中央大学理工学部情報工学科 卒業研究論文
多段階意思決定過程を用いた 精肉の最適値引き戦略
学籍番号
01D8102011E
草山 貴洋指導教員 田口 東 教授
2005
年3
月目次
第
1
章 はじめに... 1
第
2
章動的計画法
... 2
2.1 動的計画法とは...2
2.2 多段階決定過程...2
2.2.1 基本構造...2
2.2.2
N
段階決定過程...32.3 最適性の原理...4
2.3.1 性質...4
2.3.2
N
段階決定過程における最適性の原理...52.3.3 逐次関係と最適化...5
2.4 確率的多段階決定過程...6
第
3
章回帰分析
... 8
3.1 回帰分析の概要...9
3.2 重回帰分析...9
3.2.1 ダミー変数の導入...9
3.2.2 回帰式の評価...9
3.2.3 変数選択...10
第
4
章 使用データ...11
4.1 使用データ... 11
4.1.1 来客人数データ... 11
4.1.2 売上データ... 11
4.1.3 廃棄データ... 11
4.1.4 気象データ... 11
4.2 スーパーの現状...12
4.3 カテゴリの分類...12
4.4 来客人数の予測...13
4.4.1 1日の来客人数の予測...13
4.4.2 1時間ごとの来客人数の予測...16
4.5 購買率の決定...19
第5章
確率的多段階意思決定モデル
... 23
5.1 基本構造...23
5.2 モデルの概要...24
第6章 シミュレーション結果
... 28
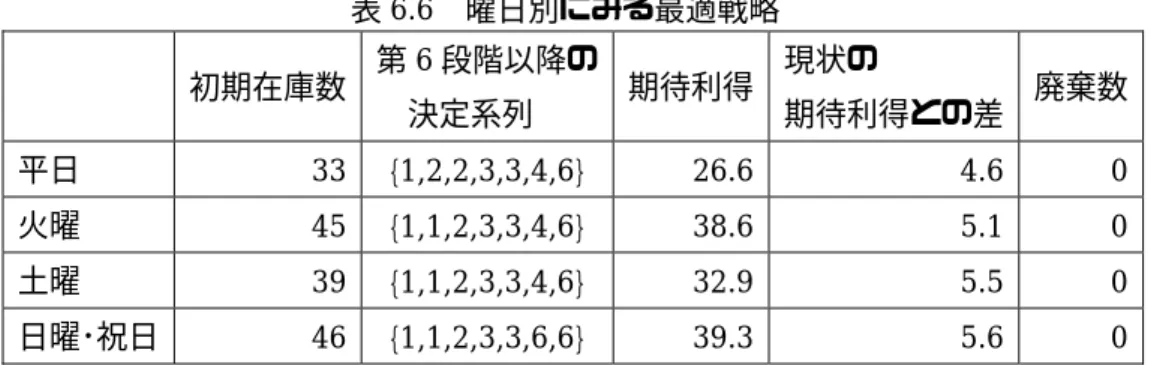
6.1 カテゴリ別最適戦略...28
6.2 初期在庫数の変化による戦略の比較...33
6.3 曜日・感謝デー・気象別最適戦略...34
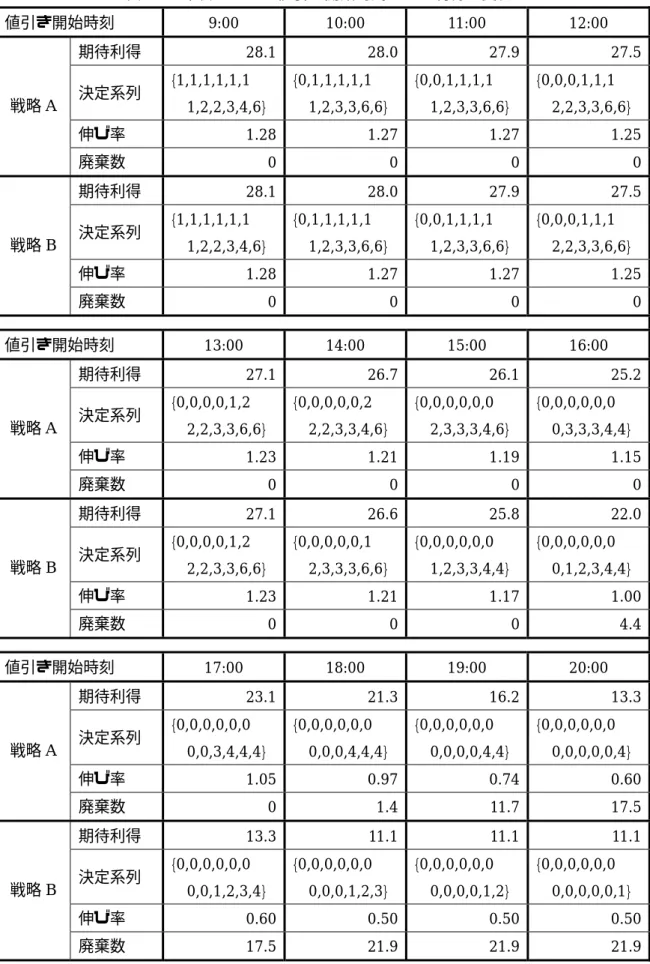
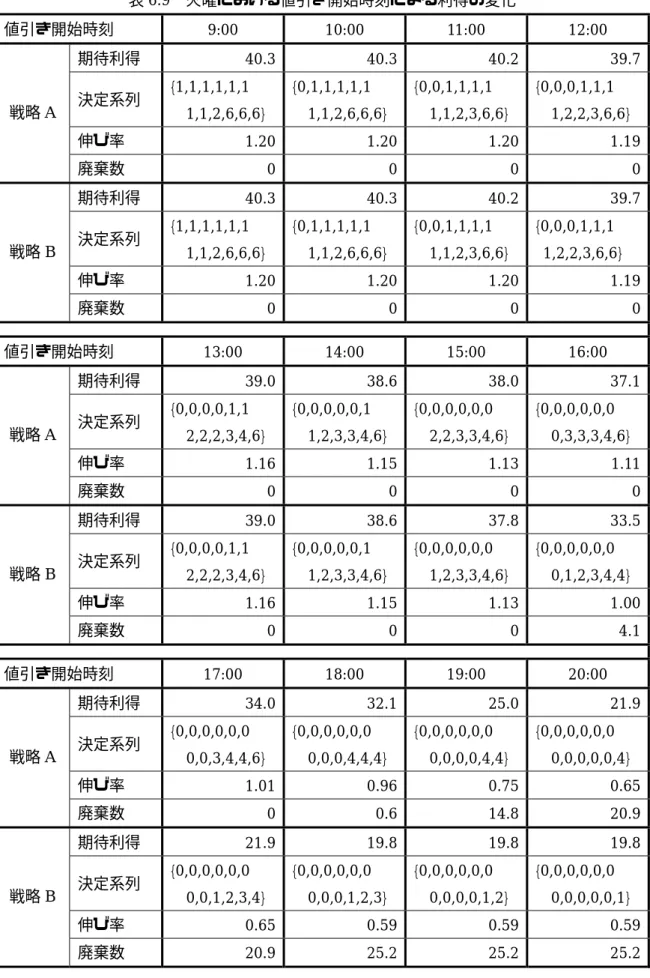
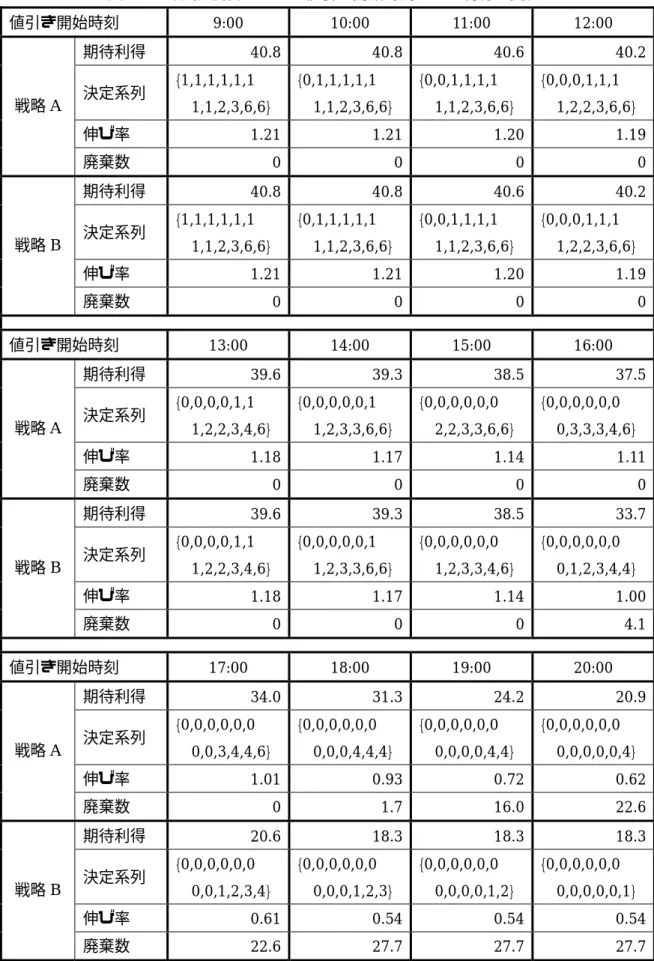
6.4 値引き開始時刻による利得の変化...36
6.5 仕入れ価格を考慮した最適な初期在庫数...41
第7章
まとめ
... 43
謝辞
... 44
参考文献
... 45
あらまし
本研究では,スーパーにおける精肉部門の売上利得の向上を目的とし,そのために最適 な値引き戦略を提案する.まず,曜日・気象・時間により時々刻々と変動する来客人数の予 測を行う.次に,各商品がどの程度の割合で売れるかという指標を定義し,これを購買率 と呼ぶ.商品が値引きされると,その値引き率に応じて各商品の購買率がどのように変化 していくかを調べる.来客人数と購買率を求めたことにより,各商品の売上数を予測する ことが可能となる.以上より,時間や在庫数の影響で変化する最適な値引き率を確率的多 段階意思決定過程を用いて逐次決定し,最適戦略と従来の値引き方法との期待利得の比較 を行い,最適戦略の有効性を示す.
キーワード:動的計画法,確率的多段階意思決定過程,重回帰分析
第
1
章 はじめに昨今の牛海綿状脳症(BSE,狂牛病)騒動や,鳥インフルエンザ騒動は精肉業界に大打撃を 与えた.国民の多くが牛肉・鳥肉の購入を控えるようになり,精肉の売上数が問題発生以前 に比べ少なからず減少している様子が数多く報道されていた.実際に,筆者はスーパーの 精肉部門でのアルバイトを通じて,売上数が減少している実情を目の当たりにした.その ため,各商品の廃棄数は大幅に増加してしまった.商品を廃棄にするならば,半額にして でも客に購入してもらうほうが店側の利益となることは自明である.
そこで,本研究では,確率的多段階意思決定過程を用いて,精肉の値引き方法の最適戦 略をモデル化し,現状の値引き方法との期待利得の比較を行い,その戦略を検証する.
第
2
章動的計画法
2.1
動的計画法とは動的計画法とは,ある目的関数を最大,または最小にする最適問題に対する手法の中で も,各時点での情況に応じて何度も決定をくだす逐次決定問題の最適解導出に極めて有力 な手続きを与える数理計画法の一分野である.問題を小さな問題に分割し,小さな問題を 解いた答えを組み合わせて,より大きな問題の答えを求めることで,最終的に求めたい答 えを得る方法で,1950年にベルマンによって開発された.
2.2
多段階決定過程多段階決定過程とは,その過程(プロセス)がいくつもの段階から成り,各段階で決定を選 択し,その決定が以後の段階で取るべき決定に影響を与えるという性質をもつ.
2.2.1
基本構造多段階決定過程の基本構造は,以下の5つの要素からなる.
1) 状態の集合
S
: 各段階における系を記述するために用いられる変数の集合.S
の 要 を状態変数という.2) 決定の集合 : 各段階で決定者に許容される選択.各段階で選択される決定の系
3) 状態変換
素
{ s
n, s
n−1, L , s
0} D
列
{ d
n, d
n−1, L , d
1}
を政策と呼ぶ.T
: 各段階での決定の結果として,状態に与える推移法則.4) 段階利得
R
: 各段階で状態及び決定により定まる実数.第 段階で得られる利得を影響を与え,プロセスの履歴には無関係であるという性質.すなわち,
第 段階以後の状態は第
n r
nと表わす.5) マルコフ性 : 各段階でのシステムの状態と選択した決定だけが次の段階での状態に
n n − 1
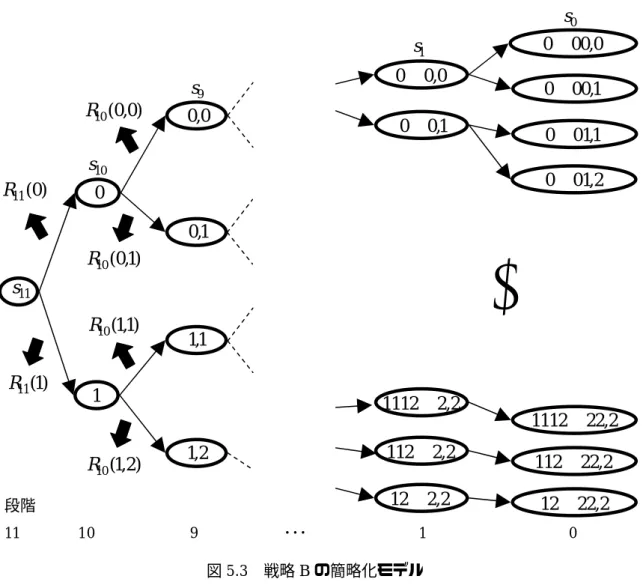
段階以前の段階における状態には関係し 多段階決定過程で態となり,図2.1のように示すことができる.
ない.
は,1つの段階のアウトプットの状態が,次の段階のアウトプットの状
第
n
段階−1
d
nd
ns
n態 段 の 番 号 は 通 常 降 順 に つ け る . 第 段 階 に お け る 決 定 に よ り 状 態 が 状
.2.2
段階決定過程階決 すなわち,システムが第 段階において,集合 の中のある
n d
ns
n) ,
1 n
(
n nn−
= T s d
に変換され,利得R
n( s
nd
n)
が得られる.s ,
2 N
N
段 定過程を考える.n S
n状態
s
nを初期状態として始動したとする.集合D
nから適当な決定d
n∈ D
nを選ぶ.その結果として,関数
R
n( s
n, d
n)
で与えられる利得を受け取り,変換T
nにしたがって第n − 1
段階 でのシステムの状態が定められる.すなわち,) ,
1 n
(
n nn
T s d
s
−=
(2.1) ある.式(2.1)をシステムの状態変換式と呼ぶ.次にシステムは第で
n − 1
段階に移り,決定s
nの集合
D
n−1から適当な決定d
n−1∈ D
n−1を選ぶ.その結果,関数R
n−1 1, d
n−1)
で与えられ る利得を受け取り,状態変換 がって,第2
(
−−1
T
n にしたn −
段階での n−2に推移する.以下同様のプロセスを繰り返し,最後に第1段 おいて決定の集 適当な決 定
d
1∈ D
1を選び,R
1( s
1, d
1)
なる利得を受け取る.そして変換T
1によってシステムは最終 状態 り,利得 定まってこの多段階決定過程は終 する.このとき,各段階 で選択する決定d
i( i − 1 , L , 1 )
は,目的関数としての受け取る利得の実数値関数, , ,
( R
nR
n−1L R
1状態
s
n−∈ S
合
D
1からR
02
階に
S
0に入R
0( s
0)
が 了= n , n )
ϕ ,
を最大(または最小)にするように選ばれる.目的関数ϕ
を最大(また 適政策といい,d
n*, d
n−1*, L , d
1*で表わす.システム 状態変換式 (2.1)を用いると,目的関数は最小)にする政策を最 の
ϕ
は次のように書ける.)) ( ), , ( , ), , ( ), , (
( R
ns
nd
nR
n−1s
n−1d
n−1L R
1s
1d
1R
0s
0ϕ
1 2 1
1
T s d d R T T s
R d s
R
n n n n− n n n n− n− n− n n= ϕ ( ( , ), ( ( , ), ), ( ( ( , d
n), d
n−1), d
n−2), L , R
0( L ))
) , , , ,
( s d d
1d
1h
n n n−L
=
(2.2) 第n − 1
段階図 段階の接続
−1
s
ns
n−2R
nR
n−12.1
すなわち,すべての状態変
態 n−
L
によ2.3
最適性の原理「最初の状態と最初の決定が何であっても,残りの決定は最初の決定の結果 と
数
s
n−1, L , s
1, s
0が消去され,目的関数値はシステムの初期状s
nと,各段階で取る決定d
n, d
1, , d
1 って定められる.2.3.1
性質最適政策は,
して生じた状態に関して最適政策となっていなければならない」という性質をもつ.簡単 に説明すると,図2.3において,パス(A,B,C,D)が最適経路だと仮定すると,BからD までの最適経路はパス(B,C,D)でなければならないということである.なぜなら,もし パス(B,E,D)がBからDまでの最適経路であるとすると,AからDまでの最適経路はパス (A,B,E,D)でなければならないが,このことは,パス(A,B,C,D)がAからDまでの最適 経路であるという仮定に矛盾する.したがって,パス(B,C,D) が最適である.
図2.3 最適性の原理
) ,
(
1 11 − −
− n n
n
s d
T
第 段階 第
) , (
1 11
s d
T )
, (
n nn
s d
T
D
1−1
D
nD
n−1
S
nS
1S
0S
n段階 第1段階
− 1 n n
) , (
n nn
s d
R R
n−1( s
n−1, d
n−1) R
1( s
1, d
1)
図2.2 段階決定過程) (
00
s R N
E
最適経路
B
C
D
E
A
2.3.2
段階決定過程における最適政策を用いて得られ
最適性の原理
N
上述の事柄を数学的に説明する.
f
n(s )
を状態がs
であるとき,る
n
段階での最大利得と定義する. 定過程で残っている段階の数を示す.初期段階N
n =
において決定d
Nを選択したとすれば,システムの状態はT
N( s , d
N)
に変化する.以)
,
( s d
N を新し 初期状態とみなし,最適政策を残り1 n
は決後は
T
N いn −
たとすれば,受け取る n−1
( T
N( s , d
N))
となる.最適性の原理によれば段階用い
利得は
f
,)) , ( ( max )
(
N 1 N Nn
s
df T s d
f
N
=
− (2.3)が成立する.式(2.3)は一種の再帰関係式であり,
N ≥ n ≥ 2
を満足するすべての についてn
成立し,特にn = 1
に対しては,)) , ( ( max )
1
(
N Nd
R T s d
s f
N
=
(2.4)が成立している.従って,逐次 を求めることができる.
.3.3
逐次関係と最適化いた再帰関係式(2.3),(2.4)を解く手続きを考える.今, 段
) (s f
n2
最適性の原理をもとにして導
n
階の決定過程で第1段階に到達しているとすれば,それ以前の事柄にかかわらず,
)) , ( ( ) , ( ) ( ) ,
(
1 1 0 0 1 1 1 0 1 1 11
s d R s R s d R T s d
R + = +
(2.5)が最大になるように決定
d
1を選ばなければならない.第 1段階以前に取られた決定系列が 最適でない場合でも同様に式(2.5)が最大となるようなd
1を選ぶ.そこで,) ( ))]
, ( ( ) , ( [
max
1 1 1 0 1 1 1 1 11
s f d
s T R d s R
d
+ =
(2.6)を考える.ただし,関数
f
1はs
1の連続関数である.次に,第2段階においては,
[ ( , ) ( , ) ( ) ]
max
2 2 2 1 1 1 0 02 1
s R d s R d s R
d
d
+ +
[ ( , ) ( ( , ), ) ( ( ( , ), )) ]
max
2 2 2 1 2 2 2 1 0 1 2 2 2 11 2
d d s T T R d d s T R d s R
d
d
+ +
=
[ ]
⎭⎬ ⎫
⎩⎨ ⎧ + +
= max max
2(
2,
2)
1(
2(
2,
2),
1)
0(
1(
2(
2,
2),
1))
1 2
d d s T T R d d s T R d s R
d
d
[ ]
⎭⎬ ⎫
⎩⎨ ⎧ + +
= max
2(
2,
2) max
1(
2(
2,
2),
1)
0(
1(
2(
2,
2),
1))
1 2
d d s T T R d d s T R d
s R
d
d
[ ( , ) ( ( , )) ( )
max
2 2 2 1 2 2 2 2 22
s f d
s T f d s R
d
+ ] =
=
(2.7)となる.同様にして,第3段階に対しては,
[ ( , ) ( ( , )) ( )
max
3 3 3 2 3 3 3 3 33
s f d
s T f d s R
d
+ ] =
(2.8)となる.したがって,第 段階(
i 1 ≤ i ≤ n
)について,[ ( , )
1 1 0max
1 1
R R R
d s
R
i i i id d
di i
+
−+ + + ]
−
L
L
[ ( , ) ( ( , )) ( )
max
i i i i 1 i i i i id
R s d f T s d f s
i
] = +
=
− (2.9)が成り立つ.よって,多段階決定過程は逐次計算可能である.ただし,目的関数が単に利 得関数
R
iの和でなく,それらの関数ϕ (R )
で与えられるときには,式(2.9)のような分解が 常に可能とは限らず,関数ϕ
に制限が必要である.2.4
確率的多段階決定過程不確実性を含む逐次決定過程で,確率変数に対する分布関数が既知の場合を確率的決定 過程という.確率的決定過程の特徴は,第
i
段階での最適決定 が状態 を観測して,不 確実な要素がなくなったときに初めて定められることである.すなわち,一般的に決定は 現在の状態に依存する.*
d
is
i確率的決定過程では,状態変換 が,過程の現在の状態 ,決定 ,および不確定要素 を記述する確率変数 で定められ,
T
ns
nd
nr
n[
n n n]
n
n
T s d r
s
+1= , ,
(2.10)のように表される.ただし,
r
nの確率分布は既知とする.目的は各段階での利得の和∑ [
= n
i
n n
n
s d
J
1
, ]
の期待値を最大にするような決定系列
d
1*, d
2*, L , d
n*を求めることである.を状態 1 から始めて 段階で得る最大期待利得と定義する.計画期間 の問題に 対しては,第1段階が終わった時点では残り期間は
) ( s
1f
nn n
) 1
( n −
段階である.[
1 1 1 12
T s , d , r
s = ]
を新しい出発状態として残り( n − 1 )
段階の間,最適政策を用いると,利得 は となる.確率変数 に対する確率分布を とすれば, 段階で の期待利得は,[
1(
1,
1,
1)
1
T s d r
f
n−] r
1F ( r
1) ( n − 1 )
[
1(
1,
1,
1) ] (
1)
1
T s d r dF r
f
n∫
−∞∞ −で与えられる.従って,最適性の原理より,
[ ]
⎭⎬ ⎫
⎩⎨ ⎧ +
= max ( , ) ∫
−∞∞ −( , , ) ( ) )
(
1 1 1 1 1 1 1 1 1 11
r dF r d s T f d
s J s
f
nn d (2.11)
が成り立ち,初期状態が規定されると最適決定系列
d
1*, d
2*, L , d
n*が逐次求められる.本研究では,この確率的多段決定過程を用いて,最適な値引き方法を提案する.
第
3
章 回帰分析3.1
回帰分析の概要あるデータ
x, y
の組に基づいて散布図を作成すると,図3.1のようになったとする.ここ で,図3.2に示すように,x
と の関係を示す散布図に直線を当てはめてみる.この直線を,に対する の回帰直線と呼び,
y
x y
x b b
y =
0+
1 (3.1) で表される式を回帰式と呼ぶ.回帰直線(あるいは回帰曲線)や回帰式を求めるための分析を 回帰分析という.回帰分析においては, は説明変数, は目的変数と呼ばれる.回帰分 析は「予測」と「要因解析」の 2 つの用途で活用されることが多く,予測での活用とは,ある1つの変数の値を別の1つまたは2つ以上の変数の値を使って予測を行うことである.
予測したい変数が目的変数であり,予測に使う変数が説明変数である.一方,要因解析で の活用とは,ある 1 つの変数が変動する要因を,他の多くの変数の中から見つけたいとい う場面での活用である.興味の対象となっている結果を示す変数が目的変数であり,その 要因となる変数が説明変数である.回帰分析において,説明変数の数は1つとは限らず,2 つ以上の場合もあり,説明変数が1つの場合を単回帰分析といい,2つ以上の場合を重回帰 分析という.本研究では,予測を行うための分析として,重回帰分析を用いる.
x y
30 40 50 60 70 80 90
30 40 50 60 70 80 90
x y
30 40 50 60 70 80 90
30 40 50 60 70 80 90
x y
図3.1 散布図 図3.2 散布図と回帰直線
3.2
重回帰分析重回帰分析とは,目的変数である
y
を 個の説明変数 の1次式で表わすこと,つまり,
k x
1, x
2, L , x
k
y = b
0+ b
1x
1+ b
2x
2+ L + b
kx
k (3.2) という とx y
の間の関係式を求める手法である. を切片(あるいは定数項), を (偏)回帰係数と呼ぶ.b
0b
1, b
2, L , b
kある変数
y
が別の変数x
1, x
2, L , x
kの変化に応じて変わるとき,x
1, x
2, L , x
kの変化がy
に与える影響を調べたり,新たにx
1, x
2, L , x
kのデータが与えられたときy
を予測するのに 用いられる.3.2.1
ダミー変数の導入重回帰分析が適用できるデータのタイプは,目的変数が量的変数のときのみである.し かし,説明変数は量的変数でも質的変数でもかまわない.ただし,説明変数に質的変数を 用いる場合には,データの値が0か1しかとらないダミー変数と呼ばれる変数を導入し,
質的なデータを変換しなければならない.説明変数がすべて質的変数の場合には,数量化 理論Ⅰ類と呼ばれる手法があるが,これは説明変数をすべてダミー変数にして回帰分析を 行うことと同等であるので,本研究では,数量化理論Ⅰ類も重回帰分析と呼ぶこととする.
3.2.2
回帰式の評価回帰式の有効性を評価するための統計量として,寄与率(あるいは決定係数)がある.寄与 率とは,目的変数
y
の変動のうちで,回帰式によって説明のつく変動の割合を示すもので ある.寄与率はR
2で表記される.しかし,寄与率は説明変数の数を増やすほど高い値にな ってしまうという性質をもっているため,無意味な変数を説明変数として使ったときにも 高い値を返してしまう.そこで,無意味な変数を説明変数として使ったときには,その 数値が下がるように,自由度で補正した寄与率(
自由度調整済み寄与率)
がある.自由度 調整済み寄与率はR
*2で表記され,以下の計算式で与えられる.) 1 1 (
1 1
22
*
R
k n
R n −
−
−
− −
=
(3.3)
ここで, はサンプルの大きさ, は説明変数の数とする.本研究では,回帰式の評価 の指標として,自由度調整済み寄与率
(
以降,寄与率と略記する)
を用いる.n k
3.2.3
変数選択不要な変数と有効な変数を取捨選択しながら,最良の回帰式を見つけることは重回帰分 析の重要な課題の一つであり,この選択を変数選択という.説明変数の有意性を判定する ための統計量として,t値もしくはp値なる2つの統計量がある.t値の絶対値が大きい(p 値の場合は絶対値が小さい)変数ほど目的変数 を予測する上での貢献度が高いと考える.t 値による結論とp 値による結論は一致する.[1]によると,「t値の絶対値が
y
2
以上ならば 有効な変数,2
未満ならば不要な変数と判定し,不要な変数を破棄して有効な変数だけで 回帰式を作るとよいとされている」とある.本研究では,t 値の絶対値が1.5
未満の説明 変数を不要な変数とみなし,破棄することとする.以上の自由度調整済み寄与率と
t
値を考慮しながら,最適な回帰式を求める.第4章
使用データ
4.1
使用データ本研究では,神奈川県にある某大型スーパーに提供して頂いた,来客人数データ・売上デ ータ・廃棄データの3種類のデータと気象庁の気象データを用いる.詳細は以下に説明する.
4.1.1
来客人数データ精肉を購入した客の人数が1時間ごとに記録されている.対象期間は2004年8月25日 (水)〜2004年10月5日(火) (ただし,2004年9月26日(日)は除く) とする.
4.1.2
売上データ各商品の売上数,売上金額が1時間ごとに記録されている.対象期間は2004年8月30 日(月)〜2004年10月5日(火) (ただし,2004年9月26日(日)は除く) とする.
4.1.3
廃棄データ各商品の廃棄数が記録されている.対象期間は2004年8月30 日(月)〜2004年10月5 日(火) (ただし,2004年9月21日(火)は除く) とする.
4.1.4
気象データ気象庁が公開している電子閲覧室(http://www.data.kishou.go.jp/index.htm)の気象デー タを用いる.対象とする地点を神奈川県の小田原とし,本研究では最高気温と降水の有無 を参照する.重回帰分析を用いる際,最高気温を以下の表4.1のように質的変数に変換する.
表4.1 最高気温の変換
期間 低い 普通 高い
8月25日〜9月10日 〜24.9℃ 25.0℃〜29.9℃ 30.0℃〜
9月11日〜9月20日 〜22.9℃ 23.0℃〜27.9℃ 28.0℃〜
9月21日〜10月5日 〜19.9℃ 20.0℃〜24.9℃ 25.0℃〜
4.2
スーパーの現状対象スーパーは24時間営業であるが,21時から翌日の9時までの時間帯は来客人数・商 品の売上数が少ないため,本研究では21時から翌日9時までの時間帯のデータは考慮せず,
研究の対象とする時間を 9 時〜21 時とする.前日に商品化された牛肉,または鳥肉は 16
時〜17時に10%,17時〜18時は20%,18時〜19時は30%,19時〜21時は50%の値引
きをして販売される.豚肉は17時〜18時に10%,18 時〜19時に20%,19 時〜20 時に
30%,20時〜21 時に50%の値引きをされる.21時の段階で,売れ残った前日の商品が廃
棄となる.
4.3
カテゴリの分類4.1節の売上データ,廃棄データの各商品を表4.2に示すカテゴリに分類する.なお,分 類の方法は,肉の種類 (牛/豚/鳥) ,産地 (国産/輸入) ,用途 (ステーキ/切り落とし/焼肉/
鍋・しゃぶしゃぶ/スライス・とんかつ/かたまり/ホルモン/生食/ミンチ) という 3 つの要素に 注目して分類した.生食には,ローストビーフ・ローストポーク・サラダが該当する.各商 品は表4.2のいずれかのカテゴリに割り当て,以降はカテゴリとして各商品を扱い,対応す るコードでそのカテゴリを呼ぶ.
表4.2 カテゴリの分類
コード 詳細 コード 詳細
1 国産牛 ステーキ類 14 豚かたまり類 2 国産牛 切り落とし類 15 豚焼肉類
3 国産牛 焼肉類 16 豚しゃぶしゃぶ類 4 国産牛 鍋・しゃぶしゃぶ類 17 豚ホルモン類 5 輸入牛 ステーキ類 20 国産純輝鳥 手羽類 6 輸入牛 切り落とし類 21 国産純輝鳥 もも類 7 輸入牛 焼肉類 22 国産純輝鳥 むね類 8 牛かたまり類 23 国産鳥 もも類 9 牛ホルモン類 24 国産鳥 ささみ類
10 国産黒豚 25 鳥ホルモン類・焼き鳥(生)類 11 国産豚 切り落とし類 26 焼き鳥バイキング
12 国産豚 スライス・とんかつ類 30 味付焼肉類 13 輸入豚 スライス・とんかつ類 31 生食類
4.4
来客人数の予測各時間における商品の売上数は,その時間の来客人数に大きく左右される.最適な値引 き戦略を行うためには,曜日・気象・時間により時々刻々と変動する来客人数を正確に把握 しなければならない.そこで,来客人数データを元に,曜日・気象を説明変数とし,重回帰 分析を用いて各時間における来客人数の予測をする.
まず,各時間における来客人数を目的変数として重回帰分析を行ったが,有益な寄与率
2
R
* が得られなかった.そこで,本研究では,1日の来客人数を目的変数として,重回帰分 析を用いて予測し,次に1日の来客人数あたりの各時間における来客人数の割合(%)を求め,その値に,はじめに予測した 1 日の来客人数を掛け合わせることで,各時間の来客人数の 予測を行うこととする.
4.4.1
1
日の来客人数の予測目的変数を 1 日の来客人数として,重回帰分析を用いて予測を行う.まず,曜日を分類 する. 7 つの曜日をそれぞれダミー変数に変換し,説明変数とすると,それぞれの曜日に 対するデータのサンプル数が少なく,有益な寄与率
R
*2を得ることができない.そこで,曜 日を2つ,もしくは3つのグループに分類して重回帰分析を行い,最も寄与率R
*2の高い組み合わせを調べる.曜日別に来客人数の平均 (図4.1) を見ると,火曜が最も多い.これは,
毎週火曜が特売日であることが大きく関係していると推測できる.土曜,日曜・祝日もやは り多く,これらの3つの曜日は明らかに他の 4つの曜日とは差があることが見てとれる.
そこで,月曜,水曜,木曜,金曜を1つのグループ (以下,グループ1と呼ぶ) として捉え,
火曜,土曜,日曜・祝日をどのように分類するかを考える.
0 500 1000 1500 2000 2500 3000 3500
月曜 火曜 水曜 木曜 金曜 土曜
日曜
・祝日 曜日
来客人数(人)
図4.1 曜日別平均来客人数
案1: 火曜,土曜,日曜・祝日をまとめてグループ2とする.
案2: 火曜をグループ2,土曜,日曜・祝日をグループ3とする.
案3: 火曜,日曜・祝日をグループ2,土曜をグループ3とする.
以上の3つの案でそれぞれ重回帰分析を行い,寄与率
R
*2で回帰式を評価する.また,説明 変数のt値が1.5未満,すなわち無意味な説明変数になっていないかを調べる.表4.3に重 回帰分析の結果を示す.表4.3 重回帰分析の結果
案 寄与率
R
*2 グループ2のt値 グループ3のt値1 0.621 8.15
2 0.657 7.49 6.67
3 0.771 9.98 3.69
上記の結果より,寄与率
R
*2の最も高い案3を採用することにする.つまり,7つの曜日 を月曜,水曜,木曜,金曜からなるグループ 1,火曜と日曜・祝日からなるグループ 2,土 曜からなるグループ3の3つのグループに分類する.t値も1.5を超えており,説得力のあ る説明変数となっていることがわかる.つぎに,このスーパーでは毎月20日,30日に感謝デーを行っているので,その影響が来 客人数に関係しているのかを調べる.感謝デーとして該当する日は8 月 30 日 (月曜) ,9 月20日 (祝日) ,9月30日 (木曜) の3日間である.さきほど求めた方法 (案3) で曜日を 3 つのグループに分類し,さらに感謝デーを説明変数に加えて重回帰分析を行ってみると,
感謝デーを加える前の寄与率
R
*2=0.771がR
*2=0.779 とわずかに向上する.また,感謝デ ーのt値=3.55となるので,来客人数の予測を行う上で少なからず感謝デーの影響があると 考えられる.最後に,気象が来客人数に及ぼす影響について調べてみる.4.1節でも述べたように,本 研究では気象の影響として,最高気温による影響と降水の有無による影響を考える.
案A: 降水の有無を説明変数に加える.
案B: 対象時間内に,1時間当たり5㎜以上の降水の有無を説明変数に加える.
案C: ダミー変数に変換した最高気温を説明変数に加える.
案D: ダミー変数に変換した最高気温と,降水の有無を説明変数に加える.
案E: ダミー変数に変換した最高気温と,1時間当たり5㎜以上の降水の有無を説明変数 に加える.
以上の5つの案でそれぞれ重回帰分析を行い,そのときの寄与率
R
*2の値で,回帰式の良 し悪しを比較する.それぞれの案の寄与率R
*2をまとめたものが,表4.4である.表4.4 寄与率
案A 案B 案C 案D 案E 寄与率
R
*2 0.822 0.820 0.837 0.835 0.831表4.4からわかるように,寄与率
R
*2が最も高いのは案CのときでR
*2=0.837であった.以上の結果より,降水の有無は説明変数に加えず,曜日を 3 つのグループに分類し,感 謝デーとダミー変数に変換した最高気温を説明変数に加える回帰式が 1 日の来客人数の予 測をする際の回帰式としては,最も有効であり,より正確な予測ができる.回帰式の切片 と,それぞれの説明変数に対する回帰係数は表4.5のとおりである.表4.5から,平日に比 べ,火曜,日曜・祝日は1100人強,土曜だと560人近く来客人数の増加が期待できること がわかる.また,感謝デーの日は感謝デーでない日に比べると,660人の来客人数の増加が 期待できる.最高気温を見てみると,低い日に比べ,高い日では 420 人近く,普通の日で は230人近くの来客人数が減少する.このことは,本研究の対象としている期間が8月下 旬〜10月上旬と夏季のデータのみであることが,大きく関係していると推測できる.
来客人数
y
は,次の式で与えられる.b
0y =
(切片)+ b
1(平日/火曜または日・祝/土曜)+ b
2(yes/no)+ b
3(高い/普通/低い) (4.1)例えば火曜,感謝デー,最高気温が普通の日であれば,
3481 224
665 1122
1918 + + − =
=
y
(4.2) となり,1日の来客人数は3481人であると予測できる.同様にして,表4.5から1日の来 客人数を予測できる.表4.5 回帰式の切片と回帰係数
切片 曜日 感謝デー 最高気温
1918 平日 0 yes 665 高い −418
火曜,日・祝 1122 no 0 普通 −224
土曜 557 低い 0
4.4.2
1
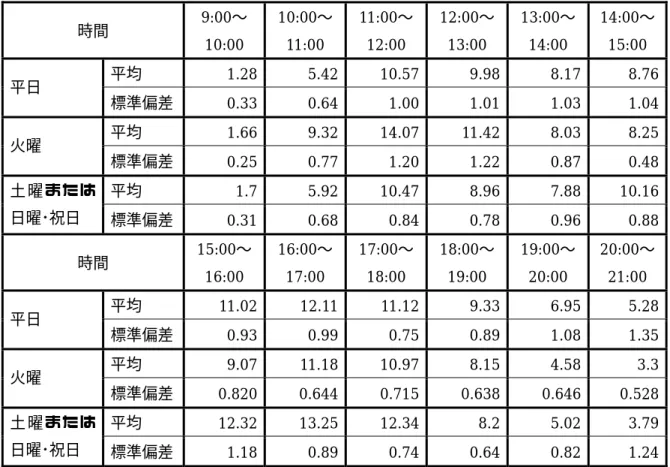
時間ごとの来客人数の予測1時間ごとの来客人数を予測するために,まず,1日の来客人数あたりの各時間における 来客人数の割合は,曜日によって左右されるのかを調べる.図4.2を見ると,折れ線の形は どの曜日も,1日を通して,昼食前と夕食前にピークを迎える形となる.そこで,曜日ごと に特徴を見てみると,火曜は10:00〜13:00の時間帯において,他の曜日よりも来客人数の 割合が高い.つまり,1回目のピークに集客力があることがわかる.このことは,火曜の特 売日には安い商品を確実に買いたいという思惑があるために,多くの客が,確実に商品の ある早い時間帯に買い物に来るのではないかと推測できる.また,土曜と日曜・祝日はわず かながら,15:00〜18:00の時間帯の割合が高く,19:00〜21:00の時間帯が少ない.残りの 月曜,水曜,木曜,金曜 (以降,平日と呼ぶ) はどの時間帯においても近い値をとなってお り,18:00〜21:00の時間帯の割合が他の曜日に比べて高いのが特徴である.
0 2 4 6 8 10 12 14 16
9:00〜
10:00 10:00〜
11:00 11:00〜
12:00 12:00〜
13:00 13:00〜
14:00 14:00〜
15:00 15:00〜
16:00 16:00〜
17:00 17:00〜
18:00 18:00〜
19:00 19:00〜
20:00 20:00〜
21:00
時間
来客人数の割合(%)
月曜 火曜 水曜 木曜 金曜 土曜 日曜・祝日
図4.2 曜日別1日の来客人数あたりの各時間における来客人数の割合の平均
つまり,この店では火曜,土曜または日曜・祝日,平日で各時間の割合の値が異なる.す なわち,1日の来客人数あたりの各時間の来客人数の割合は,曜日によって変化するという ことである.
7つの曜日を3つのカテゴリに分け,それぞれに対して感謝デーの影響を重回帰分析を用 いて調べたが,どの曜日も,感謝デーによる影響で割合が変化するということは見られな かった.また,同様に最高気温や降水の有無による影響を調べたが,それらが割合に影響 しているという結果は得られなかったため,本研究では 1 日の来客人数あたりの各時間の 来客人数の割合は曜日だけに影響を受け,感謝デーや気象には左右されないものとした.
分類した3つのカテゴリごとに来客人数の割合の平均をとったものを図4.3〜図4.6に示 し,曜日別各時間における来客人数の割合の平均と標準偏差を表4.6に示す.なお,図4.3
〜図4.6の系列の名前は日付を表わし,例えば906なら9月6日を意味する.
0 2 4 6 8 10 12 14 16
9:00〜
10:00 10:00〜
11:00 11:00〜
12:00 12:00〜
13:00 13:00〜
14:00 14:00〜
15:00 15:00〜
16:00 16:00〜
17:00 17:00〜
18:00 18:00〜
19:00 19:00〜
20:00 20:00〜
21:00
時間
来客人数の割合(%)
825 826 827 830 901 902 903 906 908 909 910 平均
図4.3 平日 (8月25日〜9月10日)
0 2 4 6 8 10 12 14 16
9:00〜
10:00 10:00〜
11:00 11:00〜
12:00 12:00〜
13:00 13:00〜
14:00 14:00〜
15:00 15:00〜
16:00 16:00〜
17:00 17:00〜
18:00 18:00〜
19:00 19:00〜
20:00 20:00〜
21:00
時間
来客人数の割合(%)
913 915 916 917 922 924 927 929 930 1001 1004 平均
図4.4 平日 (9月13日〜10月4日)
0 2 4 6 8 10 12 14 16 18
9:00〜
10:00 10:00〜
11:00 11:00〜
12:00 12:00〜
13:00 13:00〜
14:00 14:00〜
15:00 15:00〜
16:00 16:00〜
17:00 17:00〜
18:00 18:00〜
19:00 19:00〜
20:00 20:00〜
21:00
時間
来客人数の割合(%)
831 907 914 921 928 1005 平均
図4.5 火曜
0 2 4 6 8 10 12 14 16
9:00〜
10:00 10:00〜
11:00 11:00〜
12:00 12:00〜
13:00 13:00〜
14:00 14:00〜
15:00 15:00〜
16:00 16:00〜
17:00 17:00〜
18:00 18:00〜
19:00 19:00〜
20:00 20:00〜
21:00
時間
来客人数の割合(%)
828 829 904 905 911 912 918 919 920 923 925 1002 1003 平均
図4.6 土曜と日曜・祝日