二重学習器を用いる強化学習の 性質とその応用
平成 2 2 年度
三重大学大学院工学研究科電気電子工学専攻
柴 田 信 雄
三 重 大 学 大 学 院 工 学 研 究 科
二重学習器を用いる強化学習の 性質とその応用
専攻 三重大学大学院工学研究科電気電子工学専攻 研究窒 情報処理研究室
平成
21年度入学
409M224氏名 柴 田 信 雄
1 重 大 学 大 学 院 」二学研究科
目 次
1
はじめに
12
二重学習器を用いる強化学習法
32.1 Q
学 習 .
• • • • • • • • • • • • • • • • • • 42.2
アルゴリズム
52.3 Q‑table
の選択
6 2. 4 実 験 .
• • • • • 7 2. 4
.1実機実験環境.
• • • • • • • • • • • • 8 2.4.2学習空間の構成.
• • • • • • • • • • • • • 9 2. 4
.3シミュレーション実験.
• • • • • • • • • • • • • • • • • • • • • • • •• 11 2.5実験結果.
• • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • •• 123
提案手法
153.1
概 要 .
• • • • • • • • • • • • • • • • • • • • •. .
• • • • • • • • • • • • • • •• 15 3.2アルゴリズム
• • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • •• 17 3.2.1ソースエージェントの学習.
• • • • • • • • • • • • • • • • • • • • • •• 17 3.2.2ターゲ、ットエージェントの学習.
• • • • • • • • • • • • • • • • • • •• 194
シミュレーション実験
22三 重 大 学 大 学 院 工 学 研 究 科
5 6
実験結果 まとめ
参考文献 謝辞
〈 重 大 学 大 学 院 工 学 研 究 科
24 27
28
30
図 目 次
2.1 Whole Q‑table and Partial Q‑table . . . AA
V O
月i a u Q U Q U
2.2 NS chart of Learning with Dllal Q‑tables. . . . 2.3 Reslllts of sim1l1ation .
2
. 4
MieC and Poles .2.5 Experiment environment . 2.6 Action呂田
2.7 States of Pole and Goal . . . .. 10 2.8 State set . . . .. 11 2.9 Environment of simulation. . . . .. 12 2.10 Res1l1t of sim1l1ation . . . .. 14 3.1 AT‑table and Env‑table . . . .. 16 3.2 Learning algorithm of Source agent . . . .. 18 3.3 Learning algorithm of Target agent . . . .. 18 4.1 Simulation environment . . . .. 23 4.2 Actions of Source and Target agents . . . 23 5.1 Res1l1t of sim1l1ation . . . 25
1 重 大 学 大 学 院 」二学研究科
第 1 章 はじめに
人は歩いているとき,どう動くとどのように景色が変化するかを知識として記憶してい る.そして,例えば車の運転を練習するとき,アクセル操作量やハンドル操作量に対して,
知識を利用してどのように景色が変化するかで,車の動きを理解する.しかし,車の運転で は,歩いているときには起こらない景色の変化が起こることもあり,その場合は新しい知識 として学ぶ必要がある.本研究では,このような人の知識の再利用の機構をモデル化し,学 習の試行回数を削減する手法である異形態間学習を考える.
ロボットの学習法のーっとして,環境とエージ、エントの相互作用を通して学習する強化学 習
(ReinforcementLear凶
ng)[l,
Kaebling96][2,
Sutton98]がある.しかし,実環境において 複雑な環境を学習する場合,学習器が複雑膨大になり,学習時聞が増大する.そのため,強 化学習における試行回数の削減は,実環境での学習において重要な問題となる.
強化学習の効率化に関する研究には,最初にゴールに近い簡単な状況から学習し,徐々に 擾雑な状況へと移行していく
[3ぅAsada96]や,既に持っている行動政策の中で不都合な部分 のみを学習しなおすことによって学習時聞を短縮する
[4,
MinatoOO]などがある.
また,複雑なタスクを細かいサブタスクに分解した強化学習モジ、ュールを階層的に並べ て学習する階層型強化学習も研究されている
[6,
T北 部
hi03][7,
Uchibe04].これは,下位モ
ゴ.重大学大学院 工 学 研 究 科
ジュールが単純なサブ、タスクを学習し,上位の学習器が下位の学習器を利用してより高いレ ベルのタスクを学習することで学習の早期収束を目指している.
その他にも,連続状態空聞を離散化する際,タスクに応じた適切な状態数を維持すること で,過剰な状態が分割されることによる学習の遅延を防ぐ
[5,
hamagami03]や,環境に対応 する状態空聞を複数の部分空間に分け,それら部分空間における比較的単純なセンサーモータ 写像をモジュー y レとして学習・記憶しておくことで,環境の変化に伴い異なる行動の生成が 必要な場合でもモジ、ュールを組み換えることで速やかな対応が可能な
[9,
Gouko08]がある.
これらの研究は,最適な状態空間の構成法や,タスクの分割法を議論することによって学 習の効率化を図っているが,本論文では,以前に学習した知識を再利用することで学習の効 率化を図る.
知識を再利用する学習法は転移学習(Tr
ansferLearning) [12,
Taylor09]と呼ばれ,複数のタスクで知識として使える共通タスクを分離学習し,それを再利用する
[10,
Yamaguchi09]や,ニューラルネットワークを用いて異なる環境問の状態や行動の対応付けを学び,異なる 環境での学習結果を再利用する
[11,
Taylor07]などがある.これらに対し,本研究では,二 重学習器を用いる強化学習法
[8,
Nishimura06]を応用した異形態間学習を提案する.
具体的には,同じ環境で、同じタスクを形の異なるエージェントが学んだ学習結果を再利用 し,学習の効率化を図る.本論文では,
2章で,仮想空間でしか有効で無かった二重学習器 を用いる強化学習法
[8ぅNishimura06]が実機でも有効であることをシミュレーシヨン実験との比較検討によりその有効性を確認する.その後,
3章で異形態間学習を提案し,
5章でシ
ミュレーション実験の結果を示し,実機でも適用できる可能性老示す.
三 重 大 学 大 学 院 工 学 研 究 科
第 2 章
二重学習器を用いる強化学習法
人は一度経験した環境では,過去の経験から行動を選択する.そして経験していない環境 では,過去に経験した知識から適正と思われる行動を推論し,選択する.もし選択した行動 が適正行動でなくとも,その行動が不適切であることを知識と経験として蓄え,次からその 行動を選択しなくなる.二重学習器を用いる強化学習法
[8,
Nishimura06]は,この人の知識 と経験を利用する行動学習をモデル化し,ロボットが効率良く学習することを目的として いる.
具体的には.
Fig.2.1に示すように,環境に対する学習空聞を
2つ用意し,これを同時に 学習させる.一つは,環境空聞を完全に表現する全学習空間(以下,全空間と呼ぶ)とし,
これを経験の蓄積として用いる.もう一つは,全学習空間の一部を圧縮した部分学習空間 (以下部分空間と呼ぶ)とし,これを知識の蓄積として用いる.全空間は,空間が大きいの で学習は遅いが,環境に対して細かく対応付けをする.部分空間は空間が小さいので学習は 速いが,環境に対して荒く対応付けをする.行動選択をするたびに,この
2つの学習空間の より学習できている方の行動を選択し,同時に更新することで,学習が速く環境にも細かく 対応付けができる.
三 重 大 学 大 学 院 E学 研 究 科
r 一一一
/,
/ : Action
。 r ‑,一一一
I : ‑‑‑‑‑‑
,
KL‑‑‑
Color
Whole space Partia I space
Fig.2.1 Whole Q‑table and Partial Q目table
2 . 1 Q 学習
本論文では,強化学習に
Q学習を用いる.本節では
. Q学習について説明する.
Q
学習は,環境と行動の組(以下,ルールと呼ぶ.)ごとに評価値
Qをもち, 目標達成に 至るまで各ステップごとに以下の式
(2.1)式および式
(2.2)式を繰り返し用いて
. Q値を更 新することで学習する.
Q(Sk
, a ) ←
(1‑α)Q(Sk, a ) +
α( r +
γV(Sk+
l)) (2.1)V(Sk+l)
= 緊
EQ(sk?α) (2.2)ここで.
Skは現在の状態, A は行動集合,
αは選択行動.
Sk+lは遷移後の状態,パま報酬 値 ,
γ(0~γ< 1)は割引率,
α(0 <α< 1)は学習定数である.
l
レールごとの
Q値を表にしたものを
Q‑tableと呼ぶ.
三 重 大 学 大 学 院 E 学 研 究 科
2 . 2 アルゴリズム
Fig.2.2
に,二重学習器を用いる強化学習法のアルゴ、リズムを示す.ここでは
NSチャー トの説明をする.
1.環境の設定
lnit Q‑tables (1) Episode Loop
. ‑ ー ー ー ー ー ー ー ー
E 盆出盆
Select Action by Partial Q‑table (3p) Update Partial Q‑table(4p)
gL 一一‑w両長
ct Action by le Q‑table (3w)
Update Whole Q圃table(4w) Until getting reward
Fig. 2.2 NS chart
o f
Learning with Dual Q‑tablesシミュレーションで使う学習環境や学習パラメータ,タスクなどを設定する.
2. Q‑table
の初期化
学習エージェントが使う全空間
Q‑tableおよび部分空間
Q‑tableの
Q値を初期化する.3. Q‑table
の選択
学習エージ、エントが全空間
Q‑tableと部分空間
Q‑tableのどちらを用いて行動選択す るかは,どちらの
Q‑tableが有用な情報を持っているかを平均情報量を用いて判断し,
決定する.詳しくは
2.3節で説明する.
1
重 大 学 大 学 院 ̲ l : 学 研 究 科
4.
行動選択
学習エージェントは,平均情報量により選択された
Q‑tableに対し
Boltzmann選択を 使って行動を選択する.
Boltzmann選択は,式
(2.3)から行動選択確率を求めるもの である.
xp(監午a))
p(
αISk) = ー ー ゐ
81,,,α、 つ
(2.3)dεA exp~...::.ムす←....t..
ここで,
p(α1 Sk)は,ある時刻
kの状態
Skで行動
αを選択する確率,
Q(Sk,α)は,あ る時刻 kの状態
Skにおける行動
αの
Q値,Tは温度を示す.
5. Q‑table
の更新
学習エージ、エントは
2.1節で述べた
Q学習のQ値の更新関数式(2.1)および式
(2.2)を用いて学習サイクルごとに
Q値を更新し,行動を評価する.
以降, ( 3 )
ー( 5 )のサイクルを報酬を得るまで繰り返し
Q値を更新する.
2 . 3 Q ‑ t a b l e の選択
全空間
Q‑tableと部分空間
Q‑tableのどちらを使うかは,平均情報量を用いて判断する.
平均情報量とは 情報の不確かさ"を評価するものである.これを行動選択確率に当てはめ ると,平均情報量が低ければ低いほど行動が確定的であり,学習空間が有効であることを示 す.具体的には,全空間
Q‑tableと部分空間
Q‑tableの平均情報量を計算し,平均情報量が 低い学習空間を使って行動を選択することにより,環境に最適な行動が選ばれることが期待 できる.平均情報量
H(s)は,式
(2.4)で求められる.
H(s)
= ~aEAP(α|s)log-l-(2.4)
2 p(α1 s)
p(α
I s )は式
(2.3)で定義される,状態
sで行動
αの選択される確率である.
二 三 重 大 学 大 学 院 工 学 研 究 科
2 . 4 実験
本手法は,西村ら
[8,
Nishimura06]によって,シンプルなシミュレーション実験において
Fig. 2.3に示すように有効性が確認されている.全空間または部分空間だけを用いた通常 の学習に比べ,
2つの学習空間を同時に学習することにより,高速かつ正確に学習できてい ることが確認できる.すなわち,部分空間が全空間の全てを表現できる場合は
Fig.2.3(a)のように,部分空間とほぼ同じ速度で速く学習できており,部分空間が全空間の半分を表現 できる場合は,
Fig. 2.3(b)のように学習初期は部分空間を用いて速く学習が進み,学習後 半では全空聞を用いて正確に学習が出来ている.そして,部分空間が全空聞をまったく表現 できない場合に関しても,
Fig. 2.3(c)のように全空間だけを用いる場合とほぼ同じ速度で 学習できている.
本手法は,実機での学習における有効性が示されていないため,ここでは,部分空間が全 空間の一部を表現できる場合に関して実機実験をして,実機におけるこの手法の有効性を確 認する.
[耐P~旦且立主主止
40ト 羽leOrdimuy method with the pactical Q‑table 30110
¥ f The Prop回edmethod with 世lewhole and the伊氏ialQ‑tabl田
世lewhole Q‑table
[steps l1ntil reward
40
t
LThe Ordinay method 、川h / thewhole Q匂ble 30.ノ
~
. 1
Th~ ~.ropo田dme血odw出~
I /
the whole and1 I 1
e p訓alQ‑table: 20lH1
1
[
司tepsuntilr目 四rdJ 40
;・''‑'‑!''‑'I/(''んJへ...
' . . ! ‑ . , 介 . I....~. ....:...~..,. .
J ・
30島 T heOrdinary method ¥vith
1
I 1
ep副ialQ‑table 20l‑l司eProp田edmethod w出/ the whole and the partial Q‑tabl田
{' TheOrd叩arymethod with
,
〆
thewholeQ-包bl~10
50 100[叩isode] 0 50 100[episode] 0 50 !OO[叩isode]
(a)100% (b)50% (c)O% Fig. 2.3 Results of simulation
三 重 大 学 大 学 院 [ 学 研 究 科
2 . 4 . 1 実機実験環境
本論文の実験では,
Fig.2.4に示す自律移動ロボット
MieCを用いて,色の異なる
4色の ポールを
Fig.2.5の環境において黒のマーカーで示されるゴールまで運ぶタスクを学習す る.実験環境の大きさは,
O.84[mJxO.54[mJとなっている.
MieC
は三重大学機械工学科メカトロニクス研究室で開発された自律移動ロボットで,移 動機構として
2本の無限軌道を用いる.
2つの無限軌道は,
2つのモータにより,それぞれ 独立に駆動される.外部センサとしては,
CCDカメラ
(Logicool製の
QV‑4000)を搭載して いる.外部通信には無線
LANを用いる.また,
CPUカードと
FPGAカードを搭載してお り,画像処理などは
CPUカードが担当し,モータ制御などの処理は
FPGAカードが担当す る.今回使用する
MieCには永久磁石を内蔵したプレードが前方に取り付けられており,内 部に鉄を埋め込んだポールを一度捕まえると離さないようになっている.ポールおよびゴー ルの認識には搭載している
CCDカメラを用いる.
報酬はポールがゴールに入って初めてエージ、エントに与えられる.各ポールは色によって ゴールの右側に入れるか左側に入れるかが決められており,赤いポールはゴールの左 ( A ),
青はゴールの右
(B),緑と黄色は
A,
Bどちらでも良い.
Fig. 2
. 4
lVlieC and Poles Fig. 2.5 Experiment environment三 重 大 学 大 学 院 工 学 研 究 科
2 . 4 . 2 学習空間の構成
行動集合と状態空間の構成方法を説明する.
行動集合は,
Fig.2.6に示すように,
{Forward,
Backward,
Pivot turn right,
Pivot turn 1e氏}の
4つの行動で構成される.今回の実験では速度は 一定とする.
‑ ‑ ‑
Go backward Go forward
c
~= >
Pivot turn right〈 コ : : : : >
Pivot turn leftFig. 2.6 Action set
状態集合は,ポールとゴールの見え方の状態と,ポールの色の状態で構成される.ポール とゴールの見え方の状態は,
MieCの
CCDカメラから取得した画像中のポールとゴールの 重心位置によって構成する.
1.ゴールの見え方の状態空間
Fig. 2.7(a)に示すように,重心の垂直方向の位置からエージ、エントとの距離dis‑ tance{far
,
near},重心の水平方向の位置
position{left,
center,
right},マーカーの 傾き角から
direction{leftdirection,
center,
right direction}のそれぞれの組み合わせ
18(2x3x3)通りに加え,右に見えなくなったか左に見えなくなったかの
2通りの全
20通りで構成する.
2.
ポールの見え方の状態空間
Fig. 2.7(b)に示すように,重心の垂直方向の位置からエージェントとの距離dis‑ tance{far
,
near},重心の水平方向の位置
position{left,
centerぅright}の組み合わせ三 重 大 学 大 学 院
L学 研 究 科
6(2x3)
通りに加え,右に見えなくなったか左に見えなくなったかの
2通りの全
8通り で構成する.
3.
ポールの色の状態集合
Fig. 2
.4に示すように,ポールの
4色
color{red,
blue,
green,
yellow}に加え,色が不 明の状態の全
5通りで構成する.
position
‑ ・ ・ ・ 圃 ・ ・
し一一ーム‑
left center right direction
left‑direction
position
̲ ̲ 1 ‑
left center right
direction
仁 二 一 二 コ
lost‑Ieft lost‑right
front
(a)States of Goal direction
( : コ 10 口口口口口 7 一 刀 . 三 . , 口 口 . 山 , c 日 三 : ご :
lost‑Ieft lost‑right
(b )States of Pole
distance
一 ‑
right‑direction
distance
• •
Fig.2.7 States of Pole and Goal
far
near
far
near
ポールとゴールの状態の具体例を
Fig.2.8に示す.
(a)の例では, ゴールの状態は
{position,
distance,
direction}={ center,
near,
right direction}となり,ポールの状態は
{position,
dis‑三 重 大 学 大 学 院 工 学 研 究 科
tance }={ right
,
near}となる.同様に, (b)の例で、はゴールの状態は
{left,
far, center},ポー ルの状態は{
center,
far}となる.(a)Example1
I ~:'
( b
)Example2Fig. 2.8 State set
これらの状態を二重学習器を用いる強化学習に適用するため,全空聞をゴールとポールの 見え方の状態の組み合わせとポールの色の状態の組み合わせからなる
800(20x8x5)状態で 構成し,部分空聞をポールの色の状態を除いたゴールとポールの見え方の状態、の組み合わせ のみの
160(20x8)状態で構成する.
2 . 4 . 3 シミュレーション実験
今回の実験では,まず
2.4.1項で説明した実験環境のシミュレータ実験をし,その結果と 実機実験の結果を比較し,有効性を確認する.本項では,シミュレータについて説明する.
シミュレーション完験の環境を
Fig.2.9に示す.今回の完験では,初期状態として
Fig.2.9のように学習エージ、エントとポ
‑Jj;とゴールが直線上に配置される.このとき,ゴールと ポールの状態はそれぞれ{
center,
far,
center},
{center,
far}となっている.三 重 大 学 大 学 院 工 学 研 究 科
学習エージ、エントは,前後進は
0.5[pixeljstep],超信地旋回は
0.1[degjstep]の速さで移動 する.また,状態変化が起きるまでは同じ行動をとり続け,状態変化が起きて初めて
Q‑tableを更新し,次の行動を選択する.状態変化が起こらない状況になった場合(例えば壁に向 かつてまっすぐ走り続けるなど)は,負の報酬を与えて
Q‑tableを更新し,次の行動を選択 する
.。
y
2 . 5 実験結果
。
MieC
J
o b j p c t
•
(20, 25) (50, 25)
g q a l
100
X
(100,25)
Fig. 2.9 Environment of simulation
Fig. 2.10
にシミュレーション実験の結果を示す.各結果は
1000試行の平均値である.
各パラメータの値は,各
Q値の初期値は0.0,報酬
Tは正の報酬が1.
0,負の報酬が‑1.
0, 学習率
αは0.3,減衰率
γは
0.85,ボルツマン選択の温度
Tは0.07となっている.
Fig.2.10
の結果より,二重学習器を用いる強化学習法は,
1.学習初期においては全空間
Q‑tableだけを用いた場合よりも速く学習できており,
2.学習後半においては部分空間Q‑table
だけを用いた場合よりも正確に学習できている.
三 重 大 学 大 学 院 工 学 研 究 科
本項では,
Fig.2.5に示す環境で,パラメータの値や
Q‑tableの構成をシミュレータと同 じ条件で実機実験し,次の
2つのポイント
(1)学習初期および
(2)学習後半においてシミュ レーション実験と同じ傾向が見られるかどうかを確認して実機における有効性老検討する.
Table.2.1
,
Table.2.2にポイント
(1)およびポイント
(2)の実機実験の結果を示す.
Table.2.1 の結果は 1~16 エピソードまで、の全ステップ数の合計値 Table.2.2 の結果は 501
~516 エピソードまでの各エピソードのステップ数の平均値である.実機実験の結果は 4 試 行の平均値であり,シミュレ←シヨンの結果は
1000試行の平均値である.ポイント
(2)の 結果は,実機で全て学習するには多くの時聞が必要となるため,シミュレーションで
500エ
ピソードまで学習した
Q‑tableを用いて
501エピソ←ド目から学習している.
これらの結果から,ポイント ( 1 )およびポイント ( 2 )についてそれぞれ次のことが確認で きる.
1
シミュレーション結果と同様に全空間
Q‑tableだけを用いた場合と比較すると,ステッ プ数の減少,および実時間での学習時間の減少が認められ,速く学習できていること がわかる.
2.
シミュレーションの学習結果を用いて実機で学習すると,シミュレーションと同様の 傾向が確認できる.すなわち,部分空間
Q‑tableだけを用いた場合にはゴールまで多 くのステップ数が必要となっており正確に学習できていない.それに対し,二重学習 器を用いる強化学習では少ないステップ数でゴールまで到達できており正確に学習で きている.
以上の結果から二重学習器を用いる強化学習法は実機においても有効であることが確認で きた.なお,実機の結果とシミュレ←ションの結果の数値に差があるのは,実機実験の試行 回数がシミュレーション実験に対して非常に少ないためと考えられる.
三 . f t 大 学 大 学 院 仁 学 研 究 科
百 C 3
450 400 350
~ 200
ω
!~ I)
150 100 50
国 一TheOrdlnary method w耐th.同rtialQ‑table
由 周 回TheOrdinary method WI由thewhole Q‑table
ーーーTheProposed me出odwith出 @ whole and the partial Q
‑ t
ables50 100 150 200 250 300 350 400 450 500 Ep陪ode
Fig. 2.10 Result of simulation
Table 2.1 Resl
出
ofactual experiment at the point(l) Whole Q田table Dual Q‑tablesActual Simulation Actual Simulation Steps 2435 3352.8 2199 2760.7 Time[secJ 2843 2317
Table 2.2 Resl
此
ofactual experiment at the point(2) Partial Q‑table Dual Q‑tablesActual Simulation Actual Simulation Steps 81 15
1 .
6 8 12.5三 重 大 学 大 学 院 L学 研 究 科
第 3 章
提案手法
本章では, 2 章で有効性老確認した二重学習器を用いる強化学習法を応用した,異形態間 学習を提案する.
3 . 1 概要
学習エージェント(以後ターゲ、ットエージ、エントと呼ぶ)があるタスクを学習する際,同 じ環境で同じタスクを形の異なる別の学習エージ、エント(以後ソースエージ、エントと呼ぶ) が以前学んだ結果を知識として再利用することで効率的に学習する.
提案手法では,ターゲ、ツトエージ、エントは学習に次の
4つのテーブルを用いる.
1
重 大 学 大 学 院 工 学 研 究 科
1.ターゲ、ツトエージェントの
Q‑table(Target Q‑table)各状態とターゲ、ツトエージ、エントの行動で構成される
Q‑table. 2.ソースエージェントの
Q‑table(Source Q‑table)各状態とソースエージ、エントの行動で構成される
Q‑table.この
Q‑tableはすでにソ←
スエージェントによって学習されている.
3.行動変換テーブルActiontranslation table (AT‑table)
Fig. 3.1(a)
に示すように,ソースエージ、エントの行動とターゲ、ツトエージ、エントの行 動で構成されるテーブル.ソースエージ、エントの学習結果を再利用する際に,ソース エージ、エントの行動をターゲ、ツトエージ、エントの行動と対応付けるために用いられる.
これは,ターゲ、ツトエージェントの学習時に
TargetQ‑tableと共に学習される.
4.環境テーブルEnvironmenttable (Env‑table)
Fig. 3.1(b)
に示すように,ソースエージェントの学習時に,ある状態においてある行 動をとった時の状態遷移確率を記録しておくためのテープ、ル.このテーブルは
AT‑tableの学習時に用いられる.
Action of
Action of Source agent
(a)AT‑table
, ,
, ,
,
, ,
, ,
, ,
,
Next state
,L ̲ーーーーーーーーーー‑‑1‑‑ーーーーー
Action
(b)Env‑table Fig. 3.1 AT‑table and Env‑table
:.A:
大 学 大 学 院 L 学 研 究 科
提案手法では,ターゲ、ットエージェントは
2通りの方法で学習し,行動を選択する.ま ずーっ目の方法
(Way1)は ,
Target Q‑tableを用いて学習する.これは,環境とターゲ、ツト エージ、エントの行動全てを表現したテープ、ルを用いて学習するため,正確に行動を学習でき るが,状態数が多くなるため学習に時間がかかる.二つ目の方法
(Way2)は ,
Source Q‑tableとA
T‑tableを用いて学習する.具体的には,学習済みの
SourceQ‑tableが各状態に対して 出力するソースエージェントの最適行動を,
AT‑tableを用いてターゲ、ットエージェントの 行動に変換する.この方法では学習するのは状態数の少ない
AT‑tableだけでよいので学習 は非常に速く進むが,
Source Q闇tableと
AT‑tableの組み合わせではターゲ、ットエージェン
トの行動全てを正しく表現できないため,正確に学習できない.
提案手法では二重学習器を用いる強化学習法を応用し,これら二つの方法を同時に学習 し,行動選択毎により学習できている方法
(Way1または
Way2)の行動を選択する.これに より,学習初期においては速く学習の進む
Way2の行動が選択され,学習後半は正確に学習 できる
Way1の行動が選択されることで,高速かつ正確に学習することが期待できる.
3 . 2 アルゴリズム
提案手法のアルゴリズムのブロック図と
NSチャートを
Fig.3.2および
Fig.3.3に示す.
3 . 2 . 1 ソースエージ、エントの学習
ソースエージ、エントは,
Fig.3.2にしたがって,ターゲ、ツトエージ、エントの学習前にあら かじめ
SourceQ‑tableを学習し,
Env‑tableを記録する.
て 重 大 学 大 手 : I 涜 工 学 研 究 科
Current State Init Source Q‑table (1) Episode Loop
Select Action by Source Q‑table (2) Update Source Q‑table (3) Store Env‑table (4) Suitable action for SA Until getting reward
(a)Block diagram (b)NS chart Fig. 3.2 Learning algorithm of Source agent
Current State
Suitable act旧nforTA
(a)Block diagram
Init Target Q‑table and Load Source Q‑table and Env‑table(1) Episode Loop
WET
一一一一一三
ele山
ay@̲̲̲一一一一一五五
Select Action by Select Action by Target Q‑table (3.2) Source Q‑table (3.1)
Action transformation by AT‑table (4)
Update A T ‑table by Env‑table(5) Update Target Q‑table (6) Until getting reward
(b)NS chart
Fig. 3.3 Learning algorithm of Target agent
=
三 重 大 学 大 学 院 工 学 研 究 科
3 . 2 . 2 ターゲットエージ、工ントの学習
1 .
Target Q‑tableおよび
AT‑tableの初期化と
SourceQ‑tableおよび
Env‑tableの読み 込み
タ←ゲ、ットエージェントは
TargetQ‑tableを初期化し,学習済みの
SourceQ‑tableと
Env‑tableを読み込む.
Source Q‑tableと
Env‑tableの各値は,ターゲ、ットエ←ジ、エン
トの学習中に変化することはない.
2. Way(Way1
,
Way2)の選択
Way1とWay2
のどちらかを,二重学習器を用いる強化学習法と同様,各テーブルの 平均情報量を用いて選択する.各
Wayの平均情報量は式
(3.1),式
(3.2),式
(3.3), 式
(3.4),式
(3.5)によって計算される.
HQt吋 吋(8)
= ~atεAtP(αt18)
log22 p~土-
(αt18)
HQ山 rce(8)
= ~a εAsP(αS18)
log2]ー土‑
;(αSl8 )HATー 帥l
川)士宮内 ε
AtP(αt│th)log‑i‑2 p(αt 1αs) H切αyl(8)
=
HQt吋 吋(8)H
日 仰
2(8)=
HQs即 ce(8)+
HAT‑tαble(αs( 8))(3.1) (3.2) (3.3)
( 3 . 4 )
(3.5)ここで,
αtはターゲ、ツトエージ、エントの行動,
αsはソースエージ、エントの行動 ,
p(α1 8)は式
(2.3)で定義される状態
sにおいて行動
αが選択される確率,
p(αt 1αs)は式
(3.8)で定義され,
AT‑tableで行動向のときに行動向が選択される確率である.式
(3.5)の関数
αS(8)は,状態
sの時に
Boltzmann選択を用いて
SourceQ‑tableで選択された 行動向を出力する.
三 重 大 学 大 学 院 L学 研 究 科
3.行動選択
ターゲ、ツトエージ、エントは
Boltzmann選択を用いて式
(3.6)および式
(3.7)から得ら れる選択確率で
SourceQ‑tableおよび
TargetQ‑tableから行動向,
αtを選択する.
p(αS
I
Sk) p(αtI
Sk) =位
p(仏 。 づ
8山
2)~a~ εAs 位p(gS山ずSk ,a~2)
p(gta叩 t(Sk州 2 )
T
~a~叫叫(gtαづSk ,a~2)
(3.6)
(3.7)
ここで ,
p(αSI
Sk)は,ある時刻 k の状態
Skで行動向を選択する確率 ,
p(αtI
Sk)は , 状態
Skで行動向を選択する確率 ,
Qs山 間(Sk,
as)は,状態
Skにおける行動向の
Q値 ,
Qtαrget( Sk,
αt)は,状態
Skにおける行動
αtの
Q値 , Tは温度を示す.
4. AT‑table
による行動変換
Source Q‑table
で選択されたソースエージ、エントの行動向を
AT‑tableを用いてソー スエージェントの行動向に変換する
.αsの時,
αtは
Boltzmann選択を用いて式
(3.8)で得られる確率で選択される.
A
ヤ/。一如、
exp(
寸 才 一 )
p(向α│Sk)=
k / ¥'
~.._(
AT(asA"aD出
α;εAt位 p(一寸立十一)
(3.8)ここで ,
p(αtI a
s)はある時期 U k のソースエージェントの行動向
kでターゲットエー ジ、エントの行動向を選択する確率 , A T (
α知的)は,
αSkにおける
αtの
AT‑tableの値,
TAT
は温度を示す.
5. AT‑table
の更新
AT‑table
はソースエージエントの行動とターゲ、ツトエージェントの行動の対応付けを 学ぶためのテーブルである.ターゲ、ツトエージェントはソースエージェントが学習し
三 重 大 学 大 学 │ 庄 工 学 研 究 科
たときに記録した
Env‑tableの状態遷移確率の値と更新関数式
(3.9)を用いて行動選 択毎に
AT‑tableの値を更新する.
AT(αSk'αtk)
←
α(ATAT(αSkぅαtk)+
γATP(Sk+
lI
Sk,
αSk))( 3 . 9 ) ここで ,
P(Sk+lI
Sk,
aSk)=
Env(skぅSk+l,
aSk)(状態 s μ こおいてソースエ←ジ、エント の行動向 k を取ったとき,次の状態
Sk+lに遷移する確率,すなわち ,
Sk. Sk+l,
αSkにおける
Env‑tableの値),
αATおよび
γATは ,
0 <αAT < 1,
0豆
γAT< 1の範囲の イ直である.
6. Target Q‑table
の
Q値の更新
ターゲ、ツトエージ、エントは Q 学習の Q 値の更新関数式
(2.1)および式
(2.2)を用いて 学習サイクルごとに
TargetQ‑tableの
Q値を更新する.
つ~
iT(大 学 大 学 院 仁 学 研 究 科
第 4 章
シミュレーション実験
提案手法の有効性をシミュレーション実験で確認する.本章ではシミュレータの詳細を説 明する.
Fig.4.1
にシミュレーション環境を示す.状態集合は.
2. 4
.2項で説明した構成法と同様,
ゴールの見え方の状態
20通りと,オブ、ジ、ェクトの見え方の状態
8通りの組み合わせの全
160状態で構成する.ただし,今回のシミュレーシヨンではオブ、ジ、エクトの色は変化しないため,
色の状態は存在しない.
エージェントの初期配置に関しては.
Fig. 4.1に示す
2つの初期位置をエピソード毎に ランダムに選択する.
行動集合に関しては.Fig.4.2 に示すように,ソースエージ、エントは
{Forward,
Backward,
Pivot turn Left,
Pivot turn Right}の
4つの行動を,ターゲ、ツトエージ、エントは
{Forward,
BackwardぅForwardLeft,
Forward Right,
Backward Left,
Backward Right}の
6つの行動 を持っている.
学習エージ、エントは,前後進は
0.5[ p
ixelj step].超信地旋回は0.1[degjstep]の速さで移動 する.また,前後方への旋回は直進方向ヘ
0.5[pi.,relj step].回転方向へ
0.1[degjstep]移動 する.
‑ : : : . if~ 大学大学 ríjt ̲l学研究科
学習エージ、エントに与えられる報酬は
2. 4
.2項の実験とは異なり,ゴールの左右ではなく ゴ、ールの正面にオブ、ジェクトを運ぶと報酬が与えられる.また,状態変化しない状況に陥っ た場合には,
2. 4
.2項の実験同様,負の報酬を与えて各学習テーブルを更新し,次の行動を 選択する.
各パラメータの値は,各
Q値および
AT‑table,Env
‑tableの初期値は
0.0,
rは正の報酬 が1.
0,負の報酬が‑1.
0,α =
0.4,
γ = 0.9,
T = 0.05,
αAT = 0.9,
γAT = 0.35,
TAT = 0.5となっている.
。
100。 x
(20, 15)
Object
¥
¥ (5.
0, 25). ~, ¥
(20, 35)
Agent (Selected創 出 町 。 副 ionrandomly)
凶¥¥
y
Fig. 4.1 Simulation environment
Pivot Tum同ght
f 、
‑
+ーーー= 0
叩‑Pi
v
vot Tum LeftBadtward ... Left
、
8ackward ト園園田 Sac永wa同 f
Right .1
ノ F r
¥37
(a)Actions of Source agent (b ) Actions of Target agent Fig. 4.2 Actions of Source and Target agents
三 重 大 学 大 学 院 工 学 研 究 科
第 5 章 実験結果
提案手法のシミュレーション実験の結果を
Fig.5.1および
Table.5.1に示す.
Fig. 5.1
から,
Target Q‑tableだけを用いて学習
(Wayl)すると正確に学習できるが時 聞がかかっており,
Source Q‑tableとA
T‑tableだけを用いて学習
(Way2)すると速く学習 できているが正確に学習できていないことがわかる.それに対し,提案手法では
Waylと Way2を同時に学習することにより,学習初期では
Way2同様速く学習が進み,学習後半で はWayl 同様正確に学習できていることから,本手法の有効性がシミュレーション実験にお いて確認できた.
また,
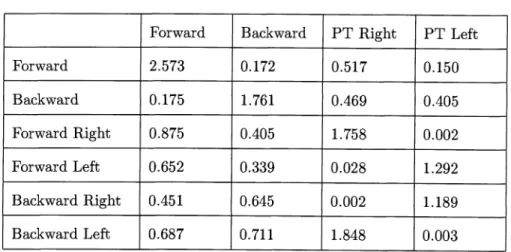
Table.5.1をみると,ソースエ←ジ、エントとターゲ、ットエージェントの行動で似た 行動(例えば
Forward(source)→ Forward(target),
Pivot turn Right→
{Forward Right,
Backward Left}
など)がそれぞれ高い値で対応付けられていることが確認できた.
二 i f ( 大 学 大 学 院 」二学研究科
450 400 350
司 300
6
E
~ 250
H Z コω200 c. i
.・)
. . .
的 150~ 100
50
。
450 400 350
可 300
"
; :
~ 250
=
C 3u) 200
。
E I
∞
150 ~~100 50
。 。
5 50010
園 田 ーThemethod with the Source and
Target agent Q‑tables and AT ‑table (wayl and way2)
叩 叩Themethod with the Source agent Q
‑ t a
ble and AT‑table (way1)圃 圃 圃Themethod with the Target agent Q‑table (way2)
i綜麟癖鱗;~
1000 1500 Episode
2000
(a)l to 3000 episodes
ー ー ー
Themethod with the Source and2500 3000
Target agent Q‑tables and AT
‑ t a
ble (wayl and way2)贋 叩 四Themethod with the Source agent Q‑table and AT‑table (wayl)
園 田 園Themethod with the Target agent Q‑table (way2)
15
留軍司""~軍中
20 25 Episode
30
(b) 1 to 50 episodes
35
;;.r:唱で
40 45 50
Fig. 5.1 Result of simulation
二 重 大 学 大 学 │ 出 ̲[学研究科
Table 5.1 Result of AT‑table
Forward Backward PT Right PT Left Forward 2.573 0.172 0.517 0.150 Backward 0.175