大学院輪講資料
Geo
タグ情報を用いた画像認識に関する研究動向
A Survey on Image Recognition Using Geo-tag Information
情報理工学系研究科 電子情報学専攻 苗村研究室 修士課程1年 48106417 白石卓也
Abstract
Geo-tag is a type of metadata of various media such as
photographs, videos, websites and more other media. In the
case of photographs, Geo-tag is GPS coordinates where it was taken.
In recent years, we have so many Geo-tagged images on the photo sharing web site, such as Flickr.
This paper shows some works, which apply geo-tag
infor-mation to image recognition problem. GPS coordinates has only 2 values, latitude and longitude, a point on the earth.
However, GPS coordinates has richer information than 2
di-mension vector. We can consider GPS coordinates as a hint of more informative resources or some works apply GPS
co-ordinates to latent semantic analysis. Geo-tag is also used
to build the database concerning the sightseeing spot and the landmark. Moreover, there are some Geolocalization works;
they estimate the place where an untagged image was taken.
1
はじめに
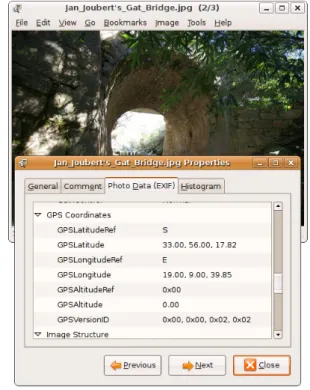
GeoタグとはGPSによって取得された緯度と経度の2つ の数値を保持するメタデータのことであり、画像メタデー タの標準フォーマットであるExif(Exchangeable image file format)の一部を為すものである。図1にあるように、Geo タグの付けられた画像データであれば、プロパティによっ てその詳細を確認できる。GPSを搭載した民生用カメラは 現在にいたるまでごく少数しかなく、ほとんど場合GPS記 録機器とデジタルカメラの時間を同期させるか、ユーザー が手間をかけて写真のGPS座標を調べて入力する必要が あった。 Geoタグ付き画像の数が増大した一つの大きな要因として、 2006年に画像共有WebサイトであるFlickrが、地図上の 点を指定することでGPS情報を手軽に登録できるインタ フェースを採用したことが挙げられる。以降Geoタグ付き 画像の数は格段に増加し、2008年の時点で、月に20万枚 ものGeoタグ付き画像がFlickrにはアップロードされて いる。
Figure 1 Geo-tag of image
2010年現在、GoogleMapsでは、様々な画像共有サイト にアップロードされているGeoタグ付き画像を地図上に マッピングし、特徴点のスティッチング技術によってその 地点にあるランドマークを、様々な視点から見ることがで きるサービスを行っている(図2)。これはコンシューマ画 像によるストリート・ビューの拡張として捉えることがで きる。このような、位置情報の単純な可視化をとっても、 Geoタグ情報は写真に新しい価値を与える情報であるとい
Figure 2 Geo-tagged Image localize in Google Maps うことが分かる。 ところで、画像認識における近年の大きな潮流として、画 像共有サイトにおいてユーザによって付けられたタグ情報 を利用した研究が数多くなされている。タグ情報とはユー ザーが自由に編集できる、画像のメタデータのことである。 テキストタグやGeoタグといったこれらの画像メタデータ は、画像自体から抽出される特徴量を利用した画像認識と 人間の認知との間にあるギャップ(semantic gap)を埋める ためのヒントとして考えられ、コンピュータビジョンの分 野だけではなく、マルチメディア系、World Wide Web系な どの様々な領域で、これらのメタデータを利用した研究が なされている。Flickr等の画像共有コミュニティサイトの 発展により、メタデータを保持した大量の画像を取得でき るようになったことで、画像認識のためのデータベースを 構築したり、認識に活用したりという研究が様々になされ ている。 本稿では、近年の、特にGeoタグを利用した画像認識に 関する研究を紹介する。GPS情報は、画像が地球上のどこ で撮影されたのるのかを表すものであり、画像の認識に関 する重要な情報源となりうる。地理的な情報を考慮するこ とで、物体やシーン、イベントの認識精度は高まると考え ることができる。例えば、海辺にボートという物体がある のは珍しくないが、山にボートがあるのは珍しい。このよ うな知識をGPS座標からどのようにして得るのかという ことが一つの課題となる。あるいは、Geoタグの付いてい ない画像が地球上のどこで撮影されたのかを推定するよう な研究もある。特に観光地などのランドマークに関する研 究などは、GPS座標とその地点での画像の特徴が強い相関 関係を持つことが多いため、Geoタグを用いた画像データ ベースの構築などに非常に向いているということが言える。 ここでは、これらの研究を大きく以下の4つに分類して 紹介する。 • Geoタグ付きの画像と、GPS座標を用いて得られる二 次的な情報を組み合わせる研究 • GPS座標の潜在的な意味を求める研究 • Geoタグ付きの画像群を利用し、認識のためのデータ ベースを構築する研究 • Geoタグの付いていない画像の地理的な位置を推定す る研究(Geolocalization) 以下各章でそれぞれの研究について述べていく。
2
外部情報を利用した
Geo
タグ付き画像の
認識
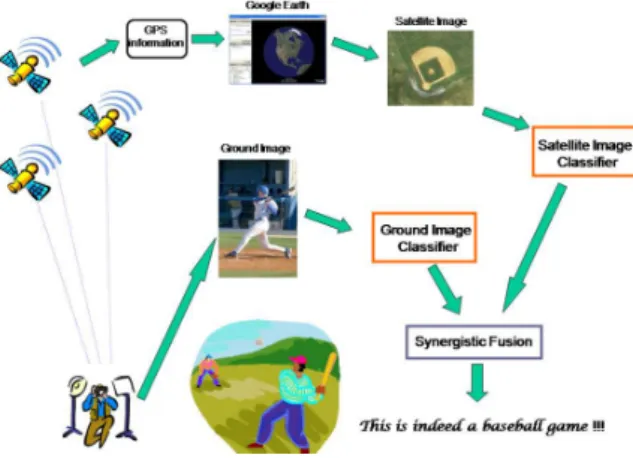
この章で述べていく研究は、2次元の座標情報でしか無 い画像のGeoタグを、より豊かな情報源への手がかりとし て用いようという手法である。GPS座標が得られるという ことは、Webなどで公開されているGPSに関連するリソー スにアクセスすることで、画像自体や座標を分析すること 以上の情報を得ることができることを意味している。 例えば、LuoらはGPS座標から得られる2次情報とし て、GoogleEarthで参照することのできる衛星写真を用い た研究を行っている[10](図3)。この研究のでは、Geoタ グ付きの画像から衛星写真を取得し、その衛星写真も分析することで、あらかじめ用意したシーンとイベントクラス (モール,野球をしているなど)に分類するタスクの精度向 上を狙っている衛星写真としては、画像のGPS座標から 得られる3つの異なる高度(25m, 50m, 150m)の衛星写真 を用いている。複数の高度からの写真を用いるのは、対象 とする環境が異なる大きさを持っていることがあるからで ある。例えば、国立公園と住宅街にある公園はその大きさ が異なる。この研究で衛星写真に求められていることは、 写真が撮影された環境を十分に表現していることであり、 対象となる環境の大きさが異なるならば、異なるスケー ルの衛星写真が必要となると考えられる。そのため、複数 の高度からの写真を用いることで、対象の大きさが異なっ ていても対応できるようにしている。手法としては、近年 の一般物体認識におけるデファクトスタンダードである bag-of-visualwords[3](ここでは、SIFT特徴量[9]とHSV 色空間でのヒストグラム)を用いて通常の地上の写真と衛 星写真を記述し,正解ラベルの付けられた学習データから それらの画像を分類するための分類器を、シーン分類にお ける頑健な識別器として知られているSVM(Supprt Vector Machine)と、リモートセンシングの分野でよく使用されて いるというmultiboost tree classifier[6]を用いて構築してい る。この手法では、最終的な分類結果を出力するための手 段としてもSVMを用いており、RBFカーネルを用いて得 られた最も良い地上画像の分類器を用いて得られたスコア と、衛星画像の分類器を用いて得られたスコアのベクトル を分類するSVMによるメタ分類器を作成している。
Figure 3 Event recognition of using third view
Luo らの手法では各分類器のスコアレベルでの混合を 行っていたが、柳井らはGeoタグ付きの地上写真とその地 点の航空写真のそれぞれの特徴レベルでの相関を直接求め ることで画像認識を行っている[12]。「山」や「ビーチ」と いった地理的なクラスから「ラーメン」「花」といった物 体レベルのクラスまでを用意しておき、Flickrからダウン ロードしたGeoタグ付き画像から、各クラスについての正 例となるのか負例となるのかを示したデータセットを作成 している。特にGPS座標も画像の特徴として組み込みんで pLSAやLDAを用いたことにより、「ディズニーランド」と いったGPS座標の分布が限定されているシーンの認識は、 単純な画像特徴による認識よりも精度が飛躍的に向上した。 また、シーンやイベントだけではなく「ラーメン」や「花」 といった物体レベルの認識についてもGeoタグ情報を利用 することで精度向上が実現できたと示している。
Joshiらは、外部の情報源として、GeonamesというGIS
(geographic information system)を用いて、GPS座標から
bag-of-geotagという特徴を各画像について求め、Geoタグ 付き画像のイベント認識を行っている[8]。GISとは、いく つかのGPS座標とその地点に関する情報(地名や国名,人 口密度,標高など)をデータベース化したシステムのことで ある。この研究ではGISを用いてGPS座標からその地点 に近いポイントに関するテキスト情報を入手し、それをテ キスト解析することでGPS座標をいわばテキストタグを得 るための手がかりとして利用している。bag-of-geotag作成 のの手順は以下のとおりである。 (1) Geoタグ付き画像のGPS座標から最も近い20個のポ イントをGeonamesから選択する (2) ポイントの集合についてを測地系(GPS座標と標高) でk = 2としてk-meansクラスタリングを行う (3) 画像のGPS座標が含まれるクラスタ内に含まれるポイ ントを選択し、これらについてのテキスト情報を得る (4) 得られたテキスト情報を精錬し、bag-of-geotagとして 使用する複数の語を得る。 こうして得られた画像Iについてのbag-of-geotag : G(I) = {w1, w2, ..., wmI}について、イベントとのオッズ比を求める
ことで、画像のイベント認識を行っている。最終的には、最 先端の画像特徴量ベースのイベント認識と組み合わせる場 合に、画像特徴量のみを使用する方法よりもbag-of-geotag
を組み合わせる方法のほうがイベント認識の精度が向上し たということを示している。
Figure 4 Event recognition framework of using ge-ographic information system
3
GPS
座標の潜在意味解析
あるGPS座標が示す場所の地理的な特徴を記述できるの は、何も画像外部の情報だけではない。GPS座標と画像の 特徴は、物理的な現実を通じて必ず何らかの関連があると 言って良い。そのためGPS座標と画像との何らかの相関を 見出すことが出来れば、 Cristaniらは、画像分類の手法として、従来の bag-of-visualwordsによるpLSAを用いたVisualトピック解析を 拡張して、Regionトピックを潜在変数として加えている [2]。pLSAは元来文書集合の生成モデルとして発展し、 bag-of-visualwordsを用いた画像認識においても様々な応用が なされている。式(1)はpLSAがどのような考え方で利用 されているのかを表現しており、まず画像IがP(I)で選ば れ、Visualトピックを表す潜在変数zがP(z|I)で選ばれた 後に、visual word wがP(w|z)で選ばれることにより、最終 的に(I, w)のペアが観測されるという画像とvisual wordの生成モデルである。 P(I, w) = P(I)
∑
z P(w|z)P(z|I) (1) このモデルを画像集合について適用し,EMアルゴリズムを 用いて尤もらしい潜在変数zを求めるというのがpLSAの 目的である。CristaniらはここにRegionトピックを追加し て、式(2)のようなモデルを作っている。 P(l, w) = P(l)∑
z P(w|z)∑
r P(z|r)p(r|l) (2) ここで、lは写真のGPS座標を表し、rはRegionトピック を表す潜在変数である。ベイズ則を用いて展開すると P(l, w) = P(l)∑
z P(w|z)∑
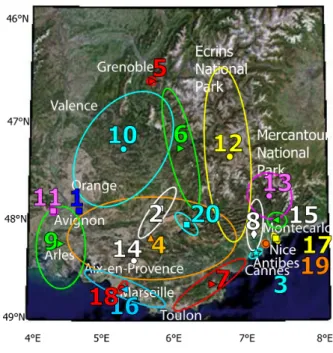
r P(z|r)p(l|r)p(r) (3) と表せる。ここで p(l|r)は地域トピックrのGPS座標上 における分布を表しており、今回の手法では、ガウス分布 を仮定している(図5)。要するに、このモデルは、どこで (Regionトピック)何を(Visualトピック)撮影するのか によって、写真に出現するvisualwordsが変わるというこ とを言っている。このモデルをGeoタグ付き画像のフラン ス南東部のの写真群について適用し、EMアルゴリズを通 して潜在変数を求めることで、同一の地理的特徴をもつ画 像群からなるクラスタを作ることに成功している。また、 この研究では、Geoタグのついていない画像がどのクラ スタに、つまりどの地域で撮影された写真なのかを求める Geolocalizationの問題にも踏み込んでいる。4
Geo
タグ付き画像を用いた効率的なデータ
ベースの構築
Flickr等の写真共有サイトは、画像のデータベース構築 の観点からも非常に有用なリソースとなっている。テキス トタグやコメントなどを活用することで画像認識のための データベースを構築するという研究は枚挙にいとまがない。 この節では、データベースの構築について、Geoタグなら ではの特性を用いた研究を紹介する。 Geoタグを用いたデータベースを構築することの特徴と して、観光地やランドマークのデータベースを構築すると いう点で、非常に効率的に行うことができるということが 挙げられる。多次元の特徴量を扱う複雑な処理をGPS座標Figure 5 distribution of region topics が近い手頃な数の画像間のみで済ませるようにすれば、明 らかに類似度の低い大量の画像間での計算を行う回数が減 少し、効率的なデータベースの構築を行うことができると 考えられる。 Quackらは、GPS座標を用いた物体とイベント認識のた めのデータベースの効率的な構築手法を提案した[11]。こ の手法では、地球を分割する100mごとの格子を与え、そ の内部でのみ高次元の画像特徴量を用いた計算を行ってい る(図6)。以下のような手順によって、地球規模の大規模 なデータベースを構築している。 (1) 地球を格子状に分け、各格子の中心の緯度経度を求め る。求めた緯度経度でFlickrを検索し、格子内にある 画像を集めてくる。 (2) 格子内ではSURF[1]によるbag-of-visualwordsを画像 特徴量として用いてクラスタリングを行ない、それら のクラスタがオブジェクト(建物や像など)かイベン ト(コンサートやお祭りなど)かを人手で判別する。 (3) クラスタの写真についているタグを利用して、クラス タへのラベル付を行う。 (4) ラベルでWikipediaの記事を検索し、その記事を各ク ラスタに関連させる。
Figure 6 A geospatial grid is overlaid over the earth
Gammeterらは、Quackらの研究の根本的な発想を受け 継ぎ、観光地やランドマークを重視したデータベース構築 手法を提案した[5]。この研究は、最初にWikipediaの記事 につけられているGeoタグ情報を利用し、全手順をすべて 自動化してデータベースを構築している。 (1) wikipediaの記事でGPS座標の情報が付いている記事 を見つけ、その座標をシード座標とする。 (2) 地球を格子状に分け、シード座標でFlickrを検索し、 シード座標を含む格子内にある画像を集めてくる。 (3) 格子内でbag-of-visualwordsを利用してk-meansクラ スタリングを行ない、オブジェクトクラスタを作る。 (4) オブジェクトクラスタの写真についているタグを利用 して、オブジェクトクラスタへのラベル付けを行う。 この研究では、このようにして構築されたデータベース 内の最近傍探索を行うことで、クエリ画像に写っている物 体の認識が行えるようにしている。この研究は、各ランド マークを表す特徴点をクエリ画像から検出し、それらの点 を囲うバウンディングボックスも表示するという、物体検 出の領域にまで踏み込んだ研究となっている(図7)。 Zhengらは、画像のGPS座標を用いて効率的に観光地の データベースを構築する手法を提案した[14]。先の2つの 研究と発想は似ているが、この研究では格子ではなくGPS 座標のみによるクラスタリングを行うことで近い位置に 存在している画像のクラスタを作っている。この手法は、 GPS座標が近い画像であれば、特に観光地に関しては、似
Figure 7 landmark recognition and detection た物体が写っているであろうという仮定の上になされてお り、やはり観光地やランドマークに特化した手法になって いる。また、各クラスタの写真の所有者の数が一定数に満 たないものは、そのクラスタは観光地の写真群ではないと みなし、削除している。この研究では、さらにwikitravelと いう旅行ガイドのテキストコーパスを用いた学習も組み合 わせて行い、より観光に特化した研究になっている。
5
Geolocalization
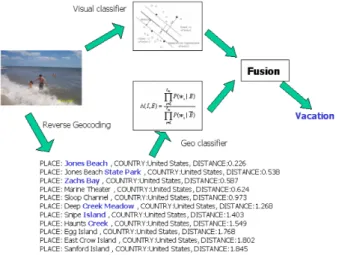
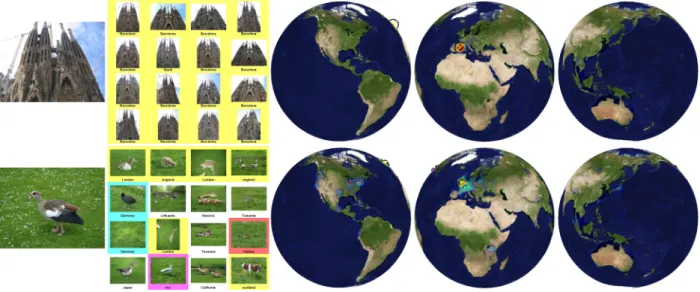
Geoタグ付きの画像から識別のモデルやデータベースを 構築すると、逆の問題も解けるのではないかという考えが 生じる。Geolocalizationとは、画像が地球上のどの地点で 撮影されたのかという問題を解決しようとするものである。 Haysらは、1枚のGeoタグの付いていない画像からGPS 座標を求めようという意欲的な研究を行った[7]。Flickrに アップロードされた世界中のGeoタグ付き画像を用いて、 巨大なデータベースを構築している。その際、ユーザーに よって付けられたテキストタグを利用し、地理的な情報を 含んでいないであろう画像は取り除いている。一般的に、 同じ地点で撮られたからといって、同じ物体が写真に収め られているという保証はない。建物の屋上から観光地とし て有名な建物を撮影したのかもしれないし,屋内でペット を撮影したのかもしれない。そのため、この研究の目的を 阻害するような、「誕生日」「コンサート」「cameraphone」 などといった地理的な情報とは無関係なテキストタグやコ メントが付けられている画像の場合はデータセットからあ らかじめ除去している。Hayらは、最終的に約650万枚も のGeoタグ付き画像を様々な画像特徴量によって記述し、 データベースを構築した。Geolocalizationは、このデータ ベースの中から、クエリ画像にに最も近い画像を最近傍探 索によって選びだし、図8のように、類似画像とそれらが 地球上のどの地点で撮影されたのかという情報を返すこと によって実現されている。この手法は、上のサグラダ・ファ ミリアについては類似した画像を取得でき、得られるGPS 座標もほぼ1点で高精度に得ることが出来ており、画像か らGPS座標を求めるというタイトル通りの結果を見せて いるが、下の芝生の上の鳥の写真では、確かに類似した写 真が得られるものの、正確なGPS座標は得ることができな い。これは画像特徴のみを用いることの、一つの限界を示 している。 Gallagherらは、IM2GPSの研究を拡張し、クエリに画 像情報だけでなくユーザーによるテキストタグも用いる手 法を提案している[4]。Flickr上の画像には様々なテキスト タグがつけられているが、これらのタグが地球上の地域に どのように分布しているのかを求め、その情報も含めるこ とで、IM2GPSより高精度なGeolocalizationを実現してい る。テキストタグは画像の特徴では記述できないsemantic gapを埋めるものとして利用されている。 結局今までのGeolocalizationは、いわゆるランドマーク が存在しないと精度の良い結果が得られないことが多かっ た。そのような問題に対する一つの解決策として、Zamir らはGoogleストリートビューのデータセットを用いるこ とによって、都市における画像のGeolocalizationを行う手 法を提案した[13]。Googleストリートビューは様々な国に おける主要な道路についての12メートルごとのパノラマ写 真が得られる重要なデータベースである。Googleストリー トビューをデータセットして用いる利点としては以下のよ うな点が挙げられる。 • 写っている場所や物体の知名度等には関係がなく、様々 な道路の周辺に写真が分布している。 • 12メートルおきに得られた写真によって、一般的な普 通の写真のデータセットと比べると均一で、かつ密にFigure 8 Results of IM2GPS 分布している。また、民生用のGPS機器より正確な位 置を得ることができる。 • 多少の歪みはあるものの、視点を限定すれば、一般的 なレンズで撮影した写真と同様の画像を簡単に得るこ とができる。 • GoogleMapsの多機能されたデータセットは、様々なア プリケーションへの拡張を容易にしてくれると予想さ れる。例えば、Geolocalizationによってカメラの地理 的な位置が分かれば、その地点でのストリートビュー の視点を動かして得られる画像とクエリ画像の間で 簡単なマッチングを行えば、カメラの東西南北や上下 の姿勢までもが分かることになる。今現在のデジタル カメラではカメラ自身の姿勢を記録することはできな いが、この研究を用いれば、十分可能になると考えら れる。 一方でデータセットが巨大で、通行人や車が写っている事 が多いなどといった欠点も抱えている。 筆者らはデータセットとして、200kmの道路の12メー トルごと各地点についての前後/側面/天頂という5枚の画 像とその地点のGPS座標のセットを作成している(図9)。 データベースが巨大になるため、比較に使用するSIFT特 徴を減らす必要がある上、Googleストリートビューでは通 行人や車なども写っているため、それらの特徴で類似度を 計算してしまうも避けたい。そこで地理的な距離が一定以 上離れている画像間で似た特徴が得られる場合、その特徴 は地理的な特徴ではないと考え除去するという方法を採っ ている。つまりGPS座標を手がかりに、必要十分な画像特 徴を得ることに成功しているのである。
6
まとめ
本稿ではGeoタグ情報が画像認識に及ぼした影響と、そ れを利用した研究について述べた。GPS座標自体が潜在的 に持っている情報やGPS座標から得られる2次的な情報を 利用する研究や、地理的な区画を利用して効率的にデータ ベースを構築する研究、そしてGeoタグのついていない画 像の地理的な位置を推定するGeolocalizationに関する研究 について述べた。 現在のところ画像におけるGeoタグはGPS座標と同義 であるが、画像フォーマットのどのように変化するのか、撮 影デバイスにどのようなセンサを搭載されるのか、、あるい は、どのような画像共有サービスが生まれるのか、という こといった事情によって、今後GPS座標以外の情報も含む ようになるはずである。例えば、近年の標準的な携帯電話 やスマートフォンには電子コンパスが搭載されており、カ メラの地理的な向きに関する情報を得ることは現在でも技 術的には問題なく出来ると思われる。より豊かなGeoタグ が利用出来るようになれば、より高度な画像認識を行うこFigure 9 Dataset of Google Street View
とができるようになるだろうと期待できる。
参考文献
[1] H. Bay, T. Tuytelaars, and L. Van Gool. Surf: Speeded up robust features. Computer Vision–ECCV 2006, pp.
404–417, 2006.
[2] M. Cristani, A. Perina, U. Castellani, and V. Murino.
Geo-located image analysis using latent representations.
In Computer Vision and Pattern Recognition, 2008.
CVPR 2008. IEEE Conference on, pp. 1–8. IEEE, 2008.
[3] G. Csurka, C. Dance, L. Fan, J. Willamowski, and
C. Bray. Visual categorization with bags of keypoints. In Workshop on statistical learning in computer vision,
ECCV, Vol. 1, p. 22. Citeseer, 2004.
[4] A. Gallagher, D. Joshi, J. Yu, and J. Luo. Geo-location inference from image content and user tags. 2009.
[5] S. Gammeter, L. Bossard, T. Quack, and L.V. Gool. I know what you did last summer: object-level
auto-annotation of holiday snaps. In Computer Vision, 2009
IEEE 12th International Conference on, pp. 614–621.
IEEE, 2010.
[6] W. Hao and J. Luo. Generalized multiclass adaboost and
its applications to multimedia classification. 2006. [7] J. Hays and A.A. Efros. IM2GPS: estimating geographic
information from a single image. In Computer Vision
and Pattern Recognition, 2008. CVPR 2008. IEEE Con-ference on, pp. 1–8. IEEE, 2008.
[8] D. Joshi and J. Luo. Inferring generic activities and
events from image content and bags of geo-tags. In
Proceedings of the 2008 international conference on Content-based image and video retrieval, pp. 37–46.
ACM, 2008.
[9] D.G. Lowe. Distinctive image features from scale-invariant keypoints. International journal of computer
vision, Vol. 60, No. 2, pp. 91–110, 2004.
[10] J. Luo, J. Yu, D. Joshi, and W. Hao. Event recognition:
viewing the world with a third eye. In Proceeding of the
16th ACM international conference on Multimedia, pp.
1071–1080. ACM, 2008.
[11] T. Quack, B. Leibe, and L. Van Gool. World-scale
min-ing of objects and events from community photo collec-tions. In Proceedings of the 2008 international
confer-ence on Content-based image and video retrieval, pp.
47–56. ACM, 2008.
[12] K. Yaegashi and K. Yanai. Can Geotags Help Image
Recognition? Advances in Image and Video Technology, pp. 361–373, 2009.
[13] A. Zamir and M. Shah. Accurate Image Localization
Based on Google Maps Street View. Computer Vision–
[14] Y.T. Zheng, M. Zhao, Y. Song, H. Adam, U.
Bud-demeier, A. Bissacco, F. Brucher, T.S. Chua, and H. Neven. Tour the world: building a web-scale
land-mark recognition engine. In Computer Vision and
Pat-tern Recognition, 2009. CVPR 2009. IEEE Conference on, pp. 1085–1092. IEEE, 2009.