不均一な置換モデルを用いた分子系統解析プログラムの高速化
6
0
0
全文
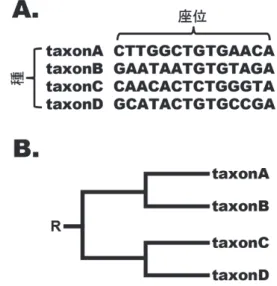
(2) Vol.2013-HPC-138 No.17 2013/2/22. 情報処理学会研究報告 IPSJ SIG Technical Report. 2. 系統樹推測法(最尤法)について. Maximum-Likelihood Inference() input initial values of branch lengths and model. 2.1 系統樹の尤度計算. parameters.. まず, 「遺伝子配列の進化プロセスは不変である」こと. WHILE. を仮定した均一な置換モデルを使用し, 図 1A に示したよ. first step or diff lnL > ε. calculate current log likelihood (lnL).. うな taxonA~D の 4 種からなる塩基配列データ D より, 図. IF first step THEN. 1B に示される系統樹の尤度を計算する方法を説明する.. initialization of diff lnL. ここで, h 番目の座位において塩基 p, q, r, s が観察され,. ELSE THEN. taxonA, B 及び taxonC, D の共通祖先における塩基をそれぞ. calculate current lnL - previous lnL (diff lnL). れ i, j, 全ての配列の共通祖先を R とし, その塩基を x と仮. FOR. 定する. また, 各塩基から次の塩基に遷移する時間は系統. FOR. number of parameters to be estimated - - - ① number of sites - - - ②. calculate 1st and 2nd derivatives of site-lnL with. 樹の各枝の長さ t1~t6 で表現されるとする(図 2).. respect to a parameter to be optimized. ENDFOR ENDFOR ENDWHILE RETURN 図3. current lnL as maximum lnL. ニュートン-ラプソン法による反復アルゴリズム. るようパラメータの最尤推定を行う必要がある. この最尤 図2. 均一な置換モデルを使用した尤度計算. ゴリズムが用いられる(図 3). このアルゴリズムでは, あ. すると, ある座位 h における図 2 の系統樹の尤度 L(θ|Dh) は次のように表現される. 1 . 推定には、一般的にニュートン-ラプソン法による反復アル. |. る枝長または置換モデルのパラメータに注目し, 他のすべ てのパラメータは固定され, 該当するパラメータのみによ る尤度関数の 1 階・2 階微分が解析的に計算される(図 3 の①). これにより, 尤度関数を 2 階までのテイラー展開. , , ,. , , ,. で近似することで, 該当するパラメータの最尤推定量を反 復的に求めることが可能である. なお, 系統樹の尤度計算 では尤度は座位ごとに計算されるので, 尤度関数の 1 階・2. . 階微分もまた座位ごとに計算される(図 3 の②). この反. , , ,. πa は taxonA~D の実配列データより推定される塩基 a の. 復計算では現在点で求めた対数尤度と1つ前の点で求めた 対数尤度の差を取り, 系統樹の対数尤度が限りなく小さな. 出現頻度である. pab(t)は枝 t における a から b への遷移確. 値にまで収束したか否かでアルゴリズムの終了判定が行わ. 率を示し, a から b への瞬間置換速度を定義した 4×4 の速. れる.. 度行列 Q(置換モデル)に基づき以下のように計算される. 2 . 2.3 最尤系統樹の探索. ここで, 均一な置換モデルを用いた解析では, 系統樹の. 最尤法による分子系統解析では, 最も大きな尤度をもつ. 各枝における塩基の置換は同じモデルによって表現される. 樹形(最尤系統樹)を, 生物の系統関係を適切に表した系. ため, 各枝の遷移確率は同一の置換モデルから計算される. 統樹として選択する. ここで, m 個の種(m >= 2)に対する. ことに注意する. なお, 各座位の置換は他の座位とは独立. 二分岐型の有根系統樹の樹形の数は[(2m-3)!] / [2m-2(m-2)!]. に起こると仮定するため, 最終的な系統樹の尤度 L(θ|D)は. であるため, m が増えるにつれ考えられる樹形の数は爆発. 各座位の尤度を総乗することで求められる.. 的に増えることが分かる. そのため, 一般的な分子系統解 析では発見的探索法によって最尤系統樹を近似的に求める. 2.2 尤度の最大化とパラメータの最尤推定. こととなる. 以下に, 発見的探索法の一つとして主に用い. 式(1)で示されるように、系統樹の尤度とは各枝長及び. られる部分木剪定・接木による山登り法を図示する(図 4).. 置換モデルの各パラメータの関数として表現される。従っ. この探索法では, まず初期系統樹を用意し, 前節で述. て、ある系統樹の尤度計算では、系統樹の尤度を最大化す. ⓒ 2013 Information Processing Society of Japan. べたニュートン-ラプソン法によって尤度の最大化を行う.. 2.
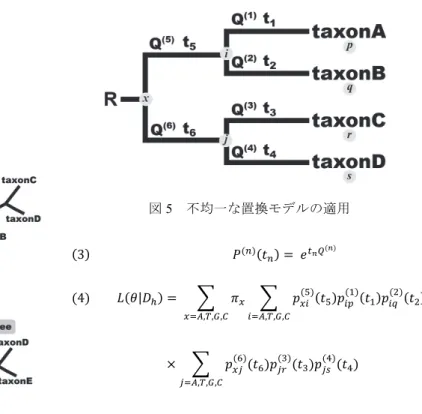
(3) Vol.2013-HPC-138 No.17 2013/2/22. 情報処理学会研究報告 IPSJ SIG Technical Report. 図5. 不均一な置換モデルの適用. 3 4 . |. , , ,. , , ,. , , ,. ルゴリズムに違いは生じない. 図4. 部分木剪定・接木による山登り法. 次に, 初期系統樹のある部分木(部分枝)を刈り取り別の. 3. 系統解析プログラムの高速化 本研究では, 不均一な置換モデルを実装した既存の系統. 場所へと接合することで, 幾つかの樹形を提案する. これ. 解析プログラムを対象とし, Message Passing Interface(MPI). らの樹形についても尤度をそれぞれ最大化し, 提案樹形の. によるプロセス並列, 及び OpenMP によるスレッド並列を. 中で最も大きな尤度をもつ樹形を選択する. さらに, 選択 された樹形の尤度と初期系統樹の尤度を比較し, 前者が後. 併用したハイブリッド並列を施すことで, 不均一な置換モ デルを使用した際問題となる計算時間の短縮を目的とした.. 者よりも大きければ新たな樹形を現在点とし, 再び部分木. 並 列 化 す る プ ロ グ ラ ム と し て は , NHML[3]を 選 択 し た .. 剪定・接木による樹形の提案, 及びそれぞれの樹形の尤度. NHML は, 配列進化に関わるパラメータのうち, 「配列中. 計算・もとの樹形の尤度との比較を行う. 最終的に, この 反復の中で提案されたどの樹形よりももとの樹形の尤度が 大きくなった場合, 樹形探索を終了し, 現在点における樹 形を最尤系統樹として選択する.. でのアデニン(A)あるいはチミン(T)の出現頻度」が系 統樹の各枝で異なることを許容する置換モデルを実装した プログラムである. 並列処理化を施す部分としては, ニュートン-ラプソン 法による反復アルゴリズムのうち, 尤度関数の 1 階・2 階. 2.4 不均一な置換モデルによる尤度計算 2.1 で説明した尤度計算は, 全ての配列が単一の置換モ デルによって表されるプロセスに従って進化するという仮 定のもとに行われる. ここで, 図 2 の系統樹の各枝 t1~t6 で の配列進化が、それぞれ異なる置換モデル Q(1)~Q(6)で表さ れるプロセスに従うと仮定した場合を考える(図 5). こ の場合, 系統樹の各枝における遷移確率 p は異なる置換モ デル Q(1)~Q(6)から計算されることになり, ある座位 h にお ける系統樹の尤度 L(θ|Xh)もまた、枝ごとに異なる遷移確率 をもとに算出される(式 3, 4). なお, 不均一モデルを使用した場合でも, ニュートン-ラ. 微分を求めるための 2 つの for 文に注目した(図 3 の①と ②). 異なる置換モデルを系統樹の各枝に当てはめた場合, 最尤推定するモデルのパラメータ数が増加するため, 図 3 ①の for 文の繰り返し数もまた増大することとなる. また, 系統解析で使用される配列データの座位数は一般的に数千 ~数万であるため, 図 3②の for 文の繰り返し数は非常に 大きい. 従って, 本研究では図 3①の for 文を MPI, 図 3② の for 文を OpenMP によってそれぞれ並列化することでプ ログラムの効率的な高速化を図った(図 6). これにより, 1 本の系統樹の尤度最大化(パラメータの最尤推定)を下 記のように並列処理させることとした.. プソン法による尤度最適化や, 系統樹探索法の基本的なア. ⓒ 2013 Information Processing Society of Japan. 3.
(4) Vol.2013-HPC-138 No.17 2013/2/22. 情報処理学会研究報告 IPSJ SIG Technical Report Maximum-Likelihood Inference() input initial values of branch lengths and model parameters. first step or diff lnL > ε. calculate current log likelihood (lnL). IF first step THEN initialization of diff lnL ELSE THEN calculate current lnL - previous lnL (diff lnL) FOR. number of parameters / number of processes. OpenMP #pragma omp parallel for FOR. で, 進化プロセスの不均一性を実現し, 最終的に A+T 含量 が生物種間で不均一な配列データを得た. 本実験では, 1000 座位からなる配列データを生成し, 並列化を行った. MPI WHILE. うに系統樹上の幾つかの点で置換モデルを変化させること. number of sites. NHML による解析に供することで, 最尤系統樹の探索が 終了するまでに要した時間を計測した. データ解析は T2K-Tsukuba システムの最大 4 ノードまでを使用した. 計 算環境の詳細は表1に示す. なお, ハイブリッド並列版 NHML によって解析を行う 際, 使用するコア数に応じて MPI のプロセス及び OpenMP のスレッドをどのように割り振るかは, 表 2 のように調整 した. この中で, MPI の 1 プロセスは 1 つのソケットに割 り当てるものとし, さらに 1 つのソケット内部のコアに OpenMP のスレッドを割り当てることとした.. calculate 1st and 2nd derivatives of site-lnL with respect to a parameter to be optimized. ENDFOR ENDFOR Allgatherv (1st and 2nd derivatives) ENDWHILE RETURN. current lnL as maximum lnL. 図6 1).. MPI 及び OpenMP による並列化. パラメータごとの尤度関数の 1 階・2 階微分の計算を MPI の各プロセスに分割.. 2).. プロセスに分けられた計算を, さらに座位ごとに OpenMP の各スレッドに分割.. また, 反復アルゴリズムの中で(初期ステップ以外で) 現在点の尤度を得るためには, 全てのパラメータについて の 1 階・2 階微分の情報が必要である. 従って, 現在点から 次の点に移る前に, 全ての MPI プロセスが全ての 1 階・2 階微分の情報を共有するよう, Allgatherv 構文を用いてプロ セス間通信を行わせた.. 図7. シミュレーションに使用したモデル系統樹. CPU. Quad-core AMD Opteron 8356 (2.30GHz) (4 コア×4 ソケット / ノード). Memory. 32GB DDR3. Network. Infiniband DDR x 4 レール. Compiler. GCC 4.1.2. MPI Library. 4. 性能評価. 表1. MVAPICH2 Ver. 1. 4. 1. T2K-Tsukuba のスペック及びソフトウェア環境. 4.1 実験条件 評価実験に使用する塩基配列データは, 図 7 に示す 12. 並列数. ノード数. プロセス数. スレッド数/プロセス. 種からなるモデル系統樹に基づいたシミュレーションによ. 2. 1. 2. 1. り生成した. このシミュレーションでは, 系統樹の根(R). 4. 1. 2. 2. にて祖先配列が生成され, 系統樹の分岐順・各枝長及び置. 8. 1. 2. 4. 換モデルの各パラメータに従って末端配列 taxonA~L が進. 16. 1. 4. 4. 32. 2. 8. 4. 64. 4. 16. 4. 化する. この際, 配列中の A+T 含量を示すパラメータの値 がそれぞれ異なる 3 つの置換モデル A, B, C(モデル A:AT = 50%, モデル B:AT = 10%, モデル C:AT = 10%)を用意 した。これにより, モデル A に従って生成された祖先配列. 表2. MPI プロセス及び OpenMP スレッドの割り振り. からそれぞれの末端配列が進化する際, 図 7 で示されるよ. ⓒ 2013 Information Processing Society of Japan. 4.
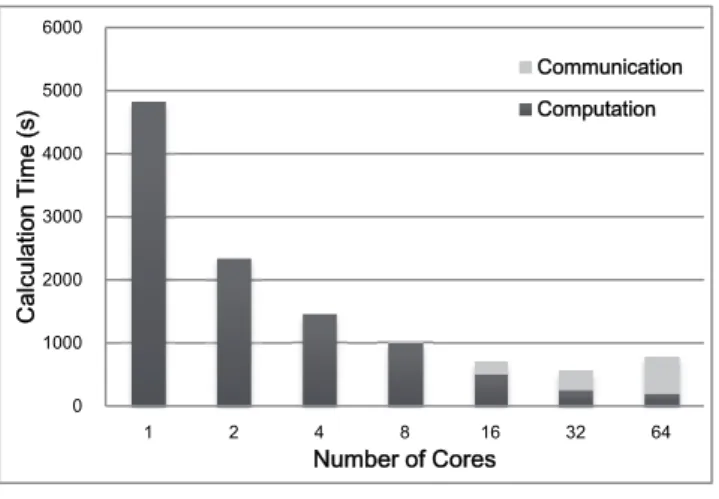
(5) Vol.2013-HPC-138 No.17 2013/2/22. 情報処理学会研究報告 IPSJ SIG Technical Report. 統解析プログラムを対象とし, MPI + OpenMP によるハイ. 6000. Calculation Time (s). 5000. Communication. ブリッド並列化を行った. 今回の実験結果では, 図 8 のよ. Computation. うにおよそ 32 コアの使用で高速化の限界に到達するとい. 4000. うデータが得られた. しかしながら, これはプログラム自 体の真の性能限界ではなく, 単に解析に使用した配列デー. 3000. タの種数に問題があったとも考えられ, より種数の多い配 2000. 列データを解析に用いれば, 32 コア以上を使用した際にも 計算時間の短縮が見込める可能性はある. ただし, 十分に. 1000. 大きな配列データを使用した場合でも, 1 本の系統樹の尤. 0 1. 2. 図8. 4. 8. 16. Number of Cores. 32. 64. 性能評価の結果. 度計算の高速化には遠からず限界が生じることもまた示唆 される. そのため, より多くの計算資源を利用するため並 列化に更なる工夫を施すことが必要である. 改善策としてはまず, 図 4 で示した系統樹探索において,. 4.2 結果と考察. 部分木剪定・接木により提案される複数の樹形の尤度計算. シミュレーションにより生成した 12 種 1000 座位からな. を同時並列的に行わせることが挙げられる. これにより,. る塩基配列データの解析結果を図 8 に示す. この結果より,. 探索に要する時間を大幅に短縮することが可能となるだろ. コア数を 32 まで増やした場合(2 ノード×4 プロセス×4. う. また, 種数の多い配列データを解析に供する場合, た. スレッド)まで, 系統樹探索にかかる時間を短縮すること. った 1 本の初期系統樹からの山登りでは膨大な樹形空間の. ができ, 最終的に逐次処理の場合に比べ 8.4 倍程度の高速. 十分な探索が行えず, 局所解に陥る恐れもある. このよう. 化が認められた. これは, 1 本の系統樹の尤度最大化を並列. な場合には, 異なる初期系統樹を複数本用意し, それぞれ. 処理することで, 系統樹探索において, 初期系統樹及び部. を出発点として山登りを行わせることで最適解に至る確率. 分木剪定・接木により提案された各樹形の尤度計算に費や. を上げる, という方法が一般的に採用される. 従って, こ. される時間がそれぞれ短縮できたためである. しかしなが. の複数点からの山登りも並列処理化することが出来れば,. ら, 使用するコア数が 64(4 ノード×4 プロセス×4 スレッ. より多くの計算資源を利用することが可能となるだろう.. ド)の場合では, 解析にかかる時間は 32 コアを使用した場. この際, 単純に複数の山登りを別々のプロセスに担当させ. 合よりも長くなった. この原因は解析に使用した配列デー. るだけでなく, プロセス間通信を活用し, 局所解に陥った. タの大きさと, MPI におけるプロセス間通信のコストとの. プロセスの救出, あるいは同一点へと収束したプロセスの. 関係にあると推測される. 今回解析に使用した配列データ. 統合など, 限りある計算資源を効率的に利用する工夫が必. の種数は 12 種であり, 一般的に解析に用いられる種数と. 要である.. しては少ない. この場合配列データから推測される系統樹 の樹形は比較的単純なものとなり, 不均一な置換モデルを. 参考文献. 適用した場合でも系統樹上のモデルの変化点が少なく, 推. [1]. Lockhart, P. J., Steel, M. A,, Hendy, M. D. and Penny, D. (1994).. 定されるパラメータ数はあまり増大しない. 従って, MPI. Recovering evolutionary trees under a more realistic model of. により並列化した for 文(図 3①)の繰り返し数は小さく, 一. sequence evolution. Molecular Biology and Evolution. 11:605–. 定数以上のプロセスで計算を分割しても並列化の恩恵はそ. 612.. れほど得られない. 一方, MPI のプロセス数が増加するに. [2]. Leigh, J. W., Susko, E., Baumgartner, M., and Roger, A. J. (2008). 従い, 尤度関数の 1 階・2 階微分の情報を共有するための. Testing congruence in phylogenomic analysis. Systematic Biology. プロセス間通信(図 6)にかかる負担は大きくなる. 以上. 57:104–115.. の理由から, 64 コアを使用した場合では, MPI のプロセス. [3]. Galtier, N., and Gouy, M. (1998) Inferring pattern and process:. 数が増加したことによる恩恵より, 通信にかかる負担が上. maximum-likelihood implementation of a nonhomogeneous. 回ってしまい, 計算時間の増長に繋がってしまったと考え. model of DNA sequence evolution for phylogenetic analysis.. られる. 実際に, 64 コアを使用した解析では、全体の解析. Molecular Biology and Evolution.15:871–879.. 時間のうち, 尤度計算に要する時間よりも通信にかかる時. [4]. 間の方が遙かに長かった(図 8).. Dutheil, J. and Boussau, B. (2008). Non-homogeneous models of sequence evolution in the Bio++ suite of libraries and programs. BMC Evolutionary Biology. 8:255-255.. 5. まとめと今後の展望 本稿では, 不均一な置換モデルを実装した既存の分子系. ⓒ 2013 Information Processing Society of Japan. [5]. Blanquart, S. and Lartillot, N. (2008) A site- and time-heterogeneous model of amino-acid replacement. Molecular Biology and Evolution. 25:842-858.. 5.
(6) 情報処理学会研究報告 IPSJ SIG Technical Report [6]. Vol.2013-HPC-138 No.17 2013/2/22. Ishikawa, S. A., Inagaki, Y., and Hashimoto, T. (2012). RY-Coding and Non-Homogeneous Models Can Ameliorate the Maximum-Likelihood Inferences From Nucleotide Sequence Data with Parallel Compositional Heterogeneity. Evolutionary Bioinformatics Online, 8, 357. ⓒ 2013 Information Processing Society of Japan. 6.
(7)
図

関連したドキュメント
Morgan, “Acoustic echo cancellation for stereophonic teleconferencing,” pre- sented at the 1991 IEEE ASSP Workshop Appls. Singal Processing Audio Acoustics, News Paltz,
機械物理研究室では,光などの自然現象を 活用した高速・知的情報処理の創成を目指 した研究に取り組んでいます。応用物理学 会の「光
全国の 研究者情報 各大学の.
事務情報化担当職員研修(クライアント) 情報処理事務担当職員 9月頃
テキストマイニング は,大量の構 造化されていないテキスト情報を様々な観点から
東京大学 大学院情報理工学系研究科 数理情報学専攻. [email protected]
[r]
2011年 9月 Cornell Univ., 4th Cornell Conference on Analysis, Probability, and Mathematical Physics on Fractals : 熊谷 隆. 2011年 9月 Beijing, The Fifth Sino-Japanese
