多変量解析を用いた日本人英語学習者の発達指標の特定
6
0
0
全文
(2) The Computers and the Humanities Symposium, Nov.2012 テストの評価と開発のために必要な基礎資料も 提 供 で き る よ う に な る (Tono, Kawaguchi, & Minegishi, 2012).. 2.研究の目的 本研究は, 7 つの異なる習熟度グループに属す る日本人英語学習者(初級・中級・上級)が, 57 項目にわたる多種多様な言語項目(語彙・品詞・ 統語構造・談話構造など)をどれくらいの頻度で 使用しているかという情報をもとに, 多変量解 析(コレスポンデンス分析とクラスター分析)を 用いて, 発達の指標となる言語項目を特定する ことを目的とする.. 3. 使用コーパス ここでは, The National Institute of Information and Communications Technology Japanese Learner English (NICT-JLE) コーパス (和泉, 内元, & 井 佐原, 2004) を利用する. この学習者コーパスは, ACTFL OPI に準拠した約 15 分間の Speaking Standard Test (SST) を受験した日本人英語学習者 の発話データから構築されており, 現時点では 日本国内において最大級の規模の発話コーパス である. そのスピーキングテストは, 複数のタスクによ って成立しており, 主に 1 枚の絵の描写, ロール プレイ, 複数の絵を使った物語の作成といった タスクを受験者は 15 分間の間に行う. それぞれ のタスクにおいて, 同一の絵が用いてられてい るわけではなく, またロールプレイも同一では ないため, タスクの違いによって, 学習者の言語 使用にも差がでることが予想されるが, 本研究 においては, すべてのデータを分析対象として おり, タスクによる言語使用の差は考慮してい ない. また NICT-JLE コーパスは, スピーキングテス トを受けた学習者の発話によって構築されてい るため, 専門の評価官が一定の基準により判定 した 9 段階の習熟度情報が 1263 名分のデータに すべて付与されているという大きな利点がある. 同一の英語学習者の発話がどのように発達する かを追跡することはできないため, 厳密な縦断 研究とはいえないが, 習熟度情報を利用するこ とで, 英語学習者の発話がどのように全体的な 傾向をもちながら, 発達するのかに関する分析 を行うことができる. また日本人英語学習者が産出する英語は, 英 語母語話者の英語とは異なり、誤りが多く不完全 である. そのため, 学習者言語の発達の様相を概. 観的に観察するためには, 大規模なデータが必 要になる. この点においても, 幅広い習熟度に分 布した学習者データから構築されている国内最 大級の NICT-JLE コーパスのサイズ(合計で 100 万語を超える)は, 学習者個人の多様な言語発達 の過程を追うことはできなくても, 全体的な学 習者言語の発達の傾向を探るためには, 非常に 有用である. NICT-JLE コーパスが準拠しているスピーキン グテストのレベルを ACTFL OPI レベルと比較す ると, 日本人英語学習者を判定するための上級 レベルは 1 つしかないが, 中級レベルが 5 つに区 分されているのが特徴的である(表 1 参照). 表 1. ACTFL OPI と SST レベルの比較 ACTFL OPI SST Superior 9 (Advanced) Advanced High Advanced Mid Advanced Low Intermediate High 8 (Intermediate High) Intermediate Mid 7 (Intermediate Mid-plus) 6 (Intermediate Mid) Intermediate Low 5 (Intermediate Low-plus) 4 (Intermediate Low) Novice High 3 (Novice High) Novice Mid 2 (Novice Mid) Novice Low 1 (Novice Low) この話し言葉コーパスにおいては, 特にレベ ル 4 (Intermediate Low) とレベル 5 (Intermediate Low-plus) に学習者が集中している(表 2. 参照). スピーキングテストの受験者は, おもにビジネ スにたずさわる日本人英語学習者であるが, レ ベル 4 (Intermediate Low) が平均的な日本人英語 話者の会話レベルであると予想される. また逆 に, レベル 9 (Advanced) に関しては, 海外での生 活年数が長い受験生が多かった. さらなる NICT-JLE コーパスの特徴として, 英 語学習者と同じスピーキングテストのタスクを 行った 20 名分の英語母語話者のデータが加えら れていることがあげられる. この母語話者デー タを用いることで, 学習者言語の特徴をより明 確にすることができるため, 本研究では分析対 象に加えている. しかしながら逆に, レベル 1 (Novice Low) とレベル 2 (Novice Mid) と判定さ れたデータに関しては, 学習者の発話が文では なく, 単語単位で構成されていることが多いう え, 多くの発話が学習者ではなく, インタビュー アーによって進められている傾向があ るため, 本研究の分析対象には含んでいない.. (c) Information Processing Society of Japan. - 56 -.
(3) 「人文科学とコンピュータシンポジウム」 2012年11月 表 2.. 使用コーパスの大きさ(レベル別). level 3 4 5 6 7 8 9 NS total. participants 222 482 236 130 77 56 40 20 1, 263. seem_appear, split_auxiliary, split_infinitive, stranded_preposition, suasive_verb, synt_negation, that_clause_by_adjective, that_clause_by_verb, that_relative_object, that_relative_subject, thrdpsn_pro, time_adv, to_clause, total_adv, total_noun, wh_clause, wh_question, wh_relative_front_preposition, wh_relative_object, wh_relative_subject. tokens 95, 352 308, 544 204, 048 130, 678 85, 395 68, 539 54, 394 84, 774 1, 031,724. スピーキングテストの受験生の数には, ばら つきがみられるが, 習熟度が上がるにつれ, 受験 生一人あたりの平均総語数は着実に増加してい ることが分かる(図 1. 参照) 5,000 4,000 3,000 2,000 1,000 0 3. 4. 5. 6. 7. 8. 9. NS. SST レベル 図 1. 平均総語数の変化(レベル別). 4. 分析項目 本研究において分析する言語項目としては , Biber (1988) が, 英語母語話者の話し言葉と書き 言葉を分析するために用いた 67 項目のうち, 以 下の 57 項目を利用した. agentless_passive, amplifer, analytic_negation, attributive_adjective, be_main_verb, by_passive, caus_adv_sub, conce_adv_sub, cond_adv_sub, conjunct, contraction, demonstrative_pronoun, discourse_particle, downtoner, emphatic, exist_there, frstpsn_pronoun, hedge, ind_clause_coorination, indef_pronoun, it_pronoun, nece_modal, nominal, other_adverbial_subordinator, past_tense, perfect_aspect, phrasal_coordination, place_adv, poss_modal, pp_postnominal_clause, predicative_adjective, predictive_modal, preposition, private_verb, proverb_do, public_verb, scndpsn_pronoun,. なお, 総語数、異語数、平均発話長は, 分析対 象に含んでいない. またプログラミング上, 頻度 を抽出するにあたって問題のあった項目も含ま れていないため, 分析対象は 57 項目となってい る. しかしながら, Biber (1988) によって選定され たこの 67 項目の選択には, 明確な基準がないこ とが Nakamura (1995) において指摘されている. 加えて, これらの言語項目は, 日本人英語母語話 者を分析するために選択されたものではないう え, 英語母語話者の話し言葉と書き言葉の違い を明確にする目的で選定されている. そのため, 日本人英語学習者にとって, 習得が困難である と考えられている冠詞などが含まれていない . しかし, 本研究を発展させた将来的な研究にお いて, (a) より書き言葉的な特徴を示す言語項目 はどれくらいのレベルまで産出されるのかとい う点と, (b) より話し言葉の特徴を示す言語項目 がどれくらいのレベルから頻繁に産出されるよ うになるのかについても分析と考察を行う必要 があるためにも, 話し言葉と書き言葉の差異を 明らかにするために選定された Biber (1988) に おける言語項目を分析対象とした. また, 日本人 英語学習者の発達の特徴を示す言語項目に関し ては, 今後 Biber (1988) において含まれていない 項目も分析対象としていく必要がある.. 5. 分析手順 まず学習者の話し言葉のデータから, 本研究の 分析に不必要な情報を削除したのち, TreeTagger (Schmid, 1994) を用いて, 品詞情報を付与した. 英語学習者のデータは語彙や構文上の誤りが多 いため, 品詞タグを自動で付与する場合, その精 度が落ちると考えられる. 例えば, 従属接続詞 の because は前置詞に, 前置詞 to は to-不定詞と して認識される (阪上他, 2008). そこで本研究で は, それぞれのレベルから品詞情報が付与され た 150 語分のサンプルを抽出し, その精度を確認 した. その結果, すべてのレベルにおいて, 90 パ ーセンテージ以上の精度があることが確認され た.. (c) Information Processing Society of Japan. - 57 -.
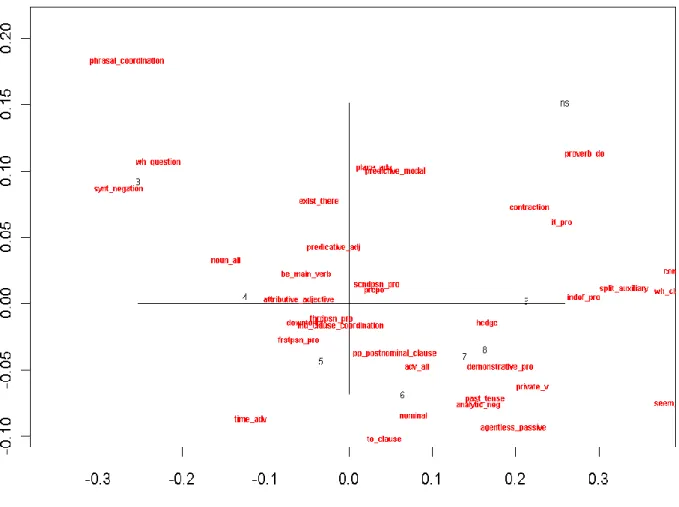
(4) The Computers and the Humanities Symposium, Nov.2012 次に各言語項目の使用頻度をレベルごとに算 出するために, Biber (1988) の手法を用いて, ア ジ ア 各 国 の 英 語 教 科 書 を 分 析 し た Murakami (2009) で使用されている Perl スクリプトを利用 させてもらった. なお本研究は, 教科書とは異な り, 誤りの多い英語学習者の話し言葉をデータ として扱っているため, より正確に学習者の言 語使用の頻度を算出できるよう Perl スクリプト に手を加えている. そして統計手法については, コレスポンデンス 分析をまずもちいて, 習熟レベルと言語項目の 関係をグループづけた後, その結果をさらにク ラスター分析を利用して詳細に分析した. Biber (1988) が分析に用いた因子分析ではなく、レベル 間の言語使用の類似関係と相違関係を探り, そ のグループづけを行うために有効であるコレス ポンデンス分析を用いている. この統計手法を 用いた学習者コーパス研究 (小林, 2007) がその 有用性はすでに明らかにしている. この統計手 法は, 膨大な変数の中から意味のあるパターン を少数の次元にまとめ, 大量のデータを要約す るため, データの全体像をつかみやすくすると いう利点がある(Baayen, 2008). そしてその処理 結果を性質の近いものは近くに, 遠いものは遠 くに配置して, 視覚化してくれるのである. つま り, 変数間の類似関係や差異を調べるような研 究にはふさわしいといえる(田畑, 2004 年; 水本, 2009 年).. 6. 結果と考察 コレスポンデンス分析の結果, 図 1 の散布図に おいて X 軸が示す Factor 1 には, 78. 7% の説明力 があった. 散布図中の数字は, 学習者のレベルを 表しており, ns は英語母語話者を示している. こ の散布図をみると, 学習者のレベルが散布図の 左側から右側にかけて上昇しており, 分析対象 となった 57 項目がそれぞれのレベルの近くに配 置されていることが分かる. レベルと言語項目 の結びつきをクラスター分析によって詳細にグ ループづけした結果は, 以下の通りである. ① レベル 3: WH questions, synthetic negation, phrasal coordination ② レベル 4: nouns, BE as main verb, predicative adjectives, ③ レベル 5: attributive adjectives, downtoners, independent clause coordination, 1st person pronouns, 3rd person pronouns. ④ レベル 6: prepositions, adverbs, causative adverbial subordinators nominalization, TO clause, past participial postnominal clause ⑤ レベル 7, レベル 8, & レベル 9: analytic negation, past tense, hedge, demonstrative pronouns, private verbs, agentless passives, indefinite pronouns ⑥ 英語母語話者: pronoun IT, contraction, DO as pro-verb, stranded preposition, perfect aspect, emphtic まず, レベル 3 (Novice High) にグループづけ られた(a) WH questions, (b) synthetic negation (e.g., I have no time at all.), (c) phrasal coordination (e.g., very difficult and very interesting) の使用頻度の増 減をレベルごとにみると, 緩い U 字型のカーブ を描いているのであるが, これらの項目はどれ もレベル 3 の初級の英語学習者によって, 最も多 く用いられていた. 次に, レベル 4 (Intermediate Low) とレベル 5 (Intermediate Low-plus) にグループづけられた言 語項目をみると, それらの言語項目は, どの習熟 レベルにおいても比較的多く使用されるもので あることが分かった. つまり, これらの項目は, 基本的な英文を構成するために欠かせない項目 であった. 例えば, 主語+動詞+補語の構文をつ くるために, (a) personal pronouns, (b) BE as main verb, (c) predicative adjectives などがその例とし てあげられるが, 特にレベル 4 において, これら の項目は特徴的に使用されているのである. そ して, この文型を用いて, 個人的な状態や話題に ついて述べている例が多く見られた (e.g., I’m tired. I’m not good at playing golf.). しかしながら, 上級レベルになると, private verbs との結びつき が強くなることが分かった。個人的な状況だけで はなく、private verbs (e.g., I can’t believe how cheap cell phones are here. I assume that she was very happy to find out the thirty percent discount and fifty percent discount at the same day.) を用いて、個人的 な心情や考えを述べる話題にも対応することが できるようになるといえるのである. さらには, (a) downtoners (e.g., Maybe it was nearly one month ago.), (b) independent clause coordination (e.g., I’m in the purchasing department, and I’m responsible for buying engine parts.), (c) predictive modals など基本的な会話を行うために 必要な項目も中級レベルと結びつきが強い言語 項目であることが明らかになった. 次にレベル 6 (Intermediate Mid) にグループづ けされた言語項目をみると, それらはより複雑 な文を構成するために, また一文中の情報密度. (c) Information Processing Society of Japan. - 58 -.
(5) 「人文科学とコンピュータシンポジウム」 2012年11月 を増加させるためには不可欠な言語項目である ことが明らかになった. その例としては, (a) nominalization (e.g., humidity, kindness, seniority), (b) past participial postnominal clause (e.g., big lodge made by wood, works written by the female novelist), (c) TO clause (e.g., we don’t have enough space to keep something we don’t want. we should raise arts manager or arts administrator to use a hall for many people), (d) preposition (e.g., I take Japanese breakfast with miso soup. ) などがある. そして, レベル 7 (Intermediate Mid-plus), レベ ル 8 (Intermediate High), レベル 9 (Advanced) およ び 英語母語話者と結びつけられた言語項目は, それ以外のレベルの英語学習者があまり使用し ない項目であることが分かった. その例として は, (a) analytic negation (e. g., it was not really fresh), (b) hedges (e.g., I’d like to have something like this . . . ), (c) emphatics (e.g., That is a bargain for sure.) などがある. 発話の発達をそれぞれのレベルと関係づけら れた代名詞を通してみると, レベル 5 には, (a) 1st person pronouns, (b) 3rd person pronouns という人 称代名詞がグループづけられており, より高い レベル 7~9 にかけては, (a) demonstrative pronouns (e.g., That’s not fair. ), (b) indefinite pronouns (e.g., I mean, anyone can come in.) などの 非人称代名詞が結び付けられていた. このこと から, 英語学習者が会話の中で, 身近な人物など のような具体的なものから, 不特定なものを指 し示すことができるようになることが見てとれ る。また, 名詞の繰り返しを避けたり, 前出の節 や文の内容を示したりすることができるように なる様子がわかる. さらに, 英語母語話者は (a) pronoun it (e.g., So I guess it’s really popular.) だけ ではなく, (b) pro-verb do (e.g., Once in a while, we do.) とグループづけられており, 代動詞を会 話の中で利用していることが明らかになった.. 7. 結論 このように言語処理技術を用いて, 大規模な 学習者コーパスのデータから頻度情報を抽出し, 多変量解析の手法を用いた結果, 日本人英語学 習者の習熟レベルの発達指標になりうると推測 される言語項目を特定することができた. 今後 は, グループ分けされた言語項目に関して, より 質的な分析を行うことで, 学習者言語の全体像 を多面的に記述することが必要となる.. 参考文献 [1] Abe, M. A corpus-based investigation of errors across proficiency levels in L2 spoken production. JACET Journal, Vol. 44, pp.1-14, 2007a. [2] Abe, M. Grammatical errors across proficiency levels in L2 spoken and written English. The Economic Journal of Takasaki City University of Economics, Vol. 49, pp.117-129, 2007b. [3] Baayen, R. H. Analyzing linguistic data: A practical introduction to statistics using R. Cambridge: Cambridge University Press, 2008. [4] Biber, D. Variation across speech and writing. New York: Cambridge University Press, 1988. [5] Biber, D., Conrad, S., & Reppen, R. Corpus linguistics: Investigating language structure and use. Cambridge: Cambridge University Press, 1998. [6] Hawkins, J. A., & Buttery, P. Using learner language from corpora to profile levels of proficiency: Insights from the English profile programme. In L. Taylor & C. J. Weir (Eds.), Language testing matters: Investigating the wider social and educational impact of assessment, pp.158-175. New York, NY: Cambridge University Press, 2009. [7] Hawkins, J. A., & Buttery, P. Criterial features in learner corpora: Theory and illustrations. English Profile Journal, Vol. 1, No. 1, pp.1-23, 2010. [8] Murakami, A. A corpus-based study of English textbooks in Japan and Asian countries: Multidimensional approach. (Unpublished master’s thesis). Tokyo University of Foreign Studies, Tokyo, 2009. [9] Myles, F. Interlanguage corpora and second language acquisition research. Second Language Research, Vol. 21, No. 4, pp.373-391, 2005. [10] Nakamura, J. (1995). Text typology and corpus: A critical review of Biber’s methodology. English Corpus Studies, Vol. 2, pp.75-90, 1995. [11] Pendar, N., & Chapelle, C. Investigating the promise of learner corpora: Methodological issues. CALICO Journal, Vol. 25, No. 2, pp.189-206, 2008. [12] Schmid, H. (1994). Probabilistic part-of-speech tagging using decision trees. Revised version of a paper presented at the International Conference on New Methods in Language Processing, Manchester, England. [13] Tono, Y., Kawaguchi, Y. & Minegishi, M. (Eds.), Developmental and Cross-linguistic Perspectives in Learner Corpus Research. Amsterdam: John Benjamins, 2010. [14] 和泉絵美, 内元清貴, 井佐原均(編): 日本 人 1200 人の英語スピーキングコーパス, 東京: アルク, 2004.. (c) Information Processing Society of Japan. - 59 -.
(6) The Computers and the Humanities Symposium, Nov.2012 [15] 小林雄一郎: The NICT JLE Corpus における 発達指標の研究―コレスポンデンス分析によ るタグ頻度解析, 言語処理学会第 13 回年次大 会発表論文集, pp.486-489, 2007. [16] 阪上辰也, 古泉隆, 小島ますみ, 杉浦正利: 品詞連鎖に着目した日本人英語学習者の中間 言語の特徴分析―学習者コーパス NICE を用い て―, 英語コーパス学会第 32 回大会研究発表, 2008. [17] 水本篤: コーパス言語学研究における多変 量解析手法の比較―主成分分 vs. コレスポン デンス分析, コーパス言語研究における量的 データ処理のための統計手法の概観, 統計数 理研究所共同研究レポート 232, pp.53-64. 2009. [18] 田畑智司: -ly 副詞の生起頻度解析による文 体識別-コレスポンデンス分析と主成分分析に よる比較研究-,電子化言語資料分析研究, pp.97-114, 2004.. Factor 1: English oral proficiency level (78.7%) 図 1:コレスポンデンスの散布図. (c) Information Processing Society of Japan. - 60 -.
(7)
図
関連したドキュメント
友人同士による会話での CN と JP との「ダロウ」の使用状況を比較した結果、20 名の JP 全員が全部で 202 例の「ダロウ」文を使用しており、20 名の CN
本稿では,まず第 2 節で,崔 (2019a) で設けられていた初中級レベルへの 制限を外し,延べ 154 個の述語を対象に「接辞
高校生の英語力到達目標は、CEFR A2レベルの割合を全国で50%にするこ とである。これに対して、2018年でCEFR
スキルに国境がないIT系の職種にお いては、英語力のある人材とない人 材の差が大きいので、一定レベル以
アジア地域の カ国・地域 (日本を除く) が,
変態期 PRL 受容体 mRNA レベルを RNase protection assay で測定した。尾ひ れでは前肢の出る stage XX で PRL 受容体 mRNA レベルが増加し、尾の退縮が
しかし,そのほとんどは,業務レベルなど,特定の分析レベルにおける効率性
圧電材料 Macro-fiber composite 部材レベル 安全性・耐久性. インピーダンス計測チップ
