する研究
著者
柏葉 祐輝
学位授与機関
Tohoku University
順序保存カーネルを用いた
時系列データの分類に関する研究
東北大学大学院 情報科学研究科
システム情報科学専攻 篠原研究室
博士課程前期二年の課程
柏葉 祐輝
2016
年
2
月
15
日
目次
第 1 章 序論 1 1.1 背景 . . . . 1 1.2 論文の構成 . . . . 2 第 2 章 準備 4 2.1 時系列データ . . . . 4 2.2 ブースティング . . . . 5 2.2.1 AdaBoost . . . . 6 2.3 既存の時系列データ類似性指標 . . . . 8 2.3.1 ユークリッド距離 . . . . 82.3.2 Dynamic Time Warping . . . . 8
2.4 既存の類似性指標を用いた分類手法 . . . . 11 第 3 章 提案手法 12 3.1 k-gram 順序保存カーネル . . . . 12 3.2 k-gram 順序保存カーネルを用いた分類手法 . . . . 15 3.2.1 単純な分類手法 . . . . 15 3.2.2 二重ブースティング . . . . 16 第 4 章 実験 18 4.1 計算時間の実験 . . . . 18 4.2 人工データを用いた正答率比較実験 . . . . 20 4.2.1 ランダム時系列データセットを用いた正答率の比較実験 . . . . . 20 4.2.2 周期性をもつ時系列データセットを用いた正答率の比較実験 . . . 21 4.2.3 異常値を含む時系列データセットを用いた正答率の比較実験 . . . 23
4.3 実データを用いた正答率比較実験 . . . . 24 4.3.1 wav データを用いたジャンル分類正答率の比較実験 . . . . 24 4.3.2 midi データを用いたジャンル分類正答率の比較実験 . . . . 26 第 5 章 まとめ 33 5.1 まとめ . . . . 33 5.2 今後の課題 . . . . 33 参考文献 35
第
1
章
序論
1.1
背景
時系列データは工学や医療,経済など様々な分野で活用されており,時系列データ解析 に関する研究は盛んに行われている.また,センサ技術の発達により容易に時系列デー タを取得することができるようになったため,扱うデータが非常に大規模になっている. そのため,時系列データをより高精度かつ高速に解析する手法が求められている. データ解析の基本的な問題のひとつにクラス分類問題がある.クラス分類問題では,特 徴ベクトル X ∈ X とラベル y ∈ {−1, 1} の組の集合 S = {(X1, y1) ,· · · , (Xm, ym)} が学 習データとして与えられ,未知のデータを分類するための識別関数 f : X → {−1, 1} を 出力する.ここで,X を入力空間と呼ぶ.クラス分類は,大きく線形分類と非線形分類 に分けることができる.非線形クラス分類では,カーネル関数を用いて暗に事例を特徴 空間へ写像してから解析を行うことが一般的である.入力空間X の事例 X が非線形変換 ϕ :X → Y で特徴空間 Y へ写像されるとすると,カーネル関数は特徴空間での事例の内 積⟨ϕ(X), ϕ(X′)⟩ を計算する関数である.文字列をはじめとする系列データに対しては, 事例を長さ k の部分文字列を次元とする特徴空間へ写像する k-gram カーネル [11] を用 いた手法が分類問題において高い精度を出している. 時系列データ分類を行うためには,2 つの時系列データ間の類似性指標を定義する必要 がある.これまでにも時系列データ間の類似性指標として,様々な距離や類似度が提案さ れてきた. [4] [1] [13].既存の時系列データ類似性指標として,ユークリッド距離 [4] や ユークリッド距離を改良した Dynamic Time Warping [1] などが知られており,これらの類似性指標は各時刻の絶対的な座標値を用いて計算することができる.しかし,時系列 データの類似性指標には個々の絶対的な座標値よりも,系列内の相対的な順序関係を用 いた方が有用である場合も多い.例えば,音楽データにおいて,同じメロディーを C 調 で弾いたデータと G 調で弾いたデータは各時刻に鳴っている音名は違うが,全体として の音程 (音の高低差) は一致しており,特徴が類似したデータであるといえる.このよう な系列の形状類似度を用いてパターン照合を行う技術として,順序保存照合と呼ばれる 方法がある [2][3][8][10].順序保存照合問題とは,テキスト T とパターン P が与えられた とき,P と順序同型な T の部分系列を出力する問題である.ここで,順序同型とは,系 列内の各値の相対的な順序関係が一致している関係のことをいう [10].系列が順序同型 であるかを判定するためには,系列を相対的な順序関係で表す必要がある.系列をこの ような大小関係による表現に変換することは,順序保存符号化,もしくは単に符号化と 呼ばれている [2] [3]. 本研究では,k-gram カーネルの特徴空間の次元を長さ k の順序保存符号化した系列パ ターン数に拡張することで,系列の形状を特徴とする類似性指標 k-gram 順序保存カー ネルを提案する.また,k-gram 順序保存カーネルを単純にクラス分類手法に適用すると, パラメータ k を適切に設定しなければならないという問題がある.そこで,k を設定せ ずにクラス分類を行う手法として二重ブースティングを提案する.さらに,計算機実験 によって k-gram 順序保存カーネルと既存類似性指標の正答率と計算時間を比較すること で,提案類似性指標の優位性を示す.
1.2
論文の構成
本論文の構成を次に示す.第 1 章では背景を述べた.次に第 2 章では,準備として時系 列データの定義と分類に用いる学習手法について述べる.また,既存の時系列データ類 似性指標であるユークリッド距離と Dynamic Time Warping について説明を行い,既存 類似性指標を用いた分類手法について説明する.第 3 章では,提案類似性指標 k-gram 順 序保存カーネルの定義と効率的な計算方法を述べ,素朴な分類手法とパラメータ k を指 定せずにクラス分類を行う二重ブースティングについて説明する.第 4 章で提案類似性 指標の計算速度と正答率の優位性を示すため,既存類似性指標との比較実験を行う.最第
2
章
準備
この章では,まず時系列データの定義と本研究で用いる機械学習アルゴリズムのブース ティングについて述べる.次に,既存の類似性指標であるユークリッド距離と Dynamic Time Warping(DTW)について説明する.最後に,ブースティングと既存類似性指標 を組み合わせて,時系列データのクラス分類を行う手法について説明する.2.1
時系列データ
ある現象を離散的な時間間隔で測定した数値列は時系列データと呼ばれ,心電図や株 価,気象データなど様々な分野で活用されている.時系列データは測定した時間 i をイン デックスとした実数 xi ∈ R を並べて表すことができる.データ長 m の時系列データ X は以下のように表すことができる. X = (x1, x2, . . . , xm) ただし xi ∈ R また,時系列データ X の i 番目から始まる長さ m 部分系列 (xi, xi+1,· · · , xi+m−1) (1 ≤ i≤ N − m + 1) を X(i,m)と表記する. 時系列データに対して,順序同型 [10] と呼ばれる関係を定義する. 定義 1 (順序同型) 長さ N の 2 つの時系列データ X = (x1, x2,· · · , xN) と Y = (y1, y2,· · · , yN) が与えられたとき,任意の 1≤ i, j ≤ N に対して xi ≤ xj ⇔ yi ≤ yj が成り立つとき,X と Y は順序同型であるという. 例 1 X = (10, 15, 30, 21, 9) と Y = (5, 7, 25, 18, 1) は順序同型である.時系列データが順序同型であるかを判定するためには,時系列データを各点の絶対的な 値ではなく,相対的な大小関係で表す必要がある.時系列データをこのような大小関係 に変換することを順序保存符号化,もしくは単に符号化と呼ぶ.時系列データを符号化 したものを符号化系列と言い,系列 X の符号化系列を Code (X) で表す.時系列データ の部分系列を符号化したものを符号化部分系列と言う.符号化した系列が一致していれ ば順序同型である. 符号化の表現には様々な方法が提案されている [2] [3].中でも最も直感的な表現方法 は,自然表現 [8] である.自然表現では,時系列データの各点の値を系列内順位で表現す る.例えば,時系列データ X = (10, 15, 30, 21, 9) と Y = (13, 19, 31, 25, 7) を自然表現で 符号化した系列 Codenr(X),Codenr(Y ) は以下のように表現される. Codenr(X) = (2, 3, 5, 4, 1) Codenr(Y ) = (2, 3, 5, 4, 1) このとき,時系列データ X と Y は符号化した系列が一致しているため順序同型である.
2.2
ブースティング
二値分類問題とは,特徴ベクトル X ∈ X とラベル y ∈ {−1,1} の組の集合 S = {(X1, y1) ,· · · , (Xm, ym)} が学習データとして与えられ,その学習データ S を基に未知 のテストデータ X′のラベルを予測する問題である.二値分類問題に対して,学習データ をもとに識別関数 f : X → {−1, 1} を生成し,その仮説を用いて二値分類を行うことを 考える.このとき,テストデータに対する正答率が高いほど識別関数 f は良い識別関数 であるといえる.しかし,精度の高い識別関数を生成するにはコストがかかるという問 題点がある.この問題点を解決するために,ブースティングと呼ばれる学習アルゴリズ ムが考案されている [6]. ブースティングは,弱仮説と呼ばれる 50%以上の正答率をもつ識別関数 h を組み合わ せて,正答率の高い統合仮説 f を生成する学習手法である.ブースティングアルゴリズ ムはいくつか提案されているが,本研究では AdaBoost [5] と呼ばれるアルゴリズムを使 用する.Algorithm 1: AdaBoost(tmax, ϵ) 弱仮説集合を H とする; 1 D1を初期の事例生成確率分布とし,t← 1 とする; 2 Repeat; 3 分布 Dtのもとでの優位度が最も高い弱仮説を htとする; 4 htの分布 Dtのもとでの優位度を γtとする; 5 htの重要度 αtを計算する; 6 f (X) = sign(∑ti=1αihi(X) ) ; 7 Dt+1を htと Dtをもとに更新; 8 t← t + 1; 9 Until (t = tmax) or (学習データでの統合仮説の正答率≥ ϵ); 10 得られた統合仮説 ftを出力; 11 2.2.1 AdaBoost
AdaBoost とは 1995 年に Freund と Schapire によって考案されたブースティングアル ゴリズムである [5].Algorithm 1 に AdaBoost のアルゴリズムを示す.AdaBoost は,ス テップ t ごとに事例生成確率分布 Dtを与え,Dtにおける学習データに対して精度の良い 弱仮説を弱仮説集合から選び出し,重みを付けて統合仮説に線形結合していく.この動 作を 10 行目に示す終了条件を満たすまで繰り返す.このとき,T 回繰り返しが行われた とすると,AdaBoost は以下のような統合仮説 f (X) を出力する. f (X) = sign ( t ∑ i=1 αihi(X) ) ただし, sign(n) = +1 (n ≥ 0) −1 (otherwise) , αiは統合仮説における弱仮説 hiの重みである.また,ステップ終了時に現ステップ t で 選ばれた弱仮説が間違えた事例の生成確率が高くなるように事例生成確率分布を更新す ることで,次ステップ t + 1 でそれらの事例に対して精度の高い弱仮説が選ばれるように する.つまり,AdaBoost は弱仮説 h1, h2,· · · , ht−1が間違いやすい事例に対して比較的精 度の良い正答率をもつ弱仮説 htを統合仮説に追加することで, その弱点を補おうという 考えの学習アルゴリズムである.
以下では AdaBoost のアルゴリズムについて詳しく説明をする.AdaBoost は入力とし て学習データ S = {(X1, y1) ,· · · , (Xm, ym)} と弱仮説集合 H = {h1, h2,· · · , hn} のほか に,最大ブースティングステップ数 tmaxと閾値正答率 ϵ が与えられる.また,ステップ t での事例確率分布 Dtにおける特徴ベクトル X の生成確率を Dt(X) と表記する. まず,初期状態の事例生成確率分布 D1を一様分布に設定する.すると,D1における 事例 Xiの生成確率は以下のようになる. D1(Xi) = 1 m (1 ≤ i ≤ m) つまり,初期確率分布 D1において事例はすべて等確率で生成される. 次に,すべての弱仮説 hi ∈ H の確率分布 Dtのもとでの優位度 γiを以下のように定義 する. γi = 1 2 ( m ∑ i=1 Dt(Xi)· y · h (Xi) ) 優位度とは分布 Dtのもとでの弱仮説の精度を表す指標で,γi > 0 であればステップ t に おいて弱仮説として有用であることを表す.すべての弱仮説 hiの中で,最も優位度が高 かった弱仮説をステップ t で統合仮説に追加する弱仮説 htとし,htの優位度を γtとする. この優位度 γtを用いることで,htの重要度 αtを以下のように計算することができる. αt=− log βt ただし βt= √ 1− 2γt 1 + 2γt 最後に,以下の式に従って htが間違った事例について,その生成確率が大きくなるよ うに確率分布を更新する. Dt+1(X) = wt(X) Wt ただし wt(X) = D1(X)· t ∏ i=1 βhi(X)·y i , Wt= m ∑ i=1 wt(Xi) 確率分布 Dtはそのままでは事例の生成確率の総和が 1 ではないため,Wtで正規化して いる. このように新たな確率分布を定めると,その直前に選ばれた弱仮説 htで正しく判別さ れる事例の Dt+1での総確率が 1 2となる.つまり,新たな分布 Dt+1のもとではその直前 のステップで選ばれた弱仮説 htの優位度は 0 になる.これは AdaBoost の大きな特徴で あり,この性質は常に成り立つ.これらの動作を各ステップごとに実行し,設定したス テップ数 tmaxに達するか,あるいは得られた統合仮説の学習データに対する正答率が ϵ 以上になったら終了する.
2.3
既存の時系列データ類似性指標
2.3.1 ユークリッド距離 ユークリッド距離は時系列データの一般的な類似性指標として知られている [4].こ の類似性指標では,データ長 M の 2 つの時系列データ X = (x1, x2,· · · , xM) と Y = (y1, y2,· · · , yM) が与えられたとき時系列データ間の距離を以下のように定義する. EuclidianDist (X, Y ) = M ∑ i=1 √ (xi− yi)2 ユークリッド距離を用いた類似性指標のメリットとしては O(M ) 時間で高速に計算で きるという点が挙げられる.しかし,ユークリッド距離の問題点として,2 つの時系列 データのデータ長が等しくなければ計算することができないという点や時間軸方向に少 しでもズレが生じると類似度が大幅に低下する点などが挙げられる.2.3.2 Dynamic Time Warping
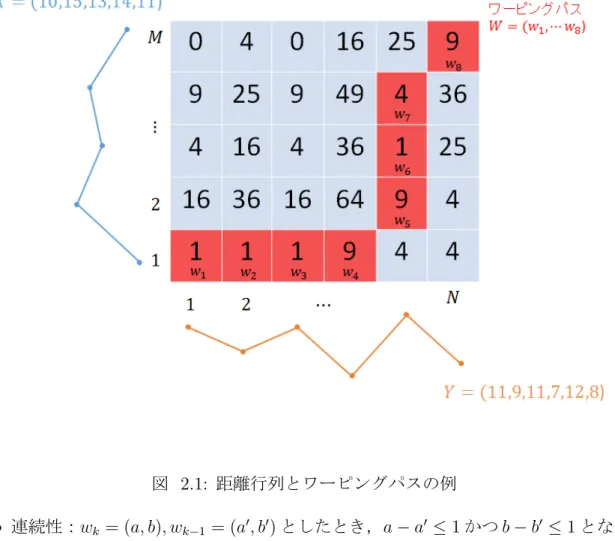
2.3.1 で述べたユークリッド距離には様々な問題点があるため,ユークリッド距離に代 わる類似性指標として Dynamic Time Warping(DTW)が提案されている [1].DTW は データ長 M, N の 2 つの時系列データ X = (x1, x2,· · · , xM),と Y = (y1, y2,· · · , yN) が 与えられたとき,一対多を許して時系列データ X のすべての点 xiを時系列データ Y の いずれかの点に対応付けて距離を計算することで時系列間の類似性指標を定義している. そのため,DTW ではユークリッド距離で定義できなかったデータ長が異なる時系列デー タ間の類似性指標を求めることができる. DTW の計算では,まず xiと yjの距離 dist(xi, yj) を要素 (i, j) の値とする M × N 距離 行列を生成する.ただし距離 dist(xi, yj) は一般に以下の式で定義される. dist(xi, yj) = (xi− yj)2 次に生成した距離行列を用いてワーピングパスとワーピングコストを求める.ワーピ ングパス W = (w1, w2, . . . , wK) とは,以下の 3 つの条件を満たす距離行列の要素の系列 である. • 境界条件:w1 = (1, 1), wK = (N, M ) とする.
図 2.1: 距離行列とワーピングパスの例 • 連続性:wk= (a, b), wk−1 = (a′, b′) としたとき,a− a′ ≤ 1 かつ b − b′ ≤ 1 となる. • 単調性:wk= (a, b), wk−1 = (a′, b′) としたとき,a− a′ ≥ 0 かつ b − b′ ≥ 0 となる つまり,ワーピンングパスは距離行列の要素 (1, 1) から隣接する右・上・右上の要素を 辿って (M, N ) へ到達する任意のルートを表したものである.また,それぞれのワーピン グパスに対してワーピングコストというものを計算することができる.ワーピングパス W = (w1, w2, . . . , wK) のワーピングコスト Cost(W ) は以下の式で求めることができる. Cost(W ) = v u u t∑K k=1 wk 図 2.1 に X = (10, 15, 13, 14, 11),Y = (11, 9, 11, 7, 12, 8) とした場合の距離行列とワーピ ングパスの例を示す.この例で示したワーピングパス W のワーピングコストは, √ 1 + 1 + 1 + 9 + 9 + 1 + 4 + 9 = √35 と求めることができる.
ワーピングパスは複数通り考えることができ,それぞれに対してワーピングコストを 計算することができる.W をすべてのワーピングパスを要素にもつ集合としたとき,時 系列データ X と Y の距離 DTWdist(X, Y ) を以下のように定義する. DTWdist (X, Y ) = min W∈WCost(W ) しかし,非常に多く存在するワーピングパスをすべて導出し,それぞれに対してワーピ ングコストを計算して最小値を求めるのは現実的な方法ではない.そのため,DTW を 計算する際には一般に以下の再帰関数を用いる. [16]
γ(i, j) = dist(xi, yj) + min
γ(i− 1, j − 1) γ(i− 1, j) γ(i, j− 1) ただし,γ(0, 0) = 0, γ(i, 0) = γ(0, j) =∞ この再帰関数を用いると,時系列データ X と Y の DTW 距離は以下のように表される. DTWdist (X, Y ) =√γ(N, M ) 以上の計算方法を用いると,DTW は O(M N ) 時間で計算することができる. DTW は近似距離を計算することで計算の高速化が可能である [9] [16] [12].例えば, Kim らの手法 [9] では本来の DTW 距離を返す関数よりも高速に計算可能な下界関数を 用いることで DTW の高速化を行っている.また,Salvador らの手法 [12] では,入力さ れた時系列データを半分のサイズに圧縮して最適なワーピングパスを計算し,元のサイ ズのワーピングパス計算では圧縮時に得られた最適なワーピングパスの周辺のみを計算 することで高速化を行っている. DTW は時系列データを最適に伸縮させてすべての点同士の距離を測ることで,類似性 指標を定めているといえる.つまり,最も距離が近い点同士が対応付けられるため,DTW は時間軸方向にズレがあっても問題なく距離を求めることができる.しかし,必ず時系
列データ X のすべての点を時系列データ Y のいずれかの点に対応させなければならない という特徴から異常値が混ざった時系列データの場合,距離が正確に測定できないとい うことが知られている [13].
2.4
既存の類似性指標を用いた分類手法
本節では,ブースティングアルゴリズムに既存の時系列データ類似性指標(ユークリッ ド距離・DTW)を適用する方法について説明する.時系列データ X とラベル y ∈ {−1, 1} の組 (X, y) を事例とする.学習データとして S ={(X1, y1) ,· · · , (Xm, ym)} が与えられた とき,以下のような弱仮説集合 H を定義する. H ={h(X) = sign(dist(Xj, X)− dist(Xi, X)) | 1 ≤ i, j ≤ m s.t. yi = +1, yj =−1} ただし,dist (X, X′) は使用する類似性指標を表しており,ユークリッド距離を用いる場 合は EuclidianDist(X, X′),DTW を用いる場合は DT W dist(X, X′) とする.この H を 弱仮説集合として AdaBoost を行うことで,既存の類似性指標を用いた時系列データ分 類が可能となる.第
3
章
提案手法
3.1
k-gram
順序保存カーネル
既存の類似性指標では,各時刻における絶対的な値の大きさを用いて時系列データ間 の類似性指標を計算してきた.しかし,時系列データの解析では個々の値の大きさでは なく,系列の形状に注目して類似性指標を定めた方が有用なことがある.そのため,本 研究では順序同型を用いた類似性指標として,k-gram 順序保存カーネルを提案する.こ の指標は,テキスト間の類似度を表す k-gram カーネル [11] を時系列データに対応させ たものと言える. まず,時系列データに含まれる符号化部分系列の出現頻度を表す順序保存符号化出現 頻度について定義する. 定義 2 (順序保存符号化出現頻度) データ長 M の時系列データ X = (x1, x2,· · · , xM) と 任意のデータ長 k≤ M の符号化系列 C = (c1, c2,· · · ck) が与えられたとき, ϕC(X) = N∑−k+1 i=1match(Code(X(i,k) ) , C) を X における C の順序保存符号化出現頻度と言う.ここで, match (a, b) = 1 (a = b) 0 (otherwise) である. 例 2 時系列データ X = (51, 84, 32, 68, 24, 12) と符号化系列 C = (2, 3, 1) が与えられたと する.この例では,簡単のため符号化表現方法として自然表現を用いる.X の長さ 3 の
符号化部分系列は Codenr(X[1 : 3]) = (2, 3, 1) Codenr(X[2 : 3]) = (3, 1, 2) Codenr(X[3 : 3]) = (2, 3, 1) Codenr(X[4 : 3]) = (3, 2, 1) であるため ϕC(X) = 2 である.また C = (1, 2, 3) とした場合,C と一致する X の符号化部分系列が存在しない ため ϕC(X) = 0 となる. ここで,長さ k のすべての符号化系列からなる集合をCk ={C | C は長さ k の符号化
系列} とする.この集合を用いて,k-gram 順序保存カーネル (Order Preserving k-gram Kernel: OPKk) を以下のように定義する. 定義 3 (k-gram 順序保存カーネル) データ長 N ,M の時系列データ X = (x1, x2,· · · , xN), Y = (y1, y2,· · · , yM) と任意の整数 k ≤ min(N, M) が与えられたとき,X と Y の k-gram 順序保存カーネルを以下のように定義する. OPKk(X, Y ) = ∑ C∈Ck ⟨ϕC(X), ϕC(Y )⟩ 例 3 時系列データ X = (2, 5, 3, 4, 7, 9, 6) と時系列データ Y = (30, 42, 48, 38, 67, 79, 90, 69, 48) の 3-gram 順序保存カーネルを考える.この例では,簡単のため符号化方法として自然表
現を用いる.まず,X と Y の長さ 3 の符号化部分系列は, Codenr ( X(1,3) ) = (1, 3, 2), Codenr ( X(2,3) ) = (3, 1, 2) Codenr ( X(3,3) ) = (1, 2, 3), Codenr ( X(4,3) ) = (1, 2, 3) Codenr ( X(5,3) ) = (2, 3, 1) Codenr ( Y(1,3) ) = (1, 2, 3), Codenr ( Y(2,3) ) = (2, 3, 1) Codenr ( Y(3,3) ) = (2, 1, 3), Codenr ( Y(4,3) ) = (1, 2, 3) Codenr ( Y(5,3) ) = (1, 2, 3), Codenr ( Y(6,3) ) = (2, 3, 1) Codenr ( Y(7,3) ) = (3, 2, 1) であるため,それぞれの順序保存符号化出現頻度は, ϕ(1,2,3)(X) = 2 ϕ(1,2,3)(Y ) = 3 ϕ(1,3,2)(X) = 1 ϕ(1,3,2)(Y ) = 0 ϕ(2,1,3)(X) = 0 ϕ(2,1,3)(Y ) = 1 ϕ(2,3,1)(X) = 1 ϕ(2,3,1)(Y ) = 2 ϕ(3,1,2)(X) = 1 ϕ(3,1,2)(Y ) = 0 ϕ(3,2,1)(X) = 0 ϕ(3,2,1)(Y ) = 1 となる.よって,系列 X と Y の 3-gram 順序保存カーネルは, OPK3(X, Y ) = 2× 3 + 1 × 0 + 0 × 1 + 1× 2 + 1 × 0 + 0 × 1 = 8 となる. 長さ k の符号化系列の集合Ckの大きさは,符号化の方法によっても変わるが,ほとん どの場合 k に対して指数的に増加していく.例えば,同じ値を許す時系列データに対す
る自然表現では,Ckの大きさは以下の式で表される Ordered Bell Number となる [7]. a(k) = k ∑ i=1 ( k i ) a(k− i) そこで,時系列データ X に含まれている符号化系列に対してのみ出現頻度を数えるこ とで,効率的に k-gram 順序保存カーネルを計算をする.このような計算方法を用いる と,入力された 2 つの時系列データに含まれる長さ k の符号化部分系列の出現頻度を求 めれば,k-gram 順序保存カーネルを計算することができる.長さ N の時系列データ X に含まれているすべての符号化部分系列の出現頻度は,佐藤らの提案した接尾辞計数表 現による符号化と計算アルゴリズムを用いることで O(kN ) 時間で計算することができ る [14] [15].このアルゴリズムを用いれば,時系列データ X, Y の k-gram 順序保存カー ネルは O(k(|X| + |Y |)) 時間で計算することができる. また,本論文では k-gram 順序保存カーネルを以下のように正規化して利用する. NormalOPKk(X, Y ) = OPKk(X, Y ) √
OPKk(X, X)OPKk(Y, Y )
以降,正規化した k-gram 順序保存カーネルを単に k-gram 順序保存カーネルと呼ぶ.
3.2
k-gram
順序保存カーネルを用いた分類手法
3.2.1 単純な分類手法 k-gram 順序保存カーネルを基にした関数を AdaBoost の弱仮説として用いる方法につ いて説明する.時系列データ X とラベル y ∈ {−1, 1} の組 (X, y) を事例とする.学習デー タとして S = {(X1, y1) ,· · · , (Xm, ym)} が与えられたとき,弱仮説集合 Hkopを以下のよ うに定義する. Hkop={h(X, k) = sign(OPKk(Xi, X)− OPKk(Xj, X))| 1 ≤ i, j ≤ m s.t. yi = +1, yj =−1} ただし,パラメータ k は事前に与えられているとする. Hk opに属する弱仮説は,2.4 節で定義した弱仮説集合に属す弱仮説と用いられる正例 Xi と負例 Xjの位置が入れ替わっているが,これは既存の類似性指標が距離を類似性指標と していたのに対して,k-gram 順序保存カーネルは時系列データ間の類似度を類似性指標Algorithm 2: DB(tmax1, ϵ1, tmax2, ϵ2) I1={} とする; 1 k← 2 とする; 2 Repeat 3 Hk opを弱仮説集合として AdaBoost(tmax1, ϵ1) を実行し,得られた統合仮説を fkとする; 4 I1← I1 ∪ {fk} ; 5 k← k + 1 ; 6 Until (終了条件を満たす)or (k が最大) 7 fi∈ I1の学習データに対する正答率 riを求める; 8 I2={fi| ri = 1.0} とする; 9 if |I2| ≤ 1 10 I1を弱仮説集合として AdaBoost(tmax2, ϵ2); 11 得られた統合仮説を F とする; 12 else 13 fi∈ I2の多数決関数を F とする; 14 endif 15 関数 F を出力 16 としているためである.弱仮説集合を Hk opとして AdaBoost を行うことで,k-gram 順序 保存カーネルを用いた時系列データ分類をすることが可能になる. 3.2.2 二重ブースティング 3.2.1 で提案した k-gram 順序保存カーネルを用いた分類手法は,既存の類似性指標を 用いた分類手法と違い,あらかじめパラメータ k を設定する必要があった.しかし,分 類に用いる時系列データによって最適な k の値は変わるため,事前に k を設定すること は非常に困難である.そのため,本研究では事前にパラメータ k を設定せずに分類を行 う分類手法として二重ブースティング(Double Boosting: DB)を提案する.二重ブース ティングのアルゴリズムを Algorithm 2 に示す. 学習データとして,S ={(X1, y1) ,· · · , (Xm, ym)} が与えられているとする.二重ブー スティングでは,まず k = 2 から順に,Hk opを弱仮説集合として AdaBoost を行い,統合 仮説 fkを求める.k は fkを求める度に 1 ずつ増やしながら更新していくが,終了条件が 満たされる,または k が最大になった時点で更新を終了する.ただし,終了条件は以下 のように定義する.
(終了条件) Algorithm 2 の 3 行目から 7 行目の繰り返しにおいて k = l であるとす る.4 行目の AdaBoost 内で行われた繰り返し回数を Tl,得られた統合仮説を fl(X) = sign(∑Tl t=1αtsign ( OPKl(Xt+, X)− OPKl(Xt−, X) )) とする.ただし,X+ t , Xt−は AdaBoost 内の t 回目の繰り返しにおいて弱仮説を決定するために用いた正例と負例である.この とき,すべての 1 ≤ t ≤ Tlに対して,OPKl(Xt+, Xt−) = 0 であれば終了条件を満たすと する. 二重ブースティングでは終了条件が満たされれば,それ以上 k を更新してもそれまで に得られた仮説以上の精度を持つ仮説は得られないと仮定している.また,k-gram 順序 保存カーネルのパラメータ k の取り得る値の最大値は定義 3 で示したように,入力され た 2 つの時系列データのデータ長のうち小さい方のデータ長である.そのため,終了条 件を満たさなくても,k が最大になった時点で k の更新を終了する. 次に,仮説 fi ∈ I1の学習データに対する正答率 riを求める.そして,ri = 1.0 となる 仮説 fiを要素としてもつ集合を I2とする.このとき,|I2| ≤ 1 であれば,I1を弱仮説集 合として AdaBoost を実行し,最終的な統合仮説 F を求める.一方,|I2| ≥ 2 であった場 合は,以下のような多数決関数 F を求める. F (X) = sign ( ∑ fi∈I2 fi(X) ) もし,|I2| ≥ 2 のときに AdaBoost を適用してしまうと,弱仮説 fi ∈ I2が 1 個のみで構成 される統合仮説が生成される.しかし,I2に含まれる仮説はすべて同精度であるため,い ずれか 1 つを選ぶよりもすべての仮説を考慮した方が識別率の高い統合仮説を生成でき ると考えられる.したがって,二重ブースティングでは|I2| ≥ 2 の場合に限り,AdaBoost を適用せず,多数決関数として F を出力する.このようなアルゴリズムを用いることで, 事前に k の設定をすることなく k-gram 順序保存カーネルを用いた時系列データ分類を行 うことができるようになる.
第
4
章
実験
k-gram 順序保存カーネルの性能を評価するため,計算時間および分類における正答率を 計算機を用いて比較実験する.
AdaBoost の入力である最大ブースティングステップ数 tmaxと閾値正答率 ϵ は,tmax=
20,ϵ = 1.0 に設定する.
計算機は CPU:Xeon EE5-2609 2.4GHz,メモリ:256GB,OS:Debian wheezy を使用 する.プログラムはデータセットの生成に MATLAB を使用し,類似性指標計算とブー スティングは C++で実装する.
4.1
計算時間の実験
実験設定 ここでは,それぞれの類似性指標の計算時間の比較を行う.ただし,計算時間とは最 終的な統合仮説の生成までにかかった類似性指標計算時間のことである.比較する類似 性指標と分類手法は以下の 5 つとする. • Algorithm 1 + ユークリッド距離(ED) • Algorithm 1 + DTW(DTW)• Algorithm 1 + Salvador らの高速化 DTW(FastDTW) • Algorithm 1 + OPK(OPKk)
ただし,Salvador らの高速化 DTW [12] では,精度と速度のトレードオフを表すパラメー タ radius を設定する必要があり,本実験では radius = 0, 20, 100 で比較を行う. 実験に使用するデータはデータ長 L = 100, 1000, 10000 の 0 以上 100 以下のランダムな 実数を並べた時系列データを用いる.また,実験に用いるデータ数は正例 50 個,負例 50 個で,それぞれのデータ長に対して 10 回学習を行った平均時間を測定する. 実験結果 表 4.1: ランダムデータセットでの計算時間 [秒] L ED OPKk DB-OPK DTW FastDTW
radius = 0 radius = 20 radius = 100 102 0.02 1.24 3.91 0.66 0.29 0.96 1.22 103 0.15 7.37 87.50 65.59 12.90 25.02 71.89 104 1.45 58.42 1544.73 6093.22 1019.12 1154.85 1630.34 表 4.1 にデータ長 L と各類似性指標の平均計算時間の関係を示す.結果より,ユーク リッド距離が最も計算が速く,続いて k-gram 順序保存カーネル,最も計算が遅いのが DTW であることが分かる.これは,ユークリッド距離と k-gram 順序保存カーネルの計 算時間が時系列データ長に比例して増加するのに対し,DTW の計算時間は時系列デー タ長の 2 乗に比例して増加するためである. また,k-gram 順序保存カーネルを用いた二重ブースティング(DB-OPK)は,Hk opを弱 仮説とした AdaBoost を繰り返し実行して最終的な統合仮説を求めるため,単独で k-gram 順序保存カーネルを用いた場合に比べて遅い結果となっている.しかし,表 4.1 より二 重ブースティングの計算時間は,L に比例していることが分かる.これは,k の更新で用 いられている終了条件が L に依らず,ほぼ一定の k で満たしているためだと考えられる. つまり,二重ブースティングの全体の計算時間はカーネルの計算のみに依存していると いえる. また,高速化 DTW はデータ長 1000 までの時系列データに対しては,二重ブースティン
グよりも高速に計算することができる.しかし,データ長が 10000 のとき,radius = 100 であれば二重ブースティングの方が高速に計算できることが分かる.これは,高速化 DTW の計算時間が DTW と同様に入力された時系列のデータ長の 2 乗に比例して増加してい るためと考えられる.したがって,さらにデータ長が大きくなると高速化 DTW は,二 重ブースティングよりも計算時間が遅くなると予想できる. 以上より,k-gram 順序保存カーネルはデータ長の大きいデータに対して,DTW より も高速に計算することが可能であるといえる.
4.2
人工データを用いた正答率比較実験
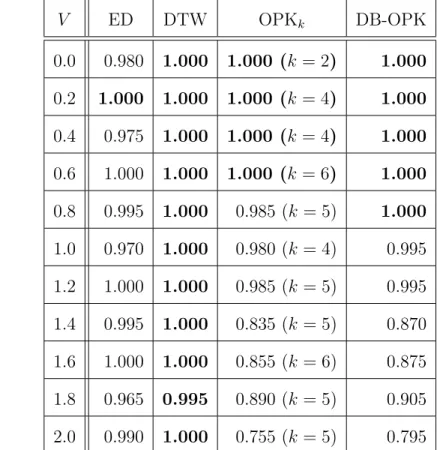
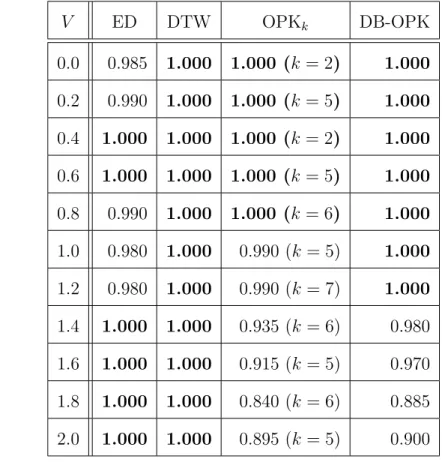
ここでは,3 つの人工的に生成したデータセットを用いて分類精度比較実験を行い,そ れぞれの類似性指標の特性を調べる.比較する類似性指標は以下の 4 つとする. • Algorithm 1 + ユークリッド距離(ED) • Algorithm 1 + DTW(DTW) • Algorithm 1 + OPK(OPKk) • 二重ブースティング(DB-OPK) 4.2.1 ランダム時系列データセットを用いた正答率の比較実験 実験設定 ここでは,ランダムな実数からなる時系列データにノイズを含めた時系列データセット を用いて,それぞれの類似性指標の正答率の比較を行う.ただし,k-gram 順序保存カー ネルの単純な分類手法では k = 2∼50 で実験を行い,最も正答率の良い k の結果を採用 する. 実験に使用するデータは,すべて人工的に生成した長さ L の時系列データとする.デー タ数は,学習データは正例 50 個,負例 50 個とし,テストデータは正例 100 個,負例 100 個とする. 正例,負例データは以下のような方法で生成する.まず,1 以上 10 以下の自然数をラン ダムに発生させ並べた,長さ L の系列 X = (x1, x2,· · · , x1000) を,正例用と負例用に 2 つ生成する.次に,この系列 X に対して,以下のようにノイズを混入させることで,デー タ X′を生成する.xiを平均,標準偏差を V とする正規分布にしたがって生成された乱 数 niとする.これにより,系列 X を素にしたノイズ入り系列 X′ = (n1, n2,· · · , n1000) を 生成する.この操作を正例,負例に対してそれぞれ 150 回繰り返すことでデータを作成 する. 本実験では,データ長 L = 100, 1000, 10000 と標準偏差 V = 0.0∼2.0(0.2 刻み) を組み 合わせた 33 通りのパラメータによるデータセットを用いて実験を行う. 実験結果 表 4.2,表 4.3,表 4.4 に L = 100,L = 1000,L = 10000 のときの,標準偏差 V と各 類似性指標の正答率の関係を示す.ただし,k-gram 順序保存カーネルの単純な分類手法 には,正答率のほかに最も正答率が高かった k の値も記載している.いずれのデータ長 においても,V の値に依らずユークリッド距離と DTW が高い正答率を出していること がわかる.これは,この実験で用いたデータには時間軸方向のズレがなく,既存類似性 指標に有利な時系列データであるためだと考えられる.一方,k-gram 順序保存カーネル は,V が小さいときは正答率が高いが,V が大きくなるにつれて正答率が下がっている ことがわかる.これはノイズが大きくなるにつれて系列内順序の変化が起こりやすくな り,上手く類似性を見つけられなくなったためだと考えられる. また,k-gram 順序保存カーネルに関して,二重ブースティングがほぼすべてのパラメー タにおいて単純な分類手法の正答率を上回っている.さらに,単純な分類手法では正答 率の最も良い k がパラメータによって変わるため,事前に最適な k を与えることが難し いことも分かる.したがって,k の設定をする必要のない二重ブースティングは,正答率 の観点では単純な分類手法よりも性能の良い分類手法であるといえる. 4.2.2 周期性をもつ時系列データセットを用いた正答率の比較実験 実験設定 ここでは,周期性をもつ時系列データにノイズを加えた時系列データセットを用いて, それぞれの類似性指標の正答率を比較する.ただし,k-gram 順序保存カーネルの単純な
分類手法では k = 2∼50 で実験を行い,最も正答率の良い k の結果を採用する. 実験に使用するデータは,すべて人工的に生成した長さ L の時系列データとする.デー タ数は,学習データは正例 50 個,負例 50 個とし,テストデータは正例 100 個,負例 100 個とする. 正例,負例データは以下のような方法で生成する.まず,正例用にサンプリング周波 数 8kHz,長さ 5 秒のリコーダーの単音波形データ Xrecorderと負例用にサンプリング周波 数 8kHz,長さ 5 秒のギターの単音データ Xgtを用意する.次に,この系列 X の長さ L の 部分列 X(i,L)に対して,ランダム時系列データセットと装用の方法でノイズを混入させ る.ただし,部分列の開始点 i はランダムに決定する.この操作を正例,負例に対してそ れぞれ 150 回繰り返すことでデータを作成する. 本実験では,データ長 L = 100, 1000, 10000 と標準偏差 V = 0.0∼2.0(0.2 刻み) を組み 合わせた 33 通りのパラメータによるデータセットを用いて実験を行う. 実験結果 表 4.5,表 4.6,表 4.7 に L = 100,L = 1000,L = 4000 のときの,偏差 V と各類似 性指標の正答率の関係を示す.ただし,k-gram 順序保存カーネルの単純な分類手法には, 正答率のほかに最も正答率が高かった k の値も記載している.まず,どのパラメータに おいてもユークリッド距離の正答率が,ランダムデータセットの場合と比較して著しく 低下していることが分かる.これは,周期性を持つ時系列データセットには時間軸方向 のズレがあるためだと考えられる.ユークリッド距離は,同じインデックスの座標間の 距離しか考慮しないため,周期がずれた時系列データ間の類似性は低くなってしまうと いう特性をもつ.つまり,このデータセットではユークリッド距離を用いた場合,同じ クラス内でも類似していない時系列データとみなされてしまうことがある.一方,DTW はランダム時系列データセットの場合と同様に高い正答率を維持している.DTW はユー クリッド距離の時間軸方向のずれに弱いという問題点を解決した手法であるため,この データセットにおいても高い正答率であると考えられる.最後に,k-gram 順序保存カー ネルは周期性を持つデータセットに対して,非常に高い正答率を出していることが分か る.このようなデータセットは,同クラス内の時系列データに同じ順序関係の部分系列
が繰り返し出現するため,形状を特徴とする類似性指標の k-gram 順序保存カーネルと相 性が良いと考えられる.以上より,k-gram 順序保存カーネルは,周期性をもつ,つまり 類似した形状を多く含む時系列データを高精度に分類可能な類似性指標であるといえる. 4.2.3 異常値を含む時系列データセットを用いた正答率の比較実験 実験設定 ここでは,異常値を含む時系列データを用いて,それぞれの類似性指標の正答率を比 較する.ただし,k-gram 順序保存カーネルの単純な分類手法では k = 2∼50 で実験を行 い,最も正答率の良い k の結果を採用する. 実験に使用するデータは,4.2.1 節で述べたランダム時系列データセットの生成方法と 4.2.2 節で述べた周期性をもつ時系列データセットの生成方法を用いて生成した長さ 1000 の時系列データに,以下の方法で異常値を混入させた系列データとする.時系列データ X に対して Rate の確率で,x1,· · · , x1000の値のうち N 個の値を 10000 倍することで,異 常値を入れる. 本実験では,混入確率 Rate = 0.5, 0.8, 1.0 と混入個数 N = 0, 1, 2, 3 を組み合わせた 12 通りのパラメータによるデータセットを用いて実験を行う.また,データ数は,学習デー タは正例 50 個,負例 50 個とし,テストデータは正例 100 個,負例 100 個とする. 実験結果 表 4.8,表 4.9,表 4.10 にランダムデータセットに対する,混入個数と各類似性指標の 正答率を示す.表 4.11,表 4.12,表 4.13 に周期性を持つデータセットに対する,混入個 数と各類似性指標の正答率を示す.ただし,k-gram 順序保存カーネルの単純な分類手法 には,正答率のほかに最も正答率が高かった k の値も記載している. いずれの混入確率でも,既存類似性指標を用いた場合は混入個数 N が大きくなるにつ れて正答率が下がっていることが分かる.特に DTW は大幅に正答率が低下しているこ とが分かる.これは,2.3.2 で述べた DTW が 2 つの時系列データの各点を必ず対応させ るため,異常値を含んだ時系列データに弱いという性質が原因と考えられる. 一方,どのパラメータの場合を見ても k-gram 順序保存カーネルは高い正答率であり,
異常値による影響を受けにくいことが分かる.この結果の原因としては以下のような考察 ができる.データ長 M の時系列データ X を考えたとき,X に含まれるデータ長 k の部分 列は M−k +1 個である.もし,X に N 個の異常値が入ったとしても,異常値によって順 序関係が変わる可能性のある部分列は高々kN 個までである.よって,M− (N + 1)k + 1 個の部分系列は異常値の影響を受けない.つまり,k と N に対して M が十分に大きけれ ば k-gram 順序保存カーネルは異常値が混入した時系列データに対しても正しく類似度を 測ることができると考えられる. 以上より,k-gram 順序保存カーネルは既存の類似性指標よりも,異常値を含む時系列 データを高精度に分類可能であるといえる.
4.3
実データを用いた正答率比較実験
ここでは,2 つの形式の音楽データセットを用いてジャンル分類実験を行い,それぞれ の類似性指標の実データに対する精度を調べる. 4.3.1 wav データを用いたジャンル分類正答率の比較実験 実験設定 ここでは,wav 形式の楽曲データを用いてそれぞれの類似性指標の楽曲分類精度を比 較するための実験を行う.比較する類似性指標は以下の 5 つとする. • Algorithm 1 + ユークリッド距離(ED) • Algorithm 1 + DTW(DTW)• Algorithm 1 + Salvador らの高速化 DTW(FastDTW) • Algorithm 1 + OPK(OPKk) • 二重ブースティング(DB-OPK) ただし,Salvador らの高速化 DTW では,精度と速度のトレードオフを表すパラメータ radius を設定する必要があり,本実験では radius = 0, 20, 100 で比較を行う.ただし, k-gram 順序保存カーネルの単純な分類手法では k = 2∼50 で実験を行い,最も正答率の 良い k の結果を採用する.
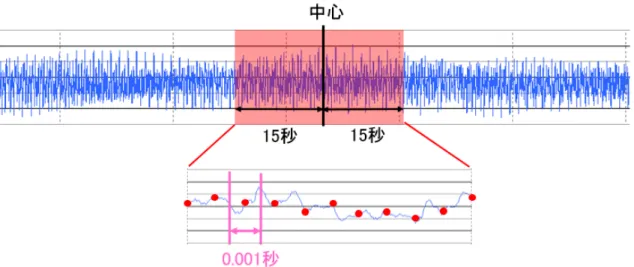
図 4.1: wav データの座標点削減の様子 実験に使用するデータは研究用楽曲データベース RWC に収録されている曲をはじめ としたポップス 280 曲,クラシック 280 曲の計 560 曲の wav データを用いる.ただし, wav データは 1 秒あたり 44100 個の座標点からなる時系列データであるため,そのまま 実験に適用することは計算時間の観点から現実的ではない.そのため,本実験では各楽 曲データに対して曲の長さを測定し,ちょうど真ん中の時点を基準点とし,その基準点 の前後 15 秒,計 30 秒を切り出す.さらに,座標値を 0.001 秒毎の平均にサンプリングし なおすことで,座標点を 30000 個まで削減した wav データを作成し,それらを実験デー タとして用いる.wav データの座標点削減の様子を 図 4.1 に示す.また,データ数は,学 習データは正例 80 個,負例 80 個とし,テストデータは正例 200 個,負例 200 個とする. 実験結果 表 4.14 に wav データを用いた各類似性指標の分類精度の関係を示す.結果より,k-gram 順序保存カーネルはユークリッド距離よりも高い正答率であるが,DTW よりも正答率は 低いことが分かる.提案手法が DTW の精度に及ばなかったのは,座標点を削減するた めに楽曲データの長さを短くしたため,類似する波形形状が出現しにくかったためだと 考えられる.しかし,高速化 DTW は DTW よりも正答率が低く,二重ブースティング とほぼ同精度であることが分かる. したがって,提案手法は wav データのような実時系列データに対して,ユークリッド
距離,高速化 DTW と同等以上の精度で分類可能な類似性指標であるといえる. 4.3.2 midi データを用いたジャンル分類正答率の比較実験 実験設定 ここでは,midi 形式の楽曲データを用いてそれぞれの類似性指標の楽曲分類精度を比 較するための実験を行う.比較する類似性指標は以下の 4 つとする. • Algorithm 1 + DTW(DTW)
• Algorithm 1 + Salvador らの高速化 DTW(FastDTW) • Algorithm 1 + OPK(OPKk) • 二重ブースティング(DB-OPK) Salvador らの高速化 DTW では,精度と速度のトレードオフを表すパラメータ radius を 設定する必要があり,本実験では radius = 0, 20, 100 で比較を行う.また,k-gram 順序 保存カーネルの単純な分類手法では k = 2∼50 で実験を行い,最も正答率の良い k の結 果を採用する. 実験に使用するデータは研究用楽曲データベース RWC に収録されている曲をはじめ としたポップス 100 曲,クラシック 100 曲の計 200 曲の wav データを用いる.学習デー タは正例 33 個,負例 33 個とし,テストデータは正例 67 個,負例 67 個とする. midi 形式のデータは時系列データではないため,midi データを時系列データに変換す る必要がある.本実験では,midi データから楽譜情報を読み取り,先頭からノートナン バーを対応させることで midi を時系列データとして扱う.また,同時に複数の音が鳴っ ている場合,高い方の音を優先させる.図 4.2 に midi から時系列データへの変換の様子 を示す. 実験結果 表 4.15 に midi データを用いた各類似性指標の分類精度の関係を示す.結果より,k-gram 順序保存カーネルが DTW,高速化 DTW よりも高い正答率であることが分かる.
図 4.2: 楽譜情報を時系列データへ変換する様子 これは,ジャンル毎に特徴的な音程が存在し,形状を特徴とする k-gram 順序保存カーネ ルは調に影響されずにその特徴を見つけられたためと考えられる. 一方で,二重ブースティングは DTW よりも正答率は高いが,k-gram 順序保存カーネ ルよりも正答率が低いことが分かる.これは,本実験で用いたデータセットでは学習デー タが少なく,学習データからテストデータに対して精度の良い k を上手く見つけられな かったことが原因と考えられる. 以上より,midi 形式のようなアナログデータを時系列に変換したような実データに対 して,提案手法は既存類似性指標よりも高い精度で分類可能であるといえる.
表 4.2: ランダム時系列データの L = 100 における各類似性指標の正答率 V ED DTW OPKk DB-OPK 0.0 0.980 1.000 1.000 (k = 2) 1.000 0.2 1.000 1.000 1.000 (k = 4) 1.000 0.4 0.975 1.000 1.000 (k = 4) 1.000 0.6 1.000 1.000 1.000 (k = 6) 1.000 0.8 0.995 1.000 0.985 (k = 5) 1.000 1.0 0.970 1.000 0.980 (k = 4) 0.995 1.2 1.000 1.000 0.985 (k = 5) 0.995 1.4 0.995 1.000 0.835 (k = 5) 0.870 1.6 1.000 1.000 0.855 (k = 6) 0.875 1.8 0.965 0.995 0.890 (k = 5) 0.905 2.0 0.990 1.000 0.755 (k = 5) 0.795 表 4.3: ランダム時系列データの L = 1000 における各類似性指標の正答率 V ED DTW OPKk DB-OPK 0.0 0.995 1.000 1.000 (k = 2) 1.000 0.2 0.990 1.000 1.000 (k = 5) 1.000 0.4 0.990 1.000 1.000 (k = 3) 1.000 0.6 0.975 1.000 1.000 (k = 4) 1.000 0.8 0.995 1.000 1.000 (k = 6) 1.000 1.0 0.990 1.000 0.980 (k = 6) 1.000 1.2 0.985 1.000 0.970 (k = 6) 0.965 1.4 1.000 1.000 0.935 (k = 6) 0.970 1.6 0.980 1.000 0.950 (k = 6) 0.970 1.8 1.000 1.000 0.830 (k = 6) 0.855 2.0 1.000 1.000 0.775 (k = 5) 0.825
表 4.4: ランダム時系列データの L = 10000 における各類似性指標の正答率 V ED DTW OPKk DB-OPK 0.0 0.985 1.000 1.000 (k = 2) 1.000 0.2 0.990 1.000 1.000 (k = 5) 1.000 0.4 1.000 1.000 1.000 (k = 2) 1.000 0.6 1.000 1.000 1.000 (k = 5) 1.000 0.8 0.990 1.000 1.000 (k = 6) 1.000 1.0 0.980 1.000 0.990 (k = 5) 1.000 1.2 0.980 1.000 0.990 (k = 7) 1.000 1.4 1.000 1.000 0.935 (k = 6) 0.980 1.6 1.000 1.000 0.915 (k = 5) 0.970 1.8 1.000 1.000 0.840 (k = 6) 0.885 2.0 1.000 1.000 0.895 (k = 5) 0.900 表 4.5: 周期性をもつ時系列データの L = 100 における各類似性指標の正答率 V ED DTW OPKk DB-OPK 0.0 0.835 1.000 1.000 (k = 3) 1.000 0.2 0.840 1.000 1.000 (k = 3) 1.000 0.4 0.730 1.000 1.000 (k = 3) 1.000 0.6 0.770 1.000 1.000 (k = 3) 1.000 0.8 0.795 1.000 1.000 (k = 4) 1.000 1.0 0.815 1.000 1.000 (k = 4) 1.000 1.2 0.695 1.000 1.000 (k = 4) 1.000 1.4 0.785 1.000 1.000 (k = 5) 1.000 1.6 0.800 1.000 1.000 (k = 4) 1.000 1.8 0.790 1.000 1.000 (k = 5) 0.995 2.0 0.760 0.995 0.985 (k = 4) 1.000
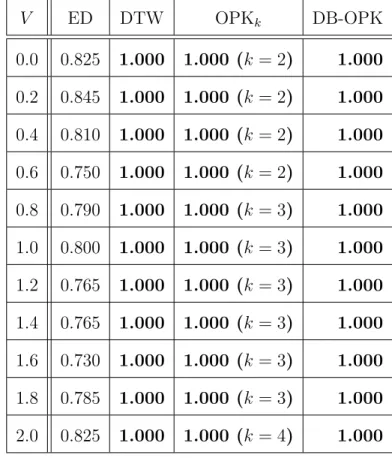
表 4.6: 周期性をもつ時系列データの L = 1000 における各類似性指標の正答率 V ED DTW OPKk DB-OPK 0.0 0.825 1.000 1.000 (k = 2) 1.000 0.2 0.845 1.000 1.000 (k = 2) 1.000 0.4 0.810 1.000 1.000 (k = 2) 1.000 0.6 0.750 1.000 1.000 (k = 2) 1.000 0.8 0.790 1.000 1.000 (k = 3) 1.000 1.0 0.800 1.000 1.000 (k = 3) 1.000 1.2 0.765 1.000 1.000 (k = 3) 1.000 1.4 0.765 1.000 1.000 (k = 3) 1.000 1.6 0.730 1.000 1.000 (k = 3) 1.000 1.8 0.785 1.000 1.000 (k = 3) 1.000 2.0 0.825 1.000 1.000 (k = 4) 1.000 表 4.7: 周期性をもつ時系列データの L = 4000 における各類似性指標の正答率 V ED DTW OPKk DB-OPK 0.0 0.830 1.000 1.000 (k = 2) 1.000 0.2 0.775 1.000 1.000 (k = 4) 1.000 0.4 0.720 1.000 1.000 (k = 4) 1.000 0.6 0.730 1.000 1.000 (k = 6) 1.000 0.8 0.745 1.000 1.000 (k = 5) 1.000 1.0 0.845 1.000 1.000 (k = 4) 1.000 1.2 0.770 1.000 1.000 (k = 5) 1.000 1.4 0.770 1.000 1.000 (k = 5) 1.000 1.6 0.755 1.000 1.000 (k = 6) 1.000 1.8 0.835 0.995 1.000 (k = 5) 1.000 2.0 0.875 1.000 1.000 (k = 5) 1.000
表 4.8: ランダムデータセットの Rate = 0.5 における各類似性指標の正答率 N ED DTW OPKk DB-OPK 0 0.990 1.000 0.980 (k = 6) 1.000 1 0.995 0.830 0.990 (k = 7) 1.000 2 0.975 0.750 0.980 (k = 6) 0.995 3 0.995 0.685 0.995 (k = 7) 1.000 表 4.9: ランダムデータセットの Rate = 0.8 における各類似性指標の正答率 N ED DTW OPKk DB-OPK 0 0.990 1.000 0.980 (k = 6) 1.000 1 0.920 0.935 0.985 (k = 6) 1.000 2 0.980 0.625 0.990 (k = 6) 1.000 3 0.955 0.655 0.990 (k = 8) 1.000 表 4.10: ランダムデータセットの Rate = 1.0 における各類似性指標の正答率 N ED DTW OPKk DB-OPK 0 0.990 1.000 0.980 (k = 6) 1.000 1 0.990 0.865 0.995 (k = 6) 1.000 2 0.985 0.585 0.990 (k = 7) 1.000 3 0.975 0.500 0.985 (k = 7) 1.000 表 4.11: 周期性をもつデータセットの Rate = 0.5 における各類似性指標の正答率 N ED DTW OPKk DB-OPK 0 0.800 1.000 1.000 (k = 3) 1.000 1 0.780 0.940 1.000 (k = 3) 1.000 2 0.770 0.825 1.000 (k = 3) 1.000 3 0.830 0.850 1.000 (k = 3) 1.000
表 4.12: 周期性をもつデータセットの Rate = 0.8 における各類似性指標の正答率 N ED DTW OPKk DB-OPK 0 0.800 1.000 1.000 (k = 3) 1.000 1 0.775 0.870 1.000 (k = 2) 1.000 2 0.755 0.790 1.000 (k = 3) 1.000 3 0.810 0.730 1.000 (k = 3) 1.000 表 4.13: 周期性をもつデータセットの Rate = 1.0 における各類似性指標の正答率 N ED DTW OPKk DB-OPK N 0.800 1.000 1.000 (k = 3) 1.000 N 0.870 0.865 1.000 (k = 2) 1.000 N 0.890 0.785 1.000 (k = 3) 1.000 N 0.615 0.615 1.000 (k = 3) 1.000 表 4.14: wav データを用いた各類似性指標のジャンル分類精度 ED OPKk DB-OPK DTW FastDTW
radius = 0 radius = 20 radius = 100 0.888 0.901 0.908 0.950 0.750 0.918 0.948
表 4.15: midi データを用いた各類似性指標のジャンル分類精度
OPKk DB-OPK DTW
FastDTW
radius = 0 radius = 20 radius = 100
第
5
章
まとめ
5.1
まとめ
本論文では,系列の形状を用いた類似性指標として,k-gram カーネルの特徴空間を順序 保存符号化した系列数に拡張した k-gram 順序保存カーネルを提案した.さらに,k-gram 順序保存カーネルを用いてデータ分類を行うには,事前に適切なパラメータ k を与える 必要があるという問題点を解決するため,k の設定を必要としない二重ブースティング を提案した. また,実験的に k-gram 順序保存カーネルが既存類似性指標の DTW より高速に計算可 能で,周期性をもつ時系列データや異常値が混入した時系列データに対しても高精度に 分類可能であることを示した.さらに,wav データと midi データを用いたジャンル分類 実験を行うことで,k-gram 順序保存カーネルが実データに対しても高精度に分類を行う ことが可能であることを示した. さらに,二重ブースティングがいずれのデータセットでも,ほぼすべてのパラメータ で単純な分類手法と同等以上の正答率であったことから,二重ブースティングは単純な 分類手法より正答率の観点では性能が良いといえる.5.2
今後の課題
今後の課題としては,k-gram 順序保存カーネルの多次元時系列データへの拡張が挙げ られる.本論文では,時系列データを 1 次元として扱ってきたが,クロマベクトルに代 表されるような多次元の時系列データの解析手法も求められている.既存類似性指標は多次元でも座標間の距離が定義できるため,容易に多次元時系列データへの拡張が可能 であるが,k-gram 順序保存カーネルは様々な制約があり,単純に多次元に拡張すること が難しい. また,他の課題として二重ブースティングの計算高速化が挙げられる.現在は k を更 新しながら Hk opを弱仮説集合とした AdaBoost を繰り返し行うため,非常に計算時間が かかっている.しかし,二重ブースティング内で行われる単純な分類手法は,それぞれ 独立に実行可能である.そのため,並列処理などの手法を用いることでアルゴリズムの 高速化が見込めると考えられる.
参考文献
[1] Donald J. Berndt and James Clifford. Finding patterns in time series: A dynamic programming approach. In PAKDD.
[2] Sukhyeun Cho, Joong Chae Na, Kunsoo Park, and Jeong Seop Sim. A fast algorithm for order-preserving pattern matching. Information Processing Letters, Vol. 115, No. 2, pp. 397–402, 2015.
[3] Maxime Crochemore, Costas S. Iliopoulos, Tomasz Kociumaka, Marcin Kubica, Alessio Langiu, Solon P. Pissis, Jakub Radoszewski, Wojciech Rytter, and Tomasz Walen. Order-preserving incomplete suffix trees and order-preserving indexes. In SPIRE, pp. 84–95, 2013.
[4] Christos Faloutsos, M. Ranganathan, and Yannis Manolopoulos. Fast subsequence matching in time-series databases. In SIGMOD, pp. 419–429, 1994.
[5] Yoav Freund and Robert E Schapire. A decision-theoretic generalization of on-line learning and an application to boosting. Journal of Computer and System Sciences, Vol. 55, No. 1, pp. 119–139, 1997.
[6] M. Kearns. Thoughts on hypothesis boosting, 1988.
[7] Jinil Kim, Amihood Amir, Joong Chae Na, Kunsoo Park, and Jeong Seop Sim. On representations of ternary order relations in numeric strings. In ICABD, pp. 46–52, 2014.
[8] Jinil Kim, Peter Eades, Rudolf Fleischer, Seok-Hee Hong, Costas S. Iliopoulos, Kun-soo Park, Simon J. Puglisi, and Takeshi Tokuyama. Order-preserving matching. Theoretical Computer Science, Vol. 525, No. 13, pp. 68–79, 2014.
[9] Sang-Wook Kim, Sanghyun Park, and Wesley W Chu. An index-based approach for similarity search supporting time warping in large sequence databases. In Data En-gineering, 2001. Proceedings. 17th International Conference on, pp. 607–614. IEEE, 2001.
[10] Marcin Kubica, Tomasz Kulczynski, Jakub Radoszewski, Wojciech Rytter, and Tomasz Walen. A linear time algorithm for consecutive permutation pattern match-ing. Information Processing Letters, Vol. 113, No. 12, pp. 430–433, 2013.
[11] Huma Lodhi, Craig Saunders, John Shawe-Taylor, Nello Cristianini, and Chris Watkins. Text classification using string kernels. Journal of Machine Learning Research, Vol. 2, pp. 419–444, 2002.
[12] Stan Salvador and Philip Chan. Toward accurate dynamic time warping in linear time and space. Intell. Data Anal., Vol. 11, No. 5, pp. 561–580, October 2007. [13] 中村哲也, 瀧敬士, 野宮浩揮, 上原邦昭. Amss : 時系列データの効率的な類似度測 定手法 (データマイニング). 電子情報通信学会論文誌. D, 情報・システム, Vol. 91, No. 11, pp. 2579–2588, 2008. [14] 佐藤雄介, 成澤和志, 篠原歩. 順序保存符号化 n-gram の高速な出現頻度計算手法. 情 報処理学会研究報告 2015-AL-151(1), pp. 1–8, 2015. [15] 佐藤雄介, 成澤和志, 篠原歩. 接尾辞係数表現による順序保存 n グラム出現頻度の効 率的な計算. 2014 年度冬の LA シンポジウム, 2015. [16] 大桃論, 陳漢雄, 古瀬一隆. タイムワーピングに基づく時系列データの類似検索:次元 縮小による効率化. 日本データベース学会 letters, Vol. 4, No. 1, pp. 17–20, 2005.