AR systems have been developed and are gaining large attentions for their convenience.
Two fundamental issues of AR technology are how to interact with virtual objects and how to integrate virtual worlds with real worlds. This thesis presents a new interaction technique which allows the user to manipulate a virtual object with his/her finger directly in a natural way, and a new integration technique supporting users to build an AR environment easily.
For the interaction with a virtual object, current AR systems support keyboard input, touch panel input, and voice input. To take full advantage of AR technology, however, it is desirable to allow users to manipulate virtual objects in a more natural way, ideally in the same way as they manipulate real objects. One such solution is to use gesture. There are many existing researches on how to recognize gestures. Most of them require stereo cameras to obtain the 3D information of gestures. Some systems use a single camera, but force users to use some particular gestures.
This thesis proposes a new technique for supporting a natural gesture called “click gesture” in AR systems. In a traditional graphical interface, a click refers to the action of placing the cursor on a target and then pressing a button on the mouse to select an object or execute a command. It is the most essential operation. Here, I define a click operation in a VR system as a natural gesture a user would make to select a virtual object or execute a graphically represented command. Existing AR systems do not support natural click interfaces, because HMD with only one camera are usually adopted to realize AR and it is difficult to recognize an arbitrary gesture without accurate depth information.
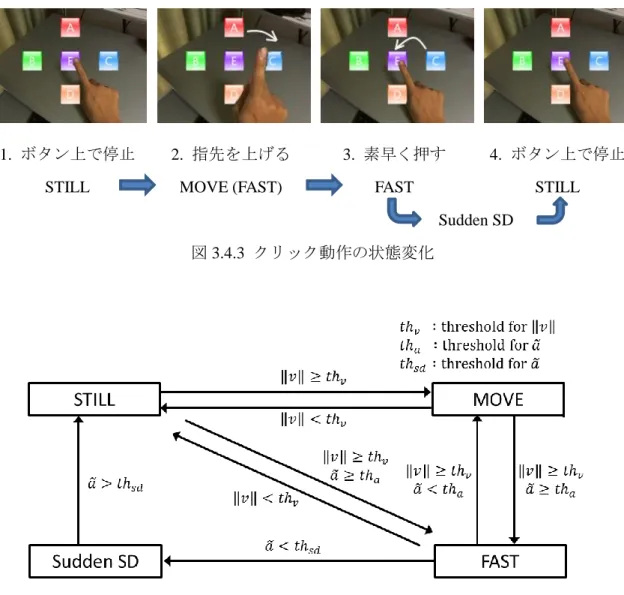
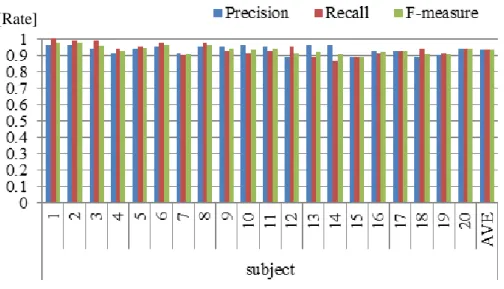
Through a study investigating how subjects perform when they are told to “click” virtual objects with their fingers without any instructions or training, it is found that the speed and acceleration of fingertips provide cues for detecting click gestures. Based on such findings, I developed a new technique for recognizing natural click gestures with a single camera by focusing on temporal differentials between adjacent frames. Two kinds of recognition algorithms were implemented. In the first algorithm, the motion of a fingertip is classified into one of the following four states (STILL, MOVE, FAST and Sudden Slow Down) and a click gesture can be modeled as the state transition diagram. The second algorithm uses the fact learnt from the primary study that the most characteristic feature of the click motion is the Sudden Slow Down state, which distinguishes the click from all other motions of the finger. Therefor the new algorithm recognizes a click gesture simply by detecting the Sudden Slow
-7-
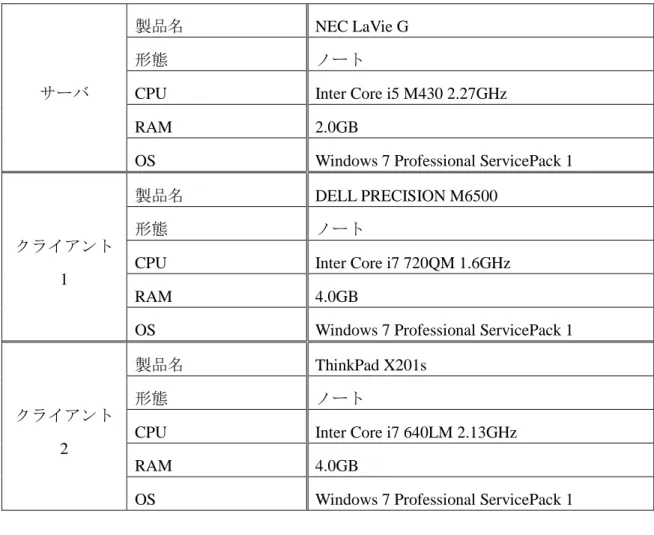
Down state. To validate the effectiveness of the proposed algorithms, experiments use two different sets of virtual buttons are conducted. The motion of the finger may vary according to the position relative to the virtual object. The first set of buttons is designed to test the factor of relative position among the virtual object, the finger and the camera. The second set of virtual buttons is designed to investigate whether the proposed detection algorithm is effective even when the virtual buttons are very close to each other. A virtual calculator consisting of 18 squared buttons is designed. Performance data in terms of precision (ratio of true clicks over all detected clicks), recall (ratio of detected clicks over all the true clicks), and F-measure for the 20 subjects are presented by detecting sudden speed drop-off. The averages of the three measures are all above 93%. The effectiveness of the recognition algorithm and the usability of the new interface were verified through the evaluation experiments.
For the position information integration of the real and virtual environments, the method using the camera and the marker has been well used. However, such method may suffer from the occlusion of the markers, especially in the case of a complicated environment. In order to solve this problem, the method proposed in this thesis uses multiple cameras and markers. When a part of the marker is absent from the field of view of a camera or when the marker is in an inappropriate angle relative to a camera, the information acquired with another camera is used. In this way, the virtual object could be displayed even if the marker went out of the view.
The technique is developed for applying AR for in-house CG video generation of crime scene, which is expected to enable the judges to understand the criminal situation naturally. Although CG images and video for depicting crimes are generally used in TV programs already, it has not been frequently used in the court. This is because subcontracting is inappropriate for confidentiality, while police or prosecution does not have any expertise for generating CG movies. I propose to support in-house CG video generation with AR technology. In the proposed system, the CG model of victim, which can usually be obtained by modifying a standard model, is rendered into the captured image of crime site, and a video depicting the process of crime can be automatically generated simply by having a user playing the role of criminal. During operation, a user of police or prosecution plays the role of the criminal wearing a HMD. CG objects are rendered in the video capturing the real criminal site and displayed to the HMD of the user. All things the policeman or the prosecution should do for generating CG video are playing a role of the criminal on site. Modeling of human motions and actual environments can be omitted in this situation. Although the AR markers may be occluded by the user and real objects, complementing marker information among multiple cameras can solve the problem.
When creating a synthetic image, the spatial relationship between a real object and a virtual object becomes important. It may be difficult for a performer to precisely grasp the spatial relationship only with the image of a first person viewpoint. Such situation is improved in the proposed system by providing the performer the image of a third person viewpoint. Since the performer can see the image of various viewpoints, it becomes easy for him/her to understand the spatial relationship among virtual objects and actual criminal site, even if the user is not well trained for using AR system.
A network is used in order to transmit images of two or more viewpoints between personal computers. A server/client model using TCP socket connection is used. The image of the third
-8-
person view acquired with the camera of a client computer is sent to a server via network. If the size of the images being transferred is large, the system can become slow depending on the traffic of network. However, real time processing is very important in case of an AR system. I solve the problem by using small images for the third-person view. The downsizing is executed before the images are transferred.
Experiments have been conducted to examine whether the complement of marker information was realized. The marker could not be detected in 765 frames without complement of marker information. Contrarily, the markers were able to be detected in all frames with complement of marker information. And, the easiness of grasping spatial relationship between the virtual and real objects by displaying additional third-person views was also examined. From the comments of all subjects, displaying third-person views helped easily grasping the spatial relationship between the virtual objects and real objects including the subjects themselves.
To summarize, this thesis address two important issues of AR technology and its applications. The first issue is how to interact with virtual objects in a more natural way and I have developed a technique allowing users to manipulate virtual objects directly with their fingers in AR systems with single camera. The second issue is how to allow naïve users to build AR systems with ease in real applications. I have proposed the technique of using multiple cameras and multiple views to ease the integration between virtual and real worlds. A prototype AR system was implemented for supporting the generation of CG videos depicting crimes.
Keywords
Augmented Reality, Wearable System, Interface, Gesture recognition, Multiple Cameras, Multiple Markers, Complement of Information, Mobile Application.
-9-
目次
1. 序論 ... 11 1.1. 拡張現実感の概要 ... 11 1.2. 本研究の位置付けと方針 ... 12 1.3. 本論文の構成 ... 13 2. 拡張現実感環境 ... 15 2.1. 技術背景 ... 15 2.2. 仮想物体とのインタラクション ... 16 2.3. 位置情報の統合 ... 18 2.3.1. 画像処理による位置合わせ ... 18 2.3.2. センサによる位置合わせ ... 19 3. 拡張現実感のための直感的クリックインタフェース ... 21 3.1. はじめに ... 21 3.2. 関連研究 ... 22 3.3. 仮想物体へのクリックに関する予備実験 ... 24 3.4. 拡張現実のためのクリック動作認識 ... 31 3.4.1. 指先の二次元位置の推定 ... 31 3.4.2. 状態遷移によるクリック動作検出 ... 33 3.4.3. 急減速によるクリック動作検出 ... 35 3.4.4. 仮想ボタンの視覚的クリック可能表示 ... 39 3.5. 評価実験 ... 41 3.5.1. 実装 ... 41 3.5.2. 実験タスク ... 42 3.5.3. クリック動作認識 ... 43 3.5.4. インタフェースのユーザビリティ評価 ... 47 3.6. 考察 ... 50 4. 拡張現実感技術による現場検証用映像生成 ... 52 4.1. はじめに ... 52 4.2. 裁判員制度 ... 53 4.2.1. 裁判員制度の導入 ... 53 4.2.2. 裁判員制度のメリット・デメリット ... 55 4.2.3. 刑事裁判の流れ ... 55 4.2.4. 裁判資料の可視化 ... 56 4.3. 関連研究 ... 56 4.3.1. 裁判資料としての CG 利用 ... 56 4.3.2. 拡張現実感技術の応用 ... 57 4.3.3. 複数視点による映像提示 ... 57 4.3.4. 拡張現実感技術とネットワークの活用 ... 58 4.4. 提案手法 ... 58 4.4.1. 概要 ... 59 4.4.2. マーカ情報の補完 ... 60 4.4.3. 複数視点による演技者支援 ... 64 4.4.4. ソケット通信によるネットワーク ... 64 4.5. 評価実験 ... 66-10- 4.5.1. 実験環境 ... 67 4.5.2. マーカ情報補完の評価実験 ... 70 4.5.3. 複数視点による演技者支援の評価実験 ... 72 4.5.4. ネットワーク遅延による操作影響の評価実験 ... 78 4.6. 考察 ... 79 5. 結論 ... 81 5.1. まとめ ... 81 5.2. 残された課題 ... 81 謝辞 ... 83 参考文献 ... 84 1. ... 84 2. ... 84 3. ... 86 4. ... 88
-11-
1. 序論
1.1. 拡張現実感の概要
近年,情報端末の高機能化や小型化,ソフトウェアの技術開発により拡張現実感(AR: Augmented Reality)を利用した技術やサービスが広く一般に普及している.拡張現実 感とは,現実環境に情報機器が作り出した情報を重ね合わせ,補足的な情報を与える 技術のことである.身近な例としては自動車などのフロントガラスに文字情報を表示 するナビゲーションシステム[1-01]や携帯電話の GPS(Global Positioning System)によ り位置情報を取得し,カメラで撮影した店舗などの情報を表示する広告の代用的な利 用[1-02],新聞や雑誌に掲載されたマーカをカメラで撮影することで記事の動画が表示 される等がある. 拡張現実感を実現するための基盤技術の 1 つとして仮想物体とのインタラクション 技術がある.従来の拡張現実感における一般的な仮想物体とのインタラクションの方 法としてはタッチパネルにおけるタッチパネル操作やキーボードによるキー入力,そ して,音声入力がある.より直感的に仮想物体を操作するためには手による直接操作 が期待される.そのため,手のジェスチャによる仮想物体の直接操作も多く研究され ている.センサが取り付けられたハンドグローブや腕輪などのデバイスを手に装着し, ジェスチャを認識する手法や手に何も付けずにカメラや赤外線センサを用いて手の動 作を検出する手法などがある. 拡張現実感を実現するためのもう 1 つの基盤技術として現実環境と仮想環境の位置 情報の統合技術がある.位置情報の統合の主な方法は 2 つある.1 つめは GPS と様々 なセンサを利用して,情報端末の位置情報を取得する方法である.GPS は衛星からの 信号を受信機で受け取り現在の位置を知るシステムであり,これにより情報端末の位 置を確認することができる.しかし,この方法の大きな課題は GPS の精度である.現 在の技術では数メートルの誤差が発生してしまう.誤差が数メートルもあると現実環 境と仮想環境の位置合わせが大きくずれてしまい,拡張現実感環境に不具合が生じる. そのため,携帯機器に搭載されている各種センサと GPS を組み合わせて位置情報の統 合を行っている.センサを組み合わせることで位置合わせの精度を高めることができ る.2 つめはカメラを用いて画像処理を利用する方法であり,この方法の中でも大き く 2 つの方法に分けることができる.1 つめは専用のマーカをカメラで撮影し,撮影 されたマーカの姿勢や形状と事前に取得しているマーカ情報を比較する.そして,マ ーカを基準にした仮想環境の座標を計算し,現実環境の位置と仮想環境の位置を統合 する.マーカとカメラを準備することで比較的簡単で正確に拡張現実感環境を実現す ることができる.しかし,マーカが隠蔽された場合はマーカ情報が読み取れず,仮想 環境の表示が途切れてしまう問題がある.2 つめはマーカレスの方法である.カメラ から撮影した画像から特徴点を抽出し,その特徴点と事前に設定してある特徴点の情 報を比較することで仮想環境の座標を算出し,現実環境と仮想環境の位置情報を統合 する.マーカレスによる方法は複雑な処理を行っているため情報処理に関する専門知 識が必要な場合がある.-12-
1.2. 本研究の位置付けと方針
拡張現実感の技術を利用したシステムが開発され一般に利用されるようになった. 拡張現実感を実現するための基盤技術の 1 つである仮想物体とのインタラクション技 術において手で直接仮想物体を操作することができれば直感的に操作することができ る.仮想物体を手で直接操作するためには手のジェスチャを認識する必要がある.赤 外線カメラやステレオカメラを利用して手の動作の 3 次元情報を取得できれば,複雑 なジェスチャを認識することができるが,新たにステレオカメラや赤外線カメラを情 報機器に接続する必要がある.また,現在の携帯端末やラップトップでは標準的にカ メラが 1 台搭載されている.1 台のカメラでは奥行き情報を直接取得することができ ないため,手の複雑な動作を認識することは困難である. 本研究では,1 台のカメラのみで直感的に仮想物体を操作できる手法を提案する. GUI(Graphic User Interface)においてマウスによるクリック入力はもっとも基本的で 重要な操作である.このクリックによる入力方法は拡張現実感においても有効な入力 操作になると考えられる.また,主な入力方法の 1 つにタッチパネルによるタッチ操 作がある.表示画面にあるアイコンを直接タッチすることで直感的に操作することが できる.現実環境でも様々な電化製品をはじめ身の周りの機器の入力操作はボタンを 押すことで,ボタンに割り当てられた機能が実行される.これらの操作に共通するこ とはアイコンやボタンなどのターゲットがあり,そのターゲットに対して指で押すこ とで入力操作を行う.この入力操作を拡張現実感環境に応用する.拡張現実感におい てターゲットに相当する仮想ボタンを提示し,指で仮想ボタンを直接選択し,ボタン を押す動作に類似したジェスチャで入力するインタフェースを構築する.この仮想ボ タンを選択する動作と押す動作に類似した入力動作,2 つの動作を組み合わせて“ク リック動作”と呼ぶ.また,1 台のカメラでクリック動作を認識する手法を設計する ことで,新たな装置を接続せず直感的に仮想ボタンを操作することが可能となる. 拡張現実感を実現するためには現実空間と仮想空間の位置情報の統合が必要であり, 2 つめの基盤技術である.現実空間と仮想空間の位置合わせには簡単で正確であるカ メラとマーカを使用する方法がある.事前にマーカに関する情報を設定しておき,カ メラでマーカを撮影し事前に設定しているマーカ情報とのマッチングを取る.そして, 撮影されたマーカを認識し,マーカの位置や姿勢を推定し仮想環境の座標系を算出す ることで,マーカ上に仮想物体を重畳表示することができる. マーカを用いる方法の問題としてマーカがカメラから隠蔽されるとマーカ情報が取 得できず,拡張現実感環境の表示が途切れてしまう場合がある.このマーカの隠蔽問 題を解決する方法としてマルチカメラとマルチマーカを使用する方法がある.マルチ カメラとマルチマーカを使用することで,ある特定のカメラで隠蔽されたマーカのマ ーカ情報を別のカメラで撮影しマーカ情報を取得する.このマーカ情報を利用して隠 蔽されたマーカの情報を補完することで,隠蔽されたマーカ上でも仮想物体を表示す ることができる.本研究ではマルチカメラとマルチマーカによるマーカの隠蔽問題を 解決する方法を応用し,警察や検察が利用する現場検証用映像のインハウス制作支援 システムを提案する.秘密情報保持のため外部委託が困難で,CG 映像制作は専門知識 が必要であり,警察や検察によるインハウス制作は困難である.そこで,カメラとマ ーカを用いて拡張現実感を実現する方法により,拡張現実感の知識があまりない警察 や検察でも犯罪現場に複数のカメラを設置し,マーカを配置することで拡張現実感環-13- 境を簡単に実現することができる.マーカにより仮想凶器や仮想被害者モデルを重畳 表示させ,犯人役の演技者が犯罪状況を演じることで,現実環境と人物動作を反映し た拡張現実感における CG 合成映像を生成することが可能となる.また,複数のカメ ラを現場に設置していることを利用し,演技者(一人称)及び視聴者(三人称)視点 映像を取得し,演技者が仮想物体との位置関係や周囲の現実環境を把握できるように 演技者へそれぞれの映像を提供する.それにより演技者は仮想環境と現実環境の位置 関係が把握しやすくなり,演技を支援することができる. 仮想物体とのインタラクション技術においては 1 台のカメラで直感的に仮想ボタン を操作するインタフェースを構築し,現実環境と仮想環境の位置統合技術では,マル チカメラとマルチマーカによるマーカ隠蔽の問題解決手法の実応用システムとして警 察や検察が利用する現場検証用映像生成のシステムを構築する.これらにより,仮想 物体とのインタラクション技術を向上させ,位置統合技術の利用範囲を広げることが できる.
1.3. 本論文の構成
本論文の構成は以下のとおりである. 第 2 章では,拡張現実感における技術背景を述べ,拡張現実感における仮想物体と のインタラクション技術と現実環境と仮想環境の位置情報の統合技術の 2 つの基盤技 術の従来手法と問題点について述べる. 第 3 章では,拡張現実感の実現のための基盤技術である仮想物体とのインタラクシ ョン技術の研究において,1 台のカメラで現実環境でのボタンを押す動作に類似した ジェスチャであるクリック動作の検出と,視覚的なフィードバックの機構を持つイン タフェースについて述べる.クリック動作の検出には 2 種類の検出手法を設計する.1 つめの手法は,指先の速度と加速度を算出し,クリック動作で特徴的な動作である急 減速に注目し,急減速動作を検出することでクリック動作を認識する.2 つめの手法 は,指先の動作を停止状態,通常状態,速い状態,急減速状態の 4 つの状態に分類し, 状態遷移によりクリック動作を認識する.また,2 種類のクリック動作の検出手法の 認識評価の実験結果とクリック動作によるインタフェースのユーザビリティ評価の実 験結果を示す. 第 4 章では,拡張現実感の実現のためのもう 1 つの基盤技術である位置情報の統合 技術の研究において,マルチマーカとマルチカメラによるマーカ情報の補完方法を利 用した実応用システムについて述べる.拡張現実感環境を実現するためにはカメラと マーカを用いることで簡単に実現することができる.しかし,マーカの隠蔽により仮 想物体の表示が途切れてしまう問題がある.その問題を解決するためにマルチカメラ とマルチマーカを用いる方法がある.ある特定のカメラでは隠蔽されたマーカを別の カメラからそのマーカを撮影する.そのマーカ情報を取得し,隠蔽されたマーカ情報 を補完することで隠蔽されたマーカ上に仮想物体を表示する.このマルチカメラとマ ルチマーカによるマーカ情報の補完方法を実応用システムである警察,検察による現 場検証用映像のインハウス制作支援システムに適応する.また,マーカの補完処理の 評価結果と演技者の映像に三人称視点映像を追加することによる演技支援の評価結果-14- について示す.
最後に第 5 章で本研究のまとめおよび残された課題について述べる.
-15-
2. 拡張現実感環境
2.1. 技術背景
拡張現実感の技術革新の前に仮想環境(VR:Virtual Reality)においての研究や技術開 発が行われてきた.現実環境では実現が困難である環境を仮想環境が可能にしてきた. 仮想環境における様々な研究が行われ,その結果,仮想環境が現実環境に近づきつつ あるが,仮想環境の臨場感や写実性の実現には多くの問題がある.臨場感や写実性を 現実環境に近づけるためには高度な技術や高負荷のかかる計算処理が必要となる.そ こで,現実環境と仮想環境を混合することで,仮想環境では実現が困難な部分を現実 環境と仮想環境を合成することで,臨場感や写実性を実現する複合現実感(MR:Mixed Reality)が注目されるようになった. 複合現実感は Milgram ら[2-01]が提唱した.複合現実感は現実環境と仮想環境を混合 し,現実環境と仮想環境がそれぞれリアルタイムに影響しあう新たな空間を構築する 技術全般を指す.また,複合現実感の中でも現実環境に仮想環境を取り込む拡張現実 感と,情報機器によって構築された仮想環境に現実環境の情報を取り込むことで仮想 環境の臨場感や写実性を高める拡張仮想感(AV:Augmented Virtuality)がある.拡張仮 想感の例では Google が提供する Google Earth[2-02]がある.Google Earth は仮想環境の 地球モデルに現実世界の写真を表示させることで仮想環境の写実性を高めている.こ のように現実環境と仮想環境は密接な関係にあり,近年は拡張現実感技術が特に注目 されている.図 2.1.1 にそれぞれの環境間の関係を示す.拡張現実感について Azuma ら[2-03]は 3 つの特徴を挙げている.1 つめは“Combines real and virtual”であり,現実世界と仮想世界を組み合わせていること,2 つめは “Interactive in real time”であり,ユーザが仮想環境のある物体に対して操作した場合 にリアルタイムの反応が必要であること,3 つめは“Registered in 3D”であり,現実世 界と仮想環境の 3 次元での統合が重要であることである. 1 つめは拡張現実感の定義そのものである.ここでは 2 つめの仮想物体とのインタ ラクションと 3 つめの現実環境と仮想環境の統合について考える. 仮想物体に対するインタラクションの主な方法として身体にセンサを装着する方法 とカメラを用いて画像処理を利用する方法があり,様々な分野で盛んに研究や技術開 発が行われている.本研究ではカメラによる画像処理を利用した仮想物体に対する新 しいインタラクション技術を提案する. 現実環境と仮想環境の統合では大きく 3 つの整合性を取る必要がある. 幾何学的整合性:仮想環境と現実環境の 3 次元的空間における位置の整合性 時間的整合性 :現実環境と仮想環境の時間的変化の整合性 光学的整合性 :現実物体と仮想物体の陰影や光環境の整合性
-16- 3 つの整合性の中でも特に重要なものは幾何学的整合性である.幾何学的整合性が 保持できなければ,時間的整合性と光学的整合性を得ることが困難である.そこで本 研究では幾何学的整合性である仮想環境と現実環境の位置統合技術に注目する. 第 2.2 節では拡張現実感の基盤技術の 1 つである仮想物体とのインタラクション技 術についての研究や問題を述べ,第 2.3 節ではもう 1 つの基盤技術である仮想環境と 現実環境の位置情報の統合技術についての研究や問題を述べる. 図 2.1.1 複合現実感環境
2.2. 仮想物体とのインタラクション
拡張現実感において仮想物体とのインタラクションは現在,タッチパネルによるタ ッチ操作やキー入力,そして,音声入力がある.さらに直感的に仮想物体を操作する ためには手によるジェスチャ操作がある.手のジェスチャを認識するためには加速度 センサが取り付けられたハンドグローブ[2-04]を装着する方法や,筋電位センサが内蔵 されたリング[2-05]を手首に装着する方法があるが,ユーザに拘束感を与えてしまう問 題もある.そこで手に何も装着せず,カメラを用いて画像処理により手のジェスチャ 認識をする研究も盛んに行われている.しかし,画像処理による手のジェスチャ認識 は困難である.その理由として手は形状変形の自由度が高く形状からの推定ができな い,照明変動によって肌色による領域抽出が難しいなどが挙げられる. 仮想物体とのインタラクションを実現するとき,手指の三次元位置を獲得する必要 があり,ステレオカメラを用いる方法がある.ステレオカメラにより左右それぞれの カメラから画像を取得し,それぞれの画像の特徴点を対応させる.対応させた特徴点 とステレオカメラの内部パラメータを利用することで画像内の手指の三次元位置を獲 得する. 仮想環境 現実環境 複合現実感環境 拡張現実感環境 拡張仮想感環境-17- 加茂ら[2-06]はステレオカメラにより指の三次元位置を求め,手のジェスチャから仮 想画面を表示させる技術を提案した.また,仮想画面を拡大縮小するジェスチャもサ ポートしている.仮想画面と手のインタラクションでは仮想画面の手前から奥へ指を 交差させることで交差点にある仮想オブジェクトを操作することができる.しかし, ステレオカメラを使用するため事前にカメラ位置の情報が必要であり,設備が大掛か りとなり持ち歩くことが困難である. 手指の三次元位置の獲得が難しい場合,特定のジェスチャにコマンドを割り当てて, 仮想物体操作を実現することもできる.Kim らの研究[2-07]ではプロジェクタによって 大画面に投影した仮想物体を手のジェスチャによって操作するシステムを開発した. 手指の姿勢推定はユーザの指先にマーカとなる指サックを取り付けることで実現して いる.ユーザは特定のジェスチャを行い,そのジェスチャをカメラで取得し,指サッ クの位置を判定することで特定のジェスチャを認識し,ジェスチャに応じた仮想物体 の操作を行う. 星野ら[2-08]は 1 台のカメラから高速に手の姿勢を推定する手法を提案した.手の画 像の大規模データベースから入力データに最も類似する手の画像を大まかに検索し, 選択された候補の中からさらに詳細に検索することで高速に手の姿勢を推定すること 可能にしている.高フレームレートカメラを使用することで速い手の動作に対応し, 手のジェスチャによる直感的な入力により複雑なロボットアーム操作を可能にしてい る. 手首に取り付けたセンサとカメラから指の曲がり方を検出する Digit[2-09]もある. 指の曲がり方からジェスチャパターンを認識し,仮想物体操作を行う.提案装置を手 首に装着するため指先は自由にジェスチャを行うことができるためハンドグローブを 装着する手法より拘束感を抑えられる.これらは装置が特殊であり,限られた環境で しか利用できないなどの問題がある. 画像処理以外から手の形状を調べる手法もある.Xu ら[2-10]は画像処理からではな く,手に流れる電気信号から手の形状を推定しようとした.腕に装着した多チャンネ ルの表面筋電センサと三次元加速度計を使用する.筋電センサと加速度計の信号を用 いて隠れマルコフモデルにより手の動作を認識する.仮想ルービックキューブの操作 による評価実験を行い,高い認識精度を得ている.また,佐藤ら[2-11]は,水槽に手を つけることで得られる電気信号から,手の形状を推定する.高周波の静電容量の変化 を捉えるセンサを利用し,実物体との接触の判定を行っている.静電容量の変化を利 用しているため水槽の水の接触の判定も可能となり固体だけでなく液体との接触によ り操作することができる.これらのシステムでは移動できるかもしれないが,仮想物 体とのインタラクションを実現するために映像内での指の位置が必要となる拡張現実 感技術との相性は悪い. 手の動作の加速度から動作を推定する方法では,Akl[2-12]による Wii リモコンを利 用したジェスチャ分類がある.Wii リモコンは任天堂より発売された据え置き型ゲー ム機 Wii[2-13]のコントローラで動きを検知する 3 軸加速度センサが搭載されている. その加速度センサを利用し,手の動作を認識している.18 種類の動作を識別すること で様々な操作を可能としている.
-18-
2.3. 位置情報の統合
拡張現実感環境を実現するためには現実空間と仮想空間の位置情報の統合が重要と なる.位置情報の統合には大きく 2 つの手法がある.1 つめはカメラなどの画像入力 装置からマーカや現実環境の画像特徴を分析して,位置情報を取得し統合する方法で ある.2 つめは GPS(Global Positioning System)や加速度センサなどのセンサを利用し て,位置情報を取得し統合する方法である.
2.3.1. 画像処理による位置合わせ
カメラを用いて画像を取得し,その画像の特徴を分析して位置情報を取得する方法 にもいくつかの方式がある.簡単に利用できる方式としてマーカとカメラを使用する 方式がある.マーカを利用して拡張現実感システムを構築するためのライブラリとし て ARToolKit [2-14]がある.ARToolKit で認識できるマーカは図 2.3.1(a)に示すように正 方形であり太枠で囲まれている.マーカによる画像処理の流れはカメラからマーカを 読み取り,画像を一定の閾値により 2 値化処理する.2 値化処理した画像中のマーカ の黒色領域の輪郭と 4 隅を検出する.検出した輪郭と 4 隅の情報と事前に取得してい るマーカのサイズを使用して,マーカの座標を算出する.マーカの中央にある図柄と 事前に取得しているマーカの図柄とのマッチングを行う.それが一致すればマーカと 認識され,図 2.3.1(b)に示すようにマーカに対応した仮想物体がマーカ上に描画される. (a) マーカ例 (b) 利用例 図 2.3.1 ARToolKit [2-14] マーカを利用する方式の利点はカメラとマーカがあれば簡単に拡張現実感環境を実 現することができる. マーカ情報はカメラで取得しやすく正確に位置を制御すること ができる.また,比較的計算処理が軽いためリアルタイム性を損なわない.欠点はマ ーカの認識が困難な状況である夜間や暗い環境,マーカの前に物体があると隠蔽によ
-19- りマーカ情報を取得することができない問題がある.また,マーカにより景観が損な われる場合がある. Baratoff ら[2-15]は現実環境に複数のマーカを様々な位置に配置し,それらのマーカ の処理を統合してより頑健な拡張現実感環境を実現している.谷藤ら[2-16]は円形のマ ーカ内に描画したテクスチャからマーカの識別とマーカの方向を推定する手法を実現 している.円形のマーカを用いることで射影変換による画像のゆがみを最小限に抑え マーカの識別精度を向上させている.マーカを利用するとズームアップや遠くからマ ーカをカメラで撮影するような場合,カメラの位置姿勢の正確な推定が困難になる問 題があった.そこで,立野ら[2-17]はマーカ内部に大きさの異なるマーカを入れ子の形 状に配置することでマーカとカメラ間の距離の大きな変化に対応できるようにした. マーカは景観が損なわれる場合があるが,それを解決するために吉田ら[2-18]はマーカ の四隅を 4 つのユニットに分けてそれぞれのユニットの形状を認識することで 1 つの マーカとして認識する.玉田ら[2-19]は.デザインルールを設計し,そのルールに従い ポスタを作成する.そして,カメラを用いてマーカの代わりにポスタを認識すること で仮想環境との位置合わせを行う.また,Park ら[2-20]や中里ら[2-21]は赤外線カメラ のみで撮影できる不可視マーカを実現している.このため,肉眼ではマーカが見えず 景観を保つことができる.赤外光を吸収するマーカを赤外線カメラで撮影し,認識す ることでカメラの位置・姿勢を推定し拡張現実感環境を実現している. マーカを使用しない方式もある.これは現実環境をカメラで撮影し,その環境の特 徴点を推定して,その特徴点から仮想環境との位置情報の統合を行う方式である.代 表的な研究として PTAM(Parallel Tracking and Mapping) [2-22]がある.これはカメラで 撮影した映像からまず,1 フレーム目の画像の特徴点を取得する.次のフレームの画 像に対しても同様に特徴点を取得する.この特徴点の対応関係を計算し,移動距離を 算出する.その移動距離より立体的な位置情報を取得する.また,PTAMM (Parallel Tracking and Multiple Mapping) [2-23]は PTAM を改良した手法であり特徴点を取得した 環境のマップを保存することが可能になった.さまざまな環境に対応することができ, 映像出力機能が追加できる.
2.3.2. センサによる位置合わせ
屋内では GPS が利用できないため磁器トラッカを利用した手法[2-24]を,屋外では GPS が利用できるため GPS を利用した手法[2-25]がある.しかし,GPS のみでは位置 精度に問題があり様々なセンサと組み合わせた方法が研究されている.神原ら[2-26] は GPS と小型慣性航法装置を併用している.慣性航法装置は複数の加速度センサから 構成されており,位置と同時にセンサの姿勢も計測することが可能である.これによ り GPS の欠点である計測周期の低さと慣性航法装置の計測誤差の蓄積をお互いに補う ことでより高精度な計測を実現している.中林ら[2-27]は GPS と HMD に内蔵されてい る三軸角度センサとマーカトラッキングを組み合わせて利用することで屋外・屋内に おける大規模空間で幾何学的整合性を実現している. これらの GPS を利用した方式は高精度な装置を使用している反面,機器構成が複雑 で大きさや重量が課題である.そこで,小田島ら[2-28]は小型で携帯が容易なハンドヘ ルド式の GPS を利用して,屋外における建物への注釈を付加するウェアラブル型拡張-20- 現実感システムを提案した.通常の GPS 装置と比較すると小型・簡略化できる反面, 測定の精度が低下する.その精度を補うためにユーザの移動時と静止時を GPS で検出 し,静止時には姿勢センサの誤差を画像処理で補正することで高精度に位置合わせを している.また,GPS を利用せず,赤外線ビーコンと歩数計を用いる手法[2-29]がある. 赤外線ビーコンの発信機を分岐点などの特定の地点に設置し、受信機をユーザに取り 付けビーコンを受信することで位置を特定する.ビーコンの送信機から離れた場合は 歩数計に内蔵されたコンパスと加速度センサによりユーザの位置を推定する.これら の手法の問題として特殊なデバイスを接続する必要があり,装置も大掛かりなものと なる.また,利用範囲が限定される場合もある.
-21-
3. 拡張現実感のための直感的クリックインタ
フェース
3.1. はじめに
拡張現実感関連の技術は,携帯端末アプリケーションなどにも広く一般に利用され るようになり,社会的な注目が集まっている.Google は 2015 年にヘッドマウントデ ィスプレイ GoogleGLASS[3-01]を発売予定である.GoogleGLASS は外向きに取り付け られたカメラと内向きに取り付けられた透過型ディスプレイを備えており,拡張現実 感のアプリケーションサービスを行うには格好の装置である.GoogleGLASS は音声入 力によるコマンド実行や眼鏡のフレーム部分に取り付けられた小さなタッチパネルに よって,コマンドの実行を行う.ディスプレイに提示される仮想世界とカメラに映る 現実世界をシームレスにつなぐためには,ジェスチャによる仮想物体の直接操作が欠 かせないと著者らは考える.本研究では,GUI において最も基本的な入力操作である クリック,タッチパネルでのタッチ入力,現実環境での家電機器などのボタン入力に 注目する.そして,図 3.1.1 に示すような仮想ボタンを押すジェスチャをクリック動作 と呼び,このジェスチャにより拡張現実感環境での自然な入力インタフェースを提案 する.クリック動作は物体を選択するポインティング動作と現実のボタンを押す動作 と類似した動作で構成される.クリック動作による仮想物体操作は,コマンド入力や ピンチ動作よりも自然な入力動作であるが,そのパターンの認識が困難であり,頑健 性を確保することが難しかった.また,1 台のカメラからは指と仮想物体の奥行き関 係を正確に把握することは難しいため,複数のカメラを使用する手法も多かった.複 数のカメラを使用することで奥行きを推定することが容易になるが事前にカメラ位置 の設定や装置が大掛かりになる問題がある. 図 3.1.1 提案するクリックインタフェース-22- 提案手法では,利用者視点で観測する 1 台のカメラで利用者の指先を検出し,その 速さおよび加速度に注目することでクリック動作の検出を可能にした.また,従来の 拡張現実感アプリケーションではジェスチャ認識のためにほぼ完全な手指の領域の取 得や複数カメラから手指の三次元的な情報が必要であった.提案手法ではほぼ完全な 手指領域の取得を必要とせず,一般に利用される 1 台のカメラが搭載された機器の利 用 を 想 定 し て お り 1 台 の カ メ ラ か ら 三 次 元的 な 情 報 を 算 出 す る .こ れ に よ り GoogleGLASS をはじめとする 1 台のカメラが搭載された機器での利用を可能にする. 本研究が目指す直感的なクリック動作検出とは,現実世界のボタンを押す動作と類 似した動作を検出して,仮想ボタンを押せるようにすることである.これにより,ユ ーザにとって知的負担がなく[3-02],かつ,学習をあまり必要とせずに仮想ボタンを押 すことができるようになると見込まれる. 本章の構成は以下のとおりである.第 3.2 節 では関連研究について紹介し,第 3.3 節では仮想物体の押し方に関する予備調査について述べる.第 3.4 節ではクリック動 作の認識のための提案手法について述べる.第 3.5 節では評価実験を示し,第 3.6 節で 本章をまとめる.
3.2. 関連研究
カメラを使った自然な入力装置(NUI: Natural User Interface)については,タンジブル インタフェース[3-03][3-04],テーブルトップインタフェース[3-05][3-06],プロジェク タカメラシステム[3-07][3-08],Kinect[3-09],iPad[3-10]などが牽引役となり,活発な議 論が行われている.中でもプロジェクタカメラシステムでは,手指の動作をカメラ画 像から認識することで,コマンド入力を行う手法が提案されてきた.カメラから得ら れる手指の領域は,安定した照明環境が得られなかったり,背景領域に様々な環境が 映り込むことで事前に想定することが困難であったり,手指による自己隠蔽が大きか ったり,動きぶれも大きかったりすることから欠損のある不完全なものであることが 多い.これらによる問題を避けるために,従来のプロジェクタカメラシステムでは, 自然さと頑健性のバランスの取れた手指の形によるコマンド入力[3-11]やピンチ動作 による平面位置指定[3-12]などが積極的に採用されてきた. 画像からの手のジェスチャ認識はコンピュータビジョンの古典的な問題のひとつで あるが,まだ完全に解決されていない.近年の手の画像認識手法については,Chaudhary らのサーベイ論文[3-13]で述べられている.画像からの手のジェスチャ認識が難しいの は,1)関節が多いために形状変形の自由度が高く,形状からの推定ができない,2)関節 が多いために,自己隠蔽が起こりやすい,3)照明変動によって,肌色による領域抽出 が難しいなどの理由による. 手の形状変形の自由度が高い問題に対しては,既知のテクスチャを持つグローブを 装着させることで解決が試みられてきた.Wang らは独自に配色されたカラーグローブ を開発し,1 台のカメラから自己隠蔽の大きな手指の姿勢の獲得を試みた[3-14].手の 領域のおおまかな形状をデータベース中の最近傍事例の姿勢から求め,細かな形状を モデルフィッティングによって得ることができる.手と同様に,変形の自由度が高い 衣服の表面を追跡するためには,格子[3-15],三角形[3-16],ドット[3-17]などの既知パ
-23- ターンを与え,複数のカメラで追跡する研究例がある.しかしこれらのいずれの手法 も,手や衣服にテクスチャのあるパターンを与えることが必要となる.手の場合には, グローブの装着を求めることで,利用できる場面が制限されてしまうことが考えられ る. 手の自己隠蔽を避けるためには,複数のカメラを用いることができる.複数のカメ ラを用いることで,手の三次元形状を推定できる利点もある.三次元仮想物体とのイ ンタラクションを実現しようとするときには,手指の三次元位置が獲得できているこ とが有利となる.Lee ら[3-18]による仮想物体と手とのインタラクションの研究では, カメラから取得した画像より肌色領域を抽出する.ステレオカメラによる視差を利用 することで手の重心と指先の三次元位置を取得し,この二点を結ぶ線分により手の方 向を算出し,その線分と仮想物体の接触判定を行うことで手と仮想物体とのインタラ クションを実現している.また,ステレオカメラによる仮想物体とのインタラクショ ンが可能なウェアラブルディスプレイデバイスの開発プロジェクト[3-19]も報告され ている.しかし,これらのシステムはステレオカメラを使用するために事前にカメラ 位置の情報が必要であり,設備が大掛かりとなり持ち歩くことが困難である. 奥行き情報を利用せず,単独のカメラから手指形状の特徴を取得し手指の位置姿勢 を推定する研究がある.Terajima ら[3-20]は高フレームレートカメラと FPGA による空 中タイピングシステムを提案した.これは高フレームレートのカメラと手のしわを強 調した画像を利用して照明による影響を低減させている.事前に取得済みの手指画像 とのマッチングをとることで高い認識率を得ている.リアルタイム処理のため独自の ハードウェアを構築している.しかし,高フレームレートのカメラと独自のハードウ ェアで構成されているため,現状の携帯端末では利用することが困難である.また, Mizuchi らの研究[3-21]では指間部に基づいて手の 3 次元位置および姿勢を推定する. カメラによる画像から低輝度値部分を推定することで指の隙間を含む手領域を抽出す る.抽出された指の隙間の特徴点と事前に取得済みのカメラの内部パラメータを利用 することで手の 3 次元位置や姿勢を推定する.指の隙間を利用しているため人差し指 で操作するクリック動作の認識には適さない. 照明変動による肌色領域の見た目が変わる問題に対しては,Kölsch らが肌色の定義 を逐次更新することで領域抽出精度を向上する手法を提案している[3-22].彼らの手法 では,拡張現実感環境で想定されるような煩雑で肌色とも近いようなテクスチャが背 景に現れる場合にも,手の領域の頑健な抽出を提供する.また,同じ研究者グループ からは形状に基づく手領域の抽出についての提案もある[3-23][3-24].彼らの手法は, 特定の手のジェスチャの検出と,ジェスチャが行われた三次元位置の推定を目的とす るものであるが,我々はさらにクリックという動きのある動作の検出を目指す.肌色 の定義を逐次更新する部分については,本研究でも積極的に利用する. 本研究では,手に何も装着せず,1 台のカメラから動きの伴うクリックという動作 を検出する手法を提案する.各フレームの静止画像だけでなく,連続したフレームか ら計算できる指先の速さおよびそのフレーム間差分を利用することでこれを実現する.
-24-
3.3. 仮想物体へのクリックに関する予備実験
利用者が仮想ボタンに対してどのようにクリック動作を行い,どういう情報により クリック動作検出を設計するかを検討するために予備実験を行った.コンピュータス キルの異なる様々な年齢の被験者 12 名(70 代 1 名,60 代 2 名,30 代 3 名,20 代 6 名) が仮想ボタンに対してどのようなクリック動作をするのか調査した.図 3.3.1 に示すよ うに被験者に映像透過型 HMD を装着して椅子に座ってもらう.HMD には図 3.3.2 に 示す Vuzix 社製の Wrap920AR を使用した.システム仕様を表 3.3.3 に示す.解像度は SVGA(800×600)でディスプレイ正面には USB ビデオカメラが 2 台組み込まれており, 水平視野角は 31 度になる.2 眼式の VGA(640×480)の映像を取得することができるが, 予備実験では単独のカメラによる入力とするため 1 台のカメラのみを利用し,カメラ で撮影した同じ画像を両方のディスプレイに表示するようにした.被験者にはディス プレイに表示される図 3.3.4 に示す仮想ボタンを押すように指示した.拡張現実感にお いては仮想物体が常に画面の手前に表示され,このままでは仮想ボタンが常に手前に 表示されてしまい指が仮想ボタンの後ろに隠れてしまう.指が仮想ボタンの後ろに隠 れないようするため,肌色領域を抽出して手指領域を画像から抽出し,手指領域を仮 想ボタンの手前に描画するようにした.被験者には仮想ボタンに対するその他のフィ ードバックは与えず,仮想ボタンに対する具体的な操作の仕方についても何も指示を 与えないようにした. 図 3.3.1 操作風景 画面上での仮想ボタンの配置による押し方の違いを検証するために,仮想ボタンは 図 3.3.4(a)のように十字型に配置した仮想ボタンが画像平面と平行に配置するものと, 図 3.3.4(b)のように画像平面とは異なる平面に横に 3 つに並んだ仮想ボタンを配置する ものの 2 種類を用意した.図 3.3.4(a)の仮想ボタンのサイズは画面サイズ 640×480 に 対し,80×80pixels の正方形で各ボタンの間隔はボタンの中心から 160pixels 離してい-25- る.図 3.3.4(b)の仮想ボタンのサイズは 120×120pixels で,ボタン間隔は 180pixels 離 している.被験者が仮想ボタンを押した場合,視覚・聴覚・触覚のいずれのフィード バックも提示しない.これはフィードバックによって仮想ボタンの押し方に影響を与 えないようにするためである. 表 3.3.3 システムの仕様 PC 製品名 ThinkPad X201s 形態 ノート
CPU Inter Core i7 640LM 2.13GHz
RAM 4.0GB
OS Windows Professional ServicePack 1
HMD 製品名 Wrap 920AR ディスプレイ 640×480pixels,LCD×2 画像センサ 640×480pixels フレームレート 最大 30fps / sec 接続インタフェース USB,ディスプレイケーブル センサ 3 軸ジャイロセンサ,6 軸独立トラッカ 図 3.3.2 Wrap920AR, Vuzix 社製
-26- (a) 平面的ボタン (b) 立体的ボタン 図 3.3.4 仮想ボタン形状 この予備実験により 12 名の被験者で共通して,以下のクリック動作が観測された. 被験者は仮想ボタンの奥行きの感覚が把握できないために,被験者ごとに異なる 奥行き位置で仮想ボタンを押す動作を行った.また,被験者は指を画像平面と平 行に移動させて,指先を仮想ボタンの位置に重ねることで仮想ボタンの位置を確 認した. 仮想ボタンを押す場合,仮想ボタンと指先の前後関係が把握できないために,指 を素早く振り上げたり,素早く振り下ろしたりして,仮想ボタンを押そうとした. 被験者 12 名のうち 10 名は,図 3.3.5(a)に示すようにまず指をゆっくり振り上げ, 次に素早く振り下ろした.残りの 2 名は図 3.3.5(b)に示すようにまず指をゆっくり 振り下ろし,次に素早く振り上げた. 仮想ボタンの画面上の配置位置によって,指先位置の水平成分の変化量が異なる. これは,カメラと指の相対位置の変化により仮想ボタンを押し込む方向が,画面 内で一定でないためだと考えられる. 予備実験の観測中,指先の速さが大きい状態は長時間続くことはなく,急加速や 急減速のみが単独で起こることはなかった.急減速の直後でクリックを意図する 被験者が多く見られた. また,被験者からは仮想ボタンを押した触覚がないため,押したことを提示するフ ィードバックがほしいという意見を得た.
-27- (a) 動作例 1 指先を上げてから押す (b) 動作例 2 指先で押してから戻す 図 3.3.5 クリック動作例 続いて,さらに詳細な指先の動作を確認するために図 3.3.6 に示す LeapMotion[25] を 使用して被験者のクリック動作の指先の三次元位置を取得した.LeapMotion は 2 つの 赤外線カメラと 3 つの赤外線照射 LED から構成される.赤外線 LED を照射された手 や指を 2 つの赤外線カメラで撮影し,画像処理によって手や指の位置を推定する.検 出範囲は半径 50cm 程度,中心角 110 度の範囲で 0.01mm の精度で認識することができ る.HMD のカメラ座標系と LeapMotion の座標系の y 方向座標軸をなるべく一致する ように LeapMotion を机の上に設置した.被験者 2 人には LeapMotion 上で仮想ボタン を押す動作を行ってもらい,指先の三次元位置の座標値を取得した.三次元位置の座 標値より速さ‖𝑣𝑡‖と,そのフレーム間差分𝑎̃ = ‖𝑣𝑡 𝑡‖ − ‖𝑣𝑡−1‖を求めた.平面的仮想ボ タンの結果を図 3.3.7 に,立体的仮想ボタンの結果を図 3.3.8 示す. 図 3.3.7,図 3.3.8 の結果から,クリック動作を行うときには急加速と急減速の動作 が発生していることがわかる.指先の停止動作はユーザによる差異はないため速い動 作から停止へと変化する急減速動作に注目する.また,仮想ボタンを押す直前の動作 である急減速動作に注目しクリック動作の判定を行うことで,実際のユーザが押すタ イミングとシステムがクリック動作を判定するタイミングとの遅延を最小限に抑える ことができる.急減速は速さのフレーム間差分の値が負の大きな値となり,クリック 動作以外では起こらないことが図 3.3.7 と図 3.3.8 の結果から読み取れる.このことは, クリック動作を行うときにだけ指先が急減速動作をすることを意味している. 図 3.3.4(a)に示す仮想ボタン表示では押す動作が Z 軸方向の画面の手前から奥方向の 移動であったのに対して,図 3.3.4(b)に示す仮想ボタン表示では押す動作が Y 軸方向の 画面上側から下側方向の移動となり,クリック動作である指先の移動方向としては違 いが見られた.しかし,図 3.3.7 と図 3.3.8 の結果に示すように,指先の速度とそのフ
-28- レーム間差分の変化の観点で見た場合には特徴的な違いは見られなかった. 被験者の仮想ボタンに対する指先の動作の観測結果による共通動作や LeapMotion によるクリック動作の測定値の結果から,以下のように設計することで直感的なクリ ックインタフェースを設計できると予想できた. 異なる奥行き位置でのクリック動作に対応する. ユーザに仮想ボタンが押せるかどうかを提示する. 素早く振り下ろす,素早く振り上げるといった急減速する動作によってクリック 動作を検出する. 水平方向の移動量と奥行き方向の移動量の両方から,指先動作の速さやその差分 を計算する. 図 3.3.6 LeapMotion コントローラ
-29- (a) 被験者 A (b) 被験者 B 図 3.3.7 LeapMotion で計測し算出した平面的ボタンでの速度と加速度の時間変化 [Differential Value] [Differential Value]
-30- (a) 被験者 A (b) 被験者 B 図 3.3.8 LeapMotion で計測し算出した立体的ボタンでの速度と加速度の時間変化 [Differential Value] [Differential Value]
-31-