卒業研究報告書
題目
並列差分進化法を用いた画像処理
指導教員
石水 隆 講師
報告者
11–1–037–0057
渋谷 俊樹
近畿大学理工学部情報学科
平成
24
年1
月31
日提出概要
近年
,
市販のデスクトップPC
やノートPC
にもマルチコア・プロセッサが用いられている.
しかし,
複数の コアによって並列処理を実行するためには,
マルチコアCPU
に対応した並列プログラムを作成する必要がある
.[3].
並列プログラムは複数のスレッドと呼ばれる処理単位から構成され,
異なるコアに割り当てられたスレッドは同時に実行される
.
既存の逐次処理のプログラムを機械的に並列プログラムに変換するコンパイラも 開発されているが,
より効率的な並列プログラムを作成するには,
アルゴリズムの段階から処理の並列化を図る 必要がある.
並列プログラムによる高速化が求められる分野には様々あるが
,
その中の一つに最適化問題がある.
今日,
様々な種類の最適化問題に対してその問題の性質に応じた解放が考案されている.
しかしながら,
制約条件が 多い場合には問題の定式化が困難となる.
そこで
,
これらの問題を解決する手法として,
生物進化をヒントに得た探索手法である進化計算を用いること が近年注目されている.
遺伝的アルゴリズム(GA : Genetic Algorithm)
に代表される進化計算の大きな特徴 は,
解空間が非常に大きく,
従来の手法では高速計算機を用いても数十年かかるような問題や,
問題の構造が分 からず数学的に定式化できないため解けないような問題に対しても,
近似解を比較的高速に得られるという点 がある.
差分進化
(DE : Differential Evolution)
とは,
決定変数が実数値を取る単目的の関数最適化問題を対象としたとした進化計算の一種である
.[4] DE
は微分不可能な多峰性関数の最適化問題にも有効に適用することがで き,
多くのベンチマーク問題や現実的な最適化問題において,
優秀な最適化アルゴリズムの1
つであることが 示されている.
また,DE
はアルゴリズムが単純であるため実装が容易である.
すなわち,DE
の最大の利点は,
強力かつシンプルであるため,
使い勝手が良いことである.
このように進化計算
,
取り分け差分進化計算は有効性が極めて高いため,
並列化により高速化することは重要で ある.
しかし,
従来の進化計算の並列化手法は,
そのプログラムを実行するハードウェアに大きく依存する.
そ こで本研究では,
ハードウェアへの依存性が低い並列化手法を検討する.
本研究では
,
上記のDE
の並列化である,
並列差分進化計算(PDE : Parallel Differential Evolution)
を用い て画像処理を行う.
本研究で対象とする画像処理は,
ぼやけた画像が与えられた際に,
その元となる鮮明な画像 を得るノイズ除去処理である.
この処理を実装することによって,
画像の類似性を視覚的に認識することによ り,
最適化問題におけるDE
の有効性を考察する.
目次
1
序論1
1.1
本研究の背景. . . . 1 1.2
本研究の目的. . . . 1 1.3
本報告書の構成. . . . 1
2
最適化問題2
2.1
最適化問題概要. . . . 2
3
進化計算3
3.1
差分進化計算(DE) . . . . 3 3.2
並列差分進化計算(PDE) . . . . 4
4
画像処理5
4.1
画像処理の手順. . . . 6 4.2
解候補個体を得る戦略. . . . 6
5
実験結果6
6
考察7
7
結論と今後の課題7
謝辞
8
参考文献
9
付録
A
付録10
.1 DifferentialEvolution
クラス. . . . 10
.1 LocalDifferentialEvolution
クラス. . . . 22
.1 MonochromePicture
クラス. . . . 28
1
序論1.1
本研究の背景近年
,
市販のデスクトップPC
やノートPC
にもマルチコア・プロセッサが用いられている.
しかし,
複数 のコアによって並列処理を実行するためには,
マルチコアCPU
に対応した並列プログラムを作成する必要がある
.[3].
並列プログラムは複数のスレッドと呼ばれる処理単位から構成され,
異なるコアに割り当てられたスレッドは同時に実行される
.
既存の逐次処理のプログラムを機械的に並列プログラムに変換するコンパイラも 開発されているが,
より効率的な並列プログラムを作成するには,
アルゴリズムの段階から処理の並列化を図る 必要がある.
並列プログラムによる高速化が求められる分野には様々あるが
,
その中の一つに最適化問題がある.
今日,
様々な種類の最適化問題に対してその問題の性質に応じた解放が考案されている.
最適化問題に対する手法には
,
オペレーションズ・リサーチや数理的計画法の他に,
人工知能,
エキスパー ト・システム,
システム理論,
ファジィ集合,
ニュートラルネットワーク等,
様々なアルゴリズムが存在してい る.
一般に,
ある最適化問題を解くにはその問題の背景に十分注意を払って,
制約条件や目的関数の評価基準を 定め,
数式もしくはグラフ等のモデルによって最適化問題を単純化する.
そして、単純化された問題に対して あアルゴリズムを適用し,
主にコンピュータ上でシミュレーションを行うことによって最適化問題の解を得る ことができる.
しかしながら,制約条件が多い場合には問題の定式化が困難となる.そこで,これらの問題を解決する手法 として,生物進化をヒントに得た探索手法である進化計算を用いることが近年注目されている.遺伝的アルゴ
リズム
(GA : Genetic Algorithm)
に代表される進化計算の大きな特徴は,解空間が非常に大きく,従来の手法では高速計算機を用いても数十年かかるような問題や
,
問題の構造が分からず数学的に定式化できないため 解けないような問題に対しても,近似解を比較的高速に得られるという点がある.差分進化
(DE : Differential Evolution)
とは,
決定変数が実数値を取る単目的の関数最適化問題を対象としたとした進化計算の一種である
[4]
.DE
は微分不可能な多峰性関数の最適化問題にも有効に適用することが でき,多くのベンチマーク問題や現実的な最適化問題において,
優秀な最適化アルゴリズムの1
つであること が示されている.また,DE
はアルゴリズムが単純であるため実装が容易である.すなわち,DE
の最大の利点 は,
強力かつシンプルであるため,
使い勝手が良いことである.1.2
本研究の目的前節で述べたように,ように進化計算,取り分け差分進化計算は有用性が極めて高いため,並列化により高 速化することは重要である.しかし,従来の従来の進化計算の並列化手法は
,
そのプログラムを実行するハー ドウェアに大きく依存する.そこで本研究では,ハードウェアへの依存性が低い並列化手法を検討する.本稿では画像の類似性を視覚的に認識することで
,
最適化問題におけるDE
の有効性を検証する.
また,
候補 個体を得る戦略をいくつか用意した上で,
どの戦略が最も優良であるかを検証するのも本研究の目的である.
1.3
本報告書の構成以下に各章の簡単な構成を示す
.
まず第
2
章では,本研究が対象とする最適化問題について説明し,続く第3
章では,進化計算について説明 する.第4
章では本研究で対象とする画像処理について述べる.第5
章で実験結果を示し,第6
章で考察を 行う.最後に第7
章で結論および今後の課題を示す.2
最適化問題最適化問題は
,
自然科学,
工学,
社会科学など様々な分野で発生する基本的な問題の1
つである.
近年では,
最 適化問題の大規模化と複雑化に伴い厳密な最適解を求めるのが難しくなっている.
必要十分な最適性を持つ近 似解を実時間内に求める必要があり,GA
やDE
などメタヒューリスティックな最適化手法への関心が高まっ ている.[5]
本研究では,
最適化手法であるDE
とPDE
を用いる.
そのため,
本章では,
最適化問題の概要につ いて記述する.
2.1
最適化問題概要最適化とは複数の選択肢から最善のものを選ぶことであり
,
最適化問題を数学的に表現すると,
与えられた 制約条件を全て満たし,
目的関数f(x)
の値が最小または最大になるような決定変数x
の値を見つける問題であ る.
この場合x
は最適解と呼ばれ,
最適解は1
つしか存在しない場合もあるが,
反対に無限個存在する場合もあ る.
一般的に最適化問題は式(1)(2)
に記述する.
目的関数
f(x)
→最小値(
最大値) (1)
制約条件
x ∈ F (2)
このとき
F
は実行可能集合あるいは実行可能領域と呼ばれており,
制約条件を満たす実行可能解(
数理計画 問題において,
実行可能領域上の点.
最適解とは限らない)
の集合である.
2.1.1
最適解と局所的最適解式
(3)
の条件を満たす実行可能解x
n∈ F
を最適解と呼ぶf (x
n) ≤ f (x),
x ∈ F (3)
また実行可能
x
n∈ F
を含む適当な集合U(x
n)
に対しては,
f (x
n) ≤ f (x),
x ∈ F ∩ U (x
n) (4)
が成り立つとき、
x
nを局所的最適解という.
図??
は最適解と局所的最適解を表している. U(x
n)
は一般的 には近傍と呼ばれ,x
に少し変形を加えることによって得られる解集合のことである.
なお,U(x
n) ∈ F
とは限 らない.
最適化問題も目的関数や制約条件が複雑になり,
実行可能集合が膨大になる場合には最適解をみつけ ることは一般的に困難である.
そのような場合には,
問題の大きさや問題を解くために与えられている時間等 を考慮して,
適切な近傍を定義して局所的最適解を求める.
3
進化計算3.1
差分進化計算(DE)
DE
はK.price, R.Storn
らによって提案された,
確率的な探索法であり,
解集団を用いた多点探索をおこなう
. DE
の重要な特徴としては,
単純な数学的演算を用いることが挙げられる.
このため,
制御パラメタの数 が少なく,
設定が容易であり問題への実装も比較的容易におこなえる. DE
において新たな解候補個体を得る 戦略は,
基底個体の選び方および交叉の種類の組み合わせで定義され, [DE/best/1/bin]
や[DE/rand/1/exp]
などが代表される
[2].
基底個体としては,
最適な関数値を持つ個体を選ぶ最適基底(best)
と,
ランダムに選 ぶランダム基底(rand)
の2
通りが主に選択される.
また,
代表的な交叉としては,
二項交叉(bin)
と指数交叉(exp)
の2
通りが使用される.
3.1.1 DE
の基本アルゴリズム標準的な
DE
の処理手順を以下に示す.
Step1 : N
P 個の個体を,
各次元の定義域においてランダムに生成して世代g=1
とする.
また,
最終世代,
収束 の条件に設定する.
Step2 :
各個体の関数値を計算する.
Step3 :
各個体x
i(i = 1,2,...N
P)
に対して以下の処理を行う.Steo3.1 :
最適個体またはランダム個体として個体x
j(j 6 = i)
を選択する.Step3.2 : x
jから差分変異親個体v
iを生成する.Step3.3 :
後述する交叉法により、対象親個体x
iと差分変異親個体v
iから子個体u
iを生成する.Step3.4 :
対象親個体x
iと子個体u
iの関数値を比較し,良い方を次世代のx
iとして残す. Step6 :
終了条件を満たしていなければ,g=g+1
としてStep3
に戻る.
3.1.2
交叉本節では、交叉について述べる.交叉とは、
2
つの親個体から新たな子個体を生成する手続である.DE
では、まず対象親個体x
i(1 ≤ i ≤ N
P)
に対して個体x
j(j 6 = i)
を選択する.x
jは、戦略best
では最も 優れた個体,戦略rand
ではランダムに選んだ個体である.次に個体x
jから差分変異親個体v
iを生成する.v
iは以下の式で与えられる.ただし,x
k, x
lはランダムに選択した個体,S
F は差分定数である.v
i:= x
j+ S
F(x
k− x, l)
本研究では簡単のために差分定数
S
F= 0
としている.すなわち,v
i= x
j である.交叉により差分変異個体
v
iと対象親個体x
iから子個体u
iを生成する.二項交叉および指数交叉による生 成は以下の手続き(5)
および(6)
で計算される.ただし,v
j,d, x
i,d, u
i,d(1 ≤ m ≤ D)
はそれぞれv
i, x
i, u
iのd
番目の要素, d
rは1 ≤ d
r≤ D
のランダムな整数であり,rand[0,1]
は範囲[0,1]
の一様乱数である.二項交叉
for(d := 1; j ≤ D; ++ d) { if (rand [0, 1] < C
R∨ d = d
r)
u
i,d:= v
i,d; else u
i,d:= x
i,d; }
(5)
指数交叉
d := d
r; do {
u
i,d:= v
i; d := (d + 1)%D;
} while (rand [0, 1] < C
R∧ d 6 = d
r) while (d 6 = d
r) {
u
i,d:= x
i,d; d := (d + 1)%D;
}
(6)
3.2
並列差分進化計算(PDE)
並列差分進化計算
(PDE)
はDE
のプロセッサネットワーク上での並列化である. PDE
では,各プロセッサ がDE
を並列に実行し,数世代に1
回の割合で最も優れた個体を隣のプロセッサに送信する.また,
移民頻度 と最適解への収束速度および最適解発見率は相関関係があり,
移民頻度を高くすると収束速度は速くなるが,
最適解発見率は低下する.[1]
3.2.1
ネットワークPDE
で用いたネットワーク構造について記述する. (1)
リング型複数のコンピュータあるいは接続機器を
1
本の環状のケーブルに接続するLAN
方式のことである. (2)
トーラス型階層構造をもったネットワークである
.
入力層,
中間層,
出力層の3
つに分かれており,
入力層から入っ た情報は中間層,
出力層を通って出力される.
(3)
ハイパーキューブ型ハイパーキューブは
,n-
キューブ、あるいは超立方体とも呼ばれ,
汎用の(
超)
並列計算の結合方法とし て注目されており,
実際にいくつかの並列システムに採用されている.
ハイパーキューブはトーラス等 のトポロジに比べて,
プロセッサ数に対する直径を小さくできる.
図
1,2,3
にそれぞれリング型,トーラス型,ハイパーキューブ型のネットワークの概念図を示す.図
1
リング型 図2
トーラス型図
3
ハイパーキューブ型3.2.2 PDE
の戦略本研究では
,
基底個体の選び方(mix
は混在,rand
はランダム,best
は最適値)
および交叉の種類(mix
は混 在,bin
は二項交叉,exp
は指数交叉)
の組み合わせた, 5
つの戦略で実験をおこなう.
本章では,
その5
つの戦略 を記述する.
• 1
つ目の戦略: [best/exp]
• 2
つ目の戦略: [rand/exp]
• 3
つ目の戦略: [best/bin]
• 4
つ目の戦略: [rand/bin]
• 5
つ目の戦略: [mix/mix]
3.2.3 PDE
の基本アルゴリズムPDE
は,
局所メモリを持つP
台のプロセッサP
p(0 ≤ p < P )
が,
リング状に接続されたプロセッサネッ トワークを仮定する. PDE
では,
プロセッサP
p(0 ≤ p < P )
がそれぞれ集団x
pi(0 ≤ i < N )
を保持する. PDE
は以下の2
つの操作を繰り返す.
ここでG
Lは移民頻度を表すパラメタである.
(1)
局所DE
操作 各プロセッサ(0 ≤ p < P )
は保持する集団x
pi(0 ≤ i < N)
に対してDE
をG
L世代計算 する.
(2)
移民操作 各プロセッサ(0 ≤ p < P )
は保持する集団の中で最良の個体x
pbest)
を右隣のプロセッサP
(p+1)modP に送信し,
左隣のプロセッサP
(p−1)modP から受信した個体x
(best(p − 1)modP )
を保持する 集団x
(ip) (0 ≤ i < N )
の中の任意の個体と入れ替える.
4
画像処理本研究では
PDE
を用いて画像処理を行う。本研究で対象とする画像処理は,ぼやけた画像が与えられたと きに、その元となる鮮明な画像を得るノイズ除去処理である.解となる画像については,以下の制限を設ける.
1.
元画像は16
×16
の2
値画像(1
または0)
とし,ぼやけた画像は,16
×16
の実数値画像(0
〜1)
とする.
2.
処理中,解画像,およびそのぼやけた画像は,直接参照することはできず,ある画像がぼやけた画像に どの程度近いかを表す評価値のみを参照できる.2.
の制約のため,プログラムは直接画像を参照できず,候補画像を生成する際に,解画像およびそのぼやけ た画像から新たな画像を生成することができない.この制約は,例えばモンタージュ画像を作るときのような 状況を想定している.解となる画像は目撃者の頭の中しか無いため,モンタージュ画像作成者は元画像を見る ことができない.よってモンタージュ画像作成者は,適当な絵を目撃者に見せて,それが解画像とどの程度近 いかの評価してもらい,その評価値を元に新たな画像を作成することを繰り替えずことで解画像に近づけて ゆく.4.1
画像処理の手順本研究で作成した画像処理の手順を以下に述べる
. DE
の部分については以下の手順で行う.
手順1
候補画像を20
個ほど生成する.
候補画像は白黒でランダムに生成する.
手順
2
候補画像同士を交叉させて新たな画像生成する.
手順
3
手順2
の画像が親画像よりも解画像に近ければ親画像と入れ替える.
手順4
手順2
の画像が充分解画像に近ければ終了,
それ以外は手順2
に戻る.
PDE
の部分については以下の手順で行う.
手順1
候補画像を生成する.
手順
2
以下の処理をG
S 世代行う手順
2.1
各プロセッサP
p(1 ≤ p ≤ P r)
で,DE
をG
L世代行う手順
2.2
各プロセッサP
p(1 ≤ p ≤ P r)
は最も良い候補画像を隣接プロセッサP
q(q = p + 1 mod P r)
に送 信する.手順
2.3
各プロセッサP
p(1 ≤ p ≤ P r)
は2.2
で受信した画像を,保持する画像の一つと置き換える.手順
3.4
保持する画像のうち最も優れた画像が充分解画像に近ければ終了,
それ以外は手順2
に戻る.
4.2
解候補個体を得る戦略本研究では,
3.2.2
節で述べた5
つの戦略で実験をおこなう.また,本研究では,
リング型のネットワーク構 造を用いて実験をおこなう.
5
実験結果本研究では,
5
つの戦略に対して,
移民頻度8
で各100
回のPDE
を行った.表1
にその実行結果を示す.また,付録に本研究で用いた画像処理の
PDE
プログラムのソースを示す.また
,5
つの戦略の中で,
最も発見率の高かった戦略[rand/exp]
で移民頻度を変えながら各100
回のPDE
を 行った.
表2
にその実行結果を示す表
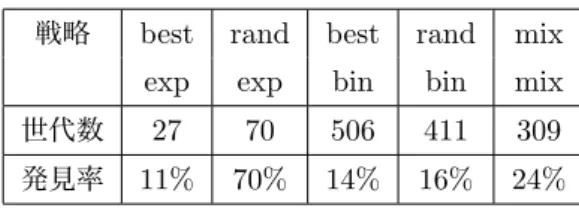
1
各戦略の解発見平均世代数と解発見率 戦略best rand best rand mix
exp exp bin bin mix
世代数
27 70 506 411 309
発見率11% 70% 14% 16% 24%
表
2
各移民頻度での解発見平均世代数と解発見率 頻度1 2 4 8 16
世代数37 49 59 68 104
発見率21% 41% 54% 76% 69%
6
考察実験結果より
,
今回用意した5
つの戦略の中では,[rand/exp]
が最も優良であることが分かった.
これ は,PDE
を用いた画像処理は,
多峰性で変数間に依存関係がある問題といえ,
集団の多様性を確保するための処 理として,
「rand
」が有用であったと思われる.
逆に
,best
では探索空間での位置によらず集団の中から淘汰する個体を選択するので,
全体としての収束性は向上するが
,
今回の処理においては,
集団を局所解に陥らせたといえる.
7
結論と今後の課題本研究では
PDE
を用いて,
画像処理をおこなった.
本研究において,
個体の選び方がランダム,
交叉の長さ の決定方法が指数的な二点交叉である[rand/exp]
が最適化問題に対し,
高確率で解を求めることが分かった.
しかし,
予想していたよりも,best
やmix
を用いた戦略の解発見率が低かったので,
局所解に陥ってしまった場 合,
また,
大域世代から探索をやり直す等の改善があるように思われた.
謝辞
本論文を結ぶにあたり
,
多忙にも関わらず親切な御指導,
御助言を賜りました石水隆講師に厚く御礼を申し上 げます.
参考文献
[1]
石水隆,
田川聖治:
並列差分進化計算の比較研究,
情報処理学会研究報告, Vol.2011-MPS-82 No.23 pp.
1-2 (2011)
[2] Storn, R. and Price, K. : Differential evolution - a simple and efficient heuristic for global optimization over continuous space, Journal of Global Optimization, Vol. 11, no. 4, pp. 341–359 (1997).
[3] Breshears, C.: The Art of Concurrency - A Thread Monkey s Guide to Writing Parallel Applications, O REILLY (2009)
[4] Storn, R. and Price, K.: Differential evolution - a simple and efficient heuristic for global optimization over continuous space, Journal of Global Optimization, Vol. 11, No. 4, pp. 341
―359 (1997)
[5]
伊藤 稔,
田中雅博Particle Swarm Optimization
の解探索性能に関する基礎的検討 第32
回知能システム シンポジウム資料(2005)
[6]
三宮信夫,喜多一,玉置久,岩本貴司,遺伝アルゴリズムと最適化,システム制御情報ライブラリー,浅 草書店,(1998)
[7]
平野廣美,遺伝的アルゴリズムと遺伝的プログラミング,パーソナルメディア,(2000) [8]
米沢保雄,遺伝的アルゴリズム 進化理論の情報学,森北出版,(1993)
[9] T.Ishimizu and K.Tagawa, Experiment Study of A Structured Differential Evolution with Mixed Strategies, Proc. the World Congress on Nature and Biologically Inspired Computing (NaBIC) , pp.598-603, (2010)
[10] Price,K.V.,Storn,R.M.andLampinen,J.A.:DifferentialEvolution
―APractical Approach to Global
Optimization, Springer (2005).
付録
A
付録本研究で用いた画像処理の
PDE
のプログラムのソースを示す.
プログラムは3
つのクラスからなる.
.1 DifferentialEvolution
クラスp a c k a g e de ; i m p o r t j a v a . io .*;
/**
* 与えられたぼやけた値画像の元画像を進化計算により得る2
*/
p u b l i c c l a s s D i f f e r e n t i a l E v o l u t i o n {
s t a t i c f i n a l int D = 32; // 問題の次元( d i m e n s i o n of p r o b l e m ) s t a t i c f i n a l int NP = 32; // 母集団の大きさ( s i z e of p o p u l a t i o n ) s t a t i c f i n a l d o u b l e F = 0 . 5 ; // 差分定数( d i f f e r e n t i a l c o n s t a n t ) s t a t i c f i n a l d o u b l e CR = 0 . 9 ; // 交叉定数( c r o s s o v e r c o n s t a n t ) s t a t i c f i n a l d o u b l e MT = 0 . 1 ; // 突然変異定数( m u t a t i o n c o n s t a n t ) s t a t i c int L G E N = 8; // 局所世代数( n u m b e r of l o c a l g e n e r a t i o n s ) s t a t i c int S G E N = 1 0 2 4 / L G E N ; // スーパー世代数( n u m b e r of s u p e r g e n e r a t i o n ) s t a t i c M o n o c h r o m e P i c t u r e t a r g e t ; // 目標画像
s t a t i c M o n o c h r o m e P i c t u r e t a r g e t s []; // 目標画像の行列 s t a t i c f i n a l int p i c t u r e S i z e = 16; // 画像のサイズ
s t a t i c f i n a l int CT = -1; // 交叉のタイプ /**
* -1: mix 混在
* 1: bin 二項交叉
* oh : exp 指数交叉
*/
s t a t i c f i n a l int IST = -1; // インデックス選択のタイプ
/**
* -1: mix 混在
* 1: r a n d ランダム
* oh : b e s t 最適値
*/
s t a t i c f i n a l int NWT = 1; // ネットワークのタイプ
/**
* 1: r i n g n e t w o r k
* 2: t o r u s n e t w o r k
* 3: h y p e r c u b e n e t w o r k
* 4: h i e r a r c h i c a l n e t w o r k
* oh : no n e t w o r k
*/
s t a t i c f i n a l int NTH = 4; // 局所計算スレッド数
s t a t i c f i n a l int R O O P N = 8; // ループ回数 s t a t i c f i n a l int GV = 1;
s t a t i c f i n a l d o u b l e E P S I L O N = 0 . 1 ; // 適応値がこれより小さくなると解とみなす
s t a t i c L o c a l D i f f e r e n t i a l E v o l u t i o n de []; // 進化計算スレッドの実装クラスのインスタンス
s t a t i c T h r e a d th []; // 進化計算スレッドのスレッドのインスタンス
s t a t i c F i l e W r i t e r pass , r P a s s ; s t a t i c P r i n t W r i t e r fp , rfp ;
s t a t i c d o u b l e f i t n e s s R e c o r d [ ] [ ] ; // 適応値記録用
s t a t i c M o n o c h r o m e P i c t u r e o p t i m u m R e c o r d []; // 最適値記録用 s t a t i c int r o o p I n d e x = 0;
s t a t i c b o o l e a n i s F i n d O p t i m u m ; // 最適解発見?
s t a t i c int f i n d O p t i m u m []; // 最適解発見時 s t a t i c int sgen , l g e n ;
p u b l i c s t a t i c v o i d m a i n ( S t r i n g [] a r g s ) {
de = new L o c a l D i f f e r e n t i a l E v o l u t i o n [ NTH ];
th = new T h r e a d [ NTH ];
// for ( L G E N =1; LGEN < 1 0 2 4 ; L G E N * = 2 ) { // S G E N = 2 0 4 8 / L G E N ;
l g e n = L G E N ; s g e n = S G E N ; if ( L G E N > GV ) {
l g e n = GV ;
s g e n = S G E N * ( L G E N / GV );
}
f i t n e s s R e c o r d = new d o u b l e [ R O O P N ][ s g e n ];
o p t i m u m R e c o r d = new M o n o c h r o m e P i c t u r e [ R O O P N ];
t a r g e t s = new M o n o c h r o m e P i c t u r e [ R O O P N ];
r o o p I n d e x = 0;
f i n d O p t i m u m = new int [ R O O P N ];
S t r i n g f n a m e = r e c o r d F i l e N a m e ();
try {
// p a s s = new F i l e W r i t e r (" f i t n e s s . txt ");
// fp = new P r i n t W r i t e r ( p a s s );
r P a s s = new F i l e W r i t e r ( f n a m e );
rfp = new P r i n t W r i t e r ( r P a s s );
} c a t c h ( I O E x c e p t i o n e ) { S y s t e m . err . p r i n t l n ( e );
}
for ( r o o p I n d e x = 0; r o o p I n d e x < R O O P N ; ++ r o o p I n d e x ) {
t a r g e t s [ r o o p I n d e x ] = t a r g e t = new M o n o c h r o m e P i c t u r e ( p i c t u r e S i z e );
for ( int i =0; i < NTH ; ++ i ) {
de [ i ] = new L o c a l D i f f e r e n t i a l E v o l u t i o n ( NP , F , CR , MT , lgen , CT , IST , target , i );
}
i s F i n d O p t i m u m = f a l s e ;
f i n d O p t i m u m [ r o o p I n d e x ] = S G E N * L G E N ; // S G E N * L G E N ;
s w i t c h ( NWT ) {
c a s e 1: // リング型ネットワーク
r i n g N e t w o r k ();
b r e a k ;
c a s e 2: // トーラス型ネットワーク
t o r u s N e t w o r k ();
b r e a k ;
c a s e 3: // ハイパーキューブ型ネットワーク
h y p e r c u b e N e t w o r k ();
b r e a k ;
c a s e 4: // 階層型ネットワーク
h i e r a r c h i c a l N e t w o r k ();
b r e a k ;
d e f a u l t : // ネットワーク無し n o N e t w o r k ();
b r e a k ; }
S y s t e m . out . p r i n t l n ( r o o p I n d e x + ": f i n d at " + f i n d O p t i m u m [ r o o p I n d e x ] + ": ");
p r i n t O p t i m u m ();
}
// fp . c l o s e ();
o u t p u t F i t n e s s R e c o r d ();
rfp . c l o s e ();
//}
}
/**
* 局所進化計算
* @ p a r a m sg スーパー世代数
*/
s t a t i c v o i d l o c a l D i f f e r e n t i a l E v o l u t i o n ( int sg ) { for ( int i =0; i < NTH ; ++ i ) {
th [ i ] = new T h r e a d ( de [ i ]);
}
for ( int i =0; i < NTH ; ++ i ) { th [ i ]. s t a r t ();
} try {
for ( int i =0; i < NTH ; ++ i ) { th [ i ]. j o i n ();
}
} c a t c h ( I n t e r r u p t e d E x c e p t i o n e ) { S y s t e m . err . p r i n t l n ( e );
}
// for ( int i =0; i < lg ; ++ i ) { // de [ i ]. p r i n t O p t i m u m ();
//}
// p r i n t F i t n e s s ( sg );
// o u t p u t F i t n e s s ( sg );
}
/**
* 最適解を得る
* @ r e t u r n M o n o c h r o m e P i c t u r e [] : 各プロセッサの最適解画像
*/
s t a t i c M o n o c h r o m e P i c t u r e [] g e t O p t i m u m () {
M o n o c h r o m e P i c t u r e opt [] = new M o n o c h r o m e P i c t u r e [ NTH ];
for ( int i =0; i < NTH ; ++ i ) {
opt [ i ] = de [ i ]. g e t O p t i m u m ();
}
r e t u r n opt ; }
/**
* 適応値を得る
* @ r e t u r n d o u b l e [] : 各プロセッサの適応値
*/
s t a t i c d o u b l e [] g e t F i t n e s s () {
d o u b l e fit [] = new d o u b l e [ NTH ];
for ( int i =0; i < NTH ; ++ i ) {
fit [ i ] = de [ i ]. g e t F i t n e s s ();
}
r e t u r n fit ; }
s t a t i c v o i d r i n g N e t w o r k () {
M o n o c h r o m e P i c t u r e opt [] = new M o n o c h r o m e P i c t u r e [ NTH ];
d o u b l e fit [] = new d o u b l e [ NTH ];
S y s t e m . out . p r i n t l n (" R i n g n e t w o r k ");
// fp . p r i n t l n (" R i n g n e t w o r k ");
// fp . p r i n t ("\ t ");
// for ( int i =0; i < NTH ; ++ i ) // fp . p r i n t ( i + "\ t ");
// fp . p r i n t l n ();
for ( int g =0; g < s g e n ; ++ g ) {
if (! i s F i n d O p t i m u m ) { // 最適値を発見するまで局所を計算するDE l o c a l D i f f e r e n t i a l E v o l u t i o n ( g );
opt = g e t O p t i m u m ();
fit = g e t F i t n e s s ();
int gv = 1;
if ( L G E N > GV ) gv = L G E N / GV ; if (( g % gv ) == ( gv - 1 ) ) {
for ( int i =0; i < NTH ; ++ i ) {
de [( i +1) % NTH ]. r e p l a c e D a t a ( opt [ i ] , fit [ i ]);
// S y s t e m . out . p r i n t ( i + " - >" + (( i +1) % NTH ) + " ");
} }
}
// S y s t e m . out . p r i n t l n ();
r e c o r d F i t n e s s ( g );
} }
s t a t i c v o i d t o r u s N e t w o r k () {
M o n o c h r o m e P i c t u r e opt [] = new M o n o c h r o m e P i c t u r e [ NTH ];
d o u b l e fit [] = new d o u b l e [ NTH ];
int w i d t h =1 , h i g h t =1;
w h i l e ( w i d t h * h i g h t < NTH ) { w i d t h *= 2;
if ( w i d t h * h i g h t == NTH ) b r e a k ; h i g h t *= 2;
}
S y s t e m . out . p r i n t l n (" T o r u s n e t w o r k ");
// fp . p r i n t l n (" T o r u s n e t w o r k ");
// fp . p r i n t ("\ t ");
// for ( int i =0; i < NTH ; ++ i ) // fp . p r i n t ( i + "\ t ");
// fp . p r i n t l n ();
for ( int g =0; g < s g e n ; ++ g ) {
if (! i s F i n d O p t i m u m ) { // 最適値を発見するまで局所を計算するDE l o c a l D i f f e r e n t i a l E v o l u t i o n ( g );
opt = g e t O p t i m u m ();
fit = g e t F i t n e s s ();
int gv = 1;
if ( L G E N > GV ) gv = L G E N / GV ; if (( g % gv ) == ( gv - 1 ) ) {
if (( g + 1 ) % ( 2 * gv ) == 0) { // 横方向のスレッドと通信 // S y s t e m . out . p r i n t l n ( g + " -");
for ( int h =0; h < h i g h t ; ++ h ) {
for ( int w =0; w < w i d t h ; ++ w ) {
de [ h * w i d t h + ( w + 1 ) % w i d t h ]. r e p l a c e D a t a ( opt [ h * w i d t h + w ] , fit [ h * w i d t h + w ]);
// S y s t e m . out . p r i n t (( h * w i d t h + w ) + " - >" + ( h * w i d t h + ( w + 1 ) % w i d t h ) + " ");
} }
} e l s e { // 縦方向のスレッドと通信
// S y s t e m . out . p r i n t l n ( g + " | " ) ; for ( int h =0; h < h i g h t ; ++ h ) {
for ( int w =0; w < w i d t h ; ++ w ) {
de [(( h + 1 ) % h i g h t )* w i d t h + w ]. r e p l a c e D a t a ( opt [ h * w i d t h + w ] , fit [ h * w i d t h + w ]);
// S y s t e m . out . p r i n t (( h * w i d t h + w ) + " - >" + ((( h + 1 ) % h i g h t )* w i d t h + w ) + " ");
} }
}
// S y s t e m . out . p r i n t l n ();
} }
r e c o r d F i t n e s s ( g );
} }
s t a t i c v o i d h y p e r c u b e N e t w o r k () {
M o n o c h r o m e P i c t u r e opt [] = new M o n o c h r o m e P i c t u r e [ NTH ];
d o u b l e fit [] = new d o u b l e [ NTH ];
int n e i g h b o r = 1 , p a i r = 2;
S y s t e m . out . p r i n t l n (" H y p e r c u b e n e t w o r k ");
// fp . p r i n t l n (" H y p e r c u b e n e t w o r k ");
// fp . p r i n t ("\ t ");
// for ( int i =0; i < NTH ; ++ i ) // fp . p r i n t ( i + "\ t ");
// fp . p r i n t l n ();
for ( int g =0; g < s g e n ; ++ g ) {
if (! i s F i n d O p t i m u m ) { // 最適値を発見するまで局所を計算するDE l o c a l D i f f e r e n t i a l E v o l u t i o n ( g );
opt = g e t O p t i m u m ();
fit = g e t F i t n e s s ();
int gv = 1;
if ( L G E N > GV ) gv = L G E N / GV ; if (( g % gv ) == ( gv - 1 ) ) {
for ( int i =0; i < NTH ; ++ i ) {
if (( i % p a i r ) < n e i g h b o r ) {
de [( i + n e i g h b o r ) % NTH ]. r e p l a c e D a t a ( opt [ i ] , fit [ i ]);
// S y s t e m . out . p r i n t ( i +" - >"+(( i + n e i g h b o r ) % NTH )+" ");
} e l s e {
de [( i - n e i g h b o r ) % NTH ]. r e p l a c e D a t a ( opt [ i ] , fit [ i ]);
// S y s t e m . out . p r i n t ( i +" - >"+(( i - n e i g h b o r ) % NTH )+" ");
} }
// S y s t e m . out . p r i n t l n ();
n e i g h b o r *= 2;
p a i r * = 2 ;
if ( n e i g h b o r >= NTH ) { n e i g h b o r = 1;
p a i r = 2;
} }
}
r e c o r d F i t n e s s ( g );
} }
s t a t i c v o i d h i e r a r c h i c a l N e t w o r k () {
M o n o c h r o m e P i c t u r e opt [] = new M o n o c h r o m e P i c t u r e [ NTH ];
d o u b l e fit [] = new d o u b l e [ NTH ];
int n e i g h b o r = 1 , p a i r = 2;
S y s t e m . out . p r i n t l n (" H i e r a r c h i c a l n e t w o r k ");
// fp . p r i n t l n (" H i e r a r c h i c a l n e t w o r k ");
// fp . p r i n t ("\ t ");
// for ( int i =0; i < NTH ; ++ i ) // fp . p r i n t ( i + "\ t ");
// fp . p r i n t l n ();
for ( int g =0; g < s g e n ; ++ g ) {
if (! i s F i n d O p t i m u m ) { // 最適値を発見するまで局所を計算するDE l o c a l D i f f e r e n t i a l E v o l u t i o n ( g );
opt = g e t O p t i m u m ();
fit = g e t F i t n e s s ();
int gv = 1;
if ( L G E N > GV ) gv = L G E N / GV ; if (( g % gv ) == ( gv - 1 ) ) {
n e i g h b o r = 1;
p a i r = 2;
w h i l e ( ( ( ( g + 1 ) / gv ) % p a i r ) == 0) { n e i g h b o r *= 2;
p a i r *= 2;
}
w h i l e ( p a i r > NTH ) {
n e i g h b o r = n e i g h b o r * 2/ NTH ; p a i r = p a i r * 2 / NTH ;
}
for ( int i =0; i < NTH ; ++ i ) {
if (( i % p a i r ) < n e i g h b o r ) {
de [( i + n e i g h b o r ) % NTH ]. r e p l a c e D a t a ( opt [ i ] , fit [ i ]);
// S y s t e m . out . p r i n t ( i +" - >"+(( i + n e i g h b o r ) % NTH )+" ");
} e l s e {
de [( i - n e i g h b o r ) % NTH ]. r e p l a c e D a t a ( opt [ i ] , fit [ i ]);
// S y s t e m . out . p r i n t ( i +" - >"+(( i - n e i g h b o r ) % NTH )+" ");
} }
// S y s t e m . out . p r i n t l n ();
} }
r e c o r d F i t n e s s ( g );
} }
/**
* ネットワーク無し
* 局所計算スレッド間の通信を一切しない
*/
s t a t i c v o i d n o N e t w o r k () {
S y s t e m . out . p r i n t l n (" No n e t w o r k ");
// fp . p r i n t l n (" No n e t w o r k ");
// fp . p r i n t ("\ t ");
// for ( int i =0; i < NTH ; ++ i ) // fp . p r i n t ( i + "\ t ");
// fp . p r i n t l n ();
for ( int g =0; g < s g e n ; ++ g ) {
if (! i s F i n d O p t i m u m ) { // 最適値を発見するまで局所を計算するDE l o c a l D i f f e r e n t i a l E v o l u t i o n ( g );
}
r e c o r d F i t n e s s ( g );
} }
/**
* 適合性表示
*/
s t a t i c v o i d p r i n t F i t n e s s () {
S y s t e m . out . p r i n t (" f i t n e s s : ");
for ( int i =0; i < NTH ; ++ i ) {
S y s t e m . out . p r i n t f ( " % 4 . 2 f " , de [ i ]. g e t F i t n e s s ( ) ) ; }
S y s t e m . out . p r i n t l n ();
}
/**
* 適合性表示
* スーパー世代ごとの適合性を表示する
* @ p a r a m sg スーパー世代数
*/
s t a t i c v o i d p r i n t F i t n e s s ( int sg ) {
S y s t e m . out . p r i n t f (" f i t n e s s : %2 d " , sg );
for ( int i =0; i < NTH ; ++ i ) {
S y s t e m . out . p r i n t f ( " % 4 . 2 f " , de [ i ]. g e t F i t n e s s ( ) ) ; }
S y s t e m . out . p r i n t l n ();
}
s t a t i c v o i d p r i n t O p t i m u m () { int i B e s t = 0;
d o u b l e f B e s t = de [ 0 ] . g e t F i t n e s s ();
for ( int i =1; i < NTH ; ++ i ) {
d o u b l e f = de [ i ]. g e t F i t n e s s ();
if ( f < f B e s t ) { i B e s t = i ; f B e s t = f ; }
}
S y s t e m . out . p r i n t l n (" T a r g e t ");
t a r g e t . s h o w P i c t u r e ();
S y s t e m . out . p r i n t l n (" O p t i m u m ");
de [ i B e s t ]. p r i n t O p t i m u m ();
// de [ i B e s t ]. o u t p u t O p t i m u m ( fp );
}
/**
* 適合性出力
* 適合性をファイルに出力する
*/
s t a t i c v o i d o u t p u t F i t n e s s () { fp . p r i n t (" f i t n e s s : ");
for ( int i =0; i < NTH ; ++ i ) {
fp . p r i n t f ( " % 4 . 2 f \ t " , de [ i ]. g e t F i t n e s s ( ) ) ; }
fp . p r i n t l n ();
}
/**
* 適合性出力
* スーパー世代ごとの適合性をファイルに出力する
* @ p a r a m g スーパー世代数
*/
s t a t i c v o i d o u t p u t F i t n e s s ( int sg ) { fp . p r i n t f (" f i t n e s s \ t %2 d \ t " , sg );
for ( int i =0; i < NTH ; ++ i ) {
fp . p r i n t f ( " % 4 . 2 f \ t " , de [ i ]. g e t F i t n e s s ( ) ) ; }
fp . p r i n t l n ();
}
/**
* 全てのの中で最も高い適合性を返すLDE
* @ r e t u r n d o u b l e : 適合性最高値
*/
s t a t i c d o u b l e g e t B e s t F i t n e s s () {
d o u b l e f B e s t = de [ 0 ] . g e t F i t n e s s ();
for ( int i =1; i < NTH ; ++ i ) {
d o u b l e f = de [ i ]. g e t F i t n e s s ();
if ( f < f B e s t ) f B e s t = f ; }
r e t u r n f B e s t ; }
/**
* 全てのの中で最も高い適合性をもつ画像返すLDE
* @ r e t u r n M o n o c h r o m e P i c t u r e : 適合性最高値の画像
*/
s t a t i c M o n o c h r o m e P i c t u r e g e t B e s t O p t i m u m (){
d o u b l e f B e s t = de [ 0 ] . g e t F i t n e s s ();
M o n o c h r o m e P i c t u r e o B e s t = de [ 0 ] . g e t O p t i m u m ();
for ( int i =1; i < NTH ; ++ i ) {
d o u b l e f = de [ i ]. g e t F i t n e s s ();
if ( f < f B e s t ) { f B e s t = f ;
o B e s t = de [ i ]. g e t O p t i m u m ();
} }
r e t u r n o B e s t ; }
/**
* F i t n e s s および O p t i m u m の記録
* @ p a r a m g スーパー世代数
*/
s t a t i c v o i d r e c o r d F i t n e s s ( int g ) {
d o u b l e b e s t F i t n e s s = g e t B e s t F i t n e s s ();
f i t n e s s R e c o r d [ r o o p I n d e x ][ g ] = b e s t F i t n e s s ; if (! i s F i n d O p t i m u m && b e s t F i t n e s s < E P S I L O N ) {
i s F i n d O p t i m u m = t r u e ;
f i n d O p t i m u m [ r o o p I n d e x ] = g * l g e n ; // g * L G E N ; }
o p t i m u m R e c o r d [ r o o p I n d e x ] = g e t B e s t O p t i m u m ();
}
/**
* @ r e t u r n データ記録用ファイル名
*/
s t a t i c S t r i n g r e c o r d F i l e N a m e () { S t r i n g f n a m e = " d a t a /";
if ( CT == -1) {
f n a m e += " mix -";
} e l s e if ( CT == 1) { f n a m e += " bin -";
} e l s e {
f n a m e += " exp -";
}
if ( IST == -1) {
f n a m e += " mix -";
} e l s e if ( IST == 1) { f n a m e += " rand -";
} e l s e {
f n a m e += " best -";
}
s w i t c h ( NWT ) { c a s e 1:
f n a m e += " r i n g ";
b r e a k ; c a s e 2:
f n a m e += " t o r u s ";
b r e a k ; c a s e 3:
f n a m e += " h y p e r c u b e ";
b r e a k ; c a s e 4:
f n a m e += " h i e r a r c h i c a l ";
b r e a k ; d e f a u l t :
f n a m e += " no ";
b r e a k ; }
if ( L G E N < 10) {
f n a m e += ( " 0 0 " + L G E N );
} e l s e if ( L G E N < 1 0 0 ) { f n a m e += ( " 0 " + L G E N );
} e l s e {
f n a m e += L G E N ; }
f n a m e += ". txt ";
r e t u r n f n a m e ; }
s t a t i c v o i d o u t p u t F i t n e s s R e c o r d () {
if ( CT == -1) {
rfp . p r i n t (" Mix \ t ");
} e l s e if ( CT == 1) {
rfp . p r i n t (" Bin \ t ");
} e l s e {
rfp . p r i n t (" Exp \ t ");
}
if ( IST == -1) {
rfp . p r i n t (" Mix \ t ");
} e l s e if ( IST == 1) {
rfp . p r i n t (" R a n d \ t ");
} e l s e {
rfp . p r i n t (" B e s t \ t ");
}
s w i t c h ( NWT ) { c a s e 1:
rfp . p r i n t (" R i n g n e t w o r k \ t ");
b r e a k ; c a s e 2:
rfp . p r i n t (" T o r u s n e t w o r k \ t ");
b r e a k ; c a s e 3:
rfp . p r i n t (" H y p e r c u b e n e t w o r k \ t ");
b r e a k ; c a s e 4:
rfp . p r i n t (" H i e r a r c h i c a l n e t w o r k \ t ");
b r e a k ; d e f a u l t :
rfp . p r i n t (" No n e t w o r k \ t ");
b r e a k ; }
rfp . p r i n t l n ( L G E N );
rfp . p r i n t ("\ t ");
int g m a x = s g e n * l g e n / GV ; if ( g m a x > 2 5 0 ) g m a x = 2 5 0 ; for ( int g =0; g < g m a x ; ++ g )
rfp . p r i n t f ( " % 2 d \ t " , g * GV );
rfp . p r i n t l n (" f i n d A t ");
int c o u n t = 0;
int sum = 0;
int s q s u m = 0;
int c o u n t T a b l e [] = new int [ 8 ] ;
for ( int i =0; i < c o u n t T a b l e . l e n g t h ; ++ i ) c o u n t T a b l e [ i ] = 0;
d o u b l e f i t n e s s S u m [] = new d o u b l e [ g m a x ];
for ( int i =0; i < f i t n e s s S u m . l e n g t h ; ++ i ) { f i t n e s s S u m [ i ] = 0;
}
int ct [] = new int [ L G E N * S G E N ];
for ( int i =0; i < ct . l e n g t h ; ++ i ) { ct [ i ] = 0;
}
for ( int r =0; r < R O O P N ; ++ r ) { rfp . p r i n t f ( " % 2 d \ t " , r );
if ( LGEN < GV ) {
for ( int g =0; g < g m a x ; ++ g ) {
rfp . p r i n t f ( " % 4 . 3 f \ t " , f i t n e s s R e c o r d [ r ][ g * GV / L G E N ]);
f i t n e s s S u m [ g ] += f i t n e s s R e c o r d [ r ][ g * GV / L G E N ];
} } e l s e {
for ( int g =0; g < g m a x ; ++ g ) {
rfp . p r i n t f ( " % 4 . 3 f \ t " , f i t n e s s R e c o r d [ r ][ g ]);
f i t n e s s S u m [ g ] += f i t n e s s R e c o r d [ r ][ g ];
} }
if ( f i n d O p t i m u m [ r ] < l g e n * s g e n ) { rfp . p r i n t l n ( f i n d O p t i m u m [ r ]);
c o u n t ++;
sum += f i n d O p t i m u m [ r ];
s q s u m += f i n d O p t i m u m [ r ] * f i n d O p t i m u m [ r ];
if ( f i n d O p t i m u m [ r ] < 16) { ++ c o u n t T a b l e [ 0 ] ;
} e l s e if ( f i n d O p t i m u m [ r ] < 32) { ++ c o u n t T a b l e [ 1 ] ;
} e l s e if ( f i n d O p t i m u m [ r ] < 64) { ++ c o u n t T a b l e [ 2 ] ;
} e l s e if ( f i n d O p t i m u m [ r ] < 1 2 8 ) { ++ c o u n t T a b l e [ 3 ] ;
} e l s e if ( f i n d O p t i m u m [ r ] < 2 5 6 ) { ++ c o u n t T a b l e [ 4 ] ;
} e l s e if ( f i n d O p t i m u m [ r ] < 5 1 2 ) { ++ c o u n t T a b l e [ 5 ] ;
} e l s e if ( f i n d O p t i m u m [ r ] < 1 0 2 4 ) { ++ c o u n t T a b l e [ 6 ] ;
} e l s e if ( f i n d O p t i m u m [ r ] < 2 0 4 8 ) { ++ c o u n t T a b l e [ 7 ] ;
}
++ ct [ f i n d O p t i m u m [ r ]];
} e l s e {
rfp . p r i n t l n (" not yet ");
} }
rfp . p r i n t (" av \ t ");
for ( int g =0; g < g m a x ; ++ g ) {
rfp . p r i n t f ( " % 4 . 3 f \ t " , ( f i t n e s s S u m [ g ] / R O O P N ));
}
rfp . p r i n t l n ();
for ( int i =1; i < c o u n t T a b l e . l e n g t h ; ++ i ) { c o u n t T a b l e [ i ] += c o u n t T a b l e [ i - 1 ] ; }
if ( c o u n t > 0) {
d o u b l e av = ( d o u b l e ) sum / c o u n t ; if ( c o u n t > 1) {
d o u b l e s t d e v = M a t h . s q r t (( d o u b l e ) ( s q s u m - av * av * c o u n t ) / ( count - 1 ) ) ; rfp . p r i n t ( c o u n t + "\ t " + av + "\ t " + s t d e v );
S y s t e m . out . p r i n t l n ( c o u n t + " av :" + av + " s t d e v :" + s t d e v );
} e l s e {
rfp . p r i n t ( c o u n t + "\ t " + av + "\ t n o n ");
S y s t e m . out . p r i n t l n ( c o u n t + " av :" + av + " s t d e v : non ");
} } e l s e {
rfp . p r i n t ( " 0 \ t n o n \ t n o n ");
S y s t e m . out . p r i n t l n ("0 av : non s t d e v : non ");
}
for ( int i =0; i < c o u n t T a b l e . l e n g t h ; ++ i ) { rfp . p r i n t ("\ t " + c o u n t T a b l e [ i ]);
}
rfp . p r i n t l n ();
for ( int r =0; r < R O O P N ; ++ r ) {
rfp . p r i n t l n (" L o o p : " + r );
rfp . p r i n t l n (" T a r g e t ");
t a r g e t s [ r ]. p r i n t P i c t u r e ( rfp );
rfp . p r i n t l n (" O p t i m u m ");
o p t i m u m R e c o r d [ r ]. p r i n t P i c t u r e ( rfp );
rfp . p r i n t f ( " % 4 . 3 f " , f i t n e s s R e c o r d [ r ][ SGEN - 1 ] ) ; rfp . p r i n t l n ();
}
for ( int i =1; i < ct . l e n g t h ; ++ i ) { ct [ i ] += ct [ i - 1 ] ;
}
for ( int i =0; i < 5 1 2 ; i + = 4 ) { rfp . p r i n t ( i + "\ t ");
}
rfp . p r i n t l n ();
for ( int i =0; i < 5 1 2 ; i + = 4 ) { rfp . p r i n t ( ct [ i ] + "\ t ");
}
rfp . p r i n t l n ();
} }
.1 LocalDifferentialEvolution
クラスp a c k a g e de ;
i m p o r t j a v a . u t i l . R a n d o m ; i m p o r t j a v a . io .*;
/**
* 与えられたぼやけた値画像の元画像を進化計算により得る2
*/
p u b l i c c l a s s L o c a l D i f f e r e n t i a l E v o l u t i o n i m p l e m e n t s R u n n a b l e { M o n o c h r o m e P i c t u r e pop []; // 母集団( p o p u l a t i o n )
d o u b l e fit []; // 母集団の適合性( f i t n e s s of the p o p u l a t i o n ) int s i z e P o p ; // 母集団の大きさ( s i z e of p o p u l a t i o n )
d o u b l e d i f f C o n s ; // 差分定数( d i f f e r e n t i a l c o n s t a n t ) 現在は未使用拡張用(:) d o u b l e c r o s s C o n s ; // 交叉定数( c r o s s o v e r c o n s t a n t )
d o u b l e m u t a t i o n C o n s ; // 突然変異定数( m u t a t i o n c o n s t a n t ) int g e n e r a t i o n ; // 世代数( n u m b e r of g e n e r a t i o n s )
int i B e s t ; // 最適解のインデックス
R a n d o m rd ; // 乱数発生用クラスのインスタンス
M o n o c h r o m e P i c t u r e t a r g e t ; // 目標となる値画像2
int p i c t u r e S i z e ; // 画像のサイズ
int c r o s s T y p e ; // 交叉のタイプ
/**
* 1: bin
* oh : exp
*/
int i n d e x S e l e c t T y p e ; // インデックス選択のタイプ /**
* 1: r a n d
* ot : b e s t
*/
int t h N u m ; // スレッド番号
/**
* コンストラクタ
* @ p a r a m int s 母集団のサイズ
* @ p a r a m d o u b l e dc 差分定数
* @ p a r a m d o u b l e cc 交叉定数
* @ p a r a m d o u b l e mc 突然変異定数
* @ p a r a m int gen 世代数
* @ p a r a m int ct 交叉のタイプ
* @ p a r a m int ist : インデックスの選択タイプランダム (ベストor )
* @ p a r a m M o n o c h r o m e P i c t u r e mp : 目標画像
* @ r a m a m int tn スレッド番号
*/
L o c a l D i f f e r e n t i a l E v o l u t i o n ( int s , d o u b l e dc , d o u b l e cc , d o u b l e mc , int gen , int ct , int ist , M o n o c h r o m e P i c t u r e mp , int tn ) { s i z e P o p = s ;
d i f f C o n s = dc ; c r o s s C o n s = cc ; m u t a t i o n C o n s = mc ; g e n e r a t i o n = gen ; if ( ct == -1) {
if ( tn % 2 == 0) { c r o s s T y p e = 0;
} e l s e {
c r o s s T y p e = 1;
} } e l s e {
c r o s s T y p e = ct ; }
if ( ist == -1) {
if ( tn % 4 < 2) {
i n d e x S e l e c t T y p e = 0;
} e l s e {
i n d e x S e l e c t T y p e = 1;
} } e l s e {
i n d e x S e l e c t T y p e = ist ; }
rd = new R a n d o m ();
t a r g e t = mp ;
p i c t u r e S i z e = mp . s i z e ;
pop = m a k e P o p u l a t i o n (); // 解の母集団設定
fit = new d o u b l e [ s i z e P o p ];
s e t I n i t i a l F i t n e s s (); // 適合性の初期値設定
t h N u m = tn ; }
/**
* 解の母集団表示関数
*/
p u b l i c v o i d p r i n t P o p u l a t i o n () {
for ( int i =0; i < s i z e P o p ; ++ i ) { if ( i == i B e s t ) {
S y s t e m . out . p r i n t l n (" b e s t ");
} e l s e {
S y s t e m . out . p r i n t l n ();
}
pop [ i ]. s h o w P i c t u r e ();
} }
/**
* 最適解表示
*/
p u b l i c v o i d p r i n t O p t i m u m () { pop [ i B e s t ]. s h o w P i c t u r e ();
S y s t e m . out . p r i n t l n (" f i t n e s s : " + pop [ i B e s t ]. g e t V a l u e ( ) ) ; }
/**
* 最適解出力
* @ p a r a m p r i n t W r i t e r fp : 出力ファイルへのポインタ
*/
p u b l i c v o i d o u t p u t O p t i m u m ( P r i n t W r i t e r fp ) { pop [ i B e s t ]. p r i n t P i c t u r e ( fp );
fp . p r i n t l n (" f i t n e s s \ t " + pop [ i B e s t ]. g e t V a l u e ( ) ) ; }
/**
* 最適解出力
* @ r e t u r n M o n o c h r o m e P i c t u r e : 最適解
*/
p u b l i c M o n o c h r o m e P i c t u r e g e t O p t i m u m () { r e t u r n pop [ i B e s t ];
}
/**
* 適合性出力
* @ r e t u r n d o u l b e 適合性