WP-01264-1.0 ホワイトペーパー
メモリ帯域幅の課題を解決する
Stratix 10 MX デバイスの実力
Manish Deo, Senior Product Marketing Manager, Altera, now part of Intel Jeffrey Schulz, In-Package I/O Implementation Lead, Altera, now part of Intel Lance Brown, Senior Strategic and Technical Marketing Manager, Altera, now part of Intel
従来のメモリ・ソリューションには技術的な制限があり、次世代のメモリ帯域幅要件 への対応が困難になってきています。このホワイトペーパーでは、こうした制限に対
処する新たなメモリの展望について解説します。Stratix® 10 MX DRAM SiP
(System-in-Package) ファミリは、1 GHz 動作が可能な高性能モノリシック FPGA ファブリック、 インテルの最先端 EMIB (Embedded Multi-die Interconnect Bridge) テクノロジ、および HBM2 (High Bandwidth Memory 2) DRAM をすべて 1 つのパッケージに統合していま す。Stratix 10 MX ファミリは、従来のメモリ・ソリューションでは対応できなかった 最も厳しいメモリ帯域幅要件に効率的に対応するのに最適です。このホワイトペー パーでは、Stratix 10 MX デバイスが多くのマーケットやアプリケーションにおけるメ モリ帯域幅の課題をどのように解決するのかを紹介します。
メモリ帯域幅の課題
メモリ帯域幅は、次世代プラットフォームにとっての大きなボトルネックです。どの システムも、パフォーマンス上のクリティカル・パスは、大量のデータを素早く処理 する能力です。演算装置 (FPGA や CPU など) は、メモリとの間で膨大なデータの読 み出し/書き込みを効率的に行わなければなりません。 多くのエンド・マーケットやアプリケーション (データ・センター、高性能コンピュー ティング・システム、放送 (8K)、ワイヤライン・ネットワーキング、データ解析、お よび IoT) がメモリ帯域幅要件の増大要因となっており、そのデータ処理量は増加の一 途をたどっています。データ・センターやネットワーキング・プラットフォームはこ うしたデータの経路であり、帯域幅の急増に対応するために、作業効率の向上と作業 量の高速化を同時に実現することを目指しています。データ・センター・トラフィッ クの総量は、2019 年には 10.4 ゼタバイト (ZB) に達すると予測されています。 図 1:2019 年までのデータ・センター・トラフィック予測 システム設計者は、現在利用できる従来技術を駆使してメモリ帯域幅要件の爆発的増 大に対応してきましたが、そうした従来技術には多くの課題があります。出典:Cisco VNI Global IP Traffic Forecast, 2014 - 2019 3.4 ZB データ・センター・トラフィックの総量 10.4 ZB データ・センター・トラフィックの総量 2014 2019 1 ゼタバイト (ZB) は、10 の 21 乗バイト、すなわち 1 兆ギガバイトに相当
ページ 2 メモリ帯域幅の課題
課題
1:I/O 帯域幅の制限
I/O 帯域幅の拡大は、市場で求められるペースに追いついていません。必要な帯域幅 を提供するのに十分なメモリ・バス幅をサポートするために、十分な I/O ピンを実装 することは物理的に不可能です。コンポーネントを追加しても、消費電力の増加や実 装面積への影響を伴うため、問題の解決にはなりません。 ワイヤライン・ネットワーキング市場が、この具体的な課題を示しています。パケッ トの格納と検索に必要な全二重帯域幅の合計は、トラフィック負荷の関数として決ま ります。システム設計者は、持続的なライン・レート性能 (100G、200G など) を保証 するのに十分なマージンを適切に確保しなければなりません。図 2 は、ワイヤライ ン・ネットワーキング分野における 200G トラフィック負荷の変曲点を示しています。 このアプリケーションの例では、基本的なデータ・プレーン・メモリ機能に対応する ために、700 本以上の I/O ピンと 5 枚の DDR4 (x72、3,200 Mbps) DIMM が必要です。 図 2 が示すように、400G システムでは 1,100 本以上の I/O ピンと 8 枚のDDR4 (x72、 3,200 Mbps) DIMM が必要になります。こうした帯域幅要件に対応してパッケージの I/O 数を増やすことは、いずれ実現が困難になります。 図 2:I/O 帯域幅の制限課題
2:消費電力バジェット
消費電力バジェットは重要な課題分野です。システム設計者は、メモリ帯域幅要件に 対応するために、ますます多くのディスクリート・メモリ (コンポーネント、DIMM など) を、標準の PCB トレースを使用して演算装置に接続しなければなりません。標 準の DDR4 x72 ビット・インタフェースは、約 130 本の並列 PCB トレースを消費しま す。大型 I/O バッファでこれらの長い PCB トレースをドライブし、その結果、ビット あたりの消費エネルギーが大幅に増加します。さらに、256 GB/s のメモリ帯域幅を必 要とするアプリケーションの場合、約 10 枚の DDR4 3,200 Mbps DIMM が必要であり、 推定総消費電力は 40 W に及びます。(1) 最高レベルの帯域幅を必要とするアプリケー ションの場合、すぐに消費電力の限界に達します。逆に、システム・レベルの消費電 力バジェットは横ばいか、あるいはさらに低く抑えられています。システム設計者は、 システム・レベルで最高のワットあたりの帯域幅を引き出すことをますます要求され ています。 (1)* 30 % の読み出し/書き込み、シングル・ランク構成と仮定。I/O およびコントローラの消費電力を含む。 100 200 400 得られるトラフィック負荷 (Gbps) 1,200 1,000 800 600 400 200 0 426 710 1,136 必要な DDR I/O 数メモリ帯域幅の課題 ページ 3
課題
3:フォーム・ファクタの縮小
従来技術を使用してメモリ帯域幅要件の増大に対応しようとすることは、多くの場 合、PCB に実装するディスクリート・メモリ・デバイスの数を増やすことを意味しま す。設計者は、適切なシステム・レベルのマージンを確保するために、特定のボー ド・レイアウト・ガイドラインに基づいてトレース長、終端抵抗、および配線レイヤ を決定します。それらのルールは、デザインの大きさやデバイスの配置間隔を制限し ています。メモリ帯域幅要件の増大に伴い、DDR などの従来のソリューションを用 いて実装面積の制約を満たしながら、メモリ帯域幅目標を達成することはますます困 難になるでしょう。図 3 に、メモリ帯域幅要件を 80 GB/s から 256 GB/s に引き上げた 場合の実装面積への影響を示します。 図 3:従来のソリューションによる実装面積の制約課題
4:JEDEC DDR 帯域幅の持続性
DDR などの従来技術は、将来のメモリ帯域幅要件を満たせるようにスケーリング (拡 張) することがますます難しくなっています。DDR テクノロジは、この 10 年間、世 代ごとにスケーリングを達成してきましたが、このスケーリングは終わりを迎えよう としています。仮に DDR4 の次の世代でも 2 倍の増加率が続くとすると、(DIMM 1 枚 あたりの) 帯域幅は、40 GB/s の範囲と推定できますが、次世代アプリケーションのメモ リ帯域幅要件は、過去 10 年間の動向をはるかに超えることが予想されています。図 4 を参照してください。 1 FPGA ( 42.5 mm2) 3 DDR4 3200 Mbps DIMM ( 133 x 30 mm2) 80 GB/s のメモリ帯域幅 3 FPGA 3 x ( 42.5 mm2) 10 DDR4 3200 Mbps DIMM 10 x ( 133 x 30 mm2) 256 GB/s のメモリ帯域幅 縮尺不同 PCB PCBページ 4 DRAM メモリの展望 図 4:DDR (DIMM) の帯域幅の予測
DRAM メモリの展望
メモリ業界は、従来技術では将来のメモリ帯域幅要件に対応できないことを認識して います。そのため、課題への対処を試みる複数の競合ソリューションが出現し、メモ リの展望は変化しつつあります。 図 5 に示すように、基本要件はコントロール・プレーン・メモリとデータ・プレー ン・メモリの両方にわたります。コントロール・プレーンまたは高速パス・メモリ (SRAM など) は通常、高いランダム・トランザクション・レートと低レイテンシを備 えています。データ・プレーン・メモリ (DRAM など) は大容量で広帯域幅です。 レガシー製品としては、標準の DDR ベースのメモリ・ソリューションが挙げられま す。広帯域幅、低消費電力、および実装面積削減の課題に対応するために進化したの が、3D ベースのメモリ・ソリューションです。これらのソリューションは、TSV (シ リコン貫通電極) テクノロジを使用して複数の DRAM を積層します。3D メモリ・ソ リューションは、メモリが垂直に積層されているため、小さい実装面積で最大限の容 量を実現できます。 3D メモリは、高速シリアル・トランシーバまたは高密度パラレル GPIO を使用して 演算装置と通信します。 Hybrid Memory Cube (HMC) は、シリアル・インタフェースを備えた 3D DRAM メ
モリです。
MoSys 社の Bandwidth Engine (BE) は、シリアル・インタフェースを備えた
DRAM メモリです。 HBM は、パラレル I/O インタフェースを備えた 3D DRAM メモリです。 2002 DDR 2004 DDR2 2007 DDR3 2013 DDR4 2018-2019 DDR5? 帯域幅 (GB/s) 20 18 16 14 12 10 8 6 4 2 3 6 12 20 40 30 従来の増加率の 約 2 倍
Stratix 10 MX (DRAM SiP) デバイス ページ 5 図 5:新たなメモリの展望 図 6 に、各種メモリの帯域幅に応じた電力効率を示します。 狭帯域幅/最も高電力効率 - LPDDR (Low-power DDR) は、電力効率が最も高く、 モバイル・エンド・マーケットに最適です。 中帯域幅/中電力効率 - DDR3/DDR4 は 10 年以上にわたってメモリ分野の主力を
占めています。WIO2 (Wide I/O 2) は、3D スタッキングを使用して演算装置の上
にメモリを積層するもので、優れた電力効率で広帯域幅化を実現します。
広帯域幅/中~高電力効率 - HBM と HMC は競合する最新テクノロジです。
図 6:電力効率および帯域幅の比較
Stratix 10 MX (DRAM SiP) デバイス
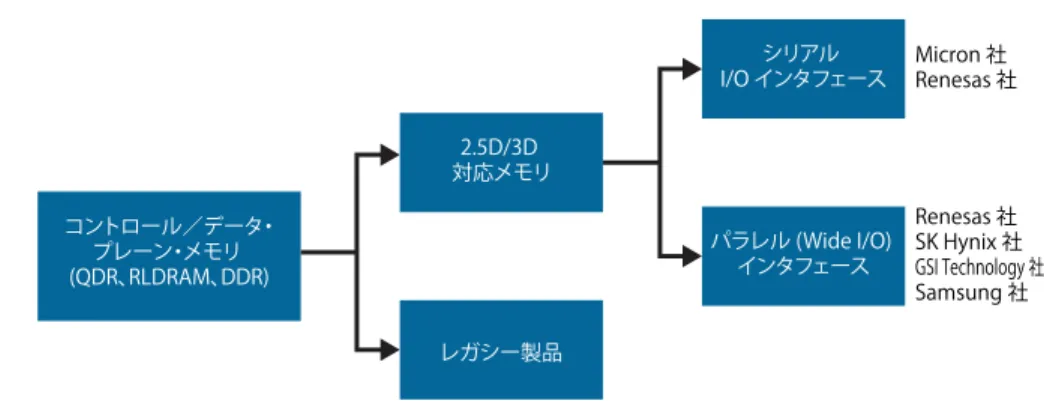
Stratix 10 MX デバイスは、高性能 FPGA と HBM2 タイルを統合した新しいタイプの 製品です。Stratix 10 MX デバイスは、帯域幅が最も重要な高性能システムの要求を満 たすために設計されたもので、DDR などの従来のソリューションと比較して 10 倍の メモリ帯域幅に加え、最高のワットあたり性能を実現します。図 7 に、この新製品の 基本構造を示します。 コントロール/データ・ プレーン・メモリ (QDR、RLDRAM、DDR) 2.5D/3D 対応メモリ レガシー製品 シリアル I/O インタフェース パラレル (Wide I/O) インタフェース Micron 社 Renesas 社 Renesas 社 SK Hynix 社 GSI Technology 社 Samsung 社 HBM2 LPDDR3 WIO2 DDR3/DDR4 HMC 電力効率 帯域幅 狭帯域幅/最も高電力効率 中帯域幅/中∼高電力効率 最も広帯域幅/中∼高電力効率 LPDDR WIO2 HMC Low-Power DDR Wide I/O 2 ハイブリッド・メモリ・ キューブ LPDDR4 縮尺不同
ページ 6 Stratix 10 MX (DRAM SiP) デバイス 図 7:Stratix 10 MX デバイス 図 7 (A):パッケージ内に統合された DRAM は、HBM2 メモリ・タイルです (パッケー ジあたり最大 4 タイルを統合)。各 HBM2 メモリ・タイルは 4 層または 8 層 (メモリ・ レイヤ) で、最大 16 の独立したチャネル (各 64 ビット) をサポートしています。各チャ ネルは最大 2 Gbps のデータ・レートで動作可能で、チャネルあたり最大 16 GB/s の合 計帯域幅を提供します。図 8 に、メモリ・チャネルおよびベース・ダイの論理的表現 を示します。 図 8:16 チャネルを備えた 4 層 HBM デバイスの論理的イメージ 図 7 (B):緑色の部分は、高性能モノリシック・コア・ファブリックとともに異なる タイルの効果的なインパッケージ統合を可能にする、インテルの EMIB テクノロジで す。EMIB インタフェースは、コア・ファブリックと HBM2 メモリ・タイル間で必要 となるデータ・レートをサポートします。このインタフェースは、標準 JEDEC およ び IEEE 1500 の仕様と互換性があります。インテルの EMIB は、複数のタイルを 1 つ のパッケージに簡潔に統合する方法を提供します。 図 7 (C):オレンジ色の部分は、インテルの EMIB テクノロジを使用してモノリシッ ク・コア・ファブリックに接続される高性能トランシーバ・タイルを示しています。 図 7 (D) は、HyperFlex アーキテクチャを使用して構築された高性能モノリシック・コ ア・ファブリックです。このコア・ファブリックは最大 1 GHz で動作可能で、従来世 代のハイエンド FPGA の最大 2 倍の性能を提供します。この高性能モノリシック・コ ア・ファブリックにより、インパッケージ・メモリ帯域幅の効率的な処理が保証され、 高性能なシステム・レベル・ソリューションが実現します。 EMIB サブストレート Stratix 10 コア・ファブリック ヒート・スプレッダ HBM2 スタック (4 層または 8 層) エンベデッド・クアッドコア ARM® Cortex®-A53 1.5 GHz プロセッサ A B C D CH6 CH7 CH4 CH5 CH2 CH3 B0 3 B0 7 64 I/O B0 11 B0 15 PS-CH0 B0 3 B0 7 64 I/O B0 11 B0 15 PS-CH0 ADD CMD CH0 B0 3 B0 7 64 I/O B0 11 B0 15 PS-CH0 B0 3 B0 7 64 I/O B0 11 B0 15 PS-CH0 ADD CMD CH1 CH0 128 64 I/O 64 I/O 64 I/O 64 I/O 64 I/O 64 I/O 64 I/O 64 I/O 64 I/O 64 I/O 64 I/O 64 I/O 64 I/O 64 I/O 64 I/O 64 I/O CH1 128 CH2 128 CH3 128 CH4 128 CH5 128 CH6 128 CH7 128 3D DRAM ベース・ダイ
Stratix 10 MX の主な特長 ページ 7
Stratix 10 MX の主な特長
Stratix 10 MX デバイスは、次世代のシステム設計者が直面する課題に対処するための 重要な特長を備えています。広いメモリ帯域幅
最大 4 個の HBM2 タイルと高性能 FPGA ファブリックを 1 つのパッケージに統合し た Stratix 10 MX デバイスは、メモリ帯域幅の課題に効果的に対処します。各 HBM2 タイルは、最大 256 GB/s の合計帯域幅を提供します。したがって、Stratix 10 MX デ バイスは 1 個のパッケージで最大 1 TB/s (1,024 GB/s) の合計帯域幅を提供します。こ の前例のない帯域幅により、機械学習、データ解析、画像認識、ワークロード・アク セラレーション、8K ビデオ処理、高性能コンピューティングなどのさまざまなアプ リケーションが可能になります。Stratix 10 MX デバイスは、DDR などの従来のメモ リ・ソリューションでは実現が不可能であったソリューションを可能にします。 図 9 は、400 GB/s のメモリ帯域幅をターゲットとするアプリケーションの実装を比較 したものです。ご覧のように、DDR テクノロジを使用した従来のメモリ・ソリュー ションでは実現が困難です。それに対し、Stratix 10 MX デバイスは効果的な実装と最 大 1 TB/s の最高帯域幅を実現します。 図 9:400 GB/s メモリ帯域幅の実装の比較 5 個の FPGA と 16 枚の DDR4-3200 DIMM Stratix 10 MX 縮尺不同 PCB PCB 実現が困難ページ 8 Stratix 10 MX の主な特長
低消費電力
Stratix 10 MX デバイスは、従来の DDR ソリューションに比べて低消費電力です。例
えば、128 GB/s のメモリ帯域幅を達成するには、約 5 枚の DDR4 (3,200 Mbps、4 GB)
DIMM デバイスが必要で、それぞれ約 4 W (I/O + PHY + コントローラ + メモリ) を消 費するため、合計推定消費電力は 22 W となります (30 % の 読み出し、30 % の書き込 み、シングル・ランク構成を想定)。Stratix 10 MX は、1 個のデバイスで同等のメモリ 帯域幅を約半分の消費電力で提供します。これは、I/O 消費電力の削減 (長い PCB ト レースに対し、EMIB までのトレースが短い)、データ・レートの低減、および 3D DRAM スタッキングの効率性によるものです。また、終端がないため、I/O バッファ 全体のキャパシタンスが低く、I/O 消費電流が低減します。 図 10:消費電力の削減と実装面積の縮小を示す例 ( 帯域幅 128 GB/s のアプリケーション )
実装面積の縮小、ボードの簡素化、使いやすさ
すでに述べたように、Stratix 10 MX デバイスは 1 個のパッケージで最大 1 TB/s の帯域 幅を提供するため、実装面積の大幅な縮小につながります。図 11 に、一連のメモリ 帯域幅要件における、DDR4 3,200 Mbps DIMM (133 mm x 30 mm) に対する実装面積の 推定縮小率を示します。Stratix 10 MX デバイスは、小さな実装面積で同等の帯域幅を 提供するため、平均で 1/15 の実装面積の縮小が可能です。 図 11:各種メモリ帯域幅要件における実装面積の推定縮小率1 個の FPGA と 5 枚の DDR4 DIMM 1 個の Stratix 10 MX デバイス
縮尺不同 PCB PCB
最大約 50% の消費電力削減
実装面積の 縮小 (mm2) 30 25 20 15 10 5 0 128 256 64 6X 9X 18X 400 24X アプリケーション帯域幅 (GB/s)データ・センター・アプリケーション ページ 9 この実装面積の縮小により、貴重なボード・スペースを開放します。その結果、設計 者は、より多くの機能を追加したり、システム・レベルでの性能と消費電力のトレー ドオフに関するより良い決定を行う柔軟性が得られます。DDR4 PCB 配線をなくすこ とにより、ボードの簡素化 (配線および層数の削減)、シグナル・インテグリティ/パ ワー・インテグリティの改善、および BOM/組み立てコストの削減につながります。 さらに、Stratix 10 MX ソリューションは、非常に使いやすいという特長もあります。 広帯域幅、低消費電力、およびより小さい実装面積を実現する Stratix 10 MX デバイス は、幅広いエンド・アプリケーションやエンド・マーケットに最適です。
データ・センター・アプリケーション
FPGA は、新たなデータ・タッチ/分析アプリケーションを可能にすることにより、 データ・センターに付加価値を提供します。HBM2 と高性能モノリシック FPGA ファ ブリックを組み合わせることにより、従来の DDR ソリューションと比較して、FPGA に対する DRAM 帯域幅が桁違いに拡大することに加え、消費電力も低減します。こ の組み合わせは潜在用途の拡大につながります。メモリ階層内の新たな層
専用ローカル・メモリを備えたオフロード・エンジンは、固有のワークロードを処理 することができます。ローカル・メモリにより、オフロード・エンジンは CPU の RAM アクセスに影響を与えることなく、メモリを多用するタスクを実行することが可能に なります。HBM2 DRAM は、速度と容量の観点からオフロード・エンジンに新たな能 力をもたらします。 メモリ・アクセスは、容量と速度 (帯域幅またはレイテンシ) とのトレードオフです。従来の FPGA は 2 階層のメモリを搭載しています。FPGA ファブリックには RAM ブ
ロックを搭載しており、小容量ながら広い帯域幅と高い同時並行性を提供します。 FPGA は 外部 DRAM に接続でき、それによって大幅な大容量化が可能ですが、その 引き換えに帯域幅が狭くなることに加え、レイテンシも増加します。図 12 に、HBM2 以前のデータ・センター内の FPGA を示します。 図 12:従来の FPGA データ・センター・アプリケーション Stratix 10 MX ソリューションは、帯域幅/容量のカーブに新たなポイントを実現しま す。ソリューションに HBM メモリを追加すると、FPGA メモリ階層におけるギャッ プが埋まります。 図 13:Stratix 10 MX のデータ・センター・アプリケーション CPU DRAM CPU FPGA DDR4 PCI Express メモリ容量 メ モ リ 帯域幅 エンベデッド RAM (オンチップ) 外部 RAM CPU DRAM Stratix 10 MX リ 帯域幅 エンベデッド RAM (オンチップ) 外部 RAM HBM DRAM HBM DRAM (インパッケージ)
ページ 10 データ・センター・アプリケーション
アプリケーションへの影響
この FPGA メモリのギャップに対処することで、新たなアプリケーションの可能性が 生まれます。例えば、辞書検索や、事前計算された中間フィールド検索結果の比較は、 性能レベルが格段に向上します。FPGA は、ディープ・パケット・インスペクション、 検索アクセラレーション、セキュリティなどのさまざまな分野におけるハイタッチ・ データ処理オフロード機能の構築に優れています。 HBM2 は、Stratix 10 MX デバイスの DRAM アクセス同時並行性の飛躍的向上も可能 にします。各 HBM2 インタフェースにおいて 16 チャネルをサポートしているため、1 個のパッケージで最大 64 DRAM チャネルまで拡張が可能です。これは、外部 DRAM の 4 ~ 6 チャネルに比べて大幅な増加です。アクセスの同時並行性が向上することに より、データ・センター・ソリューション (テーブル・ルックアップ・アクセラレー タなど) のスレッド数を大幅に増やすことが可能になります。 FPGA オフロードの重要な機能の 1 つとして、インメモリ・データ構造におけるデー タ抽出と比較があります。これらのアクセス・パターンの場合、帯域幅の拡大、チャ ネル数の増加 (インタフェースあたり 16 チャネル、最大 64 チャネル)、およびオープ ン・バンク数の増加 (64 バンクから 512 バンク) は、メモリ・サブシステム性能にプ ラスの影響を与えます。追加のチャネル数やバンク・プール数があれば、オープン DRAM バンク上でヒットするアクセスの数を増やすことができます。この実装では、 バンク活性化のペナルティを回避できるため、性能が向上します。データ・センター・ アプリケーションは大量のスレッドを並列処理します。そのため、この実装は非常に 有利です。さらに、オープン・バンク・アクセスにより、消費電力の多いバンク活性 化とプリチャージが必要最小限に抑えられるため、メモリ消費電力の削減も可能で す。キー・テーブルの場合、その重複によって有効なアクセス時間が減少するほど、 DRAM バンク数とポート数が多くなります。 全体的な FPGA メモリ構造では、アプリケーションをメモリ・サブシステムの固定 ハードウェアに合わせるのではなく、アプリケーションを中心にメモリ・サブシステ ムを構築できるため、固有の柔軟性が得られます。また、FPGA システム内のメモリ・ コントローラのポリシーも簡単にカスタマイズできます。 しかも、Stratix 10 MX ソリューションでは、中規模のデータ構造は HBM2 に格納し、 大規模なデータ構造は DDR DRAM に格納することも可能です。これは、Stratix 10 MX デバイスで構築できるスケーラブルなメモリ・サブシステムならではの能力です。アプリケーションのまとめ
Statix 10 MX デバイスは、従来の DRAM ソリューションに比べて広い帯域幅、高いア クセス同時並行性、およびより多くのオープン・バンク・アクセスを実現します。こ れらの特長により、アクセラレータ・ソリューションにおける中規模テーブル用 DRAM メモリ・サブシステムの構築に最適です。さらに、設計者は統合 HBM DRAM とブロック RAM および DDR DRAM と組み合わせて、包括的なメモリ・ソリューショ ンを構築することが可能です。ストリーミング・サイバー・セキュリティ解析のアルゴリズム・アクセラレーション ページ 11
ストリーミング・サイバー・セキュリティ解析のアルゴリズム・
アクセラレーション
高いデータ・レート (10 GbE 超) のストリーミング・サイバー・セキュリティ解析ア プリケーションの場合、FPGA を使用してアルゴリズムを高速化することは、高ス ループットのローカル・メモリが十分にないため困難です。現在のアーキテクチャで は、大容量 DDR3/4 メモリを使用して疑わしいデータをストアします。DDR3/4 メモ リへの高コストの読み出し/書き込み、限られたメモリ・サイズおよびメモリ帯域幅 のため、オンチップのデータとの協調は容易ではなく、しかもオフチップのデータに 効率よくアクセスすることは極めて困難です。 Stratix 10 MX デバイスは、広いオンチップ帯域幅による複数の高データ・レート・ス トリーム間の調整に加え、比較的大容量のオンチップ・ストレージが可能なため、ス トリーミング・サイバー・セキュリティ解析に不可欠なニーズに応えます。レイテン シの短縮により、複数の 100/400/1,000 GbE ストリームを検索し、比較的小型の計算 ノード内でそれらを調整することが可能です。Stratix 10 MX デバイスは、各 FPGA が 優れたストレージとオンチップ帯域幅を備えているため、各計算ノードの FPGA 数を 削減します。 多くの高データ・レート・ストリーミング・アプリケーションでは、データ移動の維 持がますます大きな問題となっています。例えば、現在のアプリケーションはセキュ リティ解析を実行する際、データ・ストリームを複数の CPU または FPGA にファン アウトしなければならず、複雑な外部ファブリックやチップ間タイミングからレイテ ンシが生じます。この複雑なアーキテクチャで少量のデータをオフチップにストアし なければならない場合、このオフチップ・メモリへのアクセスは、レイテンシの増加、 追加 DRAM による消費電力増加、演算装置の追加、および単位面積あたりの性能低 下という理由から高コストです。このデータ移動レートの低下は、システム・アーキ テクチャに全体的なデータ帯域幅の減少をもたらし、低速なメモリの補償を強いるこ とになります。 図 14 に、336 GB/s の推定メモリ帯域幅を持つ 128 GB の DDR4-2666 メモリを備えた 4 個の FPGA を示します。図 15 は、1,024 GB/s の帯域幅を持ち、図 14 に比べて消費 電力が約 20 % 低く、PCB の面積が 20 % 小さい Stratix 10 MX デバイスです。消費電 力バジェットおよび PCB フロアプランが同じ場合、Stratix 10 MX デバイスであれば 同じサブシステムに 4 個を実装できることになります。完全なメッシュ型のサブシス テムは、搭載されたトランシーバを利用して、従来は多数のラックを必要としたはず である多くの 1 TB/s イーサネットまたは Infiniband ストリームを処理することが可能 です。メッシュの大規模化は演算装置間のレイテンシ短縮につながり、より大規模な データベースの構築が可能になります。 図 14 の場合、完全なメッシュ型の FPGA に伴う、異なる DDR4 DIMM 間の相関デー タ・レイテンシは、たとえ適切に設計されたシステムでも無視できないレベルに達し ます。紫色の線はシステム・アーキテクトのワースト・ケース・レイテンシで、数ミ リ秒の遅延が発生します。 さらに、図 14 では、アプリケーションがデータベースのアップストリーム・フィー ドバックまたはダウンストリーム転送を実行する必要がある場合、16 枚の DDR4 DIMM をコヒーレントに組み合わせることは、Stratix 10 MX の例に比べてはるかに困 難です。従来の手法では、データベースのコピーを複数維持してレイテンシを短縮し ますが、アップストリームまたはダウンストリーム・データの送信前にコヒーレンシ を維持するためのデータベース管理が必要です。Stratix 10 MX によるデザインはコページ 12 まとめ 図 14:ストリーミング・サイバー・セキュリティ解析における従来の FPGA パーティショニング 図 15:Stratix 10 MX デバイスによる改善されたアーキテクチャ
まとめ
メモリ帯域幅は、次世代システムの要件に対応するために、急増することが予測され ています。さまざまなエンド・マーケットやアプリケーション (データ・センター、 高性能コンピューティング (HPC)、放送、データ解析、ワイヤライン・ネットワーキ ング) がメモリ帯域幅要件の増大要因となります。これらの次世代システムは、最高 レベルのメモリ帯域幅、低消費電力、より小さい実装面積を必要とします。 DDR3、DDR4、QDR、RLDRAM などの従来のメモリ・システムは、こうしたメモリ 帯域幅の急激な増加傾向への対応に苦しんでいます。これらの従来のソリューション では、さらなる広帯域幅、低消費電力、および実装面積の縮小という重要な要件を同 時に満たすことはできません。それに対し、3D スタッキング技術を利用した新たな メモリ・テクノロジは、この帯域幅要件を満たすことが可能です。アルテラが完全に サポートするそうしたテクノロジには、シリアル・メモリ・ソリューション (HMC) とパラレル・メモリ・ソリューション (HBM2) があります。 Stratix 10 MX デバイスは、インテルの特許済み EMIB テクノロジを使用して、HBM2 と高性能モノリシック FPGA ファブリックを 1 つのパッケージに効率よく統合した 新しいタイプの製品です。Stratix 10 MX デバイスは、1 つのパッケージで最大 1 TB/s の合計メモリ帯域幅を提供します。Stratix 10 MX ソリューションは、帯域幅が極めて 重要である高性能システムの要求を満たすために設計されており、従来のソリュー ションと比較して約 10 倍のメモリ帯域幅を可能にしつつ、消費電力と実装面積の削 減を同時に実現します。 FPGA FPGA FPGA FPGA 4 DDR4 DIMM 4 DDR4 DIMM 4 DDR4 DIMM 4 DDR4 DIMM 4 (21 GB/s) 4 (21 GB/s) 4 (21 GB/s) 4 (21 GB/s) 複数の 10、40、100 GbE 追加の処理 現在のストリーミング・アプリケーション ■ 総メモリ帯域幅 = 16 x 21 GB/s = 336 GB/s ■ 複雑な SERDES (Serializer/Deserializer) メッシュ・デザイン ■ 16 枚の DIMM にわたる複雑なデータベース分割 ■ 強制的なデータ・パーティショニング GA FPG 複数の 10、40、100 GbE 追加の処理 新たなストリーミング・アプリケーション ■ 総メモリ帯域幅 = 1 TB/s ■ 3 倍のメモリ帯域幅 ■ デザインの簡素化 ■ 統一されたデータベース ■ データ移動を維持 従来の手法に比べて大幅に広帯域幅、 低消費電力、および少ない実装面積を実現参考文献 ページ 13