標本データとの非類似度の組を用いた最近隣法の高次元パターンに対する性質について-香川大学学術情報リポジトリ
5
0
0
全文
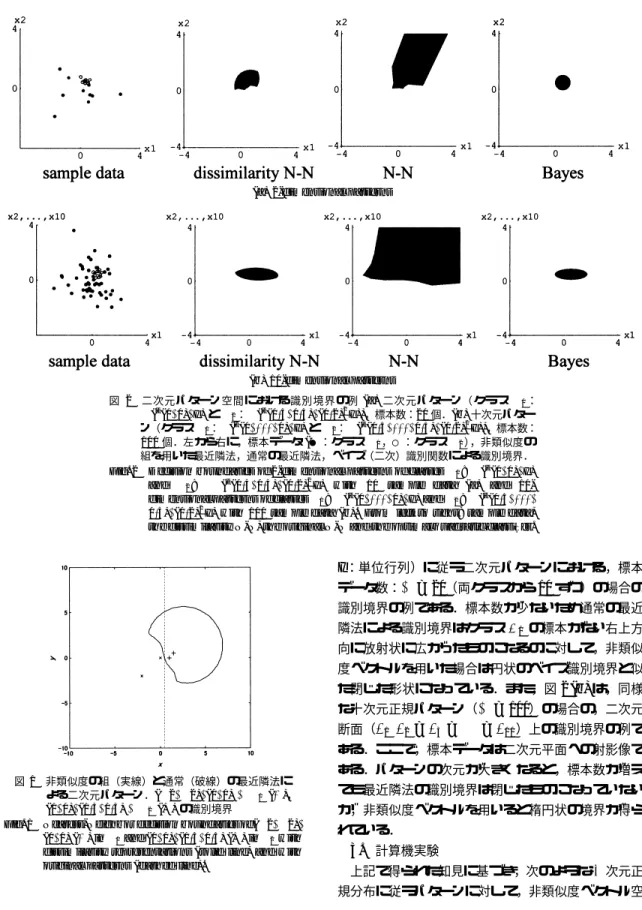
(2) 電子情報通信学会論文誌 2005/4 Vol. J88–D–II No. 4. (a) 2-dimensional patterns. (b) 10-dimensional patterns. 図 2 二次元パターン空間における識別境界の例 (a) 二次元パターン(クラス C1 : N (t (0, 0), I) と C2:N (t (0.5, 0.5), (0.2)2 I)),標本数:20 個.(b) 十次元パター ン(クラス C1:N (t (0, . . . , 0), I) と C2:N (t (0.5, . . . , 0.5), (0.2)2 I)),標本数: 100 個.左から右に,標本データ (●:クラス C1 ,○:クラス C2 ),非類似度の 組を用いた最近隣法,通常の最近隣法,ベイズ(二次)識別関数による識別境界. Fig. 2 Decision boundaries of 2-dimensional patterns of classes C1 : N (t (0, 0), I) N (t (0.5, 0.5), (0.2)2 I) with 10 sample data (a) and 10and C2 : dimensional patterns of classes C1 : N (t (0, . . . , 0), I) and C2 : N (t (0.5, . . . , 0.5), (0.2)2 I) with 100 sample data (b). From left to right: sample data, the dissimilarity N-N, the original N-N and the optimal quadratic classifier.. I :単位行列)に従う二次元パターンにおける,標本 データ数:m = 20(両クラスから 10 ずつ)の場合の 識別境界の例である.標本数が少ないため通常の最近 隣法による識別境界はクラス C1 の標本がない右上方 向に放射状に広がったものになるのに対して,非類似 度ベクトルを用いた場合は円状のベイズ識別境界と似 た閉じた形状になっている.また,図 2 (b) は,同様 な十次元正規パターン(m = 100)の場合の,二次元 断面(x1 , x2 = x3 = · · · = x10 )上の識別境界の例で ある.ここで,標本データは二次元平面への射影像で 図 1 非類似度の組(実線)と通常(破線)の最近隣法に よる二次元パターン.(−2, −2), (0, 0) ∈ C1 (×), (1, 0), (1.5, 0.5) ∈ C2 (+) の識別境界 Fig. 1 Nearest-Neighbor decision boundaries of (−2, −2), (0, 0) (×) in C1 and (1, 0), (1.5, 0.5) (+) in C2 with dissimilarity representations (solid line) and with original patterns (dashed line).. ある.パターンの次元が大きくなると,標本数が増え ても最近隣法の識別境界は閉じたものになっていない が,非類似度ベクトルを用いると楕円状の境界が得ら れている.. 3. 計算機実験 上記で得られた知見に基づき,次のような n 次元正 規分布に従うパターンに対して,非類似度ベクトル空. 814.
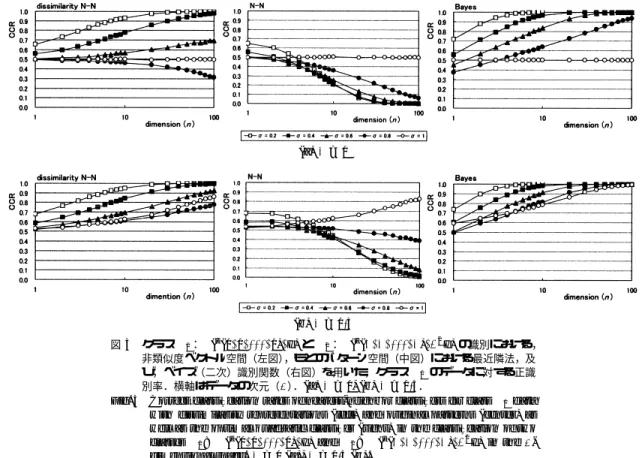
(3) レ. タ. ー. (a) µ = 0. (b) µ = 0.5 t. 図 3 クラス C1:N ( (0, 0, . . . , 0), I) と C2:N (t (µ, µ, . . . , µ), σ2 I) の識別における, 非類似度ベクトル空間(左図),もとのパターン空間(中図)における最近隣法,及 び,ベイズ(二次)識別関数(右図)を用いた,クラス C1 のデータに対する正識 別率.横軸はデータの次元(n).(a) µ = 0, (b) µ = 0.5. Fig. 3 Correct classification rates of nearest-neighbor classifiers for class C1 data with dissimilarity representations (left) and original patterns (center) as well as the optimal quadratic classifier (right) in the classification of two classes C1 : N (t (0, 0, . . . , 0), I) and C2 : N (t (µ, µ, . . . , µ), σ2 I) in the ndimensional space. µ = 0 (a), µ = 0.5 (b).. 間における最近隣法ともとのパターン空間における最. さい場合(µ = 0.5,σ ≈ 1.0 (b))を除く).それに対. 近隣法の識別性能を,計算機実験によって調べた.. して,非類似度ベクトル空間における最近隣法の場合,. t. C1 : N ( (0, 0, . . . , 0), I), C2 : N (t (µ, µ, . . . , µ), σ 2 I) (I :n 次元単位行列) クラス C1 は n 次元標準正規分布であり,クラス. 次元とともに正識別率は増加する(ただし,平均値が 同じで分散の差が小さい場合(µ = 0.0,σ = 0.8, 1.0. (a))を除く).なお,ここでは示していないが,クラス C2 のパターンに対する両者の正識別率はほとんど同 じで,二つのクラスの統計量が同一(µ = 0,σ = 1). C2 は各成分の平均値が µ,標準偏差が σ である独立 な n 次元正規分布である.標本データ数:m = 10(両 クラスから 5 ずつ),テストデータ数:1000 として,. のとき以外は次元とともに増加する.非類似度ベクト. 二つの最近隣法による識別を,異なるランダムデータ. 正識別率と等分散を仮定した線形識別関数によるもの. を用いて 1000 回行った.図 3 に,(a) µ = 0 と (b). との間の値となっている.標本データ数を増やした場. µ = 0.5 の場合について,σ を 0.2 から 1.0 まで変え たときの,クラス C1 (分散の小さくない方)に属す るパターンの正識別率を示す.横軸の次元 n は対数ス. 合(m = 100, 1000)にも,両者とも正識別率は高く. ル空間における最近隣法による正識別率は,分散の差 が大きいとき(σ = 0.2),最適な二次識別関数による. なるが,同様な結果が得られる.また,超立方体内の 一様分布のような非正規分布に従うパターン,例えば,. ケールをとっている.なお,最適なベイズ(二次)識. C1:U (−0.5, 0.5)n ,C2:U (−0.2, 0.2)n のような場合. 別関数を用いた場合の正識別率を併せて示している.. に対しても同様である.. 図から,もとのパターン空間における最近隣法の正. ただし,このようなもとのパターン空間における最. 識別率は,パターンの次元が大きくなるにつれ低下す. 近隣法と非類似度ベクトル空間における最近隣法との. ることが分かる(ただし,平均値が異なり分散の差が小. 違いは,二つのクラスの平均値の差が分散に比して小 815.
(4) 電子情報通信学会論文誌 2005/4 Vol. J88–D–II No. 4. さいときにのみ見られるものである.例えば,今回と. ることを示している.例えば,ばらつきの大きさの異. 同じ分布の場合,もとのパターン空間における最近隣. なるクラスを考えた場合,標本データ数を一定とした. 法の正識別率は,µ = 1.0 では次元とともに増加する. とき,次元が大きくなると,ばらつきの小さなクラス. ようになり,µ = 2.0 になると両者の正識別率にはほ. (C2 )の標本データ間の非類似度に比べて,ばらつき. とんど差が見られなくなる.. の大きなクラス(C1 )の標本データ間の非類似度は平. 4. む す び. 均として相対的に増大する.また,両クラスのデータ. 標本データとの非類似度を要素とするベクトル(非. 間の非類似度もやはり相対的に増大する.そのため,. 類似度ベクトル)空間における最近隣法,一般には区. 標本データとの非類似度は,クラス C1 のデータでは,. 分線形識別器による識別関数は,もとのパターン空間. クラス C1 の標本データとの類似度:大,クラス C2. においては二次の識別関数となる.そのため,クラス. の標本データとの類似度:大となるのに対して,クラ. によってパターンの分布の二次統計量(分散・共分散. ス C2 のデータでは,クラス C1 の標本データとの類. 行列)が異なる場合に,良い識別性能を有する場合が. 似度:大,クラス C2 の標本データとの類似度:小と. あることを計算機実験によって示した.. なる.このように,次元の増大とともにクラス間で非. クラス間でたとえ平均値に差があっても分散にも少. 類似度ベクトルの差異が大きくなる傾向があるわけで. し(1:0.9 程度でも)差があるような特徴が加わった. ある.このような性質をもつ標本データとの非類似度. 場合,もとのパターン空間における最近隣法はかえっ. の組の利用は,次元ののろいに対処する一つの有効な. て正識別率が低下してしまう.このことは,次元のの. ノンパラメトリックな方法であるといえよう. 文. ろいの一つの表れであり,直観的には,高次元空間に おける標本データのまばらさによるものと考えられる.. [1]. Int. Conf. Pattern Recognition (ICPR 2000), vol.2,. るクラスの識別には,原点の周りにばらつきの小さな. n 次元空間において原点を n − 1 次元超平面で囲う場 合,最小では単体のとき n + 1 枚の平面で済むが,一 般には,O(2n ) 枚の平面が必要となると考えられる.. pp.12–16, 2000. [2]. nition,” Pattern Recognit. Lett., vol.18, pp.1159– 1166, 1997. [3]. protein fold classification,” in Machine Learning and. 界を得るには O(2 ) 個の標本データが必要となるが,. Data Mining in Pattern Recognition, ed. P. Permer,. それだけの標本データがない場合には,図 2 に示した. pp.322–336, Springer-Verlag, Berlin, 2001. [4]. る.このことは,言い換えれば,標本データ数に対し 本データが存在しない方向(側)が増え,その方向の. V. Mottl, et al., “Featureless pattern recognition in an imaginary Hilbert space and its application to. n. て次元が大きくなると,ばらつきの大きなクラスの標. R.P.W. Duin, D. de Ridder, and D.M.J. Tax, “Experiments with a featureless approach to pattern recog-. そのため,最近隣法において原点を囲むような識別境. ように原点を囲めない場合が起こってしまうわけであ. “Classifiers for. dissimilarity-based pattern recognition,” Proc. 15th. 例えば,原点を平均値としてばらつきの大きさが異な クラスを囲むような識別境界が望ましい.ところが,. 献. E. Pekalska and R.P.W. Duin,. R.P.W. Duin, E. Pekalska, and D. de Ridder, “Relational discriminant analysis,” Pattern Recognit. Lett., vol.20, no.11–13, pp.1175–1181, 1999.. [5]. A.K. Jain and B. Chandrasekaran, “Dimensionality and sample size considerations in pattern recogni-. 領域は原点近傍のばらつきの小さいクラスの標本デー. tion practice,” in Handbook of Statistics, vol.2, ed.. タとの方が距離が小さくなってしまうことによる.高. P.R. Krishnaiah and L.N. Kanal, pp.835–855, North-. 次元空間における最近隣法の性質については様々なも のが知られているが [10]∼[14],このような性質はこ. Holland, 1982. [6]. れまであまり指摘されていないように思われる. それに対して,非類似度ベクトル空間における最近. 2000), vol.2, pp.1–7, 2000. [7]. tion,” J. Machine Learning Research, vol.2, pp.175–. るような特徴からなるパターンの場合でも,パターン のことは,非類似度ベクトル空間においては,もとの パターンのクラス間の二次統計量の違いによって,次 元の増大とともにクラスが線形に分離される傾向があ 816. E. Pekalska, P. Pacl´ık, and R.P.W. Duin, “A generalized kernel approach to dissimilarity-based classifica-. 隣法では,クラス間で平均値が等しく分散のみが異な の次元が大きくなるにつれ,正識別率が高くなる.こ. R.P.W. Duin, “Classifiers in almost empty spaces,” Proc. 15th Int. Conf. Pattern Recognition (ICPR. 211, 2001. [8]. L.I. Kuncheva, J.C. Bezdek, and R.P.W. Duin, “Decision templates for multiple classifier fusion: An experimental comparison,” Pattern Recognit., vol.34, pp.299–314, 2001..
(5) レ [9]. タ. ー. Y. Horikawa, “Quadratic boundaries in N-N classi-. [12]. Shaft, “When is “nearest neighbor” meaningful?,”. 6th International Conference on Signal Processing. Proc. 7th Int. Conf. Database Theory (ICDT’99),. (ICSP 2002), pp.1039–1042, 2002. [10]. [11]. K. Beyer, J. Goldstein, R. Ramakrishnan, and U.. fiers with dissimilarity-based representations,” Proc.. K. Fukunaga, Introduction to Statistical Pattern. pp.217–235, 1999. [13]. A. Hinneburg, C.C. Aggarwal, and D.A. Keim,. Recognition (2nd ed.), Academic Press, San Diego,. “What is the nearest neighbor in high dimensional. 1990.. space,” Proc. 26th Int. Conf. Very Large Database. R. Weber, H.-J. Schek, and S. Blott, “A quantitative analysis and performance study for similarity-search methods in high-dimensional spaces,” Proc. 24th Int. Conf. Very Large Database (VLDB’98), pp.194–205,. [14]. (VLDB 2000), pp.505–515, 2000. 片山紀生,佐藤真一,“類似検索のための索引技術, ” 情報. 処理,vol.42, pp.958–964, 2001. (平成 16 年 9 月 3 日受付,11 月 12 日再受付). 1998.. 817.
(6)
図
関連したドキュメント
テキストマイニング は,大量の構 造化されていないテキスト情報を様々な観点から
実際, クラス C の多様体については, ここでは 詳細には述べないが, 代数 reduction をはじめ類似のいくつかの方法を 組み合わせてその構造を組織的に研究することができる
This study examines the consciousness and behavior in the dietary condition, sense of taste, and daily life of university students. The influence of a student’s family on this
生活のしづらさを抱えている方に対し、 それ らを解決するために活用する各種の 制度・施 設・機関・設備・資金・物質・
[r]
授業設計に基づく LUNA の利用 2 利用環境について(学外等から利用される場合) 3 履修情報が LUNA に連携するタイミング 3!.
23)学校は国内の進路先に関する情報についての豊富な情報を収集・公開・提供している。The school is collecting and making available a wealth of information
続いて川崎医療福祉大学の田並尚恵准教授が2000 年の
