1.は じ め に
さまざまな分野において観測データから仮説生成や科 学発見を行う「データ中心科学」の例として,研究室の テーマの一つである「インターネットデータの異なり数 解析」について紹介するチャンスをいただいた.最先端 の研究に紛れてはなはだ単純な解析手法の紹介になり, 若干の気後れを感じてはいるが,単純なアイディアでも 応用を考えた場合に良い結果をもたらす事例として紹介 させていただく. 以下,2 章で本稿で紹介する「異なり数解析」という アイディアの基本を説明した後,初めに 3 章で社会科学 への応用事例を,次に 4 章で工学的課題解決への応用事 例を紹介する.2 章で説明するとおりアイディア自体は 至極単純であるが,その分,社会科学から工学まで応用 範囲は広い.また対象が大量のインターネットデータと いうことで実装には若干の工夫も必要となるが,5 章で 実装上の工夫について解説させていただく.2.異なり数解析とは
「延べ数」という言葉はよく用いられる.何らかのデー タの集計も延べ数で基礎となる数字を計測していること が多いように思う.「異なり数」とはその対義語である. 図 1 に,ある WWW へのアクセス数の数え方として延 べ数と異なり数を使った場合の例を示す. 今,ある WWW サーバに A 氏から H 氏まで 8 名が 1 回ずつアクセスした場合,延べ数で数えれば 8 回である (図 1 左).英語論文で「total number of access」と記さ れていたら通常はこちらの「延べ数」を意味している. 一方,ある WWW サーバに X 氏と Y 氏が 4 回ずつアク セスした場合(図 1 右),延べ数で数えれば同じ 8 回で あるが,異なり数で解析しようとした場合,「2 名から アクセスがあった」と数える. WWWサーバから見たアクセス負荷は図 1 の左右で同 じ(同じ 8 回分のアクセス負荷)であり,ネットワーク トラヒックの研究では延べ数を使った計測結果が利用さ れることが多いように思う(例えば [Fujiwara 13, Jung 02]).しかし社会科学の解析として,例えば「熱狂的な ファンが 2 名いてアクセスが 8 回になった」のと「8 名 が 1 回ずつアクセスした」のでは意味が異なる.熱狂的 少数のファンを対象にビジネスを考えるか,広く受け入 れられる商品でビジネスを考えるか,計測した「数」の 利用方法にも関係してくる.どちらで数を数えるべきか 自体が検討テーマになり得る. 一方,工学的な応用でも,この違いが重要な結果をも たらすことがある.事実,著者らが異なり数の研究を開 始したのも,ネットワークの研究 [Ishibashi 06] に触発 されてのことである.また 4 章で紹介するように,延べ 数の計測ベースでは分析が難しいネットワーク関連問題 の解決に,異なり数による計測結果が効果的である事例 も存在する. 結局のところ,分析対象の現象を捉えるデータ表現と してどちらが正しいかはケースバイケースであるが,本 稿では,余り聞き慣れない「異なり数」について紹介する.3.社会科学への応用
3・1 広告宣伝の効果分析 携帯電話を端末としたインターネット経由の情報交換 が一般的になっており,「ビッグデータ」やら「パーソネットワークデータのオンライン異なり数解析
On-line Cardinality Analysis for Newtwork Data
吉田 健一
筑波大学大学院ビジネス科学研究科Kenichi Yoshida Graduate School of Business Science, University of Tsukuba. [email protected]
三田村 健史
株式会社日本レジストリサービスTakeshi Mitamura Japan Registry Services Co., Ltd. [email protected]
Keywords:
cardinality analysis,virus detection, social science. 「データ中心科学」ナルデータ」は広告などのビジネスを進めるうえでの重 要なバズワードになりつつある.例えば日本の広告宣伝 費の内訳を見ると(図 2[電通 14]),インターネットへ の広告投資は,ここ 10 年で急速に他のマスメディアへ の投資を吸収し,テレビに次ぐ 2 番目の宣伝媒体となっ ている. 旧来のマスメディアからインターネットに投資が移っ ている現象の背景は,ネットの情報拡散能力が高いこと だけではない.ユーザが WWW 上の広告をクリックし, リンクされたページを閲覧した時点で初めて広告料金が 発生するクリック課金型広告など,効果が直接観測でき る宣伝形態が広まっていることも一因である.従来のマ スメディアは投資効果が直接計測できなかったが,ク リック課金型広告は,実際にサイトへ誘導できた人数や 購入に至った人数まで計測できるため,投資効果を時間 を追って確認できる. このような状況を考えると,単に「WWW に延べ何回 アクセスがあった」という延べ数だけでなく,クッキー などを使って「WWW に何人からアクセスがあった」と か「そのうち何人が何回以上アクセスし購入に至った」 といった異なり数を意識した解析も重要になる.宣伝活 動の結果「熱狂的なファン 2 名からのアクセスが 8 回あっ た」のと「8 名が 1 回ずつアクセスしてきた」では宣伝 の効果(より直接的には売上げ)が異なる可能性があり, 検討を要する. 著者ら [三田村 10] は,DNS のログデータを利用し て映画宣伝のために解説されたサイトへのアクセス回数 (図 3)を分析し,サイトへのアクセス回数から映画初 週の興業業績を推定する手法を報告したが,そこでも延 べ数より異なり数で計測した値を使った解析の精度が良 いという結果を得ている. 図 2 に示したように,近年 WWW は重要な宣伝活動 の場となっており,映画公開前に宣伝のための WWW サイトを立ち上げることは一般的となっている.ユーザ がその映画に興味をもち宣伝のための WWW サイトに アクセスすると,パソコンや携帯の WWW ブラウザは URLを IP アドレスに変換するために DNS という仕組 みを利用する.その結果,DNS に記録された利用記録 を調べれば,何人ぐらいの人々がその映画に興味をもっ たか分析することができる. [三田村 10] では,DNS のデータを回帰分析し,映画 の公開初週の興業収入予測を試みたが,説明変数として, 前週までの DNS サイトに記憶されたアクセス数の延べ 数より,同じアクセス数を異なり数の考えで数えた数値 を利用したほうが予測誤差が小くなることを報告して いる.異なり数の考えを使ったほうが良い理由の一つに は DNS のキャッシュが 2 回目以降のアクセスを省略す ることがある.この事例では,延べ数は何人がその映画 サイトに興味をもったかという数字を直接測るだけでな く,キャッシュの仕組みでゆがめられた情報を補う計測 手段にもなっている. 3・2 政 策 評 価 映画の興業予測に DNS データを利用した事例は, DNSデータに含まれる異なり数がマーケティングなど のビジネスに利用可能なことを示した事例である.調 べるサーバを選べば同じデータは,日本全国の動向を調 べるといった社会調査や政策評価にも使える.著者らは DNSデータを使った大規模な社会調査事例として地上 波デジタル放送の普及にエコポイント制度という政策の 効果測定を試みた[Mitamura 13].具体的には,DNSデー タに基づき毎月公表される発行エコポイント数を主成分 回帰分析(PCR)を用いて分析した. まず,エコポイント発行数を目的変数として,政府 が家電エコポイント制度に関する情報発信をするため に運営していた Web サイトやデジタル放送を普及促進 するための Web サイト関連へのアクセス数(正確には IPアドレスの異なり数)を説明変数とした PCR によ り,これらのサイトへのアクセス(すなわち Web サイ トの閲覧者の行動)がエコポイント発行数に対して有効 な情報源となることを確認した.次に PCR の過程で抽 出した各主成分と実社会での出来事との対応を調べ,各 主成分のもつ意味の解釈(例えば「第 1 主成分は“TV Broadcastingに関わる出来事に関する主成分である」) を試みた.結果を図 4 に示す. 図中の各バブルは,計測対象期間の各日付の主成分 得点を示している(言い換えると,各日付の実社会で の出来事を示している).バブルカラーは,PCR 分析 図 2 日本の広告費 図 3 映画サイトへの日ごとの DNS アクセス回数
によって抽出した第 1 主成分(“TV Broadcasting”に 対応した主成分.詳細は [Mitamura 13] を参照された い)に対応しており,より大きなバブルサイズは“TV Broadcasting”に対するより強い反応を示し,バブ ルカラーも青(下)から赤(上)に近づくほど “TV Broadcasting”に対するより強い反応を示している. 中心からの距離は,第 2 主成分(“switchover”)に対 応しており,バブルがより外に向かうほど “switchover” に対するより強い反応を示している.またチャート底か ら左右に向かう角度は,第 3 主成分(“eco-points”)に 対応しており,より左に向かうほど “eco-points”に対 するより強い反応を示し,より右に行くほどより弱い反 応を示している.バブルは計測対象期間において,特定 の推移を示すので,その方向を赤い矢印として示してい る. 図 4 に,2009 ~ 10 年を対象に分析した結果の一部を 示す(2009 ~ 11 年にかけての全分析結果は [Mitamura 13]を参照されたい).まず日本政府がアナログ放送を停 止しデジタル放送へ完全移行することを公式発表した, 2009年 2 月 2 日~ 5 月 2 日までの期間(図 4(1)),バ ブルの位置が徐々に外側に移動し,“switchover”に強い 反応が計測されている.この時期,“TV Broadcasting” と “eco-points”については,まだ強い反応は見られな い.次に家電エコポイント制度が始まった 2009 年 4 月 23日から 2009 年 7 月 23 日までの期間(図 4(2)),“TV Broadcasting”,“switchover”について大きな変化は見 られないが,“eco-points”についてはバブルの位置が左 に移動し,強い反応を示し始めている. [Mitamura 13]では分析結果をまとめ,日本政府が 行った 2009 ~ 11 年に及ぶアナログ放送の停止とデジ タル放送への移行という政策において,家電エコポイン ト制度が,その目的の一つであった地上デジタル放送対 応テレビの普及において人々の行動に効果的な影響を与 えた経済政策であったことを議論している. ここに例示した政策評価のような,大規模な社会調 査を恣意的な影響を排除しながら実施することは困難で あった.またアンケート調査が主流の調査方法であっ たと考えるが,ここで示した結果は日ごとに集計した DNSデータから実施可能であり,政策のように継続性 のある事象についても即時的に影響評価を実施可能な点 が特徴となっている.検索エンジンのデータを使って同 様な調査をすることも可能であるが,残念ながら大手検 索サービスの生データは多くが海外にあり,DNS デー タは国内に残された貴重な情報資源の一つであるといえ る.
4.不正侵入,ウイルス,DDoS の発見
4・1 基本となるアイディア 広告宣伝活動を支える重要な社会インフラであるイン ターネットの運用管理は重要な研究テーマである.特に セキュリティ面での監視は社会からのニーズも高いと考 える. 図 5 は従来からインターネットの運用管理の基礎情報 として用いられてきた帯域監視の例である.回線の利用 状況や,アプリケーションごとの利用比率は延べ数によ る数値データであり,運用管理や将来の設備計画の基礎 情報として欠くことのできない情報である.しかしなが ら,このデータからは不正侵入やインターネットウイル ス,DDoS(Distributed Denial of Service)攻撃といっ たセキュリティ面での情報は得られない.例えば DDoS 攻撃は攻撃目標のサーバに多量のパケットを送って動作 不全に陥らせる攻撃手法を用いるが,多量と言っても「1 サーバの受け取るパケットとしては多量」ということで あり,図 5 のような情報だけから検出することは難しい. インターネット全体で見れば通常の WWW などのトラ ( 左から右への凡例に合わせてデータは中央から上下に広がっている) 図 5 ネットワークトラヒックの計測([RRDtool 15] より) 図 4 地上デジタル放送とエコポイント (1)2/Feb/09-2/May/09 (2)23/Apr/09-23/Jul/09 観測期間中,徐々にバブルが外 側に移動し,Web サイトの閲覧 者が“switchover”に強い反応 を示していることを示してい る.“TV Broadcasting”と “eco-points”については,まだ 強い反応は見られない. “switchover”,“TV Broadcast-ing”についての大きな変化は 見られないが,バブルの位置が 左に移動し“eco-points”に対 する反応が強まっていることを 示している.ヒックのほうがはるかに大量であり,その影に隠れてし まう. 社会調査で使った異なり数というアイディアは,この ような場合にも有効な監視手段を与えてくれる.具体的 には延べ数だけでなく,異なり数も大きなパケットを探 せば,異常なトラヒックとしてセキュリティに関わるパ ケットを検出できることが多い.例えば DDoS 攻撃で あれば,攻撃目標となったサーバは多数の計算機からパ ケットを受け取るので,送信元 IP アドレスの異なり数 が大きな,宛先 IP アドレスを監視していれば,検出で きる(図 6 左).インターネットウイルスに感染した計 算機は次に侵入する計算機を探すために多くの計算機に 通信(すなわち侵入の試み)を行う.インターネットウ イルスは次々と新種が生れるが,多くの計算機に通信を 行うという特徴は共通であり,宛先 IP アドレスの大き な送信元 IP アドレスを監視していれば,怪しげな計算 機を検出できる(図 6 右). 4・2 IP 層データの解析事例 WIDEの MAWI ワーキンググループは,彼らの管理 下にあるバックボーンネットワークのトラヒックデー タを,プライバシーを保護するために IP アドレスを別 のアドレスに修正したうえで公開している [Mawi WG 14].表 1 に上記アイディアを確認するための実験に用 いた公開データの概要を示す. 表 2 に該当 IP パケットの出現回数(延べ数)が 5 000 以上で,宛先 IP アドレスの異なり数が 3 000 以上のパ ケットについて,送信元 IP アドレスごとに,送信元ポー ト番号および宛先ポート番号の異なり数(数が少ないも のはポート番号そのもの)を示す.送信元ポート番号の 欄で「-」で始まる数字は,区別のために異なり数に-1 を乗じた数(元の異なり数は正値)であり,「-」で始ま らない数値はポート番号そのものである.ここで ● 表中ほとんどの宛先ポート番号は不正アクセスに利 用されることが多い,よく知られたポート番号であ る.したがって左欄の送信元 IP アドレスは,新し い侵入先を探してポートスキャンを行っている計算 機のアドレスと解釈するのが自然である. 送信元自体が侵入されたいわば被害者の可能性が あり,この表に載っていることが不正アクセスの実 行犯発見に直結しないことは注意を要するが,計算 機が不正侵入に使われている疑いは極めて強い. ● 宛先ポート番号の使い方を見ると使っているポート 番号によっていくつかの種類に分類できることがわ か る. 例 え ば 3 番 目 の 118.146.40.243 は 4 000 種 類以上の送信元ポートを使っているが,2 番目の 116.148.100は 1 種類(ポート番号 30546)のみを使っ ている.下から 2 番目と 4 番目の 53.201.26.185 と 25.16.193.38は送信元ポート番号と宛先ポート番号 の使い方が似ており,同一または類似の不正侵入ソ フトを利用している可能性が高い. ● いくつかの宛先ポート番号(例えば 1998)が不正 侵入に使われているという話は余り聞かない.しか しながら,一緒に使われている他のポート番号から 判断して,今まで知られていない不正侵入の手口(ま たはソフト)に利用され始めたポート番号(例えば 侵入後の裏口として利用されるポート番号)である 可能性が高い. 上記の解析結果(例えば「1998 は新手の不正侵入手 口に利用され始めたポート番号である)は,別途該当計 算機や,ネットを通じて交換されているデータの中身を 照査しなければ確定した事実とはいえない.しかし,上 記手法は「ポート 53 は不正侵入に利用されることがあ る」といったドメイン知識なしに可能性の高い通信を検 出できる点で,新規に現れる不正侵入の手口に自動的に 図 6 異なり数による不正検知 表 1 解析例に使用した MAWI データセット Dump File File Size Start Time End Time Total Cap. Size Number of packets Avg. Rate 201409181400.dump 7,072.59MB Thu Sep 18 14:00:00 2014 Thu Sep 18 14:15:00 2014 5,428.05 MB Cap. Len: 96 bytes 107,776,143(41,807.65 MB) 389.68 Mbps stddev: 64.42 M
表 2 不信な通信例
Source IP Source Port Number Destination Port Number 1.1.129.110 -4682 4500 116.238.148.100 30546 5900 118.146.40.243 -4596 13042 130.97.85.234 -64 161 141.189.206.76 22200 22201 22202 22203 22204 22205 22206 22207 22208 1723 147.114.60.60 -4671 443 151.110.157.90 -4764 53 207.236.240.111 80 21 22 209.111.88.96 5095 5060 210.128.139.0 -4570 3389 210.208.82.129 6000 22 210.235.48.51 12200 80 3128 8080 24.77.94.54 21662 25 25.16.193.38 12200 80 1998 3128 21320 3.248.197.219 6000 22 53.201.26.185 12200 443 3128 8080 79.162.250.208 -4599 53
追従していく可能性を秘めている. 4・3 アプリケーション層の解析事例 前節の IP 層データの解析は,ネットワークに流れる IPパケットに頻出するパターンに関する異なり数を解 析する手法を使っている.例えば 1 番上の例では送信元 IPアドレスが 1.1.129.110 で宛先ポート番号が 4500 の パケットが多量に流れていることを見つけたうえで,送 信元ポート番号と宛先アドレスの異なり数が大きいこと を見つけている.同様に下から 2 番目の例は送信元 IP アドレスが 53.201.26.185 で送信元ポート番号が 12200 のパケットが多量に流れていることを見つけたうえで, 宛先アドレスの異なり数が大きく,宛先ポート番号は 443, 3128, 8080の 3(種類)であることを検出している (詳細のアルゴリズムを次章で説明する). 同じ手法はアプリケーション層の解析にも利用でき る.簡単な例題は遠隔の計算機を利用するためのアプリ ケーションである ssh サービスにアクセスしてきた外部 計算機,ユーザ名,パスワードの組合せに対するチェッ クである.表 3 と表 4 に,2014 年 5 ~ 9 月までに研究 室に設置された ssh サーバに対する外部からのアクセス を分析した結果を示す.この ssh サーバはユーザが極端 に少ないため,正規のアクセスの分離は容易であり,表 3,表 4 に記載された情報はすべて不正アクセスに関する ものである. 解析にあたっては標準の ssh daemon のログデータを利 用した.このログデータにはユーザのパスワードを保護 するために使用されたパスワードは記録されておらず *1, 外部計算機とユーザ名のみから分析を試みた.表で は,アクセス頻度の延べ数で足切りを行い,足切りの 数を 1 000,500,100 回などに変えて解析した.表を 見 て わ か る と お り 196.27.102.221,216.127.160.146, 62.113.238.125の 3 台はかなりしつこく不正侵入を試み ている.また,ユーザ名としては admin, oracle, test な どがよく試行されている. ここまでは通常の延べ数を使った解析でもできる.例 えば Apriori [Agrawal 96] のようなオーソドックスな手 法で十分である.異なり数を使った場合,上記の結果以 外に ● 送信元 “216.127.160.146”は 48 種類のユーザ名を 侵入の試みに使うのに対して,“196.27.102.221” は 747 種類のユーザ名を侵入の試みに使う. ● 他の送信元も 50 種類程度のユーザ名を使うものと, 500を超えるユーザ名を使うものに大別される. といった侵入に利用されているソフトウェアの特徴につ いての分析結果を得ることができる. sshサーバの解析例は不正侵入に関する事前知識を 使っておらず,事前にパターンファイルの形で事前知 識を用意しておく通常の不正検知の方法とは大きく異な る.使われたユーザ名の異なり数を見ただけで不正侵入 に使われたソフトに複数の種類がある可能性を指摘でき るのは,新種の侵入方法の検出に役立つ特性でもあり, 異なり数解析の有効性を示している.また同様な解析は Telnetや FTP といった ssh に性格の似たアプリケーショ ンから,DNS の Amplification attack や Botnet の制御 パケット検出のような性格の違うアプリの解析まで,幅 広く応用可能と考えられる.
5.大規模・高速処理の課題
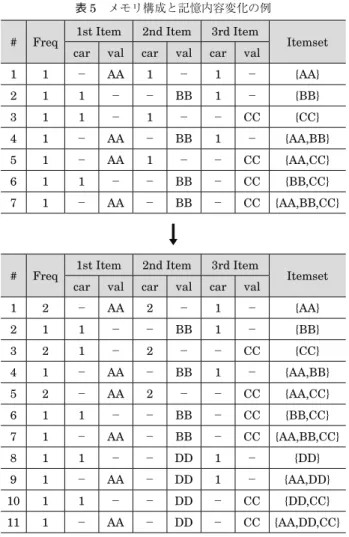
5・1 Vicar アルゴリズム 巨大なサービスとして知られる Twitter のアクセスは 2014年末には 1 日当たり 5 億件を超えている [Twitter 15].DNS-OARC [DNS-OARC 15] が 2013 年 に 収 集 表 3 不正侵入を試みた外部計算機のアドレス Threshold Attackers 1 000 196.27.102.221 216.127.160.146 62.113.238.125 500 119.7.14.114 14.63.225.57 175.119.227.143 196.27.102.221 210.66.73.143 213.239.204.162 216.127.160.146 222.161.197.241 62.113.238.125 100 106.3.43.109 108.166.204.26 113.171.10.1 113.171.10.37 113.171.10.43 113.171.10.51 113.171.10.7 114.215.136.211 119.7.14.114 122.70.133.245 125.210.216.25 137.117.210.147 14.63.215.51 14.63.225.57 150.140.139.229 175.119.227.143 180.179.50.46 183.62.109.4 183.96.27.182 190.116.38.21 192.217.120.19 196.27.102.221 198.211.2.237 199.217.113.211 202.131.140.101 203.202.241.245 208.64.253.98 210.57.212.36 210.66.73.143 211.144.82.162 212.116.87.118 213.17.226.144 213.239.204.162 216.127.160.146 218.107.10.84 218.22.211.69 218.240.21.154 220.128.78.134 221.179.89.90 222.161.197.241 222.219.187.9 58.241.61.162 59.125.251.210 61.188.185.203 62.113.238.125 96.4.34.46 表 4 不正侵入の試みに利用されたユーザ名 Threshold Attackers 500 admin oracle test 100 admin ftptest ftpuser git guest info mysql nagios oracle postgres support test testuser ubuntu user webadmin webmaster www zabbix 50 a admin amanda apache bwadmin cyrus db2inst1 demo deploy download eric ftp ftptest ftpuser git guest info jboss master mysql nagios office or-acle plesk postgres student support teamspeak teamspeak3 temp test test1 test123 test2 test3 test4 teste tester testing testuser tomcat toor ubuntu user web webadmin webmaster www xiuzuan zabbix *1 パスワードを出力するような改造は簡単である.その場合,侵 入に良く利用される使ってはいけないパスワードの収集などが できる.しかし,ログの管理を厳格化しないとセキュリティリ スクを上げる側面もあり,今回は実験しなかった.したデータによれば DNS の中核となるルート DNS サーバへは 1 日当たり 139 億件であり,それより多い. [Mitamura 13]では 3 年分のデータを分析の対象として おり,異なり数という単純な計測であっても,この規模 のデータが対象である場合,単純な処理ではすまない. 特にインターネットのバックボーンの異なり数計測は単 純な実装では現在の計算機の性能では処理が追い付かな い. 本章では大規模・高速な異なり数計測に関する実装上 の課題を説明する.以下ではまず,前章の解析事例で用 いた Vicar アルゴリズム [Yoshida 15] の概要を説明す る.Vicar は頻出アイテム集合の発見アルゴリズムであ る Apriori を以下の 3 点で修正したアルゴリズムである. ● Aprioriでは入力するトランザクションデータに含 まれるアイテムは集合の要素として扱われる.例え ば CSV ファイルの形式で入力されたデータは第 1 カラムに記載されたアイテムも第 2 カラムに記載さ れたアイテムも同じ扱いとなり,「トランザクショ ンデータにそのアイテムが含まれている」として処 理される.例えば AA BB CC DD AA DD CC BB は全く同じトランザクションデータが 2 回入力され たとして処理される. 一方 Vicar は,上記は別のトランザクションデー タとして扱う.これは Vicar が「1 番目のアイテム (AA)は宛先 IP アドレスであり,2 番目のアイテ ム(BB/DD)は宛先ポート番号である」とカラムご とに種類の違うデータを処理することを目的にして いるためである. ● 上 述 の 入 力 か ら Apriori は {AA} {BB} {CC} {DD}
{AA,BB} {AA,CC} {AA,DD} {BB,CC} {BB,DD} {CC,DD} {AA,BB,CC} {AA,BB,DD} {AA,CC,DD} {BB,CC,DD} {AA,BB,CC,DD}の 15 種類のアイテム 集合が 2 回ずつ出現したと判断する.一方 Vicar は アイテム集合としては {AA,2,CC,2} が 2 回出現した とする*2. ここで第 2 カラムと第 4 カラムの「2」は各カラ ムに何種類のアイテムが出現するかの異なり数(こ こでは BB, DD の 2 種類)を表す. ● 次節で議論するように,性能上の理由で厳密な処理 はあきらめ,異なり数は概算であり,頻出アイテム 集合の発見も不完全である. これは,異なり数の計測結果は統計処理などで利 用される基礎データを与えるもので,なるべく正確 な値が要求されるものの,多少不正確でもデータが ないよりはあったほうがよいという,割切りによる. Vicarのアルゴリズムを図 7 に示す.基本は単純な頻 出アイテム集合の数え上げアルゴリズムであり,下線 部が異なり数を数えるための修正部分で,新しい頻出 アイテム集合を見つけたとき(例えば {AA,DD,CC} を {AA,1,CC}に DD を加えたものとして発見したとき)に, 見つけた頻出アイテム集合のベースとなった頻出アイテ ム集合(この例では {AA,1,CC})の新しく要素として加 えたアイテム(この例では DD)の部分に記憶された異 なり数を 1 増やす. 上記処理のために Vicar は固定長のメモリを使って情 報を管理している.表 5 に AA BB CC AA DD CC を入力したときにメモリの内容がどう変更されていくか を示す.表中「car」で示された欄が異なり数を記憶し た部分で,それ以外は入力したトランザクションデータ のカラム位置の処理が異なるだけで,ほぼ通常の頻出ア イテム集合の抽出アルゴリズムでも記憶しているデータ である. 5・2 高速なオンライン処理のためのメモリ管理 頻出アイテム集合の発見アルゴリズムは組合せ爆発に 対応するための高速化が重要な課題であり,いろいろな アルゴリズムが提案されている.ここで説明しているア ルゴリズムは,それらに比べてナイーブなものであり, 応用も IP パケットの情報(宛先 IP アドレス,宛先ポー *2 厳密には表 5 に示す他のアイテム集合も検出する. 図 7 Vicar アルゴリズム >
ト番号,送信元 IP アドレス,送信元ポート番号の四つ が重要)など,組合せ爆発もそれほど問題にならない応 用を紹介しているが,残念ながらこのことは実装が簡単 なことを意味しない. 例えば 10 Gbps の回線に平均 500 byte のパケットが 流れることを考えると,毎秒 250 万回(2.5 M=10 G/ (500×8)回)のトランザクションが発生することになる. 最低でも 1 トランザクション当たり 24-1 個の頻出アイ テム集合の処理が必要となるので,頻出アイテム集合の 処理だけで 3 750 万回のメモリ I/O が必要となる.実際 には異なり数の処理のために,この数倍の I/O が流れる データの種類(IPv4 アドレスの場合 232+16+32+16)を記 憶するための大きさのメモリに行われる. 著者の手元の計算機(PC2-6400 規格)で DRAM メ モリにランダムアクセスした場合の限界は 107回弱で あった.最新の規格ではなく,現在ではもっと速い計算 機もあるが,通常の実装方法を使ったのでは頻出アイテ ム集合の抽出だけで,最低でも実現可能な 4 倍のメモリ 速度を必要とする.異なり数計測では,新たに受け取っ たデータが既存のデータに含まれるか否か確認するため の余分な処理もさらに必要となる.また,ここで必要と した回数はあくまで「理論的に最低」という数で,実際 にプログラムをつくる場合,この数倍のアクセスが発生 する. 以上の考察のもと,著者達は誤差を含まない異なり数 の計測を諦め,概算を求める方針(具体的には下記 2 方 針)をとった. ● 図 8 にアイディアの中核であるメモリ管理の仕組み Hash2を示す. Hash2 はデータをメモリに記憶する際に,記憶場 所の候補として記憶したいデータの hash 値を N 個 (著者らが経験的によく使うのは 4 個)計算し,計 算した N か所の中に,過去に同じデータが処理さ れた記録があればその記録をアップデートし,なけ れば N か所の中で最も利用頻度の低いデータを新 しいデータで上書きする. 古いデータが上書きされれば,当然そのデータに 関する処理結果(そのデータの出現回数や関連する 異なり数)は正しいものではなくなるが,頻度の低 いデータの処理を省略し,処理速度を向上させる. ● 図 7 中 Function Itemsets の再起呼出しはベースと なる頻出アイテム集合が,あらかじめ所定回数以上 出現したもののみで実施した. 出現頻度がべき則に従うデータは,1 回のみ出現 するデータが多数を占める.所定回数以下しか出現 していないアイテム集合をベースにした,それより 要素の多いアイテム集合の処理を省略することで, 速度を向上させる. 上記 2 方針はいずれも結果に誤差を生じさせるが, ネットワーク関連のデータはべき則に従うことが多 く,少数データの無視は,経験的には大きな問題を生 じていない.またオフラインで処理時間に余裕があれ ば,Hash2 が計算する hash 値の個数 N を増やしたり, Function Itemsetsの再起呼出しを必ず行うなどで,誤 差を小くできる.また bloom filter を使って Hash2 によ る誤差を計測する手段 [Yoshida 14] もある.少なくとも 応用例として示した例ではうまく働いている.
図 8 Hash2 メモリ管理機構 表 5 メモリ構成と記憶内容変化の例
# Freq 1st Item 2nd Item 3rd Item Itemset car val car val car val
1 1 - AA 1 - 1 - {AA} 2 1 1 - - BB 1 - {BB} 3 1 1 - 1 - - CC {CC} 4 1 - AA - BB 1 - {AA,BB} 5 1 - AA 1 - - CC {AA,CC} 6 1 1 - - BB - CC {BB,CC} 7 1 - AA - BB - CC {AA,BB,CC}
# Freq 1st Item 2nd Item 3rd Item Itemset car val car val car val
1 2 - AA 2 - 1 - {AA} 2 1 1 - - BB 1 - {BB} 3 2 1 - 2 - - CC {CC} 4 1 - AA - BB 1 - {AA,BB} 5 2 - AA 2 - - CC {AA,CC} 6 1 1 - - BB - CC {BB,CC} 7 1 - AA - BB - CC {AA,BB,CC} 8 1 1 - - DD 1 - {DD} 9 1 - AA - DD 1 - {AA,DD} 10 1 1 - - DD - CC {DD,CC} 11 1 - AA - DD - CC {AA,DD,CC}
6.ま と め
特集号にあたって研究室所属学生の研究を中心に紹介 させていただいた.この記事を少しでも面白いと思って いただけたら,それは彼らの手柄である.面白い研究を してくれた学生諸氏に感謝したい.またわかりにくい点 があれば,彼らの独立した研究を強引に異なり数という 一つの観点から紹介した吉田の責である. 「異なり数」という考え方は,見方によっては当たり 前すぎる考え方であり,文章処理などではことさら意識 せずに使われている事例もある.例えば [大森 12] は工 業製品の不具合事例文の,[長谷川 14] は Twitter の対 話データの,基礎的な統計指標として異なり数に言及し ている.また [長野 12] は,WWW 閲覧履歴の分析に異 なり数ベースの解析のほうが延べ数(彼らの用語では頻 度)ベースの解析より優れていることを主張している. 文章処理における TF/IDF という考え方は,個々の単語 の出現頻度(延べ数)や文章内の単語種類(異なり数) など,単語の出現パターンまで反映した指標である.デー タの出現回数の数え方を工夫することが分野の基礎技術 となっており興味深い.ネットワークに流れるパケット の分析などに「異なり数」を発展させ,TF/IDF 類似の 数え方を工夫することは有望な発想にも思える.◇ 参 考 文 献 ◇
[Agrawal 96] Agrawal, R., Mannila, H., Srikant, R., Toivonen, H. and Verkamo, A. I., et al.: Fast discovery of association rules., Advances in Knowledge Discovery and Data Mining, Vol. 12, No. 1, pp. 307-328(1996)
[電通 14] 日本の広告費(2014)
[DNS-OARC 15] DNS OARC Data Catalog, https://www.dns-oarc.net/oarc/data/catalog(2015),Accessed: 2015-01-15
[Fujiwara 13] Fujiwara, K., Sato, A. and Yoshida, K.: DNS traffic analysis─ CDN and the world IPv6 launch ─,J. Inf. Proc.,Vol. 21, No. 3, pp. 517-526(2013)
[長谷川 14] 長谷川貴之,鍜治伸裕,吉永直樹,豊田正史:オンライ ン上の対話における聞き手の感情の予測と喚起,人工知能学会 論文誌,Vol. 29, No. 1, pp. 90-99(2014)
[Ishibashi 06] Ishibashi, K., Mori, T., Kawahara, R., Hirokawa, Y., Kobayashi, A., Yamamoto, K. and Sakamoto, H.: Estimating top n hosts in cardinality using small memory resources, 2014 IEEE 30th Int. Conf. on Data Engineering Workshops, p. 29 (2006)
[Jung 02] Jung, J., Sit, E., Balakrishnan, H. and Morris, R.: DNS performance and the effectiveness of caching, IEEE/ACM Trans. on, Networking, Vol. 10, No. 5, pp. 589-603(2002) [Mawi WG 14] MAWI Working Group Traffic Archive Accessed:
2014-09-20, http://mawi.wide.ad.jp/mawi/(2014) [三田村 10] 三田村健史,吉田健一:DNS クエリデータに基づくコ
ンテンツへの関心度分析,信学論(B),Vol. 93, No. 10, pp. 1368-1377(2010)
[Mitamura 13] Mitamura,T. and Yoshida, K.: Analyzing people’s behavior using network data,経営情報学会誌,Vol. 22, No. 3, pp. 141-158(2013) [長野 12] 長野翔一,市川裕介,小林 透:短期的な興味プロファイ ル構築に向けたウェブ閲覧履歴のクラスタリング方式の提案, 信学論(D),Vol. 95, No. 4, pp. 734-746(2012) [大森 12] 大森信行,森 辰則:不具合事例文からの製品・部品を示 す語の抽出─語の実体性による分類─,信学論(D),Vol. 95, No. 3, pp. 697-706(2012)
[RRDtool 15] About RRDtool, http://oss.oetiker.ch/ rrdtool/(2015),Accessed: 2015-01-28
[Twitter 15] Twitter Usage Statistics Accessed: 2015-01-15, http://www.internetlivestats.com/twitter-statistics/(2015)
[Yoshida 14] Yoshida, K.: Memory management for big data mining ─ Cache hit rate estimation of LessFU, Procedia Technology, Vol. 17, pp. 114-121(2014)
[Yoshida 15] Yoshida, K.: Vicar package: Source and samples, http://www2.gssm.otsuka.tsukuba.ac.jp/staff/ yoshida/vicar/(2015) 2015年 1 月 29 日 受理