ワークロード最適化シミュレータの設計と実装
12
0
0
全文
(2) Vol. 46. No. SIG 12(ACS 11). ワークロード最適化シミュレータの設計と実装. 99. のシミュレータの命令スケジューラを 100 倍高速にし. 割込み処理をエミュレートできるようにダイナミック・. ても全体の SD は 110 となり,速度は 10 倍にしかな. バイナリ変換を拡張し,OS のシミュレートを実現した.. らない.このとき同時に命令エミュレータを 10 倍高. バイナリ変換では命令シーケンスを変換するための. 速化することができれば,全体の SD は 20 となり 55. 変換テーブルを作成する必要がある.しかし,一般に. 倍の高速化が達成できる.. それぞれの ISA が 1 対 1 に対応するとは限らず,作. そこで,本論文では高速な命令エミュレーションを. 成が困難な場合もある.しかも,ターゲット,ホスト. 実現するためのワークロード最適化シミュレータを提. のどちらかのアーキテクチャを変更するたびにこの変. 案する.これは個々のワークロードに対して最適化さ. 換テーブルを作成し直さなければならず,可搬性に欠. れたシミュレータを生成することにより,可搬性を損. ける.また,変換テーブルの作成にはターゲット,ホ. なうことなく,バイナリ変換を適用した場合と同等の. スト両方のアセンブラの知識が必要になるという問題. 高速化を達成するものである.また,命令エミュレー. もある.. ションの高速化により明らかとなった,SimpleScalar. 2.2 Cycle Accurate Simulator(CAS). の効果を SPEC CPU95 ベンチマークを用いて測定. CAS では命令エミュレーションに加えて命令スケ ジューリングをシミュレートすることにより,実際の 実行速度や詳細な挙動を知ることができる.. した.さらに,提案手法を高速マイクロプロセッサシ. このようなシミュレータとしては,SimpleScalar 1). ミュレータ BurstScalar に適用することにより,その. や RSIM 5) などがある.たとえば SimpleScalar は,. 効果を測定した.. シミュレーションのための高い柔軟性を備えており,. の実装中に存在するボトルネックの解消も行った. 提案手法を sim-fast と sim-cache に適用し,そ. 以下,2 章では関連研究について述べる.3 章では. 様々なパラメータを簡単に変更することができる.ま. 最適化シミュレータについて説明し,4 章で Simple-. たバイナリ変換を用いていないので,ホストを変更. Scalar のボトルネックについて説明する.5 章で提案 手法の評価結果を述べ,最後に 6 章でまとめを行う.. する場合もシミュレータを再コンパイルするだけでよ い.このため,多くのマイクロアーキテクチャの研究. 2. 関 連 研 究. に幅広く使用されている.しかし,この精度と可搬性. マイクロプロセッサシミュレータは計算機工学にとっ. SimpleScalar で詳細なシミュレーションを行うと SD. て欠かせないツールであり,これまでに様々な研究が 行われている. マイクロプロセッサシミュレータは,命令エミュレー. のためにシミュレーション速度が犠牲になっており, は 1,000 以上になる. そこで,CAS を高速化する研究が行われている.ま ず,シミュレーションの精度を犠牲にしたうえで,処. ションのみを行う Instruction Set Simulator(ISS)と. 理を簡略化することによって高速化する手法がある.. 命令スケジューリング計算も含めて行う Cycle Accu-. この手法では精度と性能がトレードオフの関係にあり,. rate Simulator(CAS)に大きく分けられる.これら の関連研究について順に説明する.. たとえば DirectRSIM 3) は誤差が 1∼2%と小さいが. 2.1 Instruction Set Simulator(ISS) ISS では命令エミュレーションのみを行うことによ. SD は 1,000 以上と大きく,FastILP 8) は SD が 100 程度と高速であるが誤差が 10%と大きい.SimOS 6) は複数のシミュレーションモデルを持ち,必要に応じ. り,対象の論理的な動作を高速に把握することができ. て切り替えてシミュレーションを行うことができる.. る.この命令エミュレーションを高速化する手法につ. たとえば,「詳細なシミュレーションを行いたい部分. いては,これまでにも様々な研究が行われている.. は精度重視,そうでない部分は速度重視」とすること. たとえば,高速なシミュレーションを実現した手法. ができる.. として,ダイナミック・バイナリ変換がある.この手. 精度を保ちつつ高速化を実現する方法として,命令. 法は,ターゲット ISA の命令シーケンスを,それと. スケジューリング計算に計算再利用を適用する方法が. 等価なホスト ISA の命令シーケンスに動的に変換す. ある.たとえば,我々が提案している BurstScalar 4). るものである.変換済みコードをキャッシュして再利. では命令スケジューリング計算の再利用を行うことで,. 用することによって,命令エミュレータは fetch およ. SimpleScalar と比較して最大 5.1 倍の速度を実現して いる.別の手法として,時分割並列シミュレータ9) が. び decode によるオーバヘッドを大幅に削減できる. この手法の初期の実装には Shade 2) がある.また,. Embra. 10). では,特権命令,アドレス変換,例外処理,. ある.これは,命令スケジューリング計算を時間軸で 分割し,並列にシミュレーションすることで高速化を.
(3) 100. 情報処理学会論文誌:コンピューティングシステム. 目指す.各命令区間の境界の整合性は並列区間終了後 に検証し,不一致が検出された場合には再実行を行う ので,精度は保たれる.. Aug. 2005. 以下,これらの詳細を順に説明する. 3.2 基本ブロック分割 まず,ワークロードバイナリを解析し,基本ブロッ. しかし,これらの命令スケジューリング計算のみを. クに分割する.. 高速化する手法では,命令エミュレーションの実行速. 基本ブロックの境界は分岐命令とする.つまり,分. 度によって高速化率の上限が規定されてしまうという. 岐元はすべて基本ブロックの終端となり,分岐先はす. 問題がある.. べて基本ブロックの先頭となる.ここで,分岐元アド. 両者を同時に高速化した FastSim. 7). では,バイナ. レスは分岐命令のアドレスであり明らかである,また. リ変換と ‘memoization’ と呼ばれるシミュレーション. 分岐先アドレスについては,分岐命令の種類別に以下. 結果のキャッシュを使うことにより精度を落とさずに. のように規定できる.. 高速化を実現している.これにより,SD が 190∼360 で out-of-order プロセッサのマイクロアーキテクチャ をシミュレートできる.しかし,バイナリ変換を用い るので可搬性が犠牲になっている. そこで,我々はワークロードプログラムに最適化し. • 絶対アドレスへの分岐 関数呼び出しなどで利用される.分岐先は明らか であるので,これを基本ブロックの分割点とする. • 相対アドレスへの分岐 if 文などの制御構文で利用される.分岐先は分岐 命令のアドレスから計算することができるので,. たシミュレータを使用することにより,ダイナミック・. これを分割点とする.. バイナリ変換を用いずに命令エミュレーションを高速 化する手法を提案する.. 3. 最適化シミュレータ. • レジスタの値に依存する間接分岐 関数からのリターンや分岐パターンの多い switch 文などで利用される.関数からのリターンの分岐. 本章ではシミュレータのワークロード最適化の具体. 先は呼び出し元の次のアドレスであるため,これ. 的な手法および手順について述べる.. を分割点とする.なお本論文では,これ以外のさ. 3.1 概 要 最も単純な命令エミュレータでは様々なワークロー ドプログラムに対応できるように,1 命令ずつ命令を. らなる解析が必要となるものに対しては対象とし. fetch,decode しながら実行する.この方法には,実 装が容易であるが実行速度が遅いという問題がある.. ないこととした. なお,条件付き分岐命令はすべて無条件分岐と同等 に扱うこととする. また,一般的な基本ブロックとしては十分に長い値. ミュレータのソースコードを自動生成し,それをコン. N を上限に設定し,それ以上の大きさの基本ブロッ クは強制的に複数の基本ブロックに分割した.これに. パイルすることにより最適化シミュレータを得る.つ. より,指定された命令数で正確に停止することができ. そこで,ワークロードプログラムに最適化したシ. まり,機械語レベルの最適化はコンパイラにすべて任. る.具体的には,停止までの残り命令数が N 以下に. せることにする.これにより,理論上オリジナルのシ. なったら,それ以降は 1 命令ずつシミュレーションを. ミュレータが対応するすべてのホストアーキテクチャ. 行えばよい.本論文では N = 1,000 とした.. で,高速な命令エミュレーションが実現可能である.. 3.3 シミュレータコードの生成 最も基本的な命令エミュレータでは次のように命令. 提案手法の基本的な流れは以下のようになる. • 基本ブロックに分割 ワークロードを静的に解析する.. (1). 次の PC を決定. • 最適化シミュレータのソースコードを生成 基本ブロックごとに 1 つのシミュレーション関数. (2) (3). 命令を 1 つ fetch. (4) (5) (6). レジスタ番号や即値などを decode. を生成する.. • 最適化シミュレータのコンパイル 生成されたソースコードを一般のコンパイラでコ ンパイルする.. • シミュレーションを実行. を実行する.. 命令の種類を判断 命令を実行. ( 1 ) に戻る. 単純化した例を図 1 に示す.ここで regs[N] は N 番目のレジスタ,inst.op は命令の種類,inst.rs な. コンパイルにより生成された最適化シミュレータ. どはソースレジスタなどの番号,inst.imm は即値を. でワークロードを実行する.. 表す.このように,while を 1 周するたびに命令が 1.
(4) Vol. 46. No. SIG 12(ACS 11). ワークロード最適化シミュレータの設計と実装. while(1){ inst = fetch(PC); NextPC = PC + 8; switch(inst.op){ case ADD: regs[inst.rd] = regs[inst.rs] + regs[inst.rt]; break; case ADDI: regs[inst.rd] = regs[inst.rs] + inst.imm; break; . . . } PC = NextPC; } 図 1 基本的な命令エミュレータ Fig. 1 Basic instruction emulator.. 101. while(1){ if(table[PC]!=NULL){ table[PC](); }else{ inst=fetch(PC); . . . } } 図 4 最適化されたメインループ Fig. 4 Optimized main loop.. 同様であるが,レジスタ番号や即値のように命令コー ドに含まれる値は定数に置き換える. たとえば,“addi r7, r6, $10” については,通常 は regs[inst.rd]=regs[inst.rs]+inst.imm のよ うに実行する.ここで,レジスタ番号や即値は fetch した命令コードから該当するフィールドを,マスクと シフトによってシミュレーション実行時に取り出す.. 0x00001000: add r5, r3, r2 add r6, r5, r4 addi r7, r6, $10 j 0x00002000. ;r5 ;r6 ;r7 ;PC. = = = =. r3 + r2 r5 + r4 r6 + 10 0x00002000. 図 2 簡単なソースコード Fig. 2 Simple source code.. 一方最適化シミュレータでは,レジスタ番号や即 値があらかじめ decode されているので,regs[7]=. regs[6]+10 のように実行する. すべての命令に対して上記の処理を行うことによっ て最適化シミュレータのソースコードが生成される. 図 3 の結果から,fetch と decode がすでに完了し,実. BB 0x00001000(){ regs[5] = regs[3] + regs[2]; regs[6] = regs[5] + regs[4]; regs[7] = regs[6] + 10; PC = 0x00002000; return; } 図 3 最適化された命令エミュレータ Fig. 3 Optimized instruction emulator.. 行すべき命令の種類が確定し,レジスタの番号,即値 が定数に置き換わっていることが分かる. また,メインループは図 4 のようになる.ここで, table は PC から最適化されたシミュレータ関数のポ インタを取得するための配列である.分岐先アドレス が予測できなかった場合,当該基本ブロックに対応す る関数が存在しないため,配列には NULL が格納さ れている.メインループは NULL を検出した場合,1. つずつ解釈,実行される. 次に,ワークロードに最適化されたシミュレータの ソースコードの生成方法について説明する.. 命令ずつシミュレーションを行う.. 3.4 既存のシミュレータへの適用 ワークロード最適化を既存のシミュレータに適用す. ソースコードは前節で分割された基本ブロックごと. る場合には,まず既存のシミュレータから命令エミュ. に 1 つの関数として生成される.基本ブロック内の命. レータ部分を切り出す必要がある.ワークロード最適. 令を 1 命令ずつ fetch,decode し,その命令に対応す. 化の効果を最大限に引き出すためには,他のモジュー. るソースコードを出力する.このとき,レジスタ番号. ルとの同期が少ない方がよい.ワークロード最適化で. や即値はできる限り定数に置き換える.. は基本ブロックごとにシミュレータを生成するので,. 図 2 は 0x00001000 番地から始まる 4 命令で構成 された基本ブロックである.この基本ブロックに対応. 基本ブロック中に同期が不要であるときに最大限の効 果を得ることができる.. するシミュレータソースコードは,図 3 のようにな. 組み込みには 2 つの構成が考えられる.最適化シ. る.この例を用いてソースコードの生成手順について. ミュレータから既存のシミュレータを呼び出す方法と. 説明する.. 既存のシミュレータから最適化シミュレータを呼び出. まず,基本ブロックの開始アドレスに ‘BB ’ を付加 したものを,関数名とする.次に,1 命令ずつ解析を 行い命令に対応するシミュレータコードを生成する. 生成するコードは基本的に最適化前のシミュレータと. す方法である. 前 者 の 例 と し て は sim-cache が あ げ ら れ る .. sim-cache では 1 命令ごとに命令キャッシュシミュ レータを呼び出し,さらにロードストア命令ではデー.
(5) 102. 情報処理学会論文誌:コンピューティングシステム. タキャッシュシミュレータも呼び出す.また,キャッ シュシミュレータの独立性は高く,命令エミュレータ からは 1 度の関数呼び出しで完結している.. sim-cache にワークロード最適化を組み込む場合に は,最適化シミュレータから必要に応じてキャッシュ シミュレータを呼び出せばよい.この構成ではキャッ シュシミュレータの処理が完了すると,最適化シミュ レータを継続できる. しかし,後者の場合には最適化シミュレータの途中 で同期が必要になるとシミュレーションを中断する必 要がある.中断する場合には単に最適化シミュレータ. Aug. 2005. /* HI,LO <- rs * rt, integer product of rs & rt to HI/LO */ HI = 0; LO = 0; if(RS & 020000000000) LO = RT; for(i = 0; i < 31; i++){ HI = HI << 1; HI = HI + extractl(LO, 31, 1); LO = LO << 1; if((extractl(RS, 30 - i, 1))==1){ if((037777777777 - LO) < RT) HI = (HI + 1); LO = (LO + RT); } }. から抜ければよい.ただし,最適化シミュレータは途. 図 5 乗算命令の実装 Fig. 5 Implement of MULT instruction.. 中からの再開を想定していないので,再開時には汎用 のシミュレータが利用される.つまり,最適化シミュ レータの途中で中断する割合が高くなると,ワーク ロード最適化の効果は少なくなる.. 3.5 コンパイルと実行 生成されたシミュレータコードを通常のコンパイラ でコンパイルする.このとき,コンパイラに適切な最 適化オプションを指示することにより,シミュレータ. unsigned int extractl(int word, /* target word */ int pos, /* bit positions */ int num){ /* number of bits */ return((word >> (pos + 1 - num)) & ~(~0 << num)); } 図 6 extractl 関数の実装 Fig. 6 Implement of extractl function.. コードがホストアーキテクチャに対して最適化される. なお,生成されるソースコードはワークロードの大 きさ,つまりワークロードバイナリの text 領域のサ イズに比例する.また,コンパイル時間はソースコー ドの大きさにほぼ比例する. 最適化されたシミュレータはワークロードバイナリ. する.. gcc の version 2.x までは明示的に指定しない限り, この規格を利用した最適化は行われず,違反したコー ドも意図したとおりに動作したので,問題が明らかに. を変更しない限り,同一のものを利用できる.つまり,. なることはなかった.しかし,gcc の version 3.x 以. シミュレーションパラメータや実行時引数,入力ファ. 降では ‘-O2’ 以上の最適化を指定すると,この規格に. イルを変更しても再コンパイルの必要はない.. 厳密に一致していることを利用して最適化を行う.現. 4. ボトルネックの解消. 状の SimpleScalar version 3.0 ではこの最適化の恩恵. 命令エミュレーションの高速化を実装したところ,. コードの高速化が妨げられている.. SimpleScalar に存在していた以下のボトルネックが 明らかとなった.. を受けることができず,結果的にシミュレータの実行 この問題を解決するため,浮動小数点と整数の両方 をメンバとする共用体を利用するように変更した.こ. • strict aliasing • 乗算の実装 • メモリアクセスの実装. れにより,最適化の効果をより多く得ることができる.. • キャッシュシミュレータの実装 以降では,これらのボトルネックについてその詳細. 号の計算などは省略した.. と解決策を述べる.. 4.2 乗算の実装 乗算の実装は図 5 のようになっている.ただし,符 この中で使用されている extractl 関数の実装は図 6 のようになっている.これは word に対して pos bit 目. 4.1 strict aliasing ANSI C(C89)以降の規格では浮動小数点のポイ. から (pos − num + 1) bit 目までの num 個の bit 列. ンタと,整数のポインタが同じメモリ領域を指すこと. に,乗算命令を 1 回エミュレートするたびに 62 回の. は許されず,同じ領域を指した場合の結果は不定と定. extractl 関数の呼び出しが発生する.. 義されている.これは strict aliasing と呼ばれる.し かし,この規格に違反したコードが endian.c に存在. を切り出す関数である.図 5 の実装から分かるよう. このボトルネックを解決するためには,extractl 関 数を#define マクロに置き換えればよい..
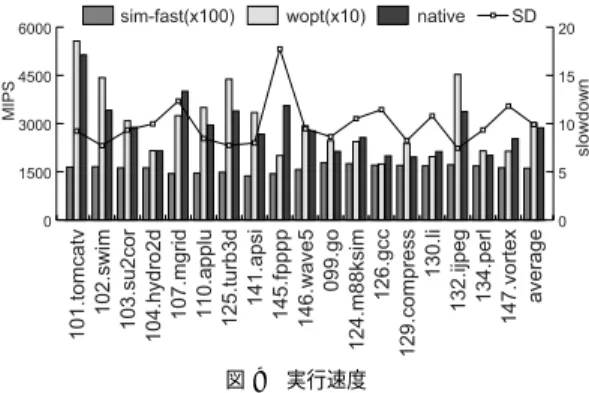
(6) Vol. 46. No. SIG 12(ACS 11). ワークロード最適化シミュレータの設計と実装. また,もう 1 つの解決方法として,乗算命令の実装 を完全に書き直す方法がある.たとえば,64 bit 整数 が利用できる環境であれば以下のように変更する.. HI = (RS * RT) >> 32; LO = (RS * RT) & ((1 << 32) - 1); 本論文ではこの手法を採用した.. 103. 4.4.2 命令アドレスの圧縮 今回使用した PISA では 1 命令が 64 bit の固定長 となっている.そのため,1 命令が 32 bit の固定長の アーキテクチャと比較すると,命令キャッシュの利用 効率が悪くなるということが予想される. この問題に対応するため,SimpleScalar にはキャッ. 4.3 メモリアクセス. シュへのアクセスを命令長が 32 bit の固定長と等価と. 32 bit ターゲットを 32 bit ホストでシミュレートす. するオプションが用意されており,これを利用するこ. る場合,ホストの仮想メモリ空間にターゲットの連続. とで命令キャッシュの利用効率を公平に比較すること. した仮想メモリ空間を確保することは困難である.. が可能となる.しかし,このオプションは実行時に与. SimpleScalar では 1 段のページテーブルを経由す. えられるので,コンパイル時には有効/無効の両方に. ることにより仮想メモリ空間を提供している.すべて. 対応するコードを出力しなければならず,オーバヘッ. のメモリアクセスごとにページの存在を確認し,初め. ドとなる.. ての書き込みアクセスであればページを確保する.し かし,この方法では 2 回目以降のアクセスでもつねに. そこで,このオプションを実行時のオプションから コンパイル時のオプションに変更した.. ページの存在を確認しなければならないので,大きな. 4.4.3 alignment の確認. オーバヘッドが発生する.. キャッシュアクセス時にはアクセスアドレスの align-. 想メモリ空間を容易に提供できる.具体的には calloc. ment が正しいかどうかを調べる必要がある.alignment が正しくないアクセスは許されず,不正なアク セスが発生するとシミュレーションが停止する.. 関数で連続する 32 bit の仮想メモリ空間を確保するこ. 提案するワークロード最適化シミュレータでは,命. とによってこれを実現する.ただし,ほとんどのワー. 令キャッシュへのアクセスのように,アクセスアドレ. クロードでは 32 bit の仮想メモリ空間のすべてを利用. スがコンパイル時に判明していることが多い.このよ. 今回使用した 64 bit ホストでは,64 bit の広大な仮 想メモリ空間が利用できるため,32 bit の連続した仮. するわけではなく,一部のメモリ空間しか使用しない.. うなアクセスに対する alignment の確認はコンパイル. calloc 関数で確保された領域は,ホスト OS の仮想. 時に 1 度だけ行えばよく,実行時に行う必要はない.. メモリ管理機構により,利用された領域から順に確保 されていき,利用されなかった領域は実際には確保さ れない☆ .そのため,大きなメモリブロックを確保す るオーバヘッドは発生しない.また,メモリを不必要. 5. 評. 価. 本論文では,SimpleScalar Tool Set version 3.0 と BurstScalar に提案手法を適用した.これによって,広. に消費し,同一マシン上の他のプロセスに悪影響を与. く利用されている SimpleScalar と同じバイナリをシ. えるということもない.. ミュレートすることができる.. 4.4 キャッシュシミュレータ 4.4.1 引数の削減 SimpleScalar ではモジュールの拡張性を意識して設. SimpleScalar については,命令エミュレータである sim-fast と,命令エミュレータにキャッシュシミュ レータが加わった sim-cache に適用した.. 計されている.このため,現状ではまったく利用され. BurstScalar については,命令エミュレーションを. ていない引数が存在し,関数呼び出しのオーバヘッド. 行うモジュールとして予備実行と先行実行があるので,. を増大させているという問題がある.実際に,キャッ. これらそれぞれに提案手法を適用した.. シュへのインタフェースである cache access 関数は 8 個の引数をとる.しかし,この中で 3 個の引数は現時 点ではまったく利用されていない. そこで,この使用されていない引数を削除した.こ れにより,関数呼び出しのオーバヘッドが減少し高速 化が期待できる.. 5.1 評 価 条 件 最適化シミュレータの評価として,ワークロード最 適化の効果と,4 章で述べたボトルネック解消の効果 を,SPEC CPU95 ベンチマークを用いて測定した. データセットには ‘train’ を用いた. 評価には Opteron(Dual 2.0 GHz,Memory 8 GB,. Linux 2.4.21)を用いた.ターゲットアーキテクチャ は PISA とした.コンパイラは gcc version 3.3.2 を ☆. 少なくとも Linux 2.4.21 では.. 用い,最適化オプションは基本的に ‘-O2’ としたが,.
(7) 104. 情報処理学会論文誌:コンピューティングシステム 表 1 キャッシュの構成 Table 1 Cache model.. キャッシュ. TLB. L1 命令 L1 データ L2 統合 命令 データ. 16 KB/32B ライン/1-way 16 KB/32 B ライン/4-way 256 KB/64 B ライン/4-way 16 エントリ/4-way 32 エントリ/4-way. Aug. 2005. 5.2.3 シミュレータのサイズ ワークロード最適化ではシミュレータのサイズが ワークロードのサイズに比例して大きくなる.今回 適用対象とした sim-fast,sim-cache,BurstScalar について,ワークロード最適化により得られたシミュ レータのサイズを表 3 に示す.ここで,insn はワー クロードバイナリ中の全命令数.text は各シミュレー. 表 2 プロセッサの構成 Table 2 Processor model. 命令発行幅 RUU LSQ メモリポート 機能 INT-ALU ユニット INT-MUL/DIV FP-ALU FP-MUL/DIV 分岐予測 予測方式 BTB RAS. 8 256 128 4 8 3 8 3 2 bit カウンタ/2 K エントリ 512 エントリ/4-way 8 エントリ. タの text 領域のサイズ,text/inst は 1 命令のシミュ レーションに必要な text 領域の平均サイズを示す. この結果から sim-fast では 1 命令をシミュレート するのに平均で 38.5 バイトの命令が必要であることが 分かる.同様に sim-cache では 87.8 バイト,Burst-. Scalar では 362.6 バイトの命令が必要であることが分 かる. 5.2.4 コンパイル時間 SPEC CPU95 に含まれる全 18 ベンチマークにつ いて,sim-fast の最適化シミュレータの make 時間 を測定した.その結果,すべての make に合計 42 分. 比較対象となるオリジナルの SimpleScalar の最適化. かかった.このうち,18 分が 126.gcc の make にか. オプションは,strict aliasing の問題を回避するため. かった時間である.. ‘-O2 -fno-strict-aliasing’ とした. sim-cache の キャッシュの 構 成 を 表 1 に 示 す. BurstScalar の評価モデルの構成を表 2 に示す.キャッ シュの構成は sim-cache と同じとした. 5.2 予 備 評 価 5.2.1 基本ブロック分割 提案手法の効果を予測するために,静的解析で把握 できなかった分岐がどの程度存在するのかを測定した. ここでは全実行命令数に対して汎用の命令エミュレー. しかし,前述のとおりシミュレーションパラメータ や実行時引数,入力ファイルを変更しても再コンパイ ルの必要はないので,このコンパイル時間は十分許容 できる.. 5.3 sim-fast sim-fast では以下の高速化を適用した. • 乗算の実装を改善(mult) • strict aliasing 対応(alias) • 仮想メモリの実装を改善(mem). 命令が予測できなかった分岐のため,汎用の命令エミュ. • ワークロード最適化(wopt) 5.3.1 高速化手法ごとの効果 まず,それぞれの高速化を単独で適用し,オリジナ. レータを使用することが分かった.それ以外のベンチ. ルの SimpleScalar に対する高速化率を測定した.結. マークでは汎用の命令エミュレータを使用した割合は. 果を図 7 に示す.. タを使用した命令数の割合を測定した. その結果,145.fpppp では約 1%,130.li では 0.1%の. 0.05%以下であった.このことから,静的解析で十分 に基本ブロックを解析できていることが分かる.. 5.2.2 乗算の実行回数 乗算の実装の改善による効果を予測するために,全 実行命令中に含まれる乗算の割合を測定した. その結果,141.apsi では 3.7%,125.turb3d では. alias での高速化率は最大 1.70 倍(129.compress), 平均 1.52 倍であった.次に,mult での高速化率に 注目すると,乗算命令の実行回数の多い 141.apsi,. 125.turb3d,132.ijpeg,107.mgrid で効果が現れてい ることが分かる.最大は 1.18 倍(141.apsi)であった. さらに,mem では最大 4.03 倍(145.fpppp) ,平均 3.34. 2.7%,132.ijpeg では 1.3%,107.mgrid では 1.2%が. 倍の高速化ができ,wopt では最大 7.89 倍(132.ijpeg) ,. 乗算命令であることが分かった.それ以外のベンチ. 平均 4.61 倍の高速化を達成することができた.ただ. マークでは乗算命令の占める割合は 0.7%以下であっ. し,145.fpppp では 0.21 倍と大きな速度低下が発生. た.このことから,乗算命令の実行割合が多いベンチ. した.これは 145.fpppp の最内ループに対応する最適. マークで改善の効果が期待できる.. 化シミュレータのサイズが 2.63 MB と,Opteron の. L2 キャッシュサイズ 1 MB を大きく超えているため,.
(8) Vol. 46. No. SIG 12(ACS 11). 105. ワークロード最適化シミュレータの設計と実装 表 3 シミュレータのサイズ Table 3 Size of simulators.. insn(×103 ) SPECfp 101.tomcatv 102.swim 103.su2cor 104.hydro2d 107.mgrid 110.applu 125.turb3d 141.apsi 145.fpppp 146.wave5 SPECint 099.go 124.m88ksim 126.gcc 129.compress 130.li 132.ijpeg 134.perl 147.vortex average. sim-fast text(×103 ) text/insn. sim-cache text(×103 ) text/insn. BurstScalar text(×103 ) text/insn. 20.6 21.4 32.5 26.6 21.8 29.4 29.7 47.2 36.5 45.2. 962 981 1,156 1,113 994 1,149 1,191 1,558 1,362 1,510. 46.6 45.9 35.6 41.9 45.6 39.1 40.0 33.1 37.3 33.4. 1,967 2,021 2,781 2,404 2,056 2,631 2,658 3,950 3,294 3,799. 95.3 94.6 85.6 90.4 94.5 89.6 89.4 83.8 90.2 84.0. 7,492 7,858 11,655 9,558 7,901 10,801 10,793 17,177 14,215 16,388. 362.9 367.9 358.8 359.5 363.0 367.8 362.9 364.3 389.4 362.5. 77.7 35.9 270.8 13.0 22.6 49.6 66.9 123.9. 2,082 1,329 8,067 759 1,036 1,606 2,314 3,569. 26.8 37.0 29.8 58.5 45.9 32.4 34.6 28.8 38.5. 5,940 3,066 20,838 1,390 2,126 4,119 5,484 9,591. 76.5 85.3 76.9 107.1 94.2 83.0 81.9 77.4 87.8. 27,278 12,839 95,378 4,790 8,191 17,909 23,901 44,233. 351.1 357.2 352.1 369.0 362.8 360.9 357.0 357.1 362.6. 図 7 sim-fast の高速化率(その 1) Fig. 7 Speedup ratio of execution time in sim-fast #1.. 図 8 sim-fast の高速化率(その 2) Fig. 8 Speedup ratio of execution time in sim-fast #2.. キャッシュミスが頻発したことが原因と考えられる.. 独での高速化率の小さい mult や alias はやはり貢献度. 次に,すべての高速化を適用した場合の高速化率を. が小さいことが分かる.一方,貢献度が最大のものは. 測定した.また,それぞれの高速化の貢献度を調べる. wopt であるが,wopt を適用しなかった場合(-wopt). ため,それぞれの高速化を適用しなかった場合の高速. の平均高速化率 3.72 に図 7 に示した wopt の平均高. 化率を測定した.測定結果を図 8 に示す.ここで,all. 速化率 4.61 を乗じた値(17.1)よりも,all の平均高. がすべての高速化を適用した場合の高速化率を示す.. 速化率 19.3 は大きくなっている.これは wopt 以外の. また,-alias は alias のみを適用しなかった場合の結果. 高速化手法,特に mem との相乗効果が生じているこ. を示しており,-mult,-mem,-wopt についても同様. とを示している.. である.. また,mem では 145.fpppp において貢献度が非常. all の結果から,最大 33.9 倍(101.tomcatv),平均. に大きいことが分かる.つまり,mem はシミュレータ. 19.3 倍の高速化を達成することができた.なお高速化 手法には相乗効果があるので,図 7 の高速化率をすべ. のサイズを小さくする効果が大きいといえる.すべて. て掛け合わせた値よりも all の値は大きくなっている.. 対応する最適化シミュレータのサイズが 0.21 MB ま. 次に,それぞれの高速化の貢献度に注目すると,単. で減少している.一方,mem を適用しなかった場合. の高速化を適用した場合,145.fpppp の最内ループに.
(9) 106. 情報処理学会論文誌:コンピューティングシステム. 図 9 実行速度 Fig. 9 Execution speed.. Aug. 2005. 図 10 sim-cache の高速化率(その 1) Fig. 10 Speedup ratio of execution time in sim-cache #1.. (-mem)は 2.02 MB であり,mem の効果が特に大き いことが分かる.. 5.3.2 実機との比較 図 7,図 8 の結果より,wopt の効果がワークロー ドごとに大きくばらついていることが分かる.たとえ ば,all では最大 33.8 倍,最低 10.4 倍と 3 倍以上の 効果の差が現れているのに対し,-wopt では 4.22 倍か ら 3.32 倍と効果のばらつきが少ない. この原因を調べるために,sim-fast のシミュレー ション速度(sim-fast),最適化シミュレータのシミュ レーション速度(wopt),シミュレータを使わずに実. 図 11 sim-cache の高速化率(その 2) Fig. 11 Speedup ratio of execution time in sim-cache #2.. 機上で直接ワークロードを実行したときの実行速度 (native)を測定した.結果を図 9 に示す.それぞれ の実行速度を MIPS で示す.ここで,sim-fast は値 を 100 倍,wopt は値を 10 倍している.また,SD は. • ワークロード最適化(wopt) • base と wopt(base+wopt) sim-cache の実行時間は sim-fast のおよそ 2.5 倍. wopt/native の実行速度比(右軸)である. まず,sim-fast の結果に注目すると,すべてのワー. である.つまり,全体の 4 割が命令エミュレーション. クロードで実行速度が 15 MIPS 程度とほぼ一定であ. る時間であるといえる.また,この 4 割を占める命. ることが分かる.一方,wopt と native では,ワーク ロードによって実行速度に大きなばらつきがあること. 令エミュレーションが 20 倍高速になると全体では約 1.6 倍の高速化になる.高速化率の測定結果を図 10. が分かる.しかし,wopt と native ではばらつきに同. に示す.. 様の傾向がみられ,SD からこれらの実行速度比はほ. で,残りの 6 割がキャッシュシミュレーションにかか. base+wopt の高速化率は,最大 1.76 倍(132.ijpeg) ,. ぼ 10 であることが分かる.ここで,145.fpppp は実. 平均 1.55 倍となっており,sim-fast に相当する実行. 行速度比が大きくなっているが,これは最内ループが. 時間が削減されていることが分かる.. 大きいことが原因と考えられる. 以上のことから,ワークロード最適化ではワーク ロード自体に存在する命令レベル並列性を引き出し,. 次に,以下の高速化を適用した.. • 命令キャッシュ圧縮オプション変更(comp) • cache access 関数の引数削減(simple). でシミュレーションを行う sim-fast と比較すると,. • alignment のコンパイル時確認(align) 測定結果を図 11 に示す. comp では最大 1.08 倍(124.m88ksim),平均 1.03. ワークロード最適化の高速化率にばらつきが発生する.. 倍 ,simple で は 最 大 1.16 倍(147.vortex),平 均. 効率的にシミュレーションを実行できていることが分 かる.この結果,ワークロードによらず一定の速度. 5.4 sim-cache sim-cache では以下の高速化を適用した. • mult,alias,mem(base). 1.10 倍の高速化が達成でき,align では最大 1.36 倍 (124.m88ksim) ,平均 1.33 倍の高速化が達成できた. さらに,すべての高速化を適用した場合と,comp,.
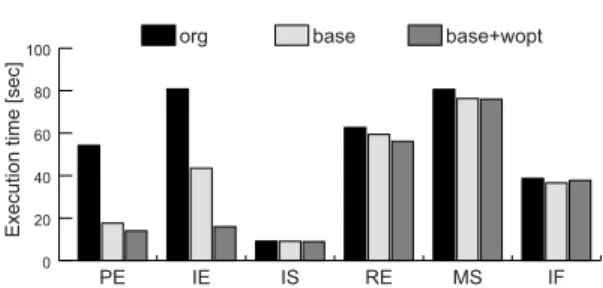
(10) Vol. 46. No. SIG 12(ACS 11). 107. ワークロード最適化シミュレータの設計と実装 表 4 BurstScalar の高速化率 Table 4 Speedup ratio of BurstScalar.. SPECfp 101.tomcatv 102.swim 103.su2cor 104.hydro2d 107.mgrid 110.applu 125.turb3d 141.apsi 145.fpppp 146.wave5 SPECint 099.go 124.m88ksim 126.gcc 129.compress 130.li 132.ijpeg 134.perl 147.vortex average. 図 12 sim-cache の高速化率(その 3) Fig. 12 Speedup ratio of execution time in sim-cache #3.. simple,align の貢献度を測定した.測定結果を図 12 に示す.ここで,all がすべての高速化を適用した場合 の高速化率を示す.また,-comp は comp のみを適用 しなかった場合の結果を示しており,-simple,-align についても同様である.すべての高速化を適用したと. org. base. base+wopt. 3.75 3.98 1.05 3.61 4.21 2.80 2.18 2.79 1.52 1.59. 5.00 5.38 1.22 4.78 6.64 3.97 3.20 4.05 2.80 1.92. 5.95 6.05 1.24 5.63 7.87 4.36 3.55 4.06 1.81 1.94. 0.84 2.38 0.86 1.59 1.36 2.21 1.60 1.90 2.23. 1.00 3.02 1.01 1.99 1.62 2.96 1.98 2.36 3.05. 0.91 2.88 0.92 1.86 1.53 3.13 1.86 2.03 3.20. きの高速化率は最大 4.01 倍(125.turb3d),平均 3.10 倍であった.貢献度では,特に align による効果が大 きいことが分かる. また,wopt を適用したときに 145.fpppp の高速化. 適用なし☆ (org),ワークロード最適化以外を適用 ,ワークロード最適化も適用(base+wopt)の, (base). SimpleScalar に対する高速化率を示す.. 率が減少している.これは,sim-fast の場合と同様. この結果から,これまで最大 4.21 倍,平均 2.23 倍. に 145.fpppp の最内ループに対応した最適化シミュ. であった高速化率が,base では最大 6.64 倍,平均 3.05. レータが大きく,命令キャッシュミスが増大したため. 倍に向上した.さらに,base+wopt で最大 7.78 倍,平. と考えられる.実際,all の場合でも最内ループに対応. 均 3.20 倍に向上した.. した部分は 1.05 MB と L2 キャッシュの容量を超えて いる.. base ではすべてのベンチマークで高速化が達成され ていることが分かる.しかし,SPECfp の 145.fpppp. 5.5 BurstScalar. と SPECint の多くのプログラムでは,base+wopt で. BurstScalar に含まれる 2 つの命令エミュレータの. 高速化率が減少している.これは,シミュレータプロ. 双方に,高速化手法を適用した.これらの命令エミュ. グラムが大きくなりすぎ,命令キャッシュミスが増加. レータは,命令スケジューラに命令トレースとロード. したためと考えられる.. ストアアドレスを供給する.命令トレースやロードス トアアドレスを取得する際にはタイミング情報は不要. 5.5.2 実行時間の内訳 BurstScalar に対する提案手法の効果を詳しく調べ. であり,命令スケジューラとの同期をとる必要はない.. るために,実行時間の内訳を測定した.102.swim の. ただし,不要な命令エミュレーションを削減するため. 結果を図 13 に示す.ここで,PE は命令トレースの. に,分岐予測ミスパスの命令エミュレーションは,実. 取得を行う予備実行,IE はロードストアアドレスの. 際に分岐予測ミスが発生してから行う.したがって,. 取得を行う先行実行,IS は命令スケジューリング計. 命令エミュレータは分岐予測器と同期をとる必要があ. 算とその結果の保存を行う詳細実行,RE は命令スケ. る.しかし,分岐予測は基本ブロックの境界で行われ. ジューリング計算の再利用を行う高速実行の実行時間. るため,ワークロード最適化との相性は良く十分な効. である.さらに,MS はキャッシュのシミュレーショ. 果が期待できる.. 5.5.1 高速化の効果 最適化を適用した結果を表 4 に示す.左から順に,. ンの実行時間,IF はそれぞれのモジュールの間のイン タフェースや分岐予測器などの実行時間である.この ☆. 文献 4) では alias など一部の最適化がすでに適用されていた ため,それらの最適化を無効にした.その結果文献 4) とは高速 化率が異なっている..
(11) 108. Aug. 2005. 情報処理学会論文誌:コンピューティングシステム. 参 考. 図 13 BurstScalar の実行時間の内訳(102.swim) Fig. 13 Breakdown of BurstScalar (102.swim).. 中で,PE と IE が命令エミュレータを含んでいる.詳 細は文献 4) を参照されたい. この結果から,PE と IE の実行時間が大きく削減さ れており,命令エミュレータに相当する部分の高速化 が達成できていることが分かる.また,MS の減少幅 が小さいが,これは BurstScalar が予備実行や先行実 行のような命令エミュレータに相当する部分からでは なく,詳細実行や高速実行からキャッシュシミュレー タを呼び出す構造のため,ワークロード最適化の効果 が得られなかったためと考えられる.. 6. ま と め 本論文では個々のワークロードに対して最適化され たシミュレータを生成することにより,可搬性を損な うことなく高速な命令エミュレーションを実現する手 法を提案した.また,命令エミュレーションの高速化 により明らかとなった,SimpleScalar の実装中に存在 するボトルネックの解消も行った. 提案手法を sim-fast と sim-cache に適用し,そ の効果を SPEC CPU95 ベンチマークを用いて測定し た.その結果 sim-fast で最大 34 倍,平均 19 倍の 高速化を,また sim-cache では最大 4.0 倍,平均 3.1 倍の高速化をそれぞれ達成した.さらに,提案手法を 高速マイクロプロセッサシミュレータ BurstScalar に 適用した結果,適用前には最大 4.2 倍,平均 2.2 倍で あった高速化率が,最大 7.9 倍,平均 3.2 倍に向上し, 平均で 1.5 倍の高速化を達成した. 以上のことから,提案手法は命令エミュレーション. 文. 献. 1) Austin, T., Larson, E. and Ernst, D.: SimpleScalar: An Infrastructure for Computer System Modeling, Computer, Vol.35, No.2, pp.59– 67 (2002). 2) Cmelik, B. and Keppel, D.: Shade: A Fast Instruction-Set Simulator for Execution Profiling, Performance Evaluation Review, Vol.22, No.1, pp.128–137 (1994). 3) Durbhakula, M., Pai, V. and Adve, S.: Improving the Accuracy vs. Speed Tradeoff for Simulating Shared-Memory Multiprocessors with ILP Processors, HPCA, Orlando, FL, pp.23–32 (1999). 4) Nakada, T. and Nakashima, H.: Design and Implementation of a High Speed Microprocessor Simulator BurstScalar, MASCOTS, pp.364–372 (2004). 5) Pai, V., Ranganathan, P. and Adve, S.: RSIM: An Execution-Driven Simulator for ILP-Based Shared-Memory Multiprocessors and Uniprocessors, 3rd WS. on Computer Architecture Education (1997). 6) Rosenblum, M., Herrod, S., Witchel, E. and Gupta, A.: Complete Computer System Simulation: The SimOS Approach, IEEE Parallel and Distributed Technology, Vol.3, No.4, pp.34– 43 (1995). 7) Schnarr, E. and Larus, J.: Fast Out-Of-Order Processor Simulation Using Memoization, ASPLOS, pp.283–294 (1998). 8) Sorin, D., Pai, V., Adve, S., Vernon, M. and Wood, D.: Analytic Evaluation of Sharedmemory Systems with ILP Processors, ISCA, pp.380–391 (1998). 9) 高崎 透,中田 尚,津邑公暁,中島 浩:時間 軸分割並列化による高性能マイクロプロセッサシ ミュレーション,先進的計算基盤システムシンポ ジウム SACSIS2005 論文集,pp.339–348 (2005). 10) Witchel, E. and Rosenblum, M.: Embra: Fast and Flexible Machine Simulation, Measurement and Modeling of Computer Systems, pp.68–79 (1996).. の高速化に非常に有効であるといえる. 謝辞 本研究は,(株)半導体理工学研究センター. (平成 17 年 1 月 24 日受付). との共同研究「SpecC によるソフトウェア記述の性能. (平成 17 年 5 月 3 日採録). 検証システム」,文部科学省 21 世紀 COE プログラム 「インテリジェントヒューマンセンシング」,および文 部科学省科学研究費補助金(基盤研究(B),研究課題 「高度情報機器開発のための高性能並 番号 17300015, 列シミュレーションシステム」)の支援によって行わ れた..
(12) Vol. 46. No. SIG 12(ACS 11). 中田. 109. ワークロード最適化シミュレータの設計と実装. 尚(学生会員). 中島. 浩(正会員). 2004 年豊橋技術科学大学大学院. 1981 年京都大学大学院工学研究. 工学研究科情報工学専攻修士課程修. 科情報工学専攻修士課程修了.同年. 了.同年同大学院工学研究科電子・情. 三菱電機(株)入社.推論マシンの. 報工学専攻博士後期課程入学.計算. 研究開発に従事.1992 年京都大学工 学部助教授.1997 年豊橋技術科学大. 機アーキテクチャとシミュレーショ ンに関する研究に従事.. 学教授.並列計算機のアーキテクチャ等並列処理に関 する研究に従事.工学博士.1988 年元岡賞,1993 年. 津邑 公暁(正会員). 坂井記念特別賞受賞.IEEE-CS,ACM,ALP,TUG. 1998 年京都大学大学院工学研究科. 各会員.. 情報工学専攻修士課程修了.2001 年 同大学院情報学研究科博士後期課程 学修認定退学.同年同大学院経済学 研究科助手.博士(情報学).2004 年豊橋技術科学大学工学部助手.計算機アーキテク チャ,並列処理応用,脳型情報処理等に関する研究に 従事.電子情報通信学会,人工知能学会,日本神経回 路学会各会員..
(13)
図



+2
関連したドキュメント
断面が変化する個所には伸縮継目を設けるとともに、斜面部においては、継目部受け台とすべり止め
ü modeling strategies and solution methods for optimization problems that are defined by uncertain inputs.. ü proposed by Ben-Tal & Nemirovski
特に、耐熱性に優れた二次可塑剤です(DOSより良好)。ゴム軟化剤と
b)工場 シミュ レータ との 連携 工場シ ミュ レータ は、工場 内のモ ノの流 れや 人の動き をモ デル化 してシ ミュレ ーシ ョンを 実 行し、工程を 最適 化する 手法で
ASTM E2500-07 ISPE は、2005 年初頭、FDA から奨励され、設備や施設が意図された使用に適しているこ
と判示している︒更に︑最後に︑﹁本件が同法の範囲内にないとすれば︑
大都市の責務として、ゼロエミッション東京を実現するためには、使用するエネルギーを可能な限り最小化するととも
