一般化レジスタ分散アーキテクチャを対象とした 複数電源電圧による低消費電力化高位合成手法
指導教授 戸川 望 教授
早稲田大学大学院 基幹理工学研究科 情報理工学専攻
5110B069–1 砂田 翔平
2012 年 2 月 6 日
1 序論 1
1.1 本論文の背景と意義 . . . . 2
1.2 本論文の概要 . . . . 4
2 消費電力を考慮した高位合成の研究動向 5 2.1 本章の概要 . . . . 6
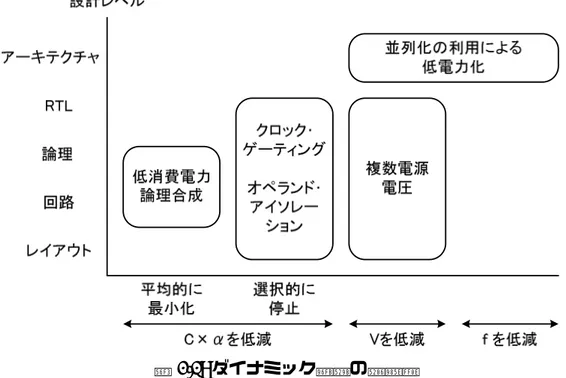
2.2 ダイナミック電力を低減する手法 . . . . 7
2.3 リーク電力を低減する手法 . . . . 14
2.4 ショート・サーキット電力を低減する手法 . . . . 18
2.5 本章のまとめ . . . . 20
3 一般化レジスタ分散アーキテクチャを対象とする高位合成手法 21 3.1 本章の概要 . . . . 22
3.2 GDRアーキテクチャ . . . . 23
3.3 問題定義 . . . . 27
3.4 GDRアーキテクチャを対象とした高位合成フロー . . . . 28
3.5 本章のまとめ . . . . 32
4 GDRを対象としたポート配置最適化複数電源電圧による低消費電力化高位合成手法 33 4.1 本章の概要 . . . . 34
4.2 準備 . . . . 35
5.4 考察 . . . . 57 5.5 本章のまとめ . . . . 58
6 結論 59
謝辞 62
参考文献 63
序論
1.1 本論文の背景と意義
今日の高度情報化社会においてシステムLSI(大規模集積回路)は重要な基盤情報技術で ある.システムLSIは携帯電話などの情報通信機器,PC,自動車の車載システム,情報家 電などに搭載され,今や日常生活に欠かせないものとなっている.近年のLSI設計プロセス に微細化の恩恵によりLSIのゲート数は数百万を超える数になり,今後もこの傾向は継続す ると予想される.それにより情報通信機器などはますます小型化,多機能化が進み,また高 機能化により高速な処理が求められてきた.さらに近年,携帯式機器の普及も急速に進んで おり,小容量のバッテリでも長時間の駆動を可能とする低消費電力化が重要度を増してきて いる.加えて高性能化による発熱の問題も低消費電力化による解決が望まれている.このよ うな高速にディジタル信号処理,画像符号化処理などを行う情報通信機器を開発するには,
複数の専用システムLSIの開発が不可欠であり,多品種少量生産型LSIを短期間,低コスト で開発することが求められている.
こうした背景から抽象度の高い動作記述(C,C++など)からハードウェア特有の概念を意 識したRTL(Register Transfer Level)記述を自動合成するシステムLSI高位合成技術が必 要とされている.高位合成技術は単に設計生産性を向上させるだけでなく,得られる回路が 高性能,小面積かつ低消費電力なものが望まれる.高位合成とは,ある処理を実行する専用 ハードウェアを設計する際に,対象となる処理のアルゴリズムを直接的に記述した「動作記 述」(C,C++など)から,レジスタやクロックによる同期などハードウェアに特有の概念を 意識したRTL記述を自動的に合成することである.大規模複雑化するLSI設計の生産性を 向上させるため,動作レベル記述による回路設計を可能とする高位合成を利用することは有 効な手段である.高位合成はすでにMentor Graphics社のCatapult C Synthesis[12],Forte Design Systems社のCynthesizer[6],などが開発されている.
現在,LSI設計プロセスの微細化が進むにつれ,配線による遅延がゲート遅延に対し相対 的に増加しており,今後もこの傾向は継続すると予想される[17].そのためLSIの高速化を 図るには高位合成の段階で配線を考慮する必要がある.従来の高位設計手法では,フロアプ ラン(モジュール配置)を高位合成の後処理として扱っていたために,モジュール(演算器,
レジスタ,コントローラ,マルチプレクサ等)間の配置関係や配線遅延情報を,高位合成の 段階で考慮することはできなかった.そこで,高位合成において配線を制御するためにフロ アプランを考慮したアーキテクチャ最適化が必要とされていた.このような要求に対し,[5]
ではRDR(Regular Distributed Register)アーキテクチャを対象とした高位合成を提案し ている.このアーキテクチャは演算器ごとに個別のレジスタを持たせることで,配線遅延を 低減するという特徴をもつレジスタ分散型アーキテクチャを基にしており,チップを均一の 大きさに分割し,その1つの区間に演算器,レジスタファイル,コントローラーを配置する
ものである.このモデルは配線遅延がレジスタ共有型より小さくなり,設計は容易化される が,回路を一定の大きさに分割するので面積のオーバーヘッドが大きくなると考えられる.
さらにこのアーキテクチャをレジスタ分散型の性能を維持しながら面積を減らすために,高 性能かつ小面積を実現可能な一般化レジスタ分散型アーキテクチャならびにその高位合成手 法が提案された.しかしこれらのアーキテクチャを対象とした手法は電力消費量については 考慮されておらず,携帯式機器の普及が進む現在,一般化レジスタ分散アーキテクチャを対 象とした高位合成の低消費電力化が望まれることは明らかである.
以上の背景に基づき,本論文では,一般化レジスタ分散アーキテクチャの遅延を増加させ ず,低消費電力化を実現する手法を提案する.提案手法では,複数電源電圧によるGDRアー キテクチャの低消費電力化の効果を最大化するよう演算器のポート配置を変更する.複数電 源電圧では低電圧化する演算器のうちの最も小さいスラックに制約を受けるため,スラック の底上げをする構成が必要とされる.これにより,従来の複数電源電圧を適用するだけでは,
オーバヘッドの影響により低消費電力化することが不可能であった入力アプリケーションの 低消費電力化を行う.
1.2 本論文の概要
本論文では,初めに低消費電力化を考慮した高位合成の研究動向を紹介する.次にレジス タ分散型とレジスタ分散・共有併用型アーキテクチャを拡張した一般化レジスタ分散アーキ テクチャを紹介する.このアーキテクチャは,中央制御回路とローカルレジスタを持つレジ スタ分散型アーキテクチャや,中央制御回路とローカルレジスタ,共有レジスタを持つレジ スタ分散・共有併用型アーキテクチャと異なり,中央制御回路,分散制御回路,ローカルレ ジスタ,共有レジスタを持つ.これを区別するため,このアーキテクチャを一般化レジスタ 分散アーキテクチャと呼ぶ.この一般化レジスタ分散アーキテクチャは,クロック周期制約 に違反する演算器に,ローカルレジスタや分散制御回路を付加することで,配線遅延を低減 し,制約を満たすようにするものである.
本論文で提案する手法では,一般化レジスタ分散アーキテクチャを複数電源電圧を用いて 低消費電力化することを目的としている.その過程でチップ上のモジュールのポート配置を 複数電源電圧に対し最適な構成とすることで,クロック周期制約を変化させずに低消費電力 化の効果を最大化する.以下に本論文の構成を示す.
第2章「低消費電力化を考慮した高位合成の研究動向」では,CMOSのLSIが電力を消費 する仕組みを述べ,電力消費量を低減する高位合成手法に関する調査を報告する.
第3章「一般化レジスタ分散アーキテクチャを対象とする高位合成手法」では一般化レジ スタ分散アーキテクチャを対象とする高位合成の流れを紹介し,レジスタ共有型との違いを 整理する.
第4章「GDRを対象としたポート配置最適化複数電源電圧による低消費電力化高位合成 手法」では,一般化レジスタ分散アーキテクチャに対応した複数電源電圧による低消費電力 化を行う手法を提案する.提案手法はポート配置を考慮していない一般化レジスタ分散アー キテクチャに対し,複数電源電圧を適用する際に最適なポート配置を求める.ここでの最適 な配置とは,複数電源電圧にとってボトルネックとなる低電圧化の対象であり,かつスラッ クの小さい演算器のスラックを増加させることである.これにより複数電源電圧による低消 費電力化の効果を高める.
第5章「計算機実験による評価」では,計算機実験により提案手法と従来手法の比較を行 い,提案手法の有効性の評価を行う.
第6章「結論」では本論文の内容について総括する.
消費電力を考慮した高位合成の研究動向
2.1 本章の概要
高位合成とは,LSI設計自動化技術の1つであり,設計生産性を飛躍的に向上させる技術で ある.この高位合成の際に,消費電力に考慮した設計を行うことで,低消費電力化したLSI を設計することができる.本章では,まずLSIが電力を消費する要素をダイナミック電力,
リーク電力,ショート・サーキット電力の3つに分け,それぞれが電力を消費する仕組みを 整理した後,それらを最適化することで低消費電力化を実現する高位合成手法を紹介する.
図 2.1: ダイナミック電力の分類.
2.2 ダイナミック電力を低減する手法
ダイナミック電力とは,CMOS回路の出力が“0から1”または“1から0”へ遷移するとき,
すなわちスイッチング時に負荷容量の充放電動作によって消費される電力のことを指す.図 2.2にCMOSインバータ回路を示し,そこでのスイッチング動作と電力消費について説明す る.インバータの入力が“1から0”となるとき,出力は“0から1”と遷移する.このとき,電 源VDDからpMOSを通って電流が流れ,負荷容量Cを充電する.pMOSにはON抵抗があ るので,充電電流によりpMOSでジュール熱が発生し,電力消費が起こる.出力が“1から
0”と遷移するときは,nMOSを通ってグラウンドへ放電電流が流れるので,nMOSで電力消
費が生じる.このようにダイナミック電力P owerdynamicは,出力負荷の充放電電流によって 消費する電力であり,式(2.1)で示される.
電源Vdd
入力
出力
負荷容量C 充電電流
pMOS
nMOS
図 2.2: CMOSインバータ.
あり,低消費電力化の基礎を整理するため,以下にダイナミック電力を低減する代表的な手 法を紹介する.
クロック
制御論理 EN
イネーブル信号
図 2.3: クロック・ゲーティング.
クロック・ゲーティング 現在,大半のLSIはクロック同期式回路で実現されており,LSI内 部に多数存在するフリップフロップにはクロック信号が接続されている.このため,クロック 信号には非常に大きな負荷容量が付いていることとなる.さらに他の論理信号と異なり,ク ロック信号は毎サイクル必ずトグルするので,スイッチング確率も大きくなる.このクロッ クのダイナミック電力を低減する手法として代表的なものがクロック・ゲーティングである.
クロック・ゲーティングはクロックのトグルが不要な場合にトグルを止めてしまう手法であ る.トグルが不要な場合とは,フリップフロップが値を保持する場合などがそれにあたり,
図2.3に示すようにクロック信号とイネーブル信号ENのANDをとることで実現される.こ れによりENが‘1’のときはクロックの立ち上がりで値がフリップフロップに格納され,EN が‘0’のときはANDゲートの出力は常に‘0’となるため,フリップフロップは値を保持する
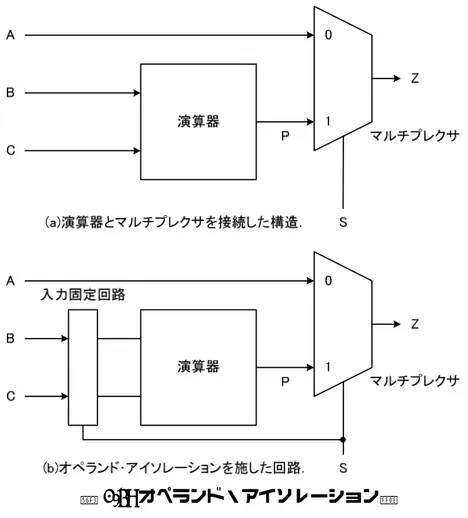
図 2.4: オペランド・アイソレーション.
オペランド・アイソレーション ビット幅の大きい加算器や乗算器が多数搭載されると,こ れらの演算器の電力消費量を無視できなくなる.オペランド・アイソレーションはここに焦 点を当て,演算器の出力が必要とされないときに,入力信号を‘0’または‘1’の値に固定す ることで,演算器内部のスイッチングを停止させることでダイナミック電力を低減する.図
2.4(a)にオペランド・アイソレーションを適用できる場合の回路を示す.ここでは演算器と
マルチプレクサが接続された構造を示しており,乗算結果PとデータAのいずれか一方の データがマルチプレクサで選択され,Zととして出力される.この回路の場合マルチプレク サでデータAが選択されるとき,乗算器内部の演算は不要なものであるため,図2.4(b)のよ うに入力を固定することでスイッチングを停止させ,電力消費を低減することができる.
比 較 器 A
C
1/2T
1/2T
1/2T
比 較 B 器
C
1/2T
1/2T
1/2T
50ns
1/T
マルチプレクサ
Z 比
較 器 A
B
Z
C
1/T
1/T
1/T
(a)AとBを加算してCと比較するデータパス回路.25ns (b)データパスを並列化した構成.
図 2.5: 並列化を利用した低電力化.
並列化を利用した低電力化 並列化を利用した低消費電力化とは,ハードウェアの並列化を 行い,性能を上げたうえでf を低減することで低消費電力化する手法である.図2.5(a)に示 すように,データAとBを加算し,加算結果とデータCを比較して大きいほうの値をZと して出力するデータパス回路を考える.そのとき性能に対して,“25nsに1回の割合で新し いデータを出力せよ”という制約を与えることとする.これを満たすために,通常の回路で はA,Bのレジスタ出力からZまでの遅延時間が25nsに収まるように設計する.しかし,並 列化を利用した低電力化においては,図2.5(b)に示すように,50nsで動作するデータパスを 二つ並列に置き,25nsずつずらして交互にデータを出力するように設計する.これにより,
一つのデータパスに対する遅延時間の制約が緩くなり,電源電圧を下げた状態の遅い動作速
低消費電力論理合成 低消費電力論理合成とは,論理合成のときにダイナミック電力を小さ くするように最適化する技術のであり,スイッチング確率αの大きい部分で負荷容量Cを減 らす最適化を行う.具体的な手法として,論理合成の過程で,スイッチング確率αの大きい ノードは論理セルの内部のノードになるようにマッピングしてCを減らす低電力テクノロ ジ・マッピング,αの大きい配線は入力容量Cの小さいピンと接続するように,論理が変わ らない範囲で接続を入れ替えるピン・スワップなどがある.この低消費電力論理合成を用い ることによる低消費電力化は[20, 31]などで検証されている.
複数電源電圧 複数電源電圧とは,回路中で高性能が必要な部分にのみ従来の電源電圧を使 い,速い動作速度が必要されない部分には低い電源電圧を使う技術である.ダイナミック電 力はCV2f αで与えられるため,電源電圧を下げることはダイナミック電力の低減化に最も 効果が大きくなる.しかし,電源電圧を下げるとMOSトランジスタの性能が低下し回路速 度が遅くなるため,回路の性能を維持したまま電力消費量を下げるには工夫が必要である.
複数電源電圧を実装する方法として,“回路ブロック単位(祖粒度)で電源電圧を変える手法”
と“ゲート単位(細粒度)で電源電圧を変える手法”がある.
粗粒度の複数電源電圧の例を図2.6[3]に示す.高速動作が要求される回路ブロック(図 2.6中の灰色で示した部分)は高い電源電圧VDDH(1.2V)で動作させ,ほかの論理ブロックお よびメモリは低い電源電圧VDDL(1V)で動作させる.電源電圧の異なるブロックに信号を送 出する場合には,信号の電圧振幅を変換する回路(レベルコンバータ)を挿入する必要があ る.レベルコンバータは複数電源電圧において,オーバヘッドとなる.そのため[22]に示す ように,その構成が研究されている.
細粒度の複数電源電圧では,高速動作が必要な部分,すなわちクリティカル・パス上にあ るゲートは従来の高い電圧で動作させ,クリティカル・パス上にないゲートは低電圧で動作 させる.論理合成を使って生成された回路では,クリティカル・パス上のゲートは全体の中
でも10〜30%程度と言われており,その他のゲートを低電圧にできる.
受信/
サンプリング
クロック生成
リ タ イ ミ ン グ
クリティカル な回路
電圧 レギュレータ
データ・クロック抽出
クロック制御
パラレル・
インタ フェース 受信
データ
再生された データ レベル
シフタ Vddi Vddh
Vdde Vdde
Vddl
図 2.6: 粗粒度複数電源電圧.
Igate ゲート
ソース
ドレイン(電圧Vdd)
Isub
Igidl
Ijunc p基盤
n+
n+
図 2.7: リーク電流.
2.3 リーク電力を低減する手法
リーク電力とは,ゲートがスイッチングしないときにも消費する電力で,図2.7に示すよ うにMOSトランジスタおよび周辺で流れる“漏れ電流(リーク電流)”によって生じる.MOS トランジスタがOFF状態でソースドレイン間に流れるサブスレッショルド・リーク電流Isub や,薄いゲート絶縁膜を通してトンネル効果によって流れるゲートリーク電流Igateが代表 的である.このほか,逆バイアスが印加されたPN接合におけるジャンクションリーク電流 Ijuncや,ゲート電極下のドレイン端に高い電界がかかることによりドレインから基盤へ流れ るGIDL(gate induced drain leakage)電流IGIDLも存在する.
リーク電力はダイナミック電力とは異なり,スイッチングを停止するだけでは低減するこ とができない.現在のCMOSLSIではサブスレッショルド・リーク電流が支配的であり,式
(2.2)に示すように,トランジスタの閾値電圧Vthと非常に深い関係がある.
Isub=I0exp
( −Vth s/ln10
)
(2.2) 式からわかるように,リーク電流を小さくするには閾値を大きくする必要がある.しかし,
閾値はトランジスタの遅延時間tdelayと式(2.3)の関係がある.
tdelay ∝ CV
(V −Vth)α (2.3)
このように閾値を大きくすると遅延時間が増大してしまう.このように閾値を介して,遅
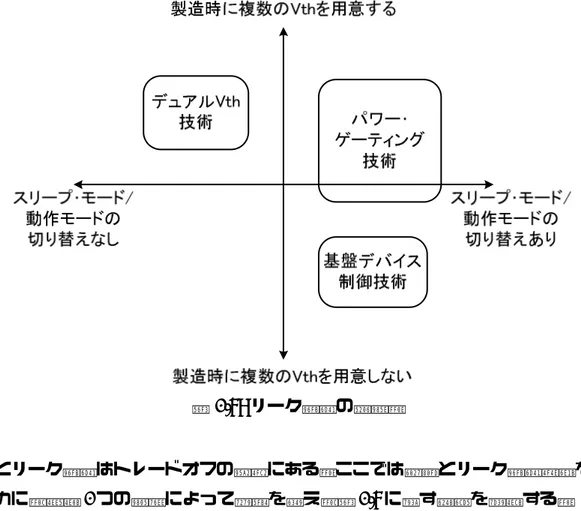
図 2.8: リーク電流の分類.
延時間とリーク電流はトレードオフの関係にある.ここでは性能とリーク電流低減を両立さ せるために,以下2つの項目によって特徴を捉え,図2.8に示す手法を紹介する.
1. 製造時に複数の閾値電圧を用意する.
2. スリープ・モード/動作モードの切り替えを行う.
複数閾値電圧 複数閾値電圧は,高い閾値はリークが小さいが低速,一方低い閾値はリーク が大きいが高速という性質に着目し,クリティカル・パスには低閾値を,それ以外の部分に は高閾値を使う手法である.標準的な設計手法として,高閾値のセルと低閾値のセルをセル ライブラリの中に用意しておき,論理合成を実行することにより,クリティカル・パス上の ゲートには低閾値のセル,その他の部分には高閾値を割り当てることでリーク電力を低減 する.
基盤バイアス制御 基盤バイアス制御技術は,基盤バイアスを印加することにより,MOS トランジスタの実行閾値を動的に変える手法である.この手法では,製造段階でMOSトラ ンジスタを低閾値で作っておき,動作時にはこの状態で高速論理動作を実現する.スタンバ イ時には,基盤バイアスを印加してトランジスタの実効閾値(の絶対値)を大きくし,リーク を低減することで低消費電力化を実現する.
仮想グラウンド線 パワー・スイッチ
(高閾値)
sleep
電源 低閾値論理ゲート
図 2.9: パワー・ゲーティング.
パワー・ゲーティング パワー・ゲーティング技術では,図2.9に示すように論理回路のすべ てを低閾値のトランジスタで構成する.さらに論理回路とグラウンドの間に,パワー・スイッ チと呼ぶnMOSトランジスタを挿入する.動作時にはパワー・スイッチをONにして,論理 回路をグラウンドとつないで動作させる.また,スリープ時にはパワー・スイッチをOFF にして,論理回路とグラウンドを電気的に遮断する.この手法の特徴は,動作時には低閾値 のトランジスタで論理動作を行うため高速である点と,スリープ時には高閾値のトランジス タですべての論理回路のリークを遮断できる点である.
電源Vdd
入力
出力
負荷容量C 貫通電流
pMOS
nMOS
t 入力
貫通電流
(a)入力と貫通電流 (b)インバータを流れる貫通電流
図 2.10: ショート・サーキット電流.
2.4 ショート・サーキット電力を低減する手法
ショート・サーキット電力とは,図2.10[25]に示すように,貫通電流によって消費される 電力である.貫通電流とはCMOS回路の出力が遷移する過程で,pMOSとnMOSの両方が 同時にオンとなる瞬間が存在し,電源VDDから2つのMOSを通ってGNDへ流れる電流で ある.
以下にショートサーキット電力を低減する代表的な手法を紹介する.
電源Vdd
出力
負荷容量C pMOS
nMOS バッファ
slewの改善
図 2.11: バッファ挿入.
バッファ挿入 ゲート出力の遷移時間が大きい場合には,その接続先の回路でショートサー キット電力が増大する.それは接続先の回路で,pMOS,nMOSともにオンとなっている時 間が長くなるためである.この電力を削減するために,図2.11[25]に示すようにバッファを 挿入し,信号波形のなまり(slew)を改善することでショートサーキット電力を低減する.
2.5 本章のまとめ
本章では高位合成における低消費電力化手法を紹介した.
2.2節「ダイナミック電力を低減する手法」ではダイナミック電力を低減する手法として クロックゲーティング,オペランドアイソレーション,低消費電力論理合成,並列化を利用 した低電力化,複数電源電圧についてまとめた.
2.3節「リーク電力を低減する手法」ではリーク電流と閾値電圧のトレードオフの関係を 示し,性能と電力消費の低減を両立する手法として複数閾値電圧,基盤バイアス制御,そし てパワー・ゲーティングを整理した.
2.4節「ショートサーキット電力を削減する手法」ではショートサーキット電力を削減す る手法としてバッファ挿入を紹介した.
一般化レジスタ分散アーキテクチャを対象
とする高位合成手法
3.1 本章の概要
一般化レジスタ分散(Generalized Distributed Register)アーキテクチャ(以下GDRアーキ テクチャと呼ぶ)[14, 15]とは,配線遅延の影響をレジスタの配置の工夫によって低減したレ ジスタ分散・共有併用型を基に,制御回路を分散させることで更なる速度の向上と面積の低 減を図ったものである.本章では,GDRアーキテクチャの特性を理解するため,このアー キテクチャの概要を述べた後,その生成アルゴリズムを示す.
3.2 GDR アーキテクチャ
GDRアーキテクチャとはクロック周期制約に対しボトルネックとなる演算器にローカル レジスタを付加し配線遅延による影響を軽減し,ボトルネックではない演算器同士はレジス タを共有することにより高性能かつ小面積な回路を得ることを可能とする.GDRアーキテ クチャでは回路内に複数の共有レジスタ群をもち,いくつかの演算器はローカルレジスタを 持つ.共有レジスタ群は共有レジスタの集合であり共有レジスタ群内のレジスタの入出力マ ルチプレクサを含むモジュールのこととする.
まず,GDRアーキテクチャで用いる2種類のレジスタを定義する.
ローカルレジスタ ある演算器に隣接して配置されたレジスタであり,その演算器の入力・出 力データしかデータを保持しない演算器専用のレジスタである.演算器がローカルレ ジスタを持つ場合は演算器の入力ポート数の入力側ローカルレジスタと1個以上の出 力側レジスタを持つ.
共有レジスタ 回路内にあるどの演算器からも利用可能なレジスタであり,共有レジスタ群 は共有レジスタが集合したものを指す.
ここで制御信号を考えない際の入力レジスタから出力レジスタまでの演算時間tdtotalは,
tdtotal =tmi +trif +tf +tmo +tf ro +treg (3.1) と計算できる.ここでtmi,trif,tf,tmo,tf ro,tregはそれぞれ入力側マルチプレクサ遅 延,入力側レジスタriから演算器fまでの配線遅延,演算器fの遅延,出力側マルチプレク サ遅延,演算器fから出力側レジスタroまでの配線遅延である.
ここでローカルレジスタを付加した場合を考えると,ローカルレジスタが付加された演算 器の入力はローカルレジスタからと決まっているので,入力側マルチプレクサが不要となる.
また入力側ローカルレジスタから演算器までの配線遅延を無視できるため,tmi = 0,trif = 0 となる.もし出力先が対象演算器のローカルレジスタである場合はt = 0,t = 0となる.
Con- torller
Functional unit
(a) When input register is a local register. (b) When input register is a shared register.
t
ft
cft
cmt
fro
o
Functional
unit
t
ft
cft
cmt
fro
o Con-
torller
Con- torller Con-
torller
t
r fiCon- torller
t
cmit
mt
regot
mot
regt
mit
ct
ct
ct
ct
c図 3.1: 演算時間.
と計算される.ここでtcmiは制御回路から入力側マルチプレクサへの配線遅延時間である.
さらに全ての制御回路は以下の式を満たす必要がある.
Tclk ≥tcmo +tmo +treg (3.4) ここでTclkはクロック周期時間であり,tcmoは制御回路から出力側マルチプレクサへの配線 遅延時間である.GDRアーキテクチャは制御回路にローカルレジスタを付加するため制御 回路の実行時間tcは上記の式では無視できる.tcmi,tcf,tcmo はボトルネックとなり得る.
これを解決するためにはある演算器専用の制御回路をその演算器の近くに配置し,配線遅延 を軽減する必要がある.そこで特定の演算器専用のローカルコントローラを導入する.すべ ての演算器にローカルコントローラを付加するのは面積オーバヘッドが増加するのでGDR アーキテクチャでは以下の2種類の制御回路を使用する.
ローカルコントローラ ある演算器に隣接して配置された制御回路であり,その演算器と演 算器に付随するローカルレジスタのマルチプレクサを制御する回路.
グローバルコントローラ 回路内にある複数の演算器および演算器,共有レジスタに付随し ているマルチプレクサを制御する回路.
図3.1(b)より共有レジスタを利用する演算器では共有レジスタから演算器の配線遅延,制
御回路から共有レジスタへの配線遅延と演算時間が増加する.制御回路から共有レジスタへ の配線遅延を削減するためにGDRではグローバルコントローラは共有レジスタの近くに配 置する.
以上のことから,GDRアーキテクチャには以下の4種類のモジュールが存在する.
• 演算器のみ
• 共有レジスタ群+グローバルコントローラ
• 演算器+ローカルレジスタ
• 演算器+ローカルレジスタ+ローカルコントローラ
Controller
Shared-reg. group with global contorller Functional
unit
Functional unit
Functional unit Functional
unit
Functional unit
Functional unit
Functional unit Functional
unit Functional
unit
Con- troller
Functional unit
Local reg.
Controller
図 3.2: 一般化レジスタ分散型アーキテクチャ.
オーバヘッドを少なくすることができる.このアーキテクチャを実現のために,各演算器に 対しローカルレジスタ,ローカルコントローラを付加するかを配置情報から決定している.
3.3 問題定義
GDRアーキテクチャの高位合成問題は入力としてCDFG,クロック周期制約,演算器の 集合とし,クロック周期制約を与えらときにDFGノードのコントロールステップ,演算器 への割り当て,変数のレジスタへの割り当て,レジスタ/コントローラ構成の決定,モジュー ル配置を行いRTLとフロアプランを出力する問題である.目的関数は入力アプリケーショ ンの実行時間を最小にし,もし同一の場合は面積を最小にすることである.
3.4 GDR アーキテクチャを対象とした高位合成フロー
GDRアーキテクチャではレジスタ・レジスタ間データ転送を用いる.レジスタ間データ 転送を扱うには,スケジューリング段階で各演算器間の配線遅延情報が必要となる.またレ ジスタの種類の決定,制御回路構成の決定のために配置情報が必要である.以上のことを満 足するには配置情報,配線遅延情報をフィードバックする合成フローが最適である.そのた め図3.3に示す合成フローが用いられる.
この合成フローは2つの段階から構成される.1つ目は初期フェーズである.ここでは配 線・配置を考慮せずにアプリケーション実行時間が最速になるようにスケジューリングとバ インディングを行い,そのスケジューリング,バインディング結果を満足するようにフロア プランを行う2.この配置を初期解とする.2つ目は改良フェーズである.このフェーズでは 初期フェーズで得られた解を繰り返し改良していくことで最適解を求める.
初期フェーズ(Initial phase)
初期フェーズではアプリケーションの実行時間が高速なるようなフロアプラン解を生成 する.まず初めに入力DFGをリストスケジューリングによりスケジューリングを行う.次 に共有レジスタ群が演算器の数あると仮定しモジュール配置を行う.モジュール配置はSA
(Simulated Annealing)により最適化する.目的関数はクロック周期制約違反の最小化と面 積の最初化である.これらの工程により,クロック周期制約違反がある可能性はあるが,ア プリケーションの実行時間が高速となるフロアプラン解を生成する.
改良フェーズ(Improvement phase)
改良フェーズではスケジューリング,レジスタ/制御回路構成決定のために配置・配線情報 とレジスタ/制御回路情報をフィードバックし,繰り返し高位合成アルゴリズムとモジュール 配置を行う.この解と配置結果を利用し,まずレジスタ/制御回路構成が配置結果を満たす かチェックを行い,満たさない場合はローカルレジスタ/ローカルコントローラを付加する.
その後スケジューリング/FUバインディングを行い,その結果からレジスタ/制御回路再構 成を行う.改良フェーズは仮想フロアプラン生成,スケジューリング/FUバインディング,
レジスタ/コントローラ構成決定,レジスタバインディング,コントローラ合成,モジュール 配置から構成される.
2スケジューリングは配線遅延を考慮していないためフロアプランがスケジューリング結果を満たすような 配置をえることは難しいがそれに近い解を得る.
Initial scheduling Initial floorplan
Virtual floorplan generation Scheduling/binding Register/controller
arrangement Register binding, Controller synthesis and
Floorplanning Solution converged?
Placement information &
register/controller configuration
Improvent phase Initial phase
Set of FUs Constraint CDFG
Functional
unit Functional unit
Functional unit
Functional unit
Controller
Functional unit
Functional unit
Controller
Floorplan at previous iteration Virtual floorplan
Functional
unit Functional unit
Functional unit
Functional unit
Controller
Functional unit
Functional unit
Controller
Con- troller
図 3.4: 仮想フロアプラン生成.
仮想フロアプラン生成 仮想フロアプラン生成では,1つ前のイタレーション時のレジスタ/
制御回路構成が1つ前のイタレーション時の配置結果で実現可能かチェックを行う.このチェッ クにより違反が発見されたならば,その演算器に仮想的にローカルレジスタ,ローカルコン トローラを付加する(図3.4).この状態で各モジュール間のデータ転送制約を計算し,次工 程のスケジューリング/FUバインディング工程に進む.
スケジューリング/FUバインディング 仮想フロアプラン生成で得られたデータ転送制約 をもとにスケジューリング/FUバインディングを行う.
レジスタ/コントローラ構成決定 スケジューリング/FUバインディング結果を基にレジス タ/コントローラ構成を決定する.スケジューリング/FUバインディングを満たすように,
ローカルレジスタ数,ローカルコントローラ数が最小化になるようにする.この工程では最 初に各演算器が使用する共有レジスタ群を割り当てる.つぎにクロック周期制約を違反する 演算器にローカルレジスタ・ローカルコントローラを付加する.最後に隣接して配置された 共有レジスタ群の併合をローカルレジスタが増加しない場合に行う.
レジスタバインディング レジスタバインディングでは,レジスタ分散・共有併用にもちい るレジスタバインディングを複数共有レジスタに拡張した手法を適用する.
コントローラ合成 コントローラの回路記述をSynopsys社のDesign Compilerに入力し,論 理合成し,遅延と面積を得る.
モジュール配置 モジュール配置の工程では,データ構造としてSequence-pair[13]を用い,
モジュール配置をSA(Simulated Annealing)によって最適化する.
SAのコスト関数は,Aをデッドスペースを含む回路の総面積,Wを各モジュールを結ぶ 総配線長,Vを各演算器間のデータ転送においてクロック周期制約条件を違反したディレイ の総合計とした時
cost= ABB
Atotal +α V
Tclock +β W
WM AX (3.5)
と計算する.ただし,α,βは,任意のパラメータである.ABBは最小矩形の面積,Atotalは モジュール面積の総計,Tclockはクロック周期,V はクロック周期制約違反の総合計,W は 配線長,WM AX は配線長の最大値であり(最小矩形の縦+横)×配線数である.
モジュール配置工程では,i回目のイタレーションにおける最終的な配置結果を,i+ 1回 目のイタレーションのモジュール配置工程におけるSAの初期配置として用いる.イタレー ションごとにSAの初期温度を下げていく.合成フローのi回目のイタレーションのSAの初 期温度をTiとしたときi+ 1回目のイタレーションの初期温度を
Ti+1 =Ti/K (3.6)
とする.ただしK>1とする.
解が収束もしくは規定回数まで上記の工程を繰り返し最良の解を出力する.
3.5 本章のまとめ
本章では,GDRアーキテクチャとその高位合成手法について紹介した.
3.2節「GDRアーキテクチャ」では,GDRアーキテクチャを紹介し,ローカルレジスタ,
共有レジスタ,ローカルコントローラ,グローバルコントローラを定義した.
3.3節「問題定義」では,GDRアーキテクチャの高位合成問題の入力と出力について整理 し,目的関数が入力アプリケーションの実行時間最小化と同一時間の場合は面積の最小化で あることを示した.
3.4節「GDRアーキテクチャを対象とした高位合成フロー」では,GDRアーキテクチャ を対象とした高位合成フローの初期フェーズ,改良フェーズ,そして改良フェーズ中の仮想 フロアプラン生成,スケジューリング/FUバインディング,レジスタ/コントローラ構成決 定,レジスタバインディング,コントローラ合成,モジュール配置について整理した.
GDR を対象としたポート配置最適化複数
電源電圧による低消費電力化高位合成手法
4.1 本章の概要
現在のLSI設計技術では,ダイナミック電力による電力消費が最も大きいと言われてい るが,プロセスの微細化に伴いリーク電力の比率が指数関数的に増加しており,今後低消費 電力化を考える上で,リーク電力を考慮する重要性が増すことは明らかである.しかしリー ク電力削減の試みは高位合成よりも下位の工程における成果[8, 11]が目覚しく,MOSの改善 等によりLSIのリーク電力削減が進められている.このように低消費電力化を行う上で,下 位工程は重要である.しかし,優れた低消費電力化高位合成手法は下位工程によって削減さ れた電力消費量の更なる削減を行うことができる.そのため,本章では3章で紹介したGDR アーキテクチャに,2.2節で紹介した複数電源電圧を適用させる低消費電力化高位合成手法 を提案する.本手法は,GDRアーキテクチャを複数電源電圧を用いて低消費電力化するこ とを目的とする.その際,GDRアーキテクチャのモジュールのポート配置を,複数電源電圧 の効果が最大となるよう最適化する.本章では初めに提案手法の説明に必要となる用語を定 義する.その後,複数電源電圧による低消費電力化の効果を最大化するポート配置について 述べ,GDRアーキテクチャを複数電源電圧によって低消費電力化する提案手法を紹介する.
図 4.1: ポートの構成.
4.2 準備
提案手法では,GDRアーキテクチャを2.2節で紹介した粗粒度の複数電源電圧によって,
低消費電力化する.
まず提案手法を説明するうえで重要となる用語を定義する.
複数電源電圧 回路内において,クロック周期制約に余裕がある箇所への供給電圧を下げる ことにより,低消費電力化を行う手法.提案手法では演算器単位で供給電圧を変化さ せるため,粗粒度の複数電源電圧を用いる.
高電圧(VDDH) 複数の電圧の中で,相対的に高い電圧のことであり,本手法ではGDRアー キテクチャが本来用いている電圧を示す.
低電圧(VDDL) 高電圧よりも低い電圧.この電圧が低く,かつ適用範囲が広いほど複数電源 電圧による低消費電力化の効果は増大する.
レベルコンバータ 電圧の異なるブロック間に配置され,送信側の電圧を受信側で使用され ている電圧に変圧する.文献[2]より,低電圧が高電圧の70%以上である場合には,高 電圧から低電圧にデータを転送する際にはレベルコンバータは不要とする.
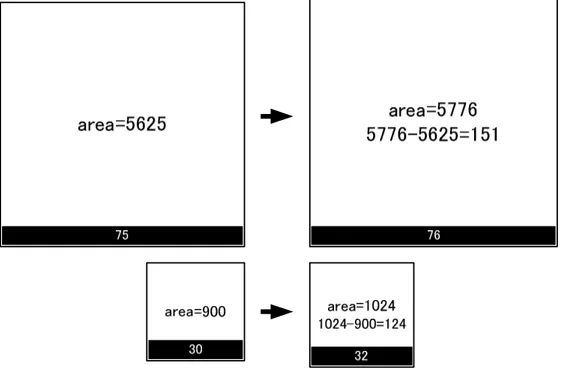
提案手法では,粗粒度,2電源の複数電源電圧を前提とする.複数電源電圧で用いる低電圧 は高位合成の段階で可変であるとする.提案手法は,まず従来のGDRアーキテクチャを基本 にフロアプランを構成する.しかし配線遅延を計算するフェーズにおいて,全てのモジュー ルが4隅のいずれかにポートを持つ構成を全探索する.この時,全ての乗算器のうち,最も スラックの小さい乗算器のスラックが最大となるポート配置を採用する.また,全ての乗算 器を低電圧化することを想定し,フロアプランや配線遅延は,図4.2に示すように,乗算器 にレベルコンバータの面積を上乗せして計算を行う.以上の操作をGDRアーキテクチャの 反復改良に組み込むことにより,乗算器のスラックを複数電源電圧に対し最適な構成とした 回路を得ることが可能である.
図 4.2: レベルコンバータの実装方法.
4.3 問題定義
本論文における高位合成問題は,入力をCDFG(Control-Data Flow Graph)とし,制約 条件に演算器制約(演算器の種類・個数),クロック周期制約を与え,RTレベルのデータパ スと制御回路,モジュール配置情報および電力消費量を出力する問題である.クロック周期 制約に対応することで,システムLSIの一部分の回路として回路を合成したい場合に,たと え供給されるクロックの周波数が先に決まっていても,そのクロック周期制約を満足しなが ら実行時間を最小化した回路が合成できる.目的関数は電力消費量の最小化である.また電 力消費が同一の場合面積を最小化する.
CDFG
高位合成において動作記述の中間形式のグラフ表現としてDFG(Data-Flow Graph),CFG
(Control-Flow Grah),CDFG(Control-Data Flow Graph)が使われてきた.DFG はデー タの流れをあらわしたグラフであり,制御構造を表現できない.CFGでは,並列処理を表 現することができない.そこで,その問題を解決するために,DFGとCFGの概念を両方取 り入れたCDFGを本論文では使用し,分岐処理の表現が容易な[26]をベースとしたCDFG モデルを使用する.
CDFGは,有向グラフG= (V, E)で表現され,ノード集合V は,演算ノード集合NOと,
分岐制御を表すノードの集合NCを含むものとする.エッジ集合Eは,データフローエッジ の集合EDとコントロール依存エッジECとメモリ依存エッジEMを含む.CDFGの例を図 4.3 に示す.
演算ノード集合NOにはADD,MULなどの演算とメモリリード,メモリライト,ローカル 配列を含む.メモリリードノードは1入力1出力であり,メモリライトノードは2入力(アド レス値と書き込む値)で出力はない.ローカル配列ノードはデータの参照時は1入力(index 値)1出力であり,データの格納時は2入力(index値と書き込む値)で出力はない.ローカ
+
+ +
+
>
-
a b c x
t if(a-b>c)
t=x+y+z+u;
else t=x+2;
図 4.3: CDFG.
化と,第三段階の低消費電力化フェーズを追加した形で構成される.初期フェーズは3.4節 で紹介したものである.ここでは改良フェーズによって得られた解を基に,低消費電力化し た解を求める.
初期フェーズ (Initial phase)
初期フェーズは,3.4節で紹介したものを用いることとする.
改良フェーズ (Improvement phase)
改良フェーズではスケジューリング,レジスタ/制御回路構成決定のために配置・配線情報 とレジスタ/制御回路情報をフィードバックし,繰り返し高位合成アルゴリズムとモジュール 配置を行う.この解と配置結果を利用し,まずレジスタ/制御回路構成が配置結果を満たす かチェックを行い,満たさない場合はローカルレジスタ/ローカルコントローラを付加する.
その後スケジューリング/FUバインディングを行い,その結果からレジスタ/制御回路再構 成を行う.次に出力されたフロアプランに対し,モジュールのポート配置の全探索を行い,
すべての乗算器のうち,最もスラックの小さい乗算器のスラックが最大となるポート配置を 採用する.改良フェーズは仮想フロアプラン生成,スケジューリング/FUバインディング,
レジスタ/コントローラ構成決定,レジスタバインディング,コントローラ合成,モジュール 配置,ポート再配置から構成される.
低消費電力化フェーズ (Low power phase)
低消費電力化フェーズでは低電圧の値を決定するために,スラック情報をフィードバック し,繰り返し電圧変化を行う.初期状態では低電圧を0[V]とし,クロック周期制約への違反 があった場合,低電圧を1段階上げる.低電圧を上昇させていき,すべての演算器がクロッ ク周期制約に違反しなくなった場合,回路は動作可能であるとみなし,その電圧を低電圧と して採用する.この過程から,電力消費量を最小にすることのできる電圧を決定する.
4.5 ポート最適化低消費電力アルゴリズム
ポート最適化低消費電力アルゴリズムでは,加算器に対して乗算器の電力消費量が極端 に大きいことに着目し,乗算器のスラックを最大化することを目的としている.乗算器のス ラックを最大化することにより,複数電源電圧の効果を高め,低消費電力化を行うことを目 的とする.以下にポート最適化低消費電力アルゴリズムを示す.
(Step1) 初期処理としてすべてのモジュールが4隅のいずれかにポートを持つ構成を全探 索し,すべての乗算器のうち,最もスラックの小さい乗算器のスラックが最大となる ポート配置をフロアプランとして採用する.
(Step2) 乗算器に低電圧を供給した場合の遅延時間を計算し,クロック周期制約を満たさな い場合,低電圧を1段階上昇させる.
(Step3) すべての演算器がクロック周期制約を満たした場合,その電圧を複数電源電圧で用 いる電圧として採用し,電力消費量を計算する.
ポート最適化 ( ステップ 1)
ポート最適化ステップでは,ポート配置の全探索を行い,すべての乗算器のスラックが複 数電源電圧に適した状態を出力する.
低電圧決定 ( ステップ 2)
低電圧決定ステップでは,乗算器を低電圧で動作させる場合の遅延時間の増加量を計算す る.遅延時間の増加量とレベルコンバータの遅延の和がスラックよりも小さい場合,すなわ ちクロック周期制約を満たす場合のうち,最も低い電圧を低電圧として出力する.
電力消費量計算 ( ステップ 3)
高位合成の詳細を記した.次に提案手法のフローを示し,各フェーズの役割を整理した.最 後に提案手法がGDRアーキテクチャを低消費電力化するアルゴリズムについて説明した.
計算機実験による評価
5.1 本章の概要
本章では,GDRアーキテクチャと提案手法を計算機上に実装し,その出力結果から本論 文で提案する低消費電力化手法を式により見積もり,その有効性を評価する.初めに実験方 法及び,実験環境,参考とした式を記す.その後,提案手法に複数のアプリケーションを入 力とした場合の結果について,3章で紹介したGDRアーキテクチャ[14, 15](GDR)と,GDR アーキテクチャに複数電源電圧のみを適用したもの(MGDR),GDRアーキテクチャのポー トを変更したのちに複数電源電圧を適用する提案手法(PMGDR)を比較する.
表 5.1: 演算器の面積,遅延,電力消費量.
面積[µm2] 遅延[ns] 電力消費量[pJ][1]
加算器 282 1.32 0.068
減算器 316 1.33 0.072
乗算器 4661 2.7 0.832
比較器 255 0.6 0.023
レジスタ(1bit) 18 0.11 0.052
マルチプレクサ(1bit) 7 0.04 0.0064
5.2 実験方法
GDRアーキテクチャと提案手法のシミュレーションプログラムをC++言語を用いて計算 機上に実装した.計算機実験に用いた計算機環境は以下のとおりである.
OS Windows 7 Home Premium
CPU Intel Core2 Duo 2.66GHz 2.67GHz Memory 4GB
対象アプリケーションとして7次FIRフィルタ(ノード数75),DCT(ノード数48),EWF(ノー ド数34),EWF3(ノード数102)を用いた.計算機実験では,GDR,MGDR,PMGDRを比 較した.計算機実験で用いた演算器の面積,遅延,電力消費量を表5.1に示す.演算器の面 積と遅延の値は[14]より,電力消費量は[1]を参考とした.レベルコンバータは論文[1]よ り,面積を113[µm2],遅延を0.25[ns],電力消費量を0.053[pJ]とした.レベルコンバータ の面積制約に対して,図5.1に示すように,低電圧モジュールの面積を増加させた.高電圧 は1[V],閾値電圧は0.5[V]とした.配線遅延は配線長の2乗に比例すると仮定し,250[µm]
当たり1[ns]と設定した.全ての対象アプリケーションにおいてクロック周期を1.7[ns]とし
た.電圧を下げた場合の演算器の遅延は論文[23]より,式(5.1)を用いた.電圧を下げた場 合の演算器の電力消費は論文[23]より,式(5.2)を用いた.
図 5.1: レベルコンバータの実装方法.
表 5.2: 計算機実験結果.
App. 手法 低電圧 電力消費量 面積
(FUs) [V] [pJ] [µm2]
FIR GDR 1.00 28.5 26208
(+3*3) MGDR 0.98 29.2 26535
PMGDR 0.91 25.2 26535
DCT GDR 1.00 15.5 29792
(+3*3) MGDR 1.00 15.5 30418
PMGDR 0.91 13.8 30418
EWF GDR 1.00 8.40 12876
(+2*1) MGDR 0.97 8.50 13104
PMGDR 0.91 7.70 13104
EWF3 GDR 1.00 25.3 23858
(+3*2) MGDR 0.99 26.1 24016
PMGDR 0.91 23.1 24016
5.3 実験結果
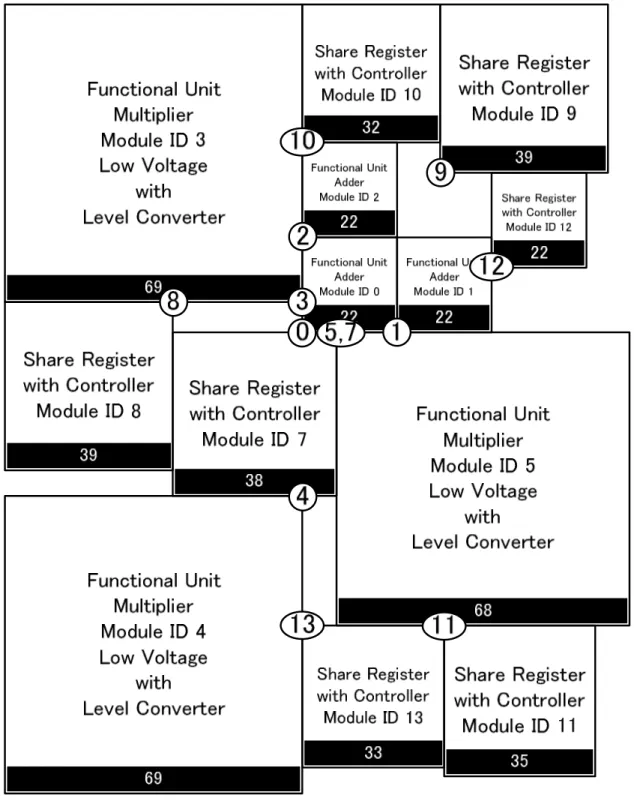
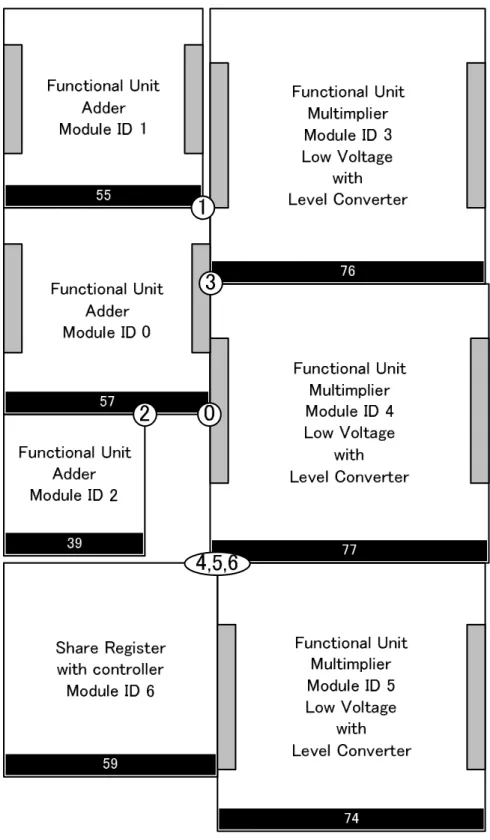
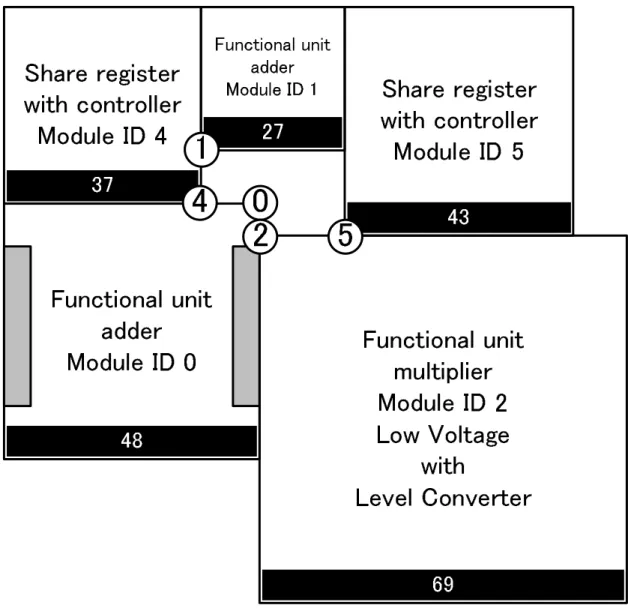
演算器における電力消費量と面積の実験結果を表5.2と図5.2,図5.3に示す.フロアプラ ン(FIR GDR)を図5.4に,フロアプラン(FIR PMGDR)を図5.5に,フロアプラン(DCT GDR)を図5.6に,フロアプラン(DCT PMGDR)を図5.7に,フロアプラン(EWF GDR)を 図5.8に,フロアプラン(EWF PMGDR)を図5.9に,フロアプラン(EWF3 GDR)を図5.10 に,フロアプラン(EWF3 PMGDR)を図5.11に示す.フロアプランの図中の数字は,対応 する番号のモジュールのポートの位置を表す.GDRと比較し,PMGDRは演算器における 電力消費量を最大で13.4%,平均で11.1%削減,面積は平均1.45%増加した.MGDRの場合 には,電力消費量が平均で1.5%増加した.
0.0 5.0 10.0 15.0 20.0 25.0 30.0 35.0
FIR DCT EWF EWF3
電力 消費 量 電力 消費 量 電力 消費 量 電力 消費 量[p J]
GDR MGDR PMGDR
図 5.2: 実験結果(電力消費量).
0 5000 10000 15000 20000 25000 30000 35000
FIR DCT EWF EWF3
面積 面積 面積 面積 [
] GDR
MGDR PMGDR μm
2
図 5.3: 実験結果(面積).
図 5.5: フロアプラン(FIR PMGDR).
図 5.7: フロアプラン(DCT PMGDR).
図 5.9: フロアプラン(EWF PMGDR).
図 5.11: フロアプラン(EWF3 PMGDR).
5.4 考察
図5.2において,FIRとEWF,EWF3の入力アプリケーションは,MGDRの電力消費量 がGDRの電力消費量を上回っている.これはスラックが少ないため,電圧を下げたことによ る電力消費の削減量よりもレベルコンバータのオーバヘッドが大きいためである.またDCT においてもGDRとMGDRを比較した場合,電力消費量は同じ値となっている.これらに 対し,全ての入力アプリケーションにおいてPMGDRの電力消費量はGDRの電力消費量を 下回っている.以上の2点から,ポート配置の最適化によってGDRを複数電源電圧によっ て低消費電力化することができるといえる.
5.5 本章のまとめ
本章では複数電源電圧による低消費電力化を考慮した一般化レジスタ分散アーキテクチャ の計算機実験を行った.提案手法は配線遅延を考慮するGDRアーキテクチャのポートを,複 数電源電圧に最適な構成とし,低消費電力化を考慮する高位合成となっている.提案手法は 従来手法と比較し,演算器における電力消費量を最大で13.4%,平均で11.1%削減した.
結論
本論文ではGDRに複数電源電圧を用いた低消費電力化高位合成手法を提案し,GDRの 性能を維持したまま演算器による電力消費量を最大13.4%,平均で11.1%削減できることを 示した.提案手法は入力アプリケーションと制約に応じて適切な低電圧とポート配置を構成 し,GDRアーキテクチャの低消費電力化を実現することが可能となる.計算機実験により 低消費電力化手法を既存手法と比較しても,GDRアーキテクチャの低消費電力化において 優れた結果を得ることを確認した.
第2章「低消費電力化を考慮した高位合成の研究動向」では,CMOSのLSIが電力を消費 する仕組みを述べ,電力消費量を低減する高位合成手法に関する調査を報告した.現在LSI の最も支配的な電力消費の要因はダイナミック電力であり,電圧は2乗のオーダで影響する ことを示した.また電圧を下げることで低消費電力化を実現する研究として,共有レジスタ 型アーキテクチャを対象としたもの[28]はあるが,GDRアーキテクチャを対象とした研究 は無い.
第3章「一般化レジスタ分散アーキテクチャを対象とする高位合成手法」ではGDRアー キテクチャを対象とする高位合成の流れを紹介し,レジスタ共有型との違いを整理した.
第4章「GDRを対象としたポート配置最適化複数電源電圧による低消費電力化高位合成 手法」では,一般化レジスタ分散アーキテクチャに対応した複数電源電圧による低消費電力 化を行う手法を提案した.提案手法はポート配置を考慮していない一般化レジスタ分散アー キテクチャに対し,複数電源電圧を適用する際に最適なポート配置を求める.これにより配 線遅延を低減し,複数電源電圧による低消費電力化の効果を高めることを確認した
第5章「計算機実験による評価」では,計算機実験により提案手法と従来手法の比較を行 い,提案手法の有効性の評価を行った.提案手法では面積は平均1.45%ほど増加したものの,
電力消費量を最大13.4%,平均11.1%削減した.よって提案手法は面積と電力消費量のトレー ドオフが存在するものの,GDRアーキテクチャを既存手法以上に低消費電力化することが できることを確認した.
最後にGDRアーキテクチャに低消費電力化を考慮した高位合成に関する今後の課題につ いて考察する.まず本提案手法の改良点は,ポート配置の最適化により,配線遅延を低減す ることから始まる.この利点を乗算器の低電圧化に利用し,複数電源電圧の効果を高めるこ とである.この複数電源電圧による低消費電力化は,電力消費のうちダイナミック電力の低 減を行う.しかし現在,プロセスの微細化に伴い,リーク電力による電力消費量がダイナミッ ク電力による消費を上回っている(図6.1).そのため,配線遅延の低減をダイナミック電力 の低減に当てるのではなく,複数閾値を用いてリーク電力の低減に役立てることが,今後よ り効果を増してくるのではないかと考えられる.また,提案手法ではポート配置を変更する ことにより,配線がチップ中央に集中すると考えられる.配線の一ヶ所集中により,論理誤 りや遅延時間増加を引き起こすクロストーク[7, 29, 27]の影響が考えられる.加えて,複数
図 6.1: リーク電流とダイナミック電流の傾向[21].
電源電圧ではレベルコンバータによる電力消費と遅延が存在し,低消費電力化を妨げるオー バヘッドとなっている.複数電源電圧をより幅広く用いるためにも,従来よりもオーバヘッ ドの小さいレベルコンバータの構成も今後の研究課題として挙げられる.
本論文全般にわたり,御指導ならびに御助言を授かった戸川望教授,柳澤政生教授,大附 辰夫教授に深く感謝いたします.
また,終始,適切な御指導および御助言を頂きました本学博士の大智輝氏に深く感謝いた します.
最後に,本論文に関する研究活動全般にわたり支援して頂いた戸川研究室および柳澤研究 室,大附研究室の皆様に感謝いたします.
[1] 阿部晋矢,戸川望, 柳澤政生, 大附辰夫, “群生化レジスタ分散アーキテクチャを対象と した低電力化高位合成手法に関する研究,” 早稲田大学戸川研究室卒業論文, 2010.
[2] J. An, H. Park and Y. Kim, “Level Up/Down converter with single power-supply volt- age for multi-VDD systems,” in Proc. Journal of semiconductor technology and sci- ence,Vol.10,No.1,March,2010.
[3] J. Carballo, J. Burns, S. Yoo, I. Vo, and V. Norman “A semi-custom voltage-island tech- nique and its application to high-speed serial links,” in Proc. International Symposium on Low Power Electronics and Design (ISLPED-03), pp.60–65, 2003.
[4] J. Chang and M. Pedram, “Energy minimization using multiple supply voltages,” in Proc. International Symposium on Low Power Electronics and Design, pp.157–162, 1996.
[5] J. Cong, Y. Fan, G. Han, X. Yang, and Z. Zhang, “Architectual synthesis integrated with global placement for multi-cycle communication,” inProc. International Conference on Computer Aided Design (ICCAD-03), pp.536–543, 2003.
[6] Forte Design Systems, Inc., http://www.forteds.com/.
[7] 廣瀬哲,安浦寛人,“クロストークを考慮したバス遅延削減手法,”電子情報通信学会論 文誌.A,基礎・境界 J83-A(8),pp989–998, 2000.
[8] 木村雅秀, “待機時電力ゼロのLSIノーマリー・オフの実現に道,” 日経エレクトロニク ス, No.1003, May, pp.55–59, 2009.
![表 5.1: 演算器の面積, 遅延, 電力消費量. 面積 [µm 2 ] 遅延 [ns] 電力消費量 [pJ ][1] 加算器 282 1.32 0.068 減算器 316 1.33 0.072 乗算器 4661 2.7 0.832 比較器 255 0.6 0.023 レジスタ (1bit) 18 0.11 0.052 マルチプレクサ (1bit) 7 0.04 0.0064 5.2 実験方法 GDR アーキテクチャと提案手法のシミュレーションプログラムを C++言語を用いて計算 機上に実装した.計算機実験](https://thumb-ap.123doks.com/thumbv2/123deta/9785788.1869053/48.892.203.705.157.340/マルチプレクサアーキテクチャシミュレーションプログラム.webp)
![表 5.2: 計算機実験結果. App. 手法 低電圧 電力消費量 面積 (FUs) [V ] [pJ] [µm 2 ] FIR GDR 1.00 28.5 26208 (+3*3) MGDR 0.98 29.2 26535 PMGDR 0.91 25.2 26535 DCT GDR 1.00 15.5 29792 (+3*3) MGDR 1.00 15.5 30418 PMGDR 0.91 13.8 30418 EWF GDR 1.00 8.40 12876 (+2*1) MGDR 0.97 8.50 1](https://thumb-ap.123doks.com/thumbv2/123deta/9785788.1869053/50.892.262.654.160.535/計算機実験結手法低電圧電力消費面積µFIR+MGDRPMGDRDCT+MGDRPMGDREWF.webp)