フロントエンド実行方式におけるエネルギー効率向上のためのインオーダ実行モード切り替えアルゴリズムの初期検討
10
0
0
全文
(2) Vol.2015-ARC-216 No.17 2015/8/5. 情報処理学会研究報告 IPSJ SIG Technical Report. のインオーダ・プロセッサと比べて大きなエネルギーを消. は,典型的なアプリケーションは実行フェーズ毎にプロ. 費する.. セッサに要求する資源は大きく変化し,実行中に適切なコ. 本論文では,OXU を停止して IXU のみで命令を実行す. アへ切り替えを行うことでエネルギー効率が向上するこ. る OXU スリープ・モードと呼ぶ低消費電力な実行モード. とを示した [4].命令レベル並列性(ILP: Instruction-level. を FXA に追加し,適宜このモードへ実行を切り替える手. Parallelism)を積極的に利用する複雑なプロセッサを利用. 法を提案する.OXU スリープ・モードでは命令のアウト・. すれば高い性能を実現できる.しかし同一のプロセッサで. オブ・オーダ実行に必要な処理を省略することで,更なる. ILP の少ないアプリケーションを実行すると,単純なプロ. エネルギー消費の削減ができる.OXU スリープ・モードで. セッサで実行した場合と性能はあまり変わらないにも関わ. はインオーダ実行で動作するため,通常の FXA 実行に比. らず,多くのエネルギーを消費する.ヘテロジニアス・マ. べて性能が大幅に低下する可能性がある.このため性能低. ルチコアでは,実行中にアプリケーションの要求に適した. 下の少ないフェーズでのみ OXU スリープ・モードに切り. コアへ切り替えを行うことで,消費エネルギー効率を向上. 替えるよう制御を行う.切り替え制御のアルゴリズムにつ. する.. いては,本論文では初期検討としてコンポジット・コア [6] で採用されている切り替え方式を採用した.. 2.2 切り替え粒度. 上記の提案手法を適用することで,SPECint2006 ベン. 一般に,ヘテロジニアス・マルチコアにおけるコアの切. チマークプログラムにおいて,従来の FXA での実行と比. り替えは,切り替えオーバーヘッドが十分に小さい場合,細. 較して 95%の性能を維持しつつ,幾何平均で 10.0%の消費. 粒度で行うほどエネルギー効率の改善につながる [6], [7].. エネルギー削減を達成した.性能/エネルギー消費量の比. これは,アプリケーション内に細粒度に存在している,イ. (PER: Performance Energy Ratio)では最大 16.7%,平均. ンオーダ実行を行っても性能が低下しない区間を利用でき. 5.8%向上することを確認した.通常のアウト・オブ・オー. るようになるためである.. ダ・スーパスカラ・プロセッサと比較すると,幾何平均で. ヘテロジニアス・マルチコアの実現例として,ARM 社. 24.5%の消費エネルギー削減,PER では平均 4.8%の向上. による big.LITTLE がある [2].しかし big.LITTLE にお. となった.. けるコア切り替え間隔は,プログラムごとに行われるなど,. また評価によって,切り替えアルゴリズムを改善するこ. 非常に粗粒度である.これは,big.LITTLE ではコア切り. とで更なるエネルギー消費量の削減が見込めることを確認. 替えを支援する特別なハードウェアを持っておらず,切り. した.適用した切り替えアルゴリズムによる実行と理想的. 替えオーバーヘッドが非常に大きいためである.コアを切. な切り替え実行の間にはエネルギー消費量に未だ大きな差. り替えるためには OS のシステム・コールを呼び出す必要. がある.適用した切り替えアルゴリズムでは,判断時に将. があり,このシステム・コール呼び出しには 100 サイクル. 来訪れるフェーズの予測を行っていないため,誤った切り. 以上のオーバーヘッドがある.また,それぞれのコアが持. 替えを行う場面が多く存在する.将来の実行に関する情報. つコヒーレント・キャッシュを介してコンテキストの移動. を切り替えアルゴリズムに取り入れることで,更なるエネ. を行うため,これによるオーバーヘッドも大きい.. ルギー消費量削減が見込める.. これに対して Lukefahr らはコンポジット・コアと呼ば. 本論文の以降の構成は以下の通りである.2 節では関連. れる手法を提案している [6].コンポジット・コアでは,コ. 研究について述べる.3 節で提案手法の基本となるフロン. ア切り替えオーバーヘッドの低減によって 1000 命令程度. トエンド実行方式について述べた後,4 節で提案手法,5. の間隔でコアを切り替えることができる.コンポジット・. 節で提案手法に用いられている切り替えアルゴリズムに. コアは,コア切り替えオーバーヘッドの低減のために,ア. ついて述べる.6 節でその評価を行い,最後に 7 節でまと. ウト・オブ・オーダ・コアとインオーダ・コアを密に結合. める.. した構成をとる.コンポジット・コアでは両コアにおいて,. 2. 関連研究 本節では,実行する命令列の特性によって実行方式を変 更する関連研究について説明する.. デコード・ステージまでのフロントエンドと,L1D キャッ シュを共有する.またコンテキストの移動を支援する特別 なハードウェアを搭載しており,小さなオーバーヘッドで コア切り替えを行うことができる.またコンポジット・コ アでは,細粒度な切り替えに対応した独自のコア切り替え. 2.1 ヘテロジニアス・マルチコアによるエネルギー効率 の向上 ヘテロジニアス・マルチコアを用いて,特性の異なる複. アルゴリズムを使用している.この切り替えアルゴリズム は本論文の提案手法にも用いられており,詳細な説明は 5 節で行う.. 数のコアを実行中に使い分けることで,エネルギー効率を. 切り替えオーバーヘッドが小さい場合,1000 命令以下. 向上させる手法が提案されている [4], [8], [11].Kumar ら. のより細粒度な切り替えを行うことでエネルギー効率がさ. c 2015 Information Processing Society of Japan ⃝. 2.
(3) Vol.2015-ARC-216 No.17 2015/8/5. 情報処理学会研究報告 IPSJ SIG Technical Report. 3.1.1 実行系 FXA は以下の二つの実行系を持つ. ( 1 ) アウト・オブ・オーダ実行系(OXU: Out-of-Order Execution Unit): 通常のスーパスカラ・プロセッサ の実行コアと同様のものである.図 2 に示すように,. OXU は SC と書かれた以降のステージに配置される. 図 1. ベースとなるアーキテクチャ. OXU は主に演算器やバイパス・ネットワーク,動的命 令スケジューリングを行うための発行キュー(IQ: Issue. Queue),ロード・ストア・キュー(LSQ:Load/Store Queue)からなる. ( 2 ) イ ン オ ー ダ 実 行 系(IXU: In-Order Execution Unit): 主に演算器とそれらを接続するバイパス・ ネットワークからなる.図 2 に示すように,IXU はフ 図 2 フロントエンド実行方式. ロントエンドのリネーム・ステージとディスパッチ・ ステージの間に配置される.FXA では,物理レジス タ・ファイル(PRF: Physical Register File)読み出し. らに向上する [6], [7] が,正しい切り替え判断を行うこと. ステージは,OXU とは別にリネーム・ステージの後に. が困難になっていく [7].粗粒度にみて性能が安定してい. も存在する.読み出されたソース・オペランドは IXU. るフェーズでも,細粒度にみると性能は大きく変動してい る.文献 [4], [6], [8], [11] で提案された手法はいずれも,直 近のサンプリング情報をもとに,今後も同様の特性を持つ. に入力され,そこで命令をインオーダに実行する.. 3.1.2 物理レジスタ・ファイル FXA では IXU にソース・オペランドを供給するため,. フェーズが現れるという仮定のもと切り替え判断を行って. フロントエンドに PRF へアクセスするパスを持つ.IXU. いる.これらの仮定は細粒度な切り替えでは成立が難しい. と OXU では PRF へのポートを一部共有する.共有され. ため,正しい切り替え判断が行えなくなっていく.文献 [7]. ているポートに対しては,OXU からのアクセスがない場. では,切り替え後に現れるフェーズの予測を行うことで切. 合にのみ IXU からアクセスする.. り替え判断の正確さを向上させている.. 3. フロントエンド実行方式 本節では,提案手法の背景としてフロントエンド実行方 式(FXA)について説明する [9].FXA では,フロントエ. 3.2 基本的な動作 IXU は OXU に対するフィルタとして働く.すなわち, IXU で実行された命令は OXU で実行されず,命令パイプ ラインから取り除かれる.. ンドでソース・オペランドの読み出しを行い,その際に実. IXU を用いた命令処理の流れを以下に記す.なお,ここ. 行可能な命令を IXU で実行する.この IXU は単純な構造. では命令は全て 1 サイクルで実行できる整数演算命令であ. で多くの命令を実行できるため,FXA では性能を向上さ. るとする.. せながら消費エネルギーを削減することができる.以下で. ( 1 ) フロントエンドのレジスタ読み出しステージにおい. は FXA の構成について説明した後,その基本的な動作に ついて説明する.. て,PRF を読み出す.. ( 2 ) 命令がレディであるかを判断する.ここで「命令がレ ディ」とは,ソース・オペランドが全て得られ,実行. 3.1 構成 以下では通常のアウト・オブ・オーダ・スーパスカラ・. 可能であることを意味する.以降では「命令がレディ」 とした場合,この意味を指すものとする.ソース・オ. プロセッサと比較しながら FXA の構成を説明する.図 1. ペランドは以下の 2 通りの経路によって得られるため,. に通常のアウト・オブ・オーダ・スーパスカラ・プロセッ. これらによって命令がレディかどうかを判定する.. サのパイプラインとブロック図を示す.同図は,物理レジ. ( a ) PRF からの読み出し.. スタ・ファイル・ベースのアーキテクチャのものである.. ( b ) IXU 内の実行結果のバイパス.. 以降では,「通常のスーパスカラ・プロセッサ」とした場. ( 3 ) 命令がレディかどうかに応じて,IXU では以下のよう. 合,このアウト・オブ・オーダ・スーパスカラ・プロセッ. に処理する:. サを指すものとする.これに対し,図 2 に FXA のブロッ. ( a ) レディな命令は IXU で実行し IQ にディスパッチ. ク図とパイプラインを示す.以下ではその実行系について. しない.実行結果は IXU を出た後に PRF に書か. 説明する.. れる.. c 2015 Information Processing Society of Japan ⃝. 3.
(4) Vol.2015-ARC-216 No.17 2015/8/5. 情報処理学会研究報告 IPSJ SIG Technical Report. ( b ) レディでない命令は,NOP として IXU をそのま ま通過する.その後,命令は通常のスーパスカラ・ プロセッサの場合と同様に IQ にディスパッチさ れ,実行される. 上記のうち通常のインオーダ・スーパスカラ・プロセッ サの場合と異なるのは,レディでない命令の処理である. 通常のインオーダ・スーパスカラ・プロセッサでは,レディ でない命令のデコード時は,依存が解消されるまでパイプ ラインをストールさせる.これに対し IXU では,レディ でない命令は NOP として通過し,パイプラインはストー ルされずに命令は流れ続ける. 一方,OXU は通常のスーパスカラ・プロセッサと同様 の構成をとるため,FXA において新たに説明することは ない.. 3.3 消費エネルギーの削減 本節では消費エネルギーがどのように削減されるのかを 説明する.FXA の消費エネルギーが削減されるのは,IXU などの追加が消費エネルギーを大きく増やさないことと,. IQ の消費エネルギーが削減されることによる.以下でこ れらの消費エネルギーを通常のスーパスカラ・プロセッサ の場合と比べながら説明した後,それらをまとめる.. IXU の追加は,コア全体の消費エネルギーを大きくは増 やさない.3.1 節で説明したように,IXU は主に演算器と バイパス・ネットワークからなる.IXU での命令実行及び バイパス・ネットワークによる動的消費エネルギーの増加 は,その分 OXU での命令実行及びバイパス・ネットワー クによる消費エネルギーを削減するため,ほぼ相殺される. 追加した演算器の静的消費エネルギーについても,整数演 算器に使用されるトランジスタ数はその他の回路に比べる と僅かであり,その影響は小さい. 一方で FXA では通常のスーパスカラ・プロセッサと比べ て IQ の消費エネルギーが大きく削減される.IXU によっ て多くの命令が実行されるため,性能を落とすことなく IQ の容量と同時発行数を削減できるためである.IQ は主に 同時発行数に比例したポート数を持つ CAM や RAM から なり,その消費エネルギーは容量とポート数,アクセス数 のそれぞれに比例する.このため,容量と同時発行数を削 減することは,IQ のアクセスあたりの消費エネルギーを 大きく削減させる.また,IXU で実行された命令は IQ に ディスパッチされなくなるため,そのアクセス回数自体も 大きく減る. このように,FXA では通常のスーパスカラ・プロセッ サと比べて IQ の消費エネルギーが大きく削減され,演算 器やバイパス・ネットワークによる消費エネルギーはあま り変わらない.この結果,FXA ではプロセッサ全体の消 費エネルギーを削減することができる.. c 2015 Information Processing Society of Japan ⃝. 4. 提案手法 3 節で説明した FXA に,より低消費電力で動作する OXU スリープ・モード を追加することを提案する.本節 ではこの OXU スリープ・モードについて説明する.以降 の説明では OXU スリープ・モードに対して,元々のフロ ントエンド実行方式の動作を OXU アクティブ・モードと 呼ぶ.. OXU スリープ・モードでは基本的に IXU のみでイン オーダに命令を実行し,アウト・オブ・オーダ実行に必要な 処理を行わないことで消費電力を削減する.一方で OXU スリープ・モードでは性能が大幅に低下する場合があるた め,そのような場合には OXU アクティブ・モードを使用 する. はじめに 4.1 節で,OXU スリープ・モードにおける動作 について説明を行う.次に 4.2 節で OXU スリープ・モー ドと OXU アクティブ・モードとの間のモード切り替え時 の動作について説明する.. 4.1 OXU スリープ・モードの動作 本節では OXU スリープ・モードの動作を説明する.. OXU スリープ・モードでは,IXU でソース・オペラン ドが全て揃わず実行できない命令が現れた場合,パイプラ インをストールさせてソース・オペランドが取得できるま でレジスタ読み出しステージで待機させる.命令は IXU の実行ステージに投入せず,後続の命令もすべてストール する.. OXU アクティブ・モードの動作と比較すると,IXU での レディでない命令に対する動作が異なる.OXU アクティ ブ・モードではレディでない命令は IXU 内を NOP とし て通過し,OXU へディスパッチされる.一方で OXU ス リープ・モードでは上記のように命令をレジスタ読み出し ステージで停止させる.. OXU スリープ・モードでの実行中,FP 命令のような IXU が実行演算器を備えていない命令に遭遇した場合は OXU スリープ・モードを終了して,OXU アクティブ・モー ドに移行する必要がある. また OXU スリープ・モードでは,OXU におけるアウ ト・オブ・オーダ実行に必要な処理を完全に省略する.具 体的にはレジスタ・リネームを省略し,論理レジスタ番号 でレジスタ・ファイルにアクセスする.また ROB および. LSQ への割り当て動作も行わない.アウト・オブ・オーダ 実行に必要な処理を完全に省略することで,OXU アクティ ブ・モードでの実行より低消費電力で命令を実行できる.. 4.2 モード切り替え時の動作 本節ではモード間の切り替え動作について説明するとと. 4.
(5) Vol.2015-ARC-216 No.17 2015/8/5. 情報処理学会研究報告 IPSJ SIG Technical Report. もに,それに伴って発生する切り替えペナルティについ. まずはじめに, 1) 実行を終えたばかりの命令区間につ. て説明する.切り替えペナルティは,OXU アクティブ・. いて,両モードにおいてそれぞれどれだけのサイクル数で. モードから OXU スリープ・モードへ移行する際にのみ発. 実行できたかを測定及び推定する. 2)目標とする総実行. 生する.. サイクル数の算出を行う.3)OXU スリープ・モードを使. 4.2.1 OXU アクティブ・モードから OXU スリープ・. 用するかの判断に用いる閾値を計算する.この閾値とは,. モードへの切り替え. OXU スリープ・モードを選択した時に起きるサイクル数. OXU アクティブ・モードから OXU スリープ・モードへ. 増加を,どの程度まで許容するかを表す値である.最後. 移行する際の動作について説明する.移行時の動作は以下. に,4)閾値と比べて,1)で得たモード間のサイクル数の. の 2 段階に分かれる.. 差が小さければ OXU スリープ・モードを使用する.上記. ( 1 ) IXU を停止し,既に OXU にある命令の実行終了を待. の 4 段階の動作を一定の命令数を実行する毎に行う.以下. つ.これは OXU スリープ・モードでは ROB を停止. では,切り替え判断におけるそれぞれの動作について詳し. するためである.実行の正しさを保つため,アウト・. く説明する.. オブ・オーダ実行されている命令が全てコミットされ るまで OXU スリープ・モードを開始しない.. 5.1 2 つのモードの実行サイクル数測定及び推定. ( 2 ) 論理レジスタ番号でレジスタ・ファイルにアクセスが. 実行を終えたばかりの命令区間について,OXU アクティ. できるように,レジスタ・ファイル内のデータの並べ. ブ・モードと OXU スリープ・モードのそれぞれで実行した. 替えを行う.. 場合にかかる実行サイクル数 Cycleactive および Cyclesleep. モード切り替えの際には上記の 2 つの動作を終える必要. を求める.2 つのモードの内どちらかは命令区間を実際に. があり,これは切り替え時のペナルティとなる.. 実行しているから,その時の実行サイクル数を測定すれば. 4.2.2 OXU スリープ・モードから OXU アクティブ・. よい.使用されてないモードでの実行サイクル数は推定に. モードへの切り替え. よって導出する.推定には線形回帰モデルを用い,命令区. OXU スリープ・モードから OXU アクティブ・モードに. 間の実行中に得られる複数のメトリックから実行サイクル. 移行する際の動作を説明する.OXU アクティブ・モード. 数を導出する.メトリックとして測定するのは,実行サイ. での実行を開始するためにはレジスタ・リネーミングを再. クル数,分岐予測ミス回数,L1 及び L2 キャッシュ・ミス. 開し,ROB を動作させる必要がある.レジスタ・リネーミ. 回数,L2 キャッシュ・ヒット回数,IXU での実行命令数,. ングについては,OXU アクティブ・モード開始時のマッ. IXU にてレディでないと判断された命令数,IXU のレジス. ピングを,論理レジスタ番号と物理レジスタ番号が同じに. タ読み出しステージのストール回数である.また分岐予測. なるように初期化する.上記の ROB への命令割り当て及. ミスの回数については,OXU で検出されたものと IXU で. びレジスタ・リネーミングの動作の再開は即座に行えるた. 検出されたものとを別々に測定する.これは,それぞれで. め,モード切り替えにおけるペナルティは発生しない.. 分岐予測ミス検出のステージが異なり,分岐予測ミス・ペ. 5. 動作モードの切り替えアルゴリズム. ナルティの大きさに差が生じるためである. 線形回帰モデルはプロファイリングによって決定してい. 本節では,動作モードの切り替えアルゴリズムを説明す. る.両モードで SPECint2006 ベンチマークを入力セット. る.提案手法では OXU スリープ・モードの使用によって. ref を用いてそれぞれ 100M 命令実行し,得られたメトリッ. 性能が大幅に低下する可能性がある.このため,OXU ス. クと性能値のセットから,リッジ回帰を用いて係数を決定. リープ・モードと OXU アクティブ・モードを切り替えて. している.今回係数の決定に使用したベンチマーク及び入. 命令を実行する.本論文における初期検討では,モード切. 力セットは評価に使用したものと同じであるが,本来は異. り替えはコンポジット・コアの論文で提案されているコア. なったものを使用すべきである.本論文においては低消費. 切り替えと同様の方法を適用する [6].. 電力モードの使用によって消費エネルギーの削減がどの程. コンポジット・コアの切り替えアルゴリズムにおいて目. 度行えるかを評価することを優先し,切り替え判断の正し. 的としているのは,ユーザの指定した性能低下の許容量を. さをある程度保証するため,評価に使用したものと同じ環. 超えない範囲で最大限 OXU スリープ・モードを使用する. 境で係数を決定した.. ことである.切り替え判断は一定の命令数を実行する毎に 行う.この一定の命令数,すなわち切り替え判断を行なっ てから次の切り替え判断を行うまでの区間を今後命令区間 と呼ぶ. 切り替え判断時の動作について以下で順に説明する.切 り替え判断における動作は 4 段階に分けることができる.. c 2015 Information Processing Society of Japan ⃝. 5.2 目標とする総実行サイクル数の算出 各モードでの命令区間の実行サイクル数の導出後,目標 とする総実行サイクル数 Cycletarget の算出を行う.切り替 え実行においては実際の総実行サイクル数 Cycleactual がこ の値と一致することを目指す.. 5.
(6) Vol.2015-ARC-216 No.17 2015/8/5. 情報処理学会研究報告 IPSJ SIG Technical Report. 全命令区間を OXU アクティブ・モードで実行した場合 の,最短の総実行サイクル数は区間ごとの Cycleactive を 累積することで得られる.この最短の総実行サイクル数と ユーザの指定する性能低下率(サイクル数の増加率ともい える)を用いて,Cycletarget を求める(式(i) ) .式(i)の. Slowdownallowed は許容する性能低下率を表しており,ユー ザが決定する値である.. Cycletarget =. ∑. Cycleactive ×(1+Slowdownallowed ) (i) 図 3. 5.3 閾値の計算 求めた目標サイクル数 Cycletarget と実際の総実行サイク. 提案手法による消費エネルギーの削減ができる性能推移の例. イクル数の増加が少ない命令区間に遭遇したということ. ル数 Cycleactual の差 Cycleerror(式(ii) )から,OXU スリー. であるから,まさに望んでいる状況での切り替えになる.. プ・モードを使用するかの判断に用いる閾値 Cyclethreshold. 2)の閾値が大きいということは,式(ii),(iii)より,目. を計算する.この閾値は,OXU スリープ・モードを選択し た時に起きるサイクル数の増加を,どの程度まで許容する かを表す値である.閾値は目標サイクル数に対する PI 制 御をもとに導出される(式(iii)).式(iii)において,比 例定数 Kp にかかっている Cycleerror は直近の命令区間ま での Cycleerror で,積分定数 Ki にかかっているのは,そ れより過去の Cycleerror を全て足しあわせたものになる.. Cycleerror = Cycletarget − Cycleactual (ii) ∑ Cyclethreshold = Kp Cycleerror + Ki Cycleerror (iii). 標サイクル数 Cycletarget に比べて現在の総実行サイクル数. Cycleactual にかなりの余裕があることを示す.この場合, モード間で実行サイクル数の差が大きい命令区間でも OXU スリープ・モードが選択されることになる.しかし,実 行サイクル数の差が大きい区間では,Cycletarget の増加量. Cycleactive × (1 + Slowdownallowed ) よりも Cycleactual の増 加量 Cyclesleep の値がかなり大きい.OXU スリープ・モー ドでの実行によって,短時間で Cycletarget と Cycleactual の 間の差がなくなり,閾値は減少する.そのため,実行サイ クル数の差が大きい命令区間での OXU スリープ・モード の実行は長く続かない.. 5.4 モードの選択 計算した閾値と比べて,次命令区間におけるモード間の. 5.5 効果. 実行サイクル数の差が小さければ,OXU スリープ・モー. 提案する OXU アクティブ・モードと OXU スリープ・. ドを使用する(式(iv)).実際には,次命令区間における. モードの切り替え実行によって,電力効率の改善が期待で. モード間の実行サイクル数の差を得る手段はないため,手. きる.これは,提案手法では 1)両モードの性能差が大き. 順(1)で導出した Cycleactive および Cyclesleep のサイクル. い命令区間では OXU アクティブ・モードの使用によって. 差を用いる.これには,直前の命令区間の実行性能と同様. 性能の低下を防ぎつつ,2)両モードの性能差が小さい命. の特性を持った命令列が次も現れるという仮定が置かれて. 令区間では OXU スリープ・モードを使用することで消費. いる.. エネルギーの削減が行えるためである. 提案手法によって性能低下を抑えながら消費エネルギー. Cyclesleep − Cycleactive ≥ Cyclethreshold Select Active Mode Cyclesleep − Cycleactive < Cyclethreshold Select Sleep Mode. の削減が行えることを図 3 の例を用いて説明する.図 3 は, ある命令列をそれぞれのモードで実行した際の性能をグラ. (iv). フにしたものである.縦軸は IPC を,横軸は実行命令数を 表す.命令列の区間 A では両モードの実行性能には大き な開きがあり,区間 B では性能差はほとんどない.赤色の 線で示すのは命令区間を OXU アクティブ・モードで実行. OXU スリープ・モードが選択される条件についてまと. した際の性能 IP Cactive で,青色の線で示すのは OXU ス. める.OXU スリープ・モードが選択されるのは,(iv)式. リープ・モードで実行した場合の性能 IP Csleep である.グ. より,1)両モードでのサイクル数 Cycleactive と Cyclesleep. ラフが太線になる部分は,切り替え実行においてそのモー. の間に差がない場合か,2)閾値 Cyclethreshold の値が大き. ドが使用されていることを示す.. い場合である.. 1)については,OXU スリープ・モードを使用してもサ. c 2015 Information Processing Society of Japan ⃝. 図 3 の区間 A のように,モード間で性能差の大きい命令 列の実行における切り替えの動作を説明する.性能差が大. 6.
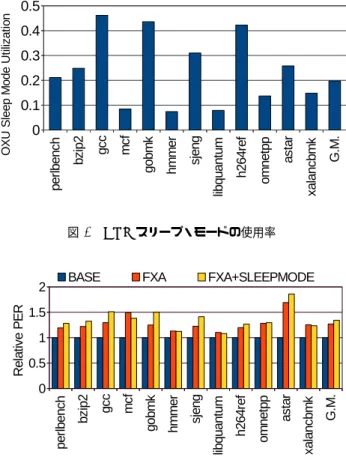
(7) Vol.2015-ARC-216 No.17 2015/8/5. 情報処理学会研究報告 IPSJ SIG Technical Report 表 1. きいということは,OXU アクティブ・モードでの実行サイ. 評価モデルの構成. クル数に比べて OXU スリープ・モードでの実行サイクル BASE. 数が大きいことを表す.5.4 節で説明したように,このよ. FXA,. LITTLE. FXA+SLEEPMODE. うな命令区間では閾値が十分に大きくない限り OXU アク. Fetch Width. 3. ←. ←. ティブ・モードが選択される.OXU スリープ・モードが. Issue Width. 4. 2. 3. 選択されたとしても,OXU アクティブ・モードに短期間. Retire Width. 3. ←. ←. で復帰する.いずれにしても実行の大半は OXU アクティ. RS. 64 entries. 32 entries. N/A. ブ・モードが行い,大幅な性能低下が起こることはない.. Function Unit ALU:2, FPU:2, ←. 図 3 の区間 B のように,モード間で性能差がない命令列. ←. MEM:2 Load Queue. 32 entries. ←. N/A. の実行における提案手法の動作を説明する.モード間で性. Store Queue. 32 entries. ←. N/A. 能差がほとんどなければ,閾値が小さくとも OXU スリー. ROB. 128 entries. ←. N/A. プ・モードが選択される.OXU スリープ・モードによっ. L1 I-cache. 48KB, 8-way,. ←. ←. ←. ←. ←. ←. Main Memory 200 cycles. ←. ←. IXU. width 3, depth 3. N/A. 64 bytes/line,. て,OXU アクティブ・モードとほぼ同じ性能で実行しな. 2 cycles. がら消費エネルギーの削減ができる. このように,提案手法ではモード間で性能差の大きい命. L1 D-cache. 64 bytes/line,. 令区間では OXU アクティブ・モードでの実行,性能差の 小さい命令区間では OXU スリープ・モードでの実行を切. 32KB, 12-way, 2 cycles. L2 cache. 512KB, 8-way,. り替えることができる.これによって大幅な性能低下を防. 64 bytes/line,. ぎながら消費エネルギーを削減する.. 12cycles. 6. 評価. N/A. 本節では提案手法を評価する.まず 6.1 節で評価環境に ついて説明し,6.2 節で評価モデルについて述べる.その 後,6.3 節にて提案手法の評価を行い,6.4 節で理想的な切 り替え実行との比較を行う.. セッサ 表 1 にベースとなるプロセッサと FXA の主な構成を示す.. BASE モデルのプロセッサのパラメータは,big.LITTLE に使用されている ARM Cortex-A57 を参考としている [1].. 6.1 評価環境. FXA+SLEEPMODE モデルにおけるモード切り替え判. 性能の評価には,鬼斬シミュレータ [13] をベースに. 断は,参考にしたコンポジット・コアの構成にならって,. 提案手法を実装したシミュレータを用いた.評価では. 1000 命令毎に行うものとする.また特に記述のない場合,. SPECint2006 に含まれるベンチマーク・プログラムを用い. 切り替え実行で許容する性能低下率は 5%とする.. た.ベンチマーク・プログラムは gcc ver.4.5.3 で,コンパ イル・オプション-O3 でコンパイルした.入力セットには. ref を使用し,プログラムの先頭 1G 命令をスキップした後. 6.3 提案手法の評価 本節では,提案手法の評価を行い,その結果について考. の 100M 命令について測定した.消費エネルギーの評価に. 察する.. は McPAT[5] を用い,22nm テクノロジを想定した.今回. 6.3.1 性能. は,OXU スリープ・モードにおいてクロック・ゲーティ. 提案手法の評価にあたって,まずはじめに 5.5 節で説明. ングは行うと仮定したが,パワー・ゲーティングは行わな. したような切り替え動作が正しく実現されていることを示. いとした.. す.FXA モデルに対する FXA+SLEEPMODE モデルの 性能比を図 4 に示す.ベンチマーク全体の性能低下率の幾. 6.2 評価モデル. 何平均は 5.3%であり,許容した性能低下率 5%を大きく逸. 評価モデルについて説明する.以下のモデルを評価した.. 脱するような性能低下は起こっていない.低消費電力モー. ( 1 ) BASE: 通常のアウト・オブ・オーダ・スーパスカラ・. ドの使用による大幅な性能低下を,提案手法の切り替え方. プロセッサ. ( 2 ) FXA: 従来のフロントエンド実行方式. 式によって防ぐことができている.. 6.3.2 消費エネルギー. ( 3 ) FXA+SLEEPMODE: 従来のフロントエンド実行. 図 5 に各評価モデルにおける,BASE モデルに対する. と OXU スリープ・モードによる実行を切り替えつつ. エネルギー消費量の比を示す.FXA+SLEEPMODE で. 実行する方式. は,BASE と比較して幾何平均で 24.5%,FXA と比較して. ( 4 ) LITTLE: 通常のインオーダ・スーパスカラ・プロ. c 2015 Information Processing Society of Japan ⃝. 10.0%のエネルギー削減となった.FXA+SLEEPMODE. 7.
(8) Vol.2015-ARC-216 No.17 2015/8/5. 情報処理学会研究報告 IPSJ SIG Technical Report. 図 4 FXA に対する FXA+SLEEPMODE の性能比. 図 5 BASE に対するエネルギー消費量の比. モデルが FXA モデルよりも少ない消費エネルギー量で実. 図 6. OXU スリープ・モードの使用率. 図 7. BASE に対する PER の比. の程度の消費エネルギー改善が行われるかを調査する.. 行できたのは,OXU スリープ・モードが活用できたため. 6.4.1 節で,6.3 節の評価に用いた切り替えアルゴリズム. である.OXU スリープ・モードでは,レジスタ・リネー. による実行と理想的な切り替え実行との比較を行う.次に. ムなどアウト・オブ・オーダ実行に必要な処理を省略する. 6.4.2 節で,理想的な切替え実行における切り替え間隔と消. ことで通常の FXA 実行よりも低消費電力で命令の実行が. 費エネルギー量の関係を調査する.. できている.. 6.4.1 理想的な切り替え実行との比較. FXA+SLEEPMODE モデルにおける OXU スリープ・. 本節では,6.3 節の評価に用いたコンポジット・コアの. モードの使用率を図 6 に示す.使用率は全命令の内どれ. 切り替えアルゴリズムによる実行と理想的な切り替え実行. だけの命令を OXU スリープ・モードで実行したかを示し. との比較を行う.適用したコンポジット・コアの切り替え. ている.OXU スリープ・モードの使用率が 25%以上で実. 方式は,理想的な切り替えとは異なる判断をする場面が多. 行できている gcc,gobmk,sjeng,h264ref,astar ベンチ. く存在する.適用した切り替え方式では,5.4 節で述べた. マークでは,いずれも FXA モデルから消費エネルギー量. ように,切り替え後は直前に実行した命令区間と同様の特. を 10%以上削減している.. 性を持つ命令列が現れるという仮定をおいている.このよ. 6.3.3 PER. うな仮定が成り立たない場面では,エネルギー効率を向上. 提案手法を適用した際の性能/エネルギー消費量(PER:. させるような有効な切り替え判断は保証されない.. Performance/Energy Ratio)を測定した結果を図 7 に示. 図 8 は,切り替えアルゴリズムについて様々な理想化. す.PER は高い値であるほど,消費エネルギーあたりの性. を行った場合に,6.3 節の評価からエネルギー削減率が. 能が高いことを表す.FXA+SLEEPMODE では幾何平均. どの程度変化するかを示したものである.凡例の PER-. で,ベース・プロセッサと比較して 34.8%,FXA と比較し. FECT ESTIMATE は,提案手法においてモード間の性. て 5.8%の PER 改善を達成した.. 能推定が正しく行われると仮定したモデルである.PER-. FECT PREDICT は,性能推定の理想化に加え次命令区 6.4 切り替えアルゴリズム. 間の実行性能が完全に予測できるとした場合のモデルで,. 本節では,提案した OXU スリープ・モードを用いた切. ORACLE は全命令区間の実行性能を知っているものとし. り替え実行について,理想的な切り替えを行えた場合にど. た理想的な切り替え判断を行うモデルである.ORACLE. c 2015 Information Processing Society of Japan ⃝. 8.
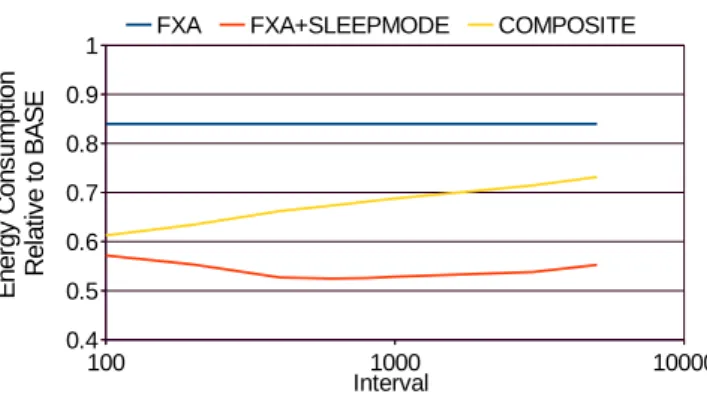
(9) Vol.2015-ARC-216 No.17 2015/8/5. 情報処理学会研究報告 IPSJ SIG Technical Report. 図 8. 切り替えを理想化した場合のエネルギー消費量. 図 9. 切り替え間隔とエネルギー消費量の関係. の切り替えについて説明する.ORACLE では,各命令区間. 費エネルギー削減量は COMPOSITE モデルよりも優って. について,OXU スリープ・モードで実行した場合に OXU. いる.これは切り替え実行による消費エネルギーの削減に. アクティブ・モードの実行からサイクル数がどれだけ増加. 加えて,元々の FXA 実行のエネルギー効率の高さという. するかがわかっている.全命令区間のうち,この増加サイ. 有利があるためである.COMPOSITE モデルがアウト・. クル数が小さいものから順に OXU スリープ・モードでの. オブ・オーダ実行とインオーダ実行の切り替えであるのに. 実行を予約していく.予約した各命令区間の増加サイクル. 対し,提案手法はエネルギー効率の高い FXA 実行とイン. 数の累計が,許容される総実行サイクル数の増加量を越え. オーダ実行との切り替えを行うため,より多くのエネル. た時点で予約を終了する.OXU スリープ・モードでの実行. ギー削減が可能になる.. を予約されなかった残りの命令区間は全て OXU アクティ ブ・モードで実行する.. FXA+SLEEPMODE モデルで 1000 命令よりも細粒度 な切り替えを行った際にエネルギー消費量が増加するの. グラフをみると,現状での切り替え実行と理想的な切り. は,切り替えペナルティ増加の影響が,より細粒度な切り. 替えが行えた場合の実行の間には,エネルギー消費量に未. 替えで新たに得られるエネルギー削減量よりも大きいため. だ大きな開きがある.これは切り替え方式を改善すること. であると考える.より細粒度な切り替えで得られるエネル. で更なるエネルギー削減が見込めることを示す.例えば,. ギー削減量が提案手法において少ない理由は明らかになっ. 図 8 の PERFECT PREDICT モデルのように,次区間の. ておらず,調査中である.. 実行性能を何らかの手法で予測し,判断に用いることがで きればエネルギー効率を向上させることができる.. 7. まとめ. PERFECT ESTIMATE モデルは提案手法の切り替えア. 一般に,アウト・オブ・オーダ・スーパスカラ・プロセッ. ルゴリズムにおける最良のモデルを示しているが,結果に. サは高性能である反面,インオーダ・プロセッサと比べて. あるように性能推定精度の向上によって得られる利益は少. 消費エネルギーが非常に大きい.この問題に対し,これま. ない.これは,更なるエネルギー削減のためには新たな切. で我々はインオーダ実行系とアウト・オブ・オーダ実行系. り替えアルゴリズムの考案が必要であることを示している.. の 2 つの実行系を使い分ける,フロントエンド実行方式を. 6.4.2 切り替え間隔との関係. 提案してきた.フロントエンド実行方式ではインオーダ実. 本節では,切り替えの判断を行う間隔を変更することで,. 行系で多くの命令を実行でき,インオーダに命令実行でき. 理想的な切り替えを行った場合に得られるエネルギー削減. るフェーズも多く存在する.このようなフェーズでの FXA. 量がどの程度変化するかを評価する.. の動作はインオーダ実行となるにも関わらず,アウト・オ. 図 9 は理想的な切り替え実行を行った場合について,切. ブ・オーダ実行系との協調のために通常のインオーダ・プ. り替え間隔を変更した場合に BASE モデルに対するエネ. ロセッサと比べて大きなエネルギーを消費する.これに対. ルギー消費量がどの程度になるかを示したものである.比. し,本論文では,フロントエンド実行方式に,アウト・オ. 較対象として,従来の FXA 実行結果を示す FXA モデル. ブ・オーダ実行系を停止してインオーダ実行系のみで命令. と,コンポジット・コア [6] の切り替え実行をモデルとし. 実行を行う低消費電力な実行モードを追加し,適宜モード. た COMPOSITE を示す.COMPOSITE モデルは BASE. を切り替えながら実行を行う手法を提案した.評価の結. モデルと LITTLE モデルの切り替えを評価に用いている.. 果,SPECint2006 ベンチマーク・プログラムにおいて,通. FXA モデルはモードの切り替えは行わないため消費エネ. 常の FXA 実行と比較して 95 %の性能を維持しつつ,平均. ルギー量は一定である.. 10.0 %のエネルギー削減,PER で平均 5.8 %の向上を果. グラフより,FXA+SLEEPMODE モデルで得られる消. c 2015 Information Processing Society of Japan ⃝. たした.またモードの切り替えアルゴリズムの初期検討を. 9.
(10) Vol.2015-ARC-216 No.17 2015/8/5. 情報処理学会研究報告 IPSJ SIG Technical Report. 行った.従来から提案されてきた切り替えアルゴリズムに よる実行と理想的な切り替え実行との比較を行った結果, 両者の間にはエネルギー消費量に未だ大きな差が存在し, 切り替えアルゴリズムの改善によって更なるエネルギー削. [12] [13]. Yeager, K.: The MIPS R10000 Superscalar Microprocessor, IEEE Micro, Vol. 16, No. 2, pp. 28–40 (1996). 塩谷亮太, 五島正裕, 坂井修一:プロセッサ・シミュレー タ「鬼斬弐」の設計と実装, 先進的計算基盤システムシン ポジウム SACSIS , pp. 120–121, (2009).. 減量の増加が見込めることを確認した. 謝辞 本研究の一部は,日本学術振興会 科学研究費補助 金 基盤研究 (C)(課題番号 25330057) ,および日本学術振 興会 科学研究費補助金 若手研究 (A)(課題番号 24680005) による補助のもとで行われた. 参考文献 [1] [2] [3] [4]. [5]. [6]. [7]. [8]. [9]. [10]. [11]. Bolaria, J.: Cortex-A57 Extends ARM’s Reach, Microprocessor Report 11/5/12-1, pp. 1–5 (2012). Greenhalgh, P.: Big.LITTLE Processing with ARM Cortex-A15 and Cortex-A7, ARM White Paper (2011). Kessler, R.: The Alpha 21264 Microprocessor, IEEE Micro, Vol. 19, No. 2, pp. 24–36 (1999). Kumar, R., Ferkas, K. I., Jouppi, N. P., Ranganathan, P. and Tullsen, D. M.: Single-ISA Heterogeneous MultiCore Architectures: The Potential for Processor Power Reduction, Proceedings of the 36th Annual International Symposium on Microarchitecture, pp. 81–92 (2003). Li, S., Ahn, J. H., Strong, R. D., Brockman, J. B., Tullsen, D. M. and Jouppi, N. P.: McPAT: An Integrated Power, Area, and Timing Modeling Framework for Multicore and Manycore Architectures, Proceedings of the 42nd Annual International Symposium on Microarchitecture, pp. 469–480 (2009). Lukefahr, A., Padmanabha, S., Das, R., Sleiman, F. M., Dreslinski, R., Wenisch, T. F. and Mahlke, S.: Composite Cores: Pushing Heterogeneity into a Core, Proceedings of the 45th Annual International Symposium on Microarchitecture, pp. 317–328 (2012). Padmanabha, S., Lukefahr, A., Das, R. and Mahlke, S.: Trace Based Phase Prediction for Tightly-coupled Heterogeneous Cores, Proceedings of the 46th Annual International Symposium on Microarchitecture, pp. 445–456 (2013). Rangan, K. K., Wei, G.-Y. and Brooks, D.: Thread Motion: Fine-grained Power Management for Multicore Systems, Proceedings of the 36th Annual International Symposium on Computer Architecture, pp. 302– 313 (2009). Shioya, R., Goshima, M. and Ando, H.: A Front-end Execution Architecture for High Energy Efficiancy, Proceedings of the 47th Annual International Symposium on Microarchitecture, pp. 419–431 (2014). Sinharoy, B., Kalla, R., Starke, W. J., Le, H. Q., Cargnoni, R., Van Norstrand, J. A., Ronchetti, B. J., Stuecheli, J., Leenstra, J., Guthrie, G. L., Nguyen, D. Q., Blaner, B., Marino, C. F., Retter, E. and Williams, P.: IBM POWER7 Multicore Server Processor, IBM Journal of Research and Development, Vol. 55, No. 3, pp. 191–219 (2011). Suleman, M. A., Mutlu, O., Qureshi, M. K. and Patt, Y. N.: Accelerating Critical Section Execution with Asymmetric Multi-core Architectures, Proceedings of the 14th International Conference on Architectural Support for Programming Languages and Operating Systems, pp. 253–264 (2009).. c 2015 Information Processing Society of Japan ⃝. 10.
(11)
図
![図 1 ベースとなるアーキテクチャ 図 2 フロントエンド実行方式 らに向上する [6], [7] が,正しい切り替え判断を行うこと が困難になっていく [7] .粗粒度にみて性能が安定してい るフェーズでも,細粒度にみると性能は大きく変動してい る.文献 [4], [6], [8], [11] で提案された手法はいずれも,直 近のサンプリング情報をもとに,今後も同様の特性を持つ フェーズが現れるという仮定のもと切り替え判断を行って いる.これらの仮定は細粒度な切り替えでは成立が難しい ため,正しい切り替え](https://thumb-ap.123doks.com/thumbv2/123deta/5852154.1542237/3.892.94.408.97.389/アーキテクチャフロントエンドフェーズサンプリングフェーズ.webp)
関連したドキュメント
繊維フィルターの実用上の要求特性は、従来から検討が行われてきたフィルター基本特
全国の宿泊旅行実施者を抽出することに加え、性・年代別の宿泊旅行実施率を知るために実施した。
Such a survey, if determined necessary, shall ensure that the attained EEDI is calculated and meets the requirement of regulation 21, with the reduction factor
「令和 3 年度 脱炭素型金属リサイクルシステムの早期社会実装化に向けた実証
はじめに
・子会社の取締役等の職務の執行が効率的に行われることを確保するための体制を整備する
当初申請時において計画されている(又は基準年度より後の年度において既に実施さ
DJ-P221 のグループトークは通常のトーンスケルチの他に DCS(デジタルコードスケル
