ソースコードの編集履歴を用いた
プログラム変更理解に関する研究
木津 栄二郎
内容梗概
ソフトウェアの保守工程やソフトウェア進化の過程では,開発者や保守者はユー ザの拡張要求や環境の変化への適応や欠陥の修正のために,ソフトウェアを動作 させているプログラムに対して変更を加える必要がある.そして,そのプログラ ムに対して変更を加える前には,開発者や保守者はそのプログラムの現在の状態 だけでなく,過去にそのプログラムに対して行われてきた変更の過程も理解して いる必要がある. そのようなプログラム変更過程を理解する開発者や保守者を支援するために,版 管理システムに記録されたソースコードの版を 2 つ取り出し,2 つの版の差分から それらの間で行われた変更内容を推測する手法が従来から提案されている.しか し,これらの手法ではそれらの版の間に行われた個々の変更内容が混ざり合った 状態で検出されてしまい,これらの手法による支援に限界があることが指摘され ている. また,この問題を解決するために開発時の細粒度変更情報を記録する手法が提 案されているが,これらが記録する変更情報は粒度が細かすぎるため,これらの 手法によって記録された情報をそのまま提示することでは開発者や保守者の支援 にはならない.開発者や保守者のプログラム変更理解を支援するには,開発者や 保守者にとって適切な粒度で変更情報を提示する必要がある. また,一般的に,プログラムの変更過程は複数のプログラム変更の適用により 達成される.このため,プログラムの変更過程の理解に有用な変更情報を提示す るためには,次に示す 2 つの作業が必要であると考えられる. 1. 個々のプログラム変更を(より正確に)検出する. 2. 検出したプログラム変更に,その内容(理由や意図など)を付与する. そのため本研究では,OperationRecorder から得られる編集操作履歴から,オブ ジェクト指向プログラミング言語 Java のプログラム要素に関する変更情報(本研 究ではプログラム変更と呼ぶ)を検出する手法を提案し,その手法を用いて過去 に行われたプログラム変更を適切な粒度で検出することで,先に示した 2 つの作 業の作業 (1) を自動化し,開発者や保守者が作業 (2) に専念できる環境を提供するを目指す. またその際には,以下の 2 つが本研究における課題となる. 1. 作業 (1) の自動化において個々のプログラム変更の検出を正確に行うこと 2. 作業 (2) において変更の内容を記述する開発者や保守者に受け入れられるプ ログラム変更を提示すること 課題 (1) については,編集操作履歴という細粒度変更情報を用いてプログラム変 更を検出することで,版間差分情報を用いる従来手法よりも正確なプログラム変 更を検出する.課題 (2) については,一度特定されたプログラム変更について,そ れらを異なる粒度で集約できるようにし,記述する開発者や保守者が集約の粒度 を変更内容を選択できるようにすることで,開発者や保守者に受け入れられるプ ログラム変更を提示することを目指す. 本研究では提案手法をツールとして実装した.本ツールを用いることで,プロ グラマは編集操作履歴が記録されているプロジェクトの,過去に行われたプログ ラム変更を閲覧することができる. 評価実験では,6 個のプロジェクトの開発時の編集操作履歴から本ツールを用い てそれぞれプログラム変更を検出し,それらの検出数と 5 つの事例における人手 で作成した変更タスクとの比較と考察によって提案手法の有用性を評価した.そ の結果,それぞれのプロジェクトのプログラム変更の検出数については,検出さ れたプログラム変更の総数を,それらを集約することで 30.3∼54.5%に減少させる ことができた.また,5 つの事例における比較と考察では,時間的な方針による集 約では,どの事例においてもプログラム理解支援に一定の効果があることがわかっ た.しかし空間的な方針による集約では,集約対象であるプログラム変更の変更 箇所周辺の構文上の構造に集約結果が影響を受ける傾向があり,その結果,人手 で作成した変更タスクに近い結果を提示する事例もあるものの,時間的な方針に よる集約よりもプログラム理解支援の効果が低いことがわかった.
i
目 次
目 次 i 図 目 次 v 表 目 次 vii 第 1 章 緒論 1 1.1 ソフトウェア保守と進化 . . . . 1 1.2 プログラム理解 . . . . 2 1.3 プログラム変更理解 . . . . 4 1.4 プログラム変更検出 . . . . 6 1.5 提案手法 . . . . 7 1.6 論文の構成 . . . . 7 第 2 章 プログラム変更の検出 9 2.1 プログラム変更の推測が困難な例 . . . . 9 2.1.1 行差分ツールの限界 . . . . 9 2.1.2 類似度に基づく差分ツールの限界 . . . 11 2.2 プログラム変更の検出手法 . . . 12 2.2.1 編集操作履歴 . . . 12 2.2.2 プログラム変更情報 . . . 14 2.3 プログラム変更の利用場面 . . . 15 第 3 章 プログラム変更の特定手法 17 3.1 概要 . . . 17 3.2 編集操作の適用 . . . 19 3.3 クラス情報の抽出 . . . 20 3.4 クラス情報の比較 . . . 23 3.4.1 クラスに関する変更の特定 . . . 25 3.4.2 フィールドに関する変更の特定 . . . 263.4.3 メソッドに関する変更の特定 . . . 28 3.4.4 編集操作によるプログラム要素の削除・追加の特定 . . . 31 3.5 プログラム要素の移動の特定 . . . . 34 3.6 プログラム要素の ID の管理 . . . 38 第 4 章 プログラム変更の集約手法 39 4.1 概要 . . . 39 4.2 集約候補の特定 . . . 39 4.2.1 時間的距離 . . . 41 4.2.2 空間的距離 . . . 41 4.3 集約規則と規則の適用手順 . . . 46 第 5 章 プログラム変更検出ツール 53 5.1 概要 . . . 53 5.2 ツールの実装 . . . 53 5.2.1 編集操作履歴の読み込み . . . 53 5.2.2 クラス情報の抽出 . . . 59 5.2.3 クラス情報の比較 . . . 61 5.2.4 実装上の制約 . . . 61 5.3 プログラム変更閲覧部 . . . 62 第 6 章 評価実験 67 6.1 実験対象 . . . 67 6.2 定量的評価 . . . . 68 6.3 定性的評価 . . . . 69 6.3.1 事例 1 . . . 72 6.3.2 事例 2 . . . 73 6.3.3 事例 3 . . . 74 6.3.4 事例 4 . . . 75 6.3.5 事例 5 . . . 79 6.4 妥当性への脅威 . . . 87 6.4.1 外的妥当性 . . . 87 6.4.2 内的妥当性 . . . 87 第 7 章 関連研究 89 7.1 版間差分を用いた手法 . . . 89 7.2 より細かな差分を用いた手法 . . . . 91
目 次 iii
第 8 章 結論 93
謝辞 95
参考文献 97
v
図 目 次
2.1 行差分ツールの限界 . . . . 10 2.2 類似度に基づく差分ツールの限界 . . . 11 2.3 検出手法の概要 . . . 13 3.1 変更特定手法 . . . 18 3.2 編集操作適用の例 . . . 19 3.3 誤った対応付けの例 . . . . 31 4.1 変更集約手法 . . . 40 4.2 集約の例 . . . 50 5.1 編集操作履歴の相違点 . . . 54 5.2 Eclipse の画面 . . . . 63 5.3 プログラム変更閲覧ウィンドウ . . . 63 5.4 操作パネルと変更閲覧パネル . . . . 64 5.5 変更場所パネルと差分パネル . . . . 64 6.1 事例 4 の開発期間における初期状態のソースコード . . . 78 6.2 CID=5747∼5754 の間におけるソースコードの変化 . . . 83vii
表 目 次
2.1 プログラム変更の分類 . . . 14 3.1 クラス・フィールド・メソッドのデータ構造 . . . 22 4.1 空間的距離の計算に用いるノードの種類 . . . 44 4.2 集約規則 . . . 47 5.1 クラス情報の抽出 API . . . 60 6.1 プロジェクトの情報 . . . . 67 6.2 検出と集約の結果 (集約後/集約前) . . . 68 6.3 事例 1 における検出結果 . . . 71 6.4 事例 2 における検出結果 . . . 73 6.5 事例 3 における検出結果 . . . 74 6.6 事例 4 における検出結果 . . . 76 6.7 事例 5 における検出結果 . . . 80 6.8 CID=5747∼5754 の間における空間的距離の一覧 . . . 821
第
1
章 緒論
1.1
ソフトウェア保守と進化
ソフトウェア保守(software maintenance)とは,開発が完了したソフトウェア が引き渡された後に,クライアントによる機能拡張の要求やそのソフトウェアを 取り巻く環境の変化や運用上発見された欠陥に対処するために,そのソフトウェ アに対して行われる修正や変更などの活動を意味する [1, 2].一般的な保守は保守 対象の経年劣化などへの対処のために行われるが,ソフトウェアには実体が無く 劣化は起きないため,そのような活動は必要ない.その代わりにソフトウェア保 守では,引き渡しが行われた後において,クライアントによる機能拡張の要求や そのソフトウェアを取り巻く環境の変化や運用上発見された欠陥に対処するため に,引き渡されたソフトウェアに対して修正や変更を行う必要がある. 一般的にソフトウェア保守の作業は,(1) 引き渡し後に発見されたソフトウェア の欠陥に対して修正を行う「修正保守(corrective)」,(2) 運用にまつわる環境が 変化した時にその変化した環境に適応できるようにソフトウェアを変更する「適 応保守(adaptive)」,(3) ソフトウェアの機能拡張や性能や保守性の向上のために 変更を行う「完全化保守(perfective)」,(4) 運用においてまだ発生していないソ フトウェアの潜在的な欠陥を未然に修正する「予防保守(preventive)」の 4 つに 分類される [1, 3, 4]. 従来より,ソフトウェア保守はウォーターフォールモデル [5] によるソフトウェ ア開発工程の最終段階として,引き渡したソフトウェアに対して対処的に修正や 変更を施す活動という位置づけであった.しかし近年では,既存のソフトウェア をベースにして別のソフトウェアを開発する派生開発 [6] や,ソフトウェア開発の 初期段階からクライアントの変更要求を柔軟に受け入れるアジャイル開発 [7] など の様々な開発手法の登場により,ソフトウェアの開発工程とその各工程で行われ るソフトウェアに対する変更の過程は複雑になってきているといえる. そのような問題に対処するために,それらの変更を積極的に取り入れる仕組み や活動であるソフトウェア進化(software evolution)という研究が注目されるよ うになった [8].ソフトウェア進化の研究では,ソフトウェアは環境の変化への対 応やクライアントやユーザの要求を満たすために,常に変更が加えられ続けることを必然とし,そのような環境に適応するためにソフトウェアが変化していく様 子をソフトウェア進化と呼んでいる [3, 8, 9]. ソフトウェア進化の研究はソフトウェア保守の研究を全面的に受け継いでいる ため,ソフトウェア進化とソフトウェア保守のそれぞれの活動は共通する部分も 多い [3].そして,その両方において,機能拡張の要求や環境の変化,欠陥への対 処といった目的のために,現在のソフトウェアに対して変更を加える必要がある. 一般的に,ソフトウェア保守や進化において修正や拡張などの目的により現在 のソフトウェアに対して変更を加える場合は,そのソフトウェアのプログラムを よく理解した上で変更を加えなくてはならない [10].未知のプログラムに対して 変更を加えるとしても,プログラマはプログラムのどこに変更を加えれば目的で ある修正や拡張を実現できるのか分からない.また仮に,プログラムをよく理解 せずにそのソフトウェアに対して変更を加えようとすると,その変更が後に欠陥 を引き起こす原因となる場合もある [11]. さらに,長期的に保守され,また進化してきたソフトウェアに対して変更を加 える場合は,そのソフトウェアの現在の状態のプログラムの理解だけでは十分で ない.過去にそのソフトウェアに対して加えられたプログラム変更の内容や,そ れらのプログラム変更が加えられてきた過程やその理由を理解しなくてはならな い [11].そのようなプログラム変更過程を把握せずにプログラムに変更を加えよ うとした場合,それまでのプログラム変更過程に対して逆行するような変更を加 えてしまう場合がある.たとえば,ある保守者 X がある潜在的な問題に対処する ための変更を加えていた場合,それらに対処するためのロジックが複雑になった とする.そして保守者 X から保守作業を引き継いだ保守者 Y は,現在の状態のプ ログラムの理解だけで,そのロジックを不必要に複雑だと判断し,潜在的な問題 が存在する状態に戻してしまうかもしれない. このように,ソフトウェア保守や進化において,プログラム理解とプログラム 変更理解は不可欠な技術である.
1.2
プログラム理解
ソフトウェア保守とソフトウェア進化で共通して必要となる作業の一つに,変 更対象であるソフトウェアの振る舞いや構造についての知識を得るためのプログ ラム理解(program comprehension)がある [10, 12]. ソフトウェア保守においては,全保守工数のうちの半分が保守対象のソフトウェ アの理解にかかり,そのソフトウェアの理解のために行われるプログラム理解に, きわめて長い時間を費やすとされている [12, 13].一般的に大規模ソフトウェアは 数十万行から数百万行のコードによって構築されているため,大規模ソフトウェ1.2. プログラム理解 3 アに対してプログラム理解をする場合では,そのソフトウェアの全てを理解する ためにかかる時間や労力は莫大なものとなる.そのためプログラマがそのような ソフトウェアに変更を加える場合は,これから加える変更に関係する場所だけを 素早く的確に理解しなくてはならない [14]. プログラム理解が必要となる場面においては,理解対象であるプログラムを書 いたプログラマ(開発者)とそのプログラムを理解するプログラマ(保守者)は 異なる場合が一般的である.たとえば,ソフトウェアを開発した組織がそのソフ トウェアの保守工程を別の組織へ外部委託する場合や,オープンソースソフトウェ アや大規模ソフトウェアの開発プロジェクトで開発を行う場合に,他人の作成し たプログラムを理解する必要がある.そのような場面において,保守を行う時点 で開発者と連絡を取れない場合は,保守者にとってプログラム理解はより難しい ものとなる [15]. また,ソフトウェアの開発工程において開発されたソフトウェアが適切に文書 化され,そのソフトウェアについてを正確に記述した文書が残されている場合は, それらの文書はプログラム理解において理解の助けとなる.しかし,ソフトウェア とそのソフトウェアの文書との間の一貫性が開発や保守の過程で損なわれた,あ るいはそもそもソフトウェアの文書化が行われていないといったことはソフトウェ ア開発の現場でしばしば見られる.そしてそのようなソフトウェアのプログラム 理解はより困難なものとなる [16]. プログラム理解では,頭の中でそのプログラムについてのモデル(メンタルモ デル:mental model)を構築すると言われている [10].メンタルモデルの構築で は,プログラマはプログラミング全般についての知識(general knowledge)を利 用しながら,そのソフトウェアについての知識(software-specific knowledge)を プログラムコードから集め,そのプログラムについての仮説を立て,それらを検 証することでメンタルモデルを構築していく. また,Murphy らの研究では被験者を使ったプログラム理解の実験を通して,プ ログラマが変更作業を行う前に,変更対象であるソフトウェアの何を理解してい るかについてを 44 種類の項目にまとめ,それらの項目を以下の 4 つのカテゴリに 分類している [17].
1. 変更作業の焦点となるプログラム要素(initial focus points)の発見 2. 2 つのプログラム要素間の関係の構築
3. 複数のプログラム要素の間における関係の構造(subgraph) 4. ある subgraph とプログラム全体との関係や別の subgraph との関係
プログラム理解を支援する技術の一つに,静的プログラム解析がある [18, 19]. 静的プログラム解析では,プログラムのソースコードを解析することで,そのプ ログラムが持つ特定の観点での情報を抽出する.たとえば,そのプログラムの構 文についての情報を得たいときは,ソースコードに対して構文解析を行うことで 取得できる.さらに,プログラムを構成する要素の型などの意味的情報やそれら の要素間の依存関係についての情報を得たいときは意味解析を行うことで取得で きる [20].また,静的プログラムスライシング技術を使うことで,プログラムの ある命令が影響を受けた命令や,影響を与える命令だけをプログラムから取り出 すことができる [19].そのソフトウェアに対してのメンタルモデルを構築する上 で,ある特定の観点についての情報を得ることができる静的プログラム解析はプ ログラマにとって助けとなる. また,ソフトウェア構成管理という技術はソフトウェア開発で作成された成果 物やその変更履歴を管理する技術である [21].そのソフトウェアについての情報 を記した文書はプログラム理解の助けとなるが,管理が不十分だとそれらのソー スコードや文書との間で一貫性が損なわれる場合がある.ソフトウェア構成管理 技術を用いてそのような一貫性を保つことで,プログラム理解に有益な文書を残 すことができる.
1.3
プログラム変更理解
ソフトウェア保守やソフトウェア進化では,そのソフトウェアの拡張や修正の ためにプログラムに対して変更が加えられる.そして,そのようなプログラム変 更を適切に行うためには,変更対象のプログラムだけでなく,そのプログラムに 加える変更のプログラムへの影響や,そのプログラムに対して過去に行われてき たプログラム変更についても考慮する必要がある [22]. プログラムに加える変更がプログラムに与える影響を特定する技術として,変 更波及解析という技術がある [23, 24, 25].変更波及解析では,プログラム間の依 存関係やプログラムの実行履歴から,ある変更の影響範囲を特定することができ, プログラマは変更を加える前にその変更がどこに影響を及ぼすかを知ることがで きる. また,プログラムのある要素へ変更により変更の行われた要素と別の要素との 間で一貫性が損なわれてしまうことで,要素間の一貫性を保つためにさらなる変 更が行われることがあり,そのような,ある要素への変更が別の要素への変更を引 き起こす現象は変更伝播(change propagation)と呼ばれる [26].Hassan らの研 究 [27] では,変更波及解析の技術で明らかになる変更の影響範囲や,ある変更で プログラムの 2 つの要素が過去に同時に行われたという事実などから,変更の加1.3. プログラム変更理解 5 えられた要素から,さらに変更が加えられる可能性のある要素を予測するヒュー リスティックを提案している. 過去に行われてきたプログラム変更の理解に関する研究として,Tao らの研究 がある [22].Tao らの研究では,過去に発表された論文の中から,過去に行われた プログラム変更に関する情報の中でどのような情報がプログラムに変更を加える 前に必要とされているかを調査している.さらに,調査によって分類されたそれ ぞれの情報について開発者に対してアンケートを実施し,プログラム変更理解に おいてどの情報がどれくらい必要とされてるか,またそれが現状でどれくらい得 にくいとされているかを明らかにしている. ソフトウェアの進化やその間に行われたソフトウェアに対するプログラム変更 をそのプログラムのソースコードだけから追跡することは非常に困難である.そ のため,ソフトウェアの進化の分野においては,ソースコードの過去から現在ま での版(スナップショット)を履歴として記録しておき,その履歴に記録されてい る版の変化からそのソフトウェアの進化や過去に行われたプログラム変更を推測 するのが一般的である [28]. プログラム変更理解の支援技術の一つとして,版管理システムが挙げられる [29]. CVS, Subversion, Git などの版管理システムはソースコードやその他の成果物の履 歴を記録・管理するツールである.版管理システムを用いた多人数による開発プ ロジェクトでは,開発しているソフトウェアのソースコードは一元的に管理され, ソフトウェアの開発者や保守者がソフトウェアに変更を加える場合は,版管理シ ステムからソフトウェアのある状態のソースコードのファイルを取り出し,取り 出したファイルに変更を加え,変更を加えたファイルを版管理システムにコミッ ト(格納)する. プログラム変更理解では,対象のソフトウェアの現在の状態だけでなく,そのソ フトウェアの履歴における全ての状態を考慮しなくてはならず,長期間に渡り進 化してきたソフトウェアのプログラム変更理解のために考慮する情報量は大量と なる.そのため,そのような問題に対処するために版管理システムに記録された 版の可視化技術が提案されている.たとえば,CVSscan [30] では,版管理システ ムである CVS で管理されているソースコードのそれぞれの版の間の差分から行単 位の変更箇所を特定し,横軸に版管理システムに記録されたそれぞれの版を,縦 軸にそれぞれの版のソースコードの行を並べ,それぞれの版間で変更が加えられ た行に対して色付けを行うことで,履歴に記録されている全ての版とそれらの間 に行われた変更を可視化している.
1.4
プログラム変更検出
本研究と関連が強いプログラム変更の理解支援技術として,プログラム変更検 出がある.プログラム変更検出ではソースコードの版が記録された履歴から,過 去に行われたプログラム変更を検出する. 従来から行われている伝統的なプログラム変更検出手法として,版管理システ ムに記録されているソースコードの 2 つの版から,UNIX diff などの行差分ツー ルを活用して 2 つの版の差分を作り出し,その差分からその間に行われたプログ ラム変更を抽出することが行われている.しかしながら,これらの変更検出手法 には限界があることが Robbes と Lanza [31] によって指摘されている. 一般的に開発者は任意のタイミングでソースコードを版管理システムへコミッ トできる.このため,単一の版間差分(連続する 2 つの版の間のコード差分)の 中に複数の変更が混ざり合うことが頻繁に発生する [32].また,単一の版間差分 の中にプログラムの変更とリファクタリングが同時に行われることが多いという 報告もある [33].このように,版管理システムに記録される単一の版間差分に対 して,必ずしも単一の変更やリファクタリングだけが含まれているわけではない. 変更が混ざり合うことを避けるために,開発環境がエディタで行われた細粒度 変更を自動的に記録し,過去に行われた個々の変更を追跡するための新しい手法 が提案されている [34, 35, 36, 37, 38, 39, 40, 41]. SpyWare [34] は,統合開発環境である Squeak においてプログラムの構文上の 変化をすべて記録する.Syde [35] や EclipseEye [36] では,Robbes らの提案する CBSE(change-based software evolution) [31] に基づき,Eclipse 上で行われた細粒 度のプログラムの変化を記録する.また,ChEOPSJ [37] では,Eclipse 上で行われた パッケージ,クラス,フィールド,メソッドなどのプログラム要素についての追加,削 除,変更を記録する.OperationRecorder [38, 39] や Fluorite [40],CodingTracker [41] では,プログラムの構文上の変化だけでなく,開発時に Eclipse 上で行われた操作 を記録している. これらの手法が提案するツールを導入することで,開発者や保守者が混ざり合っ た変更を解きほぐす手間が削減される.しかしながら,これらのツールが提示す る変更情報はテキストや単一の構文要素の変化であり,開発者や保守者がプログ ラムの変更を理解するという観点からは,その粒度が細かすぎる.特にオブジェ クト指向プログラムにおけるプログラム変更理解においては,クラス,フィール ド,メソッドなどのプログラム要素に関する追加や削除など,開発者や保守者に とって直感的な変更を把握することが重要であるといわれている [24, 25]. また,一般的に,プログラムの変更過程は複数のプログラム変更の適用により 達成される.このため,プログラムの変更過程の理解に有用な変更情報を提示す るためには,次に示す 2 つの作業が必要であると考えられる.1.5. 提案手法 7 1. 個々のプログラム変更を(より正確に)検出する. 2. 検出したプログラム変更に,その内容(理由や意図など)を付与する.これ を変更タスクと呼ぶ.
1.5
提案手法
本研究では,OperationRecorder により開発時に記録された編集操作履歴から,オ ブジェクト指向プログラミング言語 Java のプログラム要素に関する変更情報(本 研究ではプログラム変更と呼ぶ)を検出する手法を提案する. 本手法では,過去のプログラムの変更過程におけるプログラム変更を適切な粒 度で検出することで,1.4 節で示した 2 つの作業のうち,作業 (1) を自動化する. 一般的に,作業 (2) において,適切な変更内容を機械的に付与することは非常に困 難である.そこで我々は,作業 (1) を自動化し,開発者や保守者が作業 (2) に専念 できる環境を提供する.これにより,開発者や保守者によるプログラムの変更過 程の理解を支援することを目指す. またその際には,以下の 2 つが本研究における課題となる. 1. 作業 (1) の自動化において個々のプログラム変更の検出を正確に行うこと 2. 作業 (2) において変更の内容を記述する開発者や保守者に受け入れられるプ ログラム変更を提示すること 課題 (1) については,編集操作履歴という細粒度変更情報を用いてプログラム変 更を検出することで,版間差分情報を用いる従来手法よりも正確なプログラム変 更を検出する.課題 (2) については,一度特定されたプログラム変更について,そ れらを異なる粒度で集約できるようにし,記述する開発者や保守者が集約の粒度 を変更内容を選択できるようにすることで,開発者や保守者に受け入れられるプ ログラム変更を提示することを目指す.1.6
論文の構成
本論文の構成について述べる.第 2 章では,本手法の概要や本手法の動機とな る例題,本手法の利用場面などについて説明する.第 3 章では,プログラム変更を 特定する手法を説明する.第 4 章では,プログラム変更を集約する手法を説明す る.第 5 章では,本手法を実装したツールの実装と利用方法を示す.第 6 章では, ツールを用いた評価実験の結果を示し,その結果に基づく考察を述べる.第 7 章 では,本研究の関連研究を紹介する.最後に第 8 章では,本論文の結論を述べる.9
第
2
章 プログラム変更の検出
2.1
プログラム変更の推測が困難な例
提案手法では,開発者が任意のタイミングで版管理システムにソースコードを コミットするという状況を想定している.このような状況では,個々のプログラ ム変更が混ざり合うことで,正確なプログラム変更の推測が困難になり,1.4 節で 示した 2 つの作業のうちの作業 (1) の障害となる.ここでは,版間の差分を用いた プログラム変更検出ツールでは版間のプログラム変更を正確に検出できない例を 2 つ示す. 1. 行差分ツールの限界 まず,版間差分ではプログラム変更を正確に検出できない単純な例として, ある 3 つの変更を行った前後のソースコードのスナップショットから,UNIX diff を用いて推測されるプログラム変更の結果が実際に行われた変更と異なっ てしまう例を 2.1.1 節に示す. 2. 類似度に基づく差分ツールの限界 既存手法の中にはコードの類似度などを用いて,より正確な変更内容を推測 行うことものがある.ここでは,そのような手法においても正確にプログラ ム変更を検出できない例を 2.1.2 節に示す.この例ではプログラム変更の行 われた前後のスナップショットの間で同一と見なすメソッドのペア付けに焦 点を当てており,メソッドの類似度を用いてもメソッドのペア付けが正確に できない場合があることを示す.ここで,類似度に基づく差分ツールでは, メソッドヘッダ (パッケージ名,クラス名,名前,引数のリスト,戻り値の 型の組) の類似度を用いた手法 [42] とメソッド本体の類似度を用いた手法を 想定している.2.1.1
行差分ツールの限界
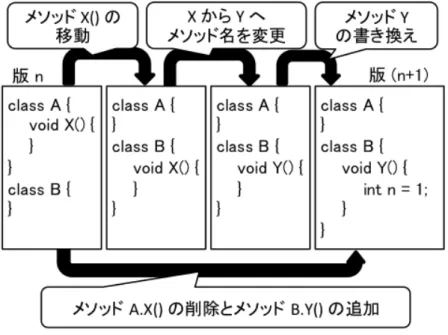
図 2.1 は以下の 3 つの変更が,版 n のソースコードと版 (n + 1) のソースコード の間で行われたことを示している.図 2.1: 行差分ツールの限界 1. メソッド X() がクラス A からクラス B へ移動 2. クラス B のメソッド X() を Y() に名前変更 3. クラス B のメソッド Y() のメソッド本体の書き換え 版 n と 版 (n + 1) のソースコードに対して UNIX diff を実行した結果は下のよ うになる. 2,3d1 < void X() { < } 6a5,7 > void Y() { > int n = 1; > } 上から 3 行はメソッド X() の削除を表し,下から 4 行はメソッド Y() の追加を 表している.この結果と上記の 3 つの変更と比較すると,「版 n におけるメソッド X() と版 (n + 1) におけるメソッド Y() が同一である」という情報が欠落している ことが分かる.このような情報の欠落により,版間におけるプログラム要素の追 跡性が失われてしまい,その版以前のそのプログラム要素の変更過程を理解する ことができなくなってしまう.
2.1. プログラム変更の推測が困難な例 11 図 2.2: 類似度に基づく差分ツールの限界 このように,行差分ツールでは個々の変更を分離することが難しい場面がある. このとき,保守者は混ざり合った複数の変更を手動で解きほぐさなければならな いが,これは面倒で時間のかかる作業である.
2.1.2
類似度に基づく差分ツールの限界
ここでは,類似度に基づく差分抽出手法で正確なプログラム変更を検出するこ とが困難な例を示す.図 2.2 では,以下の 3 つの変更が版 n のソースコードと版 (n + 1) のソースコードの間でクラス A に対して行われたことを示している. 1. メソッド X() を Y() に名前変更 2. メソッド Y() のメソッド本体の書き換え 3. メソッド X() を追加 このような変更が行われた版 n と版 (n + 1) のソースコードから正確なプログラ ム変更を検出するためには,版 n に存在するメソッド X() に対応するメソッド Y()を版 (n + 1) のソースコードにおいて特定することできるかどうかが鍵である. い ま,メソッドの類似度に基づきメソッドの対応を特定すると,メソッドヘッダに関 するトークンベースの類似度により,版 (n + 1) の X() が選ばれる.メソッド本体 のコードの類似度を用いても,X() が選ばれる可能性が高い.このように,メソッ ドヘッダや本体コードの類似度を用いても,実際に名前変更が実施された後のメ ソッド Y() の特定に失敗する可能性が残る.
2.2
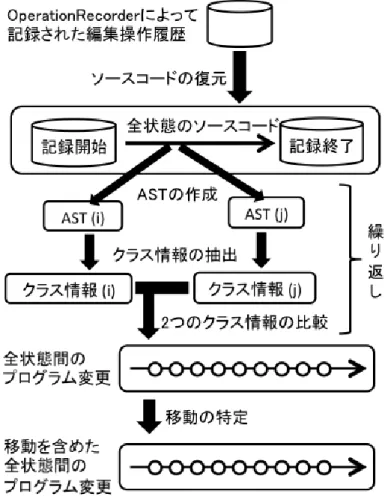
プログラム変更の検出手法
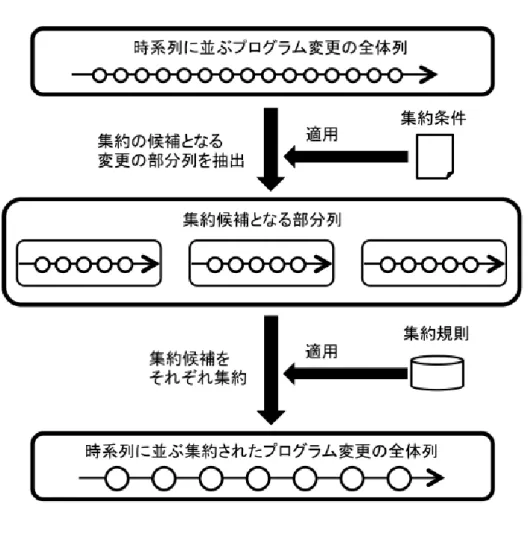
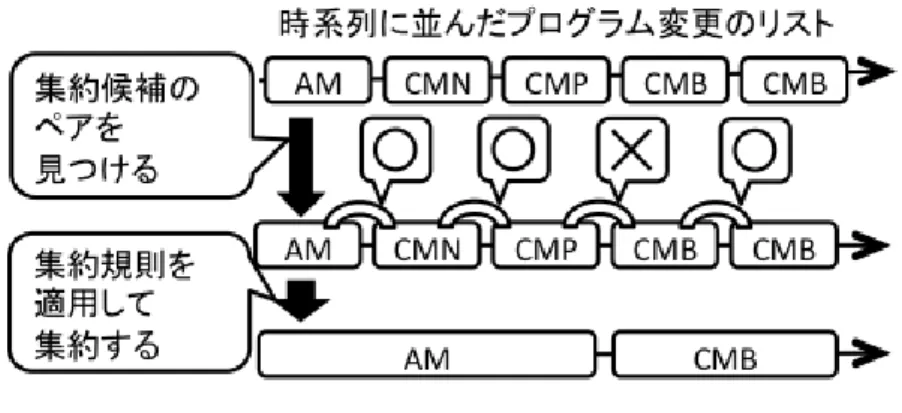
本手法の概要を図 2.3 に示す.本手法は OperationRecorder の記録する編集操作 履歴を入力とし,開発時に行われた変更内容を表すプログラム変更情報を出力す る.本手法では,まず編集操作履歴から過去のソースコードのスナップショット (特定の時刻におけるソースコード)を復元し,構文解析を適用する.次に,構文 解析可能なスナップショットのうち,時間的に隣接する 2 つを比較し,プログラム 変更を特定する.さらに,本手法では,検出したそれぞれの変更をあらかじめ定 義した規則に基づいて集約する.その際,開発者や保守者が集約の方針を与える ことができる.これにより,冗長な情報を排除しつつ,さまざまな粒度でプログ ラム変更を提示できるようになる. 次節以降では,まず本手法で利用する編集操作履歴について 2.2.1 節で述べ,本 手法で提示するプログラム変更情報の詳細を 2.2.2 節に示す.本手法の変更特定の 手法については 3 章で,本手法の変更集約の手法については 4 章でそれぞれ説明 する.2.2.1
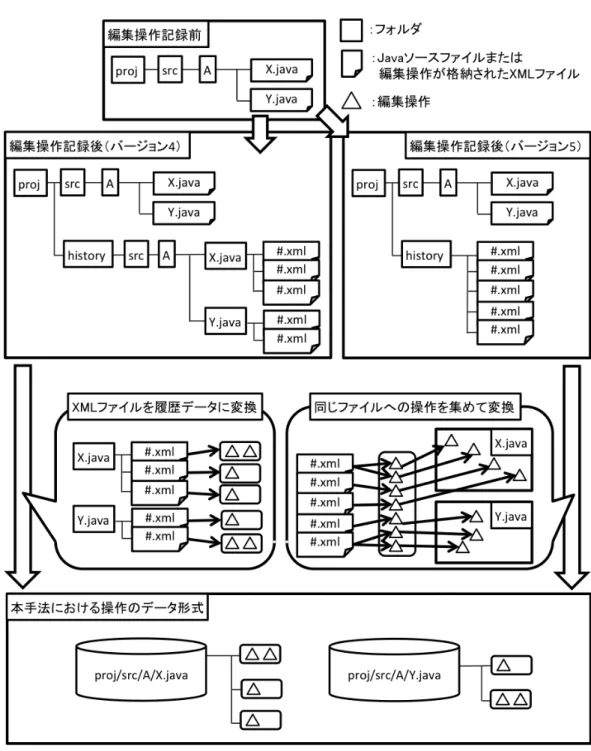
編集操作履歴
本手法で利用する編集操作履歴は OperationRecorder [39] によって記録されたも のを用いる.OperationRecorder は大森によって開発された Eclipse プラグインとし て動作する編集操作記録ツールである.OperationRecorder を入れた状態で Eclipse を起動し,OperationRecorder が提供するエディタ上で Java プログラムを開発する ことで,開発時に行われたテキスト編集操作やファイル操作など,プロジェクト に対して行われた様々な操作を記録することができる [38].本手法では編集操作 履歴に記録されている操作のうち,ソースコードの復元に関する編集操作だけを 利用する.また,利用した OperationRecorder のバージョンの違いにより,編集操 作履歴には 2 種類の形式が存在するが,本手法ではそのどちらも読み込むことが できる.2.2. プログラム変更の検出手法 13
表 2.1: プログラム変更の分類 タイプ 意味 AC クラスやパッケージにクラスを追加する DC クラスやパッケージからクラスを削除する MC 他のクラスやパッケージへクラスを移動する CCN クラスの名前を書き換える AF クラスにフィールドを追加する DF クラスからフィールドを削除する MF 他のクラスへフィールドを移動する CFN フィールドの名前を書き換える CFT フィールドの型を書き換える AM クラスにメソッドを追加する DM クラスからメソッドを削除する MM 他のクラスへメソッドを移動する CMN メソッドの名前を書き換える CMT メソッドの戻り値の型を書き換える CMP メソッドの引数を書き換える CMB メソッドの本体を書き換える
2.2.2
プログラム変更情報
OperationRecorder により記録された編集操作履歴において任意の編集操作を指 定することで,その適用直後のソースコードのスナップショットを復元できる.ま た,各編集操作には,その適用時刻が記録されている.これらの性質を利用して, 本手法では以下に示すプログラム変更情報を出力する. 識別番号 (CID) 変更を検出した順番に自動的に割り振られる. 変更の開始時刻と終了時刻 開始時刻は,その変更に関係する編集操作の中で,編 集操作が行われた時刻が最も早いものとなる.また,終了時刻は,その変更 に関係する編集操作の中で最も遅いものとなる.これらの時刻は変更検出時 に自動的に格納される. 変更箇所 変更に関係するプログラム要素を含むソースファイル,パッケージ,ク ラスの名前を指す.これらの名前はソースコードの変更前後のスナップショッ トから自動的に取得される.2.3. プログラム変更の利用場面 15 編集操作 変更に関係する編集操作の集合を指す.一つ前のプログラム変更の直後 からこの変更までの間に適用されたすべての編集操作が自動的に格納される. 変更の種類 表 2.1 に示すプログラム変更の分類のどれかである. 表 2.1 について,この手法では文献 [24, 25] と同様に,オブジェクト指向プログ ラムのソースコードの書き換えを,クラス,フィールド,メソッドに関する変更の 種類に分類する. たとえば,2.1.1 節の例において,本手法では 3 つのプログラム変更を適切に検 出できる(それぞれ,表 2.1 の MM, CMN, CMB ).さらに,開発者や保守者 の方針に従い変更の要約を提示することができる.たとえば,開発者や保守者に よっては,3 つの変更が個別に提示されるよりも単一のメソッドの移動(表 2.1 の MM)と提示された方が,その変更内容を付与する上で有益であるかもしれない. 本手法は,このような要求にも応じることができる. また,2.1.2 節の例においても,版 n と版 (n + 1) 間に行われた 3 つの変更を,本 手法で検出できることを確認している.
2.3
プログラム変更の利用場面
2.2.2 節に示したプログラム変更情報に対して,我々は,主に 2 つの利用場面を 想定している. 1. 開発者がソースコードをコミットする場面 開発者が版 (n + 1) のソースコードを版管理システムにコミットしようとし た際に,版 n と版 (n + 1) の間に行われたプログラム変更を検出して提示す る.これにより,版 (n + 1) に対するコミットコメント(コミットログ,コ ミットメッセージ)の入力を支援する.提示するプログラム変更は,版 n お よび版 (n + 1) のソースコードをコミットしたそれぞれの時刻(tnと t(n+1)と する)を利用して選択する.具体的には,検出したすべてのプログラム変更 から,開始時刻が tnより後ろ,かつ,終了時刻が t(n+1)より前のプログラム 変更だけを取り出し,開発者に提示する.たとえば,2.1.1 節の例では,版 (n + 1) のソースコードをコミットする際に,開発者に 3 つのプログラム変更 MM, CMN, CMB の存在が提示される.これにより,開発者は,それぞれ のプログラム変更に対して別々に変更の内容を記述すべきかどうかを検討す る必要性に気付く.つまり,将来のプログラム変更過程の理解のために,よ り正確な変更タスクが残される可能性が高まる.2. 保守者がプログラムの変更過程を把握する場面 保守者が特定の Java プロジェクトにおけるプログラムの変更過程を把握し ようとした際に,すべてのプログラム変更を検出して提示する.コミットの タイミングやコミットコメントに対する方針が決められていない開発では, 版間の差分を単純に利用して検出したプログラム変更は不正確になることが 多い.たとえば,2.1.1 節の例において,開発者が 3 つの変更を実行するごと にコミットしておけば,保守者は版間の差分により 3 つのプログラム変更を 把握できる.あるいは,開発者がコミットコメントとして版間に 3 つの変更 が混在していることを明記しておけば,保守者は 3 つの変更を把握できる可 能性は高くなる.しかしながら,1 章で述べたように,単一の版間差分の中 に複数の変更が混ざり合っているのが現状である.このような状況において, 既存プログラムの変更過程を理解しなければならない場合,より正確なプロ グラム変更を検出したいと考えるのは自然である.さらには,検出されたプ ログラム変更にその内容が付与され,より正確な変更タスクが残せれば,将 来の保守作業の助けになる. ここで,提案手法は通常の版管理システムによって記録される版の情報を一切 利用せずにプログラム変更を検出する.よって,提案手法によるプログラム変更 の検出結果は,版管理システムの利用の有無によって変化しない.しかしながら, 版管理システムと本手法を連携して利用することで,上記に示した利用場面を実 現できる.たとえば,利用場面 (1) では,コミットが行われた時刻の共有やコミッ トコメント入力時のエディタへのプログラム変更情報の提供を行うことで開発者 による変更内容の記述を支援できる.また,利用場面 (2) では,保守時に検出した プログラム変更情報を過去のコミットコメントに追加したり,それらを共有する 機能を提供することで,保守者当人のプログラム変更理解の支援だけでなく,将 来,保守を行う者に対してもより洗練された変更タスクを残すことができる.
17
第
3
章 プログラム変更の特定手法
3.1
概要
変更特定手法の概要を図 3.1 に示す.変更特定手法は以下の 4 つの手順で実現さ れている. 1. 過去の全状態のソースコードの復元 OperationRecorder により記録された時 間的順序に従い,過去の編集操作を適用することで,プロジェクトに存在し た Java ソースファイルの全状態のスナップショットを復元する.たとえば, プロジェクト開始から現在に至るまで編集操作を記録している場合, 図 3.1 における「記録開始」は,プロジェクト開始時点のスナップショットを意味 し,「記録終了」は最新のスナップショットを意味する.ここで,時刻 0 およ び時刻 t における S のスナップショットを S0および Stとすると,Stは時刻 0 から時刻 t の間に行われたすべての編集操作を S0に適用することで復元す ることができる.このようにして,各編集操作が適用されるごとに,その時 刻のソースコードのスナップショットを取得する.編集操作のデータ構造や ソースファイルへの編集操作の適用についての詳細は 3.2 節で説明する. 2. スナップショットの構文解析とクラス情報の抽出 それぞれのスナップショットに対して構文解析を適用する.構文解析が成功 した場合,抽象構文木 (AST: Abstract Syntax Tree) [20] を作成して,クラ スの情報を抽出する.ここでは,Stに含まれるすべてのクラスに関するクラ ス情報を集めた集合を Itと呼ぶ.クラス情報の抽出の詳細については 3.3 節 で説明する. 3. クラス情報の比較 隣接する 2 つのスナップショット Siと Sjのクラス情報 Iiと Ijを比較し,ク ラス情報の差分からプログラム変更を抽出する.ここで,構文解析可能な隣 接するスナップショット Si, Sj(i < j) とは,Siと Sjの両方とも構文解析可 能,かつ,i < k < j を満たす構文解析可能なスナップショット Skが存在し ないことを意味する.それぞれ隣接する 2 つのクラス情報からプログラム変3.2. 編集操作の適用 19 図 3.2: 編集操作適用の例 更をそれぞれ抽出することで,全状態間におけるプログラム変更を取得する ことができる.2 つのクラス情報の比較において,クラスの比較による変更 の特定については 3.4.1 節,フィールドの比較による変更の特定については 3.4.2 節,メソッドの比較による変更の特定については 3.4.3 節でそれぞれ説 明する.また,クラス情報の比較において,編集操作からプログラム要素の 削除・追加の特定を行っており,その詳細については 3.4.4 節で説明する.ま た,本手法ではクラス情報の比較の際に,各スナップショット間のプログラ ム要素の対応を把握するためにプログラム要素を識別する ID を管理してお り,その詳細については 3.6 節で説明する. 4. プログラム要素の移動 ここまでの手順によって得られた削除・追加に関するプログラム変更(DC, AC,DF,AF,DM,AM)から,プログラム要素の移動についてのプロ グラム変更(MC,MF,MM)を特定する.移動の特定についての具体的 な手順は 3.5 節で説明する.また,本手法ではプログラム要素を識別する ID を管理しており,プログラム要素の移動が特定された場合に,移動されたプ ログラム要素の対応を把握するために移動によって追加されたプログラム要 素の ID を更新している.その詳細については 3.6 節で説明する.
3.2
編集操作の適用
ここでは,ソースコードの復元における編集操作の適用について説明する.ある ソースファイルに対して行われる 1 つの編集操作には以下の情報が含まれている.1. 編集ファイル(file) 編集操作の行われたソースファイルのファイルパスが格納されている 2. 編集箇所(offset) そのソースファイルの先頭から何文字目に対してテキスト書き換えが行われ たのかのオフセットを表す数値が格納されている. 3. 編集時刻(time)
編集操作が行われた時刻がミリ秒の精度の UNIX 時刻(UNIX time)の形式 で格納されている. 4. 挿入文字列(insertedText) 編集操作によって挿入される文字列が格納されている. 5. 削除文字列(deletedText) 編集操作によって削除される文字列が格納されている. ここで,編集操作の適用の例を図 3.2 に示す.図では,編集操作適用前のソース ファイルに対して編集操作が適用され,編集操作適用後のソースファイルが作成 されたことを表している.また編集操作の持つ情報は「編集箇所」が「27」,「編集 時刻」が「1230953050143」,「挿入文字列」が「Y」,「削除文字列」が「X」となる. 編集操作の適用では,ソースファイルの編集箇所の文字が削除され,そのあとに 編集箇所に挿入文字列が挿入される.この例では,27 文字目に存在する文字「X」 が削除されてそのあとに同じ 27 文字目に文字「Y」が挿入され,右のソースコー ドが作成されている.
3.3
クラス情報の抽出
本手法ではソースファイルから AST を作成し,作成された AST からクラス情 報を抽出する.一つのソースファイルから作成された AST には,そのソースファ イルに記述されているクラスやそのクラスが持つフィールドやメソッドのノード が含まれている.また Java において,一つのソースファイルに記述できるクラス の数は一つだけではないため,本手法で AST から抽出するクラス情報には複数の クラスについての情報が含まれていることがある. ここで,ひとつのクラス,フィールド,メソッドについての情報のデータ構造 を表 3.1 に示す.表の「データ名」はそれぞれの持つデータの種類を表しており,3.3. クラス情報の抽出 21 「説明」はそのデータの説明が記載されている.表はクラス,フィールド,メソッ ドについてのデータ構造に分かれており,「クラス」,「フィールド」,「メソッド」の 下にそれぞれ続く行がそれぞれに対応するデータとなっている. さらに,それぞれのデータを本手法のどの段階で利用するかについて説明する. クラス情報の比較(3.4.1 節,3.4.2 節,3.4.3 節)において,クラスの name,フィー ルドの name, type,メソッドの name, type, param, body それぞれ利用され る.また,編集操作によるプログラム要素の削除・追加の特定(3.4.4 節)におい て,クラスの name, start, end,フィールドの className, name, start, end, メソッドの className, name, start, end が利用される.また,プログラム要素 の移動の特定(3.5 節)において,クラスの fileName, name, text,フィールド の fileName, className, text,メソッドの fileName, className, text がそ れぞれ利用される. 本手法では列挙体からもクラス情報を抽出し,抽出後はクラスとして扱う.こ のとき,各列挙体に存在する列挙子はフィールドに関する情報として抽出を行い, そのときのフィールドの型は「EnumConstant」とする.その他のフィールドやメ ソッドに関する情報の抽出についてはクラスにおけるクラス情報の抽出と同様で ある. また,抽象クラスやインターフェースからもクラス情報を抽出し,抽出後はク ラスとして扱う.このとき,抽象クラスに存在する抽象メソッドやインタフェース に存在するメソッド宣言もメソッドに関する情報として抽出を行う.これらのメ ソッドはメソッド本体を持たないため,本手法ではメソッド本体が空のメソッド として扱い情報を抽出する. 本手法では,抽出するクラスがジェネリックを行っている場合に付く型パラメー タはクラス名に含まない(たとえば,「A<T >」というクラスが定義されていた場 合,抽出されるクラス名は「A」となる).ただし,フィールドやメソッドなどの クラスメンバの型に型パラメータが指定されていた場合は,それらの型名に含め る(たとえば,「List<String>」型のフィールドが定義されていた場合,このフィー ルドの型は「List<String>」として扱われる). 本手法の解析対象である Java では,クラスや列挙体の中に別のクラスや列挙体 を内部クラスとして定義することができる.本手法では,内部クラスがスナップ ショットの中に存在するとき,本手法ではそれらをすべてトップレベルのクラスと して扱う.この場合,クラス情報のデータ構造上では抽出されたクラス間の包含関 係が失われるが,各クラスにはクラス名に完全限定名が格納されるためそれらの クラス間の包含関係を把握するこができる.(たとえば,デフォルトパッケージ内 にクラス A の中に内部クラス X が定義されている場合,クラス A とクラス X の情 報がそれぞれ抽出されるが,クラス A のクラス名は「−.A」,クラス X「−.A.X」
表 3.1: クラス・フィールド・メソッドのデータ構造
データ 説明
クラス
fileName このクラスが記述されているソースファイルの名前
name このクラスの属するパッケージを含むの完全限定名(fully-qualified name) text このクラスのソースファイル上のテキスト表現 start このクラスがソースファイル上で何文字目から始まるかを表すオフセット end このクラスがソースファイル上で何文字目に終わるかを表すオフセット fields このクラスが持つフィールドの集合 methods このクラスが持つメソッドの集合 フィールド fileName このフィールドが記述されているソースファイルの名前 className このフィールドを持つクラスの完全限定名 text このフィールドのソースファイル上のテキスト表現 start このフィールドがソースファイル上で何文字目から始まるかを表すオフセット end このフィールドがソースファイル上で何文字目に終わるかを表すオフセット name このフィールドの名前 type このフィールドの型 メソッド fileName このメソッドが記述されているソースファイルの名前 className このメソッドを持つクラスの完全限定名 text このメソッドのソースファイル上のテキスト表現 start このメソッドがソースファイル上で何文字目から始まるかを表すオフセット end このメソッドがソースファイル上で何文字目に終わるかを表すオフセット name このメソッドの名前 type このメソッドの型 param このメソッドの引数を表現するフィールドの集合 body このメソッドの本体のASTノード
3.4. クラス情報の比較 23 となる.) また,Java では匿名クラスをソースコードに定義することができるが,匿名ク ラスにはクラス名が存在しないため検出対象外としている.
3.4
クラス情報の比較
クラス情報の比較では,あるソースファイルの 2 つのスナップショットからそれ ぞれ抽出されたクラス情報の中に存在する,クラス,フィールド,メソッドの比較 を行うことで,そのスナップショットの間に行われたプログラム変更を特定する. またクラス情報の比較では,同じソースファイルについての連続する 2 つのス ナップショットを比較するため,それらの間でソースファイルのほとんどのコード を入れ替えるような書き換えが起こらない限り,片方のクラス情報に存在するプ ログラム要素のいくつかはもう片方のクラス情報にも存在することが期待できる. そのためクラス,フィールド,メソッドの比較では,それらのクラス情報の間で 同一のプログラム要素と思われるペアを見つけていき,そのペアの中で情報の一 部が違うペアをその情報に変更が起きたものとみなし,クラス情報に存在するペ アとならなかったプログラム要素を削除・追加されたものとみなすことが比較手 順の基本的な流れとなる. プログラム変更特定の手順としてはまず,2 つのクラス情報から同一のクラスで あるペアを見つけ,クラスに関するプログラム変更を特定する.そしてその中で同 一とみなされたペアのクラス同士で,それらのクラスが持つフィールドとメソッド をそれぞれ比較して,フィールドやメソッドに関するプログラム変更を特定する. クラスの比較による変更の特定については 3.4.1 節,フィールドの比較による変 更の特定については 3.4.2 節,メソッドの比較による変更の特定については 3.4.3 節 でそれぞれ説明する. また,クラス情報の比較によるプログラム変更の特定の精度を向上させるため に,本手法ではクラス情報の比較の中で,さらに編集操作によるプログラム要素 の削除・追加の特定も行っている.クラス情報を比較する前に編集操作によって プログラム要素が追加・削除されたことが分かれば,比較するプログラム要素の 候補が事前に減るため,クラス情報の比較の際に異なるプログラム要素を同一の プログラム要素とみなしてしまう誤りを減らすことができる.編集操作によるプ ログラム要素の削除・追加の具体的な手順については,3.4.4 節で説明する.Algorithm 1: ClassChange(St1, St2) 1 Ct1 ← St1に存在するすべてのクラス; 2 Ct2 ← St2に存在するすべてのクラス; 3 foreach ct1∈ Ct1 do 4 if ct1 が操作 ops(t1, t2) によって削除されたthen 5 ct1 をDCとして検出; 6 ct1 をCt1から除外; 7 ct1 が持つすべてのフィールドをDFとして検出; 8 ct1 が持つすべてのメソッドをDMとして検出; 9 end 10 end 11 foreach ct2∈ Ct2 do 12 if ct2 が操作 ops(t1, t2) によって挿入されたthen 13 ct2 をACとして検出; 14 ct2 をCt2から除外; 15 ct2 が持つすべてのフィールドをAFとして検出; 16 ct2 が持つすべてのメソッドをAMとして検出; 17 end 18 end 19 foreach ct1∈ Ct1, ct2∈ Ct2 do
20 if ct1.name = ct2.name then
21 FieldChange(ct1, ct2); 22 MethodChange(ct1, ct2); 23 ct1 をCt1から除外; 24 ct2 をCt2から除外; 25 end 26 end 27 Ct1 に存在するすべてのクラスをファイルに現れる順にソート; 28 Ct2 に存在するすべてのクラスをファイルに現れる順にソート; 29 for n← 1 to max(#Ct1, #Ct2) do
30 if Ct1[n].name6= Ct2[n].name then 31 Ct1[n]とCt2[n] を CCNとして検出; 32 FieldChange(Ct1[n], Ct2[n]); 33 MethodChange(Ct1[n], Ct2[n]); 34 Ct1[n] をCt1から除外; 35 Ct2[n] をCt2から除外; 36 end 37 end 38 Ct1 に残っているすべてのクラスをそれぞれDCとして検出; 39 Ct1 に残っているすべてのフィールドをそれぞれDFとして検出; 40 Ct1 に残っているすべてのメソッドをそれぞれ DMとして検出; 41 Ct2 に残っているすべてのクラスをそれぞれACとして検出; 42 Ct2 に残っているすべてのフィールドをそれぞれAFとして検出; 43 Ct2 に残っているすべてのメソッドをそれぞれ AMとして検出;
3.4. クラス情報の比較 25
3.4.1
クラスに関する変更の特定
アルゴリズム 1(ClassChange(St1, St2))では,t1<t2 となる時刻 t1 と時刻 t2 の スナップショットからそれぞれ取得した二つのソースファイル (St1, St2) から,主 にクラスに関する変更(AC,DC,CCN)を特定する.アルゴリズム 1 に対応 する手順の説明は以下となる. 1. クラス情報の抽出(1∼2 行目) St1, St2に存在するすべてのクラスに関する情報をそれぞれ抜き出し,それ らの集合をそれぞれ Ct1, Ct2とおく. 2. 編集操作によるクラスの削除の特定(3∼10 行目) Ct1に存在するクラスの中から時刻 t1 から時刻 t2 に行われた編集操作 ops(t1, t2) によって削除されたクラスをみつけ,これらのクラスをそれぞれクラスの削 除(DC)として特定し,各クラスが持っていたフィールドやメソッドもそ れぞれフィールドの削除(DF),メソッドの削除(DM)として特定する. ここで Ct1から見つかったクラスは,編集操作によって削除されたことが明 らかなので,これらのクラスを Ct1からそれぞれ取り除く.編集操作による DC の特定の具体的な手順については 3.4.4 節で説明する. 3. 編集操作によるクラスの追加の特定(11∼18 行目) Ct2に存在するクラスの中から時刻 t1 から時刻 t2 に行われた編集操作 ops(t1, t2) によって挿入されたクラスを見つけ,これらのクラスをクラスの追加(AC) として特定し,これらのクラスが持つフィールドやメソッドもそれぞれフィー ルドの追加(AF),メソッドの追加(AM)として特定する.ここで Ct2か ら見つかったクラスは,編集操作によって挿入されたことが明らかなので, これらのクラスを Ct2からそれぞれ取り除く.編集操作による AC の特定の 具体的な手順については 3.4.4 節で説明する. 4. 同一クラスの対応付け(19∼26 行目) Ct1, Ct2からクラスの名前が一致するペアをみつけ,これらのクラスを同一の クラスとみなす.それぞれ同一クラスとみなされたペアについて,それらが持 つフィールドやメソッドに関するプログラム変更を特定するために後述するア ルゴリズム 2(FieldChange(Ct1, Ct2))とアルゴリズム 3(MethodChange(Ct1, Ct2)) をそれぞれ呼び出す.最後に,ここでペアとなったクラスは Ct1, Ct2からそ れぞれ取り除く.5. クラスの名前の書き換えの特定(27∼37 行目) Ct1, Ct2に残されたクラスをファイルに現れる順番で上から順番に対応付けて いき,対応付けによってペアとなった 2 つのクラスをクラス名が変更された 同一のクラスとみなし,これらのクラスをクラスの名前の書き換え(CCN) として特定する.手順 4 と同様に,アルゴリズム 2(FieldChange(Ct1, Ct2)) とアルゴリズム 3(MethodChange(Ct1, Ct2))をそれぞれ呼び出し,フィール ドやメソッドについての変更を特定する.最後にここでペアとなったクラス を Ct1, Ct2からそれぞれ取り除く.29 行目の「max(#Ct1, #Ct2)」とは,二 つのクラスに関する集合 Ct1, Ct2のうち,より大きい方の要素数を意味する. 6. 残されたクラスを追加・削除として特定(38∼43 行目) 以上の手順を経て,Ct1に残されたクラス(Ct1に存在して Ct2に存在しない クラス)を,時刻 t1 から時刻 t2 の間に削除されたクラスとみなし,クラス の削除(AC)として特定する.また,Ct2に残されたクラス(Ct1に存在せ ず Ct2に存在するクラス)を,時刻 t1 から時刻 t2 の間に追加されたクラス とみなし,クラスの追加(DC)として特定する.
3.4.2
フィールドに関する変更の特定
アルゴリズム 2(FieldChange(Ct1, Ct2))では,与えられた 2 つのクラスに関する 情報 Ct1, Ct2から,フィールドに関するプログラム変更(AF,DF,CFN,CFT) を特定する.Ct1, Ct2はアルゴリズム 1 で編集前後の同一のクラスとみなされたペ アであり,Ct1が編集前のクラス,Ct2が編集後のクラスを意味する.アルゴリズ ム 2 に対応する手順の説明は以下となる. 1. フィールドの集合の取り出し(1∼2 行目) Ct1と Ct2に存在するフィールドをすべて取り出し,それぞれフィールドの 集合 Ft1,Ft2とする. 2. 編集操作によるフィールドの削除(3∼8 行目) Ft1から時刻 t1∼t2 に行われた編集操作 ops(t1, t2) によって削除されたフィー ルドをみつけ,それらをフィールドの削除(DF)として特定してフィール ドの集合から除外する.編集操作による DF の特定の具体的な手順について は 3.4.4 節で説明する. 3. 編集操作によるフィールドの追加(9∼14 行目)3.4. クラス情報の比較 27 Algorithm 2: FieldChange(Ct1, Ct2) 1 Ft1 ← Ct1に存在するすべてのフィールド; 2 Ft2 ← Ct2に存在するすべてのフィールド; 3 foreach ft1∈ Ft1 do 4 if ft1 が操作 ops(t1, t2) によって削除されたthen 5 ft1 をDFとして検出; 6 ft1 をFt1から除外; 7 end 8 end 9 foreach ft2∈ Ft2 do 10 if ft2 が操作 ops(t1, t2) によって挿入されたthen 11 ft2 をAFとして検出; 12 ft2 をFt2から除外; 13 end 14 end 15 foreach ft1∈ Ft1, ft2∈ Ft2 do
16 if ft1.name = ft2.name ∧ ft1.type = ft2.type then
17 ft1 をFt1から除外;
18 ft2 をFt2から除外; 19 end
20 end
21 foreach ft1∈ Ft1, ft2∈ Ft2 do
22 if ft1.name 6= ft2.name ∧ ft1.type = ft2.type then
23 ft1 とft2 をCFNとして検出;
24 ft1 をFt1から除外; 25 ft2 をFt2から除外;
26 else if ft1.name = ft2.name ∧ ft1.type 6= ft2.type then 27 ft1 とft2 をCFTとして検出; 28 ft1 をFt1から除外; 29 ft2 をFt2から除外; 30 end 31 end 32 Ft1 に残っているすべてのフィールドをそれぞれDFとして検出; 33 Ft2 に残っているすべてのフィールドをそれぞれAFとして検出;