DEIM Forum 2014 D1-3
列指向バッファ管理を用いた MapReduce の高速化
小沢
健史
†及川
一樹
†鬼塚
真
†本庄
利守
††
日本電信電話株式会社
〒 180–8585 東京都武蔵野市緑町 3–9–11
E-mail:
†{
ozawa.tsuyoshi,oikawa.kazuki,onizuka.makoto,honjo.toshimori
}
@lab.ntt.co.jp
あらまし 蓄積された大量のデータを安く,実用的な速度で処理するために,安価な計算機クラスタを用いて効率的
に分散計算を行うフレームワークに注目が集まっている.特に,MapReduce は最も普及している分散処理フレーム
ワークの 1 つであり,Google, Facebook, Yahoo! をはじめとする多くの企業に利用されている.MapReduce では,
処理の耐故障性を確保するため,チェックポイントとして中間出力をディスクに保存するが,既存の MapReduce 処
理系ではそのファイルレイアウトとして圧縮効率が悪いレイアウトを採用していた.本稿では,MapReduce におけ
る出力形式として圧縮効率の高い列指向バッファ管理を用いることで,MapReduce 上で動作するジョブを高速化で
きる可能性を示す.
キーワード MapReduce, Hadoop, 列指向ストレージ
1.
は じ め に
記憶装置・計算機・インターネットの発展により,産業界に おいて取り扱うデータの量が爆発的に増加しつつある.蓄積さ れた大量のデータを安く,実用的な速度で処理するために,安 価な計算機クラスタを用いて効率的に分散計算を行うフレーム ワークに注目が集まっている. 特に,MapReduceは最も普及している分散処理フレームワークの1つであり,Google, Facebook, Yahoo! をはじめとする 多くの企業に利用されている[2], [6], [16], [18].MapReduceで は,並列処理をおこなうMap関数と,Map関数の結果を集約 するReduce関数を記述するだけで,計算機の故障や,計算機 間の同期処理を意識することなく,大規模な分散処理を行うこ とができる[6]. MapReduce処理系の強みの一つとして,スキーマ定義のな い大量のデータに対して高いスループットで処理を行うことが できることが挙げられる.この特性により,従来の分散データ ベースでは処理しきれなかった量の生データを一箇所に集約し ておき,ETLを行った上でRDBMSなどにデータをインポー トするといった利用事例も出てきている( [4], [13]). MapReduce には,タスクを実行するために2種類のプロ セスがある.1つは Mapper,もう1つは Reducer である. MapperはMap関数を実行するMapTaskを処理し,Reducer はReduce関数を実行するReduceTaskを処理する. MapRe-duceで行われる処理の中には,Reducerが1つであることを 強いる処理がある.例えば,WordCountを行った後に,頻度 の多い単語順にソートする処理などである.このような処理の 場合,全ての MapTaskの結果が1つのReducerへ転送され るため,Reducerが行う処理が増大し,過負荷になってしまい 処理に時間がかかるという問題がある. この問題の対策は2つある.1つ目は,圧縮を用いて Map-Task の出力を圧縮することでReducerのIO負荷を軽減する 方法である.MapReduceのオープンソース実装の1つである
Hadoop [1]では,gzip,bzip2,LZO,LZ4,Snappyなどがサ ポートされており,ワークロードに応じて有効な圧縮コーデッ クを選択することが可能である.2つ目は,MapReduce アプ リケーションレベルでReducerへの負荷を減らすよう工夫す る方法である[12].これらの手法はデザインパターンとして命 名されており,その代表例は以下の通りである: (1) 集約処理においてMap 関数の中で事前集約する in-mapper combiningパターン. (2) 行列計算において中間結果のレコード数を減らす stripesパターン. (3) 表の結合を行う際に,小さいテーブルをあらかじめ全 ての計算機に配布しておき,Map関数のみで処理を完結させ るmemory-backed joinパターン. いずれも,Map 関数を実行するMapTaskのメモリを有効利 用し,Map関数の出力量を減らすことが共通点である.これ らの方法を用いることにより.ナイーブなMapReduceプログ ラムよりも高い性能を示すことが報告されている[12]. これらの方法には,それぞれ欠点がある.まず,1つ目の圧 縮を用いる方法は,圧縮効率が限られている.これは,Hadoop の中間出力ファイルの構造が,列指向形式と比較し圧縮と相性 が悪い行指向形式を採用している[17]ことに起因する.行指向 形式では,異なる型のデータが連続して配置されるため,圧縮 時のエントロピーが増大してしまい,圧縮効率が上がらない. 一方で,列指向形式は同じ型のデータが連続して配置されるた め,圧縮時のエントロピーが抑えられ,圧縮効率が向上する傾 向にある.2つ目のMapReduceアプリケーションレベルで負 荷を減らす方法は,ユーザがメモリ管理を自前で行うという特 性上,ユーザ自身がメモリ不足に注意を払う必要がある.また, アプリケーションごとにユーザが適切な最適化を選択し,その 都度実装を行う必要がある. そこで本稿では,MapReduceフレームワーク側でのバッファ 管理を工夫することである高速化を行う列指向バッファ管理モ ジュールを提案する.列指向バッファ管理モジュールは,中間
!"#$% &'() *+,-./ 0123 45#$% 678 678 678
678 9:;<<=> ?>@;A>?>@;A>?>@;A>?>@;A>
図 1 MapReduceの概要 出力のバッファ管理方式として圧縮効率の良いデータ構造を用 いることで,中間出力ファイルサイズの削減が可能である. 提案手法を実装して評価を行った結果,提案手法における バッファ管理モジュールが,既存のMapReduce処理系におけ るバッファ管理方式と比較し,同じ圧縮アルゴリズムを用いて 中間ファイルの大きさを25%削減できることを確認した.ま た,提案手法による中間ファイルの作成のオーバヘッドが小さ く,MapReduceジョブを高速化できる可能性を確認した. 以下,2章にて,MapReduceの基本的な挙動とそのOSS実 装であるHadoopで用いられているバッファ管理モジュールの 問題点について述べる.3章にて,既存のバッファ管理の問題 点を解決した列指向バッファ管理モジュールを提案する.4章 では,実験による圧縮率の評価を示す.5章で関連研究につい て述べ,6章で本論文をまとめる.
2.
前 提 知 識
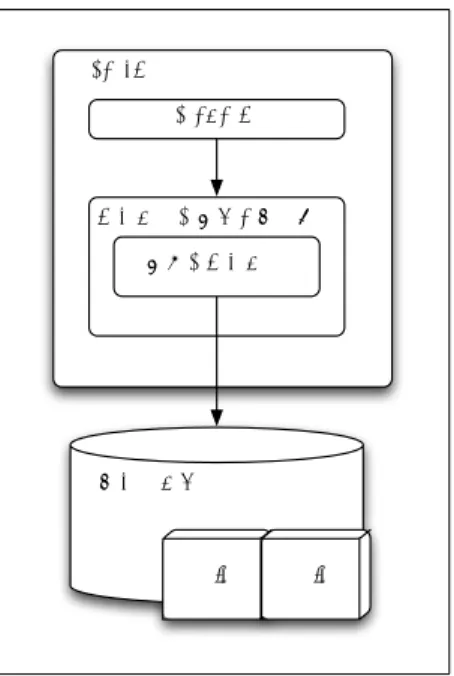
2. 1 MapReduce 図1を用いて,本研究が改善の対象とするMapReduceにつ いて説明する.MapReduceジョブはMapフェーズとReduce フェーズの2フェーズから構成される.Mapフェーズでは入 力データ(D)を読み込んでKey/Valueペア(K1, V1)を生成 し,それを入力として各ペアに対してユーザが定義したMap 関数を実行し,新たなKey/Valueペアリスト(K2, V2)を中間 データとして出力する.Reduceフェーズでは,まず中間デー タをKey 毎にグルーピング(Shuffle)する.そして各グルー プを入力としてユーザが定義したReduce関数を実行し,結果 としてKey/Valueペアリスト(K3, V3)を出力する.この一連 の流れを式として表現すると,以下のようになる. D→ map(K1, V1)→ {K2, V2} shuf f le({K2, V2}) → {K2,{V2}} reduce(K2,{V2}) → (K3, V3) MapReduce処理は複数のノード(計算機)をネットワーク で相互接続したクラスタ内で行われる.クラスタはリソースの 割り当ておよびタスクの割り当てを行うマスタノードと計算を 行うスレーブノードで構成される.クラスタ上にはDFS(分 MapTask 外部記憶装置 Map関数 バッファ管理モジュール IFIle リングバッファ IFIle 図 2 Hadoopにおけるバッファ管理の概要 IFile(Key1, Value1) Key1の長さ(1-5バイト) Value1の長さ(1-5バイト) Key1 のバイト列 Value1 のバイト列 (Key2, Value2) (Key2, Value3) (Key3, Value4) ... 図 3 Hadoopにおける Shuffle フェイズの際に用いられる中間ファ イル (IFile) のファイルレイアウト 散ファイルシステム)が構築され,入力データが格納される. MapReduceジョブを開始すると,まずマスタが入力データを ユーザの指定したサイズで分割し複数のInputSplitを生成す る.次にマスタがInputSplitの数だけMapTaskを生成し,各 スレーブに割り当てる.MapTaskが割り当てられたスレーブ ではMapper が起動され,ユーザが定義した Map関数が実 行されて,Key/Value形式の中間データが出力される.中間 データは同じKey値を持つものが一つのスレーブに集まるよ うにネットワークを介して相互に移動(shuffle)される.マス タはユーザが定義した数のReduceTaskを生成し,各スレーブ に割り当てる.このとき,中間データはKey毎に分配される. ReduceTaskが割り当てられたスレーブでは Reducerが起動 され,ユーザが定義した任意のReduce関数が実行されて,新 たにKey/Value形式の処理結果がDFSに出力される. 2. 2 Hadoop におけるShuffle時のデータ構造 MapReduce のMapTaskの出力に用いられているバッファ 管理の方式は,実装系依存である.そこで,まずMapReduce 処理系の中でも主要なオープンソース実装であるHadoopを 対象にバッファ管理方式の解析を行った.その概要図を図2に
示す. Hadoopのバッファ管理モジュールにMap関数の出力であ るKey・Valueのペアが渡されると,バイト列にシリアライズ された Keyオブジェクト,Valueオブジェクトがリングバッ ファの先頭に書き込まれる,同時に,Key・Valueそれぞれの メタデータがリングバッファの後尾に書き込まれる.そして, ユーザにより指定されたペア数を超えるか,指定されたサイズ を超えると,中間ファイルであるIFileとして書き出される.中 間出力ファイルであるIFileのレイアウトを図3に示す.IFile は,Keyの順番にソートされたKey・Valueのペアの配列で構 成されている.1エントリはKeyの長さ,Valueの長さ,バイ ト列にシリアライズされた Keyオブジェクト,バイト列にシ リアライズされたValueオブジェクトで構成される. このようなデータ構造は,MapReduce処理系のように事前 に処理するデータの型が定義できないシステムでは実装が容 易であるという利点がある.また,IFileのWriter/Readerが データの型を意識することなく書き込み・読み込みを行うこと ができるため,疎結合な設計を行うことが可能となる. 一方で,この構造は全てのKey・Valueのペアに対してデー タサイズを確保するため,レコード数の多いMapReduceタス クではオーバヘッドが大きくなるという欠点がある.また,タ プルごとにデータを保存しておくアプローチは圧縮効率が低い という指摘がある[17]. 2. 3 中間出力書き出しの必要性 MapReduceでは,ジョブを構成するプロセスの一部および 計算機の一部が故障しても故障したTaskのみをやり直すこと でジョブを中断することなく実行することができる. プロセスの故障にはMapTaskの故障とReduceTaskの故障 の2通りがある.MapTaskが故障した場合は,分散ファイル システムから再度データをロードし直し,MapTaskをやり直 す.ReduceTaskが故障した場合は,ディスクに書かれている MapTaskの中間出力をコピーしなおして,再度ReduceTask を実行する.計算機の故障が発生した場合,その計算機が保持 しているMapTaskの中間出力結果は失われてしまう.そのた め,その計算機で実行された全てのMapTask/ReduceTaskを やり直すことで,ジョブを続行する. Hadoop処理系の中には,遅延を下げるために,Shuffle の 際に中間出力を永続化しないものもある.このようなアプロー チを取り,MapTask/ReduceTaskいずれにおいて故障が発生 した場合,全ての処理は MapTaskからやり直しとなる[11]. 結果として,永続化をしない場合は,永続化をする場合と比較 し,故障からの復旧や再実行に長い時間を要する.そのため, Hadoopは標準で全てのMapTaskの出力した中間出力データ を永続化するようにしている.
3.
提 案 手 法
3. 1 列指向バッファ管理モジュール OLAP向けの読み込み特化型データベースとして,C-Store, MonetDB を初めとする列指向データベースがある[14], [17]. 列指向データベースの特徴は,データの保存形式を同じ型でま MapTask 外部記憶装置 Map関数 バッファ管理モジュール CIFile 列指向バッファ CIFile 型1用のバッファ 型2用のバッファ 型3用のバッファ ... (Key, Value) 型4用のバッファ Keyの一部 Keyの一部 Valueの一部 Valueの一部 図 4 列指向バッファを用いたバッファ管理モジュールの構成 CIFile ヘッダ 型1用のバッファ 型2用のバッファ 型3用のバッファ ... numTypes:1バイト (型の個数) Type1:1バイト (含まれている型1) Type2:1バイト (含まれている型2) Type3:1バイト (含まれている型3) ... lenType1: 4バイト (型1のバッファ長) lenType2: 4バイト (型2のバッファ長) lenType2: 4バイト (型3のバッファ長) ... 図 5 列指向バッファ管理で利用する中間データ (CIFile) のレイア ウト とめて保存する点である.このようにすることで,同じ型,似 た傾向のデータを一箇所に集めることができるため,圧縮効率 効率および複数のデータに対する演算の並列度を高めることが 可能となる[22], そこで本研究では,特に列指向データベースの圧縮特性に 着目し, 列指向データベースのデータを型ごとに保存する列 指向バッファ管理モジュールを提案する.その概要図を図4 に示す.MapTaskの中間データの型情報が残っている段階で 各型専用のバッファにルーティングを行う.バッファが指定し た大きさを超えたら,その段階でバッファごとに圧縮をかけ, CIFile(Columnar IFile)形式でデータを書き出す. 3. 2 CIFile CIFileフォーマットのレイアウトを図5に示す.CIFileは, ヘッダとシリアライズされたオブジェクトのバイト列で構成さ れている. CIFileのヘッダはデータ型がいくつ入っているかを表す1バ イトの変数numTypes,入っているデータの型を表す1バイト変数のnumTypes個含む配列,各データ型の利用しているバッ ファサイズを表す4バイトの変数をnumTypes個含む配列で 構成される.CIFileのヘッダの後ろには,型ごとにシリアライ ズされたKey・Valueオブジェクトのバイト列が保存される.
4.
評
価
提案手法である CIFileと既存技術であるIFileの比較と特 性解析を行うため,実験を行った. 実験に用いるプログラムは読み込まれたKey・Valueのペア をそのまま書き出す MapTaskと 単語の共起頻度計算を行う MapTask [12]の2種類である.読み込まれた Key・Valueペ アをそのまま書き出す MapTaskは,TextInputFromatを用 いて改行文字ごとに渡されたKey,Valueの値を直接中間ファ イルに書き込むプログラムである.本稿では,このプログラム をRawと呼ぶことにする.単語の共起頻度計算は,与えられ たテキストに連続して存在する単語のペアの回数を数え上げ るプログラムである.たとえば,”An apple is red”という内 容を保持しているテキストがあった場合,”An apple”,”apple is”,”is red”がそれぞれ1回ずつ数え上げられる.上記の例で は,探索範囲を広くして”An apple is”, ”apple is red”と数え 上げることも可能であるが,今回は隣り合っている単語のペア の回数を数え上げることとする.共起頻度計算を行うMapper は,入力テキストを空白文字ごとに区切り,Keyとして隣接す る単語を連結して作成した複合キー,Valueとして1を出力し, Reducerはその集計を行うが,今回の実験では中間データファ イルの大きさのみを評価するため, Reducer は利用しない. 中間ファイルの書き出しには,MapReduceの処理系Hadoop のIFile.Writerクラスと,提案手法の実装であるCIFile用の DataOutputクラスを用いた.なお,実験用の計算機にはAmazon EC2のm2.4xlargeを 用いた. 4. 1 異なる圧縮アルゴリズムを用いた比較 IFileとCIFileに対し, 異なる圧縮アルゴリズムを用いて圧 縮を行い,中間ファイルの大きさを比較した.中間ファイルの 書き出しの際には,非圧縮,bzip2圧縮,Snappy圧縮を利用 するようにし,比較を行った.なお,bzip2圧縮にはHadoop のBzip2Codecクラスを,Snappy圧縮には snappy-java [15] を利用した Briskプロジェクト[5]のSnappyCodecによる圧 縮を用いた.実験で用いる入力データは,PUMA Benchmark Suite [7]で公開されているデータセットのうち,Wikipedia 50GB に含まれているのデータの一部(file87)である.この データは8355840バイト・約28万行のテキストファイルで ある. 表1に,IFileと提案手法であるCIFileにおいて比較した結 果を示す.IFileがKey・Valueのペアごとに長さを付与するの
に対し,CIFileは,バッファごとに長さを付与するため,提案 手法の CIFileの方が圧縮前でも小さくなっている.また,共 起頻度計算の中間ファイルでSnappy圧縮を用いた場合,最大 で25% のデータサイズ削減を確認できた.これは,同じ型ご とにバッファをまとめて圧縮をかけた効果であると考えられる. 4. 2 CIFile内における型ごとの圧縮効率の比較 次に,CIFile内における型ごとの圧縮効率の比較を行った. 実験で用いる入力データは,前節同様,PUMA Benchmark Suiteで公開されているデータセットのうち,Wikipedia 50GB に含まれているのデータの一部(file87)である. 表2に,CIFileを用いたときの型ごとの圧縮効率の違いを 示す.圧縮率はMapTaskから出力された型,およびデータの 型によって異なるが,Rawの場合,共起頻度計算の場合の両方 において,整数よりも文字列が高い圧縮率を示している.整数 配列に対しては,p4delta [23] のような整数圧縮専用の圧縮ア ルゴリズムを用いることにより,圧縮率を向上できる可能性が ある. 4. 3 書き込み速度の比較 次に,CIFile構築のオーバヘッドを測定するために,
Map-Taskを実行してIFileとCIFileを作成し,ディスクに書き込 む速度の比較を行った.中間データには共起頻度計算の中間デー タを用い,圧縮アルゴリズムにはSnappy圧縮アルゴリズム を用いた.本実験に用いる入力データは,PUMA Benchmark Suiteで公開されているデータセットのうち,Wikipedia 50GB に含まれているデータ全体である.なお,ディスクに書き出す 際のバッファサイズは8Kバイトであり,ディスクIOとIFile およびCIFile構築は同一スレッドで行っている. 表3に,実験結果を示す.CIFileファイルサイズは,IFileと 比較して21%の削減ができている.これにより,ディスクIO 量が削減され,33%の書き込み速度向上が確認できた.提案手 法は,バッファにデータを書き込む際に型情報を用いてバッファ を移動する方式であるため,コピー回数は同じであり,オーバ ヘッドが小さい.オーバヘッドと比較し,中間データ書き出し サイズが小さくなることによるディスクIO削減の恩恵が大き いため,書き込み速度の向上が確認できた. なお,MapReduceジョブがどの程度高速化できるかに関す る評価は,今後の課題とする.
5.
関 連 研 究
Spark [21] は ,MapReduce よ り も 柔 軟 な 非 循 環 グ ラ フ (DAG)を DSL で記述することで,機械学習の計算インテ ンシブな処理を効率良く実行可能な処理系である.Sparkの採 用しているRDD [20]は,DSLから処理とメモリ内およびディ スク内に保存されている中間データの依存関係を把握すること で,復旧を効率良くにおこなうことができる仕組みである.ま た,Shark [19]はSpark上で動作するSQL処理系である.そ の他の列指向DB同様,メモリ上に載るデータを増やすために 様々な圧縮方式を用いる.Spark・Sharkともに,中間データ のデータ構造に関する言及はなく,本研究とは補完的な関係に ある.つまり,提案手法をRDDのデータ構造に採用すること で,Spark/Sharkを高速化することも可能である. CIF [8] [10]は,列指向データベース同様,分散ファイルシス テム上のファイル形式と,データの配置を工夫することで計算 機間のネットワークIOやディスクIOを削減し,MapReduce ジョブを高速化する技術である.CIF は,列ごとにデータの表 1 IFileと CIFile における中間データサイズの比較 ファイルフォーマット データ名 圧縮無しファイル (バイト) bzip2圧縮ファイル (バイト) Snappy圧縮ファイル (バイト) IFile Raw 9206558 1361111 3554898 CIFile Raw 9025188(2%削減) 1214726(11%削減) 3283301(8%削減) IFile 共起頻度計算 18806076 1819063 6095471 CIFile 共起頻度計算 17923310(5%削減) 1633830(11%削減) 4591160(25%削減) 表 2 CIFileにおける型ごとの圧縮効率の比較 データ名 型 圧縮無しファイル (バイト) bzip2圧縮ファイル (バイト) Snappy圧縮ファイル (バイト) Raw 整数 99917 32749((67%圧縮) 54374(45%圧縮) Raw 文字列 8274496 915891(88%圧縮) 2850701(65%圧縮) 共起頻度計算 整数 442138 173477(60%圧縮) 296318(32%圧縮) 共起頻度計算 文字列 13957109 1448904(89%圧縮) 4128572(70%圧縮) 表 3 IFileと CIFile における中間データサイズの比較と書き込み時間の比較 ファイルフォーマット データ名 書き込み時間 (秒) Snappy圧縮ファイル (バイト) IFile 共起頻度計算 4307 36799837380 CIFile 共起頻度計算 2880(33%削減) 29365516361(21%削減) ファイルを分割するだけでなく,データの co-location を行 う.RCFile [9],ORCFile [3] はMapReduce 処理系用のデー タフォーマットである.列が大量に存在する場合にオブジェク トのデシリアライゼーションを遅延することでMapReduce処 理系における入力を素早く行う手法である. 提案手法が対象としている MapReduceの中間ファイルは, blob 型の2列のスキーマと見なすことができるが,全ての列 に対してに読み込み・書き込みを1:1の比率で行うため,CIF, RCFile,ORCFileで高速化可能なワークロードとは異なる.ま た,提案手法であるCIFileは,CIF,RCFile,ORCFileとは 補完的な関係にある.つまり,分散ファイルシステムからの読 み込みの高速化を行う CIF,RCFile,ORCFileと,中間デー タを削減することでShuffle 処理の高速化を行うCIFileを組 み合わせて利用することで,さらなるMapReduceジョブの高 速化を行うことができる.
6.
ま と め
本稿では,MapReduceのShuffleフェイズにおける中間出 力を削減するため,列指向バッファ管理モジュールの一部であ るCIFileを提案し,そのファイル形式を利用することによる 圧縮率の向上を確認した.このことから,提案手法をHadoop に組み込むことにより,既存のMapReduceアプリケーション を未修正で高速化できる可能性がある.今後は,Hadoopへの 実装,評価を行う.また,Hiveのように型が存在する処理系で の実行効率の向上を検証する. 文 献[1] : Apache Hadoop, http://hadoop.apache.org/.
[2] : Apache Hadoop Wiki, http://wiki.apache.org/hadoop/ PoweredBy.
[3] : Create a new Optimized Row Columnar file for-mat for Hive, https://issues.apache.org/jira/browse/ HIVE-3874 (2013).
[4] : Treasure Data’s Plazma: Columnar Cloud Stor-age,http://blog.treasure-data.com/post/53534943282/ treasure-datas-plazma-columnar-cloud-storage (2013). [5] DataStax: Brisk, https://github.com/riptano/brisk. [6] Dean, J. and Ghemawat, S.: MapReduce: simplified data
processing on large clusters, Proceedings of the 6th confer-ence on Symposium on Opearting Systems Design & Im-plementation - Volume 6, OSDI’04, Berkeley, CA, USA, USENIX Association, pp. 10–10 (2004).
[7] Faraz Ahmad, Seyong Lee, M. T.: PUMA: Purdue MapRe-duce Benchmarks Suite.
[8] Floratou, A., Patel, J. M., Shekita, E. J. and Tata, S.: Column-oriented Storage Techniques for MapReduce, Proc. VLDB Endow., Vol. 4, No. 7, pp. 419–429 (2011).
[9] He, Y., Lee, R., Huai, Y., Shao, Z., Jain, N., Zhang, X. and Xu, Z.: RCFile: A Fast and Space-efficient Data Placement Structure in MapReduce-based Warehouse Systems, Pro-ceedings of the 2011 IEEE 27th International Conference on Data Engineering, ICDE ’11, Washington, DC, USA, IEEE Computer Society, pp. 1199–1208 (2011).
[10] Kaldewey, T., Shekita, E. J. and Tata, S.: Clydesdale: Structured Data Processing on MapReduce, Proceedings of the 15th International Conference on Extending Database Technology, EDBT ’12, New York, NY, USA, ACM, pp. 15–25 (2012).
[11] Li, B., Mazur, E., Diao, Y., McGregor, A. and Shenoy, P.: A platform for scalable one-pass analytics using MapReduce, SIGMOD ’11: Proceedings of the 2011 ACM SIGMOD In-ternational Conference on Management of data, New York, NY, USA, ACM, pp. 985–996 (2011).
[12] Lin, J. and Dyer, C.: Data-Intensive Text Processing with MapReduce, Morgan and Claypool Publishers (2010). [13] Ohta, K.: Hadoop meets Cloud with Multi-Tenancy, http:
//www.slideshare.net/treasure-data/hadoop-meets-cloud-with-multitenancy-16107610 (2013).
[14] Peter Boncz, Marcin Zukowski, N. N.: MonetDB/X100: Hyper-Pipelining Query Execution, Conference on Innova-tive Data Systems Research 2005 (2005).
snappy-java/.
[16] Silberstein, A. E., Sears, R., Zhou, W. and Cooper, B. F.: A batch of PNUTS: experiences connecting cloud batch and serving systems, Proceedings of the 2011 ACM SIG-MOD International Conference on Management of data, SIGMOD ’11, New York, NY, USA, ACM, pp. 1101–1112 (2011).
[17] Stonebraker, M., Abadi, D. J., Batkin, A., Chen, X., Cher-niack, M., Ferreira, M., Lau, E., Lin, A., Madden, S., O’Neil, E., O’Neil, P., Rasin, A., Tran, N. and Zdonik, S.: C-store: A Column-oriented DBMS, Proceedings of the 31st International Conference on Very Large Data Bases, VLDB ’05, VLDB Endowment, pp. 553–564 (2005).
[18] Thusoo, A., Shao, Z., Anthony, S., Borthakur, D., Jain, N., Sen Sarma, J., Murthy, R. and Liu, H.: Data warehousing and analytics infrastructure at facebook, Proceedings of the 2010 ACM SIGMOD International Conference on Manage-ment of data, SIGMOD ’10, New York, NY, USA, ACM, pp. 1013–1020 (2010).
[19] Xin, R. S., Rosen, J., Zaharia, M., Franklin, M. J., Shenker, S. and Stoica, I.: Shark: SQL and Rich Analytics at Scale, Proceedings of the 2013 ACM SIGMOD International Con-ference on Management of Data, SIGMOD ’13, New York, NY, USA, ACM, pp. 13–24 (2013).
[20] Zaharia, M., Chowdhury, M., Das, T., Dave, A., Ma, J., McCauley, M., Franklin, M. J., Shenker, S. and Stoica, I.: Resilient Distributed Datasets: A Fault-tolerant Abstrac-tion for In-memory Cluster Computing, Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation, NSDI’12, Berkeley, CA, USA, USENIX Association, pp. 2–2 (2012).
[21] Zaharia, M., Chowdhury, M., Franklin, M. J., Shenker, S. and Stoica, I.: Spark: Cluster Computing with Working Sets, Proceedings of the 2Nd USENIX Conference on Hot Topics in Cloud Computing, HotCloud’10, Berkeley, CA, USA, USENIX Association, pp. 10–10 (2010).
[22] Zukowski, M.: Balancing Vectorized Query Execution with Bandwidth–Optimized Storage, PhD thesis, Universiteit van Amsterdam (2009).
[23] Zukowski, M., Heman, S., Nes, N. and Boncz, P.: Super-Scalar RAM-CPU Cache Compression, Proceedings of the 22Nd International Conference on Data Engineering, ICDE ’06, Washington, DC, USA, IEEE Computer Society, pp. 59– (2006).