著者
上木 庸平
学位授与機関
Tohoku University
最長順序保存部分列の計算の効率化に
関する研究
東北大学大学院 情報科学研究科
システム情報科学専攻 篠原・吉仲研究室
博士課程前期二年の課程
上木 庸平
2017
年
2
月
16
日
目次
第 1 章 序論 1 1.1 はじめに . . . . 1 1.2 構成 . . . . 3 第 2 章 準備 4 2.1 表記 . . . . 4 2.2 問題定義 . . . . 4 第 3 章 LCSk+ 問題 8 第 4 章 op-LCSk+ 問題 14 4.1 O(mn) 時間・領域アルゴリズム . . . . 144.2 O(mn log k/log log k) 時間・O(n + km) 領域アルゴリズム . . . . 28
第 5 章 準動的区間最小 (最大) 値問い合わせ 30 5.1 問題定義 . . . . 30 5.2 既存手法 . . . . 30 5.3 提案手法 . . . . 32 5.4 ±1RMQ の既存手法 . . . . 33 5.4.1 スパーステーブルアルゴリズム . . . . 34 5.4.2 表引きアルゴリズム . . . . 34 5.4.3 ±1RMQ アルゴリズム . . . . 35 5.5 補題 17 の証明 . . . . 36 第 6 章 実験結果 38
第 7 章 まとめ 44
第
1
章
序論
1.1
はじめに
生命情報学や時系列データ解析 [22] などにおいて,文字列の類似度を定量的に測る手 段として最長共通部分列 (longest common subsequence, LCS ) [3] がよく用いられてい る.LCS を類似度の尺度として用いる際の大きな欠点の一つとして,LCS は文字の連続 的一致を類似度に反映できない点がある.例えば,文字列 X = ATTGGT, Y = ATTGGA,
Z = ACCCCCTCCCTCCCGCCCCG に対して,ATTGG は,X と Y ,X と Z 両方の LCS となる.
しかし,X と Y は最後の文字以外は全て一致しているため,X と Z より類似していると 判断したほうが自然である.
Benson ら [2] は,長さ k の部分文字列から構成される最長共通部分列(longest common
subsequence in k length substrings, LCSk)問題を提案した.LCSk問題では,共通部分列
は長さ k の共通部分文字列の連接で構成される必要がある.例えば,文字列 X = ATTGGT, Y = ATTGGA, k = 2 に対して,X[i : j] を X の i 番目から j 番目までの部分文字列とす ると,X[1 : 2] = Y [1 : 2] = AT, X[4 : 5] = Y [4 : 5] = GG が成り立ち,かつこのように 選ぶときが最長となる場合の一つなので,X と Y の LCS2の一つは ATGG である.また, X と文字列 Z = ACCCCCTCCGCCCCG の LCS2は空文字になる.LCS2を用いることで X と Y が X と Z より類似していると判断できる.LCSk問題に対して,n, m を入力文字列の
長さとすると,Benson らは O(mn) 時間アルゴリズムを提案した.また,Deorowicz と Grabowski [15] は k の大きさによらない O(mn) 時間アルゴリズムや平均的に速く動作す るアルゴリズムなどを提案した.
さらに,Paveti´c ら [25] は長さ k 以上の部分文字列から構成される共通部分列(longest
common subsequence in at least k length substrings, LCSk+)問題を提案した.LCSk+問
題では共通部分列は長さ k 以上の共通部分文字列の連接で構成される必要がある.彼ら
は LCSk+ は LCSkより文字列の類似度としてより適していると主張した.文字列 X =
ATTGGT, Y = ATTGGA, Z = ATCCCCGGCCCCC に対して,ATGG は X, Y と X, Z 両方の LCS2
となる.しかし,X と Y に関して X[: 5] = Y [: 5] が成り立っているため,X と Z より
類似していると判断したほうが自然である.X, Y と X, Z の LCS2+はそれぞれ ATTGG,
ATGG となるため,LCS2+を用いることで X, Y がより類似していると判断できる.LCSk+
問題は生命情報学に応用されている [26].
m, n を入力文字列の長さ,r を入力文字列間において一致している長さ k の部分文字列
の数とすると,Paveti´c らは LCSk+ 問題が n≥ m を仮定して O(n + r log r + r log n) 時間
で解けることを示した.彼らのアルゴリズムは平均的には高速に動作するが,最悪時には
r = Θ(mn) なので Θ(mn log mn) 時間必要である.また,Benson ら [2] は最悪 O(kmn)
時間のアルゴリズムを提案した.
本稿ではまず LCSk+ 問題に対して,動的計画法を用いた最悪 O(mn) 時間アルゴリズ
ムを提案する.次に,栗原ら [27] により提案された長さ k 以上の順序同型部分文字列か ら構成される最長共通部分列(longest common subsequence in at least k length
order-isomorphic substrings, op-LCSk+)問題について考える.順序同型(order-isomorphism)
は,近年注目を集めている順序保存照合(order-preserving matching)問題1 [23, 24] に おいて用いられている数値文字列の一致関係である.順序アルファベット上の文字列 S, T の相対的順序(relative order)が一致するとき,S と T は順序同型であるという.例 えば,文字列 S = (32, 40, 4, 16, 27), T = (28, 32, 12, 20, 25) に対して,S と T の相対的順 序は両方とも (4, 5, 1, 2, 3) であるため,S と T は順序同型である. 順序保存照合問題は,テキスト T とパターン P が与えられ,P と順序同型となる T 中 の部分文字列の開始位置を出力する問題である.順序保存照合問題に対して,Kim ら [23] と Kubica ら [24] は Knuth-Morris-Pratt 法を基にした O(n + m log m) 時間アルゴリズム を提案した.Cho ら [10] は Horspool 法に基づきランダム文字列に対して劣線形時間で動
1op-LCS
作するアルゴリズムを提案した.また,Chhabra と Tarhio [9] はフィルタリング法を基に したアルゴリズムを提案し,実験的に高速なアルゴリズムを提案した.また,Faro ら [16] は Chhabra と Tarhio のアルゴリズムより偽陽性が低いフィルタリング手法を提案し,よ り実験的に高速なアルゴリズムを提案した.Cantone ら [6],Chhabra ら [7],Chhabra ら [8] は SIMD(single instruction multiple data)演算を用いた実験的に高速なフィルタ リング法のアルゴリズムを提案した.
op-LCSk+問題は,LCSk+問題における文字列一致関係を順序同型に置き換えたもので
ある.栗原らは op-LCSk+ 問題が O(mnk2log k) 時間で解けることを示した.op-LCSk+
は数値文字列の類似度の尺度として用いることができる.順序同型は元々数値文字列の 波形に着目した一致関係として定義されたため,移調を考慮した楽曲の類似度に用いる ことができる.ある楽曲とそれを移調した楽曲は違う音,すなわち数値で構成されるが, 相対的な数値の変化は一致するため,2 曲の op-LCSk+を求めることで類似していると判 断できる.順序同型の性質により op-LCSk+問題は LCSk+ 問題とは異なり単純な動的計 画法では解けないため,代わりに Z アルゴリズム [20] と要素の追加に対応した準動的区 間最大値問い合わせ [17] を用いたアルゴリズムを提案する.提案アルゴリズムは実装が 容易であり,最悪 O(mn) 時間で動作する.
1.2
構成
本論文の構成は次のとおりである.まず第 2 章では表記および問題定義を述べる.第 3 章では LCSk+ 問題に対する O(mn) 時間・領域アルゴリズムを示す.また,領域計算 量は n ≥ m を仮定して O(km) に容易に削減できることを示す.次に第 4 章では op-LCSk+ 問題に対する O(mn) 時間・領域アルゴリズムを示す.また,領域計算量を削減した O(mn log k/log log k) 時間・O(n + km) 領域アルゴリズムについて述べる.第 5 章で は第 4 章で用いる要素の追加に対応した準動的区間最小値問い合わせのデータ構造につ いて詳述する.第 6 章では実験結果を述べる.最後に第 7 章でまとめと今後の課題を述 べる.
第
2
章
準備
2.1
表記
集合 Σ をアルファベットとし,Σ の要素を並べたものを文字列という.文字列 X =
(X[1], X[2],· · · , X[n]) の長さを |X| = n と表記する.文字列 X の i 番目から j 番目まで
の部分文字列を X[i : j] = (X[i], X[i+1],· · · , X[j −1], X[j]) と表す.文字列 X の i 番目か
ら始まる長さ l の部分文字列と,j 番目で終わる長さ l の部分文字列をそれぞれ X⟨i, +l⟩ =
X[i : i + l− 1], X⟨j, −l⟩ = X[j − l + 1 : j] と表す.したがって X⟨i, +l⟩ = X⟨i + l − 1, −l⟩
である. 文字列 X の i 番目までの接頭辞と j 番目以降の接尾辞をそれぞれ X[: i] と X[j :]
で表す.ただし X[: 0] を空文字とする.文字列 X の反転を XR = (X[n],· · · , X[1]) で
表す.文字列 X, Y の連接を X · Y ,もしくは XY で表す.文脈上明らかな場合,文字
列 X = (X[1], X[2],· · · , X[n]) を X = X[1]X[2] · · · X[n] と表す.また,同様の表記を
一次元の表においても用いる.すなわち,表 X = (X[1],· · · , X[n]) に対して,大きさを
|X| = n, X[i : j] = (X[i], · · · , X[j]), X⟨i, +l⟩ = X[i : i+l−1], X⟨j, −l⟩ = X[j −l+1 : j], X[: i] = X[1 : i], X[j :] = X[j : n] とする.
2.2
問題定義
LCSk+問題 [2, 25]1は,共通部分列が長さ k の共通部分文字列の連接で構成される LCS
問題である.LCSk+問題を次のように形式的に定義する.
1Paveti´c ら [25] の定義には軽微な間違いが含まれる.例えば,文字列 X = aaacaa, Y = aadaaa の
定義 1 (LCSk+ 問題). 長さがそれぞれ m, n の文字列 X, Y と整数 k ≥ 1 が与えられた とき,次の条件 (1), (2), (3) を満たす整数列 i1,· · · , it, j1,· · · , jt, l1,· · · , ltが存在する場
合,文字列 Z を X と Y の長さ k 以上の部分文字列から構成される共通部分列(common
subsequence in at least k length substrings)という.
(1) 数値列 p1,· · · , ptは次を満たす. • p1 = 1 • pt =|Z| − lt+ 1 • 2 ≤ s ≤ t に対して,ps= ps−1+ ls−1 (2) 数値列 l1,· · · , lsは 1≤ s ≤ t に対して次を満たす. • ls≥ k • X⟨is, +ls⟩ = Y ⟨js, +ls⟩ = Z⟨ps, +ls⟩ (3) 数値列 i1,· · · , it, j1,· · · , jtは 1≤ s < t に対して次を満たす. • is+ ls ≤ is+1 • js+ ls ≤ js+1 長さ k 以上の部分文字列から構成される共通部分列で最長のものを,長さ k 以上の部分 文字列から構成される最長共通部分列(longest common subsequence in at least k length
substrings, LCSk+)という.LCSk+ 問題は X と Y の LCSk+ の長さを求める問題である.
図 2.1 に定義 1 を図示したものを示す.なお,LCS1+問題は一般的な LCS 問題と等価
である.一般性を失うことなく,本論文では n≥ m を仮定する.
例 1. 文字列 X = acdbacbc, Y = aacdabca に対して X⟨1, +3⟩ = Y ⟨2, +3⟩ = acd =
Z⟨1, +3⟩ と X⟨7, +2⟩ = Y ⟨6, +2⟩ = bc = Z⟨4, +2⟩ が成り立つため,Z = acdbc が X と
Y の LCS2+ である. なお、X と Y の通常の LCS は acdabc である.
op-LCSk+問題は,LCSk+問題の文字列の一致関係を順序同型(order-isomorphism)に
𝑋 𝑌 𝑍 ⋯ 𝑙1≥ 𝑘 𝑙2≥ 𝑘 ⋯ 𝑙𝑡≥ 𝑘 𝑙1≥ 𝑘 𝑙2≥ 𝑘 ⋯ 𝑙𝑡≥ 𝑘 𝑙1≥ 𝑘 𝑙2≥ 𝑘 ⋯ 𝑙𝑡≥ 𝑘 𝑖1 𝑖2 𝑖𝑡 𝑗1 𝑗2 𝑗𝑡 𝑝1 𝑝2 𝑝𝑡 図 2.1: LCSk+ の定義 定義 2 (順序同型 [23, 24]). 順序アルファベット上の同じ長さ l の文字列 S, T に対して, 任意の 1≤ i, j ≤ l で S[i] ≤ S[j] ⇐⇒ T [i] ≤ T [j] が成り立つとき,S と T は順序同型で あるという.S と T が順序同型のとき S ≈ T ,そうでないとき S ̸≈ T と表記する. 例 2. 文字列 S = (32, 40, 4, 16, 27), T = (28, 32, 12, 20, 25), U = (33, 51, 10, 22, 42) に対 して,S ≈ T , S ̸≈ U, T ̸≈ U が成り立つ. 定義 3 (op-LCSk+ 問題 [27]). 長さ k 以上の順序同型部分文字列から構成される共通部分 列は,定義 1 における文字列一致関係を X⟨is, +ls⟩ = Y ⟨js, +ls⟩ = Z⟨ps, +ls⟩ から順序 同型 X⟨is, +ls⟩ ≈ Y ⟨js, +ls⟩ ≈ Z⟨ps, +ls⟩ に置き換えたものである.長さ k 以上の順序 同型部分文字列から構成される共通部分列で最長のものを,長さ k 以上の順序同型部分 文字列から構成される最長共通部分列(longest common subsequence in at least k length
order-isomorphic substrings, op-LCSk+)という.op-LCSk+問題は op-LCSk+の長さを求
める問題である.
例 3. 文字列 X = (14, 84, 82, 31, 74, 68, 87, 11, 20, 32), Y = (21, 64, 2, 83, 73, 51, 5, 29, 7, 71) に対して,X⟨1, +3⟩ ≈ Y ⟨3, +3⟩ ≈ Z⟨1, +3⟩ と X⟨4, +4⟩ ≈ Y ⟨7, +4⟩ ≈ Z⟨4, +4⟩ が成り
立つため,Z = (1, 3, 2, 31, 74, 68, 87) が X と Y の op-LCS3+ の一つである.
op-LCS1+問題の出力は n≥ m を仮定して常に m となるため意味をなさない.op-LCSk+
成り立つという制約を加えた op-LCSk+ 問題は k = 1 のとき NP 困難であることがすで に知られている [4].
第
3
章
LCS
k
+問題
本章では LCSk+ 問題が動的計画法により O(mn) 時間で解けることを示す.Match(i, j, l) を Match(i, j, l) = 1 (X⟨i, −l⟩ = Y ⟨j, −l⟩ のとき) 0 (X⟨i, −l⟩ ̸= Y ⟨j, −l⟩ のとき)と定義する.C[i, j] を X[: i] と Y [: j] の LCSk+の長さとする.また,Ai,j ={C[i − l, j −
l] + l· Match(i, j, l) : k ≤ l ≤ min{i, j}} とする.
例 4. X = abcdef, Y = abcbcdef, k = 3 に対する表 C の例を図 3.1(a) に示す.このと
き,A6,8 ={C[6 − l, 8 − l] + l · Match(6, 8, l) : 3 ≤ l ≤ min{6, 8}} = {3 + 3 · 1, 0 + 4 · 1, 0 +
5· 0, 0 + 6 · 0} = {6, 0} が成り立つ. 提案アルゴリズムは次の補題に基づく. 補題 1 ([2]). 任意の 0 ≤ i ≤ m, 0 ≤ j ≤ n に対して, C[i, j] =
max ({C[i, j − 1], C[i − 1, j]} ∪ Ai,j) (k≤ i ≤ m かつ k ≤ j ≤ n のとき)
0 (それ以外のとき)
(3.1) が成り立つ.
それぞれの i, j に対して max Ai,j を計算する素朴なアルゴリズムは n ≥ m を仮定し
O(m2n) 時間かかる.Benson ら [2] は max A
i,j = maxk≤l≤min{2k,L[i,j]}{C[i − l, j − l] + l}
が成り立つことを示し,これに基づいて LCSk+問題に対する O(kmn) 時間アルゴリズム
を提案した.
本稿では,問題を O(mn) 時間で解くためにそれぞれの i, j に対して max Ai,jを定数時間
で計算する方法を考える.すべての l1 ≤ l2 ≤ min{i, j} に対して,もし Match(i, j, l1) = 0
ならば Match(i, j, l2) = 0 が成り立つことと,すべての 0 ≤ i ≤ m, 0 ≤ j ≤ n,
0 < l ≤ min{i, j} に対して C[i, j] ≥ C[i − l, j − l] が成り立つことは自明である. し
たがって,max Ai,j を計算するには,L[i, j] = max{l : X⟨i, −l⟩ = Y ⟨j, −l⟩} とすると
maxk≤l≤L[i,j]{C[i − l, j − l] + l} を計算すれば十分である.
すべての 0 ≤ i ≤ m, 0 ≤ j ≤ n に対して,L[i, j] は次の自明な漸化式を基にした動的 計画法により O(mn) 時間で計算することができる. L[i, j] =
L[i− 1, j − 1] + 1 (i, j > 0 かつ X[i] = Y [j] のとき)
0 (それ以外のとき).
(3.2)
例 5. X = abcdef, Y = abcbcdef, k = 3 に対する表 L の例を図 3.1(b) に示す.
次に,それぞれの i, j に対して,maxk≤l≤L[i,j]{C[i − l, j − l] + l} を定数時間で計算す
る方法を考える.表 L がすでに計算されていると仮定する.M [i, j] を M [i, j] =
maxk≤l≤L[i,j]{C[i − l, j − l] + l} (L[i, j] ≥ k のとき)
−1 (L[i, j] < k のとき) と定義する. 例 6. X = abcdef, Y = abcbcdef, k = 3 に対する表 M の例を図 3.1(c) に示す. 表 M に関して次の補題が成り立つ. 補題 2. 任意の 0 ≤ i ≤ m, 0 ≤ j ≤ n に対して,もし L[i, j] > k ならば M [i, j] = max{M [i − 1, j − 1] + 1, C[i − k, j − k] + k} が成り立つ.
証明. l = L[i, j] とする.L[i, j] > k なので,L[i−1, j−1] = l−1 ≥ k とM [i−1, j−1] ̸= −1
a b c b c d e f 0 1 2 3 4 5 6 7 8 0 0 0 0 0 0 0 0 0 0 a 1 0 0 0 0 0 0 0 0 0 b 2 0 0 0 0 0 0 0 0 0 c 3 0 0 0 3 3 3 3 3 3 d 4 0 0 0 3 3 3 3 3 3 e 5 0 0 0 3 3 3 3 4 4 f 6 0 0 0 3 3 3 3 4 6 (a) LCS3+問題の表Cの例 a b c b c d e f 0 1 2 3 4 5 6 7 8 0 0 0 0 0 0 0 0 0 0 a 1 0 1 0 0 0 0 0 0 0 b 2 0 0 2 0 1 0 0 0 0 c 3 0 0 0 3 0 2 0 0 0 d 4 0 0 0 0 0 0 3 0 0 e 5 0 0 0 0 0 0 0 4 0 f 6 0 0 0 0 0 0 0 0 5 (b) LCS3+ 問題の表Lの例 a b c b c d e f 0 1 2 3 4 5 6 7 8 0 0 0 0 0 0 0 0 0 0 a 1 0 0 0 0 0 0 0 0 0 b 2 0 0 0 0 0 0 0 0 0 c 3 0 0 0 3 0 0 0 0 0 d 4 0 0 0 0 0 0 3 0 0 e 5 0 0 0 0 0 0 0 4 0 f 6 0 0 0 0 0 0 0 0 6 (c) LCS3+ 問題の表Mの例 図 3.1: LCS3+ 問題の計算例
maxk+1≤l′≤l{C[i−l′, j−l′]+l′}−1 である.ゆえに,M [i, j] = maxk≤l′≤l{C[i−l′, i−l′]+l′} =
max{M [i − 1, j − 1] + 1, C[i − k, j − k] + k} が成り立つ. 2 補題 2 と M [i, j] の定義により, M [i, j] =
max{M [i − 1, j − 1] + 1, C[i − k, j − k] + k} (L[i, j] > k のとき)
C[i− k, j − k] + k (L[i, j] = k のとき) −1 (L[i, j] < k のとき) (3.3) が成り立つ.式 (3.3) により,もし L[i, j], M [i− 1, j − 1], C[i − k, j − k] がすでに計算さ れているとき,それぞれの M [i, j] が定数時間で計算できることがわかる. Algorithm 1 に提案アルゴリズムの擬似コードを示す.大きさ (m + 1)× (n + 1) の表 C, L, M を式 (3.1), (3.2), (3.3) に基いた動的計画法により O(mn) 時間で計算することが
できる.文字列 X = abcdef, Y = abcbcdef に対する LCS3+ の計算例を図 3.1 に示す. なお,LCSk+の長さだけでなく,LCSk+自体を,通常の LCS 問題に対する一般的な動的 計画法のアルゴリズムと同様に表 C を辿ることにより n≥ m を仮定して O(n) 時間で計 算できる.提案アルゴリズムは大きさ (m + 1)× (n + 1) の表 3 つを使うため O(mn) 領域 必要である.なお,LCSk+の長さのみを計算したい場合,領域計算量は O(km) に容易に 削減できる(Algorithm 2).ただし,% 演算子は剰余を表す.以上より次の定理を得る. 定理 1. LCSk+問題は O(mn) 時間と O(km) 領域で解ける.
Algorithm 1: LCSk+ 問題に対する提案アルゴリズム Input: 長さ m の文字列 X, 長さ n の文字列 Y , 整数 k ≥ 1 Output: X と Y の LCSk+の長さ 1 C, L, M を 0 で初期化された大きさ (m + 1)× (n + 1) の表とする; 2 for i ← 1 to m do 3 for j ← 1 to n do
4 if X[i] = Y [j] then L[i, j]← L[i − 1, j − 1] + 1; 5 else L[i, j]← 0;
6 for i ← k to m do 7 for j ← k to n do
8 l ← L[i, j];
9 if l > k then M [i, j]← max{C[i − 1, j − 1] + 1, C[i − k, j − k] + k}; 10 else if l = k then M [i, j]← C[i − k, j − k] + k;
11 else M [i, j]← 0;
12 C[i, j]← max{C[i, j − 1], C[i − 1, j], M [i, j]};
Algorithm 2: LCSk+ 問題に対する提案アルゴリズム (O(km) 領域) Input: 長さ m の文字列 X, 長さ n の文字列 Y (ただし n ≥ m), 整数 k ≥ 1 Output: X と Y の LCSk+の長さ 1 C を 0 で初期化された大きさ (m + 1)× (k + 1) の表とする; 2 L,M を 0 で初期化された大きさ (m + 1)× 2 の表とする; 3 for j ← 1 to k − 1 do 4 for i ← 1 to m do
5 if X[i] = Y [j] then L[i, j%2]← L[i − 1, (j − 1)%2] + 1; 6 else L[i, j%2]← 0;
7 for j ← k to n do
8 for i ← 1 to k − 1 do
9 if X[i] = Y [j] then L[i, j%2]← L[i − 1, (j − 1)%2] + 1; 10 else L[i, j%2]← 0;
11 for i ← k to m do
12 l ← L[i, j%2];
13 if l > k then
14 M [i, j%2]← max{C[i−1, (j −1)%(k+1)]+1, C[i−k, (j −k)%(k+1)]+k};
15 else if l = k then M [i, j%2]← C[i − k, (j − k)%2] + k; 16 else M [i, j%2]← 0;
17 C[i, j%(k + 1)]← max{C[i, (j − 1)%(k + 1)], C[i − 1, j%(k + 1)], M [i, j%2]};
第
4
章
op-LCS
k
+問題
本章では,op-LCSk+ 問題に対する次の 2 つの提案アルゴリズムを述べる.
(1)O(mn) 時間・領域アルゴリズム
(2)O(mn log k/log log k) 時間・O(n + km) 領域アルゴリズム
4.1
O(mn)
時間・領域アルゴリズム
本節では,op-LCSk+ 問題が LCSk+ 問題と同様に O(mn) 時間で解けることを示す.
C[i, j] を X[: i] と Y [: j] の op-LCSk+ の長さと再定義する.また,Match(i, j, l) を
Match(i, j, l) = 1 (X⟨i, −l⟩ ≈ Y ⟨j, −l⟩ のとき) 0 (X⟨i, −l⟩ ̸≈ Y ⟨j, −l⟩ のとき) と再定義する.式 (3.1) が順序同型に関しても成り立つことは容易に証明できる.しかし, op-LCSk+ 問題は LCSk+ 問題と同様の単純な動的計画法では解くことができない.なぜ ならば,式 (3.2), (3.3) が次のように順序同型に関して成り立たないためである. 通常の文字列の一致関係では,2 つの一致する文字列 A, B の末尾にそれぞれ文字 a, b を追加したとき,A と B が一致していることがすでにわかっていれば,a と b が一致す るか調べることにより,新しい文字列 Aa と Bb の最長の一致する接尾辞の長さを定数時 間で計算できる.すなわち,式 (3.2) より max{l : (Aa)⟨|Aa|, −l⟩ = (Bb)⟨|Bb|, −l⟩} は定 数時間で計算できる. しかし,順序同型では末尾に文字を追加した文字列に対して,最長の順序同型な接尾 辞の長さを式 (3.2) のような単純な動的計画法で定数時間で計算することはできない.例
えば,A ≈ B を満たす文字列 A = (32, 40, 4, 16, 27), B = (28, 32, 12, 20, 25) と末尾に文
字を追加した文字列 A′ = A· (41), B′ = B· (26), A′′ = A· (15), B′′ = B· (22) に対し
て,max{l : A′⟨|A′|, −l⟩ ≈ B′⟨|B′|, −l⟩} = 3 と max{l : A′′⟨|A′′|, −l⟩ ≈ B′′⟨|B′′|, −l⟩} = 5
が成り立つ.以上のように,A ≈ B を満たす文字列と文字 a, b に対して,A と B が順 序同型であることがすでにわかっていても,max{l : (Aa)⟨|Aa|, −l⟩ ≈ (Bb)⟨|Bb|, −l⟩} は 式 (3.2) のようには計算できない.また,式 (3.3) は式 (3.2) の成立に依存しているため, 順序同型では成り立たない.本稿では,l = max{l′ : X⟨i, −l′⟩ ≈ Y ⟨j, −l′⟩} は順序保存最 長共通伸長問い合わせを用いて,maxk≤l′≤l{C[i − l′, j− l′] + l′} は準動的区間最大値問い 合わせを用いてそれぞれ定数時間で計算できることを示す. まず, max{l : X⟨i, −l⟩ ≈ Y ⟨j, −l⟩} を定数時間で計算する方法を考える.文字列 S1と
S2に対する順序保存最長共通伸長(order-preserving longest common extension, op-LCE )
問い合わせを次のように定義する.
定義 4 (op-LCE 問い合わせ). 文字列 S1, S2,S1中の位置 i1,S2中の位置 i2に対して,
op-LCE 問い合わせは opLCES1,S2[i1, i2] = max{l : S1⟨i1, +l⟩ ≈ S2⟨i2, +l⟩} を尋ねる.
例 7. 文字列 S1 = (6, 8, 2, 0, 7, 1), S2 = (0, 9, 3, 1, 4, 10) に対して,opLCES1,S2[2, 2] = 4 である.
max{l : X⟨i, −l⟩ ≈ Y ⟨j, −l⟩} = opLCEXR,YR[m− i + 1, n − j + 1] なので,max{l :
X⟨i, −l⟩ ≈ Y ⟨j, −l⟩} は文字列 XR, YRに対する op-LCE 問い合わせを用いることで求め ることができる.したがって,文字列 S1, S2に対する op-LCE 問い合わせに高々O(|S1||S2|) 時間の前処理を行い定数時間で回答する方法を考える.以降,文字列 S1, S2 を固定し, opLCES1,S2[i1, i2] を opLCE [i1, i2] と書く. 文字列 S に対して表 PrevS, NextSを,それぞれの 1≤ i ≤ |S| に対して, PrevS[i] =
j (j = argmax1≤k<i{S[k] : S[k] ≤ S[i]} が存在するとき)
−∞ (それ以外のとき), NextS[i] =
j (j = argmin1≤k<i{S[k] : S[k] ≥ S[i]} が存在するとき) ∞ (それ以外のとき)
と定義する.ただし条件を満たす j が複数存在する場合,一番大きいものを選ぶとする.
また,文字列 S に対して,それぞれの 1≤ i ≤ |S| に対して CodeS[i] = (PrevS[i], NextS[i])
と定義する.
例 8. 文字列 S = (4, 1, 4, 7, 3, 5) に対して,PrevS = (−∞, −∞, 1, 3, 2, 3), NextS = (∞, 1,
1,∞, 3, 4), CodeS = ((−∞, ∞), (−∞, 1), (1, 1), (3, ∞), (2, 3), (3, 4)) である.
表 PrevS, NextS, CodeSに関して次の 2 つの命題が成り立つ.
命題 1 ([10, 23, 24]). 文字列 S, T に対して,S ≈ T ⇐⇒ (PrevS = PrevT ∧ NextS =
NextT),すなわち,S ≈ T ⇐⇒ CodeS = CodeT が成り立つ.
命題 2 ([10, 23, 24]). 文字列 S, T が,ある正整数 i < |S|, |T | に対して S[: i] ≈ T [: i] を
満たしていると仮定する.a = PrevS[i + 1], b = NextS[i + 1] とする.命題 p, q をそれぞ
れ “T [a] < T [i + 1]”,“T [i + 1] < T [b]” とする.このとき,S[: i + 1] ≈ T [: i + 1] ⇐⇒
(p∧ q) ∨ (¬p ∧ ¬q) である.ただし,T [−∞] = −∞, T [∞] = ∞ とする.
op-LCE 問い合わせは不完全一般化順序保存接尾辞木(incomplete generalized
op-suffix-tree) [13] を構築し,最小共通祖先(least common ancestor, LCA) [1] を求めることで
回答できることを示す.トライ木(trie),圧縮トライ木(compacted trie),および不完 全一般化順序保存接尾辞木を次のように定義する. 定義 5 (トライ木 [14]). S を,任意の S ∈ S, T ∈ S \ {S} に対して S ̸= T [: |S|] を満たす アルファベット Σ 上の文字列の集合とする.S のトライ木は次の性質を満たす根付き木 である.木中のそれぞれの辺は文字 c∈ Σ でラベル付けされている.任意の内部節点に ついて,その子ノードへ向かうすべての辺のラベルはすべて異なる文字を持つ.s =|S| とすると,木は s 個の葉 l1,· · · , lsを持つ.木の根から葉 liへの路上のラベルを順に連接 して得られる文字列を Siで表すと,任意の S ∈ S′に対して,S = Siとなる葉 liが存在 する. 定義 6 (圧縮トライ木 [14]). T を文字列の集合 S のトライ木とする.T の根を除いた次 数 1 の内部節点の集合を V とする.すべての u∈ V について,節点 v を u の子孫かつ次 数が 1 ではないもの (すなわち,次数が 2 以上または葉である節点) とし,u から v への
路上のラベルを順に連接して得られる文字列を S とすると,T の u から v への路をラベ ル S の辺に置換して得られる木を S の圧縮トライ木という. 定義 7 (不完全一般化順序保存接尾辞木 [13]). アルファベット Σ 上の t 個の文字列 S1,· · · , St に対して,アルファベット (N∪{−∞, ∞})2∪{# 1,· · · , #t}上の文字列の集合 SufCodesS1,··· ,St を SufCodesS1,··· ,St ={CodeSi[j:]· #i : 1≤ i ≤ t かつ 1 ≤ j ≤ |Si|} と定義する.ただし, #1,· · · , #tを互いに相異なる終端記号とする.すなわち,#1,· · · , #tを,#1,· · · , #t̸∈ (N ∪ {−∞, ∞})2かつそれぞれの 1 ≤ i < j ≤ t に対して,# i ̸= #j を満たすものとす る.SufCodesS1,··· ,St の圧縮トライ木を T とする.T 中のそれぞれの辺 e に対して,e の ラベルの文字列を S とし,e のラベルを文字 S[1] に置き換えて得られる木を,t 個の文 字列 S1,· · · , Stの一般化順序保存接尾辞木という.一般化順序保存接尾辞木中の節点 v からその子に向かう辺のうち,ラベルの文字を空文字に置き換えた辺を,v の不完全辺 (incomplete edge)という.不完全一般化順序保存接尾辞木は,一般化順序保存接尾辞木 中のそれぞれの節点について高々1 つの不完全辺を許したものである.なお,それぞれ の CodeSi[j:]· #iに対応する不完全一般化順序保存接尾辞木中の葉は対 (i, j) を保持し,対 (i, j) が与えられたときそれに対応する葉を定数時間で計算できると仮定する.また,不 完全一般化順序保存接尾辞木中のそれぞれの節点は自身の深さを保持する. 図 4.1 に一般化順序保存接尾辞木の例を示す.不完全一般化順序保存接尾辞木につい て次の補題が成り立つ. 補題 3 ([13]). t 個の文字列 S1,· · · , Stに対して s =|S1|+· · ·+|St| とする.また,c を整数 定数とし,S1,· · · , Stをそれぞれ整数アルファベット Σ ={1, · · · , sc} 上の文字列とする.t
個の文字列 S1,· · · , Stの不完全一般化順序保存接尾辞木は最悪 O(s log2log s/ log log log s)
時間と O(s) 領域で構築できる. 補題 3 より,次の補題を得る.
補題 4. 任意の順序アルファベット上の t 個の文字列 S1,· · · , Stの不完全一般化順序保存
接尾辞木は,s =|S1|+· · ·+|St| とすると,最悪 O(s log s) 時間と O(s) 領域で構築できる.
証明. 任意の順序アルファベット上の t 個の文字列 S1,· · · , Stに対し,すべての 1≤ i ≤ tに
(−∞, ∞) #1 (1, ∞) (2, ∞) (1,2) (−∞, 1) (4,2) #1 (−∞, 1) (−∞, 3) (3,1) #1 #1 (−∞, 1) (−∞, 2) (2,1) #1 (1, ∞) #1 (1,2) (1,1) (1,3) (1,4) (1,5) (1,6) (1,2) (2, ∞) (5, ∞) #2 (2,1) (2,1) (1, ∞) (4, ∞) #2 (2,2) (3, ∞) #2 (2,3) #2 (2,4) #2 (2,5) #2 (2,6) (a) S1 = (2, 7, 8, 3, 1, 5), S2 = (1, 3, 0, 2, 6, 9)に対するSufCodesS1,S2 のトライ木 (−∞, ∞) #1 (1, ∞) (2, ∞) (1,2) (−∞, 1) (−∞, 3) #1 (−∞, 1) (−∞, 2) (1, ∞) (1,2) (1,1) (1,3) (1,4) (1,5) (1,6) (1,2) (2,1) (2,1) (2,2) (3, ∞) (2,3) #2 (2,4) #2 (2,5) #2 (2,6) lca(u, v) u v (b) S1 = (2, 7, 8, 3, 1, 5), S2 = (1, 3, 0, 2, 6, 9)の一般化順序保存接尾辞木.max{l : S1⟨1, +l⟩ ≈ S2⟨1, +l⟩}は,CodeS1[1:]· #1 とCodeS2[1:]· #2 に対応する葉u, v の最小共通祖先であるw = lca(u, v)の深さと一致する. 図 4.1: 一般化順序保存接尾辞木の例
時間で計算できる手続きを示す.文字列 T に対して,それぞれの 1 ≤ i ≤ |T | に対して RankT[i] = 1 +|{1 ≤ j ≤ |T | : T [j] < T [i]}| と定義すると,任意の文字列 T , T′に対して
T ≈ T′ ⇐⇒ RankT = RankT′ が成り立つ [23].また,任意の順序アルファベット上の 文字列 T に対して,定義より明らかに任意の 1≤ i ≤ |T | で RankT[i]∈ {1, · · · , |T |} を満 たす.なお,ソートを行うことで,文字列 T に対する RankT は O(|T | log |T |) 時間で計算 できる.したがって,文字列 S1,· · · , Stを文字列 RankS1,· · · , RankStに変換すればよい. 2 根付き木 T 中の節点 u, v の最小共通祖先 (LCA) を次のように定義する. 定義 8 (最小共通祖先 [1]). 根付き木 T 中の節点 u, v の最小共通祖先は,u と v 両方の先 祖である節点 w の中で,T において深さが最大のものである. 補題 5 ([1]). |V | を T 中の節点数とすると,O(|V |) 時間の前処理を行うことで,根付き 木 T 中の任意の 2 つの節点の最小共通祖先は定数時間と O(|V |) 領域で計算できる. 不完全一般化順序保存接尾辞木における最小共通祖先について,次の観察が成り立つ. 観察 1. T を文字列 S1と S2の不完全一般化順序保存接尾辞木とする.u, v をそれぞれ T 中の CodeS1[i1:]· #1と CodeS2[i2:]· #2に対応する葉とする.また,節点 w を u と v の最小
共通祖先とする.このとき,T における w の深さは max{l : S1⟨i1, +l⟩ ≈ S2⟨i2, +l⟩} と一
致する.
以上より,次の補題を得る.
補題 6. 順序アルファベット上の文字列 S1, S2の op-LCE 問い合わせは O((|S1|+|S2|) log(|S1|+
|S2|)) 時間の前処理を行い定数時間と O(|S1| + |S2|) 領域で回答できる. しかしながら,不完全一般化順序保存接尾辞木は実装が容易でない.本稿では,O(|S1||S2|) 時間の前処理を行い,op-LCE 問い合わせに定数時間で回答する,より実装が容易な手 法を提案する.前処理ですべての 1 ≤ i1 ≤ |S1|, 1 ≤ i2 ≤ |S2| に対して opLCE[i1, i2] を O(|S1||S2|) 時間で計算することで op-LCE 問い合わせに定数時間で回答できる. 前処理では,次に定義される表を効率よく計算する Z アルゴリズム [19, 20] を用いる.
定義 9 (Z 表). 文字列 S の Z 表 ZSを,それぞれの 1≤ i ≤ |S| に対して ZS[i] = max{l : S⟨1, +l⟩ ≈ S⟨i, +l⟩} と定義する. 補題 7 (Z アルゴリズム [20]). 文字列 S の Z 表 ZSは O(|S| log |S|) 時間と線形領域で計 算できる. 例 9. 文字列 S = (9, 16, 22, 18, 23, 27) に対する Z 表は ZS = (6, 2, 1, 3, 2, 1) である. 定義より opLCE [i1, i2] = min { Z(S1·S2)[i1:][|S1| − i1+ i2+ 1], |S1| − i1+ 1 } (4.1) が成り立つ. 文字列 S に対して,Hasan ら [20] が提案した Z アルゴリズムは O(|S| log |S|) 時間か かるため,もし Z アルゴリズムと式 (4.1) を素朴に用いると,すべての 1 ≤ i1 ≤ |S1|,
1 ≤ i2 ≤ |S2| に対して opLCE[i1, i2] を計算するのに O((|S1| + |S2|)2log(|S1| + |S2|)) 時
間必要である.
Z アルゴリズムでは前処理として表 PrevS, NextS を求める.Z アルゴリズムでは表
PrevS, NextSの計算に O(|S| log |S|) 時間かかり,それ以外のすべての操作は O(|S|) 時間
しかかからない.したがって,O(|S| log |S|) 時間の前処理を 1 回行うことでそれぞれの
1≤ i ≤ |S| に対して表 PrevS[i:], NextS[i:]を O(|S|) 時間で求めることができれば,すべて
の 1≤ i ≤ |S| に対して ZS[i:]を合計 O(|S|2) 時間で計算することができる.
表 PrevS[i:], NextS[i:]を計算するために,平衡二分探索木を用いる Hasan ら [20] のアル
ゴリズムの代わりに,Kubica ら [24] が提案したソートを基にしたアルゴリズムを修正し たものを用いる.まず前処理として,それぞれ昇順と降順に S の位置を S の要素に基づ
いて安定ソートした表 S′, S′′を O(|S| log |S|) 時間で計算する.
例 10. 文字列 S = (4, 1, 4, 7, 3, 5) に対して,S′ = (2, 5, 1, 3, 6, 4), S′′ = (4, 6, 1, 3, 5, 2) で ある.
対して次式が成り立つことを示した. PrevS[S′[j]] = S′[k] (k = max1≤l<j{l : S′[l]≤ S′[j]} が存在するとき) −∞ (それ以外のとき), NextS[S′′[j]] = S′′[k] (k = max1≤l<j{l : S′′[l] ≤ S′′[j]} が存在するとき) ∞ (それ以外のとき). (4.2)
したがって,表 PrevS[i:], NextS[i:]と S′, S′′の関係について,それぞれの 1 ≤ j ≤ |S| に対
して次式が導かれる. PrevS[i:][S′[j]− i + 1] = S′[k]− i + 1 ( k = max1≤l<j{l : S′[l]≤ S′[j]∧ S′[l]≥ i} が存在するとき ) −∞ (それ以外のとき), NextS[i:][S′′[j]− i + 1] = S′′[k]− i + 1 ( k = max1≤l<j{l : S′′[l]≤ S′′[j]∧S′′[l]≥ i} が存在するとき ) ∞ (それ以外のとき). (4.3)
Kubica らは式 (4.2) に基づきスタックを用いるアルゴリズムで表 PrevS, NextSを O(|S|)
時間で計算できることを示した.Kubica らのアルゴリズムを応用することで,式 (4.3)
に基づき表 PrevS[i:], NextS[i:]を O(|S|) 時間で計算できる.以上より,文字列 S につい
て,O(|S| log |S|) 時間の前処理を行うことでそれぞれの 1 ≤ i ≤ |S| に対して表 PrevS[i:],
NextS[i:]を合計 O(|S|2) 時間できるため,表 ZS[i:]を合計 O(|S|2) 時間で計算できること
を示せた.したがって,式 (4.1) より,すべての 1 ≤ i1 ≤ |S1|, 1 ≤ i2 ≤ |S2| に対して opLCE [i1, i2] を O(|S1||S2|) 時間で計算できる. Algorithm 3, 4, 5 に Z アルゴリズムを基にした op-LCE 問い合わせに対するアルゴリ ズムの擬似コードを示す.push(x) 操作はスタックの先頭に要素 x を追加し,top() 操作 は先頭の要素を返し,pop() 操作は先頭の要素を削除する.Algorithm 5 は上で議論した ように O(|S1||S2|) 時間かかる.Z アルゴリズムが線形領域で動作し [20],表 opLCE が O(|S1||S2|) 領域必要なため,領域計算量は合計 O(|S1||S2|) である.以上より,次の補題 が成り立つ.
補題 8. 文字列 S1, S2の op-LCE 問い合わせは O(|S1||S2|) 時間の前処理を行い定数時間
と O(|S1||S2|) 領域で回答できる.
opLCE(i, j) を文字列 XR, YR,XR中の位置 i,YR中の位置 j についての op-LCE 問い
合わせの回答とする.次に k ≤ l ≤ opLCE(m − i + 1, n − j + 1) に対して C[i − l, j − l] + l
の最大値を定数時間で計算する方法を考える.表 A を保持し,次の 2 つの操作に対応す る準動的区間最大値問い合わせ(semi-dynamic range maximum query,準動的 RMQ) のためのデータ構造を用いる. • prepend(x): 表 A の先頭に要素 x を償却定数時間で追加する. • rmq(i1, i2): A[i1 : i2] の最大値を定数時間で返す. 準動的 RMQ のデータ構造の詳細は第 5 章で述べる. 任意の 1≤ i ≤ m, 1 ≤ j ≤ n に対して,以下の自明な補題が成り立つ. 補題 9. i ≥ j を仮定しても一般性を失わない.それぞれの 1 ≤ l ≤ j に対して,A[l] =
C[i− l, j − l] + l, A′[l] = C[i− l, j − l] − j + l とする.任意の 1 ≤ i1, i2 ≤ |A| に対して,
maxi1≤l≤i2A[l] = (maxi1≤l≤i2A′[l]) + j と argmaxi1≤l≤i2A[l] = argmaxi1≤l≤i2A
′[l] が成り
立つ.
補題 9 より準動的 RMQ のデータ構造を用いることで,すべての 1≤ i ≤ m, 1 ≤ j ≤ n
に対して maxk≤l≤opLCE(m−i+1,n−j+1){C[i − l, j − l] + l} を合計 O(mn) 時間で計算できる.
Algorithm 6 に op-LCSk+ を計算するアルゴリズムを示す.図 4.2 に op-LCS2+ の計算
例を示す.上で議論したように,提案アルゴリズムは O(mn) 時間で動作する.それぞれ の準動的 RMQ のデータ構造は線形領域必要で,合計 O(mn) 個の要素が準動的 RMQ の データ構造で保持される.したがって,合計の領域計算量は O(mn) である.ゆえに次の 定理を得る.
4 0 9 6 2 0 3 1 0 1 2 3 4 5 6 7 8 0 0 0 0 0 0 0 0 0 0 5 1 0 0 0 0 0 0 0 0 0 1 2 0 0 2 2 2 2 2 2 2 3 3 0 0 2 2 2 2 2 2 2 8 4 0 0 2 2 2 2 2 4 4 7 5 0 0 2 2 4 4 4 4 5 2 6 0 0 2 2 4 5 5 5 5 (a)表Cの例 𝑘 = 2 opLCE(2, 5) = 3 𝑅1 𝐶[4,3] 𝐶[3,2] 𝐶[2,1] 𝐶[1,0] 2 2 0 0 + + + + −3 −2 −1 0 = = = = −1 0 −1 0 max 𝑘≤𝑙≤opLCE(2,5){𝐶 5 − 𝑙, 4 − 𝑙 + 𝑙} = 𝑅1.rmq 2,3 + min 5,4 = 4 𝐶[5,4]のとき 𝐶[6,5]のとき 𝑘 = 2 opLCE(1, 4) = 3 𝑅1 𝐶[5,4] 𝐶[4,3] 𝐶[3,2] 𝐶[2,1] 𝐶[1,0] 4 2 2 0 0 + + + + + −4 −3 −2 −1 0 = = = = = 0 −1 0 −1 0 max 𝑘≤𝑙≤opLCE(1,4){𝐶 6 − 𝑙, 5 − 𝑙 + 𝑙} = 𝑅1.rmq 2,3 + min 6,5 = 5
(b) C[5, 4], C[6, 5]のときのmaxk≤l≤opLCE(m−i+1,n−j+1){C[i − l, j − l] + l}の計算例
Algorithm 3: 表 PrevS[i:],NextS[i:]を計算するアルゴリズム
1 Function preprocess(S, i, S′, S′′)
2 s, t を push, top, pop 操作に対応する空のスタックとする;
3 Prev , Next を大きさ|S| − i + 1 の表とする;
4 for j ← 1 to |S| do
5 if S′[j]≥ i then
6 while s̸= ∅ and s.top() > S′[j] do s.pop(); 7 if s = ∅ then Prev[S′[j]− i + 1] ← −∞; 8 else Prev [S′[j]− i + 1] ← s.top() − i + 1;
9 s.push(S′[j]);
10 if S′′[j]≥ i then
11 while t ̸= ∅ and t.top() > S′′[j] do t.pop(); 12 if t = ∅ then Next[S′′[j]− i + 1] ← ∞; 13 else Next [S′′[j]− i + 1] ← t.top() − i + 1;
14 t.push(S′′[j]);
Algorithm 4: 表 ZS[:i1]を計算する Z アルゴリズム
1 Function Z-function(S, i1, S′, S′′)
2 (Prev , Next )← preprocess(S, i1, S′, S′′);
3 S ← S[i1 :]; 4 Z を大きさ|S| の表とする; 5 Z[1]← |S|; 6 L← 1; 7 R ← 1; 8 for i ← 2 to |S| do 9 Z[i]← 0;
10 if i ≤ R then Z[i] ← min{R − i + 1, Z[i − L + 1]} ;
// S[: Z[i] + 1]≈ S[i : i + Z[i]] か確認する
11 p← S[Prev [Z[i] + 1] + i − 1] < S[i + Z[i]];
12 q ← S[i + Z[i]] < S[Next [Z[i] + 1] + i − 1];
13 while i + Z[i]≤ |S| ∧ ((p ∧ q) ∨ (¬p ∧ ¬q)) do 14 Z[i]← Z[i] + 1; 15 if i + Z[i]− 1 > R then 16 L← i; 17 R ← i + Z[i] − 1; 18 return Z;
Algorithm 5: op-LCE 問い合わせに対するアルゴリズム 1 Function preprocess-opLCE(S1, S2) 2 opLCE を大きさ|S1| × |S2| の表とする; 3 S ← S1· S2; 4 S′, S′′をそれぞれ昇順と降順に S の位置を S の要素に基づいて安定ソートした表 とする; 5 for i1 ← 1 to |S1| do 6 Z ← Z-function(S, i1, S′, S′′); 7 for i2 ← 1 to |S2| do 8 opLCE [i1, i2]← min { Z[|S1| − i1+ i2+ 1],|S1| − i1+ 1 } ; 9 return opLCE ;
Algorithm 6: op-LCSk+ 問題に対する提案アルゴリズム Input: 長さ m の文字列 X, 長さ n の文字列 Y , 整数 k ≥ 2 Output: X と Y の op-LCSk+の長さ 1 C を 0 で初期化された大きさ (m + 1)× (n + 1) の表とする; 2 −n + k ≤ i ≤ m − k に対して Riを準動的 RMQ のデータ構造とする; 3 opLCE ← preprocess-opLCE(XR, YR); 4 for i ← 0 to m − k do 5 if i < k then n′ ← n − k; 6 else n′ ← k − 1;
7 for j ← 0 to n′ do Ri−j.prepend(C[i, j]− min{i, j}); 8 for i ← k to m do
9 for j ← k to n do
10 l ← opLCE[m − i + 1, n − j + 1];
11 if l≥ k then M ← Ri−j.rmq(k, l) + min{i, j};
12 else M ← 0;
13 C[i, j]← max{C[i, j − 1], C[i − 1, j], M};
14 Ri−j.prepend(C[i, j]− min{i, j});
4.2
O(mn log k/log log k)
時間・
O(n + km)
領域アルゴリズム
本節では前節の O(mn) 時間・領域アルゴリズムを修正することにより,op-LCSk+ 問
題が n ≥ m を仮定して O(mn log k/log log k) 時間と O(n + km) 領域で解けることを示
す.Algorithm 2 と同様に表 C を列優先順(column-major order)で計算する.表 C は Algorithm 6 の 13 行目より現在の列と前回の列のみを保持すれば十分なので,Algorithm 2
と同様に剰余演算を用いて大きさを (m + 1)× 2 に削減できる.栗原ら [27] は次の補題を
示した.
補題 10 ([27]). 任意の 1 ≤ i ≤ m, 1 ≤ j ≤ n に対して maxk≤l≤opLCE(m−i+1,n−j+1){C[i −
l, j− l] + l} = maxk≤l≤min{2k,opLCE(m−i+1,n−j+1)}{C[i − l, j − l] + l} が成り立つ.
補題 10 より,Algorithm 6 中の RMQ のデータ構造はそれぞれ先頭から高々2k 個の要 素を保持すれば十分である.しかし,前章で用いた準動的 RMQ は要素の削除に対応して いないため,要素の削除に対応した動的 RMQ(dynamic range minimum query) [5, 21] を用いる.
補題 11 (動的 RMQ [5]). 長さ s の表 A を保持し,A 中の位置 i1, i2に対して A[i1 : i2] の最
大値を O(log s/ log log s) 時間で計算し,A の要素の追加と削除を償却 O(log s/ log log s) 時間で行える線形領域で動作するデータ構造が存在する.
Algorithm 6 で準動的 RMQ の代わりに動的 RMQ を用いて,14 行目で要素を先頭に追 加した後,もし保持している要素数が 2k より多い場合末尾の要素を削除を行うことで, 動的 RMQ のデータ構造に関しての領域計算量は合計 O(km) に削減することができる. また,動的 RMQ の各操作は合計 O(mn log k/ log log k) 時間必要である.
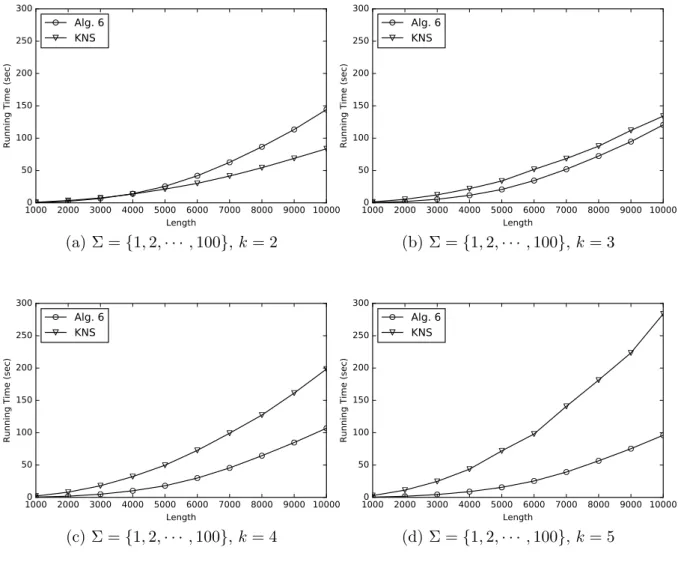
表 opLCEXRYR に関して,最初に表全体を計算するのではなく,必要な列を逐次的に 計算することで O(m) 領域に削減することができる.表 C の j 列目を計算するには,表 opLCEXRYRの n−j +1 列目,すなわちそれぞれの k ≤ i ≤ m に対して opLCEXRYR[m− i + 1, n− j + 1] が必要である.これは式 (4.1) より,それぞれの k ≤ i ≤ m に対して opLCEXRYR[m− i + 1, n − j + 1] = min { Z(YRXR)[n−j+1:][n + j− i + 1], j − 1 } が成り立つ ため,線形時間・領域で計算することができる.また,Z アルゴリズムの前処理で計算す るソートした表は n≥ m を仮定して O(n) 領域必要である.以上より,次の定理を得る.
第
5
章
準動的区間最小
(
最大
)
値問い合わせ
本章では準動的区間最小値問い合わせ(semi-dynamic range minimum query, 準動的
RMQ)問題に対する最悪定数問い合わせ時間と償却定数追加時間で動作し線形領域必 要なアルゴリズムを提案する.まず,Fischer [17] の既存手法を述べる.Fischer のアルゴ リズムは実装が難しいため,同等の計算量で動作する,実装が容易なアルゴリズムを提 案する.
5.1
問題定義
準動的 RMQ 問題を次のように定義する. 定義 10 (準動的 RMQ 問題 [17]). 表の末尾もしくは先頭どちらか一方のみに要素を追加 する操作に対応する表 A に対して,準動的 RMQ 問題は,A 中の位置 1≤ i1 ≤ i2 ≤ |A|に対して rmqA(i1, i2) = argmini1≤j≤i2{A[j]} を求める.区間内に最小値となる位置が複数
存在する場合,最右の位置を求める.
簡単化のために,表の末尾に要素を追加する操作のみを考える.
5.2
既存手法
この問題に対して,Fischer [17] は 2 次元最小ヒープ(2d-Min-Heap) [18] と動的最小 共通祖先(dynamic least common ancestor, dynamic LCA)問い合わせ [11] を用いたア ルゴリズムを示した.
𝐴 = 𝐵 = 𝐸 = 𝐷 = 4 6 5 7 3 4 5 3 0 1 5 1 2 3 4 5 6 7 8 2 3 4 8 7 6 0 1 2 1 3 4 3 1 0 5 6 7 6 5 0 8 0 1 2 1 2 3 2 1 0 1 2 3 2 1 0 1 1 2 4 5 9 10 11 15 rmq𝐴(2,4) rmq𝐴(5,7) rmq𝐷2,5 + 1 rmq𝐷(9,11) lca(2,4) lca(5,7) -∞ 4 6 5 7 3 4 5 3 図 5.1: 2 次元最小ヒープ [18] と±1RMQ アルゴリズム [1] を用いた準動的 RMQ の計算 例.図の右の木は A = (4, 6, 5, 7, 3, 4, 5, 3) の 2 次元最小ヒープである.2 次元最小ヒープ の灰色の節点および辺と表 B, E, D の灰色の数字は A[8] = 3 に対応する要素を表す.破 線は rmqA(2, 4), rmqA(5, 7) の答えを表す.
定義 11 (2 次元最小ヒープ (2d-Min-Heap) [18]). 長さ n の表 A = (A[1],· · · , A[n]) の 2 次
元最小ヒープ H は,節点{0, · · · , n} を持つ順序木である.それぞれの 1 ≤ i ≤ n に対し て,j < i かつ A[j] < A[i] を満たす最大の j について,節点 i の親を節点 j とする.ただ し,A[0] =−∞ とする.子の順序はラベルが左から右に増えるように選ばれる. 2 次元最小ヒープに関して,次の補題が成り立つ. 補題 12 ([18]). H を長さ n の表 A の 2 次元最小ヒープとする.節点 u を節点 i1, i2の LCA とする.このとき,もし i1 = u ならば,rmqA(i1, i2) = u である.そうでないとき,u の 子かつ i2の先祖である節点を v とすると,rmqA(i1, i2) = v である. また,2 次元最小ヒープに関して,次の観察と命題が成り立つ. 観察 2 ([17]). 表 A の 2 次元最小ヒープを H とする.表 A の末尾に要素 x を追加した 表を A′ = A· (x) とする.H の根から葉へ辿る最右路上の節点を順に u 1, u2,· · · , usとし
v = max1≤i≤s{ui : A[ui] < x} とする.このとき,H の節点 v の最右の子となるように節
点|A| + 1 を追加したものと,A′の 2 次元最小ヒープ H′は一致する.
補題 13 ([17]). 表 A の 2 次元最小ヒープを H とする.表 A の末尾に要素 x を追加した表 の 2 次元最小ヒープは H から償却定数時間で更新できる.
観察 2 より,新たに追加される節点は必ず葉になることに注意する.Cole と Hariharan [11] は次の補題を示した.
補題 14 (動的 LCA [11]). 木を保持し,葉を追加する操作と任意の 2 つの節点の LCA を 求める操作を最悪定数時間と線形領域で行えるデータ構造が存在する. 補題 13, 14 より,次の補題が得られる. 補題 15 ([17]). 準動的 RMQ 問題は,線形領域で最悪定数問い合わせ時間と償却定数追 加時間で解ける.
5.3
提案手法
Fischer の提案アルゴリズムで用いる動的 LCA のアルゴリズムは実装が容易ではない. 本節では,同等の計算量で動作する,実装が容易な準動的 RMQ のアルゴリズムを提案 する.提案アルゴリズムは 2 次元最小ヒープと Bender と Farach-Colton [1] が提案した ±1RMQ 問題に対するアルゴリズムを用いる.定義 12 (±1RMQ 問題 [1]). すべての 1 ≤ i < |A| に対して A[i + 1] − A[i] = ±1 を満た
すような表 A と,A 中の位置 1 ≤ i1 ≤ i2 ≤ |A| に対して,±1RMQ 問題は rmqA(i1, i2)
を求める.
H を表 A の 2 次元最小ヒープとする.E′と D′をそれぞれ H を根から行きがけ順
(pre-order) に辿って得られるオイラー巡回路 (Euler tour) 上の節点とその深さ,s を H の最
右路上の辺の数とし,E と D をそれぞれ E′[:|E′| − s],D′[:|D′| − s] とする.また,そ
れぞれの 1≤ i ≤ |A| に対して B[i] = min{1 ≤ j ≤ |E| : E[j] = i} とする.このとき,明
らかに次の命題が成り立つ.
命題 3. すべての 1≤ i < |D| に対して,D[i + 1] − D[i] = ±1 が成り立つ.
命題 4. |D| = |E| = O(|A|),|B| = |A| が成り立つ.
表 A 中の位置 1≤ i1 < i2 ≤ |A| に対して,lca(i1, i2) を H 中の節点 i1, i2の LCA とす
る.命題 3 より,表 D に対して±1RMQ が適用できる.Bender と Farach-Colton [1] が示
した LCA と RMQ の関係を 2 次元最小ヒープ H に適用することにより次の補題を得る.
補題 16 ([1]). 表 A 中の位置 1 ≤ i1 ≤ i2 ≤ |A| に対して,u = lca(i1, i2) とすると,
また,LCA と RMQ の関係について次の観察が成り立つ.
観察 3. 表 A 中の位置 1≤ i1 ≤ i2 ≤ |A| に対して,u = lca(i1, i2) とする.u の子かつ i2
の先祖である節点を v とすると,rmq が最右の最小値となる位置を返すことに注意して
v = E[rmqD(B[i1], B[i2]) + 1] が成り立つ.
補題 12, 16 と観察 3 より,次式を得る. rmqA(i1, i2) =
E[rmqD(B[i1], B[i2])] (E[rmqD(B[i1], B[i2])] = i1のとき)
E[rmqD(B[i1], B[i2]) + 1] (E[rmqD(B[i1], B[i2])]̸= i1のとき).
(5.1) 図 5.1 に準動的 RMQ の計算例を示す.表 A の末尾に要素を追加したとき,定義より 表 B, E, D は末尾に要素が追加されるように更新される.そのため,表 A, B, E, D への 要素の追加操作は命題 4 より,事前に追加要素数が与えられるかもしくは動的配列 [12] で保持すれば償却定数時間で行える.よって,式 (5.1) より,表 D の±1RMQ が準動的 に,すなわち表の末尾に要素を追加する操作に償却定数時間で対応する最悪定数問い合 わせ時間のアルゴリズムを示せばよい. 補題 17. 表の末尾もしくは先頭どちらか一方のみに要素を追加する操作を許した準動的 ±1RMQ 問題は,線形領域で償却定数追加時間と最悪定数問い合わせ時間で解ける. 補題 17 の証明は後述する.補題 17 と式 (5.1) より,次の補題を得る. 補題 18. 準動的 RMQ 問題は,線形領域で償却定数追加時間と最悪定数問い合わせ時間 で解ける.
5.4
±1RMQ
の既存手法
補題 17 を証明するために,Bender と Farach-Colton [1] が提案した±1RMQ の既存手 法を応用する.本節では彼らの既存手法を詳述する.彼らのアルゴリズムでは RMQ のア ルゴリズムであるスパーステーブル(sparse table)アルゴリズムと表引き(table lookup) アルゴリズムを組み合わせる.5.4.1 スパーステーブルアルゴリズム
スパーステーブルアルゴリズムは,長さ n の表 A に対して O(n log n) 時間の前処理を 行い,RMQ に対して定数問い合わせ時間を実現するアルゴリズムである.それぞれの
0≤ j ≤ ⌊log2n⌋, 1 ≤ i ≤ n − 2j+ 1 に対して,STA[i, j] = rmqA(i, 2j) とすると,次の漸
化式が成り立つ. STA[i, j] = i (j = 0 のとき)
STA[i, j− 1] (A[STA[i, j− 1]] < A[STA[i + 2j−1, j− 1]] のとき) STA[i + 2j−1, j− 1] (それ以外のとき). (5.2) 式 (5.2) に基づいた動的計画法により,表 STAは O(n log n) 時間で計算することができ る.表 A 中の位置 1 ≤ i1 ≤ i2 ≤ n に対して rmqA(i1, i2) は,l =⌊log2(i2− i1+ 1)⌋ とす ると次式より定数時間で計算できる. rmqA(i1, i2) = STA[i1, l] (A[STA[i1, l]] < A[STA[i2− 2l+ 1, l]] のとき) STA[i2− 2l+ 1, l] (A[STA[i1, l]]≥ A[STA[i2− 2l+ 1, l]] のとき). (5.3) 5.4.2 表引きアルゴリズム 表引きアルゴリズムは,長さ n の表 A に対して O(n2) 時間の前処理を行い,RMQ に 対して定数問い合わせ時間を実現するアルゴリズムである.それぞれの 1≤ i ≤ j ≤ n に 対して TLA[i, j] = rmqA(i, j) とすると次の漸化式が成り立つ. TLA[i, j] = i (i = j のとき)
TLA[i, j− 1] (A[TLA[i, j− 1]] < A[j] のとき)
j (それ以外のとき).
(5.4)
0 1 2 3 1 1 2 4 4 2 2 2 4 4 3 3 4 4 4 4 4 4 4 4 5 5 5 7 7 6 6 7 7 7 7 7 7 8 8 9 10 9 9 10 10 10 10 10 11 11 11 12 12 図 5.2: A = (3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5, 8) に対する表 STAの例.A[12] = 8 に対応する要 素を灰色で示す. 1 2 3 4 5 1 1 2 3 3 3 2 2 3 3 3 3 3 3 3 4 4 4 5 5 図 5.3: A = (2, 1, 0, 1, 2) に対する表 TLAの例. 5.4.3 ±1RMQ アルゴリズム すべての 1 ≤ i < n に対して A[i + 1] − A[i] = ±1 を満たすような長さ n の表 A に対 して,O(n) 時間の前処理を行い±1RMQ に対して定数問い合わせ時間を実現するアルゴ リズムを示す.表 A を重なり無く長さ s = ⌈(log2n)/2⌉ のブロックに分割する.簡単化 のために,n > 1 かつ n が s で割り切れると仮定する.n が s で割り切れない場合,A の 末尾に±1 の制約を満たすように n が s で割り切れるまでダミーデータを追加すればよ い.このとき,A には高々⌈(log2n)/2⌉ − 1 個しか要素が追加されないため計算量には影 響を与えない.m をブロック数,すなわち m = n/s = n/⌈(log2n)/2⌉ とする.表 A の i 番目のブロック A⟨s(i − 1) + 1, +s⟩ を Aiと表記する.それぞれの 1 ≤ i ≤ m に対して,
A′[i] を Aiの最小値とする.表 A′に対するスパーステーブル STA′ は,|A′| = m なので, O(m log m) = O(n) 時間で構築できる.
表 A の各ブロックに対して表引きアルゴリズムを用いる.すなわち,それぞれの 1 ≤ i ≤ m に対して表 TLAiを計算する.ただし,素朴に式 (5.4) に基づき TLAiを計算する と合計 O(n2) 時間必要なので,表 A が±1 の制約を満たしていることに注目した工夫を する.それぞれの 1≤ i ≤ m に対して Aiの正規化ブロック Niを,それぞれの 1≤ j ≤ s に対して Ni[j] = Ai[j]− Ai[1] と定義する.表 A のすべてのブロックの正規化ブロックの 集合を N ={Ni : 1≤ i ≤ m} とする.なお,集合の定義より |N| ≤ m が成り立つこと に注意する.ここで次の命題が成り立つ. 命題 5 ([1]). 長さ s の表 T1, T2に対して,それぞれの 1≤ i ≤ s と定数 c に対して T2[i] =
T1[i] + c が成り立っているならば,任意の 1≤ i ≤ j ≤ s に対して rmqT2(i, j) = rmqT1(i, j) が成り立つ. 命題 6 ([1]). |N| = O(√n) が成り立つ. 証明. 表 A は±1 の制約を満たし,ブロックの大きさが s = ⌈(log2n)/2⌉ であることに注 目すれば,正規化ブロックは 2⌈(log2n)/2⌉−1 = O(√n) 通り存在する. 2 すべての N ∈ N に対して TLN を計算すると O( √ n× ((log2n)/2)2) = O(n) 時間かか る.計算済みの TLN と命題 5 を用いることにより,すべての 1 ≤ i ≤ m に対して TLAi を線形時間で計算することができる. すべての TLAiと,表 A′に対するスパーステーブル STA′が計算されたとすると,rmqA(i1, i2) は高々A′に対するスパーステーブルによる RMQ を 1 回と i 1と i2が所属するブロックの 表引きアルゴリズムによる RMQ を 2 回計算することにより,定数時間で計算できる.
5.5
補題
17
の証明
本節では補題 17 の証明を示す.第 5.4 章で示した Bender と Farach-Colton [1] の既存 ±1RMQ アルゴリズムは事前に最終的な表 A の大きさ n が与えられれば,償却定数追加 時間と最悪定数問い合わせ時間で動作することがわかる.したがって,次の補題を得る.補題 19. 準動的±1RMQ 問題は事前に最終的な表の大きさ n が与えられれば,償却定数 追加時間と最悪定数問い合わせ時間で解ける. 準動的±1RMQ のデータ構造 R に対して,大きさを R に追加された要素数とし,容 量を R を最初に作成するときに指定する R に追加される最終的な要素数とする.次に, 事前に容量が与えられなくても,動的配列 [12] と同様に指数的に容量を増やした準動的 ±1RMQ を作成していくことにより,償却定数追加時間が実現できることを示す.準動 的±1RMQ のデータ構造で保持される最終的な表を A とし,その大きさを n とする.最 初は容量 0 の準動的±1RMQ のデータ構造を保持する.それぞれの 1 ≤ i ≤ n に対して, i 回目の追加操作を次のように行う. (i− 1 が 2 のべき乗であるとき) 現在保持している準動的±1RMQ のデータ構造を破棄し,新たに容量 2i の準動的 ±1RMQ のデータ構造を作成する.それぞれの 1 ≤ j ≤ i に対して,A[j] を新しい 準動的±1RMQ のデータ構造に追加する. (それ以外のとき) 現在保持している準動的±1RMQ のデータ構造に A[i] を追加する. i 回目の追加操作の時間計算量を ciとすると,補題 19 より i− 1 が 2 のべき乗のときは線 形時間,それ以外のときは償却定数時間なので n ∑ i=1 ci ≤ n + ⌊log∑2n⌋ j=0 2j < n + 2n = 3n が成り立つ.そのため,償却定数追加時間で動作することがわかる.また,最悪定数問 い合わせ時間で動作することは自明である.以上より,補題 17 は成り立つ.