2015 年度 修士論文
臓器の位置関係を考慮した 3D 医用画像の 多臓器同時セグメンテーション
指導教員 石川博 教授
早稲田大学大学院 基幹理工学研究科 情報理工・情報通信専攻 5114F088-1 森田皆人
2016 年 2 月 1 日 提出
目 次
目 次 i
図 目 次 iii
表 目 次 v
第1章 はじめに 1
1.1 研究背景 . . . . 1
1.2 研究目的 . . . . 3
1.3 本論文の構成 . . . . 3
第2章 医用画像セグメンテーション 5 2.1 3次元医用画像 . . . . 5
2.2 セグメンテーション . . . . 6
2.3 関連研究 . . . . 8
2.4 従来手法のエネルギー関数 . . . . 9
2.4.1 従来手法のエネルギー項 . . . . 9
第3章 提案手法 11 3.1 概要 . . . . 11
3.2 データ項とアトラス項の間の重みを考慮しないエネルギー項の検討 . . . 13
3.3 1階データ項とアトラス項の間の重みを考慮しないエネルギー項の検討 . 13 3.4 1階以上の場合の確率分布推定の改善 . . . . 14
3.4.1 セルごとに学習したデータを用いたエネルギー式 . . . . 15
3.5 2階データ項とアトラス項の間の重みを考慮しないエネルギー項の検討 . 15 第4章 実験 18 4.1 実験目的 . . . . 18
4.2.1 方法 . . . . 18
4.2.2 結果 . . . . 19
4.2.3 考察 . . . . 21
4.3 1階データ項とアトラス項の間の重みを考慮しないエネルギー項 . . . . . 23
4.3.1 方法 . . . . 23
4.3.2 結果 . . . . 23
4.3.3 考察 . . . . 23
4.4 2階データ項とアトラス項の間の重みを考慮しないエネルギー項 . . . . . 27
4.4.1 方法 . . . . 27
4.4.2 結果 . . . . 29
4.4.3 考察 . . . . 34
第5章 おわりに 37 謝辞 38 参考文献 39 付 録A エネルギー最小化に用いられるアルゴリズム 42 A.1 MRF . . . . 42
A.2 MAP 推定 . . . . 42
A.3 劣モジュラ条件 . . . . 43
A.4 QPBO . . . . 44
A.5 α 拡張. . . . 44
A.6 融合移動 . . . . 45
図 目 次
1.1 CT 画像とその画像にラベル付けされた画像の組の例 . . . . 4
1.2 複数症例の CT 画像をラベル付けしたものを並べたもの . . . . 4
2.1 ラベリング画像を 3次元モデルにしたもの . . . . 6
2.2 ラベル付け画像の色と臓器の対応を表したもの. . . . 7
3.1 提案手法や従来手法の組み合わせ方のイメージ図 . . . . 12
3.2 高階項で用いるクリークの形 . . . . 16
3.3 セルを重ねたときの学習イメージ . . . . 17
4.1 データ項とアトラス項の間の重みを考慮しないエネルギー項を用いたセグ メンテーション結果 . . . . 20
4.2 あるスライスに対するセグメンテーション結果の比較 . . . . 22
4.3 1階のデータ項とアトラス項の間の重みを考慮しないエネルギー項を用い たセグメンテーション結果 . . . . 24
4.4 セル単位での学習を行ったときのセルの大きさによるセグメンテーション 結果比較 . . . . 25
4.5 1階のデータ項とアトラス項の間の重みを考慮しないエネルギー項を用い てセルの大きさを固定したときのセグメンテーション結果 . . . . 26
4.6 あるスライスに対するセグメンテーション結果の比較 . . . . 28
4.7 高階項のセルの大きさを変更してセグメンテーションを行ったときの結果 30 4.8 セルの重ねあわせを考慮して学習をったときのセグメンテーション結果 . 31 4.9 高階項と平滑化項の間の重みの比を様々に変更したときのセグメンテー ション結果 . . . . 32
4.10 高階項の用いるクリークの組み合わせを変更してセグメンテーションを 行ったときの結果 . . . . 33
4.11 高階項の実験において効果のあったものを取り入れ、セグメンテーション を行ったときの結果 . . . . 33
4.12 あるスライスに対するセグメンテーション結果の比較 . . . . 35
4.13 あるスライスに対するセグメンテーション結果の比較 . . . . 36
A.1 二値の場合のグラフカットのイメージ . . . . 43
A.2 α 拡張と融合移動の違い . . . . 45
表 目 次
4.1 従来手法によるセグメンテーション結果 . . . . 20 4.2 データ項とアトラス項の間の重みを考慮しないエネルギー項を用いたセグ
メンテーション結果 . . . . 21 4.3 1階のデータ項とアトラス項の間の重みを考慮しないエネルギー項を用い
たセグメンテーション結果 . . . . 24 4.4 1階のデータ項とアトラス項の間の重みを考慮しないエネルギー項を用い
て、セルの大きさを固定したときのセグメンテーション結果 . . . . 25 4.5 高階項の実験において効果のあったものを取り入れ、セグメンテーション
を行ったときの結果 . . . . 31
第 1 章 はじめに
1.1 研究背景
近年、医療行為における様々な場面において、画像の利用頻度は増加を続けており、現 代医学に必要不可欠なツールとなっている。画像を用いた医療行為のことを画像診断と いい、画像を生成するために、様々な医療機器が用いられている[24]。そのような医療機 器としては、例えば、X 線診断装置や X 線 CT 装置、核医学診断装置、MRI 装置、超 音波診断装置などといったものが挙げられる。先ほど挙げた装置では、それぞれ画像を 撮影する原理や、得られる画像から判断できることは異なっている。
画像診断において、上で述べた医療機器の性能は高度化しているが、その結果、画像 の量・質の増加は医師の医療行為の限界を越えようとしている。従来の医療現場におい ては、画像診断は医師の定性的な評価によってのみ行われていた。だが、画像の高度化 や画像診断の機会の増加により、画像診断に定量性が求められるようになった。そのた め、コンピュータを使った画像解析の導入・利用や、コンピュータ支援診断が必要とさ れている[24]。
医用画像処理とは、医用画像に対して何らかの処理を行い、得られる情報の価値を高め ることである。具体例として、画像のイメージングや、画像認識などが挙げられる。画 像のイメージングとは、画像に写りづらいものや写らないものを、写るものにする、また は、より鮮明に写るようにするということである。これができるようになることで、今 まで診断することが難しかった病変の進行を発見することや、定量化することができる ようになるという利点がある。また、画像認識とは、画像中に含まれる対象物が何であ るかを自動的に判定するものである。イメージングと同様に、画像認識が行えることで、
病変の進行を発見することも可能となり得る[24]。 本研究では、画像認識のうち、臓器 のセグメンテーションを対象とする、医用画像セグメンテーションを行う。
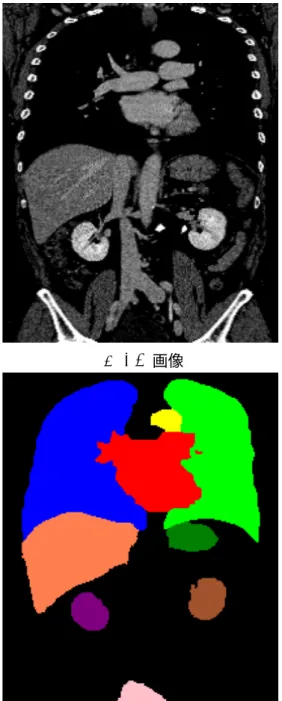
医用画像セグメンテーションとは、医用画像に含まれる臓器などの対象物を抽出する ことである。本研究における対象物は、人間の胸部から腹部に存在する様々な臓器を指 している。医用画像セグメンテーションは、3次元 CT 画像を入力としたとき、CT 画 像とその正解ラベルデータから予め学習しておいた様々な特徴を学習して、入力 3次元
CT 画像をセグメンテーションした結果を出力とする。ラベルは、各臓器に異なった色が 与えられており、臓器の種類を表す。医用画像セグメンテーションを行うことで、複数臓 器についての位置や大きさ、隣接関係などを得ることができる。これらのセグメンテー ションは CT 画像一枚一枚に対して行われる二次元的なものであるが、連続した CT 画 像をセグメンテーションすることで、三次元的な情報を得ることも可能である。医用画 像セグメンテーションによる診断支援の一例として、臓器の 3D モデルを用いた手術ナ ビゲーションが挙げられる。これは、あらかじめ患者から撮影しておいた医用画像に対 して臓器を抽出し、臓器の 3D モデルを作成しておくことで、コンピュータ上に次に行 うべき手技のナビゲーション画像を表すというものである。このような診断支援を行う ことで、医師の負担を減らすことができ、結果として、医療の質の向上へと繋げること ができる。
従来のセグメンテーションの問題点として、臓器によっては抽出が高精度に行うことが できないという点が挙げられる。これは、従来手法では 1ボクセルのみに対しての位置 情報や CT 値情報を用いていたためである。臓器による抽出の難しさの比較として、以
下に図1.1、図1.2を表す。図1.1において、例えば肺は周囲の CT 値と比較して明らか
に黒いため、データ項を用いれば判別ができるといえる。しかし、複数人の CT 画像の うち、同じ座標の部分を表示したものを図1.2に示す。これにおいて、例えば濃い緑色と 茶色のラベルはそれぞれ胃 + 十二指腸、胃 + 十二指腸内容物を表しているが、これは CT 画像によって様々な場所にあるといえ、また、CT 値も図1.1を見るだけでは他の臓 器と見分けがつかないため、従来手法では抽出が難しい臓器であるといえる。
この問題を解決するために、セグメンテーションに用いるエネルギー項をより広範の ものに拡張することを考える。エネルギー項の設計の方法として、例えば、文献[14]で は、高階エネルギーを用いたエネルギー最小化の提案をしている。高階エネルギーとは、
3 ボクセル以上の関係を用いたエネルギー項である。エネルギーの設計の際に使用する ボクセルの数から 1 を引いたものを、エネルギー項の階数と呼ぶ。このエネルギー項を 用いる利点として、エネルギーの計算に用いるボクセルの数を増やすことが可能となり、
複数ボクセルにまたがった CT 値情報や位置情報を使用できる点が挙げられる。高階エ ネルギーを用いる際には、エネルギー項の定義の仕方により、従来手法よりも良いセグ メンテーション結果が得られることがある。そのため、どのようなボクセルの関係を用 いるか、どのような画像中の特徴を学習させるかは、非常に重要な問題である。
1.2 研究目的
本研究では、従来手法では高精度に抽出することができなかった臓器を、より複雑な 臓器の位置関係を用いて、高精度にセグメンテーションすることを目的とする。
本研究では、従来手法で用いられていたラベル値や CT 値の情報を、より多くのボク セルについて同時に用いることで、セグメンテーション結果を向上させることを試みる。
用いる情報やボクセルの組み合わせの方法は様々なものが挙げられる。例えば、臓器の 隣接関係の情報をエネルギー項に加えていくこと[22] が挙げられる。これは、「臓器の隣 接関係には特徴がある」という仮定のもと設計されるエネルギー項である。本研究では、
これを拡張し、 3 個以上のボクセルをエネルギー項の設計に使用することで、複雑な形 状や臓器の位置関係を表すことを考える。そのようにして設計されるエネルギー項のう ち、本研究では、 3 ボクセルから成るエネルギー項について考える。このエネルギー項 を、2 階のデータ項と呼ぶこととする。また、エネルギー項の設計の際に、従来独立し て用いられていたデータ項とアトラス項をひとまとめにし、学習やセグメンテーション を行う。このとき、 CT 値と位置情報の条件付き確率を用いる。
本研究では、新たに提案されたエネルギー項を用いてセグメンテーションを行う。これ を、あらかじめ与えられている正解ラベルデータと比較し、精度の良し悪しを評価する。
1.3 本論文の構成
本論文では、2章において、医用画像セグメンテーションとはどのようなものであるか を、関連研究を交えて述べる。3章において、提案手法について述べる。4章において、
具体的な実験内容と、その結果・考察について述べる。
図 1.1: CT 画像とその画像にラベル付けされた画像の組の例。左の画像は CT 画像に写 る臓器にラベルを割り振った画像で、右の画像はCT 画像を表す。
図 1.2: 複数症例のCT 画像をラベル付けしたものを並べたもの。臓器によって位置があ る程度定まっているものと、そうでないものがある。
第 2 章 医用画像セグメンテーション
2.1 3 次元医用画像
本研究では、対象とする医用画像として、胸部から腹部が写っている 3 次元 CT のも のとする。CT 画像は、X線 CT 装置を利用し、身体の内部を画像として可視化したも のである。この装置は、走査ガントリ、撮影テーブル、操作コンソール、電源ユニットな どから構成される[24]。このとき測定された X 線の量をデジタル信号にしてコンピュー タで計算することで、CT 画像が生成される。
CT 画像はボクセルごとに実数値を持ち、値の単位は、HU (Hounsfield unit) である。
これは、臨床目的のための単位で、X 線吸収係数に比例し、水を0、空気を −1000 とな るように正規化したものである。この吸収率を用いて、以下の式で各ボクセルの CT 値 を求めることができる。
CTvalue = ut−uw
uw ×1000 (2.1)
ここで、骨や臓器の X 線吸収係数は ut 、水の X 線吸収係数は uw である。 X 線吸収 率は組織ごとに異なっているため、CT 値は組織を区別するために用いることができる。
一般的に、X 線が通り抜けづらい骨のような部位はCT値が大きくなるため白く表示し、
X 線が通り抜けやすい空気などは CT 値が小さくなるため黒く表示するようになってい る[23]。
3 次元CT 画像は、被撮影者の右手から左手の方向に x 軸をとる。被撮影者の胸から 背の方向にy 軸をとる。被撮影者の頭から足の方向にz 軸をとる。CT 画像はそれぞれ の座標軸に直交するように作られている。
症例ごとの身長や体の大きさによって、3次元 CT画像の大きさも異なっている。その ため、事前に画像間の位置合わせを行う。これは、それぞれの CT 画像に写っている範 囲が個人差があるということを解決するため、CT画像のいくつかの部分を目印に、CT 画像の抜き出しを行う。そして、抜き出した画像の大きさが一定になるようにサイズの 変更を行う。このようにしてレジストレーションを行い、体の大きさなどといった個人 差を解消したCT 画像を実験に用いることを前提とする。
図 2.1: ラベリング画像を3 次元モデルにしたもの。臓器の位置や相対的な位置関係がよ り見やすくなっている。
2.2 セグメンテーション
本研究では、出力として、 3 次元ラベリング画像を得る。ラベリング画像とは、入力 である 3次元CT 画像に対し、どこにどの臓器が写っているかを表すラベルを割り振っ たあとの画像を表す。ラベリング画像の情報を用いて、ラベリング画像を 3 次元化した ものの例を、図2.1に示す。この画像は、 Slicer[1] というソフトを用いて構成される。
本研究で行うラベリング問題として、セグメンテーションを定義する。 CT の撮影対 象である立方体の領域を各方向ごとに格子状に分割したボクセルの集合を考え、V とお く。すると、CT 画像は、各ボクセルν ∈ V に CT 値を与える関数X :V →R で表され る。 本研究では、ラベルが割り当てられている臓器以外の全てのものを、背景ラベルと して定義する。背景及び M 個の異なる臓器を表すラベル値の集合を L :={0,1, ..., M} とし、0を背景ラベルとする。臓器名とラベルの色・ラベル値の対応は、図 2.2 で表され る。画像 X に対して、各ボクセルに臓器ラベルを与えるラベリング L:V → Lを、 X に対するセグメンテーションと定義する。
本研究で解くべき問題は、付録 A の MAP 推定により、ラベリング L を決定するこ とである。グラフカットを用いたエネルギー関数の最小化を考えることで、この問題を 近似的に解くことが可能となる。このとき用いられる具体的なアルゴリズムについては、
図 2.2: ラベル付け画像の色と臓器の対応を表したもの。臓器の種類が多岐に渡ることが わかる。
付録Aにて述べる。
2.3 関連研究
この節では、医用画像に対しセグメンテーションを行っている一般的なものについて 述べる。対象となる医用画像として、2 次元医用画像・3次元医用画像・4 次元医用画 像が対象となる。 2 次元の医用画像を複数枚重ね上げたものが 3 次元医用画像である。
また、 3次元医用画像を作成する際に、連続的な撮影による作成を行うことで、時間変 化を捉えることも可能となる。このような画像を、 4次元の医用画像と呼ぶ[25]。
研究によって、対象とする医用画像の次元数は異なっている。[12, 2] では、 2次元の 医用画像を対象にしている。[21, 5, 6, 16, 13, 4, 14, 18] では、 3 次元の医用画像を対象 にしており、[10, 11]では4 次元の医用画像を対象にしている。
セグメンテーションに用いられる医用画像の種類は、研究によって異なる。例えば、
[20, 10] では、CT画像を対象とした研究であり、本研究でも CT 画像を対象として研究
を行っている。その他にも、例えば [12] では、超音波画像を対象とした研究を行ってお り、また、[7, 17, 19] では、 MRI 画像を対象とした研究を行っている。
セグメンテーションの対象とされるものは研究ごとに異なっている。例えば、[6]では、
癌や腫瘍などの病巣を対象とする。[20, 13, 15, 14] では、臓器を対象としており、その 中でも、単一臓器を対象とするもの[12, 6, 17] と、複数臓器を対象とするもの[16, 14, 5]
に大別できる。
本研究では、胸部・腹部領域の画像を対象にセグメンテーションを行っているが、頭部 領域の画像を対象にセグメンテーションを行う研究[7, 17, 19] も存在する。 上述のよう に、研究において対象としている領域や臓器・腫瘍などによって、用いられる画像の種類 は異なっている。例えば、 CT 画像は空間分解能が優れているため、内部構造の細かい 部分を撮影する際に用いられる。一方、MRI 画像はコントラスト分解能が優れているた め、僅かなコントラストの違いを検出したい場合に用いられる。また、超音波画像はリア ルタイムに画像を得ることが可能であるため、臓器の動体診断を行う場合に用いられる。
臓器のセグメンテーションを行う場合、人体臓器のセグメンテーションに有効な「確率 アトラス」と呼ばれる臓器情報の表現形式が使われることが多い[24]。これは、「各症例 間で臓器の位置はあまり激しく変化しない」という事前知識を利用して設計される。確 率アトラスは、ボクセルごとに対象の臓器の存在確率を表現したものであり、臓器の位 置に関する有効な情報を与えるものである[25]。
上記のように、医用画像に対するセグメンテーションを行っている研究は多岐に渡り 存在する。だが、対象となる臓器の種類はそれほど数が多いとはいえない。それに対し、
本研究は 22 種類のラベルを用いるため、より多くの臓器の関係を一度のセグメンテー ションにより得ることができる。これにより、例えば、3 次元モデルの作成を行うとき、
3次元モデルをより多くの臓器から構成することができるようになる。また、関連研究に おいて、非線形レジストレーションを行う研究は数多く存在した。だが、そのような画 像においては、臓器の形状情報や、骨格の形などを過剰に変形させる可能性があり、その 結果、人の身体の位置情報の価値が失われる恐れがあった。また、非線形レジストレー ションは計算コストが多くかかってしまうという問題点がある。そのため、本研究の独 自性として、線形変換のみでレジストレーションされた医用画像を用い、学習データに 用いられているラベルは 22種類としたことが挙げられる。
2.4 従来手法のエネルギー関数
本研究の比較対象として、文献[22]で用いられた手法を用いる。また、この手法を従 来手法と呼ぶこととする。従来手法のエネルギー関数は、以下のように表す。
E(L) =w1∑
v∈V
g(Lv) +w2∑
v∈V
a(Lv) +w3 ∑
(u,v)∈S
huv(Lu, Lv) (2.2)
ここで、V はラベルが振り分けられるボクセルの集合を表し、ボクセル間の隣接関係を 表す集合を S ⊂V ×V とする。例えば、 (u, v)∈S のとき、ボクセル u と v は隣接し ていると考える。また、 Lは画像全体のボクセルに対するラベルの振り分け方を表すも のであり、 Lv は、ボクセルv でのラベルを表している。式(2.2)の重みw1,w2, w3 は、
それぞれのエネルギー項の影響力を調整するものである。エネルギー項の影響力を変え ることでセグメンテーション結果は大きく変わっていくため、重みを適切につけること は適切なセグメンテーション結果の為には不可欠なものである。
2.4.1 従来手法のエネルギー項
式(2.2)の g は、データ項と呼ばれる。これは、あるボクセルに対しラベルが与えられ
たとき、そのボクセルが持つ CT 値 に対して与えられたラベルがどれほどの出現確率を 持つのかによって、値が変わっていくというものである。
式(2.2)の a は、アトラス項と呼ばれるものである。これは、個人差は存在するもの の、人間の臓器の大まかな位置や大きさなどはある程度決まっているという前提に基づ いて設計されたエネルギー項である。 この項では、ラベルの種類が与えられたとき、そ のボクセルに対して、そのラベルの出現確率がどれほどであるかという値を用いる。そ して、出現確率が大きいほどエネルギーが小さくなるというエネルギー項の設計が行わ れている。
式(2.2)の hは、平滑化項と呼ばれる。これは、隣接するボクセル間でラベルがどのよ
うな関係にあるべきかという前提を反映したものである。事前知識として、「画像のラベ ル値は隣接するボクセルに対してあまり激しく変化しない」という前提があるため、隣 接するボクセルのラベルが異なっていた場合にエネルギーが増加するというものになっ ている。また、同じ臓器である場合、隣接するボクセル間の CT 値はあまり激しく変化 しないと考えられるので、隣接するボクセルの CT値の情報もエネルギー項に組み込み、
差の大小で値が変化するように定義する。平滑化項は、以下の式で定義される。
huv(Lu, Lv) =
1
|Iu−Iv|+ϵ (Lu ̸=Lv) 0 (Lu =Lv)
(2.3)
式(2.3)において、 Iu は、あるボクセル u が持つ CT 値を表す。
CT 画像が与えられたときに、画像上に写っている臓器に対し、手動で正しくラベル を与え、臓器をラベルによって区別したものを事前に作成しておく。これを、 CT 画像 に対する正解ラベルデータと呼ぶ。そのような画像の組の例を図1.1に表す。正解ラベル データは、例えば骨といったような本研究で用いないものは写っておらず、 CT 画像に 写っている臓器の位置を写したものとなっている。なお、これらのデータは、徳島大学 放射線科から提供されている。
セグメンテーションを行うにあたり、事前に CT 画像と正解ラベルデータから学習を 行う。これは、データ項とアトラス項など、事前情報によって定義されるエネルギー項 を用いる際に必要なものである。学習の具体的な例として、データ項では、 ラベルごと にどのような CT 値をとるかの統計をとる。アトラス項では、ラベルごとにどのボクセ ルで現れるかの統計をとる。これらのものをセグメンテーションの際に用いる。
第 3 章 提案手法
3.1 概要
本研究の概要を述べる。式(2.2)において、データ項、アトラス項、平滑化項がそれぞ れ独立している。それぞれのエネルギー項の影響力を決める重みは、総当り的に実験を 行い、最良である結果を返すときの重みを探し出す必要がある。しかし、その重みを探 し出すには時間がかかり、また、十分な正解データがなければ正しい重みを設定するこ とはできない。
従来手法との違いとして、従来手法で用いていたデータ項とアトラス項に代えて、新 しいエネルギー項を設計するという点が挙げられる。データ項とアトラス項は、症例か ら学習を行い、その統計をエネルギー項に用いるものである。式(2.2)において、これら の項は独立して用いられているが、エネルギー項を独立して用いると、それぞれに固有 の重みが与えられているため、確率分布を無視した値になってしまう。提案手法はこれ を一つに組み合わせて用いる。このようにする利点として、データ項とアトラス項の同 時確率を推定することで、エネルギー関数から得られる値が確率分布に沿ったものにな るという点が挙げられる。また、用いるエネルギー項の数が減ることで、最適な重みの 推定もしやすくなるという利点もある。
高階項を定義する際も同様に、エネルギー項を独立に定義するのではなく、一つの項に 組み合わせ、同時確率を推定するよう設計する。このようにすることで、確率分布に沿っ た値を用いることができるようになる。また、データ項とアトラス項を組み合わせたと きと同様、用いるエネルギー項の数が減ることで、最適な重みの推定がしやすくなる。
提案手法のエネルギー関数は、式(3.1)で表せる。
E(L) = Epropose(L) +w ∑
(u,v)∈S
huv(Lu, Lv) (3.1)
ここで、Epropose(L)という項は提案手法によるエネルギー項を表す。従来手法との違い
として、従来手法で用いられていたデータ項とアトラス項の代わりに、新しいエネルギー 項を設計するという点が挙げられる。
D
0
1
2
+ A + P
+ P
D A
+ A +
+ P
D ଵ A ଵ
+ P
D ଶ A ଶ
D ଵ D
図 3.1: 提案手法や従来手法をどのように組み合わせて用いるかを表したイメージ図。 D, A, Pはそれぞれデータ項、アトラス項、平滑化項を表しており、数字は階数を表してい る。
従来手法におけるエネルギー項と、新たに定義されたエネルギー項と、それを用いる際 のイメージ図として、図3.1 を示す。この図において、D, A, Pはそれぞれデータ項、ア トラス項、平滑化項を表している。縦向きに並べられていたり、添字として用いられてい る数字は階数を表しており、提案したエネルギー項の階数を表している。例えば、D1A1
というものは、 3.3 節にて述べられている項を表す。上図のように、全ての項は平滑化 項と組み合わせて用いられる。
また、新しく定義したエネルギー項は、学習の際に様々な工夫をこらすことで、より よいセグメンテーション結果を得ることが期待された。それらの工夫について、 3.4 節 で述べる。
これらのエネルギー項を定義し、エネルギー関数に組み込んだことで、今までセグメ ンテーション精度が低かった臓器に対して、精度の向上が見られた。
3.2 データ項とアトラス項の間の重みを考慮しないエネル ギー項の検討
3.1 節で述べたように、位置情報とCT 値情報を結合し、同時確率を推定するようなエ ネルギー項を設計する。エネルギー項は、以下の式で表される。
E0da(L) = ∑
u∈V
E0da(Lu|Iu) (3.2)
= ∑
u∈V
−logP(Lu|Iu) (3.3)
P(Lu|Iu) = P(Iu|Lu)×P(Lu)
P(Iu) (3.4)
セグメンテーションに用いるのは、CT 値を条件としたときのラベルの出現確率である。
左辺を直接求めることなく、右辺の形に変形して求める理由として、左辺の値をそのま ま学習すると、症例から得られる確率密度分布が疎なものになってしまうという問題が あるためである。
3.3 1 階データ項とアトラス項の間の重みを考慮しないエネ ルギー項の検討
3.2 節で述べたように、 位置情報と CT 値情報を結合したエネルギー項を設計するこ とで、セグメンテーション精度が向上することが期待できる。また、文献 [22]では、 従 来手法で用いられているデータ項を拡張し、 1 階のデータ項を使用することで、セグメ ンテーションの精度の向上に貢献している。そこで、 3.2 節で述べたように、このエネ ルギー項においても、 1階のデータ項の部分とアトラス項を結合することで、確率分布 に沿った推定ができ、セグメンテーションの際に最適な重みが推定しやすくすることが できる。
エネルギー項は、以下の式で表される。
E1da(L) = ∑
(u,v)∈S
E1da(Lu, Lv|Iu, Iv) (3.5)
= ∑
(u,v)∈S
−logP(Lu, Lv|Iu, Iv) (3.6)
P(Lu, Lv|Iu, Iv) = P(Iu, Iv|Lu, Lv)×P(Lu|Lv)×P(Lv)
P(Iu, Iv) (3.7)
式(3.7)において、右辺の分子の第二項と第三項は、ラベルの組み合わせの同時確率を、
条件付き確率の形に変形して導出している。その理由として、このような形にすること で、1 ボクセルに対する位置情報を用いたエネルギー項が使用可能になるという点が挙 げられる。従来手法において、位置情報が最もセグメンテーションに有効であったため、
それを活かすためにこのような変形を行っている。
3.4 1 階以上の場合の確率分布推定の改善
3.3節で述べたように、CT値の情報を用いるエネルギー項と、位置情報を用いるエネ ルギー項を結合したエネルギー項を用いることで、より高精度で、この二つの情報に対 する重みによらない頑健なセグメンテーション結果が得られることが予想される。だが、
このエネルギー項を用いる際、注目ボクセルと隣接ボクセルのラベル値の組み合わせを 学習する必要がある。その際、本研究では用いることのできる症例数が限られているの で、ラベル値の組み合わせの数に相当する量の学習データを用意することが難しいとい う問題点が存在する。そのため、ラベル値の組み合わせの学習を行う際に、ボクセル単 位での学習を行うかわりに、CT 画像をN 分割した領域を単位にして学習を行うことを 考える。このようにすることで、隣接関係を N 分割した領域単位で考えることができ、
十分な量の学習データを用意することができる。ここで、N 分割した領域をセルと呼ぶ こととする。
また、 セルごとの領域で考える利点として、位置情報をある程度ぼかすことができる ことが挙げられる。現在行っている位置合わせは、体表に基づく線形変換による位置合 わせであり、臓器の位置ごとに非線形な位置合わせを行っているような研究[16]に比べ、
位置情報が正しいとは言えないものであった。本研究では、位置合わせが不十分であると いう課題を、ある程度ぼかされた位置情報を用いることにより、解決することを試みる。
これを行うことで、学習データでは存在しない位置に臓器が存在していた場合などに対 応することができるため、多くの症例に対応することができるようになると予期される。
3.4.1 セルごとに学習したデータを用いたエネルギー式
セルごとに学習したデータを用いたエネルギー項は、以下の式で表される。
EN p(L) = ∑
(u,v)∈S
EN p(Lu, Lv) (3.8)
= ∑
(u,v)∈S
−logP(Lu, Lv|Iu, Iv) (3.9)
P(Lu, Lv|Iu, Iv) = P(Iu, Iv|Lu, Lv)×Pr(Lu|Lv)×P(Lv)
Pr(Iu, Iv) (3.10)
式 (3.10) において、Pr はセルを単位にして学習を行った時の確率を表している。右辺
の分子の第一項は、条件としてラベルの組み合わせを考えているため、位置によらず一 定の値をとると考えられる。そのため、ボクセル単位での学習を行う。右辺の分子の第 三項は、従来手法におけるアトラス項と同じ確率の計算を行っている。位置情報は今ま でのセグメンテーション結果に対し最も貢献していたものであるため、そのまま用いる ことを考える。そのため、ボクセル単位での学習を行う。
3.5 2 階データ項とアトラス項の間の重みを考慮しないエネ ルギー項の検討
1階のデータ項とアトラス項を組み合わせてエネルギー項を構成することで、より高精 度なセグメンテーション結果が得られることが期待できる。また、エネルギー項を設計 する際に、より多くのボクセルを用いたエネルギー項にすることで、様々な臓器の隣接 関係が表すことが可能となる。
そこで、文献 [22] にて定義されていたエネルギー項を、3 ボクセルの項に拡張し、エ ネルギー項として用いることでセグメンテーション結果の向上を図ることを考える。こ れは、0 階から1 階へとデータ項を拡張することにより、セグメンテーションの精度の 向上が見られたため、 2階へと拡張することによってもセグメンテーション結果が向上
x y z
図 3.2: 高階項で用いるクリークの形を表す。クリークの種類は 11 種類存在する。
することを期待して行う。このようにする利点として、3 ボクセル分のラベルや CT 値 の組み合わせを、同時確率を用いて表現することができるようになるという点が挙げら れる。
高階項を用いたエネルギー項は、以下の式で表される。
Eh(L) = ∑
(u,v,w)∈T
Eh(Lu, Lv, Lw) (3.11)
= ∑
(u,v,w)∈T
−logP(Lu, Lv, Lw|Iu, Iv, Iw) (3.12)
P(Lu, Lv, Lw|Iu, Iv, Iw) (3.13)
= P(Iu, Iv, Iw|Lu, Lv, Lw)×P(Lu, Lv, Lw)
P(Iu, Iv, Iw) (3.14)
= P(Iu|Lu)×P(Iv|Lv)×P(Iw|Lw)×Pr(Lu|Lv, Lw)×Pr(Lv|Lw)×P(Lw)
Pr(Iu, Iv, Iw) (3.15) 式 (3.12) において、隣接する 3 ボクセルの集合を T ⊂V ×V ×V と表す。図 3.2 に、
本研究で用いるクリークの組み合わせを表す。本研究では、 11 通りのクリークを用い、
全てのクリークにおいて、各ボクセルは繋がっているものであると考える。式 (3.15) の 分子の第一項は、条件としてラベルの組み合わせを考えているため、それぞれが独立し て出現すると考えられる。そのため、独立した項に変更して計算を行う。右辺の分子の 第三項は、同時確率を条件付き確率の形に変更することを考える。3.4.1 節と同様、位置 をぼかしたり、学習症例を増やしたい項に関してはセルごとの学習を行う。
図 3.3: セルを重ねたときの学習イメージを表す。図において、青い直方体がセルを重ね ないときの学習範囲を表し、緑の直方体がセルを重ねたときの学習範囲を表す。緑の直 方体は必ず青い直方体を含むように設計し、各軸方向に数ボクセル大きくなっている。
高階項の学習において、セルごとの学習を行うが、従来のセルごとの学習において、セ ルの境界において学習値が大きく変わってしまい、なめらかなセグメンテーションが行 えないのではないかという問題があった。そのため、高階項の学習においては、セルご との学習に加え、学習範囲をセルに対して広げ、他のセルとある程度重ねることで、こ の問題を解決することを試みる。学習範囲の変更についてのイメージ図を、図 3.3 に示 す。この図において、青い直方体がセルを重ねない時の学習範囲のイメージを表してお り、緑色の直方体がセルを重ねる時の学習範囲のイメージを表している。青い直方体に 対し、緑の直方体同士は各方向に数ボクセル大きくなっており、その部分が他の緑の直 方体と重なっている。このようにすることで、セルの境界における学習値の急激な変化 を緩和し、セグメンテーション結果に悪影響を及ぼすことのないようにする。
第 4 章 実験
4.1 実験目的
この実験では、学習データを用いたセグメンテーションを行い、従来手法よりも臓器 が高精度に抽出することをねらいとする。この実験を行うことで、まず、提案手法で設 計されたエネルギー項が、多臓器セグメンテーションに対し有用性を持っているのか確 かめることが可能となる。また、従来手法であるデータ項、平滑化項、アトラス項を用 いた手法と、提案手法のエネルギー項と様々な項を用いたセグメンテーションの性能を 比較し、どれほどの効果を上げることができるのかも確かめることが可能となる。
4.2 データ項とアトラス項の間の重みを考慮しないエネル ギー項
4.2.1 方法
3.2 節で述べたようなエネルギー項に用いる出現確率を学習する。出現確率を学習する 際に、まず、症例ごとにそれぞれの出現頻度をカウントしていき、それを学習に用いる症 例数分足し合わせる。その後、症例数に応じて正規化を行い、テスト用の学習データを 作成する。 CT 値を学習する際は、ビンの幅を10にして学習を行う。これは、CT 値の 丸め込みを行わないと、 CT 値とラベル値の組み合わせが膨大な量となってしまい、学 習がうまく行えないためである。
学習・テスト用に用いる症例数は24症例である。本論文では、学習を行うときに leave-
one-outで学習・テストを行う。学習・テストに用いられる画像サイズはどの症例も事前
に統一しておく。セグメンテーション結果の評価方法として、本研究では Jaccard Index を用いる。 Jaccard Index の計算式について、以下に示す。
JI =
∑
r|Sr∩Tr|
∑ (4.1)
ここで、r はラベル値を表し、Sr は、正解データに rが与えられたボクセルの集合を表 す。 Tr は、セグメンテーションデータに rが与えられたボクセルの集合を表す。この値 は下限値が 0、上限値が 1となっており、1に近づくほどよいという指標になっている。
本研究では、 各症例に対してのセグメンテーション結果と、正解ラベルデータの間に
対し Jaccard Index を計算することで、どれだけ正解データに近い結果が得られたかと
いう一致率を計算する。テストを行った各症例ごとに Jaccard Index を計算し、各症例 間の平均をとることでセグメンテーションの精度の指標とする。一致率の計算は臓器全 体・各臓器に対して行い、様々な角度からの評価を行えるようにする。また、本研究で は、位置合わせの際に、膀胱・前立腺・子宮のラベルが与えられている範囲も除外するこ とがあったため、この三つのラベルを評価指標から除外した。
なお、今後の実験においても、テスト用の学習データの出現確率の計算方法や正規化、
CT 値の丸め込み、 leave-one-out を用いた学習・テスト、Jaccard Indexによる評価に ついては共通である。
この項を用いる際に、重みの比によって、セグメンテーション結果に大きな影響を与 えることが考えられる。そのため、最適な重みの比を探しだす必要がある。本研究では、
重みの比を探しだす方法として、総当り的に重みの比の組み合わせを用いて実験し、臓 器全体の一致率が高いものを最適な比とするという方法を用いた。結果の項では、最適 な重みの近傍の重みによる結果も載せ、重みによりどれほどの結果の変化をもたらすか を考察する。
4.2.2 結果
比較対象として、データ項、平滑化項、アトラス項を用いた時のセグメンテーション 結果を示す。表 4.1 に、セグメンテーション結果を表す。表では、症例ごとに正解ラベ ルデータとの一致率をそれぞれ計算し、その平均をとった値を表す。
続いて、式 (3.3)で定義した項と、平滑化項を用いた時のセグメンテーション結果を示 す。図4.1に、セグメンテーション結果を表す。図上には、症例ごとに正解ラベルデータ との一致率をそれぞれ計算し、その平均をとった値を表す。また、図4.1において、臓器 全体の一致率が最も高かった時の結果を、表 4.2 に示す。
表 4.1: 従来手法によるセグメンテーション結果
ラベル 一致率 ラベル 一致率
臓器全体 0.762 胃+十二指腸 0.28
右肺 0.951 胃+十二指腸内腔 0
左肺 0.941 胃+十二指腸内容物 0.208
心臓 0.656 脾臓 0.775
大動脈 0.29 右腎臓 0.561
食道 0 左腎臓 0.614
食道内腔 0 下大静脈 0
肝臓 0.712 静脈(門脈+脾静脈+上腸間膜静脈) 0
胆嚢 0.263 膵臓 0
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
1 10 100 1000
全体 右肺 左肺 心臓 大動脈 食道 食道内腔 肝臓 胆嚢
胃+十二指腸 胃+十二指腸内腔 胃+十二指腸内容物 脾臓
右腎臓 左腎臓 下大静脈 静脈 膵臓
図 4.1: データ項とアトラス項の間の重みを考慮しないエネルギー項を用いたセグメン テーション結果。横軸は臓器の種類を表し、縦軸は一致率を表す。各臓器に対して、一 致率の平均を表している。
表 4.2: データ項とアトラス項の間の重みを考慮しないエネルギー項を用いたセグメン テーション結果
ラベル 一致率 ラベル 一致率
臓器全体 0.774 胃+十二指腸 0.278
右肺 0.915 胃+十二指腸内腔 0.189
左肺 0.903 胃+十二指腸内容物 0.083
心臓 0.69 脾臓 0.718
大動脈 0.468 右腎臓 0.574
食道 0 左腎臓 0.618
食道内腔 0.077 下大静脈 0.139
肝臓 0.796 静脈(門脈+脾静脈+上腸間膜静脈) 0.022
胆嚢 0 膵臓 0.092
4.2.3 考察
二つの結果を比較すると、臓器全体の一致率は、データ項とアトラス項の間の重みを 考慮しないエネルギー項を用いたセグメンテーション結果の方が一致率が高くなること がわかる。これより、提案したエネルギー項は理論的に正しく考えられているものであ るということが言える。また、データ項とアトラス項の間の重みの比を考慮しなくても、
ある程度よい結果を得ることができていると考えられる。これは、学習が確率的に正し く行えていることを表している。
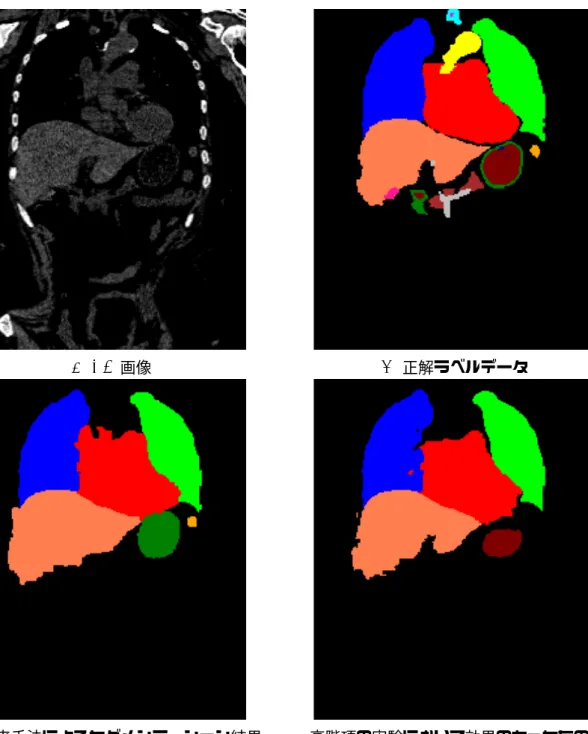
一方、従来手法による結果は、臓器が抽出できていないものが多い。これは、平滑化項 を強めたため、細かい臓器が抽出できなくなってしまったためであると考えられる。具 体的なラベル付けの結果について、図4.2 に示す。これを見ると、提案手法では、大動脈 や下大静脈や胃+十二指腸のラベルが、従来手法に比べてより正確にラベル付けされてい ることがわかる。また、平滑化項を強めすぎたことで、従来手法では、肝臓のラベルが 広がりすぎてしまっていることがわかる。
(a) CT画像 (b)正解ラベルデータ
(c)従来手法によるセグメンテーション結果 (d)データ項とアトラス項の間の重みを考慮しな いエネルギー項を用いたセグメンテーション結果 図 4.2: ある 1スライスで比較したセグメンテーション結果。
4.3 1 階データ項とアトラス項の間の重みを考慮しないエネ ルギー項
4.3.1 方法
3.3 節で述べたようなエネルギー項に用いる出現確率を学習する。出現確率を学習する 際に、まず、症例ごとにそれぞれの出現頻度をカウントしていき、それを学習に用いる 症例数分足し合わせる。その後、症例数に応じて正規化を行い、テスト用の学習データ を作成する。
また、 3.4 節で述べたように、このエネルギー項では、セルの大きさによって実験結 果が変化することが予想される。そのため、セルの大きさを1 辺約 10,15,20 ボクセルに 設定し、それぞれの場合においてどれほどの一致率を得られるのかを調べる。また、セ ルの大きさを変え、平滑化項との重みの比率を変えて実験を行うことで、セグメンテー ション結果を求める。
4.3.2 結果
式 (3.6) で定義した項と、平滑化項を用いた時のセグメンテーション結果を示す。こ
のとき、ボクセル単位で学習を行い、平滑化項との比率を変えてセグメンテーションを 行ったものを、図4.3に表す。また、図4.3において、臓器全体の一致率が最も高かった 時の結果を、表 4.3 に示す。
セル単位で学習を行い、セルの大きさや平滑化項との重みの比を変えてセグメンテー ションを行ったものを、図4.4に表す。
セルの大きさを適切に設定したときの学習データを用いてセグメンテーションを行っ たときの各臓器のセグメンテーション結果について、図4.5に表す。図には、症例ごとに 正解ラベルデータとの一致率をそれぞれ計算し、その平均をとった値を表す。また、図 4.5において、臓器全体の一致率が最も高かった時の結果を、表 4.4 に示す。
4.3.3 考察
従来手法の結果と比較すると、ボクセル単位での学習を行った場合の臓器全体の一致率 は上がっている。だが、0階のデータ項とアトラス項の間の重みを考慮しないエネルギー 項を用いたものと比較すると、臓器全体の一致率は下がっている。これは、階数を増や
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0 200 400 600
全体 右肺 左肺 心臓 大動脈 食道 食道内腔 肝臓 胆嚢
胃+十二指腸 胃+十二指腸内腔 胃+十二指腸内容物 脾臓
右腎臓 左腎臓 下大静脈 静脈 膵臓
図 4.3: 1階のデータ項とアトラス項の間の重みを考慮しないエネルギー項を用いたセグ
メンテーション結果。横軸は臓器の種類を表し、縦軸は一致率を表す。各臓器に対して、
一致率の平均を表している。
表 4.3: 1 階のデータ項とアトラス項の間の重みを考慮しないエネルギー項を用いたセグ
メンテーション結果
ラベル 一致率 ラベル 一致率
臓器全体 0.766 胃+十二指腸 0.176
右肺 0.908 胃+十二指腸内腔 0
左肺 0.883 胃+十二指腸内容物 0.25
心臓 0.712 脾臓 0.619
大動脈 0.449 右腎臓 0.485
食道 0 左腎臓 0.57
食道内腔 0 下大静脈 0.085
肝臓 0.782 静脈(門脈+脾静脈+上腸間膜静脈) 0.009
胆嚢 0 膵臓 0
0.765 0.77 0.775 0.78 0.785 0.79 0.795
0.01 0.1 1 10 100 500
10( ⼀辺⻑さ ) 15
20
図 4.4: 1階のデータ項とアトラス項の間の重みを考慮しないエネルギー項を用いて、セ
ル単位での学習を行ったときの、セルの大きさによるセグメンテーション結果比較。横 軸は 1 階のデータ項の重みを 1と設定したときの平滑化項の重みの比を表し、縦軸は一 致率を表す。各臓器に対して、一致率の平均を表している。
表 4.4: 1 階のデータ項とアトラス項の間の重みを考慮しないエネルギー項を用いて、セ
ルの大きさを固定したときのセグメンテーション結果
ラベル 一致率 ラベル 一致率
臓器全体 0.79 胃+十二指腸 0.266
右肺 0.927 胃+十二指腸内腔 0.002
左肺 0.92 胃+十二指腸内容物 0.25
心臓 0.706 脾臓 0.753
大動脈 0.523 右腎臓 0.62
食道 0 左腎臓 0.682
食道内腔 0 下大静脈 0.202
肝臓 0.809 静脈(門脈+脾静脈+上腸間膜静脈) 0.046
胆嚢 0.048 膵臓 0.124
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0.01 0.1 1 10 100 1000
全体 右肺 左肺 心臓 大動脈 食道 食道内腔 肝臓 胆嚢
胃+十二指腸 胃+十二指腸内腔 胃+十二指腸内容物 脾臓
右腎臓 左腎臓 下大静脈 静脈 膵臓
図 4.5: 1階のデータ項とアトラス項の間の重みを考慮しないエネルギー項を用いて、セ
ルの大きさを固定したときのセグメンテーション結果。横軸は臓器の種類を表し、縦軸 は一致率を表す。各臓器に対して、一致率の平均を表している。
したことによるラベル値や CT 値の組み合わせの増加に対し、学習する症例数が不足し ており、学習の精度に問題があり、セグメンテーションの精度に影響したためであると 考えられる。
一方、セル単位での学習を行った場合の臓器全体の一致率は、従来手法に比べ、向上 している。これは、提案したエネルギー項が理論的に正しいものであることを示してお り、また、隣接するボクセルに対し、臓器のラベル付けが依存関係を持つことを示して いる。また、セルの大きさを様々に変化させてセグメンテーションを行った場合、セル の大きさに応じて一致率は変化している。図4.4より、セルの大きさは一辺 15ボクセル と設定したときが最も良い結果を持つ。これは、セルが大きすぎると学習としての精度 が下がってしまい、セルが小さすぎると十分な学習データが取れないというトレードオ フを満たしている部分であると考えられる。
1 階のデータ項と平滑化項の重みの比について、 1:100 が最適な重みの比であると考 えられる。このときの臓器ごとの一致率を見ると、いくつかの臓器では一致率が下がっ てしまっているが、一致率が上がっている臓器も数多く存在する。このことから、重み の比をこの部分で設定することに問題はないと考えられる。
具体的なラベル付けの結果について、図 4.6 に示す。これを見ると、提案手法は、従 来手法に比べ、いくつかのラベルが抽出できていることがわかる。また、従来手法では、
左右の腎臓は楕円のような形で抽出されていたのに対し、提案手法では、腎臓の窪みの 部分も正確に抽出することができている。これらのことから、臓器全体の一致率は向上 したと推測できる。
4.4 2 階データ項とアトラス項の間の重みを考慮しないエネ ルギー項
4.4.1 方法
3.5 節で述べたようなエネルギー項に用いる出現確率を学習する。出現確率を学習する 際に、まず、症例ごとにそれぞれの出現頻度をカウントしていき、それを学習に用いる 症例数分足し合わせる。その後、症例数に応じて正規化を行い、テスト用の学習データ を作成する。
(a) CT画像 (b)正解ラベルデータ
(c)従来手法によるセグメンテーション結果 (d) 1階のデータ項とアトラス項の間の重みを考 慮しないエネルギー項を用い、セル単位の学習を 行った時のセグメンテーション結果
図 4.6: あるスライスに対するセグメンテーション結果の比較。
このエネルギー項では、セルの大きさを変更することで、セグメンテーション結果に 影響を与えることが予想される。そのため、セルの大きさを1 辺約 10,15,20 ボクセルと 変更してセグメンテーションを行い、どれほどの一致率が得られるのかを調べる。
このエネルギー項では、3.5節で述べたように、セル単位での学習を行う。だが、セル の切れ目で学習の値が急激に変化してしまい、セグメンテーションに悪影響を及ぼす可 能性があるため、セルをある程度重ねて学習を行うことを提案する。そのような工夫を 行うことで、どれほどの一致率を得られるのかを調べる。
このエネルギー項は、平滑化項と組み合わせてセグメンテーションを行う。このとき、
重みの比率を変えることでセグメンテーション結果に影響を及ぼすことが考えられる。そ のため、重みを様々に変更してセグメンテーションを行い、どれほどの一致率が得られ るのかを調べる。
このエネルギー項では、図 3.2 のように、提案できるクリークの種類は全部で11 種類 存在する。クリークの組み合わせによって一致率は変化すると思われるため、様々な組 み合わせでセグメンテーションを行い、どれほどの一致率が得られるのかを調べる。
上記の実験により、適切やセルの大きさやクリークの組み合わせ等の情報が得られる。
これらを組み合わせてセグメンテーションを行い、どれほどの一致率を得られるのかを 調べる。
4.4.2 結果
式 (3.12) で定義した項を用いた時のセグメンテーション結果を示す。セルの大きさを
変えて学習したデータを用いてセグメンテーションを行った結果を、図4.7に表す。図に は、正解ラベルデータと比較した、臓器全体の一致率と、臓器ごとの一致率の平均を表 す。ここでは、3ボクセルが z 軸方向に一直線に連なっている 1つのクリークを使って セグメンテーションを行う。
セルの重ねあわせを考慮した学習データを用いてセグメンテーションを行った結果を、
図4.8に表す。図には、正解ラベルデータと比較した、臓器全体の一致率と、臓器ごとの 一致率の平均を表す。セルの重ねあわせの範囲は現在のセルの大きさに対する割合で表 され、両側それぞれセルの大きさの何 %かが重なっている。また、この実験をする際の セルの大きさは 1辺 15 ボクセルに設定されている。ここでは、 3ボクセルが z 軸方向 に一直線に連なっている 1つのクリークを使ってセグメンテーションを行う。
平滑化項との重みの比を様々に変更してセグメンテーションを行った結果を、図4.9に 表す。図には、正解ラベルデータと比較した、臓器全体の一致率と、臓器ごとの一致率
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
全体 右肺 左肺 心臓 大動脈 食道 食道内腔 肝臓 胆嚢 胃+十二指腸 胃+十二指腸内腔 胃+十二指腸内容物 脾臓 右腎臓 左腎臓 下大静脈 静脈 膵臓
一辺10 一辺15 一辺20
図 4.7: 高階項のセルの大きさを変更してセグメンテーションを行ったときの結果。横軸 は臓器の種類を表し、縦軸は一致率を表す。各臓器に対して、一致率の平均を表してい る。セルの大きさを変更し、それぞれの場合の結果を表している。
の平均を表す。ここでは、3 ボクセルがz 軸方向に一直線に連なっている 1つのクリー クを使ってセグメンテーションを行う。
用いるクリークの組み合わせを変化させてセグメンテーションを行った結果を、図4.10 に表す。図には、正解ラベルデータと比較した、臓器全体の一致率と、臓器ごとの一致率 の平均を表す。ここでは、3 ボクセルがz 軸方向に一直線に連なっている 1つのクリー クを使ってセグメンテーションした場合と、 3 つのクリークを使ってセグメンテーショ ンした場合、11種類のクリーク全てを同時に用いてセグメンテーションした場合の結果 を比較する。
上記の実験結果を考慮し、効果のあったものを組み合わせてセグメンテーションを行っ た結果を、図4.11に表す。図には、正解ラベルデータと比較した、臓器全体の一致率と、
臓器ごとの一致率の平均を表す。図では、高階項の重みを 1 に固定し、平滑化項の重み を変更したときの結果を表している。また、図4.11において、臓器全体の一致率が最も 高かった時の結果を、表 4.5 に示す。


![図 2.1: ラベリング画像を 3 次元モデルにしたもの。臓器の位置や相対的な位置関係がよ り見やすくなっている。 2.2 セグメンテーション 本研究では、出力として、 3 次元ラベリング画像を得る。ラベリング画像とは、入力 である 3 次元 CT 画像に対し、どこにどの臓器が写っているかを表すラベルを割り振っ たあとの画像を表す。ラベリング画像の情報を用いて、ラベリング画像を 3 次元化した ものの例を、図 2.1 に示す。この画像は、 Slicer[1] というソフトを用いて構成される。 本研究で行うラ](https://thumb-ap.123doks.com/thumbv2/123deta/9853852.1898524/12.892.242.643.121.460/ラベリングセグメンテーションラベリングラベリングラベリング.webp)