著者
佐藤 市也
学位授与機関
Tohoku University
深層学習を用いた
系列データ解析に関する研究
東北大学大学院 情報科学研究科
システム情報科学専攻 篠原・吉仲研究室
博士課程前期二年の課程
佐藤 市也
2017
年
2
月
15
日
目次
第 1 章 序論 1 1.1 はじめに . . . . 1 1.2 本論文の構成 . . . . 2 第 2 章 準備 3 2.1 系列データ . . . . 3 2.2 ワンホット表現 . . . . 4 2.3 ニューラルネットワーク . . . . 4 2.3.1 再帰型ニューラルネットワーク . . . . 6 2.3.2 長短期記憶ネットワーク . . . . 7 2.4 XGBoost . . . . 8 第 3 章 混合分布言語モデル 10 3.1 言語モデル . . . . 10 3.1.1 n-gram 言語モデル . . . . 10 3.1.2 ニューラルネットワーク言語モデル . . . . 11 3.2 混合分布言語モデル . . . . 11 3.3 混合分布言語モデルによる合成 . . . . 13 3.3.1 ニューラル補間型 n-gram 言語モデル . . . . 13 3.3.2 ニューラル & n-gram 合成型言語モデル . . . . 14 第 4 章 提案モデル 17 4.1 XGBoost & n-gram 合成型言語モデル . . . . 174.2 ニューラル & XGBoost 合成型言語モデル . . . . 18
5.1 実験 1 . . . . 22
5.1.1 Sequence PredIction ChallengE (SPiCe) . . . . 22
5.1.2 SPiCeデータセット . . . . 23 5.1.3 実験結果 . . . . 26 5.2 実験 2 . . . . 29 5.2.1 サイバー救助犬センサーデータ . . . . 29 5.2.2 実験結果 . . . . 29 第 6 章 まとめ 32 6.1 まとめ . . . . 32 6.2 今後の課題 . . . . 32 参考文献 34
第
1
章
序論
1.1
はじめに
データを扱う情報技術は年々進化している.各種センサを搭載した小型デバイスから のデータ収集,クラウドデータベースを活用したデータウェアハウスによるデータ集積, 機械学習を利用したデータ解析,などを扱う多くの技術が大規模データに対して容易に 適用できるようになった.多種多様なデータの中でも特に時系列データは Web サービス やセンサからの収集が容易であることから大規模化してきている.こういった技術の進歩 の中で,Google による機械翻訳技術 [13, 6] や文章読み上げ技術 [12] といった,系列デー タに対して深層学習を利用した解析手法の研究が盛んに行われるようになった. 系列データの解析手法のひとつとして,自然言語データによく用いられるモデリング である言語モデルがある.言語モデルでは系列データ X = (x1, x2, . . . , xN)が与えられた とき,次にシンボル xN +1が得られる確率を条件付き確率 p(xN +1| X) で表す.既存の言 語モデルとしては n-gram やニューラルネットワークを用いた言語モデル等がある.特に ニューラルネットワークを用いた言語モデルは,Bengio らによる初期のニューラルネット ワーク言語モデル [3] に始まり,Mikolov らによる再帰型ニューラルネットワークを用い た言語モデル [8] や,Sundermeyer らによる長短期記憶ネットワークを用いた言語モデル [11]と近年ますますの発展を見せている.そういった既存の言語モデルに対して,Neubig と Dyer は統一的な定式化を行った混合分布言語モデルを提案した [9].混合分布言語モ デルは既存の言語モデルを表現することのみならず,複数の言語モデルを組み合わせて 表現することができる.新しい組み合わせとして XGBoost を交えた新しいモデルを提案する.XGBoost とは回 帰木や決定木を用いた勾配ブースティングであり [4],データマイニング・コンペティショ ン Kaggle1などで深層学習とともに実績を残している手法である.また,既存研究におい て実験結果の示されている自然言語データ以外に,加速度センサから作成した系列デー タにも混合分布言語モデルが有効であることを示す.
1.2
本論文の構成
本論文の構成を以下に示す.本章では本論文の取り上げる題材に関する背景を述べた. 次に第 2 章では準備として本論文が取り扱う系列データの定義と,多クラス分類問題に 使われる機械学習の手法について深層学習を中心に述べる.第 3 章では確率的言語モデ ルについて説明し,Graham Neubig と Chris Dyer によって提案された混合分布言語モデ ルに関する説明を行う.そして第 4 章では第 3 章で述べた混合分布言語モデルの重み係 数ベクトルと分布行列に関する改善手法を提案する.第 5 章では既存手法と提案手法の 比較をおこなうため,2 種類のデータセットを用いて実験を行う.最後に第 6 章で本論文 の総括と今後の展望について述べる.第
2
章
準備
本章ではまず本論文が取り扱う系列データの定義を行う.そしてデータをベクトル化す る処理について説明した後,多クラス分類を行う際に学習器として用いるニューラルネッ トワークと XGBoost について説明をする.2.1
系列データ
DNAの塩基配列や文章における単語列,音声における音素列のようなシンボルの並び を系列データと呼ぶ.異なる種類のシンボル間には順序関係や類似性は仮定しない.本 論文では系列データを扱う際,シンボルを正の整数として扱い xi ∈ N で表す.このとき, 長さ N の系列データ X は以下のように表すことができる. X = (x1, x2, . . . , xN) 系列データを扱う際,対象とするシンボルの集合 Σ をアルファベットと呼び,アルファ ベットの要素数 σ =|Σ| をアルファベットサイズと呼ぶ. 系列データの学習は入力として系列データ X と正解シンボル y の 2 つ組からなる k 個 の学習データ ((X1, y1), (X2, y2), . . . , (Xk, yk))を受け取り,出力として予測関数 f : Σ∗ → Σを返す.この予測関数に対して学習に用いたデータとは異なる l 個のテストデータ ((X1′, y1′), (X2′, y′2), . . . , (Xl′, yl′))を用いて f (Xi′)と yi′ を比較したときに,f (Xi′)と y′iが一 致する数が多ければ多いほど予測関数 f は良い予測関数であるといえる.f がどれだけ 良い予測関数であるかを定量的に示すための精度指標としては正答率や F 値,ROC 曲線 の AUC など様々な値が目的に応じて用いられる.は入力データを複数のクラスへの分類する問題,多クラス分類として捉えることができ る.よって入力として受け取った系列データ X に続くシンボル y を予測する系列予測問 題は,多クラス分類器を用いて解くことができる.
2.2
ワンホット表現
系列データから学習を行う際,シンボルをそのまま整数値として扱わず,多次元のベ クトルへ変換することが多い.シンボルからベクトルへの変換方法のひとつとしてワン ホット表現がある.アルファベット Σ ={a1, a2, . . . , ai, . . . , aσ} において,シンボル aiの ワンホット表現とは i 番目の要素にだけ 1 が入り,他の要素は全て 0 となるベクトルを指 す.ワンホット表現で表されるベクトルはスパースなベクトルとなる. 本論文ではワンホット表現のみを用いるが,ベクトル表現の別手法として Skip-gram や Continous Bag of Words を用いた分散表現もある [7].2.3
ニューラルネットワーク
ニューラルネットワークとは複数のノードが接続したネットワーク構造のモデルである. 入力として多次元のベクトルを受け取り,多次元のベクトルを出力する.ネットワークは ノードと呼ばれるユニットを複数含んだ層の積み重ねによって構成される.このニュー ラルネットワークを多層に重ねたモデルを用いた機械学習を総称して深層学習 [14, 15] と 呼ぶ.深層学習の各手法は多クラス分類問題の学習器に用いることができる.ニューラ ルネットワークの一例として図 2.1 に多層パーセプトロンを示す. 多層パーセプトロンは入力,中間,出力の 3 種類の層からなるネットワークであり,1 つの層には複数のノードが含まれる.多次元ベクトルが入力層に渡され,層から層へ値 が伝播していき,最終的に出力層のノードの値をネットワークが出力するベクトルとす る.入力ベクトル x における i 番目の要素を xiとし,xiにかかる重みを wi,入力ベクト ルと重みベクトルのサイズを|x| = |w| = n,バイアス項を b,活性化関数を f,ノード から出力される値を x′としたとき,各ノードで以下の計算を行うことで入力の値から出!
"!
#!
$2
"2
# 図 2.1: 多層パーセプトロンネットワーク!
"
!
#
!
$
!′
&
"
&
#
&
$
'
!
(
= * + &
,
!
,
$
,-"
+ '
= * /
0
1 + '
図 2.2: ニューラルネットワークのノードとノードの計算 力の値を計算する(図 2.2). x′ = f ( n ∑ i=1 wixi+ b) = f (wTx + b) (2.1) 活性化関数にはシグモイド関数やハイパボリックタンジェント,正規化線形関数 (Rectified Linear Unit; ReLU)などが用いられる.ネットワークは出力したベクトルと正解であるベクトルの値を比較することで誤差を 計算し,誤差逆伝播法により各ノードにかかる重みの値を調整する.訓練データを用い てこの逆伝播を何度も繰り返し,ネットワーク全体の重みを調整することでモデルは学 習を行う.
( ) ( ) ) 図 2.3: 深層学習と再帰型ニューラルネットワークの関係図 系列予測問題にニューラルネットワークを用いる場合,入力として系列データ X を, 正解データとして次に来るシンボル y を与える.X に含まれる全てのシンボルと y はワ ンホット表現を用いて長さ σ のベクトルに変換された状態でニューラルネットワークに 与えられる.多層パーセプトロンの場合,X は長さが σ|X| である 1 つのベクトルとして 表される.このときニューラルネットワークの出力が y に近づくようにモデルの学習を 行う. 2.3.1 再帰型ニューラルネットワーク 入力層から出力層に向けて一方向に値を伝播させていくモデルを順伝播型ネットワー クと呼ぶのに対し,フィードバックループ機能を追加したノードを含むモデルを再帰型 ニューラルネットワーク (Recurrent Neural Network; RNN) と呼ぶ.また,再帰型ニュー ラルネットワークを改良したモデルとして次項で説明する長短期記憶ネットワークがあ る.図 2.3 に深層学習で用いられる代表的なモデルの関係図を示した. 多層パーセプトロンでは入力 X を単一のベクトルとして表したように,順伝播型ニュー ラルネットワークは系列データに含まれるシンボルの前後に対する影響を扱いにくい.対 して再帰型ニューラルネットワークにおいて系列データを扱う際には 1 回の入力が系列 データごとではなくシンボルごとに行われる.再帰型ニューラルネットワークはある時 点でのノードの出力を,そのノードに対する次の入力と一緒に加えるため,系列データ におけるシンボルの順序性を表現できるモデルとなっている(図 2.4). ニューラルネットワークにおけるノードの計算式(式 2.1)は再帰型ニューラルネット
1
31′
34"1′
31′
3= * /
0(1
3+ 1′
34")
図 2.4: 再帰型ニューラルネットワークのノード ワークにおいては以下の式で表される. x′t = f (W xt+ Rx′t−1+ b) (2.2) 式 2.1 とは異なり,1 つのノードが入出力する値のどちらもベクトルとなっている.xtと x′tはそれぞれ時刻 t における入力ベクトルと出力ベクトルを表しており,b はバイアスベ クトルを表している.フィードバックループによって 1 つ前の時刻の出力 x′t−1が入力に 加わったため,x′t−1にかける再帰重み R が入力重み W とは別に必要となる.x のサイズ を k とすると W と R は k× k の行列である. 2.3.2 長短期記憶ネットワーク 再帰型ニューラルネットワークはフィードバックループにより過去に入力された情報を 利用することができるようになったが,短期的にしか情報を保持することができず,系列 内で長期に渡る影響を利用することはできなかった.この短所を克服するため Hochereiter と Schmidhuber[5] により長短期記憶ネットワーク (Long Short Term Memory; LSTM) が 提案された.長短期記憶ネットワークはフィードバックループを持つノードにメモリー セルと入力,出力,忘却の 3 つのゲートを加えたモデルである(図 2.5). 再帰型ニューラルネットワークと同様に一つ前の時刻の出力を入力に加えて計算を行 う.通常の入力とは別に 3 つのゲートがあるため,入力重みと再帰重みが再帰型ニュー ラルネットワークの四倍必要になり,それぞれ W, Win, Wout, Wf or, R, Rin, Rout, Rf orと 表す.時刻 t におけるメモリーセルに格納されるベクトルを ctとし,通常入力と各ゲー トにおける活性化関数の計算結果をそれぞれ一時的に z, zin, zout, zf orとおくことにする. 二つのサイズが同じベクトル a と b の要素積を a◦ b と表す.このとき長短期記憶ネット1
31
31
31′
34"1′
34"1′
34"1′
31
31′
34" i ei g 図 2.5: 長短期記憶ネットワークの図 ワークにおけるノードの計算式は以下の式で表される. z = f (W x + Rx′t−1) zin = f (Winx + Rinx′t−1)zout = f (Woutx + Routx′t−1)
zf or = f (Wf orx + Rf orx′t−1) ct = z◦ zin+ ct−1◦ zf or x′t = zout◦ f(ct)
2.4
XGBoost
複数の決定木や回帰木を弱学習器として,勾配ブースティングというアンサンブル学 習手法用いて作られた分類器をブースティング木と呼ぶ.XGBoost は勾配ブースティ ング木を改良したブースティングシステム,分類器とその構築アルゴリズム,ライブラ リの総称である [4].XGBoost は従来のブースティング木に比べて並列化が容易であり, 学習データがスパースであるとき高速に動き,大規模データをメモリ上で効率よく扱え るといった多くの利点がある. ある回帰木がベクトル x を入力したときに f (x) を出力するとする.XGBoost が K 個の 回帰木により構成されていたとき,入力 x に対する XGBoost の出力は ϕ(x) =∑Kk=1fk(x) で表される.XGBoost の学習に用いる学習用データを ((x1, y1), (x2, y2), . . . (xn, yn))とすると,XGBoost の目的関数は以下の式で表される. L(ϕ) = n ∑ i=1 l(yi, ϕ(x)) + K ∑ k=1 Ω(fk) 第 1 項目が損失項であり,l は損失関数を表す.損失関数には対数尤度や平均二乗誤差な どが使われる.第 2 項目が正則化項であり,Ω は正則化関数を表す.正則化には L1 ノル ムや L2 ノルムなどが用いられる.XGBoost は目的関数 L を最小化するように回帰木を 追加することで学習を行う.
第
3
章
混合分布言語モデル
本章では系列データ予測に用いるモデリング手法としてまず言語モデルを説明し,複数 の言語モデルを統一する定式化である混合分布言語モデルについて述べる.そして既存 の言語モデルを混合分布言語モデルで表現し,混合分布言語モデルにより得られた新た な言語モデルに関して説明する.3.1
言語モデル
言語モデルでは系列データ X = (x1, x2, . . . , xN)が与えられたとき,次に得られるシン ボルが xN +1である確率を条件付き確率 p(xN +1| X) で表す.このモデルにより長さ N の 系列データ X が生成される確率を p(X) =∏Ni=1p(xi| x1, x2, . . . , xi−1)と表せる.言語モ デルは機械翻訳など様々な応用に用いられ,広く研究されている. 数ある言語モデルの中で最もよく研究されているのは n-gram を数え上げることで得 られる n-gram 言語モデルであったが,近年ではニューラルネットワークを用いたニュー ラルネットワーク言語モデルが n-gram 言語モデルよりも精度が良いとして注目されて いる [3, 8, 11].しかしニューラルネットワーク言語モデルはモデルを得る学習時とモデ ルを活用する予測時の両方の場面において,n-gram 言語モデルよりも計算処理コストが 高い. 3.1.1 n-gram 言語モデル系列データ X における長さ n の連続した部分系列 (xi, xi+1, . . . xi+n−1)を n-gram と呼
値を指定したとき,1-gram から n-gram まで全ての長さの全部分系列の出現頻度を数え 上げ,部分系列の長さごとに各シンボルの出現頻度確率を求める. n-gram言語モデルは入力として X が与えられたとき,X の接尾辞を長さ 1 から n ま での n 種類をとり,各接尾辞ごとに次に来るシンボルの確率分布を求める.n 種類の接 尾辞に対して得られた次に来るシンボルの確率をシンボルごとに合計していき,最も確 率の高いシンボルを最終的に出力とする. n-gramの出現頻度を元に構築する n-gram 言語モデルにおいて,n のサイズやアルファ ベットサイズによっては訓練データ中の出現頻度が 0 となる部分系列の組み合わせが存 在する.これをゼロ頻度問題と呼ぶ.ゼロ頻度問題に対する解決方法をスムージングと 呼び,加算スムージング,ラプラススムージング,Kneser-Ney スムージングなどがある. ただし,本論文における比較実験ではこれらスムージング処理は行っていない. 3.1.2 ニューラルネットワーク言語モデル ニューラルネットワーク言語モデルは最初に Bengio ら [3] により多層パーセプトロン を用いたモデルとして提案され,その後 Mikolov ら [8] により再帰型ニューラルネット ワークを用いたモデルに,Sundermeyer ら [11] により長短期記憶ネットワークを用いた モデルへと改良されていった. 言語モデルとしてニューラルネットワークを利用する方法は,多クラス分類問題を解 くときとほぼ同じである.ニューラルネットワークは系列データ X を入力したときに, 次に出現すると予測されるシンボルの確率分布を出力するようネットワーク全体の重み を誤差逆伝播法により学習する.言語モデルはニューラルネットワークから出力された 確率分布の中で最も確率の高いシンボルを次にくるシンボルとして出力する.
3.2
混合分布言語モデル
混合分布言語モデルは Neubig と Dyer により提案された従来の言語モデルを統一的に 表すことのできる言語モデルのフレームワークである [9].混合分布言語モデルは下記の ベクトルと行列の積として定式化される. p = DλB
δ
8×8
M
GS
:
"
:
#
⋮
:
<
=
1
0
⋯
⋯
0
0
⋮
⋱
⋮
0 ⋯ 1
B
"
B
#
B
C
⋮
B
<
n /
L
T GS 8×D
M
GS
L
:
"
:
#
⋮
:
<
=
E
","
E
#,"
⋯
⋯
E
",$
E
#,$
⋮
⋱
⋮
E
<,"
⋯ E
<,$
B
"
B
#
B
C
⋮
B
$
/
/
図 3.1: n-gram 言語モデル pは次に得られるシンボルの確率分布を表し,長さ σ かつ総和が 1 となるベクトルであ る.p における j 番目の要素 pjは p(xN +1= j| X) に対応する.λ と D はそれぞれ重み係 数ベクトルと分布行列を表している.D が A× B の行列であったとき,λ のサイズは B となる.分布行列 D は複数の確率分布を行列化したものであり,各列が確率分布に対応 する.重み係数ベクトル λ は分布行列 D に含まれる複数の確率分布をどう組み合わせて 最終的な確率分布 p を得るか,その重み付けの係数として用いられる.これにより,X の後に続くシンボル xN +1が j である確率 p(xN +1 = j| X) は下記の計算で求めることが できる. p(xN +1= j| X) = K ∑ k=1 dk,jλk 上記の定式化を利用することで既存の言語モデルは統一的に表現することができるよ うになる.次に混合分布言語モデルにおける n-gram 言語モデルとニューラルネットワー ク言語モデルの定式化について述べる. n-gram言語モデル 混合分布モデルでは各 n-gram の確率分布が D における各列に対応し,D は σ× n 行 列となる.重み係数ベクトル λ は事前に決定されたヒューリスティックな値として,固 定値を用いる(図 3.1).3.1.1 節で述べたように,予測時にシンボルの確率を単純に合計 する場合 λ は全ての要素が同じ値のベクトルとなる.13
B
δ
8×8
M
GS
:
"
:
#
⋮
:
<
=
1
0
⋯
⋯
0
0
⋮
⋱
⋮
0 ⋯ 1
B
"
B
#
B
C
⋮
B
<
n /
L
T GS 8×D
M
GS
:
"
:
#
⋮
:
<
=
E
","
E
#,"
⋯
⋯
E
",$
E
#,$
⋮
⋱
⋮
E
<,"
⋯ E
<,$
B
"
B
#
B
C
⋮
B
$
/
/
図 3.2: ニューラルネットワーク言語モデル ニューラルネットワーク言語モデル 混合分布モデルでは,ニューラルネットワークの出力が重み係数ベクトル λ となり, Dの各列は j 番目のシンボルの出現確率が 1 であるクロネッカーのデルタ分布 δjとなる (図 3.2).これは n-gram 言語モデルにおいて重み係数ベクトル λ がヒューリスティック な値であったのに対し,ニューラルネットワーク言語モデルでは分布行列 D がヒューリ スティックな値となることを示している.クロネッカー δ をアルファベットサイズ分だけ 横に並べるため,D は σ× σ の単位行列となる.3.3
混合分布言語モデルによる合成
Neubigと Dyer は混合分布言語モデルにより従来の言語モデルに対して統一的な定式 化を行い,この定式化に基いて各言語モデルを改良したモデルを提案した. 3.3.1 ニューラル補間型 n-gram 言語モデル ニューラル補間型 n-gram 言語モデルは n-gram 言語モデルとニューラルネットワーク 言語モデルを組み合わせたモデルである.混合分布言語モデルで表現する際に n-gram 言 語モデルは分布行列 D を,ニューラルネットワーク言語モデルは重み係数ベクトル λ を 学習するモデルであった.また,n-gram 言語モデルの λ はデータから学習したものではn /
L
T GS 8 ×D
M
GS
:
"
:
#
⋮
:
<
=
E
","
E
#,"
⋯
⋯
E
",$
E
#,$
⋮
⋱
⋮
E
<,"
⋯ E
<,$
B
"
B
#
B
C
⋮
B
$
/ )
/
/-/
図 3.3: ニューラル補間型 n-gram 言語モデル なく,事前にヒューリスティックに決定した値を用いていた.そこでニューラル補間型 n-gram言語モデルはニューラルネットワークによりデータから学習された λ を用いて確 率分布 p を計算する.(図 3.3) また,λ のサイズがアルファベットサイズ σ であったニューラルネットワーク言語モ デルに比べ,ニューラル補間型 n-gram 言語モデルは λ のサイズが n で済むため,計算効 率は良くなる.ニューラル補間型 n-gram 言語モデルの構築手順は以下の通りとなる. 1. 訓練データの系列データから n-gram を数え上げる. 2. 系列データ X を入力として受け取り,n-gram 言語モデルから分布行列 D を作成 する. 3. ニューラルネットワークに対して X を入力したときに得られた出力を λ とする. 4. arg max Dλが正解を示すようにニューラルネットワークの重みを調整する. 5. 訓練データを用いて規定回数だけ 2–4 を繰り返す. 3.3.2 ニューラル & n-gram 合成型言語モデルニューラル & n-gram 合成型言語モデルはニューラル補間型 n-gram 言語モデル(3.3.1)
n /
L
T GS 8 ×D
B
8 ×8
δ
M
GS
:
"
:
#
⋮
:
<
=
E
","
E
#,"
⋯
⋯
E
",$
E
#,$
⋮
⋱
⋮
E
<,"
⋯ E
<,$
1
0
⋯
⋯
0
0
⋮
⋱
⋮
0 ⋯ 1
B
"
B
#
B
C
⋮
B
$G<
M
GS
:
"
:
#
⋮
:
<
=
E
","
E
#,"
⋯
⋯
E
",$
E
#,$
⋮
⋱
⋮
E
<,"
⋯ E
<,$
1
0
⋯
⋯
0
0
⋮
⋱
⋮
0 ⋯ 1
B
"
B
#
B
C
⋮
B
$G<
/
/
( /)
/
( /)
n /
L
T GS 8 ×D
B
8×8
δ
図 3.4: ニューラル & n-gram 合成型言語モデル このとき,重み係数ベクトル λ は長さ n + σ のベクトルとなり,最初の n 個の要素, λ1, . . . , λnは n-gram 確率分布の重み係数を示し,続く σ 個の要素,λn+1, . . . , λn+σはクロ ネッカー δ にかかる重み係数を示す.このモデルの利点として 3 つの点が挙げられる.1 つ目はこのニューラル & n-gram 合成型言語モデルであれば n-gram 言語モデルとニュー ラルネットワーク言語モデルの両方で使用されるすべての情報を利用できる点である. ニューラル補間型 n-gram 言語モデルはあくまで n-gram による確率分布を組み合わせる 重み係数ベクトルの学習にニューラルネットワークを利用しているだけであり,ニュー ラルネットワーク言語モデルにおける情報量を活かせていなかった.n-gram 確率分布か らなる行列の横にクロネッカー δ 分布からなる行列を並べることで n-gram 言語モデルと ニューラルネットワーク言語モデル両方の情報を扱うことができるようになる.二つ目 は効率的に計算ができる n-gram が言語モデルとして十分多くの事象を捉え,ニューラル ネットワークは n-gram が捕捉しきれなかった事象に集中して学習をすることができる点 である.そして 3 つ目の利点は,計算が容易であるために n-gram は大量のデータから学 習が可能であり,その大規模なデータから学習したモデルを小規模なデータセットでの ニューラルネットワークのブートストラップ学習に使えるという点である. しかしこのまま学習を行おうとすると n-gram に対応する部分の行列が既に学習済みで あるため,ニューラルネットワーク言語モデルに対応する部分の重み係数 λn+1, . . . , λn+σ の学習が進まず,局所解に陥ってしまう.この問題を回避するため Neubig と Dyer は重プアウトはニューラルネットワークにおける過学習を防ぐため,学習時にランダムに選 ばれたノードへの入力を 0 とする手法である [10].対してブロックドロップアウトはラン ダムなタイミングで 1 つの層全体への入力を全て 0 とする手法である.Neubig と Dyer は ニューラル & n-gram 合成型言語モデルにおいて λ を学習する際に,50% の確率で n-gram の確率分布からなる分布行列 D をゼロ行列に置き換え,これをブロックドロップアウト とした.これによりクロネッカー δ にかかる λ の学習を促すことができるようになる. ニューラル & n-gram 合成型言語モデルの構築手順は以下の通りとなる. 1. 訓練データの系列データから n-gram を数え上げる. 2. 系列データ X を入力として受け取り,分布行列 D を 50% の確率で n-gram 言語モ デルから 50% の確率でゼロ行列から作成する. 3. ニューラルネットワークに対してを X を入力したときに得られた出力を λ とする. 4. arg max Dλが正解を示すようにニューラルネットワークの重みを調整する. 5. 訓練データを用いて規定回数だけ 2–4 を繰り返す.
第
4
章
提案モデル
混合分布言語モデルはモデルの構築に 2 段階の学習を行う.それぞれ系列 X を入力とし て分布行列 D を出力する分類器と,系列 X を入力として重み係数ベクトル λ を出力する 分類器の構築である.この 2 段階の学習において従来の n-gram とニューラルネットワー ク以外に XGBoost を用いた言語モデルを提案する.本章で扱うニューラルネットワーク はすべて長短期記憶ネットワークを用いる.4.1
XGBoost & n-gram
合成型言語モデル
ニューラル & n-gram 合成型言語モデル (3.3.2) では重み係数ベクトル λ を出力する学習 器にニューラルネットワークを用いた.XGBoost & n-gram 合成型言語モデルではニュー ラルネットワークの代わりに XGBoost を用いることで,n-gram 言語モデルと XGBoost 言語モデルを組み合わせた言語モデルを作成する(図 4.1).
XGBoost & n-gram 合成型言語モデルの構築手順は以下通りとなる.
1. 訓練データの系列データから n-gram を数え上げる.
2. 系列データ X を入力として受け取り,分布行列 D を 50% の確率で n-gram 言語モ デルから 50% の確率でゼロ行列から作成する.
3. XGBoostに対してを X を入力したときに得られた出力を λ とする. 4. arg max Dλが正解を示すように XGBoost を学習させる.
18
n /
L
T GS 8 ×D
B
8 ×8
δ
M
GS
:
"
:
#
⋮
:
<
=
E
","
E
#,"
⋯
⋯
E
",$
E
#,$
⋮
⋱
⋮
E
<,"
⋯ E
<,$
1
0
⋯
⋯
0
0
⋮
⋱
⋮
0 ⋯ 1
B
"
B
#
B
C
⋮
B
$G<
:
#
⋮
:
<
=
E
#,"
⋮
⋯
⋱
E
#,$
⋮
E
<,"
⋯ E
<,$
1
0
⋯
0
0
⋮
⋱
⋮
0 ⋯ 1
B
#
B
C
⋮
B
$G<
/
/
( /)
/
( /)
n /
L
T GS 8 ×D
B
8×8
δ
図 4.1: XGBoost & n-gram 合成型言語モデル
系列データ X を入力したとき n-gram は n 個のサイズ σ の確率分布ベクトルを出力し, XGBoostはサイズ σ の重み係数ベクトル λ を出力する.
4.2
ニューラル
& XGBoost
合成型言語モデル
ニューラル & n-gram 合成型言語モデル (3.3.2) は分布行列 D を得るために n-gram 言 語モデルを利用する.ニューラル & XGBoost 合成型言語モデルはこの n-gram の代わり に XGBoost を用いて,系列データ X に対する複数の確率分布を用意する.XGBoost か ら得られた複数の確率分布に対して λ を用いた線形和を取ることで最終的なシンボルの 確率分布 p が得られる(図 4.2). ニューラル & XGBoost 合成型言語モデルの構築手順は以下通りとなる. 1. 訓練データを用いて初期値の異なる m 個の XGBoost に対して系列データ X を入 力したときに次のシンボル ˜xの確率分布を出力するように学習させる. 2. 系列データ X を入力として受け取り,分布行列 D を 50% の確率で XGBoost から 50%の確率でゼロ行列から作成する. 3. ニューラルネットワークに対してを X を入力したときに得られた出力を λ とする. 4. arg max Dλが正解を示すようにニューラルネットワークを学習させる.
B
δ
8 ×8
GS
8 ×H
M
GS
:
"
:
#
⋮
:
<
=
E
","
E
#,"
⋯
⋯
E
",I
E
#,I
⋮
⋱
⋮
E
<,"
⋯ E
<,I
1
0
⋯
⋯
0
0
⋮
⋱
⋮
0 ⋯ 1
B
"
B
#
B
C
⋮
B
IG<
:
"
:
#
⋮
:
<
=
E
","
E
#,"
⋯
⋯
E
",$
E
#,$
⋮
⋱
⋮
E
<,"
⋯ E
<,$
E′
","
E′
#,"
⋯
⋯
E′
",I
E′
#,I
⋮
⋱
⋮
E′
<,"
⋯ E′
<,I
B
"
B
#
B
C
⋮
B
$GI
n /
L
T GS 8 ×D
M
GS
GS
8 ×H
/
( /)
/ )
/
-/
( /)
図 4.2: ニューラル & XGBoost 合成型言語モデル 5. 訓練データを用いて規定回数だけ 2–4 を繰り返す. 系列データ X を入力したとき,XGBoost はサイズ σ の確率分布ベクトルを出力し, ニューラルネットワークはサイズ σ の重み係数ベクトル λ を出力する.上記の手順によ り学習した XGBoost とニューラルネットワークを用いてニューラル & XGBoost 合成型言語モデルは系列データ X に対して次にくるシンボル ˜xを予測する.
4.3
ニューラル補間
XGBoost & n-gram
合成型言語モデル
ニューラル & n-gram 合成型言語モデル (3.3.2) は分布行列 D を得るためにクロネッ カーの δ 分布を用いる.ニューラル補間 XGBoost & n-gram 合成型言語モデルはこのク ロネッカーの δ 分布の代わりに XGBoost から得られる確率分布を用いる.重み係数ベク トル λ は既存手法(3.3.2)と同様にニューラルネットワークを用いる(図 4.3).
ニューラル補間 XGBoost & n-gram 合成型言語モデルの構築手順は以下の通りとなる. 1. 訓練データの系列データから n-gram を数え上げる.
2. 訓練データを用いて初期値の異なる m 個の XGBoost に対して系列データ X を入
力したときに次のシンボル ˜xの確率分布を出力するように学習させる.
3. 系列データ X を入力として受け取り,n-gram から得られる行列と XGBoost から 得られる行列を横に連結した行列を分布行列 D とする.
20 B δ 8 ×8 GS 8 ×H
:
#⋮
:
<=
E
#,"⋯
E
#,I⋮
⋱
⋮
E
<,"⋯ E
<,I0
⋮
⋯
⋱
0
⋮
0 ⋯ 1
B
#B
C⋮
B
IG<:
":
#⋮
:
<=
E
","E
#,"⋯
⋯
E
",$E
#,$⋮
⋱
⋮
E
<,"⋯ E
<,$E′
","E′
#,"⋯
⋯
E′
",IE′
#,I⋮
⋱
⋮
E′
<,"⋯ E′
<,IB
"B
#B
C⋮
B
$GI n / L T GS 8 ×D M GS GS 8 ×H / ( /) / ) / -/ ( /)図 4.3: ニューラル補間 XGBoost & n-gram 合成型言語モデル
4. ニューラルネットワークに対してを X を入力したときに得られた出力を λ とする. 5. arg max Dλが正解を示すようにニューラルネットワークを学習させる. 6. 訓練データを用いて規定回数だけ 3–5 を繰り返す. 系列データ X を入力したとき n-gram と XGBoost はサイズ σ の確率分布ベクトルを出 力し,ニューラルネットワークはサイズ σ の重み係数ベクトル λ を出力する.この言語 モデルは最も多くの学習器を用いるため,最も表現力の高いモデルである一方で,最も ハイパーパラメータ数の多いモデルとなる.また,学習する必要のある学習器も多いた め,最終的に言語モデルを利用して系列予測できるようになるまでに要する時間も最も かかるようになる.
第
5
章
実験
これまでに述べた既存手法と提案手法の比較を行うため 2 種類のデータセットを用いて 比較実験を行う.それぞれ実験 1,実験 2 として次節から順に説明していく.
プログラムは全て Python を使用し,ニューラルネットワークには Preferred Networks 社が公開するニューラルネットワーク用ライブラリ Chainer1を,XGBoost には機械学習
オープンソースコミュニティDistributed (Deep) Machine Learning Community (DMLC) の公開する XGBoost ライブラリ2を利用した.
本章では以下に示す 7 種類の言語モデルの比較実験を行う.
• n-gram 言語モデル (Ngram)
• ニューラルネットワーク言語モデル (NN) • XGBoost を用いた言語モデル (XGB)
• ニューラル & n-gram 合成型言語モデル (NN/Ngram) • XGBoost & n-gram 合成型言語モデル (XGB/Ngram) • ニューラル & XGBoost 合成型言語モデル (NN/XGB)
• ニューラル補間 XGBoost & n-gram 合成型言語モデル (NN/XGB+Ngram)
実験は混合分布言語モデルに基いて言語モデル組み合わせた際に,組み合わせによっ て精度が変化することを示すために行う.このため上記のモデルにおいてニューラルネッ トワークと XGBoost を分類器として用いるが,言語モデルごとのハイパーパラメータ調 整は行わない.実験ごとにハイパーパラメータは変更するが,実験内では分類器のハイ パーパラメータは全て共通のものを用いる. 1https://github.com/pfnet/chainer 2https://github.com/dmlc/xgboost
5.1.1 Sequence PredIction ChallengE (SPiCe)
Sequence PredIction ChallengE (SPiCe)とは第 13 回 International Conference in Gra-matical Inferenceにおいて開催された系列データ予測コンペティションである.参加者 は与えられた訓練用データセットから系列データに続くシンボルの候補を順に 5 つ出力 するモデルを構築する.構築したモデルを用いてテスト用データセットから各系列デー タごとにシンボル予測を行う.各系列データに対して得た 5 つの予測シンボル候補を用 いて評価関数からスコア算出し,全系列データの平均スコアをデータセットに対する最 終的なスコアとする. コンペティション期間中,参加者は各々の手法を用いて構築したモデルから評価用テ ストデータに対して予測を行いスコアを競う.この評価用テストデータに対するモデル 適用結果の提出は何度でもできるため,参加者たちはこのスコアを参考にしてモデルの 改善を行う.テストデータから得られたスコアはウェブサイトで公開され,参加者の提 出した予測候補に基いて随時更新されていく.コンペティションの最終順位は評価用テ ストデータとは別に用意された最終評価用テストデータを用いて行われ,このデータに 対する予測結果の提出はコンペティションの最後に一度だけ可能である.
スコアに用いる評価関数には正規化減価累積利得 (Normalized Discounted Cumulated
Gain; NDCG)が用いられた.参加者は 1 つの系列データに対して次に来ると予測したシ ンボルを 5 つ列挙し,コンペティションの運営者が正解の確率分布を基にして以下の式 から NDCG を計算する. N DCG5(a1, . . . , a5) = ∑5 k=1 p(xn+1=ak|X) log2(k+1) ∑5 k=1 pk log2(k+1) ここで a1, . . . , a5 はモデルの予測した 5 つのシンボル候補であり,a1 から順に予測確率 の高いシンボルであるとする.p(ai|X) は aiの実際の確率値であり,pkは正解シンボル の中で k 番目の候補シンボルの確率値である.予測した 5 つの候補が順序も含めて全て 正しかった場合 NDCG は 1 になり,逆に 5 つの候補シンボルのうちどれも正解と異なっ ていた場合 NDCG は 0 となる.定義から分かる通り NDCG においては与えられた系列 データの次にくるシンボルとして最も確からしいシンボル 1 つを当てるだけではなく,2
番目に確からしいシンボル,3 番目に確からしいシンボルと他の候補も当てなければなら ない.このため,SPiCe においてモデルは与えられた系列データ X に続く単一のシンボ ルを予測するのではなく,シンボルの確率分布を予測する必要がある.
我々はチーム ushitora として SPiCe に参加し,Neubig と Dyer の提案したニューラル & n-gram合成型言語モデルと XGBoost を用いて最終的に 3 位に入賞した [2].
5.1.2 SPiCeデータセット
SPiCe中に使用されたデータセットのことを SPiCe データセットと呼ぶ.SPiCe デー タセットは特徴が異なる 15 問のデータセットによって構成されている.各データセット ごとにモデル学習用の訓練データ(train)と開催期間中のモデル評価用のテストデータ (public),最終提出モデル評価用のテストデータ(private)の 3 セットが用意されてい
る.本論文では train と public のみを扱う.
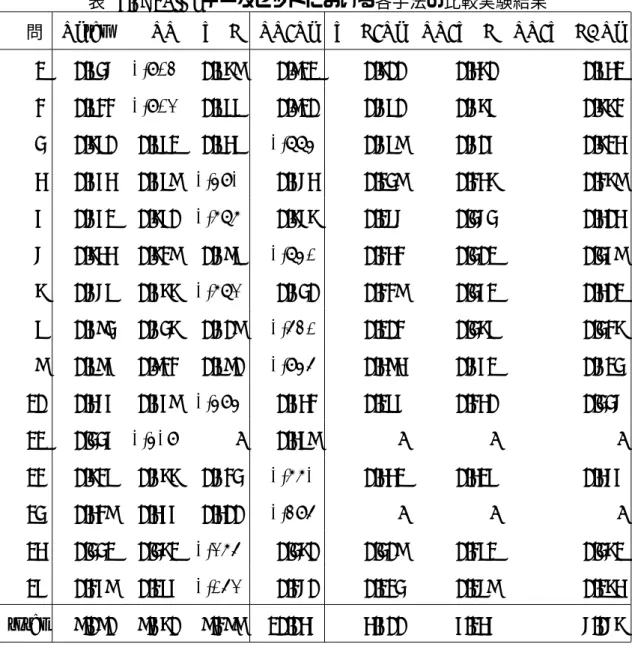
表 5.1 に SPiCe データセットにおける各問に関する各種数値を示した.Ntrainと Ntest
はそれぞれ train と public に含まれている系列データの数を示す.|Σ| はアルファベット サイズを,|Σtrain| は実際に train の中に含まれていたシンボルの種類数を表している. avg lengthは train における系列の平均長を示し,line variety は train に含まれる全系 列に対して系列長-シンボル比の平均をとった値である.系列長-シンボル比とは,ある 系列を見たときに系列長に対して何種類のシンボルが出現しているかを示す比である. line varietyの値が 1 に近づくほど 1 つの系列には様々なシンボルが出現していることを 示し,0 に近づくほど一つの系列の中で出現するシンボルが同じものに偏っていることを 示している.|Σ| が極端に大きい問 11 や,|Σ| が近い値でも avg length が大きく異なる 問 4 と問 15 など,問題セットごとに特徴が分かれていることがわかる.表 5.1 における 全数値はコンペティション中に得られた値である. 続いて表 5.2 に SPiCe データセットを作成する際に元となったデータセットを示した. 合成データと実データが混ざった構成となっており,実データは自然言語,ソフトウェ ア,生物学と様々な分野からのデータを元にして作成されている.実データを用いた問 題セットは候補となる 1 番目のシンボルの確率が 1 となり,2 番目以降のシンボルはすべ て 0 となる.表 5.2 はコンペティション終了後に SPiCe 運営チームが発表したものであ
表 5.1: SPiCe データセットに関する各種数値
問 Ntrain Ntest |Σ| |Σtrain| avg length line variety
1 20000 5000 20 20 41.229 0.449 2 20000 5000 10 10 41.727 0.311 3 20000 5000 10 10 41.793 0.313 4 5987 748 33 33 7.466 0.863 5 33654 5000 49 49 119.336 0.239 6 5000 5000 60 24 24.911 0.592 7 65438 5000 20 20 59.120 0.281 8 13903 5000 48 48 30.916 0.474 9 5000 5000 11 11 25.543 0.398 10 54932 4847 20 20 35.807 0.452 11 32384 4049 6093 6093 25.543 0.914 12 200000 3000 21 21 28.739 0.632 13 26544 3318 665 665 7.659 0.894 14 10000 5000 27 27 40.846 0.417 15 50000 5000 32 32 49.648 0.537
表 5.2: SPiCe データセットを作成する際に元となったデータ 問 Type 1 合成データ (2 状態 非定常性隠れマルコフモデル) 2 合成データ (2 状態 非定常性隠れマルコフモデル) 3 合成データ (4 状態 非定常性隠れマルコフモデル) 4 自然言語 (英語動詞, 文字単位, Penn Treebank) 5 自然言語 (文字単位の言語モデル, Penn Treebank) 6 部分的に合成, ソフトウェア (RERS 2013 問題 34) 7 生物学 (タンパク質族 PF13855, full set, Pfam)
8 自然言語 (POS センテンス化をしたスペイン語, Ancora) 9 部分的に合成, ソフトウェア (RERS 2013 problem 42) 10 生物学 (タンパク質族 PF00400, RP15 subset, Pfam) 11 自然言語 (Flickr-8000 の英語見出し) 12 合成データ (PAUTOMAC generator) 13 自然言語 (Twitter タイプミスコーパスからの英語スペリング集) 14 部分的に合成 (ALERGIA, DFA, 問題 4 がベース) 15 部分的に合成 (ALERGIA, DFA, 問題 5 がベース)
5.1.3 実験結果 各モデルにおいて用いる長短期記憶ネットワークと XGBoost のハイパーパラメータを それぞれ表 5.3 と表 5.4 に示す.また n-gram 長は 10 とする. データセット各問に対する各言語モデルの NDCG のスコアを表 5.5 に示す.問 11 に 関してはメモリ制約により実験が行えなかったため,問 13 に関しては実験プログラムが 終了しなかったため一部空欄となっている.各問のスコアについて最も大きい値を太字 で示した. モデルによって得意とする問題が異なっており,総合的な性能を測るために全スコア を合計するとニューラル & n-gram 合成型言語モデルは n-gram 言語モデルとニューラル ネットワーク言語モデルのどちらよりも高い合計スコアとなった.混合分布言語モデル に基づいた n-gram 言語モデルとニューラルネットワーク言語モデルの合成による精度向 上は,SPiCe データセットにおいても有効であることが確かめられた. XGBoostを用いたモデルにおいて問 11 が空欄となっているのはメモリオーバーフロー を起こしたためである.問 11 はアルファベットサイズが 6093 ととても大きく,シンボ ルをワンホット表現へ変換するととても巨大なベクトルになる.一方で XGBoost は系列 性を意識した構成ではないため,言語モデルとして扱うためには系列単位で入力が必要 となる.このためシンボルを表すベクトルサイズが増加すると入力サイズも乗算で増え ていき,アルファベットサイズが非常に大きいと訓練時にメモリオーバーフローを起こ してしまう.長短期記憶ネットワークは系列性のある入力に対応しているため,ネット ワークに対してシンボル単位で入力が可能である. 問 11 を除いてスコアを合計すると,ニューラルネットワーク言語モデルは 9.161,XG-Boostを用いた言語モデルは 9.299 であり,XGBoost の方がスコアが高くなっている.こ のことから混合分布言語モデルに基いて XGBoost を用いた提案モデル 3 種は,ニューラ ル & n-gram 合成型言語モデルと同等かそれ以上のスコアを得ることが期待されていた が,どのモデルもそれぞれの言語モデル単体で実験を行った時に比べてスコアを落とす結 果となってしまった.これは SPiCe データセットを用いた全ての実験を通して,XGBoost
のハイパーパラメータを統一して設定したこと原因と考えられる.ニューラルネットワー クや XGBoost などの分類器を単体で言語モデルに利用する場合と,混合分布言語モデ ルに基づいて他の言語モデルと組み合わせて利用する際には分類器に要求する能力が異 なってくる.その点でニューラルネットワークは単体で言語モデルに利用する場合でも, n-gram言語モデルと組み合わせて利用する場合でも,同様に能力を発揮できる分類器で あったのに対し,XGBoost はハイパーパラメータを変える必要があったと考えられる.
表 5.3: XGBoost のパラメータ(実験 1) parameter value
step size shrinkage 0.1 subsample 0.5 colsample bytree 0.6 max depth 10 maximum delta step 10
表 5.4: LSTM のパラメータ(実験 1) parameter value epoch 20 unit 256 batchsize 20 BPTT length 35 grad clip 5 optimizer Adam 表 5.5: SPiCe データセットにおける各手法の比較実験結果 問 Ngram NN XGB NN/Ng XGB/Ng NN/XGB NN/XGB+Ng 1 0.836 0.914 0.879 0.911 0.700 0.470 0.841 2 0.822 0.913 0.888 0.910 0.680 0.675 0.772 3 0.780 0.881 0.848 0.885 0.689 0.605 0.724 4 0.554 0.589 0.590 0.564 0.139 0.247 0.279 5 0.651 0.750 0.787 0.767 0.166 0.363 0.404 6 0.744 0.729 0.698 0.852 0.242 0.301 0.359 7 0.668 0.577 0.783 0.630 0.229 0.351 0.401 8 0.593 0.637 0.609 0.642 0.102 0.378 0.327 9 0.895 0.922 0.890 0.956 0.494 0.651 0.613 10 0.465 0.559 0.595 0.542 0.185 0.240 0.336 11 0.335 0.509 - 0.489 - - -12 0.728 0.677 0.623 0.770 0.441 0.415 0.465 13 0.429 0.455 0.400 0.496 - - -14 0.331 0.371 0.376 0.370 0.309 0.281 0.371 15 0.259 0.155 0.263 0.260 0.123 0.169 0.174 total 9.090 9.670 9.299 10.045 4.500 5.145 6.067
5.2
実験
2
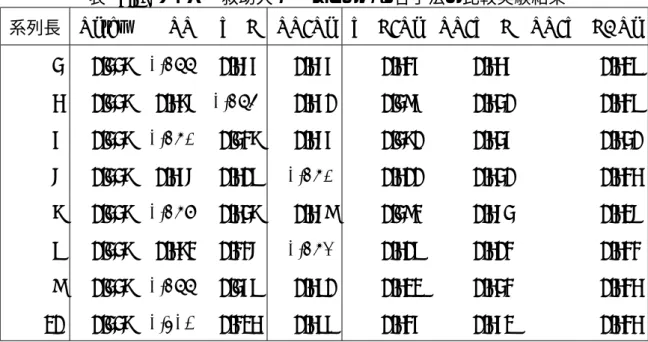
5.2.1 サイバー救助犬センサーデータ 災害救助犬にとりつけたセンサから X・Y・Z の 3 軸加速度を計測したデータを元に, 以下の手順に従ってラベル系列データを作成する.時刻 t における 3 軸の加速度をそれぞ れ Ax t, A y t, Aztとしたとき,加速度のノルムを∥At∥ = √ (Ax t)2+ (A y t)2+ (Azt)2とする. 1. 全時刻の加速度から各時刻における加速度の絶対値∥At∥ を求める. 2. ∥At∥ を 1 秒ごとに区切って抽出し,最小二乗法により一次近似する. 3. 近似直線の傾き a と一秒間に含まれる∥At∥ の中央値 b から以下の場合分けに従っ て,抽出した 1 秒の区間に対してラベルを設定する. (a) aが 2 より大きいとき,上昇中であるとしてラベル 1 をつける. (b) aが−2 未満であるとき,下降中であるとしてラベル 2 をつける. (c) aが−2 以上 2 以下かつ b が系列全体の ∥At∥ の中央値を上回ったとき,高加速 度を維持しているとしてラベル 3 をつける. (d) aが−2 以上 2 以下かつ b が系列全体の ∥At∥ の中央値以下であったとき,低加 速度を維持しているとしてラベル 4 をつける. 上記手順により 1 秒間の加速度データを 4 種類のラベルに分類し,加速度センサーデー タをラベル系列データに変換する.このラベル系列データにおける各ラベルをシンボル として,全データから部分系列を抽出することで実験用データセットとする.ラベルの 予測を行う際に何秒前までの情報を用いれば十分かを調べるため,部分系列の系列長を 3から 10 までそれぞれ別に抽出し,8 種類のデータセットを用意する.評価指標として 正答率を用いる. 5.2.2 実験結果 各モデルにおいて用いる分類器,長短期記憶ネットワークと XGBoost のハイパーパラ メータをそれぞれ表 5.6 と表 5.7 に示した.また n-gram 長は 3 とする. 系列長と各言語モデルの正答率の関係を表 5.8 に示す.表 5.6: XGBoost のパラメータ(実験 2) parameter value
step size shrinkage 0.1 subsample 0.5 colsample bytree 0.6 max depth 10 maximum delta step 10
表 5.7: LSTM のパラメータ(実験 2) parameter value epoch 40 unit 100 batchsize 5 BPTT length 15 grad clip 5 optimizepr Adam 表 5.8: サイバー救助犬データにおける各手法の比較実験結果 系列長 Ngram NN XGB NN/Ng XGB/Ng NN/XGB NN/XGB+Ng 3 0.337 0.488 0.465 0.465 0.425 0.445 0.418 4 0.337 0.476 0.486 0.450 0.395 0.430 0.428 5 0.337 0.472 0.327 0.465 0.370 0.435 0.430 6 0.337 0.456 0.408 0.472 0.400 0.430 0.424 7 0.337 0.479 0.437 0.469 0.392 0.463 0.416 8 0.337 0.472 0.226 0.473 0.408 0.402 0.422 9 0.337 0.488 0.358 0.480 0.411 0.432 0.424 10 0.337 0.501 0.214 0.488 0.425 0.451 0.424
どの系列長においてもおおむねニューラルネットワーク言語モデルが最も正答率が高 く,n-gram 言語モデルと合成することで精度が下がってしまった.
また各提案モデルの正答率について,ニューラル & n-gram 合成型言語モデル (NN/Ngram) は 0.370–0.425,XGBoost & n-gram 合成型言語モデル (XGB/Ngram) は 0.402–0.463, ニューラル & XGBoost 合成型言語モデル (NN/XGB) は 0.416–0.430 とどれもニューラ ルネットワーク言語モデル(NN)の最低スコア(0.456)に及ばなかった. サイバー救助犬データセットにおいては混合分布言語モデルは精度向上に繋がらず, ニューラルネットワーク言語モデルが最も良いモデルという結果となった.これは系列 長が 3–10 という比較的短い系列に対する 4 クラス分類という問題に対しては複雑な言語 モデルを用いると過学習を起こしてしまうためではないかと考えられる.よりモデルが シンプルになるようにハイパーパラメータを調整するか学習に用いる訓練データを増や すことで精度向上が見込める.
第
6
章
まとめ
6.1
まとめ
本論文では Neubig と Dyer により提案された複数の言語モデルを組み合わせる混合分 布言語モデルの一般性を示すため,既存研究でなされていた n-gram 言語モデルとニュー ラルネットワーク言語モデル以外の,XGBoost を用いた言語モデルを組み合わせた新た な言語モデルを提案した.さらに混合分布言語モデルを自然言語データだけでなく加速 度を元にしたラベル列データにも適用し,異なる分野のデータに対する有効性を実験的 に確認した.6.2
今後の課題
今後の課題としては n-gram 言語モデルにおけるスムージングの追加があげられる.本 論文では使用していないが,Neubig と Dyer の研究では改良型 Kneser-Ney スムージング を用いている.スムージングを行うことで n-gram を使用する言語モデル全体の精度向上 が見込めるので,Kneser-Ney スムージング処理を行った n-gram 言語モデルを用いて再 度比較実験を行う必要がある.また,本研究ではニューラルネットワークでも XGBoost でもワンホット表現によって シンボルをベクトル化していたが,ワンホット表現以外にも様々なベクトル変換手法が 存在する.特に Skip-gram や Continuous Bag-Of-Words といった分散表現によるベクト ル化が様々なタスクで精度改善に繋がっている [7].各シンボルに対して分散表現を用い てベクトル化を行えば精度改善が見込めると考えられる.
提案手法のアイデアは複数の機械学習手法を組み合わせるというものであった.手法 の組み合わせが増えれば増えるほど,チューニングの必要があるハイパーパラメータの 種類は増えていく.ハイパーパラメータをチューニングするためにはそれぞれの学習機 を一度学習させなければならないため,非常に時間がかかってしまう.出来得る限り少 ない試行回数での効率的なハイパーパラメータのチューニングが必要となる.
参考文献
[1] Waleed Ammar, George Mulcaire, Miguel Ballesteros, Chris Dyer, and Noah A. Smith. One parser, many languages. CoRR, 2016.
[2] Borja Balle, R´emi Eyraud, Franco Luque, Ariadna Quattoni, and Sicco Verwer. Results of the Sequence PredIction ChallengE (SPiCe): a Competition on Learning the Next Symbol in a Sequence. In 13th International Conference in Grammatical
Inference, Vol. 57. JMLR W&CP, 2016.
[3] Yoshua Bengio, R´ejean Ducharme, Pascal Vincent, and Christian Janvin. A neural probabilistic language model. Journal of Machine Learning Research, pp. 1137–1155, 2003.
[4] Tianqi Chen and Carlos Guestrin. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge
Discovery and Data Mining, pp. 785–794, 2016.
[5] Sepp Hochreiter and J¨urgen Schmidhuber. Long short-term memory. Neural
Com-putation, pp. 1735–1780, 1997.
[6] Melvin Johnson, Mike Schuster, Quoc V. Le, Maxim Krikun, Yonghui Wu, Zhifeng Chen, Nikhil Thorat, Fernanda B. Vi´egas, Martin Wattenberg, Greg Corrado, Mac-duff Hughes, and Jeffrey Dean. Google’s multilingual neural machine translation system: Enabling zero-shot translation. CoRR, 2016.
[7] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. CoRR, 2013.
[8] Tomas Mikolov, Martin Karafi´at, Lukas Burget, Jan Cernock`y, and Sanjeev Khu-danpur. Recurrent neural network based language model. In Interspeech, Vol. 2, pp. 1045–1048, 2010.
[9] Graham Neubig and Chris Dyer. Generalizing and hybridizing count-based and neural language models. In Proceedings of the 2016 Conference on Empirical Methods
in Natural Language Processing, pp. 1163–1172, November 2016.
[10] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: A simple way to prevent neural networks from overfitting.
Journal of Machine Learning Research, Vol. 15, pp. 1929–1958, 2014.
[11] Martin Sundermeyer, Ralf Schl¨uter, and Hermann Ney. Lstm neural networks for language modeling. In Interspeech, pp. 194–197, 2012.
[12] A¨aron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew W. Senior, and Koray Kavukcuoglu. Wavenet: A generative model for raw audio. CoRR, 2016.
[13] Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Lukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, Greg Corrado, Macduff Hughes, and Jeffrey Dean. Google’s neural machine translation system: Bridging the gap between human and machine trans-lation. CoRR, 2016.
[14] 麻生英樹, 安田宗樹, 前田新一, 岡野原大輔, 岡谷貴之, 久保陽太郎, ボレガラダヌシ カ. 深層学習 Deep learning. 近代科学社, 2015.