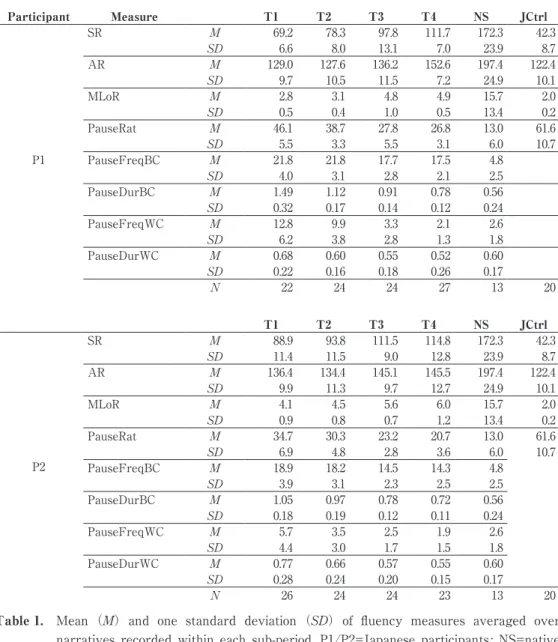
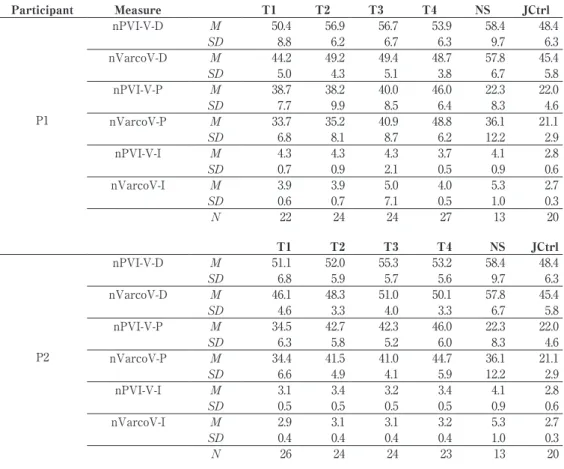
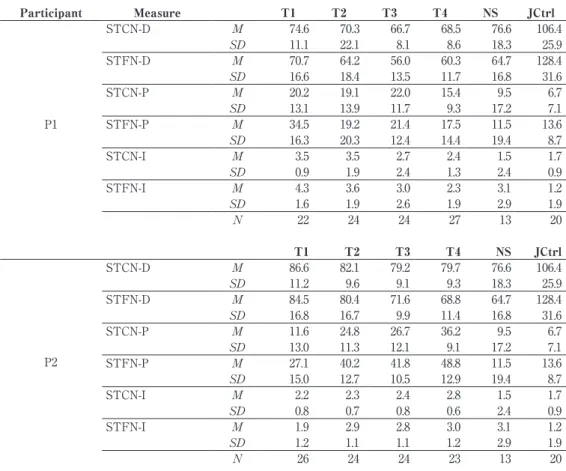
Development of fluency and English speech rhythm through individual-based, long-term speech training in the formal instruction settings
全文
図



関連したドキュメント
Today Iʼm going to make a speech about my dream... )in
Work Values, Occupational Engagement, and Professional Quality of Life in Counselors- in Training: Assessment in Constructivist- Based Career Counseling Course.. Development of
Whereas tube voltages and HVLs for these four X-ray units did not significantly change over the 103-week course, the outputs of these four X-ray units increased gradually as
In this thesis, I intend to examine how freedom of speech has been legally protected in consideration of fundamental human rights, and how the double standards in the
In order to estimate the noise spectrum quickly and accurately, a detection method for a speech-absent frame and a speech-present frame by using a voice activity detector (VAD)
patient with apraxia of speech -A preliminary case report-, Annual Bulletin, RILP, Univ.. J.: Apraxia of speech in patients with Broca's aphasia ; A
Amount of Remuneration, etc. The Company does not pay to Directors who concurrently serve as Executive Officer the remuneration paid to Directors. Therefore, “Number of Persons”
– Study on the method of reducing the dose of highly contaminated pipes by means of remote operations (removal or decontamination) and the method of installing equipment for
