受け入れ可能性評価は、受け入れ可能性評価の特殊なケースです。文法評価は、受容性評価の特殊なケースです。 (例) 受容性の評価に使用される刺激に対して均一に反応しない。 。
この意味で、特徴的な反応パターン(バイアス)の存在を認識し、それを修正しない限り、受容性評価の結果から内面化されたシステム(言語知識)の実態が明らかになるわけではないとは言えません。言語学者であるはずなのに、受容性の判断が何なのかに自信を持って答えることができない(ほとんどの)人々のためのガイド。
論点 1
先行研究で「コンテキスト」と呼ばれる要素は、C x R の 2 つの効果が混合されたものです。従来のモデルでは、R と C が別個であることは想定されていません。次のどれを意味しますか? 。
答え 2
C を操作することにより、式 ei の受け入れ可能性をある程度まで高めることができます (ei が文法的である限り)。この結果を言語処理や心理学に使用するのは困難です。
答え 1
私は、本質的な複雑さを維持しながら、複雑な現実をモデル化するという汚い仕事が大好きです。実を言うと、科学的な観点から見ると、それは私にとってまったく幸せなことではありません。アプリオリに、評価者の反応は定性的に同じであると私は信じています。と推測される。
これを均一応答の仮定といいますが、この仮定を捨てて、応答の個人差を明示する R を導入するとどうなるでしょうか。一般的な E に対する R の十分な数の応答を分類しない限り、R が仮定する C の実際の状態を理解する方法はありません。
条件で ( 予稿の 191 名でなく )
受容レベルに基づいて文章を分類できますか?いずれの場合も、一部の査読者 (10 ~ 100 人) のみが評価を付けました。言い換えれば、データは欠損値でいっぱいです。
この欠損値の問題を解決するために、以下の分析では欠損値クラスタリングと呼ばれる方法を使用します。全体的な構造の保存は保証されていますが、個々のケースが属するクラスターを区別することが特に重要です。 、他のケースとの距離は不正確です(実際の属性と距離と比較して)。
S の階層的クラスタリングの拡大図 (すべてのケースで SAMPLED)。
- 異なる評定値の平均値と 異なるばらつきをもち
- それを基準にしてクラス 分け = タイプ分けが可能で
- その要因は明らかに R の 反応の違い
- 個数事例数が 80 より少な い評定者を除外
- 最大値は 99 個
1] 述語が同じであれば、合否判定の結果も同様になるでしょうか?これは秩序効果の副作用である可能性が高い。理由はクラウドの仕様のようです(ランダムなレンダリング順序はありません!)。
評価者のグループが共有する効果を差し引いた後にこれが言えるとしたら興味深いでしょう。合格率が低下すると、S4、S3、S2、S1 に広がります。3】 乖離の原因によって反応が異なります。 。
S1:余分な語彙要素がある場合 S2:選択制約違反がある場合 S3:必要な語彙要素がない場合 分離=種類に分離可能 分離=種類に分離可能。
その理由は明らかにRの反応の違いです。査読者は受け入れレベルに基づいて分類できますか?受容性の分布がほぼガウス分布であることは予想外でした。
受け入れパターンの階層的クラスタリング。
C LUSTER MEMBERS
S CATTER PLOT OF A VERAGED RESPONSES
S CATTER PLOT OF A VERAGED RESPONSES WITH F ITTING CURVES (2 ND ORDER P OLYNOMIAL )
S CATTER PLOT OF A VERAGED RESPONSES WITH F ITTING CURVES (3 RD ORDER P OLYNOMIAL )
論点 2
しかし、それらの反応は無秩序ではなく、いくつかの特徴的な反応パターンが認められます。言い換えれば、評価者は特定の反応パターンを内面化しているのです。使用されるデータは別の目的に設計されているため、得られる分析結果は限られています。
論点 3
論点 4
論点 5
論点 6
言語研究の現状において証拠の質を向上させるために体系的に覚えておくべきこと。広義のコンテキスト C* の効果は存在しますが、広義のコンテキスト C* の効果は存在するものの、その本質は解明されていないことに注意することが重要です。
それは個人の知識に還元できるものではないようです。代表的な評価者とそうでない評価者を区別することが重要です。受容性評価では、代表的な評価者とそうでない評価者を区別することが重要です。社会調査として受容性評価の大規模な調査が行われる必要があります。
次回の研究助成をもとに、日本語による合格性評価データベースを構築します。 D.言語研究者評価のための認定制度のプロトタイプ:受容性評価(開発課題)研究データベースに基づく。受け入れ評価は集合知であると仮定します。
刺激文の平均評価の変化の大きさを見つけます。
付録 1
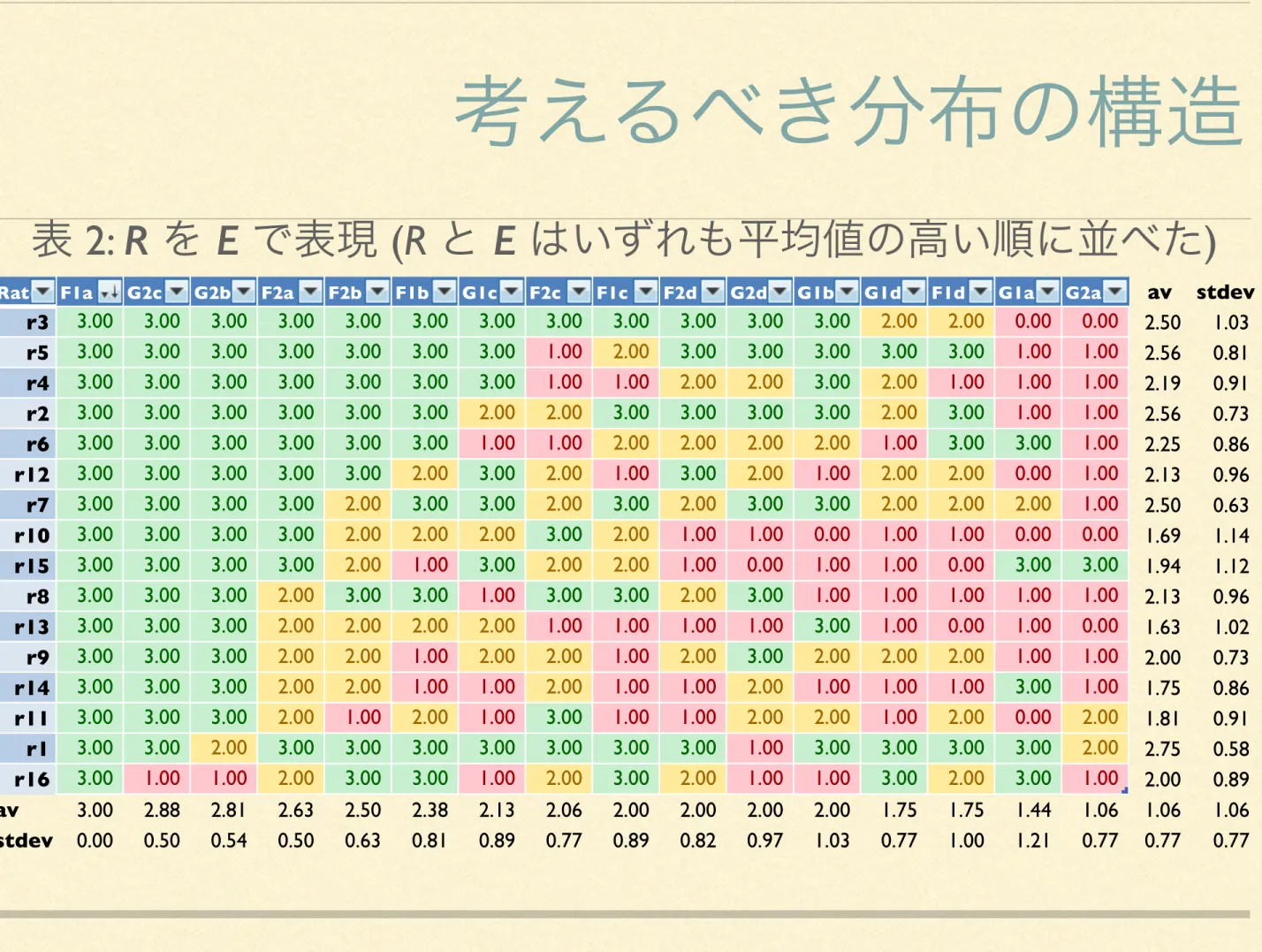
この結果に基づいて、F1a、…、G2d のどれが許容できると考えるべきで、どれが許容できないと考えるべきでしょうか? 。
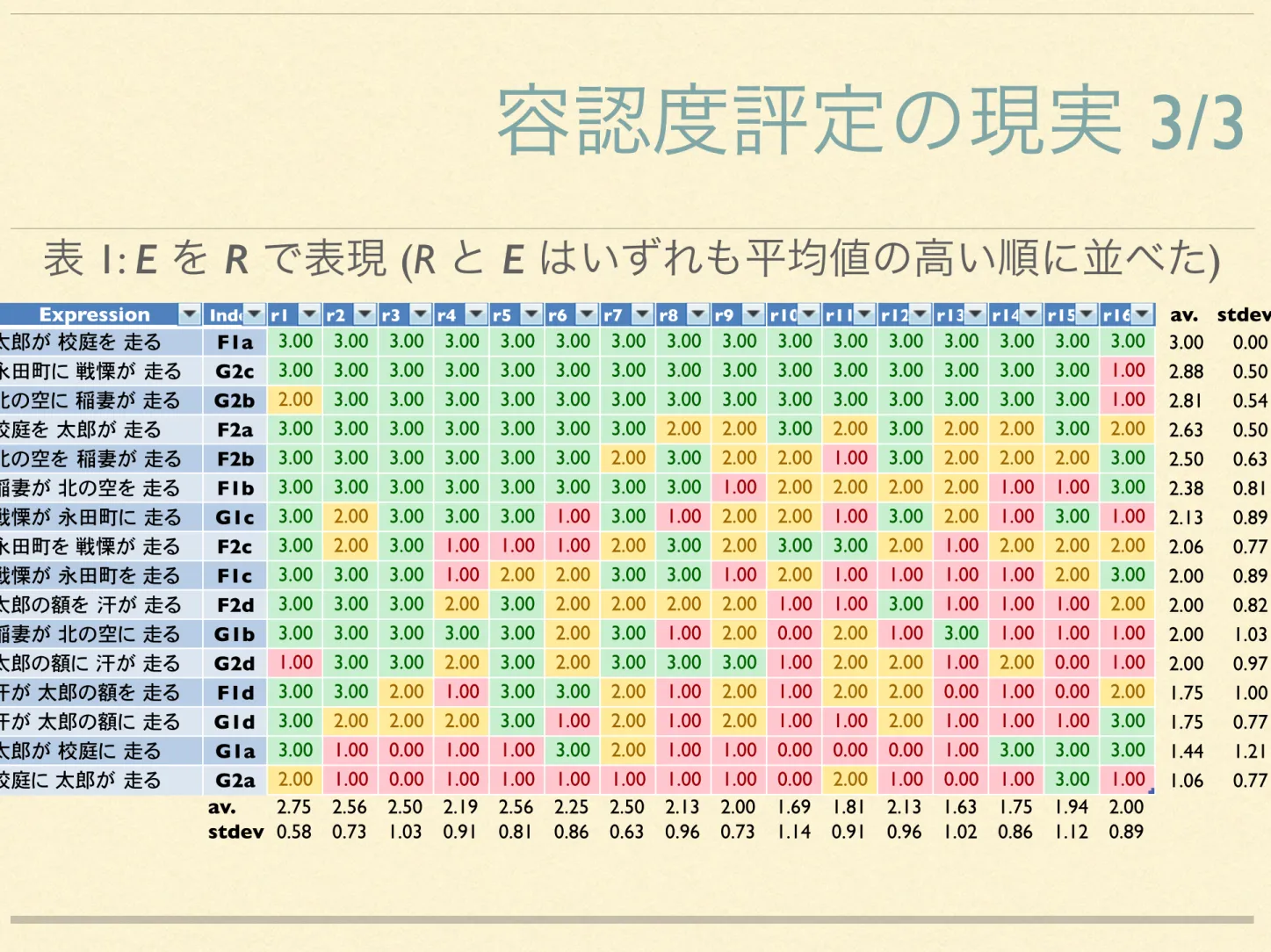
平均評定値が 2.0 を越える場合を 容認可能とし,それ以下を不能?
付録 2
モデルに R を追加すると何が学べるでしょうか?解釈の柔軟性 = 仮定の範囲、逸脱を検出する高い能力、判断の鋭さなどの追加特性。慣れや疲労の影響による判断基準の変化。
これは、同様の評価傾向を持つ評価者を集めて、得られた回答を比較しないと正確に説明できません。
付録 4
それでも、全体的なグループ化はよく保たれています。