確率的潜在モデルに基づいた複数の部分的な回答データからの仮
想的な全回答データ作成方法の検証
Varification of a method that creates virtual full-answered data
from partial-answered data based on Probabilistic Latent Model
寺田 祐介
1 ∗櫻井 瑛一
1本村 陽一
1Yusuke Terada
1Eiichi Sakurai
1Youichi Motomura
11
産業技術総合研究所
1
National Institute of Advanced Industrial Science and Technology (AIST)
Abstract: Taking a questionnaire is effective way to model consumer awareness. However hearing
a lot of questions is very hard from the point of view of answer accuracy and response rate. One way to solve this problem, we take partial questionnaires that differ among answers and merge some answers so as to contain all answers of questions in the original questionnaire. In this study, we propose a method that is merging the partial answers based on Probabilistic Latent Model. The experimental result shows that the proposed method can create virtual answer data which is similar to original answer data from the viewpoint of latent segments in answer data.
1
はじめに
昨今データを大量に収集し解析を行うビッグデータ 解析やその結果を応用した AI 技術開発が盛んに行われ ているが,解析に必要なデータを集めることは多くの 場合でコストや難度が高い.特に,消費者の特徴と購 買理由を結びつけて分析する消費者のモデル化におい て,POS データから購入傾向や商品を組み合わせた購 入の分析がなされているが,より深く消費者の行動を モデル化するためには,購買時に近い状況で不特定多 数の消費者からデータをとる必要がある.しかし,こ のような場面でのアンケートに許容される時間の短さ を考慮すると,回答率や回答精度の面で大規模に長い 設問のアンケートを収集することは困難であり,消費 者の詳細な特徴を推定することが難しい. 長い設問の一部のみをユーザーに質問し,そのユー ザーの潜在的なクラスを推測する動的アンケートシステ ム [田村 18] が提案されている.この研究ではユーザー に合わせて動的に設問を提示することで,少ない設問 によるユーザーセグメントの推定精度向上を可能とし ている.しかし,部分的な回答しか得られないため,全 設問の回答データに比べて詳細な特徴を分析できない. そこで我々は,ユーザーセグメントを用いて,類似 する複数ユーザーの部分的な回答を得てそれらを統合 ∗連絡先: 国立研究開発法人産業技術総合研究所 人工知能研究センター 東京都江東区青海 2-4-7 E-mail: [email protected] することで全設問の回答データを生成することについ て考えた.これにより,短いアンケートを多人数に行 いその結果を集約化することで,仮想的に素別の設問 に回答したアンケートの作成を目指す.この手法が妥 当である場合,店頭で消費者に少ない設問のアンケー トを行うだけで、消費者の行動の詳細なモデル化の実 現が期待できる.本稿では,複数のアンケートをマー ジして実際に仮想的なアンケートデータとなるかにつ いて検証を行った.2
提案手法で用いた方法
本章では,動的アンケートシステム [田村 18] を先行 研究として記述する.また,動的アンケートシステムに おいて Probabilistic Latent Semantic Analysis(PLSA) [Hofmann99] と Bayesian Network[Pearl88][本村 16] を 用いているため,この 2 つの手法についても説明する.2.1
PLSA
PLSA は所属行列型のデータや共起データの分析に 用いる統計手法であり [Hofmann99],自然言語処理や 購買行動分析 [原田 16] などに用いられる,2 つの条件 付き独立な変数間の潜在セグメント分析である. 文書データに PLSA を適用した例について記述する. 文書データ内の文章 d と単語 w の 2 変数が条件付独立図 1: Bayesian Network の例 であると仮定することで,潜在変数 c を用いて同時確 率分布を以下のように定義する. P (d, w) =∑ c∈C P (c)P (d|c)P (w|c). このモデルのパラメータを EM アルゴリズムにて最 尤推定し,潜在変数との条件付き確率分布を算出する. 本研究では,アンケートデータにおいてユーザーと設 問の選択肢の間に潜在する変数が存在していると考え, PLSA をアンケートデータに用いることにより,ユー ザーセグメントを推定するクラスタリングを行った.
2.2
Bayesian Network
Bayesian Network[Pearl88][本村 16] は確率的グラフ ィカルモデルの一種で,不確かなドメインに対して構 造を表すために用いられる. 以下では,図 1 のような関係の 5 つの確率変数が存 在した場合での,Bayesian Network の同時確率分布を 定義する. P (X1, X2, X3, X4, X5) = P (X1)P (X2)P (X3|X1)P (X4|X1, X2)P (X5|X3, X4). 上記の式の通り,図 1 のネットワーク図における同 時確率分布を Bayesian Network は一意に定義するこ とができ,通常の連鎖則での同時確率分布の表現に比 べモデルのパラメータ数を削除することが可能である. この特性は,不確かなドメインのモデル探索における 学習や推論などの面においてモデル化の際に非常に有 用である. 本研究ではこの Bayesian Network を,アンケート データの設問の選択肢がユーザーセグメントを説明す る構造となるようにモデル化した.2.3
動的アンケートシステム
動的アンケートシステム [田村 18] はベイジアンネッ トワークによる潜在セグメント説明モデルを用いて,ア ンケートユーザーの潜在セグメントへの影響が大きい 設問を逐次推定および提示を行い,限られた設問数で ユーザーセグメントを推定するシステムである. この動的アンケートシステムは,すべての設問に回 答しているアンケートデータに対し PLSA を用いたク ラスタリングと,得られた潜在セグメントをアンケー トの設問の選択肢が説明する構造の Bayesian Network を構築する.この Bayesian Network にすでに回答され ている設問と潜在セグメントをエビデンスとして与え た際の各設問の選択確率の変化量を Kullback-Leibler Divergence(KL Divergence) により算出する.この変 化量の合計 (ProbChange) が大きい設問を潜在セグメ ント推定に重要であると判断し逐次ユーザーへ提示を 行う. 潜在セグメントの集合を C ={c1, . . . , cx, . . . , cX}, 設問の集合を Q ={Q1, . . . , Qy, . . . , QY},設問 Qyに おける選択肢の集合を Qy={q1, . . . , qk, . . . , qny} とす る.このとき,各潜在セグメントをエビデンスとして与 えたときの設問 Qyにおける確率値の変化量 P robCha-nge(Qy) は KL Divergence を DKLとして,以下の式 で定義される. P robChange(Qy) = ∑ qk∈Qy ∑ cx∈C ∑ z∈{0,1} DKL(Pnew(qk, cx= z), Pold(qk)). 上記の式において Pold(qk) はすでに回答された設問 をエビデンスとして与えた際に推定される選択肢 qkの 選択確率,Pnew(qk, c = x) はすでに回答された設問と 潜在セグメント c に z = {0, 1}(0 = 所属していない , 1 = 所属している) をエビデンスで与えた際に推定さ れる選択肢 qkの選択確率である. この式で算出される P robChange(Qy) を回答されて いない設問の集合全てで行い,最も大きい値となった 設問が重要度の高い提示される設問となる. [田村 18] では 5 つの設問を逐次提示するシステムを 構築していたため,動的アンケートシステムの外観図 は図 2 となる. 本研究ではこの動的アンケートシステムをユーザー に限られた設問でユーザーセグメントを推定する際の 提示すべき設問選定に用いた.3
提案手法
本章では提案手法である,類似する複数ユーザーの 部分的な回答から全設問の回答データを生成する手法 について記述する.図 2: 動的アンケートシステムの外観図 [田村 19]
3.1
基本的な方針
本手法では,ユーザーセグメントを推定可能な完全 に回答されたアンケートデータを,部分的に回答された アンケートデータから工夫して作成する.設問は,ユー ザーセグメントを推定することに必要な設問 (Qmust) とそれ以外の設問 (Qwithout) に分類する.そして,回 答を前者は必ず得ることとし,後者をランダムに回答 しあとでまとめ上げることを考える. また Qmustの選択方法は,動的アンケートシステム で用いられたユーザーセグメントへの影響が大きい設 問を,あらかじめ用意しているアンケートデータの全 ユーザーに対し推定し,出現頻度の高い上位の設問を 選定した.3.2
データのマージ
全設問の回答データを作成するために,部分的な回 答データの束ごとにマージを行う.マージは選択肢ごと に回答を加算して行うが,Qmustと Qwithoutではデー タの束内での存在する回答数の差により,マージ後に取 りうる値の範囲が異なるという問題が存在する.この 問題を解決するため,Qmustの範囲を Qwithoutの範囲 に合わせるダウンスケールを行う.ここで,データの束 内のユーザー集合を U ={U1, . . . , Un, . . . , UN},アン ケートの設問集合を Q ={Q1, . . . , Qy, . . . , QY} とし, 設問 Qyの選択肢の集合を Qy ={q1, . . . , qk, . . . , qny} とする.また,ユーザー Unの設問 Qyが回答されてい るかどうかを a(Un, Qy) ={0, 1}(0 = 回答されている , 1 = 回答されていない) とおき,ユーザー Unの設問 Qyにおける選択肢 qkの回答を次の式で定義する. r(Un, Qy, qk) = { 0 or 1 if a(Un, Qy) = 1 N ull if a(Un, Qy) = 0. 設問 Qyにて,r(Un, Qy, qk) = 1 ならば選択肢 qkを選 択していることを意味し,r(Un, Qy, qk) = 0 ならば選択 肢 qkを選択していないことを示す.また,r(Un, Qy, qk) = N ull は選択肢 qkの回答が不明であるということを 表す.マージした後,ダウンスケールされた仮想的な 全設問の回答データの設問 Qyにおける選択肢 qkの回 答を rmerge(Qy, qk),Qwithoutに属する設問 Qyを提示 されたユーザーの集合を Uwithout,yとし,設問 Qmust の id を Imust={m1, . . . , mα, . . . , mA},設問 Qwithout の id を Iwithout={w1, . . . , wβ, . . . , wB},データの束 内での Qwithoutの存在する回答の数を repeat とおく ことで,マージを以下の式で定式化する. rmerge(Qy, qk) = { repeat N ∑N n=1r(Un, Qy, qk) if y∈ Imust ∑Un∈Uwithout,yr(Un, Qy, qk) if y∈ Iwithout.
4
使用したデータセット
本研究で使用したデータセットは,「アルコールの嗜 好調査」,「パンのわくわく感などに関する調査」,「自 動車の購入に関する調査」の 3 つのアンケートデータ より,ユーザーの性格に関する共通の設問でマルチア ンサー形式の設問を抜き出し使用した.該当データは 12 設問・136 選択肢の 11069 ユーザーであり、この中 から回答の誠実さに関する設問に正しく回答している 9504 ユーザーのデータをデータセットとして使用した.5
評価実験
提案手法への評価実験では,アンケートデータの潜 在セグメントと提案手法により作成したデータの潜在 セグメントの比較を行い,提案手法の妥当性について 検証する.評価実験は,以下の 4 段階に分かれるため, 評価実験の第 1∼ 3 段階をデータ作成手順,第 4 段階 を評価方法としてそれぞれ記述する. • 前準備 • 部分的な回答データの束の作成 • 仮想的な全設問の回答データの作成• Jensen-Shannon Divergence(JS Divergence) に
5.1
データ作成手順
本節では仮想的な全設問の回答データ作成の手順に ついて記述する. 5.1.1 前準備 9504 ユーザー全員のアンケートデータに対して PLSA による潜在セグメントの推定を行い,本実験では 4 つ に分類した.この潜在セグメントを正解セグメントと 本研究では表記する.この正解セグメントを 12 設問の 136 選択肢が説明するような構造の Bayesian Network を作成した.Bayesian Network の作成には,Bayesian Network 構築ソフトウェアの BayoNet[本村 03] を用い た.Bayesian Network と動的アンケートシステムでの 潜在セグメント推定に重要な設問を洗い出すアルゴリ ズムを用い,ユーザーごとの重要な設問を上位 3 個算 出し,全ユーザーを通して選ばれた回数が多い上位 2 個の設問を Qmustとした. 5.1.2 部分的な回答データの束の作成 前準備で決定した,Qmustをエビデンスとして Bay-esian Network より各ユーザーの潜在セグメント推定を 行う.この推定された潜在セグメントごとにユーザーを 分類したのち,ランダムで 15 ユーザーを選出し,推定 された潜在セグメント内のユーザー数と同じ数のデー タの束を作成した.このデータの束内において,Qmust 以外の 10 個の設問 Qwithoutより各ユーザーが 2 個ずつ 設問の回答を残し,8 個の設問の回答を消すことによっ て疑似的な不完全のアンケート回答データを作成した. この残す設問の選び方は,各ユーザーの Qwithoutの設 問をいくつ残すかを number(本研究では 2) として,以 下の式, repeat = ⌈ N× number B ⌉ を満たすように,count,repeat,N ,B を設定した.本 研究では N = 15,B = 10,number = 2,repeat = 3 と設定した.そして,各ユーザー Unに対して設問 Qy を回答したか否かを示す a(Un, Qy) は,以下の 4 つの 条件式を満たすように決定した. ∑N n=1a(Un, Qmα) = N (∀mα∈ Imust), ∑Nn=1a(Un, Qwβ) = repeat (∀wβ∈ Iwithout),
∑Α
α=1a(Un, Qmα) = A (∀Un∈ U),
∑B
β=1a(Un, Qwβ) = count (∀Un∈ U).
この条件を満たした a(Un, Qy) = 1 に対応するユー ザー Unの設問 Qyを残し部分的な回答データの束と した. 5.1.3 仮想的な全設問の回答データの作成 作成された部分的な回答データの束をデータの束の 設問ごとにマージとダウンスケールを行うことによっ て 9504 個の値の範囲が [0,3] である仮想的な全設問の 回答データの作成を行った.このマージ及びダウンス ケールのアルゴリズムは第 3 節の提案手法にて記述し た rmerge(Qy, qk) に従い算出した.
5.2
評価方法
本節では,最初に評価で用いる Jensen-Shannon Di-vergence について紹介し,評価指標について記述する. 5.2.1 JS Divergence 本節では評価尺度で用いる KL Divergence および JS Divergence について記述する. KL Divergence は確率分布間の距離を表す尺度と解 釈できる量であり,2 つの確率分布の類似度を表す指 標としてよく用いられる.本研究で扱う確率分布は離 散確率分布であるため,2 つの離散確率分布 p(x),q(x) に対する KL Divergence の式を以下に表す. DKL(p, q) = ∑ x p(x) lnq(x) p(x). この KL Divergence は対称な量ではないため, DKL(p, q)̸= DKL(q, p) となる.そこで本研究では,以 下に定義される JS Divergence を用いた. DJ S(p, q) = 1 2(DKL(p, r) + DKL(q, r)) = 1 2 ( ∑ x p(x) lnp(x) r(x) + ∑ x q(x) lnq(x) r(x) ) . ただし,r(x) =p(x)+q(x) 2 である. KL Divergence と JS Divergence のどちらも 0 以上 の値をとり,0 に近いほど確率分布間の距離が短く,類 似度が高いと考えることができる. 5.2.2 評価指標 データ作成手順によって作成された仮想的な全設問の 回答データの潜在セグメントとアンケートデータの正 解セグメントを比較するため,作成したデータ対して新 たに PLSA を行い,潜在セグメント推定を行った.この PLSA では,マージしたデータがダウンスケールにより 整数とならないため,四捨五入によって値が{0, 1, 2, 3} となる調整を行った.次に,それぞれのデータの潜在セグメントごとの選 択肢の選択確率を求めたのち,JS Divergence を作成し たデータとアンケートデータの潜在セグメントのすべ ての組み合わせで算出し,潜在セグメントの類似度を 求めた.アンケートデータの正解セグメントの集合を C ={c1, . . . , cx, . . . , cX},作成したデータの潜在セグ メントの集合を Cmerge ={cm1, . . . , cmγ, . . . , cmΓ} と する.また,全ての設問をまたぐ選択肢の集合を S = {s1, . . . , se, . . . , sE} とする.cxの選択肢の選択確率分布 を P (S|cx),cmγの選択肢の選択確率分布を P (S|cmγ) をとして,正解セグメント cxと潜在セグメント cmγの 類似度 score(cx, cmγ) を以下の式で定義する. score(cx, cmγ) = DJ S(P (S|cx), P (S|cmγ)). この類似度の計算を行い,提案手法の評価を行った.
6
結果・考察
本章では,提案手法の評価を行ったのち,元のアン ケートデータにおける正解セグメントと作成された全 設問の回答データにおける潜在セグメントの設問ごと の選択肢の選択確率の合計について考察を行う.6.1
提案手法の評価
作成された全設問の回答データに PLSA を適用した 結果,赤池情報量規準により最もよいと評価されたモ デルにおいて 5 つの潜在セグメントに分類された.この 5 つの潜在セグメントと正解セグメントの類似度の計算 を第 5.2.2 項の方法で行った結果が表 1 である.ここで cmγは作成されたデータにおける潜在セグメント,cxは 正解セグメントを表している.また,数値はそれぞれの 潜在セグメントでの選択肢の選択確率を JS Divergence によって比較した類似度であり,数値が小さいほど類 似していることを表す.そして,正解セグメント cxと もっとも類似している潜在セグメント cmγの数値を赤 く表示している. それぞれの正解セグメントに類似している潜在セグ メントが 1 つずつ存在し,全ての正解セグメントと類似 していない潜在セグメント cm4が 1 つ生成されている.6.2
設問ごとの選択確率の比較
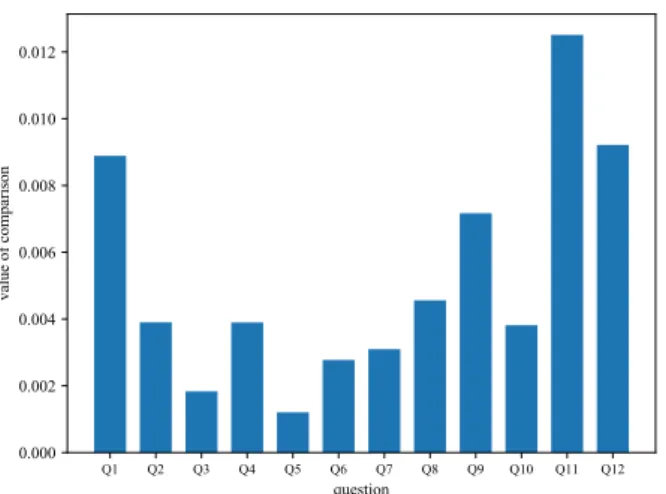
設問ごとの比較をするために,JS Divergence の評価 式の一部を用い,以下の式によって潜在セグメントご とに設問の比較を行う. 表 1: 類似度の評価 cm1 cm2 cm3 cm4 cm5 c1 0.0813 0.1982 0.2434 0.2704 0.2552 c2 0.1799 0.1838 0.0629 0.4353 0.3545 c3 0.2763 0.2183 0.2886 0.2668 0.0815 c4 0.2169 0.1009 0.2255 0.3380 0.2369 図 3: c1と cm1の設問ごとの選択確率の比較 comparison(cx, cmγ, Qy) = 1 2 ∑ qk∈Qy ( pcxln pcx (pcx+pcmγ) 2 + pcmγln pcmγ (pcx+pcmγ) 2 ) , where pcx = p(qk|cx), pcmγ = p(qk|cmγ). この式を対応する 2 つの潜在セグメントの組 (c1, cm1), (c2, cm3),(c3, cm5),(c4, cm2) に適応した棒グラフが図 3,4,5,6 である.横軸に設問,縦軸に比較した値 comparison(cx, cmγ, Qy) をとっている. 図 3∼6 から,設問 Q11はどの潜在セグメントの組 み合わせにおいても,設問の選択確率の乖離が大きい が,この設問は「あなたがふだん接触する情報源は何 ですか。」という内容であり,年齢や性別といった因子 に影響を与える設問である.本研究で扱ったアンケー トデータは一部の年齢層に絞ったデータではないため, この乖離が作成された全回答データに及ぼす影響は小 さいと考えらえる.図 4: c2と cm3の設問ごとの選択確率の率比較 図 5: c3と cm5 の設問ごとの選択確率の比較
7
まとめ
今回の実験での,複数の部分的な回答データをマー ジして実際に仮想的なアンケートデータとなるかの検 証は,正解セグメントとは異なる潜在セグメントが生 じたが,それぞれの正解セグメントに対応する類似し た潜在セグメントが作成されており,可能であるとい える. しかし,実際にシステムを実装する上での各ユーザー へのアンケートの割り振るアルゴリズムなど,考察お よび考案するべき課題が存在しており,さらなる研究 が必要である. 謝辞 本研究(の一部)は国立研究開発法人科学技術振興機 構(JST)の研究成果展開事業「センター・オブ・イノ ベーション(COI)プログラム」の支援によって行 われた.また,本研究は,国立研究開発法人新エネル 図 6: c4と cm2の設問ごとの選択確率の比較 ギー・産業技術総合開発機構(NEDO)の委託事業「人間 と相互理解できる次世代人工知能技術の研究開発」の 支援を受けて行った.参考文献
[田村 18] 田村脩, 櫻井瑛一, 本村陽一. Bayesian Net-work を用いた動的アンケートシステムの提案. 人工 知能学会全国大会論文集, JSAI2018, 1P102 (2018) [田村 19] 田村脩, 櫻井瑛一, 本村陽一. Bayesian Net-work を用いた動的アンケートシステムによる 設問の回答推定. 人工知能学会全国大会論文集, JSAI2019, 4B3J301 (2019)[Hofmann99] T.Hofmann. Probabilistic Latent Se-mantic Analysis. Proceedings of the Fifteenth
Conference on Uncertainty in Artificial Intelli-gence, UAI’99, No.8, pp.289–296 (1999)
[原田 16] 原田奈弥, 山下和也, 本村陽一. ID 付 POS データによる購買行動の季節変化分析と可視化.
SIG-SAI, Vol.27, No.7, pp.1–7 (2016)
[Pearl88] J.Pearl. Probabilistic Reasoning in Intelli-gence System: Networks of Plausible Inference.
Morgan Kaufmann Publishers Inc. (1988)
[本村 03] 本村陽一. ベイジアンネットソフトウェア BayoNet. 計測と制御, Vol.42, No.8, pp.693–694 (2003)
[本村 16] 本村陽一. 第 9 章『ベイジアンネットワーク と確率的潜在意味解析による確率的行動モデリン グ』, 『確率的グラフィカルモデル』(鈴木譲 他). 共立出版 (2016)

![図 2: 動的アンケートシステムの外観図 [田村 19] 3.1 基本的な方針 本手法では,ユーザーセグメントを推定可能な完全 に回答されたアンケートデータを,部分的に回答された アンケートデータから工夫して作成する.設問は,ユー ザーセグメントを推定することに必要な設問 (Q must ) とそれ以外の設問 (Q without ) に分類する.そして,回 答を前者は必ず得ることとし,後者をランダムに回答 しあとでまとめ上げることを考える. また Q must の選択方法は,動的アンケートシステム で用い](https://thumb-ap.123doks.com/thumbv2/123deta/8242760.1283706/3.892.90.426.128.387/アンケートシステムユーザーセグメントアンケートシステム.webp)