TSUBAME3.0 利用の手引き
第 22 版
i
目次
1. TSUBAME3.0 概要 ··· 1 1.1. システム概念 ··· 1 1.2. 計算ノードの構成 ··· 2 1.3. ソフトウェア構成 ··· 3 1.4. ストレージ構成 ··· 3 2. システム利用環境 ··· 4 2.1. アカウントの取得 ··· 4 2.2. ログイン方法 ··· 4 2.3. パスワード管理 ··· 5 2.4. ログインシェルの変更 ··· 5 2.5. TSUBAME ポイントの確認 ··· 6 2.6. ストレージサービス(CIFS) ··· 6 3. ユーザ利用環境 ··· 7 3.1. 利用環境の切換え方法 ··· 7 3.1.1. 利用可能な module 環境の表示 ··· 7 3.1.2. module 環境の設定情報表示 ··· 7 3.1.3. module 環境のロード ··· 7 3.1.4. module 環境の表示 ··· 7 3.1.5. module 環境のアンロード ··· 8 3.1.6. module 環境の初期化 ··· 8 3.2. バッチスクリプト内での利用 ··· 8 3.3. Intel コンパイラ ··· 9 3.3.1. コンパイルの主なオプション ··· 9 3.3.2. コンパイルの推奨最適化オプション ··· 10 3.3.3. Intel 64 アーキテクチャーのメモリモデル指定 ··· 11 3.4. 並列化 ··· 11 3.4.1. スレッド並列(OpenMP と自動並列化) ··· 11 3.4.2. プロセス並列(MPI) ··· 12 3.5. GPU 環境 ··· 13 3.5.1. インタラクティブ、バッチキューへのジョブ投入··· 13 3.5.2. 対応アプリケーション ··· 13 3.5.3. CUDA 対応の MPI ··· 13 3.5.4. NVIDIA GPUDirect ··· 14 3.5.5. GPUDirect RDMA ··· 15ii
3.5.6. GPU の COMPUTE MODE の変更 ··· 16
4. ジョブスケジューリングシステム ··· 17 4.1. 利用可能な資源タイプ ··· 17 4.2. ジョブの投入 ··· 18 4.2.1. バッチジョブの流れ ··· 18 4.2.2. ジョブスクリプト ··· 18 4.2.3. ジョブスクリプトの記述例シングルジョブ/GPU ジョブ ··· 20 4.2.4. ジョブスクリプトの記述例 SMP 並列 ··· 21 4.2.5. ジョブスクリプトの記述例 MPI 並列 ··· 22 4.2.6. ジョブスクリプトの記述例プロセス並列/スレッド並列(ハイブリッド) ··· 24 4.2.7. ジョブの投入 ··· 25 4.2.8. ジョブの状態確認 ··· 25 4.2.9. ジョブの削除 ··· 26 4.2.10. ジョブの結果確認 ··· 27 4.2.11. アレイジョブ ··· 27 4.3. インタラクティブジョブの投入 ··· 27 4.3.1. インタラクティブノードを利用した X 転送 ··· 28 4.4. シグナル通知/チェックポイント ··· 29 4.5. 予約実行 ··· 31 4.6. ストレージの利用 ··· 32 4.6.1. Home ディレクトリ ··· 32 4.6.2. 高速ストレージ領域 ··· 32 4.6.3. ローカルスクラッチ領域 ··· 33 4.6.4. 共有スクラッチ領域 ··· 33 4.7. SSH ログイン ··· 35 5. ISV アプリケーション ··· 37 5.1. ANSYS ··· 38 5.2. Fluent ··· 40 5.3. ABAQUS ··· 43 5.4. ABAQUS CAE ··· 44
5.5. Marc & Mentat / Dytran ··· 45
5.5.1. Marc & Mentat / Dytran の概要 ··· 45
5.5.2. Marc & Mentat / Dytran のマニュアル ··· 45
5.5.3. Marc の使用方法 ··· 45
5.5.4. Mentat の使用方法 ··· 45
5.6. Nastran ··· 47
iii 5.8. Gaussian ··· 49 5.9. GaussView ··· 51 5.10. AMBER ··· 53 5.10.1. AMBER の概要 ··· 53 5.10.2. AMBER の使用方法 ··· 53 5.11. Materials Studio ··· 56 5.11.1. ライセンス接続設定方法 ··· 56 5.11.2. ライセンス利用状況の確認方法 ··· 57 5.11.3. Materials Studio の起動方法 ··· 58 5.12. Discovery Studio ··· 59 5.12.1. ライセンス接続設定方法 ··· 59 5.12.2. ライセンス利用状況の確認方法 ··· 60 5.12.3. Discovery Studio の起動方法 ··· 61 5.13. Mathematica ··· 62 5.14. Maple ··· 64 5.15. AVS/Express ··· 66 5.16. AVS/Express PCE ··· 67 5.17. LS-DYNA ··· 68 5.17.1. LS-DYNA の概要 ··· 68 5.17.2. LS-DYNA の使用方法 ··· 68 5.18. LS-PrePost ··· 72 5.18.1. LS-PrePost の概要 ··· 72 5.18.2. LS-PrePost の使用方法 ··· 72 5.19. COMSOL ··· 74 5.20. Schrodinger ··· 75 5.21. MATLAB ··· 76 5.22. Arm Forge ··· 77 6. フリーウェア ··· 78 6.1. 量子化学/MD 関連ソフトウェア ··· 79 6.1.1. GAMESS ··· 79 6.1.2. Tinker ··· 79 6.1.3. GROMACS ··· 80 6.1.4. LAMMPS ··· 81 6.1.5. NAMD ··· 81 6.1.6. CP2K ··· 82 6.2. CFD 関連ソフトウェア ··· 83 6.2.1. OpenFOAM ··· 83 6.3. 機械学習、ビックデータ解析関連ソフトウェア ··· 84
iv 6.3.1. CuDNN ··· 84 6.3.2. NCCL ··· 84 6.3.3. Caffe ··· 84 6.3.4. Chainer ··· 84 6.3.5. TensorFlow ··· 85 6.3.6. R ··· 85 6.3.7. Apache Hadoop ··· 85 6.4. 可視化関連ソフトウェア ··· 87 6.4.1. POV-Ray ··· 87 6.4.2. ParaView ··· 87 6.4.3. VisIt ··· 87 6.5. その他フリーウェア ··· 88 6.5.1. gimp ··· 88 6.5.2. gnuplot ··· 88 6.5.3. tgif ··· 88 6.5.4. ImageMagick ··· 88 6.5.5. pLaTeX2e ··· 89 6.5.6. Java SDK ··· 89 6.5.7. PETSc ··· 89 6.5.8. fftw ··· 90 6.5.9. singularity ··· 90 改定履歴 ··· 92
1
1. TSUBAME3.0 概要
1.1. システム概念
本システムは、東京工業大学における種々の研究・開発部門から利用可能な共有計算機です。本システム の倍精度総理論演算性能は 12.15PFLOPS、総主記憶容量は 135TiB、磁気ディスク容量は 15.9PB です。各計算 ノード及びストレージシステムは Omni-Path による高速ネットワークに接続され、また現在は 10Gbps の速度 でインターネットに接続、将来的には SINET5 を経由し 10Gbps の速度でインターネットに接続されます(2017 年 8 月時点)。TSUBAME3.0 の全体概念を以下に示します。 図 1-1 TSUBAME3.0 の概念図2
1.2. 計算ノードの構成
本システムの計算ノードは SGI ICE XA 540 ノードで構成されたブレード型大規模クラスタシステムです。 1 台の計算ノードには、Intel Xeon E5-2680 v4(2.4GHz、14core)を 2 基搭載し、総コア数は 15,120 コアと なります。また、主記憶容量は計算ノードあたり 256GiB を搭載し、総主記憶容量は、135TiB となります。 各計算ノードは、Intel Omni-Path インタフェースを 4 ポート有しており、Omni-Path スイッチによりファッ トツリーで接続されます。 図 1-2 SGI ICE XA TSUBAME3.0 のマシンの基本スペックは次の通りです. 表 1-1 計算ノードの構成 演算部名 計算ノード 540 台 ノード構成 (1台あたり)
CPU Intel Xeon E5-2680 v4 2.4GHz× 2CPU
コア数/スレッド 14 コア / 28 スレッド×2CPU
メモリ 256GiB
GPU NVIDIA TESLA P100 for NVlink-Optimized Servers ×4
SSD 2TB
3
1.3. ソフトウェア構成
本システムのオペレーティングシステム(OS)は、下記の環境を有しています。
⚫ SUSE Linux Enterprise Server 12 SP2
OS 構成は、サービス実行形態に応じて動的に変更されます。 また、本システムで利用可能なアプリケーションソフトウェアに関しては 「6. ISV アプリケーション」、「7. フリーウェア」を参照ください。
1.4. ストレージ構成
本システムでは、様々なシミュレーション結果を保存するための高速・大容量のストレージを備えていま す。計算ノードでは高速ストレージ領域として Lustre ファイルシステムにより、Home ディレクトリは GPFS+cNFS によりファイル共有されています。また、各計算ノードにローカルスクラッチ領域として 2TB の SSD が搭載されています。本システムで利用可能な、各ファイルシステムの一覧を以下に示します。 表 1-2 TSUBAME3.0 のファイルシステム 用途 マウント 容量 ファイルシステム 備考 Home ディレクトリ /home 40TB GPFS+cNFS 共有アプリケーション配備 /apps 高速ストレージ領域 1 /gs/hs0 4.8PB Lustre 高速ストレージ領域 2 /gs/hs1 4.8PB Lustre 高速ストレージ領域 3 /gs/hs2 4.8PB Lustre ローカルスクラッチ領域 /scr 各ノード 1.9TB xfs(SSD)4
2. システム利用環境
2.1. アカウントの取得
本システムを利用するには、予め利用申請を行い、ユーザ ID を取得する必要があります。 学外利用者、学内利用者、臨時利用者の場合で新規利用申請の方法が異なります。それぞれの利用者区分 についての操作は、TSUBAME3.0 ポータル利用説明書を参照ください。2.2. ログイン方法
ログインノードにアクセスするためには、ログインに使う SSH 公開鍵をアップロードする必要があります。 公開鍵の登録の操作は、TSUBAME3.0 ポータル利用説明書を参照ください。 本システムを利用するには、まずログインノードにログインする必要があります。ログインノードへの ログインは、ロードバランサによる自動振り分けが行われます。利用イメージを以下に示します。 図 2-1 計算機の利用イメージ ログイン先には、SSH で接続します。また、ファイル転送は SFTP で接続します。 login.t3.gsic.titech.ac.jp 任意のログインノードにログインしたい場合は、以下のホスト名(FQDN)を指定してください。 login0.t3.gsic.titech.ac.jp login1.t3.gsic.titech.ac.jp バッチジョブ実行 ログイン処理 login0.t3.gsic.titech.ac.jp ログイン処理部 (ログインノード) login1.t3.gsic.titech.ac.jp ログイン用アドレス にアクセス login.t3.gsic.titech.ac.jp ユーザ ログイン ジョブ投入 計算ノード 計算ノード ロードバランサ による振り分け ・・・5
Linux/Mac/Windows(Cygwin)から X 転送オプションを有効にして接続するには以下の例のようになります。 例)アカウント名が gsic_user、秘密鍵が~/.ssh/t3-key の場合
$ ssh [email protected] -i ~/.ssh/t3-key -YC
最初にログインする際、クライアントの設定によっては以下のようなメッセージが出ることが有ります。 その場合は ”yes” と入力してください。
The authenticity of host ' login0.t3.gsic.titech.ac.jp (131.112.3.21)' can't be established. ECDSA key fingerprint is SHA256:RImxLoC4tBjIYQljwIImCKshjef4w7Pshjef4wtBj
Are you sure you want to continue connecting (yes/no)?
※ログインノードには、プロセスあたり 4GB のメモリ制限があります。プログラムの実行は、ジョブスケ ジューラを経由して実行してください。ジョブスケジューラに関しては「4. ジョブスケジューリングシス テム」を参照ください。
2.3. パスワード管理
本システムのユーザアカウントは LDAP サーバで管理され、システム内の認証は SSH の鍵認証で行っていま す。このため、計算ノードの利用にあたってパスワードを意識する必要はありませんが、学内から高速スト レージへのアクセスなどパスワードが必要になるケースがあります。 パスワードの変更が必要になる場合は、 TSUBAME3.0 利用ポータルから行ってください。パスワードのル ールについては、TSUBAME3.0 利用ポータルのパスワード設定のページをご覧ください。2.4. ログインシェルの変更
ユーザ登録の時点で各ユーザアカウントのログインシェルは bash となっています。デフォルトのログインシ ェルを変更するには chsh コマンドを利用ください。利用可能なログインシェルは bash,csh,ksh,tcsh,zsh となります。引数なしの chsh コマンドで利用可能なログインシェルを確認することができます。 $ chshUsage: chsh shell(/bin/bash /bin/csh /bin/sh /bin/ksh /bin/tcsh /bin/zsh).
以下は、ログインシェルを tcsh に変更する例です。 $ chsh /bin/tcsh
Please input Web Portal Password(not SSH Passphrase)
Enter LDAP Password: xxxxxx <-- パスワードを入力してください Changing shell succeded!!
6
2.5. TSUBAME ポイントの確認
コマンドでの TSUBAME ポイントの確認は t3-user-info group point コマンドにて確認できます。以下は、 TESTGROUP の TSUBAME ポイントを確認する例です。
$ t3-user-info group point -g TESTGROUP gid group_name point --- xxxx TESTGROUP 800000000
参加している TESTGROUP の TUBAME ポイントが 800000000 ポイントある状況が確認できます。
2.6. ストレージサービス(CIFS)
TSUBAME3.0 では、高速ストレージ領域に対して学内の Windows/Mac 端末から CIFS によるアクセスが可能で す。以下のアドレスでアクセスすることができます。 \\gshs.t3.gsic.titech.ac.jp アカウントは TSUBAME3.0 のアカウント、パスワードはポータルで設定したパスワードになります。Windows からアクセスする際には、以下のように TSUBAME ドメインを指定してください。 ユーザー名 TSUBAME\<TSUBAME3.0 アカウント名> パスワード <TSUBAME3.0 アカウントのパスワード> /gs/hs0、/gs/hs1、/gs/hs2 に対応して、T3_HS0、T3_HS1、T3_HS2 となっています。グループディスクと して購入したディレクトリへアクセスしてください。
7
3. ユーザ利用環境
3.1. 利用環境の切換え方法
本システムでは、module コマンドを使用することでコンパイラやアプリケーション利用環境の切り替えを 行うことができます。3.1.1.利用可能な module 環境の表示
利用可能な module 環境は module avail または module ava で確認できます。
$ module avail
読み込めるバージョンについては TSUBAME 計算サービス Web ページのシステム構成>アプリケーションソ フトウェアをご確認下さい。
[アプリケーションソフトウェア]http:/www.t3.gsic.titech.ac.jp/applications
3.1.2.module 環境の設定情報表示
module 環境の設定情報を確認したい場合、「module whatis モジュール名」を実行します。
$ module whatis intel/17.0.4.196
intel/17.0.4.196 : Intel Compiler version 17.0.4.196 (parallel_studio_xe_2017) and MKL
3.1.3.module 環境のロード
module 環境をロードしたい場合、「module load モジュール名」を実行します。
$ module load intel/17.0.4.196
バッチスクリプトにおいてロードする module は、コンパイル時と同様のものをロードしてください。
3.1.4.module 環境の表示
現在使用している module 環境を確認したい場合、「module list」を実行します。
$ module list
Currently Loaded Modulefiles:
8
3.1.5.module 環境のアンロード
ロードした module 環境をアンロードしたい場合「module unload モジュール名」を実行します。
$ module list
Currently Loaded Modulefiles:
1) intel/17.0.4.196 2) cuda/8.0.61 $ module unload cuda
$ module list
Currently Loaded Modulefiles: 1) intel/17.0.4.196
3.1.6.module 環境の初期化
ロードした module 環境を初期化したい場合、「module purge」を実行します。
$ module list
Currently Loaded Modulefiles: 1) intel/17.0.4.196 2) cuda/8.0.61 $ module purge
$ module list
No Modulefiles Currently Loaded.
3.2. バッチスクリプト内での利用
バッチスクリプト内で module コマンドを実行する場合、以下のとおり、バッチスクリプト内で module コ マンドの初期設定を行う必要があります。
【実行シェルが sh, bash の場合】 . /etc/profile.d/modules.sh module load intel/17.0.4.196
【実行シェルが csh, tcsh の場合】 source /etc/profile.d/modules.csh module load intel/17.0.4.196
9
3.3. Intel コンパイラ
本システムではコンパイラとして、Intel コンパイラ、PGI コンパイラおよび GNU コンパイラが利用できま す。Intel コンパイラの各コマンドは以下のとおりです。
表 3-1 コマンド名とコマンド形式
コマンド 言語 コマンド形式
ifort Fortran 77/90/95 $ ifort [オプション] source_file
icc C $ icc [オプション] source_file
icpc C++ $ icpc [オプション] source_file
利用する際は、module コマンドで intel を読み込んでください。--help オプションを指定して頂くとコン パイラオプションの一覧が表示されます。
3.3.1.コンパイルの主なオプション
コンパイルの最適化オプションを以下に示します。 表 3-2 コンパイラの主なオプション オプション 説明 -O0 すべての最適化を無効にします。 -O1 最適化を有効にします。コードサイズを大きくするだけで高速化に影響を与えるよう な一部の最適化を無効にします。 -O2 最適化を有効にします。一般的に推奨される最適化レベルです。 ベクトル化は O2 以上のレベルで有効になります。O オプションを指定しない場合、 デフォルトでこちらが指定されます。 -O3 O2 よりも積極的に最適化を行い、融合、アンロールとジャムのブロック、IF 文の折 りたたみなど、より強力なループ変換を有効にします。-xCORE-AVX2 Intel プロセッサー向けの Intel アドバンスト・ベクトル・エクステンション 2 (Intel AVX2)、Intel AVX、SSE4.2、SSE4.1、SSSE3、SSE3、SSE2、SSE 命令を生成し ます。Intel AVX2 命令セット対応の Intel プロセッサー向けに最適化します。 -xSSE4.2 Intel プロセッサー向けの Intel SSE4 高効率および高速な文字列処理命令、Intel
SSE4 ベクトル化コンパイラ命令およびメディア・アクセラレーター命令、および Intel SSSE3、SSE3、SSE2、SSE 命令を生成します。Intel SSE4.2 命令セット対応の Intel プロセッサー向けに最適化します。
10 SSSE3 命令セット対応の Intel プロセッサー向けに最適化します。x オプションを指 定しない場合、デフォルトでこちらが指定されます。 -qopt-report=n 最適化レポートを生成します。デフォルトでは、レポートは.optrpt 拡張子を持つフ ァイルに出力されます。nには、0 (レポートなし) から5 (最も詳しい) の詳細レ ベルを指定します。デフォルトは 2 です。 -fp-model precise 浮動小数点演算のセマンティクスを制御します。浮動小数点データの精度に影響する 最適化を無効にし、中間結果をソースで定義された精度まで丸めます。 -g -g オプションはオブジェクト・ファイルのサイズを大きくするシンボリック・デ バッグ情報をオブジェクト・ファイルに生成するようにコンパイラに指示します。 -traceback このオプションは、ランタイム時に致命的なエラーが発生したとき、ソースファイル のトレースバック情報を表示できるように、オブジェクト・ファイル内に補足情報を 生成するようにコンパイラに指示します。 致命的なエラーが発生すると、コールスタックの 16 進アドレス (プログラム・カ ウンター・トレース) とともに、ソースファイル、ルーチン名、および行番号の相関 情報が表示されます。 マップファイルとエラーが発生したときに表示されるスタックの 16 進アドレス を使用することで、エラーの原因を特定できます。 このオプションを指定すると、実行プログラムのサイズが増えます。
3.3.2.コンパイルの推奨最適化オプション
コンパイルの推奨最適化オプションを以下に示します。本システムに搭載している Intel Xeon E5-2680 v4 は、Intel AVX2 命令セットに対応していますので、-xCORE-AVX2 オプションを指定することができます。 -xCORE-AVX2 を指定すると、コンパイラがソースコードを解析し、最適な AVX2、AVX、SSE 命令を生成します。 推奨最適化オプションは積極的な最適化を行い、かつ安全なオプションです。最適化のために計算の順序を 変更する可能性があり、結果に誤差が生じる場合があります。 表 3-3 推奨最適化オプション オプション 説明 -O3 O2 最適化を行い、融合、アンロールとジャムのブロック、IF 文の折りたたみなど、 より強力なループ変換を有効にします。
-xCORE-AVX2 Intel プロセッサー向けの Intel アドバンスト・ベクトル・エクステンション 2 (Intel AVX2)、Intel AVX、SSE4.2、SSE4.1、SSSE3、SSE3、SSE2、SSE 命令を生成し ます。Intel AVX2 命令セット対応の Intel プロセッサー向けに最適化します。
11 上記のオプションを使用することにより、プログラムの性能が悪化した場合、最適化のレベルを-O2 に下 げるかベクトル化のオプションを変更してください。また、結果が一致していない場合、浮動小数点のオプ ションも試してみてください。
3.3.3.Intel 64 アーキテクチャーのメモリモデル指定
次のいずれかのメモリモデルを使用して実行バイナリを作成します。 表 3-4 メモリモデル メモリモデル 説明 small (-mcmodel=small) コードとデータのすべてのアクセスが、命令ポインター (IP) 相対アドレス指定で行 われるように、コードとデータはアドレス空間の最初の 2GB までに制限されます。 -mcmodel オプションを指定しない場合、デフォルトでこちらが指定されます。 medium (-mcmodel=medium) コードはアドレス空間の最初の 2GB までに制限されますが、データは制限されませ ん。コードは IP 相対アドレス指定でアクセスできますが、データのアクセスは絶対 アドレス指定を使用する必要があります。 large (-mcmodel=large) コードもデータも制限されません。コードもデータもアクセスは絶対アドレス指定を 使用します。 IP 相対アドレス指定は 32 ビットのみ必要ですが、絶対アドレス指定は 64 ビット必要です。これは、コ ードサイズとパフォーマンスに影響します。(IP 相対アドレス指定の方が多少速くアクセスできます。) プログラム内の共通ブロック、グローバルデータ、静的データの合計が 2GB を越えるとき、リンク時に次 のエラーメッセージが出力されます。<some lib.a library>(some .o): In Function <function>: : relocation truncated to fit: R_X86_64_PC32 <some symbol> ………
: relocation truncated to fit: R_X86_64_PC32 <some symbol>
この場合は、-mcmodel=medium と-shared-intel を指定してコンパイル/リンクして下さい。medium メモリ モデルまたは large メモリモデルを指定した場合、Intel のランタイム・ライブラリの適切なダイナミッ ク・バージョンが使用されるように、-shared-intel コンパイラ・オプションも指定する必要があります。
3.4. 並列化
3.4.1.スレッド並列(OpenMP と自動並列化)
12
OpenMP、自動並列化を使用する場合のコマンド形式を以下に示します。
表 3-5 コマンド形式(OpenMP/自動並列化)
言語 コマンド形式
OpenMP Fortran 77/90/95 $ ifort -qopenmp [オプション] source_file C $ icc -qopenmp [オプション] source_file C++ $ icpc -qopenmp [オプション] source_file 自動並列化 Fortran 77/90/95 $ ifort -parallel [オプション] source_file
C $ icc -parallel [オプション] source_file C++ $ icpc -parallel [オプション] source_file
‘-qopt-report-phase=openmp’ オプションを使用することで OpenMP 最適化フェーズのレポートを作成す ることができます。 ‘-qopt-report-phase=par’ オプションを使用することで自動並列化フェーズのレポートを作成すること ができます。
3.4.2.プロセス並列(MPI)
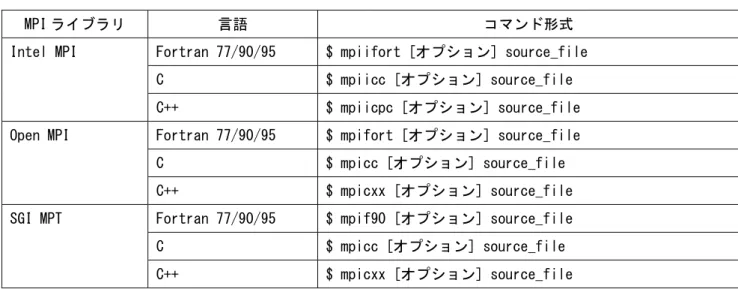
Fortran/C/C++ プログラムに MPI ライブラリをリンクし、プロセス並列プログラムを作成/実行すること ができます。MPI を使用する場合のコマンド形式を以下に示します。利用する際は、module コマンドで各 MPI を読み込んでください。表 3-6 コマンド形式(MPI)
MPI ライブラリ 言語 コマンド形式
Intel MPI Fortran 77/90/95 $ mpiifort [オプション] source_file C $ mpiicc [オプション] source_file C++ $ mpiicpc [オプション] source_file Open MPI Fortran 77/90/95 $ mpifort [オプション] source_file
C $ mpicc [オプション] source_file C++ $ mpicxx [オプション] source_file SGI MPT Fortran 77/90/95 $ mpif90 [オプション] source_file C $ mpicc [オプション] source_file C++ $ mpicxx [オプション] source_file
13
3.5. GPU 環境
本システムでは GPU(NVIDIA TESLA P100)の利用環境を提供しております。3.5.1.インタラクティブ、バッチキューへのジョブ投入
ログインノード(login0,1)には、GPU を搭載しておらず、コンパイル、リンクのみ実行可能です。インタ ラクティブでの実行、デバックについては、バッチシステムを使用して実行可能です。詳細については、4. ジ ョブスケジューリングシステムを参照ください。3.5.2.対応アプリケーション
現在の GPU 対応アプリケーションは次の通りです。(2017.12.18 現在) ・ABAQUS 2017 --- ABAQUS 利用の手引(別冊) を参照ください。 ・NASTRAN 2017.1 --- NASTRAN 利用の手引(別冊) を参照ください。 ・ANSYS 18 --- ANSYS 利用の手引(別冊) を参照ください。 ・AMBER 16 --- AMBER 利用の手引(別冊) を参照ください。 ・Maple 2016 --- Maple 利用の手引(別冊) を参照ください。 ・Mathematica 11.2 --- Mathematica 利用の手引(別冊) を参照ください。 ・MATLAB --- MATLAB 利用の手引(別冊) を参照ください。・Allinea Forge --- Allinea Forge 利用の手引(別冊) を参照ください。 ・PGI Compiler --- PGI コンパイラ 利用の手引(別冊) を参照ください。
他のアプリケーションにつきまても、順次展開してまいります。
3.5.3.CUDA 対応の MPI
CUDA 版に対応した MPI 環境を用意しております。
OpenMPI + gcc 環境
# CUDA、Open MPI 環境の読込(gcc は、デフォルトで設定されています。)
module load cuda openmpi/2.1.2
OpenMPI + pgi 環境
# CUDA、PGI 環境の読込(最初にコンパイラ環境を読み込みます。)
14
# Open MPI 環境の読込(コンパイラに応じた OpenMPI の環境が設定されます。)
module load openmpi/2.1.2
OpenMPI + pgi 環境(PGI バンドル版)
# CUDA、PGI 環境の読込(最初にコンパイラ環境を読み込みます。)
module load cuda pgi
# Open MPI 環境の読込
module load openmpi/2.1.2-pgi2017
PGI バンドル版においては、バッチシステムからとの連携がない為、実行時にホストリストを指定する必要 があります。以下にジョブスクリプト例を示します。 #!/bin/sh #$ -cwd #$ -l f_node=10 #$ -l h_rt=1:00:00 #$ -N test . /etc/profile.d/modules.sh module load cuda pgi
module load openmpi/2.1.2-pgi2017
grep ^r $PE_HOSTFILE|awk '{print $1,$2}' > ./hostlist
mpirun --hostfile ./hostlist --mca oob_tcp_if_include ib0 --mca btl_tcp_if_include ib0 -npernode 4 -n 40 -x LD_LIBRARY_PATH -x PATH ./a.out
OpenMPI + Intel 環境
# CUDA、Intel 環境の読込(最初にコンパイラ環境を読み込みます。)
module load cuda intel
# Open MPI 環境の読込(コンパイラに応じた OpenMPI の環境が設定されます。)
module load openmpi/2.1.2
3.5.4.NVIDIA GPUDirect
現在、NVIDIA GPUDirect (GPUDIRECT FAMILY)としては、4 つの機能(GPUDIRECT SHARED GPU SYSMEM、GPUDIRECT P2P、GPUDIRECT RDMA、GPUDIRECT ASYNC)があります。(2017.12.18 現在)
このうち、TSUBAME3.0 では、GPUDIRECT SHARED GPU SYSMEM、GPUDIRECT P2P、GPUDIRECT RDMA をサポート しております。
15 ・GPUDIRECT SHARED GPU SYSMEM(Version1)
MPI の送受信バッファに CUDA pinned メモリやデバイスメモリのアドレスを直接指定することができる機 能です。デバイスメモリのアドレスを指定した場合には実際にはデータがホストメモリ上のバッファを経 由して転送されます。
・GPUDIRECT P2P(Version2)
PCI-Express、NVLink を経由した GPU 間の直接データ転送(P2P)の機能です。TSUBAME 3.0 では、ノードあ たり、4GPU を搭載しておりますが、1 つの CPU あたり、PLX switch を介して 2 つの GPU に接続しており ます。4GPU 間は、高速な NVLink で接続されています。
・GPUDIRECT RDMA(Version3)
ホストメモリを介することなく GPU とインターコネクト間(TSUBAME3.0 では、Intel Omni-Path)で直接 データ転送(RDMA)をすることにより異なるノードの GPU 間の高速なデータ転送を実現する機能です。 ・GPUDIRECT ASYNC ホストメモリを介することなく GPU とインターコネクト間で非同期通信する機能です。現在、TSUBAME3.0 の の Intel Omni-Path では、未対応です。 参考) http://on-demand.gputechconf.com/gtc/2017/presentation/s7128-davide-rossetti-how-to-enable.pdf GPUDirect については、以下の URL も参照ください。 https://developer.nvidia.com/gpudirect http://docs.nvidia.com/cuda/gpudirect-rdma
3.5.5.GPUDirect RDMA
OpenMPI での GPUDirect RDMA の実行方法を以下に示します。以下、2 ノード、MPI×2 での実行例になりま す。
# mpirun -mca pml cm -mca mtl psm2 -np 2 -npernode 1 -bind-to core -cpu-set 0 -x
CUDA_VISIBLE_DEVICES=0 -x PSM2_CUDA=1 -x PSM2_GPUDIRECT=1 -x LD_LIBRARY_PATH -x PATH [プログラム]
・CUDA_VISIBLE_DEVICES --- GPU の指定
・PSM2_CUDA --- Omni-Path での CUDA 有効 ・PSM2_GPUDIRECT --- GPUDirect RDMA 有効
16
3.5.6.GPU の COMPUTE MODE の変更
資源タイプ F の f_node を利用した場合、GPU の COMPUTE MODE を変更することが出来ます。GPU の COMPUTE MODE を変更するには、ジョブスクリプトの中で、f_node を指定した上で、#$ -v GPU_COMPUTE_MODE=<利用す るモード> を指定してください。利用可能なモードは以下の 3 つです。 モード 説明 0 DEFAULT モード 1 つの GPU を複数のプロセスから同時に利用できる。 1 EXCLUSIVE_PROCESS モード 1 つの GPU を 1 プロセスのみが利用できる。1 プロセスから複数スレッドの利用は可能。 2 PROHIBITED モード GPU へのプロセス割り当てを禁止する。 以下はスクリプトの例となります。 #!/bin/sh #$ -cwd #$ -l f_node=1 #$ -l h_rt=1:00:00 #$ -N gpumode #$ -v GPU_COMPUTE_MODE=1 /usr/bin/nvidia-smi インタラクティブで利用する場合、qrsh は以下のような形となります。
$ qrsh -g [TSUBAME3 グループ] -l f_node=1 -l h_rt=0:10:00 -pty yes -v TERM –v GPU_COMPUTE_MODE=1 /bin/bash
17
4. ジョブスケジューリングシステム
本システムのジョブスケジューリングには、シングルジョブ・並列ジョブを優先度や必要なリソースに従 い効率的にスケジューリングする、「UNIVA Grid Engine」を採用しています。
4.1. 利用可能な資源タイプ
本システムでは計算ノードを論理的に分割した資源タイプを利用して、システムリソースを確保します。 ジョブ投入の際には、資源タイプをいくつ使うかを指定します(例:-l f_node=2)。利用できる資源タイプ の一覧を以下に示します。 表 4-1TSUBAME3 の資源タイプ一覧 ・「使用物理 CPU コア数」、「メモリ(GB)」、「GPU 数」は、各資源タイプ 1 つあたりの使用可能な量です。 ・[資源タイプ名] =[個数]で同じ資源タイプを複数指定できます。資源タイプの組み合わせはできません。 ・実行可能時間の最大値は 24 時間です。 ・TSUBAME3 では「同時に実行可能なジョブ数」や「実行可能な総スロット数」など各種制限値があります。 (スロット=資源タイプ毎に設定されている物理 CPU コア数 x 利用ノード数(qstat コマンドの slots と同等))現在の制限値の一覧は以下の URL で確認できます。 http://www.t3.gsic.titech.ac.jp/resource-limit 利用状況に応じて随時変更する可能性がありますのでご注意ください。 資源タイプ 資源タイプ名 使用物理 CPU コア数 メモリ (GB) GPU 数 F f_node 28 240 4 H h_node 14 120 2 Q q_node 7 60 1 C1 s_core 1 7.5 0 C4 q_core 4 30 0 G1 s_gpu 2 15 1
18
4.2. ジョブの投入
本システムでジョブを実行するには、ログインノードへログインして qsub コマンドを実行します。4.2.1.バッチジョブの流れ
ジョブを投入するためにはジョブスクリプトを作成し投入します。または、コマンドラインにキュー名な どを指定してジョブを投入することもできます。投入コマンドは”qsub”です。 表 4-2 バッチジョブの流れ 順序 説明 1 ジョブスクリプトの作成 2 qsub を使用しジョブを投入 3 qstat などを使用しジョブの状態確認 4 必要に応じて qdel を使用しジョブのキャンセル 5 ジョブの結果確認 qsub コマンドは、課金情報(TSUBAME3 ポイント)を確認し、ジョブを受け付けます.4.2.2.ジョブスクリプト
ジョブスクリプトの記述方法を以下に示します。 #!/bin/sh #$ -cwd #$ -l [資源タイプ名] =[個数] #$ -l h_rt=[経過時間] #$ -p [プライオリティ] [module の初期化] [プログラミング環境のロード] [プログラム実行] ・資源タイプの指定などはコマンドラインで指定するか、またはスクリプトファイルの最初のコメントブロ ック(#$)に記述することで有効になります。資源タイプ、実行時間は必須項目になるため必ず指定するよ うにしてください。19 qsub コマンドの主なオプションを以下に示します。 表 4-3qsub コマンドの主なオプション オプション 説明 -l [資源タイプ名] =[個数] (必須) 資源タイプを指定します。 -l h_rt=[経過時間] (必須) Wall time(経過時間)を指定します。[[HH:]MM:]SS で指定することができま す。HH:MM:S や MM:SS や SS のように指定することができます。 -N ジョブ名を指定します。(指定しない場合はスクリプトファイル名) -o 標準出力ファイル名を指定します。 -e 標準エラー出力ファイル名を指定します。 -j y 標準エラー出力を標準出力ファイルに統合します。 -m ジョブについての情報をメールで送信する条件を指定します。 a バッチシステムによりジョブが中止された場合 b ジョブの実行が開始された場合 e ジョブの実行が終了した場合 abe のように組み合わせることも可能です。 -M 送信先メールアドレスを指定します。 -p (プレミアムオプション) ジョブの実行優先度を指定します。 -3,-4 を指定すると通常よりも高い課金 係数が適用されます。設定値の-5,-4,-3 は課金規則の優先度 0,1,2 に対応し ます。 -5 : 標準の実行優先度です. (デフォルト) -4 : 実行優先度は-5 より高く,-3 より低くなります. -3 : 最高の実行優先度となります. -t タスク ID の範囲を指定します。 開始番号-終了番号[:ステップサイズ] で指定することができます。 -hold_jid 依存関係にあるジョブ ID を指定します。 指定された依存ジョブが終了しなければ、発行ジョブは実行されません。 -ar 予約ノードを利用する際に 予約 AR ID を指定します。 本システムではジョブ投入環境の環境変数渡しの-V オプションは利用できません。ご注意ください。
20
4.2.3.ジョブスクリプトの記述例シングルジョブ/GPU ジョブ
シングルジョブ(並列化されていないジョブ)を実行する時に作成するバッチスクリプトの例を以下に示し ます。GPU を使用するジョブも利用する GPU で利用する module の読み込み以外はシングルジョブと同様にな ります。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #!/bin/sh # カレントディレクトリでジョブを実行する場合に指定 #$ -cwd #$ -l f_node=1 # 実行時間を指定 #$ -l h_rt=1:00:00 #$ -N serial # Module コマンドの初期化 . /etc/profile.d/modules.sh # CUDA 環境の読込
module load cuda
# Intel Compiler 環境の読込
module load intel ./a.out
21
4.2.4.ジョブスクリプトの記述例 SMP 並列
SMP 並列ジョブを実行する時に作成するバッチスクリプトの例を以下に示します。計算ノードはハイパー スレッディングが有効になっています。使用するスレッド数につきましては,明示的に指定してください。 1 2 3 4 5 6 7 8 9 10 11 12 #!/bin/sh #$ -cwd # 資源タイプ F 1 ノードを使用 #$ -l f_node=1 #$ -l h_rt=1:00:00 #$ -N openmp . /etc/profile.d/modules.sh module load cudamodule load intel
# ノード内に 28 スレッドを配置
export OMP_NUM_THREADS=28 ./a.out
22
4.2.5.ジョブスクリプトの記述例 MPI 並列
MPI 並列ジョブを実行する時に作成するバッチスクリプトの例を以下に示します。使用する MPI 環境によ り使い分けをお願いします。OpenMPI でスレーブノードにライブラリ環境変数を渡たすには、 -x LD_LIBRARY_PATH を利用する必要があります。 Intel MPI 環境 1 2 3 4 5 6 7 8 9 10 11 12 13 #!/bin/sh #$ -cwd # 資源タイプ F 4 ノードを使用 #$ -l f_node=4 #$ -l h_rt=1:00:00 #$ -N flatmpi . /etc/profile.d/modules.sh module load cudamodule load intel
# Intel MPI 環境の読込
module load intel-mpi
# ノードあたり 8 プロセス MPI 全 32 プロセスを使用 mpiexec.hydra -ppn 8 -n 32 ./a.out OpenMPI 環境 1 2 3 4 5 6 7 8 9 10 11 12 13 #!/bin/sh #$ -cwd # 資源タイプ F 4 ノードを使用 #$ -l f_node=4 #$ -l h_rt=1:00:00 #$ -N flatmpi . /etc/profile.d/modules.sh module load cuda
module load intel
# Open MPI 環境の読込
module load openmpi
# ノードあたり 8 プロセス MPI 全 32 プロセスを使用
23 SGI MPT 環境 1 2 3 4 5 6 7 8 9 10 11 12 13 14 #!/bin/sh #$ -cwd # 資源タイプ F 4 ノードを使用 #$ -l f_node=4 #$ -l h_rt=1:00:00 #$ -N flatmpi . /etc/profile.d/modules.sh module load cuda
module load intel
# SGI MPT 環境の読込 module load mpt # ノードあたり 8 プロセス MPI 全 32 プロセスを使用 mpiexec_mpt -ppn 8 -n 32 ./a.out ※ 投入したジョブに対して割り当てられているノードリストは、$PE_HOSTFILE にファイルが格納されま す。 $ echo $PE_HOSTFILE /var/spool/uge/r6i0n4/active_jobs/4564.1/pe_hostfile $ cat /var/spool/uge/r6i0n4/active_jobs/4564.1/pe_hostfile r6i0n4 28 all.q@r6i0n4 <NULL>
24
4.2.6.ジョブスクリプトの記述例プロセス並列/スレッド並列(ハイブリッド)
プロセス並列/スレッド並列(ハイブリッド)のジョブを実行する時に作成するバッチスクリプトの例を以 下に示します。使用する MPI 環境により使い分けをお願いします。OpenMPI でスレーブノードにライブラリ 環境変数を渡たすには、-x LD_LIBRARY_PATH を利用する必要があります。 Intel MPI 環境 1 2 3 4 5 6 7 8 9 10 11 12 13 14 #!/bin/sh #$ -cwd # 資源タイプ F 4 ノードを使用 #$ -l f_node=4 #$ -l h_rt=1:00:00 #$ -N hybrid . /etc/profile.d/modules.sh module load cudamodule load intel module load intel-mpi
# ノード内に 28 スレッドを配置
export OMP_NUM_THREADS=28
# ノードあたり MPI 1 プロセス、全 4 プロセスを使用
mpiexec.hydra -npernode 1 -n 4 ./a.out
OpenMPI 環境 1 2 3 4 5 6 7 8 9 10 11 12 13 14 #!/bin/sh #$ -cwd # 資源タイプ F 4 ノードを使用 #$ -l f_node=4 #$ -l h_rt=1:00:00 #$ -N hybrid . /etc/profile.d/modules.sh module load cuda
module load intel module load openmpi
# ノード内に 28 スレッドを配置
export OMP_NUM_THREADS=28
# ノードあたり MPI 1 プロセス、全 4 プロセスを使用
25
4.2.7.ジョブの投入
ジョブを実行するために、バッチリクエストを事前に作成する必要があります。qsub コマンドにジョブ投 入スクリプトを指定することで、ジョブがキューイングされ実行されます。qsub コマンドを使用してジョブ を投入する例を以下に示します。 $ qsub -g [TSUBAME3 グループ] スクリプト名 表 4-4 ジョブ投入時のオプション オプション 説明 -g TSUBAME3 グループ名を指定します。 スクリプトの中ではなく qsub コマンドのオプションとしてつけてください。グ ループ指定が未指定の場合は資源タイプ 2 つまで、経過時間 10 分間まで、優先 度-5 の「お試し実行」となります。4.2.8.ジョブの状態確認
qstat コマンドはジョブ状態表示コマンドです。 $ qstat [オプション] qstat コマンドの主なオプションを以下に示します。 表 4-5 qstat コマンドのオプション オプション 説明 -r ジョブのリソース情報を表示します。 -j [ジョブ ID] ジョブに関する追加情報を表示します。 qstat コマンドの実行結果を以下に示します。 $ qstatjob-IDprior nameuser statesubmit/start at queuejclass slotsja-task-ID
--- 307 0.55500 sample.sh testuser r 02/12/2015 17:48:10 [email protected] ・・・省略・・・
26 qstat コマンドの表示内容を以下に示します。 表 4-6 qstat コマンドの表示内容 表示項目 説明 Job-ID ジョブ ID を表示します。 prior 優先度を表示します。 name ジョブ名を表示します。 user ジョブのオーナーを表示します。 state ジョブのステータスを表示します。 r 実行中 qw 待機中 h ホールド中 d 削除中 t 移動中 s サスペンド状態、一時停止 S サスペンド状態、キューのサスペンド状態 T サスペンド状態、制限超過によるサスペンド E エラー状態 submit/start at 投入/開始日時を表示します。 queue キュー名を表示します。 jclass ジョブクラス名を表示します。 slots 利用しているスロット数を表示します。 (スロット=資源タイプ毎に設定されている物理 CPU コア数 x 利用ノード数) ja-task-ID アレイジョブに関してタスク ID を表示します。
4.2.9.ジョブの削除
バッチジョブを削除する場合には、qdel コマンドを使用します。 $ qdel [ジョブ ID] 以下にジョブを qdel した結果を示します。 $ qstatjob-IDprior nameuser statesubmit/start at queuejclass slotsja-task-ID
--- 307 0.55500 sample.sh testuser r 02/12/2015 17:48:10 [email protected]
$ qdel 307
27 $ qstat
job-IDprior nameuser statesubmit/start at queuejclass slotsja-task-ID
---
4.2.10.ジョブの結果確認
UGE のジョブの標準出力はジョブを実行したディレクトリの「スクリプトファイル名.o ジョブ ID」というフ ァイルに保管されます。また、標準エラー出力は「スクリプトファイル名.e ジョブ ID」です。
4.2.11.アレイジョブ
ジョブスクリプト内に含まれる操作をパラメータ化して繰り返し実行する機能としてアレイジョブ機能があ ります。アレイジョブで実行される各ジョブをタスクと呼び、タスク ID によって管理されます。またタスク ID を指定しないジョブ ID は、タスク ID 全部を範囲とします。 タスク番号の指定は、qsub コマンドのオプションもしくはジョブスクリプト内で定義します。投入オプショ ンは -t 開始番号-終了番号:ステップサイズ として指定します。ステップサイズが 1 の場合は省略可能です。 以下に例を示します。 # ジョブスクリプト内にて以下を指定 #$ –t 2-10:2 上記例(2-10:2)では、開始番号 2、終了番号 10、ステップサイズ 2 (1 つ飛ばしのインデックス)が指定さ れ、タスク番号 2、4、6、8、10 の 5 つのタスクによって構成されます。 各タスクのタスク番号は $SGE_TASK_ID という環境変数に設定されるため、この環境変数をジョブスクリプ ト内で利用することで、パラメータスタディが可能となります。結果ファイルはジョブ名の後ろにタスク ID が付いた形で出力されます。 また、実行前/実行中に特定のタスク ID を削除したい場合には、以下のように qdel の-t オプションを使用 します。$ qdel[ジョブ ID] –t [タスク ID]
4.3. インタラクティブジョブの投入
本システムのジョブスケジューラでは、インタラクティブにプログラムやシェルスクリプトを実行する機 能を有しています。インタラクティブジョブを実行するためには、qrsh コマンドを使用し、-l で資源タイプ、 経過時間を指定します。qrsh でジョブ投入後、ジョブがディスパッチされるとコマンドプロンプトが返って
28 きます。exit にてインタラクティブジョブを終了します。インタラクティブジョブの使用方法を以下に示し ます。 $ qrsh -g [TSUBAME3 グループ] -l [資源タイプ]=[個数] -l h_rt=[経過時間] -g オプションのグループ指定が未指定の場合は資源タイプ 2 つまで、経過時間 10 分間まで、優先度-5 の 「お試し実行」となります。 資源タイプ F 1 ノード数、経過時間 10 分を指定した例 $ qrsh -g [TSUBAME3 グループ] -l f_node=1 -l h_rt=0:10:00 Directory: /home/4/t3-test00 Mon Jul 24 02:51:18 JST 2017
4.3.1.インタラクティブノードを利用した X 転送
qrsh で接続したノードから直接 X 転送を行う場合は、下記の手順にて接続ください。 (1) X 転送を有効にしてログインノードに ssh (2) X 転送を有効にして qrsh コマンドの実行 コマンド実行例 例では 2 時間接続で、割り当てノードとして r0i0n0 が割り当てられた場合を想定しております。 割り当てノードはコマンド実行時に空いているノードですので、明示的にノードを指定することはできませ ん。 #qrsh の実行$ qrsh -g [TSUBAME3 グループ] -l s_core=1 -l h_rt=2:0:0 -pty yes -display $DISPLAY -v TERM /bin/bash Thu Sep 21 08:17:19 JST 2017
r0i0n0:~> module load <読み込みたいアプリケーション> r0i0n0:~> <実行したいアプリケーションの実行コマンド>
29
4.4. シグナル通知/チェックポイント
ジョブが -notify オプションとともにサブミットされた場合、サスペンド(SIGSTOP)/終了(SIGKILL)の停 止信号が送られる前に警告シグナル(SIGUSR1、SIGUSR2)をジョブに送信することができます。本システム では遅延時間は 60 秒に設定されています。 # ジョブスクリプト内にて以下を指定 #$ –notify 以下の例ではジョブスケジューラからの SIGKILL が来た際に再キューイング(exit 99)を行い、計算プログラ ムから再実行を行います。 #!/bin/sh # 他の指定については記載を省略 #$ -notify # SIGUSR2 シグナルをトラップtrap 'exit 99' SIGUSR2
# リスタートの場合処理をスキップ if [ $RESTARTED = 0 ]; then # 前処理プログラムの実行 ./preprogram.exe fi # 計算プログラムの実行 ./mainprogram.exe ジョブが-ckpt オプションとともにサブミットされた場合は、チェックポインティングに対応したアプリ ケーションではジョブの状態を保存し、ジョブが休止または中断した際にこの時点から再開する処理をする ことができます。 # ジョブスクリプト内にて以下を指定 #$ –ckpt user –c オプション qsub コマンドの関連オプションを以下に示します。 オプション 説明 -ckpt user チェックポイント環境の名前。 -c ジョブのチェックポイントがトリガされる状態遷移を指定します。 s ジョブホストの実行デーモンが停止した場合にチェックポイントを設 定します。 m キューで定義された min_cpu_interval の間隔でチェックポイントを
30 設定します。現在の設定は 5 分です。 x ジョブがサスペンドされた場合にチェックポイントを設定します。 sx のように組み合わせることも可能です。 以下の例ではジョブホストの停止、ジョブのサスペンド、ジョブホストの不明状態の際に再キューイングを 行い、計算プログラムから再実行を行います。 #!/bin/sh # 他の指定については記載を省略 #$ -ckpt user #$ -c sx # 1 回目の実行/リスタートの場合の処理を記載 if [ $RESTARTED = 0 ]; then ./preprogram.exe # 前処理プログラムの実行 fi ./mainprogram.exe # 計算プログラムの実行 また、DMTCP を使用した場合は以下の例のようになります。 #!/bin/sh # 他の指定については記載を省略 #$ -ckpt user #$ -c sx module load dmtcp export DMTCP_CHECKPOINT_DIR=<イメージの保存先> export DMTCP_COORD_HOST=`hostname` export DMTCP_CHECKPOINT_INTERVAL=<チェックポイント取得間隔>
dmtcp_coordinator --quiet --exit-on-last --daemon 2>&1 # DMTCP の実行 # 1 回目の実行/リスタートの場合の処理を記載 if [ $RESTARTED = 0 ]; then dmtcp_launch ./a.out # DMTCP 経由でプログラムの実行 else $DMTCP_CHECKPOINT_DIR/dmtcp_restart_script.sh # イメージからのリスタート fi DMTCP については以下のページを参照ください。 http://dmtcp.sourceforge.net/
31
4.5. 予約実行
計算ノードを予約することにより、”24 時間を越えるジョブ”の実行が可能です。 ”72 ノードを超えるジョブ”に関しては、TSUBAME3 における各種制限値の制約を受けるため、大規模ジ ョブを投入の場合はお問い合わせください。 http://www.t3.gsic.titech.ac.jp/contact-t3 予約実行の流れは以下のようになります。 表 4-7 予約実行の流れ 順序 説明 1 TSUBAME ポータルから予約の実行 2 TSUBAME ポータルから予約状況の確認、キャンセル 3 予約ノードに対して qsub を使用しジョブを投入 4 必要に応じて qdel を使用しジョブのキャンセル 5 ジョブの結果確認 ポータルからの予約の実行、予約状況の確認、予約のキャンセルに関して「TSUBAME3.0 ポータル利用説明書」 をご参照ください。 予約時間になりましたら、予約グループのアカウントでジョブの実行ができるようになります。予約 ID であ る AR ID を指定したジョブ投入の例を以下に示します。$ qsub -g [TSUBAME3 グループ] –ar [AR ID] スクリプト名
予約実行で利用できる資源タイプは f_node,h_node,q_node になります。q_core,s_core,s_gpu は利用できま せん。
ジョブ投入後の ジョブの状態確認 は qstat コマンド、ジョブの削除は qdel コマンドを使用します。 また、スクリプトの書式は通常実行時のものと同じになります。
32
4.6. ストレージの利用
本システムでは、Home ディレクトリ以外にも 高速ストレージ領域の Lustre ファイルシステム、ローカル スクラッチ領域の SSD 領域、SSD をまとめて作成する共有スクラッチ領域の BeeGFS On Demand といった様々 な並列ファイルシステムを 利用することができます.4.6.1.Home ディレクトリ
HOME ディレクトリはユーザあたり 25GiB を利用できます。使用容量は t3-user-info disk home コマンドにて確認できます。以下は、TESTUSER の HOME ディレクトリ の容量を確認する例です。
$ t3-user-info disk home
uid name b_size(GB) b_quota(GB) i_files i_quota --- xxxx TESTUSER 7 25 101446 2000000 25GB のクォータ制限のうち、7GB 利用し、inode 制限については、200 万のクォータ制限のうち、約 10 万 利用している状況が確認できます。
4.6.2.高速ストレージ領域
高速ストレージ領域は Lustre ファイルシステムで構成され、グループディスクとして購入することで利用 することができます。グループディスクの購入方法は「TSUBAME3.0 ポータル利用説明書」をご参照ください。グループディスクの使用容量は t3-user-info disk group コマンドにて確認できます。以下は、TESTGROUP のグループディスクの容量を確認する例です。
$ t3-user-info disk group –g TESTGROUP
/gs/hs0 /gs/hs1 /gs/hs2
gid group_name size(TB) quota(TB) file(M) quota(M) size(TB) quota(TB) file(M) quota(M) size(TB) quota(TB) file(M) quota(M) ---
xxxx TESTGROUP 0.00 0 0.00 0 59.78 100 7.50 200 0.00 0 0.00 0
指定した TESTGROUP グループでは、/gs/hs1 のみ購入し、100TB のクォータ制限のうち、約 60TB 利用し、 inode 制限については、2 億のクォータ制限のうち、750 万利用している状況が確認できます。
33
4.6.3.ローカルスクラッチ領域
SSD をローカルスクラッチ領域として使用することができます。利用する際には、$TMPDIR にローカルスク ラッチ領域のパスが設定されます。ジョブスクリプトの中で、作業領域のパスを指定することにより参照可 能です。 ローカルスクラッチ領域は各計算ノードの個別領域となり共有されていないため、ジョブスクリプト内から のインとアウトをローカルホストにステージングする必要があります。下記の例では、使用する計算ノード が 1 ノードの場合に、ホームディレクトリからローカルスクラッチ領域にインプットデータセットをコピー し、結果をホームディレクトリに返します。(複数ノードは対応していません) #!/bin/sh # 計算に必要な入力ファイルのコピー cp –rp $HOME/datasets $TMPDIR/ # 入力、出力を指定する計算プログラムの実行./a.out $TMPDIR/datasets $TMPDIR/results
# 必要な結果ファイルのコピー
cp –rp $TMPDIR/results $HOME/results
4.6.4.共有スクラッチ領域
資源タイプ F の f_node を利用したバッチスクリプトの場合のみ、確保した複数の計算ノードの SSD をオン デマンドに共有ファイルシステムとして作成する BeeGFS On Demand を利用できます。BeeGFS On Demand を 有効にするには、ジョブスクリプトの中で、f_node を指定した上で、#$ -v USE_BEEOND=1 を指定してくだ さい。BeeGFS On Demand は計算ノード上の/beeond にマウントされます。以下はスクリプトの例となります。
#!/bin/sh #$ -cwd #$ -l f_node=4 #$ -l h_rt=1:00:00 #$ -N flatmpi #$ -v USE_BEEOND=1 . /etc/profile.d/modules.sh module load cuda
module load intel module load intel-mpi
34
インタラクティブで利用する場合、qrsh は以下のような形となります。利用しない場合と比べ、ディスクの マウント処理に少し時間を要します。
$ qrsh -g [TSUBAME3 グループ] -l f_node=2 -l h_rt=0:10:00 -pty yes -v TERM –v USE_BEEOND=1 /bin/bash
BeeGFS On Demand 共有スクラッチ領域はジョブで確保されたタイミングで作成されるため、ジョブスクリプ ト内からのインとアウトを/beeond にステージングする必要があります。下記の例では、ホームディレクト リから BeeGFS On Demand 共有スクラッチ領域にインプットデータセットをコピーし、結果をホームディレク トリに返します。 #!/bin/sh # 計算に必要な入力ファイルのコピー cp –rp $HOME/datasets /beeond/ # 入力、出力を指定する計算プログラムの実行
./a.out $TMPDIR/datasets /beeond/results
# 必要な結果ファイルのコピー
35
4.7. SSH ログイン
資源タイプ f_node でジョブを行ったノードには直接 ssh でログインできます。 確保したノードは以下の手順により、確認することができます。 t3-test00@login0:~> qstat -j 1463 ============================================================== job_number: 1463 jclass: NONE exec_file: job_scripts/1463 submission_time: 07/29/2017 14:15:26.580 owner: t3-test00 uid: 1804 group: tsubame-users0 gid: 1800supplementary group: tsubame-users0, t3-test-group00 sge_o_home: /home/4/t3-test00 sge_o_log_name: t3-test00 sge_o_path: /apps/t3/sles12sp2/uge/latest/bin/lx-amd64:/apps/t3/sles12sp2/uge/latest/bin/lx-amd64:/home/4/t3 -test00/bin:/usr/local/bin:/usr/bin:/bin:/usr/bin/X11:/usr/games sge_o_shell: /bin/bash sge_o_workdir: /home/4/t3-test00/koshino sge_o_host: login0 account: 2 0 0 0 0 0 600 0 0 1804 1800 cwd: /home/4/t3-test00
hard resource_list: h_rt=600,f_node=1,gpu=4 mail_list: t3-test00@login0 notify: FALSE job_name: flatmpi priority: 0 jobshare: 0 env_list: RGST_PARAM_01=0,RGST_PARAM_02=1804,RGST_PARAM_03=1800,RGST_PARAM_04=2,RGST_PARAM_05=0,RGST_PARAM _06=0,RGST_PARAM_07=0,RGST_PARAM_08=0,RGST_PARAM_09=0,RGST_PARAM_10=600,RGST_PARAM_11=0 script_file: flatmpi.sh parallel environment: mpi_f_node range: 56
36 department: defaultdepartment binding: NONE
mbind: NONE
submit_cmd: qsub flatmpi.sh
start_time 1: 07/29/2017 14:15:26.684 job_state 1: r
exec_host_list 1: r8i6n3:28, r8i6n4:28 <-- 確保したノード r8i6n3、r8i6n4 granted_req. 1: f_node=1, gpu=4
usage 1: wallclock=00:00:00, cpu=00:00:00, mem=0.00000 GBs, io=0.00000 GB, iow=0.000 s, ioops=0, vmem=N/A, maxvmem=N/A
binding 1:
r8i6n3=0,0:0,1:0,2:0,3:0,4:0,5:0,6:0,7:0,8:0,9:0,10:0,11:0,12:0,13:1,0:1,1:1,2:1,3:1,4:1,5:1,6:1 ,7:1,8:1,9:1,10:1,11:1,12:1,13,
r8i6n4=0,0:0,1:0,2:0,3:0,4:0,5:0,6:0,7:0,8:0,9:0,10:0,11:0,12:0,13:1,0:1,1:1,2:1,3:1,4:1,5:1,6:1 ,7:1,8:1,9:1,10:1,11:1,12:1,13
resource map 1: f_node=r8i6n3=(0), f_node=r8i6n4=(0), gpu=r8i6n3=(0 1 2 3), gpu=r8i6n4=(0 1 2 3)
37
5. ISV アプリケーション
ライセンス契約上、ISV アプリケーションを利用できる利用者は限られます。東工大に所属する「1.学生証・ 職員証」以外の利用者は以下に挙げるアプリケーション以外の ISV アプリケーションを利用できません。 1. Gaussian/Gauss View 2. AMBER 3. Intel Compiler 4. PGI Compiler 5. Arm Forge ISV アプリケーションの一覧表を以下に示します。 ソフトウェア名 概要 ANSYS 解析ソフトウェア Fluent 解析ソフトウェア ABAQUS 解析ソフトウェア ABACUS CAE 解析ソフトウェアMarc & Mentant / Dytran 解析ソフトウェア
Nastran 解析ソフトウェア Patran 解析ソフトウェア Gaussian 量子化学計算プログラム GaussView 量子化学計算プログラム プリポストツール AMBER 分子動力学計算プログラム Materials Studio 化学シミュレーションソフトウェア Discovery Studio 化学シミュレーションソフトウェア Mathematica 数式処理ソフトウェア Maple 数式処理ソフトウェア AVS/Express 可視化ソフトウェア AVS/Express PCE 可視化ソフトウェア LS-DYNA 解析ソフトウェア LS-PrePost 解析ソフトウェア プリポストツール COMSOL 解析ソフトウェア Schrodinger 化学シミュレーションソフトウェア MATLAB 数値計算ソフトウェア Arm Forge デバッガ Intel Compiler コンパイラ PGI Compiler コンパイラ
38
5.1. ANSYS
GUI での利用手順を以下に示します。 $ module load ansys
$ launcher
CLI での利用手順を以下に示します。 $ module load ansys
$ mapdl mapdl コマンドの代わりに以下のコマンドも使用できます。 (ANSYS18.2 の場合。バージョンによって異なります。) $ ansys182 exit と入力すると終了します。 入力ファイルを指定すると非対話的に実行されます。 実行例 1
$ mapdl [options] < inputfile > outputfile
実行例 2
39 バッチキューシステムを使用する場合は、シェルスクリプトを作成し CLI で以下のように実行します。 sample.sh を使用する場合 $ qsub sample.sh スクリプト例:MPI 並列処理 #!/bin/bash #$ -cwd #$ -V #$ -l f_node=2 #$ -l h_rt=0:10:0 . /etc/profile.d/modules.sh module load ansys
mapdl -b -dis -np 56 < inputfile > outputfile
スクリプト例:GPU 使用 #!/bin/bash #$ -cwd #$ -V #$ -l f_node=1 #$ -l h_rt=0:10:0 . /etc/profile.d/modules.sh module load ansys
mapdl -b -dis -np 28 -acc nvidia -na 4 < inputfile > outputfile
ANSYS のライセンス利用状況を以下のコマンドで確認できます。
40
5.2. Fluent
Fluent は熱流体解析アプリケーションです。利用手順を以下に示します。
GUI での起動手順を以下に示します。 $ module load ansys
41 CLI での起動手順を以下に示します。
$ module load ansys $ fluent -g exit と入力すると終了します。 journal ファイルを使用してインタラクティブに実行する場合は以下のようにコマンドを実行します。 journal ファイル名が fluentbench.jou、3D の場合 $fluent 3d -g -i fluentbench.jou バッチキューシステムを使用する場合は、シェルスクリプトを作成し CLI で以下のように実行します。 sample.sh を利用する場合 $ qsub sample.sh
42 スクリプト例:MPI 並列処理(f_node 利用時) #!/bin/bash #$ -cwd #$ -V #$ -l f_node=2 #$ -l h_rt=0:10:0 . /etc/profile.d/modules.sh module load ansys
JOURNAL=journalfile
OUTPUT=outputfile
VERSION=3d
fluent -mpi=intel -g ${VERSION} -cnf=${PE_HOSTFILE} -i ${JOURNAL} > ${OUTPUT} 2>&1
スクリプト例:MPI 並列処理(h_node 利用時) #!/bin/bash #$ -cwd #$ -V #$ -l h_node=1 #$ -l h_rt=0:10:0 . /etc/profile.d/modules.sh module load ansys
JOURNAL=journalfile
OUTPUT=outputfile
VERSION=3d
fluent -ncheck -mpi=intel -g ${VERSION} -cnf=${PE_HOSTFILE} -i ${JOURNAL} > ${OUTPUT} 2>&1 f_node 以外の利用では資源をまたぐ設定ができないため、#$ -l {資源名}=1 (例えば h_node では#$ -l h_node=1)とし、コマンド中に「-ncheck」オプションを入れてください。
Fluent のライセンス利用状況を以下のコマンドで確認できます。
43
5.3. ABAQUS
インタラクティブでの利用手順を以下に示します。 $ module load abaqus
$ abaqus job=inputfile [options]
バッチキューシステムを使用する場合は、シェルスクリプトを作成し CLI で以下のように実行します。 sample.sh を利用する場合 $ qsub sample.sh スクリプト例:MPI 並列処理 #!/bin/bash #$ -cwd #$ -V #$ -l q_core=1 #$ -l h_rt=0:10:0 . /etc/profile.d/modules.sh module load abaqus
# ABAQUS settings. INPUT=s2a ABAQUS_VER=2017 ABAQUS_CMD=abq${ABAQUS_VER} SCRATCH=${TMPDIR} NCPUS=4 ${ABAQUS_CMD} interactive \ job=${INPUT} \ cpus=${NCPUS} \ scratch=${SCRATCH} \
44
5.4. ABAQUS CAE
ABAQUS CAE の利用手順を以下に示します。 $ module load abaqus
$ abaqus cae
45
5.5. Marc & Mentat / Dytran
5.5.1.Marc & Mentat / Dytran の概要
各製品の概要はエムエスシーソフトウェア株式会社の Web サイトをご参照ください。 Marc: http://www.mscsoftware.com/ja/product/marc
Dytran: http://www.mscsoftware.com/ja/product/dytran
5.5.2.Marc & Mentat / Dytran のマニュアル
下記ドキュメントをご参照ください。
Marc & Mentat Docs (mscsoftware.com)
Dytran Docs (mscsoftware.com)
5.5.3.Marc の使用方法
インタラクティブでの利用手順を以下に示します。 使用したいバージョンに適宜読み替えてご実行ください。 $ module load intel intel-mpi cuda marc_mentat/2017 サンプルファイル(e2x1.dat)の場合
$ cp /apps/t3/sles12sp2/isv/msc/marc/marc2017/demo/e2x1.dat ./ $ marc -jid e2x1
5.5.4.Mentat の使用方法
Mentat の起動手順を以下に示します。
使用したいバージョンに適宜読み替えてご実行ください。 $ module load intel intel-mpi cuda marc_mentat/2017 $ mentat
46 メニューバーの File > Exit をクリックすると終了します。
Mentat のライセンス利用状況を以下のコマンドで確認できます。
47
5.6. Nastran
使用したいバージョンに適宜読み替えてご実行ください。 Nastran の起動手順を以下に示します。
$ module load nastran/2017.1 サンプルファイル (um24.dat) の場合 $ cp /apps/t3/sles12sp2/isv/msc/MSC_Nastran/20171/msc20171/nast/demo/um24.dat ./ $ nast20171 um24 Nastran のバッチ投入手順を以下に示します。 サンプルファイル (parallel.sh) の場合 $ qsub parallel.sh スクリプト例:CPU 並列処理 #!/bin/bash #$ -cwd #$ -l q_core=1 #$ -l h_rt=0:10:00 #$ -V export NSLOTS=4 . /etc/profile.d/modules.sh
module load cuda openmpi nastran/2017.1
mpirun -np $NSLOTS \
nast20171 parallel=$NSLOTS um24
Nastran のライセンス利用状況を以下のコマンドで確認できます。
48
5.7. Patran
Patran の起動手順を以下に示します。
使用したいバージョンに適宜読み替えてご実行ください。 $ module load patran/2017.0.2
$ pat2017
終了する際は File>EXIT
Patran のライセンス利用状況を以下のコマンドで確認できます。
49
5.8. Gaussian
インタラクティブな利用手順を以下に示します。
GPU を利用するモジュールを読み込む場合(環境変数 GAUSS_CDEF 及び GAUSS_GDEF を自動設定します) $ module load gaussian16/revision_gpu
$ g16 inputfile
revisionには使用するリビジョンを指定してください。Gaussian16 Rev.B01 の場合は以下の通りです。 $ module load gaussian16/B01_gpu
デフォルトモジュールを読み込む場合(環境変数 GAUSS_CDEF/GAUSS_GDEF は設定されません)
H30 年 9 月現時点のデフォルトモジュールは、GPU 向け環境変数を自動設定しない B01 ですが、次回のメン テナンス時にはデフォルトモジュールを GPU 向けの B01_gpu に変更予定です。
$ module load gaussian16 $ g16 inputfile
Linda 並列版モジュールを読み込む場合 $ module load gaussian16_linda $ g16 inputfile バッチキューシステムを使用する場合は、シェルスクリプトを作成し CLI で以下のように実行します。 sample.sh を使用する場合 $ qsub sample.sh スクリプト例:ノード内並列処理 Glycine の構造最適化および振動解析(IR+ラマン強度)を計算する場合のサンプルスクリプトです。 下記の glycine.sh、glycine.gjf を同一ディレクトリ上に配置し、下記コマンドを実行することで計算がで きます。計算後に glycine.log、glycine.chk が生成されます。 解析結果の確認については GaussView にてご説明します。 $ qsub glycine.sh glycine.sh #!/bin/bash #$ -cwd #$ -l f_node=1 #$ -l h_rt=0:10:0 #$ -V