16章 Flat Clustering
クラスタリングアルゴリズムとは、複数のドキュメントからなる集合を、複数のクラスタ (cluster)と呼ばれるサブセットへグルーピングするアルゴリズムのことです。このアルゴ リズムの目的は、自然でわかりやすく、かつそれぞれが同じではないクラスタを作ること です。別の言い方をすれば、それぞれ同じクラスタに含まれるドキュメント同士は可能な 限り似ているべきであり、それぞれ違うクラスタに含まれるドキュメント同士は可能な限 り似ていないべきです。 図 16.1 明確なクラスタ構造を持つデータセットの例 クラスタリングは教師なし学習 (unsupervised learning) の一種類としてよく知られていま す。「教師なし」とは、アルゴリズム中に、ドキュメントをクラス分けしてくれる人間の 専門家を必要としないということを意味します。クラスタリングでは、クラスタはデータ の分布とその構成によって決定されます。図16.1がそのシンプルな例です。この例では見 た目から明らかなように3つのクラスタからなります。この章及び17章では教師なし学習 によるクラスタを発見するアルゴリズムを紹介します。 クラスタリングとクラシフィケーションは、それほど違うようには見えないでしょう。な ぜなら結局、両方共ドキュメントの集合を複数のグループにわけるためです。しかし、こ の後で見るように、両者における問題点はまったく異なるものです。クラシフィケーショ ンは、教師あり学習の一種です(13章、237ページ)。我々のクラスタリングでの最終的な 目的は人間の専門家がデータに対して行うカテゴリ分類を再現することです。クラスタリ ングを代表とする教師なし学習においては、この様な教師を必要としません。 クラスタリングにおいて重要な入力は距離指標(distance measure)です。図16.1では距離 指標は2次元平面上の距離となっています。この指標を用いると、図中のデータは3つのク ラスタに分類されます。ドキュメントのクラスタリングでは、ユークリッド距離がよく用いられます。異なった距離指標を用いると、異なったクラスタリングが生成されます。そ のため、距離指標はクラスタリングの結果に影響を与える、重要な指標となるのです。 フラットクラスタリング(flat clustering)はクラスタ間にいかなる関係構造も存在しない、 フラットなクラスタ集合を生成します。階層的クラスタリング(hierarchical clustering) は、クラスタ間に階層を生成します。これについては17章で述べます。また17章では、ク ラスタを自動的にラベリングするという別の問題についても言及します。 2つ目のクラスタリングの重要な分類は、ハードクラスタリングアルゴリズムとソフトク ラスタリングアルゴリズムという分類です。ハードクラスタリングでは、各ドキュメント は必ず一つのクラスタに分けられるという、厳密な(hard)割り当てを行うものです。ソフ トクラスタリングでは、ドキュメントの割り当てが複数のクラスタ間に分配されます。緩 い(soft)割り当てでは、各ドキュメントは複数のクラスタの部分的な要素となります。次元 削減の方法である潜在的セマンティックインデックス(Latent semantic indexing)はソフト クラスタリングアルゴリズムの一種です(18章、382ページ)。 この章ではいくつかの具体例を紹介し(16.1節)、我々が解決しなければならない問題の定 義を行い(16.2節)、クラスタの質を評価する指標について議論することにより(16.3節)、 クラスタリングをいかに情報検索で用いるのか説明します。その後、2つのクラスタリン グ手法、ハードクラスタリングアルゴリズムであるK-means(16.4節)と、ソフトクラスタ リングアルゴリズムであるexpectation maximization(EM)アルゴリズム(16.5節)を紹介しま す。K-meansはシンプルでかつ効率的であるため、もっとも広く使われているクラスタリ ング手法です。EMアルゴリズムは、K-meansの一般化であり、特徴が多数あり、分散し ている集合に対しても適用できます。
16.1 Clustering in information retrieval
クラスタ仮定(cluster hypothesis)は情報要求に対してクラスタリングを用いる際の基本的 な前提事項を述べています。 <クラスタ仮説> 同じクラスタ中に含まれるドキュメントは、情報要求に対して似 た振る舞いをする この仮定は検索クエリに関連したドキュメントを取ってくると、そのドキュメントと同じ クラスタに含まれる他のドキュメントも同じく検索クエリに関連している、ということを 意味します。これは同じ語を多数含むドキュメントをまとめて、1つのクラスタとするた めこのようになります。このクラスタ仮定は、14章の隣接仮説(contiguity hypothesis)と本
質的に同じものす。双方とも、関連したドキュメントは似た振る舞いをする、と仮定して います。 表16.1 情報検索におけるクラスタリングの適用例 表16.1は情報検索における、クラスタリングの代表的な適用例です。それぞれクラスタの 対象とするドキュメントが検索結果またはコレクションまたはコレクションのサブセット であり、情報検索システムにおいて改善しようとしている点がユーザエクスペリエンスま たはユーザインターフェースまたは検索システムの効果・効率である点が異なります。 表16.1の最初の適用例は検索クエリに対して返ってきた検索結果(ドキュメント)のクラス タリングです。情報検索における一般的な検索結果の表示方法はシンプルなリストです。 ユーザは探している情報を見つけるまでリストを上から下に順に見ていきます。これに対 して、検索結果のクラスタリングを行うと、類似ドキュメントがまとめて出力されます。 これは検索語が複数の意味を持つような場合に特に有用です。図16.2はjaguarについての 例です。ここでは3種類の意味、車・動物・アップルのOSが出てきます。Vivisimoサーチ エンジン(http://vivisimo.com)が返してくるcluster resultsのパネルは単純なリストより検索 結果を理解するためにより効率的なユーザインターフェースとなっています。
図16.2 再現性を高めるための検索結果のクラスタリング。上位に動物のjaguarは含まれていない が、Clustered resultsパネルのcatクラスタをクリックすることで簡単にアクセスできる。
よりよいユーザインターフェースは、表16.1の2つ目の適用例であるScatter-Gatherの目的 でもあります。Scatter-Gatherでは全ドキュメントからクラスタリングを行い、その中か らユーザが必要なクラスタを複数選択します。その選択されたグループをマージし、マー ジした結果を再びクラスタリングします。このプロセスを求めるクラスタが見つかるまで 繰り返します。図16.3がこの例になります。
図16.3 Scatter-Gatherのユーザセッションの例。New York Timesのニュースは 8つのクラスタに クラスタリングされる(scattered)。ユーザは、これらの中から3つをより小さい集合である
International Storiesに集め(gather)、再度クラスタリング(scattered)する。このプロセスは、 Trinidadのような関連文書が見つかるまで繰り返される。
図16.3のような自動的に生成されたクラスタはOpen Directory(http://dmoz.org)のようなき ちんと人手で作られた階層的な木構造とは異なるものになってしまうという問題がありま す。また、自動的に各クラスタを説明するようなラベルをつけるのは難しいという問題も あります(17.7節、363ページ)。しかし、クラスタによるナビゲーションは従来の情報検索 のキーワードサーチに変わる興味深い方法であります。これは特にユーザがどんな検索語 を使ったらいいか分からないため、検索よりブラウジングをしたいという場合に有効で す。 ユーザの選択を媒介として繰り返しクラスタリングを行うScatter-Gatherの代替として、 コレクションに対して静的な階層的クラスタリングを行うという、ユーザの行動に影響さ れない方法があります(表16.1のコレクションクラスタリング)。グーグルニュースとその 前身であるColumbia NewsBlasterシステムは、この方法を用いている例の一つです。
ニュースの場合、ユーザが最新のニュース速報にアクセスできるように、頻繁にクラスタ を再計算する必要があります。ニュース記事の読者は実際には検索をしたいわけではな く、最新の出来事に関する記事のサブセットを発見したいため、クラスタリングはニュー ス記事の集合によく適してます。 4番目のクラスタリングの適用例はコレクション全体をクラスタリングすることにより、 クラスタ仮説を直接検索結果を改善するために使います。まず標準的な転置インデックス をクエリにマッチする最初のドキュメントを選ぶために使います。その後、それらのド キュメントと同じクラスタに含まれるドキュメントを、たとえクエリとの関連度が低いド キュメントでも検索結果に含めます。これにより例えば、クエリがcarだとして、carのド キュメントがautomobileのドキュメントのクラスタに含まれているとき、car以外の単語 (automobile、vehicleなど)が使われているドキュメントを検索結果に含めることが出来ま す。相互に関連性が高いドキュメントの集合は全体が関連しているため、これにより recallを向上させることが出来ます。 より最近では、このアイデアは言語モデルに対して使われています。226ページの式 (12.10)は、情報検索の言語モデルアプローチにおけるスパースなデータの問題を避けるた めに、ドキュメントdのモデルをコレクションのモデルに置き換えることを示していま す。しかし、このコレクションはドキュメントdではあまり一般的ではない単語を含むド キュメントを多数含んでいます。このコレクションモデルでドキュメントdのクラスタか ら作られたモデルを置き換えることにより、ドキュメント中での単語の出現率をより正確 に見積ることができます。 またクラスタリングは検索のスピードアップをすることもできます。6.3.2節(113ページ)で 見たように、ベクタースペースモデルでの検索はクエリにもっとも近いドキュメントを見 つけることになります。転置インデックスによりこのクエリにもっとも近いドキュメント の探索を高速に行うことができます。しかし、例えば潜在的セマンティックインデックス (18章)のように、たまにこの転置インデックスを効率的に使えないことがあります。この 場合、すべてのドキュメントとクエリの類似度を計算することによって探すことも出来ま すが、それは非常に遅くなってしまいます。クラスタ仮説はこれに対する代替案を提供し ます。それは、クエリにもっとも近いクラスタを見付け、そのクラスタ中のドキュメント のみを考えることです。これにより探索範囲は小さな集合となるため、すべての類似度を 計算することができ、通常の方法でドキュメントのランキングをすることが出来ます。ク ラスタ数はドキュメント数よりとても少ないため、もっと近いクラスタを見つけることが 素早く行え、またクエリにマッチするドキュメントはそれぞれ似たようなものになりかつ 同じクラスタないのドキュメントもそれぞれ似ているためです。このアルゴリズムは不正
確ですが、その検索の質は、それほど下がらないと期待できます。そのため7.1.6節(130 ページ)の内容は本質的にクラスタリングの適用例になり得ます。
16.2 Problem statement
まずハードフラットクラスタリングのゴールを次のように決めます。(i)ドキュメント集合 D={d1,...,dN}、(ii)クラスタ数K、(iii)クラスタリングの質を計る目的関数(objective function)の3つが与えられたとき、この目的関数の結果を最小化する(または場合によって は最大化する)γ:D->{1,...,K}の割り当てを計算することです。多くの場合、さらにγは全射 である、つまりK個のクラスタのすべてが空ではないことを必要とします。 目的関数はドキュメント間の類似度や距離によって決められます。後で述べる、K-means クラスタリングの目的関数は、ドキュメントとそのクラスタの重心の平均距離を最小化 し、同時にクラスタ中の各ドキュメントとその重心の類似度を最大化することとなりま す。14章で出てきた類似度の指標と距離関数の議論はこの章でも同様に使えます。14章と 同じく類似度と距離の両方をドキュメント間の関連性の尺度として使います。 ドキュメントについて、望ましい類似度の種類はトピックの類似度やベクタースペースモ デル上の同じ次元での高い値を持つこととなります。例えば、Chinaについてのドキュメ ントはChineseやBeijingやMaoのような次元で高い値を持ち、UKについてのドキュメント はLondonやBritainやQueenに対して高い値を持ちます。トピックの類似度としてベクトル 空間でのコサイン類似度やユークリッド距離を適用できます(6章)。トピック以外の類似 度、例えば言語的な類似度を計ろうとした場合、違う指標がふさわしくなります。トピッ クの類似度を計算する場合、ストップワードを無視できるが、英語のドキュメントのクラ スタ(theがよくあらわれ、laはあまりあらわれない)か、フランス語のドキュメントのクラ スタ(theはあまりあらわれない、laがよくあらわれる)かを分割する時にはストップワード も重要になります。 <用語解説> ハードクラスタリングのもう一つ別の定義として、ドキュメントが一つ以上 のクラスタの完全なメンバーとなることが使われることもあります。パーティショナルク ラスタリングは各ドキュメントは正確に一つのクラスタに含まれるクラスタリングです (しかしpartitional 階層化クラスタリング(17章)では、クラスタのすべての要素が、その親 クラスタの要素でもあります)。複数の集合に属す要素を許すハードクラスタリングの定 義を用いている場合は、ソフトクラスタリングとハードクラスタリングの違いはハードク ラスタリングはその属する度合いが0か1となり、ソフトクラスタリングは非ゼロのあらゆ る値をとれることになります。ある研究者は、各ドキュメントが必ず一つのクラスタに属する完全な(exhaustive)クラス タリングと、いくつかのドキュメントはどのクラスタにも属さないという不完全な(non-exhaustive)クラスタリングというものにわけました。各ドキュメントが一つのクラスタに 属するか、またはクラスタに属さないという不完全なクラスタリングは排他的(exclusive) とも呼ばれます。この本ではクラスタリングは完全なものと定義する。
16.2.1 Cardinality - The number of clusters
クラスタリングにおける難しい問題は、Kで表されるクラスタ数またはクラスタのカー ディナリティ(cardinality)と呼ばれるものを決定することです。Kはよく経験やその分野の 知識から推測で決められます。K-meansでは、Kを決めるための方法を紹介し、目的関数 にKの選択を含めるヒューリステックな方法を紹介します。アプリケーションによって は、Kの範囲が決められていることもあります。例えば、図16.3のScatter-Gatherでは 1990年代初頭のコンピュータのモニタのサイズや解像度ではK=10以上の数は表示できま せんでした。 我々の目的は目的関数を最適化することであるため、クラスタリングの問題も本質的には 探索の問題です。もっとも単純な解法は、すべての可能な組み合わせでのクラスタリング を行い、その中でもっとも良いものをとる方法です。しかし、これは指数関数的な組み合 わせがあり、この方法は現実的ではありません。この様な理由により、多くのフラットク ラスタリングは分割を繰り返すことにより、より純粋にしていく方法をとります。検索が あまりよくない開始点(seed)からスタートすると、全体最適をし損なうことがあります。 よい開始点を見つけることはフラットクラスタリングにおいて解決しなければならないも う一つの重要な問題です。
16.3 Evaluation of clustering
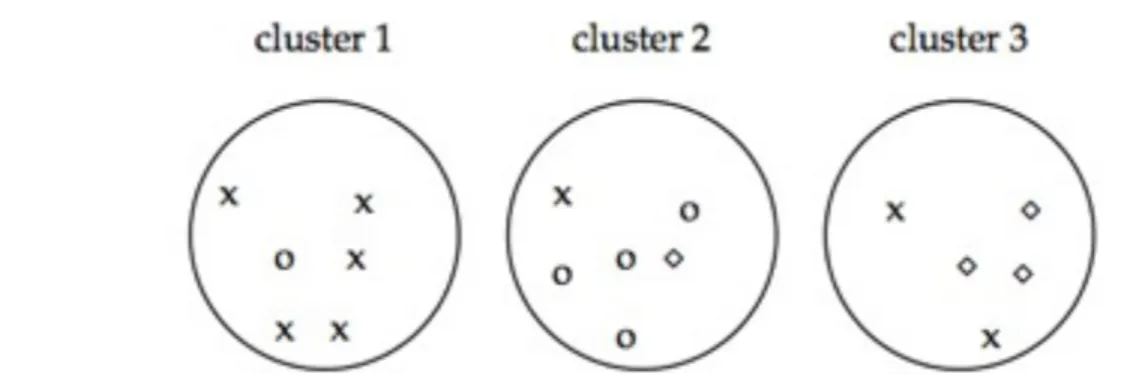
典型的なクラスタリングの目的関数は、クラスタ内のドキュメントの類似度を高くし(つ まり同じクラスタ内のドキュメントを類似させる)、クラスタ間のドキュメントの類似度 を低くする(つまり違うクラスタ間のドキュメントは類似しない)ということを定式化した ものです。これはクラスタリングの質の内部評価(internal criterion)といいます。しかし、 アプリケーションによい結果をもたらすために、内部評価上の高い点数が必ずしも必要と いうわけではありません。内部評価の代わりに、そのアプリケーションの興味を直接評価 することがあります。検索結果のクラスタリングでは、様々なクラスタリングアルゴリズ ムを使ったときにユーザが正しい答えが見つけるまでの時間を計る方法があります。これ がもっとも直接的な評価ですが、特に多くのユーザによる評価を必要とする場合、非常に 高価となります。ユーザによる評価の代わりに、評価用のベンチマークまたはgold standard(8.5節の151 ページと13.6節の258ページ)の集合を使うことができます。gold standardは、内部判定に 合意のとれた人間の審判によって提供されます(8章140ページ)。この指標を用いて、クラ スタリングがgold standardのクラスといかに一致するかを評価する外部評価(external criterion)を行うことができます。例えば、図16.2のjaguarの検索結果での最適化されたク ラスタは、car・animal・operating systemの3つに対応するクラスで構成されています。 この種の評価では、gold standardで提供された分類だけを用いて、クラスのラベルは用い ません。 この章ではクラスタリングの質を評価する4つの外部評価を紹介します。純度(purity)はシ ンプルで明確な評価指標です。正規化相互情報量(normalized mutual information)は情報理 論的な解釈を与えることができます。Rand indexはクラスタを作るときのfalse-positiveと false-negativeにペナルティーを与えます。これに加えて、F値(F measure)ではそれぞれの エラーに違う重みをつけます。 純度を計るために、各クラスタはそのクラスタに最もよく出現するクラスに割り当てら れ、その割り当ての正確さは各クラスタに対して正しく割り当てられていたドキュメント の数を全ドキュメント数Nで割ることによって計算します。定式化すると、 (16.1) ここで Ω = {ω1,ω2,...,ωk} はクラスタの集合とし、 C = {c1,c2,....,cj} はクラスの集合とし ます。式(16.1)のωkはωkに含まれているドキュメントと解釈し、cjはcjに含まれているド キュメントの集合とします。
Figure 16.4 Purity as an external evaluation criterion for cluster quality. Majority class and number of members of the majority class for the three clusters are: x, 5 (cluster 1); o, 4 (cluster 2); and ⋄, 3
(cluster 3). Purity is (1/17) × (5 + 4 + 3) ≈ 0.71.
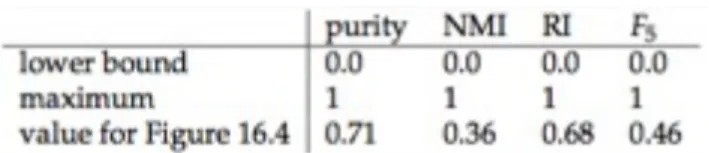
図16.4でこの純粋度をいかに計算するか示します。悪いクラスタリングにおいては純度は 0に近くなり、完全なクラスタリングでは1になります。純度とこの章で述べる他の指標と の比較を表16.2に載せます。
Table 16.2# The four external evaluation measures applied to the clustering in Figure 16.4.
高い純度はクラスタ数を多くすることで簡単に達成できます。特に各ドキュメントがそれ ぞれ自分だけを含むクラスタとなるとき必ず1になります。そのため、この方法によるク ラスタの質の評価はクラスタ数とのトレードオフなしでは使うことができません。 このトレードオフを実現する指標が正規化相互情報量(normalized mutual information, NMI)です。 (16.2) が相互情報量になります(cf 13章、252ページ)。 (16.3) (16.4) ここでP(ωk)、P(cj)、P(ωkハットcj)はそれぞれクラスタωk、クラスcj、とその共通部分に ドキュメントが含まれる確率です。式(16.4)は式(16.3)を最尤推定量(MLE)で書き直した式 となります(つまり、各確率の推定量は対応する関連の出現頻度に等しい)。 Hは5章で定義されたエントロピーです(91ページ)。 (16.5) (16.6) 同じく2つ目の式は確率の最尤推定量に基づく式です。 式(16.3)の I(Ω;C) はこのクラスタが何であるかを知ることにより、そのクラスタが何であ るか分かるという情報です。 I(Ω;C) の最小値はクラスの構成要素がランダムなクラスタで 0になります。この場合、ドキュメントに関する知識はそのクラスが何であるかについて 何も新しい情報を与えてくれません。最大の相互情報量はクラスタリングΩexactで完全に
クラスが分けられたときに得られます。しかしΩexactでの相互情報量はより小さいクラス タにわけたときも得ることができます(exercise 16.7)。特にK=Nの時のクラスタリングで あるone-documentクラスタは最大の相互情報量を持ちます。そのため、相互情報量も純 粋度と同じ問題点を持ちます。クラスタ数が多くなってもペナルティを与えることができ ず、この他が同じならクラスタ数が少ない方がよいという、偏りを定式化できません。 式(16.2)の正規化数である分母の [H(Ω)+H(C)]/2 がこの問題を解決します。それはエント ロピーはクラスタ数が大きくなると増える傾向にあるためです。例えば、 H(Ω) は K = N の時に最大値 logN を取り、NMIは最小となる。またNMIは正規化されているため、数の 違うクラスタ同士を比べるのに使えるます。 [H(Ω)+H(C)]/2 は I(Ω;C) の最大値であるた め、この式の分母として選ばれました(exercise 16.8)。したがって、NMIは常に0と1の間 をとります。 別のクラスタリングの情報理論における解釈としては、コレクションの中のN(N-1)/2通り のドキュメントのペアから一つを選ぶという決定の連続です。ある2つのドキュメントが 類似していてかつその時だけ同じくラスタに入れたい。true-positiveは類似したドキュメ ントが同じクラスタに入た場合、true-negativeは類似していないドキュメントが違うクラ スタに入った場合です。また2種類のエラーがある。false-positiveは2つの本来は類似して いないドキュメントを同じドキュメントに入れてしまった場合です。false-negativeは2つ の類似したドキュメントを違うドキュメントとしてしまった場合です。Rand index(RI)は それぞれの決定が正しかったパーセンテージを計ります。これは単に正確性(accuracy)と 同じものです(8.3節、143ページ)。 例として、図16.4のRIを計算します。まず最初にTP+FPを計算します。3つのクラスタは それぞれ6、6、5点あります、そのため"positive"な部分、つまり同じクラスタに含まれる ドキュメントの数は もちろんクラスタ1のxのペア、クラスタ2のoのペア、クラスタ3のダイヤのペアとxのペア がtrue positiveです。
よってFP=40-20=20となります。 FNとTNも同様に計算でき、以下の分割表(contingency table)のようになります。 そのためRIは(20+72)/(20+20+24+74)=0.68となります。 RIではFPとFNに等しい重みを与えています。類似のドキュメントが間違って分割される のは、類似していないドキュメントが同じクラスタに配置された時より悪いです。そのた めF値(f measure)を使ってβ>1の値を使いFNに対してFPよりペナルティを与えることによ り、recallに対してより重みを与えることができます。 分割表に基づいて、 P = 20/40 = 0.5 と R = 20/44 = 0.455 となります。これにより β = 1 の時 F1 = 0.48 、 β = 5 の時 F5 = 0.456 となります。情報検索では、F値でクラスタを評 価するというのは、この指標が既にコミュニティ内で一般的になっているという利点もあ ります。
16.4 K-means
K-meansはもっとも重要なフラットクラスタリングアルゴリズムです。その目的はドキュ メントとそのクラスタの中心の2乗のユークリッド距離の平均値(6章、121ページ)を最小 化させることです。ここでクラスタの中心はクラスタωに含まれるドキュメントの中央値 または重心μです。 この定義ではいつものようにドキュメントは実数の空間上の正規化されたベクトルを表し ています。14章でもRocchioクラシフィケーションのために重心を使いました(269ペー ジ)。ここでもこれは同じような役割を果たします。K-meansにおける理想的なクラスタ は、重心がちょうど中心になるような球形です。理想的にはそのクラスタはオーバーラッ プしないべきで、Rocchioクラシフィケーションで求めていたものと同じものになりま す。違いはクラスタリングではラベル付けされたトレーニングセットを持っておらず、ど のドキュメントが同じクラスタに入ってほしいかを知っているだけです。重心がいかにクラスタを代表しているかの指標がresidual sum of square(差分の2乗和?) またはRSSと呼ばれます、これは各ベクトルの重心からの距離の2乗をすべてのベクトル について合計したものです。 (16.7) RSSはK-meansにおける目的関数で、我々のゴールはこれを最小化させることです。ド キュメント数Nは定数なので、重心がドキュメントの集合をどの程度代表しているかとい うRSSを最小化させることは2乗距離の平均を最小化させることと等しいです。 K-meansの最初のステップはランダムにシードと呼ばれる最初のクラスタの重心を表すK 個のドキュメントを選ぶことです。その後、RSSを最小化させるようにクラスタの中心を 移動させていきます。図16.5のように重心が定まるまで以下の2つのステップを順に繰り 返します。まずドキュメントをもっとも近い重心を持つクラスタに割り当てて、次にその できあがった新しいクラスタの要素で重心の再計算を行います。図16.6はK-meansアルゴ リズムの9回目の繰り返しのスナップショットを示しています。表17.2(364ページ)の重心 の列がその重心の例を示しています。
図16.5 K-meansアルゴリズム。ほとんどのいIRアプリケーションでは、ベクトル は流さ が正規化されているべきである。シードを選ぶもう一つの方法は、364ページで議論されている。
また以下の終了条件の一つを適用します。 • 繰り返しをある一定回数I回繰り返したら終了する。この条件ではクラスタリングのアル ゴリズムの実行時間を制限しますが、場合によっては繰り返し回数が充分でなく、クラ スタリングの質が低下することがあります。 • クラスタへの割り当て(つまり割り当て関数γ)が、繰り返しで変化しなくなったとき。こ の場合、部分的な最小値に陥ったとき以外は、よいクラスタリングが得られますが、実 行時間が受け入れがたいほど長くなるかもしれません。 • 重心μが変化しなくなるとき。これはλが変化しなくなったときと同じです (exercise16.5)。 • RSSが閾値より小さくなったら終了。これは終了時のクラスタリングの質を保証しま す。通常は終了することを保証するため、これと繰り返し回数の上限をセットで使いま す。 • RSSの減少値が閾値θより小さくなったら終了。小さなθを選ぶと、収束に近いことを意 味します。これも非常に長い実行時間を必要とするため、繰り返し回数の上限を同時に 使います。 ここでK-meansによって繰り返しごとに単調にRSSが減少することを証明します。本章で は「減少」という語を「減少もしくは変化しない」という意味で用います。まず、RSSが 割り当てステップによって減少することを示します。これは、各ベクトルはもっとも近い 重心に割り当てられるため、その距離が影響するRSSは減少します。次に再計算ステップ でも減少することを証明します。まずRSSkを最小とするベクトルを見つけます。 (16.8) (16.9) x_m, v_mはm番めの各ベクトルの要素です。最小値では微分係数は0になるので次を得ま す。 (16.10) これは重心の定義でもあります。よって前の重心から、新しい重心に移ることでRSSkは 減少します。RSSkの合計であるRSSも再計算ステップで減少します。
クラスタリングの組み合わせは有限個しかないので、単調減少な関数は最終的にローカル なかもしれませんが最小値に到達します。しかし複数の等距離の重心がある時にドキュメ ントをクラスタに割り当てる場合に気をつけなければいけません。さもないと、このアル ゴリズムはコストの同じクラスタリングをずっと繰り返すことになります。 これによりK-meansの収束性が証明されます。しかし、残念ながら目的関数がグローバル な最小値になることは保証されません。これは、他のドキュメントと非常にかけ離れてお り、どのクラスタにもうまくマッチしないという、外れ値(outlier)が多数ドキュメント集 合に含まれている場合に問題となります。しばしば、この外れ値をシードとして選んでし まうと、以降の繰り返しで他のベクトルがそのクラスタに割り当てられなくなってしまう ことがあります。そのため、他にもより小さいRSSとなる可能性があるにもかかわらず、 結局1つのドキュメントしか含まれないクラスタ、シングルトンクラスタ(singleton cluster)になってしまいます。図16.7は悪い初期値を選んでしまうと最適でないクラスタリ ングになってしまう例です。 図16.7 K-meansによるクラスタリングの結果は、初期シードに依存する。d2とd5では、K-means は、{{d1,d2,d3}, {d4,d5,d6}}という局所最適となる。d2とd3では、{{d1,d2,d4,d5}, {d3,d6}}という K=2における全体最適となる。 もう一つのよく出る最適でないクラスタリングの例としては、空のクラスタがあります (exercise 16.11)。 シード選択の効率的な方法は、(i)シードセットから外れ値を取り除く(ii)複数のシードにつ いて試してみて、その中でもっともコストが低かったものを選ぶ(iii)階層クラスタリング などの他の方法でシードを得る、などがあります。決定的階層的クラスタリングは、k-meansより予測可能であるため、サイズがクラスタ数Kのi倍であるiK(例えばi=5やi=10)程 度の小さなランダムに選んだサンプルによる階層的クラスタリングによりよいシードが得 られます(詳しくは17章366ページのBuckshotアルゴリズム)。 他の初期化の方法は、シードをクラスタ対象のベクトルから選ばない方法です。様々なド キュメント集合に対してよく動く頑健な方法はランダムにi個(例えばi=10)のベクトルを選 び、その重心をシードとする方法です。16.6節でより洗練された初期化法を紹介します。
K-meansの時間計算量はどの程度でしょう?計算時間の大部分は、ベクトル間の距離を計 算するのに使われます。よってこの操作のコストはθ(M)です。よって再割り当ての計算量 はθ(KNM)となります。再計算ステップでは、各ベクトルが重心計算に一度使われるた め、このステップの時間計算量はθ(NM)となります。これをある一定回数I回繰り返すた め、合計の時間計算量はθ(IKNM)となります。よって、K-meansはその要素である繰り返 し回数、クラスタ数、ベクトル数、空間の次元数のすべてに対して線形となります。これ は17章の階層的クラスタリングより効率的であることを意味します。ここでは固定の繰り 返し回数Iという、実際には若干注意しなければならない値を使っています。しかし多くの 場合、K-meansはすぐに完全な収束、またはそれに近い状態となります。後者の場合で も、各繰り返しで少数のドキュメントが入れ替えられるだけでになるため、この場合にI 回で繰り返しを終えても、クラスタリングの質にほとんど影響を与えません。 以降の議論で微妙な点が一点あるります。線形なアルゴリズムとは言っても、Θ(...)の中身 が大きくなれば遅くなり、また次元数Mは通常大きくなります。ここで高次元の2つのド キュメント間の距離を測るのは問題とはなりません。これらのベクトルはスパースなの で、Mのうち一部しか距離の計算に用いられないためです。しかし、重心はスパースでは ありません。これは集合に含まれるドキュメントのすべての要素を集めているためです。 その結果、K-meansのナイーブな実装では距離計算で時間を消費します。しかし、この重 心-ドキュメント間の類似度をドキュメント-ドキュメント間の類似度を計算するのと同じ くらい早く計算する方法があります。この方法では、最も重要なk単語(たとえばk=1000) だけ考えますが、それでもクラスタの質はほとんど低下せず、高速な割り当てが行えます (詳しくは16.6のリファレンス)。 同様に効率性の問題は、クラスタの重心ではなく、medoidを計算するK-meansの変形で ある、K-medoidによっても対処できます。ここでmedoidとは、重心に最も近いドキュメ ントとします。そのため、medoidは結局スパースなドキュメントベクトルであるため、距 離計算を素早く行えます。
16.4.1 Cluster cardinality in K-means
16.2節で、クラスタ数Kはフラットクラスタリング一つの入力であると述べました。も し、妥当なKの値を知らない場合、どうすればよいのでしょう? もっともナイーブなアプローチは、目的関数そのものを使って、Kの最適な値を選ぶ方法 であります。RSSmin(k)をKクラスタの時の全クラスタでのRSSの最小値とし、RSSmin (k)がKによって単調に減少することを示します(exercise16.13)。これは最終的にはk=N(N はドキュメント数)のときに0となります。結局、最後はドキュメントは自分自身のみを含
むクラスタとなります。明らかにこれは求める最適なクラスタではありません。この問題 を解決する方法は、以下のようにRSSmin(k)を推測することです。まず、Kクラスタのク ラスタリングをi回行い(それぞれシードを変える)、各RSSを計算します。これにより、i個 のRSS値のうちの最小値を得ます。この最小値をRSSmin(k)とします。その後クラスタ数 Kの値を増やして、RSSmin(k)を計算し、曲線の「ひざ」となるRSSの減少値が著しく小 さくなった点を見つけます。図16.8では、わずかに傾斜が平らになったk=4と明らかに平 らなk=9の2点が存在します。この方法では最適値が1つになるとは限りません。そのた め、可能なK(この場合4と9)の中から最適値を選ぶためにはほかの指標が必要となりま す。 図16.8 K-meansのクラスタ数の関数としてのRSSminの見積り。1203個のReuters-RCV1文書のク ラスタリングでは、RSSminの線がフラットになる箇所が4クラスタと9クラスタの2つある。文書 はChina, Germany, Russia, Sportsのカテゴリから選ばれ、K=4クラスタリングはReutersクラシ フィケーションに最も近付く 2つめのクラスタ数を評価する方法は、新しいクラスタに対してペナルティを与える方 法、すべてのドキュメントが含まれる一つのクラスタから始めたとして、Kを順に増やし ていくことにより最適なクラスタ数を探す方法です。この方法でクラスタ数を決定するた めには、以下の2つの要素をあわせた一般化された目的関数が必要となります。それはク ラスタのプロトタイプからドキュメントがどれだけ離れているかという乖離度(distortion) (K-meansの場合はRSS)と、モデルの複雑度(model complexity)です。ここではクラスタリ ングをデータのモデルとして考えます。クラスタリングにおけるモデルの複雑度はクラス タ数、もしくはそれに関する関数となります。K-meansの場合は、以下のようなKの選択 関数を導入します。 (16.11)
ここでλは重み関数です。大きなλを選択すると、クラスタ数は少なくなります。λ=0の場 合はクラスタに対してなんのペナルティも与えず、K=Nが最適な解となります。 式(16.11)の難しさは、λを決定しなければならないことです。ただ、以前の2乗の式を見て の通り、Kを直接決定するのよりかは簡単です。場合によっては、過去の類似のデータ セットを用いて良いλを選択することができます。たとえば、定期的にニュース記事から ニュースのクラスタを作成する場合、以降も正しいKを与えてくれる決まったあるλの値が あることが多くなります。しかし、今回の適用例の場合、Kが変化するため過去の経験に 基づいてKを決めることはできません。 (16.11)の理論的な正しさは、赤池情報量またはAICと呼ばれる乖離度とモデルの複雑性の トレードオフを表す情報学的な指標があります。AICの一般的な形式は次のようになりま す。 (16.12) ここではKクラスタでのデータの最尤推定量のログのマイナスの値-L(K)が乖離度の指標 で、Kクラスタでのモデルのパラメタ数q(K)がモデルの複雑度になる。データの良いモデ ルの最初の指標は各データがモデルによりよく表されていることである。これが乖離度の 目的です。しかしモデルは小さくあるべき(つまりモデルの複雑度は小さくあるべき)で、 データを表現できていないモデル(つまり複雑度がゼロ)は意味がありません。AICはモデ ル選択の時に乖離度とモデルの複雑度の2つを重み付けされた指標にする理論的正当性を 与えています。 K-meansではAICを用いて以下のように書けます。 (16.13) 式(16.13)は式(16.11)でλ=2Mとした特別な場合です。 式(16.12)からしき(16.13)を導出するためには、K-meansではK個の各要素がそれぞれ独立 に動く値であるため、q(k)=KMであり、また厳密な割り当てでモデルがクラスタの事前確 率に等しく、球形の共分散行列となるガウシアンモデルにしたがうならL(k)=-(1/2)RSSで あることに注意しなければならない(exercise 16.16)。 AICの導出はいくつかの仮定の上に成り立っています。たとえば、そのデータは独立であ りさらに分散している必要があります。この仮定は情報検索のデータセットではほんの一 部の場合でしか正しくありません。結果、AICはテキストクラスタリングでは調整なしに
はほとんど適用できません。図16.8ではベクトル空間の次元はM=50000となっています。 これは2MK > 50000はRSSの小さい単語(RSSmin(1) < 5000、この図では示していない)が 支配的で、式の最小値はK=1の時であります。しかし、K=4のとき(特に4つのクラスが China, Germany, Russia, Suports)のときK=1の選択より良いことを知っています。実際、 λの推測をする必要があることに注意すれば、式(16.11)は式(16.13)より便利です。
16.5 Model-based clustering
この章では、K-meansの一般化であるEMアルゴリズムを紹介します。このアルゴリズム はK-meansより多くの種類のドキュメントに適用できます。 K-meansでは、集合を代表するような重心を探しました。K個の重心はそれぞれデータを 生成するモデルとも考えられます。このモデルでは最初にランダムに1つの重心を選び、 その後適当にノイズを加えていると見ることができます。この時ノイズが正規分布である と、クラスタの形は球状になります。model-based clusteringではデータはモデルに従って 生成されると仮定し、そのデータから元のモデルを再現しようと試みます。データから再 現しようとしているモデルはクラスタと各クラスタへのドキュメントの割り当てで定義さ れます。 モデルのパラメータを推測するためによく使われる指標は、最大尤度です。K-meansでは exp(-RSS)の値がデータから生成された特定のモデル(つまり重心の集合)の尤度に比例し ていると考えられます。K-meansでは最大尤度と最小のRSSは同じ指標です。このモデル のパラメータをΘで表します。K-meansではΘ={μ1,...,μk}です。 より一般的には、最大尤度による指標はデータDから生成される尤度のログを最大化させ るパラメータΘを選択することです。 L(D|Θ)はクラスタリングの良さを測定する目的関数です。同数のクラスタ数の2つのクラ スタリングが与えられたとき、L(D|Θ)が大きい方を選びます。 これは12章(218ページ)での言語モデルや13.1節(245ページ)のテキストクラシフィケー ションに対して取ったアプローチと同じです。テキストクラシフィケーションでは、特定 のドキュメントを生成する尤度を最大化するクラスを選びました。ここでは、与えられた ドキュメント集合を生成する尤度が最大となるクラスタリングΘを選びます。一度Θを選 んだら、各ドキュメントークラスタのペアに対してその割り当てられる確率P(d|ωk;Θ)を 計算できます。緩い割り当ての例では、Chinese carsはそれぞれの要素を含んでいることを反映して、 Chinaとautomobilesの2つのクラスタに対してそれぞれ0.5ずつ割り当てられます。k-meansのようなハードクラスタリングでは、2つのトピックに対して同時に関連している 様なモデルを作れません。 モデルに基づくクラスタリングでは、ある領域の知識を組み込むフレームワークを提供し ます。K-meansと17章の階層的アルゴリズムでは、データに対して厳密な仮定を必要とし ます。たとえば、K-meansによるクラスタリングでは、球状になることを仮定していま す。モデルに基づくクラスタリングはもっと柔軟性があります。クラスタリングのモデル はデータの分散を知っている場合でも適用できる、ベルヌーイ(表16.3の例に含まれる)や 球状に分散していないガウシアン(ドキュメントクラスタリングで重要となるもう一つの モデル)を含むそのほかの種類でも適用できます。 モデルに基づくクラスタリングでよく使われるアルゴリズムはexpectation maximizeation algorithmもしくはEMアルゴリズムと呼ばれるアルゴリズムです。EMクラスタリングはL (D|Θ)を最大化させる繰り返しのアルゴリズムです。EMは様々な確率モデルに対して適用 できます。ここでは11.3節(204ページ)や13.3節(243ページ)で見た分散である、多変数の ベルヌーイ分散において使ったとして話します。 (16.14) ここでΘ={Θ1,...,Θk}、Θk=(αk,q1k,...,qMk)とし、qmk=P(Um=1|ωk)はモデルのパラメータ です。P(Uk=1|ωk)はクラスタkのあるドキュメントが単語tmを含んでいる確率です。確率 αkはクラスタωkの事前確率です、これはdについて何の情報も持っていないときにドキュ メントdがωkに含まれる確率です。 よってこの混合モデルは次のようになります。 (16.15) このモデルでは、確率αkのクラスタωkをまず選び、パラメータqmkのドキュメントの単語 を生成するドキュメントを生成します。多変数ベルヌーイのドキュメントの代表はM個の ブール値を持つベクトル(実際の値を持つベクトルではなく)であることを思い出してくだ さい。
データからクラスタリングのパラメータを推測するために、EMをどのように使うので しょう。これはL(D|Θ)を最大化させるパラメータΘを以下に選択するのかというこです。 EMとk-meansは予測ステップ(exception step)が再割り当てに対応し、最大化ステップ (maxmization step)がパラメータの再計算に対応していて類似しています。k-meansのパラ メータは重心ですが、本節でのEMのインスタンスのパラメータはαkとqmkです。 最大化ステップではqmと事前確率αkは以下のように再計算されます。 (16.16) ここでI(tm in dn)はtmがdnに含まれていれば1そうでなければ0で、rnkは以下の繰り返しで 計算されるドキュメントdnがクラスタkに割り当てられる値です(この初期化の問題はすぐ あとで述べます)。ここでは、部分的にクラスタに割り当てられたドキュメントを除い た、表13.3(248ページ)から計算した多変数のベルヌーイのパラメータを推測する最大尤 度があります。この最尤推定量はモデルから得られるデータの尤度を最大化します。 予測ステップでは現在のパラメータqmkとαkが与えられたときのクラスタへのドキュメン トのソフトな割り当てを計算します。 (16.17) この予測ステップでは式(16.14)と式(16.15)をドキュメントdnからωkを作る尤度を計算す るために使います。これは表13.3の多変数ベルヌーイでのクラスタリングの手順です。 よって、この予測ステップはベルヌーイナイーブベイズクラシフィケーションとの違いは ありません(標準化も含む、つまり分母で割り、クラスタ間の分散の確率を得ます)。 11ドキュメントを表16.3のようにEMを用いて2つのクラスタにクラスタしました。25回繰 り返した収束後、最初の5ドキュメントはクラスタ1に割り当てられ(ri1=1.00)、最後の6ド キュメントはクラスタ2に割り当てられます(ri1=0.00)。ここでは、最後の割り当てはハー ド割り当てになりました。EMは通常ソフトな割り当てに収束します。25回目の繰り返し の後、クラスタ1に対する事前確率α1はクラスタ1に11ドキュメントのうち5つが割り当て られたので、5/11=0.45となります。ある単語は最初の割り当てが明らかに偏っていたた め一つのクラスタにすぐ割り当てられました。たとえば、クラスタ2の要素は最初の繰り 返しでは、sugarという単語を共有しているため、ドキュメント7とドキュメント8に偏っ ていました(最初の繰り返しではr81=0)。不明確なコンテキストで現れる単語のパラメータ
に対して、収束には非常に時間がかかります。シードとなるドキュメント6と7は両方とも sweetという単語を含んでいました。結果。クラスタ2に明らかに割り当てられるまでに 25回の繰り返しを必要としました(25回目の繰り返しでqsweet,1=0)。 良いシードを見つけることはK-meansよりEMにとってクリティカルな問題です。EMは シードをよく選ばないと、ローカルな最適値に行き着きやすくなります。これはほかの EMの適用例でも現れる一般的な問題です。しかし、K-meansのように、最初のクラスタ へのドキュメントの割り当てをほかのアルゴリズムで計算します。たとえば、ハードクラ スタリングであるK-meansで初期値を計算して、EMでソフトにします。 表16.3 EMクラスタリングアルゴリズム。表は文書の集合(a)とEMクラスタリングにおける繰り返 しのためのパラメータ(b)を示す。