2015 年度 修士論文
実行時要求緩和のためのゲーム理論を応用した 環境モデル分析手法に関する研究
2016 年 2 月 1 日 ( 月 ) 提出
指導 : 深澤 良彰 教授
早稲田大学 大学院 基幹理工学研究科 情報理工・情報通信専攻 深澤研究室
学籍番号 : 5114F001-9
相澤 和也
第1章 はじめに 1
1.1 リアクティブシステムに対する制御器合成技術 . . . 1
1.2 制御器合成技術の抱えるトレードオフと課題 . . . 1
1.3 実行時制御器合成とそのための要求緩和手法の提案 . . . 2
1.4 本論文の構成 . . . 3
第2章 背景 4 2.1 対象システム例:荷物運搬ロボットシステム . . . 4
2.2 制御器合成技術 . . . 5
2.2.1 環境モデル . . . 6
2.2.2 要求の論理式 . . . 8
2.2.3 制御器モデルの合成 . . . 10
2.3 制御器合成技術の抱えるトレードオフと課題 . . . 11
第3章 関連研究 14 3.1 複数モデルを利用した研究 . . . 14
3.2 自己適応システムに関する研究 . . . 14
3.3 自己適応システムの検証手法に関する研究 . . . 15
3.4 要求緩和に関する研究 . . . 16
第4章 提案 18 4.1 実行時制御器合成によるトレードオフへの対処 . . . 18
4.2 Analyzeを実現する単純手法とその課題 . . . 20
4.3 環境モデル分析による要求緩和手法の提案 . . . 22
4.4 分析対象となるグラフの生成 . . . 23
4.5 分割型到達可能性ゲームの定義 . . . 24
4.5.1 ゲームの定義 . . . 26
4.5.2 ゲームの勝利戦略と勝利領域 . . . 27
4.5.3 分析対象となるグラフへのゲームの適用 . . . 29
4.6 勝利領域と部分勝利領域の生成 . . . 30
4.6.1 プレイヤー0の勝利領域 . . . 30
4.6.2 プレイヤー0の部分勝利領域 . . . 31
4.7 環境モデルの更新に伴う分析対象空間の更新 . . . 35
4.8 分析対象空間におけるシミュレーション検査と要求緩和の決定 . . 36
第5章 評価 37 5.1 ケーススタディで用いるリアクティブシステム . . . 37
5.2 ケーススタディとその結果 . . . 38
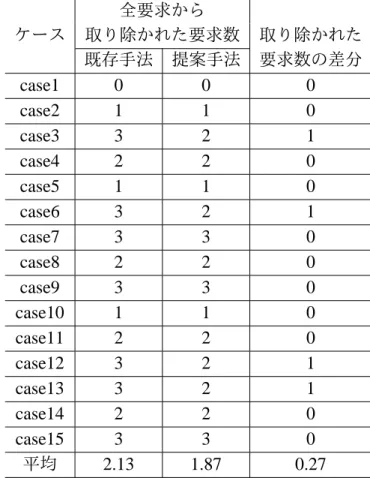
5.2.1 研究課題1の評価 . . . 38
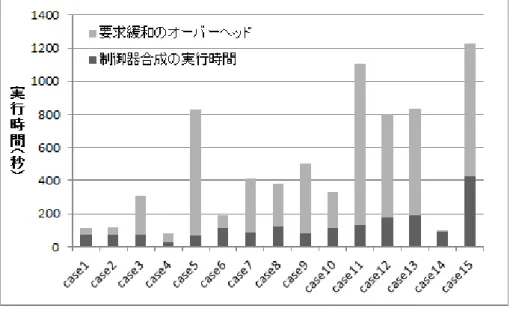
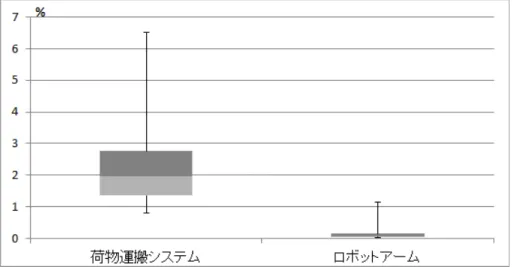
5.2.2 研究課題2に対する結果 . . . 40
5.2.3 提案手法の限界 . . . 46
第6章 おわりに 47 6.1 まとめ . . . 47
6.2 今後の課題. . . 48
1.1 リアクティブシステムに対する制御器合成技術
ロボット制御システムなどの、外部環境と相互作用を行うシステムはリアクティ ブシステムと呼ばれる。システムは外部から与えられる入力、あるいは環境を観 測して得られた結果に応じて適切な振る舞い実行し、与えられた要求を満たそう とする。外部入力や環境の観測結果に応じてシステムの振る舞いを決定する役割 を担うものを本研究では制御器と呼ぶ。今日まで開発者がリアクティブシステム の制御器を誤りなく設計出来るように様々な研究がなされてきた。
Jackson[16]らはリアクティブシステムと環境、及びその両者が共有する空間を
モデル化することでリアクティブシステムと環境との相互作用を効果的に捉える ことが可能であることを指摘している。また、振る舞いの仕様が要求を満たすかを 検査する技法の一つとしてLTSA[18]をはじめとするモデル検査が知られている。
近年ではこれらの技術とゲーム理論[13]を用いて制御器を合成する技術が提案さ
れている[20][6]。この制御器合成技術はモデル化した環境と形式化した要求を入
力することによって、以下のような問題を作成し、それを解く技術である。
E||C |= R (1.1)
ただしEは環境のモデル、Rは形式化された要求の集合、Cは与えられたE上でR を保証可能な制御器のモデルを表す。つまり、この問題は上記のようなCが存在 するかを判定し、存在する場合はそのようなCを発見するというものである。こ の制御器モデルを実行時に参照することで開発者は与えた環境モデルの範囲で与 えた要求を保証可能な制御器のモデルを得ることが出来る。従って開発者はこの 制御器合成技術を利用することによって数学的な保証を持ってシステムを制御す ることが可能なのである。以降、本研究ではリアクティブシステムの実行時に制 御器モデルを参照することを、制御器モデルを実行するという。
1.2 制御器合成技術の抱えるトレードオフと課題
制御器合成技術は入力した環境のモデルと形式化された要求から問題を生成す るが、この問題は環境モデルと形式化された要求の複雑さに応じて難しくなり、や がて解くことが困難になる。従って制御器合成技術を利用するにあたっては、解
2015年度 修士論文
早稲田大学 基幹理工学研究科 情報理工・情報通信専攻 深澤研究室 けるような問題が生成されるように環境モデルと形式化された要求を入力する必 要がある。具体的には環境のモデルまたは形式化された要求のどちらかの複雑さ を軽減するのである。
環境モデルの複雑さを軽減するとはすなわち、環境下で発生しうる事象のうち、
発生することが期待されない一部を環境モデルから取り除くことで環境モデルに 理想化を施すことである。環境モデルに理想化を施すことで、要求はより複雑な ものを与えることが可能となり、出力される制御器モデルはより複雑で多様な要 求を保証可能となる。しかし環境モデルに対する理想化が実環境下で崩れ、モデ ルから取り除いた事象が発生する危険性がある。この場合、制御器モデルではこ れらの事象が考慮されていないためリアクティブシステムは動作不能となってし まう。
一方で形式化された要求の複雑さを軽減するとはすなわち、与えられた全要求 の集合からいくらかの要素を取り除くことである。本研究ではこれを要求の緩和 という。この要求の緩和を行うことで、環境モデルは複雑なものを与えることが 可能となり、出力される制御器モデルは多様な環境下で動作を継続することが可 能である。しかし一方で保証される要求は本来の要求に対して部分的なものとなっ てしまう。
このように制御器合成技術には入力する環境モデルと形式化された要求の間に トレードオフが存在する。開発者が制御器合成技術を用いる際にはこのトレード オフを考え、環境モデルの理想化並びに要求の緩和を考えなければならない。し かし設計段階で、実行時の事象の発生に関する不確実性を完全に予測することは 困難である。これが制御器合成技術を利用する上での課題となる。
1.3 実行時制御器合成とそのための要求緩和手法の提案
本研究では実行時の環境に則した要求緩和を実施することで実環境の持つ不確 実性に対処する。具体的には、実行時に観測によって得られた情報を用いて環境モ デルを更新し、その環境モデル上で最大限保証可能な要求の集合を発見し、それ らを入力として制御器モデルを実行時に再合成する。そして再合成した制御器モ デルを実行中の制御器モデルと切り替えることで設計段階で施した理想化の崩れ に対処するのである。これにより、開発者に最も理想化された環境モデルとリア クティブシステムが満たすべき全要求を入力とした制御器モデルを利用すること を許容する。実環境と環境モデルに施した理想化との差異は実行時に吸収される。
実行時の観測情報を利用した環境モデルの更新はSykesら[27]の手法を適用す ることによって可能である。本研究では環境モデルが更新された時に、その環境モ デル下で制御器モデルが合成可能な要求の集合を最大化する手法を提案する。こ こで最大化とは、より開発者の意図に沿うような要求の集合を指す。この時、要 求が満たすべき要件は以下の2つである。
要件1 緩和後の要求と更新後の環境モデルを入力として制御器合成を行った際に、
制御器モデルが合成可能であること。
要件2 緩和後の要求と更新後の環境モデルから合成された制御器モデルは実行中 の制御器モデルと可換であること
本研究では到達可能生ゲームを応用することによって、これらを満たすような要 求の集合を効率的に発見する手法を提案する。また、既存の手法と比較を行い過 剰な要求緩和が防げることを2つの作業ロボットのケーススタディによって確認 する。また、要求を発見し、制御器を合成するまでの時間的なオーバーヘッドに ついても評価した上で本手法の有用性を確認する。
1.4 本論文の構成
本論分の構成は以下の通りである。まず、第2章では制御器合成技術の概要と 技術が抱える課題について、具体的な例を用いて述べる。第3章では関連研究に ついて記述し、本研究の取り組む課題を分類する。第4章では課題を解決するた めのフレームワークを挙げ、フレームワーク実現のために必要となる要求緩和の 手法を提案する。第5章では2つのリアクティブシステムを想定したモデルを用い てケーススタディを行い本手法の有用性を示し、また限界についても述べる。第6 章ではまとめと今後の課題について述べる。
第 2 章 背景
2.1 対象システム例:荷物運搬ロボットシステム
本研究の説明をする上で、倉庫内の自動荷物運搬ロボットシステムを例として 利用する。このシステムは通販サイト等で依頼を受けた商品を出荷するための倉 庫で利用されることを想定している。ただし説明を容易にするために、図2.1に示 すような簡素な空間で動作するような例を扱う。
図2.1: 倉庫内の荷物運搬ロボットシステム
倉庫内をロボットが移動し、荷物を倉庫内のストレージエリアから配達エリア に移動することがこのシステムの目的である。倉庫は以下の3つのエリアから構 成されている。
図中e: 荷物が保管されているストレージエリア 図中w: 荷物の出荷準備を行う配達エリア
図中m: 配達エリアとストレージエリアを繋ぐ通路
ロボットは配達エリアから動作を開始して以下の動作を行うことが可能である。
move.{e/w}: {ストレージエリア/配達エリア}に向かって移動する
pickup: 荷物を持ち上げる動作を行う
putdown: 荷物を下ろす動作を行う
また、それぞれの動作の結果は観測可能である。つまりシステムはmove{e/w}を 行った結果、倉庫内のどのエリアにいるか、あるいはpickup,putdownの動作が成 功したか失敗したかを認識することが出来る。
システムの目的を達成するために以下のような要求の集合を持っている。
要求1 ロボットは荷物がストレージエリアから配達エリアに運ばれるまで動作を 続ける。
要求2 ロボットは荷物を一定の動作数以内で運ぶことが出来る。
要求3 ロボットは配達エリアを出発したら荷物を持たずに再び配達エリアに入る ことが無い。
要求4 ロボットはストレージエリアを出発したら荷物を持ったまま再びストレー ジエリアに入ることが無い。
要求5 ロボットはストレージエリアで必ずpickupを行い、配達エリアでputdown を行うことが出来る。また、荷物を持っていない状態でputdownを行わず、
荷物を持っている状態でpickupは行わないようにする。
要求1はロボットが目的を達成するまで動作を継続するためのものである。要求2 はシステムが不要な動作を繰り返さないようにするためのものである。また要求3
〜5は倉庫内での出荷する荷物とそうでない荷物の混同を防ぐためのものである。
本システムを対象として環境モデルを構築する際に考えられる理想化としては、
「ロボットの動作が全て期待通りの結果を得られる」というものがある。すなわち move.{e/w}では意図したエリアに到達することができ、pickupやputdownによる 荷物の扱いが必ず成功するということである。ただし、これらはロボットのアク チュエータやセンサーの不具合、あるいは倉庫内部の突発的に発生した障害物に 阻まれる等によって、崩れる可能性が存在する。
要求の集合のうち要求2〜4は前述した環境の理想化が崩れると実際に満たせな くなる。例えば要求2はいずれかの動作が期待通りの結果を得られず同じ動作を 繰り返すことになった場合、満たすことが出来なくなる。要求3,4はmove.{e,w}
の結果、期待した方向と逆の方向に進む等する可能性がある場合には満たすこと が出来なくなる。
以上のようなシステム例を用いて今後の手法の説明を行う。
2.2 制御器合成技術
制御器合成技術はリアクティブシステムとその外部環境との相互作用を表した環 境モデルと、環境モデル上で満たされるべき要求を表した論理式を入力として、与 えられた環境モデル上で与えられた要求を満たすことが保証された制御器モデルが
2015年度 修士論文
早稲田大学 基幹理工学研究科 情報理工・情報通信専攻 深澤研究室 存在するかを判定し、存在する場合は出力するような技術である。本研究ではこの制 御器合成技術を実装したツールとしてMTSA(Modal Transition System Analyzer)[5]
を対象とする。以下、MTSAにおいて利用される環境モデルと要求、並びに出力 される制御器モデルを説明する。
2.2.1 環境モデル
MTSAにおける環境モデルはリアクティブシステムとその外部環境との相互作 用をLTS(Labelled Transition System)[18]によってモデル化したものである。
制御器モデルはこの環境モデル上で表現された相互作用を基にして合成される。
LTSモデルは次のようなタプルによって定義される。
定義2.1 LTSはE = (S,A,∆,s0)で表現される。Sは状態の集合、Aはアクション の集合、∆⊆ (S× A×Sは遷移関係、そしてs0 ∈ Sは初期状態である。また、Eに おける状態とアクションを用いて遷移関係に従うようなt = s,a,s′,a′,... をトレー スと呼ぶ。
ただし環境モデルではアクションをリアクティブシステムが制御可能なアクショ ンと、制御はできないが観測することが可能なアクションの2つに分けている。こ のようにすることで環境モデル上でリアクティブシステムと外部環境の相互作用 を明示的に表現する
定義2.2 A= Ac∪Amである。Acはリアクティブシステムで制御可能なアクショ ン、Amはリアクティブシステムが観測可能なアクションである。
MTSAでは環境モデルの記述をFSP(Finite State Process)に則って行う。
図2.2に倉庫における荷物運搬ロボットシステムと外部環境との相互作用をFSP によって記述したものを示す。ただし図2.2は荷物運搬ロボットシステムがアク ションを行った時に観測できる環境側のアクションは、常に期待されたものであ るという理想化がなされたものである。
図2.2中のMAP[‘{w,m,e}]はそれぞれ図2.1の配達エリア、通路、ストレージエ
リアに対応し、それぞれの状態で起こりうるアクションが記述されている。例えば MAP[‘w]ではリアクティブシステム側がmove.[‘e]、move[‘w]、pickup、putodown のいずれかを取ることができ、その結果として起こりうるarrive.[‘m]、arrive.[‘w]、 putsuccess, pickupfailの観測可能なアクションと、MAP上での次の行き先が記述 されている。
また、図2.3に同システムのロボットの振る舞いのFSPによるモデルを示す。図 2.3にはロボットの行える振る舞いとその取りうる全ての結果が記述されている。
また、ロボットは配達が完了した際にはendedアクションを用いてその完了を通
知し、resetアクションによって他の荷物配達作業に移行する。
図2.2: FSPによる荷物運搬ロボットシステムの倉庫の記述
図2.3: FSPによる荷物運搬ロボットシステムのロボットの記述
2015年度 修士論文
早稲田大学 基幹理工学研究科 情報理工・情報通信専攻 深澤研究室 これら2つのモデルを並列合成することによって環境モデルが構築される。並 列合成によって得られるLTSモデルを図2.4に示す。
図2.4: 荷物運搬ロボットシステムのLTSモデル
2.2.2 要求の論理式
MTSAにおける要求は環境モデル上で満たすべき性質をFLTL[12](Fluent Linear
Temporal Logic)によって記述したものである。FLTLはイベントベースのモデル
に対してLTLによる性質を与えやすくするために用いられる。FLTLによる要求 は、環境モデル上のアクションとそれらから構成されるfluentを用いて記述され る。fluentの定義は以下である
定義2.3 f l =< If l,Tf l >によって表される論理要素をfluentという。If l,Tf l ⊆ A かつIf l∩Tf l =Φであるような開始アクションIf lと終端アクションTf lによって 構成され、この論理要素はLTSのトレースにおいて、開始アクションから終了ア クションまでの間が真となる。
また、演算子としては一般的な論理式の演算子に加えてnext演算子X、strong until 演算子U、の他にweak until演算子W、always演算子[]、eventually演算子<>等が 用いられ、時間に関する性質の記述も可能である。
記述出来る要求としては大きく分けて2種類存在する。1つ目はリアクティブシ ステムが動作する上で常に成立するべき性質を表すsafety property、2つ目はいつか は必ず成立するべき性質を表すliveness propertyである。safety propertyはalways 演算子を用いて[]pと記述され、liveness propertyはalways演算子とeventually演 算子を用いて[]<>pと記述される。ここでpは論理要素である。本研究では提案
する手法の性質上、safety propertyに要求を限定しているため、これ以降ではこの safety propertyを扱う。
荷物運搬ロボットシステムの要求を記述したFLTL式およびそのFLTLの記述に 際して定義したfluentを図2.5に示す。
図2.5: FLTLによる荷物運搬ロボットシステムの要求記述
前項で説明した荷物運搬ロボットシステムにおける要求と図2.5との対応を説 明する。要求1はTransferBeforeEndによって表されている。これは荷物の配達 完了を表すENDEDというfluentが真となるならばストレージで荷物を持ち上げ
(BEEN_PICKING)、持ち上げた荷物を配達エリアで下ろした(BEEN_PUTTING)
状態であることが常に求められているということである。同様に要求3はDONT_MO- VE_BACK_WITHOUT_PICKが要求4はDONT_MOVE_BACK_WITHOUT_PUT が、要求5はPICK_E, PUT_W, PICKONCE, PUTONCEの4つがそれぞれ表してい る。要求2はFLTLでの記述が手間となるため、同様の効果を得られるLTSモデ ルを環境モデルと並列合成することによってMTSAに入力する。
図2.6: 要求2をを表すLTSモデル
2015年度 修士論文
早稲田大学 基幹理工学研究科 情報理工・情報通信専攻 深澤研究室
2.2.3 制御器モデルの合成
制御器モデルの合成は環境モデルと要求の論理式を入力として行われる。入力 された環境モデルと要求の論理式から分析対象となる空間を構築し、その空間か ら要求を満たすことが可能な制御器モデルを発見する。
はじめに要求の論理式から、その要求が満たされているかを観測するためのモ ニターがLTSモデルとして生成される。モニターモデルは要求の論理式を違反す るようなトレースを受理しないモデルである。分析対象となる空間はこのモニター モデルと環境モデルを並列合成することによって生成される。
荷物運搬ロボットシステムにおける要求4のモニターモデルを図2.7に、またこ のモニターモデルと環境モデルを並列合成して生成される分析対象空間の一部を 図2.8に示す。両図中の-1によって表されている状態は要求が違反されたことを示 す状態でありこの状態を含むトレースは受理されないものと考える。
図2.7: 要求4のモニターモデル
図2.8: 環境モデルと要求4から生成された分析対象となる空間の一部 このようにして合成される空間では環境モデル上のどのようなトレースが要求 を満たしえるかを分析することが可能となる。分析にはゲーム理論が利用される。
リアクティブシステムと外部環境とをプレイヤーとした2人対戦のゲームとして 捉えられ、リアクティブシステム側は要求を満たし続けることが勝利条件であり、
環境側は要求を違反させることが勝利条件となる。この時にリアクティブシステ ムが制御可能なアクションを適切に取り続けることで勝利条件を満たせるかを分 析し、その結果として制御器モデルが合成される。
荷物運搬ロボットシステムにおいて合成される制御器モデルを図2.9に示す。こ れは図2.4に示す理想的な環境モデルと図2.5および図2.6に示された全要求を入 力として合成された制御器モデルである。
図2.9: 合成される制御器モデル
2.3 制御器合成技術の抱えるトレードオフと課題
制御器合成技術は入力される環境モデルと要求の論理式によっては制御器が合 成不可能となってしまう。入力から生成される分析対象の空間においてリアクティ ブシステム側で制御可能なアクションをどのように取ったとしても受理不可能な トレースとなってしまう場合である。このような状態を引き起こす要因は2つ存 在する。
1つは環境モデルにおいてリアクティブシステムが制御出来ない(しかし観測は 可能であるような)アクションによる遷移が多く含まれているということである。
このような遷移が受理不可能なトレースを回避出来ない状態を多く作り出すこと で制御器モデルが合成不可能となってしまう。しかし一方で、環境モデルは環境で 起こりうる事象に対応する遷移を可能な限り含めるべきである。なぜならば、も し環境モデルに対応する遷移が含まれていないような事象が起きた場合、制御器 モデル上でも遷移が存在せず、リアクティブシステム内でのエラーを引き起こす からである。
もう1つは入力する要求の増加である。このような場合はトレースを受理不可 能とする状態への遷移関係が増加してしまう。要求の増加に伴ってそのような遷
2015年度 修士論文
早稲田大学 基幹理工学研究科 情報理工・情報通信専攻 深澤研究室 移が増加すればリアクティブシステムはやはり受理不可能なトレースを回避出来 なくなってしまい、制御器モデルが合成不可能となってしまう。しかし、当然な がらリアクティブシステムに対する要求は可能な限り満たされるべきである。
例えば図2.2に示した倉庫の環境モデルに図2.10に示すような遷移を追加するこ とを考える。この遷移は配達エリアであるMAP[‘w]において、ロボットがmove[‘e]
のアクションを行った時に動作が失敗し、通路であるMAP[‘m]ではなく配達エリ アに戻ってきてしまうような事象を表した遷移である。この遷移を追加した環境 モデルから合成される制御器モデルは、実環境で同様の事象が起きても継続して 動作が可能である。しかし、この遷移を加えた環境モデルとリアクティブシステ ムの全要求を入力すると制御器モデルは出力出来ないのである。この遷移を加え た環境モデルとシステムに与えられている要求から生成された分析対象となる空 間の一部を図2.11に示す。分析対象となる空間には赤く囲ったアクションによる 遷移が加わる。これは環境の観測から得られるアクションによる受理不能状態へ の遷移であり、モデル上の状態2においてリアクティブシステムはこの遷移を回 避することは不可能である。しかし、リアクティブシステムはこの状態2を回避 しようとしても他の要求を違反してしまう。このような空間においては解となる 制御器モデルは存在しないのである。従ってこの遷移を追加するためには、要求 となる論理式を適切に取り除くことが必要となるのである。
図2.10: 環境モデルに遷移が追加される例
図2.11: 遷移が追加された環境モデルから生成された空間
このように制御器合成技術を利用する際には環境モデルと要求の間にトレード オフが存在する。もし、実際の環境でリアクティブシステムが観測する結果が常 に期待通りのものであるならば(すなわちリアクティブシステムが制御可能なア クションを行った時に、そのアクションに期待される通りの環境の変化が観測で きるならば)、環境モデルから期待される観測結果以外の結果を取り除くという理 想化が可能である。そしてそのように理想化された環境では、より多くの要求が
満たせる制御器が合成可能となる。しかし、もし環境が厳しく、観測される結果 が期待通りではない場合、環境モデルに対する理想化を施すことが出来ないため、
要求の一部を諦める必要がある。実環境でこの理想化に関する不確実性を予測す ることは困難である。従って開発者は環境モデルに対して適切な理想化を施すこと が出来ず、リアクティブシステムを適切に合成出来ないという課題が挙げられる。
第 3 章 関連研究
3.1 複数モデルを利用した研究
背景に挙げた課題に対する研究としてD Ippolitoらの研究が挙げられる[7]。彼 らは複数のモデルを利用することによって環境の持つ不確実性に対処している。彼 らは異なる段階の理想化を施した複数の環境モデルとそれぞれの環境モデル下で 保証することが可能な要求、そしてそれらを入力として制御器合成を実行して得 られた制御器モデルのセットを全順序で用意し、実行時に観測した事象に対応可 能なセットに実行時に切り替え、段階的に環境モデルの理想化と保証可能な要求 を緩和するという手法を提案している。そのようにすることによって、リアクティ ブシステムは実行時に発生する事象に対して、継続的に動作を続けることを可能 としながら、保証可能な要求をある程度保証する事を可能としているのである。
彼らの提案した手法では一貫性を保ちながら制御器を切り替えるために複数の 環境モデル間、並びに複数の制御器モデル間でシミュレーションの関係を保つこ とを条件としている。このシミュレーションの関係を保つためには、上位の環境モ デルで発生が想定されている事象は下位のモデルでも同様に想定されている必要 がある。この関係に従って環境モデルを全順序的に用意することから開発者は環 境モデルに対する理想化が崩れる順番を事前に予測しておく必要がある。この予 測が外れた場合、環境モデルの理想化と保証される要求は過剰に緩和される。環 境モデルに対する理想化が崩れる順番に関する不確実が実行時に存在し、設計段 階での対応は困難である。従って彼らの手法では過剰な緩和を引き起こす可能性 があることが課題であると考えられる。
3.2 自己適応システムに関する研究
設計段階で予測できない環境の不確実性に対処するシステムとしては自己適応 システム[24]の研究が多数存在する。自己適応システムとは環境の変化に合わせ てシステムが自身の要求を満たせるように振る舞いや構造を実行時に変更するシ ステムのことである。
本研究では特に振る舞いを変更するシステムに関する研究に焦点を当てる。振 る舞いの変更は実行時に要求の違反を検出した場合に、その要求を再び満たすた めに行われている。
Wenyiら[21]は実行時に起きた要求の違反とそれが起きた時の環境の情報、そ してその時に有効であった振る舞いの変更をケースとして蓄積し、環境で新たに 発生した要求違反に対してはそのケースを基に対処する手法を提案している。こ の手法では蓄積されたケースによる推論とゴールモデルを用いた推論の2つを併 用して適応を行う。それによる要求の改善の程度を評価し、良いものはケースと して蓄積することで、実行時の最適な振る舞いを学習させている。
Calinescuら[4]はシステムの振る舞い仕様を複数用意し、実行時に最も適する仕
様を発見し切り替える手法を提案している。この時振る舞い仕様を、その振る舞い によって得られる報酬と共に遷移モデルとしてモデル化しておく。実行時の観測結 果から各モデル内の遷移確率を決定し、確率モデルチェッカーによってどの仕様が 最も要求を満たしうるのかを実行時に検証する。彼らの手法では確率モデルチェッ キングによって保証を与えた上で仕様を選択することが可能である。ただし、こ の手法は実行時の検証にかかる時間的コストが問題視されているがGerasimouら [10]によって高速化手法が提案されている。
Ghezziら[11]は実行時に振る舞いの全可能性を表したモデル上で確立論理に基
づいた決定を行うことで非機能要求を満たしうる振る舞いを選択する手法を提案 している。振る舞い仕様のモデルとそれぞれの振る舞いに対応する実装コード、そ してそれぞれの振る舞いが非機能要求に与える影響を入力することでモデルを生 成する。実行時にこの生成したモデル上でマルコフ決定過程に基づいた振る舞い 決定を行っている。
Kleinら[17]は制御理論の技術を用いることによって、システムに与えるパラ
メーターを制御器を導出している。対象システムを数式によってモデル化し古典 制御における制御器合成の過程を経て制御器を導出する。この制御器はトレード オフのあるようなパラメーターを操作し、その一方の品質を常に基準値に保つよ うにしている。従って、システムが厳しい環境下に置かれるような場合でももう 一方の品質を落とすことを許容してパラメータを調節することで品質を維持する ことが出来る。彼らの手法に基づいて合成された制御器は品質に対して制御理論 に基づく数学的な保証が与えられる。従って背景に述べた制御器合成技術に類似 しているが、彼らは連続量に対する制御器を合成しているのに対し、今回対象と している技術では離散的な振る舞いの制御器を合成しているのである。
3.3 自己適応システムの検証手法に関する研究
本研究では実行時に制御器合成技術を利用することによって実行時に可能な限 り要求を保証しながら振る舞いを切り替えることを目的としている。自己適応シ ステムが正しい振る舞いを行えるかを検証することを目的とした研究はいくつか 存在する。検証にあたってはモデル検査や回帰テスト、SATソルバーを用いた手 法等が存在する。
2015年度 修士論文
早稲田大学 基幹理工学研究科 情報理工・情報通信専攻 深澤研究室
Fredericks[8][9]らは実行時に適応によって振る舞いを切り替えた際に、その振
る舞いに対して回帰テストを行うこようにして実行時検証を行っている。この回 帰テストを行うにあたって設計段階で用意したテストスイートが実行中の環境で 利用出来なくなることを想定し、テストを遺伝的アルゴリズムによって実行環境 に適応させる手法を提案している。ただしテストの適応は非機能要求を対象とし ており、機能要求に対して行われるものではない。
Yangら[30]は自己適応システムの相互作用を表した状態遷移図に基づいて設計 した際に、そのモデル上で発生しうる要求の違反を反例として挙げる手法を提案 し、開発者のシステム検証の補助を試みている。彼らは設計したモデルに実環境 における制約と、実システムと環境との間にある不確実性を情報として加えるこ とで現実でおこりうる要求の違反をSATソルバーを用いて発見し、反例として出 している。ただし、あくまで有り得る反例を列挙するに留まるため、背景で挙げ た制御器合成技術のような保証は与えていない。
機能要求の検証に取り組んだ研究としてZhangら[31]のものが挙げられる。彼 らは自己適応システムをある振る舞いモデルから別の振る舞いモデルに切り替え るシステムとして捉え、一貫性を保った切り替えが出来るように検証を行ってい る。振る舞いのモデルやモデル間の切り替えを表した遷移に対して線形時相論理 式によって制約を与え、その性質を検証するアルゴリズムを提案している。また、
彼らは検証アルゴリズムを細分化し、一度検証が完了したモデルに変更が加わっ た場合でも部分的な検証を行うだけで性質を保証可能にしている。本研究では実 行中の環境変化を扱うことから、アルゴリズムを変更箇所に適用するという彼ら の手法に類似した着眼点を持って取り組んでいる。
3.4 要求緩和に関する研究
システムの要求に関しては様々な研究がなされている。設計段階で要求自体が 持つ不確実性に対応する研究[25][28][14]や要求と設計のトレーサビリティを高め る研究[19]がある。特に自己適応システムを対象として実行時に要求を扱う研究 も近年盛んに行われている[15][26][22]。その中でも実行時の要求緩和に取り組む 研究に言及する。
Angelopoulosら[2][3]はシステムの要求をゴールモデルとして与え、これを利
用して実行時のシステムの再構成と要求緩和を行っている。ゴールモデル内の各 要求に対してその要求を満たしているかの指標を紐付けして監視する。指標によっ て要求が違反されていることを把握した場合には、代替動作への切り替えや要求 緩和などの適応を行う。また、要求間に順位付けを行うことで適応決定時の要求 の衝突を防いでいる。
Whittleら[1]は自己適応システムの要求緩和を明示的に宣言するためにRELAX
という言語を提案している。RELAXはシステムに対する要求が環境の変化に応じ て緩和してよいものか、緩和する際に関わる環境の不確実性は何か、また、緩和す
る際に用いられる代替要求とそれによる他の要求に対する影響を記述することが 出来る。また、Ramirezら[23]はこのRELAXに加えてClaims[29][]というものを 使って実行時に適応動作の妥当性を評価している。Claimsとは不確実性に対する 印付けとして用いられ、自己適応システム内で不完全な情報に対して適応決定を 行うための原理が記録されている。このClaimsでおいている前提が崩れた時に、
ClaimsをRELAXによって緩和する事で適応を行い継続的に動作させるのである。
以上に挙げたものはいずれも非機能的な要求を扱ったものであり、機能的な要求 に関する自己適応システムの手法はあまり研究されてこなかった。本研究で取り 組む課題はこの機能的な要求に関する自己適応システムに分類される。また、本 研究では機能的な要求の緩和についても扱う。
第 4 章 提案
4.1 実行時制御器合成によるトレードオフへの対処
本研究では実行時環境に合わせて制御器を再合成し実行中の制御器との切り替 えを行う適応エンジンフレームワークを考える。本フレームワークの目的は変化 する環境の中でもリアクティブシステムの動作を継続させつつ、継続にあたって 必要な要求緩和は最低限に留めることである。これによって設計段階で環境モデ ルに対して施した理想化が崩れても、それに応じた適切な要求緩和を動的に実施 し、リアクティブシステムは可能な限り要求を満たしながら動作を継続すること が可能になるのである。本フレームワークを利用することで、開発者は設計段階 で環境モデルと要求との間にあるトレードオフに縛られることがなくなる。最大 限の理想化を施した環境モデルとリアクティブシステムに対する全要求、そして それらから合成された制御器モデルを用意すれば良い。環境モデルと実環境との 差異によって発生するエラーは本フレームワークによって自動的に吸収されるの である。
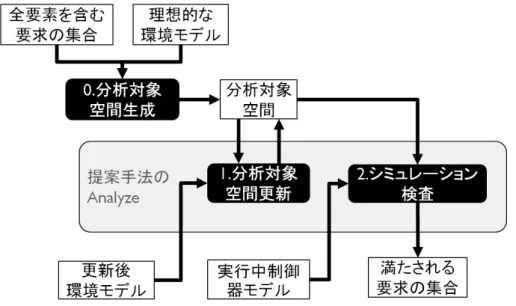
本フレームワークを設計するにあたっては自己適応システムの概念を利用する。
フレームワークの概観を図4.1に示す。
図4.1: フレームワークの概観
本フレームワークではリアクティブシステムの外部に適応エンジンを用意する。
適応エンジンの目的は外部環境の観測結果に応じて適切な制御器に切り替えるこ とである。適応エンジンは自己適応システムで用いられるMAPEループの概念に 沿って設計される。MAPEループとは自己適応システムの基本的なプロセスであ る環境の観測(Monitor), 環境の分析(Analyze), 適応の計画(Plan) 適応の実行
(Execute)によって組まれるループのことである。
開発者はこのフレームワークに最も理想化を施した環境モデルとリアクティブ システムに対する要求の全集合、そしてそれらから合成された制御器モデルをこ のフレームワークに入力する。
本手法におけるMAPEループは以下のように構成する。
Monitor リアクティブシステムの制御器のエラーを監視する。エラーを検出した際
にはリアクティブシステムの実行トレースを利用して環境の変化を環境モデ ルに反映する。すなわち、エラーの直前まで環境モデルに含まれていなかっ たことが原因でエラーとなってしまった事象に相当する遷移を環境モデルに 追加するということである。入力は環境モデルと実行トレースであり、出力 は遷移が追加された環境モデルである。この更新はSykesらの手法[27]を用 いることによって可能である。
Analyze 環境モデルの更新に伴って要求緩和が必要であるかを分析し、必要な場
合は適切な緩和を行う。ここでいう要求の緩和とは、リアクティブシステム に対して与えられた要求を表す論理式の集合から、いくらかの論理式を取り 除いた部分集合を作り、それを新たにリアクティブシステムに対する要求と することである。従って与えられた要求の論理式自体の制約を弱めるような 要求の緩和は本研究の対象外である。要求緩和をするにあたっての要件は以 下の2つである。
要件1 緩和後の要求と更新後の環境モデルを入力として制御器合成を行った 際に、制御器が合成可能であること
要件2 緩和後の要求と更新後の環境モデルから合成された制御器は実行中 の制御器と可換であること
要件1はPlanで制御器モデルが出力可能とするために必要であり、要件2は
Executeで制御器モデルの切り替えを可能とするために必要である。これら
2つの要件を満たしながら必要最低限の緩和が施された要求の集合を出力す
る。AnalyzeではMonitorで更新した環境モデルと分析空間を入力する。分
析空間は適切な要求緩和を発見可能な空間であり、リアクティブシステムに 対する全要求と環境モデルから生成される。このAnalyzeの具体的な手法は 以降で説明する。
Plan Monitorによって更新された環境モデルとAnalyzeによって緩和された要求 の集合を入力して制御器合成を実行し制御器モデルを得る。制御器合成には MTSAを用いる。
2015年度 修士論文
早稲田大学 基幹理工学研究科 情報理工・情報通信専攻 深澤研究室
Execute 実行中の制御器からPlanで生成された制御器への切り替えを行う。この
切り替えではD Ippolitoら[7]の手法を採用する。彼らは制御器モデル間に シミュレーションの関係を持たせることによって一貫性を保ちながら安全に 制御器を交換することを可能にしている。
定義4.1 2つのLTSモデルEとFを考える。Fの任意の状態sを接頭辞とす る任意のトレースt = s,a,...からアクションのみを取り出したアクション列 t′= a,a′,a′′...がEにおいても適切な状態s′を開始状態とすることによって 同様に得られる時、EはFをシミュレートするという。
定義より、EがFをシミュレートするとはF上で起こりうる一連のアクショ ン列がE上でも同様に起こすことできるということである。本研究では合成 される制御器モデルが実行中の制御器モデルをシミュレート出来るように要 求を緩和することで実行中に安全な切り替えを可能にする。
本フレームワークの構築にあたって、Monitor、Plan、Executeは既存の手法を活 用することで実現できる。しかしAnalyzeプロセスで挙げるような要件を満たす 要求緩和の手法を実現している研究は我々の調査の範囲では存在しない。そこで 本研究ではこの要求緩和の手法を提案する。このプロセスを実現する際の課題を 示し、その課題を解決することが提案する手法の目的である。
4.2 Analyze を実現する単純手法とその課題
前項で述べたフレームワークのAnalyzeプロセスを、制御器合成技術を用いた 単純手法によって実現することとその課題を述べる。
単純手法は設計段階で緩和後の要求の候補を用意し、実行時にはその候補を逐 次検査するという考え方に基づいている。検査では候補を用いて実際に制御器合 成を行い、要件に見合う制御器モデルが合成出来るかを確かめている。このプロ セスによって要件に見合う要求の集合と制御器モデルを得る。従ってこの手法は図 4.1におけるAnalyzeとPlanの2つのプロセスを担っている。図4.2に概観を示す。
この手法では緩和の候補となる要求の集合を設計段階で複数用意する。この候 補は開発者の手によって用意される。システムに与えられた全ての要素を持つ集 合から最低限の要素のみを持つ集合までを全順序で並べ、より高い要求から順に
n,n-1...1と異なる要求レベルを割り当てる。この要求の集合の候補と要求レベルは
図4.1における分析空間に相当するものである。
この手法における入力は更新後の環境モデルと実行中の制御器モデル、そして 要求の集合の候補と要求レベルである。要求レベルはリアクティブシステムの実 行開始段階では最高のレベルが設定されている。
図4.2: 単純手法の概観
まずMonitorから出力された更新後の環境モデルが入力された時に、要求の集合
を候補から選択する。この選択はその時点での要求レベルに基づいて行われ、要 求レベルに紐付けられた要求の集合が結果として出力される。
選択された要求と環境モデルから制御器合成を実行する。このとき、制御器モ デルが合成されなければ要求緩和として要求のレベルを1つ下げ、要求選択に戻 る。制御器モデルが合成出来た場合、その制御器モデルのシミュレーション検査 を行う。
シミュレーション検査では合成された制御器モデル上で現在の制御器モデルが 取りうるパスをチェックする。現在の制御器モデルのもつすべてのパスが合成され た制御器モデルにも存在するのであればシミュレーションの関係は成立する。シ ミュレーションの関係が不成立であるならば、要求緩和を行い、再度要求の選択 を行う。
以上をシミュレーションの関係が成立するような制御器モデルが合成されるか、
要求レベルが1に達するまで繰り返す。シミュレーションの関係を保てる制御器 モデルが合成されたならばそれをExecuteに入力する。要求レベルが1に達しても 制御器モデルが合成出来ない場合は、現在の環境で要求を満たせるような制御器 モデルは合成出来ないと判定する。
この手法によって実行時の環境の更新に応じて制御器モデルの再合成が可能で あるが、この単純手法では2つの要因によって実行時間が膨大になってしまう。1 つ目は要求緩和の成否を判定するために実際に制御器モデルを合成する必要があ
2015年度 修士論文
早稲田大学 基幹理工学研究科 情報理工・情報通信専攻 深澤研究室 るということである。そして2つ目は要求の集合の候補を逐次検査していく必要が あるということである。制御器合成技術は時間的コストが無視できず、実行時の 利用は可能な限り減らすべきである。しかし単純手法では候補の中から要件を満 たすような要求の集合が発見されるまで制御器合成を繰り返す必要があり、候補 となる要求の集合の数が増えればその分、実行時間も増大する可能性がある。こ れは実行時間中に重大な遅延を引き起こしかねないのである。
4.3 環境モデル分析による要求緩和手法の提案
本項では単純手法が抱える実行時間の課題を解決するために、到達可能性ゲー ムを応用した効率的な要求緩和手法を提案する。本手法では制御器合成技術が合 成時に生成している分析対象空間に着目する。環境モデルと要求の論理式から合 成される分析対象空間については以下のことがいえる。
• 要求をsafety propertyに限定した時、1つの分析対象空間内においてどの要
求を違反した(満たせなくなった)かはそれぞれ独立に検査することが可能 である。
• 環境モデルに遷移が追加されたことによって影響を受けるのは一部分である 単純手法では環境モデルが更新される度に、あるいは候補となる要求の集合を 変更する度に、分析対象空間を新たに生成・分析しており、これが実行時間を膨 大にしていると考えられる。そこで本手法では環境モデルの更新に応じて分析対 象空間を更新し、その更新によって違反することになる要求を発見する。
制御器合成の際に行われる分析は要求をsafety propertyに限定したときには、分 析対象空間上で行われる到達可能性ゲーム[13]を解くこととみなせる。この到達 可能性ゲームを拡張した分割型到達可能性ゲームを定義することで要求毎に違反 を発見することを可能にし、また、分析対象空間を環境モデルの更新に合わせて 更新することで、更新後の環境モデル下で違反される要求を効率的に発見し取り 除くことを可能にする。図4.3に本手法の概観を示す。
分析対象空間の生成は理想的な環境モデルとリアクティブシステムに与えられ る全要求の論理式を入力に行う。
制御器合成と同様にそれぞれの要求の論理式から要求のモニターモデルを生成 し、環境モデルと並列合成をすることによって分析対象となるグラフを生成する。
生成した分析対象のグラフを分割型到達可能性ゲームとみなし、処理を施した結 果を分析対象空間として出力する。この出力された分析対象空間では、どの状態 がどの要求を違反しうるかを判断することが出来る。
実行時の分析対象空間の更新は更新後の環境モデルから更新によって加えられ た遷移を抽出し、その遷移を基に行う。
図4.3: 提案手法の概観
シミュレーション検査は更新後の分析対象空間と実行中の制御器モデルを入力 し、制御器モデルのパスを分析対象空間上で再現した時に要求を違反しうる状態 を制御器モデルが通り得るかを検査する。違反しうる状態を通るのであれば、そ の状態を通る事によってどの要求が満たされなくなるのかも分析し、満たされな くなる要求の候補を挙げる。これらの候補の中からリアクティブシステムにとっ て最善となる要求緩和を決定する。なお、本研究においては満たされなくなる要 求の候補を挙げるまでを研究範囲とし、要求間の優劣の決定については他の手法 に依存するものとする。
以上のようにすることで、実行時の効率的な要求緩和を図る。
次項以降で分析対象となるグラフの生成、分割型到達可能性ゲームの定義とそ の分析方法について述べる。
4.4 分析対象となるグラフの生成
分析対象となるグラフの並列合成方法について説明する。本手法における並列 合成とは環境モデル上での状態遷移時のアクションに従って要求のモニターモデ ル上でも状態を遷移させることで出来るそれぞれのモデルの状態からなる対を状 態とし、それらを環境モデルの遷移によって繋げていくことでモデルを構築するこ とである。ただし環境モデルが更新されたときに、分析対象のグラフも同様に更 新可能にするために、分析対象のグラフの各状態はその状態が生成された際の環 境モデルの状態および要求のモニターモデルの状態の対と紐付けが行われている。
背景の図2.8で挙げた分析対象となる空間を例に挙げる。これは図2.4の環境モ デルと図2.7の要求のモニターモデルから並列合成されている。この時の各状態間
2015年度 修士論文
早稲田大学 基幹理工学研究科 情報理工・情報通信専攻 深澤研究室 の紐付けの一部を表4.1に示す。
各モデル上の状態0はいずれも初期状態を表すことから分析対象となる空間の 状態0に対する環境モデルとモニターモデルの状態対の紐付けは(0,0)となる。分 析対象となる空間の状態0において、環境モデルを状態0からarrive.wのアクショ ンによって状態1へ遷移させたとき、モニターモデルには対応する遷移が無いこ とから状態遷移は発生しない。そのような状態対(1,0)が分析対象となる空間の状 態1と対応している。また、分析対象となるモデルの状態6において、環境モデル の状態6からarrive.eによって状態7に遷移すると、モニターモデルもarrive.eに よる遷移をもつため、これに従って状態1へと遷移し、状態対は(7,1)となりこれ が分析対象となる空間の状態7に相当している。
表4.1: 図2.8の状態と図2.4、図2.7の状態対との紐付け関係 図2.8の状態 (図2.4の状態,図2.7の状態)
0 (0,0)
1 (1,0)
2 (2,0)
3 (3,0)
4 (4,0)
5 (5,0)
6 (6,0)
7 (7,1)
11 (11,1)
12 (4,1)
14 (6,2)
-1 (7,-1)
紐付けする状態対の要素数は並列合成する環境モデルと全モニターモデルの個 数の和に等しい。また、各要求において受理不能を表す状態-1に到達した状態対 では、状態-1に到達したモニターモデルの状態遷移を無視する形で状態遷移を継 続し、状態対を継続して生成しておく。このようにすることで、状態-1に到達し たモニターモデルに対応する要求が緩和された後の分析も可能になる。この情報 は後述する環境モデルの更新を反映する際に利用する。
4.5 分割型到達可能性ゲームの定義
本手法で用いる分割型到達可能性ゲームの定義を行う。
分割型到達可能性ゲームの定義にあたって、一般的な到達可能性ゲーム[13]を 説明する。到達可能性ゲームとはあるプレイヤーがある状態に到達する事が勝利
条件となるようなゲームを指している。これを環境側が要求を違反するような状 態に到達する事を勝利条件として適用する。環境と制御器をゲーム上でのプレイ ヤーとして想定し、制御器側は要求を守り続ける事を、環境側は要求を違反する ような状態に到達する事を勝利条件とする。互いに勝利条件を満たすように振る 舞う事を考えることによって、制御器側が勝利できる、すなわち環境モデル下に おいて要求を満たし続けられるような状態の集合を発見する。この状態の集合を 発見することを到達可能性ゲームを解くという。
図4.4に到達可能性ゲームの例を示す。到達可能性ゲームが行われるグラフは環 境側に属する状態と制御器側に属する状態、及びそれらを繋ぐ遷移から構成され ている。環境側に属する状態では環境がその状態から出る任意の遷移に従って移 動し、制御器側に属する状態では制御器が遷移を選んで移動する。初期状態から 始めて移動を繰り返した時に環境側の勝利状態に到達出来るのであれば環境側の 勝利であり、そうでない場合は制御器側の勝利である。
環境側が適切に遷移を選択すれば制御器側の遷移に関わらず必ず環境側の勝利 となるような状態が存在する。そのような状態の集合を環境側の勝利領域と呼ぶ。
制御器側についても同様の状態の集合が存在し、これを制御器側の勝利領域と呼 ぶ。到達可能性ゲームは決定ゲームである事が知られている。決定ゲームとはグ ラフ上のすべてのグラフが必ず環境側または制御器側の勝利領域に含まれるよう なゲームのことであり、初期状態の選び方によってどちらが勝利するかを判別す ることが出来る。。
図4.4: 到達可能性ゲームの例
しかし本研究においては、制御器が要求を満たせるか否かに加えて、満たせな くなる場合、どの要求が満たせなくなるのかを特定する事を目的としている。従っ て、勝利条件となる状態の集合を複数に分割するゲームを考える。本研究ではこ のようなゲームを分割型到達可能性ゲームと呼ぶ。図4.5に本研究における到達可 能性ゲームの例を示す。これは図4.4と同じグラフ、および同じ環境側の勝利状態 を持つ。ただし、分割型到達可能性ゲームではこの勝利状態がいくつかの集合を 構成しており、勝利状態に到達した場合、どの集合に属する勝利状態かを知るこ とが出来る。本研究ではリアクティブシステムに対するそれぞれの要求を違反す る状態の集合を構成することで、どの要求違反が起きたのかを特定できるように
2015年度 修士論文
早稲田大学 基幹理工学研究科 情報理工・情報通信専攻 深澤研究室 する。また、この時、環境側の勝利領域も分割し、どの勝利領域がどの要求違反 に対応するものであるかを特定する。本項ではこの分割型到達性可能ゲームを定 義し、次項では分割型到達可能性ゲームの勝利領域を特定する。
図4.5: 到達可能性ゲームの例
4.5.1 ゲームの定義
一般にゲームはアリーナと勝利条件によって構築され、アリーナ上でプレイと 呼ばれるパスが設定した勝利条件を満たすかによって勝敗を決定する。以下では アリーナとプレイ、そして分割型到達可能性ゲームにおける勝利条件を定義する。
また、以降ではゲームの参加者をそれぞれプレイヤー0,プレイヤー1とする。
• アリーナ
アリーナは以下のように定義される。
A= {V0,V1,E} (4.1)
ここでV0はプレイヤー0の手番を意味する状態の集合、V1はプレイヤー1 の手番を意味する状態の集合であり、V0とV1は互いに素である。E ⊆ (V0∪ V1)×(V0∪V1は状態間の遷移関係である。また、V0とV1を合わせたものをV としておく(この時、EはE ⊆ V ×V )と書く事も可能である)。また、v ∈V からの遷移先の集合はvE = {v′∈V|(v,v′) ∈ E}と記述することにする。
• プレイ
アリーナ上でのゲームのプレイは次に挙げるようなものであるとする。まず、
アリーナ場を移動するトークンを用意し、ある初期状態v ∈V に設置する。
もしvがプレイヤー0の手番であるならばプレイヤー0はv′ ∈ vEを満たす 任意のv′に移動させる。対称的に、もしvがプレイヤー1の手番であるなら ばプレイヤー1はv′∈vEを満たす任意のv′に移動させる。これを無限に繰 り返すか、遷移を持たないような状態に到達するまで繰り返す(以後、この ような状態を手詰まりと呼ぶ)。この時に生成されるパスをプレイと呼び、
以下のように形式的に定義する。
あるアリーナA={V0,V1,E}上におけるプレイπは以下のいずれかである。
– ω = {0,1,2,...}としたときのi ∈ ωに対してvi+1 ∈ viEが成り立つ無限 のパス
π = v0v1v2...∈Vω
– 全てのi < lに対してvi+1 ∈viEが成り立ちvlE = ϕである有限のパス π = v0v1v2...vl ∈V+
• 分割型到達可能性ゲームとゲームの勝利条件
アリーナ Aとある状態の集合族{Xi}i∈I = {Xi|r ∈ I,Xi ⊆ V}の対を分割型到 達可能性ゲームとして定義する。
DR( A,{Xi}i∈I) (4.2) ただしi ∈ Iは任意の添字集合である。
また上記のゲームのあるプレイπが任意のXi ∈ {Xi}i∈I に属する状態、ある いはプレイヤー1の手詰まりを含むとき、そのπはプレイヤー0の勝利であ るとし、そうでないようなπはプレイヤー1の勝利とする。これを勝利条件 とする
一般には到達可能性ゲームはアリーナAと状態の集合X の対G( A,X )をいう。
本研究では適用する問題の性質上、ゲームの勝ち負けに加えてどのような勝利条 件で勝利したのかを分析する必要がある。我々は、勝利条件となる集合Xを細か く分割した集合族{Xi}i∈I として捉えてゲームを定義することでこの問題に取り組 む。勝利条件を集合族{Xi}i∈Iとして持つことで、どの勝利条件を満たしたのかを 添字iを持って分かるようにしている。
定理4.1 DR( A,{Xi}i∈I)はX = {x ∈V|x ∈ Xi,Xi ∈ {Xi}i∈I}であるようなG( A,X )と 同値である。
証明4.1 DR( A,{Xi}i∈I)とG( A,X )は同じアリーナを持つ事から同じプレイを持つ ことは明らかである。また、X = {x ∈V|x ∈ Xi,Xi ∈ {Xi}i∈I}より任意のXi ∈ {Xi}i∈I
に属する状態は同様にXにも属す。従ってプレイπが任意のXi ∈ {Xi}i∈Iに属する 状態を含むとき、πは同様にXに属する状態も含む。これは同様にして逆も真で ある。したがってDR( A,{Xi}i∈I)とG( A,X )は同じアリーナと同じ勝利条件を持つ こととなるので、2つのゲームは同値である。
4.5.2 ゲームの勝利戦略と勝利領域
上記のゲームにおいて、一方のプレイヤーが、もう一方のプレイヤーが行うトー クンの移動の仕方とは非依存に、常に勝利出来るような条件、あるいは状態を考 える。それらを勝利戦略と勝利領域として定義する。