逆転の余地を考慮した評価関数の設計とどうぶつしょうぎによる評価
中屋敷 太一
1,a)金子 知適
2,b) 概要:コンピュータプログラムはいくつかの有名なゲームで,人間を超える結果を達成することに成功し たが,その強さを人間の学習に役立てるなどの点ではまだ研究が進んでいない.本稿では逆転の余地を考 慮した評価関数の設計手法を提案する.従来の強さのための研究では,評価関数は勝ち負けの正確さを表 現することが第一の目的であった.しかし,勝敗が完全に正確に表現されたとしても必ずしも人間の考え 方に有用であるとは言えない.逆転の余地は従来の評価関数の研究では考慮が難しい観点の一つである. 本研究ではSoft Q-learningで使われるSoft valueを応用することでそれを実現する.Soft Q-learningは 方策をなるべく決定的にならないように学習する強化学習の手法であり,選択肢の多様さを評価する観点 でゲームにおける逆転の余地と関連が深い.この提案手法を「どうぶつしょうぎ」を利用した計算機実験 で評価した.どうぶつしょうぎは完全解析されたゲームの1つであり,理論的には後手必勝であるが,数 億局面の広さの状態空間を持ち,ある程度難しいゲームである.提案手法で設計した評価関数に基づくプ レイヤは,他のプレイヤより後手番で安全勝ちを行ったり,先手番で逆転勝ちを狙うことに優れることが 対局実験により示された.Design of Evaluation Functions Considering Recovery
and Its Evaluation in Dobutsu Shogi
Taichi Nakayashiki
1,a)Tomoyuki Kaneko
2,b)Abstract: Computer programs have surpassed human players in many popular games, however it is on
progress how to utilize them for humans to improve their ability. In this paper, we propose a method to design an evaluation function considering recovery from losing positions. The main goal of previous works of evaluation functions focused on how to identify game theoretical values of win or lose. Even if we have an ultimate evaluation function that captures win or lose perfectly, it could not always be useful for humans. For example, it is difficult for existing evaluation functions to choose better move to keep opportunities of recovery from losing positions. We address the problem by soft value, which is proposed in soft Q-learning. A reinforcement learning algorithm called soft Q-learning aims to learn a policy with a decent entropy, in which there is similarity with our situation in evaluation of the number of ways towards possible recovery. We evaluate the method with computational experiments in the game of ”Dobutsu shogi”. Dobutsu shogi is a solved game where the second player wins at the initial position though, the size of the state space is a couple of hundred million and therefore the game is difficult enough. Players with evaluation functions yielded by our proposed method play more safely in winning positions and more deliberately in losing positions than other players.
1 東京大学大学院総合文化研究科
Graduate School of Arts and Sciences, The University of Tokyo
2 東京大学大学院情報学環
Interfaculty Initiative in Information Studies, the University of Tokyo a) [email protected] b) [email protected]
1.
はじめに
コンピュータのハードウェア,アルゴリズムの両面の進 歩により,コンピュータプログラムは様々なゲームで人間 よりも強いものとなってきている.例えば,1997年にはオンのガルリ・カスパロフに勝利した.その後2013年に
将棋で,プロ棋士5名とコンピュータプログラム5つが
それぞれ対局を行った電王戦において,コンピュータプロ グラムが勝利を収めた[2].さらに2016年には,強いコン
ピュータプログラムを作るのが難しいと言われていた囲碁 において,Gooogle DeepMindが開発したAlphaGo [3]が, トップ棋士のイ・セドルと対局し勝利した[4].2019年に は,多人数の不完全情報ゲームである麻雀で,Microsoftが 開発したSuper Phoenix [5]が,オンラインの対局サイト 天鳳*1において人間のトッププレイヤーに匹敵する成績を 達成した[6]. このような進歩の中で,いくつかのゲームでは完全解析 が行われている.例えば「どうぶつしょうぎ」は完全解析 されたゲームの1つであり,初期局面では後手勝ちである ことが判明している[7]. ゲームにおけるコンピュータプログラムの利用方法とし て有望な方向性の1つは,人間の実力向上を助けることで ある.例えば,将棋においてコンピュータプログラムを用 いて自動解説を行うことなどが研究されている[8].本研究 では,完全解析が行われたゲームである「どうぶつしょう ぎ」を用いて,完全解析の結果から,完全解析の結果以上 に人間にとって有用な情報を示す手法について提案する. どうぶつしょうぎを人間が対局する上で,人間にとっては 指し手の間違えにくさなどといった,逆転の余地を考慮す ることが重要である.そこで我々は,評価関数に逆転の余 地を取り入れることに注目した.例えば,あと1手で勝て る局面と10手で勝てる局面を比較すると,あと1手で勝 てる局面の方が指し手を間違える可能性が少なく,勝ちや すいと考えられる.完全解析結果では,このような人間が 間違える可能性を考慮していないため,どちらも同じ値で ある.我々は,容易に勝つことができる局面や,実際に勝 つことが難しい局面,すぐには負けない局面等に対しての 値を区別する,逆転の余地を考慮した評価関数を設計する ことを目指した.
2.
先行研究
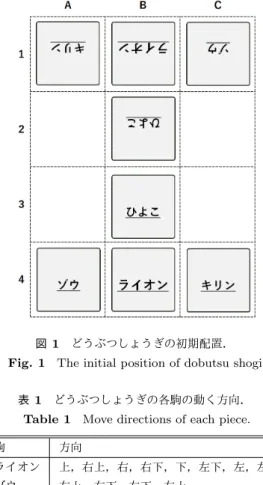
本節では,はじめにゲーム「どうぶつしょうぎ」の紹介 を行い,その完全解析について簡単に記述する.その次に 強化学習の手法の1つであるSoft Q-learningについて簡 単に記述する. 2.1 どうぶつしょうぎとその完全解析 どうぶつしょうぎは将棋の派生ゲームの一つであり,そ のルールは将棋に比べて大きく単純化されている.縦4升, 横3升の盤面が使用され,駒の種類はライオン,ゾウ,キ リン,ひよこ,にわとりの5種類である.初期局面は図1 *1 https://tenhou.net/ 図1 どうぶつしょうぎの初期配置.Fig. 1 The initial position of dobutsu shogi.
表1 どうぶつしょうぎの各駒の動く方向.
Table 1 Move directions of each piece.
駒 方向 ライオン 上,右上,右,右下,下,左下,左,左上 ゾウ 右上,右下,左下,左上 キリン 上,右,下,左 ひよこ 上 にわとり 上,右上,右,下,左,左上 である.それぞれの駒は表1で示される方向にちょうど1 マスだけ動くことができる.ひよこが相手陣*2に到達する と,にわとりに成ることができる.勝利条件はキャッチ, トライの2つがあり,いずれか一方を先に満たしたプレイ ヤの勝利となる. • キャッチ:相手のライオンを取ることをキャッチと呼 び,キャッチしたプレイヤの勝ちとなる. • トライ:自分のライオンを,先手なら1段目,後手な ら4段目に移動することをトライと呼ぶ.次の手で相 手にキャッチされる場合を除き,トライしたプレイヤ の勝ちとなる. どうぶつしょうぎは,将棋と比べてルールが単純化され ため,取りうる状態数が少なく,完全解析が行われてい る[7].完全解析の結果,初期局面では後手必勝であり,ま た初期局面から到達可能な局面数は246,803,167局面であ ることが知られている. 2.2 Soft value 通常の強化学習では,エージェントは獲得する報酬の最 大化を目指す.しかしその際に,同じ報酬が得られる2つ *2 先手の場合はA1, B1, C1が相手陣.後手の場合はA4, B4, C4 が相手陣である.
の行動がある場合に片方の行動のみを学習するといった 問題などがある.このような問題に対処するため,得られ る報酬の最大化を目指しながら方策のエントロピーの最 大化も目指すエントロピー最大化強化学習が提案されて
いる.エントロピー最大化強化学習の手法の1つにSoft
Q-learning [9]がある.本節では,Soft Q-learningの枠組 みで定義されたSoft Q-valueおよびSoft valueについて簡
単に記述する. 方策πのもとでのSoft Q-value Qπ softは式(1)で定義さ れる. Qπsoft(st, at) = rt+Eat∼π [∞ ∑ i=1 γi(rt+i+ αH(π(·|st+i))) ] (1) ここでstは時刻tでの状態,atは行動,rtは報酬,γは割 引率,H(π)は方策πのエントロピー,αはエントロピー項 の重要度を表すパラメータである.さらに,価値関数Soft
value Vsoft(st)を式(2)で定義すると,Qπsoft(st, at)は再帰
的に式(3)で書くことが出来る[9], [10]. Vsoftπ (st) =Eat∼π[Q π soft(st, at)− α log π(st, at)] (2) Qπsoft(st, at) = rt+ γEst+1∼π[V π soft(st+1)] (3) このように定義されるQπsoftを用いて強化学習を行う ことで,得られる報酬の最大化を目指しながらエントロ ピーの最大化を目指すことができる.このQπ soft(st, at)か らSoftmax関数を用いて作られる方策π (式(4))は,方策 改善定理[11]に従うことが示されている[9]. π(s, a) = exp (Q π soft(s, a)/τ ) ∑ bexp (Qπsoft(s, b)/τ ) (4) ここでτ はSoftmax関数の温度であり,τ → ∞でπ(s,·) は一様分布となる.また学習中にはτ = αを用いる.な お,学習アルゴリズムの詳細は文献[9]を参照されたい.
3.
手法
我々は,Soft valueを用いることで,どうぶつしょうぎに おいて完全解析結果の勝敗の理論値よりも人間にとって分 かりやすい勝ち負けの指標を作ることができると考えた. これは次の考察による.理論値が勝ちの局面であっても, 合法手の中に勝敗不変手*3が少ないほど勝ちきることが難 しいと考えられる.この場合には,方策のエントロピーが 比較的小さくなる.一方で,合法手の中に勝敗不変手が多 い場合には,方策のエントロピーは比較的大きくなる.そ こで負けの局面では,相手の方策のエントロピーが小さく なるような手を選ぶと,逆転勝ちの余地を残しやすいと考 えられる. また副次的ではあるが,Soft valueを用いる利点として, *3 勝ちの局面から勝ちの局面へ遷移する手のこと. 価値関数を計算することができれば,その価値関数から方 策も計算可能であることが挙げられる.この利点により, 実際に対局において指し手を選ぶ際に,決定的ではなく確 率的に指し手を選ぶことができる.この点は,コンピュー タプログラムどうしの対局では重視されないが,人間との 対局の楽しさを考えると利点となる.どうぶつしょうぎにおけるSoft Q-valueおよびSoft value
を,基本的に式(2)と式(3)に従い計算を行う.以下に, 具体的な計算手順と,どうぶつしょうぎに適用する際に注 意する事柄について記述する. ( 1 )末端局面*4sの価値関数V (s)を,勝ちならば1,負け ならば0とする. ( 2 )ある局面sの全ての子局面sc ∈ children(s)の価値関 数V (sc)が計算済みである場合に,式(2)と式(3)に従 いV (s)の計算を行う(後退解析).ここでr = 0, γ = 1 とする.二人ゼロ和ゲームであるため,1ステップ後 の価値関数の値は符号を反転して使用する. ( 3 )手順(2)でV (s)を計算可能な局面が無くなるまで手 順(2)を繰り返す. ( 4 )完全解析結果を参照し,勝敗が決するまでの残り手数 が短い局面から,(2)と同様にV (s)の計算を行う.こ の際に,子局面scの価値関数V (sc)が未計算の場合 には,V (sc) = 0とする.この意味は次の段落で説明 する. なお,上記の計算手法中に現れる局面は,全て初期局面か ら到達可能な局面であるとする. 文献[7]では,各局面が勝ち,負け,および引き分けの いずれであるかを計算したため,同一局面の再現に対して も問題なく対処できる.一方で,Soft Q-valueを計算する 際には,子局面の価値関数が全て計算済みである必要があ るため,千日手が発生する局面について注意を払う必要が ある.この問題の具体例を図2に示す.局面sE は末端局 面であり,sEは手番の負けであるとする.勝ち負けのみ を計算する後退解析では,sAは手番プレイヤが勝つこと ができる子局面(sE)を保持しているため,sAを勝ちノー ドとすることができる.その後,sA→ sD → sC → sBの 順に各局面の勝敗を決定することができる.一方で,局面 sAのSoft Q-valueを計算する際には,局面sBについて も計算済みである必要がある.しかし,局面sBを計算済 みにするためには,局面sAを計算済みにする必要があり, 計算が止まってしまう.そこで手順(4)を導入して,この ような場合にはV (sB) = 0と仮定し,Soft Q-valueおよび Soft valueの計算を行う.
4.
実験
本節では,3節の手法で作成したどうぶつしょうぎにお *4 ゲームのルールで終局し勝敗が定まった局面のこと.sA sB sC sD sE 図2 引き分けを仮定しないと計算ができない例.
Fig. 2 An example of necessity of draw assumption.
けるSoft Q-valueの評価を行う. 本手法では,エントロピー項を用いることで,完全解析 結果では負けの局面でも逆転勝ちを狙えるようにすること を目指した.そこで,まずはじめに,一定確率で最善手以 外を指すプレイヤに対して対局実験を行い,負けの局面で 逆転できているかどうかを測定した. 次に,本手法で作成したSoft Q-valueが,人間にとって 分かりやすい指標として使用できるかどうかを検討するた めに,その値の付き方について観察を行った. 4.1 対局実験 実際のどうぶつしょうぎの対局を通してSoft Q-valueを 評価するにあたって,我々は次の4つのプレイヤを用意 した. • Top-n-randomized:合法手を,勝ち,引き分け,負け の順にソートし,上位n手の中から一様ランダムに選 択する.
• Soft Q-value (α, τ):子局面のSoft Q-valueを温度τ
のSoftmax関数(式(4))を用いて確率分布にする.そ の確率分布に従い指し手を選択する.τ = 0の場合に は,最もSoft Q-valueが大きい局面に遷移する手を選 択する. • Expectation (α, τ):式(2)からエントロピー項を除い たものを用いる.それ以外はSoft Q-value(τ )と同様 に指し手を選択する.
• Shortest win longest lose:勝ち局面では最短で勝てる
手,負け局面では最長で負ける手の中から指し手を選 択する.そのため,このプレイヤは決して逆転負けを
しない.
Top-2-randomizedに対して,Top-1-randomized,Soft Q-value (α = 0.1, τ = 0),そしてExpectation (α = 0.3, τ = 0)で対局を行った.対局は先手,後手それぞれ100,000局 行った.結果を表2に示す.結果から,Soft Q-value(0)は, 先手番でも全て勝利していることがわかる.相手の勝敗不 変手率*6を見ると,他のプレイヤに比べて,この値が小さく なっていることがわかる.このことから,Soft-Q-value(0) プレイヤは,エントロピーを導入することにより,自分が 負けている状況では相手が正しい手を選ぶことが難しい局 面を選んでいると考えられる.また,Shortest win longest
loseプレイヤよりも相手の勝敗不変手率が低い値になって いることから,負けまでの手数は長いが一直線で負けてし まう局面よりも,負けまでの手数が短くなっても複雑な局 面を選んでいると考えられる. 4.2 評価関数と終局までの手数の関係 Soft valueと,勝敗が決するまでの残り手数の散布図を 描画した (図3).また,比較するため,Expectationにつ いても同様に描画した (図4).これらの散布図を作成する にあたり,無作為にサンプルした10,000局面を使用した. また,残り手数が1手以下の局面は,描画の対象局面から 除外した.散布図中の青い点は,完全解析結果が勝ちであ る局面,オレンジの点は完全解析結果が負けの局面である. なお,図中の点の透明度は図の見やすさのためのみの目的 で使用した. この結果から,どちらも終局までの手数が長いほど0に 近い値を示す傾向があることがわかる.また,Soft value はExpectationに比べ変化がなだらかであり,また青い点 の領域とオレンジの点の領域の重なりが少ないことがわか る.そのため,Soft valueは,局面の勝ち負けの情報を保持 しながら,その中で勝ちやすい局面や,負けやすい局面を 表現することができていると考えられる.また,付録A.4 で,完全解析結果とは異なる性質を持つことを観察した. 4.3 対局時の方策のエントロピー 4つのプレイヤーは確率分布に従い指し手を選択するた め,対局時のエントロピーを測定することができる.エン トロピーが大きいと,対局時に様々な手を指すと言える.
Top-2-randomized,Soft Q-value (0.1), Expectation (0.1), Shortest win longest loseプレイヤのそれぞれの対局時の
エントロピーを測定した.測定には小節4.1での行われた
対局を用いた.結果を表3に示す.
この結果から,Soft Q-valueとExpectationのエントロ ピーが高くなっていることがわかる.計算時にエントロ ピー項を含まないExpectationの方が,エントロピー項
表2 勝敗不変手率*5とTop-2-randomizedプレイヤに対する,各プレイヤの勝率. Table 2 The theoretically correct moves ratio and win rate against top-2-randomized.
プレイヤ 先手勝率 後手勝率 プレイヤの勝敗不変手率 相手プレイヤの勝敗不変手率
Top-1-randomized 0.40374 1.00000 0.39386 0.37861
Soft Q-value (α = 0.1, τ = 0) 1.00000 1.00000 0.39970 0.09889 Expectation (α = 0.3, τ = 0) 0.99868 0.99963 0.39175 0.26828 Shortest win longest lose 1.00000 1.00000 0.42720 0.26984
0
20
40
60
80
100
120
140
# moves to Terminal
1.0
0.5
0.0
0.5
1.0
図3 Soft value (α = 0.1)と残り手数の散布図 Fig. 3 Scatter plot between soft value (α = 0.1)and the number of moves to terminal.
0
20
40
60
80
100
120
140
# moves to Terminal
1.00
0.75
0.50
0.25
0.00
0.25
0.50
0.75
1.00
図4 Expectation (α = 0.3)と残り手数の散布図 Fig. 4 Scatter plot between Expectation (α = 0.3)and the number of moves to terminal.
表3 各プレイヤの対局時のエントロピー.
Table 3 Entropy of each player in the matches.
プレイヤ エントロピー
Top-2-randomized 0.6931
Soft Q-value (α = 0.1, τ = 0.1) 1.0636 Expectation (α = 0.3, τ = 0.1) 1.1037 Shortest win longest lose 0.3407
を含むSoft Q-valueより対局時のエントロピーが大きく なっているが,これは図3と図4の結果から説明できる. Expectationでは,初期局面などの終局まで手数がかかる 局面では,勝ちの手と負けの手がどちらも0に近い値に なっていると考えられる.そのため,対局時の方策が一様 分布に近い形となる.一方で,Soft Q-valueではエントロ ピーを考慮しながらも,勝ちの局面と負けの局面が区別で きていると考えられる.結果として,Expecatationに比べ て対局時のエントロピーが小さくなる.実際に,表2から, ExpectationよりもTop-2-randomizedに対する勝率が高 いことがわかる.
Top-n-randomizedプレイヤのnや,Soft Q-value,
Ex-pectationプレイヤのτを変更することで,対局時のエント
ロピーを変えることができる.そこでTop-2-randomizedプ レイヤと対局した際のエントロピーごとの勝率を測定した. 結果を図5に示す.さらにSoft Q-valueとExpectationを
0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75
Entropy
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
Win rate against top-2-randomized
top-n-randomized
Soft Q-value
Expectation
図5 異なるエントロピーでのTop-2-randomizedに対する勝率. Fig. 5 Win rate against top-2-randomized along entropy.
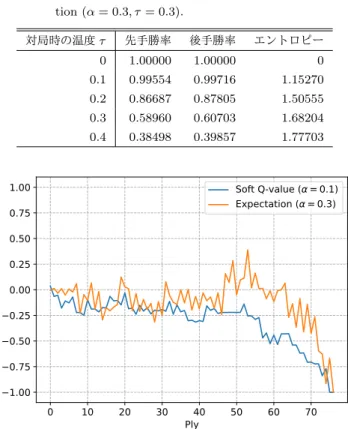
比較するため,Soft Q-value (α = 0.1, τ )とExpectation (α = 0.3, τ = 0.3)の対局実験も行った.結果を表4に示 す.これらの結果から,Expectationと比較すると,Soft Q-valueは勝率の減少幅を抑えながら,高いエントロピー を実現している,つまり様々な手を指すことがわかる. 4.4 初期局面から後手必勝手順78手の評価値の推移 初期局面は,先手がどのような手を指しても,後手が 間違うことがなければ,最長でも78手で終局する (棋譜
表4 Expectation (α = 0.3, τ = 0.3)プレイヤに対する Soft Q-value (α = 0.3)の勝率.
Table 4 Win rate of soft Q-value (α = 0.3) against Expecta-tion (α = 0.3, τ = 0.3). 対局時の温度τ 先手勝率 後手勝率 エントロピー 0 1.00000 1.00000 0 0.1 0.99554 0.99716 1.15270 0.2 0.86687 0.87805 1.50555 0.3 0.58960 0.60703 1.68204 0.4 0.38498 0.39857 1.77703
0
10
20
30
40
50
60
70
Ply
1.00
0.75
0.50
0.25
0.00
0.25
0.50
0.75
1.00
Soft Q-value ( = 0.1)
Expectation ( = 0.3)
図6 初期局面からの後手必勝手順に対する評価値の推移Fig. 6 The values of evaluation functions from the initial po-sition to a terminal popo-sition.
はA.2節に記載).その78手で終局する対局に対し,Soft Q-valueとExpectationの評価値の推移を描画した(図6). 完全解析結果では,この78手の手順の中に現れる局面は 全て後手勝ちであり,人間がその値を参考に学習するのは 困難である.一方で,今回提案した手法では,それがどの 程度正しいかどうかには議論の余地があるものの,値を区 別することには成功している.これまでの実験から,この 評価関数は逆転の余地を考慮しており,完全解析結果の理 論値に比べて人間のどうぶつしょうぎの学習を手助けでき ると期待できる.また,Soft Q-valueとExpectationを比
較すると,Soft Q-valueによる評価値は1手ごとの変動が 少なく,人間がより容易に参考にできると考えられる.
5.
まとめと今後の課題
本稿では,完全解析されたゲーム「どうぶつしょうぎ」 で,逆転を目指す手法について検討した.Soft Q-valueを 用いて方策のエントロピーを考慮することで,単純に最も 負けまでの手数が長い手を指すよりも,逆転勝ちの余地が ある手を指すことができた.これは,手数が長いだけで一 本道で負けてしまう手順よりも,相手にとって間違えやす い手順を選ぶことができているためだと考えられる.また, Soft Q-valueの観察結果から,容易な勝ちと難しい勝ちの 局面に対する値を区別できており,人間にとって完全解析 の理論値そのものよりも役立つ指標になると考えられる. 今後の課題として,今回考慮した2人ゲームにおけるエ ントロピー項を,強化学習の枠組みに取り入れることが挙 げられる.エントロピーを考慮することによって,強化学 習においても逆転の余地を考慮するようになり,よりロバ ストな学習ができるようになると期待できる. 参考文献[1] Campbell, M., Hoane, A. and hsiung Hsu, F.: Deep Blue, Artificial Intelligence, Vol. 134, No. 1, pp. 57 – 83 (online), DOI: https://doi.org/10.1016/S0004-3702(01)00129-1 (2002).
[2] 公 益 社 団 法 人 日 本 将 棋 連 盟: 第2回 将 棋 電 王 戦/五 番 勝 負. https://www.shogi.or.jp/match/denou/2/ index.html 2020/10/10閲覧.
[3] Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., van den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M., Dieleman, S., Grewe, D., Nham, J., Kalchbrenner, N., Sutskever, I., Lillicrap, T., Leach, M., Kavukcuoglu, K., Grae-pel, T. and Hassabis, D.: Mastering the game of Go with deep neural networks and tree search, Nature, Vol. 529, No. 7587, pp. 484–489 (online), available from ⟨http://dx.doi.org/10.1038/nature16961⟩ (2016). Arti-cle.
[4] DeepMind: The Google DeepMind challenge match. https://deepmind.com/alphago-korea 2020/10/10閲 覧.
[5] Li, J., Koyamada, S., Ye, Q., Liu, G., Wang, C., Yang, R., Zhao, L., Qin, T., Liu, T.-Y. and Hon, H.-W.: Suphx: Mastering Mahjong with Deep Reinforcement Learning (2020).
[6] Microsoft: 麻 雀 AI Microsoft Suphx が 人 間 の ト ッ プ プ レ イ ヤ ー に 匹 敵 す る 成 績 を 達 成. https://news.microsoft.com/ja-jp/2019/08/29/ 190829-mahjong-ai-microsoft-suphx/ 2020/10/12 閲覧. [7] 田中哲朗: 「どうぶつしょうぎ」 の完全解析,研究報告 ゲーム情報学(GI),Vol. 2009, No. 3, pp. 1–8 (2009). [8] 金子知適: コンピュータ将棋を用いた棋譜の自動解説と評 価,情報処理学会論文誌,Vol. 53, No. 11, pp. 2525–2532 (2012).
[9] Haarnoja, T., Tang, H., Abbeel, P. and Levine, S.: Reinforcement Learning with Deep Energy-Based Poli-cies, CoRR, Vol. abs/1702.08165 (online), available from ⟨http://arxiv.org/abs/1702.08165⟩ (2017).
[10] Haarnoja, T., Zhou, A., Hartikainen, K., Tucker, G., Ha, S., Tan, J., Kumar, V., Zhu, H., Gupta, A., Abbeel, P. and Levine, S.: Soft Actor-Critic Algorithms and Appli-cations (2019).
[11] Sutton, R. S. and Barto, A. G.: Introduction to Rein-forcement Learning, MIT Press, Cambridge, MA, USA, 2nd edition (2018). Complete Draft.
[12] 将棋世界編集部: 三段コース問題集,日本将棋連盟(2010). [13] 将棋世界編集部: 四段コース問題集,日本将棋連盟(2009).
付
録
A.1
使用した環境
本稿で行った実験には,次の性能の計算機およびコンパ イラを使用した.
• OS:Ubuntu 20.04.1 LTS (Focal Fossa)
• CPU:AMD Ryzen 7 1700 Eight-Core Processor
• コンパイラ:g++ 9.3.0 上記の環境でSoft Q-valueの計算を行ったところ,1ス レッドの実行で約1時間程度の計算時間を要した.
A.2
初期局面からの後手必勝手順 78 手の棋譜
図6を描く際に使用した棋譜である.田中が文献[7]で 示したものである.+C4C3KI -A1A2KI +C3C4KI -B2B3HI
+A4B3ZO -C1B2ZO +B3A2ZO -B1A2LI
+00B3KI -00C2ZO +B3B2KI -A2B2LI
+00A3ZO -B2A2LI +C4C3KI -00B2HI
+A3B2ZO -A2B2LI +00B3HI -B2B1LI
+B4A3LI -00A2KI +A3B4LI -00A3ZO
+B4A4LI -B1C1LI +C3C4KI -A3B2ZO
+B3B2HI -C1B2LI +00C3ZO -B2A1LI
+C3B4ZO -00B3HI +B4C3ZO -A1B1LI
+00A3HI -A2A1KI +C3B4ZO -B3B4NI
+A4B4LI -00B3ZO +C4C3KI -B1B2LI
+C3C2KI -B2C2LI +00C3HI -C2B2LI
+00C1ZO -B2C1LI +B4B3LI -C1B1LI
+00C2ZO -B1C1LI +A3A2HI -00B2KI
+B3B4LI -A1A2KI +C2B3ZO -00A3ZO
+B4C4LI -B2B3KI +C4B3LI -C1B1LI
+00C1KI -B1A1LI +C1C2KI -00B1HI
+B3C4LI -B1B2HI +C2B2KI -A2B2KI
+C3C2HI -00B4KI +C4C3LI -B2B3KI
+00C1HI -B3C3KI
A.3
評価値と残り手数の関係へのエントロピー
項の影響
本稿でSoft valueを計算するにあたり,エントロピー項 の重要度を左右するハイパーパラメータαが存在する.い くつかのハイパーパラメータで小節4.2の実験を行った結 果を,図A·1,図A·2,および図A·3に示す.Soft valueと Expectationはエントロピー項の有無だけが異なる.その ため,これらの図の違いはエントロピー項の影響である. この結果から,エントロピー項をバックアップする影響で, 評価値の分布がなだらかになっていることがわかる. ハイパーパラメータαに関して,どの値が良いかは難し い問題だが,本稿ではあまり極端でないものを主な実験に 用いた.A.4
興味深い Soft value を持つ局面
本稿ではSoft valueを用いる逆転を考慮した評価関数の
設計手法について提案した.本節では,初期局面から到達 な局面のなかで,興味深いSoft valueを持つ局面について 掲載する.
A.4.1 理論的な勝敗とSoft valueが最も異なる局面
Soft valueが,単純に完全解析の値を終局までの手数に 比例して縮小させた値に近いのかどうかを調べるため,勝 敗の理論値である{1, 0, −1}と最も値が異なる局面を調べ た.その結果,図A·5の局面が,Soft valueと解析結果の 値が最も違う局面であることがわかった.この局面は,現 在の手番は先手番であり,解析結果は後手勝ちの局面で ある.また後手が勝つまでに59手を要する.この局面の Soft valueは0.330877であり,先手有利を示すものであっ た.以上のことから,解析結果の理論値や勝敗が決定する までの最短手数だけでは評価できない特徴について評価し ていることがわかる. A.4.2 次の一手問題集への活用 将棋などを人間が学習する際には,ある局面の次の一手 を考える問題集が使用されることがある.このような問題 集は人間の実力に合わせて出題されることがある[12], [13]. Soft valueが適切に逆転の余地を考慮出来ていると仮定 する.このときある局面で,Soft valueが大きく完全解析 結果が勝ちのときには簡単な勝ち局面であると考えること ができる.また完全解析結果が勝ちでも,Soft valueが小 さいときには難解な勝ちであると考えられる.もし簡単な 勝ち局面と難解な勝ち局面を判断することができれば,次 の一手問題集の自動生成をすることができる. Soft valueと完全解析結果を照らし合わせることで得ら れる,簡単な勝ち局面の例と,難解な勝ち局面の例を図A·4 に示す.正解手順は複数あるため,一例を表A·1に示す. 実際にこれらの局面を人間が簡単,難解と考えるかどう かは更なる調査を要するが,本手法を活用し,次の一手問 題集の自動生成へ応用することを展望できる. A.4.3 初期局面の提案 どうぶつしょうぎの初期局面では,完全解析の結果78手 で後手勝ちであることが知られている.本小節では,Soft valueが最も引き分けに近い,78手で後手勝ちの局面と, 79手で先手勝ちの局面を図A·6に示す.人間同士が対局 する際に,これらの局面を初期局面として活用することも, Soft valueの応用例として考えられる.
0 20 40 60 80 100 120 140 # moves to Terminal 0.5 0.0 0.5 1.0 1.5 2.0 図A·1 Soft value (α = 0.3)と 残り手数の散布図 Fig. A·1 Scatter plot between
soft value (α = 0.3) and the number of moves to terminal.
0 20 40 60 80 100 120 140 # moves to Terminal 1.00 0.75 0.50 0.25 0.00 0.25 0.50 0.75 1.00 図A·2 Expectation (α = 0.2)と 残り手数の散布図 Fig. A·2 Scatter plot between
Expectation (α = 0.2) and the number of moves to terminal.
0 20 40 60 80 100 120 140 # moves to Terminal 1.00 0.75 0.50 0.25 0.00 0.25 0.50 0.75 1.00 図A·3 Expectation (α = 0.4)と 残り手数の散布図 Fig. A·3 Scatter plot between
Expectation (α = 0.4) and the number of moves to terminal.
(a)簡単な5手先手勝ち.(b)難解な5手先手勝ち.(c)簡単な7手先手勝ち.(d)難解な7手先手勝ち.(e)簡単な9手先手勝ち.(f)難解な9手先手勝ち. 図A·4 簡単な勝ちと難解な勝ちの局面例.
Fig. A·4 Examples of easy or hard positions to win. 表A·1 正解手順の一例.
Table A·1 Move sequence examples to win.
局面 手順
(a) +00C2Z0 -B2B3HI +C2B1ZO -B3B4NI +A2A1LI (b) +B3C2LI -00A4HI +C1B1KI -A1A2LI +C2C1LI
(c) +B3B2KI -B1B2HI +A2B2KI -00C2KI +A3A2LI -C2B2KI +A2A1LI (d) +A3A2LI -00B2ZO +A1B1KI -C1C2LI +B1B2KI -C2C1LI +A2A1LI
(e) +C4C3NI -C2C1LI +B4B3NI -B2B3KI +A4B3ZO -00A2HI +A3A2LI -B1A1KI +A2A1LI (f) +00C1ZO -00A1HI +C2B3ZO -A2B3NI +C3C2LI -00A2ZO +C1B2ZO -B3B2NI +C2C1LI
図A·5 解析結果とSoft valueが最も異なる局面. Fig. A·5 The position at which the solved value
and the soft value are most different.
(a) 78手で後手勝ちの局面.(b) 79手で先手勝ちの局面. 図A·6 Soft valueが0に近い局面例.