評価値軸・設計変数上の解の継続変化に対する群知能アルゴリズムのためのメカニズムの設計とその追従性の評価
16
0
0
全文
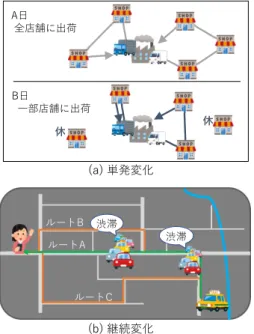
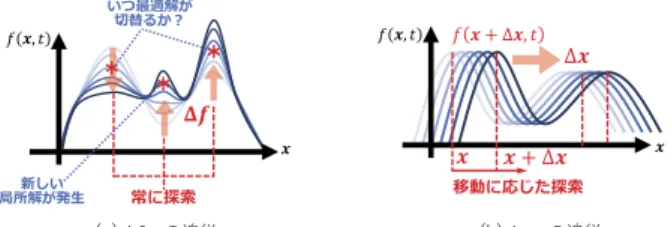
(2) 進化計算学会論文誌 Vol. 11. 30. No. 3(2020). れている [Nguyen 12].しかし,これらの従来研究で全 ての動的最適化問題に対応できているわけではない.ま だ,十分な議論がされていない観点の一つとして,変化 の発生間隔の観点に 着目することができる.変化の発生 間隔の観点として, これらの 2 つの問題を図 1(a-b) を 用いて説明する.これらの図において,縦軸は解の変化 を,横軸は時間 t の経過を,実線は解の変化の推移を模 擬している.ここで動的最適化問題の変化として,最適 解の別の解への変化や局所解の数の変化など様々な種類 を考慮することができる.図 1(a-b) では,これらの変化 による問題の評価値の変化を包括し解の変化と表現する. 図 1(a) は,解の変化が時間経過に対してまばらに発生 することにより, 変化の発生までは一定の値をとり変化 の発生後は一気に別の評価値をとることによって階段状 の変化となる.このように,変化が非連続的に発生する こと問題を本研究では「単発変化」と称する.単発変化. 図 1 2 種類の変化の発生. では,変化の発生から発生までの期間は静的環境として 最適解を探索可能となり,変化の発生を知覚し環境の変 化によって出現する新たな最適解を迅速に捕捉する探索. の変化 ∆x」の 2 つに分割する. 「評価値軸上の変化 ∆f 」. 方法が求められる.一方で,変化が連続的に発生する問. は探索空間全体が大域的に変化することで最適解が変化. 題とは,図 1(b) に示すように,解の変化が時間経過に応. する問題であり, 「設計変数軸上の変化 ∆x」は,最適解そ. じて常に発生している問題である.また,2 本の実線で. のものが局所的に変化することで起こる問題である.こ. 示したように時間経過によって様々な傾向により解が変. れら 2 つの要素をそれぞれ解決する 2 つのメカニズムを. 化することが考えられる.例えば,ある変化は青色の実. 提案すると共に,これら 2 つの要素が混合した問題にお. 線のように周期的に, 別の変化は緑色の実線のようにラ. いて,2 つのメカニズムの組み合わせで変化に追従可能. ンダムに 変化するなどが挙げられる.このような変化を. か検証する.このため,本研究ではそれぞれの問題に対. 本研究では「継続変化」と称する.継続変化では,静的. するメカニズムの検証のために,これらのメカニズムを. 環境として探索可能は期間が存在せず最適解は常に変化. 来研究で着目されている動的最適化問題の大半は,単発. 3 つの群知能アルゴリズム,Particle Swarm Optimization アルゴリズム [Eberhart 95],Artificial Bee Colony アル ゴリズム [Karaboga 07],Social Spider Optimization ア ルゴリズム [Cuevas 16] に適用し,継続変化への追従性. 変化にのみ着目している.単発変化と継続変化において,. を比較評価する.また,本論文は連続値の最大化問題を. 時間経過による最適解の変化の仕方が異なるため,それ. 想定し,群知能アルゴリズムはそれに基づいて記述して. ぞれ別の探索行動が求められる.このため,継続変化に. いる.. するため,アルゴリズムは最適解の変化に追従する必要 がある.このような単発変化と継続変化の観点では,従. 追従可能な手法については改めて議論されることが求め られる.. 本論文の構成は以下の通りである.2 章では動的最適 化問題,特に継続変化における 2 つの変化について説明. 本研究では,この継続変化への対応のために,課題と. する.次に,3 章ではメカニズムを組み込む群知能アル. なる変化の要素を分類し, その要素ごとに追従するため. ゴリズムについて説明する.4 章では「評価値軸上の変. のメカニズムを提案する.また,これらのメカニズムは,. 化 ∆f 」とそのためのメカニズムと, 「評価値軸上の変化. 複数の群知能アルゴリズムに組み込むことができるよう 設計する.これは,群知能アルゴリズムが継続変化への. ∆x」とそのためのメカニズムについてそれぞれ記述す る.5 章にて継続変化への追従性を検証するための問題. 追従に対して特に有用と期待できる特徴を有しているた. の詳細を記述し,その検証結果を示し各メカニズムの効. めであり,多くの群知能アルゴリズムの解更新の方法が. 果について考察する.最後に 6 章にて本研究の結論と今. 類似しているため共通のメカニズムを組み込みやすいと. 後の課題をまとめる.. いう利点があるためである.このため,本研究では,継 続変化において課題となる変化の要素に対応したメカニ. 2. 動的最適化問題. ズムを提案し,それを SOPs のための既存の群知能アル ゴリズムに組み込むことで継続変化への追従性を獲得す. 2·1 単発変化と継続変化. ることを目的とする。継続変化において課題となる変化. 単発変化と継続変化における変化は,その変化前後に. の要素として, 「評価値軸上の変化 ∆f 」と「設計変数軸上. 類似性を有することを仮定している.これは変化前の環.
(3) 評価値軸・設計変数上の解の継続変化に対する群知能アルゴリズムのためのメカニズムの設計とその追従性の評価. 31. る.その後,B 日 (図の下部) では一部の店舗の休業によ り配送する店舗が A 日と変化し 3 店舗 (図の「休」がな い 3 店舗) のみとなるため,新たな配送最適化が必要と なる.また,A 日で解となる経路を利用することで B 日 の経路を探索することにより,その日ごとで別々の問題 として探索するよりも高い探索性能を期待することがで きる. このように,ある状況から別の状況への変化が日 ごと・月ごとなどで区切ることが可能な問題は単発変化 である.一方で.同じ動的最適化問題であっても図 2(b) に示すようなタクシーの乗客までの経路の最適化問題は 変化の発生が連続的な問題となる.図 2(b) は町の地図を 模しており,その地図上にタクシーとその利用客が存在 している.このような状況においては渋滞などの道路状 況の変化などによりタクシーから乗客までの最適経路が 変化することで最適な経路が変化することを考慮しなけ ればならない.例えば,図 2(b) では図の右下に位置する タクシーが左側に位置する乗客への経路を探索している 図2. 動的最適化問題における単発変化と継続変化. 様子を示している.ここで最短経路となる緑色の線で示 したルート A 上に 2 地点渋滞が発生しており,時間経過 によりこれらの渋滞状況が変化することを考慮して橙色 で示したルート B やルート C を探索し,時間が最短とな る経路を探索する必要がある.このような道路状況が刻 一刻と変化することで 環境変化が常に発生している問題 は 変化の発生が連続的な問題と言える.このように,単 発変化と継続変化では,変化がどのように発生するかに よって適用可能な実問題は異なる.また,継続変化は実 問題の中でも特に実時間性の高い問題と言える.. 図3. 単発変化におけるアプローチ. 2·2 単発変化における従来研究 本節では,単発変化が従来研究においてどのように対. 境と比べ類似性の一切ない環境に変化する場合,どのよ. 処されているか説明する.従来の単発変化における動的. うな最適化手法を用いた場合でも変化発生時から新しく. 最適化問題において,多点探索アルゴリズムでは大別し. 探索しなおす方法以上に探索性能を向上させることは困. て 6 種類のアプローチが提案されている [Nguyen 12].ま. 難なためである.このため,変化の前後で何らかの類似. た, 動的最適化問題において,環境変化を検知すること. 性があること前提として変化に対応するための最適化手. が可能であるかにより,アプローチ方法が異なる.これ. 法が設計される.また,問題によってこれらの変化の類. らのアプローチは以下の 6 種類である.. 似性の内容が既知である場合と完全に未知である場合と. 解の記憶 [Goldberg 87]:変化毎に変化発生直前の最適. の 2 通りが考えられる.類似性の傾向が既知である場合. 解を記憶し,変化発生時にそれら過去の最適解を再度探. とは,例えば同じ変化が繰り返し発生することがわかっ. 索するアプローチ.. ている場合が,変化が一定で線形に増加あるいは減少す る場合などがある. 前章にて記述したように,単発変化と継続変化は変化. 予測 [Hatzakis 06]:過去の最適解から次の最適解の位 置を予測モデルにより推定し,それに基づいて変化発生 時に個体を再配置するアプローチ.. の発生が非連続的か連続的かの観点から分類している.. 変化検知時の多様化 [Hu 02]:変化を検知すると全て. ここで,これら 2 つの変化と実問題との関連を説明する.. の個体を再配置することで解の多様性を高め,新しい最. これら変化の発生が非連続的な問題と連続的な問題とし. 適解を 探索するアプローチ.. て,図 2(a-b) を例として説明する.まず,変化の発生が. 多様性の維持 [Grefenstette 92]:一部の個体を常に大域. 非連続的な問題とは図 2(a) に示すように,ある工場から. 的に探索させることで変化に対して常に備えながら探索. 各店舗への配送最適化が挙げられる. 図 2(a) において,. するアプローチ.. ある A 日 (図の上部) においては全ての店舗 (図上部の 5. Self-adaptation[Grefenstette 99]:変化に合わせて各個. 店舗) に 2 台の車両を用いた配送最適化が行われるとす. 体が適応的にパラメータを変更しながら探索するアプ.
(4) 進化計算学会論文誌 Vol. 11. 32. No. 3(2020). ローチ.. Multi-population[Oppacher 99]:個体群を予め複数に 分割することにより,探索空間を広く探索するアプローチ. これらのアプローチの多くは,一部の個体が常に同じ 解を探索し,その解の評価値の変化の有無によって変化 を検知するメカニズムを必要としている.6 種類のアプ. 図4. 継続変化の要素の分解. ローチのうち,解の記憶・予測・変化検知時の多様化の. 3 種類のアプローチはこの変化検知メカニズムを必要と する. また,単発変化の特徴,つまり変化前後の類似性 の特徴に合わせて用いられるアプローチが異なる. 例え ば,最適解に同じ変化が繰り返し発生する問題では解の 記憶や予測のアプローチが有効である.このような繰り 返し発生する変化を再帰的な変化と呼ばれるが,この再 帰的な変化では過去の解の再利用が重要になるためであ る. 一方で,再帰的な変化でない問題についてはそれ以. この際,探索が進めば進むほどある 1 つの解に収束して いくため,その解の周囲を探索する範囲が徐々に狭まる. ここでΔ x の変化では最適解が現在の位置から徐々に移 動する.このため,探索が進み個体が一つの解に収束す るほど,解の近傍を探索する範囲が狭まり,∆x の変化 に対応することができない.このため,継続変化を想定 とする最適化手法として新たな手法が必要とされる.. 外のアプローチにより対応できる.特に,変化検知時の 多様化や多様性の維持のアプローチは変化前後の類似性. 2·3 継続変化へのアプローチ. が未知の状況にも対応できるランダム探索を重視した手. 前節で述べたように従来のアプローチでは継続変化に. 法と言える. また,これらのアプローチと単発変化への. よる常に変化する最適解に追従することが期待できない.. 適用について図 3 にまとめる.この図のように,単発変. このため,継続変化には独自の手法を用いることが必要. 化は静的環境下において環境変化が発生し次の静的環境. となる.そこで,本研究では継続変化を図 4 に示すように. に移行する.単発変化における最適解は,静的環境ごと. 「評価値軸上の変化 ∆f 」と「設計変数軸上の変化 ∆x」. に 1 つに定まる.このように単発変化では,変化の発生. の 2 つに分割する.図 4 の左右のグラフは,縦軸に評価. に合わせて新しい最適解を迅速に発見することが重要に. 値 f( x, t) を,横軸に設計変数 x,実線で現在の評価値の. なる.このため,6 種類のアプローチでは静的環境下の. ランドスケープを,破線で未来の評価値のランドケープ. 探索ではその時の最適解のアーカイブ (解の記憶) や一部. をそれぞれ模擬している.ここで,図の左側では,ラン. 個体の大域的探索 (多様性の維持) などが実行され,変化. ドケープ全体の変化を局所解ごとの変化として捉えると,. 発生のタイミングでは,変化検知時の多様化のアプロー. 性」の 3 つのアプローチは,最良個体などの解を維持し. 3 つの局所解が左から「移動 + 評価値増」, 「移動 + 評価 値減」, 「評価値減 (局所解の消失)」と変化している.次 に図の右側では,これらの 3 つの変化について評価値軸 と設計変数軸の 2 軸別々の変化として分解する.このよ うに,継続変化を局所解ごとに「評価値軸上の変化 ∆f 」 と「設計変数軸上の変化 ∆x」という 2 つの要素が混合 する変化して考えることができる.これらの 2 つの変化. その評価値を毎世代計算することで,その評価値に変化. 要素によって,最適解は異なる様子で変化するため,そ. があった時間に変化の発生として判別するメカニズムに. れぞれ別のアプローチで変化に追従する必要がある.こ. より変化を検知する.これにより,各アプローチは変化. れらの最適解の変化の様子と,それらへのアプローチに. 検知時にそれぞれの方法により変化に対処している.し. ついて図 5(a-b) を用いて説明する.まず, 「評価値軸上. かし,継続変化では常に変化が発生している状態として. の変化 ∆f 」では,図 5(a) に示すように目的関数の評価. 判別される.このため毎世代にそれぞれのアプローチが. 値と設計変数の 2 軸で表現した空間において,評価値軸. 実施されるため十分にこれらの機能が働かない.例えば,. の方向に解のランドスケープが徐々に変化することを意. チや予測のアプローチが実行される. しかし,これらのアプローチは 2 つの問題から継続変 化では十分に探索能力を発揮できない.1 つは,継続変化 では変化発生を検知するメカニズムが成り立たないこと である.前述の「解の記憶」「予測」「変化検知時の多様. 「変化検知時の多様性」の場合は毎世代全ての個体を再. 味する.これにより,ランドケープのピーク (各局所解). 配置するため探索が進まず, 「解の記憶」「予測」でも毎. の高低が変わり,もしくは,今までは局所解が存在しな. 世代の小さな変化に対して解の記憶や予測モデルの構築. かった領域が徐々に盛り上がることで新たなピークが発. をするため,継続変化に対して大域的に追従することが. 生する.これらの各局所解の高低が変化・新たな局所解. できない.もう 1 つは,単発変化の想定した最適化手法. の発生により,最適解がそれらの局所解の中から移動す. では後述する「設計変数空間軸上の変化 ∆x」への対応. る.この変化に追従するためには,どの局所解が最適解. が困難なことである.これは 6 種類のアプローチ全てで. となった場合でも追従できるように各局所解を探索し続. 問題となる.単発変化を想定した最適化手法の場合,毎. けることが重要になる.次に, 「設計変数軸上の変化 ∆x」. 世代での探索は現在の有望解に収束するように探索する.. では,図 5(b) に示すような目的関数の評価値と設計変数.
(5) 評価値軸・設計変数上の解の継続変化に対する群知能アルゴリズムのためのメカニズムの設計とその追従性の評価. 33. 内に散らばる 1 つ 1 つの個体が独自に探索することで, 探索空間の局所的な変化を網羅的に捕捉することが可能 なためである.また,それぞれの局所的な変化に合わせ て,個々の個体の探索するベクトルを調整することが容 易である. これらの特徴は,常に解が変化している継 続変化において, 特に有効に作用することが期待でき る.更に,多くの群知能アルゴリズムが個体間のベクト 図5. 2 つの変化要素へのアプローチ. ル演算により解更新するため,同一の改良を加えやすい という利点もある.また,本研究では群知能アルゴリズム. の 2 軸で表現した空間において,設計変数軸の方向にラ. として Particle Swarm Optimization アルゴリズム (PSO). 化に追従するためには,最適解の移動する方向を重点的. [Eberhart 95],Artificial Bee Colony アルゴリズム (ABC) [Karaboga 07],Social Spider Optimization アルゴリズム (SSO) [Cuevas 16] の 3 つの手法を用いる.PSO と ABC. に探索することが重要になる.このように継続変化にお. は群知能アルゴリズムの中で最も研究されている手法の. いては,2 つの軸上の変化それぞれについて全く異なる. 一つであるためであり, SSO は最近提案された手法であ. ンドケープが徐々に変化することを意味する.これによ り,最適解が少しずつ位置を変えることになる.この変. 方法で追従する必要がある. ここで本論文における継続変化は,毎世代に発生する. り,局所的な近傍探索を行うため ∆x に対して特に有効 性が期待されたためである.. 変化 (∆f と ∆x) の大きさが,群知能アルゴリズムによっ て探索している解の分布の大きさ以上にならないことを. 3·2 ア ル ゴ リ ズ ム. 前提としている.これは現在の解が分布していない領域. 本節では,本論文で用いる 3 つのアルゴリズムについて. へ環境が大きく変化する場合,提案する既知の群知能ア. それぞれ説明する.なお,全てのアルゴリズムにおいて,. ルゴリズムへの改良メカニズムのみではそのような変化. アルゴリズムの個体数を N , 各個体を xi (i = 1, 2, . . . , N ),. に追従することは非常に困難なためである.また,同様. とする.また,その評価値は f (xi ) で示す.. に本論文において提案するメカニズムは局所解の数が時 間経過によって増加しないことを前提としている.これ. § 1 Particle Swarm Optimization アルゴリズム Particle Swarm Optimization (PSO) [Eberhart 95] は群. は「評価値軸上の変化 ∆f 」へのアプローチとして,複数. 知能アルゴリズムの一種であり,魚や鳥の群れの行動を. の局所解を探索し続けることが課題になるが,各局所解. 模したアルゴリズムである.PSO において,群れはさま. の探索それぞれに対して一定数の個体が必要となる.こ. ざまな速度で変数空間を移動する複数の粒子(個体)と. のため,局所解の数が時間経過により増加した場合にお. して形成される.個体群は相互に情報共有することで各. いて,全ての局所解を探索し続けるためには群内の個体. 自の速度ベクトル v i (i = 1, 2, . . . , N ) を更新し,群れの. 数が一定の手法では対応が困難となる.. 中で最良個体の位置に徐々に収束する.PSO においては 全ての個体が以下の式に従って解を更新する.. 3. 群知能アルゴリズム. v t+1 i = wv t i + c1 r 1 (xpbest − xt i ) + c2 r 2 (xgbest − xt i ) (1). 3·1 継続変化への追従のための利点 群知能アルゴリズムは,一般的に 1 つ 1 つの個体に対. xt+1 i = xt i + v t+1 i. (2). し設計変数を割り当てて個体の解とし,個体間での情報. ここで r 1 と r 2 は範囲 [0, 1] の一様乱数であり,w,c1 ,c2. 共有や相互作用により設計変数空間(探索空間)を個体. はパラメータであり,式の各項の重み係数である.この 2. 群が探索することで最適解を発見することを目指す.ま. 式により,全ての個体が自身が探索した最良の解 (パーソ. た,群知能アルゴリズムは個体間の相互作用により探索. ナルベスト) xpbest と群れ全体の最良個体 xgbest に近づ. を進行するため,アルゴリズムの 1 回の繰り返しにおい. くように探索する. また,各個体 xt i は,その評価値を. て,全ての個体が少なくとも 1 回は探索行動を実施する. それぞれ計算し,それらの評価値が記録されている各々. ことと, 個体間の相互作用として複数の解 (他個体の解. のパーソナルベストの評価値 f ( xpbest ) よりも高い場. や過去の探索で得られた解) からのベクトル演算により. 合,現在の位置にパーソナルベスト xpbest を更新する.. 解更新することが一般的な特徴である.このような特徴. 更に,全ての個体のうち最良個体の評価値 f ( xgbest ) よ. を有するため,群知能アルゴリズムは最適化問題の中で. りも評価値が高い個体がある場合,その個体を新たな最. も,特に動的最適化問題,特に継続変化に対して効果的. 良個体として更新する.. であると期待できる.何故なら,GA や DE のように複. § 2 Artificial Bee Colony アルゴリズム Artificial Bee Colony アルゴリズム (ABC) [Karaboga 07] では蜂 (個体) の群れ全体をコロニーと称し,コロニー. 数の個体を親個体としてその設計変数の組み合わせを子 個体として新しい解を生成するのではなく, 探索空間.
(6) 進化計算学会論文誌 Vol. 11. 34. は 3 種類の探索フェーズを持つ個体群で構成される.そ. 新する.. れぞれの探索フェーズは Employed bee, Onlooker bee,. Scout bee と呼称され,順番にその探索フェーズを実施す る.3 つの探索フェーズの内の 2 つである Employed bee と Onlooker bee のフェーズでは解の探索を担当し,探索 前の解よりも良い解が見つかればその解に個体の割り当 て解として更新する. これらのフェーズにおいて個体 xi の更新には以下の式を用いる.. vij = xij + ϕ(xij − xkj ). (3). ここで vij は個体 xi の次の解候補 vi の j 番目の設計 変数であり,xij は現在の個体 xi の j 番目の設計変数 である.また,xk はランダムに決定される別個体であ り,ϕ = [−1, 1] は一様乱数である.解の候補 vi による. No. 3(2020). f t+1 = i. f ti + α · V ibci · (xc − f ti ) +β · V ibbi · (xb − f ti ) if P F < r +δ · (rand − 1/2) f ti − α · V ibci · (xc − f ti ) −β · V ibbi · (xb − f ti ) otherwise +δ · (rand − 1/2). (4). mti + α · V ibfi · (xf − mti ) if wNf +i +δ · (rand − 1/2) < wNf +m t+1 ∑Nm mi = m h ·wNf +h h=1 t mi + α · ( ∑Nm w h=1 Nf +h −mti ) otherwise (5). 解の更新は以下のように f (v i ) > f (xi ) ならば,xi ) =. v i ),triali = 0 とし,f (v i ) ≤ f (xi ) ならば,個体は現 在の解に留まり,triali = triali+1 とする.これにより 個体はより評価値の良い位置に解を移動させる.ここで,. Employed bee のフェーズでは全ての個体が 1 回ずつ探 索し,Onlooker bee のフェーズではルーレット選択によ り有望な個体が個体数と同じ回数だけ探索する. また,. Scout bees のフェーズでは,triali が閾値 limit 以上に なった個体は,それまでの解を放棄して新しい解を探索. ここで α, β, δ, rand は [0, 1] の範囲の乱数であり,V ibb,. V ibc,V ibf はそれぞれ,群全体の最良個体 xb ,最近傍か つ自分よりも評価値の高い個体 xc , 最近傍のメス個体 xf による重み付けであり,評価値が高く距離が近いほど大 きな値をとる.また,メス群は式 (4) により確率 P F で 最良個体と近傍の優良個体に近づき,確率 1 − P F で離 れるよう探索する.ここで wi は全個体の評価値を最小値. することで探索空間全体を大局的に探索する.. 0,最大値 1 となるように正規化した値である.この wi を用いて,式 (5) では wNf +m としてオス群内での正規. § 3 Social Spidere Optimization アルゴリズム. 化した評価値の中央値を示す. これによりオス群の上位 半数の個体は近傍のメスに近づき,下位半数の個体はオ. Social Spider Optimization (SSO) アルゴリズムは社会 性を持つ特殊な蜘蛛の群に着想を得て設計されたアルゴ リズムである [Cuevas 16].社会性蜘蛛と呼ばれるこの種 の蜘蛛は一つの大きな巣で共同生活し,オスとメスによ り異なる役割を持っており,蜘蛛の巣を伝う振動により コミュニケーションをとることが知られている.SSO は このような社会性蜘蛛の特徴から着想を得たアルゴリズ ムであり,オスとメスの個体がそれぞれ別の更新式によ り解を更新する.また,それぞれの解更新とは別にオス 個体とメス個体が交配オペレーターと呼ばれるメカニズ ムにより新たな解を生成することで,2 つの群間が相互 に補い合う.このようなオスメスの独自の解更新と群間 の相互作用により SSO は探索のバランスと個体の多様性. ス群の加重平均点に近づくよう探索する.また,SSO で はオスの周囲 M R 以内にメスが存在した場合,交配オペ レーターが実行される.交配オペレーターでは該当のオ スとその周囲 M R 以内の全てのメスによる小集団 Tg を 生成し,この Tg を構成する個体の設計変数を組み合わ せることで新しい個体を生成する.新しい個体の生成に は,設計変数の次元 j ごとに個体の重みによるルーレッ ト選択で Tg から 1 つの個体 xi を選択し,その個体の 次元 j の設計変数 xij を新しい個体の設計変数として利 用する.これにより生成された個体は群れ全体で最低の 評価値を持つ個体と比較され,評価値が高ければこの個 体と入れ替えらえる.このとき,個体の性別は入れ替え 前の性別を維持する.. の維持を実現する.. SSO は群全体をメス群とオス群の 2 つに分割し,それ. 4. 継続変化への追従のためのメカニズム. ぞれの個体数を Nf と Nm と表す.なお,その個体数の バランスはメス群の個体数を Nf = f loor[(0.9 − rand · 0.26) · N ] とし,オス群の個体数は Nm = N − Nf となる. また,メス群とオス群において,それぞれの個体は F = {f 1 , f 2 , . . . , f Nf },M = {m1 , m2 , . . . , mNm } で表現さ れる.メス群とオス群はそれぞれ以下の式により解を更. 本章では,2.3 節で説明した 2 つの変化の要素「評価値 軸上の変化 ∆f 」と「設計変数軸上の変化 ∆x」それぞれ に追従するメカニズムをそれぞれ紹介する.また,これ らのメカニズムは,それぞれの変化の要素のために,以前 我々が提案したアルゴリズムから,様々な群知能アルゴリ.
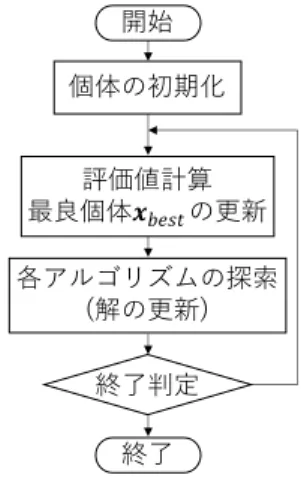
(7) 評価値軸・設計変数上の解の継続変化に対する群知能アルゴリズムのためのメカニズムの設計とその追従性の評価. 図6. 35. ALIS メカニズムにおける探索範囲の限定. ズムに適用可能なメカニズムとして改良部分を取り出し たものである.これらは,評価値軸上の変化 ∆f に追従 するために ABC に改良を加えた ABC based on Adaptive. Local Information Sharing (ABC-ALIS)[Takano 18] であ り, 設計変数軸上の変化 ∆x に追従するために SSO に 改良を加えた SSO based on Jumping Over Future Best (SSO-JOFB)[Takano 19] である.これらの手法から個々 の群知能アルゴリズム (ABC,SSO) とは独立して機能す る改良メカニズムのみを ALIS メカニズムと JOFB メカ. 図7. 群知能アルゴリズムの共通フロー. ニズムとして本章で紹介する. ここで,提案する 2 つのメカニズムの説明に前に,群知 能アルゴリズムとして共通するフレームワークについて 説明する.前章で紹介した 3 つの群知能アルゴリズムや他. 図8. ALIS メカニズムにおける探索個体数の制限. の多くの群知能アルゴリズムは図 7 に表すフローチャー トに従って探索を進めている.図 7 において,各アルゴ リズムはまず個体の初期化として各個体の初期位置をラ. ためにランダムに選択していた他の個体 xother の取得に 制限を加えることで,アルゴリズムの大局的収束性能を. ンダムに決定する.次に,全ての個体は評価値を計算し,. 低下させ,評価値軸上の変化への追従性の維持を可能と. その中で最良個体を決定する.ここで,各アルゴリズム. する.また,新たな局所解の発生に対応するために,局. において最良個体を表す表記が異なるため,その統一の. 所的な領域を探索できる個体数を限定し余剰個体によっ. ために以後は最良個体を xbest と表す.次に,各アルゴ. て新たな解を探索する. 更に,様々な解のランドスケー. リズムの探索として,アルゴリズムごとの解の更新式を. プに対応するために,個体の位置情報の共有範囲を適応. 用いて個体の位置を変更する.PSO であれば式 (1), (2),. 的に変化させることにより局所解の位置に合わせた範囲. ABC であれば式 (3),SSO であれば (4), (5) により探索. を設定する.. する.各アルゴリズムにはこれ以外の処理も含まれる場. § 1 局所間の情報共有. 合もあるが,図 7 では提案メカニズムの組み込みのため に,アルゴリズム共通の処理のみ表した.これ以後はこ のフローチャートに対して改良をくわえることで継続変 化に追従する.加えて提案メカニズムの表記統一のため に,各アルゴリズムの更新式における解更新する個体以 外の個体,つまり,各更新式の添え字が i 以外の個体を総 称して他個体 xother と呼ぶ.これは,PSO では xgbest ,. ABC では xk ,SSO では xc ,xb ,xf ,mh が該当する. また,各更新式においてこれら xother の項の乱数を統一 して r で表す.これは,PSO では r2 ,ABC では ϕ,SSO では α,β が該当する.これらの変数は本章における提 案メカニズムの記述に用いる.. 個体 xti の探索における新しい解 xt+1 の生成の際に選 i 択する他の個体 xother について,従来では群れ全体から 選択していたのに対し,個体 xi を中心にユークリッド距 離 d の範囲内の個体のみに限定する.これにより,個体 はある近傍のユークリッド距離 d の範囲内のみ移動する ことになる.一方,近傍に個体が存在しない場合は,現 在の解から距離 d の範囲内をランダムに探索する.この 探索範囲の限定方法の概略図を図 6 に示す.図 6 におい て,赤い菱形が探索個体を示し,図 6 の左部のように個々 の個体は破線の円で描いた共有範囲 d を持つ.この共有 範囲 d を持つことで図の右部に描いた色が青色になるに つれて評価値が高くなる模擬的な探索空間において 2 つ の局所解それぞれを個体が探索し,1 つの局所解のみに. 4·1 評価値軸上の変化への追従:ALIS メカニズム 複数の局所解を同時に探索し続けるために,全ての個. 収束せずに複数の局所解の探索を継続できる.. § 2 新しい局所解の探索. 体で共有されていた他個体の位置情報を近隣の個体間の. 評価値軸上の変化における新しい局所解の発生に対応. みに局所的に限定することにより,探索領域全体に個体. するために,常に一定数の個体が新たな局所解の発生の. を分散させる.具体的には,各個体が新しい解の生成の. 探索を継続する必要がある.このため,局所的探索で余.
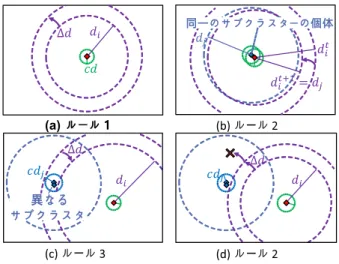
(8) 進化計算学会論文誌 Vol. 11. 36. No. 3(2020). なランドケープで複数の局所解を探索し続けるためには 範囲 d 内の局所解の数に従って共有範囲 d を調整するメ カニズムが必要である.この目的のために,以下の説明 する個体 xi 毎に共有範囲 di を設定し,その個別の共有 範囲 di を状況に応じて適応的に変更する.. ALIS メカニズムにおいて,共有範囲 di は個体 xi 毎 に設定され個別に変更する.共有範囲を調整するために, 本研究では,個体 xi の半径 cd の範囲に集まる他の個体 を個体 xi のサブクラスターと設定し,このときの半径 cd の範囲は,近接範囲と呼ぶ.近接範囲 cd は,1 つの個体 が 1 つの局所解にあるかどうかを判断するため,個体 xi の共有範囲 di よりもはるかに小さく設定する.共有範囲 図 9 探索範囲調整のための 4 つのルール. 剰となった個体を確率的に探索空間全体で大域的なラン ダム探索をさせるメカニズムを追加する.まず,各個体 は localranki を算出する.各個体の評価値の高低から共 有半径 d 内の自身も含めた全個体のランク付けにより自 身のランクを localranki として記録する.次に,各個体 はランダム探索の実行確率 Ps を localranki と Nl を用 いてシグモイド関数に基づく次式により算出する.. 1 (6) 1 + e2(−localranki +Nl ) ここで,Nl を変曲点として localranki が Nl から 1 に 近づくほど変化確率 Ps は 0 に限りなく近い値となりラン ダム探索しづらくなる.一方で,localranki が Nl から増 加すると変化確率 Ps は 1 に限りなく近い値をとり確実に ランダム探索することになる.これにより共有半径 d 内 において基準となる個体数 Nl よりも localranki が高い 個体はその場をとどまり, Nl よりも localranki が低い Ps =. di は個体の検索の初期,中期,および後期の段階向けに 設計された 4 つのルール(つまり,ルール 1 から 4)に より更新される.ルール 1 は検索の初期段階用に設計さ れており,サブクラスターが形成されない場合に適用さ れる.ルール 2 は,検索の中間段階用に設計されている. これは,サブクラスターが形成され,localranki ≠ 1 を 満たす場合に適用される. ルール 3 および 4 は,検索の 後期段階用に設計されている.localranki = 1 を満たし, 他のサブクラスターが範囲 di にある場合,ルール 3 が 適用さる.一方,localranki = 1 を満たし,他のサブク ラスターが di の範囲にない場合ルール 4 が適用される. これら 4 つのルールの状況を図 9(a)∼(d) に示す.これ らの図では,小さな赤いひし形は個体 xi を,個体 xi の 周りの紫色の破線の円は共有範囲 di を,緑色の点線の円 は近接範囲 cd を表す.また,空色のひし形と破線と点線 は,それぞれ他の個体 xj とその共有範囲 dj と近接範囲. cd を示す.4 つのルールの詳細は次のようになる.ルー ル 1 は,アルゴリズムの開始直後や個体がランダム 探索 をした直後など,検索の初期段階で適用される.検索の 初期段階では,個体の共有範囲 di は狭く,個体は他の個. 個体は確率的にランダム探索を実行する.これにより局. 体とほとんど情報を共有できない.この場合,各個体は,. 所的に余剰となった個体が一定数,新たな領域の探索を. 図 9(a) に示すように,他の個体と通信するために共有範. 継続することが可能となる.ここでの探索個体数の制限. 囲 di を ∆d だけ拡大する.次に,ルール 2 は,個体が近. 方法の概略図を図 8 に示す.この図は,図 6 と同様に色. 傍の他の個体と情報を共有することで適切な解を探索し. が青色になるにつれて 評価値が高くなる模擬的な探索空. ている場合など,検索の中間段階で適用される.高い評. 間を用いて説明する.ここで各個体は自身の localranki. 価値の解が発見されると,他の個体がその周りに集まり,. からランダム探索する確率を算出し,基準個体数 Nl を超. サブクラスターが形成される.ここで 2 つ以上の局所解. える個体は高確率でランダム探索を行う.これにより各. と重ならないように共有範囲を調整する必要があるため,. 局所解を探索する個体数を制限し,新たな局所解の発生. 図 9(b) に示すようにサブクラスターに所属する個体は自. に備えて様々な領域の探索を継続することが可能となる.. 身の共有範囲 di を,サブクラスター内の localrankj = 1. § 3 共有範囲の適応的変化 共有範囲 d は,探索空間で可能な限り多くの局所解を. の有望個体 xj の共有範囲 dj に変更する.最後に,ルー. 捕捉できるように設定する必要がある.しかし,共有範. 探索 の後期段階で適用される.このとき,個体は捕捉し. 囲 d に複数の局所解が存在する場合,ほとんどの個体は. た 1 つ局所解を探索している.共有範囲は,2 つ以上の. ごく少数の局所解のみに集まり,他の局所解を捕捉でき. 局所解と重ならないようにするために狭くする必要があ. ない.このため,探索空間内に局所解が不均一に分布し. るが, 大域的探索能力を高めるためにはできる限り広く. ていた場合,一律の共有範囲 d を用いて複数の局所解を. 設定する必要がある.このように適切に共有範囲を設定. 探索し続けることは困難である.この問題に対処し,様々. するために,共有範囲 di 内で他のサブクラスターが知覚. ル 3 とルール 4 は,サブクラスターが形成された後など,.
(9) 評価値軸・設計変数上の解の継続変化に対する群知能アルゴリズムのためのメカニズムの設計とその追従性の評価. 図 10. 37. 4 つのルールの処理. される場合は図 9 (c) に示すように共有範囲 di は減少し, そうでない場合は,図 9(d) に示すように,共有範囲 di をその値のまま維持する.ここで,共有範囲 di の調整に おける処理の流れを図 10 に示す.図 10 は 4 つのルール. 図 11. ALIS メカニズムの組み込み. による共有範囲 di の調整の実際の処理を木構造で表して おり,3 つの条件によりルールを判定する.まず,はじ めの条件は,サブクラスターの形成の有無であり,個体 i について近接範囲 cd 内に他の個体 xj が存在の有無によ り判定される.近接範囲 cd 内に他の個体が存在しない場 合はルール 1 が適用される.次の条件は localranki = 1 の判定である.localranki ≠ 1 の場合はルール 2 として,. localrankj = 1 となる xj の共有範囲 dj を次の共有範囲 として参照する.最後の条件は,共有範囲内の他のサブ クラスターの存在の有無である.これは共有範囲 di 内か つ近接範囲 cd 外に他の個体 xk が存在し,さらに xk の 近傍範囲内に別個体 xohter が存在するか否かにより共有 範囲内の他のサブクラスターを判定する.他のサブクラ スターが存在する場合はルール 3 が,存在しない場合は ルール 4 が適用される.. § 4 群知能アルゴリズムへの組み込み. 説明する.図 12 は,図の左側と右側で 2 つの部分に分か れており,左から右へ時間 t から時間 t = t + 1 までに時 間が進んだ状況を示している.図の左側では,時間 t に おける目的関数 f (x,t) のランドスケープが実線で示さ れている.一方,図の右側では,時間 t + 1 における目的 関数 f (x,t + 1) のランドスケープが実線で示され,過去 のランドスケープ f (x,t) は 破線で示されている.この 図では,時刻 t で,最良個体が最適解のピークを発見し, 残りの 3 つの個体がそこに収束しようとしている.しか し,時間 t + 1 での最適解のピーク位置の移動により,4 つの個体は最適解に追従できなくなる.このように,最 良個体が最適解を発見した場合でも,最適解のピーク位 置から徐々に離れていき,最終的に最適解を見失う.こ のように,すべての個体が現在の最良個体に収束する探 索方法では,設計変数軸上の変化への適用は困難となる. ここで JOFB メカニズムが想定する ∆x の変化は,短時. 図 11 に前述の 3 つの節のメカニズムを図 7 に示した. 間では大きく変化しないことを前提としている.JOFB. フローに組み込んだアルゴリズムのフローチャートを表. メカニズムで想定するのは,現在の最適解の近傍に移動. す.4·1·1 節の共有個体計算は評価値計算とアルゴリズ. した場合,つまり個体群が分布し探索可能な範囲内への. ムの探索の処理の間に,4·1·2 節の余剰個体の再配置と. 移動する場合である.個体群の分布から大きく離れた位. 4·1·3 節の共有範囲の調整はアルゴリズムの探索の後に. 置に最適解が移動した場合は,JOFB メカニズムでは最. それぞれ組み込まれる.探索に必要な共有個体計算は解. 適解を捕捉することができない.しかし,この場合は実. 更新の前に実施され,その結果を受けて余剰個体の再配. 質的には現在の最適解が消滅し新しい最適解が発生した. 置と共有範囲の調整が行われる.これにより,ALIS メカ. 状況と同様の状況となることから,ALIS メカニズムと. ニズムは複数の局所解を捕捉しつつ,新しい局所解を探. して前節の「新しい局所解の探索」で記述したランダム. 索することで「評価値軸上の変化 ∆f 」に対応する.. 探索をする余剰個体により対応する. このための方法と して,評価値軸上の変化の方向に対して指向性を持った. 4·2 設計変数軸上の変化への追従:JOFB メカニズム 設計変数軸上の変化への対応として,設計変数軸上の. 探索方法を実現する.このために,探索の範囲と方向の. 2 つの観点から改良を施す.. 変化による最適解が徐々に移動することを予測し先回り して探索する能力が必要とされる. 設計変数軸上の変化における最適解の変化を図 12 で. § 1 探索範囲に対する指向性 探索の範囲に指向性を持たせる改良について説明する..
(10) 進化計算学会論文誌 Vol. 11. 38. 図 12. No. 3(2020). 最適解の連続的移動. この改良では,前述した他個体 xother が含まれる項の乱 数 r を拡張する.例えば,乱数 r の範囲が PSO の r2 のよ うに [0,1] と下限が 0,上限が 1 の場合は,上限を変数 λ として [0, λ] に拡張する.また,乱数 r の範囲が ABC の ϕ のように [−1,1] と下限が −1,上限が 1 の場合は,上 限下限両方を [−λ, λ] に拡張する. この拡張により,各個. 図 13. JOFB メカニズムにおける探索指向性. 体は探索範囲を最良個体を含む他個体を飛び越えた位置 まで拡張する.このように探索範囲を拡張することによ. できる.. り,次世代では,最適解が現在の世代の最適解を超えて 移動した場合でも,その変化に対応可能となる.このメ. § 3 群知能アルゴリズムへの組み込み. カニズムを図 13(a) で説明する.図 13(a) の構成は図 12. 図 14 に前述の 3 つの節のメカニズムを図 14 へ組み込. と同様である.このメカニズムにより,図 13(a) に示すよ. みしたアルゴリズムのフローチャートを表す.4·2·1 節. うに,最良個体以外の個体は最良個体に収束せず,最良. の探索の範囲に指向性の改良については,各アルゴリズ. 個体の向こう側を探索する.図 13(a) の右側に示すよう. ムの探索における更新式への改良のため,フローチャー. に,連続的に移動する最適解の位置を捕捉できる.これ. ト上の組み込みはない.一方で 4·2·2 節の探索の方向に. は最適解が絶えず動いている場合,群れが収束した位置. 指向性の改良については,最良個体 xbest の更新後に未. は常に最適解から外れるためである.このとき,群れが. 来の最良個体 xt+1 best を推定する.これにより,JOFB メカ. 十分に収束している場合,群れの端に位置する個体が最. ニズムは最適解の移動に追従することで「設計変数軸上. 良個体となり,図 12 の右側に示すように評価値のピーク. の変化 ∆x」に対応する.. は群れから見てこの最良個体の向こう側に存在する.こ のため最良個体の反対側を検索することにより,最適解 の追跡性能を改善することが可能となる.. § 2 探索方向に対する指向性 次に,探索の方向に指向性を持たせる改良について説 明する.各個体が将来の最適解が移動すると考えられる 方向に指向性を持って移動するメカニズムである.この メカニズムでは,各アルゴリズムの更新式における他個 体 xother のうち,最良個体 xbest となる個体の位置を未 来の最良個体の推定位置に変更する.なお,ABC のよう に xother に最良個体 xbest が含まれないアルゴリズムに ついては,別の xother と交換する. このメカニズムは, 図 13(b) を用いて説明する.図 13(b) の構成は,図 12 お. 図 14. よび図 13(a) の構成と同じである.将来の最良個体の推. JOFB メカニズムの組み込み. 定位置は,以下の式により過去の t-1 の最良個体と現在 の最良個体の位置から計算される. t−1 t t xt+1 best = xbest + (xbest − xbest ). 5. 実. 験. (7). 上式により,最適解が均一に移動するときに,最適解 の移動するピークをより正確に捕捉できる.このメカニ ズムは,群れが最良個体に収束するアルゴリズムに適用. ALIS メカニズムと JOFB メカニズムの継続変化への 追従性を比較するために,Case1 として「評価値軸上の 変化 ∆f 」の,Case2 として「設計変数軸上の変化 ∆x.
(11) 評価値軸・設計変数上の解の継続変化に対する群知能アルゴリズムのためのメカニズムの設計とその追従性の評価. 39. の,Case3 として ∆f と ∆x が両方の関数最適化問題に 適用し,それぞれの変化の要素への追従性を検証する.. 5·1 実 験 設 定 § 1 Case1 の実験設定 Case1 に用いる関数を下記の式に示す. g1 (x, t) = Npeaks. 1−. X. n=0. [. sin (ωt + αn ) + 1 2. (8) 図 15. Case1 の概形. 図 16. Case2 の概形. M 1 X (xm − r cos (2πn/Npeaks + mπ/2))2 exp(− )] 2 m=0 402. 上式は Npeaks 個の局所解を持つ多峰性関数である.こ こで,原点から r の距離に各局所解が均等に配置される. また,それぞれの局所解のピークの高さは一様乱数の集 合 α = {αn = rand[0, 2π) | n = 1, 2, . . . , Npeaks } により 0 以上 2π 未満の範囲で変化する.また,変化の速さのコ ントロールを ω = 2π/oneCycle により設定する.変化の 1 周期の間隔を oneCycle とし,oneCycle ごとに α の乱 数を更新する. これにより上式は,各局所解の評価値が 時間 t の経過とともに徐々に変化することで,それらの局 所解の中から最適解が推移する.また,局所解の位置が 一定時間 oneCycle で変更されるため,常に異なる順番 で局所解の中から最適解が推移する.ここで Case1 では, 設計変数空間の次元数 M = 2,局所解の数 Npeaks = 10,. クトル Hi ,Wi ,Xi は各局所解の高さ (評価値),幅 (評 価値の勾配),目的関数空間上での位置をそれぞれ示して おり,時間 t により任意の変化を設定することができる. 本研究では,DOPs における最適解の連続性変化に焦点 を当てているため,連続的に最適解の位置が変化する単. 各局所解と原点との距離 r = 350 とし, oneCycle = 400. 峰性動的関数となるようにこれらのベクトルを以下のよ. として時間 t が 400 の倍数ごとに周期的に増減している. うに設定する.まず,局所解の数を m = 1 とし,その最. 各局所解の評価値の位相がランダムに変化 するように設 定する.また,この実験の概形を図 15(a-b) に示す.図. 15(a) は評価値のランドスケープの概形であり,白色か ら紫色のグラデーションで示した評価値のランドスケー. 適解の高さを Hi (t) = 50,幅を Wi (t) = 1 とし時間の 経過によって変化せず一定とする.次に,最適解の位置 の変化 Xi (t) については以下の式により算出する.. プにおいて,10 個の局所解が赤い矢印で示した方向に変 化している.また,図 15(b) は評価値軸上から俯瞰的に 設計変数空間を表した図であり,赤い菱形が各局所解を. Xi (t) = r sin(. π 2π t + j) T 2. (j = 1, 2, . . . , n). (10). 示し,青い実線は最適解の推移を示している.このよう に,Case1 では各局所解の設計変数の位置は不変である. ここで n は式 (9) と同様に目的関数空間の次元数,r は. が,各局所解の評価値が変化し最適解がランダムに推移. 原点から最適解までの距離を制御する係数である.T は. することで,評価値軸上の変化 ∆f のみが発生する問題. 式 (10) の周期であり,この値が小さくなるほど時間 t の. となる.. 一回の変化に対する移動距離が大きくなる.また,この. § 2 Case2 の実験設定 Case2 として継続変化の方向の変化への追従性の検証の ために,Moving Peaks Benchmark(MPB)[Branke 99, Li 08, Li 13] を採用する.MPB の目的関数は以下の式を用. 移動する最適解が再度同じ位置に戻ってくるのは時間 t が周期 T の倍数になった場合となる.また,Case2 にお いて,次元数 n = 2,最適解の周回する円周の半径 r = 4, 移動する周期 T = 200 と設定する.また,この実験の概 形を図 16 に示す.図 15 は評価値のランドスケープの概. いる. v u n uX (xj − Xji (t))2. t maxm i=0 Hi (t)/(1 + Wi (t) ·. 形であり,白色から紫色のグラデーションで示した評価値 のランドスケープにおいて,最適解が赤い矢印で示した ). 方向に変化している.このように Case2 では単峰のラン. (9). ドスケープにおいて,評価値の変化しない最適解のピー. 式 (9) は m 個の局所解を持つ最大化問題であり,n は. ク位置が設計変数軸上を移動することで設計変数軸上の. g2 (x, t) =. i=1. n. 目的関数空間の次元数を示す.また,式 (9) においてベ. 変化 ∆x のみが発生する問題となる..
(12) 進化計算学会論文誌 Vol. 11. 40. No. 3(2020). 高い評価値を維持するためである.これらの Case では 最適解に近い評価値を持つ局所解が存在するため,複数 の解候補のうち最も高い評価値のみを評価すると,最適 解を捕捉したときの評価と局所解のみ捕捉した評価を明 確に区別することができない.複数の局所解の中から最 適解を発見し追従し続けることが可能かを評価するため, 最適解までの距離の割合を用いる.また,この評価指標 は 2·1 節で紹介したタクシー経路最適化問題であれば次 図 17. のような想定となる.この経路最適化の表した図 2(b) に. Case3 の概形. おいて,渋滞が時間経過により悪化することでルート A の乗客までの到達時間が長くなり渋滞の迂回経路である. § 3 Case3 の実験設定 Case3 に用いる関数を下記の式に示す.. ルート B や C が最適解となる可能性がある.また,これ ら迂回経路は分岐となる T 字路までタクシーが到達する. g3 (x, t) =. まで解として最適解として選択可能であるため,最適解. Npeaks. 1−. X. n=0. exp(−. [. sin (2ωt + αn ) + 1 2. (11). M 1 X (xm − r cos (ωt + 2πn/Npeaks + mπ/2))2 )] 2 m=0 402. になる可能性がある局所解 (迂回経路) も同時に探索し評 価した上で最適解を決定する.また,タクシー経路探索 問題において,実際の最適解が未知の可能性もあるが,本 実験では毎世代 (毎時間) の最適解が既知であることを前 提とする. 提案手法は Case1 では PSO,ABC,SSO に. 設計変数空間の次元数 M = 2,局所解の数 Npeaks = 10,. ALIS メカニズムを組み込んだ PSO-ALIS,ABC-ALIS, SSO-ALIS を,Case2 では JOFB メカニズムを組み込ん だ PSO-JOFB,ABC-JOFB,SSO-JOFB を,Case3 では Case1-2 の 6 つの手法と共に両方のメカニズムを組み込ん だ PSO-ALISJOFB,ABC-ALISJOFB,SSO-ALISJOFB. 各局所解と原点との距離 r = 400 とし,oneCycle = 500. を適用する.また,比較手法として,改良を加えていない. として時間 t が 500 の倍数ごとに新しい局所解が発生す す.図 17 は評価値のランドスケープの概形であり,白. PSO と ABC,SSO を用いると共に,単発変化において 提案された SPSO[Parrott 04] と CPSO[Blackwell 02] を 全ての Case において適用する.SPSO と CPSO はそれ. 色から紫色のグラデーションで示した評価値のランドス. ぞれ多様性の維持のアプローチに属する手法であり,変. ケープにおいて,最適解が赤い矢印で示した方向に変化. 化を検知するメカニズムを必要としないため継続変化で. している.Case3 では各局所解の設計変数が半径 400 上. も追従性を期待できる.また,SPSO は各局所解を探索. の円周を周回しつつ,評価値が変化することで,評価値. し続ける手法のため評価値軸上の変化 ∆f に,CPSO は. 軸上の変化 ∆f と設計変数軸上の変化 ∆x が同時に発生. 各個体が近傍の個体と反発しながら探索するため最適解. する問題となる.. 近傍を重点的に探索するため設計変数軸上の変化 ∆x に. ここで各変数は Case1 の式 (8) と同様であり,式 (8) と の変更点は cos 項内に時間 t によって変化する項を追加し たことである.これにより,Case1 の各局所解が設計変数 軸上の円周上を周回することになる.ここで Case3 では,. るように設定する.また,この実験の概形を図 17 に示. 特に有効であると期待できる.また,Case1 - 3 それぞれ. 5·2 評価基準とパラメータ設定 Case1 と Case2,Case3 それぞれにおいて,実験は 30 回の実施する.また,アルゴリズムが 1 回繰り返すごと に時間 t = t + 1 とする.また 1 回の実験について,終 了条件を t = 2000 に設定する.また,アルゴリズムの継. における各アルゴリズムのパラメータは表 1-表 3 に示す. ここで ALIS メカニズムと JOFB メカニズムのパラメー タは以下のように設定される.ALIS メカニズムには局 所的探索の個体数を調整する Nl ,共有範囲の調整幅 ∆d, サブクラスターの設定範囲 cd の 3 つのパラメータを持. 続変化への追従性能を測る指標として,問題の最適解と. つ.まず,Nl については全個体数と必要なサブクラス. アルゴリズムが発見した最良解とのユークリッド距離を. ターの数から適切な値を設定できる.サブクラスター内. 探索空間の大きさで割った値の全時間・全実験での平均. の個体数は Nl より小さい値で維持するため,全個体数. 値を用いる.また,以後,最適解までの距離の割合と称. を Nl で割った数以上のサブクラスターを形成すること. する.この指標により探索空間の大きさと比べてどれほ. は困難である.このため,局所解の数が予め判断可能な. ど最適解に近づいたかを比較する.この値が 0 に近いほ. 問題については,その数のサブクラスターを形成できる. ど最適解付近を最良個体が探索していることになり,よ. Nl を設定する.しかし,多くの問題は局所解の数がわか. り追従性が高いことを意味する.この評価基準を用いる. ることはないため,個体数が許す限りのサブクラスター. 理由は,Case1 と Case3 において最適解に近い評価値を. を用意ことが望ましい.ここで各サブクラスターが効果. 持つ局所解が存在し,それらの局所解が一定期間はその. 的な探索を継続するためには 10 体前後の個体がそれぞ.
(13) 評価値軸・設計変数上の解の継続変化に対する群知能アルゴリズムのためのメカニズムの設計とその追従性の評価. 41. れ必要となるため,Nl = 10 前後に設定することが妥当 となる.加えて,Case1 と Case3 の局所解の数は 10 個で あるため,この設定が最も適切である.次に,共有範囲 の調整幅 ∆d とサブクラスターの設定範囲 cd は以下のよ うに設定する各個体の共有範囲 di は毎世代ごとに ∆d だ け増減する.この調整によりサブクラスターごとの共有 範囲が決定されるため,決定変数空間の大きさに対して. Nl により設定した数のサブクラスターが共有範囲を適 切に調整できるような ∆d を設定する必要がある.ここ 図 18 実験結果 Case1. でサブクラスターの形成,つまり局所解に数体の個体が 収束するまでおおよそ 10 世代ほど必要と仮定し,Case1 と Case3 では (決定変数空間の大きさ 1000) ÷ (サブク ラスター数 10) ÷ (サブクラスターの形成までの世代数. 10) として ∆d= 10 と設定する.サブクラスターの設定 範囲 cd については ∆d よりも小さな値である必要があ るが,値が小さすぎるとサブクラスターまで多くの世代 数を必要とする.このため,論文の Case1 と Case3 では. ∆d の 10%,決定変数空間の大きさ 1000 の 0.1%の大き さである cd = 1 と設定する.次に,JOFB メカニズムの パラメータとして乱数の範囲を拡張する λ を設定する. ここで,4.2 節の図 10(a) にて示したように従来の探索 範囲が α とした場合,JOFB メカニズムでが最良個体か らα*λの範囲を探索する.JOFB メカニズムの目的は最 良個体を中心とした範囲を十分に探索することであるた め,α で示した範囲についても探索を継続する必要があ る.このため,従来の探索範囲αと新しい探索範囲 α ∗ λ の探索のバランスをとるため,λ = 2 と設定することが 妥当となる.この設定により,各個体は従来の探索範囲 と新しい探索範囲をそれぞれ等確率で探索される.. 5·3 実 験 結 果. 図 19 実験結果 Case2. ABC-JOFB,SSO-JOFB) の最適解との距離の割合が減 少した.また,単発変化のための従来手法である CPSO と SPSO よりもこれらの手法の結果は良好であるため, JOFB メカニズムが 3 つの群知能アルゴリズム全てにお いて Case2 で特に有効に作用していることがわかった. また,マンホイットニーの U 検定を実施し,全ての手法 の間で p < 0.05 の有意差を確認した. § 3 Case3 の実験結果 図 20 に Case3 の実験結果を示す.図 20 は縦軸に最適. § 1 Case1 の実験結果 図 18 に Case1 の実験結果を示す.図 18 は縦軸に最適. 解との距離の割合を,横軸に各アルゴリズムの結果を表. 解との距離の割合を,横軸に各アルゴリズムの結果を表. ム (PSO,ABC,SSO) 全てにおいて,JOFB メカニズム. している.この結果から,PSO から PSO-ALIS,ABC か. のみ組み込んだ手法,ALIS メカニズムのみ組み込んだ. ら ABC-ALIS,SSO から SSO-ALIS と,全ての群知能. 手法,両方の手法を組み込んだ手法の順で良好な結果を. アルゴリズムで ALIS メカニズムを組み込むことで,最. 得られた.特に,ABC-ALISJOFB と PSO-ALISJOFB の. 適解との距離の割合が減少した.更に,ALIS メカニズム. 値は非常に小さく,この二つの手法がこの Case において. を組み込んだ各手法は,CPSO と SPSO の結果よりも良. 特に有効であることがわかる.しかし,SSO-ALISJOFB. 好な結果となっていることから,ALIS メカニズムが 3 つ. は ABC-ALIS の結果よりも最適解との距離の割合は多き. の群知能アルゴリズム全てにおいて,評価値軸上の変化. く,SPSO とほぼ同等の結果となった.また,マンホイッ. ∆f のためのメカニズムとして特に有効に作用している ことがわかった.また,マンホイットニーの U 検定を実 施し,全ての手法の間で p < 0.05 の有意差を確認した. § 2 Case2 の実験結果 図 19 に Case2 の実験結果を示す.図 19 は縦軸に最. トニーの U 検定を実施し,全ての手法の間で p < 0.05 の. 適解との距離の割合を,横軸に各アルゴリズムの結果を. 価値軸上の変化 ∆f と設計変数軸上の変化 ∆x と各手法. 表している.この結果から,Case1 と同様に改良を加え. の関係について議論する.まず,Case1 と Case2 の実験. している.これらの結果から,3 つの群知能アルゴリズ. 有意差を確認した.. 5·4 考. 察. 本節では,Case1 から Case3 の実験結果をまとめ,評. ていない群知能アルゴリズム (PSO,ABC,SSO) よりも. 結果から,ALIS メカニズムと JOFB メカニズムはそれぞ. JOFB メカニズムを組み込んだ 3 つの手法 (PSO-JOFB,. れ評価値軸上の変化 ∆f と設計変数軸上の変化 ∆x に対.
(14) 進化計算学会論文誌 Vol. 11. 42. No. 3(2020). 表 1 Case1 のパラメータ. PSO PSO-ALIS ABC ABC-ALIS SSO SSO-ALIS SPSO CPSO. 個体数 N. アルゴリズム独自パラメータ. メカニズムのパラメータ. 100 100 100 100 100 100 100 100. w = c1 = 0.01, c2 = 1.0 w = c1 = 0.01, c2 = 1.0 limit=5 P F = 0.9, M R = 500 P F = 0.9, M R = di w = 0.8, c1 = c2 = 1.4, d = 100 w = 0.8, c1 = c2 = 1.4, Q = 2.0. ∆d = 10, cd = 1, Nl = 10 ∆d = 10, cd = 1, Nl = 10 ∆d = 10, cd = 1, Nl = 10 -. 表 2 Case2 のパラメータ. PSO PSO-JOFB ABC ABC-JOFB SSO SSO-JOFB SPSO CPSO. 個体数 N. アルゴリズム独自パラメータ. メカニズムのパラメータ. 20 20 20 20 20 20 20 20. w = c1 = 0.01, c2 = 1.0 w = c1 = 0.01, c2 = 1.0 limit=5 P F = 0.9, M R = 5 P F = 0.9, M R = 5 w = 0.8, c1 = c2 = 1.4, d = 5 w = 0.8, c1 = c2 = 1.4, Q = 2.0. λ = 2.0 λ = 2.0 λ = 2.0 -. 置は不変である問題では局所解を捕捉し続けることが容 易であるため,ABC-ALIS の結果が他の手法よりも良好 な結果となったと考えられる.このように,ALIS メカ ニズムと JOFB メカニズムは組み込み先の群知能アルゴ リズムの特徴を維持しながら継続変化への追従性を獲得 されることができる.. 6. ま 図 20 実験結果 Case3. と. め. 本論文では,DOPs における環境変化が継続的に発生 する問題 (継続変化) について,評価値軸上の変化と設計. して有効に作用することが明らかになった,また,3 つの. 変数軸上の変化の 2 つの変化に分割し,それぞれの変化. 群知能アルゴリズム全てで変化への追従性を獲得できて. に対して特に有効なメカニズムとして ALIS メカニズム. いることから,提案メカニズムが複数の群知能アルゴリ. と JOFB メカニズムの 2 つを上げた.また,これらのメ. ズムに適用可能であることを示している.また,Case3 の. カニズムが複数の群知能アルゴリズムに対して有効に作. 結果から,JOFB メカニズムと ALIS メカニズムを両方と. 用するか検証した.これらの 2 つのアルゴリズムの継続. も組み込むことで,お互いの働きを妨げることなく,評価. 変化への追従性を検証するために,Case1 として評価値. 値軸上の変化 ∆f と設計変数軸上の変化 ∆x が混在する. 軸上の変化 ∆f への追従性を検証のために 10 個の局所. 変化に追従できることが明らかになった.次に,Case1 か. 解の評価値が継続的に変化することで最適解が変わる問. ら Case3 において,提案メカニズムを組み込んだ 3 つの. 題を,Case2 として設計変数軸上の変化 ∆x への追従性. 群知能アルゴリズムの追従性能が異なっていた.例えば,. を検証するために 1 つの最適解が円周上を常に移動する. Case1 では ABC-ALIS が他の手法を大きく上回る結果と なっているが,Case2 では ABC-JOFB よりも SPO-JOFB と SSO-JOFB の結果の方が良好な結果となっている.こ. 問題を,Case3 として ∆f と ∆x への追従性を検証する. れは群知能アルゴリズムの探索方法の違いよって問題に. Case2,Case3 において,ALIS メカニズムと JOFB メカ ニズムを 3 つの群知能アルゴリズム (PSO,ABC,SSO) に組み込んだ 9 つの手法と,それらの改良を加えていな い 3 つの手法 (PSO,ABC,SSO),単発変化のためのア. 対する追従性に差が生じていると考えられる.ABC は現 在の解よりも良い解が得られなかった場合は元の位置に 戻るように探索する.これにより,Case1 は局所解の位. ために 10 個の局所解の評価値が変化し,そのピーク位 置が移動する問題をそれぞれ用意した.これら Case1 と.
図
+6

![図 12 最適解の連続的移動 この改良では,前述した他個体 x other が含まれる項の乱 数 r を拡張する.例えば,乱数 r の範囲が PSO の r 2 のよ うに [0 , 1] と下限が 0 ,上限が 1 の場合は,上限を変数 λ として [0 , λ] に拡張する.また,乱数 r の範囲が ABC の ϕ のように [ − 1 , 1] と下限が − 1 ,上限が 1 の場合は,上 限下限両方を [ − λ , λ] に拡張する. この拡張により,各個 体は探索範囲を最良個体を含む他個体を飛び](https://thumb-ap.123doks.com/thumbv2/123deta/6853401.1171437/10.892.485.792.113.368/最適連続移動この改良前述他個含まれるとしてのようλにより.webp)
![図 17 Case3 の概形 § 3 Case3 の実験設定 Case3 に用いる関数を下記の式に示す. g 3 (x, t) = 1 − N peaksX n=0 [ sin (2ωt + α n ) + 12 (11) exp( − 1 2 XM m=0 (x m − rcos (ωt + 2πn/N peaks + mπ/2)) 2402 )] ここで各変数は Case1 の式 (8) と同様であり,式 (8) と の変更点は cos 項内に時間 t によって変化する項を追加し たことである.これによ](https://thumb-ap.123doks.com/thumbv2/123deta/6853401.1171437/12.892.164.363.116.273/Case概形Case実験設定用いる関数下記示す=−αここでによっ.webp)

関連したドキュメント
大学設置基準の大綱化以来,大学における教育 研究水準の維持向上のため,各大学の自己点検評
学期 指導計画(学習内容) 小学校との連携 評価の観点 評価基準 主な評価方法 主な判定基準. (おおむね満足できる
100~90 点又は S 評価の場合の GP は 4.0 89~85 点又は A+評価の場合の GP は 3.5 84~80 点又は A 評価の場合の GP は 3.0 79~75 点又は B+評価の場合の GP は 2.5
各テーマ領域ではすべての変数につきできるだけ連続変量に表現してある。そのため
5.2 5.2 1)従来設備と新規設備の比較(1/3) 1)従来設備と新規設備の比較(1/3) 特定原子力施設
100~90点又はS 評価の場合の GP は4.0 89~85点又はA+評価の場合の GP は3.5 84~80点又はA 評価の場合の GP は3.0 79~75点又はB+評価の場合の GP は2.5
ヘッジ手段のキャッシュ・フロー変動の累計を半期
具体的な取組の 状況とその効果
