論 文
局所線形写像に基づくハッシング
入江 豪
†a)新井 啓之
†b)谷口 行信
†c)Hashing with Locally Linear Projections
Go IRIE
†a), Hiroyuki ARAI
†b), and Yukinobu TANIGUCHI
†c)あらまし 高速な類似画像検索を目的とした新しいハッシング法を提案する.これまでに提案されてきた多く のハッシング法は,特徴量空間におけるデータのユークリッド距離に基づく近接性をバイナリ空間に保存しよう とする定式化に基づくものであった.しかし,類似画像検索においては,特徴量空間上のユークリッド近傍が必 ずしも同じクラスに属しているとは限らないため,十分な検索精度を得ることができないという問題があった.
我々は,類似画像の集合が特徴量空間上に非線形多様体を成すという知見に基づき,これを正確に捉え,バイナ リ空間に最適に保存するハッシング法を提案する.まず,局所線形スパース再構成により,特徴量空間上,低次 元な局所線形構造として現れる非線形多様体を捕捉する.次に,捉えた局所線形構造をバイナリ空間に最適に保 存する線形写像を求め,この写像によってハッシュ関数を構成する.様々な画像ベンチマークデータセットを用 いた評価によって,従来の種々のハッシング法に対して優れた類似画像検索精度が得られることを確認した.
キーワード 類似画像検索,局所線形,ハッシング
1.
ま え が き類似画像検索は,コンピュータビジョン,マルチメ ディア分野における基本的な問題の一つである.特徴 量空間
F ⊂ R
DとデータベースX := {x
i∈ F}
ni=1が所与の下,クエリ画像
q ∈ F
に対する類似画像を 得たい.ここでいう類似画像とは,クエリと同一の意 味クラスに属する画像である(例えば,同一の被写体 を撮影した画像等).最も単純には特徴量空間F
上をL
2線形探索(しらみ潰し探索)すればよいが,デー タ数n
,及び,特徴量空間次元D
に対してそれぞれ 線形時間を要するため,大規模な画像データベースに 対しては現実的ではない.木構造インデクス(kd-tree
等)[1]
を用いることで,O (log n )
時間での探索を実現 できるが,典型的な木構造インデクスは次元に対する 計算量が指数関数的に増大してしまうため[2]
,高次元 な特徴量ベクトルを用いることの多い類似画像検索に†日本電信電話株式会社 NTTメディアインテリジェンス研究所,
横須賀市
NTT Media Intelligence Laboratories, NTT Corporation, 1–1 Hikarinooka Yokosuka-shi, 239–0847 Japan
a) E-mail: [email protected] b) E-mail: [email protected] c) E-mail: [email protected]
は適当ではない.
この問題に対し,ハッシングと呼ばれる近似近傍探 索法が注目されつつある.ハッシングでは,特徴量空 間
F
からバイナリハミング空間H := {± 1 }
cへの写 像φ : F −→ H
(ハッシュ関数)により,データベー スエントリ∀x ∈ X
(またはクエリq ∈ F
)をハッ シュと呼ぶc
ビットのバイナリコードy := φ ( x ) ∈ H
(または
y
q:= φ ( q ) ∈ H
)に変換する.ハッシュによ る探索時間はo ( n )
(sub-linear
時間)となり,効率的 な類似画像検索が可能となる.本論文では,効率的な 類似画像検索のためのハッシングについて議論する.典型的なハッシングの問題は,特徴量空間
F
上に分 布するデータ(特徴量ベクトル)の近傍構造をできる 限り保存するようなハッシュ関数φ
を求めることであ る.よく知られた方法として,random projection
の 集合をハッシュ関数として用いた場合に,ハッシュの衝 突確率がF
上での類似度と一致するという原理に基づ くハッシング法Locality Sensitive Hashing (LSH) [3]
があり,後にこれをカーネル拡張した
Kernelized LSH
(KLSH)
等も提案された[4]
.しかし,LSH
やKLSH
は,データとは無関係にハッシュ関数φ
を構成する ため,十分な検索精度を得るためには多くのハッシュ ビット数c
が必要であるという問題があった.そこで,より最近では,
φ
をデータから学習することによって,よりコンパクトなハッシュを得ようとする試みがなさ れてきている.
最も単純な方法として,主成分分析
(PCA)
を用い るものがある[5]
.特に優れた方法として,PCA
によ り得られた初期写像をバイナリ量子化誤差最小化に 基づいて改善するIterative Quantization (ITQ) [6]
がある.一方で,
PCA
は単純な線形次元削減法で あり,非線形なデータ構造を考慮できないという限 界がある.この観点で,非線形次元削減法を取り入 れる試みもなされている[7]
〜[9]
.Spectral Hashing (SH) [7]
やAnchor Graph Hashing (AGH) [8]
は,近 傍に存在するデータペア間の近接性を保つような非 線形次元削減法Laplacian Eigenmaps (LE) [10]
に基 づいてハッシュを求める.また,Inductive Manifold Hashing (IMH-tSNE) [9]
は,t-Distributed Stochas- tic Neighbor Embedding (t-SNE) [11]
と呼ばれる確 率的次元削減法を用いている.この他,クラスタリング 法によって近傍集合を捉えようとする手法も提案され ている[12], [13]
.ここに述べたような従来のハッシン グ法の多くは,本質的にはデータ分散(PCA
ベースの 手法[5], [6]
),あるいは,近接性([7]
〜[9], [12], [13]
) の保存を目的とした定式化に基づく.言い換えれば,特徴量空間
F
上の近傍を保存するハッシュ関数を獲得 しようとする方法である.本論文では,特徴量空間
F
が,互いに近接した複 数の非線形多様体を内包するケースに対するハッシン グの問題を考える.事実,実世界の画像においてこう いったケースはよく観測される.例えば,物体を様々 な角度から撮影した画像の集合は,物体ごとに一つず つ固有の非線形多様体を形成することが知られてい る[14]
.また,類似画像の集合は特徴量空間内に非線 形多様体を形成することが知られており[15]
,測地線 に沿った探索を行うことにより,通常のユークリッド 近傍探索に比べ,有意に良い類似画像検索精度が得ら れることが知られている[15], [16]
.これらの知見に基 づけば,類似画像検索の目的においては,F
上の各非 線形多様体を区別し,クエリと同一の多様体に沿って 近傍を探索できることが望ましい.しかし,これまで のハッシング法は原理的にこれを達成しない.F
上で の近傍がいかに正確に保存されようとも,各非線形多 様体を区別することはできないからである(図1
).この問題に対し,我々は特徴量空間上の非線形多様 体構造を正確に捉え,これをハミング空間に最適に保
存するハッシング法を提案する.非線形多様体は,局 所的には幾つかの近傍点によって線形にスパンされる 空間(接空間)の貼り合わせとして表現される.この 事実を鑑み,提案法は
F
上の局所的な線形幾何構造を 保存することを目的とした定式化に基づいている.ま ず,局所線形スパース再構成を用いることにより,各 非線形多様体の局所線形幾何構造を個別に捕捉する.その後,捉えた局所線形幾何構造を,ハミング空間に 最適に復元するハッシュ関数
φ
を求める.様々な画像 ベンチマークデータセットを用いた評価によって,従 来の種々のハッシング法を改善できることを示す.提案法は,著者らが先行研究
[17]
にて提案したハッ シング法を改善したものである.両者は,局所線形幾 何構造を保存するという原理は共通しているが,方法 は大きく異なる.[17]
の方法は,ハッシュ関数を陽に 求めるものではなく,したがって,未知のデータに対 してはノンパラメトリックにハッシュを構成するため の複雑な処理を経る必要があった.一方,提案法では,パラメトリックな線形ハッシュ関数を求めるため,い かなる未知データに対するハッシュも効率的に求める ことができるという利点がある.実際,
[17]
の方法で は,ハッシュの生成に約5 msec
を要していたところ,本論文の方法では
1
桁以上少ない時間で実行できるこ とを確認した(表1
,2
参照).2.
局所線形写像によるハッシング特徴量空間
F ⊂ R
Dが複数の非線形多様体を内包 しているとし,その数,及び,各多様体の次元は未知 とする.目的は,この多様体構造を可能な限り正確に 保存するハッシュ関数φ : F −→ H
を求めることであ る.幾つかの従来法[5], [6]
に倣い,本論文では,以下 のように定義される線形ハッシュ関数を考える:φ ( x ) = sign( A
( x − b )) (1)
ここで,A ∈ R
D×c: F −→ R
cは線形写像,b ∈ R
D はデータベースX = {x
i∈ F}
ni=1の平均ベクトルで ある.非線形なハッシュ関数と比較し,線形ハッシュ 関数は単純であり,ハッシング時間(特徴量をハッシュ に変換するために必要な時間)及びメモリ双方の観点 で効率的であるという利点がある.一般性を失うこと なく,特徴量は次元ごとに平均0
にシフトすることが できるので,b = 0
としてよい:φ ( x ) = sign( A
x ) (2)
本論文の問題は,この線形ハッシュ関数のパラメータ である線形写像
A
を求めることである.まず,提案法のアイディアをサポートする基本的な 事実について述べる.
M
をF
に埋め込まれたd
次元(部分)多様体
( d D )
であるとする:定義
1
(d
次元多様体)d
次元多様体M
は,M
上各 点での近傍がR
dに同相な位相空間である.単純には,
M
は局所的にユークリッドな空間である.以下の知見を導入する.
事実
1
(局所線形構造)d
次元多様体M
が可微分で あり,X
によって十分密にサンプルされているとする.このとき,
M
上の任意の点x ∈ M
における接空間 は,X
に含まれる同接空間上高々d + 1
個の近傍点に よって近似的に線形スパンできる.M
が線形多様体である場合には,d + 1
個の点によっ てその構造を一意に定めることができるため,これは 明らかに成り立つ(注1).また,定義1
より,d
次元多 様体が非線形であっても,その各点近傍ではR
dに同 相であるから,この事実は成立する.事実
1
より,d
次元多様体構造は,∀x ∈ X
においてこ れと同一多様体上にある少なくともd + 1
個の近傍点 による線形再構成を求めることで捉えることができる.以上の事実に基づき,提案法を構成する.提案法は,
大きく下記の二つのステップによって構成される:
1.
局所線形構造の捕捉.F
上の非線形多様体構造を 捕捉する.事実1
に基づき,これは,∀x ∈ X
に対し て,それと同一多様体上にある少なくともd + 1
個の 近傍点による線形再構成を求めることで実現される.2.
局所線形構造の保存.上記捕捉した局所線形構造 を,ハミング空間H
に最適保存する線形ハッシュ関数φ : F −→ H
を求める.提案法は局所線形構造を保存する線形写像によるハッ シング法であるため,以降,提案法を局所線形写像
(
Locally Linear Projections: LLP
)と呼ぶ.以下,各ステップについて説明する.
2. 1
局所線形構造の捕捉本節の目的は,
∀x ∈ X
に対し,これを線形再構成 する近傍点の集合,及び,その線形再構成重みを得る ことである.本論文では,F
に含まれる各非線形多様(注1):簡単な例を挙げれば,1次元の線形多様体(直線)は2点を固 定すれば一意に定まり,2次元の場合は3点を固定すれば一意に定まる.
図1 近接する二つの1次元多様体上の点x∈ X とそ のユークリッド近傍点の集合N(x),及び,xを最 も効率的に線形再構成可能な同一多様体上の近傍点
(黒丸)の関係.
Fig. 1 Two 1-dimensional manifolds close with each other. A pointx∈ X, its Euclidean neighbor- hoodN(x), and the neighbor points on the same manifolds with xthat are able to lin- early reconstructxmost efficiently.
体の構造をそれぞれ個別に捕捉したい.一般に,ある 点
x ∈ X
についてこれを線形再構成可能な近傍点の 組合せは無数に存在するが,提案法では,下記条件を 充足する近傍点集合を得たい.条件
1 x
が存在するd
次元多様体M
x上にあり,x
を線形再構成するd + 1
個の近傍点.もし,
M
xがF
上で他の多様体と十分に離れており,かつ,
M
xの次元d
が既知であれば,d + 1
個のユーク リッド近傍点は条件1
を満たす.しかし,実際には多 様体は互いに近接していることが多く,また各多様体 の次元も未知である.例えば,図1
に示すように,二 つの1
次元多様体が,一方の多様体上の点x
付近で近 接しているような場合,ユークリッド近傍集合N ( x )
は,他方の多様体上にある点を自然に含んでしまう.一方,
M
xがX
によって十分密にサンプルされて いるとき,条件1
を満たす近傍点(図1
中,黒丸で示 す2
点)を含むような,十分大きなユークリッド近傍 点の集合N ( x ) ( |N ( x ) | ≥ d + 1)
は必ず取ることが できる.そこで,適当な大きさのN ( x )
を得た上で,その中から条件
1
を満たす近傍点を選択する問題を解 く.事実1
より,ある点x ∈ X
を最も効率的に線形 再構成できるのは,条件1
を満たす同一多様体上の近 傍点だけを用いた場合である.これは図1
の例でいえ ば黒丸で示す2
点に他ならない.したがって,x
を小 さい誤差で線形再構成可能な,できる限り少数の近傍 点を発見すればよく,これは,下記の局所線形スパー ス再構成[18]
として定式化できる:(LLSR)
min
wiλs
iw
i1
+ 1
2 x
i−
xj∈N(xi)
w
ijx
j2
(3)
s.t.: w
i1 = 1 . (4)
第1
項 はL
1 ス パ ー ス 項 で ,再 構 成 重 みw
i:=
( w
i1, . . . , w
in)
の内,少数の要素だけを非ゼロ化し ようとする項である.s
i:= ( s
i1, . . . , s
in)
はx
iから 遠方にある点ほど重みが0
になりやすいように誘引す る定数ベクトルであり,例えばs
ij:=
xi−xjjxi−xjと 固定すればよい(注2).なお,
{j|x
j∈ N / ( x
i) }
に対応す るw
i(及びs
i)の要素は,その値を強制的に0
とす ればよく,変数として扱う必要はない.こうすること で実質的に問題のサイズを小さくすることができ,計 算効率上の利点がある.第2
項は近傍点による線形再 構成誤差である.解w
iは,x
iを線形再構成可能なで きる限り少数の近傍点に対応する重みw
ijのみが非ゼ ロとなり,これが条件1
を満たす近傍点集合となって いることが期待できる.結果,F
上の多様体構造はW := [ w
1, . . . , w
n]
によって捕捉することができる.問題
(LLSR)
は典型的なsparse coding solver
で解 くことができる.w
iは非常にスパースであることが想 定されるため,本論文ではhomotopy algorithm [19]
を用いて解く.なお,経験的に,
|N ( x
i) |
は数十程度 で十分であり,これはLSH
等の効率的な近似近傍探 索法により定数時間で得ることができる.2. 2
局所線形構造の保存前節で捕捉した局所線形構造
W
を最適に保存する 線形ハッシュ関数φ : F −→ H
を得たい.x
iに対応 するハッシュをy
i∈ H
と表す.最も自然には,局所 線形構造W
をH
上にできる限り再現すればよく,こ れは下記のように定式化できる:min
Y∈{±1}n×c
i
y
i−
xj∈N(xi)
w
ijy
j2
(5)
s.t.: Y
Y = nI
c(6)
ここで,
Y := [y
1, . . . , y
n]
である.目的関数(5)
は,W
を固定した下で,∀y ∈ H
を線形再構成した場 合の誤差であり,これをY
について最小化すること で,W
をH
上に最適に復元するY
を求めることが できる.(6)
はビットの冗長性を無くすため,ビット ごとに無相関化されることを要請する制約である[7]
.Y = sign( X
A )
であるから,行列表現を用いれば,i
y
i−
xj∈N(xi)
w
ijy
j2
(7)
(注2):xiから距離が遠いほど大きくなるような定数であればよい.
= tr( Y
M Y ) (8)
= tr(sign( A
X ) M sign( X
A )) (9)
ただし,M := ( I
n−W )
( I
n− W )
である.結果,問 題は次のように書くことができる:A∈R
min
D×ctr(sign( A
X ) M sign( X
A )) (10) s.t.: sign( A
X )sign( X
A ) = nI
c(11)
この問題は,符号関数の存在によりNP
困難である.そこで,従来のハッシング法
[5], [6]
同様,符号関数を 無視することで下記のように緩和する:(LLP) min
A∈RD×c
tr( A
XM X
A ) (12) s.t.: A
XX
A = nI
c(13) XM X
,及び,XX
はいずれも半正定値対称である から,この問題は典型的な一般化固有値問題に帰着し,その解は
( XX
)
−1( XM X
)
のc
個の最小固有値に 対応するc
個の固有ベクトルA = [e
1, . . . , e
c] ∈ R
D×c として最適に求めることができる.求めた線形写像A
によって,線形ハッシュ関数を規定することができる.なお,結果的に問題
(LLP)
は線形次元削減法の 一 種 で あ るNeighborhood Preserving Embedding (NPE) [21]
と同一の問題となる.NPE
と提案法はW
の計算方法において異なる.NPE
は最小2
乗法に よりこれを求めるが,提案法は局所線形スパース再構 成によって求める.単純な最小2
乗法を用いるNPE
では,条件1
を満たすような点を求めることができな いが,提案法では,条件1
を満たすような近傍点の発 見とこれらによる線形再構成を同時に最適化できると いう利点がある(2. 1
参照).2. 3
バイナリ量子化誤差最小化符号関数を無視した緩和の影響によって,問題
(LLP)
を解くことで得た写像A
によるハッシュ関数は大きな バイナリ量子化誤差を含む場合があり,検索精度低下 の原因となる.そこで,[6], [22]
に倣い,バイナリ量子 化誤差を最小化することで,写像A
を改善することを 考える.以下の最適化問題を導入する.(OPP) min
Y∈{±1}n×c,R
Y − X
AR
2F(14)
s.t.: R
R = I
c(15)
ただし
R ∈ R
c×cは正規直交行列である.目的関数(14)
は,ハッシュY
(未知)と,X
A
(既知)に対し て正規直交行列R
(未知)による変換を与えたものと の誤差である.したがって,上記問題は,バイナリ量 子化誤差をR
によって最小化しようとしているに他な らない.この問題はOrthogonal Procrustes Problem
(OPP)
として知られており,多クラスセグメンテーション
[22]
やITQ [6]
に利用されている.問題(OPP)
は非凸であるが,Y
とR
それぞれを固定した場合の 部分問題はいずれも凸である.したがって,これらを 交互に固定して繰り返し解くことにより,効率的に局 所解を得ることができる[6], [22]
.最終的に,得られ たR
を用いてA ← AR
と改善する.ここで,新しく得られた写像
A ← AR
は,元の問 題(LLP)
の最適性に影響を与えない.事実
2
(最適性)問題(LLP)
の目的関数(12)
は,A
に対する任意の正規直交行列R ∈ R
c×cによる変換に 対して不変である.R
R = RR
= I
cであるから,A = AR
を(12)
に 代入することで容易に確認できる:tr(( R
A
) XM X
( AR )) = tr( A
XM X
A ) (16)
事実2
より,問題(OPP)
を解くことで,元の局所線 形構造保存の最適性を全く失うことなく,バイナリ量 子化誤差を最小化できる.なお,提案法により生成さ れる写像A ← AR
は,一般にPCA
により得られる初 期写像をバイナリ量子化誤差最小化によって改善するITQ [6]
のそれとは異なることに注意されたい.PCA
による写像と問題(LLP)
を解いて得られる写像A
は 全く異なるからである.この差異は,後の実験結果に おいても検索精度の差異として確認することができる.3.
計 算 量提案法
LLP
のハッシング,及び,ハッシュ関数学習 の計算量を議論する.3. 1
ハッシングハッシングは時間
/
空間計算量共に,ハッシュビット 数c
,特徴量空間F
の次元D
に対してそれぞれ線形O ( cD )
であり,データベースの画像数n
には依存しな い.これは,他の線形写像に基づくハッシング法[3], [6]
と同様である.また,多くの場合,非線形ハッシング 法
[4], [7]
〜[9], [12]
に比べ効率的である.3. 2
ハッシュ関数学習ハッシュ関数学習は,局所線形構造の捕捉(問題
(LLSR)
)及び保存(問題(LLP)
)の2
ステップから なる.まず前者について,
homotopy algorithm [19]
を用 いて問題(LLSR)
を解く場合,N (x)
を特徴量空間F
上の近傍点集合とすれば,時間計算量は特徴量当り 平均O ( t
3+ |N ( x ) | )
となり[19]
,n
には依存しない.ここで,
t
はW
の列当りの平均非ゼロ要素数である(
t D
).N ( x )
を求める上で,厳密な線形探索を実 行する場合O ( nD )
時間を要するが,提案法において は,適当な大きさの近傍点集合さえ得られていればそ こから同一多様体上の近傍点を選択できるため(2. 1
参照),厳密な近傍点集合を求める必要はない.した がって,任意の近似近傍探索法を利用することで,こ れを定数時間で求めることが可能である(注3).これら の計算は容易に並列化可能であり,マルチCPU
を用 いることで実用上の計算時間を削減することもできる.続いて,後者については問題
(LLP)
を解く必要 がある.W
が非常にスパースであるため,M
も非 常 に ス パ ー ス で あ り,そ の 平 均 的 な 非 ゼ ロ 要 素 数 はt × t
(t D
)である.よって,XM X
及びXX
はO (( D
2+ t
2) n )
で求めることができる.更 に,スパースな一般化固有値問題はLanczos
法によっ てO ( cDt )
時間で解くことができる[20]
.したがって,問題
(LLP)
を解くために必要な時間計算量はO (( D
2+ t
2) n + cDt )
,すなわちn
に対して線形であ る.空間計算量はO (( D + t ) n + D
2)
であり,こちら もn
に対して線形である.なお,問題(OPP)
を解く 場合には,更にO ( ncD + c
2)
の計算時間が必要であ るが,これもn
に対して線形である.4.
評 価提案法
LLP
の性能を評価する.提案法は,バイナ リ量子化誤差最小化を導入する場合,しない場合の2
種類のハッシュ関数を得ることができるため(2. 3
参 照),以降,前者をLLP
,後者をLLP
0と表す.本論文では,次の七つの既存ハッシング法と比較す る:
LSH [3]
,KLSH [4]
,ITQ [6]
,KMH [12]
,SH [7]
,AGH [8]
,IMH-tSNE [12]
.LSH
とITQ
は提案法と 同じ線形ハッシング法,その他は非線形なハッシュ関(注3):実験的にも,LSHを用いて収集した場合と厳密な線形探索によ り収集した場合とでは,ほぼ精度差がないことを確認している.
数に基づくハッシング法である.また,
LSH
,KLSH
はランダムにハッシュ関数を生成する方法,ITQ
は データの分散に基づいてハッシュ関数を学習する方法,KMH
はK -means
クラスタリングに基づいて近傍を 保存する方法,SH
,AGH
,IMH-tSNE
は局所的な近 接性を保存する方法である.更に,2. 2
での議論に基 づき,NPE [21]
に符号関数を適用することによって 得られるハッシング法についても評価する.提案法同 様,バイナリ量子化誤差最小化の有無により2
種類の ハッシュ関数を得ることができるため,前者をNPE
, 後者をNPE
0と表す.実装誤りを防ぐため,これらの 従来手法は(LSH
を除いて)全て各提案者によって 公開されているMATLAB
コードを用いて実行した.公平性のため,各手法のパラメータについては,推奨 値がある場合はそれを適用し,その他のものについて は事前実験によってチューニングした.具体的には次 のように設定した:
KLSH
のカーネルグラミアンを求 めるためのサンプル数は300 [4]
とし,KMH
の部分 空間数は4
とした[12]
.また,AGH
及びIMH-tSNE
のアンカー数は300 [8], [9]
に固定し,周辺アンカー数 は{2 , 3 , 5 , 10 , 20}
の中からベストなものを選定した.また,提案法である
LLP
及びLLP
0のパラメータλ
(
2. 1
参照)についてもベストなものを選定した.本実験では,ハッシング法の一般的なプロトコルに 則して評価を実施する
[6], [7]
.まず,各データセット をクエリセットとデータベースセットに分割する.ク エリセットはクエリとして用いる画像サンプルの集合 であり,データベースセットはハッシュ関数の学習,及び,データベースとして利用されるサンプル群であ る.評価尺度は
[6]
に倣い,クエリ画像に対するハミ ング距離の近いものから順にランキング(ハミングラ ンキング)を生成し,上位10
〜50
件の適合率を評価 する(注4).適合率の計算においては,クエリと同一意 味クラスに属する画像を正解,そうでない画像を不正 解として判定する.なお,ハミングランキングは線形 探索であるが,ハミング距離計算はXOR
とビット数 カウントのみで実行できるため,実用上非常に高速な 計算が可能であることが知られている[6]
(注5).(注4):同一距離にあるものが複数存在する場合には,その順序は特徴 量空間上距離の昇順に選択するものとする.
(注5):実際に,本論文で用いるCOILデータセットにおいて計測した ところ,64-bitのハッシュによる探索は特徴量空間でのL2線形探索に 比べ約80倍高速であった.
4. 1
データセット本論文では,以下の多様な規模,次元,種類を含む 三つの異なる画像ベンチマークデータセットを利用 する.
COIL
(注6):100
種類の物体の周囲を360
度(計72
方 向)から撮影した画像が含まれており,計7200
枚の画 像で構成される[23]
.各物体について無作為に10
枚ず つ計1000
枚をクエリセットとし,残り6200
枚をデー タベースセットとした.各画像を32×32
にリサイズし,各ピクセルの
RGB
値を並べた計32 × 32 × 3 = 3072
次元のベクトルを特徴量とした.クエリと同一の物体 を検索できた場合に正解とする.a-Pascal
(注7):PASCAL VOC challenge 2008
コンペ ティション(注8)で利用された画像から抽出した計12695
枚の画像で構成される[24]
.各画像は20
種類の異なる 物体(people, dog, car
等)のいずれか一種を被写体 とする自然画像である.各物体について25
枚ずつ,計500
枚をクエリセットとし,残りをデータベースセッ トとした.先行研究[24]
に則り,1792
次元のtexton
ヒストグラム,896
次元の色ヒストグラム,7000
次元 の量子化Histogram of Oriented Gradients (HOG)
のヒストグラム,63
次元のエッジ方向ヒストグラムを 抽出して得た計9751
次元のベクトルを,PCA
によっ て512
次元に次元削減したものを特徴量とした.クエ リと同一の物体を検索できた場合に正解とする.NUS-WIDE
(注9):269648
枚の自然画像を含むデータ セットであり[25]
,ハッシング法の評価にも利用されて いる[8]
.各画像には,81
種類の意味ラベル(animal, buildings, person
等)が重複を許して付与されてい る.先行事例[8]
に倣い,本論文では21
の最頻意味ラ ベルのみを対象とする.無作為抽出した500
画像をク エリセットとし,それ以外をデータベースセットとし た.各画像を144
次元のcolor correlogram
で表現し,これを特徴量とした.クエリ画像に付与された意味ラ ベルの内,一つでも共通するラベルをもつ画像を検索 できた場合に正解とする.
4. 2
結 果COIL
における精度.図2
に,COIL
における検索精(注6):http://www.cs.columbia.edu/CAVE/software/softlib/coil-100.
php
(注7):http://vision.cs.uiuc.edu/attributes/
(注8):http://pascallin.ecs.soton.ac.uk/challenges/VOC/voc2008/
(注9):http://lms.comp.nus.edu.sg/research/NUS-WIDE.htm
(a)P vs #bits (b) 64-bits (c) 48-bits (d) 24-bits 図2 COILデータセットにおける検索精度.(a)は,様々なビット数のハッシュを用い
た場合のトップ10適合率を示している.(b-d)は,ビット数を固定した下で,様々 な検索画像数における適当率を示している(それぞれ(b) 64ビット,(c) 48ビッ ト,(d) 24ビットの場合の結果).
Fig. 2 Retieval performance on COIL. (a) Pecision at top 10 retrieved points vs.
the number of bits; Precision vs. the number of retrieved points for (b) 64-, (c) 48-, and (d) 24-bit codes.
度の比較結果を示す.図
2 (a)
は,様々なビット数を 用いた場合のトップ10
適合率,図2 (b-d)
は,ぞれぞ れ様々な検索件数における適合率を示している.まず,いずれのビット数,いずれの検索件数の場合に おいても,提案法である
LLP
が最も良い精度を示して おり,LLP
0がそれに次ぐ精度を示している.Second best
(従来法の内,最もいい精度を示した方法)であ るSH
に対するゲインは,32
ビットハッシュを用いた ときに最大11 . 8%
であった.COIL
においては,LLP
,LLP
0の差はほぼ見られなかった.物体の周囲を取り 囲むように撮影されたCOIL
は,明確な非線形多様体 構造を有することが知られている[14]
.結果,非線形 多様体を捉える局所線形構造保存の効果が顕著に表れ,相対的にバイナリ量子化誤差の効果が小さくなったも のと考えられる.このことは,
PCA
とバイナリ量子 化誤差最小化に基づくITQ
と比較して,LLP
,LLP
0 双方が常に優位であることからも見て取れる.また,NPE
よりもLLP
が,NPE
0よりもLLP
0が高い精度 を得ていることから,提案法の方がより正確に非線形 多様体構造を捉えることができていることが覗える.以上の結果から,局所線形構造を保存する提案法の高 い優位性が確認できた.
a-Pascal
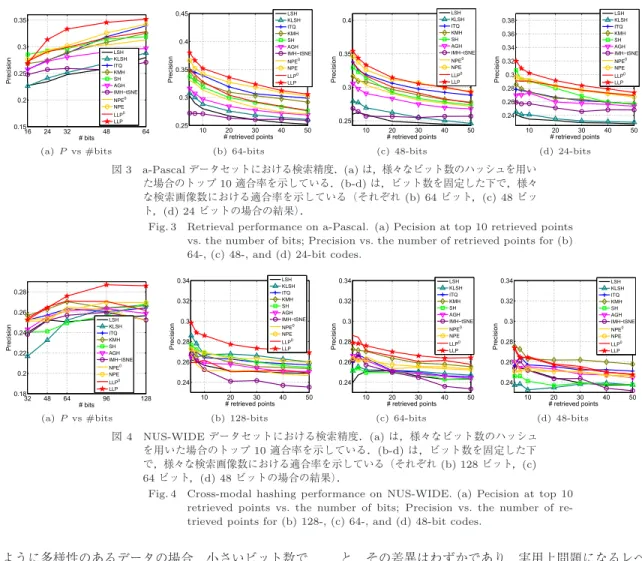
における精度.a-Pascal
における検索精度 の比較結果を図3
に示す.COIL
同様,図3 (a)
が様々 なビット数でのトップ10
適合率,図3 (b-d)
が様々な 検索件数における適合率である.本データセットにおいても,ほぼ全ての条件下で
LLP
が最も良い精度を示しており,提案法の優位性が 確認できる結果となった.トップ10
適合率(図3 (a)
) において,second best
(SH
かITQ
のいずれか)に対するゲインは,
32
ビットハッシュを用いたときに 最大12 . 5%
であった.一方,COIL
の場合とは異なり,LLP
0に対してLLP
が常に良い精度を示しているこ とが分かる.自然画像データセットは,その特徴量が 空間上に広く分布しやすく,バイナリ量子化誤差最小 化の効果が大きいことが知られている[6]
.このこと は,条件によってITQ
がLLP
0を上回る精度を示し ていることからも見て取れ,LLP
やNPE
の場合にも 同様にその優位性に表れたものと理解できる.なお,LLP
はITQ
よりも常に良い精度を示しており,この ことは,自然画像においても局所線形構造保存が有効 であることを示唆している.また,NPE
よりも優位 であることから,これをより正確に捉える方法である ことが確認できる.NUS-WIDE
における精度.NUS-WIDE
における 検索精度の比較結果を図4
に示す.本データセットに おいては,データの多様性を鑑み,128
ビットまでの ハッシュを用いた結果を示す.図4 (a)
が様々なビット 数でのトップ10
適合率,図4 (b-d)
が様々な検索件数 における適合率である.まず,図
4 (a)
より,ほとんどの場合において,提案法
LLP
が最も良いトップ10
適合率を示しているこ とが分かる.また,条件によってLLP
0及びKMH
が それに次ぐ性能を示した.Second best
(KMH
,SH
,KLSH
のいずれか)に対するLLP
のゲインは,96
ビッ トハッシュを用いたときに最大8 . 6%
であり,特にビッ ト数が多い場合にLLP
の高い優位性を確認すること ができる.一方で,図4 (d)
に見られるように,ビッ ト数が小さい場合にはKMH
の方がLLP
よりも良い 検索精度を示している.この理由は,NUS-WIDE
の(a)Pvs #bits (b) 64-bits (c) 48-bits (d) 24-bits
図3 a-Pascalデータセットにおける検索精度.(a)は,様々なビット数のハッシュを用い
た場合のトップ10適合率を示している.(b-d)は,ビット数を固定した下で,様々 な検索画像数における適合率を示している(それぞれ(b) 64ビット,(c) 48ビッ ト,(d) 24ビットの場合の結果).
Fig. 3 Retrieval performance on a-Pascal. (a) Pecision at top 10 retrieved points vs. the number of bits; Precision vs. the number of retrieved points for (b) 64-, (c) 48-, and (d) 24-bit codes.
(a)Pvs #bits (b) 128-bits (c) 64-bits (d) 48-bits
図4 NUS-WIDEデータセットにおける検索精度.(a)は,様々なビット数のハッシュ
を用いた場合のトップ10適合率を示している.(b-d)は,ビット数を固定した下 で,様々な検索画像数における適合率を示している(それぞれ(b) 128ビット,(c) 64ビット,(d) 48ビットの場合の結果).
Fig. 4 Cross-modal hashing performance on NUS-WIDE. (a) Pecision at top 10 retrieved points vs. the number of bits; Precision vs. the number of re- trieved points for (b) 128-, (c) 64-, and (d) 48-bit codes.
ように多様性のあるデータの場合,小さいビット数で はその全ての多様体の局所線形構造を正確に保存する ことができず,混同が発生したものと考えられる.こ のことは,図
4 (a-c)
において,ビット数を増加させて いくにつれて次第に精度が大きく改善されていること からも読み取ることができる.計算時間.ハッシュ関数学習及びハッシングに掛かる 時間を計測した.表
1
がCOIL
,表2
がa-Pascal
にお ける結果である.いずれの場合も,2 . 53 GHz
のIntel Xeon CPU
及び64 GB RAM
を搭載したワークス テーション上で,MATLAB
により実行した.まず,ハッシュ関数学習時間については多くの従来 法と同じオーダではあるものの,やや遅い傾向にある.
例えば,
COIL
においてはITQ
の約1 . 9
倍,a-Pascal
においては約7 . 2
倍の時間を要した.しかしながら,更に一桁大きな時間を要している
KMH
と比較すると,その差異はわずかであり,実用上問題になるレベ ルではない.また,ハッシュ関数学習はオフラインで 実施するものであり,
LLP
,LLP
0は容易に並列化可 能であることから(3.
参照),更に時間を削減するこ とも可能であると考える.類似画像検索を高速化するというハッシング本来 の目的においては,オンライン処理であるハッシング 時間が重要である.この点においては,線形ハッシン グ法
6
種(LLP
,LLP
0,NPE
,NPE
0,LSH
,及びITQ
)が,他の非線形ハッシング法に比べて高速であ り,SH
と比較した場合で約1 . 5
倍,最も遅いKMH
と比較した場合に最大で47 . 8
倍高速であった.以上 のことから,提案法は十分に高速な類似画像検索を実 現できるといえる.ハッシュルックアップ探索.本実験では,ハミングラン キング方式に基づく検索精度を評価してきたが,ハッ
表1 COILにおける処理時間.
Table 1 Timing results on COIL dataset.
ハッシュ関数学習(sec) ハッシング(msec)
LSH [3] 0.02 0.39
KLSH [4] 26.43 1.93
ITQ [6] 312.47 0.40
KMH [12] 9861.83 19.11
SH [7] 306.07 0.61
AGH [8] 294.96 2.74
IMH-tSNE [9] 241.50 2.03
NPE0 351.57 0.39
NPE 375.42 0.40
LLP0(Ours) 598.04 0.40
LLP (Ours) 608.34 0.40
表2 a-Pascalにおける処理時間.
Table 2 Timing results on a-Pascal dataset.
ハッシュ関数学習(sec) ハッシング(msec)
LSH [3] 0.001 0.065
KLSH [4] 4.754 0.365
ITQ [6] 14.211 0.072
KMH [12] 1125.784 0.545
SH [7] 5.534 0.237
AGH [8] 179.553 0.490
IMH-tSNE [9] 209.056 0.437
NPE0 62.353 0.069
NPE 65.318 0.071
LLP0(Ours) 95.563 0.068
LLP (Ours) 102.312 0.072
(a) (b)
図5 ハッシュルックアップ探索精度.ハミング距離2以 内のバケットをルックアップ探索した場合の適合率 を示している.それぞれ(a) COIL,(b) a-Pascal での結果.
Fig. 5 Hash lookup search performance (within Hamming radius 2) on (a) COIL and (b) a- Pascal.
シュによる検索方式としてはもう一つ,ルックアップ 探索がある.ルックアップ探索は,ハッシュによるルッ クアップテーブル(バケット)を構成し,このテーブ ルを用いて探索を実行する方式である.
図
5
に,ルックアップ探索による類似画像検索精度 を示す.従来研究[7], [8]
に倣い,クエリからのハミ ング半径が2
以下のバケットのみをルックアップ探索 し,「探索した全バケットに格納されている全ての画図6 量子化誤差最小化によるバケット当りに含まれる平 均画像数の変化について.
Fig. 6 On changes of average number of images over buckets made by binarization loss minimiza- tion.
像数に対する正解画像数の割合」により適合率を求め た.まず,図
5 (a)
に示すCOIL
においては,多くの 場合においてLLP
0が最もよく,LLP
,LSH
,SH
,及 びAGH
がそれに次ぐ精度であった.このことから,COIL
のように明確な非線形多様体構造をもつデータ においては,提案法の局所線形構造保存の効果による 優位性が確認できる.図5 (b)
に示すa-Pascal
におい ては,一部条件によってはLSH
が優位であるものの,LLP
0とSH
が同程度に高い精度を得る結果となった.また,ルックアップ探索の場合には
LLP
よりもLLP
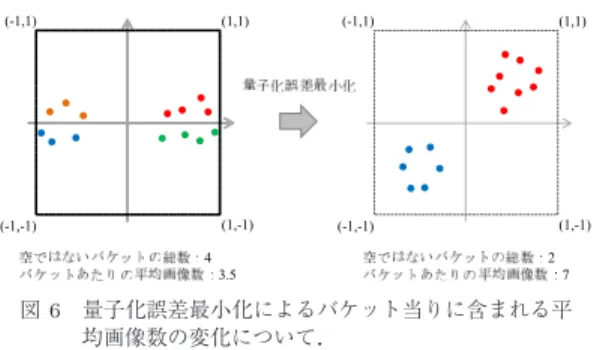
0の方が一貫して高い精度を得ていることが分か る.これは,バイナリ量子化誤差最小化の効果によっ て,バケット当りに含まれる画像数が平均的に増加し,相対的にエントリのある(空ではない)バケット数が 減少するためである.直感的な説明として,
2
ビット ハッシュの場合について説明する.図6
は,符号関数 によってバイナリ化する前のデータ分布の一例を示す.左図は量子化誤差最小化を施す前のデータ分布であ る.これを符号関数によってバイナリ化すると,図中 同色の点は同一バケットに格納されるため,空ではな いバケットの総数は
4
,バケット当りの平均画像数は3 . 5
となる.一方,右図は,バイナリ量子化誤差最小 化を施した場合の図である.バイナリ量子化誤差最小 化は,元のデータ分布を超立方体の頂点に近づけるよ うな回転を求めることで実現しているため,この例の 場合は右図のように配置される.これを同様に符号関 数によってバイナリ化すると,空ではないバケットの 総数は2
に減少し,バケット当りの平均画像数も7
に 増加することになる.このことは3
ビット以上の場合 にも同様に起こる.更に,
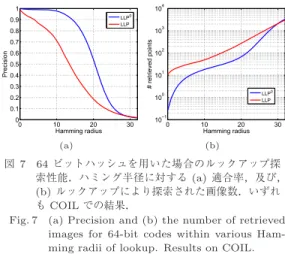
LLP
及びLLP
0の性質の違いを分析すべく,ルックアップするバケットのハミング半径を
0
〜32
ま(a) (b)
図7 64ビットハッシュを用いた場合のルックアップ探 索性能.ハミング半径に対する(a)適合率,及び,
(b)ルックアップにより探索された画像数.いずれ もCOILでの結果.
Fig. 7 (a) Precision and (b) the number of retrieved images for 64-bit codes within various Ham- ming radii of lookup. Results on COIL.
で変化させた場合の適合率と,検索された画像数(探 索したバケットに含まれるエントリ数の総和)を図
7
に示す(注10).図7 (a)
が示すとおり,全てのハミング 半径において,適合率自体はLLP
0の方が良い一方,検索した画像の数は
LLP
の方が常に多いことが分か る.特に,探索半径が小さい場合にはLLP
がLLP
0の10
倍程度の画像数を検索していることが分かる.一般 に,ビット数の加減によっても精度と検索可能な画像 数を調整することは可能であるものの,LLP
とLLP
0 を比較した場合,同一ビット数におけるルックアップ 探索であれば,LLP
はより少ないルックアップ回数で より多くの画像を検索する傾向にあり,LLP
0は少数 の画像をより精度よく検索する傾向にあるといえる.学習データ数による精度の変化.一般に,検索精度は 学習データ数(データベースセットサイズ)に依存す る.提案法については,事実
1
より,各点で同一の非 線形多様体上,少なくともd + 1
個の近傍点が取れれ ば,本来の非線形多様体を捉えることができるが,こ れよりも少ない近傍点数しか取れないほどに疎な場合 には,本来の非線形多様体を捉えることが困難になり,精度低下が想定される.この精度低下の程度を評価す べく,
COIL
,a-Pascal
の二つのデータセットについ て,学習データ数を全数の1 / 2
,3 / 4
,4 / 4
(全て)と 変化させていったときの検索精度を評価した.比較の ため,分散に基づくハッシング法であるITQ
も併せ て評価した.非線形多様体に基づく提案法と比較して,分散は大域的な性質であり,学習データ数に対する収
(注10):実用上,半径32までのルックアップは非常に時間が掛かるた め現実的ではないが,ここでは飽くまで探索半径と検索される画像数の 傾向を分析する目的でこれを実行している.
(a) (b)
図8 学習データ数の検索精度への影響.それぞれ(a) COIL,(b) a-Pascalでの結果.
Fig. 8 Retrieval performance sensitivity to the num- ber of training images on (a) COIL and (b) a-Pascal.
束も早く性能劣化が小さいことが想定されるためであ る.結果を図
8
に示す.この結果,(1) ITQ
に比べて,提案法
LLP
は学習データ数に対する性能変化が大き く,また,(2)
学習データ数の増加に伴い,LLP
の性 能は顕著に改善されていくことが見て取れる.パラメータの影響.パラメータ
λ
の値が検索精度に 与える影響を調査した結果を図10
に示す.結果から,λ
は検索精度に少なからず影響を与えることが分か る.したがって,クロスバリデーション等により事前 にチューニングする方がより良好な検索精度を得るこ とができるといえる.一方,ほとんどの場合,各デー タセットにおけるsecond best
に対して同等以上の精 度を示していることから,提案法の安定した有効性を 確認することができる.KMH
によるバイナリ量子化誤差最小化.提案法で は,正規直交行列によるバイナリ量子化誤差最小化法 を検討した.一方,KMH [12]
は,K -means
による非 等方的な量子化を行うことで,更に小さい量子化誤差 を達成できることが知られている.KMH
は処理時間 の点で不利(表1
,2
参照)ではあるが,これを提案 法LLP
に組み込むことも可能である.そこで,LLP
(
NPE
)について,KMH
を組み込んだ手法LLP
KMH(
NPE
KMH)の検索精度を評価した.結果を図9
に 示す.いずれのデータにおいても,LLP
とLLP
KMH(
NPE
とNPE
KMH)の間に大きな差異は見られなかっ た.理由として,直交する固有ベクトルとして線形写 像を求めるLLP
(NPE
)の場合,同一多様体上のデー タは写像先空間の軸上に偏って分布しやすく,結果と してKMH
の非等方的な量子化の効果が出にくかった 可能性が考えられる.(a) (b)
図9 バイナリ量子化誤差最小化法の違いによる検索精度 への影響.それぞれ(a) COIL,(b) a-Pascalでの 結果.
Fig. 9 Results with different binarization loss mini- mization methods. (a) COIL and (b) a-Pascal.
(a) (b)
図10 LLPにおけるパラメータλの検索精度への影響.
それぞれ(a) COIL,(b) a-Pascalでの結果.
Fig. 10 Retrieval performance sensitivity toλon (a) COIL and (b) a-Pascal.
(a) (b)
図11 線形次元削減法としての評価.それぞれ(a) COIL,
(b) a-Pascalにおけるトップ10検索精度.
Fig. 11 Performance as linear dimensionality reduc- tion methods. Top 10 precision on (a) COIL and (b) a-Pascal.
線形次元削減法としての評価.提案法はハッシング法 ではあるが,求めた写像
A
を線形次元削減として用い ることも可能である.この観点から,LLP
0,NPE
0,PCA
それぞれにより線形次元削減した後,L
2線形探 索して検索を行った場合の精度を比較評価した(注11). 結果を図11
に示す.いずれのデータにおいても,LLP
0 が一番よい精度を示しており,次元削減法としての有(注11):この場合,バイナリ量子化誤差最小化は結果に影響を与えない ため,NPE0,LLP0のみ評価している.
効性も見て取れる結果となった.
NPE
0とPCA
を比 較した場合,COIL
においてはNPE
0が優位によく,a-Pascal
においてはほぼ同程度の精度であった.この 理由は,a-Pascal
に比べてCOIL
の方が多様体構造が 強く表れるデータであり,かつ個々の多様体が区別し やすいからであると考えられる.5.
む す び効率的な類似画像検索のため,特徴量空間に含まれ る非線形多様体構造を保存する線形ハッシング法,局 所線形写像(
LLP
)を提案した.まず,非線形多様体 は局所線形な幾何構造として捉えることができること を示し,局所線形構造を捕捉する局所線形スパース再 構成を導入した.次いて,捉えた局所線形構造をハミ ング空間に最適に保存する線形写像を求める定式化と その解法を述べた.実験によって,提案法LLP
の性 質を明らかにし,また,従来の種々のハッシング法に 対する高い優位性を確認した.文 献
[1] T. Sellis, N. Roussopoulos, and C. Faloutsos, “The R+-Tree: A dynamic index for multi-dimensional ob- jects,” Proc. International Conference on Very Large Data Bases (VLDB), pp.507–518, 1987.
[2] R. Weber, H.-J. Schek, and S. Blott, “A quantitative analysis and performance study for similarity-search methods in high-dimensional spaces,” Proc. Interna- tional Conference on Very Large Data Bases (VLDB), pp.194–205, 1988.
[3] M.S. Charikar, “Similarity estimation techniques from rounding algorithms,” Proc. Annual ACM Sym- posium on Theory of Computing (STOC), pp.380–
388, 2002.
[4] B. Kulis, P. Jain, and K. Grauman, “Kernel- ized locality-sensitive hashing,” IEEE Trans. Pat- tern Anal. Mach. Intell., vol.34, no.62, pp.1092–1104, 2012.
[5] J. Wang, S. Kumar, and S.-F. Chang, “Semi- supervised hashing for large-scale search,” IEEE Trans. Pattern Anal. Mach. Intell., vol.34, no.12, pp.2393–2406, 2012.
[6] Y. Gong, S. Lazebnik, A. Gordo, and F. Perronnin,
“Iterative quantization: a procrustean approach to learning binary codes for large-scale image retrieval,”
IEEE Trans. Pattern Anal. Mach. Intell., vol.35, no.12, pp.2916–2929, 2013.
[7] Y. Weiss, A. Torralba, and R. Fergus, “Spectral hash- ing,” Proc. Advances in Neural Information Process- ing Systems (NIPS), pp.1753–1760, 2008.
[8] W. Liu, J. Wang, S. Kumar, and S.-F. Chang, “Hash- ing with graphs,” Proc. Int. Conf. Machine Learning
(ICML), pp.1–8, 2011.
[9] F. Shen, C. Shen, Q. Shi, A. van den Hengel, and Z.
Tang, “Inductive hashing on manifolds,” Proc. Conf.
Computer Vision and Pattern Recognition (CVPR), pp.1562–1569, 2013.
[10] M. Belkin and P. Niyogi, “Laplacian eigenmaps for dimensionality reduction and data representation,”
Neural Computation, vol.15, no.6, pp.1373–1396, 2003.
[11] L.J.P. van der Maaten and G.E. Hinton, “Visual- izing high-dimensional data using t-SNE,” J. Ma- chine Learning Research (JMLR), vol.9, pp.2579–
2605, 2008.
[12] K. He, F. Wen, and J. Sun, “K-means hashing:
An affinity-preserving quantization method for learn- ing binary compact codes,” Proc. Conf. Computer Vision and Pattern Recognition (CVPR), pp.2938–
2945, 2013.
[13] J.-P. Heo, Y. Lee, J. He, S.-F. Chang, and S.-E.
Yoon, “Spherical hashing,” Proc. Conf. Computer Vision and Pattern Recognition (CVPR), pp.2957–
2964, 2012.
[14] H. Murase and S.K. Nayar, “Visual learning and recognition of 3-D objects from appearance,” Int. J.
Computer Vision (IJCV), vol.14, pp.5–24, 1995.
[15] D. Zhou, J. Weston, A. Gretton, O. Bousquet, and B. Sch¨olkopf, “Ranking on data manifolds,” Proc.
Advances in Neural Information Processing Systems (NIPS), 2003.
[16] K.Q. Weinberger and L.K. Saul, “Unsupervised learning of image manifolds by semidefinite program- ming,” Int. J. Computer Vision (IJCV), vol.70, no.1, pp.77–90, 2006.
[17] G. Irie, Z. Li, X.-M. Wu, and S.-F. Chang, “Locally linear hashing for extracting non-linear manifolds,”
Proc. Conf. Computer Vision and Pattern Recogni- tion (CVPR), 2014.
[18] E. Elhamifar and R. Vidal, “Sparse manifold cluster- ing and embedding,” Proc. Advances in Neural Infor- mation Processing Systems (NIPS), pp.55–63, 2011.
[19] D.L. Donoho and Y. Tsaig, “Fast solution of l1- norm minimization problems when the solution may be sparse,” IEEE Trans. Inf. Theory, vol.54, vo.11, pp.4789–4812, 2008.
[20] G.W. Stewart, Matrix Algorithms Volume II, SIAM, 2001.
[21] X. He, D. Cai, S. Yan, and H.-J. Zhang, “Neighbor- hood preserving embedding,” Proc. Int. Conf. Com- puter Vision (ICCV), pp.1208–1213, 2005.
[22] S.X. Yu and J. Shi, “Multiclass spectral clustering,”
Proc. Int. Conf. Computer Vision (ICCV), pp.313–
319, 2003.
[23] S.A. Nene, S.K. Nayar, and H. Murase, “Columbia object image library (COIL-100),” Technical Report, CUCS-006-96, 1996.
[24] A. Farhadi, I. Endres, D. Hoiem, and D.A. Forsyth,
“Describing objects by their attributes,” Proc. Conf.
Computer Vision and Pattern Recognition (CVPR), pp.1778–1785, 2009.
[25] T.-S. Chua, J. Tang, R. Hong, H. Li, Z. Luo, and Y.-T. Zheng, “NUS-WIDE: A real-world web im- age database from national university of singapore,”
Proc. ACM Int. Conf. Image and Video Retrieval (CIVR), 2009.
(平成26年3月28日受付,7月14日再受付)
入江 豪 (正員)
2004慶大・理工卒.2006同大大学院修 士課程了.同年日本電信電話(株)入社.
以来,マルチメディア検索,マルチモーダ ル解析の研究に従事.2012〜2013米コロ ンビア大客員研究員.現在,NTTメディ アインテリジェンス研究所研究主任.博士
(情報理工学).
新井 啓之 (正員)
1989東理大・理工・物理卒.1991北大・
理・修士課程(物理学専攻)了.同年日本電 信電話(株)入社.図面認識技術,画像認 識技術の研究開発と実用化に従事.2001〜
2005 NTTデータ技術開発本部.2005よ りNTTメディアインテリジェンス研究所
(現職).2001〜2006情報通信研究機構(NICT)ナチュラルビ ジョンプロジェクト特別研究員.博士(情報科学).
谷口 行信 (正員)
1990東大・工・計数卒.1992同大大学 院工学系研究科修士課程了.同年日本電信 電話(株)入社.現在NTTメディアイン テリジェンス研究所主幹研究員.博士(工 学).映像メディア処理,メディア流通技 術の研究開発に従事.2000年本会論文賞 受賞.