1.は じ め に
膨大なデータから有益な知識を発掘するデータマイニ ングの研究が盛んに行われており,企業においても,日々 蓄積される大量かつ多様なデータ,いわゆるビッグデー タをビジネスに活用しようとする動きが活発化してい る [情報通信白書 14].特に最近,SNS などのソーシャ ルメディアの爆発的な普及に伴い,ビッグデータのもつ データ構造は,従来の単純な表構造から,Web 上あるい は実世界のどの場所で利用者が何を参照したか,などの, 人・物・場所といった多様な情報のつながりを表現する グラフ構造へとシフトしてきている.グラフ構造がもつ さまざまな情報のつながりを分析して隠された関係性を 捉え,それらを新たなコミュニケーションの支援や利用 者ごとにカスタマイズされた情報推薦へ利活用する期待 は大きい.NTT ソフトウェアイノベーションセンタで は,多様なアプリケーションサービスを提供する基盤技 術の研究開発の一つとして,ビッグデータをリアルタイ ムかつスケーラブルに分析する基盤技術やグラフ構造を 高速に分析する技術の研究開発に取り組んでいる. グラフ構造は,「ノード」とノード間を結ぶ「エッジ」 から構成されるデータ構造である.例えばカーナビや乗 換案内では,交差点や駅をノード,道路や線路をエッジ としてグラフ構造を構築し,ノード間の移動コストの低 い経路を出力する.人と人との交友関係をグラフで表現大規模グラフ構造データからの
コミュニティ抽出と重要度計算
─高速化への取組みと応用─
Finding Communities and Ranking for Large-Scale Graphs
─ Fast Algorithms and Applications ─
飯田 恭弘
日本電信電話株式会社 NTT ソフトウェアイノベーションセンタYasuhiro Iida NTT Software Innovation Center, Nippon Telegraph and Telephone Corporation. [email protected], http://www.sic.ecl.ntt.co.jp/
岸本 康成
(同 上)Yasunari Kishimoto [email protected], http://www.sic.ecl.ntt.co.jp/
藤原 靖宏
(同 上)Yasuhiro Fujiwara [email protected], http://www.sic.ecl.ntt.co.jp/
塩川 浩昭
(同 上)Hiroaki Shiokawa [email protected], http://www.sic.ecl.ntt.co.jp/
鬼塚 真
大阪大学大学院情報科学研究科マルチメディア工学専攻ビッグデータ工学講座Makoto Onizuka Big Data Engineering Laboratory, Department of Multimedia Engineering, Graduate School of Information Science and Technology, Osaka University.
[email protected], http://www-bigdata.ist.osaka-u.ac.jp/
Keywords:
graph mining, community detection, personalized PageRank. 「企業における AI 研究の最前線」したソーシャルグラフでは,人をノードとした大規模な グラフ構造になる(図 1). また,twitter などのマイクロブログにおけるメッセー ジのやり取り関係をグラフ構造で表現すれば,情報の 伝播,拡散の経路や影響力の高さなどを把握できる [ 榎 14].ほかにも,企業間の取引関係をグラフ構造として 分析し,産業構造の把握や地域の活性化に活かそうとす る取組みも始まっている [中小企業白書 14]. 我々の周りには多くのグラフ構造のデータが存在する が,これらの中には巨大なものや日々変化するものもあ る.例えば Google 社は数十億の Web ページ [Google] からなるグラフを有し,Facebook 社は約 13 億のアクティ ブユーザ [Facebook 14] からなるソーシャルグラフを有 する.また,頻繁に変化するものとしては EC サイトな どにおける利用者と商品の閲覧・利用・購買関係などが あげられる.このようなグラフ構造のデータから,有益 な情報をタイムリーに抽出し,それをビジネスに活用し 続けるためには,この抽出処理を高速に行い,短時間の うちに処理を終えなければならない.例えば,図 1 のよ うな大規模かつ複雑なソーシャルグラフから,つながり の強い人の集まり(コミュニティ)や影響力の大きな人 を高速に抽出できれば,タイムリーかつ効率的に新商品 を宣伝するといったことが可能になると期待される.本 稿では,我々が取り組んでいる大規模なグラフ構造デー タを高速に処理する手法とその応用例を紹介する. 本稿の構成は以下のとおりである.2 章では,グラフ 構造をもつデータのマイニング手法の動向を述べつつ, グラフ構造のデータから密なノードの集まりを抽出する コミュニティ抽出手法と,ノード間のつながりによって 重要度を計算する手法を中心に述べる.3 章では,2 章で 述べた手法を高速化する手法を述べる.4 章では,グラ フマイニングの応用例を紹介し,5 章で本稿をまとめる.
2. グラフマイニングとは?
グラフ構造をもつデータから価値ある知識の獲得を 目指すグラフマイニングの研究は,頻出パターンの発見 [Inokuchi 00],構造の予測 [鹿島 07] ,エッジが密なノー ド群を抽出する部分グラフの抽出(コミュニティ抽出な ど),ノードの重要度の計算(Personalized PageRank など)など,多岐にわたる.中でも,コミュニティ抽出 によりソーシャルグラフなどから関係の密な集団を特定 したり,影響力の高いノードを見つけるなどのことは, 商品の推薦やターゲット広告などによりビジネス機会を 増やすことにつながる(図 2). 以下では,我々がビジネスへの応用性が高いと考える コミュニティ抽出手法と,影響力の高いノードを探索す る PageRank の手法の二つについて述べる. 2・1 コミュニティ抽出 グラフ構造から,部分グラフ内のノード間のエッジ 密度が,相対的に部分グラフ外へのエッジ密度よりも高 くなるような部分グラフを切り出すことを,クラスタリ ングもしくはコミュニティ抽出と呼ぶ.コミュニティ 抽出の手法には,Min-max cut [Ding 01] ,Normalized cut[Shi 00] ,Modularity [Newman 04] ,SCAN [Xu07] などがある.Min-max cut はグラフを二つに分割す る際,部分グラフ間のエッジ数を最小にし,部分グラ フ内のエッジ数を最大にするよう分割することで,部 分グラフ間のエッジ密度が疎になるように分割する. Normalized cutも部分グラフ間のエッジ密度を疎にする 分割手法だが,部分グラフ間のエッジを最小にするよう グラフを分割する際,各部分グラフ内のノードからすべ てのノードに出ていくエッジ総数を加味することで,外 に出ていくエッジの少ない極端に小さな部分グラフがで きないよう工夫している. Modularityは大規模なグラフ構造から高速にコミュ ニティを抽出する手法として,近年最も注目を集めて いる指標の一つである [Aggarwal 11].Modularity は, 切り出した部分グラフがランダムグラフから異なるほ ど良い値となる指標である.切り出した部分グラフの Modularityが高ければ,それは適切にコミュニティを 抽出していることを示す.抽出したコミュニティ集合を C,コミュニティ i からコミュニティ j へ接続されてい るエッジ数を eij,グラフ構造全体に含まれるエッジの総 数を m とすると,Modularity は次のように定義される. [定義 1] Modularity Q 図 3 は例としてノードが 12 個,エッジの総数が 19 個の グラフを分割していく様子を示している. 図 3 の左側のようにグラフ全体を一つのクラスタに すると Modularity Q は 0 である.中央,および右側の 図 2 コミュニティ抽出と PageRank 図 3 グラフの分割
ように部分グラフに分割していく場合は,それぞれ, {22/2m −(23/2m)2} + {14/2m −(15/2m)2}= 0.43, {12/2m −(15/2m)2}+ {6/2m −(8/2m)2}+ {14/2m − (15/2m)2}= 0.49, と い う 値 を 取 る. 右 側 が 最 も 高 い Modularity 値であり,中央に比べて右側がより適 切にコミュニティ抽出ができていることが示される. Modularityは 0 から 1 の値をとり,1 に近づくほど良 いクラスタに分割できているとみなせる. Modularityに基づく手法のほかのクラスタリングと しては,構造的な類似度に基づく手法である SCAN に も注目が集まっている [Xu 07].SCAN は,部分グラフ を切り出すとともに,二つの部分グラフをつなぐノード (ハブ)やエッジが一つしかないノード(外れ値)も抽 出することができる. 2・2 PageRank Webページ間のハイパーリンクによる参照関係(図 4)に基づき Web ページの重要度を計算する手法として PageRank [Page 98]がある.PageRank は一般的には ランダムサーファモデルによってモデル化される.すな わち,サーファはランダムに Web ページを選択し,一 定の確率でページ内にあるハイパーリンクをクリックし て他の Web ページに移動する. この操作を繰り返して得られる各 Web ページへのアク セス確率が PageRank 値である.N 個の Web ページを ノードとし,それらのリンクをエッジとするグラフ構造 を考えたとき,PageRank 値は,以下の式で定義される. [定義 2] PageRank p pは各 Web ページの PageRank 値を表すベクトルであ る.A は正規化された隣接行列で,ノード i からノード j へリンクが張られているとき,A の要素 Aijに 1/Oiを設 定する.ここで Oiは,ノード i の出次数(ノード i から 出ているリンクの数)である.例えば,図 5 の左側のよ うな Web ページのリンク関係がある場合,隣接行列は 図 5 の右側のように表現できる.c は所定のノード群に ジャンプする確率である.q は N 次元ベクトルで,各要 素に同じ値を設定する.すなわち,サーファがリンクを 辿って次々と他の Web ページへ移動する場合([定義 2] における(1−c)Ap の項)と,一定の割合で他のノード にジャンプすること([定義 2] における cq の項)をモ デル化している. PageRankの値を求める問題は,ノード数を N とした ときの N 次元一次方程式の問題であるので,①逆行列 による手法と②反復法の二つの求め方がある.反復法で 求める場合,[定義 2] の式を p が収束するまで繰り返し 適用する.この収束値として得られた p が,N 個のノー ドにおけるおのおのの重要度を示すものとなる.なお, PageRankは,あるノードからリンクの重みに比例した ランダムウォークを行った結果を定常状態確率分布とし て得ることもできる.
Personalized PageRankは,PageRank を拡張し,q の各要素にユーザの好みによる重み付けしたものであ り,問合せ分布とも呼ばれる(例えば Web ブラウザの お気に入りに登録した URL 群など).これを加味するこ とで,ユーザが良く訪問するノードやそれにリンクされ た近傍のノードの重要度を高めることができる. ノードの重要性の指標としては,ほかにも SimRank が提案されている [Jeh 02].SimRank では,リンクの 「張られ方」が似ているページ同士は類似度が高いもの とする.対の各ノードへのリンクをもつノードの間の類 似度をノード対の類似度に伝搬させることで類似度を計 算する.
3. 高速化への取組み
ビジネスで活用するための情報を大規模なグラフ構造 から抽出するには,試行錯誤しながら大量のデータを何 度も分析するため,分析処理の速度が重要となる.本章 では,Modularity の最大化によるコミュニティ抽出の 高速化,Personalized PageRank 計算の高速化の手法に ついて述べる. 3・1 コミュニティ抽出の高速化 Modularityの最大化は NP 困難であるため,近年の 研究では,貪欲法を用いてより高い Modularity の値を より高速に求めることに主眼が置かれている.例えば 数億ノード規模のグラフ構造に対して,高速かつ高い 図 4 Web ページ間の参照関係 図 5 隣接行列を用いた表現Modularity値を示す方法として Louvain 法 [Blondel 08] が知られている.この手法では,Modularity 値の 局所最適化とノードの集約により,コミュニティ抽出処 理におけるノードとエッジの参照数を減らしている(図 6).具体的には,二つのフェーズからなるパスを繰り 返すことでコミュニティを抽出する.最初のフェーズ は,グラフ構造を構成する各ノードがそれぞれ別のコ ミュニティである状態から処理を開始する.その後,任 意の順にノードを選択し,これに隣接するノードの中か ら,これら二つのノードを同一のコミュニティとみな すことで最も Modularity が向上するような隣接ノード を一つ選択する.この同一のコミュニティとみなす操作 を,Modularity 値が向上する限り繰り返す.次のフェー ズでは同一のコミュニティと判定されたすべてのノード とエッジを 1 ノードへ集約する操作を行う.Modularity 値が向上する限り,これら二つのフェーズからなるパス を反復し,コミュニティを抽出する.収束した処理結果 を 1 ノードに集約することで,処理に必要となるノード とエッジの参照数を削減させている. 我々は,この手法のさらなる高速化に取り組んでいる [Shiokawa 11].これは図 7 に示す二つの工夫で実現し ている.一つは,グラフ構造の統計情報に基づき分析す るノードの計算順序を最適化したことである.具体的に は,ノードから何本エッジが出ているかという「次数」 の情報に基づいて,計算時間が短いノード(次数が少な いノード)から計算していくようにした.次数が高いノー ドからは多数のエッジが出ているため,参照すべきエッ ジ数の増加に伴って,計算量が増加するからである.も う一つの工夫は,同じクラスタ(グループ)に所属する と判断できるノードを順次単一の(仮想)ノードに集約 して取り扱うことである.集約することでノードやエッ ジの総数が減り,以降の分析が次々と高速化される.一 例が,エッジが一つしかない(接続先のノードが一つし かない)ノードの集約である.こうしたノードは,複雑 な計算をしなくても接続先のノードと同一のクラスタに 属するのが自明なので「接続先のノードと同一のノード」 としてすぐに集約できる.一般的に,グラフ構造をもつ データにはこうしたノードが多いため,この集約処理は 非常に効果的である.これらの工夫により,既存の 10 ∼ 60 倍の高速化を実現している. また,我々は CPU の SIMD 命令を利用した並列処理 による高速化 [塩川 13] や,2 章で述べた構造的な類似 度によりコミュニティ抽出を行う手法である SCAN の 高速化 [塩川 14] にも取り組んでいる. 3・2 Personalized PageRank 計算の高速化 Personalized PageRankを高速に処理するものとし て,インド工科大学が開発した Basic Push Algorithm
[Gupta 08]は上位にランキングされるノードを近似的に
求めるもので,重要度の上限値を事前に計算した重要な ノードからの関連度合いを用いて計算している.INRIA と Twente 大学のチームが開発した手法は,Monte Carlo 法を用いて Personalized PageRank におけるノード間の 遷移確率を計算し,上位にランキングするものだけを高 速に見つけるものである [Avrachenkov 11]. 我々は Personalized PageRank の高速化を図 8 に示 す二つの工夫で実現している [Fujiwara 12, Fujiwara 13a].一つは,各ノードの重要度計算を効率化したこと である.具体的には,グラフを表す隣接行列を行列分解 した後の行列内のゼロ要素を増やすために,隣接行列の 行と列を並び替える行列変換を行う.ゼロ要素は掛けて もゼロになるので,そこは計算する必要がなくなる.こ の処理によって重要度の計算を高速化している.もう一 つの工夫は,すべてのノードの正確な重要度を計算する 代わりに,より計算負荷の低い「重要度の上限値」を計 算して効率的に探索空間を足切りすることである.グラ フから重要度が高い k 個のノードを抽出する処理は以下 図 6 ノードの集約 図 7 コミュニティ抽出の高速化 , , . . . 図 8 PageRank 計算の高速化 ,
タをもとに人のつながりの分析を行った.ここでは例と して政治家が属するコミュニティや関係性,重要度など を図示した活用例を示す(図 9).グラフデータの構築 方法は以下のとおりである.Wikipedia の衆議院議員一 覧のページを取得し,さらにその議員のページのリンク をたどる.議員をノードとして,その Wikipedia のペー ジに他の議員のページへのリンクがあれば,その議員同 士でエッジをはることでグラフ構造を構築し,こうして 得られたグラフをコミュニティ抽出と PageRank によっ て分析した.表示には前述のグラフ分析・可視化ツー ル Gephi を使用している.また,Wikipedia からの人 名の抽出にはオープンソースの形態素解析ツールである MeCab [Kudo 04] を使用した. 同じコミュニティに属する政治家のノードは同じ色 に,PageRank により計算した影響力の高い議員ほど ノードの直径が大きくなるようにしている.ノード数は 約 3 000 である.これらにより,「安倍晋三氏と麻生太 郎氏はともに影響力が大きい」,「鳩山邦夫氏の影響力は 大きいが,安倍氏,麻生氏とはコミュニティが異なる」 などの解析結果が表示された.また,Wikipedia から芸 のようになる.まず,全ノードについて重要度の上限値 を計算する.続いて上限値が高いノードから正確な重要 度を計算していく.これにより,一時的に上位 k 個の重 要なノードが見つかる.この上位 k 番目の正確な重要度 よりも上限値が低いノードについては重要度を計算する 必要がないため「枝刈り」する.これによってトータル の計算負荷を削減した.これらの工夫により,既存手法 の精度を落とすことなく 50 倍以上の高速化を実現して いる. また,我々は,2 章で述べた類似度計算の手法である SimRankの高速化 [Fujiwara 13b] にも取り組んでいる.
4. グラフマイニングの応用
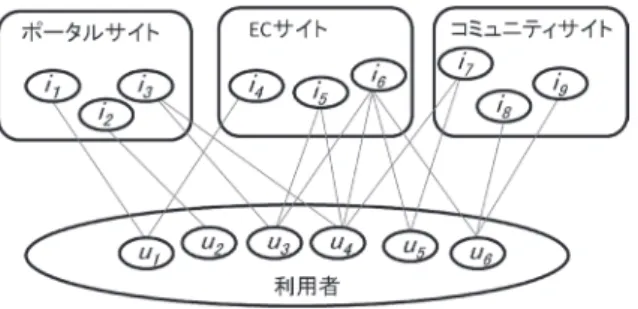
グラフマイニングの応用は幅広く,以下に代表的な応 用事例をあげる.グラフ構造からのコミュニティ抽出に より,画像を人と背景といったように複数の領域に分割 する試みがある [Abin 14].画素間で RGB などの色情 報を特徴ベクトルにして,その類似度が一定以上であれ ば,画素間にエッジを張り,グラフ構造を構築する.こ のグラフ構造にコミュニティ抽出を適用し,画像領域 を分割する.脳科学においては脳を細かい領域に分割 し,各領域間の神経線維による構造的接続性や fMRI な どの信号の相関による機能的接続性をグラフ構造で表 現し,コミュニティ抽出により脳の機能 [Meunier 09] や構造上 [Hagmann 08] のまとまりを抽出しようとす る研究がある.また,PageRank については,これを ベースとして,利用者の嗜好に合わせて商品をスコア付 けする ItemRank [Gori 07] や,与えたキーワードをも とにデータベース内のオブジェクトをスコア付けする ObjectRank [Balmin 04]などが提案されている. 本章では,グラフマイニング結果を可視化するツール を紹介するとともに,我々が取り組んでいるグラフマイ ニングの応用例として,主に Web 上で扱われる情報を 対象にした例を紹介する. 4・1 可 視 化 グラフ構造の分析結果を可視化は,ひとめで全体像を 把握したり,重要な情報の発見を容易にすることに役立 つ.このような可視化ツールのうち広く普及しているも のの一つに Gephi [Mathieu 09] がある.これは CSV 形 式などのいくつかの形式のファイルを読み込み,ノー ドとエッジで表されるグラフ構造を表示する.また, Modularityや PageRank を計算する機能を備えている. 我々は,開発した高速アルゴリズムを広く利用できるよ うに,Java などの汎用言語で利用可能なソフトウェア ライブラリや,Gephi のプラグインを開発している. 4・2 人のつながりの分析 我々は,グラフマイニングを用いて Wikipedia のデー 図 9 衆議院議員の関係の例 図 10 同じアイドルグループのメンバから成るコミュニティ能人や俳優といった分野でコミュニティ抽出を行い,同 じアイドルグループに属するメンバが同一のコミュニ ティになったり,影響力の大きいメンバが大きく表示さ れることを確認している(図 10).さらに,ある有名ブ ロガーに影響を与えているのは誰か知りたい,といった 場合などにも活用できる. 4・3 技術動向の系譜の抽出 論文データをグラフマイニングで分析すれば,技術動 向を抽出することができる.我々は,電子情報通信学会 にて蓄積されている 16 万件以上の論文,10 万件規模の 技術用語,そして 10 万人規模の論文著者のデータから, コミュニティ抽出手法により「技術領域」を抽出すると ともに,Personalized PageRank により「技術領域の経 年変化」を抽出した.手法のおおまかな流れは,①デー タを 10 年単位で分割,② 10 年ごとのデータを二部グ ラフ化しグラフからクラスタを抽出,③隣接する年代間 で近傍クラスタ同士を見つけクラスタの時系列変化とす る,である.具体的には,1970 年代以降のデータを 10 年ごとの期間(年代)で区切るとともに,一つの論文に 含まれる著者と要約に含まれる単語を抽出して二部グラ フを作成する(図 11). ここからクラスタを特定することで,著者と単語のつ ながりの強いまとまりを技術領域として抽出する.抽出 した技術領域は,全体で 82 個となった.これらの技術 領域のまとまりを「技術領域クラスタ」と呼ぶことにす る. 技術動向が年代間でどのように変遷していくかを知る には,技術領域クラスタを年代間で関連づけなければな らない.そこで我々は,技術領域クラスタ間で共通する 著者や単語が多いほど,年代間でその二つの技術領域ク ラスタは類似していると考えた.具体的には,著者や単 語の重要度を Personalized PageRank で算出しておき, 技術領域クラスタ間で,共通する著者と単語の重要度を 足し合わせ,それを類似度とする(図 12). 経年変化の把握では,類似度 0.4 以上のクラスタ間に 関連があるものとした.こうすることで,年代ごとに技 術領域クラスタがいくつか出来上がり,さらにそれら の技術領域クラスタが年代をまたいで関連付けられるこ とになる.このようにして得られた技術年表の一例を図 13に示す. 構築した技術年表から,キーワード(論文のキーワー ド欄に記載された単語)に着目すると,いくつかの興 味深い技術トレンドがわかる.無線通信では,「衛星 通信」⇒「センサネットワーク」⇒「Wireless sensor network」という無線通信技術の変遷や「陸上移動通信」 ⇒「移動通信,衛星通信」という通信技術の変遷がわかっ た.このほかにも,文字認識や音声認識では,「HMM(隠 れマルコフモデル),ニューラルネットワーク,パター ン認識」⇒「強化学習」⇒「自然言語処理」という変遷 に加え,「大語彙連続音声認識,マルチエージェントシ ステム」⇒「statistical machine translation,音声対話 システム」という文字認識や音声認識の技術を用いたア プリケーションの変遷が把握できた.また,数値解析や 半導体の分野は技術キーワードには大きな変化が見られ なかったが,論文件数が 2000 年以降に減少傾向がわかっ た. 4・4 情 報 推 薦 グラフマイニングを使って,さまざまなアイテム(商 品やサービス)を利用者に推薦することも可能である [堤田 11].ポータルサイトや EC サイトではさまざま な異なる種類のコンテンツが扱われており,さまざまな サイトで利用者のアクセスログが蓄積されている.こう したログを活用して,集客力のあるサービスドメインの 利用者を他のドメインへ誘導して新規利用者の増加を 見込むことも考えられる [堤田 12].この場合,利用者 と,複数のノードにまたがるおのおののアイテム商品や サービスをそれぞれノードとする二部グラフを作成して 図 11 論文の著者と単語からなる二部グラフ 図 13 技術年表の例 図 12 技術領域クラスタ間の類似度
おく(図 14).推薦対象の利用者を表すノードを起点と して,各ノードへの到達確率を計算する.この処理は Personalized PageRankを計算することと同等である. そして,最終的にアイテムを表すノードについてのみ, 前述の利用者ノードからの関連度を計算しランキングす る. このような手法により,例えば利用者 u3に対して, 似た傾向をもつ利用者 u4が利用するアイテム i7を推薦 することが可能となる.また,多くの利用者が利用する アイテム i6を抽出し,他の利用者にこれを推薦すると いったことが可能である. 4・5 負 荷 平 準 化 コミュニティ抽出手法を用いれば,処理を等粒度に分 割することも可能である.例えば地理情報をもとに人口 動態や道路混雑状況を計算するような処理を考えると, 単純に緯度経度で分割して並列処理をしたとしても,各 分割単位で処理コストが不均衡になってしまう.そこで, コミュニティ抽出により,処理時間が全分割単位で平準 化されるように地理情報を分割することが考えられる. 時々刻々と変化する人口動態や道路混雑状況に対して, このような処理コストの平準化を保つためには,一定時 間ごとにそのときどきに応じた適切な再分割が必要なた め,高速なコミュニティ抽出の技術が重要となってくる (図 15).
5. お わ り に
本稿では,我々が取り組むグラフマイニングについて, その高速化の研究概況や活用例について述べた.今後, グラフマイニングの研究を進めていくうえで,さまざま な場面からデータを容易に抽出し,グラフ構造として蓄 積する手法や,コミュニティ抽出および PageRank の 計算対象とするデータ領域を容易に可変可能な環境の構 築,GraphLab [Low 10] のような並列処理によるスケー ラビリティの確保なども重要と考えている. 人間が生み出すデータは日々多様化し,大容量化して いる.これらの膨大なデータから新たな知識を獲得した り,ビジネス価値の創出や経営判断に活用し続けていく ため,企業における取引関係の分析や通信トラヒックの 分析などの適用分野を開拓していくことが今後の課題で ある.◇ 参 考 文 献 ◇
[Abin 14] Abin, A. A. Mahdisoltani, F. and Beigy, H.: Wise image segmentation based on community detection, The Imaging
Science Journal, Vol. 62, No. 6, pp. 327-336 (2014)
[Aggarwal 11] Aggarwal, C. C.: Social Network Data Analytics, 1st edition, Springer Publishing Company, Incorporated (2011)
[Avrachenkov 11] Avrachenkov, K. and Litvak, N.: Quick detection of top-k personalized PageRank lists, Proc. WAW (2011)
[Balmin 04] Balmin, A., Hristidis, V. and Papakonstantinou, Y. Objectrank: Authority-based keyword search in databases,
Proc. VLDB (2003)
[Bastian 09] Bastian, M., Heymann, S. and Jacomy, M.: Gephi: An open source software for exploring and manipulating networks, Proc. ICWSM (2009)
[Blondel 08] Blondel, V., Guillaume, J., Lambiotte, R. and Lefebvre, E.: Fast unfolding of communities in large networks,
J. Statistical Mechanics: Theory and Experiment, Vol. 2008,
P10008(2008)
[中小企業白書 14] 中小企業白書 2014, コネクターハブ企業と地域 産業構造分析システム,中小企業庁(2014)
[Ding 01] Ding, C. H. Q., He, X., Zha, H., Gu, M. and Simon, H. D.: A min-max cut algorithm for graph partitioning and data clustering, Proc. IEEE(2001)
[榎 14] 榎 美紀,村上明子,レイモンド ルディー,小口正人:ソー シャルメディア上の情報拡散分析,DEIM Forum 2014, B4-6 (2014)
[Facebook 14] Facebook Reports First Quarter 2014 Results, http://investor.fb.com/releasedetail.cfm?ReleaseID=842071 [Fujiwara 12] Fujiwara, Y., Nakatsuji, M., Yamamuro, T.,
Shiokawa, H. and Onizuka, M.: Efficient personalized pagerank with accuracy assurance, Proc. KDD(2012) [Fujiwara 13a] Fujiwara, Y., Nakatsuji, M., Shiokawa, H.,
Mishima, T. and Onizuka, M.: Fast and exact top-k algorithm for PageRank, Proc. AAAI(2013)
[Fujiwara 13b] Fujiwara, Y., Nakatsuji, M., Shiokawa, H. and Onizuka, M.: Efficient search algorithm for SimRank, Proc.
ICDE(2013)
[Google] Crawling & Indexing, http://www.google.com/intl/ en/insidesearch/howsearchworks/crawling-indexing.html [Gori 07] Gori, M. and Pucci,A.: ItemRank: A random-walk
based scoring algorithm for recommender engines, Proc. IJCAI (2007)
[Gupta 08] Gupta, M., Pathak, A. and Chakrabarti, S. : Fast algorithms for top-k personalized PageRank queries, Proc.
WWW(2008)
[Hagmann 08] Hagmann, P., Cammoun, L., Gigandet, X., Meuli, R., Honey, C. J. Wedeen, V. J. and Sporns, O.: Mapping the structural core of human cerebral cortex, PLOS Biology, Vol. 6, Issue, 7, e159(2008)
[Inokuchi 00] Inokuchi, A., Washio, T. and Motoda, H.: An Apriori-based algorithm for mining frequent substructures from graph data, Proc. PKDD(2000)
図 14 利用者とアイテムの二部グラフ
[Jeh 02] Jeh, G. and Widom, J.: SimRank: A measure of structural-context similarity, Proc. KDD(2012)
[鹿島 07] 鹿島久嗣:ネットワーク構造予測,人工知能学会誌, Vol. 22, No. 3, pp. 344-351(2007)
[Kudo 04] Kudo, T., Yamamoto, K. and Matsumoto, Y.: Applying conditional random fields to Japanese morphological analysis,
Proc. EMNLP(2004)
[Low 10] Low, Y., Gonzalez, J., Kyrola, A., Bickson, D., Guestrin, C. and Hellerstein, J. M.: Graphlab: A new parallel framework for machine learning, Proc. UAI(2010)
[Mathieu 09] Mathieu, B., Sebastien H. and Mathieu J.: An open source software for exploring and manipulating networks,
Proc. ICWSM(2009)
[Meunier 09] Meunier, D., Lambiotte, R., Fornito, A., Ershce, K. D. and Bullmore, E. T.: Hierarchical modularity in human brain functional networks, Frontiers in Neuroinformatics, Vol. 3, No. 37, pp. 1-12 (2009)
[Newman 04] Newman, M. and Girvan, M.: Finding and evaluating community structure in networks, Phys. Rev. E, Vol. 69, 026113 (2004)
[Page 98] Page, L., Brin, S., Motwani, R. and Winograd, T.: The PageRank citation ranking: Bringing order to the web, Technical Report, Stanford Digital Library Technologies Project(1998)
[Shi 00] Shi, J. and Malik, J.: Normalized cuts and image segmentation, IEEE Trans. Pattern Anal. Mach. Intell., Vol. 22, No. 8, pp. 888-905(2000)
[Shiokawa 11] Shiokawa, H., Fujiwara, Y. and Onizuka, M.: Fast Algorithm for Modularity-based Graph Clustering, AAAI Press (2013) [塩川 13] 塩川浩昭,山室 健,藤原靖宏,鬼塚 真:SIMD 命令によ るモジュラリティに基づくグラフクラスタリングの並列化,日 本データベース学会論文誌,Vol. 12, No. 1, pp. 91-96(2013) [塩川 14] 塩川浩昭,藤原靖宏,鬼塚 真:構造的類似度に基づくグ ラフクラスタリングの高速化,DEIM Forum 2014, D6-2(2014) [堤田 11] 堤田恭太,中辻 真,内山俊郎,藤村 考:メタデータ付き
推薦のためのグラフマイニング,25th Annual Conf. Japanese
Society for Artificial Intelligence(2011)
[堤田 12] 堤田恭太,中辻 真,内山俊郎,戸田浩之,内山 匡:ア クセスログを用いたクロスドメイン環境における情報推薦,情 処学研報,Vol. 2012-DBS-154, No.4, pp. 1-8(2012)
[Xu 07] Xu, X., Yuruk, N., Feng, Z. and Schweiger, T. A. J.: Scan: A structural clustering algorithm for networks, Proc. KDD (2007) [情報通信白書 14] 平成 26 年版 情報通信白書,データが切り拓く 未来社会,総務省(2013) 2014年 7 月 15 日 受理