音素列を対象とした発音ミス検知による
正解語提示手法の検討
A Method for Suggesting Correct Word by Pronunciation Mistake Detection
for Phoneme Sequences
上村 航平
1鷹野 孝典
2Kohei Kamimura
1, Kosuke Takano
21
神奈川工科大学大学院
工学研究科 情報工学専攻
1Graduate School of Engineering, Kanagawa Institute of Technology
Course of Information and Computer Sciences
2神奈川工科大学
情報学部 情報工学科
2Department of Information and Computer Sciences
Kanagawa Institute of Technology
Abstract: This paper presents a method for suggesting correct word by pronunciation mistake detection for
phoneme sequences. In many applications where text inputs are required, spell mistake correction is an important function to reduce type errors of users. Meanwhile, with the advance of speech recognition technology, a function of speech input is incorporated into many software and devices to operate them without inputs by keyboard, mouse, and finger touch. However, to the best of our knowledge, there is no method to correct pronunciation errors for speech input by a user, although the speech recognition function can show only the words whose pronunciations are similar to the ones that the user made by speech. In this study, we propose a method for correcting pronunciation mistake by extending a function of spell mistake correction based on edit distance. By applying pronunciation score for phoneme sequences proposed in our previous study, it is expected that our method reduces the number of candidate pronunciation from incorrect pronunciation to be corrected.
1. はじめに
文書作成ソフトやWeb サイトにおけるテキスト入 力欄の入力補助機能として,ユーザのタイピングミ スによる英単語スペル修正機能が組み込まれるよう になった.一方,言語コーパスの規模拡大や深層学 習の適用とともに,ユーザの発音音声に対して,音 声認識機能は著しく精度向上したものの,ユーザの 発話ミスを推定して,正しい語へと修正してくれる 機能は我々の知る限り存在していない.例えば,既 存の音声認識システムでは,ユーザが「word」を意 図して発音した音声が認識できない場合,認識でき ないとするか,あるいは発音がある程度近い「ward」 などを認識結果として出力するだけにとどまってお り,その修正候補を提示するような機能を備えてい ない. 我々は先行研究として,外国語学習において、学 習者が発話を苦手とする音素列を抽出する手法を提 案してきた[4].この手法では,学習者の苦手な音素 (発音誤り音素)をn-gram として抽出し,スコア付 けを行う.これにより,単一の苦手な音素だけでな く,音素の組み合わせに着目した苦手な発音を持つ 英単語の抽出が可能となる. 本研究では,この音素列ごとの発音スコアを適用 することにより,音素列を対象とした発音ミス検知 による正解語提示手法を提案する.提案手法の特徴 は,音素列の発音スコアを「この音素列の発音の間 違いやすさ」と捉えることにより,ユーザの発音音 声が認識できない場合などに,発話スコアの高い英 単語を優先的に修正候補として絞り込むことにより, 発音音声に対する修正候補の探索数を削減する点に ある.2. 研究動機
英単語スペル修正のモデルとして,入力単語w に 人工知能学会研究会資料 SIG-KBS-B901-09 - 61 -対する修正単語c を,条件付確率 P(c | w)が最大とな る修正単語c を抽出する問題を考える.P(c | w)は, ベ イズの 定理を 適用す るこ とによ り,P(c | w) = P(w | c) x P(c) / P(w) となり,右辺は P(w | c) P(c)に 比例するので,P(w | c) x P(c)を最大とする修正単語 c を抽出する問題として捉えることができる. ここで,P(c)は修正候補語 c の頻出率として計算 できる.また,P(w | c)を最大とする修正候補語 c は, 元の単語w から修正候補語 c を得るのに必要な編集 操作の回数を最小にするものとして計算できる.こ こで,元の単語w から修正候補語 c を得るのに必要 な編集操作の回数を編集距離と定義する.編集操作 は , 元 の 単 語 w か ら , 文 字 を 取 り 除 く 「 削 除 (deletion) 」, 隣 り 合 う 文 字 を 入 れ 替 え る 「 転 位 (transposition)」,1 つの文字を別な文字に変える「置 換 (alteration),文字を追加する「挿入 (insertion)」で 定義できる.編集距離が大きくなるほど,修正候補 単語の数は増加し,修正候補単語を導出するための 探索数が増加する.ただし,編集距離が1 の場合で も80%程度,編集距離が 2 の場合では,95%程度の スペルミスをカバーできるとされる[5][6]. 本研究では,この方法を発音音声に適用し,誤っ た発音音声に対する発音修正候補を見つけることに より,発音ミスを検知し正解語の提示を行う.本研 究では,このような発音ミス検知に基づいた正解語 提示を「発音ミス修正」と呼ぶ. しかし,発音ミス修正は,タイピング時における スペルミス修正に比べて,編集距離をより大きく考 慮する必要があると考えられる.これは,音の前後 や中間に発生する音の伸び縮みやリンキングによる 音の増減,および個々人や国や地域に依存した発音 特徴の違い[1]により発音ミスが生じることが多く, 発音ミスは単音ではなく,音素列単位で出現しやす いと考えられるためである.一方,前述したように 編集距離が大きくなると,それに伴い修正候補単語 の数は増加し,探索数が増加する. 本研究では,先行研究で提案した発話スコアを用 いることにより,発話スコアの高い英単語を優先的 に修正候補として絞り込むことにより,発音音声に 対する修正候補の探索数を削減可能であると考えた. 具体的には,wax の正しい発音は[wæks]であるが, [wækth]と認識された場合,編集距離の小さいものか ら修正単語候補を全探索する必要がある.しかし, ユーザが[ks]を頻繁に間違いやすいという情報があ れば,語尾に[ks]を含む単語を修正単語候補として絞 り込むことにより,探索数を減らすことができると 考えられる.本研究では,このようにユーザの発音 音声に対して,発音ミスをしやすい音素列に着目す ることにより,修正候補の探索数を削減した発音ミ ス修正手法の実現を目指す.
3. 関連研究
これまで様々なデータを対象として,ユーザから の入力誤りを検知し,修正する手法が提案されてい る.鈴木らは,ハミングを問い合わせのクエリとす る楽曲検索システムにおいて,検索者のハミング間 違いに強固な検索システムの実現を目的として,旋 律情報に変換したハミングに対し,文書検索におけ るスペル修正の技術を適用するハミングミス修正手 法を提案している[3].文献[5]では,検索エンジンへ の入力における英文内の前置詞の用法誤りを検知し, 修正するために,ユーザが入力した前置詞を含む英 文から検索用クエリを生成し,そのクエリを元に検 索した結果から前置詞の出現頻度率を計算し,ユー ザに提示する手法が提案されている[5].久保田らは, 文献[5]の手法において,名詞が複数並ぶ日付の表現 や複合名詞等を含む英文を適切に検出・修正ができ ないという課題を提起し,ユーザの入力した英文か ら生成した初期の検索クエリによる検索だけでなく, 初期検索クエリからさらに前後の前置詞との組み合 わせなどを考慮した再検索クエリを生成し,それら 全てのクエリによる検索結果から,修正候補となる 前置詞を提示する手法を提案し,検索精度の向上を 確認した[6]. このような従来研究に対して,本研究では,編集 距離に基づいたタイピングにおけるスペルミス修正 手法を,先行研究において示した発音スコアを適用 して拡張することにより,効率的な発音ミス修正手 法の実現を目指している.4. 発音スコアの算出手法
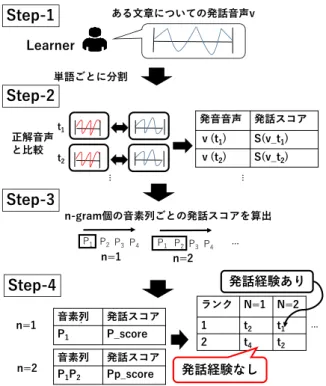
先行研究で提案した,学習者の発音音声から苦手 とする音素列を抽出し,発音スコアとして算出する 手法について述べる (図 1). Step-1:発話音声の抽出 n 個の単語 t1, t2, …, tnが含まれる文章siを発話し た場合: 学習者 u の発話音声 vuにおいて,各単語の 発話音声vu(t1),vu(t2),…,vu(tn)を抽出する.ここで, 単語txの発音記号(音素)の列をP(tx) = {px,1, px,2, …, px,m}とする. Step-2:単語に対する発話スコアの算出 vu(tx)と txの正解音声と比較することにより発話ス コアs(tx)を,類似度計量手法を用いて算出する. - 62 -図 1: 発話スコアの算出手法の概要図 Step-3:音素に対する発話スコアの算出 単語txの発話記号の列についてn-gram 抽出(n=1, 2, …, m)を行う. ngram(P(tx), n) = { ng1, ng2, …, ngl } ngk = { px,k px,k+1 … px,k+m-1} また,各n-gram 音素列 ngkの発話スコアs(tx, ngk) を下記の2 つの方法で算出する. (1) 間違えた音素を含む n-gram 音素列 ngkを抽出し, 発話スコアs(tx)を割り当てる. (2) 全ての n-gram 音素列 ngkに対して等しく発話ス コアs(tx)を割り当てる. Step-4: 単語のランキング これまでに発話した単語列T = {t1, t2, …, tq} に対 して,Step-3 で n-gram 単位で算出した音素列集合 PS = {ps1, ps2, …, pst} を抽出し,各音素列 psxに対する 発話スコアを算出する.ここで,N は素列 psxの出現 頻度である. s(psx) = ∑𝑡𝑘∈𝑇𝑠(𝑡𝑘, 𝑝𝑠𝑥)⁄ 𝑁 さらに,単語tiから抽出される音素列集合をPSjと すると,各単語 tiの発話スコアを下記のように算出 する. ここで,M は音素列集合 PSjの要素数である. s(ti) = ∑𝑝𝑠𝑥∈𝑃𝑆𝑗𝑠(𝑝𝑠𝑥)⁄ 𝑀 単語 tiは発話スコア s(ti)に基づいて,ランキング されユーザに提示される
5. 提案方式
本研究では,4 章で示した n-gram 音素列の発音ス コアに基づいた音素列を対象とした発音ミス検知に よる正解語提示手法を提案する.ここで,音素列の 発音スコアは「この音素列の発音の間違いやすさ」 と捉えることができる.図2 に提案手法の概要図を 示す. 図 2:提案方式の概要図 提案手法は,音素列ごとの発音スコアの高い英単 語を優先的に修正候補として絞り込むことにより, 発音音声に対する修正候補の探索数を削減する.以 下に提案手法を用いた修正候補単語の取得手順を示 す.ここで,4 章で示した手法を用いて,ユーザ u の 発音音声の履歴から,音素列psxの発音スコアs(psx) を算出し,発音スコアデータベースに記録されてい るものとする. Step-1: 発音音声の入力 ユーザu は,音声認識機能を利用した入力システ ムに発音音声v を入力する. Step-2: 発音音声からの音素列の抽出 Step-1 での入力音声 v から音素列 (発音記号の列) ps(v)を抽出する. Step-3: 発音ミスの検知 2 章で説明したスペルミス修正の手法を適用し, Learner ある文章についての発話音声v Step-1 Step-2 正解音声 と比較 Step-3 n-gram個の音素列ごとの発話スコアを算出 Step-4 音素列 発話スコア P1 P_score 音素列 発話スコア P1P2 Pp_score n=1 n=2 ランク N=1 N=2 1 t2 t1 2 t4 t2 発話経験なし 発話経験あり … 単語ごとに分割 発音音声 発話スコア v(t1) S(v_t1) v(t2) S(v_t2) n=1 n=2 P1 P2P3P4 P1 P2P3P4 … … … … t1 t2 … i Step-1:発音音声の入力 ユーザの発話音声v 音声認識を伴う 入力システム Step-2:発音音声からの音素列の抽出 音声認識を伴う 入力システム wéʤ Step-3:発音ミスの検知 w e 1 e 80 2 r 78 3 l 70 n=2 1 ie 120 2 er 112 3 ai 103 事前に算出した発音スコア Delete insertion éʤ éwʤ ewrd wiéʤ Transposition alteration insertion wʤé wéiʤ [éʤ, éwʤ,,,wé ] wéi ʤ Delete alteration insertion wé wéʤi Transposition ・ ・ 発音スコア データベース 全修正候補単語 データベース n=1 wéʤ [発音スコアの高い音素列を含む 全修正候補音素列集合X] iéʤ wʤ alteration Delete 編集距離:1 編集距離:2 Step4:正解単語の提示 修正候補音素列 [iéd, éʤs,,,wén ] 編集距離:1 編集距離:2 … ユーザ 編集距離が最も短い修正候補音素列集合を選択 wiʤ [éʤ, éwʤ,,,wé ] 修正候補音素列のうち,しきい値θを超える音素列を探索 éʤ éʤ:Edge Step-3で探索した音素列に対応した単語をユーザに提示 - 63 -発音ミス修正を行う.具体的には,下記式において, V が最大となる ps(c)を求める.ここで,c は発音ミ ス修正の結果として提示される修正単語である. V(ps(v), ps(c)) = P(ps(v) | ps(c)) x P(ps(c)) ここで,P(ps(v) | ps(c))を最大とする ps(c)を計算す るために,音素列ps(v),ps(c)間の編集距離を最小と するps(c)を探索する.V の値がしきい値θを超える ps(c)を見つけることにより,発音音声 v の発音ミス を検知する. この処理過程において,音素列ps(c)に対する編集
操作(delete, transposition, alteration, insertion)を行う ことにより,ps(w)に合致するものを見つける.ここ で,ps(c)の候補音素列集合 X を,発音スコアデータ ベースに記録されている,発音スコアs(psx)の高い音 素列psxを含む音素列の集合として抽出しておく. このように音素列の発音スコアの高い音素列を含 む英単語を優先的に修正候補として絞り込むことに より,発音音声に対する修正候補の探索数を削減す ることが可能となる. Step-4: 正解単語の提示 Step-3 で見つけた V の値がしきい値θを超える ps(c)に対応付けられる単語 c を,発音ミスした音声 に対する正解単語としてユーザに提示する. 以下に,Step-3 における修正候補の探索数の削減 について,具体例を用いて示す.ここでは,ユーザ がword [wˈɚːd]を意図したが,実際には[wˈɚːs]と発音 した場合を考える. 例えば,編集距離を 1 としてw を p に置換して 音素列[pˈɚːs']を生成した場合,全単語を探索した場 合,全単語数N 回について V(ps(v), ps(c))を計算する 必要がある.従って,編集距離1 の置換を対象とし た場合は,(発音記号の個数)3 x N 回の比較処理が必 要となる. 一方,発音スコアを持つ単語を対象とした場合は, その単語数 Ns (<N)回の計算が必要となるので,(発 音記号の個数)3 x Ns 回の比較処理を行う.結果とし て,全単語を探索した場合と比べて,探索数をNs/N 削減することができる.例えば,10 個の音素列[pˈɚːs], [tˈɚːs], [nˈɚːs], [vˈɚːs], [kˈɚːs], [wˈɚːd], [wˈɚːm], [wˈɚːθ], [wˈɚːs], [wˈɚːk]が探索単語の候補である場 合 に 比 べ て , 発 音 ス コ ア を 持 つ 音 素 列 が[kˈɚːt], [wˈɚːd], [tˈɚːm]の 3 個であれば,探索数を 3/10 に削 減できる. さらに,発音スコアを持つ単語集合が,発音スコ ア順にソートされているとすれば,置換した音素列 と パ タ ー ン が 一 致 す る も の( こ こ で は 2 番 目 の [wˈɚːd])が見つかった時点で,その発音列が V(ps(v), ps(c))を最大にするものであるので,探索処理をそこ で終了することができる.
6. まとめと今後の課題
本稿では,音素列ごとの発音スコアを適用するこ とにより,音素列を対象とした発音ミス検知による 正解語提示手法を示した.提案方式の有用性は,編 集距離に基づいたタイピングにおけるスペルミス修 正手法を,先行研究において示した発音スコアを適 用して拡張することにより,探索処理を削減した効 率的な発音ミス検知・修正を実現可能な点にある. 今後は,プロトタイプを用いた実験により,提案 手法の実現可能性を検証する予定である.参考文献
[1] 南條浩輝:音多言語音声の音声認識, 日本音響学会誌, Vol. 74, No.9, pp. 531-534(2018) [2] 河合剛,石田朗,広瀬啓吉: 2 言語の音響モデルを用 いた音声認識による非母語発音誤りの検出と発音評 価, 日本音響学会誌, Vol. 57, No. 9, pp. 569-580, (2000) [3] 鈴木督史,川越恭二:スペル修正技術を用いた楽曲検 索システム,音楽情報科学(MUS)研究報告,Vol. 2009-MUS-82, No.4, pp.1-6, (2009) [4] 上村航平,鷹野孝典:外国語学習者が発音・聞き取り を苦手とする音素列の抽出手法の検討,DEIM Forum 2019 [5] 有富隼, 太田学: 検索エンジンによる英文前置詞誤 り修正支援, DBSJ Journal, Vol.9, No. 1, pp.70-75, (2010) [6] 久保田 朗, 太田 学: 検索エンジンを用いた英文前置詞誤りの自動検出と修正, データベースシステム 研究報告(DBS), Vol. 2011-DBS-153, No. 2, pp. 1 – 8, (2011)
[7] Roger Mitton: Spellchecking by computer: The Journal of the Simplified Spelling Society, Vol 20, No 1, (1996) [8] Daniel Jurafsky, James H. Martin: SPEECH LANGUAGE
PROCESSING, (2009)
[9] Ahmad Alsuhaim: Teaching Pronunciation via Computer Technology: Principles and Best Practices, CATESOL Journal, Vol.30, No.1, pp195-212, (2018)
[10] Richard Cauldwell: Listening and Pronunciation require separate models of speech, Proceedings of the 5th Pronunciation in Second Language Learning and Teaching Conference, pp.40-44, (2014)
[11] Marla Tritch Yoshida: Choosing Technology Tools to Meet Pronunciation Teaching and Learning Goals, CATESOL Journal, Vol.30, No.1, pp195-212, (2018)