5.1 文書校正処理と統語的誤り検出の高速化
5.1.1 文書校正処理の目的 日本語ワードプロセッサの付加価値を高めるために望まれることは,誤入力・誤変換の軽減,表記 のゆれの排除などであり,仮名漢字変換用のフロントエンドプロセッサ(以下 FEP と記す)の改良や, 日本語の言語構造を考慮した編集・操作系,あるいは字面情報,形態素情報を利用した校正・推敲 支援システムの提案がなされている[76], [78], [88]-[92]. この目的のためのアプローチの代表的なものとして,日本語文の入力の際,即時的な応答を考慮 して,シソーラスと格フレーム[75]を用いた仮名漢字変換(AI 変換)機構を利用するもの,および既存 の文書全体をバッチ処理的にチェックするものとが存在する[76]. また,文章の作成上,経験的に知られている誤り易い箇所を正規表現等による文字列パターンと して登録しておき,これを中心に高速にサーチし,推敲対象としてユーザに注意を促すものなどがあ る[78], [92]. こうしたシステムやツールの設計上の方針は,迅速かつ正確に問題を含む箇所(誤り表記部分), あるいは経験的に含むと予測される箇所を検出・指摘することである. ところで,これらの提案の実装内容を見てみると,その多くはワークステーション以上のクラスのコ ンピュータを使う場合がほとんどであり,本来ワードプロセッシングが要求するパーソナルベースの環 境に代表されるような小規模システムでは,実装がきわめて困難であるのが現状である. そこで,本稿では,本来ワープロの実装がなされるはずの小規模システムを対象として,実用的な パフォーマンスを得る文法チェッキングの高速化手法について述べる. 5.1.2 従来方式の拡張 5.1.2.1 JFK 構造のグループ化−解析モードの導入− 解析のモジュール性をより強調するために,統語構造を反映するような JFK タイプのグループ化 (grouping)が可能である.これをTable 5-1-1 に示す.Table 5-1-1 Category of JFK Type
Group JFK Type G0 K GJ J or JK GF F or FK GB JF or JFK グループ化の目的は,校正支援のための誤り検定を行う上で,パージングモジュール(parsing module)を分割する点にある.モジュール分割により得られる利点は,ローカルな最適化が容易に なることである.このことは効率面で優位に立てることを意味している. Table 4-3 に示した結果をグループ別頻度分布で表現するとFig. 5-1-1 のようになる. グループG0 の JFK 構造(全体の 4.7%)では,自立語辞書,および付属語接続行列[58], [76]によ る探索の必要性が全くない.グループGJ(28.1%), および GF(5.6%)では,それぞれ非平仮名表記 の自立語辞書検索,および平仮名表記の自立語辞書検索が要求される.GJ, GF に関しては,活
用を意識する必要はない.また,グループ GB(61.6%)では,非平仮名表記の自立語辞書検索と, 付属語接続行列による付属語解析,およびJ-F 間の接続検定が要求される.
0.000
0.100
0.200
0.300
0.400
0.500
0.600
0.700
0.800
G0
GJ
GF
GB
JFK Group
Frequency Rate
Clinical Case
Article of NLP
Fig. 5-1-1 Histogram of JFK-Groups
以上のことから,校正支援におけるチェッキングのためのパージングアルゴリズムは,グループ毎 に設定すべきであることが確認できる.
すなわち,JFK 構造のグループ化により,表4のように,無効モード(I-Mode),自立部チェックモ ード(J-Mode),付属部チェックモード(F-Mode),文節チェックモード(B-Mode)の4つの解析モード が存在すると結論できる.
Table 5-1-2 Analyzing Mode for Each JFK-Group
Analyzing Contents Objective Mode JFK J-part F-part Main Name Extraction Checking Checking Group I-Mode Yes No No G0 J-Mode Yes Yes No GJ F-Mode Yes No Yes GF B-Mode Yes Yes Yes GB
解析処理の内容には、①文節抽出(JFK Extraction),②自立部チェック(J-part Checking), ③付属部チェック(F-part Checking)の3種類が存在する.
5.1.2.2 文字列長の利用−レベル分割1− JFK 構造の約 60%以上を占めるグループ GB の解析では,文字列長に注目して,より詳細なレ ベル分割を行うことで,解析効率の向上を期待できる.これは,B-Mode の解析モジュールを更に分 割するという意味である. J,F,K,各部の文字列長頻度を4.3.2 で示した文書について調べ,割合をTable 5-1-3 にまと める.また,頻度分布グラフをFig. 5-1-2 に示す.
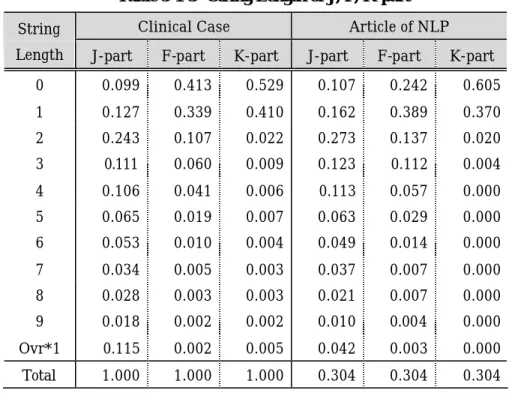
Table 5-1-3 String Length of J, F, K-part
Clinical Case Article of NLP String
Length J-part F-part K-part J-part F-part K-part 0 0.099 0.413 0.529 0.107 0.242 0.605 1 0.127 0.339 0.410 0.162 0.389 0.370 2 0.243 0.107 0.022 0.273 0.137 0.020 3 0.111 0.060 0.009 0.123 0.112 0.004 4 0.106 0.041 0.006 0.113 0.057 0.000 5 0.065 0.019 0.007 0.063 0.029 0.000 6 0.053 0.010 0.004 0.049 0.014 0.000 7 0.034 0.005 0.003 0.037 0.007 0.000 8 0.028 0.003 0.003 0.021 0.007 0.000 9 0.018 0.002 0.002 0.010 0.004 0.000 Ovr*1 0.115 0.002 0.005 0.042 0.003 0.000 Total 1.000 1.000 1.000 0.304 0.304 0.304 *1: Over 10 characters Table 5-1-3から,J,F,K の各分布が左側に偏っていることが分かる.このことは,文字列長に注 目した解析が可能であることを示唆している. 実際,J 部では,長さが1のときは五段動詞の語幹が大部分を占める.また,長さが2のときは,名 詞,およびサ変名詞が大部分を占める.3文字以降では,複合名詞,カタカナ表記の単語,および 英文字略語,英単語が占めている.累積頻度でみると,J 部の場合,臨床症例文書では,4文字ま でで全体の68.6%,6文字まででは 80.5%を占めている.自然言語処理関連論文では,4 文字まで で全体の77.8%,6文字まででは 89.0%を占めている. F 部では,長さが3文字以下の場合,助詞と用言の活用語尾がほとんどを占める.4文字以上の 場合は,助動詞を含む用言の活用語尾の割合が目立つ.また,7文字を越えるような場合は,複数 の助動詞を含む用言か,あるいは,「こと」,「もの」,「とき」などの補助体言や平仮名表記の自立語 を含むものが多くなる.累積頻度では,臨床症例文書の場合,2文字までで全体の85.8%,4文字ま でで95.9%を占める.自然言語処理関連論文の場合は,それぞれ 76.8%,および 93.7%となる.
0.000 0.100 0.200 0.300 0.400 0.500 0.600 0 2 4 6 8 10 Length Frequency Rate
J-part F-part K-part
(a) Clinical Case
0.000 0.100 0.200 0.300 0.400 0.500 0.600 0.700 0 2 4 6 8 10 Length Frequency Rate
J-part F-part K-part
(b) Article of NLP
Fig. 5-1-2 Frequency Rate of JFK Length
5.1.2.3 平仮名列の出現確率の利用−レベル分割2− 4文字以下のF 部が全体の 90%以上を占めるという事実から,その文字列パターンの出現確率 にも当然偏りがあることが容易に予測できる. パターンの出現確率の偏りは,F 部解析におけるパターンマッチングの優先順位を決定できる. すなわち,グループGB の解析モジュールのレベル分割に寄与するヒューリスティクスとして利用可 能であるといえる.
そこで,JFK 構造を抽出した際の F 部文字列長別頻度のうち,高頻度を獲得したもの上位 10 位 をTable 5-1-4 に示す.
Table 5-1-4 High Frequency F-part (1 to 4 characters)
Clinical Case Article of NLP
3258の 629 した 144 による 164 であった 1263の 252 する 122 である 70 について 2214 を 377 では 141 である 94 となった 919 を 146 した 111 および 60 における 1782に 318 にて 138 された 79 していた 643に 144 では 108 による 27 において 1324は 296 する 103 であり 63 えられた 426が 96 から 101 として 27 えられる 1172が 271 より 97 により 49 における 404は 94 また 70 された 24 としては 771 と 186 から 95 として 45 められた 172 と 69 この 60 される 22 であると 673で 181 めた 90 および 43 している 165で 67 して 58 となる 21 のための 550 し 164 には 80 したが 38 について 129な 65 には 54 により 19 すなわち 310な 149 その 77 のため 37 したため 99 し 41 への 33 という 17 している 261 も 130 また 56 しかし 33 えられる 81 り 34 いた 32 であり 16 としての Table 5-1-4 の順位を意識して F 部解析時の優先順位を決定すればよいことがわかる. 5.1.2.4 解析モードとレベル分割 以上の結果についてまとめる. 字種による分割手法を,JFK 構造で定式化することにより,形式文節の統語構造を明確に反映さ せることができる.また,JFK 構造クラスのグループ化により,解析モードの導入が可能となると共に, そのモジュール性を強調することができる.このため,校正支援のための誤り検定において,従来の 形態素解析よりも最適化の余地が生まれる.さらに,文字列長,およびパターンの出現確率によるヒ ューリスティクスを用いることで,最適化を強化することができる. 本章で述べた内容から,次章では校正支援に向けた具体的な解析の高速化手法を提案する. 5.1.3 高速化手法の提案とHSPの開発 ここでは,従来の解析アルゴリズムの問題点を指摘し,これに対処する新たな手法として,JFK 構 造を利用した文節接続解析について述べる.また,本手法を利用してパソコン上に実装した日本語 文書校正支援ツールHSP について触れる. 5.1.3.1 従来の解析アルゴリズム 校正支援で扱う統語的検定処理(文法レベルでの誤り検出)では,自然言語処理における構文 解析の一部,もしくはその前段までの処理を対象とする.一般には,「形態素解析レベルの処理」と 呼ばれている. この処理は,厳密には2つのフェーズに分割して捉えることができる.第1のフェーズは形態素抽 出であり,入力文字列を解析単位(形態素)に分割すると同時に,辞書との照合を行うことが目的で ある.アルゴリズムには,最長一致法や分割数最小法などが用いられる.第2のフェーズは,抽出さ
れた解析単位の接続検定であり,解析単位の統語的な接続条件を満たすか否かを調べることが目 的である.第1,第2フェーズの両方を同時に捉えるアルゴリズムとしては,最尤一致法などが知られ ている. 解析アルゴリズムにおける2つのフェーズを図式化すると以下のようになる.
Phase 1
Morpheme Extraction
Phase 2
Connective Evaluation
Encounter with Errors
Encounter with Errors
global
loop backtrack
loop
Fig. 5-1-3 2 phases of popular morpheme -analysis
最初に入力文字列をすべて処理するためのループがある.各フェーズでは,入力文字列に混入 するエラーによって例外処理が発生する.第1フェーズにおけるエラーの大半は「未知語の検出」で あると判断できるため,特に深刻な状況を生み出さない.これに対して,第2フェーズにおけるエラー は,バックトラックを起動し,ローカルなループを形成する形で反映される. このバックトラックが頻繁に発生すれば,全体の処理は大きな影響を受ける.よって,こうした状況 は積極的に回避しなければならない. 5.1.3.2 解析の簡略化 上記の処理アルゴリズムとしては,先に触れた最長一致法,もしくは最尤一致法が用いられる.両 者の違いは,バックトラックのタイミングと解析精度に大きく反映される.特に後者では,再帰を用い なければ,状態保存というスタック動作と評価関数による最適値の決定という第3フェーズが存在す るため,解析速度の低下は避けられない.したがって,バックトラックを失くすことは,従来のアルゴリ ズムでは不可能である. そこで,解析の簡略化について検討すると,Fig. 5-1-3 におけるグローバルループ,およびバック トラック・ループの反復数を軽減できればよいという点に注目することができる.前者は第1フェーズ により抽出した形態素の数に依存し,後者は第2フェーズによる接続可能な形態素の組み合わせの 数に依存する.通常,接続検定における各形態素は,品詞により同定されるため,品詞分類の詳細 度によっても,バックトラックが発生する確率は変化することが指摘できる.
5.1.3.3 文節接続解析の提案 5.1.3.3.1 制御構造 以上から,「形態素解析では,バックトラック・ループの反復数は解析最小単位に依存する」という 点に注目することができる.よって,率直にこの最小単位をよりマクロな単位で捉え直すことで,処理 効率の向上を期待することができる.さらに,漢字かな混じり文を対象とする場合,字種を越えた形 態素は,用言の送り仮名に関するもの以外存在しない.そこで,字種によるリミッタを設けることで最 適化が容易になる.
Encounter with Errors
Encounter with Errors
globalloop
Phase 1
3-part Formal Phrase
JFK Extraction
Phase 2a
JIRITSU-GO
Collation
Phase 3
FUZOKU-GO
Connective Evaluation
Phase 2b
FUZOKU-GO
Morpheme Extarction
Encounter with Errors
backtrack loop
Fig. 5-1-4 Phrase Connective Analysis
ここで,解析最小単位として前章で定義した JFK 構造による3つ組形式文節を用いた処理を行え ばよいことに気づく.
Fig. 5-1-4 における第1フェーズは JFK 構造の抽出である.抽出されたJFK 構造の型からグルー プが判定され,グループの違いにより解析モードが選択されて処理が振り分けられる.
具体的には,解析モードが無効モード(I-Mode)の場合は,そのままグローバルループを回り,自 立部チェックモード(J-Mode)の場合は,第2フェーズa のみが,付属部チェックモード(F-Mode)の場 合は第2フェーズ b を通り,第3フェーズが実行されてグローバルループを回る.文節チェックモード (B-Mode)の場合は,全フェーズが実行されて,グローバルループを回る. 5.1.3.3.2 J-Mode の処理 J-Mode では,グループ GJ,すなわち(J, _, *)の JFK 構造を解析する.処理は自立語辞書との照 合を行うだけである.このとき問題となるのが複合名詞の解析である. J 部の文字列 S が辞書エントリに存在しない場合,校正支援というレベルでは,辞書に存在しな いものは無条件にエラーであるとする立場(完全一致条件)と,辞書エントリの文字列 T1, T2, ..., Tn の連接が S に等しい場合に限り正しいとする立場(部分一致条件)の違いである.前者は第2種の 過誤を助長し,後者は第1種の過誤を助長する.いずれの場合も解析精度は落ちることになる.
第2種の過誤では,以下のような例が考えられる. S = 日本語文書校正支援ツール 辞書にない T1 = 日本語 辞書にある T2 = 文書 ある T3 = 校正 ある T4 = 支援 ある T5 = ツール ある これに対して,「日本文書校正支援ツール」では,「日本」と「文書」の間に「語」が抜けているという 指摘ができないという意味では第1種の過誤である. これに対処する方法として,品詞による制約(例えば接尾辞は部分一致条件では辞書エントリか ら外すなど)や,分割数による制約(例えば5分割以上の部分一致は認めないなど)や,文字列長に よる制約(7文字を越える文字列は完全一致条件のみ適用するなど)を考えることができるが,いず れの場合も問題が残る. HSP では,完全一致条件と部分一致条件による解析はユーザが選択できるようになっている. 5.1.3.3.3 F-Mode の処理 F-Mode では,(_, F, *)の解析を行う. 多くの場合,平仮名表記された接続詞(「しかし」,「したがって」など)や副詞(「たいへん」,「すべ て」など),あるいは連体詞類(「その」,「このような」など)が処理対象となるので,完全一致条件で自 立語辞書を検索する.このモードで問題となるのは,一般名詞が平仮名表記された場合である.こ れは B-Mode に移行することで,第2種の過誤となるような解析エラーを幾らか吸収することができる. ただ,「にほんごでは,」などのように ,明らかに仮名漢字変換のし忘れによる部分が現れた場合は, むしろエラーとして検出すべきなので,B-Mode への移行には制限を付けなければならない. 5.1.3.3.4 B-Mode の処理 B-Mode では,(J, F, *)の解析を行う. JFK 構造を利用した文節解析では,F 部の解析がもっとも重要となる.これは,J 部すなわち非平 仮名列が自立語要素から構成されるのに対して,F 部が付属語要素から構成される点に起因する. 付属語要素は,自立部の品詞を同定する際の手がかりとなる. 例えば,F 部が「べられたので」という文字列であれば,J 部に来るべき品詞は,下一段活用動詞 のうち,「べ」に先行できるもの(「食」,「述」など)のみである.また,F 部が「まで」の場合は,名詞の みである. 故に,F 部の解析が成功すれば,J 部との接続条件が決まり,J-F 間の接続検定が可能となる. B-Mode では,基本的に,J 部とF 部とを独立に検査する.すなわち,J 部は J-Mode と同様の処理 を施し,F 部は付属誤接続行列による検定を行う. 実際には,前章で述べた通り,レベル分割を行って効率を高める工夫をしている. まず,レベル1では,F 部に対して,文字列長と平仮名出現頻度のヒューリスティクスにより,1文字, 2文字,3文字の場合に限って,完全一致条件によるマッチングをとる.マッチングに成功した場合,
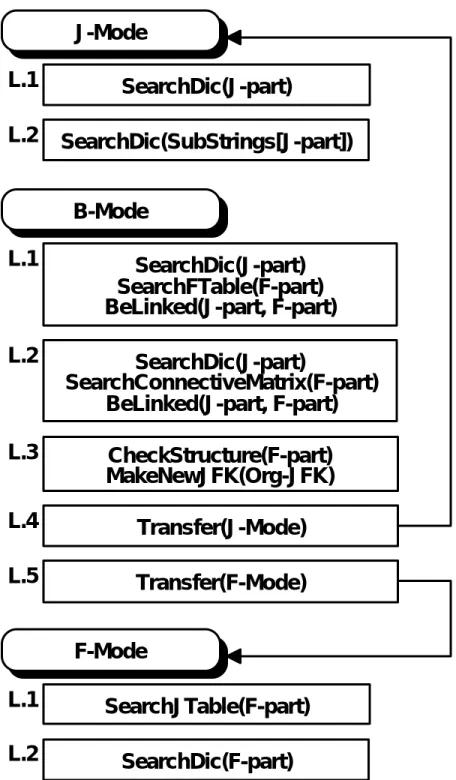
J 部の品詞リストを調べ,F 部パターンと接続可能か調べる.マッチングに失敗した場合,レベル2に 進む. レベル2では,付属部接続行列によりF 部が認識可能か調べる.認識に成功した場合,J 部との接 続を調べる.認識に失敗した場合,レベル3に進む. 付属語接続行列による解析では,F 部の認識に対して,最長一致法による部分文字列の切出しと, 切り出された部分文字列間の接続を調べている.ゆえに,F 部の認識が停止した位置を知ることが できる.認識が停止するとは,F 部に不明文字列が含まれることを意味する.不明平仮名列をα,β とすれば,次の場合が考えられる. 1) (J, αF, *) 2) (J, Fβ, *) レベル3では,上記のどちらであるかを調べる.1)の場合は,レベル4へ進む.2)の場合はレベル5 へ進む. レベル4では,レベル3で得られたαに対して次の処理を行う.すなわち,αは,F 部の前半にある ので,J 部へシフトし,(Jα, F, *)を得ることで再度 B-Mode により解析する.Jαが新たな J として認識 されるならば解析は成功し,そうでなければ失敗する. これに対して,レベル5では,レベル3で得られたβに対して次の処理を行う.すなわち,βは,F 部の後半にあるので,ここで JFK 構造を分割し,(_, β, _)を生成することができる.生成した JFK 構 造は,F-Mode に移行することで解析可能である. 各解析モードとレベル階層の関係をFig. 5-1-5 にまとめる.
J-Mode
SearchDic(J-part)
L.1
SearchDic(SubStrings[J-part])
L.2
B-Mode
SearchDic(J-part)
SearchFTable(F-part)
BeLinked(J-part, F-part)
SearchDic(J-part)
SearchConnectiveMatrix(F-part)
BeLinked(J-part, F-part)
CheckStructure(F-part)
MakeNewJFK(Org-JFK)
Transfer(J-Mode)
Transfer(F-Mode)
L.1
L.2
L.3
L.4
L.5
F-Mode
SearchJTable(F-part)
SearchDic(F-part)
L.2
L.1
Fig. 5-1-5 Analyzing Modes and Level Hierarchies
5.1.3.4 HSPの開発
以 上の議 論 を踏 まえた上で,日本語文章の作成,および 推 敲・校正 を支 援するシステム 「HSP(High-Speed Proofreading tools)」[76], [92]の開発を行った.HSP は,スタンドアローンのパソ コン上で稼動する個人向けワードプロセッシングのための統合環境として実現されている.パーザな ど,プログラムの大部分は MS-DOS 上で,また統合環境としてのインタフェースなど一部は MS-Windows 上で稼働する.
HSP Integrator
Analyzer
Based on JFK
Dictionary
Manager
Jiritsu-go
Dictionary
Fuzoku-go
Rule Base
Web Server
CGI
Fig. 5-1-6 HSP System 本システムは日本語で記述された文書を対象とする文法チェッカとして機能する. チェック内容としての機能分類は表7に示すとおりであり,入力文の表記や記述の誤りなどを指摘 する.また,指摘された内容の編集環境をユーザに提供することができる. 分類 機能内容 校正支援 自立語表記の誤り検定 付属語表記の誤り検定 文節の検定 括弧の対応検定 推敲支援 助詞の存在判定 助動詞の存在判定 格判定 複合名詞句の存在判定 引用符の存在判定 漢字への読み仮名付け 統計情報 特定品詞要素の計数 文字・語・文節・文における統計値計算 5.1.4 HSPの評価実験 ここでは,日本語文書校正支援ツール HSP を用いて,前章で提案した手法の評価を行う.以下, 評価実験の内容について述べた後,結果を示し考察を加える.5.1.4.1 実験 全角文字と改行コードのみからなる日本語で記述されたプレーンテキストを3種類用意し,各文書 について解析の精度,速度を中心に評価を行った.また,精度向上のための学習機能を付加した 場合との比較を行った. ここで,解析精度の測定に関し,公正を期すために最初に文書内の未知語以外のすべてのエラ ーを人手により修正した.未知語とは,自立語辞書にエントリが存在しない語という意味である.その 後,ランダムなエラー を専用のエラー生成プログラムを用いて文書内の任意の位置に作成し,この エラーを HSP により検出させた.エラーの種類は,①文字抜け(脱字),②文字余りの2種類に限定 した.1文中に含まれるエラーの個数をおよそ0.8程度とした.この値は,A4サイズ1頁あたり22個の エラーが含まれる割合である. 文字抜けは,JFK 構造で見た場合,F 部,すなわち平仮名列の任意部分の1文字を削除すること で作成した.また,文字余りは,F 部の任意部分に任意の平仮名1文字を挿入することで作成した. J 部,すなわち非平仮名列についてはエラーを作成しなかった.この理由は,未知語の検出に関 しては文字抜け,文字余り双方のエラーを 100%検出可能なので,特に問題とならないと判断したた めである. エラー生成プログラムは,文字抜け,および文字余りの双方に関して,その処理結果が完全に統 語エラーとなることを保証していない.すなわち,たまたま統語的に意味のある生成を行う可能性が ある. 5.1.4.2 解析精度について HSP では,文書に含まれる表記上の誤りと文法上の誤りとを文節を単位として検出することができ る.ここで,システムが検出できない誤り(第1種の過誤)と,システムが過剰に検出してしまった誤り (第2種の過誤)とをカウントし,以下の式により定義される適合率と再現率を求める. 定義: 総検出件数=J 部検出件数+F 部検出件数 適合率=(総検出件数−過剰検出件数)÷総検出件数 再現率=(真の件数−検出漏れ件数)÷真の件数 実験では,3文書に対してそれぞれ,B-Mode による解析を4回,F-Mode による解析を1回行い, 各 B-Mode の結果とこれらの平均値,および F-Mode の結果をパーセンテージで Table 5-1-5 に示 す.
Table 5-1-5 Detection Accuracy of HSP
Text 精度 B-1st B-2nd B-3rd B-4th Average F-Mode CA.DOC 適合率 96.69 98.62 94.81 95.42 96.39 78.47 再現率 84.84 88.02 87.54 83.89 86.07 80.99 GE.DOC 適合率 82.58 79.75 84.91 78.91 81.54 57.61 再現率 81.01 87.50 87.66 81.69 84.47 80.92 NA.DOC 適合率 94.38 91.77 93.87 99.36 94.85 73.80 再現率 85.31 79.67 82.70 87.15 83.71 79.31 B-Mode による解析を4回行った理由は,学習効果の遷移を確認するためである.これについて は,5.1.4.4 で詳しく述べる. 表8から,適合率,再現率ともに高い値を示していることが確認できる.また,先に述べたように, F-Mode では,付属部のみを解析対象としているため,適合率,再現率とも低い値を示す傾向があ る. 5.1.4.3 解析速度について HSP では,解析条件を変えて文書のチェックを行うことができる.解析モードの違いによる解析速 度の変化をFig. 5-1-7 に示す.
0
1,000
2,000
3,000
4,000
5,000
6,000
7,000
8,000
B
J
F
I
Analyzing Mode
Speed [char/s]
CA.DOC GA.DOC NA.DOC Average
Fig. 5-1-7 Analyzing Speed
通常の文書では,A4 サイズ1頁が 1500 文字換算となるので,B-Mode では平均 0.43 [page/s], J-Mode, F-Mode, I-Mode ではそれぞれ平均 0.56, 1.98, 6.02 [page/s]となる.
校正支援という立場では,何らかのエラー検出を行わなければならないと考えられるので,文節抽 出のみ行うI-Mode の利用は,文章の統計情報取得程度の価値しかないかもしれない.また,フロン トエンドプロセッサとしての仮名漢字変換の性能を考慮すれば,付属部の検定を行うF-Mode の利 用価値は高い. 通常の文章作成では,インクリメンタルな作業が主体であるため,繰り返し文章を吟味する必要に 迫られる場合が多い.この意味では自立部の検定を行うJ-Mode が有効である. また,ソフトウェアプロダクトのマニュアル作成など,大量の文章を対象として使用できる単語や表 現のチェックには,B-Mode によるバッチ処理が効果的であると思われる. 5.1.4.4 学習効果について 一般に,解析のコストを下げるためには,無駄なバックトラックを極力排除することがより効果的で ある.また,解析用の自立語辞書の拡充をはかることが重要である. しかしながら,辞書などのスタティックなデータのみでは,解析対象となる文章の質の差を吸収す ることは困難である. そこで,HSP では,解析履歴を用いてデータキャッシングを行うことで,動的な対応を行ってい る. 具体的には,JFK 構造の J 部,および F 部に対して,それぞれ解析成功履歴,および解析失敗履 歴を残す.これら合計4つの履歴情報はキャッシュとして解析の速度向上に寄与する.キャッシュの 種類とJFK 構造の解析結果との関係をTable 5-1-6 に示す.
Table 5-1-6 Type of Cache
Cache Name J-part Result F-part Result J-Cache Success - F-Cache - Success E-Cache - Failure U-Cache Failure - Table 5-1-6 に示した4種類のキャッシュをまとめて,HSP の学習機能として認めることができる. 実際,J-Cache, および F-Cache は,解析の初段で成功したパターンをキャッシングすることで,自 立語辞書および付属語接続行列へのアクセス回数を大幅に低減することが可能である.また, U-Cache は,いわゆる「未知語」を自動的に獲得する機能として有効である.さらに,E-Cache は, コストを増大させる(システムにとって不利な)誤りパターンを保持するため,システムへの負荷を軽 減させる働きを持つ. これらキャッシング効果を約500 文の文章からなる情報処理1種のテキストデータについて調べた 結果がFig. 5-1-8 である.
0% 10% 20% 30% 40% 50% 60% 70% 80% 0 100 200 300 400 500 600 Analyzed Sentences
Cache Hit Ratio
U-Cache J-Cache F-Cache E-Cache
Fig. 5-1-8 Cache Hit Ratio
ここでキャッシュヒット率とは,被検索文字列がキャッシュに存在する場合をヒットとし,ヒットした件 数とキャッシュへのアクセス回数との割合をパーセンテージで示したものである. Fig. 5-1-8 を見ると,F-Cache を除いて全てのキャッシュは 250 文程度までは順調にヒットしてい ることがわかる.それ以降は頭打ちとなるが,これは,本キャッシュがFIFO バッファをベースとしてい るため,有効データがフラッシュされたことによる.しかし,通常の文章では,250 文は A4 換算でお よそ10 頁以上となり,性能としては十分であると考えられる. 学習による解析精度への効果は,B-Mode による4回の解析結果について調べた.これを Fig. 5-1-9 に示す. また,同様に,学習による解析速度への効果を調べた.これをFig. 5-1-10 に示す.
0% 2% 4% 6% 8% 10% 12% 14% 1 2 3 4 Times of Analysis
Error Ratio per Case
CA.DOC GE.DOC NA.DOC
Fig. 5-1-9 Error Ratio
0 100 200 300 400 500 600 700 800 1 2 3 4 Times of Analysis
Analyzing Speed [char/s]
CA.DOC GE.DOC NA.DOC
Fig. 5-1-10 Analyzing Speed
Fig. 5-1-9,および Fig. 5-1-10 から,解析効率が学習機能により向上していることが確認できる. 実際,1文節あたりのエラー率は 4∼10%低下し,かつ解析速度は頭打ちを 100%とした場合,10∼ 30%向上している.