人工知能学会研究会資料 SIG-SWO-047-11
機械学習を用いた地図画像の多クラス分類
Multi-class classification of map images using machine learning
山口元気
1∗桂井麻里衣
1Genki Yamaguchi
1Marie Katsurai
11
同志社大学理工学部インテリジェント情報工学科
1
Department of Intelligent Information Engineering and Sciences, Doshisha University
Abstract: 世界中で作成された地図画像は,スマートフォンとの連携により観光コンテンツとして の活用が期待されている.その種類は古地図やイラストマップなど多岐に渡るため,観光の目的に応 じて適切な地図を提供するには,地図画像をクラス分類する必要がある.本論文では,クラスラベル 付き地図画像データセットを構築し,機械学習に基づく画像認識のベースライン性能を報告する.1
はじめに
観光客の増加を目的とし,各地域の観光資源に特色を あてたイラストマップが世界中で発行されている.加 えて,人文学や図書館情報学において歴史資料のデジ タル化が進み,大量の古地図がオープンデータとして公 開されている.これらの多様な地図は,スマートフォ ンとの連携により,新たな観光コンテンツを生む.例 として,GPS で取得した現在地をスマートフォン上の 地図画像にマッピングし,歩きながら地域情報や歴史 体験を楽しむサービスが展開されている [1]. 地図と観光に関するシステムの高機能化には,各地図 画像がもつ情報をコンピュータに認識させる必要があ る.大量に蓄積された画像に対する手動アノテーショ ンは労力が非常に大きいため,画像認識技術の適用が 解決策となりうる.しかし,地図という特定ドメイン に関する画像認識の研究は非常に報告が少ない.これ は研究用データセットが普及していないことが原因で ある.そこで本研究では,コンピュータビジョン技術 により地図データの応用可能性を高めることを目的と し,新たにクラスラベル付き地図画像データセットを 構築した.本論文において,分類問題の設計方法を報 告するとともに,現在画像認識分野で主流とされてい る二つのアプローチによる地図画像分類のベースライ ン性能を提供する. ∗連絡先:同志社大学理工学部インテリジェント情報工学科 〒 610-0394 京都府京田辺市多々羅都谷 1-3 E-mail: [email protected]2
データセットの構築
本研究では,地図画像分類器の学習用データセットを 構築した.まず,地図投稿サービス Stroly1から,2018 年 12 月 14 日時点で閲覧可能な 2266 枚の画像を収集し た.地図画像の多クラス分類問題を設計するため,こ れらの画像を目視で精査し,互いに排反となる 10 個の クラスを定義した.各クラスの内容は下記のとおりで ある. • 航空写真:航空機を用いて地上を撮影した写真. • 文化系地図:神社・仏閣などの散策マップや町歩 き地図. • グルメマップ:カフェやレストランなどグルメ情 報が記載された地図. • メモ地図:手描きメモのように,限られた情報の みを含む地図. • 路線図:公共交通機関の接続や配置を表した地図. • 詳細地図: 縮尺の正確な地図. • 防災地図:災害発生時に対応できる情報が記載さ れた地図. • 内部地図: テーマパークなどの施設内部の地図. • 古地図:昭和前半より以前に作成された地図. • 地形図:等高線により地形を精細に表した地図. 1https://stroly.com/ja/図 1: 10 クラスに含まれる地図の例. 表 1: 本研究で構築した地図画像データセットの詳細. クラス 枚数 クラス 枚数 航空写真 23 詳細地図 287 文化系地図 771 防災地図 49 グルメマップ 68 内部地図 123 メモ地図 113 古地図 706 路線図 53 地形図 56 次に,地図と呼べない画像(例:テレビゲームのマップ 画像)を除外した.残った 2249 枚に対し,10 個のク ラスのいずれかへ手動で分類した.各クラスに該当し た地図画像の枚数を表 1 に示す.表に示すように,本 データセットは各クラスの画像枚数に偏りがある.ま た,それぞれのクラスに割り当てられた地図画像の例 を図 1 に示す.図のように,観光用に作成されたイラ ストマップは文化系地図またはグルメマップに分類さ れた.
3
クラス分類器の学習
本章では,地図画像分類のための二つのアプローチ として,Support Vector Machine(SVM)に基づく画 像分類手法と,Convolutional Neural Network(CNN) に基づく画像分類手法を説明する.3.1
SVM を用いた地図画像分類
分類器を SVM とする場合,対象ドメインの分類に適 した特徴量の設計が必要となる.従来,イラスト画像 認識では,色ヒストグラムが盛んに用いられてきた [2]. 本論文では画像を RGB 色空間から HSV 色空間に変換 し,各色チャネルのビン数を(H,S,V)=(10,3,2)と した 60 次元の画像特徴ベクトルを算出する.これらの ベクトルを入力として多クラス SVM を学習する.3.2
CNN を用いた地図画像分類
一般に,CNN の学習には大量のラベル付きデータ セットが必要である.しかし,2 章のデータセットは CNN のパラメータ数に比べて非常に少ない.この問題 を考慮し,事前に別のタスクに向けて学習した CNN の パラメータを初期値としたファインチューニングを行 う.具体的には,ImageNet2で学習済みの VGG16 [3] を用いる.モデルの構成は,VGG16 の全結合層を取り 除いたモデルに新たな 1024 次元の全結合層を加え,出 力層はクラスと同数の 10 次元とする.モデルに地図画 像が入力されたとき,再学習したパラメータにより各 クラスに属する確率を推定し,最も確率の高いクラス へ割り当てる.4
実験
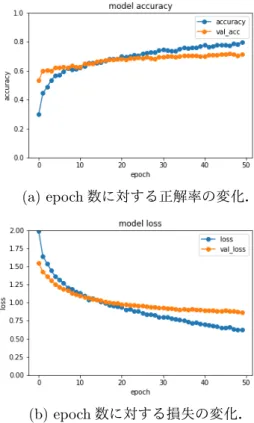
2 章のクラスラベル付き地図画像データセットを用い て,SVM と CNN による地図画像分類のベースライン性 能を示す.データセットはトレーニング画像 1799 枚,テ スト画像 450 枚に分割した.SVM の実装には,Python の機械学習ライブラリである scikit-learn3を用いた. SVM のカーネルとして,線形と非線形 Radial Basis 2http://www.image-net.org/ 3https://scikit-learn.org/stable/表 2: カーネル SVM と線形 SVM の正解率比較. C 1 10 100 1000 10000 0.1 0.521 0.557 0.567 0.586 0.599 γ 0.01 0.339 0.521 0.556 0.565 0.575 0.001 0.339 0.339 0.521 0.554 0.565 線形 0.546 0.561 0.573 0.575 0.577 表 3: カーネル SVM による多クラス分類結果. class Precision Recall F 値 画像枚数 航空写真 0.75 0.43 0.55 7 詳細地図 0.60 0.48 0.53 58 文化系地図 0.59 0.82 0.69 163 防災地図 0.00 0.00 0.00 5 グルメマップ 0.40 0.11 0.17 8 内部地図 0.50 0.24 0.32 21 メモ地図 0.67 0.42 0.51 24 古地図 0.79 0.79 0.79 134 路線図 0.00 0.00 0.00 11 地形図 0.20 0.11 0.14 9 Function (RBF) の二種類を比較する.また,RBF カー ネル SVM のパラメータとして,γ∈ {0.1, 0.01, 0.001} と C ∈ {1, 10, 100, 1000, 10000} の組合せをそれぞれ実 験した.SVM のカーネルとパラメータ変更によるテス ト画像分類正解率を表 2 に示す.RBF カーネルを用い て,γ = 0.1,C = 10000 としたときが最も高い正解率 を示した.次に,最も良いパラメータを用いたときの 各クラス分類に対する Precision, Recall, F 値を算出し た.得られた結果を表 3 に示す.参考のため,各クラ スに分類された画像枚数もあわせて記す.全クラスの 中で,航空写真と古地図は比較的高い Precision を示し た.一方,防災地図と路線図に関しては 1 枚も正しく 分類できなかった.これは色ヒストグラムしか用いて いないことが原因と考えられる. CNN の実装には,Python の深層学習ライブラリ Keras4を用いた.入力画像サイズは 224× 224 ピクセ ルとし,epoch 数は 50,バッチサイズは 16 とした.損 失関数は交差エントロピーとし,Stochastic Gradient Descent 法で最適化した.トレーニング画像 1799 枚 のうち,1619 枚で学習し,180 枚をバリデーションに 用いた.学習およびバリデーションデータにおける各 epoch での精度と損失の変化の様子を図 2 に示す.図 より,CNN の過学習は抑えられているといえる.次に, CNN を用いてテスト画像の多クラス分類正解率を算出 した結果を表 4 に示す.比較のため,表 2 で最も性能 の良かった SVM の結果も再掲する.表に示すように, 4https://keras.io/ja/ (a) epoch 数に対する正解率の変化. (b) epoch 数に対する損失の変化. 図 2: epoch 数に対する正解率と損失の変化. 表 4: カーネル SVM と CNN の正解率の比較. SVM CNN 正解率 0.599 0.716 CNN の分類精度は SVM を遥かに上回った.これは近 年の画像認識に関する様々な研究と同様の結果である. SVM は手動による特徴設計が必要なことを鑑みると, CNN により地図画像分類に有効な特徴を発見すること は有用と考えられる. 最後に,CNN でテスト画像 450 枚を分類した際に得 られた混同行列を図 3 に示す.図より,1 枚も正しく 分類できていないクラスがあることがわかる.それら のクラスは学習用画像枚数が少ない.ゆえに,学習用 データセットの拡張が必要と考えられる.
5
ウェブ画像検索によるデータセッ
ト拡張
2 章で作成したデータセットを拡張するために,Google 画像検索5を通じて追加の地図画像を収集した.各クラ スで用いた検索キーワードを表 5 に示す.日本語のみ では十分な結果が得られなかったクラスについては,英 5https://www.google.co.jp/imghp?hl=ja図 3: CNN でテスト画像 450 枚を分類した際の混同 行列.
表 5: 画像検索に使用した検索ワード. クラス 検索キーワード
航空写真 航空写真,aerial
詳細地図 詳細地図,web map,detail map 文化系地図 お散歩マップ,参拝地図 防災地図 防災地図 グルメマップ グルメマップ,food map 内部地図 案内図,園内地図 メモ地図 メモ地図,memo map 古地図 古地図,old map 路線図 路線図,route map 地形図 地形図,topographic 語のキーワードも用いた.収集した画像は著者が目視 で精査し,不適切な画像を除外した.最終的に,各ク ラス 100 枚,合計 1,000 枚の地図画像を保存した.
5.1
データセット拡張後の実験結果
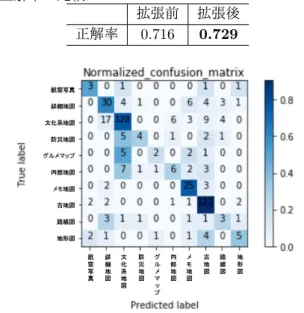
新たに収集した 1,000 枚をトレーニング画像に加え, CNN を学習した.CNN は 4 章と同様に実装した.ト レーニング画像 2,799 枚のうち,2,519 枚で学習し,280 枚をバリデーションに用いた.テスト画像には 4 章と 同一の 450 枚を用いた.CNN によるテスト画像の多 クラス分類正解率を表 6 に示す.データセット拡張に より同一テスト画像での正解率を向上できた.加えて, 本実験で得られたテスト画像 450 枚の混同行列を図 4 に示す.図 3 と図 4 の比較から,最初のデータセット を学習した際に正しく分類されなかった防災地図と路 線図が,データセット拡張後に正しく分類できたこと がわかる.ゆえに,分類対象のクラスに対応する画像 表 6: データセット拡張前後の CNN による多クラス分 類正解率の比較. 拡張前 拡張後 正解率 0.716 0.729 図 4: データセット拡張後に学習した CNN でテスト画 像 450 枚を分類した際の混同行列. をウェブから収集することは有用と考えられる.今後 は,分類性能向上に向けて地図画像データセットを効 率的に拡張する方法を検討する.6
むすび
本論文では,地図画像認識に関する研究の第一歩と して,新たにクラスラベル付き地図画像データセット を構築した.色ヒストグラムに基づく SVM と CNN の 分類正解率の比較により,他の画像認識タスクと同様, 画像枚数が少ない条件でも CNN の方が高い正解率で 分類できることを示した.SVM のように手動設計によ る特徴量を用いる場合,色以外の画像特徴量(エッジ, テクスチャなど)も抽出すべきと考えられる.それに 加え,CNN による分類ではデータセットを拡張するこ とで,幅広い地図画像を分類するのに有効な各クラス ごとの特徴を発見できることを示した. 4 章で構築したデータセットでは,画像枚数の少ない クラスの分類精度が問題となった.Google 画像検索に よりデータセットを拡張した結果,同一テスト画像に 対する認識性能の向上がみられた.今後はデータセッ トを効率的に拡張する方法を検討する. さらなる分類精度向上には,画像特徴のみならず,テ キストの情報を深層学習に導入するアプローチが考え られる [4].本研究においても,地図画像に文字認識を 適用し,画像とテキストを入力としたネットワーク構 造を提案する予定である.謝辞
本研究を遂行するにあたり,地図画像データを提供 していただきました株式会社 Stroly 様にお礼申し上げ ます.
参考文献
[1] H. Vermeluen, T. Takahashi, M. Takahashi, K. Ohtsuka, T. Nakagawa, and H. Ueda. Stroly: A historic and illustrated maps platform. In Second
International Conference on Culture and Comput-ing, pp. 195–196, 2012.
[2] E. Garces, A. Agarwala, D. Gutierrez, and A. Hertzmann. A similarity measure for illus-tration style. ACM Transactions on Graphics,
Vol. 33, No. 4, July 2014.
[3] K. Simoyan and A. Zisserman. Very deep convolu-tional networks for large-scale image recognition. In International Conference on Learning
Repre-sentations, 2015.
[4] S. Sanjo and M. Katsurai. Recipe popularity pre-diction with deep visual-semantic fusion. In
Pro-ceedings of the 2017 ACM on Conference on Infor-mation and Knowledge Management, CIKM ’17,