首都大学東京 令和元年度 修士論文
SNSを用いた
観光地周辺の迷いやすい場所の発見
首都大学東京大学院
システムデザイン研究科 システムデザイン専攻 情報科学域
学修番号:18860606 氏名:鈴木 亮平
指導教員:石川 博 教授
令和2年2月21日
i
論文要旨
近年,観光地や慣れていない土地へ訪問した時の徒歩移動において,Google Mapsをはじめ としたスマートフォンなどの地図アプリの利用及び,地図アプリの経路探索機能を用いて目的 地まで移動するのが一般的である.しかし,近距離にある複数の場所を巡る場合やわかりやす いランドマークがある場合などでは,観光案内板や観光パンフレットに載っている周辺地図の 使用や,目的地の方向を確z認して進むなど,地図アプリを使用せずに感覚を頼りに移動をす る場合も多くみられる.どちらの場合でも慣れてない土地においては,地図に対して進行方向 がわからなくなる,現在地の認識がずれるなどの理由から,曲がる交差点を間違える,向かう 方向を間違えるなど,道に迷い,想定よりも到着に時間がかかるといった状況に陥ることがあ る.地図アプリにおいては現在地や向いている方向を表示する機能が搭載されているものもあ るが,精度が通信状況に左右されるなど,これらの状況にならないとは言い切れない.
スマートフォンやタブレット端末の普及により,マイクロブログなどのソーシャルメディ アが普及し,利用者が著しく増加している.観光地を訪れた多くのユーザーは,その場の雰囲 気や感想,実際の体験などを共有する投稿をしている.
マイクロブログのひとつであるTwitterでは,投稿一つにつき140字までという字数制限がつ いており,時間や場所を問わず,気軽に投稿することができるという特徴がある.ツイートに は緯度経度情報から所在地を取得できるジオタグと呼ばれるデータを付与することができる.
したがって,Twitter上にはユーザーの体験由来の地域特有の情報が蓄積されていると捉える ことができる.これらの情報は人々の意見や感情を直感的に,かつリアルタイムに反映して いる.
データ量が膨大にある一方で,データとして整形がされておらず,使用用途にあわせて データを整形し,情報を抽出する必要がある.そこで,Twitterに限らず,マイクロブログにお いて位置情報が付与された投稿を用いて,観光情報を抽出する研究が盛んに行われている.
本論文では,「道に迷う」はユーザーのその地域における体験であると仮定し,位置情報付きツ イートから道に迷っている時にツイートされたと考えられるツイート(以下,迷子ツイート)を 教師あり機械学習を用いて抽出する.「道に迷う」をより多くのユーザーが体験している場所
論文要旨 ii は地域特有の性質として迷いやすい場所であると考えることができる.そこで,抽出した迷子 ツイートの分布から迷いやすいスポットを発見する.迷いやすいスポットを発見することによ り,案内図の作成や経路推薦を行う際に,よりユーザーが迷いにくい情報の提供に貢献する.
本論文の構成は次の通りである.
1章では,研究背景および本研究の目的を述べる.
2章では,関連研究として,観光分野に限らない,マイクロブログに投稿されたデータか ら有益な情報を抽出する研究や観光分野において行動パターンを抽出し,観光ルートや経路の 推薦に利用される研究,地域の情報を抽出する研究について述べ,本論文の位置付けを明らか にする.
3章では,迷いやすいスポット発見のための提案手法について述べる.はじめに,Twitter ユーザーの投稿した位置情報付きツイートの投稿内容に基づいた特等ベクトルをWord2Vecを 用いて作成する手順について述べる.次に,作成した特徴ベクトルと機械学習手法を用いて,
迷子ツイートの抽出方法について述べる.本論文では,迷子ツイートに含まれている可能性が 高い単語または単語の組み合わせを人手で決定し,教師あり機械学習を用いて抽出した単語ご とに分類器を作成し,迷子ツイートを抽出する.続いて,地図をグリッドで区切り,グリッド で区切られたメッシュ内の迷子ツイート数に応じて色分け,可視化手順を述べる.
4章では,提案手法に基づいた実験と結果を示す.実際のデータを用いて提案手法をもと に迷子ツイートを抽出し,迷子ツイートの投稿場所をもとに迷いやすいスポットを可視化す る.本論文では,Twitterの位置情報付きツイートを収集し,その中から迷子ツイートを人手で 抽出し,学習データおよびテストデータとした.また,教師あり機械学習手法としてSupport Vector Machine,Random Forestの2手法を用い,それぞれで精度の高い分類器を利用した.
続いて,抽出した迷子ツイートを元に地図上に可視化を行った.
5章では,4章の実験結果の可視化結果を元に観光地周辺の迷いやすいスポットの特徴につい て考察する.
6章では,本論文のまとめと今後の展望について述べる.
iii
目次
論文要旨 i
第1章 はじめに 1
第2章 関連研究 4
2.1 マイクロブログの情報抽出に関する研究. . . . 4
2.2 地域の情報の抽出に関する研究 . . . . 4
2.3 ユーザーの行動分析に関する研究 . . . . 5
第3章 提案手法 6 3.1 提案手法 . . . . 6
3.2 投稿内容に基づいた特徴ベクトルの作成. . . . 6
3.3 迷子ツイートの抽出 . . . . 7
3.4 迷いやすいスポットの可視化 . . . . 7
第4章 実験 8 4.1 データセット . . . . 8
4.2 実装. . . . 8
4.3 迷子ツイートの抽出 . . . . 9
4.4 地図上に可視化 . . . . 10
第5章 考察 11 第6章 まとめと今後の課題 14 6.1 まとめ . . . . 14
6.2 今後の課題 . . . . 14
謝辞 16
目次 iv
参考文献 17
発表論文 19
1
第 1 章
はじめに
近年,観光地や慣れていない土地へ訪問した時の徒歩移動において,Google Maps*1をはじ めとした地図アプリの利用及び,地図アプリの経路探索機能を用いて目的地まで移動する場合 が増えている*2.株式会社ゼンリン*3の2018年に行った地図利用実態調査*4では,移動の際に スマートフォンの地図アプリまたは地図アプリのスクリーンショットを利用していると答えた ユーザーが75.3%となっている.しかし,上記のアンケートの結果から地図アプリを使用して いないユーザーも一定数いると考えられる.
普段スマートフォンの地図アプリを利用しないユーザーに限らず,近距離にある複数の場 所を巡る場合やわかりやすいランドマークがある場合などでは,観光案内板や観光パンフレッ トに載っている周辺地図の使用や,目的地の方向を確認して進むなど,地図アプリを使用せず に感覚を頼りに移動をする場合も多くみられる.観光地の雰囲気を味わいたいなどといった理 由からあえて地図を使わず景色を頼りに移動する観光客も存在する.
上記のどれらの場合にとっても,地図に対して進行方向がわからなくなる,現在地の認識 がずれるなどの理由から,道に迷う,想定よりも到着に時間がかかるといった状況に陥ること がある.地図アプリにおいては現在地や向いている方向を表示する機能が搭載されているもの もあるが,精度が通信状況に左右されるなど,これらの状況にならないとは言い切れない.実 際に,株式会社ゼンリンが2016年に行った地図利用実態調査内の迷子実態調査*5では,82.9% の人が大人になってから道に迷った経験があると回答している.
道に迷ってしまうという体験は,観光においてマイナスの印象を残してしまったり,その
*1https://www.google.com/maps/
*2総 務 省 情 報 通 信 政 策 研 究 所「 位 置 情 報 の 利 用 に 対 す る 意 識 調 査 」(2014 年) https://www.soumu.go.jp/iicp/chousakenkyu/data/research/survey/telecom/2014/location- info.pdf
*3https://www.zenrin.co.jp/index.html
*4https://www.zenrin.co.jp/product/article/map-18/index.html
*5https://www.zenrin.co.jp/product/article/map-16/index.html
第1章 はじめに 2 あとの行程が崩れてしまうなど好ましくない影響を与える場合が大半である.このような体験 をせず,スムーズな観光地訪問を可能とするために,ホームページやパンフレットなどで道に 迷わないように情報が提供されている.しかしながら,それらの情報も十分でない場合も多 く,訪問者にとってわかりやすく,最適な情報を提供することが求められている.
また,スマートフォンやタブレット端末の普及により,マイクロブログなどのソーシャルメ ディアが普及し,観光地を訪れた多くのユーザーは,その場の雰囲気や感想,実際の体験など を共有する投稿をしている.マイクロブログのひとつであるTwitter*6では,投稿一つにつき 140字までという字数制限がついており,時間や場所を問わず,気軽に投稿することができる という特徴がある.また,ツイートには緯度経度情報から所在地を取得できるジオタグと呼ば れるデータを付与することができる.ユーザーは,観光地などを訪問した事実や体験した内容 をその場で投稿する機会が多い.したがって,Twitter上にはユーザーの体験由来の地域特有 の情報が蓄積されていると捉えることができる.しかし,データ量が膨大にある一方で,デー タとして整形がされておらず,使用用途にあわせてデータを整形し,情報を抽出する必要があ る.そこで,Twitterに限らず,マイクロブログにおいて位置情報が付与された投稿を用いて,
観光情報を抽出する研究が盛んに行われている.
本研究では,「道に迷う」はユーザーのその地域における体験であると仮定する.より多く のユーザーが「道に迷う」体験を受けている地域は,地域の特徴として道が複雑,ランドマー クがない,似たような施設を混同してしまうなど,道に迷いやすい原因が存在している場所で あると考えることができる.
そこで本論文では,位置情報付きツイートから道に迷った時に呟く可能性が高い単語を人手 で決定し,ツイートを抽出する.その中から道に迷っている時にツイートされたと考えられる ツイート(以下,迷子ツイート)を教師あり機械学習を用いて抽出する.抽出した迷子ツイート の分布から迷いやすいスポットを発見する.迷いやすいスポットを発見することにより,案内 図の作成や経路推薦を行う際に,よりユーザーが迷いにくい情報の提供に貢献する.
本論文の構成は次の通りである.2章では,関連研究について述べる.3章では,迷子スポッ ト発見のための提案手法として,ユーザーの投稿した位置情報付きツイートの投稿内容に基づ いた特徴ベクトルを作成し,作成した特徴ベクトルと機械学習手法を用いて, 迷子ツイート の抽出方法について述べる.4章では,提案手法に基づきTwitterの位置情報付きツイートの投 稿文から特徴ベクトルを作成し,分類器を作成する.分類器を用いて迷子ツイートを抽出して メッシュごとに集計,地図上に可視化を行う,5章では,実験によって得られた結果から観光 地周辺の迷いやすいスポットの考察を行う.周辺の交通アクセスや施設の状況から迷いやすい
*6https://twitter.com/
第1章 はじめに 3 原因を考察する.6章では,本研究のまとめと今後の展望を述べる.
4
第 2 章
関連研究
本章では,関連研究について述べる.観光分野に限らず,マイクロブログに投稿されたデー タから有益な情報を抽出する研究[1, 2, 3, 4, 5] が盛んに行われている.観光分野においては,
行動パターンを抽出し,観光ルートや経路の推薦に利用する研究や,地域の情報を抽出する研 究が行われている.
2.1 マイクロブログの情報抽出に関する研究
亘理ら[1]は,電車の混雑具合に関する情報を含んでいるツイートを抽出することを目的とし て,“混雑”,“混む”などの混雑ワードや“比較的”,“予想以上”などの比較ワードと駅名から なる駅名ワードを定義し,混雑表現辞書を作成,混雑ワードや比較ワードの自動抽出手法を提 案している.従来研究が位置情報を元に混雑状況のリアルタイム取得を目標しているのに対し て,本研究では,抽出した位置情報付きツイートを場所ごとに集計・可視化することによって 地域属性の取得を目標にしている.
三浦ら[2]は,ユーザーの属性に起因する訪問地の違いに着目して,位置情報付きツイートか らユーザーごとの特徴量を作成し,属性を推定,実際にユーザーの男女の推定を行い,場所に よってツイートの投稿者に男女の割合に違いが出ることをあげている.
2.2 地域の情報の抽出に関する研究
長谷川ら[6]は,Twitter上に投稿されたコンテンツの中から, 地域の特徴を表す特徴語を抽
出し,地域特徴語辞書を構築する手法および,構築された地域特徴語辞書を利用してTwitter からユーザーの観光体験を検索する手法を提案している.本研究では,迷子体験に限定し,汎 用的な単語辞書を用いて迷いやすい特徴をもつ地域の発見を提案する.
高木ら[7]はランドマークを目印とした経路推薦システムにおいて,ランドマークを視認性だ
第2章 関連研究 5 けでなく,位置ベースソーシャルメディアであるFoursquareの情報を用いて話題性をもとに抽 出する手法を提案している.ユーザーの移動において有益な情報を抽出するという点で共通し ているが,本研究では,地理的情報ではなく,ユーザーの体験をもとに抽出する.
堂前ら[8]は,ツイートの中のトピックには,地域に偏りがあるものと共通で現れるものが あるという仮定のもと,文章の確率的な生成モデルであるLDA(Latent Dirichlet Allocation) から得たトピックを利用し,Twitterユーザの生活に関わる地域を推定している. 本研究でも,
ツイート中のトピックに地域の特性が現れるとして,メッシュごとに可視化することで迷子ス ポットの発見に取り組む.
2.3 ユーザーの行動分析に関する研究
新井ら[9]は,観光スポットでの観光客のツイートを収集し,てがかり語や品詞の特徴から 観光ツイートを“食事”,“景観”,“行動”,“土産”に分類し,観光ツイートの時間帯分布,観光 ルート内における観光スポットの共起頻度から,観光ルート推薦手法を提案している.投稿内 容からツイート内容を推定している点が共通しているが,本研究では,従来研究においてのて がかり語となる,迷子の時につぶやかられる可能性の高い単語を含むツイートを抽出し,教師 あり機械学習で分類することにより迷子ツイートの高精度での抽出を提案する.
6
第 3 章
提案手法
3.1 提案手法
本章では,Twitterユーザーの投稿した位置情報付きツイートの投稿内容を元に,迷子ツイー トを抽出し,迷いやすいスポットを発見するための提案酒保について述べる.
はじめに提案手法の大まかな流れを説明する.
1. 投稿内容に基づいた特徴ベクトルの作成 2. 特徴ベクトルの作成.
3. 迷子ツイートの抽出. 4. 迷いやすいスポット可視化
本研究では,迷子ツイートが一定数呟かれているエリアを迷いやすいスポットとした.
3.2 投稿内容に基づいた特徴ベクトルの作成
3.2.1 前処理
本節では,特徴ベクトル作成の前処理について述べる.はじめに,本研究で使用する位置情 報付きツイートのうち,InstagramやFoursquareなど他のソーシャルメディアと連携している ツイート及びリプライ,リツイートを除去する.次に,投稿内容から,URL部分や記号,絵文 字を取り除く.
3.2.2 特徴ベクトルの作成
本節では,位置情報付きツイートの投稿内容を用いて特徴ベクトルを作成する方法について 述べる.
はじめに,形態素解析を行い単語を分割し,基本型に直す処理を行う.その後,品詞判定を
第3章 提案手法 7
図3.1 迷子ツイート抽出の流れ
行う.ユーザーの発信している情報を適切に特徴ベクトル化するため,名詞,動詞,形容詞及 び助動詞と判定された単語を抽出する.続いて,抽出した各単語に対してWord2Vec [10]を用 いて単語ベクトルを作成する.ツイート内の各単語ベクトルの和を,そのツイートの特徴ベク トルとする.
3.3 迷子ツイートの抽出
本節では,3.2.2節で作成したツイートごとの特徴ベクトルを用いて教師あり機械学習で迷子 ツイートを抽出する方法について述べる.
図3.1に流れを示す.はじめに,迷子ツイートに含まれている可能性が高い単語または単語の 組み合わせを人手で決定する.迷子ツイートに含まれる可能性が高い単語とは“迷う”や“迷子” など,単語の組み合わせは「“道”と“わかる”と“ない”」や「“ここ”と“どこ”」などの一般的に 道に迷っている時に呟くと考えられる単語である.“わかる”,“ない”に関しては“わからない”
が3.2.2節の処理により分割,基本型になっていることを想定している.次に,教師あり機械学
習を用いて,抽出した単語ごとに分類器を作成し,迷子ツイートを抽出する.本研究では,教 師あり機械学習手法として,Support Vector Machine (SVM)とRandom Forestを用いた.各 分類器において,グリッドサーチを行い各パラメータを決定した.また,Stratified K-Fold法 により,交差検証を行い,F値の平均を推定精度とした.
3.4 迷いやすいスポットの可視化
本節では,迷子ツイートの地図上への可視化方法について述べる.
ユーザーがどのような場所で迷子ツイートを投稿しているかを可視化するため,地図を一定 距離ごとのグリッドで区切り,グリッドで区切られたメッシュ内で投稿されている迷子ツイー トの数に応じてメッシュを色分けする.
8
第 4 章
実験
本章では,実際にTwitterから収集したツイートを用いて,3.1章で提案した手法により迷子 ツイートを抽出,迷子スポットを可視化する.
4.1 データセット
本節では,本研究で用いたデータセットについて述べる.2016年1月1日から2018年12月31 日の3年間の間に投稿された位置情報付きツイートをランダムに収集した.3.2.1節の処理の結 果,15,298,856件が収集できた.
4.2 実装
3.2.2節の形態素解析及び品詞判定にはMecab*1を用いた.Mecabの辞書データには新語・固
有語表現に強く,語彙数も多いmecab-ipadic-NEologd[11]
Word2Vecの実装にはPythonのライブラリであるgensim*2を用い,事前学習にはWikipedia 日本語版*3のデータを用いて事前学習しているjapanese-word2vec-model-builder*4にて公開 されているデータを使用した.
SVMおよびRandom Forestの実装にはscikit-learn[12]のSVC,Random Forestを使用した.
*1http://taku910.github.io/mecab/
*2urlhttps://radimrehurek.com/gensim/
*3https://ja.wikipedia.org/wiki/
*4https://github.com/shiroyagicorp/japanese-word2vec-model-builder Copyright (c) 2013-2017 Shiroyagi Corporation. https://shiroyagi.co.jp
第4章 実験 9
表4.1 分類器性能
機械学習手法 条件1 条件2 正答率 0.859 0.750
SVM F値 0.857 0.769
Random 正答率 0.846 0.541 Forest F値 0.838 0.521
4.3 迷子ツイートの抽出
4.3.1 分類器作成
本節では,3.3節にもとづく迷子ツイートの抽出結果について述べる.本論文では,迷子ツ イートに含まれている可能性が高い単語または単語の組み合わせとして「“迷う”または“迷 子”」を含むツイートを条件1,「“道”と“わかる”と“ない”」を含むツイートを条件2としての2 通りで迷子ツイートの抽出を行なった.
教師データとして,条件1では正解不正解ツイートを各300件,条件2では正解不正解ツイー トを各150件抽出し,これらの特徴ベクトルを特徴量として,機械学習に入力した.また,K
= 5と設定して,正解不正解のラベルのツイート数が等しくなるようにデータを5分割し,1つ をテストデータ,残りの4つを教師データとして,交差検証を行なった.
4.3.2 分類・抽出結果
SVM, Random Forestで分類を行った結果を表4.1に示す.正答率とF値は,Stratified K- Foldを用いて交差検証を行った結果を平均した値を示している.
分類を行った結果,条件1では正答率とF値が,SVMにおいて,それぞれ0.859,0.838とな り,Random Forestにおいて,それぞれ0.846, 0.838となった.条件2では,SVMにおいて,そ れぞれ0.750,0.769,となり,Random Forestにおいて,それぞれ0.541,0.521となった.条 件1ではわずかではあるが,条件1,条件2双方において,Random ForestよりもSVMが正答率,
F値共に高く,分類性能が高いと考えられるため,迷子ツイートの抽出にはSVMの分類器を用 いた.条件1と比べて,条件2の分類性能が低くなってしまっているのは,“道”が“迷う”や“迷 子”と比べてより一般的に使われる語であること,教師データが少ないことが原因と考えられ る.作成した分類器を用いて抽出を行なった結果,迷子ツイートと思われるツイートが84,192 件抽出された.
第4章 実験 10
表4.2 色分けされたグリッド数 投稿数(件) メッシュ数 メッシュの色
1〜2 2,797 白
3〜4 59 橙
5〜9 48 緑
10以上 22 赤
4.4 地図上に可視化
本節では,3.4 に基づいて地図を一定距離四方のグリッドに区切り,メッシュ内での投稿さ れた迷子ツイートの数に応じて色分けを行なった.今回は抽出した迷子ツイートのうち5,000 件をサンプリングし,グリッドを250m間隔とした.色分けされたメッシュ数および,色の内 訳を表4.2に示す.本論文では,メッシュ内に迷子ツイートが確認できたもののうち,迷子ツ イート件数が1〜2件のものを白,3〜4件のものを橙,5〜9件のものを緑,10件以上のものを赤 で色分けを行なった.
11
第 5 章
考察
本章では,4.4節の結果をもとに,各地域の迷子ツイートが多かったスポットについて考察を 行う.
迷子ツイートの投稿数に応じて地図上に色分けしたものを,図5.1,図5.2,図5.3に示す.
まず,図5.1の東京タワーを含むAで囲んだメッシュに注目する.東京タワー周辺の鉄道の路 線および駅名,駅から東京タワーまでの所要時間を表5.1に示す.JRや地下鉄の駅が複数存在 しており,東京タワーへの道順だけでなく,他の駅への道順の表示案内により迷いやすくなっ ていることが考えられる.また,東京タワー下にはアミューズメント施設などが併設されてお り,展望台や施設などの屋内での移動において迷子ツイートが投稿されている可能性が考えら れる.
次にBで囲んだメッシュに注目する.このメッシュは六本木ヒルズを含むメッシュとなって いる.六本木ヒルズは森美術館など観光目的で訪れるスポットも含むが,有数のオフィス街で もあり,ビジネス目的の来訪者も多く,迷子スポットである可能性は考えられるが,観光目的 の訪問者にとって迷いやすい場所であるかはさらなる検証が必要である.
続いて,Cで囲んだ銀座周辺のメッシュ群に注目する.二つのメッシュにまたがって迷子ツ イートを確認できる.メッシュ内および近辺は,直結していない地下鉄駅が複数存在するエリ アである.地下鉄の乗り換えや,目的地へ向かう際に,複数存在する出口を間違える,自分の 利用した駅を他の地下鉄の駅と間違えるなど,複数の迷う理由が推測できる.六本木ヒルズと 同じく,観光目的の訪問者にとって迷いやすい場所であるかはさらなる検証が必要である.
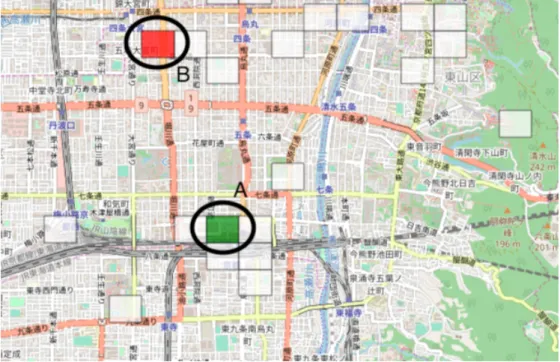
次に,図5.2の京都駅を含むAで囲んだメッシュに注目する.メッシュ内はほぼ京都駅構内と なっており,施設内部での迷子であることが推測される.京都駅構内は構造が複雑であること が知られており,観光客にとって迷いやすい場所である可能性が高い.
続いて,Bで囲んだメッシュに注目する.メッシュ内には駅や名が知られている観光地は確 認できない.この場所はあくまで経由地点であると考えられ,さらなる検証が必要であるが,
第5章 考察 12
表5.1 東京タワー周辺の駅および所要時間 路線 駅名 所要時間(分) 大江戸線 赤羽橋 5 日比谷線 神谷町 7 三田線 御成門 6 浅草線 大門 10
JR 浜松町 15
図5.1 東京タワー周辺の迷子ツイート投稿数により色分けを行なった可視化結果
なんらかの要因が存在しており,迷いやすい場所だと考えることができる.
図5.3のUSJを含むAで囲んだメッシュに注目する.赤い部分はUSJ内部となっており,アト ラクションの場所がわからないなど迷っている可能性も考えられるが,混雑に起因する同伴者 とはぐれた場合の迷子を多く含んでいる可能性が高い.右上の緑のメッシュについても,駅か らUSJまでのルートを含んでおり,ほぼ一本道であることからUSJに向かおうとしている最中 に迷っているとは考えにくい,しかし,周辺施設は入り組んでおり,迷いやすいスポットであ る可能性があり,さらなる検証が必要である.
第5章 考察 13
図5.2 京都駅周辺の迷子ツイート投稿数により色分けを行なった可視化結果
図5.3 USJ周辺の迷子ツイート投稿数により色分けを行なった可視化結果
14
第 6 章
まとめと今後の課題
6.1 まとめ
本研究では,ソーシャルメディアであるTwitterから取得した膨大な位置情報付きツイートか ら,教師あり機械学習を用いて迷子の時に投稿したと思われる迷子ツイートを抽出し,道に迷 いやすいスポットを発見する手法を提案した.位置情報付きツイートの投稿文からWord2Vec を用いて特徴ベクトルを作成した.迷子ツイートに含まれる可能性の高い単語を人手で決定 し,作成した特徴ベクトルを元に迷子ツイートを単語を含むツイートの中から抽出する分類器 を教師あり機械学習手法であるSupport Vector Machine (SVM)とRandom Forestを用いて 実装した.本論文の実験においては各条件においてSVMの正答率およびF値がRandom Forest を上回ったため,迷子ツイートの抽出においてはSVMで作成した分類器を使用した.次に,地 図を250m間隔のグリッドで区切り,メッシュ内の迷子ツイートの投稿数を算出し,投稿数が多 い場所を可視化した.その結果,東京タワーおよび六本木ヒルズ周辺,京都駅周辺,USJ周辺 において,迷子ツイートの多い迷いやすいスポットがあることを発見した.この迷いやすいス ポットの情報は,迷いにくい経路案内や,迷いやすい原因の特定への一助となる可能性がある.
6.2 今後の課題
本章では,行った実験に関して今後の課題を説明する.メッシュ内の迷子ツイートの投稿数 によって迷いやすいスポットの可視化を行ったが,総投稿数の多いメッシュは迷子になりやす いかどうかに関わらず,一定数の迷子ツイートが抽出されてしまう点がある.迷子ツイートの 数だけでなく,総ツイートにおける迷子ツイートの割合を考慮してメッシュの分類,色分けを 行い,分析する必要があると考える. 本論文では日本語のツイートのみを対象としており,
形態素解析および品詞判定の段階で日本語以外のツイートを除外した.しかし,外国語ツイー トを対象とすることで訪日外国人にとっての迷いやすいスポットを発見できる可能性がある.
第6章 まとめと今後の課題 15 具体的には対象とする言語に対してWord2Vecの事前学習を行い特徴ベクトルを作成する.そ の言語において迷子ツイートに含まれる可能性の高い単語を決定し,分類器を作成する. ま た,迷いやすいスポットでの迷う原因の特定へのアプローチが課題としてあげられる.例とし て,周辺の観光地への移動中に迷っているのか,周遊行動中に迷っているかなどである.具体 的には,迷子ツイートを投稿したユーザーを抽出し,前後の位置情報付きツイートを用いて経 路を推定するなどがあげられる.ソーシャルメディアの位置情報を用いた経路軌跡の抽出に関
する研究[13, 14, 15]は盛んに行われている.また,発見した迷子スポットを考慮した経路推薦
システムの構築などがあげられる.
16
謝辞
本論文の執筆では,多くの方からのご支援とご協力をいただきました.本研究を進めるにあ たり,指導教員である,首都大学東京システムデザイン学部 石川博教授には,貴重な時間を割 いて,時に厳しく時に優しく様々なご指導を頂きました.また,本論文の主査を務めて下さい ました.心から感謝いたします.
本論文の副査となっていただくことを快く承諾していただき,副査を務めてくださいまし た,首都大学東京システムデザイン学部 片山薫准教授,同 横山昌平准教授に心から感謝いた します.
本研究を進めるにあたり,様々な面で議論し,支えていただいた群馬大学理工学部 荒木徹也 特任助教,岡山理科大学総合情報学部情報科学科 廣田雅春講師に心から感謝いたします.ゼミ などを通じて,有益な議論やご指摘を多数いただきました首都大学東京システムデザイン学部 石川研究室の皆様,および友人・知人の皆様に心から感謝いたします.
皆様のお力添えがあり,ここに修士論文を完成させることができたことに深く感謝いたし ます.
令和2年2月21日
17
参考文献
[1] 亘理湧,豊田哲也,大原剛三. 鉄道の混雑検出センサとして機能するtwitterユーザの推定. 第79 回全国大会講演論文集, 2017.
[2] 三浦理緒,廣田雅春,加藤大受,荒木徹也,遠藤雅樹,石川博. マイクロブログのジオタグを 用いた訪問地の違いに着目したユーザ性別推定手法の提案. 第10回データ工学と情報マネ ジメントに関するフォーラム, 2018.
[3] 古賀裕之, 谷口忠大. 潜在トピックに着目したtwitter 上のユーザ推薦システムの構築. ヒューマンインタフェースシンポジウム, pp. 867–872, 2010.
[4] 落合涼, 伊與田光宏. 投稿場所に着目したソーシャルメディア上の情報拡散の分析. 第80 回全国大会講演論文集, 2018.
[5] Tatsuya Fujisaka, Ryong Lee, and Kazutoshi Sumiya. Discovery of user behavior pat- terns from geo-tagged micro-blogs. InProceedings of the 4th International Conference on Uniquitous Information Management and Communication. ACM, 2010.
[6] 長谷川馨亮,馬強,吉川正俊. Twitterからの地域特徴語辞書の構築とその観光情報検索へ の応用. 第6回データ工学と情報マネジメントに関するフォーラム, 2014.
[7] 森永寛紀,若宮翔子,谷山友規,赤木康宏,小野智司,河合由起子,川崎洋. 点と線と面のラ ンドマークによる道に迷いにくいナビゲーション・システムとその評価. 情報処理学会論 文誌, Vol. 57, No. 4, pp. 1227–1238, 2016.
[8] 堂前友貴,関洋平. 地域に偏りのあるトピックを用いたtwitterユーザの生活に関わる地域 推定. 研究報告データベースシステム(DBS), 2013.
[9] 新井晃平,新妻弘崇, 太田学. Twitter を利用した観光ルート推薦の一手法. 第7回データ 工学と情報マネジメントに関するフォーラム, 2015.
[10] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems 26, pp. 3111–3119, 2013.
[11] 佐藤敏紀,橋本泰一, 奥村学. 単語分かち書き用辞書生成システムneologdの運用-文書分
参考文献 18 類を例にして. 研究報告自然言語処理(NL), 2016.
[12] Fabian Pedregosa, Ga¨el Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, and Vincent Dubourg. Scikit-learn: Machine learning in python. Journal of machine learning research, Vol. 12, No. 10, pp. 2825–2830, 2011.
[13] Jing Yuan, Yu Zheng, and Xing Xie. Discovering regions of different functions in a city using human mobility and pois. In Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 186–194. ACM, 2012.
[14] Mirco Nanni and Dino Pedreschi. Time-focused clustering of trajectories of moving objects.Journal of Intelligent Information Systems, Vol. 27, No. 3, pp. 267–289, 2006.
[15] 倉田陽平. 大量写真データをもとにした観光地内の主要観光ルート網の自動抽出に向けて. 観光情報学会第8 回研究発表会, pp. 49–52, 2013.
19
発表論文
国内研究会
1. 鈴木 亮平,廣田 雅春, 荒木 徹也, 遠藤 雅樹,石川 博 : 位置情報付きツイートを用いた 観光地周辺の迷いやすいスポットの発見,データベースシステム研究会(2019.9)