観測情報の信頼性に着目した
ビデオゲームエージェントの自律的行動獲得
藤井 叙人
*1
佐藤 祐一
∗1
若間 弘典
∗1
片寄 晴弘
*2
Autonomously Acquiring a Video Game Agent’s Behavior Imposed by Biological Constraints Nobuto Fujii*1, Yuichi Sato∗1and Hironori Wakama∗1and Haruhiro Katayose*2
Abstract – ビデオゲーム開発におけるコンピュータプレイヤ(COM)の振る舞いの実装にあたり,経路
探索や機械学習による振る舞いの自律的獲得手法が多々提案されている.これらの手法では,時に人間プレ イヤよりも優れた振る舞いや戦略の獲得に成功しているものの,非常に「機械的」であり,「人間的」である とは言いがたい.本研究では,強化学習の枠組みに人間の“生物学的制約”を導入することで,人間プレイ ヤに人間的であると解釈されるような振る舞いの自律的獲得を目指す.アクションゲームの“Infinite Mario
Bros.”を学習対象とし,“生物学的制約”として,センサ系や運動系の“ゆらぎ”,知覚と運動制御のプロセス
における“遅れ”,キー操作による身体的な“疲れ”を導入することで,COMの振る舞い獲得を試みる.ま た,得られたCOMの振る舞いの評価,及び,本研究の発展可能性について述べる.
Keywords : Video game agent, COM player, Human player, Machine learning, Q-learning, Biological perceptual and Physical constraints, Autonomously strategy acquisition system, behavior pattern, Infinite Mario Bros., Super Mario Bros.
1 はじめに
ユーザとシステムとのインタラクションデザイ ンは,現在のIT研究領域の中核として位置付け られ,多くの研究成果が報告されている.従来の 検討の多くはユーザビリティの確保を主眼とした ものであった.これに対し,システムへの人間ら しさの実装と,それがユーザに及ぼす影響の重要 性に認識が進み,最近では,ヒューマノイド型ロ ボットの主要研究テーマの一つに取り上げられる に至っている.機械への人間らしさの実現が可能 なのか,また,どう実現されるのかは人工知能の根 幹的な興味の一つであり,古くは,J.Weizenbaum によるELIZA(1966)[15],戸田らによるNENEプ ロジェクト(1988)[17]が知られている.現在では, ビデオゲームデベロップメント分野において,シ
*1
関 西 学 院 大 学 大 学 院理 工 学 研 究 科情 報 科 学 専 攻, nob- [email protected]
*2
関西学院大学 理工学部 人間システム工学科, [email protected]
*1Department of Informatics, Graduate School of Science and Technology, Kwansei Gakuin University, mail:[email protected]
*2Department of Human System Interaction, School of Science and Technology, Kwansei Gakuin University, mail:[email protected]
ステム(コンピュータ:COM)の実装という具体的 なニーズに根ざした実践的な研究開発が執り行わ れている.
ビデオゲームは,人間プレイヤの相手(協力関係 ないし敵対関係)という視点から分類すると,人間 が相手を務める場合と,COMが相手を務める場合 の二つに分類される.後者においては,COMの振 る舞いや戦略が人間プレイヤの楽しみを決めると 言っても過言ではない.そのため,市販ビデオゲー ムでは,プログラマの経験に基づく綿密な作り込 みと,数多くのデバッグプレイにより,これらの実 現がなされてきた.しかし,極めて煩雑な作業で あり,リアリティを追求すると開発コストが膨大 とならざるをえない.その解決策として,COMの 振る舞いや戦略の自動獲得に向けての研究が行わ れている.具体的には,学習フェーズを持たない 経路探索に帰着するアプローチ[14, 7],人間のプ レイデータや学習試行に基づく機械学習によるア プローチ[20, 19, 5, 18, 4]などが提案されており, 将棋やトランプゲームに適用され,自動化の可能 性が実証されている.
COMの 振 る 舞 い や 戦 略 に 関 連 す る コ ン テ ス ト として,“Mario AI Competition”[1, 9]や“世界コン
ピュータ将棋選手権”[3]などが毎年開催されてい る.これらのコンテストでは,最も強い振る舞い や戦略を有するアルゴリズムが優勝となり,その アプローチとして経路探索や機械学習が多く用い られている.しかしながら,これらの手法で獲得 されたCOMの振る舞いや戦略は,時に人間のエ キスパートより優れているものの,機械的で人間 離れしており,人間プレイヤに楽しみを提供する という目的に立った場合,十分な成果が得られて いるとは言いがたい.人間らしい振る舞いや戦略 の自動獲得には,プログラマのヒューリスティック スが多数必要となるため,強い振る舞いや戦略を 獲得するよりも困難である.
本研究では,「人間プレイヤがゲームをしている」 と感じられるような「振る舞い」や「戦略」を,可 能な限りヒューリスティックスを排除した環境下で 自律的に獲得する機構(自律的行動獲得機構)に ついて検討する.その方策として,強化学習の枠 組み[19, 5, 18, 4]に対して,人間の“身体的制約” をパラメータとして組み込み,身体的制約下で学 習を進め最適化することで,「人間プレイヤがゲー ムをしている」ような振る舞いが表出されるかに ついて検証する.人間の“身体的制約”として組み 込むのは,見間違いや手が滑ったというようなセ ンサ系や運動系の「ゆらぎ」,知覚と運動制御の一 連のプロセスにおける「遅れ」,キー操作による身 体的な「疲れ」というシンプルな生物学的制約の みである.
以下,第2章で関連研究を紹介し,第3章で,本 研究で自律的行動獲得に使用する学習方法と,学 習対象とする“Infinite Mario Bros.”の仕様ついて 紹介する.第4章で,自律的行動獲得機構の実装 方法について述べ,第5章で,学習実験によって COMの振る舞いの獲得状況について検証する.第 6章で,本研究で獲得されたCOMの振る舞いが人 間らしいかどうか議論する.
2 関連研究
本 研 究 で は ,ヒュー リ ス ティック ス の 導 入 に 代 わって,人間の身体的制約を強化学習の枠組みに 組み込むことにより,人間らしいと感じられる振 る舞いを自律的に獲得する機構の構築を目指す.本
章では,振る舞いや戦略を自動的に獲得する関連 研究と,人間の身体的制約に関する関連研究を紹 介する.
2.1 「振る舞い」や「戦略」を自動的に獲得する 手法
振る舞いや戦略を自動的に獲得する手法として, 経路探索問題に帰着する手法[14, 7]と,人間のプ レイデータや試行による機械学習を用いる手法が ある.
経路探索問題によるアプローチのうち代表的なも のとして,Robinは,2009年のMario AI Competi- tionにおいて,A*アルゴリズムに基づいたエージェ ントを構築し優勝している[14].Mario AI Compe- titionとは,“Infinite Mario Bros.”(ランダムに生成 されるマリオライクなステージを,制限時間中に 攻略するアクションゲーム.詳しい仕様は第3章 で説明する.)を対象としたエージェント評価コン テストである[1, 9].マリオや敵キャラクタの動き を事前に学習・解析し,A*アルゴリズムを用いた ルート探索によってステージを攻略することで,敵 キャラクタを可能な限り避け,ステージをより早 く,より遠くまで攻略することが可能となってい る.しかし,経路探索問題の解法を用いて構築さ れたエージェントは,極めて最適な行動パターン を獲得しているものの,その「振る舞い」は人間 離れしたものといえる.
機械学習を用いるアプローチとして,教師あり 学習[20, 10, 13],教師なし学習,強化学習[19, 5, 18, 4, 12, 11, 16, 6]の3つに大きく分類される.
教師あり学習は,事前に与えられた大量のデー タセットを教師データ(入力データに対して出力 されるべきデータの例)とし,有用なルールを学 習する手法である.人間のプレイデータによる教 師あり学習の代表的な研究として,保木は,将棋 を対象としたコンピュータ将棋プログラムである Bonanzaを提案している[20].Bonanzaは,プロ棋 士の棋譜6万局のデータを教師とし,将棋の局面 における評価関数を自動学習することで,従来手 法よりも良い戦略を得ることに成功している.将 棋のように強いプレイヤの膨大な棋譜データが用 意できる場合には,自動学習による戦略獲得は有 効である.
一方,強化学習は,同じ機械学習に分類される アプローチでも,膨大な事例を与える必要がなく, 自身の「振る舞い」の試行を重ねて最適な戦略を 獲得していく.
藤田らは,カードゲームのHeartsを題材とし,Q 学習を用いて戦略獲得に成功している[19, 5].カー ド52枚を使用するため巨大な状態空間となること, 相手の所持するカードは観測できないため部分観 測状況となること,4人対戦のマルチエージェント ゲームであること,の3つをHeartsにおける戦略 学習の困難性と考察している.その上で,解決手 法として,パーティクルフィルタ,相手の行動予測 器,状態を評価する状態価値関数,ゲームの特徴 に基づく次元圧縮を提案している.計算機実験と して,提案手法に基づく学習エージェントと,人 間の熟達者とを対戦させた結果,人間の熟達者よ りも優れた戦略を得ることに成功している.
また,藤井らはポケットモンスターや遊戯王とい ったメジャーなトレーディングカードゲーム(TCG)
を基にした戦略型ビデオTCGを設定し,多層パー セプトロンを用いた戦略獲得を検討している[18, 4].戦 略 型 ビ デ オ TCGで の 戦 略 学 習 は ,将 棋 や
Heartsと異なる学習フレームワークが必要となる.
準備段階でのカードの組合せ,魔法などの特殊効 果,罠などの特定の条件で発動する効果,といっ た戦略型ビデオTCG特有の戦略学習が必要不可欠 だからである.計算機実験として,提案手法に基 づく学習エージェントと,異なる戦略をもつ3つ のルールベース戦略とを対戦させた結果,相手の 戦略に適応できる戦略の獲得に成功している.
これらの研究では,学習対象のゲームに対する 振る舞いや戦略の自動獲得には成功しているもの の,それが人間らしいかどうかという議論はなさ れていない.
2.2 人間の“身体的制約”の導入
生物の“身体的制約”がシステムの振る舞いにど のような影響を与えるかの検討を実施した研究と
して,Cabreraらは,人間の指先による直立棒の制
御実験を実施している[8].人間は,情報処理能力 の限界により反応に「遅れ」が生じ,また,物体 の位置を観測するうえで「誤差(ゆらぎ)」が生じ る,といった行動制御の特徴がある.この実験で
は,指先の動きの特徴的スケールが反応時間より も短い場合が頻繁に観測され,また,訓練によっ て制御がうまくなるという実験結果が示されてい る.この結果から,身体的制約を意識的もしくは 無意識的に考慮し,指先の行動制御に対してノイ ズを取り入れているのではないか,とCebreraら は提唱している.
人間は,“身体的制約”を考慮し,安全性とパフ ォー マ ン ス を 両 立 す る 行 動 制 御 を 実 現 し て い る . ゲームの振る舞いや戦略の自動獲得において,積 極的に“身体的制約”を組み込んだ研究例は報告さ れていないが,ステージ条件が変わった場合に頑 健な動作をする方略や行動パターンが獲得される 可能性がある.
3 強化学習手法と学習対象ゲーム 本研究では,人間の持つ“身体的制約”を強化学 習エージェントに組み込むことで,「人間らしい」と 感じられるゲームの振る舞いの自動的な獲得を目 指す.振る舞い学習に用いる強化学習手法として Q学習を用い,人間の持つ“身体的制約”として, センサ系や運動系の「ゆらぎ」,知覚と運動制御の プロセスにおける「遅れ」,キー操作による身体的 な「疲れ」を,Q学習を実施する際の付帯条件と して課す.以下,振る舞い学習に用いる強化学習 手法のQ学習,学習対象とするアクションゲーム
“Infinite Mario Bros.”のルールについて説明する. 3.1 強化学習手法の検討
振る舞いの学習には大量の学習データが必要と なるが,ビデオゲームにおいては,教師データと なる熟達者のプレイデータが大量に用意できない ため,学習試行により振る舞いの獲得が可能な強 化学習の手法を用いる.また,将棋やTCGと違い, ゲームの状態の評価はあまり重要ではなく,ある ゲームの状態におけるエージェントの行動に対す る評価が重要となる.本研究では,上記を鑑み,行 動に対して直接評価を与え学習することができる Q学習を用いて,自律的行動獲得機構を実装する. 3.2 Q学習の概要
Q学習は,あるゲーム状態における行動の価値 を学習する強化学習手法の一つである.あるゲー
ム状態をs,その状態下でエージェントが可能な行 動をaとした場合,状態sと行動aを組とし,そ の組に対するQ値とよばれる評価値を算出する. あるゲーム状態での最適行動は数式1で決定され, Q値が最も高い行動が最適であると出力する.ま た,Q学習におけるQ値の更新式は数式2であり, エージェントが行動するたびにQ値を更新するこ とで振る舞いの獲得が可能となる.
argmaxatQ(st,at) (1) Q(st,at) = (1 − α)Q(st,at) + α((r + γmaxpQ(st+1,p)) (2)
数式2において,tはゲームのフレーム,stはフ レームtにおける状態,at はフレームtにおいて とった行動,Q(st,at)は(st,at)に対応するQ値で ある.α は学習率呼ばれ,Q値の更新において新 たな報酬をどれだけ重視するかを示す値であり,γ は割引率と呼ばれる0以上1以下の定数である.r は状態stにおいて行動atをとったことによって得 られる報酬である.エージェントの行動選択手法 としてはϵ −greedy法を用いる.ϵ −greedy法は,
1 − ϵの確率でQ値が最大となる最適行動を選択し,
ϵ の確率でランダムに行動を選択する. 3.3 Infinite Mario Bros.
学習対象としては,ゲーム世界の状態が正確に 観測できること,リアルタイムにプレイヤ操作を 反映できるゲームであること,かつ,限りなく同 じ状況を再現できることが求められる.また,強 化学習において行動パターンを獲得するためには, 明 確 な 学 習 目 標 が 設 定 で き る こ と も 重 要 で あ る . 本研究では,“Inifinite Mario Bros.”[2]を学習対象 とし,振る舞いの獲得と,その比較,検証を実施 する.第2章で述べたRobinのエージェント[14] を1つの最適解として扱うこととし,学習環境等
はRobinのエージェントのものと同一に設定する.
“Inifinite Mario Bros”は,世界的に有名なゲームで ある“Super Mario Bros.”を模したアクションゲー ムであり,そのゲーム画面を図1に示す.
“Infinite Mario Bros.”における仕様は以下のとお りである.
• ステージの自動生成
図1 “Infinite Mario Bros.”のゲーム画面 エージェントは,制限時間内に進んだ距離 や 倒 し た 敵 の 数 か ら 算 出 さ れ る ス コ ア を 競う.
事前に与えたシード値に従って無限にステー ジが生成される.
• エージェントの操作キャラクタ(マリオ) エージェントはマリオを操作する.エージェ ントによるマリオの操作はキー入力(LEFT, RIGHT, DOWN, SPEED, JUMP)により行う. フレーム毎のキーの押下状態により,マリオ は対応した行動を行う.また,マリオには「で かマリオ」「ちびマリオ」が存在する.「でか マリオ」でダメージを受けた場合は「ちびマ リオ」に変化し,「ちびマリオ」でダメージ を受けた場合は死亡する.ダメージについて は,後述の接触判定において説明する.穴に 落ちた場合は「でかマリオ」「ちびマリオ」を 問わず,死亡する.
• 敵キャラクタ
複数種類の敵キャラクタが登場し,敵キャラ クタはそれぞれ独自のアルゴリズムで動作し ている.この敵キャラクタはいわゆる「お邪 魔キャラ」として設定されており,エージェ ントはこの敵キャラクタを避けて進むか,倒 して進むか,どのように処理するかが求めら れる.マリオは敵キャラクタとの接触判定に よってダメージを受ける場合がある.踏むこ とができる敵キャラクタは,踏む以外の行動
で接触した場合ダメージを受ける.踏むこと ができない敵キャラクタは,接触した場合ダ メージを受ける.
• スコアの獲得
マリオが死亡する,または,設定された制限 時間に達すると攻略は終了し,スコアを獲得 する.スコアは既定の評価関数で計算され, 敵キャラクタを倒した数,ステージを攻略し た距離などに応じてスコアが上昇する.獲得 スコアが高いほど優秀なエージェントとして 評価することができる.
• エージェントの観測情報
観測情報として,マリオの座標,マリオの状 態,画面内の敵キャラクタの種類および座標, 地形情報といったものを観測情報として得る ことができる.エージェントの観測する地形 情報は,ステージに配置されているブロック のうち,画面内にある22 × 22のブロックの 配置情報となる.“Infinite Mario Bros.”は毎 秒24フレームで動作しており,エージェン トは毎フレーム観測情報を受け取り,マリオ の行動制御を行うためのキー入力を返す必要 がある.
“Infinite Mario Bros.”はWebサイトからダウン ロード可能なオープンソースであり,プレイヤは
“Super Mario Bros.”のようなゲームをJAVA環境で プレイすることができる.ゲームにおける詳細な パラメータも制御可能であるため,COMの振る舞 いを自動的に獲得する機構の構築に適していると いえる.
4 “身体的制約”下での行動パターン獲得
“身体的制約”の「ゆらぎ」と「遅れ」を強化学 習の枠組みに組み込むことにより,観測情報が必 ずしも信頼できる情報ではない「非理想環境」で 学習を進めることになる.そのため,正確なゲー ムの状態を得ることができず,エージェントの自 律的行動獲得には困難性が生じる.本章では,こ の困難性を解決し,エージェントの振る舞いを獲 得するための手法について述べる.まず,強化学 習の枠組みにおける身体的制約の扱いについて説
明し,次に,観測情報とエージェントの行動にお ける状態圧縮について述べる.最後に,Q学習に おける報酬の設定について記述する.
4.1 学習機構における“身体的制約”の扱い 人間の“身体的制約”による「ゆらぎ」「遅れ」「疲 れ」を,強化学習の枠組みに組み込むにあたり,「観 測位置情報のゆらぎ」「情報認識の遅れ」「キー操 作の疲れ」として以下のとおり定義する.
1. 観測位置情報のゆらぎ
人間プレイヤは,観測した操作キャラクタと 敵キャラクタの位置(座標)を正確に認識す ることは難しく,観測位置情報には誤差(ゆ らぎ)が発生する.つまり,観測した座標は, 正 し い 座 標 に 対 し て ノ イ ズ が 付 与 さ れ た 情 報と扱うことができる.これを観測位置情報 のゆらぎと定義し,操作キャラクタ,敵キャ ラクタの座標に対してガウスノイズを付与し たものを,エージェントの観測とすることで 再現する.節3.2で述べた数式1のQ(st,at) の計算の際にstとして与える操作キャラク タと敵キャラクタの位置情報に対して,さま ざまな分散(分散8=ブロック半分,分散16= ブロック1つ分)をもつガウスノイズを付与 する.
2. 情報認識の遅れ
人間プレイヤは,ゲームの状態を観測し認識 してから,実際に行動をするまでに遅れが発 生する.つまり,実際に行動する時点では観 測情報は過去の情報となっている.これを情 報認識の遅れと定義し,エージェントの観測 するゲーム状態を数フレーム過去の情報にす ることで再現する.節3.2で述べた数式1の Q(st,at)の計算の際にstとして与えるゲーム
状態を,数フレーム前の状態(遅れ6フレー ム=0.25秒,遅れ12フレーム=0.5秒)とする. 3. キー操作の疲れ
人間プレイヤは,キー操作を極めて短時間で, または,長時間連続して実施すると疲れが生 じる.これをキー操作の疲れと定義し,エー ジェントは可能な限り少ないキー操作で攻略
するよう学習することで再現する.節3.2で 述べた数式2のQ値の更新の際に,報酬rに キー操作による負の報酬として与える.報酬 rについては,節4.3で詳しく述べる.
上記の1.,2.における,位置情報に付与するガ ウスノイズの分散値の大きさ,情報認識の遅れの 大きさについては,観測情報の信頼性パラメータ として定義する.信頼性パラメータを操作するこ とで,観測情報に対する信頼性を変化させること が可能となる.
4.2 観測情報と行動の状態圧縮
Q学習は学習時間が状態数の指数関数オーダー となる.そのため,現実的な学習時間で学習が収 束し,行動パターンを獲得できるような状態数に 状態圧縮する必要がある.そこで,観測情報は以 下のとおり圧縮する.
• マ リ オ を 中 心 と し た 7 × 7ブ ロック の 地 形 情報
エージェントが観測可能な地形情報は画面を
22 × 22ブロックに分割したものである.し
かし,1フレームあたりのマリオの移動距離 は小さく,画面内全ての地形情報がマリオの 行動に影響することはない.そこで,学習に 使用する地形情報は,マリオを中心とした7
×7ブロックとする.
• マリオを中心とした7 × 7ブロックの敵キャ ラクタの配置
地形情報と同じく,1フレームあたりのマリ オの移動距離は小さいため,マリオに近い敵 キャラクタの位置情報が重要となる.また, 観測情報における敵キャラクタの位置は座標 で与えられるが,x軸y軸単位の座標で状態 設定した場合,状態数の肥大化につながる. そこで,学習に使用する敵キャラクタの配置 は,マリオを中心とした7 × 7ブロックのブ ロック単位の座標に圧縮する.
• 「でかマリオ」か「ちびマリオ」か
「でかマリオ」か「ちびマリオ」かは,マリ オの行動に大きく影響しない.しかし,「で
表1 行動の種類とキー入力の組み合わせ 行動の種類 (Left,Right,Down,Jump,Speed)
右に歩く (OFF,ON,OFF,OFF,OFF)
右に走る (OFF,ON,OFF,OFF,ON)
右に歩きジャンプ (OFF,ON,OFF,ON,OFF) 右に走りジャンプ (OFF,ON,OFF,ON,ON)
左に歩く (ON,OFF,OFF,OFF,OFF)
左に走る (ON,OFF,OFF,OFF,ON)
左に歩きジャンプ (ON,OFF,OFF,ON,OFF) 左に走りジャンプ (ON,OFF,OFF,ON,ON)
しゃがむ (OFF,OFF,ON,OFF,OFF)
かマリオ」でダメージを受けた場合は「ちび マリオ」に変化するだけで攻略を続行できる が,「ちびマリオ」でダメージを受けた場合は 死亡扱いになるため,より長く攻略を進める うえでは,Q学習の観測情報として設定する 必要がある.
• マリオの進行方向
“Infinite Mario Bros.”においてマリオの進行 方向は重要である.例えば右に敵キャラクタ がいる状況を想定した場合,マリオが右に移 動している場合は,その敵キャラクタを考慮 した行動をとる必要がある.しかし,マリオ が左に移動している場合は,敵キャラクタか ら離れていく行動となるため,その敵キャラ クタを考慮する必要性は少ない.そこで,マ リオの進行方向を8方向+停止の9状態とし て設定する.
次に,行動の設定について述べる.マリオの制 御はキー入力のよって行う.このキー入力の組み 合わせにおいて,行動制御に影響がある9つの組 み合わせを,可能な行動として設定する(表1).
節3.2で述べたQ(st,at)の算出において,stと atには上記の状態圧縮を施したものとすることで, 計算量を削減し現実的な学習時間で学習を収束さ せることが可能となる.
4.3 報酬の設定
Mario AI Competitionでは「敵キャラクタを可能 な限り避け,ステージをより早く,より遠くまで攻 略する」ことが目標とされている.そのため,ス
テージを早く攻略することに対して正の報酬を与 え,逆にダメージを受ける,死亡するといった攻 略を阻害する要因に対して負の報酬を与えること が望ましい.また,節4.1で述べた,キー操作によ る疲れを実現するため,キー操作を変更した場合 は負の報酬を与える必要がある.
そこで,報酬rewardを以下のとおり設定する.
reward = distance + damaged + death + keyPress (3)
数式3において,distanceは行動によって進ん だ距離であり,そのまま正の報酬とする.damaged は行動によってダメージを受けた場合に与える負
の報酬,deathは行動によって死亡した場合に与え
る負の報酬である.また,keyPressは前フレーム から行動を変更した場合に与える負の報酬である.
5 計算機実験
本章では,自律的行動獲得機構を用いて,実際 に行動パターンを獲得することができたかについ て検証を行う.また,観測情報の変化により獲得 行動パターンにどのような違いが生まれたかにつ いて考察する.
5.1 エージェントの学習性能の検証
提案した自律的行動獲得機構が有効であること を示すため,異なる身体的制約を与えた場合にお ける獲得スコアの推移を調べる.毎回新たにラン ダム生成されるステージを対象として学習試行を 行い,学習試行回数は10万ゲーム,200ゲームご との獲得スコアの平均をとる.Q学習に関連するパ ラメータ設定として,学習率α を0.2,割引率γ を 0.9,ϵ −greedy法におけるランダム選択確率を0.05 と設定した.また,報酬rにおけるdistanceは進 んだ距離×2.0,damagedは-50.0,deathは-100.0, keyPressは-5.0とした.エージェントに与える身 体的制約の信頼性パラメータとして,遅れ6フレー ム(約0,25秒)・分散8(半ブロック分相当),遅れ12 フレーム(約0.5秒)・分散16(1ブロック分相当), および理想環境に相当する遅れ0フレーム・分散0 という3組を用い,3つのエージェントを用意し た.また,獲得スコアの比較対象として第2章で
紹介したRobinのエージェントを用いた.その結
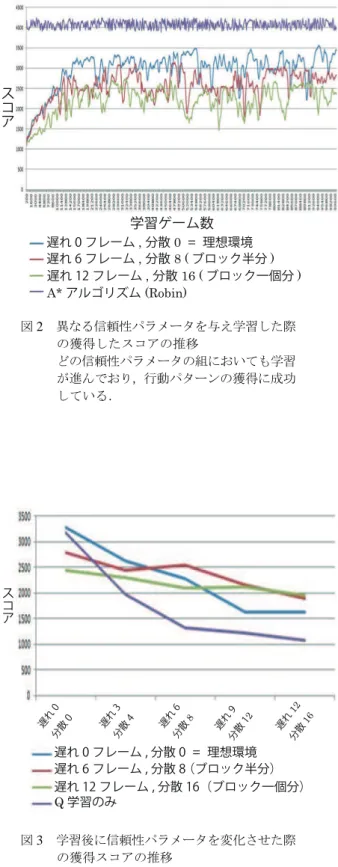
果を図2に示す.図2から,どの信頼性パラメー タの組においても学習が進んでいることを確認で きた.理想環境に相当する信頼性パラメータを与 えたエージェントの獲得スコアについて,最適解 に相当するA*エージェントの獲得スコアに近いス コアを獲得できていることから,自律的行動獲得 機構により,比較的良い行動パターンを学習でき ていることが示された.
次に,あらかじめ信頼性パラメータを与え行動 パターンを獲得したエージェントに対して,新た に様々な信頼性パラメータを与えて獲得スコアが どのように変化するか検証する.Q学習に関連す るパラメータおよび信頼性パラメータは先程と同 じものを用い,自律的行動獲得機構により3つの エージェントを用意した.比較対象として,“身体 的制約”を考慮しない,Q学習のみを用いたエー ジェントも用意した.学習試行回数は10万ゲーム と し ,10万 ゲ ー ム 試 行 後 に 学 習 を ス トップ さ せ , 様々な信頼性パラメータを与え200ゲームの獲得 スコアの平均をとった.その結果を図3に示す.図 3において,Q学習のみのエージェントは,信頼性 パラメータによって観測情報の変化が大きくなる につれ,大きく性能が低下していることがわかる. 一方,自律的行動獲得機構によるエージェントは 観測情報の変化が大きくなるにつれ,スコアの減 少は見られるが,対応手法を持たせていないエー ジェントと比べると減少の幅は小さい.この結果 から,学習に用いた環境から更に環境が変化した 場合でも,性能の揺れ幅を小さく抑えることがで きたことがわかる.また,状況の変化に弱いとい う強化学習の問題を低減できたことがわかる.自 律的行動獲得機構が,環境の変化に対して適切に 対応できていることが示された.
5.2 行動パターンの検証
身体的制約を与えたエージェントが獲得した行 動パターンが,理想環境で獲得した行動パターン と比べ,どのように変化したか検証する.理想環 境(遅れ0フレーム・分散0)と,非理想環境(遅 れ6フレーム・分散8)で学習したエージェントの 行動パターンを比較する.それぞれの最適な行動 パターンを比較するために,毎回同じステージが 生成されるようにした状態で10万ゲーム学習試行
図2 異なる信頼性パラメータを与え学習した際 の獲得したスコアの推移
どの信頼性パラメータの組においても学習 が進んでおり,行動パターンの獲得に成功 している.
図3 学習後に信頼性パラメータを変化させた際 の獲得スコアの推移
身体的制約の導入により環境の変化に対す る性能の揺れ幅を抑制することに成功して いる.
を行い,試行中最も高いスコアを獲得したプレイ を比較する.Q学習に関連するパラメータ設定は 5.1節と同じものを用いた.
比較の結果,現れた行動パターンの傾向の違い について図4∼図6に示す.図4は,触れることが できない敵キャラクタの攻略における行動パター ンの違いである.理想環境では最小限のジャンプ でノンストップで攻略しているのに対し,非理想 環境では大きくジャンプし,また途中一瞬止まる ような動作をしつつ攻略した.次に,図5は大量 の敵キャラクタが存在する区間の攻略における行 動パターンの違いである.理想環境では正確な行 動制御を持って敵キャラクタが大量に存在する区 間を攻略しているのに対し,非理想環境では区間 の手前で待機し,安全にいける状態に変化するの を待ってから攻略した.最後に,図6は落ちると死 亡する穴に対する攻略における行動パターンの違 いである.理想環境では穴に落ちる寸前のところ で最小限のジャンプで攻略しているのに対し,非 理想環境では穴の少し手前で大きくジャンプをし, 余裕を持って攻略した.理想環境ではパフォーマ ンスのみを重視しており,非理想環境では安全性 も考慮した行動パターンを獲得しているといえる.
“身体的制約”を強化学習に組み込むことで行動パ ターンの特徴が変化していることが示された.
6 行動パターンの人間らしさの考察 6.1 行動パターンの視聴実験
自律的行動獲得機構によって獲得した行動パター ンがどの程度「人間らしさ」を持ったかについて, 初期的検討を行う.初期的検討として5.2節で用 いた2つのエージェントのプレイ動画と,人間プ レイヤのプレイ動画を被験者6名による視聴実験 によって人間らしさを判定した.エージェントの プレイ動画は,5.2節と同じQ学習に関連するパ ラメータを用い,学習対象のステージに対して10 万回学習試行を行い,試行中最も高いスコアを獲 得したプレイログを抽出した.人間プレイヤのプ レイ動画は,対象のステージを15分間プレイして もらい,最も高いスコアを獲得したプレイを採用 した.
2つのエージェントと人間プレイヤのプレイ動
図4 理想環境(左)と非理想環境(右)での獲 得行動パターンの比較画像(敵を回避) 理想環境では最小限のジャンプで走り抜け るのに対し,非理想環境では大きくジャン プする.
図5 理想環境(左)と非理想環境(右)での獲 得行動パターンの比較画像(大量の敵が存 在)
理 想 環 境 で は た め ら わ ず に 攻 略 し て い る のに対し,非理想環境では安全になるまで 待つ.
図6 理想環境(左)と非理想環境(右)での獲 得行動パターンの比較画像(穴を飛び越え る)
理想環境では穴のギリギリからジャンプし て い る の に 対 し ,非 理 想 環 境 で は 余 裕 を 持ってジャンプする.
画に対し,「踏めない敵が存在する」「敵が大量に存 在する」「穴が存在する」といった特定の区間で切 り取った動画をそれぞれ6動画ずつ作成した.比 較手法は,シェッフェの一対比較法の浦の変法を用 いた.同じ区間を対象とした2動画を被験者に視 聴してもらい,どちらが人間らしかったかを4段 階で点数化し判定してもらった.
実験の結果,ある1区間について,非理想環境 のエージェントが理想環境のそれよりも人間らし いという有意傾向が見られた(有意水準0.1).ま た,人間プレイヤが理想環境のエージェントより も人間らしいという有意傾向も見られた.この区 間は,触れることのできない敵キャラクタの存在 する区間である.理想環境のエージェントは最小 限のジャンプを行いノンストップで攻略するとい う行動パターンであったが,人間プレイヤおよび 非理想環境のエージェントは,敵キャラクタに対し てためらうかのように一瞬止まり,その後大きく ジャンプして回避する行動パターンであった.「何を 基準に人間らしいと判断したか」という自由記述 質問において,「敵キャラクタの前で一瞬ブレーキ をかける」「ためらいがある」といった回答があっ たことから,安全性を考慮した行動パターンが人 間らしいと感じる要因の一つであること,“身体的 制約”を強化学習の枠組みに組み込むことで人間ら しい行動パターンの獲得に成功していることが示 された.
6.2 様々なゲームジャンルへの適用に向けて 第5章の実験結果から,強化学習の枠組みに人 間の身体的制約を導入することで,状況の変化に 対して適切に対応できていること,人間プレイヤ だと解釈されるような行動パターンの獲得が可能 であることが示された.
ビデオゲームエージェントにおける「人間らし さ」は,ゲームジャンルごと,ゲームタイトルご とに違った要素が必要となる.それゆえ,ビデオ ゲームに人間らしいエージェントを組み込む場合, ゲームタイトルに合った人間らしさの解析が重要 となる.しかし,本研究では,“身体的制約”のみ を組み込むことで,「人間プレイヤがゲームをして いる」ような行動パターンが表出できる可能性を 示した.様々なゲームジャンル,ゲームタイトル
に対して,自律的行動獲得機構は有効であると考 えられる.
7 おわりに
本稿では,ビデオゲームを対象とし,人間離れ した「機械的な」行動パターンではなく,「人間プ レイヤがゲームをしている」ような行動パターン を自律的に獲得する機構を提案した.ヒューリス ティックスをできる限り排除するため,人間の“身 体的制約”のみを強化学習の枠組みに組み込むこと で実現した.本研究の自律的行動獲得機構を用い た計算機実験では,“身体的制約”下において,最 適解に近い行動パターンを学習できていること,環 境の変化に対して適切に対応できていることが示 された.また,視聴実験では,“身体的制約”を考 慮し学習することで,安全性とパフォーマンスを 両立した人間らしい行動パターンの表出が可能で あることが示された.“人間プレイヤのためのビデ オゲームエージェント”の自律的行動獲得の可能性 を示すことができたといえる.
今後の課題として,身体的制約である“ゆらぎ”,
“遅れ”,“疲れ”の信頼性パラメータや報酬の与え 方を調整すること,信頼性パラメータや報酬の変 化によって行動パターンの特徴も変化するか検証 すること,また,他のゲームジャンルにも同様の 手法が適応可能か検討すること等が挙げられる.
参考文献 [1] Mario AI Championship 2012
. http://www.marioai.org/. [2] Infinite Mario Bros.
. http://www.mojang.com/notch/mario/. [3] World Computer Shogi Championship
. http://www.computer-shogi.org/.
[4] Nobuto Fujii, Mitsuyo Hashida, and Haruhiro Katayose. Strategy-acquisition system for video trading card game. International Conference on Ad- vances in Computer Entertainment Technology 2008 (ACE 2008), pp. 175–182, December 2008. [5] Hajime Fujita and Shin Ishii. Model-based rein-
forcement learning for partially observable games with sampling-based state estimation. Neural Com- putation, Vol. 19, pp. 3051–3087, 2007.
[6] BINKLEY Kevin J., SEEHART Ken, and Hagiwara Masafumi. A study of artificial neural network ar- chitectures for othello evaluation functions. Trans- actions of the Japanese Society for Artificial Intelli- gence, Vol. 22, pp. 461–471, November 2007.
[7] Jia jia Tang. A heuristic pathfinding approach based on precomputing and post-adjusting strategies for online game environment. In Games Innovations Conference (ICE-GIC), 2010 International IEEE Consumer Electronics Society, pp. 1–8, December 2010.
[8] J.L.Cabrera and J.G.Milton. On-off intermittency in a human balancing task. Physical Review Letters, Vol. 89, No. 15, September 2002.
[9] J.Togelius, S.Karakovskiy, J.Koutnik, and J.Schmidhuber. Super mario evolution. In 2009 IEEE Conference on Computational Intelligence and Fames(CIG’09), pp. 156–161, 2009.
[10] Toshiki Matsui, Tsuyoshi Hashimoto, Jyunichi Hashimoto, and Haruki Noguchi. An enhancement of the bonanza method by game progress criterion. In IPSJ SIG Technical Reports GI, Vol. 59, pp. 9–15, June 2008.
[11] McPartland.M. Reinforcement learning in first per- son shooter games. Computational Intelligence and AI in Games, Vol. 3, No. 1, pp. 43–56, March 2011. [12] Kathryn Merrick. Modeling motivation for adap- tive nonplayer characters in dynamic computer game worlds. Computers in Entertainment (CIE) - Theo- retical and Practical Computer Applications in En- tertainment, Vol. 5, No. 4, January 2007.
[13] Takuya Obata and Takashi Ito. Machine learning of move orderng in alpha-beta search. In IPSJ SIG Technical Reports GI, Vol. 27, pp. 49–54, March 2009.
[14] Julian Togelius, Sergey Karakovskiy, and Robin Baumgarten. The 2009 mario ai competition. Evo- lutionary Computation (CEC) 2010 IEEE, pp. 1–8, 2010.
[15] Joseph Weizenbaum. Eliza–a computer program for the study of natural language communication be- tween man and machine. Commungicatins of the ACM, Vol. 9, No. 1, January 1966.
[16] Osaki Y., Shibahara K., Tajima Y., and Kotani Y. An othello evaluation function based on temporal dif- ference learning using probability of winning. In 2008 IEEE Conference on Computational Intelli- gence and Fames(CIG’08), pp. 205–211, December 2008.
[17] 戸田正直.日常会話システムneneの開発:人間の 情報処理への認知科学的アプローチ. 日本音響学 会誌, Vol. 42, No. 2, pp. 144–149, February 1986. [18] 藤井叙人,片寄晴弘. 戦略型トレーディングカー
ド ゲ ー ム の た め の 戦 略 獲 得 手 法. 情 報 処 理 学 会 論文誌, Vol. 50, No. 12, pp. 2796–2806, December 2009.
[19] 藤田肇,石井信.マルチエージェントカードゲーム のための強化学習法の改良.電子情報通信学会技 術研究報告, Vol. 102, No. 731, pp. 167–172, 2003. [20] 保木邦仁.局面評価の学習を目指した探索結果の 最適制御. 第11回ゲームプログラミングワーク ショップ, pp. 78–83, 2006.